Глава 9. Панельные данные
- Оглавление
- Главная
- Про Учебник+
- Контакты
AAA
Если в выборке содержатся данные о нескольких объектах, каждый из которых наблюдается в течение нескольких моментов времени, то такие данные называют панельными (panel data или longitudinal data). Например, ежегодные данные о доходе и потреблении в 50 регионах некоторой страны за период с 1992 по 2011 годы.
В отличие от пространственных данных, на которых мы концентрировались в предыдущих главах, теперь для обозначения наблюдений нам будет удобно использовать не один, а два индекса:
\(x_{\text{it}},\)
где \(i = 1,\ldots,n\) — номер объекта (например, региона),
\(t = 1,\ldots,T\) — номер момента времени (например, номер года).
Есть несколько причин для использования панельных данных в прикладных исследованиях:
1. Большое количество наблюдений. Представьте, что вы проводите исследование, опираясь на информацию по странам мира. Если вы используете пространственные данные, то в вашем распоряжении, по всей видимости, будет менее 200 наблюдений. Ведь даже если вы включите в выборку все независимые государства-члены ООН, то их окажется меньше двухсот. А если оставить только те из них, по которым доступна достаточно полная статистическая информация, список окажется ещё короче. С другой стороны, применив панельные данные, вы будете иметь возможность использовать гораздо больше точек. Например, получив информацию о 100 странах за 10 лет, вы сможете строить регрессии по 100*10=1000 наблюдений.
Количество доступных наблюдений зависит от того, имеете ли вы дело со сбалансированной или несбалансированной панелью. Панель называется сбалансированной, если существует наблюдение для каждого объекта и для каждого момента времени. В этом случае общее число наблюдений равно \(n*T\). Когда в данных есть пропуски, панель называется несбалансированной. В этом случае общее число наблюдений меньше, чем \(n*T\), однако все равно может оставаться достаточно большим. Если возникновение пропусков является экзогенным, то для несбалансированных панелей можно использовать те же методы оценивания, что и для сбалансированных.
В этом случае общее число наблюдений равно \(n*T\). Когда в данных есть пропуски, панель называется несбалансированной. В этом случае общее число наблюдений меньше, чем \(n*T\), однако все равно может оставаться достаточно большим. Если возникновение пропусков является экзогенным, то для несбалансированных панелей можно использовать те же методы оценивания, что и для сбалансированных.
2. Возможность отслеживать динамику для множества объектов. Использование панельных данных позволяет анализировать распределение тех или иных эффектов во времени. Например, постепенное изменение потребления сигарет в некоторой стране после принятия антитабачных законов в ряде её регионов.
3. Дополнительный способ устранения эндогенности.
 Такой шанс появляется за счет учета неоднородности моделируемых объектов.
Такой шанс появляется за счет учета неоднородности моделируемых объектов.Чтобы понять, как указанная неоднородность может затруднять оценивание, рассмотрим пример. Представим, что нас интересует ответ на такой вопрос: влияет ли закон, разрешающий гражданам носить с собой личное огнестрельное оружие, на уровень преступности? Ответ на него, действительно, вовсе не очевиден. Сторонники закона утверждают, что его введение позволяет снизить преступность, так как гражданские лица получат шанс защититься от злоумышленников. Их оппоненты возражают, что в результате введения такого закона преступность, наоборот, вырастет из-за избыточного количества огнестрельного оружия на руках у населения и его спонтанного использования.
Пусть мы располагаем панельными данными о регионах некоторой страны, и уровень преступности в них описывается следующим уравнением:
\(y_{\text{it}} = \beta x_{\text{it}} + \mu_{i} + \varepsilon_{\text{it}}\ \ (9.1)\)
Здесь \(y_{\text{it}}\) — уровень преступности в регионе i в год t;
\(x_{\text{it}}\) — бинарная переменная, которая равна единице, если в регионе i в год t введен закон, разрешающий гражданам носить личное огнестрельное оружие, и равная нулю в противном случае;
\(\varepsilon_{\text{it}}\) — это, как обычно, случайные ошибки модели;
\(\mu_{i}\) — ненаблюдаемая переменная, характеризующая специфические особенности каждого из регионов. Например, культурные или институциональные особенности, которые трудно поддаются измерению. Так как все регионы разные, почти нет шансов полностью учесть их специфику в наблюдаемых контрольных переменных. Поэтому такой фактор в модели наверняка останется. Обратите внимание, что у этой переменной нет индекса
Например, культурные или институциональные особенности, которые трудно поддаются измерению. Так как все регионы разные, почти нет шансов полностью учесть их специфику в наблюдаемых контрольных переменных. Поэтому такой фактор в модели наверняка останется. Обратите внимание, что у этой переменной нет индекса
-
С одной стороны, мы не можем включить её в модель непосредственно, так как она не является наблюдаемой.
-
С другой стороны, если она коррелирована с интересующей нас переменной \(x_{\text{it}}\), то её невключение приведет к несостоятельности оценки коэффициента \(\beta\) из-за пропуска существенной переменной (см. главу 7).
Таким образом, неоднородность объектов часто становится причиной эндогенности регрессоров.
Именно этот класс моделей рассматривается в параграфах 9.1–9.4. Затем в параграфах 9.5–9.6 обсуждается альтернативный подход к оцениванию — модель со случайными эффектами. В конце главы, в параграфе 9.7, обобщена информация о спецификационных тестах, которые помогут выбрать наиболее подходящий в каждом случае метод работы с панельными данными.
Суслов В.И., Лапо В.Ф., Талышева Л.П., Ибрагимов Н.М. Эконометрия-3
- формат pdf
- размер 2.
 74 МБ
74 МБ - добавлен 16 августа 2011 г.
 74 МБ
74 МБКурс лекций — Красноярск: СФУ. — 194с.
Содержание:
Системы регрессионных уравнений.
Невзаимозависимые системы.
Взаимозависимые или одновременные уравнения.
Оценка параметров отдельного уравнения.
Оценка параметров системы идентифицированных уравнений.
Динамические регрессионные модели.
Модель распределенного лага.
Авторегрессионная модель с распределенным лагом.
Модели частичного приспособления, адаптивных ожиданий и исправления
ошибок.
Интегрированные процессы, ложная регрессия и коинтеграция.
Концепция коинтеграции.
Векторная авторегрессия.
Модели дискретного выбора.
Панельные данные.
Объединения по времени независимых одномерных (псевдопанельных) данных.
Панельные данные.

Базовая модель панельных данных.
Модель с фиксированными эффектами.
Модель со случайными эффектами.
Качество подгонки и выбор наиболее адекватной модели.
Читать онлайн
Похожие разделы
- Академическая и специальная литература
- Финансово-экономические дисциплины
- Финансово-экономическая периодика
Смотрите также
- формат pdf, htm
- размер 974.86 КБ
- добавлен 10 мая 2008 г.
Пособие предназначено для студентов экономических факультетов в качестве вспомогательного учебного материала к первой части курса Эконометрия. Теоретическая часть пособия подготовлена по материалам лекционного курса, прочитанного в 1992-1996 гг. на экономическом факультете НГУ, практическая же часть в значительной мере построена по результатам работы по программе Темпус в 1995-97 гг. Оглавление: 1. Описательная статистика 1.1. Ряды наблюдений и…
Теоретическая часть пособия подготовлена по материалам лекционного курса, прочитанного в 1992-1996 гг. на экономическом факультете НГУ, практическая же часть в значительной мере построена по результатам работы по программе Темпус в 1995-97 гг. Оглавление: 1. Описательная статистика 1.1. Ряды наблюдений и…
- формат pdf
- размер 2.2 МБ
- добавлен 27 апреля 2009 г.
Донецкий институт туристического бизнеса, 2005. Построение простой линейной регрессии. Множественная регрессия. Исследование мультиколлинеарности согласно алгоритму Фаррара–Глобера. Тестирование гетероскедастичности. (Параметрический тест Гольдфельда – Квандта). Производственная функция Кобба–Дугласа.
- формат djvu
- размер 4.82 МБ
- добавлен 18 июля 2011 г.
М. : Статистика, 1977. — 232 с. Рассматриваются макроэконометрические и микроэконометрические модели, основные методы математической статистики, применяемые в экономических исследованиях, а также содержатся начальные сведения по теории вероятностей.
: Статистика, 1977. — 232 с. Рассматриваются макроэконометрические и микроэконометрические модели, основные методы математической статистики, применяемые в экономических исследованиях, а также содержатся начальные сведения по теории вероятностей.
Статья
- формат pdf
- размер 766.53 КБ
- добавлен 11 января 2010 г.
Конспект лекций — Эконометрия Основные требования для построения модели одномерной линейной регрессии. Оценки параметров простой линейной регрессии на основе МНК. Коэффициент детерминации. Его свойства. Скорректированный коэффициент детерминации. Его свойства. Проверка модели на адекватность. Критерий Фишера. Проверка значимости параметров модели. Критерий Стьюдента. Основные предположения в многофакторном регрессионном анализе. Оценка неизвестны…
Оценка неизвестны…
Статья
- формат doc
- размер 203.22 КБ
- добавлен 18 октября 2010 г.
ВНУ им. В. Даля. Кафедра прикладной статистики. Предмет, метод и задача дисциплины. Метод наименьших квадратов. Двухфакторная линейная модель: предсказание одного фактора на основании другого. Многофакторная регрессия: основные понятия. Интерпретация результатов многофакторного моделирования. Статистические выводы по многофакторной модели. Сложности и проблемы, связанные с множественной регрессией. Составление отчетов: представление результатов м…
Практикум
- формат pdf
- размер 962.41 КБ
- добавлен
08 декабря 2010 г.

Методическое пособие. Эконометрия 1: регрессионный анализ. 53 с. Методическое пособие для студентов П-Ш курсов экономического факультета НГУ Эконометрия I: регрессионный анализ Курс эконометрии I состоит из двух частей: регрессионный анализ и временные ряды. Данное пособие предназначено для 1-й части курса, которая изучается в ГУ семестре. Пособие включает 7 разделов: 1. Описательная статистика. 2. Случайные ошибки измерения. 3. Алгебра линейной…
- формат pdf
- размер 901.24 КБ
- добавлен 26 апреля 2011 г.
Наглядное пособие. — Красноярск: СФУ, 194с. Данное пособие написано на основе курсов, читаемых на экономическом факультете Новосибирского государственного университета. При создании учебника авторы стремились систематизировать и объединить в единое целое в рамках одного источника различные разделы экономической статистики и эконометрии. Оглавление Системы регрессионных уравнений Невзаимозависимые системы Взаимозависимые или одновременные ура…
Оглавление Системы регрессионных уравнений Невзаимозависимые системы Взаимозависимые или одновременные ура…
Практикум
- формат doc
- размер 833.83 КБ
- добавлен 28 февраля 2011 г.
– Донецк, ДонТУ,2008. – 50с. В Методических рекомендациях по дисциплине «Эконометрия» приведен необходимый для решения практических вопросов теоретический материал, решение типовых задач, реализованное на компьютере с помощью прикладных программ Excel, а также контрольные задания. Методические рекомендации по дисциплине «Эконометрия» разработаны доцентом кафедры «Финансы и банковское дело» Л. Д. Слепневой. – Донецк, ДонТУ,2008. – 50с
- формат pdf
- размер 3.37 МБ
- добавлен
09 мая 2009 г.

Данный учебник написан на основе курсов, читаемых на экономическом факультете Новосибирского государственного университета. При создании учебника авторы стремились систематизировать и объединить в единое целое в рамках одного источника различные разделы экономической статистики и эконометрии.
Практикум
- формат pdf
- размер 1.63 МБ
- добавлен 28 октября 2011 г.
Методические указания к выполнению лабораторной работы №5 по дисциплине «Эконометрия» для студентов специальности 8.050201 – «Менеджмент организаций» дневной формы обучения. – Севастополь: Изд-во СевНТУ, 2008г. – 36 с. Целью методических указаний является получение навыков применения методов анализа временных рядов с использованием средств, предоставляемых Gretl 1. 7.1. Содержание: Цель работы Теоретический раздел Анализ тренда Декомпозиция…
7.1. Содержание: Цель работы Теоретический раздел Анализ тренда Декомпозиция…
Краткое руководство по программе Gretl
I. Введение
Программа регрессии Gretl — мощная бесплатная программа. доступен для загрузки с веб-сайта SourceForge. это открытый исходную эконометрическую программу и будет работать на компьютерах под управлением Операционные системы Windows, MAC OS X или Linux.
II. Загрузка и установка программы Gretl
A. Руководство по программе Gretl доступно по этой ссылке: http://gretl.sourceforge.net/gretl-help/gretl-guide.pdf
B. Программа Gretl для Windows доступна для загрузки на по следующей ссылке: gretl-2018a-64.exe для 64-битной Windows
Для установки программы нажмите на ссылку выше, сохраните файл в
ваш жесткий диск, а затем нажмите * Run * при появлении запроса. В
подсказок, примите параметры установки по умолчанию, после чего программа
создайте значок на рабочем столе для Gretl. Дважды щелкните на
значок на рабочем столе для запуска программы.
Дважды щелкните на
значок на рабочем столе для запуска программы.
Примечание. Если вы планируете использовать программу исключительно в Iona компьютерных лабораториях, вы можете избежать повторной загрузки файла программы сохранив файл на локальный диск U:. Для этого сначала нажмите на ссылку программы, а затем нажмите Сохранить и иметь программа сохранена на вашем локальном диске U:. После загрузки завершено, нажмите «Выполнить» при появлении запроса, примите установку значения по умолчанию, и на вашем рабочем столе будет создан значок Gretl. Чтобы чтобы использовать программу Gretl в любое время в будущем, все, что у вас есть нужно открыть диск U: и дважды щелкнуть по файл gretl-2018a-64.exe.
B. Инструкция по установке программы Gretl на MAC OS находится доступен по следующей ссылке: http://gretl.sourceforge.net/osx.html.
Определите, какой у вас более новый (на базе Intel) или более старый (на базе Apple
на базе) Mac, затем щелкните ссылку, которая соответствует вашему конкретному
компьютер, сохраните файл на жесткий диск и нажмите *Выполнить*
когда будет предложено. При появлении подсказок примите параметры установки по умолчанию и
затем программа создаст значок Гретл на рабочем столе.
Дважды щелкните значок на рабочем столе, чтобы запустить программу.
При появлении подсказок примите параметры установки по умолчанию и
затем программа создаст значок Гретл на рабочем столе.
Дважды щелкните значок на рабочем столе, чтобы запустить программу.
III. Подготовка и импорт файлов данных Excel
«Рекомендуемый» способ анализа данных с помощью программы Gretl: сначала создать книгу Excel, а затем «импортировать» данные в программа.
ПРИМЕЧАНИЕ. Как и в большинстве статистических программ, импорт данных работает лучше всего. когда данные были сохранены в виде файла MS Excel с разделителями-запятыми (csv) рабочие листы.
A. Для создания и сохранения данных в файл MS Excel с разделителями-запятыми (csv) рабочих листов:
и. Запустите программу MS-Excel и либо (а) введите данные в
пустой лист или (b) открыть сохраненный файл Excel и нажать на
рабочий лист, содержащий данные для импорта.
ii. Убедитесь, что каждый столбец данных начинается с имени переменной. что (а) начинается с буквы и (б) не длиннее восьми
последовательных символов по длине.
что (а) начинается с буквы и (б) не длиннее восьми
последовательных символов по длине.
III. Убедитесь, что, кроме заголовков столбцов, все данные
состоит из цифр. Gretl игнорирует буквенно-цифровые значения, поэтому
обязательно сначала преобразуйте категориальные переменные (например, да, нет) в
числовые переменные (например, 1, 0). ПРИМЕЧАНИЕ: вы можете использовать *Редактировать* Excel
Замените *, чтобы выполнить преобразование.
IV. Удалите все рабочие листы, кроме одного, содержащего данные
v. Чтобы сохранить данные, нажмите * Файл * Сохранить как *, а затем введите
имя файла и щелкните файл MS Excel с разделителями-запятыми (csv) в качестве
тип файла.
B. Чтобы импортировать сохраненный рабочий лист Excel в программу Gretl:
Запустите Gretl и нажмите * File * Open Data * User File *, измените
тип файла (внизу справа) в CSV, а затем укажите папку
содержащие данные. Затем ответьте на запрос о том, являются ли данные
недатированные или временные ряды или панели. Если данные представляют собой временные ряды
или панель, вам нужно будет ввести дополнительную информацию о том, как
данные измеряются, т. е. начальная дата данных,
количество периодов времени и т. д. После того, как вы импортировали данные,
дважды щелкните имена переменных, чтобы убедиться, что программа
правильно обработал данные.
Затем ответьте на запрос о том, являются ли данные
недатированные или временные ряды или панели. Если данные представляют собой временные ряды
или панель, вам нужно будет ввести дополнительную информацию о том, как
данные измеряются, т. е. начальная дата данных,
количество периодов времени и т. д. После того, как вы импортировали данные,
дважды щелкните имена переменных, чтобы убедиться, что программа
правильно обработал данные.
IV. Описательная статистика и простые графики
A. Чтобы получить описательную статистику, выделите имена переменных для которого вы хотите получить статистику, а затем нажмите * View * Summary Статистика *ОК*. Чтобы получить коэффициенты корреляции, нажмите * Просмотр * Корреляционная матрица * *ОК*.
B. Чтобы получить простые двумерные графики, щелкните * Просмотр * Указанный график
vars * X-Y scatter *, а затем укажите переменные, которые вы хотите
график по осям X и Y.
назад наверх
V. Регрессия обычных наименьших квадратов программы, нажмите * Модель * * Обыкновенные наименьшие квадраты *, определите зависимая переменная и независимые переменные, а затем нажмите * OK *. Вкладка *Анализ* сгенерирует дополнительную статистику включая прогнозируемые значения и остатки и доверительные интервалы для коэффициентов. Вкладка * Графики * будет генерировать разные графики остатков.
VI. Тестирование и исправление последовательной (автоматической) корреляции
Gretl сгенерирует статистику Дарбина-Уотсона после обычного
оценивается регрессия методом наименьших квадратов. Результаты для
Тест Бреуша-Годфри на автокорреляцию также можно получить с помощью
нажав на *Тесты*Автокорреляция* и введя нужный
количество лагов. Для оценки обобщенных методов наименьших квадратов (GLS)
исправлены результаты, нажмите *Модель *Временной ряд*, выберите
метод оценки (например, авторегрессионная оценка), а затем
определить зависимые и независимые переменные и количество
Срок AR отстает (обычно на 1). Для оценки скорректированного стандарта Newey-West
ошибки, запустите регрессию по методу наименьших квадратов (OLS), но
также нажмите на * Надежные стандартные ошибки * Настроить * и на *
Вкладка HCCE * убедитесь, что * HAC * выделен для * временного ряда
данные *.
Для оценки скорректированного стандарта Newey-West
ошибки, запустите регрессию по методу наименьших квадратов (OLS), но
также нажмите на * Надежные стандартные ошибки * Настроить * и на *
Вкладка HCCE * убедитесь, что * HAC * выделен для * временного ряда
данные *.
VII. Проверка и исправление гетероскедастичности
После оценки обычной регрессии методом наименьших квадратов можно
проверить на гетероскедастичность, нажав *Тесты*
Гетероскедастичность * и вход в желаемый тест, например, Белый
Тест. Чтобы оценить скорректированные результаты, выполните обычный метод наименьших квадратов.
регрессия, но также нажмите * Надежные стандартные ошибки * Настроить *
и на вкладке *HCCE* убедиться, что нужный метод коррекции
(например, HC1) выделен для * данных поперечного сечения *.
VIII. Модели логит-регрессии
Для создания модели логит-регрессии на бинарном манекене (1,0)
зависимая переменная, щелкните *Модель* * Ограниченная зависимая переменная *
Логит *Двоичный*, а потом идентифицирует зависимое и независимое
переменные.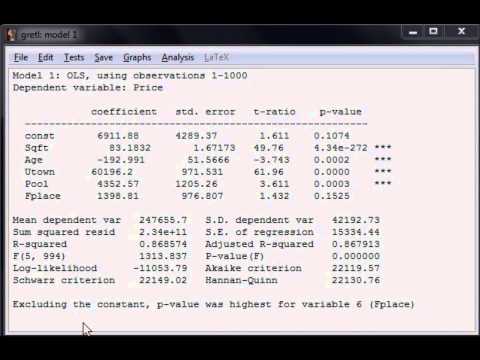 Затем Gretl сгенерирует логит-результаты, в том числе
преобразованные коэффициенты, измеряющие предельные воздействия
объяснители оценивались по их средним значениям.
Затем Gretl сгенерирует логит-результаты, в том числе
преобразованные коэффициенты, измеряющие предельные воздействия
объяснители оценивались по их средним значениям.
IX. Создание новых переменных
Новые переменные можно создать из существующих, нажав *
Добавьте * Новая переменная *, а затем введите формулу для вычисления
новая переменная. Например, если вы хотите умножить X1 на X2
чтобы создать интерактивную переменную с именем X1X2, затем нажмите * Добавить *
Новая переменная * и введите в поле формулы X1X2 = X1 * X2. Делать
убедитесь, что если имена переменных написаны с большой буквы, ваша формула
включает имена с заглавной буквы.
X. Подвыборки
Чтобы выбрать подвыборки набора данных, щелкните * Образец * и *
Установите диапазон *, а затем определите диапазон наблюдений, которые вы хотите
включить в последующие анализы. Вы также можете использовать *
Команда Sample * для включения случайной выборки наблюдений или
определить выражения, которые будут выбирать/отклонять те случаи, которые соответствуют
к выражению.
Вы также можете использовать *
Команда Sample * для включения случайной выборки наблюдений или
определить выражения, которые будут выбирать/отклонять те случаи, которые соответствуют
к выражению.
XI. Регрессии панельных данных
Для анализа данных панели в программе Gretl нажмите на *Model* * Панель * * Фиксированные или случайные эффекты*, определите зависимую переменную и независимые переменные и модель, которую вы хотите оценить, укажите, хотите ли вы включить временные манекены, а затем нажмите * ХОРОШО *. Вкладка *Тесты* будет генерировать дополнительную статистику включая тесты на гетероскедастичность и серийную корреляцию.
XII. Сохранение проектов
Если вы хотите сохранить сеанс Gretl для будущего анализа и хотите
чтобы избежать повторного импорта рабочего листа данных Excel и повторного создания любых
преобразования данных, которые вы уже сделали, то вы должны получить
Gretl, чтобы сохранить ваш проект.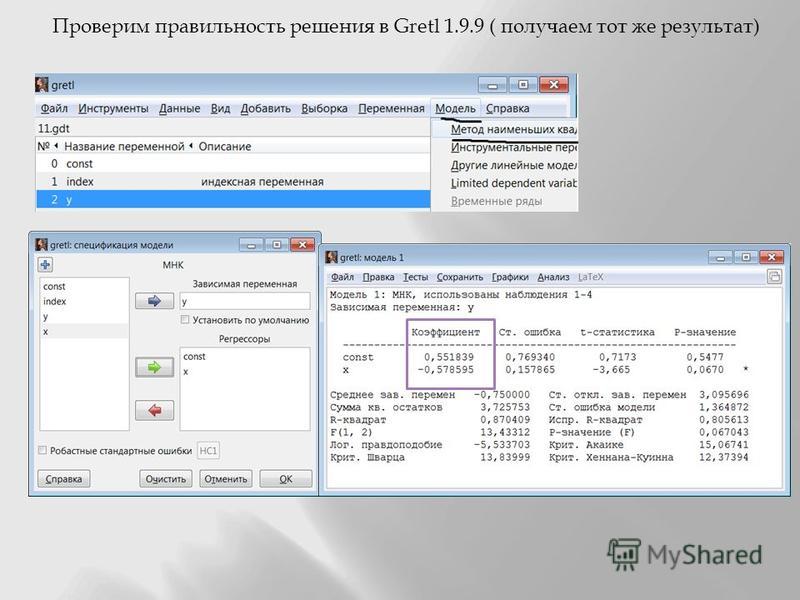 Для этого нажмите * Файл * Сохранить данные *,
укажите папку, в которой вы хотите сохранить проект, и назовите
проект. Затем вы можете снова открыть проект, запустив Gretl
программы, нажав на *Файл*Открыть данные*Файл пользователя*, а затем
ввод имени сохраненного проекта. Гретл воссоздаст все
переменные, которые были доступны на момент сохранения проекта.
Для этого нажмите * Файл * Сохранить данные *,
укажите папку, в которой вы хотите сохранить проект, и назовите
проект. Затем вы можете снова открыть проект, запустив Gretl
программы, нажав на *Файл*Открыть данные*Файл пользователя*, а затем
ввод имени сохраненного проекта. Гретл воссоздаст все
переменные, которые были доступны на момент сохранения проекта.
задняя часть наверх
панельных данных — Некогерентные временные ряды в gretl
$\begingroup$
Это мое первое исследование с использованием Gretl.
У меня есть панель из 197 человек за 66 месяцев, сложенных в виде временных рядов. У одного человека значения месяцев январь, февраль, марс, апрель, ноябрь, декабрь. За летние месяцы май, июнь, июль, август, октябрь и сентябрь данных нет. так что мои данные идут с 2005-11 по 2016-04 с пропущенными 6 месяцами каждый год.
Неудивительно, что Гретль не замечает, что летние месяцы отсутствуют. Он связывает данные вместе и распознает мои данные с 2005-11 по 2011-04.
Кто-нибудь из вас знает, как решить эту проблему и заставить Гретл понять, что у меня есть только 6 месяцев в году?
Он связывает данные вместе и распознает мои данные с 2005-11 по 2011-04.
Кто-нибудь из вас знает, как решить эту проблему и заставить Гретл понять, что у меня есть только 6 месяцев в году?
Моей первой идеей было включить пропущенные значения для летних месяцев. Возможно ли это в Gretl или мне нужно сделать это в Excel?
Я уже проверил руководство и различные интернет-платформы, но не смог найти решение. Поэтому я благодарен за любое предложение. С уважением, x739Green
- временной ряд
- панель данных
- gretl
$\endgroup$
1
$\begingroup$
Я не вижу никаких преимуществ в том, чтобы вставлять НС в слоты с мая по октябрь за каждый год, если, возможно, вы не рассчитываете, что в какой-то момент сможете заполнить их реальными данными. Я бы предложил создать переменную, которая записывает месяц года при каждом наблюдении.