
Лучший ответ по мнению автора | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||
 12.15
12.15
|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Посмотреть всех экспертов из раздела Учеба и наука > Математика
Решено
В «Детском мире» продавали двухколесные и трехколесные велосипеды. Коля пересчитал все рули и колеса.Получилось 11 рулей и 29 колес.Сколько трехколесных велосипедов продавали в «Детском мире»?
Коля пересчитал все рули и колеса.Получилось 11 рулей и 29 колес.Сколько трехколесных велосипедов продавали в «Детском мире»?
В магазине продавали двухколёсные и трёхколёсные велосипеды.Миша пересчитал все рули и все колёса.Получилось 12 рулей и 27 колёс.Сколько трёхколёсных велосипедов пролавали в магазине?
математика 1 класс. М.И.Моро, С.И. Волкова На каждой корзине записано, сколько в ней яблок. Соедини линией рисунки. на которых нарисовано одинаковое количество яблок, и запиши два верных равенства
Данный пример использовался на экзамене upsc в декабре 2013 и лишь один человек смог решить его … 1,3,5,7,9,11,13,15 нужно взять 3 числа и только сложением получить 30.
В «Детском мире» продавали двухколёсные и трёхколёсные велосипеды. Миша пересчитал все рули и все колёса. Получилось 12 рулей и 27 колёс. Сколько трёхколёсных велосипедов продавали в «Детском мире»?
Пользуйтесь нашим приложением
Лучший ответ по мнению автора | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
 .. — Учеба и наука
.. — Учеба и наука
| |||||||||||||||||
 02.21
02.21Другие ответы
| ||||||||||||
|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Посмотреть всех экспертов из раздела Учеба и наука > Математика
| Похожие вопросы |
1. АВCDA1B1C1D1 – прямоугольный параллелепипед. АВ = 2 см, АD = 7 см, АА1 = 4 см. Найти расстояние между прямыми АВ и СD.
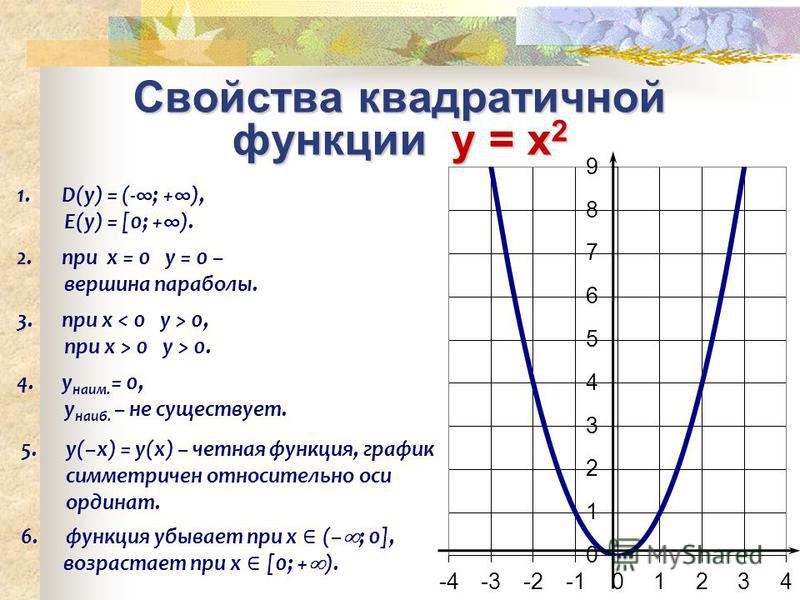
АВCDA1B1C1D1 – прямоугольный параллелепипед. АВ = 2 см, АD = 7 см, АА1 = 4 см. Найти расстояние между прямыми АВ и СD.
Решено
sinx-sin2x+sin5x-sin(pi+8x)=0
Решено
Через гіпотенузу АВ прямокутного трикутника АВС проведено площину a на відстані корень из 11 см від вершини С. Висота СК трикутника АВС ділить
Помогите решить математику
Решено
Дано куб з ребром 12. Знайти довжину проекції діагоналі бічної грані на площину верхньої грані.
Пользуйтесь нашим приложением
r — построить график функции в блестящем
Обычно мы хотим возвращать значения из функций, а не пытаться получить к ним доступ, например, [["plot_env"]][["plotGD"]] . В R , чтобы вернуть несколько элементов из функции, мы должны обернуть их в list() . Для вашего приложения функция
Для вашего приложения функция function.clustering() должна возвращать 3 элемента: данные о покрытии, таблицу кластеризации и точечную диаграмму. Это обрабатывается:
return(list(
"Данные" = таблица_данных_1,
"Сюжет" = сюжетGD,
«Покрытие» = покрытие
))
Обратите внимание, что plotGD — это просто объект графика, а не напечатанный график. Последний печатает график в окне/панели построения, поэтому вам нужно выполнить двойную гимнастику [[]][[]] .
Аналогично кабелю. Возвратите data.frame (или data.table или матрицу) и выполните стилизацию внутри серверной функции.
Наконец, чтобы использовать function.LetCoverage , мы просто передаем третий элемент, возвращаемый функцией кластеризации. Это сделает сюжет и визуализирует его.
HTH,
Рабочее приложение: библиотека
(блестящая)
библиотека (ggplot2)
библиотека (рдист)
библиотека (геосфера)
библиотека (kableExtra)
библиотека (readxl)
библиотека (tidyverse)
#база данных
df<-структура (список (Свойства = c (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20) ,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35), широта = c(-23,8, -23,8, -23,9, -23,9, -23,9 , -23,9, -23,9, -23,9, -23,9, -23,9, -23,9, -23,9, -23,9, -23,9,
+ -23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,-23,9,- 23,9, -23,9, -23,9, -23,9), долгота = c(-49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,7,
+ -49. 7, -49,7, -49,7, -49,7, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6 ,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6), отходы = c(526, 350, 526, 469, 285, 175, 175, 350, 350, 175, 350, 175 , 175, 364,
+ 175, 175, 350, 45,5, 54,6,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350)), class = "data.frame", row.names = c(NA, -35L))
function.clustering <- function(df, k, Filter1, Filter2) {
#df — это база данных
#k - количество кластеров
#Filter1 равен 1, если используются все свойства
#Filter1 равен 2, чтобы ограничить использование свойств, которые могут привести к образованию отходов
7, -49,7, -49,7, -49,7, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6 ,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6), отходы = c(526, 350, 526, 469, 285, 175, 175, 350, 350, 175, 350, 175 , 175, 364,
+ 175, 175, 350, 45,5, 54,6,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350)), class = "data.frame", row.names = c(NA, -35L))
function.clustering <- function(df, k, Filter1, Filter2) {
#df — это база данных
#k - количество кластеров
#Filter1 равен 1, если используются все свойства
#Filter1 равен 2, чтобы ограничить использование свойств, которые могут привести к образованию отходов S
если (Фильтр1 == 2) {
Q1 <- матрица (квантиль (df $ Waste, probs = 0,25))
Q3 <- матрица (квантиль (df $ Waste, probs = 0,75))
L <- Q1 - 1,5 * (Q3 - Q1)
S <- Q3 + 1,5 * (Q3 - Q1)
df_1 <- подмножество (df, Отходы > L[1])
df <- подмножество (df_1, Отходы < S[1])
}
#кластер
координаты <- df[c("Широта", "Долгота")]
d <- as. dist(distm(координаты[ 2:1]))
fit.average <- hclust(d, method = "среднее")
#Количество кластеров
кластеры <- cutree(fit.average, k)
nclusters <- матрица (таблица (кластеры))
df$cluster <- кластеры
#Локализация
center_mass <- матрица (nrow = k, ncol = 2)
для (я в 1: к) {
center_mass[я, ] <-
с(
средневзвешенное значение(
подмножество (df, кластер == i) $ Latitude,
подмножество (df, кластер == i) $ Отходы
),
средневзвешенное значение(
подмножество (df, кластер == i) $ Долгота,
подмножество (df, кластер == i) $ Отходы
)
)
}
координаты $ кластер <- кластеры
center_mass <- cbind (center_mass, матрица (c (1: k), ncol = 1))
#Покрытие
покрытие <- матрица (nrow = k, ncol = 1)
для (я в 1: к) {
вспомогательное_расстояние <-
distm (rbind (подмножество (координаты, кластер == i), center_mass [i, ]) [ 2: 1])
покрытие[i, ] <- max(aux_dist[nclusters[i, 1] + 1, ])
}
покрытие <- cbind (покрытие, матрица (c (1: k), ncol = 1))
colnames(coverage) <- c("Coverage_meters", "cluster")
#Сумма отходов от кластеров
sum_waste <- матрица (nrow = k, ncol = 1)
для (я в 1: к) {
sum_waste[i,] <- sum(subset(df, cluster == i)["Отходы"])
}
sum_waste <- cbind (sum_waste, матрица (c (1: k), ncol = 1))
colnames(sum_waste) <- c("Potential_Waste_m3", "cluster")
#Выходная таблица
data_table <- Уменьшить (слияние, список (df, покрытие, sum_waste))
таблица_данных <-
data_table[порядок(data_table$cluster, as. numeric(data_table$Properties)),]
data_table_1 <-
агрегат(. ~ кластер + Coverage_meters + Potential_Waste_m3,
data_table[ c(1, 7, 6, 2)],
нанизывать)
# Точечная диаграмма
подавлятьPackageStartupMessages (библиотека (ggplot2))
df1 <- as.data.frame(center_mass)
colnames(df1) <- c("Широта", "Долгота", "кластер")
г <-
ggplot (данные = df, aes (
х = долгота,
у = широта,
цвет = фактор (кластеры)
)) + geom_point(aes(x = долгота, y = широта), size = 4)
Centro_View <-
г + геотекст(
данные = дф,
отображение = aes(
х = оценка (долгота),
у = оценка (широта),
метка = Отходы
),
размер = 3,
hюст = -0,1
) + геом_точка(
данные = df1,
отображение = aes (долгота, широта),
цвет = "зеленый",
размер = 4
) + геотекст(
данные = df1,
отображение = aes (x = долгота, y = широта, метка = 1: k),
цвет = "черный",
размер = 4
)
сюжетGD <-
Centro_View +
ggtitle("Точечная диаграмма") +
тема (plot. title = element_text (hjust = 0,5))
возврат(список(
"Данные" = таблица_данных_1,
"Сюжет" = сюжетGD,
«Покрытие» = покрытие
))
}
function.LetControl <- функция (покрытие) {
m <- среднее (покрытие [ 1])
MR <- среднее (абс (разница (покрытие [ 1])))
d2 <- 1,1284
LIC <- m - 3*(MR/d2)
ЛСК <- m + 3*(MR/d2)
сюжет(
покрытие[ 1],
тип = "б",
пч = 16,
ylim = c(LIC - 0,1 * LIC, LSC + 0,5 * LSC),
оси = ЛОЖЬ
)
ось (1, при = 1:35)
ось(2)
коробка()
сетка()
аблайн (h = MR,
лвд = 2)
abline(h = LSC, lwd = 2, col = "красный")
abline(h = LIC, lwd = 2, col = "красный")
}
пользовательский интерфейс <- флюидная страница(
titlePanel("Кластеризация"),
макет боковой панели(
боковая панель(
helpText(h4("Генерация кластеризации")),
radioButtons("filter1", h4("Ненужный потенциал"),
варианты = список ("Выбрать все свойства" = 1,
«Исключить свойства, которые производят меньше, чем L, и больше, чем S» = 2),
выбрано = 1),
radioButtons("filter2", h4("Покрытие кластера"),
варианты = список("Использовать ограничения по умолчанию" = 1,
"Не ограничивать охват" = 2
), выбрано = 1),
теги$hr(),
helpText(h4("Вы удовлетворены решением?")),
helpText(h5("(1) Да")),
helpText(h5("(2) Нет")),
helpText(h5("(a) Изменить количество кластеров")),
sliderInput("Слайдер", h4("Количество кластеров"),
мин. = 2, макс. = 34, значение = 8),
helpText(h5("(b) Изменить параметры фильтра"))
),
основная панель(
uiOutput("таблица"),
plotOutput("ScatterPlot"),
plotOutput("LetCoverage"),
)))
сервер <- функция (ввод, вывод) {
f1<-renderText({input$filter1})
f2<-renderText({input$filter2})
Кластеризация модели <-реактивная (function.clustering (df, input $ Slider, 1,1))
вывод$таблица <- renderUI({
data_table_1 <- Modelclustering()[[1]]
x <- kable(data_table_1[order(data_table_1$cluster), c(1, 4, 2, 3)], align = "c", row.names = FALSE)
x <- kable_styling (kable_input = x, full_width = FALSE)
HTML(х)
})
output$ScatterPlot <- renderPlot({
Кластеризация модели()[[2]]
})
output$LetCoverage <- renderPlot({
function.LetControl(Modelclustering()[[3]])
})
}
# Запускаем приложение
блестящее приложение (пользовательский интерфейс = пользовательский интерфейс, сервер = сервер)
 7, -49,7, -49,7, -49,7, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6 ,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6), отходы = c(526, 350, 526, 469, 285, 175, 175, 350, 350, 175, 350, 175 , 175, 364,
+ 175, 175, 350, 45,5, 54,6,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350)), class = "data.frame", row.names = c(NA, -35L))
function.clustering <- function(df, k, Filter1, Filter2) {
#df — это база данных
#k - количество кластеров
#Filter1 равен 1, если используются все свойства
#Filter1 равен 2, чтобы ограничить использование свойств, которые могут привести к образованию отходов
7, -49,7, -49,7, -49,7, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6, -49,6 ,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6,-49,6), отходы = c(526, 350, 526, 469, 285, 175, 175, 350, 350, 175, 350, 175 , 175, 364,
+ 175, 175, 350, 45,5, 54,6,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350,350)), class = "data.frame", row.names = c(NA, -35L))
function.clustering <- function(df, k, Filter1, Filter2) {
#df — это база данных
#k - количество кластеров
#Filter1 равен 1, если используются все свойства
#Filter1 равен 2, чтобы ограничить использование свойств, которые могут привести к образованию отходов  dist(distm(координаты[ 2:1]))
fit.average <- hclust(d, method = "среднее")
#Количество кластеров
кластеры <- cutree(fit.average, k)
nclusters <- матрица (таблица (кластеры))
df$cluster <- кластеры
#Локализация
center_mass <- матрица (nrow = k, ncol = 2)
для (я в 1: к) {
center_mass[я, ] <-
с(
средневзвешенное значение(
подмножество (df, кластер == i) $ Latitude,
подмножество (df, кластер == i) $ Отходы
),
средневзвешенное значение(
подмножество (df, кластер == i) $ Долгота,
подмножество (df, кластер == i) $ Отходы
)
)
}
координаты $ кластер <- кластеры
center_mass <- cbind (center_mass, матрица (c (1: k), ncol = 1))
#Покрытие
покрытие <- матрица (nrow = k, ncol = 1)
для (я в 1: к) {
вспомогательное_расстояние <-
distm (rbind (подмножество (координаты, кластер == i), center_mass [i, ]) [ 2: 1])
покрытие[i, ] <- max(aux_dist[nclusters[i, 1] + 1, ])
}
покрытие <- cbind (покрытие, матрица (c (1: k), ncol = 1))
colnames(coverage) <- c("Coverage_meters", "cluster")
#Сумма отходов от кластеров
sum_waste <- матрица (nrow = k, ncol = 1)
для (я в 1: к) {
sum_waste[i,] <- sum(subset(df, cluster == i)["Отходы"])
}
sum_waste <- cbind (sum_waste, матрица (c (1: k), ncol = 1))
colnames(sum_waste) <- c("Potential_Waste_m3", "cluster")
#Выходная таблица
data_table <- Уменьшить (слияние, список (df, покрытие, sum_waste))
таблица_данных <-
data_table[порядок(data_table$cluster, as.
dist(distm(координаты[ 2:1]))
fit.average <- hclust(d, method = "среднее")
#Количество кластеров
кластеры <- cutree(fit.average, k)
nclusters <- матрица (таблица (кластеры))
df$cluster <- кластеры
#Локализация
center_mass <- матрица (nrow = k, ncol = 2)
для (я в 1: к) {
center_mass[я, ] <-
с(
средневзвешенное значение(
подмножество (df, кластер == i) $ Latitude,
подмножество (df, кластер == i) $ Отходы
),
средневзвешенное значение(
подмножество (df, кластер == i) $ Долгота,
подмножество (df, кластер == i) $ Отходы
)
)
}
координаты $ кластер <- кластеры
center_mass <- cbind (center_mass, матрица (c (1: k), ncol = 1))
#Покрытие
покрытие <- матрица (nrow = k, ncol = 1)
для (я в 1: к) {
вспомогательное_расстояние <-
distm (rbind (подмножество (координаты, кластер == i), center_mass [i, ]) [ 2: 1])
покрытие[i, ] <- max(aux_dist[nclusters[i, 1] + 1, ])
}
покрытие <- cbind (покрытие, матрица (c (1: k), ncol = 1))
colnames(coverage) <- c("Coverage_meters", "cluster")
#Сумма отходов от кластеров
sum_waste <- матрица (nrow = k, ncol = 1)
для (я в 1: к) {
sum_waste[i,] <- sum(subset(df, cluster == i)["Отходы"])
}
sum_waste <- cbind (sum_waste, матрица (c (1: k), ncol = 1))
colnames(sum_waste) <- c("Potential_Waste_m3", "cluster")
#Выходная таблица
data_table <- Уменьшить (слияние, список (df, покрытие, sum_waste))
таблица_данных <-
data_table[порядок(data_table$cluster, as. numeric(data_table$Properties)),]
data_table_1 <-
агрегат(. ~ кластер + Coverage_meters + Potential_Waste_m3,
data_table[ c(1, 7, 6, 2)],
нанизывать)
# Точечная диаграмма
подавлятьPackageStartupMessages (библиотека (ggplot2))
df1 <- as.data.frame(center_mass)
colnames(df1) <- c("Широта", "Долгота", "кластер")
г <-
ggplot (данные = df, aes (
х = долгота,
у = широта,
цвет = фактор (кластеры)
)) + geom_point(aes(x = долгота, y = широта), size = 4)
Centro_View <-
г + геотекст(
данные = дф,
отображение = aes(
х = оценка (долгота),
у = оценка (широта),
метка = Отходы
),
размер = 3,
hюст = -0,1
) + геом_точка(
данные = df1,
отображение = aes (долгота, широта),
цвет = "зеленый",
размер = 4
) + геотекст(
данные = df1,
отображение = aes (x = долгота, y = широта, метка = 1: k),
цвет = "черный",
размер = 4
)
сюжетGD <-
Centro_View +
ggtitle("Точечная диаграмма") +
тема (plot.
numeric(data_table$Properties)),]
data_table_1 <-
агрегат(. ~ кластер + Coverage_meters + Potential_Waste_m3,
data_table[ c(1, 7, 6, 2)],
нанизывать)
# Точечная диаграмма
подавлятьPackageStartupMessages (библиотека (ggplot2))
df1 <- as.data.frame(center_mass)
colnames(df1) <- c("Широта", "Долгота", "кластер")
г <-
ggplot (данные = df, aes (
х = долгота,
у = широта,
цвет = фактор (кластеры)
)) + geom_point(aes(x = долгота, y = широта), size = 4)
Centro_View <-
г + геотекст(
данные = дф,
отображение = aes(
х = оценка (долгота),
у = оценка (широта),
метка = Отходы
),
размер = 3,
hюст = -0,1
) + геом_точка(
данные = df1,
отображение = aes (долгота, широта),
цвет = "зеленый",
размер = 4
) + геотекст(
данные = df1,
отображение = aes (x = долгота, y = широта, метка = 1: k),
цвет = "черный",
размер = 4
)
сюжетGD <-
Centro_View +
ggtitle("Точечная диаграмма") +
тема (plot. title = element_text (hjust = 0,5))
возврат(список(
"Данные" = таблица_данных_1,
"Сюжет" = сюжетGD,
«Покрытие» = покрытие
))
}
function.LetControl <- функция (покрытие) {
m <- среднее (покрытие [ 1])
MR <- среднее (абс (разница (покрытие [ 1])))
d2 <- 1,1284
LIC <- m - 3*(MR/d2)
ЛСК <- m + 3*(MR/d2)
сюжет(
покрытие[ 1],
тип = "б",
пч = 16,
ylim = c(LIC - 0,1 * LIC, LSC + 0,5 * LSC),
оси = ЛОЖЬ
)
ось (1, при = 1:35)
ось(2)
коробка()
сетка()
аблайн (h = MR,
лвд = 2)
abline(h = LSC, lwd = 2, col = "красный")
abline(h = LIC, lwd = 2, col = "красный")
}
пользовательский интерфейс <- флюидная страница(
titlePanel("Кластеризация"),
макет боковой панели(
боковая панель(
helpText(h4("Генерация кластеризации")),
radioButtons("filter1", h4("Ненужный потенциал"),
варианты = список ("Выбрать все свойства" = 1,
«Исключить свойства, которые производят меньше, чем L, и больше, чем S» = 2),
выбрано = 1),
radioButtons("filter2", h4("Покрытие кластера"),
варианты = список("Использовать ограничения по умолчанию" = 1,
"Не ограничивать охват" = 2
), выбрано = 1),
теги$hr(),
helpText(h4("Вы удовлетворены решением?")),
helpText(h5("(1) Да")),
helpText(h5("(2) Нет")),
helpText(h5("(a) Изменить количество кластеров")),
sliderInput("Слайдер", h4("Количество кластеров"),
мин.
title = element_text (hjust = 0,5))
возврат(список(
"Данные" = таблица_данных_1,
"Сюжет" = сюжетGD,
«Покрытие» = покрытие
))
}
function.LetControl <- функция (покрытие) {
m <- среднее (покрытие [ 1])
MR <- среднее (абс (разница (покрытие [ 1])))
d2 <- 1,1284
LIC <- m - 3*(MR/d2)
ЛСК <- m + 3*(MR/d2)
сюжет(
покрытие[ 1],
тип = "б",
пч = 16,
ylim = c(LIC - 0,1 * LIC, LSC + 0,5 * LSC),
оси = ЛОЖЬ
)
ось (1, при = 1:35)
ось(2)
коробка()
сетка()
аблайн (h = MR,
лвд = 2)
abline(h = LSC, lwd = 2, col = "красный")
abline(h = LIC, lwd = 2, col = "красный")
}
пользовательский интерфейс <- флюидная страница(
titlePanel("Кластеризация"),
макет боковой панели(
боковая панель(
helpText(h4("Генерация кластеризации")),
radioButtons("filter1", h4("Ненужный потенциал"),
варианты = список ("Выбрать все свойства" = 1,
«Исключить свойства, которые производят меньше, чем L, и больше, чем S» = 2),
выбрано = 1),
radioButtons("filter2", h4("Покрытие кластера"),
варианты = список("Использовать ограничения по умолчанию" = 1,
"Не ограничивать охват" = 2
), выбрано = 1),
теги$hr(),
helpText(h4("Вы удовлетворены решением?")),
helpText(h5("(1) Да")),
helpText(h5("(2) Нет")),
helpText(h5("(a) Изменить количество кластеров")),
sliderInput("Слайдер", h4("Количество кластеров"),
мин. = 2, макс. = 34, значение = 8),
helpText(h5("(b) Изменить параметры фильтра"))
),
основная панель(
uiOutput("таблица"),
plotOutput("ScatterPlot"),
plotOutput("LetCoverage"),
)))
сервер <- функция (ввод, вывод) {
f1<-renderText({input$filter1})
f2<-renderText({input$filter2})
Кластеризация модели <-реактивная (function.clustering (df, input $ Slider, 1,1))
вывод$таблица <- renderUI({
data_table_1 <- Modelclustering()[[1]]
x <- kable(data_table_1[order(data_table_1$cluster), c(1, 4, 2, 3)], align = "c", row.names = FALSE)
x <- kable_styling (kable_input = x, full_width = FALSE)
HTML(х)
})
output$ScatterPlot <- renderPlot({
Кластеризация модели()[[2]]
})
output$LetCoverage <- renderPlot({
function.LetControl(Modelclustering()[[3]])
})
}
# Запускаем приложение
блестящее приложение (пользовательский интерфейс = пользовательский интерфейс, сервер = сервер)
= 2, макс. = 34, значение = 8),
helpText(h5("(b) Изменить параметры фильтра"))
),
основная панель(
uiOutput("таблица"),
plotOutput("ScatterPlot"),
plotOutput("LetCoverage"),
)))
сервер <- функция (ввод, вывод) {
f1<-renderText({input$filter1})
f2<-renderText({input$filter2})
Кластеризация модели <-реактивная (function.clustering (df, input $ Slider, 1,1))
вывод$таблица <- renderUI({
data_table_1 <- Modelclustering()[[1]]
x <- kable(data_table_1[order(data_table_1$cluster), c(1, 4, 2, 3)], align = "c", row.names = FALSE)
x <- kable_styling (kable_input = x, full_width = FALSE)
HTML(х)
})
output$ScatterPlot <- renderPlot({
Кластеризация модели()[[2]]
})
output$LetCoverage <- renderPlot({
function.LetControl(Modelclustering()[[3]])
})
}
# Запускаем приложение
блестящее приложение (пользовательский интерфейс = пользовательский интерфейс, сервер = сервер)
Quick-R: Scatterplots
Simple Scatterplot
There are many ways to create a scatterplot in R. The basic function is plot( x , y ) , where x и y — числовые векторы, обозначающие точки (x, y) для построения.
The basic function is plot( x , y ) , where x и y — числовые векторы, обозначающие точки (x, y) для построения.
# Простая диаграмма рассеяния
attach(mtcars)
plot(wt, mpg, main="Пример диаграммы рассеяния",
xlab="Вес автомобиля", ylab="Мили на галлон", pch=19)
щелкните для просмотра
(Чтобы попрактиковаться в построении простой диаграммы рассеяния, попробуйте этот интерактивный пример из DataCamp.)
# Добавить линии соответствия
abline(lm(mpg~wt), col="red") # регрессия line (y~x)
lines(lowess(wt,mpg), col="blue") # lowess line (x,y)
щелкните для просмотра
Функция Scatterplot() в пакете car предлагает многие расширенные функции, в том числе линии соответствия, маргинальные диаграммы, условное обозначение фактора и интерактивная идентификация точек. Каждая из этих функций не является обязательной.
# Расширенная диаграмма рассеяния MPG в зависимости от веса
#
по количеству автомобильных цилиндров
библиотека (автомобиль)
Scatterplot(mpg ~ wt | cyl, data=mtcars,
xlab="Вес автомобиля", ylab="Мили на галлон",
main="Расширенный график рассеяния",
labels=row.names(mtcars))
щелкните для просмотра
Матрицы рассеяния
Существует как минимум 4 полезные функции для создания матриц рассеяния. Аналитики должны любить матрицы диаграмм рассеяния!
# Базовая матрица рассеяния
пар(~миль на галлон+расход+драт+вес,данные=mtcars,
main="Простая матрица рассеяния")
щелкните для просмотра
Пакет решетки предоставляет опции для обработки матрицы рассеяния на фактор.
# Матрицы диаграммы рассеяния из пакета решетки
библиотека (решетка)
splom(mtcars[c(1,3,5,6)], groups=cyl, data=mtcars,
panel=panel. superpose,
superpose,
key=list(title="Три варианта цилиндра",
columns=3,
points=list(pch=super.sym$pch[1:3],
col=super.sym$col[1:3]),
text=list(c("4 цилиндра", "6 цилиндров", "8 цилиндров"))))
щелкните, чтобы просмотреть
Пакет car может обусловить матрицу диаграммы рассеяния фактором и опционально включать линии наилучшего соответствия, а также диаграммы, плотности или гистограммы на главной диагонали, а также ковер-графики на полях. клеток.
# Матрицы диаграммы рассеяния из автомобиля Пакет
library(car)
scatterplot.matrix(~mpg+disp+drat+wt|cyl, data=mtcars,
main="Three Cylinder Options")
щелкните для просмотра
Пакет gclus предоставляет опции для изменения порядка переменных так, чтобы те, у которых более высокая корреляция, были ближе к главной диагонали. Он также может кодировать ячейки цветом, чтобы отразить размер корреляций.
# Матрицы диаграммы рассеяния из пакета glus
library(gclus)
dta <- mtcars[c(1,3,5,6)] # получить данные
dta.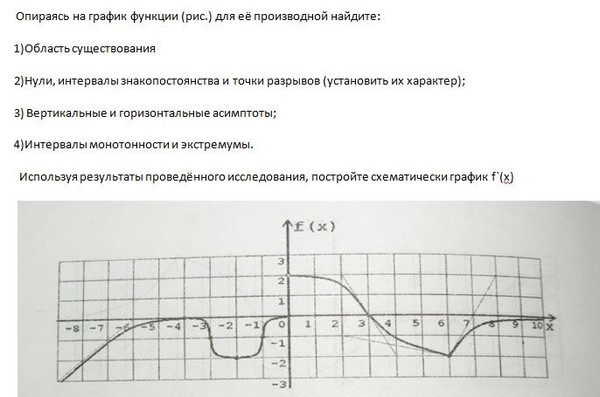 r <- abs(cor(dta)) # получить корреляции
r <- abs(cor(dta)) # получить корреляции
dta.col <- dmat.color(dta.r) # получить цвета
# переупорядочить переменные так, чтобы переменные с наивысшей корреляцией
# были ближе всего к диагонали
dta.o <- order.single(dta.r)
cpairs(dta, dta.o, panel.colors=dta.col, gap=.5,
main="Переменные, упорядоченные и окрашенные по корреляции"
)
щелкните для просмотра
Диаграммы рассеяния с высокой плотностью
Когда имеется много точек данных и значительное перекрытие, диаграммы рассеяния становятся менее полезными. Есть несколько подходов, которые можно использовать, когда это происходит. 9Функция 0038 hexbin(x, y) в пакете hexbin обеспечивает двумерное объединение в шестиугольные ячейки (выглядит лучше, чем кажется).
# Диаграмма рассеяния высокой плотности с биннингом
библиотека (hexbin)
x <- rnorm(1000)
y <- rnorm(1000)
bin<-hexbin(x, y, xbins=50)
plot(bin, main="Hexagonal Binning")
щелкните для просмотра
Другой вариант диаграммы рассеивания со значительным перекрытием точек — sunflowerplot .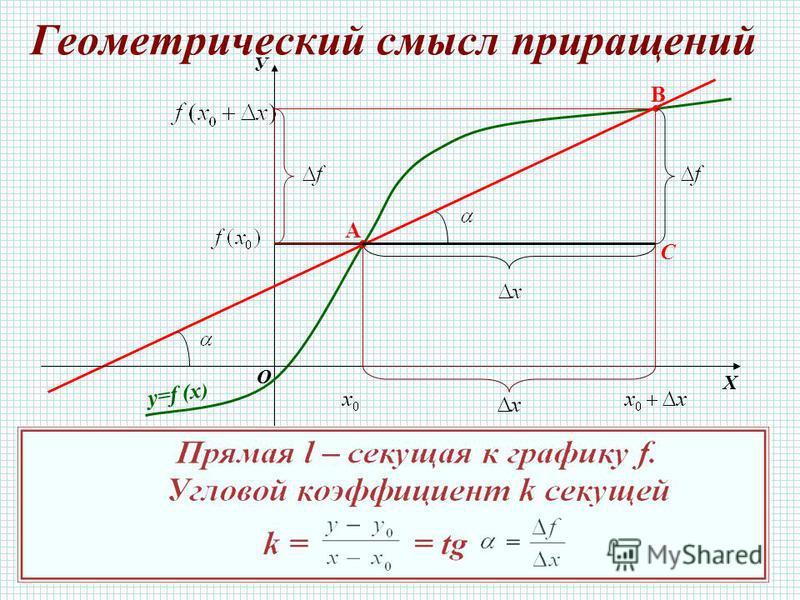 Подробности см. в справке (подсолнечник) .
Подробности см. в справке (подсолнечник) .
Наконец, вы можете сохранить диаграмму рассеяния в формате PDF и использовать прозрачность цвета, чтобы просвечивать перекрывающиеся точки (эта идея исходит от B.S. Everrit в HSAUR).
# Диаграмма рассеяния высокой плотности с прозрачностью цвета
pdf("c:/scatterplot.pdf")
x <- rнорм(1000)
y <- rнорм(1000)
plot(x,y, main="Пример диаграммы рассеяния PDF", col=rgb(0,100,0,50,maxColorValue=255), pch=16)
dev.off()
щелкните для просмотра
Примечание: Вы можете использовать функцию col2rgb() для получения значений rbg для цветов R. Например, col2rgb(" темно-зеленый ") дает r=0, g=100, b=0. Затем добавьте альфа-уровень прозрачности в качестве 4-го числа в цветовом векторе. Нулевое значение означает полную прозрачность. См. справку (rgb) для получения дополнительной информации.
Трехмерные диаграммы рассеяния
С помощью пакета scatterplot3d можно создать трехмерную диаграмму рассеяния. Используйте функцию диаграмма рассеяния3d( x , y , z ).
# 3D Scatterplot
library(scatterplot3d)
attach(mtcars)
scatterplot3d(wt,disp,mpg, main="3D Scatterplot")
библиотека (scatterplot3d)
attach(mtcars)
scatterplot3d(wt,disp,mpg, pch=16, highlight.3d=TRUE,
type="h", main="3D Scatterplot")
щелкните для просмотра
# 3D-диаграмма рассеяния с раскраской и вертикальными линиями
# и плоскость регрессии
библиотека (scatterplot3d)
attach(mtcars)
s3d <-scatterplot3d(wt,disp,mpg, highlight pch=16 3d=TRUE,
type="h", main="3D Scatterplot")
fit <- lm(mpg ~ wt+disp)
s3d$plane3d(fit)
щелкните для просмотра
Вращающиеся 3D-диаграммы рассеяния
Вы также можете создать интерактивную трехмерную диаграмму рассеяния, используя plot3D( x , y , z ) функция в пакете rgl.