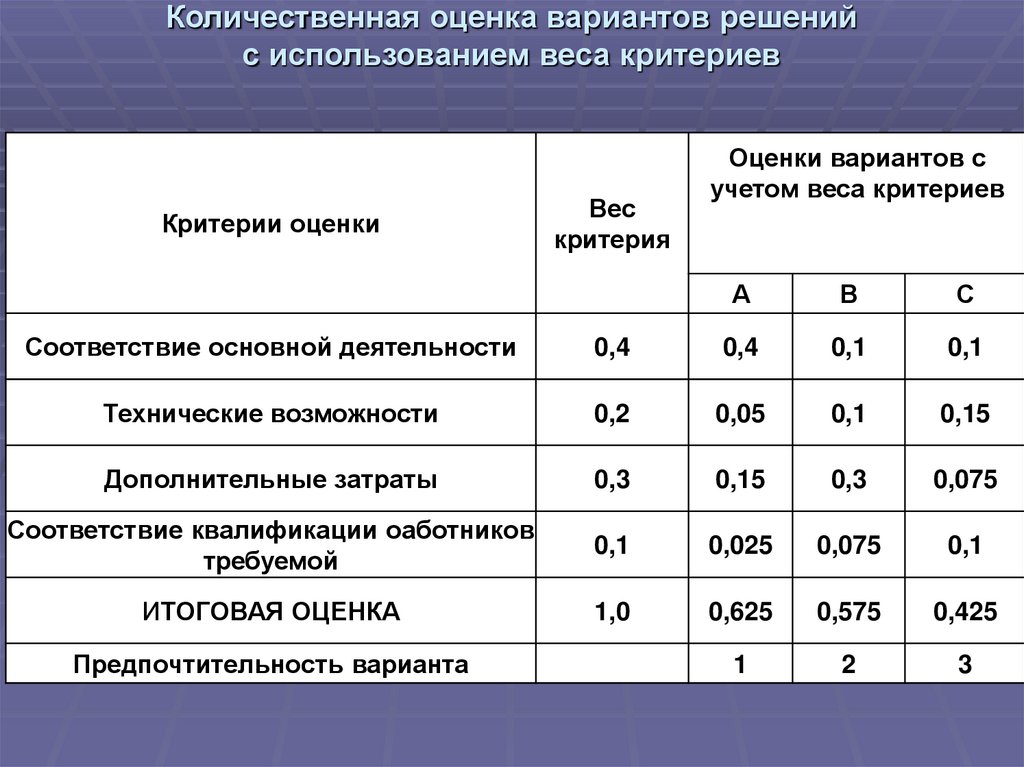
Методы принятия управленческих решений тест Синергии с ответами
Метод анализа иерархий предполагает …
Декомпозицию
Метод математического программирования …
+применяется для расчета лучшего варианта решения по критерию оптимальности принятия управленческих решений
не применяется для проведения расчетов управленческих решений
применяется для подсчета вариантов принятия управленческих решений
Метод справедливого компромисса применяется, потому что …
глобальное качество альтернативы представляет собой сумму локальных (частных) качеств
+имеется тесная связь с решением в некооперативных играх
необходимо провести анализ критериев
необходимо провести детализированный анализ проблемы
Методы психологической активизации и методы подключения новых интеллектуальных источников относятся …
+к активизирующим методам
к методам сценариев
к эвристическим методам
Управление проектом – это …
декомпозиция проблемы на составляющие элементы
формализованное представление экономической задачи
+профессиональная деятельность по руководству ресурсами
Альтернатива – это …
+один из возможных способов достижения цели или один из конечных вариантов решений
вариант действий ЛПР (лица, принимающего решения)
способ выражения различий в оценке альтернативных вариантов с точки зрения участников процесса выбора
В условиях, когда значения параметра достоверности прогноза меньше единицы, для определения наиболее выгодных стратегий используется критерий …
Гурвица
Лапласа
+Ходжа–Лемана
Величину общего эффекта от использования информации, содержащейся в прогнозе для ЛПР Vd , можно определить как …
Vx=uB(Vf–Vr)
Vy=Vf(uB–uA)
+Vd=Vx+Vy
Величина дополнительного выигрыша, получаемого вследствие повышения достоверности прогноза Vy, может быть определена по формуле …
Vx=uB(Vf–Vr)
+Vy=Vf(uB–uA)
Vd=Vx+Vy
Величина дополнительного выигрыша, получаемого вследствие изменения принимаемого решения Vх, может быть определена по формуле …
+Vx=uB(Vf–Vr)
Vy=Vf(uB–uA)
Vd=Vx+Vy
Метод мозгового штурма относится к … методам
количественным
формализованным
+эвристическим
Параметрический метод относится к … методам
+формализованным
количественным
эвристическим
Метод синектики относится к … методам
формализованным
количественным
+эвристическим
Метод фокальных объектов относится к … методам
количественным
формализованным
+эвристическим
Морфологический метод относится к … методам
количественным
+формализованным
эвристическим
Транспортная задача относится к классу …
управленческих задач
экономических задач
+задач линейного программирования (ЗЛП)
Применение ММ-критерия оправдано, если …
имеется тесная связь с решением в некооперативных играх
необходимо провести детализированный анализ проблемы
+необходимо исключить какой бы то ни было риск
Основные достоинства системы «ринги» заключаются в том, что …
+тщательно и всесторонне исследуется решаемая проблема
+принимаемые решения более обоснованы
решения принимаются весьма оперативно
+реализация решений проходит быстро и эффективно
менеджер несет персональную ответственность за результаты принятого решения
Процессы принятия управленческих решений в организациях, как правило, …
носят индивидуальный характер
протекают в паритетных группах
+протекают в иерархических группах
Метод справедливого компромисса применяется, потому что …
глобальное качество альтернативы представляет собой сумму локальных (частных) качеств
+имеется тесная связь с решением в некооперативных играх
необходимо провести анализ критериев
необходимо провести детализированный анализ проблемы
К группе методов исследования операций относится …
метод Дельфи
метод управления запасами
+метод линейного программирования
метод теории игр
метод разработки сценария
Под нормализацией векторного критерия при многокритериальной оптимизации понимается …
анализ критериев
поиск оптимального решения
декомпозиция задачи на составляющие части
+приведение всех критериев к единой шкале измерения
ЛПР (лицо, принимающее решения) – это …
человек, который лично работает в рассматриваемой области деятельности, является признанным специалистом по решаемой проблеме, может и имеет возможность высказать суждения по ней
группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
+субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы, суверенно воспользоваться положительными результатами от решения проблемы или взять на себя всю ответственность за неуспех, неудачу, за напрасные расходы
Активная группа – это …
группа лиц, принимающих решение
+группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
группа людей, владеющих проблемой
Решение, принятое по заранее определенному алгоритму, называется …
детерминированным
+стандартным
хорошо структурированным
формализованным
Под эффективностью управленческого решения понимается …
результат, полученный от реализации решения
разность между полученным эффектом и затратами на реализацию решения
+отношение эффекта от реализации решения к затратам на его разработку и осуществление
достижение поставленной цели
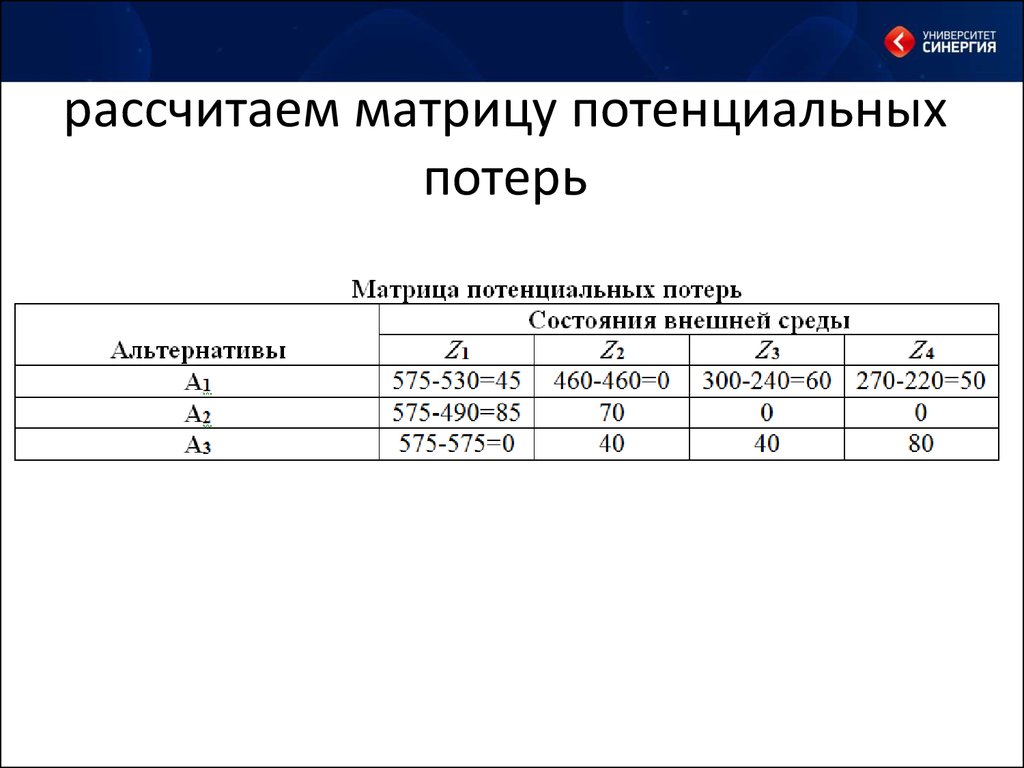
На основании матрицы потерь строится критерий …
Лапласа
Гурвица
Вальда
+Сэвиджа
Метод анализа иерархий предполагает …
декомпозицию проблемы на простые составляющие части
+иерархическое представление задачи
разработку оптимальной структуры управления
+полнота, действительность, разложимость, неизбыточность и минимальность
полнота, действительность, неизбыточность и минимальность
полнота, действительность, разложимость, и минимальность
Эксперт – это …
группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
+человек, который лично работает в рассматриваемой области деятельности, является признанным специалистом по решаемой проблеме, может и имеет возможность высказать суждения по ней
субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы, суверенно воспользоваться положительными результатами от решения проблемы или взять на себя всю ответственность за неуспех, неудачу, за напрасные расходы
Дерево решений – это …
философское видение процесса управления
суть процесса принятия решений
+графическое представление процесса принятия решений
Полнота набора критериев означает, что …
критерии должны быть определены так, чтобы не дублировался учет одних и тех же аспектов решаемой проблемы
критерии должны быть такими, чтобы их можно было объяснять другим, особенно в тех случаях, когда важнейшей целью работы является выработка и защита определенной позиции
+критерий должен охватывать все важные аспекты проблемы
Процессы принятия управленческих решений в организациях, как правило, …
носят индивидуальный характер
протекают в паритетных группах
+протекают в иерархических группах
Критерий – это …
вероятностный показатель оценки альтернатив
+способ выражения различий в оценке альтернативных вариантов с точки зрения участников процесса выбора
один из возможных способов достижения цели или один из конечных вариантов решений
Понятие «чистый риск» означает …
+вероятность получения убытка или нулевого результата
возможными величинами прибыли и убытков
все издержки, связанные с решением, минус вероятная прибыль количественную оценку
вероятности получения запланированной прибыли разность между максимально
Риск при принятии управленческих решений заключается …
в невозможности прогнозировать результаты решения
+в вероятности потери ресурсов или неполучения дохода
в отсутствии необходимой информации для анализа ситуации
в опасности принятия неудачного решения
… представляет собой набор прогнозов по каждому рассматриваемому решению, его реализации, а также по возможным положительным и отрицательным последствиям
Активизирующий метод
Эвристический метод
+Метод сценариев
Критерий Вальда – это критерий …
средневзвешенного выигрыша
недостаточного основания
+максимального гарантированного результата
пессимизма-оптимизма
наименьших возможных потерь
Критерий Гурвица – это критерий …
+пессимизма-оптимизма
наименьших возможных потерь
максимального гарантированного результата
средневзвешенного выигрыша
недостаточного основания
Критерий Сэвиджа – это критерий …
средневзвешенного выигрыша
+наименьших возможных потерь
недостаточного основания
пессимизма-оптимизма
максимального гарантированного результата
Максиминные и минимаксные критерии относятся к принятию решений в условиях …
риска
определенности
+неопределенности
Основу принятия всех решений на всех этапах процесса выработки решений составляют …
+предпочтения ЛПР (лица, принимающего решения)
как предпочтения ЛПР, так и предпочтения эксперта
предпочтения эксперта
Для более эффективной реализации управленческого решения …
+необходимо сформулировать имеющиеся ограничения
необходима система контроля
необходима оперативная система управления
Под владельцем проблемы понимается …
+человек, решающий проблему и ответственный за принятые решения
субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы
человек, фактически осуществляющий выбор наилучшего варианта действия
Метод равномерной оптимизации применяется, если …
+глобальное качество альтернативы представляет собой сумму локальных (частных) качеств
отсутствуют исходные данные
необходимо провести анализ критериев
необходимо провести детализированный анализ проблемы
Метод дельфи относится к методам
Количественные
В большинстве случаев принятие решений заключается …
в генерации возможных альтернатив решений, их оценке и выборе лучшей альтернативы
Метод «Дельфи» относится к … методам
Количественным
Вопрос № 26. Механизированный контроль, ручной контроль, автоматизированный контроль, автоматический контроль — это виды контроля по:
Механизированный контроль, ручной контроль, автоматизированный контроль, автоматический контроль — это виды контроля по:
Ответ: степени механизации
Вопрос № 27. Релевантная информация позволяет:
Ответ: объективно рассчитать риск
Вопрос № 28. Направление методологии научного познания и социальной практики, в основе которого лежит исследование объектов как систем, имеющих выход (цель), вход, связь с внешней средой, обратную связь, — называется ________________ подходом к менеджменту.
Ответ: системным
Вопрос № 29. Метод анализа, применяемый при изучении сложных явлений, отдельные элементы которых неизмеримы, и позволяющий провести разложение по факторам относительных и абсолютных отклонений обобщающего показателя, называется:
Ответ: индексным
Вопрос № 30. Дерево целей разрабатывается для:
Ответ: программы
Методы принятия управленческих решений. Вариант 7
Вопрос № 31. Научный подход к менеджменту, направленный на исследование и усиление взаимосвязей: между отдельными подсистемами и элементами системы менеджмента, между стадиями жизненного цикла объекта управления, между уровнями управления по вертикали, между субъектами управления по горизонтали, — называется:
Научный подход к менеджменту, направленный на исследование и усиление взаимосвязей: между отдельными подсистемами и элементами системы менеджмента, между стадиями жизненного цикла объекта управления, между уровнями управления по вертикали, между субъектами управления по горизонтали, — называется:
Ответ: интеграционным
Вопрос № 32. Работодатели, как правило, придают большое значение опыту при найме на работу, потому что …
Ответ: суждение на основе опыта является основой множества повседневных управленческих решений
Вопрос № 33. Научный подход к менеджменту, ориентированный на постоянное возобновление производства товара для удовлетворения потребностей конкретного рынка с меньшими, по сравнению с лучшим аналогичным объектом на данном рынке, совокупными затратами на единицу полезного эффекта, называется:
Ответ: воспроизводственным
Вопрос № 34. Прогноз развития организации строится на основании:
Ответ: комплексной оценки последствий принятых управленческих решений и анализе перспектив внешней среды
Вопрос № 35. Средство передачи информации — это:
Средство передачи информации — это:
Ответ: канал
Методы принятия управленческих решений. Вариант 8
Вопрос № 36. Проблемы, в которых не всегда просматриваются условия, факторы, причинно-следственные связи — это:
Ответ: слабо структурированные проблемы
Вопрос № 37. Как правило, одного лишь суждения будет недостаточно для принятия решения, когда ситуация …
Ответ: уникальна или очень сложна
Вопрос № 38. То, что решение должно охватывать весь управляемый объект, все сферы его деятельности, все направления развития — это:
Ответ: необходимая полнота содержания решения
Вопрос № 39. Задачи, которые не очерчиваются достаточно четко, в которых далеко не всегда просматриваются направления, причинно-следственные связи, — это проблемы …
Ответ: слабо структурированные
Вопрос № 40. Теория математической статистики в проблемной ситуации не действует, потому что …
Ответ: как правило, неизвестны не только вероятность того или иного события, того или иного результата, но и вообще невозможно предсказать, каким по природе будет результат
Методы принятия управленческих решений. Вариант 9
Вариант 9
Вопрос № 41. Если не хватает времени на сбор дополнительной информации или затраты на нее чересчур высоки, то руководителю необходимо …
Ответ: действовать в точном соответствии с прошлым опытом, суждениями или интуицией и сделать предположение о вероятности событий
Вопрос № 42. Описательный подход к ППР называется:
Ответ: дескриптивным
Вопрос № 43. Задачи, которые имеют четкую структуру, причинно-следственные связи, аналоги, — это проблемы …
Ответ: стандартные
Вопрос № 44. Метод анализа, заключающийся в получении ряда корректированных значений обобщающего показателя путем последовательной замены базисных значений факторов — сомножителей фактическим, — называется:
Ответ: методом цепных подстановок
Вопрос № 45. Научный подход к менеджменту, рассматривающий функции управления как взаимосвязанные, а процесс управления — как сумму всех функций, серию непрерывных взаимосвязанных действий, — называется:
Ответ: процессным
Методы принятия управленческих решений. Вариант 44
Вариант 44
Вопрос № 216. Основным импульсом управленческого решения является необходимость:
Ответ: ликвидации, уменьшения актуальности или решения проблемы
Вопрос № 217. Качество и эффективность рационального управленческого решения достигаются лишь в том случае, когда …
Ответ: соблюдается технология принятия и реализации решения, процесс осуществляется в определенной последовательности
Вопрос № 218. Убытки предпринимателя, затраты на снижение величины этих убытков или затраты по возмещению таких убытков и их последствий называются:
Ответ: стоимостью риска
Вопрос № 219. Геологические работы, сплав леса по рекам, сезонность сельскохозяйственного производства, пушной промысел — это:
Ответ: сферы применения периодических и сезонных видов управленческих решений
Вопрос № 220. Принцип ________________ характеризует не только процесс выявления, но и оценку устойчивых тенденций и взаимосвязей в развитии производства и создании теоретического аналога реальных экономических процессов (с их полной и точной имитацией).
Ответ: адекватности
Методы принятия управленческих решений. Вариант 45
Вопрос № 221. Величина дополнительного выигрыша, получаемого вследствие повышения достоверности прогноза Vy, может быть определена по формуле …
Ответ: Vy=Vf(uB–uA)
Вопрос № 222. Набор критериев должен удовлетворять таким требованиям, как …
Ответ: полнота, действительность, разложимость, неизбыточность и минимальность
Вопрос № 223. Метод справедливого компромисса применяется, потому что …
Ответ: имеется тесная связь с решением в некооперативных играх
Вопрос № 224. Величину общего эффекта от использования информации, содержащейся в прогнозе для ЛПР Vd , можно определить как …
Ответ: Vd=Vx+Vy
Вопрос № 225. Решение, принятое по заранее определенному алгоритму, называется …
Ответ: стандартным
Методы принятия управленческих решений. Вариант 46
Вопрос № 226. Метод фокальных объектов относится к … методам
Метод фокальных объектов относится к … методам
Ответ: эвристическим
Вопрос № 227. Активная группа – это …
Ответ: группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
Вопрос № 228. Для более эффективной реализации управленческого решения …
Ответ: необходимо сформулировать имеющиеся ограничения
Вопрос № 229. Величина дополнительного выигрыша, получаемого вследствие изменения принимаемого решения Vх, может быть определена по формуле …
Ответ: Vx=uB(Vf–Vr)
Вопрос № 230. Метод математического программирования …
Ответ: применяется для расчета лучшего варианта решения по критерию оптимальности принятия управленческих решений
Методы принятия управленческих решений. Вариант 47
Вопрос № 231. ЛПР (лицо, принимающее решения) – это …
Ответ: субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы, суверенно воспользоваться положительными результатами от решения проблемы или взять на себя всю ответственность за неуспех, неудачу, за напрасные расходы
Вопрос № 232. Эксперт – это …
Эксперт – это …
Ответ: человек, который лично работает в рассматриваемой области деятельности, является признанным специалистом по решаемой проблеме, может и имеет возможность высказать суждения по ней
Вопрос № 233. Критерий Сэвиджа – это критерий …
Ответ: наименьших возможных потерь
Вопрос № 234. Метод анализа иерархий предполагает …
Ответ: иерархическое представление задачи
Вопрос № 235. Понятие «чистый риск» означает …
Ответ: вероятность получения убытка или нулевого результата
Методы принятия управленческих решений. Вариант 48
Вопрос № 236. Под владельцем проблемы понимается …
Ответ: человек, решающий проблему и ответственный за принятые решения
Вопрос № 237. В условиях, когда значения параметра достоверности прогноза меньше единицы, для определения наиболее выгодных стратегий используется критерий …
Ответ: Ходжа–Лемана
Вопрос № 238. Управление проектом – это …
Управление проектом – это …
Ответ: профессиональная деятельность по руководству ресурсами
Вопрос № 239. Применение ММ-критерия оправдано, если …
Ответ: необходимо исключить какой бы то ни было риск
Вопрос № 240. Альтернатива – это …
Ответ: один из возможных способов достижения цели или один из конечных вариантов решений
Методы принятия управленческих решений МФПА Тест с ответами
Правильных ответов не менее 97%
Для быстрого поиска по странице нажмите Ctrl+F и в появившемся окошке напечатайте слово запроса (или первые буквы)
Метод математического программирования …
+применяется для расчета лучшего варианта решения по критерию оптимальности принятия управленческих решений
не применяется для проведения расчетов управленческих решений
применяется для подсчета вариантов принятия управленческих решений
Метод справедливого компромисса применяется, потому что …
глобальное качество альтернативы представляет собой сумму локальных (частных) качеств
+имеется тесная связь с решением в некооперативных играх
необходимо провести анализ критериев
необходимо провести детализированный анализ проблемы
Методы психологической активизации и методы подключения новых интеллектуальных источников относятся …
+к активизирующим методам
к методам сценариев
к эвристическим методам
Управление проектом – это …
декомпозиция проблемы на составляющие элементы
формализованное представление экономической задачи
+профессиональная деятельность по руководству ресурсами
Друзья, более 600 собак Воронежского приюта Дора очень нуждаются в поддержке! Приют бедствует, не хватает средств на корм и лечение. Не откладывайте добрые дела, перечислите прямо сейчас любую сумму на «Голодный телефон» +7 960 111 77 23 или карту сбербанка . По всем вопросам обращаться +7 903 857 05 77 (Шамарин Юрий Иванович)
Не откладывайте добрые дела, перечислите прямо сейчас любую сумму на «Голодный телефон» +7 960 111 77 23 или карту сбербанка . По всем вопросам обращаться +7 903 857 05 77 (Шамарин Юрий Иванович)
Альтернатива – это …
+один из возможных способов достижения цели или один из конечных вариантов решений
вариант действий ЛПР (лица, принимающего решения)
способ выражения различий в оценке альтернативных вариантов с точки зрения участников процесса выбора
В условиях, когда значения параметра достоверности прогноза меньше единицы, для определения наиболее выгодных стратегий используется критерий …
Гурвица
Лапласа
+Ходжа–Лемана
Величину общего эффекта от использования информации, содержащейся в прогнозе для ЛПР Vd , можно определить как …
Vx=uB(Vf–Vr)
Vy=Vf(uB–uA)
+Vd=Vx+Vy
Величина дополнительного выигрыша, получаемого вследствие повышения достоверности прогноза Vy, может быть определена по формуле …
Vx=uB(Vf–Vr)
+V
Vd=Vx+Vy
Величина дополнительного выигрыша, получаемого вследствие изменения принимаемого решения Vх, может быть определена по формуле …
+Vx=uB(Vf–Vr)
Vy=Vf(uB–uA)
Vd=Vx+Vy
Метод мозгового штурма относится к … методам
количественным
формализованным
+эвристическим
Параметрический метод относится к … методам
+формализованным
количественным
эвристическим
Метод синектики относится к … методам
формализованным
количественным
+эвристическим
Метод фокальных объектов относится к … методам
количественным
формализованным+эвристическим
Морфологический метод относится к … методам
количественным
+формализованным
эвристическим
Транспортная задача относится к классу …
управленческих задач
экономических задач
+задач линейного программирования (ЗЛП)
Применение ММ-критерия оправдано, если …
имеется тесная связь с решением в некооперативных играх
необходимо провести детализированный анализ проблемы
+необходимо исключить какой бы то ни было риск
Основные достоинства системы «ринги» заключаются в том, что …
+тщательно и всесторонне исследуется решаемая проблема
+принимаемые решения более обоснованы
решения принимаются весьма оперативно
+реализация решений проходит быстро и эффективно
менеджер несет персональную ответственность за результаты принятого решения
Процессы принятия управленческих решений в организациях, как правило, …
носят индивидуальный характер
протекают в паритетных группах
+протекают в иерархических группах
Метод справедливого компромисса применяется, потому что …
глобальное качество альтернативы представляет собой сумму локальных (частных) качеств
+имеется тесная связь с решением в некооперативных играх
необходимо провести анализ критериев
необходимо провести детализированный анализ проблемы
К группе методов исследования операций относится …
метод Дельфи
метод управления запасами
+метод линейного программирования
метод теории игр
метод разработки сценария
Под нормализацией векторного критерия при многокритериальной оптимизации понимается …
анализ критериев
поиск оптимального решения
декомпозиция задачи на составляющие части
+приведение всех критериев к единой шкале измерения
ЛПР (лицо, принимающее решения) – это …
человек, который лично работает в рассматриваемой области деятельности, является признанным специалистом по решаемой проблеме, может и имеет возможность высказать суждения по ней
группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
+субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы, суверенно воспользоваться положительными результатами от решения проблемы или взять на себя всю ответственность за неуспех, неудачу, за напрасные расходы
или напишите нам прямо сейчас
Написать в WhatsApp
Активная группа – это …
группа лиц, принимающих решение
+группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
группа людей, владеющих проблемой
Решение, принятое по заранее определенному алгоритму, называется …
детерминированным
+стандартным
хорошо структурированным
формализованным
Под эффективностью управленческого решения понимается …
результат, полученный от реализации решения
разность между полученным эффектом и затратами на реализацию решения
+отношение эффекта от реализации решения к затратам на его разработку и осуществление
достижение поставленной цели
На основании матрицы потерь строится критерий …
Лапласа
Гурвица
Вальда
+Сэвиджа
Метод анализа иерархий предполагает …
декомпозицию проблемы на простые составляющие части
+иерархическое представление задачи
разработку оптимальной структуры управления
Набор критериев должен удовлетворять таким требованиям, как …
+полнота, действительность, разложимость, неизбыточность и минимальность
полнота, действительность, неизбыточность и минимальность
полнота, действительность, разложимость, и минимальность
Эксперт – это …
группа людей, имеющая общие интересы и старающаяся оказать влияние на процесс выбора и его результат
+человек, который лично работает в рассматриваемой области деятельности, является признанным специалистом по решаемой проблеме, может и имеет возможность высказать суждения по ней
субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы, суверенно воспользоваться положительными результатами от решения проблемы или взять на себя всю ответственность за неуспех, неудачу, за напрасные расходы
Дерево решений – это …
философское видение процесса управления
суть процесса принятия решений
+графическое представление процесса принятия решений
Полнота набора критериев означает, что …
критерии должны быть определены так, чтобы не дублировался учет одних и тех же аспектов решаемой проблемы
критерии должны быть такими, чтобы их можно было объяснять другим, особенно в тех случаях, когда важнейшей целью работы является выработка и защита определенной позиции
+критерий должен охватывать все важные аспекты проблемы
Процессы принятия управленческих решений в организациях, как правило, …
носят индивидуальный характер
протекают в паритетных группах
+протекают в иерархических группах
Критерий – это …
вероятностный показатель оценки альтернатив
+способ выражения различий в оценке альтернативных вариантов с точки зрения участников процесса выбора
один из возможных способов достижения цели или один из конечных вариантов решений
Понятие «чистый риск» означает …
+вероятность получения убытка или нулевого результата
возможными величинами прибыли и убытков
все издержки, связанные с решением, минус вероятная прибыль количественную оценку
вероятности получения запланированной прибыли разность между максимально
Риск при принятии управленческих решений заключается …
в невозможности прогнозировать результаты решения
+в вероятности потери ресурсов или неполучения дохода
в отсутствии необходимой информации для анализа ситуации
в опасности принятия неудачного решения
… представляет собой набор прогнозов по каждому рассматриваемому решению, его реализации, а также по возможным положительным и отрицательным последствиям
Активизирующий метод
Эвристический метод
+Метод сценариев
Критерий Вальда – это критерий …
средневзвешенного выигрыша
недостаточного основания
+максимального гарантированного результата
пессимизма-оптимизма
наименьших возможных потерь
Критерий Гурвица – это критерий …
+пессимизма-оптимизма
наименьших возможных потерь
максимального гарантированного результата
средневзвешенного выигрыша
недостаточного основания
Критерий Сэвиджа – это критерий …
средневзвешенного выигрыша
+наименьших возможных потерь
недостаточного основания
пессимизма-оптимизма
максимального гарантированного результата
Максиминные и минимаксные критерии относятся к принятию решений в условиях …
риска
определенности
+неопределенности
Основу принятия всех решений на всех этапах процесса выработки решений составляют …
+предпочтения ЛПР (лица, принимающего решения)
как предпочтения ЛПР, так и предпочтения эксперта
предпочтения эксперта
Для более эффективной реализации управленческого решения …
+необходимо сформулировать имеющиеся ограничения
необходима система контроля
необходима оперативная система управления
Под владельцем проблемы понимается …
+человек, решающий проблему и ответственный за принятые решения
субъект, который всерьез намерен устранить стоящую перед ним проблему, выделить на ее разрешение и реально задействовать имеющиеся у него активные ресурсы
человек, фактически осуществляющий выбор наилучшего варианта действия
Метод равномерной оптимизации применяется, если …
+глобальное качество альтернативы представляет собой сумму локальных (частных) качеств
отсутствуют исходные данные
необходимо провести анализ критериев
необходимо провести детализированный анализ проблемы
или напишите нам прямо сейчас
Написать в WhatsApp
Анализ основных компонентов (PCA) Объяснение
Цель этого поста — предоставить полное и упрощенное объяснение анализа основных компонентов (PCA). Мы шаг за шагом расскажем, как это работает, чтобы каждый мог понять и использовать его, даже те, у кого нет сильной математической подготовки.
Мы шаг за шагом расскажем, как это работает, чтобы каждый мог понять и использовать его, даже те, у кого нет сильной математической подготовки.
PCA – это метод, который широко освещается в Интернете, и о нем есть несколько замечательных статей, но многие тратят слишком много времени на эту тему, тогда как большинство из нас просто хотят узнать, как это работает в упрощенном виде.
Анализ главных компонентов можно разбить на пять этапов. Я пройдусь по каждому шагу, предоставляя логические объяснения того, что делает PCA, и упрощая математические понятия, такие как стандартизация, ковариация, собственные векторы и собственные значения, не сосредотачиваясь на том, как их вычислять.
Как вы делаете анализ главных компонентов?
- Стандартизировать диапазон непрерывных исходных переменных
- Вычислить ковариационную матрицу для выявления корреляций
- Вычисление собственных векторов и собственных значений ковариационной матрицы для определения основных компонентов
- Создание вектора признаков для определения, какие основные компоненты оставить
- Повторное преобразование данных по осям основных компонентов фон необходим для контекста.

Обзор метода главных компонентов (АГК). | Видео: наглядное объяснениеЧто такое анализ главных компонентов?
Анализ главных компонентов, или PCA, представляет собой метод уменьшения размерности, который часто используется для уменьшения размерности больших наборов данных путем преобразования большого набора переменных в меньший, который по-прежнему содержит большую часть информации в большом наборе. .
Уменьшение числа переменных в наборе данных, естественно, происходит за счет точности, но хитрость в уменьшении размерности заключается в том, чтобы пожертвовать небольшой точностью ради простоты. Потому что меньшие наборы данных легче исследовать и визуализировать, а также значительно упростить и ускорить анализ данных для алгоритмов машинного обучения без обработки посторонних переменных.
Подводя итог, идея PCA проста — уменьшить количество переменных в наборе данных, сохранив при этом как можно больше информации.
Пошаговое объяснение PCA
Шаг 1: Стандартизация
Целью этого шага является стандартизация диапазона непрерывных исходных переменных, чтобы каждая из них вносила равный вклад в анализ.
Более конкретно, причина, по которой так важно выполнить стандартизацию до PCA, заключается в том, что последний весьма чувствителен к отклонениям исходных переменных. То есть, если существуют большие различия между диапазонами исходных переменных, те переменные с большими диапазонами будут доминировать над переменными с малыми диапазонами (например, переменная, которая находится в диапазоне от 0 до 100, будет доминировать над переменной, которая находится в диапазоне от 0 до 1). ), что приведет к необъективным результатам. Таким образом, преобразование данных в сопоставимые масштабы может предотвратить эту проблему.
Математически это можно сделать путем вычитания среднего значения и деления на стандартное отклонение для каждого значения каждой переменной.
После завершения стандартизации все переменные будут преобразованы в один масштаб.
Шаг 2. Вычисление ковариационной матрицы
Целью этого шага является понимание того, как переменные набора входных данных отличаются от среднего по отношению друг к другу, или, другими словами, увидеть, есть ли какие-либо отношения между ними. Потому что иногда переменные сильно коррелированы таким образом, что содержат избыточную информацию. Итак, чтобы идентифицировать эти корреляции, мы вычисляем ковариационную матрицу.
Ковариационная матрица представляет собой p × p симметричную матрицу (где p — количество измерений), которая содержит в качестве элементов ковариации, связанные со всеми возможными парами исходных переменных. Например, для трехмерного набора данных с тремя переменными x , y и z ковариационная матрица представляет собой матрицу 3 × 3 из:
Ковариационная матрица для трехмерных данныхПоскольку ковариация переменной с самой собой — это ее дисперсия (Cov(a,a)=Var(a)), на главной диагонали (сверху слева направо внизу) мы фактически имеем дисперсии каждой исходной переменной.
А поскольку ковариация коммутативна (Cov(a,b)=Cov(b,a)), элементы ковариационной матрицы симметричны относительно главной диагонали, что означает, что верхняя и нижняя треугольные части равны.Что ковариации, которые мы имеем в виде элементов матрицы, говорят нам о корреляциях между переменными?
На самом деле имеет значение знак ковариации:
- Если положительный, то: две переменные увеличиваются или уменьшаются вместе (коррелированные)
- Если отрицательный, то: одна увеличивается, когда другая уменьшается (обратно коррелированная)
Теперь что мы знаем, что ковариационная матрица — это не более чем таблица, в которой суммированы корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
Шаг 3. Вычисление собственных векторов и собственных значений ковариационной матрицы для определения главных компонент
Собственные векторы и собственные значения — это понятия линейной алгебры, которые нам необходимо вычислить из ковариационной матрицы, чтобы определить главных компонентов данных.
Прежде чем перейти к объяснению этих концепций, давайте сначала разберемся, что мы подразумеваем под основными компонентами.Главные компоненты – это новые переменные, построенные как линейные комбинации или смеси исходных переменных. Эти комбинации выполняются таким образом, что новые переменные (т. е. главные компоненты) не коррелированы, а большая часть информации в исходных переменных сжата или сжата в первые компоненты. Итак, идея состоит в том, что 10-мерные данные дают вам 10 основных компонентов, но PCA пытается поместить максимально возможную информацию в первый компонент, затем максимально оставшуюся информацию во второй и так далее, пока не будет что-то вроде показанного на графике осыпи ниже.
Процент дисперсии (информации) для каждого по ПКТакая организация информации в основных компонентах позволит вам уменьшить размерность без потери большого количества информации, и это за счет отбрасывания компонентов с низкой информацией и рассмотрения оставшихся компонентов в качестве ваших новых переменных.
Здесь важно понимать, что основные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
С геометрической точки зрения главные компоненты представляют направления данных, которые объясняют максимальное количество дисперсии , то есть линии, которые фиксируют большую часть информации о данных. Связь между дисперсией и информацией здесь заключается в том, что чем больше дисперсия, переносимая линией, тем больше дисперсия точек данных вдоль нее, и чем больше дисперсия вдоль линии, тем больше информации она содержит. Проще говоря, просто подумайте о главных компонентах как о новых осях, обеспечивающих лучший угол для просмотра и оценки данных, чтобы различия между наблюдениями были лучше видны.
Hiring NowView All Remote Data Science Jobs
Как PCA создает основные компоненты
Поскольку количество основных компонентов равно количеству переменных в данных, основные компоненты строятся таким образом, что учитывается первый главный компонент для максимально возможной дисперсии в наборе данных.
Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так, как показано ниже. Можем ли мы угадать первый главный компонент? Да, это примерно линия, которая соответствует фиолетовым меткам, потому что она проходит через начало координат, и это линия, в которой проекция точек (красные точки) наиболее разбросана. Или, говоря математическим языком, это линия, которая максимизирует дисперсию (среднее значение квадратов расстояний от спроецированных точек (красные точки) до начала координат).Второй главный компонент рассчитывается таким же образом, при условии, что он не коррелирует с первым главным компонентом (т. е. перпендикулярен) и учитывает следующую по величине дисперсию.
Это продолжается до тех пор, пока не будет вычислено в общей сложности p главных компонентов, равное исходному количеству переменных.
Теперь, когда мы понимаем, что мы подразумеваем под главными компонентами, давайте вернемся к собственным векторам и собственным значениям.
Первое, что вам нужно знать о них, это то, что они всегда идут парами, так что каждый собственный вектор имеет собственное значение. И их количество равно количеству размерностей данных. Например, для трехмерного набора данных есть 3 переменные, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.Без лишних слов, именно собственные векторы и собственные значения стоят за всей магией, объясненной выше, потому что собственные векторы ковариационной матрицы на самом деле информация) и которые мы называем основными компонентами. А собственные значения — это просто коэффициенты, присоединенные к собственным векторам, которые дают 90 059 величину дисперсии, переносимую в каждом основном компоненте .
Ранжируя собственные векторы в порядке их собственных значений, от большего к меньшему, вы получаете главные компоненты в порядке значимости.
Пример:
Предположим, что наш набор данных двумерный с двумя переменными x,y и что собственные векторы и собственные значения ковариационной матрицы таковы:
в порядке убывания получаем λ1>λ2, что означает, что собственный вектор, соответствующий первой главной компоненте (PC1), равен v1 , а тот, который соответствует второму компоненту (PC2), — v2.
Имея главные компоненты, чтобы вычислить процент дисперсии (информации), приходящийся на каждый компонент, мы делим собственное значение каждого компонента на сумму собственных значений. Если мы применим это к приведенному выше примеру, мы обнаружим, что ПК1 и ПК2 несут соответственно 96% и 4% дисперсии данных.
Шаг 4: Вектор признаков
Как мы видели на предыдущем шаге, вычисление собственных векторов и их упорядочение по собственным значениям в порядке убывания позволяет нам найти главные компоненты в порядке значимости. На этом шаге мы выбираем, оставить ли все эти компоненты или отбросить менее значимые (с низкими собственными значениями), и сформировать из оставшихся матрицу векторов, которую мы называем Вектор признаков .
Итак, вектор признаков — это просто матрица, столбцами которой являются собственные векторы компонентов, которые мы решили сохранить. Это делает его первым шагом к уменьшению размерности, потому что, если мы решим оставить только p собственных векторов (компонентов) из n , окончательный набор данных будет иметь только p измерений.
Пример :
Продолжая пример из предыдущего шага, мы можем либо сформировать вектор признаков с обоими собственными векторами v 1 и v 2:
Или отбросить собственный вектор v 2, который имеет меньшее значение, и сформировать вектор признаков только с v 1:
уменьшить размерность на 1 и, следовательно, приведет к потере информации в конечном наборе данных. Но, учитывая, что против 2 несли только 4% информации, потери не будут значительны, и мы по-прежнему будем иметь 96% информации, которую несет 9.0059 v 1.
Итак, как мы видели в примере, вам решать, сохранять ли все компоненты или отбрасывать менее важные, в зависимости от того, что вы ищете. Потому что, если вы просто хотите описать свои данные в терминах новых переменных (главных компонентов), которые не коррелированы, не стремясь уменьшить размерность, не нужно исключать менее значимые компоненты.
Последний шаг: преобразование данных по осям главных компонентов
На предыдущих шагах, кроме стандартизации, вы не вносите никаких изменений в данные, вы просто выбираете главные компоненты и формируете вектор признаков, но набор входных данных всегда остается в исходных осях (т.
е. в члены исходных переменных).На этом шаге, который является последним, цель состоит в том, чтобы использовать вектор признаков, сформированный с использованием собственных векторов ковариационной матрицы, чтобы переориентировать данные с исходных осей на те, которые представлены главными компонентами (отсюда и название Основные компоненты). Анализ компонентов). Это можно сделать, умножив транспонирование исходного набора данных на транспонирование вектора признаков.
Ссылки :
- [Steven M. Holland, Univ. of Georgia]: Анализ основных компонентов
- [skymind.ai]: Собственные векторы, собственные значения, PCA, ковариация и энтропия
- [Линдси И. Смит]: Учебное пособие по анализу основных компонентов
Интуиция, стоящая за оценкой логарифмических потерь. В машинном обучении классификация… | Гаурав Дембла
Фото Кристофера Бернса на UnsplashВ машинном обучении проблема классификации относится к прогнозному моделированию, где необходимо предсказать метку класса для данного наблюдения (записи).
В то время как входные данные (функции) состоят из непрерывных или категориальных переменных, выходные данные всегда являются категориальной переменной. Например, на основе входных характеристик, таких как информация о погоде (влажность, температура, облачно/солнечно, скорость ветра и т. д.) и время года, можно предсказать, будет ли сегодня «дождь» или «нет дождя» (выходная переменная). в вашем городе. Другой пример, основанный на содержании электронного письма и информации об отправителе, позволяет предсказать, является ли оно «спамом» или «не спамом» (он же «ветчина»).Потеря журнала — один из основных показателей для оценки производительности задачи классификации. Но что это означает концептуально? Когда вы гуглите этот термин, вы легко получаете хорошие статьи и блоги, непосредственно посвященные математике. Тем не менее, я планирую использовать здесь другой подход — рассказать об интуиции, стоящей за метрикой, а затем предоставить формулу, используемую для расчета метрики.
Помните, что есть еще одна важная метрика, активно используемая для оценки производительности алгоритма классификации — 9.0035 ROC-AUC оценка . После того, как у вас будет четкое представление о показателе потерь журнала, вы можете просмотреть мой другой блог «Интуиция, стоящая за показателем ROC-AUC», в частности, о контрасте между двумя показателями.
Этот блог пытается ответить на следующие вопросы.
1. Что такое вероятность предсказания?
2. Что концептуально означает потеря журнала?
3. Как рассчитывается значение логарифмических потерь?
4. Как рассчитывается показатель логарифмических потерь модели?
5. Как интерпретировать показатель логарифмических потерь?
Что такое вероятность предсказания?
Алгоритмы бинарной классификации сначала предсказывают вероятность того, что запись будет отнесена к классу 1, а затем классифицируют точку данных (запись) по одному из двух классов (1 или 0) в зависимости от того, превысила ли вероятность пороговое значение, которое обычно устанавливается на 0,5 по умолчанию.
Итак, прежде чем прогнозировать класс записи, модель должна предсказать вероятность того, что запись будет отнесена к классу 1. Помните, что именно от этой прогнозируемой вероятности записи данных зависит значение логарифмических потерь.
Что концептуально означает потеря журнала?
Логарифмическая потеря показывает, насколько близка вероятность предсказания к соответствующему фактическому/истинному значению (0 или 1 в случае двоичной классификации). Чем больше прогнозируемая вероятность отличается от фактического значения, тем выше значение логарифмической потери.
Рассмотрим проблему классификации спама и ветчины для электронных писем. Давайте представим класс спама как 1, а класс ветчины как 0. Рассмотрим спам по электронной почте (фактическое значение = 1) и статистическую модель, которая предсказывает электронное письмо как спам с вероятностью 1. Поскольку вероятность прогноза совсем не фактическое значение 1, значение логарифмической потери, связанное с прогнозом наблюдения, равно 0, что указывает на отсутствие расхождения/ошибки вообще.
(На самом деле значение логарифмических потерь достаточно ничтожно, чтобы его можно было рассматривать как 0 во всех смыслах.) Мы обсудим вычисление позже, когда установим концептуальное понимание этого термина.Рассмотрим другое электронное письмо со спамом, которое прогнозируется с вероятностью 0,9. Вероятность прогноза модели составляет 0,1 от фактического значения 1, и, следовательно, значение логарифмических потерь, связанное с прогнозом, больше нуля (точнее, 0,105).
Теперь давайте посмотрим на любительское электронное письмо. Модель предсказывает это как спам с вероятностью 0,2, что является еще одним способом сказать, что модель собирается классифицировать его как ветчину (при условии, что порог вероятности по умолчанию равен 0,5). Абсолютная разница между вероятностью предсказания и фактическим значением, которое равно 0 (поскольку это ветчина), составляет 0,2, что больше, чем то, что мы наблюдали в двух предыдущих наблюдениях. Значение логарифмических потерь, связанное с прогнозом, равно 0,223.
Обратите внимание, что значение логарифмических потерь для худшего прогноза (дальше от фактического значения) выше, чем для лучшего прогноза (ближе к фактическому значению).
Теперь предположим, что есть набор из 5 различных писем со спамом, предсказанных с широким диапазоном вероятностей (являющихся спамом) — 1,0, 0,7, 0,3, 0,009 и 0,0001. Вы, должно быть, сейчас думаете, как спам-письмо могло быть предсказано как спам с такой вероятностью 0,0001. Давайте подыграем и предположим, что обученная статистическая модель не идеальна и, следовательно, делает (действительно) плохую работу с последними тремя наблюдениями (и, вероятно, классифицирует их как ветчину, поскольку их вероятности предсказания ближе к 0, чем к 1). ). Обратите внимание, как значение логарифмических потерь растет экспоненциально (а не линейно) по мере того, как предсказанное наблюдение оказывается дальше от фактического значения 1,9.0003
На самом деле, если бы мы предсказывали электронные письма со спамом со всеми возможными вероятностями предсказания от 0 до 1, график выглядел бы следующим образом.
Чем ниже вероятность предсказания истинного наблюдения 1, тем выше его значение логарифмических потерь.Аналогично, для электронных писем, предсказанных в широком диапазоне вероятностей, график будет выглядеть следующим образом, зеркально отображая приведенный выше график. Чем выше вероятность предсказания истинного наблюдения 0, тем выше его значение логарифмических потерь.
Подводя итог, можно сказать, что чем дальше вероятность предсказания от фактического значения, тем выше его логарифмическое значение потерь.
При обучении модели классификации мы хотели бы, чтобы наблюдение было предсказано с вероятностью, максимально близкой к фактическому значению (0 или 1). Следовательно, логарифмическая потеря оказывается хорошим выбором для функции потерь во время обучения и оптимизации моделей классификации, при этом чем дальше вероятность прогноза от ее истинного значения, тем выше штраф за прогноз.
Как рассчитывается значение логарифмических потерь?
Теперь, когда вы понимаете интуицию, стоящую за логарифмическими потерями, мы можем обсудить формулу и способы ее расчета.
, где i — данное наблюдение/запись, y — фактическое/истинное значение, p — вероятность предсказания, а ln — натуральный логарифм (логарифмическое значение с использованием основания e ) числа.
Как рассчитывается показатель логарифмических потерь модели?
Как показано выше, значение логарифмических потерь рассчитывается для каждого наблюдения на основе фактического значения наблюдения ( y ) и прогнозируемой вероятности ( стр. ). Чтобы оценить модель и обобщить ее навыки, показатель логарифмических потерь модели классификации сообщается как среднее значение логарифмических потерь всех наблюдений/прогнозов. Как показано ниже, среднее значение логарифмических потерь данных трех прогнозов составляет 0,110.
, где N — количество наблюдений (здесь 3).
Модель с безупречным мастерством имеет логарифмическую оценку потерь, равную 0. Другими словами, модель предсказывает вероятность каждого наблюдения как фактическое значение.
Что показатель логарифмических потерь для задачи классификации, то среднеквадратическая ошибка (MSE) для задачи регрессии. Обе метрики показывают, насколько хороши или плохи результаты прогнозирования, указывая, насколько далеки прогнозы от фактических значений.
Модель с более низкой оценкой потерь журнала лучше, чем модель с более высокой оценкой потерь журнала, при условии, что обе модели применяются к одному и тому же распределению набора данных. Мы не можем сравнивать показатели логарифмических потерь двух моделей, примененных к двум разным наборам данных.
Как интерпретировать показатель логарифмических потерь?
Рассмотрим образец из 10 электронных писем с 9 ответами. Поскольку только одно электронное письмо (из 10) является спамом, мы могли бы построить наивную модель классификации , которая просто предсказывает вероятность того, что каждое электронное письмо является спамом, равное 0,1. Как показано ниже, логарифмическая оценка этой наивной модели составляет 0,325.
Как показано ниже, при сбросе вероятности предсказания каждого письма на 0,08 (чуть меньше 0,1) показатель потери журнала оказывается равным 0,328. Точно так же, если мы установим вероятность предсказания на 0,12 (чуть больше 0,1), мы получим логарифмическую оценку потерь 0,327. Короче говоря, если мы установим вероятность прогнозирования электронных писем на значение, отличное от 0,1, мы получим более высокий показатель потери журнала.
Даже приведенный ниже рисунок подтверждает наше вышеупомянутое открытие — установка вероятности электронных писем на 0,1 дает наименьшую оценку потери журнала для набора данных, которая будет рассматриваться как базовая оценка для данного выборочного набора данных.
Базовый показатель логарифмических потерь для набора данных определяется из наивной модели классификации, которая просто привязывает все наблюдения с постоянной вероятностью, равной % данных с наблюдениями класса 1.
Для сбалансированного набора данных с соотношением сторон 51:49отношение класса 0 к классу 1, наивная модель с постоянной вероятностью 0,49 даст логарифмическую оценку потерь 0,693, которая считается базовой оценкой для этого набора данных.Чем выше дисбаланс в наборе данных, тем ниже базовая оценка логарифмических потерь набора данных из-за меньшей доли наблюдений (в данном случае класса 1), которые оказывают большее влияние на средние значения логарифмических потерь.
Поскольку прогнозирование низкого постоянного значения вероятности для несбалансированного набора данных приводит к очень низкому значению логарифмических потерь, в таких случаях следует осторожно интерпретировать навыки модели, оцениваемые с использованием логарифмических потерь. На самом деле значения логарифмических потерь всегда следует интерпретировать в контексте базовой оценки, полученной в наивной модели.
Когда мы строим статистическую модель на заданном наборе данных, модель должна превзойти базовый показатель логарифмических потерь, тем самым доказав, что она более совершенна, чем наивная модель.

 А поскольку ковариация коммутативна (Cov(a,b)=Cov(b,a)), элементы ковариационной матрицы симметричны относительно главной диагонали, что означает, что верхняя и нижняя треугольные части равны.
А поскольку ковариация коммутативна (Cov(a,b)=Cov(b,a)), элементы ковариационной матрицы симметричны относительно главной диагонали, что означает, что верхняя и нижняя треугольные части равны. Прежде чем перейти к объяснению этих концепций, давайте сначала разберемся, что мы подразумеваем под основными компонентами.
Прежде чем перейти к объяснению этих концепций, давайте сначала разберемся, что мы подразумеваем под основными компонентами.
 Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так, как показано ниже. Можем ли мы угадать первый главный компонент? Да, это примерно линия, которая соответствует фиолетовым меткам, потому что она проходит через начало координат, и это линия, в которой проекция точек (красные точки) наиболее разбросана. Или, говоря математическим языком, это линия, которая максимизирует дисперсию (среднее значение квадратов расстояний от спроецированных точек (красные точки) до начала координат).
Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так, как показано ниже. Можем ли мы угадать первый главный компонент? Да, это примерно линия, которая соответствует фиолетовым меткам, потому что она проходит через начало координат, и это линия, в которой проекция точек (красные точки) наиболее разбросана. Или, говоря математическим языком, это линия, которая максимизирует дисперсию (среднее значение квадратов расстояний от спроецированных точек (красные точки) до начала координат). Первое, что вам нужно знать о них, это то, что они всегда идут парами, так что каждый собственный вектор имеет собственное значение. И их количество равно количеству размерностей данных. Например, для трехмерного набора данных есть 3 переменные, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
Первое, что вам нужно знать о них, это то, что они всегда идут парами, так что каждый собственный вектор имеет собственное значение. И их количество равно количеству размерностей данных. Например, для трехмерного набора данных есть 3 переменные, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.

 е. в члены исходных переменных).
е. в члены исходных переменных). В то время как входные данные (функции) состоят из непрерывных или категориальных переменных, выходные данные всегда являются категориальной переменной. Например, на основе входных характеристик, таких как информация о погоде (влажность, температура, облачно/солнечно, скорость ветра и т. д.) и время года, можно предсказать, будет ли сегодня «дождь» или «нет дождя» (выходная переменная). в вашем городе. Другой пример, основанный на содержании электронного письма и информации об отправителе, позволяет предсказать, является ли оно «спамом» или «не спамом» (он же «ветчина»).
В то время как входные данные (функции) состоят из непрерывных или категориальных переменных, выходные данные всегда являются категориальной переменной. Например, на основе входных характеристик, таких как информация о погоде (влажность, температура, облачно/солнечно, скорость ветра и т. д.) и время года, можно предсказать, будет ли сегодня «дождь» или «нет дождя» (выходная переменная). в вашем городе. Другой пример, основанный на содержании электронного письма и информации об отправителе, позволяет предсказать, является ли оно «спамом» или «не спамом» (он же «ветчина»).
 (На самом деле значение логарифмических потерь достаточно ничтожно, чтобы его можно было рассматривать как 0 во всех смыслах.) Мы обсудим вычисление позже, когда установим концептуальное понимание этого термина.
(На самом деле значение логарифмических потерь достаточно ничтожно, чтобы его можно было рассматривать как 0 во всех смыслах.) Мы обсудим вычисление позже, когда установим концептуальное понимание этого термина.
 Чем ниже вероятность предсказания истинного наблюдения 1, тем выше его значение логарифмических потерь.
Чем ниже вероятность предсказания истинного наблюдения 1, тем выше его значение логарифмических потерь.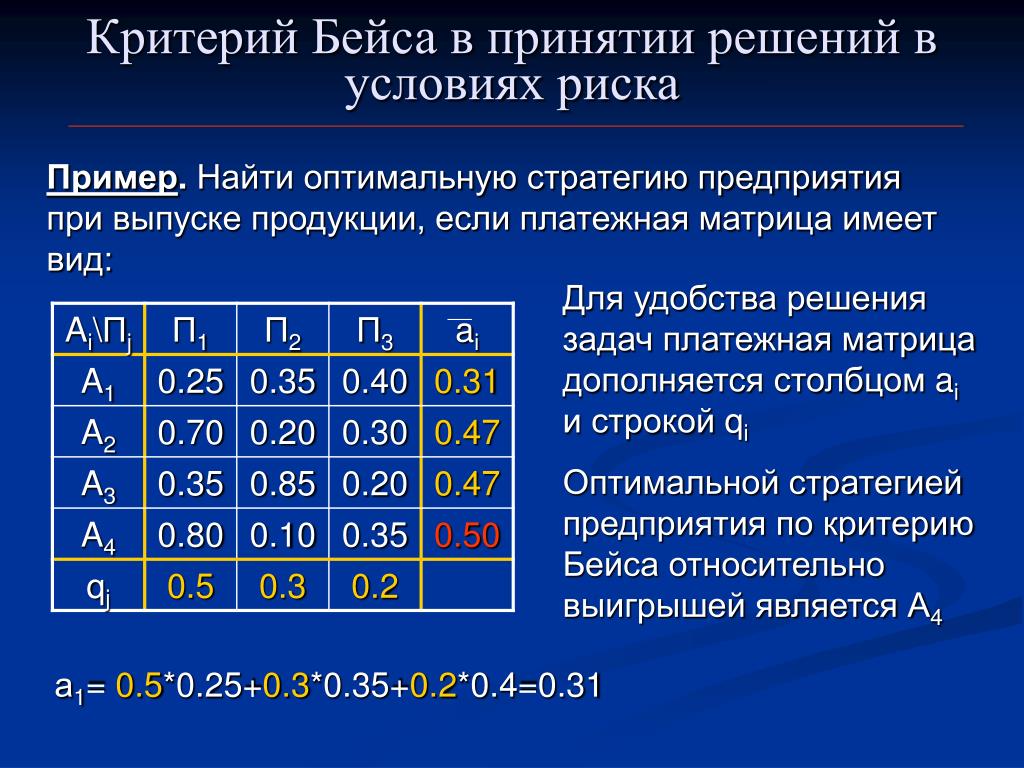
 Для сбалансированного набора данных с соотношением сторон 51:49отношение класса 0 к классу 1, наивная модель с постоянной вероятностью 0,49 даст логарифмическую оценку потерь 0,693, которая считается базовой оценкой для этого набора данных.
Для сбалансированного набора данных с соотношением сторон 51:49отношение класса 0 к классу 1, наивная модель с постоянной вероятностью 0,49 даст логарифмическую оценку потерь 0,693, которая считается базовой оценкой для этого набора данных.