
Распределения вероятностей
Случайная переменная — это величина, которая может принимать любое из набора взаимоисключающих значений с определенной вероятностью.
Распределение вероятности показывает вероятности всех возможных значений случайной переменной. Это теоретическое распределение, которое выражено математически и имеет среднее и дисперсию — аналоги среднего и дисперсии в эмпирическом распределении.
Каждое распределение вероятности определяется некоторыми параметрами, параметры служат обобщающими величинами (например среднее, дисперсия), характеризующими данное распределение (т.e. их знание позволит подробно описать распределение).
С помощью соответствующей статистики можно произвести оценку этих параметров в выборке В зависимости от того, является ли случайная переменная дискретной или непрерывной, распределение вероятности может быть либо дискретным, либо непрерывным.
Дискретные распределения
Моделируют вероятность наступления дискретных событий, например, выпадение герба или решки (распределение Бернулли), число выпадений герба или решки при многократном бросании монеты (биномиальное распределение), выпадения определенного числа очков при бросании игральной кости (полиномиальное или мультиномиальное распределение).
Примеры дискретных величин самые разнообразные: число телефонных звонков за день, количество перевезенных пассажиров, количество дефектов в партии продукции, количество распавшихся атомов за определенный промежуток, число квантов света, попавших на сетчатку глаза и множество других в физике, технике, биологии, медицине, экономике, транспорте, телефонии.
Основные дискретные распределения:
Биномиальное распределение
Геометрическое распределение
Гипергеометрическое распределение
Полиномиальное (мультиномиальное) распределение
Распределение Пуассона
Распределения Кокса
| Распределение |
Вероятность |
Параметры |
|---|---|---|
|
Равномерное дискретное |
, k=1, 2,. |
N=1, 2,… |
|
Бернулли | ||
|
Биномиальное распределение | ||
|
Распределение Пуассона | ||
|
Геометрическое распределение | ||
|
Отрицательно-биномиальное |
 ..,N
..,NНепрерывные распределения
Моделируют вероятность наступления непрерывных событий, например, длительность телефонного звонка, момент наступления телефонного звонка, уровень шума в сети, расход электроэнергии за день, местоположение дефектов в микросхеме, количество осадков за месяц, биржевые данные, расстояние, пройденное молекулой газа до следующего столкновения и т.
Задавая распределение, вы строите вероятностную модель и затем оцениваете вероятности наступления более сложных событий, например, вероятность того, что количество прерванных звонков в сети превысит норму, вероятность того, что производственный процесс выйдет за допустимые пределы, количество бракованных деталей будет критическим, вероятность возникновения взрыва при ядерной реакции и т. д.
Основные непрерывные распределения:
Равномерное распределение
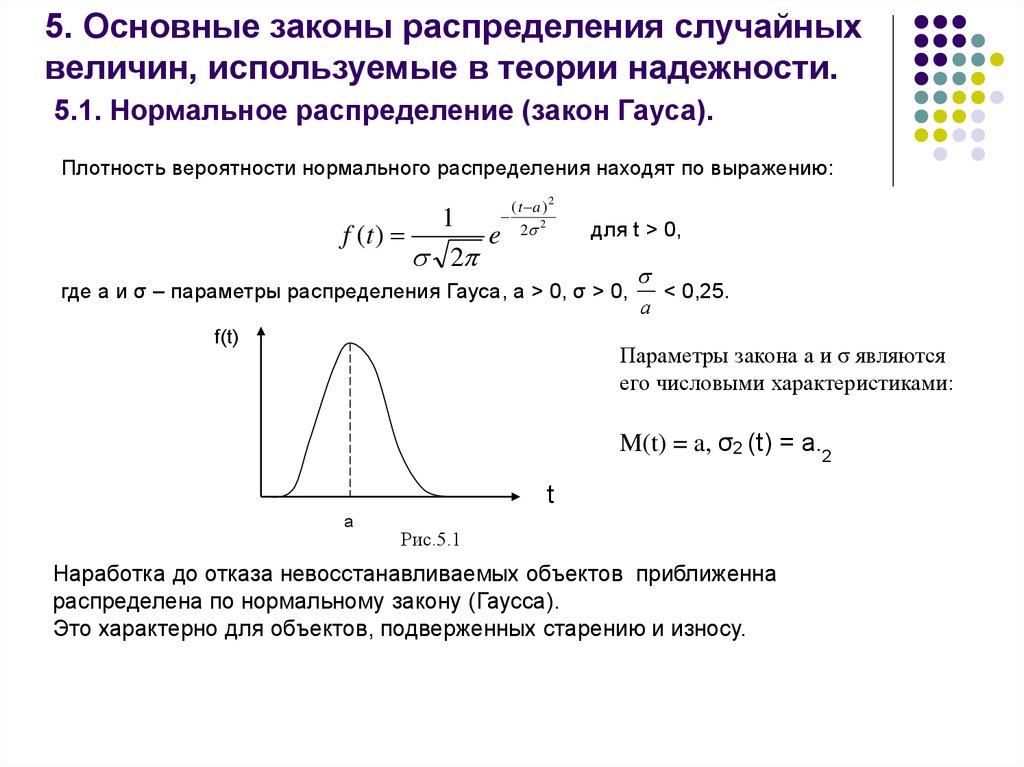
Нормальное распределение
Многомерное нормальное распределение
Логнормальное распределение
Экспоненциальное распределение
Гамма распределение
Распределение Эрланга
Распределение Стьюдента
Распределение Фишера
| Распределение |
Плотность |
Параметры |
|---|---|---|
|
Равномерное на [a,b] | ||
|
Нормальное (гауссовское) | ||
|
Гамма | ||
|
Бета | ||
|
Экспоненциальное | ||
|
Двусторонне-экспоненциальное | ||
|
Хи-квадрат | ||
|
Стьюдента |
| |
|
F | ||
|
Коши |
Связанные определения:
Cимметричное распределение
Двумерная функция распределения
Логнормальное распределение
Плотность распределения вероятностей
Полимодальное распределение
Распределение при выполнении нулевой гипотезы
Унимодальное распределение
Условная функция распределения
Функция распределения
Эмпирическая функция распределения
В начало
Содержание портала
шпаргалка data scientist-а / Хабр
У data scientist-ов сотни распределений вероятности на любой вкус.
 С чего начать?
С чего начать?
Data science, чем бы она там не была – та ещё штука. От какого-нибудь гуру на ваших сходках или хакатонах можно услышать:«Data scientist разбирается в статистике лучше, чем любой программист». Прикладные математики так мстят за то, что статистика уже не так на слуху, как в золотые 20е. У них даже по этому поводу есть своя несмешная диаграмма Венна. И вот, значит, внезапно вы, программист, оказываетесь совершенно не у дел в беседе о доверительных интервалах, вместо того, чтобы привычно ворчать на аналитиков, которые никогда не слышали о проекте Apache Bikeshed, чтобы распределённо форматировать комментарии. Для такой ситуации, чтобы быть в струе и снова стать душой компании – вам нужен экспресс-курс по статистике. Может, не достаточно глубокий, чтобы вы всё понимали, но вполне достаточный, чтобы так могло показаться на первый взгляд.
Вероятностные распределения – это основа статистики, так же как структуры данных – основа computer science.
Существуют сотни различных распределений, некоторые из которых на слух звучат как чудовища средневековых легенд, типа Muth или Lomax. Тем не менее, на практике более-менее часто используются около 15. Каковы они, и какие умные фразы о них требуется запомнить?
Итак, что такое распределение вероятности?
Всё время что-то происходит: кидаются кубики, идёт дождь, подъезжают автобусы. После того, как это что-то произошло, можно быть уверенным в некотором исходе: кубики выпали на 3 и 4, выпало 2.5 см дождя, автобус подъехал через 3 минуты.
Например, подбрасывание правильной монетки имеет два исхода: она упадёт либо орлом, либо решкой (предполагая, что она не приземлится на ребро и её не стащит в воздухе чайка). Перед броском мы верим, что с шансом 1 к 2 или с вероятностью 0.5 она упадёт орлом. Точно так же, как и решкой. Это распределение вероятности двух исходов броска, и, если вы внимательно прочитали это предложение, то вы уже поняли распределение Бернулли.
Несмотря на экзотические названия, распространённые распределения связаны друг с другом достаточно интуитивными и интересными способами, позволяющими легко их вспоминать и уверенно о них рассуждать.
Каждое распределение иллюстрируется примером её функции плотности распределения (ФПР). Эта статья только о тех распределениях, у которых исходы – одиночные числа. Поэтому, горизонтальная ось каждого графика – набор возможных чисел-исходов. Вертикальная – вероятность каждого исхода. Некоторые распределения дискретны — у них исходы должны быть целыми числами, типа 0 или 5. Таковые обозначаются редкими линиями, по одной на каждый исход, с высотой, соответствующей вероятности данного исхода. Некоторые – непрерывны, у них исходы могут принять любое численное значение, типа -1.32 или 0.005. Эти показаны плотными кривыми с областями под секциями кривой, которые дают вероятности. Сумма высот линий и областей под кривыми — всегда 1.
Распечатайте, отрежьте по пунктирной линии и носите с собой в кошельке. Это — ваш путеводитель в стране распределений и их родственников.
Бернулли и равномерное
Вы уже встретились с распределением Бернулли выше, с двумя исходами – орлом или решкой. Представьте его теперь как распределение над 0 и 1, 0 – орёл, 1 – решка. Как уже понятно, оба исхода равновероятны, и это отражено на диаграмме. ФПР Бернулли содержит две линии одинаковой высоты, представляющие 2 равновероятных исхода: 0 и 1 соответственно.
Представьте его теперь как распределение над 0 и 1, 0 – орёл, 1 – решка. Как уже понятно, оба исхода равновероятны, и это отражено на диаграмме. ФПР Бернулли содержит две линии одинаковой высоты, представляющие 2 равновероятных исхода: 0 и 1 соответственно.
Распределение Бернулли может представлять и неравновероятные исходы, типа броска неправильной монетки. Тогда вероятность орла будет не 0.5, а какая-то другая величина p, а вероятность решки – 1-p. Как и многие другие распределения, это на самом деле целое семейство распределений, задаваемых определёнными параметрами, как p выше. Когда будете думать «Бернулли» – думайте про «бросок (возможно, неправильной) монетки».
Отсюда весьма небольшой шаг до того, чтобы представить распределение поверх нескольких равновероятных исходов: равномерное распределение, характеризуемое плоской ФПР. Представьте правильный игральный кубик. Его исходы 1-6 равновероятны. Его можно задать для любого количества исходов n, и даже в виде непрерывного распределения.
Думайте о равномерном распределении как о «правильном игральном кубике».
Биномиальное и гипергеометрическое
Биномиальное распределение можно представить как сумму исходов тех вещей, которые следуют распределению Бернулли.
Киньте честную монету два раза – сколько раз будет орёл? Это число, подчиняющееся биномиальному распределению. Его параметры – n, число испытаний, и p – вероятность «успеха» (в нашем случае – орла или 1). Каждый бросок – распределённый по Бернулли исход, или испытание. Используйте биномиальное распределение, когда считаете количество успехов в вещах типа броска монеты, где каждый бросок не зависит от других и имеет одинаковую вероятность успеха.
Или представьте урну с одинаковым количество белых и чёрных шаров. Закройте глаза, вытащите шар, запишите его цвет и верните назад. Повторите. Сколько раз вытащился чёрный шар? Это число также подчиняется биномиальному распределению.
Эту странную ситуацию мы представили, чтобы было легче понять смысл гипергеометрического распределения. Это распределение того же числа, но в ситуации если бы мы не возвращали шары обратно. Оно, безусловно, двоюродный брат биномиального распределения, но не такое же, так как вероятность успеха изменяется с каждым вытащенным шаром. Если количество шаров достаточно велико по сравнению с количеством вытаскиваний – то эти распределения практически одинаковы, так как шанс успеха изменяется с каждым вытаскиванием крайне незначительно.
Это распределение того же числа, но в ситуации если бы мы не возвращали шары обратно. Оно, безусловно, двоюродный брат биномиального распределения, но не такое же, так как вероятность успеха изменяется с каждым вытащенным шаром. Если количество шаров достаточно велико по сравнению с количеством вытаскиваний – то эти распределения практически одинаковы, так как шанс успеха изменяется с каждым вытаскиванием крайне незначительно.
Когда где-то говорят о вытаскивании шаров из урн без возврата, практически всегда безопасно ввернуть «да, гипергеометрическое распределение», потому что в жизни я ещё не встречал никого, кто реально наполнял бы урны шарами и потом вытаскивал их и возвращал, или наоборот. У меня даже знакомых нет с урнами. Ещё чаще это распределение должно всплывать при выборе значимого подмножества некоторой генеральной совокупности в качестве выборки.
Прим. перев.
Тут может быть не очень понятно, а раз туториал и экспресс-курс для новичков — надо бы разъяснить. Генеральная совокупность — есть нечто, что мы хотим статистически оценить. Для оценки мы выбираем некоторую часть (подмножество) и производим требуемую оценку на ней (тогда это подмножество называется выборкой), предполагая, что для всей совокупности оценка будет похожей. Но чтобы это было верно, часто требуются дополнительные ограничения на определение подмножества выборки (или наоборот, по известной выборке нам надо оценить, описывает ли она достаточно точно совокупность).
Генеральная совокупность — есть нечто, что мы хотим статистически оценить. Для оценки мы выбираем некоторую часть (подмножество) и производим требуемую оценку на ней (тогда это подмножество называется выборкой), предполагая, что для всей совокупности оценка будет похожей. Но чтобы это было верно, часто требуются дополнительные ограничения на определение подмножества выборки (или наоборот, по известной выборке нам надо оценить, описывает ли она достаточно точно совокупность).
Практический пример — нам нужно выбрать от компании в 100 человек представителей для поездки на E3. Известно, что в ней 10 человек уже ездили в прошлом году (но никто не признаётся). Сколько минимум нужно взять, чтобы в группе с большой вероятностью оказался хотя бы один опытный товарищ? В данном случае генеральная совокупность — 100, выборка — 10, требования к выборке — хотя бы один, уже ездивший на E3.
В википедии есть менее забавный, но более практичный пример про бракованные детали в партии.
Пуассон
Что насчёт количества заказчиков, звонящих по горячей линии в техподдержку каждую минуту? Это исход, чьё распределение на первый взгляд биномиальное, если считать каждую секунду как испытание Бернулли, в течение которой заказчик либо не позвонит (0), либо позвонит (1). Но электроснабжающие организации прекрасно знают: когда выключают электричество – за секунду могут позвонить двое или даже больше сотни людей. Представить это как 60000 миллисекундных испытаний тоже не поможет – испытаний больше, вероятность звонка в миллисекунду меньше, даже если не учитывать двух и более одновременно, но, технически – это всё ещё не испытание Бернулли. Тем не менее, срабатывает логическое рассуждение с переходом к бесконечности. Пусть n стремится к бесконечности, а p – к 0, и так, чтобы np было постоянным. Это как делить на всё более малые доли времени со всё менее малой вероятностью звонка. В пределе мы получим распределение Пуассона.
Но электроснабжающие организации прекрасно знают: когда выключают электричество – за секунду могут позвонить двое или даже больше сотни людей. Представить это как 60000 миллисекундных испытаний тоже не поможет – испытаний больше, вероятность звонка в миллисекунду меньше, даже если не учитывать двух и более одновременно, но, технически – это всё ещё не испытание Бернулли. Тем не менее, срабатывает логическое рассуждение с переходом к бесконечности. Пусть n стремится к бесконечности, а p – к 0, и так, чтобы np было постоянным. Это как делить на всё более малые доли времени со всё менее малой вероятностью звонка. В пределе мы получим распределение Пуассона.
Так же, как и биномиальное, распределение Пуассона – это распределение количества: количества раз того, как что-то произойдёт. Оно параметризуется не вероятностью p и количеством испытаний n, но средней интенсивностью λ, что, в аналогии с биномиальным, просто постоянное значение np. Распределение Пуассона – то, о чём надо вспоминать, когда идёт речь о подсчёте событий за определённое время при постоянной заданной интенсивности.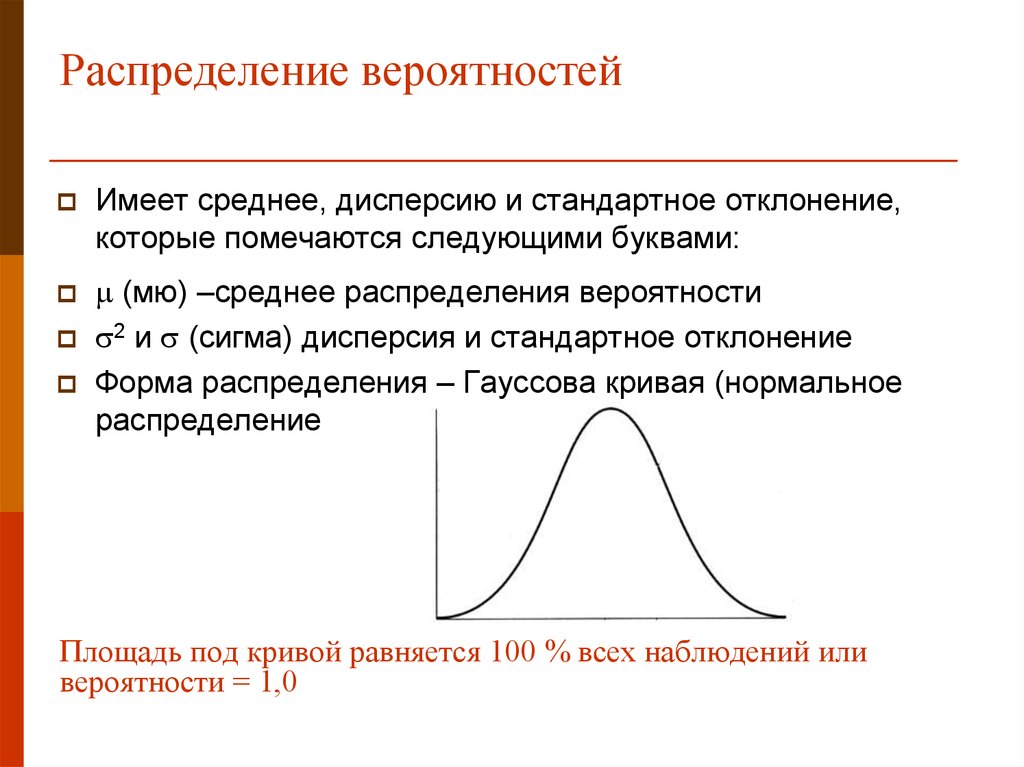
Когда есть что-то, типа прихода пакетов на роутер или появления покупателей в магазине или что-то, ожидающее в очереди – думайте «Пуассон».
Прим. перев.
Я бы месте автора я рассказал про отсутствие памяти у Пуассона и Бернулли (распределений, а не людей) и предложил бы в разговоре ввернуть что-нибудь умное про парадокс закона больших чисел как его следствие.
Геометрическое и отрицательное биномиальное
Из простых испытаний Бернулли появляется другое распределение. Сколько раз монетка выпадет решкой, прежде, чем выпасть орлом? Число решек подчиняется геометрическому распределению. Как и распределение Бернулли, оно параметризуется вероятностью успешного исхода, p. Оно не параметризуется числом n, количеством бросков-испытаний, потому что число неудачных испытаний как раз и есть исход.
Если биномиальное распределение это «сколько успехов», то геометрическое это «Сколько неудач до успеха?».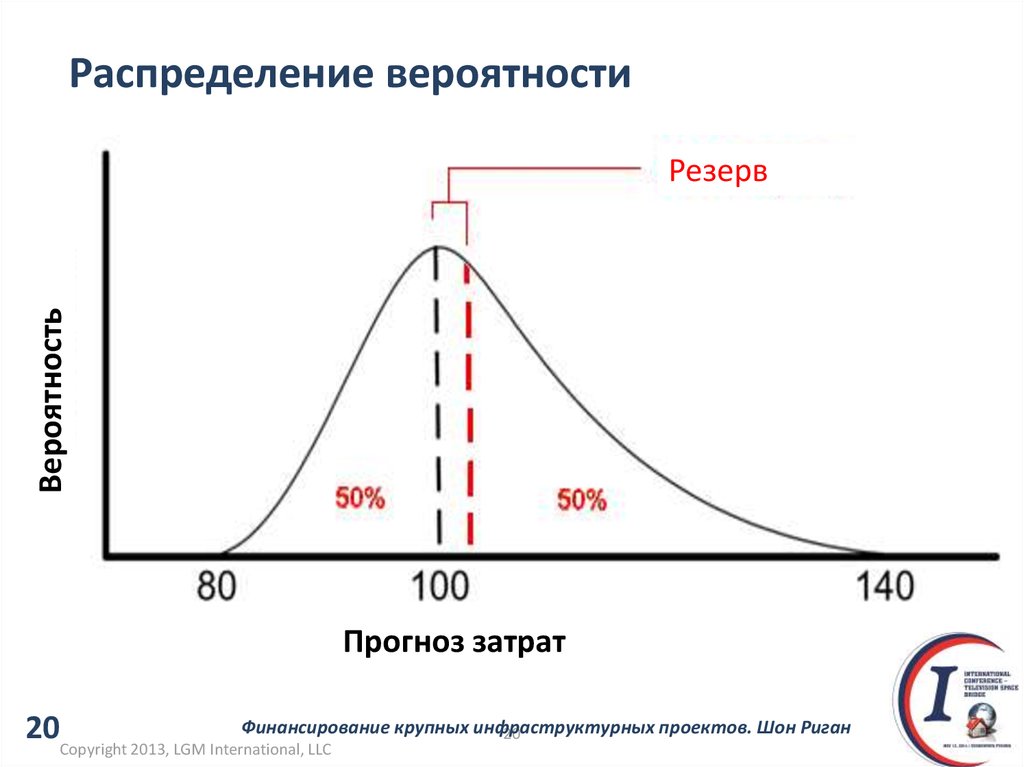
Отрицательное биномиальное распределение – простое обобщение предыдущего. Это количество неудач до того, как будет r, а не 1, успехов. Поэтому оно дополнительно параметризуется этим r. Иногда его описывают как число успехов до r неудач. Но, как говорит мой лайф-коуч: «Ты сам решаешь, что есть успех, а что — неудача», так что это тоже самое, если при этом не забыть, что вероятность p тоже должна правильной вероятностью успеха или неудачи соответственно.
Если нужна будет шутка для снятия напряжения, можно упомянуть, что биномиальное и гипергеометрическое распределение – это очевидная пара, но и геометрическое и отрицательное биномиальное так же весьма похожи, после чего заявить «Ну и кто же так их все называет, а?»
Экспоненциальное и Вейбула
Снова о звонках в техподдержку: сколько пройдёт до следующего звонка? Распределение этого времени ожидания как будто бы геометрическое, потому что каждая секунда, пока никто не звонит – это как неуспех, до секунды, пока, наконец, звонок не произойдёт. Количество неудач –это как количество секунд, пока никто не звонил, и это практически время до следующего звонка, но «практически» нам недостаточно. Суть в том, что это время будет суммой целых секунд, и, таким образом, не получится посчитать ожидание внутри этой секунды до непосредственно звонка.
Количество неудач –это как количество секунд, пока никто не звонил, и это практически время до следующего звонка, но «практически» нам недостаточно. Суть в том, что это время будет суммой целых секунд, и, таким образом, не получится посчитать ожидание внутри этой секунды до непосредственно звонка.
Ну и, как и раньше, переходим в геометрическом распределении к пределу, относительно временных долей – и вуаля. Получаем экспоненциальное распределение, которое точно описывает время до звонка. Это непрерывное распределение, первое такое у нас, потому что исход не обязательно в целых секундах. Как и распределение Пуассона, оно параметризуется интенсивностью λ.
Повторяя связь биномиального с геометрическим, Пуассоновское «сколько событий за время?» связано с экспоненциальным «сколько до события?». Если есть события, количество которых на единицу времени подчиняется распределению Пуассона, то время между ними подчиняется экспоненциальному распределению с тем же параметром λ. Это соответствие между двумя распределениями необходимо отмечать, когда обсуждается любое из них.
Экспоненциальное распределение должно приходить на ум при размышлении о «времени до события», возможно, «времени до отказа». По факту, это такая важная ситуация, что существуют более обобщённые распределения чтобы описать наработку-на-отказ, типа распределения Вейбула. В то время, как экспоненциальное распределение подходит, когда интенсивность — износа, или отказов, например – постоянна, распределение Вейбула может моделировать увеличивающуюся (или уменьшающуюся) со временем интенсивность отказов. Экспоненциальное, в общем-то, частный случай.
Думайте «Вейбул» когда разговор заходит о наработке-на-отказ.
Нормальное, логнормальное, Стьюдента и хи-квадрат
Нормальное, или гауссово, распределение, наверное, одно из важнейших. Его колоколообразная форма узнаётся сразу. Как и e, это особенно любопытная сущность, которая проявляется везде, даже из внешне самых простых источников. Возьмите набор значений, подчиняющихся одному распределению – любому! – и сложите их. Распределение их суммы подчиняется (приблизительно) нормальному распределению. Чем больше вещей суммируется – тем ближе их сумма соответствует нормальному распределению (подвох: распределение слагаемых должно быть предсказуемым, быть независимым, оно стремится только к нормальному). То, что это так, несмотря на исходное распределение – это потрясающе.
Распределение их суммы подчиняется (приблизительно) нормальному распределению. Чем больше вещей суммируется – тем ближе их сумма соответствует нормальному распределению (подвох: распределение слагаемых должно быть предсказуемым, быть независимым, оно стремится только к нормальному). То, что это так, несмотря на исходное распределение – это потрясающе.
Прим. перев.
Меня удивило, что автор не пишет про необходимость сопоставимого масштаба суммируемых распределений: если одно существенно доминирует надо остальными — сходиться будет крайне плохо. И, в общем-то, абсолютная взаимная независимость необязательна, достаточна слабая зависимость.
Ну сойдёт, наверное, для вечеринок, как он написал.
Это называется «центральная предельная теорема», и надо знать, что это, почему так названо и что означает, иначе моментально засмеют.
В её разрезе, нормальное связано со всеми распределениями.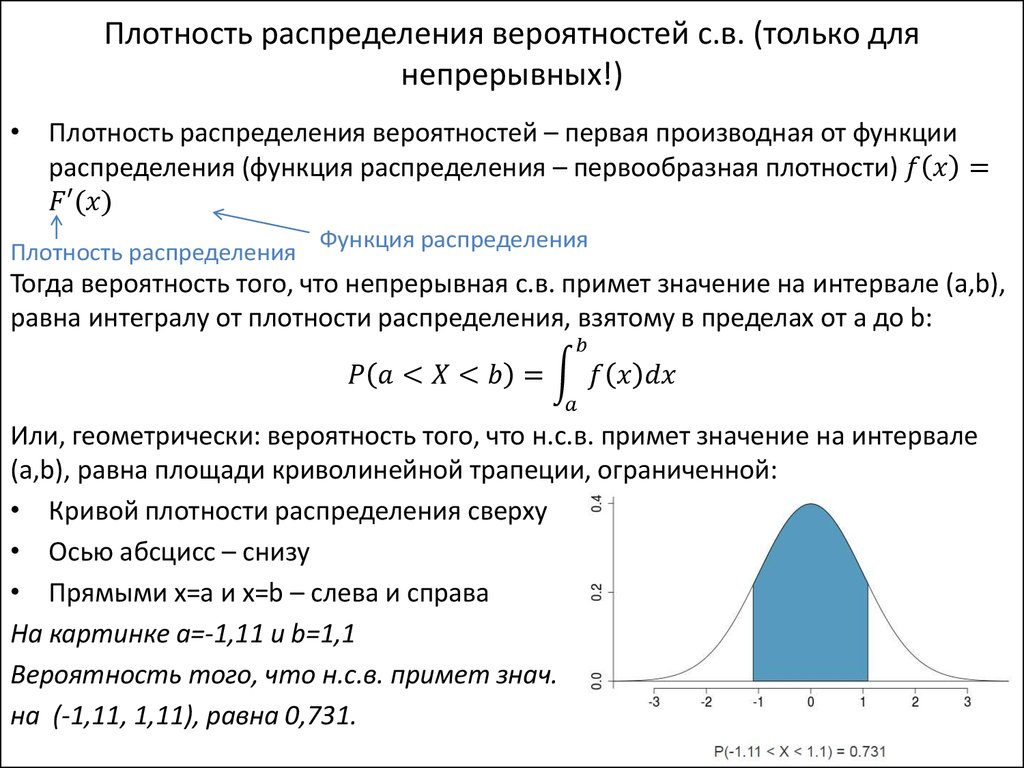 Хотя, в основном, его связывают с распределениями всяких сумм. Сумма испытаний Бернулли следует биномиальному распределению и, с увеличением количества испытаний, это биномиальное распределение становится всё ближе в нормальному распределению. Аналогично и его двоюродный брат – гипергеометрическое распределение. Распределение Пуассона – предельная форма биномиального – так же приближается к нормальному с увеличением параметра интенсивности.
Хотя, в основном, его связывают с распределениями всяких сумм. Сумма испытаний Бернулли следует биномиальному распределению и, с увеличением количества испытаний, это биномиальное распределение становится всё ближе в нормальному распределению. Аналогично и его двоюродный брат – гипергеометрическое распределение. Распределение Пуассона – предельная форма биномиального – так же приближается к нормальному с увеличением параметра интенсивности.
Исходы, которые подчиняются логнормальному распределению, дают значения, логарифм которых нормально распределён. Или по-другому: экспонента нормально распределённого значения логнормально распределена. Если суммы – нормально распределены, то запомните так же, что произведения распределены логнормально.
t-Распределение Стьюдента – это основа t-теста, который многие нестатистики изучают в других областях. Оно используется для предположений о среднем нормального распределения и так же стремится к нормальному распределению с увеличением своего параметра. Отличительная особенность t-распределения – его хвосты, которые толще, чем у нормального распределения.
Отличительная особенность t-распределения – его хвосты, которые толще, чем у нормального распределения.
Если толстохвостый анекдот недостаточно раскачал вашего соседа – переходите в довольно забавной байке про пиво. Больше 100 лет назад Гиннесс использовал статистику, чтобы улучшить свой стаут. Тогда Вильям Сили Госсет и изобрёл полностью новую статистическую теорию для улучшенного выращивания ячменя. Госсет убедил босса, что другие пивовары не поймут, как использовать его идеи, и получил разрешение на публикацию, но под псевдонимом «Стьюдент». Самое известное достижение Госсета – как раз это самое t-распределение, которое, можно сказать, названо в честь него.
Наконец, распределение хи-квадрат – распределение сумм квадратов нормально-распределенных величин. На этом распределении построен тест хи-квадрат, который сам основан на сумме квадратов разниц, которые должны быть нормально распределены.
Гамма и бета
В этом месте, если вы уже заговорили о чём-то хи-квадратном, разговор начинается всерьёз. Вы уже, возможно, говорите с настоящими статистиками, и, наверное, стоит уже откланиваться, поскольку могут всплыть вещи типа гамма-распределения. Это обобщение и экспоненциального, и хи-квадрат распределения. Как и экспоненциальное распределение, оно используется для сложных моделей времен ожидания. Например, гамма-распределение появляется, когда моделируется время до следующих n событий. Оно появляется в машинном обучении как «сопряжённое априорное распределение» к парочке других распределений.
Вы уже, возможно, говорите с настоящими статистиками, и, наверное, стоит уже откланиваться, поскольку могут всплыть вещи типа гамма-распределения. Это обобщение и экспоненциального, и хи-квадрат распределения. Как и экспоненциальное распределение, оно используется для сложных моделей времен ожидания. Например, гамма-распределение появляется, когда моделируется время до следующих n событий. Оно появляется в машинном обучении как «сопряжённое априорное распределение» к парочке других распределений.
Не вступайте в разговор об этих сопряжённых распределениях, но если всё-таки придётся, не забудьте сказать о бета-распределении, потому что оно сопряжённое априорное к большинству упомянутых здесь распределений. Data-scientist-ы уверены, что оно именно для этого и сделано. Упомяните об этом ненароком и идите к двери.
Начало мудрости
Распределения вероятности — это то, о чём нельзя знать слишком много. По настоящему заинтересованные могут обратиться к этой супердетализированной карте всех распределений вероятности. Надеюсь, этот шуточный путеводитель даст вам уверенность казаться «в теме» в современной технокультуре. Или, по крайней мере, способ с высокой вероятностью определить, когда надо идти на менее ботанскую вечеринку.
Надеюсь, этот шуточный путеводитель даст вам уверенность казаться «в теме» в современной технокультуре. Или, по крайней мере, способ с высокой вероятностью определить, когда надо идти на менее ботанскую вечеринку.
Шон Овен – директор Data Science в Cloudera, Лондон. До Клаудеры он основал Myrrix Ltd. (сейчас проект Oryx) для коммерционализации широкомасштабных рекомендательных систем в реальном времени на Hadoop. Он так же контрибьютор Apache Spark и соавтор O’Reilly Media’s Advanced Analytics with Spark
Типы и использование в инвестировании
Что такое распределение вероятностей?
Распределение вероятностей — это статистическая функция, описывающая все возможные значения и вероятности, которые случайная величина может принимать в заданном диапазоне. Этот диапазон будет ограничен минимальным и максимальным возможными значениями, но именно то, где возможное значение, вероятно, будет нанесено на график распределения вероятностей, зависит от ряда факторов.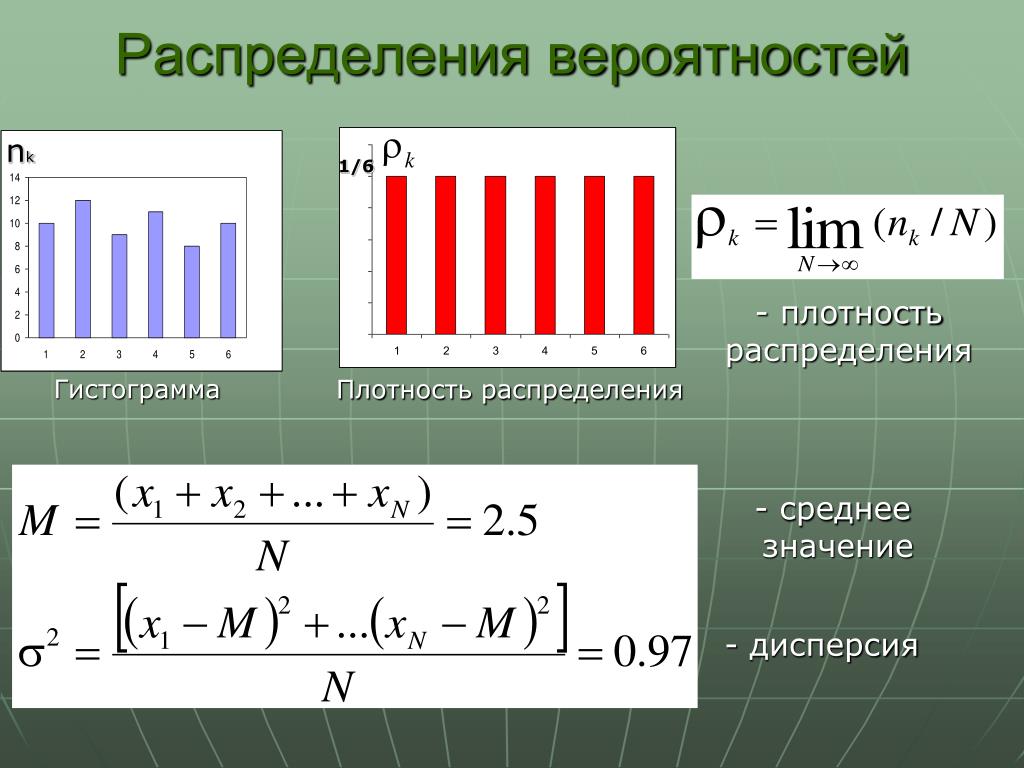 Эти факторы включают среднее значение распределения (среднее), стандартное отклонение, асимметрию и эксцесс.
Эти факторы включают среднее значение распределения (среднее), стандартное отклонение, асимметрию и эксцесс.
Как работает распределение вероятностей
Возможно, наиболее распространенным распределением вероятностей является нормальное распределение, или «колоколообразная кривая», хотя существует несколько широко используемых распределений. Как правило, процесс генерации данных о каком-либо явлении определяет его вероятностное распределение. Этот процесс называется функцией плотности вероятности.
Распределения вероятностей также можно использовать для создания кумулятивных функций распределения (CDF), которые суммируют вероятность событий кумулятивно и всегда начинаются с нуля и заканчиваются на 100%.
Ученые, финансовые аналитики и управляющие фондами могут определить распределение вероятности конкретной акции, чтобы оценить возможную ожидаемую доходность, которую акция может принести в будущем. История доходности акции, которую можно измерить за любой временной интервал, вероятно, будет состоять только из части доходности акции, что приведет к ошибке выборки при анализе. Увеличивая размер выборки, эту ошибку можно значительно уменьшить.
Увеличивая размер выборки, эту ошибку можно значительно уменьшить.
Основные выводы
- Распределение вероятностей отображает ожидаемые результаты возможных значений для заданного процесса генерации данных.
- Распределения вероятностей бывают разных форм с различными характеристиками, определяемыми средним значением, стандартным отклонением, асимметрией и эксцессом.
- Инвесторы используют распределения вероятностей для прогнозирования доходности активов, таких как акции, с течением времени и для хеджирования своих рисков.
Типы вероятностных распределений
Существует множество различных классификаций вероятностных распределений. Некоторые из них включают нормальное распределение, распределение хи-квадрат, биномиальное распределение и распределение Пуассона. Различные распределения вероятностей служат разным целям и представляют разные процессы генерации данных. Биномиальное распределение, например, оценивает вероятность того, что событие произойдет несколько раз в течение заданного числа испытаний и с учетом вероятности события в каждом испытании. и может быть получен путем отслеживания того, сколько штрафных бросков делает баскетболист в игре, где 1 = попадание в корзину, а 0 = промах. Другим типичным примером может быть использование честной монеты и определение вероятности того, что эта монета выпадет орлом за 10 бросков подряд. Биномиальное распределение равно дискретный , в отличие от непрерывного, поскольку только 1 или 0 являются допустимым ответом.
и может быть получен путем отслеживания того, сколько штрафных бросков делает баскетболист в игре, где 1 = попадание в корзину, а 0 = промах. Другим типичным примером может быть использование честной монеты и определение вероятности того, что эта монета выпадет орлом за 10 бросков подряд. Биномиальное распределение равно дискретный , в отличие от непрерывного, поскольку только 1 или 0 являются допустимым ответом.
Наиболее часто используемым распределением является нормальное распределение, которое часто используется в финансах, инвестициях, науке и технике. Нормальное распределение полностью характеризуется своим средним значением и стандартным отклонением, что означает, что распределение не является асимметричным и имеет эксцесс. Это делает распределение симметричным, и на графике оно изображается в виде колоколообразной кривой. Нормальное распределение определяется средним (средним) значением, равным нулю, и стандартным отклонением, равным 1,0, с асимметрией, равной нулю, и эксцессом, равным 3.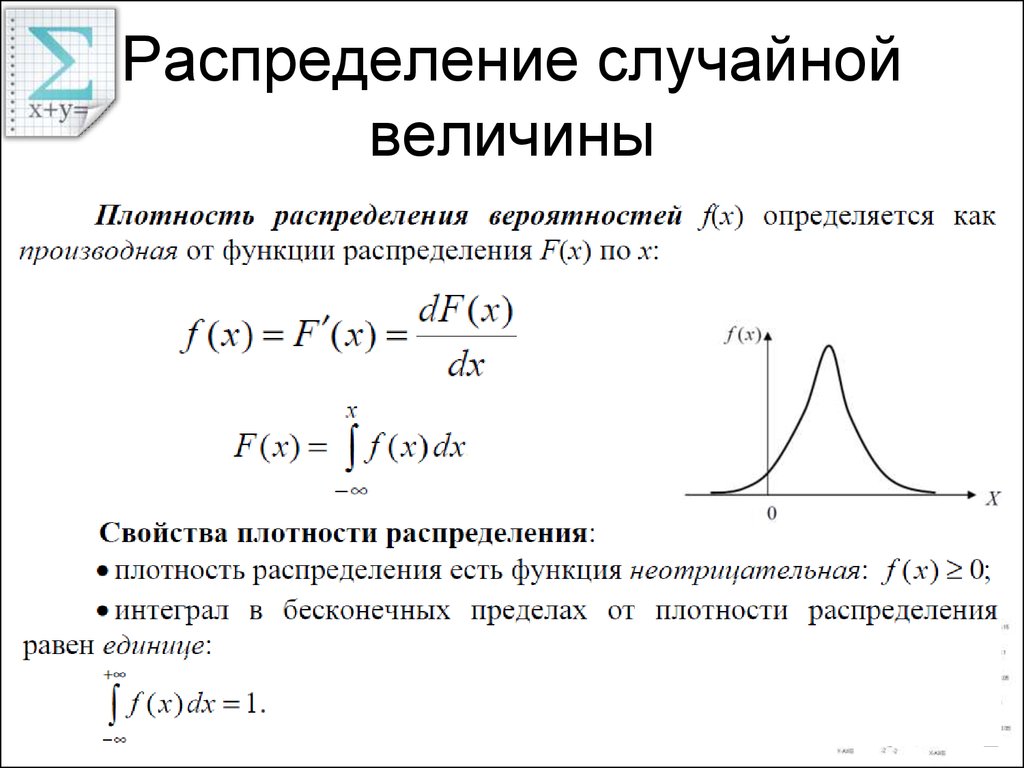 При нормальном распределении примерно 68% собранных данных будут находиться в пределах +/- одного стандарта. отклонение среднего; примерно 95% в пределах +/- двух стандартных отклонений; и 99,7% в пределах трех стандартных отклонений. В отличие от биномиального распределения, нормальное распределение является непрерывным, что означает, что представлены все возможные значения (в отличие от только 0 и 1 без промежуточных значений).
При нормальном распределении примерно 68% собранных данных будут находиться в пределах +/- одного стандарта. отклонение среднего; примерно 95% в пределах +/- двух стандартных отклонений; и 99,7% в пределах трех стандартных отклонений. В отличие от биномиального распределения, нормальное распределение является непрерывным, что означает, что представлены все возможные значения (в отличие от только 0 и 1 без промежуточных значений).
Распределения вероятностей, используемые в инвестировании
Часто предполагается, что доходность акций имеет нормальное распределение, но в действительности они демонстрируют эксцесс с большими отрицательными и положительными доходами, которые, кажется, возникают больше, чем можно было бы предсказать при нормальном распределении. Фактически, поскольку цены акций ограничены нулем, но предлагают потенциально неограниченный потенциал роста, распределение доходности акций было описано как логарифмически нормальное. Это видно на графике доходности акций, где хвосты распределения имеют большую толщину.
Распределения вероятностей часто используются в управлении рисками, а также для оценки вероятности и суммы убытков, которые может понести инвестиционный портфель, на основе распределения исторической доходности. Одним из популярных показателей управления рисками, используемых в инвестировании, является стоимость под риском (VaR). VaR дает минимальные убытки, которые могут возникнуть с учетом вероятности и временных рамок портфеля. В качестве альтернативы инвестор может получить вероятность убытка для суммы убытка и временных рамок, используя VaR. Злоупотребление и чрезмерная зависимость от VaR были названы одной из основных причин финансового кризиса 2008 года.
Пример распределения вероятностей
В качестве простого примера распределения вероятностей рассмотрим число, наблюдаемое при броске двух стандартных шестигранных игральных костей. Каждая кость имеет вероятность 1/6 выпадения любого числа, от одного до шести, но сумма двух игральных костей сформирует распределение вероятностей, изображенное на изображении ниже.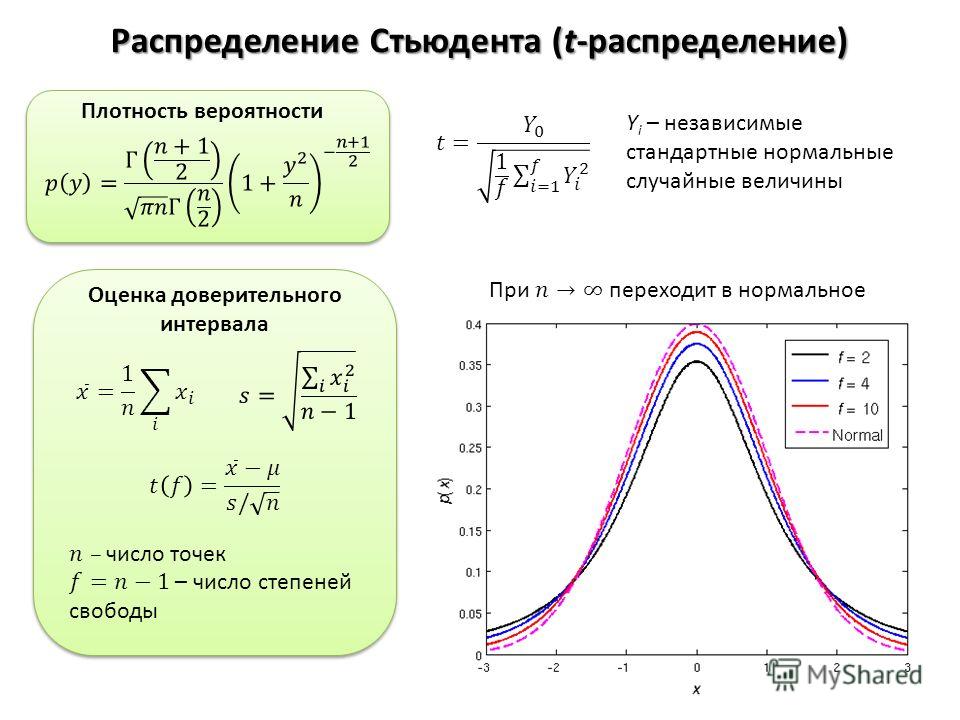 Семь — самый распространенный результат (1+6, 6+1, 5+2, 2+5, 3+4, 4+3). С другой стороны, два и двенадцать гораздо менее вероятны (1+1 и 6+6).
Семь — самый распространенный результат (1+6, 6+1, 5+2, 2+5, 3+4, 4+3). С другой стороны, два и двенадцать гораздо менее вероятны (1+1 и 6+6).
1.3.6.1. Что такое вероятностное распределение
1.3.6.1. Что такое распределение вероятностей| 1.
Исследовательский анализ данных 1.3. Методы ЭДА 1.3.6. Распределения вероятностей
| |||
| Дискретные распределения | Математическое определение дискретной функции вероятности,
p(x) — функция, удовлетворяющая следующим свойствам.
| ||
| Функции массы вероятности в сравнении с функциями плотности вероятности | Дискретные функции вероятности называются вероятностной массой. | ||

 то есть дискретный
функция, которая допускает отрицательные значения или значения больше единицы,
не функция вероятности. Условие, что вероятности
sum to one означает, что хотя бы одно из значений должно встречаться.
9{\ infty} {е (х) дх} = 1 \]
то есть дискретный
функция, которая допускает отрицательные значения или значения больше единицы,
не функция вероятности. Условие, что вероятности
sum to one означает, что хотя бы одно из значений должно встречаться.
9{\ infty} {е (х) дх} = 1 \]