Курсы валют онлайн | График курса доллара к рублю
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 gif» bgcolor=»#cee3f9″ valign=»bottom»>
gif» bgcolor=»#cee3f9″ valign=»bottom»>Редакция · Реклама на сайте · | |||||||||||||
 gif»>
gif»>Разбираемся, как измерять разнообразие слов / Хабр
Привет в Новом году. Я тут добрался на праздниках до одной темы, которая пылится у меня уже полгода в закладках. Поговорим сегодня о метриках лексического разнообразия. Эти метрики показывают насколько богат текст на разные слова, помогая нам оценить его сложность. В этой небольшой заметке я кратко расскажу историю вопроса, о современных метриках, а в конце покажу результаты предварительных экспериментов. Тетрадка доступна по ссылке.
Внезапно
Пока искал КДВП, нашел вот этот чудесный репозиторий. А КДВП не нашел.
Говоря про оценку сложности текстов, вот как это можно проиллюстрировать [9]:
- Комфортное чтение текста, содержащего большое количество разных слов, подразумевает знание этих слов, иначе придется часто смотреть в словарь.
- Если посмотреть немного с другой стороны, тексты можно разделить по разнообразию на уровни для комфортного чтения.
 Например, для детей по возрасту или для людей, изучающих второй язык.
Например, для детей по возрасту или для людей, изучающих второй язык. - По динамике разнообразия можно судить о патологии развития речевых способностей. Например, в норме ребенок по мере развития будет использовать новая слова, которые он слышит, для описания окружающего мира. Другими словами увеличивается лексическое разнообразие речи.
- Использование разнообразных слов заставляет тратить больше мыслетоплива при чтении, поскольку чаше происходит декодирование новых слов.
- Немного необычный случай. В этой статье [4], авторы попытались измерить рост разнообразия научных идей через лексическое разнообразие ключевых слов из статей, хоть и неудачно.
 Например, для детей по возрасту или для людей, изучающих второй язык.
Например, для детей по возрасту или для людей, изучающих второй язык.Давайте приступим к самим метрикам.
TTR
История этих метрик началась в 1944 году, когда впервые была предложена метрика Token-Type Ratio. Это интуитивная метрика придет в голову любому, кто достаточно долго подумает о том, как можно измерить разнообразие слов в тексте.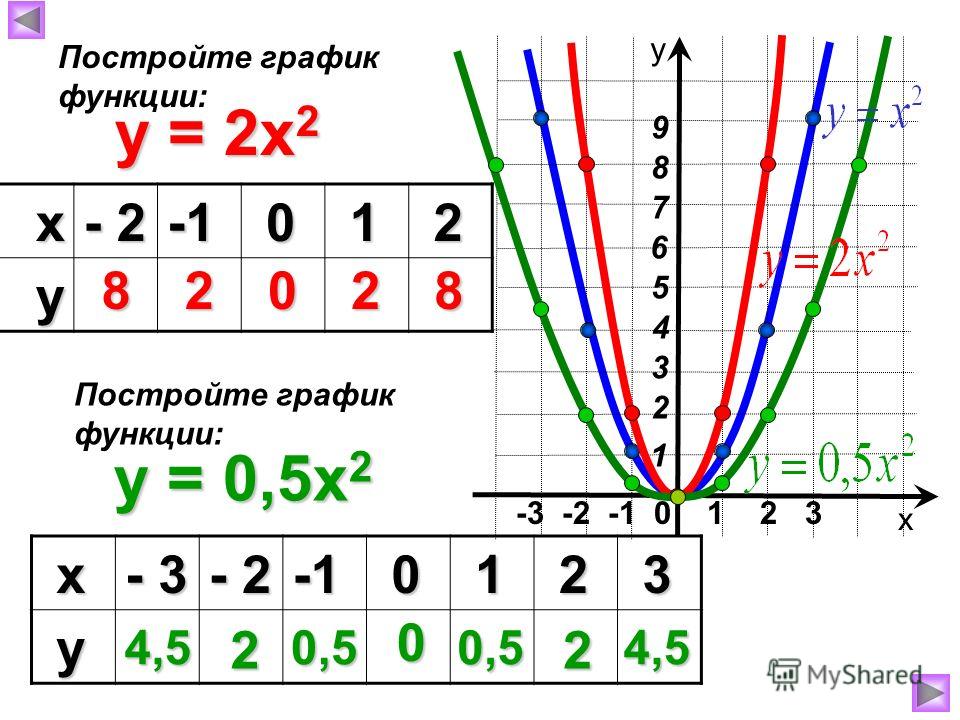 Считается она по следующей формуле
Считается она по следующей формуле
где V — количество уникальных слов, в N — количество всех слов («токен» и «слово» далее по тексту синонимы). Однако у этой формулы есть фундаментальный недостаток — ее значение нелинейно зависит от размера измеряемого текста. Происходит это потому, что при достаточно большом объеме текста количество уникальных слов является почти константой. Поэтому вместо линейной зависимости, мы получаем что-то похожее на гиперболу.
С тех пор набралась тьма [1] вариантов подсчета TTR с поправками на длину, но идела пока так никто и не нашел. Однако, исходя из этой статьи [2], на данный момент комбинация из трех метрик MTLD, vocd (HD-D) и Maas является лучшим вариантом для измерения лексического многообразия. Кроме того, в этой [3] статье заявлено, что vocd (HD-D) лучше других подходит для корпусов малого размера. Про них я и расскажу.
MTLD
Одна из новейших метрик оценки лексического разнообразия текстов [2].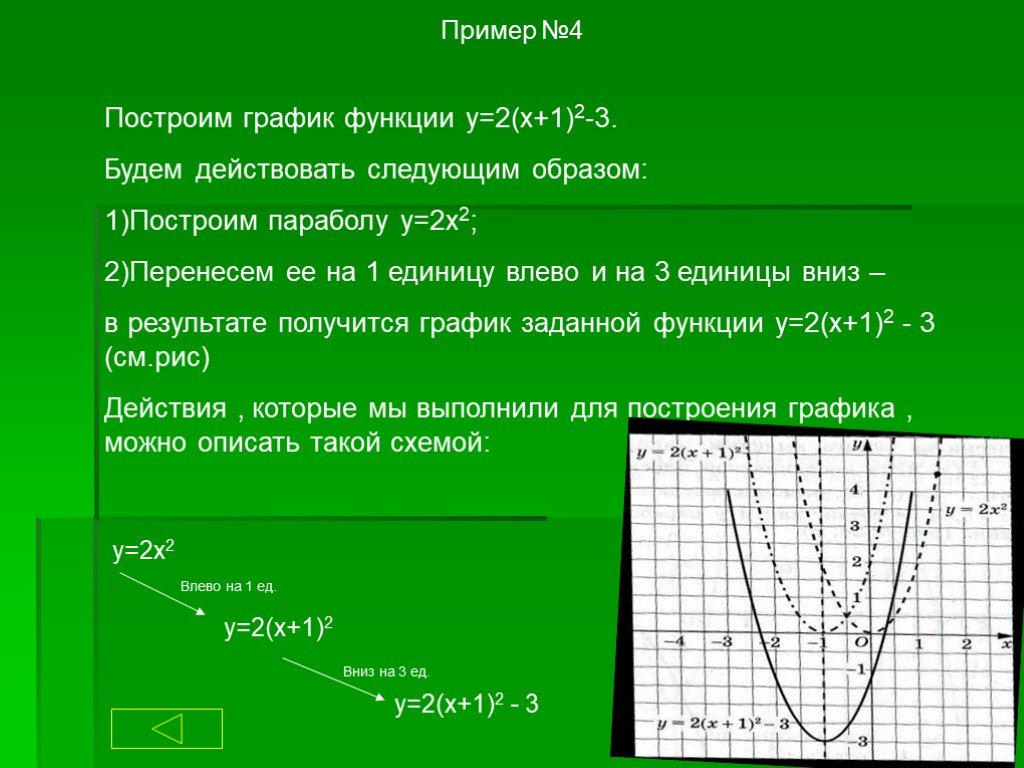 Создатели руководствовались наблюдениями за динамикой TTR для решения проблемы зависимости от длины. Оказывается, если построить график значений TTR в зависимости от количества токенов, то получится примерно следующая картина.
Создатели руководствовались наблюдениями за динамикой TTR для решения проблемы зависимости от длины. Оказывается, если построить график значений TTR в зависимости от количества токенов, то получится примерно следующая картина.
На этом графике можно выделить три региона. В регионе (а) TTR равняется 1, поскольку в начале все токены уникальны. Как только начинают появляться повторения, значение TTR резко проседает в регионе (b). После этого снова наблюдается рост TTR, что говорит нам о наборе новой порции уникальных токенов. Можно видеть, что такие колебания повторяются несколько раз, пока не настанет т.н. точка стабилизации или насыщения, после которой нет значительных изменений в количестве уникальных токенов или повторении старых. Дальнейшее убывание прямой связано с тем, что повторений будет становиться больше и больше, по стандартному сценарию.
 Отсюда логично предположить, что чем больше токенов требуется для достижения этой точки, тем более разнообразней получается текст.
Отсюда логично предположить, что чем больше токенов требуется для достижения этой точки, тем более разнообразней получается текст.Опираясь на это, будем считать MTLD следующим образом. Начиная с первого токена в тексте, будем брать промежуток токенов длинною от единицы и считать его TTR. Если TTR на промежутке не достиг значения точки стабилизации, тогда увеличиваем промежуток на 1 вправо. Если достиг, то увеличиваем счетчик т.н. факторов на один и обозначаем начало нового промежутка там, где был конец предыдущего промежутка. Делаем так по всему тексту. Если последний кусок заканчивается раньше, чем будет достигнута точка стабилизации, то считаем какой процент этот кусок составляет до точки стабилизации и прибавляем это к счетчику факторов. Наконец, поделим количество всех токенов на то, что у нас получилось в счетчике и получим MTLD.
Стоит упомянуть, что авторы рекомендуют считать MTLD с двух сторон текста, а в качестве результата отдавать среднее.
Преимуществом MTLD над многими другими метриками является внятная интерпретируемость, а также использование всего объема текста, чем страдают другие метрики, основанные на использовании промежутков. Например, они могут отбрасывать слова в конце, если из них нельзя сформировать полное окно. Однако, прежде чем использовать MTLD для конкретного языка или может даже домена, необходимо сначала найти точку стабилизации.
voc-d
Так называется программа в среде Unix для подсчета метрики лексического разнообразия D [5]. Часто можно встретить о ней мнение, как о стандарте подсчета лексического разнообразия. Идея метрики основывается на вероятностной интерпретации TTR, благодаря которой, с историей в несколько работ, появилась аппроксимирующая формула для TTR с одним параметром D
Если нарисовать графики семейства функции, то получится следующее
Это очень похоже на то, как ведет себя реальный TTR.
Идея программы voc-d заключается в построении эмпирического TTR и нахождения такого параметра D, которое бы лучше всего описывало полученную зависимость. Найденное значение D и принимается за оценку разнообразия. Эмпирический TTR строится как набор средних значений 100 подсчетов TTR на отрезках от 35 до 50 токенов. Сами отрезки случайно выбираются из текста. Чем выше D, тем больше разнообразие.
HD-D
Однако, со временем, исследователи заметили [6] интересную вещь в процедуре voc-d, а именно то, что это на самом деле процедура довольно избыточная и вносит шум в результат. Считать тоже самое можно гораздо проще.
Если внимательно рассмотреть процедуру семплирования voc-d, то можно понять, что это ничто иное, как аппроксимация TTR всевозможных комбинаций r слов, где r принимаеи значение от 35 до 50. Рассмотрим отрезок текста из 35 токенов. Каждый новопоявившийся токен в очередном семпле такого отрезка из 35 токенов вносит в TTR 1/35 всего значения. Вполне очевидно, что они не равноправны, ведь явно одни слова появляются чаще других.
Для примера возьмем слово кротовуха. Допустим, оно 10 раз встречается в тексте длиной в сто слов, тогда вероятность хотя бы раз встретить его в выборке 35 токенов равняется 0.98966. По другому говоря, это слово хотя бы один раз встретится в 98.966% комбинаций из 35 токенов данного текста. Таким образом, вклад нашего слова в TTR всевозможных комбинаций 35 слов будет складываться из части токена в TTR (1/35) и пропорции семплов (0. 98966), где оно может появиться, если мы будем рассматривать все комбинации. Тогда вклад
98966), где оно может появиться, если мы будем рассматривать все комбинации. Тогда вклад кротовухи расчитывается как $1/35*0.98966$. Значение всего TTR для 35 токенов будет сумма вероятностей всех слов в тексте.
Авторы также показали, что эти полученные значения почти идеально коррелируют со значениями D, а расхождения они объясняют шумом, который появляется в процедуре voc-d.
Я получил массу удовольствия, разбираясь как все эти метрики устроены. Однако, есть проблема. В этих статьях ни слова не сказано, как эти метрики поведут себя на других языках. Более того, MTLD явно нуждается в настройке на язык.
Меня, в первую очередь, интересовало поведения метрики при изменении длины текстов, но, к сожалению, устраивать тесты по всем правилам, которые описаны в статьях, у меня нет возможности. Поэтому я провел простой эксперимент, наглядно показывающий на графике, как изменяется значение трех метрик, а именно MTLD, HD-D и Mass на 10 разных документах длиной в 500 токенов из 3 разных доменов, а именно интервью, новости и википедия.
В качестве источника данных я использовал OpenCorpora. Здесь меня поджидала боль в виде отсутствия внятного разделения корпуса на домены. Они номинально есть, но либо инструмент их неправильно парсил, либо они там действительно номинально. Пришлось вручную фильтровать и собирать подходящие тексты. Однако, в целом, это мелочи. Я очень рад, что существует такой проект. Но, к сожалению, судя по активности, он медленно умирает.
Ниже представлены графики трех метрик плюс TTR на токенах с фильтрованой пунктуацией.
Новости
Википедия
Интервью
На графике TTR хорошо видно и гиперболоподобную зависимость, и те регионы, которые мы обсуждали в рассказе про MTLD. Интересно, что некоторые документы явно выбиваются из общей картины. Для MTLD здесь точка стабилизации установлена в 0.83. Видно, что, с оговорками графики похожи на линейные, но на некоторых документах метрику не слабо так колбасит.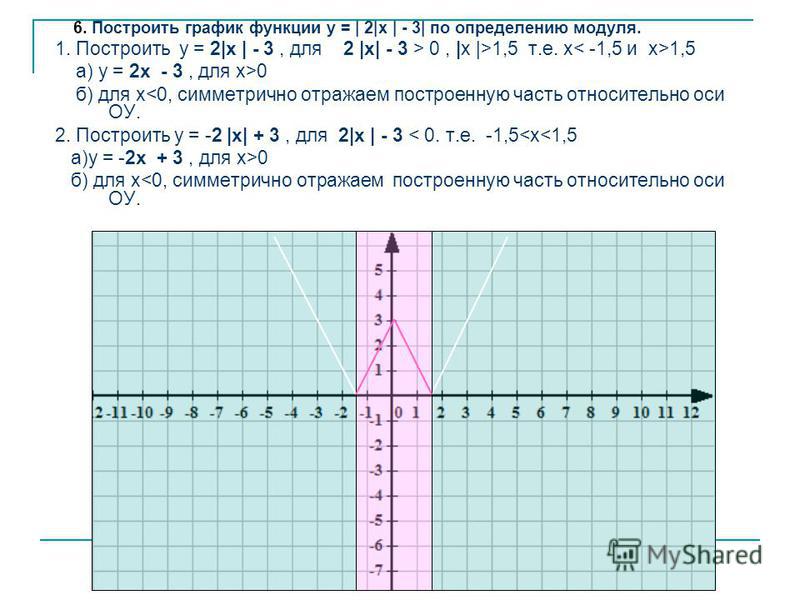 Метрика Mass отражает TTR полностью. HD-D же выглядит самой линейной среди всех, хотя мне кажется подозрительным маленький разброс по значениям. А еще считается она катастрофически долго по сравнению с остальными. Можно сделать общее наблюдение о том, что точка стабилизации прослеживается во всех метриках, поэтому использовать документы длиной раньше, чем эта точка достигается, лучше не стоит.
Метрика Mass отражает TTR полностью. HD-D же выглядит самой линейной среди всех, хотя мне кажется подозрительным маленький разброс по значениям. А еще считается она катастрофически долго по сравнению с остальными. Можно сделать общее наблюдение о том, что точка стабилизации прослеживается во всех метриках, поэтому использовать документы длиной раньше, чем эта точка достигается, лучше не стоит.
Смотря на графики выделяющихся документов, я подумал, что возможно стоит лемматизировать слова, все-таки английский не так богат на морфологию. Вооружившись pymorphy2, я повторил эксперимент, результаты ниже
Новости
Википедия
Интервью
Если сравнивать, то видно, что некоторые выбросы сгладились, но не сильно.
Как видно, метрики далеко не идеальны. MTLD и HD-D безусловно обладают большей линейностью, чем TTR, однако, их локальные изменения вызывают вопросы.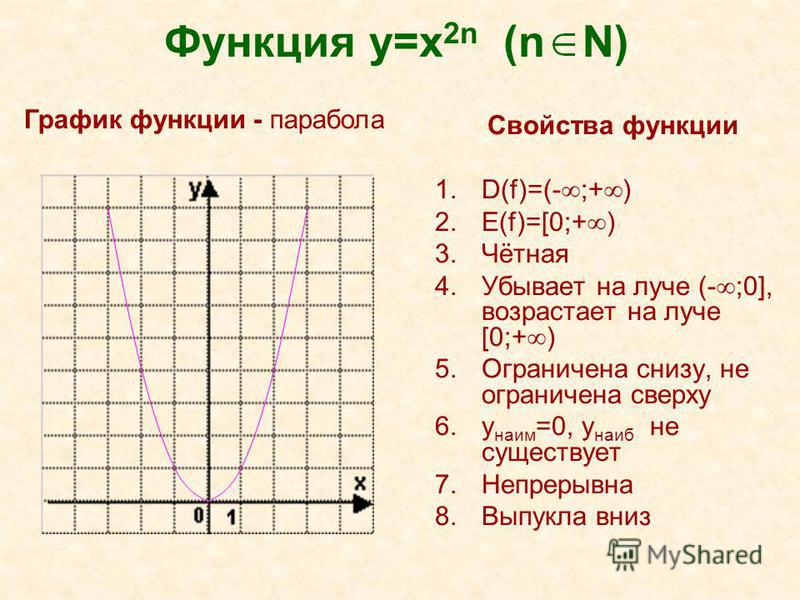 Однако, нужно помнить, что никто и не говорил, что они идеальны. Существуют работы [8], кстати, которые призывают перестать пытаться запихнуть информацию о таком сложном явлении, как лексическое разнообразие, в одну цифру. Вместо этого предлагается использовать несколько параметров.
Однако, нужно помнить, что никто и не говорил, что они идеальны. Существуют работы [8], кстати, которые призывают перестать пытаться запихнуть информацию о таком сложном явлении, как лексическое разнообразие, в одну цифру. Вместо этого предлагается использовать несколько параметров.
Я тут решил создал канал в телеге. Буду там постить выжимки из статей (может быть тогда очередь закончится), мысли, части вот таких статей и анонсы самих статей.
[1] quanteda documentation: Calculate lexical diversity
[2] MTLD, vocd-D, and HD-D. A validation study of sophisticated approaches to lexical diversity assessment
[3] Finding Appropriate Lexical Diversity Measurements for Small-Size Corpus
[4] Combining keyphrase extraction and lexical diversity to characterize ideas in publication titles
[5] Measuring Vocabulary Diversity Using Dedicated Software
[6] vocd. A theoretical and empirical evaluation
[7] Measure Lexical Diversity
[8] Capturing the Diversity in Lexical Diversity
[9] Lexical Diversity an Language Development
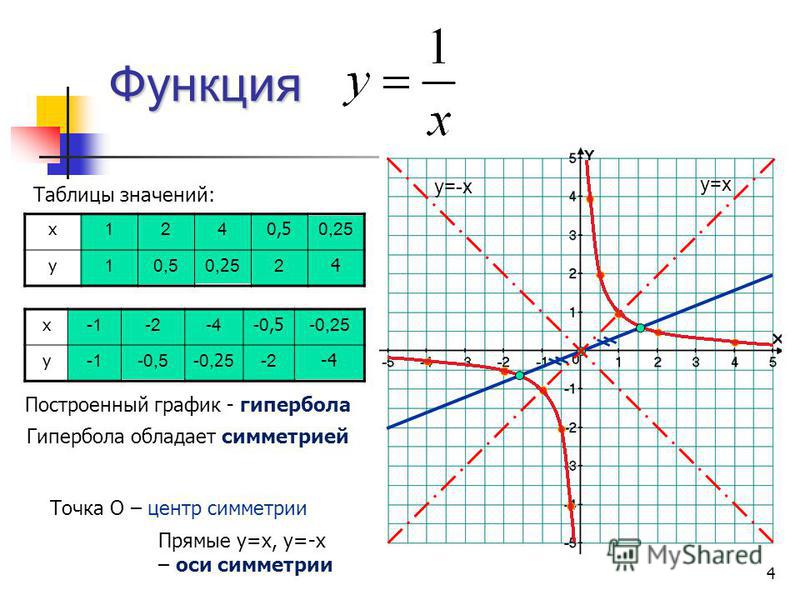
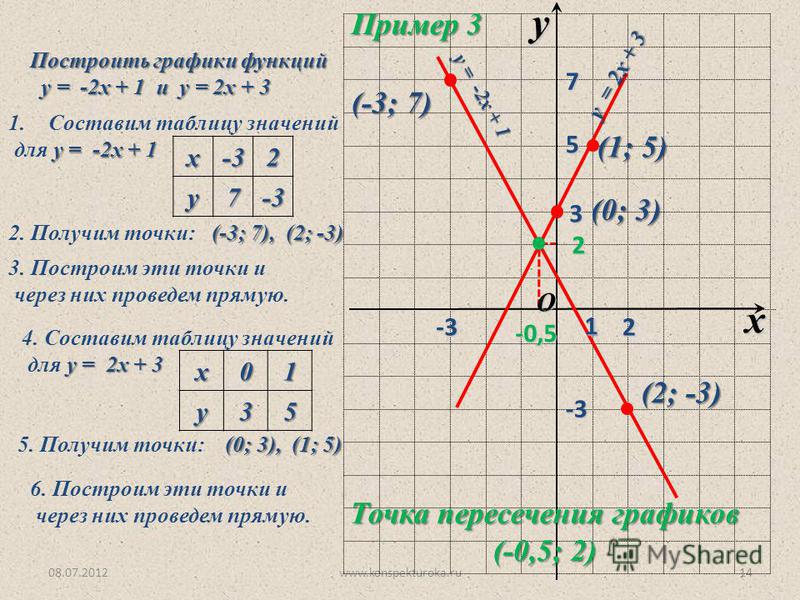
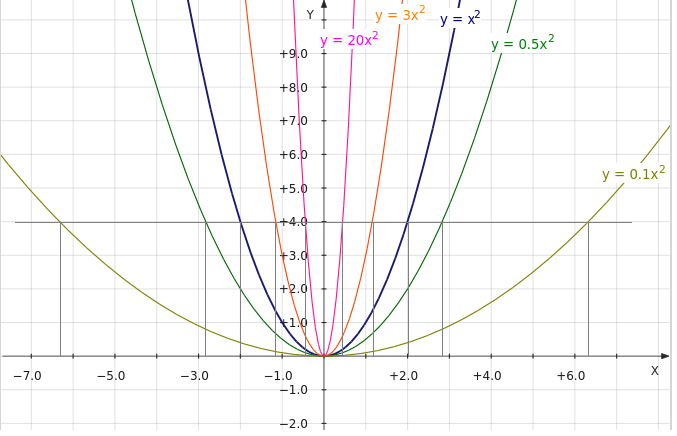
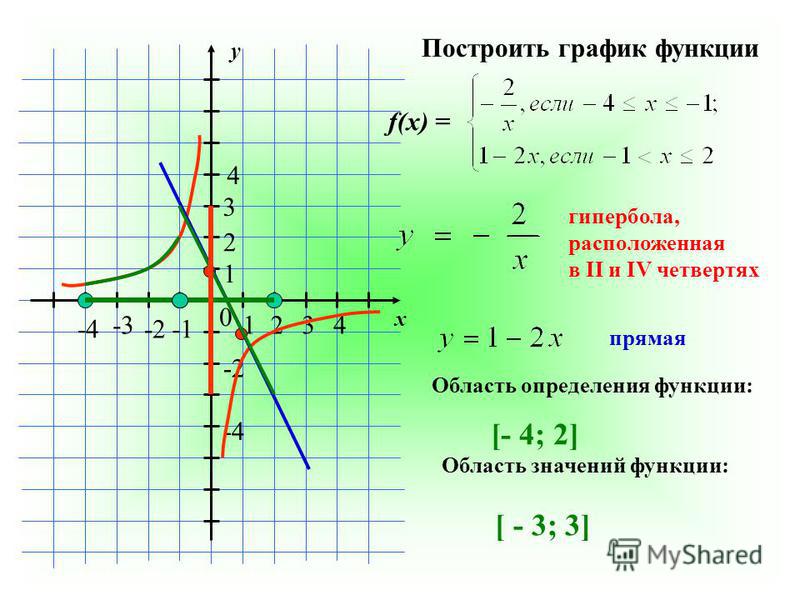
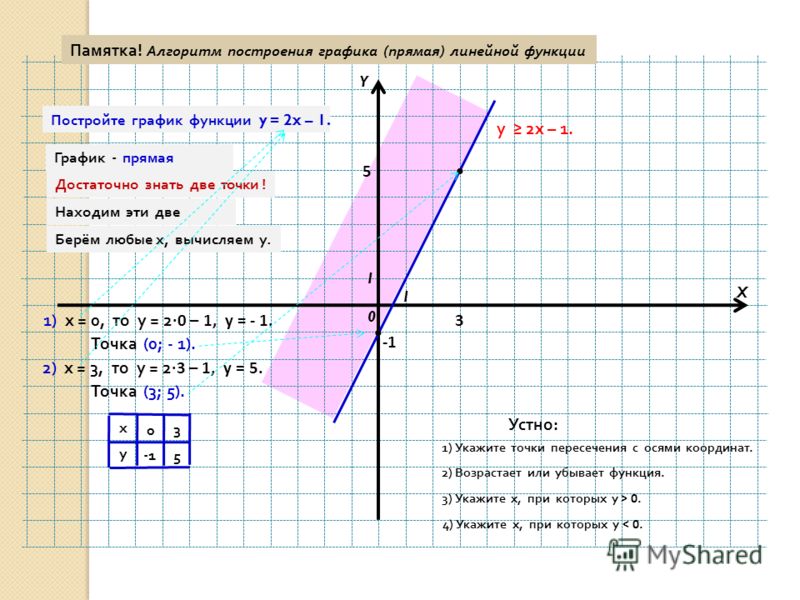
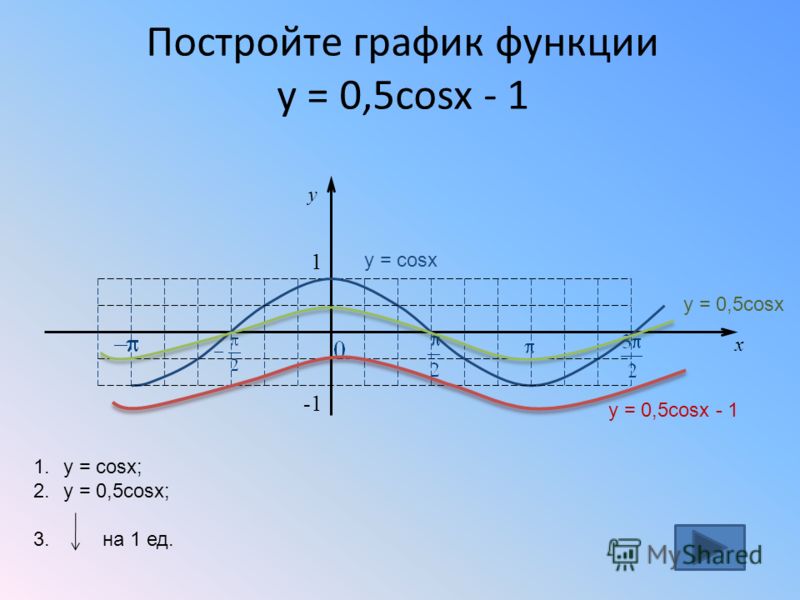
parent-functions-worksheet-pdf — Google Suche
AlleBilderBücherVideosMapsNewsShopping
Suchoptionen
[PDF] Parent Function Worksheet 1 — SharpSchool
cdn5-ss13. sharpschool.com › File › Quadratics › transformation_hmwk
sharpschool.com › File › Quadratics › transformation_hmwk
For задача 1-6, пожалуйста, укажите имя родительской функции и опишите представленное преобразование. Вы можете использовать свой графический калькулятор для сравнения …
[PDF] РОДИТЕЛЬСКИЕ ФУНКЦИИ
mshillig.org › …
Рабочий лист родительских функций. # 1- 7 Дайте имя родительской функции и опишите представляемое преобразование. 1. g(x) = x 2 – 1.
[PDF] Рабочий лист родительской функции #2
site.isdschools.org › bjones › useruploads › алгебра-2 › родительская функция… -1 Название проверки родительской функции. Сопоставьте название и уравнение с графиком. Названия: А) абсолютная величина Б) кубическая. в) линейный. г) квадратичный. Е) радикальное.
[PDF] 1_График родительских функций и преобразований
lindblomeagles.org › ourpages › auto › ДЕНЬ 7 Граф родительских функций
30.09.2015 · Рабочий лист от Kuta Software LLC. Средняя математика 3 … 1_Графика: Родительские функции и преобразования. Нарисуйте график с помощью преобразований …
Средняя математика 3 … 1_Графика: Родительские функции и преобразования. Нарисуйте график с помощью преобразований …
[PDF] Рабочий лист родительской функции 1
rmsалгебра.weebly.com › загрузки › alg_-_dl_-_16-3_equations_of_tr…
8 Algebra CC. ДЛ 16-3. Основной вопрос: Как мы можем написать уравнение преобразованной функции? Сделайте сейчас: A. Какое уравнение сдвинет график y = x. 2 …
[PDF] 4- Parent functions and trans wrkksht.pdf
www.cabarrus.k12.nc.us › cms › lib › Centricity › Domain › 4- Paren…
Algebra II: Translations on Parent Обзор функций. 2. f(x) = x-1. Для задачи 1–6 укажите название родительской функции и опишите …
[PDF] Общие родительские функции — Колледж Джорджа Брауна
www.georgebrown.ca › сайты › файлы › загруженные файлы › tlc › _documents
Общие родительские функции. Репетиторский и учебный центр, Колледж Джорджа Брауна … Квадратичная функция: f(x) = x.