
Генерация аудио диффузионной нейросетью. Стоит ли использовать обычную диффузию для генерации мел-спектрограмм? / Хабр
В уходящем году вы могли видеть множество нейросетей для генерации изображений. Скорее всего, даже ваша бабушка слышала про Stable Diffusion или DALL-E, но эти нейросети объединяет одна очень важная деталь — они основаны на методе обратной диффузии. Этот подход к генерации стал самым популярным в 2022 году. Почему бы не попробовать применить его не для генерации картинок, а для музыки или пения птиц?
В этой статье я расскажу о том, как генерировать аудио с помощью классической диффузионной нейросети, и нюансах этого подхода.
▍ Что такое звук? Мел-спектрограммы
Звук — это волновое явление, которое может быть создано механическими колебаниями в воздухе, жидкостях или твёрдых телах. Когда мы слышим звук, наши уши передают сигналы нашему мозгу (подробнее про мозг чуть ниже), который интерпретирует эти сигналы как различные звуки, например голоса, музыку или обычные шумы. На компьютерах звук хранится в виде набора амплитуд, меняющихся тысячи раз в секунду.
На компьютерах звук хранится в виде набора амплитуд, меняющихся тысячи раз в секунду.
Звук в виде набора амплитуд нечасто используют в нейросетях, хоть и для некоторых архитектур это возможно, но в основном используются мел-спектрограммы.
Спектрограммы мела — это графическое представление спектра звука на основе мелового анализа. Преобразование Фурье — это техника, которая используется для определения частотного состава звука. Стоит сказать, что наш слуховой аппарат и есть преобразователь Фурье, и мозг принимает уже не волны, а спектр. В спектрограмме мела время располагается на горизонтальной оси, а частота — на вертикальной. Каждая точка на спектрограмме соответствует определённой частоте звука в определённый момент времени.
Фраза «графическое представление звука» явно наталкивает на возможность использования нейросетей для обработки и генерации изображений для модальности звука. Давайте попробуем использовать диффузию для их генерации!
▍ Диффузионные нейросети
Я разбирал работу диффузионных нейросетей в этой статье, но концепция проста:
Научите модель восстанавливать зашумлённое изображение, и она сможет генерировать новые из рандомного шума.

Но генерировать мел-спектрограммы не так просто. Диффузионные нейросети требуют очень больших мощностей для работы с картинками большого разрешения, и один из самых простых вариантов — масштабировать картинку спектрограммы из 512 х 512 пикселей в 64 х 64 пикселя, а на выходе преобразовывать обратно посредством отдельной нейросети для апскейла или простым масштабированием.
▍ Идея
Идея проста — попробовать применять сжатые спектрограммы для генерации каких-то простых звуков, типа пения птиц.
Мы обучаем диффузионную нейросеть, адаптированную под ЧБ, на мел-спектрограммах и преобразуем их в звук с помощью алгоритма Гриффина-Лима.
Я взял данные с библиотеки звуков BBC, преобразовал в спектрограммы и сжал до 64 пикселей, чтобы диффузионную модель можно было обучить на моей Nvidia RTX 3060, т. к. на больших разрешениях кончалась память. Код диффузии является модификацией Diffusion-Models-pytorch, которую делал я с OxDEADFACE. Также за помощь спасибо Cene655.
Также за помощь спасибо Cene655.
Вот небольшой пайплайн модели:
▍ Подготовка данных
1. Нарезка дорожек аудио на отрезки по 5 секунд. Для преобразования звука в спектрограмму нужного размера аудио должны быть строго по 5 секунд каждое.
Для этой задачи мной был написан этот код:
import os
input_filename = "/content/bird.mp3"
output_folder = "output"
if not os.path.exists(output_folder):
os.makedirs(output_folder)
command = f"ffmpeg -i {input_filename} -f segment -segment_time 5 {output_folder}/11out%03d.wav"
os.system(command) Вы можете запустить его в моём блокноте Colab.
2. Преобразование аудиофайлов в спектрограммы
Нейросеть будет работать со спектрограммами, и для создания датасета наши аудиофайлы нужно преобразовать в них. Мы используем код из Riffusion Manipulation.
Для этого я сделал вот этот блокнот colab, в 4-й ячейке есть массовая конвертация всех файлов из заданной папки.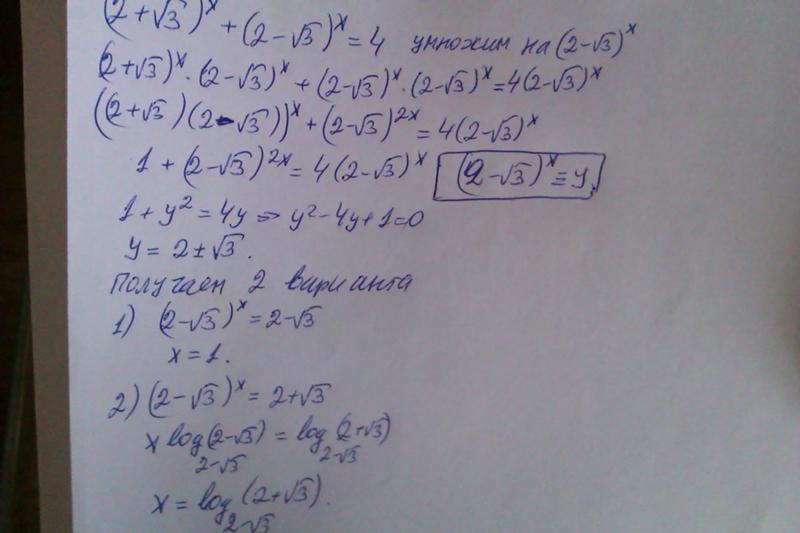
3. Сжатие спектрограмм до 64 х 64 пикселей.
Это можно сделать самым обычным масштабированием, что значительно ускоряет нашу модель.
import os
from PIL import Image
# Имя папки с исходными изображениями
input_folder = 'input'
# Имя папки для сжатых изображений
output_folder = 'output'
# Создаём папку для сжатых изображений, если она не существует
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Перебираем все файлы в папке с исходными изображениями
for file in os.listdir(input_folder):
# Игнорируем файлы, которые не являются изображениями
if not file.endswith('.jpg') and not file.endswith('.png'):
continue
# Открываем изображение
image = Image.open(os.path.join(input_folder, file))
# Сжимаем изображение до размера 64 x 64 пикселей
image = image.resize((64, 64))
# Сохраняем сжатое изображение в папку output
image.save(os.path.join(output_folder, file))
Теперь датасет полностью готов к обучению.
▍ Код модели
Сначала мы создаём файл ddpm, где определяем все параметры модели и её обучения.
Код
import os
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import optim
from utils import *
from modules import UNet
import logging
from torch.utils.tensorboard import SummaryWriter
logging.basicConfig(format="%(asctime)s - %(levelname)s: %(message)s", level=logging.INFO, datefmt="%I:%M:%S")
class Diffusion:
def __init__(self, noise_steps=1000, beta_start=1e-4, beta_end=0.02, img_size=64, device="cuda"):
self.noise_steps = noise_steps
self.beta_start = beta_start
self.beta_end = beta_end
self.img_size = img_size
self.device = device
self.beta = self.prepare_noise_schedule().to(device)
self.alpha = 1. - self.beta
self.alpha_hat = torch.cumprod(self.alpha, dim=0)
def prepare_noise_schedule(self):
return torch. linspace(self.beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.
beta[t][:, None, None, None]
if i > 1:
noise = torch.randn_like(x)
else:
noise = torch.zeros_like(x)
x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise
model.train()
x = (x.clamp(-1, 1) + 1) / 2
x = (x * 255).type(torch.uint8)
return x
def train(args):
setup_logging(args.run_name)
device = args.device
dataloader = get_data(args)
model = UNet().to(device)
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
mse = nn.MSELoss()
diffusion = Diffusion(img_size=args.image_size, device=device)
logger = SummaryWriter(os.path.join("runs", ))
l = len(dataloader)
for epoch in range(args.epochs):
logging.info(f"Starting epoch {epoch}:")
pbar = tqdm(dataloader)
for i, (images, _) in enumerate(pbar):
images = images.to(device)
t = diffusion.
linspace(self.beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.
beta[t][:, None, None, None]
if i > 1:
noise = torch.randn_like(x)
else:
noise = torch.zeros_like(x)
x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise
model.train()
x = (x.clamp(-1, 1) + 1) / 2
x = (x * 255).type(torch.uint8)
return x
def train(args):
setup_logging(args.run_name)
device = args.device
dataloader = get_data(args)
model = UNet().to(device)
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
mse = nn.MSELoss()
diffusion = Diffusion(img_size=args.image_size, device=device)
logger = SummaryWriter(os.path.join("runs", ))
l = len(dataloader)
for epoch in range(args.epochs):
logging.info(f"Starting epoch {epoch}:")
pbar = tqdm(dataloader)
for i, (images, _) in enumerate(pbar):
images = images.to(device)
t = diffusion. sample_timesteps(images.shape[0]).to(device)
x_t, noise = diffusion.noise_images(images, t)
predicted_noise = model(x_t, t)
loss = mse(noise, predicted_noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix(MSE=loss.item())
logger.add_scalar("MSE", loss.item(), global_step=epoch * l + i)
sampled_images = diffusion.sample(model, n=images.shape[0])
save_images(sampled_images, os.path.join("results", args.run_name, f"{epoch}.jpg"))
torch.save(model.state_dict(), os.path.join("models", args.run_name, f"ckpt.pt"))
def launch():
import argparse
parser = argparse.ArgumentParser()
args = parser.parse_args()
args.run_name = "DDPM_Uncondtional"
args.epochs = 500
args.batch_size = 8
args.image_size = 64
args.dataset_path = r"D:\AudioDatasets\Songs64"
args.device = "cuda"
args.lr = 3e-4
train(args)
if __name__ == '__main__':
launch()  linspace(self.beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.
linspace(self.beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.

Далее нам потребуются дополнительные утилиты для загрузки датасета в модель utils. py.
py.
Код
import os
import torch
import torchvision
from PIL import Image
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
def plot_images(images):
plt.figure(figsize=(32, 32))
plt.imshow(torch.cat([
torch.cat([i for i in images.cpu()], dim=-1),
], dim=-2).permute(1, 2, 0).cpu())
plt.show()
def save_images(images, path, **kwargs):
grid = torchvision.utils.make_grid(images, **kwargs)
ndarr = grid.permute(1, 2, 0).to('cpu').numpy()
im = Image.fromarray(ndarr)
im.save(path)
def get_data(args):
transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
torchvision.transforms.Grayscale(num_output_channels=1)
])
dataset = torchvision.datasets.ImageFolder(args.dataset_path, transform=transforms)
dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True)
return dataloader
def setup_logging(run_name):
os. makedirs("models", exist_ok=True)
os.makedirs("results", exist_ok=True)
os.makedirs(os.path.join("models", run_name), exist_ok=True)
os.makedirs(os.path.join("results", run_name), exist_ok=True)
И самым главным является modules.py, где мы задаём Unet.
Код
import torch
import torch.nn as nn
import torch.nn.functional as F
class EMA:
def __init__(self, beta):
super().__init__()
self.beta = beta
self.step = 0
def update_model_average(self, ma_model, current_model):
for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
old_weight, up_weight = ma_params.data, current_params.data
ma_params.data = self.update_average(old_weight, up_weight)
def update_average(self, old, new):
if old is None:
return new
return old * self.beta + (1 - self.beta) * new
def step_ema(self, ema_model, model, step_start_ema=2000):
if self. step < step_start_ema:
self.reset_parameters(ema_model, model)
self.step += 1
return
self.update_model_average(ema_model, model)
self.step += 1
def reset_parameters(self, ema_model, model):
ema_model.load_state_dict(model.state_dict())
class SelfAttention(nn.Module):
def __init__(self, channels, size):
super(SelfAttention, self).__init__()
self.channels = channels
self.size = size
self.mha = nn.MultiheadAttention(channels, 4, batch_first=True)
self.ln = nn.LayerNorm([channels])
self.ff_self = nn.Sequential(
nn.LayerNorm([channels]),
nn.Linear(channels, channels),
nn.GELU(),
nn.Linear(channels, channels),
)
def forward(self, x):
x = x.view(-1, self.channels, self.size * self.size).swapaxes(1, 2)
x_ln = self.ln(x)
attention_value, _ = self.mha(x_ln, x_ln, x_ln)
attention_value = attention_value + x
attention_value = self. ff_self(attention_value) + attention_value
return attention_value.swapaxes(2, 1).view(-1, self.channels, self.size, self.size)
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None, residual=False):
super().__init__()
self.residual = residual
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, mid_channels),
nn.GELU(),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, out_channels),
)
def forward(self, x):
if self.residual:
return F.gelu(x + self.double_conv(x))
else:
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.maxpool_conv = nn. Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, t):
x = self.maxpool_conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class Up(nn.Module):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.conv = nn.Sequential(
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels, in_channels // 2),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, skip_x, t):
x = self. up(x)
x = torch.cat([skip_x, x], dim=1)
x = self.conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class UNet(nn.Module):
def __init__(self, c_in=1, c_out=1, time_dim=256, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn. Conv2d(64, c_out, kernel_size=1)
def pos_encoding(self, t, channels):
inv_freq = 1.0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self. outc(x)
return output
class UNet_conditional(nn.Module):
def __init__(self, c_in=1, c_out=1, time_dim=256, num_classes=None, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn.Conv2d(64, c_out, kernel_size=1)
if num_classes is not None:
self.label_emb = nn.Embedding(num_classes, time_dim)
def pos_encoding(self, t, channels):
inv_freq = 1. 0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t, y):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
if y is not None:
t += self.label_emb(y)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.outc(x)
return output step < step_start_ema:
self.reset_parameters(ema_model, model)
self.step += 1
return
self.update_model_average(ema_model, model)
self.step += 1
def reset_parameters(self, ema_model, model):
ema_model.load_state_dict(model.state_dict())
class SelfAttention(nn.Module):
def __init__(self, channels, size):
super(SelfAttention, self).__init__()
self.channels = channels
self.size = size
self.mha = nn.MultiheadAttention(channels, 4, batch_first=True)
self.ln = nn.LayerNorm([channels])
self.ff_self = nn.Sequential(
nn.LayerNorm([channels]),
nn.Linear(channels, channels),
nn.GELU(),
nn.Linear(channels, channels),
)
def forward(self, x):
x = x.view(-1, self.channels, self.size * self.size).swapaxes(1, 2)
x_ln = self.ln(x)
attention_value, _ = self.mha(x_ln, x_ln, x_ln)
attention_value = attention_value + x
attention_value = self.
step < step_start_ema:
self.reset_parameters(ema_model, model)
self.step += 1
return
self.update_model_average(ema_model, model)
self.step += 1
def reset_parameters(self, ema_model, model):
ema_model.load_state_dict(model.state_dict())
class SelfAttention(nn.Module):
def __init__(self, channels, size):
super(SelfAttention, self).__init__()
self.channels = channels
self.size = size
self.mha = nn.MultiheadAttention(channels, 4, batch_first=True)
self.ln = nn.LayerNorm([channels])
self.ff_self = nn.Sequential(
nn.LayerNorm([channels]),
nn.Linear(channels, channels),
nn.GELU(),
nn.Linear(channels, channels),
)
def forward(self, x):
x = x.view(-1, self.channels, self.size * self.size).swapaxes(1, 2)
x_ln = self.ln(x)
attention_value, _ = self.mha(x_ln, x_ln, x_ln)
attention_value = attention_value + x
attention_value = self. ff_self(attention_value) + attention_value
return attention_value.swapaxes(2, 1).view(-1, self.channels, self.size, self.size)
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None, residual=False):
super().__init__()
self.residual = residual
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, mid_channels),
nn.GELU(),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, out_channels),
)
def forward(self, x):
if self.residual:
return F.gelu(x + self.double_conv(x))
else:
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.maxpool_conv = nn.
ff_self(attention_value) + attention_value
return attention_value.swapaxes(2, 1).view(-1, self.channels, self.size, self.size)
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None, residual=False):
super().__init__()
self.residual = residual
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, mid_channels),
nn.GELU(),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(1, out_channels),
)
def forward(self, x):
if self.residual:
return F.gelu(x + self.double_conv(x))
else:
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.maxpool_conv = nn. Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, t):
x = self.maxpool_conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class Up(nn.Module):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.conv = nn.Sequential(
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels, in_channels // 2),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, skip_x, t):
x = self.
Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, t):
x = self.maxpool_conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class Up(nn.Module):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.conv = nn.Sequential(
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels, in_channels // 2),
)
self.emb_layer = nn.Sequential(
nn.SiLU(),
nn.Linear(
emb_dim,
out_channels
),
)
def forward(self, x, skip_x, t):
x = self. up(x)
x = torch.cat([skip_x, x], dim=1)
x = self.conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class UNet(nn.Module):
def __init__(self, c_in=1, c_out=1, time_dim=256, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn.
up(x)
x = torch.cat([skip_x, x], dim=1)
x = self.conv(x)
emb = self.emb_layer(t)[:, :, None, None].repeat(1, 1, x.shape[-2], x.shape[-1])
return x + emb
class UNet(nn.Module):
def __init__(self, c_in=1, c_out=1, time_dim=256, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn. Conv2d(64, c_out, kernel_size=1)
def pos_encoding(self, t, channels):
inv_freq = 1.0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.
Conv2d(64, c_out, kernel_size=1)
def pos_encoding(self, t, channels):
inv_freq = 1.0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self. outc(x)
return output
class UNet_conditional(nn.Module):
def __init__(self, c_in=1, c_out=1, time_dim=256, num_classes=None, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn.Conv2d(64, c_out, kernel_size=1)
if num_classes is not None:
self.label_emb = nn.Embedding(num_classes, time_dim)
def pos_encoding(self, t, channels):
inv_freq = 1.
outc(x)
return output
class UNet_conditional(nn.Module):
def __init__(self, c_in=1, c_out=1, time_dim=256, num_classes=None, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128, 32)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256, 16)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256, 8)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128, 16)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64, 32)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64, 64)
self.outc = nn.Conv2d(64, c_out, kernel_size=1)
if num_classes is not None:
self.label_emb = nn.Embedding(num_classes, time_dim)
def pos_encoding(self, t, channels):
inv_freq = 1. 0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t, y):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
if y is not None:
t += self.label_emb(y)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.outc(x)
return output
0 / (
10000
** (torch.arange(0, channels, 2, device=self.device).float() / channels)
)
pos_enc_a = torch.sin(t.repeat(1, channels // 2) * inv_freq)
pos_enc_b = torch.cos(t.repeat(1, channels // 2) * inv_freq)
pos_enc = torch.cat([pos_enc_a, pos_enc_b], dim=-1)
return pos_enc
def forward(self, x, t, y):
t = t.unsqueeze(-1).type(torch.float)
t = self.pos_encoding(t, self.time_dim)
if y is not None:
t += self.label_emb(y)
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.outc(x)
return output
Вот и вся нейросеть. После обучения для инференса можно использовать слегка модифицированный ddpm. inferddpm.
После обучения для инференса можно использовать слегка модифицированный ddpm. inferddpm.
Код
import os
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import optim
from utils import *
from modules import UNet
import logging
from torch.utils.tensorboard import SummaryWriter
logging.basicConfig(format="%(asctime)s - %(levelname)s: %(message)s", level=logging.INFO, datefmt="%I:%M:%S")
class Diffusion:
def __init__(self, noise_steps=1000, beta_start=1e-4, beta_end=0.02, img_size=64, device="cuda"):
self.noise_steps = noise_steps
self.beta_start = beta_start
self.beta_end = beta_end
self.img_size = img_size
self.device = device
self.beta = self.prepare_noise_schedule().to(device)
self.alpha = 1. - self.beta
self.alpha_hat = torch.cumprod(self.alpha, dim=0)
def prepare_noise_schedule(self):
return torch.linspace(self. beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self. beta[t][:, None, None, None]
if i > 1:
noise = torch.randn_like(x)
else:
noise = torch.zeros_like(x)
x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise
model.train()
print(f'{torch.min(x):.2f} {torch.mean(x):.2f} {torch.max(x):.2f} {x.shape}')
# x = (x.clamp(-1, 1) + 1) / 2
print(f'{torch.min(x):.2f} {torch.mean(x):.2f} {torch.max(x):.2f} {x.shape}')
x = -x
# x = x - torch.min(x)
x = x - torch.mean(x)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
x = x.clamp(0, torch.inf) / torch.max(x)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
x = (x * 255).type(torch.uint8)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
return x
def train(args):
setup_logging(args.run_name)
device = args.device
dataloader = get_data(args)
model = UNet(). to(device)
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
mse = nn.MSELoss()
diffusion = Diffusion(img_size=args.image_size, device=device)
logger = SummaryWriter(os.path.join("runs", ))
l = len(dataloader)
for epoch in range(args.epochs):
logging.info(f"Starting epoch {epoch}:")
pbar = tqdm(dataloader)
for i, (images, _) in enumerate(pbar):
images = images.to(device)
t = diffusion.sample_timesteps(images.shape[0]).to(device)
x_t, noise = diffusion.noise_images(images, t)
predicted_noise = model(x_t, t)
loss = mse(noise, predicted_noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix(MSE=loss.item())
logger.add_scalar("MSE", loss.item(), global_step=epoch * l + i)
sampled_images = diffusion.sample(model, n=images.shape[0])
save_images(sampled_images, os.path.join("results", args. run_name, f"{epoch}.jpg"))
torch.save(model.state_dict(), os.path.join("models", args.run_name, f"ckpt.pt"))
def infer(args):
setup_logging(args.run_name)
device = args.device
model = UNet().to(device)
diffusion = Diffusion(img_size=args.image_size, device=device)
checkpoint = torch.load('D:\Python\VS code\Diff\models\DDPM_Uncondtional_bird\ckpt.pt')
model.load_state_dict(checkpoint)
model.eval()
sampled_images = diffusion.sample(model, n=1)
save_images(sampled_images, os.path.join("results", f"tes47t.jpg"))
def launch():
import argparse
parser = argparse.ArgumentParser()
args = parser.parse_args()
args.run_name = "DDPM_Uncondtional"
args.epochs = 500
args.batch_size = 8
args.image_size = 64
args.dataset_path = r"D:\AudioDatasets\Songs64"
args.device = "cuda"
#args.lr = 3e-4
args.lr = 0.00015
infer(args)
if __name__ == '__main__':
launch() beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.
beta_start, self.beta_end, self.noise_steps)
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
def sample_timesteps(self, n):
return torch.randint(low=1, high=self.noise_steps, size=(n,))
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 1, self.img_size, self.img_size)).to(self.device)
for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self. beta[t][:, None, None, None]
if i > 1:
noise = torch.randn_like(x)
else:
noise = torch.zeros_like(x)
x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise
model.train()
print(f'{torch.min(x):.2f} {torch.mean(x):.2f} {torch.max(x):.2f} {x.shape}')
# x = (x.clamp(-1, 1) + 1) / 2
print(f'{torch.min(x):.2f} {torch.mean(x):.2f} {torch.max(x):.2f} {x.shape}')
x = -x
# x = x - torch.min(x)
x = x - torch.mean(x)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
x = x.clamp(0, torch.inf) / torch.max(x)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
x = (x * 255).type(torch.uint8)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
return x
def train(args):
setup_logging(args.run_name)
device = args.device
dataloader = get_data(args)
model = UNet().
beta[t][:, None, None, None]
if i > 1:
noise = torch.randn_like(x)
else:
noise = torch.zeros_like(x)
x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise
model.train()
print(f'{torch.min(x):.2f} {torch.mean(x):.2f} {torch.max(x):.2f} {x.shape}')
# x = (x.clamp(-1, 1) + 1) / 2
print(f'{torch.min(x):.2f} {torch.mean(x):.2f} {torch.max(x):.2f} {x.shape}')
x = -x
# x = x - torch.min(x)
x = x - torch.mean(x)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
x = x.clamp(0, torch.inf) / torch.max(x)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
x = (x * 255).type(torch.uint8)
print(f'{torch.min(x):.2f} {torch.max(x):.2f} {x.shape}')
return x
def train(args):
setup_logging(args.run_name)
device = args.device
dataloader = get_data(args)
model = UNet(). to(device)
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
mse = nn.MSELoss()
diffusion = Diffusion(img_size=args.image_size, device=device)
logger = SummaryWriter(os.path.join("runs", ))
l = len(dataloader)
for epoch in range(args.epochs):
logging.info(f"Starting epoch {epoch}:")
pbar = tqdm(dataloader)
for i, (images, _) in enumerate(pbar):
images = images.to(device)
t = diffusion.sample_timesteps(images.shape[0]).to(device)
x_t, noise = diffusion.noise_images(images, t)
predicted_noise = model(x_t, t)
loss = mse(noise, predicted_noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix(MSE=loss.item())
logger.add_scalar("MSE", loss.item(), global_step=epoch * l + i)
sampled_images = diffusion.sample(model, n=images.shape[0])
save_images(sampled_images, os.path.join("results", args.
to(device)
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
mse = nn.MSELoss()
diffusion = Diffusion(img_size=args.image_size, device=device)
logger = SummaryWriter(os.path.join("runs", ))
l = len(dataloader)
for epoch in range(args.epochs):
logging.info(f"Starting epoch {epoch}:")
pbar = tqdm(dataloader)
for i, (images, _) in enumerate(pbar):
images = images.to(device)
t = diffusion.sample_timesteps(images.shape[0]).to(device)
x_t, noise = diffusion.noise_images(images, t)
predicted_noise = model(x_t, t)
loss = mse(noise, predicted_noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix(MSE=loss.item())
logger.add_scalar("MSE", loss.item(), global_step=epoch * l + i)
sampled_images = diffusion.sample(model, n=images.shape[0])
save_images(sampled_images, os.path.join("results", args. run_name, f"{epoch}.jpg"))
torch.save(model.state_dict(), os.path.join("models", args.run_name, f"ckpt.pt"))
def infer(args):
setup_logging(args.run_name)
device = args.device
model = UNet().to(device)
diffusion = Diffusion(img_size=args.image_size, device=device)
checkpoint = torch.load('D:\Python\VS code\Diff\models\DDPM_Uncondtional_bird\ckpt.pt')
model.load_state_dict(checkpoint)
model.eval()
sampled_images = diffusion.sample(model, n=1)
save_images(sampled_images, os.path.join("results", f"tes47t.jpg"))
def launch():
import argparse
parser = argparse.ArgumentParser()
args = parser.parse_args()
args.run_name = "DDPM_Uncondtional"
args.epochs = 500
args.batch_size = 8
args.image_size = 64
args.dataset_path = r"D:\AudioDatasets\Songs64"
args.device = "cuda"
#args.lr = 3e-4
args.lr = 0.00015
infer(args)
if __name__ == '__main__':
launch()
run_name, f"{epoch}.jpg"))
torch.save(model.state_dict(), os.path.join("models", args.run_name, f"ckpt.pt"))
def infer(args):
setup_logging(args.run_name)
device = args.device
model = UNet().to(device)
diffusion = Diffusion(img_size=args.image_size, device=device)
checkpoint = torch.load('D:\Python\VS code\Diff\models\DDPM_Uncondtional_bird\ckpt.pt')
model.load_state_dict(checkpoint)
model.eval()
sampled_images = diffusion.sample(model, n=1)
save_images(sampled_images, os.path.join("results", f"tes47t.jpg"))
def launch():
import argparse
parser = argparse.ArgumentParser()
args = parser.parse_args()
args.run_name = "DDPM_Uncondtional"
args.epochs = 500
args.batch_size = 8
args.image_size = 64
args.dataset_path = r"D:\AudioDatasets\Songs64"
args.device = "cuda"
#args.lr = 3e-4
args.lr = 0.00015
infer(args)
if __name__ == '__main__':
launch()
Результаты инференса отмасштабировать до 512 х 512 можно так.
Код
import os
from PIL import Image
# Имя папки с исходными изображениями
input_folder = 'input'
# Имя папки для сжатых изображений
output_folder = 'output'
# Создаём папку для сжатых изображений, если она не существует
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Перебираем все файлы в папке с исходными изображениями
for file in os.listdir(input_folder):
# Игнорируем файлы, которые не являются изображениями
if not file.endswith('.jpg') and not file.endswith('.png'):
continue
# Открываем изображение
image = Image.open(os.path.join(input_folder, file))
# Сжимаем изображение до размера 512 x 512 пикселей
image = image.resize((512, 512))
# Сохраняем сжатое изображение в папку output
image.save(os.path.join(output_folder, file))
Но использование нейросетей для апскейла, подобных Real-ESRGAN, даст менее шумный результат.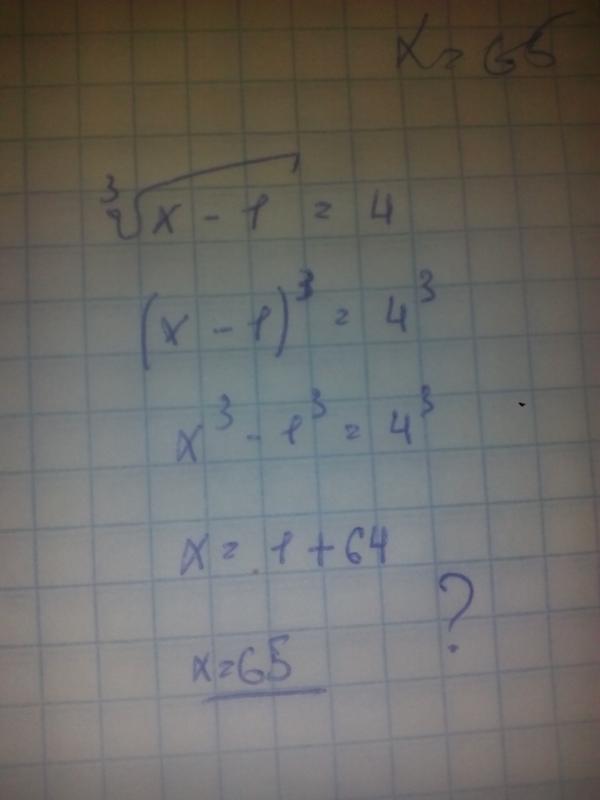
Ну и остался один шаг — преобразование сгенерированной мел-спектрограммы в аудиофайл. Код преобразования спектрограммы в аудио находится на последнем блоке в этом колабе.
▍ Результаты
Модель учится не очень хорошо на таких данных, в будущем нужно будет найти более подходящий для этого метод. Но при достаточном количестве данных и хорошем обучении можно получить неплохие аудиодорожки. Вот это сгенерированное пение птицы.
В целом из-за плохой сходимости модели я бы не назвал это лучшим подходом для генерации аудио, но эксперимент и его возможность оказались довольно интересными. Во второй статье по теме я покажу более эффективный способ генерации аудио, теперь уже связанный с латентной диффузией.
Решить уравнение корень из (15-3x) = 1 + x
Алгебра, 20.06.2019 15:10, МарияКажевникова
Показать ответы
Другие вопросы по: Алгебра
.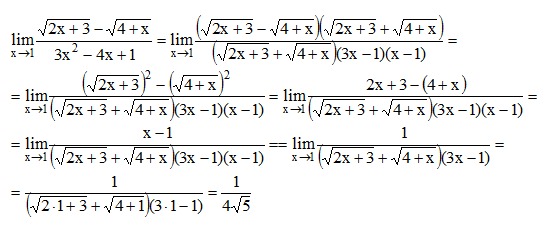 (Урожай яблок в 16 т 128 кг рассчитывали уложыть в 576 одинаковых ящиков, в мастерской сделали ящики большего размера, и их потребовалось на 72 меньше. сколько килограммов яблок п…
(Урожай яблок в 16 т 128 кг рассчитывали уложыть в 576 одинаковых ящиков, в мастерской сделали ящики большего размера, и их потребовалось на 72 меньше. сколько килограммов яблок п…
Опубликовано: 28.02.2019 01:20
Ответов: 3
Дима и павлик одновременно отправились в поход из одного пункта в одном направлении, однако павлик делал остановку для отдиха через каждое 2400м, а дима через каждое 2800м. на ткак…
Опубликовано: 28.02.2019 18:50
Ответов: 1
Сочинение-рассказ о жизни в древней руси(по выболу) крестьянина , горожанина, купца, князя….
Опубликовано: 03.03.2019 16:20
Ответов: 2
Составить распорядок дня по со словами always, usually, often, sometimes, класс…
Опубликовано: 03.03.2019 18:20
Ответов: 3
Y+3/9y(в квадрате)+3y+1 + 3/27y(в кубе)-1 = 1/3y-1. ..
..
Опубликовано: 04.03.2019 04:00
Ответов: 2
Сколько фотонов испускает за полчаса лазер, если мощность его излучения 2мвт? длина волны излучения 750нм….
Опубликовано: 04.03.2019 04:10
Ответов: 3
Знаешь правильный ответ?
Решить уравнение корень из (15-3x) = 1 + x…
Популярные вопросы
Выезжая из села велосепедист заметил на мосту пещехода иду щего в том же напровлении и догнал его через 12 минут найдите скорость пешехода если скорость велосепедиста 15 км/ч а рас…
Опубликовано: 27.02.2019 08:10
Ответов: 1
Спишите предложения, расставляя знаки препинания: 1)месяц бледнел на западе и готов был погрузиться в черные свои тучи висящие на дальних вершинах как клочки разорванного занавеса…
Опубликовано: 01. 03.2019 10:00
03.2019 10:00
Ответов: 2
Конь-огонь скачет по земле со скоростью 1500 м/мин, а по небу в 3 раза быстрее. какое расстояние он преодолеет, если путь по земле длился 20 мин, а по небу в 4 раза меньше?…
Опубликовано: 01.03.2019 15:30
Ответов: 2
Подскажите, какие примеры (из жизни, из лит-ры) можно в с1 по по теме «воспитание художественного вкуса у молодёжи»?…
Опубликовано: 03.03.2019 00:10
Ответов: 1
Доповiдь на тему»життя-найвища цiннiсть»…
Опубликовано: 03.03.2019 00:40
Ответов: 1
1)запиши названия, законов принятых в эти годы: 1497год- 1550год- 1581год- 2) придумай названия этому этапу социально- развития россии….
Опубликовано: 03.03.2019 11:40
Ответов: 2
В200г раствора содержится 10г соли.