
Как правильно писать логи (?) / Хабр
Тема может и банальная, но когда программа начинает работать как то не так, и вообще вести себя очень странно, часто приходится читать логи. И много логов, особенно если нет возможности отлаживать программу и не получается воспроизвести ошибку. Наверно каждый выработал для себя какие то правила, что, как и когда логировать. Ниже я хочу рассмотреть несколько правил записи сообщений в лог, а также будет небольшое сравнение библиотек логирования для языков php, ruby и go. Сборщики логов и системы доставки не будут рассматриваться сознательно (их обсуждали уже много раз).
Есть такая linux утилита, а также по совместительству сетевой протокол под названием syslog. И есть целый набор RFC посвящённый syslog, один из них описывает уровни логирования https://en.wikipedia.org/wiki/Syslog#Severity_level (https://tools.ietf.org/html/rfc5424). Согласно rfc 5424 для syslog определено 8 уровней логирования, для которых также дается краткое описание.
- что-то происходит и надо знать что
- что-то сломалось и нужно дополнительно активировать триггер
По триггеру может происходить: уведомление об ошибке на email, аварийное завершение или перезапуск программы или другие типичные сценарии.
В языке Go в котором всё упрощено до предела, стандартный логер тоже прилично покромсали и оставили следующие варианты:
- Fatal — вывод в лог и немедленный выход в ОС.
- Panic — вывод в лог и возбуждение «паники» (аналог исключения)
- Print — просто выводит сообщение в лог
Запутаться, что использовать в конкретной ситуации уже практически невозможно. Но сообщения в таком сильно усеченном виде сложно анализировать, а также настраивать системы оповещения, типично реагирующих на какой нибудь Alert\Fatal\Error в тексте лога.
Я часто при написании программы с нуля повсеместно использую debug уровень для логирования с расчётом, что на продакшене будет выставлен уровень логирования info и тем самым сократится зашумлённость сообщениями. Но в таком подходе часто возникают ситуация, что логов вдруг становится не хватать. Трудно угадать, какая информация понадобиться, что бы отловить редкий баг. Возможно рационально всегда использовать по умолчанию уровень info, а в обработчиках ошибок уровень error и выше.
Есть ещё тонкий момент, когда вы пишите что то вроде logger.debug(entity.values) — то при выставленном уровне логирования выше debug содержимое entity.values не попадёт в лог, но оно каждый раз будет вычисляться отъедая ресурсы. В Ruby логеру можно передать вместо строки сообщения блок кода: Logger.debug { entity.values }. В таком случае вычисления будут происходить только при выставленном соответствующем уровне лога. В языке Go для реализации ленивого вычисления в логер можно передать объект поддерживающий интерфейс Stringer.
После того, как разобрались с использованием уровней логов, нужно ещё уметь связывать разрозненные сообщения, особенно это актуально для многопоточных приложений или связанных между собой отдельных сервисов, когда в логах все сообщения оказываются вперемешку.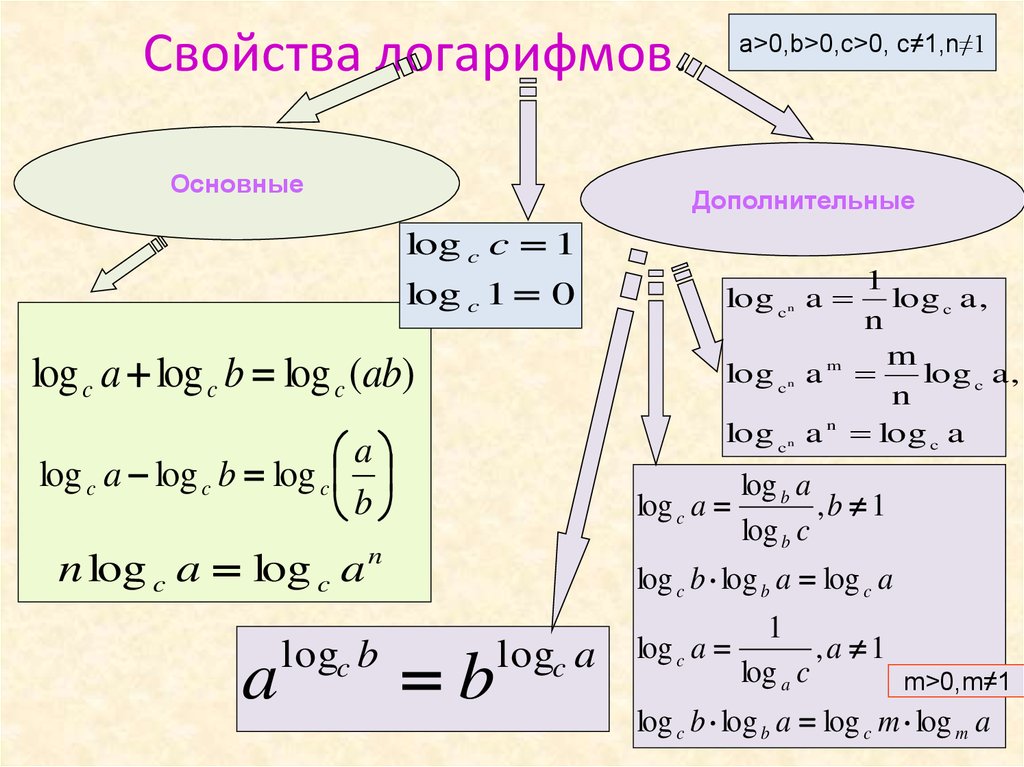
Типичный формат строки сообщения в логе можно условно разделить на следующие составные части:
[system info] + [message] + [context]
Где:
system info: метка времени, ид процесса, ид потока и другая служебная информацияmessage: текст сообщенияcontext: любая дополнительная информация, контекст может быть общим для сообщений в рамках какой то операции.
Для того, чтобы связать пары запрос\ответ часто используется http заголовок X-Request-ID. Такой заголовок может сгенерировать клиент, или он может быть сгенерирован на стороне сервера. Добавив его в контекст каждой строчки лога появится возможность лёгким движением руки найти все сообщения возникшие в рамках выполнения конкретного запроса. А в случае распределенных систем, заголовок можно передавать дальше по цепочке сетевых вызовов.
Но с единым контекстом в рамках запроса возникает проблема с различными ORM, http клиентами или другими сервисами\библиотеками, которые живут своей жизнью. И ещё хорошо, если они предоставляют возможность переопределить свой стандартный логер хотя бы глобально, а вот выставить контекст для логера в рамках запроса зачастую не реально. Данная проблема в основном актуальна для многопоточной обработки, когда один процесс обслуживает множество запросов. Но например в фрэймворке Rails имеется очень тесная интеграция между всеми компонентами и запросы ActiveRecord могут писаться в лог вместе с глобальным контекстом для текущего сетевого запроса. А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
И ещё хорошо, если они предоставляют возможность переопределить свой стандартный логер хотя бы глобально, а вот выставить контекст для логера в рамках запроса зачастую не реально. Данная проблема в основном актуальна для многопоточной обработки, когда один процесс обслуживает множество запросов. Но например в фрэймворке Rails имеется очень тесная интеграция между всеми компонентами и запросы ActiveRecord могут писаться в лог вместе с глобальным контекстом для текущего сетевого запроса. А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
reqLog := log.WithField("requestID", requestID)
После этого такой экземпляр логера можно передать как зависимость в другие объекты. Но отсутствие стандартизированного интерфейса логирования (например как psr-3 в php) провоцирует создателей библиотек хардкодить малосовместимые реализации логеров. Поэтому если вы пишите свою библиотеку на Go и в ней есть компонент логирования, не забудьте предусмотреть интерфейс для замены логера на пользовательский.
Резюмируя:
- Логируйте с избытком. Никогда заранее не известно сколько и какой информации в логах понадобится в критический момент.
- Восемь уровней логирования — вам действительно столько надо? По опыту должно хватить максимум 3-4, и то при условии, что для них настроены обработчики событий.
- По возможности используйте ленивые вычисления для вывод сообщений в лог
- Всегда добавляйте текущий контекст в каждое сообщение лога, как минимум requestID.
- По возможности настраивайте сторонние библиотеки таким образом, чтобы они использовали логер с текущим контекстом запроса.
Архитектура логирования / Хабр
Мой опыт разработки в основном строится вокруг разнообразных сетевых cервисов под Windows и Linux. Я обычно стремлюсь добиться максимальной кроссплатформенности вплоть до бинарной совместимости. И конечно, накопилось некоторое количество стабильных решений связанных с логированием.
Топик написан как продолжение к этой статье и будет полезен в первую очередь начинающим программистам.
Здесь я собираюсь осветить следующие вопросы:
- Внутреннее свойство логгера и примеры софта который его использует.
- Объемы, уровни и детализация сообщений лога.
- Общие правила конфигурации в разработке, в бою и в расследовании.
Итак, начну со своих дополнений к предыдущей статье.
Я как и автор пользуюсь NLog’ом и разумеется широко использую его особенности. Конечно, после
их реализации в любом другом логгере, нижеописанную практику можно применять и у них.
Кстати, log4net продолжает развиваться.
Собственно, требуемых дополнений к «Фичам добропорядочного логгера» всего два:
- Наблюдение/перезагрузка файла конфигурации — это уже не просто полезное, а весьма необходимое умение.
- Минимальное вмешательство в выключенном состоянии.
Под капотом NLog
Сразу обсудим полезность второй фичи.
Часто, при разработке кода, возникает необходимость посмотреть значение какой либо переменной в процессе выполнения. Обычно, используют дебаггер и останавливают программу в интересующем месте. Для меня же, это явный признак, что этом месте будет полезен Trace вывод. В комплекте с юнит-тестами мы сразу получаем развертку этой переменной во времени и протокол для сравнения с тестами в других условиях. Таким образом, дебаггером я практически не пользуюсь.
Очевидно, что в боевом применении, даже выключенное подробное логирование, может мешать как скорости выполнения так и параллельности.
В NLog используются следующие приемы:
- Кэширование уровня логирования в volatile переменной. Это не требует блокировки или синхронизации потоков.
- Простой метод выяснения необходимости логирования. При некоторых условиях может приводить к inline-вставке кода в процессе jit-компиляции. А это превращает логику в простой условный пропуск участка кода и избавляет от копирования и передачи параметров функции логирования.

- Подробные перегрузки методов логирования. Минимизируют преобразование типов, а также берегут от напрасного боксинга, до того как мы выяснили о необходимости логирования.
- Отложенная генерация сообщения делегатом. Позволяет наглядно и легко задавать сложную генерацию сообщений.

Исходный код класса можно посмотреть тут.
Отлично! Для NLog можно быть уверенным, что ваши сколь угодно детальные сообщения могут быть отключены и это минимально скажется на производительности. Но, это не повод посвящать логированию половину кода.
Что и как логировать
Следует придерживаться правил:
- Вывод в лог следует размещать на отдельной строке.
- Сообщение должно быть максимально коротким и информативным.
- Локализовывать можно только редкие или фатальные сообщения.
- Аргументы желательно брать из локальных переменных метода или внутренних переменных класса данного метода.
- Не желательно использовать преобразования типов.

В целом, при выводе в лог, всегда отмечайте, то количество потенциально лишних вычислений, которые потребуются для случая когда лог отключен.
Простой пример (фрагмент некоторого класса):private static Logger Log = LogManager.GetCurrentClassLogger();<br/>
<br/>
public string Request(string cmd, string getParams)<br/>
{<br/>
Uri uri = new Uri(_baseUri, cmd + "?" + getParams);<br/>
Log.Debug("Request for uri:`{0}'", uri);<br/>
HttpWebRequest webReq = (HttpWebRequest)WebRequest.Create(uri);<br/>
webReq.Method = "GET";<br/>
webReq.Timeout = _to;<br/>
<br/>
string respText;<br/>
try<br/>
{<br/>
string page;<br/>
using (WebResponse resp = webReq.GetResponse())<br/>
using (Stream respS = resp. GetResponseStream())<br/>
GetResponseStream())<br/>
using (StreamReader sr = new StreamReader(respS))<br/>
page = sr.ReadToEnd();<br/>
Log.Trace("Response page:`{0}'", page);<br/>
return page;<br/>
}<br/>
catch(Exception err)<br/>
{<br/>
Log.Warn("Request for uri:`{0}' exception: {1}", uri, err.Message);<br/>
throw;<br/>
}<br/>
}
Все аргументы логирования требовались для логики. Сообщение Debug отмечает аргументы с которыми мы пришли в функцию. В обработчике ошибки мы дублируем входные параметры на случай отключения Debug уровня. А это уже даст информацию при необходимости написать юнит-тест. Стек исключения не выводим, так как остается возможность сделать это вышестоящим обработчиком.
Вообще, в текущем обработчике ошибок полезно детализировать контекст который к привел к исключению и специфичные особенности исключения. В примере было бы полезно вывести поле Status для случая WebException.
В примере было бы полезно вывести поле Status для случая WebException.
Гарантии сохранности лога
Несмотря на некоторые возможности NLog по авто записи логов, нет гарантии сохранности лога при завершении процесса.
Что интересно, попытка завершить запись обработкой события AppDomain.ProcessExit не совсем корректна. В конфигурации может быть настроено много разных способов записи в лог, в том числе и по сети. А обработчик этого события находится в ограниченном окружении. В .Net это время работы не более 2х секунд, а в Mono это остановленный ThreadPool. Поэтому, полезно позаботиться о завершении процесса в более дружественном окружении.
Первое, что следует сделать, это обработать событие AppDomain.UnhandledException. В нем следует записать в лог полную информацию об ошибке и вызвать LogManager.Flush(). Обработчик этого события использует тот же поток, который и вызвал исключение, а по окончании, немедленно выгружает приложение.
private static readonly Logger Log = LogManager.GetCurrentClassLogger();<br/>
<br/>
public static void Main(string[] args)<br/>
{<br/>
AppDomain.CurrentDomain.UnhandledException += OnUnhandledException;<br/>
(...)<br/>
LogManager.Flush();<br/>
}<br/>
<br/>
static void OnUnhandledException(object sender, UnhandledExceptionEventArgs e)<br/>
{<br/>
Log.Fatal("Unhandled exception: {0}", e.ExceptionObject);<br/>
LogManager.Flush();<br/>
}
Кроме того, следует вызывать LogManager.Flush() везде, где потенциально возможно завершение процесса. В конце всех не фоновых потоков.
Если ваше приложение представляет собой win-service или Asp.Net, то следует обработать соответствующие события начала и завершения кода.
Сколько логировать
Серьезная проблема для разработчика. Всегда хочется получать больше информации, но код начинает выглядеть очень плохо. Я руководствуюсь следующими соображениями.
Всегда хочется получать больше информации, но код начинает выглядеть очень плохо. Я руководствуюсь следующими соображениями.
Вывод в лог это по сути комментарий. Логирование уровня Trace по большей части их и заменяет.
Уровни Trace и Debug читают разработчики, а все что выше — техподдержка и админы. Поэтому до уровня Info сообщения должны точно отвечать на вопросы: «Что произошло?», «Почему?» и по возможности «Как исправить?». Особенно это касается ошибок в файлах конфигурации.
Качественный состав уровней логирования уже разобран в предыдущей статье, здесь рассмотрим только количественный состав:
- Trace — вывод всего подряд. На тот случай, если Debug не позволяет локализовать ошибку. В нем полезно отмечать вызовы разнообразных блокирующих и асинхронных операций.
- Debug — журналирование моментов вызова «крупных» операций. Старт/остановка потока, запрос пользователя и т.п.
- Info — разовые операции, которые повторяются крайне редко, но не регулярно. (загрузка конфига, плагина, запуск бэкапа)
- Warning — неожиданные параметры вызова, странный формат запроса, использование дефолтных значений в замен не корректных. Вообще все, что может свидетельствовать о не штатном использовании.
- Error — повод для внимания разработчиков. Тут интересно окружение конкретного места ошибки.
- Fatal — тут и так понятно. Выводим все до чего дотянуться можем, так как дальше приложение работать не будет.
 (загрузка конфига, плагина, запуск бэкапа)
(загрузка конфига, плагина, запуск бэкапа)Боевое развертывание
Предположим, разработка дошла до внедрения.
Отложим вопросы ротации логов, размера файлов и глубины истории. Это все очень специфично для каждого проекта и настраивается в зависимости от реальной работы сервиса.
Остановлюсь только на смысловой организации файлов. Их следует разделить на 3 группы. Может потребуется развести логи модулей в разные файлы, но дальше я все равно буду говорить об одном файле для каждой группы.
- Группа Info, с соответствующим уровнем для всех источников. Это информация для администратора. Здесь могут быть следующие вещи: когда приложение стартовало, правильно ли вычитаны конфиги, доступны ли требуемые сервисы, и т.д. Его основное свойство: файл изменяет размер только при перезагрузке приложения. В процессе работы, файл расти не должен. Это поможет обеспечить автоматизированный внешний контроль успешности запуска приложения. Достаточно проверить отсутствие в файле ключевых слов Error и Fatal. Проверка всегда будет занимать предсказуемо малое время.
- Группа Warning. Это тоже информация для администратора. Этот файл при нормальной работе должен отсутствовать или быть пустым. Соответственно мониторинг его состояния сразу укажет на сбои в работе. Гибко настроив фильтры по разным источникам, можно подобрать достаточно точный критерий, когда вообще следует обратить внимание на сервис.
- Группа Наблюдение. Как правило в ходе внедрения выделяются некоторые проблемные модули. Информация от них в детализации Debug как раз и направляется сюда.
 Это информация для администратора. Здесь могут быть следующие вещи: когда приложение стартовало, правильно ли вычитаны конфиги, доступны ли требуемые сервисы, и т.д. Его основное свойство: файл изменяет размер только при перезагрузке приложения. В процессе работы, файл расти не должен. Это поможет обеспечить автоматизированный внешний контроль успешности запуска приложения. Достаточно проверить отсутствие в файле ключевых слов Error и Fatal. Проверка всегда будет занимать предсказуемо малое время.
Это информация для администратора. Здесь могут быть следующие вещи: когда приложение стартовало, правильно ли вычитаны конфиги, доступны ли требуемые сервисы, и т.д. Его основное свойство: файл изменяет размер только при перезагрузке приложения. В процессе работы, файл расти не должен. Это поможет обеспечить автоматизированный внешний контроль успешности запуска приложения. Достаточно проверить отсутствие в файле ключевых слов Error и Fatal. Проверка всегда будет занимать предсказуемо малое время.
Если приложение успешно внедрено, то в работе остаются только первые две группы.
Расследование сбоев
Когда работающий сервис подает признаки ошибки, то не следует его пытаться сразу перезагружать. Возможно нам «повезло» поймать ошибки связанные с неверной синхронизацией потоков. И не известно сколько в следующий раз ждать ее повторения.
В первую очередь следует подключить заготовленные заранее конфиги для группы наблюдения. Как раз это и должен позволять делать приличный логгер. Когда мы получили подтверждение о том, что новая конфигурация успешно применена, то пытаемся опять спровоцировать сбой. Желательно несколько раз. Это обеспечит возможность для его воспроизведения в «лабораторных» условиях. Дальше уже работа программистов. А пока можно и перезагрузиться.
Вывод в лог желательно сделать асинхронным.
Пример, боевой настройки.<nlog autoReload="true"><br/>
<targets><br/>
<target name="fileInfo" type="AsyncWrapper" queueLimit="5000" overflowAction="Block"><br/>
<target type="File" fileName="${basedir}/logs/info. log" /><br/>
log" /><br/>
</target><br/>
<target name="fileWarn" type="AsyncWrapper" queueLimit="5000" overflowAction="Block"><br/>
<target type="File" fileName="${basedir}/logs/warn.log" /><br/>
</target><br/>
</targets><br/>
<br/>
<rules><br/>
<logger name="*" minlevel="Info" writeTo="fileInfo" /><br/>
<logger name="*" minlevel="Warn" writeTo="fileWarn" /><br/>
</rules><br/>
</nlog>
При настройке фильтров следует учитывать относительность уровней логирования для каждой из подсистем. Например, некоторый модуль, имея Info сообщение об инициализации, может быть создан для каждого подключенного пользователя. Разумеется, его вывод в Info группу следует ограничить уровнем Warn.
Чего с логгером делать не следует
Логгер должен быть простым и надежным как молоток. И у него должна быть четко очерчена область применения в конкретном проекте. К сожалению, разработчиков часто трудно удержать. Паттерны проектирования, это в основном полезно, но не этом случае. Достаточно часто стал замечать предложения выделить для логгера обобщенный интерфейс (пример) или реализовать обертку в проекте, чтобы отложить муки выбора NLog vs log4net на потом.
И у него должна быть четко очерчена область применения в конкретном проекте. К сожалению, разработчиков часто трудно удержать. Паттерны проектирования, это в основном полезно, но не этом случае. Достаточно часто стал замечать предложения выделить для логгера обобщенный интерфейс (пример) или реализовать обертку в проекте, чтобы отложить муки выбора NLog vs log4net на потом.
Что бы ни было тому причиной, надо точно помнить, что в первую очередь, такие удобства напрочь убивают компилятору возможность оптимизации.
Не стоит напрямую выводить информацию логгера пользователю, даже с фильтрами. Проблема в том, что эта информация зависит от внутренней структуры программы. Вряд ли вы в процессе рефакторинга пытаетесь сохранить вывод логгера. Наверное, здесь стоит просто задуматься и разделить функционал. Возможно, в проекте просто требуется еще один уровень логирования. В этом случае как раз и уместна будет обертка над логгером.
Чего же мне еще не хватает в NLog?
- Дополнительные перегрузки методов логгера, для того чтобы избежать генерации классов лямбда-функций. Хочется иметь вызов вида
Log.Trace<TArg1, TArg2>(Func<TArg1, TArg2, string> messageCreater, TArg1 arg1, TArg2 arg2)
Но на текущий момент, самый короткий человекочитаемый вариант подразумевает скрытую генерацию класса:
Log.Trace(() => MessageCreate(arg1, arg2)) - Бинарная совместимость. Помогает быстро тестировать сервисы на разных платформах. В NLog очень много инструкций условной компиляции в зависимости от платформы. Т.е. бинарник для Mono может неожиданно работь в DotNet. А очень желательна предсказуемость, хотя бы и в ограниченной комплектации.
- Условная расширяемость. Понятно, что с бинарной совместимостью придется жертвовать функционалом, но у нас уже есть удобный механизм расширений. Осталось только, чтобы он фильтровал расширения в зависимости от платформы. Вместе с предыдущей возможностью, это еще и дает простое развертывание через копирование директории с IL-бинарниками.
- Логгирование внутренних сообщений в общем контексте. Был бы полезен список создаваемых в системе логгеров. К сожалению, не уверен, что можно избежать рекурсии. Например, когда вывод в файл начнет писать ошибки вывода в себя же.
 Хочется иметь вызов вида
Хочется иметь вызов вида Был бы полезен список создаваемых в системе логгеров. К сожалению, не уверен, что можно избежать рекурсии. Например, когда вывод в файл начнет писать ошибки вывода в себя же.
Был бы полезен список создаваемых в системе логгеров. К сожалению, не уверен, что можно избежать рекурсии. Например, когда вывод в файл начнет писать ошибки вывода в себя же.NLog, Log4Net, Enterprise Library, SmartInspect…
Разнообразные сравнения логгеров между собой, упускают одну важную деталь.
Важно сравнивать не только ограничения/возможности, но и возможность быстро добавить свои «хотелки».
Поэтому, буду пока дружить с NLog.
Чего и Вам желаю.
Законы логарифмов — GeeksforGeeks
Логарифм — это показатель степени или степень, в которую возводится основание для получения определенного числа. Например, «а» — это логарифм «m» по основанию «x», если x m = a, то мы можем записать это как m = log x a. Логарифмы изобретены, чтобы ускорить расчеты, и время будет сокращено, когда мы умножаем много цифр, используя логарифмы. Теперь давайте обсудим законы логарифмов ниже.
Законы логарифмов
Есть три закона логарифмов, которые выводятся с использованием основных правил возведения в степень. Законами являются закон правила продукта, закон правила частного, закон правила мощности. Рассмотрим законы подробнее.
Законами являются закон правила продукта, закон правила частного, закон правила мощности. Рассмотрим законы подробнее.
Первый закон логарифма или Закон правила произведения
Пусть a = x n и b = x m , где основание x должно быть больше нуля и x не равно нулю. т. е. x > 0 и x ≠ 0. Отсюда мы можем записать их как
n = log x a и m = log x b ⇢ (1)
Используя первый закон показателей, мы знаем, что x n × x m = x n + m ⇢ (2)
Теперь умножаем a и b, получаем это как,
ab = x n × x m
ab = x n + m (Из уравнения 2)
Теперь применим логарифм к приведенному выше уравнению, мы получаем log как ниже, x
Из уравнения 1 мы можем записать как log x ab = log x a + log x b
Итак, если мы хотим умножить два числа и найти логарифм произведения, то складываем отдельные логарифмы двух чисел. Это первый закон логарифмов/правил произведения.
Это первый закон логарифмов/правил произведения.
log x AB = log x A + log x B
Мы можем применить этот закон для более двух чисел, то есть,
log x ABC = log x. а + журнал x б + журнал х в.
Второй закон логарифма или правило частного
Пусть a = x n и b = x m , где основание x должно быть больше нуля и x не равно нулю. т. е. x > 0 и x ≠ 0. Отсюда мы можем записать их как
n = log x a и m = log x b ⇢ (1)
Используя первый закон показателей, мы знаем что x n / x m = x n – m ⇢ (2)
Теперь мы умножаем a и b и получаем как,
a/b = x n / x m
a/b = x n – m ⇢ (Из уравнения 2)
Теперь применим логарифм к приведенному выше уравнению, мы получаем, как показано ниже,
7 log
x (a/b) = n – mИз уравнения 1 мы можем записать как log x (a/b) = log x a – log x b
Итак, если мы хотим Чтобы разделить два числа и найти логарифм деления, мы можем вычесть отдельные логарифмы двух чисел. Это второй закон логарифмов / частный закон правила.
Это второй закон логарифмов / частный закон правила.
log x (a/b) = log x a — log x b
Третий закон логарифма или закона о правилах мощности
Пусть x N ⇢ ( i),
Где основание x должно быть больше нуля и x не равно нулю. т. е. x > 0 и x ≠ 0. Отсюда мы можем записать их как
n = log x a ⇢ (1)
Если мы возведем обе части уравнения (i) в степень m ‘ то мы получаем это следующим образом,
A M = (x N ) M = x NM
Пусть A M — одно количество и применить логарифм к вышеупомянутому уравнению,
Log x A м. = nm
log x a m = m.log x a
Это третий закон логарифмов. В нем говорится, что логарифм степени числа может быть получен путем умножения логарифма числа на это число.
Проблема 1: Log Expand 21.
Решение:
Как мы знаем, что log x AB = log x A + Log x B (от первого. закон логарифма)
Итак, log 21 = log (3 × 7)
= log 3 + log 7
Задача 2: Разверните log (125/64).
Решение:
Поскольку мы знаем, что log x ( a/b) = log x a – log x b (из второго закона логарифма)
Итак, log (125/64) = log 125 – log 64
= log 5 3 – log 4 3
log x a m = m.log x a (из третьего закона логарифма), мы можем записать это как
= 3 log 5 — 3 log 4
= 3 (log 5 — log 4)
Задача 3: Запишите 3log 2 + 5 log3 – 5log 2 в виде единичного логарифма.
Решение:
3log 2 + 5 log3 – 5log 2
= log 2 3 + log 3 5 – log 2 5
= log 8 + log 0 2 × 90 9 32 ) – log 32
= log 1944 – log 32
= log (1944/32)
Задача 4: записать log 16 – log 2 в виде единичного логарифма.
Решение:
log(16/2)
= log(8)
= log(2 3 )
= 3 log 20007
Задача 5: Записать 3 Log 4 как один логарифм
Решение:
Из закона о правилах мощности мы можем написать его как,
= log 4 3
= log 64.
Задача 6: Запись 2 Log 3- 3 Log 2 в виде единого логарифма
Решение:
Log 3 2 — Log 2 3
= Log
= логарифм (9/8)
Задача 7. Запишите log 243 + log 1 в виде единичного логарифма
Решение:
log (243 × 1)
= log 243
5 900 Ru Logarithm | SuperprofЧто такое логарифм
Логарифмическая и экспоненциальная функции обратны друг другу. Например, экспоненциальная функция.
Логарифм числа с логарифмическим основанием e известен как натуральный логарифм. Это выражается математически как или . Значение e равно 2,71828… Логарифм числа по основанию десяти выражается как и известен как десятичный логарифм.
Лучшие репетиторы по математике
Поехали
Основные свойства логарифмов
Вот некоторые из основных свойств логарифмической функции:
- Основание логарифмической функции должно быть больше 0 и не равно 1, т.е. в , и .
- Основание логарифма не может быть отрицательным, поэтому оно всегда должно быть положительным
- Логарифм нуля не существует
- Логарифм единицы равен нулю. Это может быть выражено как , где — основание логарифма
- Логарифм по тому же основанию и числу равен 1. Например, логарифм числа b по основанию b равен единице. Математически это можно выразить как . Например, мы можем записать логарифмическую функцию в экспоненциальной форме как .
- Если логарифм имеет экспоненциальную форму и основание, а число логарифма одинаковое, то оно равно значению показателя степени. Математически это можно выразить как .
Правила логарифмирования
Когда в вопросе используется термин «расширить», необходимо применить логарифмические правила, чтобы упростить выражение и найти значения. Не находите логарифмы с помощью калькулятора, потому что вы должны записывать ответы в виде целых чисел или дробей, тогда как калькулятор выдаст вам десятичное число. Так же, как правила экспоненты, существуют разные логарифмические правила. Эти логарифмические правила вместе с соответствующими примерами поясняются ниже:
1 Правило произведения логарифмов
Логарифм произведения двух чисел равен сумме логарифмов чисел. Это может быть выражено математически как:
Примеры
1 Расширить
Согласно правилу логарифмического произведения
Предположим, и .
Если 2 возвести в степень 2, ответ будет 4, т. е. . Точно так же, если 2 возвести в степень 3, ответ равен 8, т. е. . Следовательно, значения для и равны 2 и 3 соответственно. Следовательно, окончательный ответ:
=
2 Расширить
Согласно правилу логарифмического произведения
Предположим, и . Запишите эти две логарифмические функции в экспоненциальной форме следующим образом:
Если 5 возвести в степень 3, ответ будет 125, т. е. . Точно так же, если 5 возвести в степень 4, ответ будет 625, т. е. . Следовательно, значения для и равны 3 и 4 соответственно. Следовательно, окончательный ответ:
=
2 Правило логарифмического отношения
Логарифм деления m и n равен разности логарифма m и логарифма n.
Примеры
1 Расширить
Согласно правилу логарифмического отношения . Предположим и . Запишите эти две логарифмические функции в экспоненциальной форме следующим образом:
Мы знаем, что, когда 2 в степени 3 равно 8, т. е. 2 в степени 2 равно 4, т. е. . Следовательно, окончательный ответ будет таким:
2 Расширить
Согласно правилу логарифмического отношения . Предположим и . Запишите эти две логарифмические функции в экспоненциальной форме следующим образом:
Мы знаем, что 2 в степени 6 равно 64, т. е. а 2 в степени 5 равно 32, т. е. . Следовательно, окончательный ответ будет:
Помните, что правила логарифмического произведения и частного применимы только к функции, имеющей одно и то же основание.
3 Правило степени логарифма
Логарифм степени равен произведению степени или показателя степени на логарифм числа. Это может быть выражено математически как:
Примеры
1 Расширить
В соответствии с правилом степени логарифма,
Предположим . Сначала мы преобразуем в экспоненциальную форму следующим образом:
Мы знаем, что 2 в степени 3 равно 8, т. е. .
2 Расширить
Согласно правилу логарифмической степени,
Предположим . Во-первых, мы преобразуем в экспоненциальную форму следующим образом:
Мы знаем, что 3, возведенное в степень 2, равно 9, т.
4 Правило переключения основания логарифма
Основание a логарифмической функции b равно обратной величине логарифма a с основанием b. Это может быть выражено математически как:
Примеры
1 Докажите
Сначала решим левую часть приведенного выше выражения.
Допустим .
Преобразовав приведенную выше логарифмическую форму в экспоненциальную запись, мы получим следующее выражение:
Поскольку 2 в степени 5 равно 32, т. е.
Теперь мы решим правую часть приведенного выше уравнения. выражение
Допустим . Когда мы запишем его в экспоненциальной форме, то получим следующее выражение:
Мы знаем, что 2 в степени 5 равно 32. Следовательно, мы можем сказать, что 32 в степени равно 2. Следовательно, что равно 5,
2 Докажите
Давайте сначала решим левую часть приведенного выше выражения.
Допустим .
Записав в экспоненциальной записи, получим следующее выражение:
Так как 5 в степени 3 равно 125, т.
Мы знаем, что 5 в степени 3 равно 125. Следовательно, мы можем сказать, что 125 в степени равно 5. Следовательно, что равно 3. Следовательно, это логарифмическое правило доказано, поскольку левая часть равна правой части.
Здесь вы можете найти авторитетных репетиторов по математике.
5 Правило корня логарифма
Логарифм корня равен произведению между логарифмом подкоренного числа и индексом корня. Это может быть выражено математически как:
Примеры
1 Развернуть
Согласно правилу корня логарифма, . Предполагать . Преобразуем это логарифмическое выражение в экспоненциальную форму следующим образом:
Мы знаем, что 2 в степени 3 равно 8, т.е.
2 Расширить
Согласно правилу корня логарифма, . Предполагать . Преобразуем это логарифмическое выражение в экспоненциальную форму следующим образом:
Мы знаем, что 3, возведенное в степень 2, равно 9, т.
6 Изменение основания
Математически это логарифмическое правило можно описать следующим образом:
Примеры
10007
Сначала решите левую часть выражения, приведя ее к экспоненциальной форме:
Так как 2 в степени 2 равно 4, следовательно, значение x равно 2. Теперь, решим правую часть равенства. Предположим и . Преобразуйте эти логарифмические функции в экспоненциальные формы, чтобы найти их значения:
и
Мы знаем, что 4, возведенное в степень 1, равно 4, поэтому . Точно так же 4, возведенное в степень, равно 2, поэтому . Подставьте эти значения в выражение .
Следовательно, логарифмическое правило доказано на этом примере, поскольку левая часть равна правой части.
2 Докажите
Сначала решите левую часть выражения, приведя ее к экспоненциальной форме:
3. Теперь решим правую часть логарифмического уравнения.
 В логарифмической форме это можно записать как:
В логарифмической форме это можно записать как: Поскольку 3 в степени 1 равно 3, значит .
Поскольку 3 в степени 1 равно 3, значит . Поскольку логарифм является обратной функцией экспоненциального уравнения, мы перепишем эти два логарифма в показательные уравнения следующим образом:
Поскольку логарифм является обратной функцией экспоненциального уравнения, мы перепишем эти два логарифма в показательные уравнения следующим образом: Помните, что правило верно для логарифма числителя — логарифма знаменателя, а не наоборот. Математически это можно выразить так:
Помните, что правило верно для логарифма числителя — логарифма знаменателя, а не наоборот. Математически это можно выразить так: Например, из приведенных выше примеров можно сделать вывод, что можно записать в виде одной логарифмической функции вид . Выражения объединяются в одно выражение, потому что они имеют общую основу а. Мы не можем объединить в одно выражение, потому что обе логарифмические функции имеют разные основания a и b. То же правило применяется к правилу произведения логарифмов.
Например, из приведенных выше примеров можно сделать вывод, что можно записать в виде одной логарифмической функции вид . Выражения объединяются в одно выражение, потому что они имеют общую основу а. Мы не можем объединить в одно выражение, потому что обе логарифмические функции имеют разные основания a и b. То же правило применяется к правилу произведения логарифмов. е. .
е. . е. Когда мы запишем его в экспоненциальной форме, то получим следующее выражение:
е. Когда мы запишем его в экспоненциальной форме, то получим следующее выражение: е. . Это означает, что .
е. . Это означает, что .