
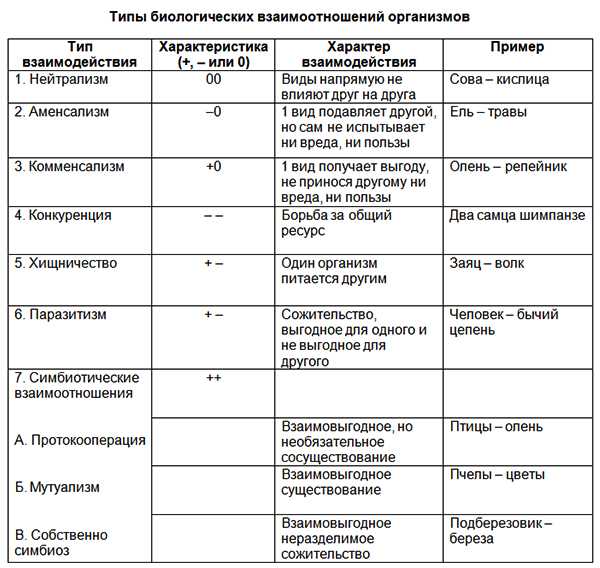
§5. Хранение информации — Ответы рабочая тетрадь Босов 5 класс
55. Впишите в клеточки слова-ответы.
а) Самый первый инструмент хранения информации.
Память.
б) Собственная (внутренняя) памят человека.
Оперативная память.
в) Внешняя память — записные книжки, справочники, энциклопедии и т.д.
Долговременная память.
г) Любой материальный объект, используемый для фиксации и хранения в нем информации.
Носитель информации.
56. Для хранения информации человек придумал различные информационные носители. Ни рисунке изображены некоторые из них. Обведите эти носители.
57. Воспользуйтесь текстом учебника, а также справочниками и энциклопедиями и подберите к каждой дате, указанной в левой колонке, соответствующее событие в правой колонке.
58. Составьте пары. Для каждого примера информации из левого столбика подберите соответствующий носитель информации.
59. Заполните таблицу. Укажите для каждого примера информационный носитель и форму представления информации.
60. Укажите компьютерные устройства для хранения информации.
61. Догадайтесь, о каких носителях информации идет речь.
Диск, камень, кассета, книжка, дискета, бумага, флеш, винчестер.
62. Что обеспечит самый оперативный доступ к информации о дате рождения человека?
Память этого человека.
63. Заполните схему «Хранение информации».
64.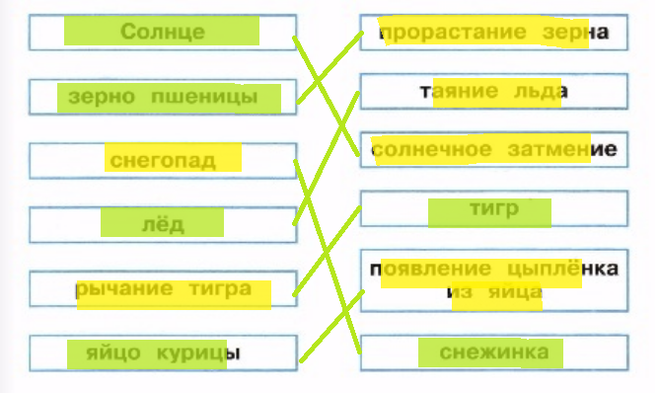 Впишите в клеточки слова-ответы.
Впишите в клеточки слова-ответы.
а) Информация, ханящаяся во внешней памяти и обозначенная именем.
Файл.
б) Контейнер для файлов.
Папка.
65. Выберите цепочки символов, которые могут использоваться в качестве имен файлов.
66. Выберите наиболее удачное имя для файла с письмом другу.
Письмо_Пете
67. Установите соответствие между компьютерами и аналогичными им некомпьютерными объектами.
68. Разгадайте кроссворд «Хранение информации».
По горизонтали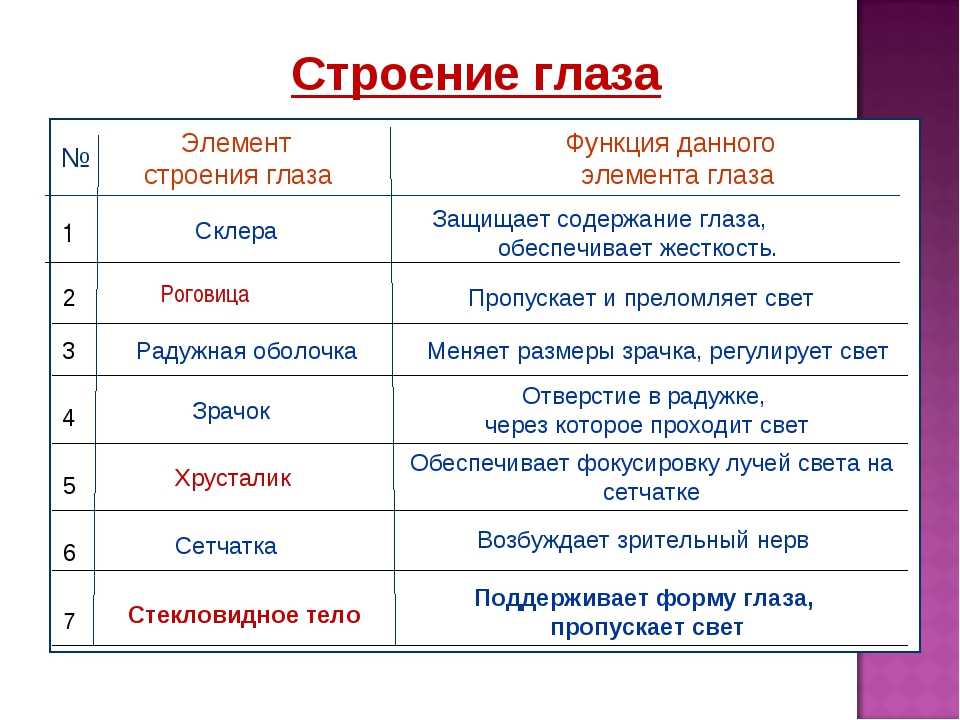 7. Носитель информации, позволяющий сохранять для потомков лица людей, пейзажи и т. д. 8. Один из самых распространённых носителей информации с давних времён до наших дней. 10. Страна, где изобрели бумагу. 11. Древний носитель информации, сделанный из кожи животных.
7. Носитель информации, позволяющий сохранять для потомков лица людей, пейзажи и т. д. 8. Один из самых распространённых носителей информации с давних времён до наших дней. 10. Страна, где изобрели бумагу. 11. Древний носитель информации, сделанный из кожи животных.
По вертикали. 1. Первый прибор для записи и воспроизведения звука. 2. Носитель информации в Древней Руси. 4. Записные книжки и другие внешние хранилища информации можно назвать: … память. 6. Любые сведения об окружающем мире. 9. Носитель информации из стеблей тростника.
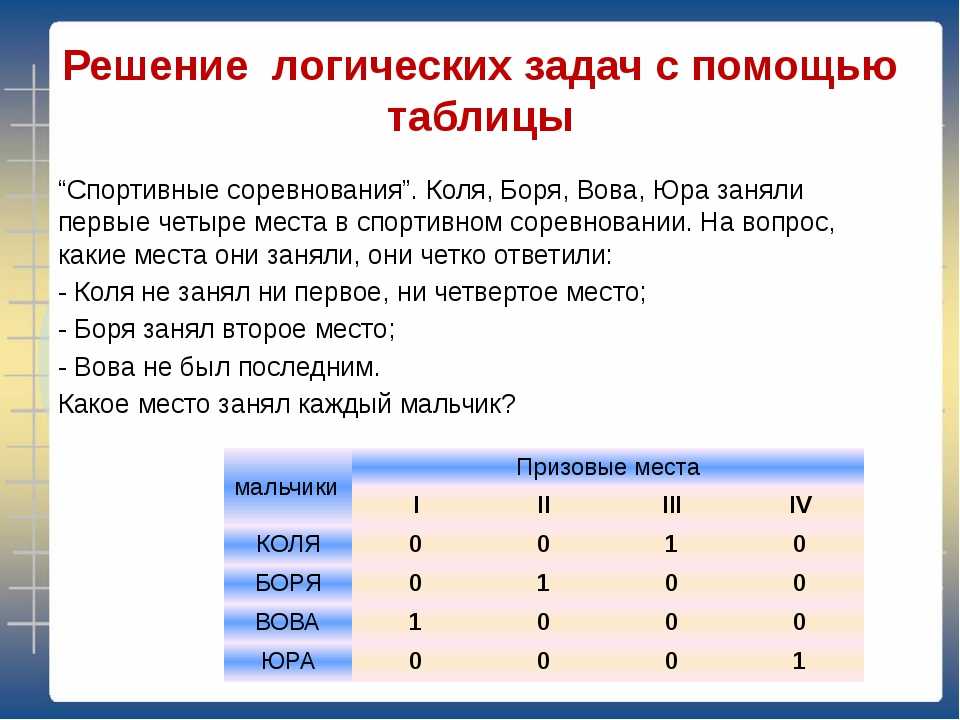
69. Девочки Аня, Маша и Варя купили себе флешки синего, белого и красного цветов. На вопрос, у кого из них какая флешка, одна из девочек ответила: «У Ани флешка синяя, у Маши — не синяя, а у Вари — не белая». Впоследствии выяснилось, что в овете верно сказано о цвете флешки только у одной девочки. Какого цвета флешки у каждой из девочек?
По условию мы имеем:
У Ани флешка синяя, у Маши — не синяя, а у Вари — не белая.
Если будем считать, что девочка верно ответила про Аню и у нее действительно синяя флешка, тогда у Маши тоже синяя, а у Вари — белая. У двух девочек одинакового цвета и такого не может быть.
Если же правда, что у Маши не синяя флешка, тогда у Ани не синяя и у Вари белая. В этом случае мы только можем сказать про Варю, что у нее белая флешка, а узнать флешки у Ани и Маши не сможем.
Если правда, что у Вари не белая флешка, то у Ани белая, а у Маши синяя. Этот вариант нам подходит.
Ответ: У Ани — белая, у Маши — синяя, у Вари — красная
Хранение информации. Память человека и память человечества. Информатика. 5 класс
Похожие презентации:
Пиксельная картинка
Информационная безопасность. Методы защиты информации
Электронная цифровая подпись (ЭЦП)
Этапы доказательной медицины в работе с Pico. Первый этап
История развития компьютерной техники
От печатной книги до интернет-книги
Краткая инструкция по CIS – 10 шагов
Информационные технологии в медицине
Информационные войны
Моя будущая профессия. Программист
Программист
1. Хранение информации
Память человека и память человечестваОперативная и долговременная память
Файлы и папки
Это интересно
2. Ключевые слова
• Память человека• Память человечества
• Носители информации
• Файл
• Папка
3. Память человека и память человечества
Память – самый первый инструмент хранения информации.Существует память отдельного человека
и память человечества, содержащая все знания,
накопленные людьми, которыми мы можем воспользоваться.
4. Память человека и память человечества
Хранение информации – процесс такой же древний,как и жизнь человеческой цивилизации.
5. Хранение информации
Фотография позволила сохранить дляпотомков зримые свидетельства
прошедших времён.
Жозеф Нисефор Ньепс
– первый
в мире фотограф
Камера-обскура
Ньепса
Первая фотография в мире,
«Вид из окна», 1826 г.
6. Хранение информации
Человек научился хранить звуковуюинформацию.
 В 1877 году Томасом Эдисоном
В 1877 году Томасом Эдисономбыл создан первый прибор для записи и
воспроизведения звука — фонограф.
Патефон,
30-е гг. XX в.
Томас Алва
Эдисон изобретатель
Фонограф Эдисона,
конец XIX в.
Катушечный
магнитофон,
70-е гг. XX в.
Кассетный
магнитофон,
конец XX в.
7. Хранение информации
В 1895 году в Париже был продемонстрирован первыйв мире кинофильм «Прибытие поезда».
Первый короткометражный фильм
Изобретатели кинематографа «Прибытие поезда на вокзал Ла
братья Люмьер, конец XIX в. Сьота», 1895 г.
8. Хранение информации
Современный компьютер может хранить в своейпамяти различные виды информации: текстовую,
графическую, числовую и табличную, звуковую и
видеоинформацию.
9. Оперативная и долговременная память
Собственную память человека,можно назвать оперативной,
потому что содержащаяся в
ней информация
воспроизводится достаточно
быстро.
Записные книжки, справочники,
энциклопедии и другие внешние
хранилища информации можно
назвать долговременной
памятью.
10. Носитель информации
!Носитель информации – это любой
материальный объект, используемый для
хранения на нём информации.
Давайте подумаем
Задание: Оставьте те картинки, которые
относятся к внутренней памяти человека
или компьютера. Лишнее уберите.
Давайте подумаем
Задание: Оставьте те картинки, которые
относятся к внешней памяти человека или
компьютера. Лишнее уберите.
Давайте подумаем
Задание: Укажите те предметы, которые
НЕ являются информационными носителями
информации. Лишнее уберите.
14. Файлы и папки
Программы и данные хранятся на устройствахдолговременной памяти в виде файлов.
!
Файл – это информация, хранящаяся
во внешней памяти и обозначенная именем.
Имя файла:
расписание.txt
Имя
. Расширение
(не более 255 символов)
Расширение говорит о типе
информации, хранящейся
в файле и о программе,
в которой он был создан.
Пример:
.txt – текстовая информация
.
 mp3 – звуковая информация
mp3 – звуковая информация.avi – видео информация
15. Файлы и папки
!Папка – это контейнер для файлов.
Система хранения файлов напоминает хранение
большого количества книг в библиотеке:
16. Файлы и папки
Каждый файл хранится в папке или во вложенной папке(папка, расположенная внутри папки):
Мои рисунки
Мои
документы
Мои
сочинения
Мои
фотографии
Мои игры
Моя музыка
Мои фильмы
17. Самое главное
• Существует память отдельного человека и памятьчеловечества.
• Память человека можно назвать оперативной
памятью, а любые внешние хранилища информации
можно назвать долговременной памятью.
• Носитель информации – это любой материальный
объект, используемый для хранения на нём
информации.
• Файл – это информация, хранящаяся во внешней
памяти компьютера как единое целое и
обозначенная именем.
• Файлы по определённым признакам группируют
в папки.
18.
 Вопросы и задания?
Вопросы и задания?Вопросы и задания
1. Составьте пары. Для каждого примера информации
из левого столбика подберите соответствующий
носитель информации.
Эскиз карнавального
костюма
Цифровая фотография
Колонка «Происшествия»
в газете
Музыкальная
композиция
Бумага
Альбом
для рисования
Флеш-память
Цветок
Аудиодиск
Запах цветка
19. Вопросы и задания
?Вопросы и задания
2. Догадайтесь, о каких носителях информации
идёт речь.
ИСКД — ДИСК
СЕКДИАТ
— ДИСКЕТА
— БУМАГА
АМНКЕЬ
— КАМЕНЬ
АГУБАМ
АСКСТЕА
— КАССЕТА
ЛФЕШ
АКЖКИН — КНИЖКА
ЧЕВИСТЕРН
— ФЛЕШ
— ВИНЧЕСТЕР
20. Вопросы и задания
?Вопросы и задания
3. Как называется:
а) Информация, хранящаяся во внешней памяти и
обозначенная именем.
Ф А Й Л
Проверка
б) Контейнер для файлов.
П А П К А
Проверка
21. Вопросы и задания
?6. Установите соответствие:
Имя файла
Библиотека
Файл
Шкаф
Папка
Полка
Диск
Книга
Вложенная папка
Название книги
22.
 Это интересноНайдите в электронном приложении к учебнику эти
Это интересноНайдите в электронном приложении к учебнику этиресурсы и познакомьтесь с ними
1. Анимация
«Файлы и папки»
(sc.edu.ru)
2. Тренажёр «Определение
носителя информации»
(вариант ученика) (sc.edu.ru)
23. Это интересно
Найдите в электронном приложении к учебнику этиресурсы и познакомьтесь с ними
1. Презентация
«Хранение информации.
История и
современность»
2. Презентация
«Носители информации»
English Русский Правила
python — Как разбить список на пары всеми возможными способами
Взгляните на itertools.combinations .
matt@stanley:~$ питон Python 2.6.5 (r265:79063, 16 апреля 2010 г., 13:57:41) [GCC 4.4.3] на Linux2 Введите «помощь», «авторское право», «кредиты» или «лицензия» для получения дополнительной информации. >>> импортировать itertools >>> список (itertools.combinations (диапазон (6), 2)) [(0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (1, 2), (1, 3), (1, 4), ( 1, 5), (2, 3), (2, 4), (2, 5), (3, 4), (3, 5), (4, 5)]
5
Я не думаю, что в стандартной библиотеке есть функция, которая делает именно то, что вам нужно. Просто используя
Просто используя itertools.combinations , вы можете получить список всех возможных отдельных пар, но на самом деле не решает проблему всех допустимых комбинаций пар.
Вы можете легко решить это с помощью:
import itertools
защита all_pairs(lst):
для p в itertools.permutations(lst):
я = итер (р)
выходной почтовый индекс (я, я)
Но это даст вам дубликаты, так как рассматривает (a,b) и (b,a) как разные, а также дает все порядки пар. В конце концов, я решил, что проще написать код с нуля, чем пытаться фильтровать результаты, поэтому вот правильная функция.
по умолчанию all_pairs(lst):
если len(lst) < 2:
урожай []
возвращаться
если len(lst) % 2 == 1:
# Обработка списка нечетной длины
для i в диапазоне (len (lst)):
для результата в all_pairs(lst[:i] + lst[i+1:]):
дать результат
еще:
а = 1ст[0]
для i в диапазоне (1, len (lst)):
пара = (а, лст [я])
для отдыха в all_pairs(lst[1:i]+lst[i+1:]):
выход [пара] + остаток
Он рекурсивный, поэтому столкнется с проблемами стека с длинным списком, но в остальном делает то, что вам нужно.
>>> для x в all_pairs([0,1,2,3,4,5]):
распечатать х
[(0, 1), (2, 3), (4, 5)]
[(0, 1), (2, 4), (3, 5)]
[(0, 1), (2, 5), (3, 4)]
[(0, 2), (1, 3), (4, 5)]
[(0, 2), (1, 4), (3, 5)]
[(0, 2), (1, 5), (3, 4)]
[(0, 3), (1, 2), (4, 5)]
[(0, 3), (1, 4), (2, 5)]
[(0, 3), (1, 5), (2, 4)]
[(0, 4), (1, 2), (3, 5)]
[(0, 4), (1, 3), (2, 5)]
[(0, 4), (1, 5), (2, 3)]
[(0, 5), (1, 2), (3, 4)]
[(0, 5), (1, 3), (2, 4)]
[(0, 5), (1, 4), (2, 3)] 10
Как насчет этого:
элементов = ["я", "ты", "он"]
[(items[i],items[j]) для i в диапазоне(len(items)) для j в диапазоне(i+1, len(items))]
[('я', 'ты'), ('я', 'он'), ('ты', 'он')]
или
элементов = [1, 2, 3, 5, 6] [(items[i],items[j]) для i в диапазоне(len(items)) для j в диапазоне(i+1, len(items))] [(1, 2), (1, 3), (1, 5), (1, 6), (2, 3), (2, 5), (2, 6), (3, 5), ( 3, 6), (5, 6)]
1
Концептуально похоже на ответ @shang, но не предполагает, что группы имеют размер 2:
import itertools
def generate_groups (lst, n):
если не лст:
урожай []
еще:
для группы в (((lst[0],) + xs) для xs в itertools. combinations(lst[1:], n-1)):
для групп в generate_groups([x для x в списке, если x не в группе], n):
выход [группа] + группы
pprint (список (генерировать_группы ([0, 1, 2, 3, 4, 5], 2)))
combinations(lst[1:], n-1)):
для групп в generate_groups([x для x в списке, если x не в группе], n):
выход [группа] + группы
pprint (список (генерировать_группы ([0, 1, 2, 3, 4, 5], 2)))
 combinations(lst[1:], n-1)):
для групп в generate_groups([x для x в списке, если x не в группе], n):
выход [группа] + группы
pprint (список (генерировать_группы ([0, 1, 2, 3, 4, 5], 2)))
combinations(lst[1:], n-1)):
для групп в generate_groups([x для x в списке, если x не в группе], n):
выход [группа] + группы
pprint (список (генерировать_группы ([0, 1, 2, 3, 4, 5], 2)))
Получается:
[[(0, 1), (2, 3), (4, 5)], [(0, 1), (2, 4), (3, 5)], [(0, 1), (2, 5), (3, 4)], [(0, 2), (1, 3), (4, 5)], [(0, 2), (1, 4), (3, 5)], [(0, 2), (1, 5), (3, 4)], [(0, 3), (1, 2), (4, 5)], [(0, 3), (1, 4), (2, 5)], [(0, 3), (1, 5), (2, 4)], [(0, 4), (1, 2), (3, 5)], [(0, 4), (1, 3), (2, 5)], [(0, 4), (1, 5), (2, 3)], [(0, 5), (1, 2), (3, 4)], [(0, 5), (1, 3), (2, 4)], [(0, 5), (1, 4), (2, 3)]]
Мой босс, вероятно, не обрадуется Я потратил немного времени на эту забавную задачу, но вот хорошее решение, которое не требует рекурсии и использует itertools.product . Это объясняется в документации :). Результаты кажутся нормальными, но я не слишком много проверял.
импорт itertools
защита all_pairs(lst):
"""Сгенерировать все наборы уникальных пар из списка `lst`.
Это эквивалентно всем _partitions_ `lst` (рассматривается как индексированный
set), которые имеют 2 элемента в каждом разделе.
Вспомните, как мы вычисляем общее количество таких разделов. Начиная с
список
[1, 2, 3, 4, 5, 6]
снимают первый элемент и выбирают его пару [из любого
остальные 5]. Например, мы можем выбрать нашу первую пару (1, 4).
Затем мы снимаем следующий элемент, 2, и выбираем, какой это элемент.
в паре с (скажем, 3). Итак, таких разделов 5 * 3 * 1 = 15.
Это похоже на множество вложенных циклов (т. е. рекурсию), потому что 1 может
выбрать 2, и в этом случае нашим следующим элементом будет 3. Но если абстрагироваться от того, «что
следующий элемент ", и вместо этого просто думает о том, какой индекс находится в
оставшийся список, наш выбор является статическим и может помочь
Функция itertools.product().
"""
N = длина (1)
selection_indices = itertools.product(*[
xrange(k) для k в обратном порядке(xrange(1, N, 2)) ])
для выбора в selection_indices:
# вычислить список, соответствующий вариантам
тмп = лст[:]
результат = []
для индекса по выбору:
result. append((tmp.pop(0), tmp.pop(index)) )
дать результат
 Это эквивалентно всем _partitions_ `lst` (рассматривается как индексированный
set), которые имеют 2 элемента в каждом разделе.
Вспомните, как мы вычисляем общее количество таких разделов. Начиная с
список
[1, 2, 3, 4, 5, 6]
снимают первый элемент и выбирают его пару [из любого
остальные 5]. Например, мы можем выбрать нашу первую пару (1, 4).
Затем мы снимаем следующий элемент, 2, и выбираем, какой это элемент.
в паре с (скажем, 3). Итак, таких разделов 5 * 3 * 1 = 15.
Это похоже на множество вложенных циклов (т. е. рекурсию), потому что 1 может
выбрать 2, и в этом случае нашим следующим элементом будет 3. Но если абстрагироваться от того, «что
следующий элемент ", и вместо этого просто думает о том, какой индекс находится в
оставшийся список, наш выбор является статическим и может помочь
Функция itertools.product().
"""
N = длина (1)
selection_indices = itertools.product(*[
xrange(k) для k в обратном порядке(xrange(1, N, 2)) ])
для выбора в selection_indices:
# вычислить список, соответствующий вариантам
тмп = лст[:]
результат = []
для индекса по выбору:
result.
Это эквивалентно всем _partitions_ `lst` (рассматривается как индексированный
set), которые имеют 2 элемента в каждом разделе.
Вспомните, как мы вычисляем общее количество таких разделов. Начиная с
список
[1, 2, 3, 4, 5, 6]
снимают первый элемент и выбирают его пару [из любого
остальные 5]. Например, мы можем выбрать нашу первую пару (1, 4).
Затем мы снимаем следующий элемент, 2, и выбираем, какой это элемент.
в паре с (скажем, 3). Итак, таких разделов 5 * 3 * 1 = 15.
Это похоже на множество вложенных циклов (т. е. рекурсию), потому что 1 может
выбрать 2, и в этом случае нашим следующим элементом будет 3. Но если абстрагироваться от того, «что
следующий элемент ", и вместо этого просто думает о том, какой индекс находится в
оставшийся список, наш выбор является статическим и может помочь
Функция itertools.product().
"""
N = длина (1)
selection_indices = itertools.product(*[
xrange(k) для k в обратном порядке(xrange(1, N, 2)) ])
для выбора в selection_indices:
# вычислить список, соответствующий вариантам
тмп = лст[:]
результат = []
для индекса по выбору:
result.
привет!
2
Нерекурсивная функция для поиска всех возможных пар, порядок которых не имеет значения, т. е. (a,b) = (b,a)
def combinanttorial(lst):
количество = 0
индекс = 1
пары = []
для элемента 1 в списке:
для element2 в lst[index:]:
пары.добавление((элемент1, элемент2))
индекс += 1
обратные пары
Так как это не рекурсивно, у вас не будет проблем с памятью при работе с длинными списками.
Пример использования:
my_list = [1, 2, 3, 4, 5] печать (комбинаторный (мой_список)) >>> [(1, 2), (1, 3), (1, 4), (1, 5), (2, 3), (2, 4), (2, 5), (3, 4), ( 3, 5), (4, 5)]
1
Попробуйте следующую функцию рекурсивного генератора:
def pairs_gen(L):
если len(L) == 2:
выход [(L[0], L[1])]
еще:
первый = L. pop (0)
для i, e в перечислении (L):
секунда = L.pop (i)
для list_of_pairs в pairs_gen(L):
list_of_pairs.insert(0, (первая, вторая))
выход list_of_pairs
L.insert(i, второй)
L.insert(0, первый)
 pop (0)
для i, e в перечислении (L):
секунда = L.pop (i)
для list_of_pairs в pairs_gen(L):
list_of_pairs.insert(0, (первая, вторая))
выход list_of_pairs
L.insert(i, второй)
L.insert(0, первый)
pop (0)
для i, e в перечислении (L):
секунда = L.pop (i)
для list_of_pairs в pairs_gen(L):
list_of_pairs.insert(0, (первая, вторая))
выход list_of_pairs
L.insert(i, второй)
L.insert(0, первый)
Пример использования:
>>> для пар в pairs_gen([0, 1, 2, 3, 4, 5]): ... печатать пары ... [(0, 1), (2, 3), (4, 5)] [(0, 1), (2, 4), (3, 5)] [(0, 1), (2, 5), (3, 4)] [(0, 2), (1, 3), (4, 5)] [(0, 2), (1, 4), (3, 5)] [(0, 2), (1, 5), (3, 4)] [(0, 3), (1, 2), (4, 5)] [(0, 3), (1, 4), (2, 5)] [(0, 3), (1, 5), (2, 4)] [(0, 4), (1, 2), (3, 5)] [(0, 4), (1, 3), (2, 5)] [(0, 4), (1, 5), (2, 3)] [(0, 5), (1, 2), (3, 4)] [(0, 5), (1, 3), (2, 4)] [(0, 5), (1, 4), (2, 3)]
Я сделал небольшой набор тестов для всех совместимых решений. Мне пришлось немного изменить функции, чтобы заставить их работать в Python 3. Интересно, что самая быстрая функция в PyPy в некоторых случаях является самой медленной функцией в Python 2/3.
импорт itertools
время импорта
из коллекций импортировать OrderedDict
def tokland_org (lst, n):
если не лст:
урожай []
еще:
для группы в (((lst[0],) + xs) для xs в itertools.combinations(lst[1:], n-1)):
для групп в tokland_org([x вместо x в списке, если x не в группе], n):
выход [группа] + группы
tokland = лямбда x: tokland_org(x, 2)
деф gatoatigrado (lst):
N = длина (1)
selection_indices = itertools.product(*[
диапазон (k) для k в обратном порядке (диапазон (1, N, 2)) ])
для выбора в selection_indices:
# вычислить список, соответствующий вариантам
tmp = список (список)
результат = []
для индекса по выбору:
result.append((tmp.pop(0), tmp.pop(index)) )
дать результат
деф шанг(Х):
лст = список(Х)
если len(lst) < 2:
доходность
возвращаться
а = 1ст[0]
для i в диапазоне (1, len (lst)):
пара = (а, лст [я])
для отдыха в shang(lst[1:i]+lst[i+1:]):
выход [пара] + остаток
деф смихр(Х):
лст = список(Х)
если не лст:
выход [кортеж()]
Элиф лен(лст) == 1:
выход [кортеж (lst)]
Элиф лен(лст) == 2:
выход [кортеж (lst)]
еще:
если len(lst) % 2:
для i в (Нет, Истина):
если я не в списке:
лст = лст + [я]
ПАД = я
ломать
еще:
в то время как chr(i) в lst:
я += 1
PAD = хр (i)
лст = лст + [PAD]
еще:
ПАД = Ложь
а = 1ст[0]
для i в диапазоне (1, len (lst)):
пара = (а, лст[я])
для отдыха в смихре(lst[1:i] + lst[i+1:]):
rv = [пара] + остальные
если PAD не False:
для i, t в перечислении (rv):
если PAD в t:
rv[i] = (t[0],)
ломать
доходность rv
защита adeel_zafar(X):
L = список (Х)
если len(L) == 2:
выход [(L[0], L[1])]
еще:
первый = L. pop (0)
для i, e в перечислении (L):
секунда = L.pop (i)
для list_of_pairs в adeel_zafar(L):
list_of_pairs.insert(0, (первая, вторая))
выход list_of_pairs
L.insert(i, второй)
L.insert(0, первый)
если __name__ =="__main__":
импортировать время
импорт pprint
Кандидаты = дикт (токланд = токланд, гатоатиградо = гатоатиградо, шанг = шанг, смихр = смихр, adeel_zafar = adeel_zafar)
для я в диапазоне (1,7):
результаты = [замороженный набор ([замороженный набор (x) для x в кандидате (диапазон (i * 2))]) для кандидата в кандидатах. значения ()]
утверждать len(frozenset(результаты)) == 1
print("Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой")
times = dict([(k, timeit.timeit('list({0}(range(6)))'.format(k), setup="from __main__ import {0}".format(k), number= 10000)) для k в кандидатах. ключи()])
pprint.pprint([(k, "{0:.3g}".format(v)) для k,v в OrderedDict(sorted(times.items(), key=lambda t: t[1])).items ()])
print("Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой")
times = dict([(k, timeit.timeit('list(islice({0}(range(52)), 800))'.format(k), setup="from itertools import islice; from __main__ import {0 }".format(k), число=100)) для k в кандидатах.ключи()])
pprint.pprint([(k, "{0:.3g}".format(v)) для k,v в OrderedDict(sorted(times.items(), key=lambda t: t[1])).items ()])
"""
print("10000-я перестановка предыдущей серии:")
gens = dict([(k,v(range(52))) для k,v в кандидатах.items()])
десятки тысяч = dict([(k, list(itertools.islice(permutations, 10000))[-1]) for k, перестановки в gens.items()])
для пары в tenthousands.items():
печать (пара [0])
печать (пара [1])
"""
 pop (0)
для i, e в перечислении (L):
секунда = L.pop (i)
для list_of_pairs в adeel_zafar(L):
list_of_pairs.insert(0, (первая, вторая))
выход list_of_pairs
L.insert(i, второй)
L.insert(0, первый)
если __name__ =="__main__":
импортировать время
импорт pprint
Кандидаты = дикт (токланд = токланд, гатоатиградо = гатоатиградо, шанг = шанг, смихр = смихр, adeel_zafar = adeel_zafar)
для я в диапазоне (1,7):
результаты = [замороженный набор ([замороженный набор (x) для x в кандидате (диапазон (i * 2))]) для кандидата в кандидатах. значения ()]
утверждать len(frozenset(результаты)) == 1
print("Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой")
times = dict([(k, timeit.timeit('list({0}(range(6)))'.format(k), setup="from __main__ import {0}".format(k), number= 10000)) для k в кандидатах.
pop (0)
для i, e в перечислении (L):
секунда = L.pop (i)
для list_of_pairs в adeel_zafar(L):
list_of_pairs.insert(0, (первая, вторая))
выход list_of_pairs
L.insert(i, второй)
L.insert(0, первый)
если __name__ =="__main__":
импортировать время
импорт pprint
Кандидаты = дикт (токланд = токланд, гатоатиградо = гатоатиградо, шанг = шанг, смихр = смихр, adeel_zafar = adeel_zafar)
для я в диапазоне (1,7):
результаты = [замороженный набор ([замороженный набор (x) для x в кандидате (диапазон (i * 2))]) для кандидата в кандидатах. значения ()]
утверждать len(frozenset(результаты)) == 1
print("Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой")
times = dict([(k, timeit.timeit('list({0}(range(6)))'.format(k), setup="from __main__ import {0}".format(k), number= 10000)) для k в кандидатах. ключи()])
pprint.pprint([(k, "{0:.3g}".format(v)) для k,v в OrderedDict(sorted(times.items(), key=lambda t: t[1])).items ()])
print("Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой")
times = dict([(k, timeit.timeit('list(islice({0}(range(52)), 800))'.format(k), setup="from itertools import islice; from __main__ import {0 }".format(k), число=100)) для k в кандидатах.ключи()])
pprint.pprint([(k, "{0:.3g}".format(v)) для k,v в OrderedDict(sorted(times.items(), key=lambda t: t[1])).items ()])
"""
print("10000-я перестановка предыдущей серии:")
gens = dict([(k,v(range(52))) для k,v в кандидатах.items()])
десятки тысяч = dict([(k, list(itertools.islice(permutations, 10000))[-1]) for k, перестановки в gens.items()])
для пары в tenthousands.items():
печать (пара [0])
печать (пара [1])
"""
ключи()])
pprint.pprint([(k, "{0:.3g}".format(v)) для k,v в OrderedDict(sorted(times.items(), key=lambda t: t[1])).items ()])
print("Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой")
times = dict([(k, timeit.timeit('list(islice({0}(range(52)), 800))'.format(k), setup="from itertools import islice; from __main__ import {0 }".format(k), число=100)) для k в кандидатах.ключи()])
pprint.pprint([(k, "{0:.3g}".format(v)) для k,v в OrderedDict(sorted(times.items(), key=lambda t: t[1])).items ()])
"""
print("10000-я перестановка предыдущей серии:")
gens = dict([(k,v(range(52))) для k,v в кандидатах.items()])
десятки тысяч = dict([(k, list(itertools.islice(permutations, 10000))[-1]) for k, перестановки в gens.items()])
для пары в tenthousands.items():
печать (пара [0])
печать (пара [1])
"""
Похоже, что все они генерируют один и тот же порядок, так что наборы не нужны, но это гарантия будущего. Я немного поэкспериментировал с преобразованием Python 3, не всегда понятно, где строить список, но я попробовал несколько вариантов и выбрал самый быстрый.
Я немного поэкспериментировал с преобразованием Python 3, не всегда понятно, где строить список, но я попробовал несколько вариантов и выбрал самый быстрый.
Вот результаты тестов:
% echo "pypy"; pypy all_pairs.py; эхо "питон2"; питон all_pairs.py; эхо "питон3"; python3 all_pairs.py
пипи
Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой
[('гатоатиградо', '0,0626'),
('адель_зафар', '0,125'),
(«смихр», «0,149'),
(«шан», «0,2»),
(«токланд», «0,27»)]
Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой
[('gatoatigrado', '0,29'),
('адель_зафар', '0,411'),
(«смихр», «0,464»),
(«шан», «0,493»),
(«токланд», «0,553»)]
питон2
Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой
[('gatoatigrado', '0,344'),
('адель_зафар', '0,374'),
(«смихр», «0,396'),
(«шан», «0,495»),
(«токланд», «0,675»)]
Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой
[('адель_зафар', '0,773'),
(«шан», «0,823»),
(«смихр», «0,841»),
(«токланд», «0,948»),
(«gatoatigrado», «1. 38»)]
питон3
Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой
[('gatoatigrado', '0,385'),
('адель_зафар', '0,419'),
(«смихр», «0,433»),
(«шан», «0,562»),
(«токланд», «0,837»)]
Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой
[('смихр', '0,783'),
(«шан», «0,81»),
('адель_зафар', '0,835'),
(«токланд», «0,969'),
(«gatoatigrado», «1.3»)]
% pypy --версия
Python 2.7.12 (5.6.0+dfsg-0~ppa2~ubuntu16.04, 11 ноября 2016 г., 16:31:26)
[PyPy 5.6.0 с GCC 5.4.0 20160609]
% python3 --версия
Питон 3.5.2
 38»)]
питон3
Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой
[('gatoatigrado', '0,385'),
('адель_зафар', '0,419'),
(«смихр», «0,433»),
(«шан», «0,562»),
(«токланд», «0,837»)]
Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой
[('смихр', '0,783'),
(«шан», «0,81»),
('адель_зафар', '0,835'),
(«токланд», «0,969'),
(«gatoatigrado», «1.3»)]
% pypy --версия
Python 2.7.12 (5.6.0+dfsg-0~ppa2~ubuntu16.04, 11 ноября 2016 г., 16:31:26)
[PyPy 5.6.0 с GCC 5.4.0 20160609]
% python3 --версия
Питон 3.5.2
38»)]
питон3
Время получения всех перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 6-элементной колоды, пока она не станет пустой
[('gatoatigrado', '0,385'),
('адель_зафар', '0,419'),
(«смихр», «0,433»),
(«шан», «0,562»),
(«токланд», «0,837»)]
Время получения первых 2000 перестановок наборов неупорядоченных пар, состоящих из двух розыгрышей из 52-элементной колоды, пока она не станет пустой
[('смихр', '0,783'),
(«шан», «0,81»),
('адель_зафар', '0,835'),
(«токланд», «0,969'),
(«gatoatigrado», «1.3»)]
% pypy --версия
Python 2.7.12 (5.6.0+dfsg-0~ppa2~ubuntu16.04, 11 ноября 2016 г., 16:31:26)
[PyPy 5.6.0 с GCC 5.4.0 20160609]
% python3 --версия
Питон 3.5.2
Так что я говорю, используйте решение gatoatigrado.
по умолч. f(l):
если л == []:
урожай []
возвращаться
лл = л[1:]
для j в диапазоне (len (ll)):
для конца в f(ll[:j] + ll[j+1:]):
выход [(l[0], ll[j])] + конец
Использование:
для x в f([0,1,2,3,4,5]):
распечатать х
>>>
[(0, 1), (2, 3), (4, 5)]
[(0, 1), (2, 4), (3, 5)]
[(0, 1), (2, 5), (3, 4)]
[(0, 2), (1, 3), (4, 5)]
[(0, 2), (1, 4), (3, 5)]
[(0, 2), (1, 5), (3, 4)]
[(0, 3), (1, 2), (4, 5)]
[(0, 3), (1, 4), (2, 5)]
[(0, 3), (1, 5), (2, 4)]
[(0, 4), (1, 2), (3, 5)]
[(0, 4), (1, 3), (2, 5)]
[(0, 4), (1, 5), (2, 3)]
[(0, 5), (1, 2), (3, 4)]
[(0, 5), (1, 3), (2, 4)]
[(0, 5), (1, 4), (2, 3)]
2
Л = [1, 1, 2, 3, 4]
ответ = []
для i в диапазоне (len (L)):
для j в диапазоне (i+1, len(L)):
если (L[i],L[j]) нет в ответе:
ответ. присоединить((L[i],L[j]))
распечатать ответ
[(1, 1), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
 присоединить((L[i],L[j]))
распечатать ответ
[(1, 1), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
присоединить((L[i],L[j]))
распечатать ответ
[(1, 1), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
Надеюсь, это поможет
Надеюсь, это поможет:
Д = [0, 1, 2, 3, 4, 5]
[(i,j) для i в L для j в L]
выход:
[(0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (1, 0), (1, 1), (1, 2), (1, 3), (1, 4), (1, 5), (2, 0), (2, 1), (2, 2), (2, 3) , (2, 4), (2, 5), (3, 0), (3, 1), (3, 2), (3, 3), (3, 4), (3, 5), ( 4, 0), (4, 1), (4, 2), (4, 3), (4, 4), (4, 5), (5, 0), (5, 1), (5, 2), (5, 3), (5, 4), (5, 5)]
1
Этот код работает, когда длина списка не кратна 2; он использует хак, чтобы заставить его работать. Возможно, есть лучшие способы сделать это... Это также гарантирует, что пары всегда находятся в кортеже и что он работает независимо от того, является ли ввод списком или кортежем.
по умолчанию all_pairs(lst):
"""Вернуть все комбинации пар элементов ``lst``, где порядок
внутри пары и порядок пар не имеет значения.
Примеры
========
>>> для i в диапазоне (6):
... список (all_pairs (диапазон (i)))
...
[[()]]
[[(0,)]]
[[(0, 1)]]
[[(0, 1), (2,)], [(0, 2), (1,)], [(0,), (1, 2)]]
[[(0, 1), (2, 3)], [(0, 2), (1, 3)], [(0, 3), (1, 2)]]
[[(0, 1), (2, 3), (4,)], [(0, 1), (2, 4), (3,)], [(0, 1), (2,) , (3, 4)], [(0, 2)
, (1, 3), (4,)], [(0, 2), (1, 4), (3,)], [(0, 2), (1,), (3, 4)] , [(0, 3), (1, 2)
, (4,)], [(0, 3), (1, 4), (2,)], [(0, 3), (1,), (2, 4)], [(0, 4 ), (1, 2), (3,)],
[(0, 4), (1, 3), (2,)], [(0, 4), (1,), (2, 3)], [(0,), (1, 2), (3, 4)], [(0,),
(1, 3), (2, 4)], [(0,), (1, 4), (2, 3)]]
Обратите внимание, что если в списке нечетное количество элементов, один из
пары будут синглтоном.
использованная литература
==========
http://stackoverflow.com/questions/5360220/
как-разделить-список-на-пары-всеми-возможными-способами
"""
если не лст:
выход [кортеж()]
Элиф лен(лст) == 1:
выход [кортеж (lst)]
Элиф лен(лст) == 2:
выход [кортеж (lst)]
еще:
если len(lst) % 2:
для i в (Нет, Истина):
если я не в списке:
лст = список(лст) + [я]
ПАД = я
ломать
еще:
в то время как chr(i) в lst:
я += 1
PAD = хр (i)
lst = список (lst) + [PAD]
еще:
ПАД = Ложь
а = 1ст[0]
для i в диапазоне (1, len (lst)):
пара = (а, лст[я])
для отдыха в all_pairs(lst[1:i] + lst[i+1:]):
rv = [пара] + остальные
если PAD не False:
для i, t в перечислении (rv):
если PAD в t:
rv[i] = (t[0],)
ломать
доходность rv
 Примеры
========
>>> для i в диапазоне (6):
... список (all_pairs (диапазон (i)))
...
[[()]]
[[(0,)]]
[[(0, 1)]]
[[(0, 1), (2,)], [(0, 2), (1,)], [(0,), (1, 2)]]
[[(0, 1), (2, 3)], [(0, 2), (1, 3)], [(0, 3), (1, 2)]]
[[(0, 1), (2, 3), (4,)], [(0, 1), (2, 4), (3,)], [(0, 1), (2,) , (3, 4)], [(0, 2)
, (1, 3), (4,)], [(0, 2), (1, 4), (3,)], [(0, 2), (1,), (3, 4)] , [(0, 3), (1, 2)
, (4,)], [(0, 3), (1, 4), (2,)], [(0, 3), (1,), (2, 4)], [(0, 4 ), (1, 2), (3,)],
[(0, 4), (1, 3), (2,)], [(0, 4), (1,), (2, 3)], [(0,), (1, 2), (3, 4)], [(0,),
(1, 3), (2, 4)], [(0,), (1, 4), (2, 3)]]
Обратите внимание, что если в списке нечетное количество элементов, один из
пары будут синглтоном.
использованная литература
==========
http://stackoverflow.com/questions/5360220/
как-разделить-список-на-пары-всеми-возможными-способами
"""
если не лст:
выход [кортеж()]
Элиф лен(лст) == 1:
выход [кортеж (lst)]
Элиф лен(лст) == 2:
выход [кортеж (lst)]
еще:
если len(lst) % 2:
для i в (Нет, Истина):
если я не в списке:
лст = список(лст) + [я]
ПАД = я
ломать
еще:
в то время как chr(i) в lst:
я += 1
PAD = хр (i)
lst = список (lst) + [PAD]
еще:
ПАД = Ложь
а = 1ст[0]
для i в диапазоне (1, len (lst)):
пара = (а, лст[я])
для отдыха в all_pairs(lst[1:i] + lst[i+1:]):
rv = [пара] + остальные
если PAD не False:
для i, t в перечислении (rv):
если PAD в t:
rv[i] = (t[0],)
ломать
доходность rv
Примеры
========
>>> для i в диапазоне (6):
... список (all_pairs (диапазон (i)))
...
[[()]]
[[(0,)]]
[[(0, 1)]]
[[(0, 1), (2,)], [(0, 2), (1,)], [(0,), (1, 2)]]
[[(0, 1), (2, 3)], [(0, 2), (1, 3)], [(0, 3), (1, 2)]]
[[(0, 1), (2, 3), (4,)], [(0, 1), (2, 4), (3,)], [(0, 1), (2,) , (3, 4)], [(0, 2)
, (1, 3), (4,)], [(0, 2), (1, 4), (3,)], [(0, 2), (1,), (3, 4)] , [(0, 3), (1, 2)
, (4,)], [(0, 3), (1, 4), (2,)], [(0, 3), (1,), (2, 4)], [(0, 4 ), (1, 2), (3,)],
[(0, 4), (1, 3), (2,)], [(0, 4), (1,), (2, 3)], [(0,), (1, 2), (3, 4)], [(0,),
(1, 3), (2, 4)], [(0,), (1, 4), (2, 3)]]
Обратите внимание, что если в списке нечетное количество элементов, один из
пары будут синглтоном.
использованная литература
==========
http://stackoverflow.com/questions/5360220/
как-разделить-список-на-пары-всеми-возможными-способами
"""
если не лст:
выход [кортеж()]
Элиф лен(лст) == 1:
выход [кортеж (lst)]
Элиф лен(лст) == 2:
выход [кортеж (lst)]
еще:
если len(lst) % 2:
для i в (Нет, Истина):
если я не в списке:
лст = список(лст) + [я]
ПАД = я
ломать
еще:
в то время как chr(i) в lst:
я += 1
PAD = хр (i)
lst = список (lst) + [PAD]
еще:
ПАД = Ложь
а = 1ст[0]
для i в диапазоне (1, len (lst)):
пара = (а, лст[я])
для отдыха в all_pairs(lst[1:i] + lst[i+1:]):
rv = [пара] + остальные
если PAD не False:
для i, t в перечислении (rv):
если PAD в t:
rv[i] = (t[0],)
ломать
доходность rv
Я добавляю свой вклад, основанный на замечательных решениях, предоставленных @shang и @tokland. Моя проблема заключалась в том, что в группе из 12 человек я также хотел увидеть все возможные пары, когда размер вашей пары не совпадает с размером группы. Например, для размера входного списка 12 я хочу увидеть все возможные пары с 5 элементами.
Моя проблема заключалась в том, что в группе из 12 человек я также хотел увидеть все возможные пары, когда размер вашей пары не совпадает с размером группы. Например, для размера входного списка 12 я хочу увидеть все возможные пары с 5 элементами.
Этот фрагмент кода и небольшая модификация должны решить эту проблему:
import itertools
def generate_groups (lst, n):
если не лст:
урожай []
еще:
если len(lst) % n == 0:
для группы в (((lst[0],) + xs) для xs в itertools.combinations(lst[1:], n-1)):
для групп в generate_groups([x для x в списке, если x не в группе], n):
выход [группа] + группы
еще:
для группы в (((lst[0],) + xs) для xs в itertools.combinations(lst[1:], n-1)):
group2 = [x вместо x в списке, если x не в группе]
для grp в (((group2[0],) + xs2) для xs2 в itertools.combinations(group2[1:], n-1)):
yield [группа] + [группа]
Таким образом, в этом случае, если я запущу следующий фрагмент кода, я получу следующие результаты. Последний фрагмент кода — это проверка работоспособности, чтобы убедиться, что у меня нет перекрывающихся элементов.
Последний фрагмент кода — это проверка работоспособности, чтобы убедиться, что у меня нет перекрывающихся элементов.
я = 0
для x в generate_groups([1,2,3,4,5,6,7,8,9,10,11,12], 5):
печать (х)
для элемента в x[0]:
если элемент в x[1]:
распечатать('перерыв')
ломать
>>> [(1, 2, 3, 4, 5), (6, 7, 8, 9, 10)] [(1, 2, 3, 4, 5), (6, 7, 8, 9, 11)] [(1, 2, 3, 4, 5), (6, 7, 8, 9, 12)] [(1, 2, 3, 4, 5), (6, 7, 8, 10, 11)] [(1, 2, 3, 4, 5), (6, 7, 8, 10, 12)] [(1, 2, 3, 4, 5), (6, 7, 8, 11, 12)] [(1, 2, 3, 4, 5), (6, 7, 9, 10, 11)] ...
Не самый эффективный или быстрый, но, вероятно, самый простой. Последняя строка — это простой способ дедупликации списка в python. В этом случае на выходе будут такие пары, как (0,1) и (1,0). Не уверен, рассматривали бы вы эти дубликаты или нет.
л = [0, 1, 2, 3, 4, 5]
пары = []
для х в л:
для у в л:
пары.добавлять((х,у))
пары = список (набор (пары))
печать (пары)
Вывод:
[(0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (1, 0), ( 1, 1), (1, 2), (1, 3), (1, 4), (1, 5), (2, 0), (2, 1), (2, 2), (2, 3), (2, 4), (2, 5), (3, 0), (3, 1), (3, 2), (3, 3), (3, 4), (3, 5) , (4, 0), (4, 1), (4, 2), (4, 3), (4, 4), (4, 5), (5, 0), (5, 1), ( 5, 2), (5, 3), (5, 4), (5, 5)]
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как создать все пары внутри групп?
Рассмотрим следующий набор данных.

прозрачный год ввода str3 b bx 2001 азбука 32 2001 НБК 14 2001 г. 23 2001 НБК 14 2002 азбука 11 2002 НБК 21 2002 ВБ 192002 стр. 30 2003 азбука 25 2003 НБК 16 2003 НБК 16 2003 КБС 19 2003 стр. 28 2003 азбука 25 конец
В этом примере год является групповой переменной. Что мы хотим сделать, так это создать набор данных, содержащий все пары переменных b в течение каждого года . Например, для года 2001 нам нужны наблюдения, которые соединяют nbc с abc и cbs . Однако мы не хотим nbc в паре с самим собой. Далее пара nbc с cbs считается дублирующей перестановкой cbs с nbc . Мы хотим чтобы сохранить только одну из каждой повторяющейся перестановки. Надеюсь, данные за 2001 год что-то будут выглядеть вот так,
2001 abc cbs 32 23 2001 абв нбк 32 14 2001 cbs nbc 23 14
Существует страница часто задаваемых вопросов Stata, написанная Ником Коксом.
Наш подход будет заключаться в использовании команды joinby . Для этого нам придется сохраните данные во временный файл и измените имена переменных перед использованием joinby команда.
Вот фрагмент кода, который создаст все возможные пары без дубликатов перестановки.
/* поиск и удаление дубликатов в течение года */ по году b, сортировка: gen i=_n сохранить, если я == 1 брось я временный файл temp1 сохранить `temp1', заменить /* создаем все возможные пары с помощью joinby */ rename b c /* переименовать до объединения */ rename bx cx /* переименовать до соединения */ присоединиться к году, используя `temp1' удалить, если b==c /* удалить, если b и c совпадают */ egen d1=concat(b c) /* создаем пары соединений в порядке 1 */ egen d2=concat(c b) /* создаем пары соединений в порядке 2 */ заменить d1=d2, если b>c /* d1 имеет пары в порядке возрастания */ /* найти и удалить повторяющиеся перестановки в течение года */ по году d1, сортировка: gen i=_n сохранить, если я == 1 /* очистить переменные на дисплее */ падение d2 брось я год заказа b c bx cx список
Запуск приведенного выше кода дает следующий результат.
