
Множества и словари в Python
Содержание
- Ссылки на контесты
- Множества Python
- Создание и изменение множества
- Математические операции
- Проверки
- Сводная таблица по множествам (cheatsheet)
- Неизменяемые множества
- Словари Python
- Создание и изменение словаря
- Примечание о числовых ключах
- Использование DictView: циклы и множественные операции
- Словарь с упорядоченными ключами OrderedDict
- Создание и изменение словаря
- Начинающие (участвовать)
- Основные (участвовать)
- Продвинутые (участвовать)
Множество (set) — встроенная структура данных языка Python, имеющая следующие свойства:
- множество — это коллекция
- Множество содержит элементы
- множество неупорядоченно
- Множество не записывает (не хранит) позиции или порядок добавления его элементов.

- элементы множества уникальны
- Множество не может содержать два одинаковых элемента.
- элементы множества — хешируемые объекты (hashable objects)
- В Python множество
setреализовано с использованием хеш-таблицы. Это приводит к тому, что элементы множества должны быть неизменяемыми объектами. Например, элементом множества может быть строка, число, кортежtuple, но не может быть списокlist, другое множествоset…

Эти свойства множеств часто используются, чтобы проверять вхождение элементов, удаление дубликатов из последовательностей, а также для математических операций пересечения, объединения, разности…
Создание и изменение множества
Запустите в терминале Python в интерпретируемом режиме и проработайте примеры ниже.
Пустое множество создаётся с помощью функции set
>>> A = set() >>> type(A) <class 'set'> >>> len(A) 0 >>> A set()
Обратите внимание, что размер множества множества можно получить с помощью функции len.
Добавим несколько элементов
>>> A.add(1)
>>> A
{1}
>>> A.add(2)
>>> A
{1, 2}
>>> A.add(2)
>>> A
{1, 2}
Заметьте, что повторное добавление не имеет никакого эффекта на множество.
Также, из вывода видно, что литералом множества являются фигурные скобки {}, в которых через запятую указаны элементы. Так, ещё один способ создать непустое множество — воспользоваться литералом
>>> B = {1, 2}
>>> B
{1, 2}
При попытке добавления изменяемого объекта возникнет ошибка
>>> B.add([3,4,5]) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list'
Здесь произошла попытка добавить массив в множество B.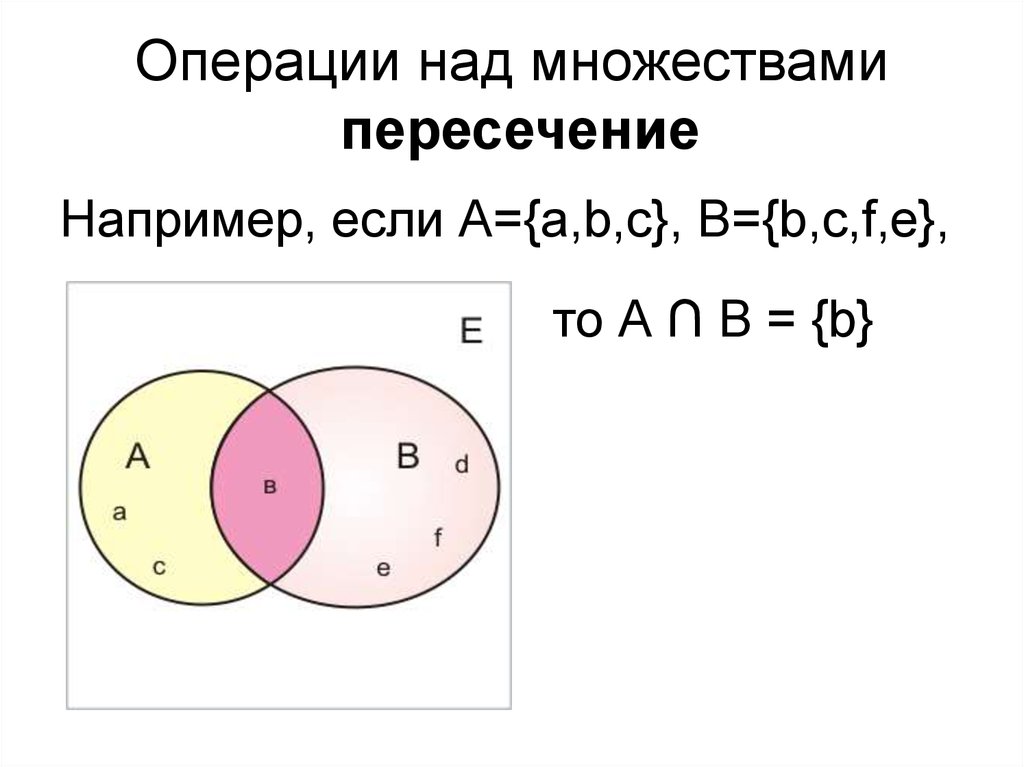
У операции добавления set.add существует обратная — операция удаления set.remove
>>> B
{1, 2}
>>> B.remove(1)
>>> B
{2}
>>> B.remove(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 3
При попытке удаления элемента, не входящего в множество, возникает ошибка KeyError.
Однако, существует метод set.discard, который удаляет элемент из множества, только в том случае, если этот элемент присутствовал в нём.
Математические операции
Множества Python поддерживают привычные математические операции
Проверки
Чтобы проверить вхождение элемента в множество используйте логический оператор in
>>> B = {1, 2}
>>> B
{1, 2}
>>> 3 in B
False
Асимптотика x in set — O(1).
Стоит отметить, что операторinработает и с другими коллекциями.'AA' in 'bbAAcc'или вхождение элемента в массив5 in [1, 2, 5, 6]. Асимптотики в данном случае нужно уточнять в документации.
 Например, можно проверять вхождение подстроки в строку
Например, можно проверять вхождение подстроки в строку Одинаковые множества
>>> A = {1, 2, 3}
>>> B = {1, 2, 3}
>>> A == B
True
>>> B.add(4)
>>> A
{1, 2, 3}
>>> B
{1, 2, 3, 4}
>>> A == B
False
Проверка на нестрогое подмножество set.issubset
>>> A
{1, 2, 3}
>>> B
{1, 2, 3, 4}
>>> A.issubset(B)
True
>>> B.issubset(A)
False
>>> A.issubset(A)
True
Проверка на нестрогое надмножество set.issuperset
>>> A
{1, 2, 3}
>>> B
{1, 2, 3, 4}
>>> A.issuperset(B)
False
>>> B.issuperset(A)
True
>>> B.issuperset(B)
True
Операции получения новых множеств
>>> A = {1, 2, 4}
>>> B = {1, 2, 3}
>>> A. union(B) # union - объединение множеств
{1, 2, 3, 4}
>>> A.intersection(B) # intersection - пересечение
{1, 2}
>>> A.difference(B) # difference - разность множеств
{4}
>>> B.difference(A)
{3}
>>> A.symmetric_difference(B) # symmetric_difference - симметрическая разность
{3, 4}
>>> B.symmetric_difference(A)
{3, 4}
 union(B) # union - объединение множеств
{1, 2, 3, 4}
>>> A.intersection(B) # intersection - пересечение
{1, 2}
>>> A.difference(B) # difference - разность множеств
{4}
>>> B.difference(A)
{3}
>>> A.symmetric_difference(B) # symmetric_difference - симметрическая разность
{3, 4}
>>> B.symmetric_difference(A)
{3, 4}
union(B) # union - объединение множеств
{1, 2, 3, 4}
>>> A.intersection(B) # intersection - пересечение
{1, 2}
>>> A.difference(B) # difference - разность множеств
{4}
>>> B.difference(A)
{3}
>>> A.symmetric_difference(B) # symmetric_difference - симметрическая разность
{3, 4}
>>> B.symmetric_difference(A)
{3, 4}
Сводная таблица по множествам (cheatsheet)
Обозначения
elem — Python-объект
A — множество
set- B, C,..
1. В случае использования в методах A.method_name(B, C,..): B, C,.. являются любыми итерируемыми объектами. Методы допускают такие аргументы, например,
{-1}.union(range(2)) == {-1, 0, 1}вернётTrue.2. В случае использования c операторами, например, A > B или A & B & C & …: B, C,.. являются множествами. Дело в том, что эти операторы определены для операндов типа
set(и такжеfrozenset, о которых речь позже).

| Операция | Синтаксис | Тип результата |
|---|---|---|
| Вхождение элемента | elem in A | bool |
| Равенство | A == B | bool |
| A.issubset(B) или A <= B | bool | |
| Является строгим подмножеством | A < B | bool |
| Является нестрогим надмножеством | A.issuperset(B) или A >= B | bool |
| Явяляется строгим надмножеством | A > B | bool |
| Объединение множеств | A.union(B, C,..) | set |
| A | B | C | … | set | |
| Пересечение множеств | A.intersection(B, C,..) | set |
| A & B & C & … | set | |
| Разность множеств | A. … … | set |
Кроме того, у операций, порождающих новые множества, существует inplace варианты. Для методов это те же названия, только с префиксом _update, а для соответствующих операторов добавляется знак равенства =. Ниже показан вариант для операции разности множеств
>>> A = {1, 2, 3, 4}
>>> B = {2, 4}
>>> A.difference_update(B)
>>> A
{1, 3}
>>> A = {1, 2, 3, 4}
>>> B = {2, 4}
>>> A -= B
>>> A
{1, 3}
Неизменяемые множества
В Python существует неизменяемая версия множества — frozenset.
Этот тип объектов поддерживает все операции обычного множества set, за исключением тех, которые его меняют.
Неизменяемые множества являются хешируемыми объектами, поэтому они могут быть элементами множества set.
Так можно реализовать, например, множество множеств, где множество set состоит из множеств типа frozenset.
Для создания frozenset используется функция
>>> FS = frozenset({1, 2, 3})
>>> FS
frozenset({1, 2, 3})
>>> A = {1, 2, 4}
>>> FS & A
frozenset({1, 2})
>>> A & FS
{1, 2}
В этом примере показано создание frozenset из обычного множества {1, 2, 3}.
Обратите внимание на тип возвращаемого объекта для операции пересечения &.
Возвращаемый объект имеет тип, соответствующий типу первого аргумента.
Такое же поведение будет и с другими операциями над множествами.
Словарь (dictionary) в Python — это ассоциативный массив, реализовать который вы пробовали на прошлом занятии. Ассоциативный массив это структура данных, содержащая пары вида ключ:значение. Ключи в ассоциативном массиве уникальны.
В Python есть встроенный ассоциативный массив — dict.
- ключом может быть только хешируемый объект
- значением может быть любой объект
Создание и изменение словаря
Пустой словарь можно создать двумя способами:
>>> d1 = dict()
>>> d2 = {}
>>> d1
{}
>>> d2
{}
>>> type(d1)
<class 'dict'>
>>> type(d2)
<class 'dict'>
Добавить элемент в словарь можно с помощью квадратных скобок:
>>> domains = {}
>>> domains['ru'] = 'Russia'
>>> domains['com'] = 'commercial'
>>> domains['org'] = 'organizations'
>>> domains
{'ru': 'Russia', 'com': 'commercial', 'org': 'organizations'}
Из этого примера видно, что литералом словаря являются фигурные скобки, в которых через запятую перечислены пары в формате ключ:значение.
Например, словарь domains можно было создать так 
Доступ к элементу осуществляется по ключу:
>>> domains['com'] 'commercial' >>> domains['de'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'de'
Удалить элемент можно с помощью оператора del.
Если ключа в словаре нет, произойдет ошибка KeyError
>>> domains
{'ru': 'Russia', 'com': 'commercial', 'org': 'organizations'}
>>> del domains['de']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'de'
>>> del domains['ru']
>>> domains
{'com': 'commercial', 'org': 'organizations'}
Кроме того, для добавления, получения и удаления элементов есть методы dict.setdefault, dict.get, dict.pop, которые задействует дополнительный аргумент на случай, если ключа в словаре нет
>>> d1 = {}
>>> d1.setdefault('a', 10)
10
>>> d1. setdefault('b', 20)
20
>>> d1
{'a': 10, 'b': 20}
>>> d1.setdefault('c')
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.setdefault('a', 123)
10
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.get('a')
10
>>> d1.get('d') # вернул None
>>> d1.get('d', 'NoKey')
'NoKey'
>>> d1.pop('d')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'd'
>>> d1.pop('d', 255)
255
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.pop('a', 255)
10
>>> d1
{'b': 20, 'c': None}
 setdefault('b', 20)
20
>>> d1
{'a': 10, 'b': 20}
>>> d1.setdefault('c')
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.setdefault('a', 123)
10
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.get('a')
10
>>> d1.get('d') # вернул None
>>> d1.get('d', 'NoKey')
'NoKey'
>>> d1.pop('d')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'd'
>>> d1.pop('d', 255)
255
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.pop('a', 255)
10
>>> d1
{'b': 20, 'c': None}
setdefault('b', 20)
20
>>> d1
{'a': 10, 'b': 20}
>>> d1.setdefault('c')
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.setdefault('a', 123)
10
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.get('a')
10
>>> d1.get('d') # вернул None
>>> d1.get('d', 'NoKey')
'NoKey'
>>> d1.pop('d')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'd'
>>> d1.pop('d', 255)
255
>>> d1
{'a': 10, 'b': 20, 'c': None}
>>> d1.pop('a', 255)
10
>>> d1
{'b': 20, 'c': None}
Примечание о числовых ключах
Ключом может являться и число: int или float.
Однако при работе со словарями в Python помните, что два ключа разные, если для них верно k1 != k2 # True.
Вот пример:
>>> d = {0: 10}
>>> d
{0: 10}
>>> d[0] = 22
>>> d
{0: 22}
>>> d[0.0] = 33
>>> d
{0: 33}
>>> 0. 0 != 0
False
 0 != 0
False
0 != 0
False
Поэтому при возможности избегайте в качестве ключей float-объектов.
Использование DictView: циклы и множественные операции
Если попробовать пройтись в цикле по словарю, то это будет проход по ключам
>>> d = {'a': 10, 'c': 30, 'b': 20}
>>> for k in d:
... print(k)
...
a
c
b
Зачастую необходимо пройтись в цикле по ключам, значениям или парам ключ:значение, содержащиеся в словаре.
Для этого существуют методы dict.keys(), dict.values(), dict.items().
Они возвращают специальные DictView объекты, которые можно использовать в циклах:
>>> d = {'a': 10, 'c': 30, 'b': 20}
>>> for k in d.keys():
... print(k)
...
a
c
b
>>> for v in d.values():
... print(v)
...
10
30
20
>>> for k, v in d.items():
... print(k, v)
...
a 10
c 30
b 20
Объекты DictView, содержащие только ключи, ведут себя подобно множествам. Кроме того, если
Кроме того, если DictView объекты для значений или пар содержат неизменяемые объекты, тогда они тоже ведут себя подобно множествам.
Это означает, что привычные для множеств операции пересечения, вхождения и другие также работают с DictView.
>>> d
{'a': 10, 'c': 30, 'b': 20}
>>> dkeys = d.keys()
>>> 'abc' in dkeys
False
>>> 'c' in dkeys
True
>>> {'a', 'b', 'c'} == dkeys
True
>>> dkeys & {'b', 'c', 'd'}
{'b', 'c'}
Словарь с упорядоченными ключами OrderedDict
Это может понадобится для отправки задач на ejudge.
Если внимательно просмотреть примеры на циклы выше, то видно, что порядок итерирования в циклах совпадает с порядком добавления элементов в словарь.
Однако, такое поведение у стандартных словарей dict гарантируется, начиная с версии 3.7 (лабораторные примеры были сделаны из-под версии 3.7.4).
Узнать свою версию Python можно, например, из терминала python3 —version или зайдя в интерпретируемый режим (версия будет написана сверху).
Если для вашей программы важно упорядочивание элементов, но вы не знаете, какой версии интерпретатор будет исполнять ваш скрипт, то вам нужно воспользоваться упорядоченной версией словарей OrderedDict.
Она находится в стандартной библиотеке collections.
Упорядоченный словарь поддерживает все операции, что и обычный словарь.
>>> import collections
>>> od = collections.OrderedDict()
>>> od
OrderedDict()
>>> od['a'] = 10
>>> od['c'] = 30
>>> od['b'] = 20
>>> od
OrderedDict([('a', 10), ('c', 30), ('b', 20)])
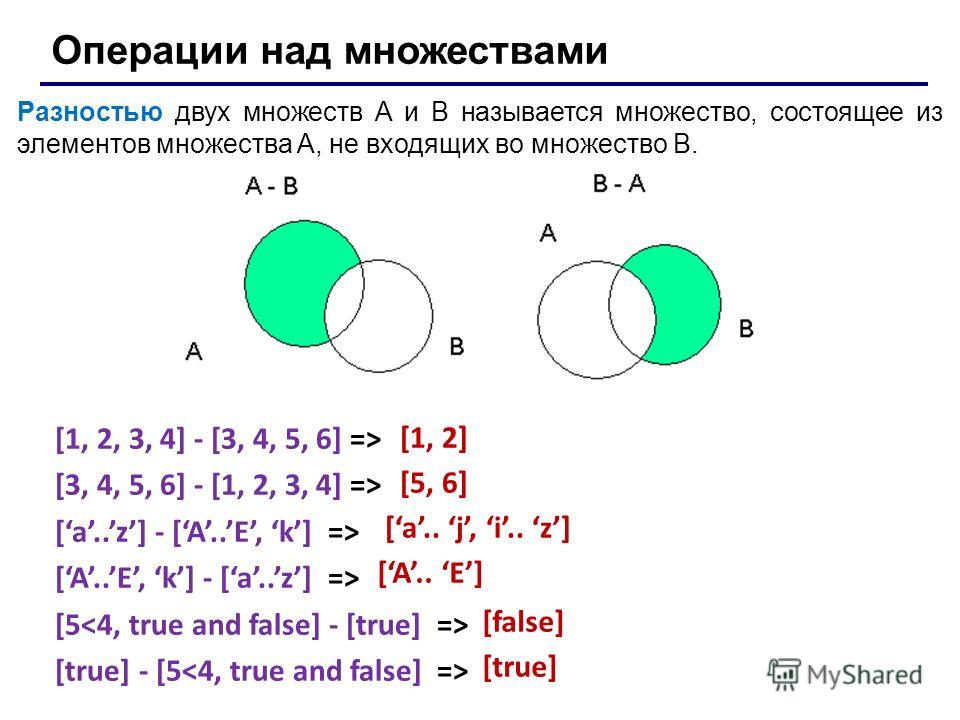
Python 3: Операции над множествами: вычитание, пересечение, объединение, сравнение
Смотреть материал на видео
На этом занятии мы рассмотрим несколько полезных функций для работы с множествами, а также вопросы, связанные с операциями над множествами и их сравнения.
Для определения длины (числа элементов) множества используется функция len:
a={"abc", (1,2), 5, 4, True}
len(a)Для проверки наличия значения в множестве используется оператор in:
"abc" in a
Он возвращает True, если значение
имеется и False в противном
случае. Или можно проверить на непринадлежность какого-либо значения:
Или можно проверить на непринадлежность какого-либо значения:
7 not in a
Пересечение множеств
Для любых двух множеств:
setA = {1,2,3,4}
setB = {3,4,5,6,7}можно вычислять их пересечение, то есть, находить значения, входящие в состав обоих множеств. Это делается с помощью оператора &:
setA & setB
Здесь создается новое множество с соответствующими значениями. Сами исходные множества остаются без изменений. Мы можем сохранить ссылку на этот результат вот так:
res = setA & setB
Или, сделать так:
setA = setA & setB
это же будет эквивалентно такой записи:
setA &= setB
Если пересекающихся значений нет, например, вот с таким множеством:
setC = {9, 10, 11}то результатом:
setA & setC
будет пустое
множество.
Этот оператор можно заменить эквивалентным методом intersection:
setA = {1,2,3,4}
setB = {3,4,5,6,7}
setA.intersection(setB)который возвращает результат пересечения этих множеств. Сами же множества остаются без изменений. То есть, его обычно используют так:
res = setA.intersection(setB)
Но если мы хотим выполнить эквивалент вот такой операции:
setA &= setB
то для этого следует использовать метод intersection_update:
setA.intersection_update(setB)
Теперь множество seta хранит результат пересечения.
Объединение множеств
Противоположная операция – объединение двух множеств выполняется с помощью оператора |:
setA = {1,2,3,4}
setB = {3,4,5,6,7}
setA | setBна выходе получим новое множество неповторяющихся значений из обоих множеств:
{1, 2, 3, 4, 5, 6, 7}
Эту же операцию можно записать и так:
setA |= setB
тогда на
результат объединения будет ссылаться переменная setA. Или же можно
воспользоваться методом
Или же можно
воспользоваться методом
setA.union(setB)
который возвращает множество из объединенных значений.
Вычитания множеств
Следующая операция – это вычитание множеств. Например, для множеств:
setA = {1,2,3,4}
setB = {3,4,5,6,7}операция
setA - setB
возвратит новое множество, в котором из множества setA будут удалены все значения, существующие в множестве setB:
{1, 2}
Или, наоборот, из множества setB вычесть множество setA:
setB – setA
получим значения
{5, 6, 7}
из которых исключены величины, входящие в множество setA.
Также можно выполнять эквивалентные операции:
setA -= setB # setA = setA - setB setB -= setA # setB = setB - setA
В этом случае
переменные setA и setB будут ссылаться
на соответствующие результаты вычитаний. setB
setB
то есть, множество, составленное из значений, не входящих одновременно в оба множества. В данном случае получим результат:
{1, 2, 5, 6, 7}
Сравнение множеств
Множества можно сравнивать между собой:
На равенство
setA == setB
В данном случае получим False, т.к. множества не равны. Они считаются равными, если все элементы, входящие в одно множество, также принадлежат другому множеству и мощности этих множеств равны (то есть они содержат одинаковое число элементов). Например, такие:
setA = {7,6,5,4,3}; setB = {3,4,5,6,7}тогда оператор
setA == setB
вернет значение True. Как видите, порядок элементов в множествах не играет роли при их сравнении.
На неравенство
Противоположное сравнение на неравенство записывается так:
setA != setB
и возвращает True, если множества
не равны и False, если равны.
На больше, меньше
В Python операторы <, > применительно к множествам, по сути, определяют вхождение или не вхождение одного множества в другое. Математически, одно множество принадлежит (входит) другому, если все элементы первого множества принадлежат элементам второго множества:
Например, возьмем множества
setA = {7,6,5,4,3}; setB = {3,4,5}тогда операция
setB < setA
вернет True, а операция
setA < setB
значение False. Но, если хотя бы один элемент множества setB не будет принадлежать множеству setA:
setB.add(22)
то обе операции вернут False.
Для равных множеств
setA = {7,6,5,4,3}; setB = {3,4,5,6,7}обе операции также вернут False. Но вот такие операторы:
setA <= setB setA >= setB
вернут True.
Это основные операции работы над множествами. В качестве самостоятельного задания напишите программу, которая из введенного с клавиатуры текста определяет число уникальных слов. Для простоты можно полагать, что слова разделяются пробелом или символом переноса строки ‘\n’.
Видео по теме
#1. Первое знакомство с Python Установка на компьютер
#2. Варианты исполнения команд. Переходим в PyCharm
#3. Переменные, оператор присваивания, функции type и id
#4. Числовые типы, арифметические операции
#5. Математические функции и работа с модулем math
#6. Функции print() и input(). Преобразование строк в числа int() и float()
#7. Логический тип bool. Операторы сравнения и операторы and, or, not
#8. Введение в строки. Базовые операции над строками
Базовые операции над строками
#9. Знакомство с индексами и срезами строк
#10. Основные методы строк
#11. Спецсимволы, экранирование символов, row-строки
#12. Форматирование строк: метод format и F-строки
#13. Списки — операторы и функции работы с ними
#14. Срезы списков и сравнение списков
#15. Основные методы списков
#16. Вложенные списки, многомерные списки
#17. Условный оператор if. Конструкция if-else
#18. Вложенные условия и множественный выбор. Конструкция if-elif-else
#19. Тернарный условный оператор. Вложенное тернарное условие
#20. Оператор цикла while
#21. Операторы циклов break, continue и else
#22. Оператор цикла for. Функция range()
Функция range()
#23. Примеры работы оператора цикла for. Функция enumerate()
#24. Итератор и итерируемые объекты. Функции iter() и next()
#25. Вложенные циклы. Примеры задач с вложенными циклами
#26. Треугольник Паскаля как пример работы вложенных циклов
#27. Генераторы списков (List comprehensions)
#28. Вложенные генераторы списков
#29. Введение в словари (dict). Базовые операции над словарями
#30. Методы словаря, перебор элементов словаря в цикле
#31. Кортежи (tuple) и их методы
#32. Множества (set) и их методы
#33. Операции над множествами, сравнение множеств
#34. Генераторы множеств и генераторы словарей
#35. Функции: первое знакомство, определение def и их вызов
#36.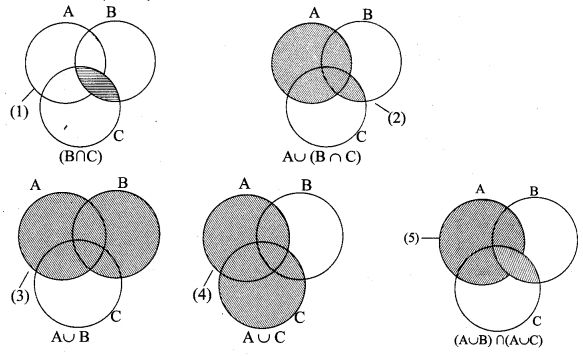 Оператор return в функциях. Функциональное программирование
Оператор return в функциях. Функциональное программирование
#37. Алгоритм Евклида для нахождения НОД
#38. Именованные аргументы. Фактические и формальные параметры
#39. Функции с произвольным числом параметров *args и **kwargs
#40. Операторы * и ** для упаковки и распаковки коллекций
#41. Рекурсивные функции
#42. Анонимные (lambda) функции
#43. Области видимости переменных. Ключевые слова global и nonlocal
#44. Замыкания в Python
#45. Введение в декораторы функций
#46. Декораторы с параметрами. Сохранение свойств декорируемых функций
#47. Импорт стандартных модулей. Команды import и from
#48. Импорт собственных модулей
#49. Установка сторонних модулей (pip install).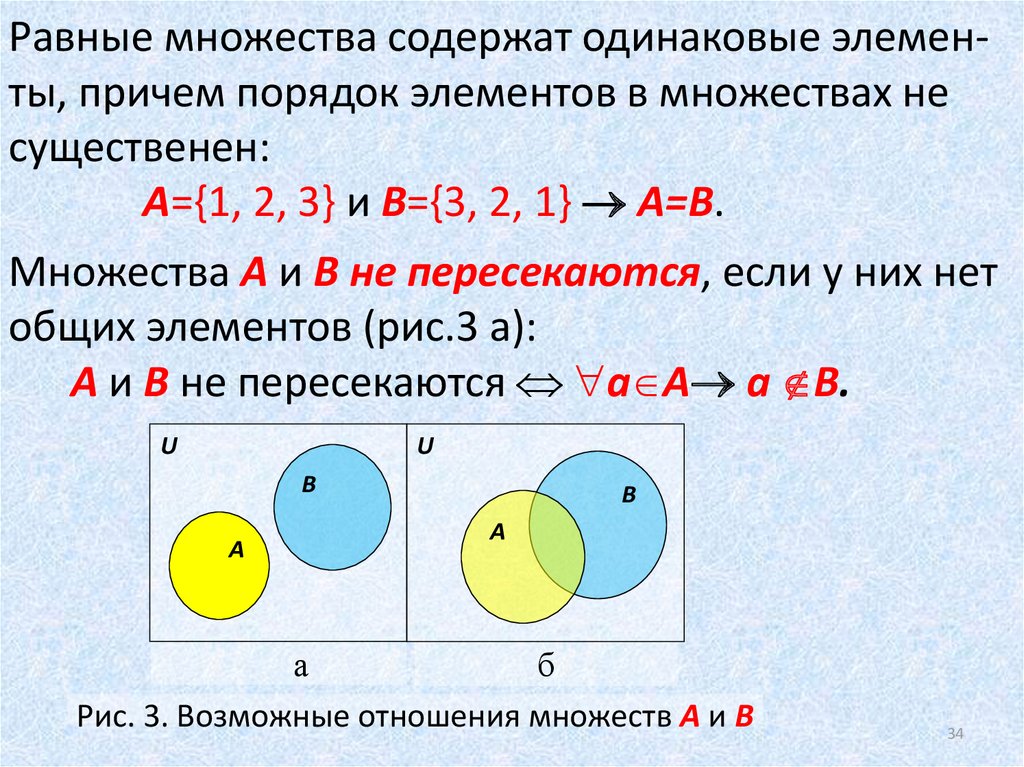 Пакетная установка
Пакетная установка
#50. Пакеты (package) в Python. Вложенные пакеты
#51. Функция open. Чтение данных из файла
#52. Исключение FileNotFoundError и менеджер контекста (with) для файлов
#53. Запись данных в файл в текстовом и бинарном режимах
#54. Выражения генераторы
#55. Функция-генератор. Оператор yield
#56. Функция map. Примеры ее использования
#57. Функция filter для отбора значений итерируемых объектов
#58. Функция zip. Примеры использования
#59. Сортировка с помощью метода sort и функции sorted
#60. Аргумент key для сортировки коллекций по ключу
#61. Функции isinstance и type для проверки типов данных
#62. Функции all и any. Примеры их использования
#63. Расширенное представление чисел. Системы счисления
Расширенное представление чисел. Системы счисления
#64. Битовые операции И, ИЛИ, НЕ, XOR. Сдвиговые операторы
#65. Модуль random стандартной библиотеки
#66. Аннотация базовыми типами
#67. Аннотации типов коллекций
#68. Аннотации типов на уровне классов
#69. Конструкция match/case. Первое знакомство
#70. Конструкция match/case с кортежами и списками
#71. Конструкция match/case со словарями и множествами
#72. Конструкция match/case. Примеры и особенности использования
collections.abc — Абстрактные базовые классы для контейнеров — Документация Python 3.11.3
Новое в версии 3.3: Ранее этот модуль был частью модуля collections .
Исходный код: Lib/_collections_abc.py
Этот модуль предоставляет абстрактные базовые классы,
может использоваться для проверки того, предоставляет ли класс определенный интерфейс; для
например, является ли он хэшируемым или является отображением.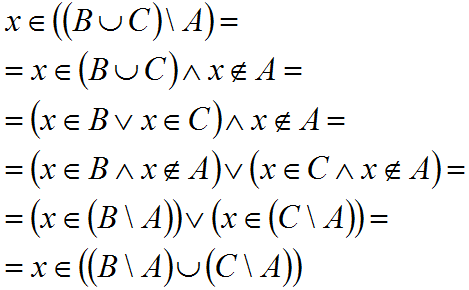
issubclass() или isinstance() тест для интерфейса работает в одном
из трех способов.
1) Вновь написанный класс может наследоваться непосредственно от одного из абстрактные базовые классы. Класс должен предоставить требуемый реферат методы. Остальные методы примеси происходят от наследования и могут быть переопределяется при желании. Другие методы могут быть добавлены по мере необходимости:
класс C(Последовательность): # Прямое наследование
def __init__(self): ... # Дополнительный метод, не требуемый ABC
def __getitem__(self, index): ... # Обязательный абстрактный метод
def __len__(self): ... # Обязательный абстрактный метод
def count(self, value): ... # Опционально переопределить метод примеси
>>> issubclass(C, Последовательность) Истинный >>> isinstance(C(), Последовательность) Истинный
2) Существующие классы и встроенные классы могут быть зарегистрированы как «виртуальные
подклассы» азбуки. Эти классы должны определять полный API
включая все абстрактные методы и все методы примесей.
Это позволяет пользователям полагаться на тесты
Эти классы должны определять полный API
включая все абстрактные методы и все методы примесей.
Это позволяет пользователям полагаться на тесты issubclass() или isinstance() .
чтобы определить, поддерживается ли полный интерфейс. Исключение
это правило для методов, которые автоматически выводятся из остальных
API:
класс D: # Без наследования
def __init__(self): ... # Дополнительный метод, не требуемый ABC
def __getitem__(self, index): ... # Абстрактный метод
def __len__(self): ... # Абстрактный метод
def count(self, value): ... # Метод Mixin
def index(self, value): ... # Метод Mixin
Sequence.register(D) # Регистрация вместо наследования
>>> issubclass(D, последовательность) Истинный >>> isinstance(D(), Последовательность) Истинный
В этом примере класс D не нужно определять __содержит__ , __iter__ и __reversed__ , потому что
в операторе, итерация
логика, и функция reversed() автоматически возвращается к
используя __getitem__ и __len__ .
3) Некоторые простые интерфейсы легко узнаваемы по наличию
требуемые методы (если эти методы не были установлены на Нет ):
класс Е:
деф __iter__(я): ...
деф __следующий__(следующий): ...
>>> issubclass(E, Iterable) Истинный >>> isinstance(E(), Iterable) Истинный
Сложные интерфейсы не поддерживают этот последний метод, поскольку
интерфейс — это больше, чем просто наличие имен методов. Интерфейсы
указать семантику и отношения между методами, которые не могут быть
выводится исключительно из наличия конкретных имен методов. Для
например, зная, что класс предоставляет __getitem__ , __len__ и __iter__ недостаточно, чтобы отличить последовательность от Отображение .
Новое в версии 3.9: эти абстрактные классы теперь поддерживают [] . См. общий тип псевдонима
и PEP 585 .
Коллекции Абстрактные базовые классы
Модуль коллекций предлагает следующие ABC:
Азбука | Наследуется от | Абстрактные методы | Методы смешивания |
|---|---|---|---|
| | ||
| | ||
| | ||
| | | |
| | | |
| | | |
| | ||
| | ||
| | | |
| | | |
| | | Унаследовано |
| | | Унаследованный |
| | | |
| | | Унаследовано |
| | | |
| | | Унаследованные |
| | | |
| | | |
| | | |
| | | |
| | ||
| | | |
| | ||
| | | |
| | | |
Сноски
- 1(1,2,3,4,5,6,7,8,9,10,11,12,13,14)
Эти ABC переопределяют объект
.для поддержки тестирование интерфейса путем проверки наличия необходимых методов и не были установлены на __subclasshook__() None. Это работает только для простых интерфейсы. Более сложные интерфейсы требуют регистрации или прямой подклассы.- 2
Проверка
isinstance(obj, Iterable)обнаруживает классы, которые зарегистрированы какIterableили имеют__iter__()метод, но он не обнаруживает классы, которые повторяются с__getitem__()метод. Единственный надежный способ определить является ли объект итерируемым, это вызватьiter(obj).
 __subclasshook__()
__subclasshook__() Коллекции Абстрактные базовые классы – подробные описания
- класс collections.abc.Container
ABC для классов, предоставляющих метод
__contains__().
- класс collections.abc.Hashable
ABC для классов, предоставляющих метод
__hash__().

- класс collections.abc.Sized
ABC для классов, предоставляющих метод
__len__().
- класс collections.abc.Callable
ABC для классов, предоставляющих метод
__call__().
- класс collections.abc.Iterable
ABC для классов, предоставляющих метод
__iter__().Проверка
isinstance(obj, Iterable)обнаруживает зарегистрированные классы какIterableили которые имеют метод__iter__(), но он не обнаруживать классы, которые повторяются с помощью__getitem__() 9Метод 0004. Единственный надежный способ определить, является ли объект итерируемым это вызватьiter(obj).
- класс collections.abc.Collection
ABC для размерных классов итерируемых контейнеров.
Новое в версии 3.
6.
 6.
6.- класс collections.abc.Iterator
ABC для классов, предоставляющих
__iter__()и__next__()метода. См. также определение итератор.
- класс collections.abc.Reversible
ABC для итерируемых классов, которые также предоставляют
__reversed__()метод.Новое в версии 3.6.
- класс collections.abc.Generator
ABC для классов генераторов, реализующих протокол, определенный в PEP 342 , который расширяет итераторы с помощью
send(),бросить()изакрыть()методы. См. также определение генератора.Новое в версии 3.5.
- класс collections.abc.Sequence
- класс collections.abc.MutableSequence
- класс collections.abc.ByteString
ABC для доступных только для чтения и изменяемых последовательностей.
Замечание по внедрению: некоторые методы примесей, такие как
__iter__(),__reversed__()иindex(), сделать повторные вызовы базового метода__getitem__(). Следовательно, если__getitem__()реализовано с константой скорость доступа, методы примесей будут иметь линейную производительность; однако, если базовый метод является линейным (как это было бы с связанный список), миксины будут иметь квадратичную производительность и будут скорее всего нужно перепрошивать.Изменено в версии 3.5: В метод index() добавлена поддержка stop и start аргументы.

- класс collections.abc.Set
- класс collections.abc.MutableSet
ABC для доступных только для чтения и изменяемых наборов.
- класс collections.abc.Mapping
- класс collections.abc.MutableMapping
ABC для доступных только для чтения и изменяемых сопоставлений.

- класс collections.abc.MappingView
- класс collections.abc.ItemsView
- класс collections.abc.KeysView
- класс collections.abc.ValuesView
ABC для представления отображения, элементов, ключей и значений.
- класс collections.abc.Awaitable
ABC для ожидаемых объектов, которые можно использовать в
awaitвыражения. Пользовательские реализации должны предоставлять__await__()метод.Объекты Coroutine и экземпляры
CoroutineABC — все экземпляры этой ABC.Примечание
В CPython сопрограммы на основе генератора (генераторы, украшенные
типов.coroutine()) являются awaitables , хотя у них нет метода__await__(). Использованиеisinstance(gencoro, Awaitable)для них вернетFalse. Используйтеinspect.для их обнаружения. isawaitable() Новое в версии 3.5.
 isawaitable()
isawaitable() - класс collections.abc.Coroutine
ABC для классов, совместимых с сопрограммами. Они реализуют следующие методы, определенные в Coroutine Objects:
отправить(),бросить()изакрыть(). Пользовательские реализации также должны реализовывать__ожидание__(). Всеэкземпляра Coroutineтакже являются экземплярамиОжидается. См. также определение сопрограммы.Примечание
В CPython сопрограммы на основе генератора (генераторы, украшенные
типов.coroutine()) являются awaitables , хотя у них нет метода__await__(). Использованиеisinstance(gencoro, Coroutine)для них вернетFalse. Используйтеinspect.isawaitable()для их обнаружения.Новое в версии 3.5.
- класс collections. abc.AsyncIterable
ABC для классов, обеспечивающих
__aiter__метод. См. также определение асинхронного итерируемого.Новое в версии 3.5.
 abc.AsyncIterable
abc.AsyncIterable- класс collections.abc.AsyncIterator
ABC для классов, которые предоставляют
__aiter__и__anext__методы. См. также определение асинхронного итератора.Новое в версии 3.5.
- класс collections.abc.AsyncGenerator
ABC для классов асинхронных генераторов, реализующих протокол определено в PEP 525 и PEP 492 .
Новое в версии 3.6.
Примеры и рецепты
ABC позволяют нам запрашивать классы или экземпляры, предоставляют ли они конкретная функциональность, например:
Размер = Нет
если isinstance (myvar, collections.abc.Sized):
размер = длина (мойвар)
Некоторые из ABC также полезны в качестве примесей, упрощающих разработку
классы, поддерживающие API-интерфейсы контейнеров. Например, чтобы написать класс, поддерживающий
полный
Например, чтобы написать класс, поддерживающий
полный Установите API, необходимо только предоставить три базовых
абстрактные методы: __contains__() , __iter__() и __len__() .
ABC предоставляет оставшиеся методы, такие как __and__() и isdisjoint() :
класс ListBasedSet (коллекции.abc.Set):
''' Реализация альтернативного набора, в которой предпочтение отдается пространству, а не скорости
и не требует, чтобы элементы набора были хешируемыми. '''
def __init__(самостоятельно, повторяемый):
self.elements = lst = []
для значения в итерации:
если значение не в списке:
lst.append(значение)
защита __iter__(я):
вернуть его (self.elements)
def __contains__(я, значение):
возвращаемое значение в self.elements
защита __len__(я):
вернуть len(self.elements)
s1 = ListBasedSet('abcdef')
s2 = ListBasedSet('defghi')
перекрытие = s1 & s2 # Метод __and__() поддерживается автоматически
Примечания по использованию Set и MutableSet в качестве миксина:
Поскольку некоторые операции с наборами создают новые наборы, необходимо использовать методы миксина по умолчанию.
способ создания новых экземпляров из итерируемого. Конструктор класса
предполагается иметь подпись в форме ClassName(iterable). Это предположение учитывается во внутреннем методе класса, называемом_from_iterable(), который вызываетcls(iterable)для создания нового набора. ЕслиMixin Setиспользуется в классе с другим подпись конструктора, вам нужно будет переопределить_from_iterable()с помощью метода класса или обычного метода, который может создавать новые экземпляры из повторяемый аргумент.Для переопределения сравнений (предположительно для скорости, т.к. семантика исправлена), переопределить
__le__()и__ge__(), тогда другие операции автоматически последуют их примеру.Setmixin предоставляет метод_hash()для вычисления значения хеш-функции. за набор; однако__hash__()не определен, так как не все наборы являются хешируемыми или неизменяемыми. Чтобы добавить возможность хеширования набора с помощью миксинов,
наследовать от Set()иHashable(), затем определить__хэш__ = Set._хэш.
 способ создания новых экземпляров из итерируемого. Конструктор класса
предполагается иметь подпись в форме
способ создания новых экземпляров из итерируемого. Конструктор класса
предполагается иметь подпись в форме 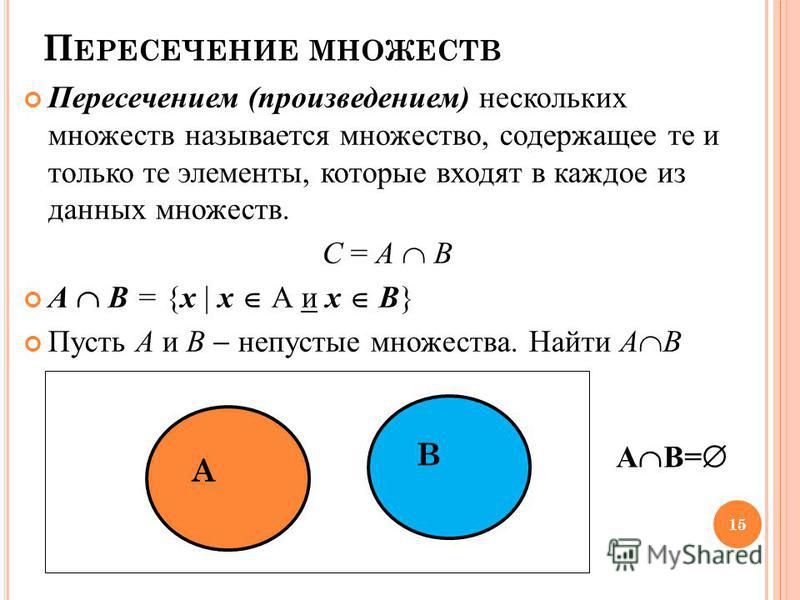 Чтобы добавить возможность хеширования набора с помощью миксинов,
наследовать от
Чтобы добавить возможность хеширования набора с помощью миксинов,
наследовать от См. также
Рецепт OrderedSet для пример построен на
MutableSet.Дополнительные сведения об ABC см. в модуле
abcи PEP 3119 .
ABC Set - Подарочный набор по уходу за кожей для очищения кожи, против старения, против морщин – My Organic Zone
Перейти к информации о продукте1 / из 1
Простая процедура
Подробнее о нашем стартовом наборе
Как
Начните эту базовую процедуру с нашего натурального очищающего средства для лица. Будь то в душе или над раковиной, используйте теплую воду и создайте легкую пену. Аккуратно помассируйте лицо, чтобы удалить грязь и бактерии. Удалите теплой водой и высушите.
Будь то в душе или над раковиной, используйте теплую воду и создайте легкую пену. Аккуратно помассируйте лицо, чтобы удалить грязь и бактерии. Удалите теплой водой и высушите.
После высыхания нанесите несколько капель нашей сыворотки с гиалуроновой кислотой на лицо (и, если хотите, на шею), чтобы глубоко увлажнить все слои кожи. Оставьте на несколько минут, пока не высохнет.
Наконец, добавьте этот последний защитный слой успокаивающего увлажнения с помощью нашего крема с ретинолом для длительного комфорта.
Подробности
Типы кожи: Нормальная + Жирная + Комбинированная + Сухая + Чувствительная
Проблемы ухода за кожей: Сухая кожа, стареющая кожа, морщины и тонкие линии, жирная кожа, закупоренные поры
Ингредиенты
Очищающее средство для лица: Масло апельсиновой корки, сок листьев алоэ вера, вода, экстракт цветов ромашки, экстракт сока листьев оливы, масло ши, кокоил изетионат натрия, метилолеилтаурат натрия, лаурилбетаин, гуаргидроксипропилтримония хлорид, глюконолактон, бензоат натрия
Ретиноловый крем: Ретинол, вода, алоэ вера, гиалуронат натрия, подсолнечное масло, экстракт зеленого чая, масло ши, токоферол, африканское пальмовое масло, пентиленгликоль, масло жожоба, пантенол, фосфолипиды, прополис, полисорбат 20, фосфат калия, глицерилстеарат, феноксиэтанол. , Этилгексилглицерин, ксантановая камедь, цетиловый спирт, стеариновая кислота, глицерин
, Этилгексилглицерин, ксантановая камедь, цетиловый спирт, стеариновая кислота, глицерин
Сыворотка с гиалуроновой кислотой: Гиалуроновая кислота, витамин С, витамин Е, деионизированная вода, гамамелис, алоэ вера, кошерный растительный глицерин, масло жожоба, зеленый чай дикой природы, этилгексилглицерин, ретинол, эфирное масло герани, целлюлоза
Переработка 101
1. Промыть + высушить: промыть пустые контейнеры, чтобы удалить остатки продукта, и дать им высохнуть
2. Удалите этикетки: все наши банки, бутылки, тюбики и внешняя упаковка могут быть переработаны с вашим обычным перерабатываемым содержимым. Не забудьте заранее разделить бумагу и этикетки, чтобы упростить процесс переработки. Помните, что правила утилизации могут различаться в зависимости от того, где вы живете, поэтому не забудьте освежить в памяти местные правила!
Давайте посмотрим поближе
Почему мы объединили эти продукты вместе
очищающее средство для лица
Первый шаг в вашем простом уходе за кожей.