
Сообщество Экспонента
- вопрос
- 22.09.2022
Математика и статистика, Системы управления, Изображения и видео, Робототехника и беспилотники, Глубокое и машинное обучение(ИИ), Другое
Коллеги, добрый день. Необходимо использовать corrcoef, а массивы разной длины. Как сделать кол-во элементов одинаково?
Коллеги, добрый день. Необходимо использовать corrcoef, а массивы разной длины. Как сделать кол-во элементов одинаково?
7 Ответов
- вопрос
- 20.09.2022
Другое, Встраиваемые системы, Цифровая обработка сигналов, Системы управления
Здравствуйте!Возникла необходимость менять некоторое строчки в сишном файле автоматически, используя матлабовский скрипт. Прошерстил весь интернет, в т.ч. англоязычные форумы, не смог ничего найт…
Здравствуйте!Возникла необходимость менять некоторое строчки в сишном файле автоматически, используя матлабовский скрипт.
- MATLAB
20.09.2022
- Публикация
- 15.09.2022
Системы управления, Другое
Видел видос на канале экспоненты по созданию топливной системы. Вопрос заключается в наличии более полного описания готового примера или соответсвующее документации. Я новичок в симулинке и ещё многого не знаю. Адекватных и раскрытых пособий по созданию гидрав…
Моделирование гидравлических систем в simulink
- Публикация
- 10.09.2022
Системы управления, Электропривод и силовая электроника, Другое
Планирую написать книгу про модельно-ориентированное программирование с автоматическим генерированием кода применительно к разработке разнообразных микропроцессорных систем управления электроприводов. В этой книге в научно-практическо-методической форме я план…
Планирую написать книгу про модельно-ориентированное программирование с автоматическим генерированием кода применительно к разработке разнообразных микропроцессорных систем управления электроприводов.
- Публикация
- 24.08.2022
Цифровая обработка сигналов, Системы связи, Математика и статистика
&…
Здесь собрана литература по комбинированным методам множественного доступа, в которых используется разделение пользователей в нескольких ресурсных пространствах.
- вопрос
- 23.08.2022
Математика и статистика, Радиолокация, Цифровая обработка сигналов
Есть записанный сигнал с датчика (синус с шумом). Как определить соотношение сигнал/шум?
Есть записанный сигнал с датчика (синус с шумом). Как определить соотношение сигнал/шум?
4 Ответа
- ЦОС
- цифровая обработка сигналов
23.08.2022
- Публикация
- 23.08.2022
Цифровая обработка сигналов, Системы связи, Математика и статистика
&. ..
..
Здесь соборана литература по методам множественного доступа с поляризационным разделением и разделением по орбитальном угловому моменту.
- Публикация
- 16.08.2022
Цифровая обработка сигналов, Системы связи, Математика и статистика
Здесь собрана литература по методам множественного доступа с пространственным разделением.
- вопрос
- 22.07.2022
Изображения и видео, Цифровая обработка сигналов, Математика и статистика, Биология, Встраиваемые системы, Глубокое и машинное обучение(ИИ), Автоматизация испытаний, ПЛИС и СнК, Системы управления, Другое
Здравствуйте. Мне нужно обработать большое количество файлов с похожими названиями, каждый блок файлов относится к отдельному объекту, например: file_1_1.txt file_1_2.txt file_1_3.txt file_1_4.txt fil…
Здравствуйте. Мне нужно обработать большое количество файлов с похожими названиями, каждый блок файлов относится к отдельному объекту, например:
file_1_1.txt
file_1_2.txt
file_1_3.txt
file_1_4.txt
fil…
Мне нужно обработать большое количество файлов с похожими названиями, каждый блок файлов относится к отдельному объекту, например:
file_1_1.txt
file_1_2.txt
file_1_3.txt
file_1_4.txt
fil…
2 Ответа
- чтение
22.07.2022
- вопрос
- 17.07.2022
Математика и статистика, Цифровая обработка сигналов
Уважаемые коллеги, добрый вечер! В общем, возникла проблема следующего характера. Имеется сигнал, достаточно большой объем точек, длительность порядка 35-40 секунд. Он представлят собой последовательн…
Уважаемые коллеги, добрый вечер! В общем, возникла проблема следующего характера. Имеется сигнал, достаточно большой объем точек, длительность порядка 35-40 секунд. Он представлят собой последовательн…
- MATLAB
- Signal Processing
17.07.2022
Формулы по статистике — n1.doc
приобрести
Формулы по статистике
скачать (97. 8 kb.)
8 kb.)
Доступные файлы (1):
| n1.doc | 357kb. | 21.04.2010 21:05 | скачать |
- Смотрите также:
- Справочник — Все формулы по математике за 11 класс (Справочник)
- Шпаргалка — Тригонометрия (Шпаргалка)
- Формулы по статистике с описанием (Документ)
- 90 тригонометрических формул (Документ)
- Формулы по статистике (Документ)
- Шпоры — Математика 10-11 класс (Шпаргалка)
- Лекции по статистике (Лекция)
- Основные формулы по математике (Документ)
- Шпаргалка — Основные формулы (Шпаргалка)
- Все формулы по математике и геометрии (Документ)
- Справочник — Все формулы по алгебре и геометрии в школе (Справочник)
- Формулы по Математике, Геометрии, Тригонометрии для подготовки к ЕГЭ и ГИА (Документ)
n1.doc
СОДЕРЖАНИЕ
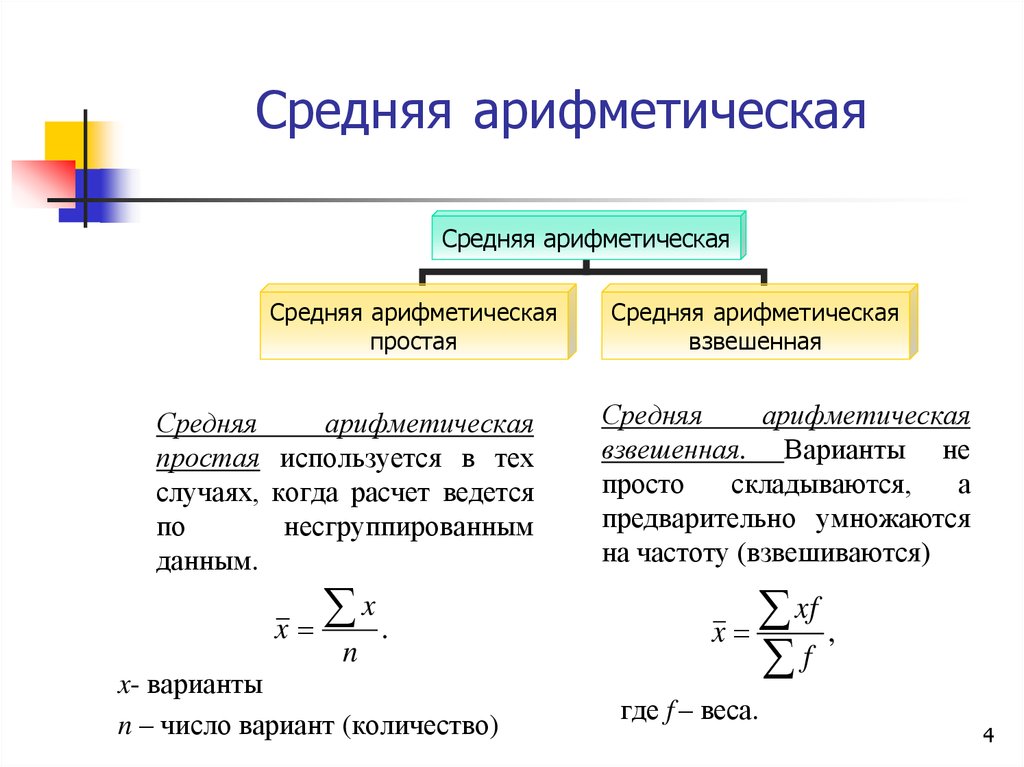
Средние величины: 3
Простая формула: 3
Средняя гармоническая: 3
Средняя арифметическая 3
Средняя геометрическая 3
Среднее квадратическое 3
Средняя арифметическая взвешенная: 3
Средняя гармоническая взвешенная: 3
Показатели вариации 3
Среднее линейное отклонение: 3
Простая: 3
взвешенная: 3
Дисперсия 3
Среднее квадратическое отклонение: 3
Коэф. осцилляции 3
осцилляции 3
Относительное линейное отклонение. 3
Коэф. вариации. 4
Дисперсия: 4
Способ моментов: 4
Межгрупповая дисперсия: 4
Внутригрупповая дисперсия: 4
Коэффициент детерминации: 4
Эмпирическое кореляц. отн-е. 4
Ряды динамики 4
Моментные РД – вычисление средней. 4
Абсолютный прирост 4
Темп роста базовый. 4
Темп роста цепной: 4
Темп прироста цепной: 5
Темп прироста базовый: 5
Абсолютное значение 1% прироста. 5
Ср. абсолютный прирост: 5
Ср. темп роста. 5
Ср. темп прироста. 5
Ср. значение 1% прироста. 5
Ур-е прямой: 5
Ошибка аппроксимации: 5
Индексы. 5
P — цен 5
Z – себест-ть ед. прод., т. е. затраты на пр-во ед. прод. 5
W – уровень производит. труда (ср. выработка на 1 раб) 5
t – трудоёмкость 5
Индекс физич. объёма. 6
Общий индекс товарооборота: 6
Индекс товарооборота: 6
Общий индекс физического объёма товарооборота: 6
Общая формула для вычисления всех Интегральных показателей: 6
Индекс Цен по Пааше. 6
6
Индекс Цен По Ласпейресу: 6
Индекс Цен По Фишеру: 6
Индекс переменного состава: 6
Индекс постоянного состава: 7
Индекс структурных сдвигов: 7
Выборочное наблюдение. 7
Предельная ошибка выборки: 7
Средний размер ошибки признака: 7
Средняя ошибка доли признака: 7
Средний размер ошибки признака: 7
Средняя ошибки доли признака: 7
Взаимосвязи м/у явлениями: 8
Лин. коэф корелляции: 8
Коэф. эластичности 8
Ошибка апроксимации: 8
Расчёт дисперсии: 8
C видов экономической деят-ти. 8
Коэф. роста выпуска товаров: 8
Темп роста выпуска: 8
Темп прироста выпуска товаров: 8
Среднегодовой коэффициент роста выпуска товаров: 8
Среднегодовой темп роста выпуска товаров: 8
Среднегодовой темп прироста выпуска товаров: 8
С рынка товаров и услуг. 9
Коэф неравномерности поставки продукции 9
Дисперсия: 9
Абсолютный размер отклонения (выполнения контракта) 9
Сумма переплаты населения: 9
Территориальный индекс цен: 9
Эмпирический коэф. эластичности: 9
эластичности: 9
Эмпирический коэф. эластичности динамики: 9
Средний коэф. эластичности: 9
Теоретический коэф. эластичности. 9
По уравнению параболы: 9
С оборота торговли и товарных запасов: 9
Валовый оборот торговли: 9
Удельный вес продажи товара в объёме оборота торговли: 10
Виды Относительных Величин 10
Средние величины:
n – число единиц совокупности
xi – значение признака.
Простая формула:
Средняя гармоническая:
Средняя арифметическая
Средняя геометрическая
Среднее квадратическое
ИСС = суммарное значение или объём осредняемого признака/число единиц.
Средняя арифметическая взвешенная:
Средняя гармоническая взвешенная:
Показатели вариации
Среднее линейное отклонение:
Простая:взвешенная:
Дисперсия
Среднее квадратическое отклонение:
Коэф.
 осцилляции
осцилляцииОтносительное линейное отклонение.
Коэф. вариации.
Дисперсия:
Способ моментов:
Межгрупповая дисперсия:
Внутригрупповая дисперсия:
Коэффициент детерминации:
Эмпирическое кореляц. отн-е.
Ряды динамики
Моментные РД – вычисление средней.
Если рас-е м/у датами и времени одинаковы:
неодинаково:
Абсолютный прирост
Темп роста базовый.
T=y1/y0
Темп роста цепной:
Темп прироста цепной:
Темп прироста базовый:
Абсолютное значение 1% прироста.
Ср. абсолютный прирост:
Ср. темп роста.
Ср. темп прироста.
Ср. значение 1% прироста.
Ур-е прямой:
Ошибка аппроксимации:
Индексы.

P — цен
P = Оборот торговли/кол-во прод. товаров.
Z – себест-ть ед. прод., т. е. затраты на пр-во ед. прод.
Z = Себестоимость прод., всего – затраты по отгр. прод. / кол-во прод.
W – уровень производит. труда (ср. выработка на 1 раб)
W = V произвед. прод. (WT) / число раб. (Т).
t – трудоёмкость
t = 1/N
T = t*q
Индекс физич. объёма.
Общий индекс товарооборота:
Индекс товарооборота:
Общий индекс физического объёма товарооборота:
Общая формула для вычисления всех Интегральных показателей:
Индекс Цен по Пааше.
Индекс Цен По Ласпейресу:
Индекс Цен По Фишеру:
Индекс переменного состава:
Индекс постоянного состава:
Индекс структурных сдвигов:
Выборочное наблюдение.

Предельная ошибка выборки:
— средняя ошибка репрезентативности;
t – коэффициент кратности ошибки.
Средний размер ошибки признака:
Средняя ошибка доли признака:
Средний размер ошибки признака:
Средняя ошибки доли признака:
Т – численность ген. сов-ти,
n – численность выборочной сов-ти
— доля данного признака в выборке.
Взаимосвязи м/у явлениями:
Лин. коэф корелляции:
Коэф. эластичности
Ошибка апроксимации:
Расчёт дисперсии:
C видов экономической деят-ти.
Коэф. роста выпуска товаров:
начальный уровень ряда.
Qn – конечный уровень ряда.
Темп роста выпуска:
Темп прироста выпуска товаров:
Среднегодовой коэффициент роста выпуска товаров:
Среднегодовой темп роста выпуска товаров:
Среднегодовой темп прироста выпуска товаров:
С рынка товаров и услуг.

Коэф неравномерности поставки продукции
— средняя величина поставки.
— простая
— взвешенная.
Дисперсия:
% выполнения плана = Факт/План (отч.)
Абсолютный размер отклонения (выполнения контракта)
Сумма переплаты населения:
Территориальный индекс цен:
pA – цены на товары по сравнимому объекту А
pb – цены на товары по сравнимому объекту В.
q – количество проданных товаров.
Эмпирический коэф. эластичности:
Эмпирический коэф. эластичности динамики:
Средний коэф. эластичности:
Теоретический коэф. эластичности.
а1 – первая производная соотв. ф-ии.
хi – значение I – фактора.
— теоретическое значение результативного признака.
По уравнению параболы:
С оборота торговли и товарных запасов:
Валовый оборот торговли:
ВОТ = ОРТ+ООТ
Розница+опт
Оборот розничной торговли = товарооборот
Оборот торговли в сопост.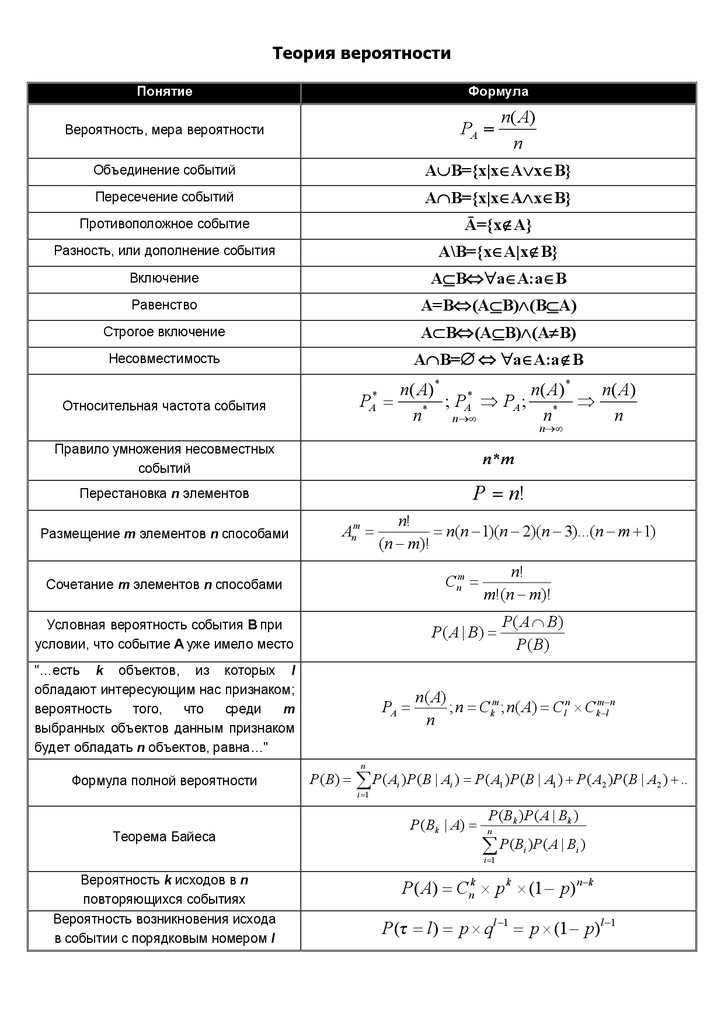 ценах = оборот в факт. ценах/Индекс цен.
ценах = оборот в факт. ценах/Индекс цен.
Удельный вес продажи товара в объёме оборота торговли:
— оборот торговли по i группе товаров
— общий объём оборота торговли.
Время обращения товаров в днях = Ср. сумма запасов за период/Однодневный оборот торговли.
Скорость обращения товаров = Оборот торговли за период/ср. сумма запасов за период.
С – скорость обращения в числе оборотов за период.
— средняя сумма запасов за период.
В – время обращения в днях
Виды Относительных Величин
ОВ выполнения плана = факт отчётного периода/Плановое задание (на отчётный период).
ОВ план. задания = план на тек. период/факт за баз. период.
ОВ динамики = Факт отчётного/факт базисного периода
ОВ план. задания*ОВ выполнения плана = ОВ динамики, всего.
ОВ структуры = 1 часть/вся сов-ть.
ОВ сравнения = показатели по объекту А/по В
ОВ интенсивности:
Фондоотдача основных средств (Н) = товарооборот/среднегодовая стоимость основных средств.
Excel. Часть 2. Статистика
Как с помощью математических и статистических функций получить выводы из данных
- Редакция
08.05.2020
Поделиться
В первом выпуске «Мастерской» об Excel «Важные истории» рассказали о том, как устроена программа, как импортировать и сохранять данные, что такое формулы и функции, как выполнить сортировку и фильтрацию данных. В этот раз – подробнее о списке функций, которые пригодятся журналистам для получения статистических выводов из данных.
Чаще всего дата-журналисты анализируют данные, чтобы найти в них новые тенденции и ответы на вопросы:
- Какие масштабы у явления?
- Какую часть целого составляет то или иное явление?
- Насколько изменилась ситуация по сравнению с предыдущим периодом?
- Ситуация ухудшилась или улучшилась, показали выросли или упали?
Получить ответы на эти вопросы помогают математические и статистические функции Excel.
- Для примера будем использовать набор данных по количеству заболевших коронавирусом в России, собранный Медиазоной на основе данных федерального Роспотребнадзора и его региональных штабов.
 Исходные данные в формате json можно сказать здесь, а сводные данные по России, переведенные нами в формат xlsx, удобный для работы в Excel, здесь.
Исходные данные в формате json можно сказать здесь, а сводные данные по России, переведенные нами в формат xlsx, удобный для работы в Excel, здесь.
 Исходные данные в формате json можно сказать здесь, а сводные данные по России, переведенные нами в формат xlsx, удобный для работы в Excel, здесь.
Исходные данные в формате json можно сказать здесь, а сводные данные по России, переведенные нами в формат xlsx, удобный для работы в Excel, здесь.Процент от целого
Для того, чтобы получить представление о масштабах явления, принято считать, какую долю целого оно составляет. Например, в исследовании «Важных историй» о насилии над пожилыми говорится о том, что 82,5% таких преступлений совершаются родственниками пострадавших.
С помощью вычисления процента можно посчитать, какая доля выявленных заболевших выздоровела на сегодня в России, согласно официальным данным. Произвести такие расчеты позволяют Google Spreadsheets. Формула для подсчета процента выглядит так: =Часть / Целое * 100. В нашем примере: =Число выздоровевших / Число заболевших * 100.
Формула расчета процентного изменения
Прирост или падение.
 Процентное изменение
Процентное изменениеЧтобы показать, как ситуация меняется со временем, считают изменение. Например, согласно официальным данным, 7 мая в России выявили на 702 заболевших больше, чем днем ранее – рост продолжается.
Прийти к такому выводу помогает простая формула вычитания: =Новое значение – Старое значение. Например: =Значение за этот год – Значение за предыдущий год. В нашем случае: =Значение за сегодня – значение за вчера. Если число получилось положительным, это указывает на прирост, если отрицательным – на падение.
Чаще всего абсолютные величины не дают нам представления о ситуации: 702 человека – это много или мало? А если днем ранее было выявлено на 471 человека больше, чем до этого, то темпы прироста увеличились или снизились?
В таких случаях показывают процентное изменение, которое тоже может быть положительным или отрицательным – сообщающем о росте или падении. Оно покажет, что 7 мая прирост составил 6,8%, и этот показатель остался на уровне предыдущего дня. Значит темпы прироста не изменились, несмотря на то, что в абсолютных числах в эти дни было выявлено разное количество заболевших людей.
Значит темпы прироста не изменились, несмотря на то, что в абсолютных числах в эти дни было выявлено разное количество заболевших людей.
Процентное изменение рассчитывается по формуле: =(Новое значение – Старое значение) / Старое значение * 100. В нашем случае: =(Количество заболевших на сегодня – Количество заболевших на вчера) / Количество заболевших на вчера * 100.
Формула расчета процентного изменения
Среднее арифметическое
Еще одна распространенная операция над данными – это поиск среднего значения. Среднее необходимо, чтобы сделать обобщенный вывод из данных. Например, чтобы узнать, что, в среднем, за последнюю неделю в день выявляли 10 тыс. зараженных.
Формула среднего арифметического выглядит так: =Сумма всех значений / Количество значений. В нашем случае: = Сумма всех новых выявленных случаев заражения за неделю / 7. Чтобы не вводить формулу, можно воспользоваться функцией СРЗНАЧ, которая считает среднее арифметическое. В скобках после функции надо указать диапазон значений, среднее которых мы ищем: =СРЗНАЧ(диапазон).
Вычислять среднее нужно еще и для того, чтобы увидеть выпадающие значения в ряде чисел, как например, в расследовании «Важных историй» о закупках аппаратов ИВЛ. Если посчитать среднюю цену поставки аппарата ИВЛ и сравнить ее с остальными ценами, это позволит сделать вывод о том, какая часть закупок была совершена по завышенной цене.
Медиана
Существует несколько видов среднего, и не всегда для корректных выводов подходит среднее арифметическое. Иногда, когда значения в наборе данных сильно отличаются – например, в списке зарплат есть очень низкие и очень высокие, среднее арифметическое может искажать картину.
В таких случаях лучше считать медиану. Медиана показывает число в середине упорядоченного набора чисел. Это похоже на границу, которая делит данные пополам: половина данных находится выше нее, а половина – ниже. Рассчитывается она так: =МЕДИАНА(диапазон). В случае с количеством заболевших по дням медиана полезной не будет, но если бы мы работали с данными по возрастам заболевших, можно было бы посчитать не среднее, а медиану.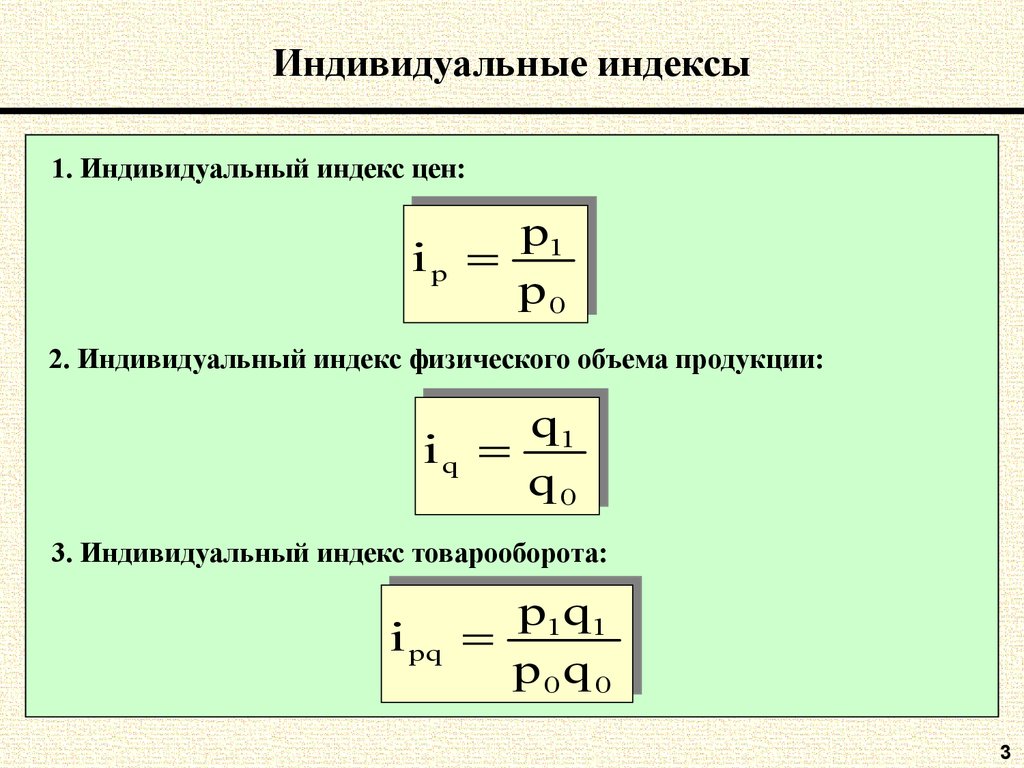 Она показала бы возраст, ниже и выше которого находится равное количество заболевших. Исходя из медианы, можно было бы сказать, что половина заболевших моложе (или старше), например, 45 лет.
Она показала бы возраст, ниже и выше которого находится равное количество заболевших. Исходя из медианы, можно было бы сказать, что половина заболевших моложе (или старше), например, 45 лет.
Мода
Мода в статистике – это еще один вид среднего, она показывает цифру, которая встречается в наборе данных чаще других. Она рассчитывается с помощью соответствующей функции, после которой указывается диапазон значений =МОДА(диапазон).
Среднее, медиана и мода
Вычислять моду из данных о количестве заболевших бесполезно, но если бы мы анализировали, например, данные об оценках студентов за экзамен, мода показала бы самую часто встречающуюся отметку. Если большинство сдали экзамен на пятерки и только пара студентов получили двойки, средняя успеваемость была бы меньше 5, но мода показала бы, что чаще всего студенты получали все-таки наивысшую оценку.
Максимум и минимум
Часто журналистов интересует, когда какое-либо явление достигало своего пика или наоборот оказывалось наименее заметным. В прошлом выпуске мы уже рассказывали, как быстро найти минимум и максимум с помощью сортировки. То же самое можно сделать и с помощью функций МИН и МАКС, после которых в скобках необходимо указать диапазон значений. Например: = МАКС(диапазон). Так можно быстро узнать, что рекорд по выявлению новых случаев заболевания за сутки был поставлен 7 мая.
В прошлом выпуске мы уже рассказывали, как быстро найти минимум и максимум с помощью сортировки. То же самое можно сделать и с помощью функций МИН и МАКС, после которых в скобках необходимо указать диапазон значений. Например: = МАКС(диапазон). Так можно быстро узнать, что рекорд по выявлению новых случаев заболевания за сутки был поставлен 7 мая.
На душу населения
При сравнении данных из разных выборок, например, по разным странам или регионам важно учитывать, что в них проживает разное количество людей, и это влияет на результаты сопоставления. Например, сравнивая масштабы распространения коронавируса в разных странах, часто показывают не только абсолютное количество зараженных, но и показатель в пересчете на душу населения.
Пересчет на душу населения
Формула для подсчета количества случаев в пересчете на душу населения такая: = Количество выявленных заболевших / Численность населения * 100 000. В таком случае полученный результат будет показывать количество выявленных случаев на 100 тыс. населения (иногда считают на 10 тыс. населения, тогда последняя цифра в формуле меняется на 10 000).
населения (иногда считают на 10 тыс. населения, тогда последняя цифра в формуле меняется на 10 000).
Статистика Формулы 1 по итогам прошлого сезона
В Формуле 1 опубликовали статистику по итогам прошлого сезона, отметив, что чемпионат входит в число наиболее динамично развивающихся крупных спортивных событий. Число подписчиков Формулы 1 достигло 49,1 миллионов человек, при этом у неё самый высокий коэффициент вовлечённости по сравнению с другими крупными спортивными соревнованиями в 2021 году.
Социальные сети и цифровые платформы
В прошлом году число подписчиков Формулы 1 в социальных сетях (Facebook, Twitter, Instagram, YouTube, Tiktok, Snapchat, Twitch и китайские социальные сети) выросло на 40% – до 49,1 миллионов, количество просмотров видео – на 50% до 7 миллиардов, а коэффициент вовлечённости – на 74% до 1,5 миллиардов.
При этом болельщики стали чаще смотреть видео на официальном сайте, в приложении и в социальных сетях – этот показатель достиг 7,04 миллиардов просмотров, что на 44% больше, чем в 2020 году. Количество уникальных посетителей увеличилось на 63% (до 113 миллионов человек), а число просмотров страниц выросло на 23% (до 1,6 миллиардов). Число подписчиков на китайских цифровых платформах (Weibo, WeChat, Toutiao и Douyin) увеличилось на 39% до 2,7 миллионов человек. Таким образом, в цифровой сфере Формула 1 опережает по популярности другие крупные спортивные события. Доля цифровых технологий в общем количестве минут просмотра видео (на цифровых платформах и в телетрансляциях) увеличилась с 10% (в 2020 году) до 16% в 2021-м.
Количество уникальных посетителей увеличилось на 63% (до 113 миллионов человек), а число просмотров страниц выросло на 23% (до 1,6 миллиардов). Число подписчиков на китайских цифровых платформах (Weibo, WeChat, Toutiao и Douyin) увеличилось на 39% до 2,7 миллионов человек. Таким образом, в цифровой сфере Формула 1 опережает по популярности другие крупные спортивные события. Доля цифровых технологий в общем количестве минут просмотра видео (на цифровых платформах и в телетрансляциях) увеличилась с 10% (в 2020 году) до 16% в 2021-м.
Рейтинг телетрансляций
Финал сезона в Абу-Даби посмотрели 108,7 миллионов человек, что на 29% больше, чем у этой же гонки в 2020 году. Кроме того, Гран При Абу-Даби обладает самым высоким рейтингом среди всех гонок прошлого года.
Общая аудитория телевизионных трансляций в 2021 году составила 1,55 миллиардов человек – на 4% больше, чем в 2020 году. Довольно высокий рейтинг был у первой гонки сезона – Гран При Бахрейна посмотрели 84,5 миллионов человек – а также у Гран При Великобритании (79,5 миллионов человек), Италии (80,4 миллиона человек) и Бразилии (82,1 миллион), где проводили спринт.
На некоторых рынках увеличилась аудитория телевизионных трансляций, в первую очередь в Нидерландах, где рейтинг Формулы 1 вырос на 81% по сравнению с 2020 годом. Кроме того, выросла популярность спорта в США (на 58%), Франции (на 48%), Италии (на 40%) и в Великобритании (на 39%).
Общее количество уникальных просмотров телетрансляций (количество зрителей, которые посмотрели по меньшей мере одну гонку по ходу сезона) в 2021 году составило 445 миллионов, что на 3% больше, чем в 2020-м. Самым крупным рынком по этому показателю стал Китай (70,8 миллионов уникальных просмотров, что на 13% больше, чем в 2020-м), но зафиксирован также заметный рост в Испании (на 272%), в России (на 129%) и в США (на 53%) по сравнению с 2020 годом.
В целом среднее число зрителей на Гран При в 2021 году составило 70,3 миллиона человек. На рынках, где между 2020 и 2021 годами не менялись договорённости о трансляциях, этот показатель достиг 60,3 миллионов зрителей, то есть за год вырос на 13%, и считается лучшим показателем с 2013 года. При этом в Формуле 1 не принимали в расчёт Германию и Бразилию, с которыми в прошлом году были заключены новые контракты на трансляции. Там тоже были довольно высокие показатели, хотя и ниже, чем на других рынках. Это показывает, что аудитория платных каналов со временем продолжит расти. Теперь в Бразилии гораздо более подробные и продолжительные трансляции, чем в 2020-м. За прошлый год аудитория Sky в Германии выросла на 55% по сравнению с 2020 годом.
При этом в Формуле 1 не принимали в расчёт Германию и Бразилию, с которыми в прошлом году были заключены новые контракты на трансляции. Там тоже были довольно высокие показатели, хотя и ниже, чем на других рынках. Это показывает, что аудитория платных каналов со временем продолжит расти. Теперь в Бразилии гораздо более подробные и продолжительные трансляции, чем в 2020-м. За прошлый год аудитория Sky в Германии выросла на 55% по сравнению с 2020 годом.
Посещаемость гонок
В 2021 году Гран При посетили 2,69 миллионов человек, что является довольно высоким показателем, учитывая, что во многих странах действовали ограничения по посещаемости, а некоторые гонки пришлось провести без зрителей из-за ситуации с Covid-19. Хотя это меньше, чем 4,16 миллионов человек в эпоху до пандемии, но такая посещаемость доказывает высокий спрос на гонки, и в Формуле 1 ждут, что после окончания пандемии этот показатель вернётся в норму.
На три гоночных уик-энда Гран При пришло более 300000: в США (400000 человек), Мексике (371000 человек) и в Великобритании (356000 человек) – при этом во всех этих странах посещаемость выросла по сравнению с 2019 годом, когда можно было проводить гонки без ограничений на количество зрителей. На 11 Гран При пришло более 100000 болельщиков: в Бельгии (213000 человек), Нидерландах (195000 человек), Турции (190000 человек), Бразилии (181000 человек), Абу-Даби (153000 человек), Саудовской Аравии (143 000 человек), Австрии (132000 человек) и Венгрии (130000 человек).
На 11 Гран При пришло более 100000 болельщиков: в Бельгии (213000 человек), Нидерландах (195000 человек), Турции (190000 человек), Бразилии (181000 человек), Абу-Даби (153000 человек), Саудовской Аравии (143 000 человек), Австрии (132000 человек) и Венгрии (130000 человек).
Стефано Доменикали, президент Формулы 1: «Прошлый сезон стал особенным. Борьба за титул шла до последней гонки, при этом каждый гоночный уик-энд был необычайно интересным. Мы снова стали принимать зрителей, которых считаем сердцем и душой нашего спорта. Хотя наши возможности были ограничены из-за Covid-19, я рад увидеть 2,6 миллионов болельщиков на трибунах по всему миру.
Кроме того, мы зафиксировали очень высокие показатели в сфере телетрансляций и цифровых платформ, что в очередной раз доказало рост интереса к Формуле 1. Мы с нетерпением ждём начала сезона из 23 Гран При, который станет вызовом для всех команд и гонщиков, и где мы увидим новое поколение машин, построенных по новому регламенту. Я знаю, что наши болельщики считают дни до первой гонки».
Статистические функции (справка)
Чтобы просмотреть более подробные сведения о функции, щелкните ее название в первом столбце.
Примечание: Маркер версии обозначает версию Excel, в которой она впервые появилась. В более ранних версиях эта функция отсутствует. Например, маркер версии 2013 означает, что данная функция доступна в выпуске Excel 2013 и всех последующих версиях.
|
Функция |
Описание |
|
СРОТКЛ |
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего. |
|
СРЗНАЧ |
Возвращает среднее арифметическое аргументов. |
|
СРЗНАЧА |
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения. |
|
СРЗНАЧЕСЛИ |
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию. |
|
СРЗНАЧЕСЛИМН |
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям. |
БЕТА. РАСП РАСП
|
Возвращает интегральную функцию бета-распределения. |
|
БЕТА.ОБР
|
Возвращает обратную интегральную функцию указанного бета-распределения. |
|
БИНОМ.РАСП
|
Возвращает отдельное значение вероятности биномиального распределения. |
|
|
Возвращает вероятность пробного результата с помощью биномиального распределения. |
|
БИНОМ.ОБР
|
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему. |
|
ХИ2.РАСП
|
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.РАСП.ПХ
|
Возвращает одностороннюю вероятность распределения хи-квадрат. |
|
ХИ2. |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.ОБР.ПХ
|
Возвращает обратное значение односторонней вероятности распределения хи-квадрат. |
|
|
Возвращает тест на независимость. |
|
ДОВЕРИТ.НОРМ
|
Возвращает доверительный интервал для среднего значения по генеральной совокупности. |
|
ДОВЕРИТ.СТЬЮДЕНТ
|
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента. |
|
КОРРЕЛ |
Возвращает коэффициент корреляции между двумя множествами данных. |
|
СЧЁТ |
Подсчитывает количество чисел в списке аргументов. |
|
СЧЁТЗ |
Подсчитывает количество значений в списке аргументов. |
|
СЧИТАТЬПУСТОТЫ |
Подсчитывает количество пустых ячеек в диапазоне. |
|
СЧЁТЕСЛИ |
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию. |
|
СЧЁТЕСЛИМН |
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям. |
|
КОВАРИАЦИЯ.Г
|
Возвращает ковариацию, среднее произведений парных отклонений. |
|
КОВАРИАЦИЯ.В
|
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных. |
|
КВАДРОТКЛ |
Возвращает сумму квадратов отклонений. |
|
ЭКСП.РАСП
|
Возвращает экспоненциальное распределение. |
|
F.РАСП
|
Возвращает F-распределение вероятности. |
|
F.РАСП.ПХ
|
Возвращает F-распределение вероятности. |
|
F.ОБР
|
Возвращает обратное значение для F-распределения вероятности. |
|
F.ОБР.ПХ
|
Возвращает обратное значение для F-распределения вероятности. |
|
F.ТЕСТ
|
Возвращает результат F-теста. |
|
ФИШЕР |
Возвращает преобразование Фишера. |
|
ФИШЕРОБР |
Возвращает обратное преобразование Фишера. |
|
ПРЕДСКАЗ |
Возвращает значение линейного тренда. Примечание: В Excel 2016 эта функция заменена на ПРЕДСКАЗ.ЛИНЕЙН из нового набора функций прогнозирования. Однако она по-прежнему доступна для совместимости с предыдущими версиями. |
|
ПРЕДСКАЗ. |
Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS). |
|
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ
|
Возвращает доверительный интервал для прогнозной величины на указанную дату. |
|
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ
|
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду. |
|
ПРЕДСКАЗ. |
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда. |
|
ПРЕДСКАЗ.ЛИНЕЙН
|
Возвращает будущее значение на основе существующих значений. |
|
ЧАСТОТА |
Возвращает распределение частот в виде вертикального массива. |
|
ГАММА
|
Возвращает значение функции гамма |
|
ГАММА. |
Возвращает гамма-распределение. |
|
ГАММА.ОБР
|
Возвращает обратное значение интегрального гамма-распределения. |
|
ГАММАНЛОГ |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАММАНЛОГ.ТОЧН
|
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАУСС
|
Возвращает значение на 0,5 меньше стандартного нормального распределения. |
|
СРГЕОМ |
Возвращает среднее геометрическое. |
|
РОСТ |
Возвращает значения в соответствии с экспоненциальным трендом. |
|
СРГАРМ |
Возвращает среднее гармоническое. |
|
ГИПЕРГЕОМ.РАСП |
Возвращает гипергеометрическое распределение. |
|
ОТРЕЗОК |
Возвращает отрезок, отсекаемый на оси линией линейной регрессии. |
|
ЭКСЦЕСС |
Возвращает эксцесс множества данных. |
|
НАИБОЛЬШИЙ |
Возвращает k-ое наибольшее значение в множестве данных. |
|
ЛИНЕЙН |
Возвращает параметры линейного тренда. |
|
ЛГРФПРИБЛ |
Возвращает параметры экспоненциального тренда. |
|
ЛОГНОРМ.РАСП
|
Возвращает интегральное логарифмическое нормальное распределение. |
|
ЛОГНОРМ.ОБР
|
Возвращает обратное значение интегрального логарифмического нормального распределения. |
|
МАКС |
Возвращает наибольшее значение в списке аргументов. |
|
МАКСА |
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МАКСЕСЛИ
|
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек. |
|
МЕДИАНА |
Возвращает медиану заданных чисел. |
|
МИН |
Возвращает наименьшее значение в списке аргументов. |
|
МИНЕСЛИ
|
Возвращает минимальное значение из заданных определенными условиями или критериями ячеек. |
|
МИНА |
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МОДА.НСК
|
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных. |
|
МОДА. |
Возвращает значение моды набора данных. |
|
ОТРБИНОМ.РАСП
|
Возвращает отрицательное биномиальное распределение. |
|
НОРМ.РАСП
|
Возвращает нормальное интегральное распределение. |
|
НОРМ.ОБР
|
Возвращает обратное значение нормального интегрального распределения. |
|
НОРМ. |
Возвращает стандартное нормальное интегральное распределение. |
|
НОРМ.СТ.ОБР
|
Возвращает обратное значение стандартного нормального интегрального распределения. |
|
ПИРСОН |
Возвращает коэффициент корреляции Пирсона. |
|
ПРОЦЕНТИЛЬ.ИСКЛ
|
Возвращает k-ю процентиль для значений диапазона, где k — число от 0 и 1 (не включая эти числа). |
|
ПРОЦЕНТИЛЬ.ВКЛ
|
Возвращает k-ю процентиль для значений диапазона. |
|
ПРОЦЕНТРАНГ.ИСКЛ
|
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы). |
|
ПРОЦЕНТРАНГ.ВКЛ
|
Возвращает процентную норму значения в наборе данных. |
|
ПЕРЕСТ |
Возвращает количество перестановок для заданного числа объектов. |
|
ПЕРЕСТА
|
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов. |
|
ФИ
|
Возвращает значение функции плотности для стандартного нормального распределения. |
|
ПУАССОН.РАСП
|
Возвращает распределение Пуассона. |
|
ВЕРОЯТНОСТЬ |
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов. |
|
КВАРТИЛЬ.ИСКЛ
|
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы. |
|
КВАРТИЛЬ.ВКЛ
|
Возвращает квартиль набора данных. |
|
РАНГ.СР
|
Возвращает ранг числа в списке чисел. |
|
РАНГ.РВ
|
Возвращает ранг числа в списке чисел. |
|
КВПИРСОН |
Возвращает квадрат коэффициента корреляции Пирсона. |
|
СКОС |
Возвращает асимметрию распределения. |
|
СКОС.Г
|
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего. |
|
НАКЛОН |
Возвращает наклон линии линейной регрессии. |
|
НАИМЕНЬШИЙ |
Возвращает k-ое наименьшее значение в множестве данных. |
|
НОРМАЛИЗАЦИЯ |
Возвращает нормализованное значение. |
|
СТАНДОТКЛОН.Г
|
Вычисляет стандартное отклонение по генеральной совокупности. |
|
СТАНДОТКЛОН.В
|
Оценивает стандартное отклонение по выборке. |
|
СТАНДОТКЛОНА |
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения. |
|
СТАНДОТКЛОНПА |
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения. |
|
СТОШYX |
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. |
|
СТЬЮДРАСП
|
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.2Х
|
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.ПХ
|
Возвращает t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ОБР
|
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы. |
|
СТЬЮДЕНТ. |
Возвращает обратное t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ТЕСТ
|
Возвращает вероятность, соответствующую проверке по критерию Стьюдента. |
|
ТЕНДЕНЦИЯ |
Возвращает значения в соответствии с линейным трендом. |
|
УРЕЗСРЕДНЕЕ |
Возвращает среднее внутренности множества данных. |
|
ДИСП. |
Вычисляет дисперсию по генеральной совокупности. |
|
ДИСП.В
|
Оценивает дисперсию по выборке. |
|
ДИСПА |
Оценивает дисперсию по выборке, включая числа, текст и логические значения. |
|
ДИСПРА |
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения. |
|
ВЕЙБУЛЛ.РАСП
|
Возвращает распределение Вейбулла. |
|
Z.ТЕСТ
|
Возвращает одностороннее значение вероятности z-теста. |


 ОБР
ОБР





 ETS
ETS
 ETS.СТАТ
ETS.СТАТ
 РАСП
РАСП



 ОДН
ОДН
 СТ.РАСП
СТ.РАСП







 ОБР.2Х
ОБР.2Х
 Г
Г

Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Подробнее об этих различиях.
Excel (по категориям)
Excel (по алфавиту)
Основные статистические функции в Excel: использование, формулы
Зная статистические формулы и приемы можно обработать, проанализировать и упорядочить большое количество информации. В Эксель инструменты статистики выведены в отдельную категорию функций. Давайте посмотрим, как их найти, а также, какие из них являются наиболее популярными среди пользователей.
В Эксель инструменты статистики выведены в отдельную категорию функций. Давайте посмотрим, как их найти, а также, какие из них являются наиболее популярными среди пользователей.
- Использование статистических функций
- СРЗНАЧ
- МАКС
- МИН
- СРЗНАЧЕСЛИ
- МЕДИАНА
- НАИБОЛЬШИЙ
- НАИМЕНЬШИЙ
- МОДА.ОДН
- СТАНДОТКЛОН
- СРГЕОМ
- Заключение
Использование статистических функций
Смотрите также: “Основные математические функции в Excel: использование, формулы”
Формулы функций в Excel можно вводить вручную непосредственно в той ячейке, где планируется выполнить соответствующие расчеты. Это легко применимо к таким простым действиям, как сложение, вычитание, умножение и деление. Но запомнить формулы сложных функций уже непросто, поэтому проще воспользоваться специальным помощником, который встроен в программу.
Итак, чтобы вставить функцию в ячейку, выполняем одно из следующих действий:
- Находясь в любой вкладке программы щелкаем по значку “Вставить функцию” (fx), которая находится с левой стороны от строки формул.
- Переходим во вкладку “Формулы”, где видим в левом углу ленты инструментов кнопку “Вставить функцию”.
- Используем сочетание клавиш Shift+F3.

Независимо от выбранного способа выше перед нами появится окно вставки функций. Щелкаем по текущей категории и из раскрывшегося списка выбираем пункт “Статистические”.
Далее будет предложен на выбор один из статистических операторов. Отмечаем нужный и жмем OK.
На экране отобразится окно с аргументами выбранной функции, которые нужно заполнить.
Примечание: существует еще один способ выбора требуемой функции. Находясь во вкладке “Формулы” в блоке инструментов “Библиотека функций” щелкаем по значку “Другие функции”, затем выбираем пункт “Статистические” и, наконец, в открывшемся перечне (который можно листать вниз) – нужный оператор.
Давайте теперь рассмотрим наиболее популярные функции.
СРЗНАЧ
Смотрите также: “Как посчитать среднее значение в Excel: формула, функции, инструменты”
Оператор вычисляет среднее арифметическое значение из указанных значений (диапазона). Формула функции выглядит таким образом:
=СРЗНАЧ(число1;число2;…)
В качестве аргументов функции можно указать:
- конкретные числа;
- ссылки на ячейки, которые можно указать как вручную (напечатать с помощью клавиатуры), так и находясь в соответствующем поле щелкнуть по нужному элементу в самой таблице;
- диапазон ячеек – указывается вручную или путем выделения в таблице.
- переход к следующему аргументу происходит путем щелчка по соответствующему полю напротив него или просто нажатием клавиши Tab.
МАКС
Функция помогает определить максимальное значение из заданных чисел (диапазона). Формула оператора следующая:
=МАКС(число1;число2;…)
В аргументах функции, также, как и в случае с оператором СРЗНАЧ можно указать конкретные числа, ссылки на ячейки или диапазоны ячеек.
МИН
Функция находит минимальное число из указанных значений (диапазона ячеек). В общем виде синтаксис выглядит так:
=МИН(число1;число2;…)
Аргументы функции заполняются так же, как и для оператора МАКС.
СРЗНАЧЕСЛИ
Функция позволяет найти среднее арифметическое значение, но при выполнении заданного условия. Формула оператора:
=СРЗНАЧЕСЛИ(диапазон;условие;диапазон_усреднения)
В аргументах указываются:
- Диапазон ячеек – вручную или с помощью выделения в таблице;
- Условие отбора значений из заданного диапазона (больше, меньше, не равно) – в кавычках;
- Диапазон_усреднения – не является обязательным аргументом для заполнения.
МЕДИАНА
Оператор находит медиану заданного диапазона значений. Синтаксис функции:
=МЕДИАНА(число1;число2;…)
В аргументах указываются: конкретные числа, ссылки на ячейки или диапазоны элементов.
НАИБОЛЬШИЙ
Функция позволяет найти из указанного диапазона значений с заданной позицией (по убыванию). Формула оператора:
=НАИБОЛЬШИЙ(массив;k)
Аргумента функции два: массив и номер позиции – K.
Допустим, имеется ряд чисел 4, 6, 12, 24, 15, 9. Если мы укажем в качестве аргумента “K” число 2, результатом будет значение, равное 15, т.к. оно второе по величине в выбранном диапазоне.
НАИМЕНЬШИЙ
Функция также, как и оператор НАИБОЛЬШИЙ, выполняет поиск из указанного диапазона значений. Правда, в данном случае счет идет по возрастанию. Синтаксис оператора следующий:
=НАИМЕНЬШИЙ(массив;k)
МОДА.ОДН
Функция пришла на замену более старому оператору “МОДА” (теперь находится в категории “Полный алфавитный перечень”). Позволяет определять число, которое повторяется чаще остальных в выбранном диапазоне. Работает функция по формуле:
=МОДА. ОДН(число1;число2;…)
ОДН(число1;число2;…)
В значениях аргументов указываются конкретные числовые значения, отдельные ячейки или их диапазоны.
Для вертикальных массивов, также, используется функция МОДА.НСК.
СТАНДОТКЛОН
Функция СТАНДОТКЛОН также устарела (но ее все еще можно найти, выбрав алфавитный перечень) и теперь представлена двумя новыми:
- СТАДНОТКЛОН.В – находит стандартное отклонение выборки
- СТАДНОТКЛОН.Г – определяет стандартное отклонение по генеральной совопкупности
Формулы функций выглядят следующим образом:
- =СТАДНОТКЛОН.В(число1;число2;…)
- =СТАДНОТКЛОН.Г(число1;число2;…)
СРГЕОМ
Оператор находит среднее геометрическое значение для заданного массива или диапазона. Формула функции:
=СРГЕОМ(число1;число2;…)
Заключение
В программе Excel более 100 статистических функций. Мы лишь рассмотрели те, которые используются пользователями чаще других, а также, где их можно найти и как заполнить аргументы для получения корректного результата.
Мы лишь рассмотрели те, которые используются пользователями чаще других, а также, где их можно найти и как заполнить аргументы для получения корректного результата.
Смотрите также:
- Почему Эксель не считает формулу: что делать
- Сортировка и фильтрация данных в Excel
Формулы статистики
На этой веб-странице перечислены формулы статистики, используемые в Stat Trek учебники. Каждая формула ссылается на веб-сайт страница, которая объясняет, как использовать формулу.
Параметры
- Среднее значение населения = μ = ( Σ X i ) / N
- Стандартное отклонение населения = σ = sqrt [ Σ ( X i — μ ) 2 / N ]
- Дисперсия населения = σ 2 = Σ ( X i — μ ) 2 / N
- Дисперсия доли населения = о P 2 = PQ / n
- Стандартизированная оценка = Z = (X — μ) / σ
- Коэффициент корреляции населения = ρ = [ 1 / N ] * Σ { [ (X i — μ X ) / σ x ] * [ (Y i — μ Y ) / σ y ] }
Статистика
Если не указано иное, эти формулы предполагают
простая случайная выборка.
- Выборочное среднее = x = ( Σ x i ) / n
- Стандартное отклонение выборки = s = sqrt [ Σ ( x я — x) 2 / (n — 1)]
- Выборочная дисперсия = с 2 = Σ ( х i — x) 2 / (n — 1)
- Дисперсия доли выборки = s p 2 = pq / (n — 1)
- Доля объединенной выборки = p = (p 1 * n 1 + p 2 * n 2 ) / (n 1 + n 2 )
- Стандартное отклонение объединенной выборки = с р = sqrt [ (n 1 — 1) * с 1 2 + (n 2 — 1) * с 2 2 ] / (n 1 + n 2 — 2) ]
- Выборочный коэффициент корреляции = г = [ 1 / (п — 1) ] * Σ { [ (х я — х) / с x ] * [ (у я — у) / s y ] }
Корреляция
- Корреляция Пирсона произведение-момент = r = Σ (xy) / sqrt [ ( Σ x 2 ) * ( Σ y 2 ) ]
- Линейная корреляция (выборочные данные) = r = [ 1 / (n — 1) ] * Σ { [ (x i — x) / с x ] * [ (y i — y) / с y ] }
- Линейная корреляция (данные населения) =
ρ = [ 1 / N ] * Σ { [ (X i — μ X ) / σ x ] * [ (Y i — μ Y ) / σ y ] 1 } 9004
Простая линейная регрессия
- Линия простой линейной регрессии: ŷ = b 0 + b 1 x
- Коэффициент регрессии = б 1 = Σ [ (х i — Икс) (у я — у) ] / Σ [ (х я — x) 2 ]
- Пересечение наклона регрессии = b 0 = y — b 1 * x
- Коэффициент регрессии = b 1 = r * (s y / s x )
- Стандартная ошибка наклона регрессии = с б 1 = sqrt [ Σ(y i — ŷ i ) 2 / (п — 2) ] / sqrt [ Σ(x я — х) 2 ]
Подсчет
- n факториал:
н! = п * (п-1) * (п — 2) * . . . * 3 * 2 * 1. По соглашению,
0! = 1.
- Перестановки n вещей, взятых r за один раз: n P r = n! / (н — р)!
- Комбинации из n вещей, взятых r за один раз: n C r = n! / г!(п — г)! = n P r / r!
Вероятность
- Правило сложения: Р (А ∪ В) = Р(А) + Р(В) — Р(А ∩ В)
- Правило умножения: Р (А ∩ В) = P(A) P(B|A)
- Правило вычитания: P(A’) = 1 — P(A)
Случайные величины
В следующих формулах X и Y являются случайными переменные и a и b являются константами.
- Ожидаемое значение X = E(X) = μ x = Σ [ x i * P(x i ) ]
- Дисперсия X = Var(X) = σ 2 = Σ [ х i — Е(х) ] 2 * Р(х i ) = Σ [ x i — μ x ] 2 * P(x i )
- Нормальная случайная величина = z-показатель = z = (X — μ)/σ
- Статистика хи-квадрат = Χ 2 = [ ( n — 1 ) * s 2 ] / σ 2
- f статистика = ж = [ с 1 2 /σ 1 2 ] / [ с 2 2 /σ 2 2 ]
- Ожидаемое значение суммы случайных величин = E(X + Y) = E(X) + E(Y)
- Ожидаемое значение разницы между случайными величинами = E(X — Y) = E(X) — E(Y)
- Дисперсия суммы независимых случайных величин = Var(X + Y) = Var(X) + Var(Y)
- Дисперсия разности между независимыми случайными величинами = Var(X — Y) = Var(X) + Var(Y)
Выборочные распределения
- Среднее выборочного распределения среднего = μ х = μ
- Среднее выборочное распределение доли = μ p = P
- Стандартное отклонение пропорции = σ р = sqrt[ P * (1 — P)/n ] = sqrt( PQ / n )
- Стандартное отклонение среднего = σ x = σ/sqrt(n)
- Стандартное отклонение разности выборочных средних = σ d = sqrt[ (σ 1 2 / n 1 ) + (σ 2 2 / n 2 ) ]
- Стандартное отклонение разности пропорций выборки = о д = sqrt{ [P 1 (1 — P 1 ) / номер 1 ] + [P 2 (1 — P 2 ) / n 2 ] }
Стандартная ошибка
- Стандартная ошибка пропорции = SE p = с р = sqrt[ p * (1 — p)/n ] = sqrt( pq / n )
- Стандартная ошибка разности пропорций = SE p = с р = sqrt{ p * ( 1 — p ) * [ (1/n 1 ) + (1/n 2 ) ] }
- Стандартная ошибка среднего = SE х = s x = s/sqrt(n)
- Стандартная ошибка разности выборочных средних = SE д = с д = sqrt[ (s 1 2 / п 1 ) + (s 2 2 / n 2 ) ]
- Стандартная ошибка разности средних парных выборок = SE д = с д = { квт [ (Σ(d i — d) 2 / (n — 1) ] } / sqrt(n)
- Стандартная ошибка объединенной выборки = с в пуле знак равно sqrt [ (n 1 — 1) * s 1 2 + (n 2 — 1) * с 2 2 ] / (n 1 + n 2 — 2) ]
- Стандартная ошибка разности пропорций выборки = с д = sqrt{ [p 1 (1 — p 1 ) / п 1 ] + [p 2 (1 — p 2 ) / n 2 ] }
Дискретные вероятностные распределения
- Биномиальная формула: P(X = x) = б( х ; н, Р ) = n C x * P x * (1 — P) n — x = n C x * P x * Q n — x
- Среднее биномиального распределения = μ x = n * P
- Дисперсия биномиального распределения = σ x 2 = n * P * ( 1 — P )
- Отрицательная биномиальная формула: P(X = x) = b*( x ; r, P ) = x-1 С р-1 * P r * (1 — P) x — r
- Среднее отрицательного биномиального распределения = μ x = rQ / P
- Дисперсия отрицательного биномиального распределения = σ x 2 = r * Q / P 2
- Геометрическая формула: P(X = x) = g( x ; P ) = P * Q x — 1
- Среднее геометрическое распределение = μ x = Q / P
- Дисперсия геометрического распределения = σ х 2 = Q / P 2
- Гипергеометрическая формула: P(X = x) = h( x ; N , n , k ) = [ k C x ] [ N-k C n-x ] / [ N C n ]
- Среднее значение гипергеометрического распределения = μ x = n * k / N
- Дисперсия гипергеометрического распределения = σ x 2 = п * к * ( Н — к ) * ( Н — п ) / [Н 2 * ( Н — 1 ) ]
- Формула Пуассона: P( x; µ ) = (e -µ ) (µ x ) / x!
- Среднее значение распределения Пуассона = μ x = μ
- Дисперсия распределения Пуассона = σ x 2 = μ
- Полиномиальная формула: P = [ n! / ( п 1 !
* п 2 ! * . .. п к ! )]
* ( стр 1 п 1 * p 2 n 2 * . . .
* стр к п к )
Линейные преобразования
Для следующих формул предположим, что Y является линейное преобразование случайной величины X, определяемой уравнением: Y = aX + b.
- Среднее линейного преобразования = E(Y) = У = аХ + б.
- Дисперсия линейного преобразования = Var(Y) = а 2 * Вар(Х).
- Стандартизированная оценка = z = (x — μ x ) / σ x .
- t статистика = t = (x — μ x ) / [s/sqrt(n)].
Оценка
- Доверительный интервал: Выборочная статистика + Критическое значение * Стандартная ошибка статистики
- Погрешность = (Критическое значение) * (Стандартное отклонение статистики)
- Погрешность = (Критическое значение) * (Стандартная ошибка статистики)
Проверка гипотез
- Стандартизированная статистика испытаний = (Статистика — Параметр) / (Стандартное отклонение статистики)
- Одновыборочный z-критерий для пропорций: z-оценка = z = (p — P 0 ) / sqrt( p * q / n )
- Двухвыборочный z-критерий для пропорций: z-показатель = z = z = [(p 1 — p 2 ) — d ] / SE
- Одновыборочный t-критерий для средних: t статистика = t = (x — μ) / SE
- Двухвыборочный t-критерий для средних значений: t статистика = t = [ (x 1 — x 2 ) — d ] / SE
- Стьюдентный критерий для средних значений: t статистика = t = [ (x 1 — х 2 ) — Д ] / SE = (d — D) / SE
- Статистика критерия хи-квадрат = Χ 2 = Σ[ (Наблюдаемое — Ожидаемое) 2 / Ожидаемое ]
Степени свободы
Правильная формула для степеней свободы (DF) зависит от ситуации (характер тестовой статистики, количество образцов, исходные предположения и др.
).- Одновыборочный t-критерий: DF = n — 1
- Двухвыборочный t-критерий: ДФ = (s 1 2 /n 1 + с 2 2 /n 2 ) 2 / { [ (с 1 2 / № 1 ) 2 / (n 1 — 1) ] + [ (с 2 2 / п 2 ) 2 / (n 2 — 1) ] }
- Двухвыборочный t-критерий, объединенная стандартная ошибка: DF = n 1 + n 2 — 2
- Простая линейная регрессия, тестовый наклон: DF = n — 2
- Критерий согласия хи-квадрат: DF = k — 1
- Критерий хи-квадрат на однородность: DF = (r — 1) * (c — 1)
- Тест хи-квадрат на независимость: DF = (r — 1) * (c — 1)
Размер выборки
Ниже первые две формулы находят наименьшие размеры выборки. требуется для достижения фиксированной погрешности, используя простой случайная выборка. Третья формула распределяет выборку по стратам на основе пропорционального плана.
четвертая формула, распределение Неймана, использует стратифицированную выборку для
минимизировать дисперсию при фиксированном размере выборки. И последняя формула,
оптимальное распределение, использует стратифицированную выборку для минимизации дисперсии,
при фиксированном бюджете.- Среднее (простая случайная выборка): п = { z 2 * о 2 * [Н/(Н-1)]} / {МЕ 2 + [ z 2 * σ 2 / (N — 1) ] }
- Доля (простая случайная выборка): n = [(z 2 * p * q) + ME 2 ] / [ME 2 + z 2 * p * q / N ]
- Пропорциональная стратифицированная выборка: n h = ( N h / N ) * n
- Распределение Неймана (стратифицированная выборка): n ч = n * ( N ч * σ ч ) / [ Σ ( N i * σ i ) ]
- Оптимальное распределение (стратифицированная выборка):
n h = n * [ ( N h * σ h ) / sqrt( c h 9) ] / [ Σ ( N я * σ я ) / sqrt( c i ) ]
10 лучших статистических формул — пустышки
Формулы — от них просто не уйти, когда изучаешь статистику.
Вот десять статистических формул, которые вы будете часто использовать, и шаги для их расчета.Доля
Некоторые переменные являются категориальными и определяют, к какой категории или группе принадлежит человек. Например, «статус отношений» — это категориальная переменная, и человек может быть холостым, встречающимся, состоящим в браке, разведенным и т. д.
Фактическое количество людей в любой данной категории называется частотой для этой категории. Пропорция , или относительная частота представляет процент людей, попадающих в каждую категорию. Доля данной категории, обозначенная цифрой p — частота, деленная на общий размер выборки.
Итак, чтобы рассчитать пропорцию, вам
Подсчитайте всех лиц в выборке, попадающих в указанную категорию.
Разделите на n , количество особей в выборке.
Среднее
Среднее , или среднее набора данных — это один из способов измерения центра набора числовых данных.
Обозначение для среднегоФормула для среднего
, где x представляет каждое значение в наборе данных.
Чтобы вычислить среднее, вам
Сложите все числа в наборе данных.
Разделить на n количество значений в наборе данных.
Медиана
Медиана набора числовых данных — это еще один способ измерения центра. Медиана — это среднее значение после упорядочения данных от наименьшего к наибольшему.
Чтобы вычислить медиану, выполните следующие действия:
Расположите числа от меньшего к большему.
При нечетном количестве чисел выберите то, которое находится ровно посередине. Вы определили медиану.
Для четного количества чисел возьмите два числа точно посередине и усредните их, чтобы найти медиану.
Стандартное отклонение выборки
стандартное отклонение выборки является мерой степени изменчивости в выборке.
. Вы можете думать об этом, в общих чертах, как о среднем расстоянии от среднего. Формула стандартного отклонения:Чтобы рассчитать стандартное отклонение, вам
Найти среднее всех чисел,
Возьмите каждое число и вычтите из него среднее значение.
Возведение в квадрат каждого из полученных значений.
Сложите их все.
Разделить на n – 1.
Извлеките квадратный корень.
Процентиль
Процентили — это способ определения отдельного значения относительно всех других значений в наборе данных. При прохождении стандартизированного теста вы получаете индивидуальный необработанный балл и процентиль. Например, если вы попадаете в 90-й процентиль, 90 процентов результатов тестов всех учащихся такие же или ниже ваших (и 10 процентов выше ваших). В общем, находясь на k 90 299-й процентиль означает, что 90 298 k 90 299 процентов данных лежат в этой точке или ниже, а (100 – 90 298 k 90 299 ) процентов лежат выше нее.
Чтобы рассчитать процентиль, вам
Преобразование исходного значения в стандартную оценку с помощью формулы z ,
, где x — исходное значение,
— это среднее значение совокупности всех значений, а
— стандартное отклонение всех значений генеральной совокупности.
Используйте таблицу Z , чтобы найти соответствующий процентиль для стандартной оценки.
Погрешность выборочного среднего
Погрешность для вашего образца mea n ,
— это ожидаемая сумма, на которую среднее значение выборки будет варьироваться от выборки к выборке. Формула погрешности для
, относящийся к образцам размером 30 и более, равен
., где z * — стандартное нормальное значение для желаемого уровня достоверности.
Чтобы рассчитать погрешность для
ты
Определите доверительный уровень и найдите соответствующий z *.
Найти стандартное отклонение
и размер выборки n .
Умножить z * на
разделить на квадратный корень из n .
Необходимый размер образца
Если вы хотите рассчитать доверительный интервал для среднего значения совокупности с определенной погрешностью, вы можете определить необходимый размер выборки, прежде чем собирать какие-либо данные. Формула размера выборки для
это
, где z * — стандартное нормальное значение доверительного уровня, MOE — желаемая погрешность, а
— стандартное отклонение. Потому что
— это неизвестное значение, которое вам нужно, возможно, вам придется провести пилотное исследование (небольшое экспериментальное исследование), чтобы сделать предположение о значении стандартного отклонения.
Чтобы рассчитать размер выборки для
выполнить следующие шаги:
Умножить z * умножить на с .
Разделить на требуемый предел погрешности, MOE.
Квадрат ит.
Округлите любую дробную сумму до ближайшего целого числа (так вы достигнете желаемого MOE или выше).
Тестовая статистика для среднего
При проверке гипотезы для среднего значения генеральной совокупности вы берете среднее значение выборки и выясняете, насколько оно далеко от заявленного значения с точки зрения стандартного балла. Стандартная оценка называется тестовая статистика c . Формула тестовой статистики для среднего значения:
где
— заявленное значение для среднего значения совокупности (значение, которое находится в нулевой гипотезе).
Чтобы вычислить статистику теста для среднего значения выборки для выборок размером 30 и более, вы должны
Расчет выборочного среднего,
и стандартное отклонение выборки, s .
Дубль
Расчет стандартной ошибки,
Разделите результат шага 2 на стандартную ошибку, найденную в шаге 3.
Корреляция
Образец Корреляция является мерой силы и направления линейной зависимости между двумя количественными переменными X и Y . Он не измеряет никакие другие типы отношений и не применяется к категориальным переменным. Формула корреляции
Чтобы рассчитать корреляцию, вам
Найдите среднее значение всех значений x и назовите его
Найдите среднее значение всех значений и и назовите его
.Найдите стандартное отклонение всех значений x и назовите его s x . Найдите стандартное отклонение всех значений y и назовите его s y .
Для каждой ( x , y ) пары в наборе данных возьмите x минус
и у минус
и умножьте их вместе.
Сложите все эти продукты вместе, чтобы получить сумму.
Разделите сумму на s x x s y .
Разделите результат на n – 1, где n это количество ( x , y ) пар. (Это то же самое, что умножить на единицу n – 1.)
Линия регрессии
Изучив диаграмму рассеяния между двумя числовыми переменными и вычислив выборочную корреляцию между двумя переменными, вы можете заметить линейную зависимость между ними. В этом случае было бы уместно оценить линию регрессии для оценки значения переменной отклика ( Y ) с учетом значения независимой переменной ( X ).
Перед расчетом линии регрессии необходимо пять сводных статистик:
Среднее значение x значений
Среднее значение и значений
Стандартное отклонение значений x (обозначается как с x )
Стандартное отклонение y значений (обозначается s y )
Корреляция между X и Y (обозначается как r )
Итак, чтобы рассчитать наиболее подходящую линию регрессии, вам
Найдите уклон по формуле
Найдите точку пересечения y- по формуле
Соедините результаты шагов 1 и 2, чтобы получить линию регрессии: y = m x + b .
Подробное руководство по базовой формуле статистики
Большинству учащихся трудно изучать статистику. Но вот несколько основных статистических формул, которые могут помочь учащимся начать работу со статистикой. Но прежде мы изучим эти формулы. Начнем со знакомства со статистикой.
Статистика — это один из разделов математики, который используется для изучения анализа данных. Методы статистики создаются для изучения больших данных и их свойств.
Статистические формулы используются несколькими компаниями для расчета отчетов людей или сотрудников. В следующих параграфах мы обсудим несколько статистических формул, которые используются для разных целей.
Прежде чем перейти к основным формулам статистики; давайте проверим, можете ли вы проанализировать, какое утверждение является статистическим, а какое нестатистическим.
Q1 . В зоопарке совиные обезьяны обычно весят больше, чем паукообразные?
(A) Статистические (B) Нестатистические Q2 .
В колледжах Нью-Йорка тренерам по футболу обычно платят больше, чем тренерам по теннису? (A) Статистические (B) Нестатистические Q3. Сколько зубов у Алана во рту?»
(A) Статистические (B) Нестатистические Q4. Сколько дней в июле месяце?
(A) Статистические (B) Нестатистические Q5. Какова общая площадь ушей жирафа?
(A) Статистические (B) Нестатистические Q6. А вообще какой средний рост у жирафов?
(A) Статистические (B) Нестатистические Q7. Есть ли у Дева докторская степень? степень?
(A) Statistical (B) Not statistical Answers:–
- Statistical
- Statistical
- Not statistical
- Не статистически
- Статистический
- Статистический
- Нестатистический
После того, как вы проверили свои статистические знания, теперь вы можете приступить к проверке основных формул статистики.
Какова цель использования статистики? Это поможет вам решить статистические задачи.Содержание
Статистика — это наука об анализе, представлении, сборе, интерпретации, организации, анализе и представлении больших данных. Его можно определить как функцию заданных данных. Вот почему статистика сочетается с классификацией, представлением, сбором и упорядочиванием числовой информации. Это также облегчает интерпретацию нескольких результатов и прогнозирование различных возможностей для будущих приложений. С помощью статистики можно найти несколько показателей центральных данных и отклонений разнородных значений от основных значений.
Что такое формулы элементарной статистики?Для всех статистических вычислений базовая концепция и формулы среднего, моды, стандартного отклонения, медианы и дисперсии являются ступеньками. Таким образом, мы представили все подробности по базовой формуле статистики:
где
среднее или среднее
x = данные наблюдений
x (бар) = среднее значение
n = общее количество наблюденийТеоретически, это сумма компонентов набора, деленная на общее количество компонентов.
Вы можете легко понять всю концепцию вычисления среднего значения. Таким образом, формула среднего:Среднее значение = (сумма всех данных элементов) / общее количество. элементов
Способность среднего используется для отображения всего набора данных с одним значением.
МедианаЭто центральное значение всего набора данных. Но если множество имеет нечетное число значений, то центральное значение множества можно рассматривать как медиану. С другой стороны, если конкретный набор содержит даже нет. наборов, то два центральных значения можно использовать для вычисления медианы.
Медиану можно использовать для разделения набора данных на две разные части. Чтобы вычислить медиану, вы должны расположить компоненты набора в порядке возрастания; только тогда вы можете найти медиану данных.
Медиана = (n+1)/2 ; , где n — нечетное число
Или
Медиана = [(n/2) член + ((n/2) + 1)] /2 ; , где n — четное число
Это формула базовой статистики для расчета медианы заданных данных.
РежимЭто значение часто используется в одном наборе данных. Или мы можем сказать, что мода — это сводка набора данных с одними данными.
Режим = Часто используемые данные в заданном наборе
ДисперсияИспользуется для расчета отклонения набора данных по его среднему значению. Следовательно, это должно быть положительное значение, и оно также используется для измерения значения стандартного отклонения, которое считается основным понятием статистических значений.
Где дисперсия; х = заданные предметы; х бар = среднее значение; и n = общее количество элементов
Стандартное отклонениеЭто квадратный корень из дисперсии данной информации.
S =
Где S = стандартное отклонение и квадратный корень из дисперсии.
Некоторые примеры основных статистических формулНиже приведены некоторые примеры основных статистических формул, которые вам следует знать:
Среднее: Найдите среднее значение данных 1,2,3,4,5. Среднее значение = (сумма всех данных элементов) / общее количество.
Следовательно, среднее = (1+2+3+4+5)/5
15/5 =3
Следовательно, среднее = 3
Медиана: Если n нечетное число :Найдите медиану данных 10,20,30,40,50.
Затем можно рассчитать медиану, записав набор данных в порядке возрастания, т.е.
10,20,30,40,50
Следовательно, 30 — это медиана, так как это центральное значение набора данных.
Или Медиана = (n+1)/2 ;
Где n=5, поэтому (5+1)/2 = 3, что означает, что третий член является медианой набора данных.
Если n четное числоНайдите медиану данных 4,10,15,2.
Затем можно рассчитать медиану, записав набор данных в порядке возрастания, т. е.
2,4,10,15
1310 Медиана = [(n/2) срок + ((n/2) + 1)] /2 ; , следовательно,
[(4/2) + (4/2)+1)]/2 = 2,5
Это означает, что 2-й и 3-й члены будут использоваться для медианы, т.
е.(4+10)/2 = 7 , Медиана 7 .
Режим: Найти режим данных 1,1,2,2,2,3,3,3,3,4,4.Поскольку число 3 повторяется 4 раза; поэтому мода данных равна 3.
ДисперсияНайдите дисперсию данных 10,5,-6,3,12.]/5
[100+25+36+9+144]/5 = 62,8
Дисперсия равна 62,8.
Стандартное отклонениеВ приведенном выше примере мы рассчитали дисперсию данных. Теперь, используя значение дисперсии, мы можем вычислить стандартное отклонение.
S = √ (дисперсия)
S = √ (62,8)
= 7,92
Следовательно, стандартное отклонение равно 7,92.
Ниже мы упомянули некоторые важные формулы статистики. Студенты могут использовать любой из них в соответствии со своими потребностями.
ЗаключениеТермины статистики Базовая формула статистики Процентиль Преобразуйте исходную формулу с помощью стандартной формулы z. Затем используйте Z-таблицу для ее решения.
Здесь x — исходное значение, среднее значение генеральной совокупности, а σ — стандартное отклонение.Погрешность среднего значения выборки Здесь Z * – стандартное нормальное значение, σ – стандартное отклонение, а n – размер выборки. Объем выборки Здесь Z * — стандартное нормальное значение, σ — стандартное отклонение, а MOE — предел погрешности. Тестовая статистика для среднего Здесь — выборочное среднее, σ — стандартное отклонение и n выборочное среднее. Корреляция Здесь x — стандартное отклонение всех значений x и sy — стандартное отклонение всех значений x . Линия регрессии. Доля объединенной выборки p = (p1 * n1 + p2 * n2) / (n1 + n2)
Здесь n1 и n2 — размер выборки 1 и выборки 2, а p1 и p2 — доля выборки, взятая из совокупностей 1 и 2 соответственно. 92
Здесь σ1 и σ2 — стандартные отклонения данной совокупности 1 и 2, с 1 и с 2 — стандартное отклонение совокупности 1 и 2 соответственно.Одновыборочный t-тест для среднего . Двухвыборочный t-критерий для средних значений t = [(x1 – x2) – d] / SE
Здесь x1 и x2 — среднее значение выборки 1 и 2, SE — стандартная ошибка, d — предполагаемая разница между средними значениями генеральной совокупности.Статистика критерия хи-квадрат уровень категориальной переменной. Среднее отрицательного биномиального распределения μ = r / P
Здесь r — количество успехов, μ — среднее число испытаний, а P — вероятность успеха.Стандартное нормальное распределение Z = ( x – 41310 x – 41310 x — μ) / µ µ). переменная, а σ — стандартное отклонение X.Хи-квадрат критерия согласия DF = k – 1
Здесь DF — степень свободы, а K — уровни категориальной переменной.В этом блоге есть актуальная информация о основных формулах статистики, которые могут помочь вам понять основную концепцию статистики. Поскольку статистика имеет разные термины, такие как среднее значение, медиана, мода, дисперсия и стандартное отклонение, вы можете использовать вышеупомянутый пример для решения проблемы этих статистических терминов.
Даже в этом случае, если у вас возникнут трудности с выполнением статистических заданий; то вы можете получить лучшую справку по назначению статистики прямо сейчас. Тем не менее, у нас есть команда экспертов, которые могут мгновенно помочь вам с вашими запросами, и мы доступны для вас 24 * 7 и доставляем данные без плагиата до истечения срока вместе с отчетом о плагиате.
Часто задаваемые вопросыQ1.
Как рассчитать базовую статистику?Вот некоторые из основных формул статистики:
1. Стандартное отклонение популяции = σ = sqrt [ Σ ( Xi – μ )2 / N ]
2. Среднее значение популяции = μ = ( Σ Xi ) / N.
3. Дисперсия доли популяции = σP2 = PQ / n .
4. Дисперсия населения = σ2 = Σ ( Xi – μ )2 / N.
5. Стандартизированная оценка = Z = (X – μ) / σQ2.
Типы статистики по математике ?Статистика в основном подразделяется на два типа:
1. Описательная статистика
2. Логическая статистикаФормула статистики | Калькулятор (пример и шаблон Excel)
Формула статистики (оглавление)
- Формула
- Примеры
- Калькулятор
Термин «статистика» относится к разделу математики, который занимается анализом чисел и данных.
Формула статистики относится к набору мер дисперсии или центральной тенденции, которые помогают понять и интерпретировать определенный набор данных.Формулы
Среднее x̄ = Σxi / N
Медиана = (N+1) th / 2 члена; когда N нечетно
[ N th / 2 член + ( N / 2 + 1) th член ] / 2 ; when N is evenMode = The value in the data set that occurs most frequently
Variance = Σ(xi – x̄) 2 / N
Where
- x i : i th Термин в наборе данных
- N : Количество переменных в наборе данных
Давайте рассмотрим пример, чтобы лучше понять расчет формулы статистики.
Вы можете скачать этот шаблон формулы Excel для статистики здесь — Шаблон Excel для формулы статистики
Формула статистики — Пример № 1
Давайте возьмем пример набора данных с нечетным числом переменных, чтобы проиллюстрировать формулу статистики: 21, 27, 34, 39, 22, 45, 19, 27, 29, 43, 36, 24, 27, 31 , 25, 45, 21, 38, 30. Количество переменных, N = 19. Рассчитайте среднее значение, медиану, моду и дисперсию вышеуказанного набора данных.
Решение:
Среднее вычисляется по приведенной ниже формуле
Среднее0007 Среднее значение = (21 + 27 + 34 + 39 + 22 + 45 + 19 + 27 + 29 + 43 + 36 + 24 + 27 + 31 + 25 + 45 + 21 + 38 + 30) / 19
- Среднее = 30,7
 . . * 3 * 2 * 1. По соглашению,
0! = 1.
. . * 3 * 2 * 1. По соглашению,
0! = 1. .. п к ! )]
* ( стр 1 п 1 * p 2 n 2 * . . .
* стр к п к )
.. п к ! )]
* ( стр 1 п 1 * p 2 n 2 * . . .
* стр к п к ) ).
). четвертая формула, распределение Неймана, использует стратифицированную выборку для
минимизировать дисперсию при фиксированном размере выборки. И последняя формула,
оптимальное распределение, использует стратифицированную выборку для минимизации дисперсии,
при фиксированном бюджете.
четвертая формула, распределение Неймана, использует стратифицированную выборку для
минимизировать дисперсию при фиксированном размере выборки. И последняя формула,
оптимальное распределение, использует стратифицированную выборку для минимизации дисперсии,
при фиксированном бюджете. Вот десять статистических формул, которые вы будете часто использовать, и шаги для их расчета.
Вот десять статистических формул, которые вы будете часто использовать, и шаги для их расчета. Обозначение для среднего
Обозначение для среднего Вы можете думать об этом, в общих чертах, как о среднем расстоянии от среднего. Формула стандартного отклонения:
Вы можете думать об этом, в общих чертах, как о среднем расстоянии от среднего. Формула стандартного отклонения: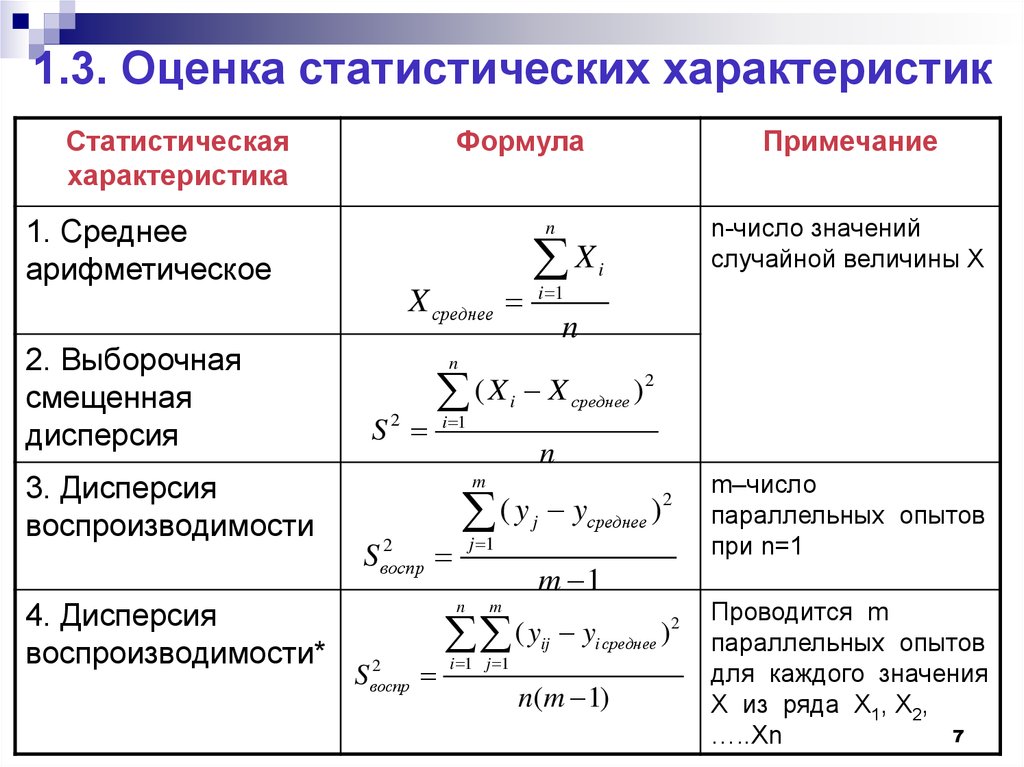





 В колледжах Нью-Йорка тренерам по футболу обычно платят больше, чем тренерам по теннису?
В колледжах Нью-Йорка тренерам по футболу обычно платят больше, чем тренерам по теннису?  Это поможет вам решить статистические задачи.
Это поможет вам решить статистические задачи. Вы можете легко понять всю концепцию вычисления среднего значения. Таким образом, формула среднего:
Вы можете легко понять всю концепцию вычисления среднего значения. Таким образом, формула среднего:

 е.
е. Затем используйте Z-таблицу для ее решения.
Затем используйте Z-таблицу для ее решения.  92
92  переменная, а σ — стандартное отклонение X.
переменная, а σ — стандартное отклонение X.
 Формула статистики относится к набору мер дисперсии или центральной тенденции, которые помогают понять и интерпретировать определенный набор данных.
Формула статистики относится к набору мер дисперсии или центральной тенденции, которые помогают понять и интерпретировать определенный набор данных.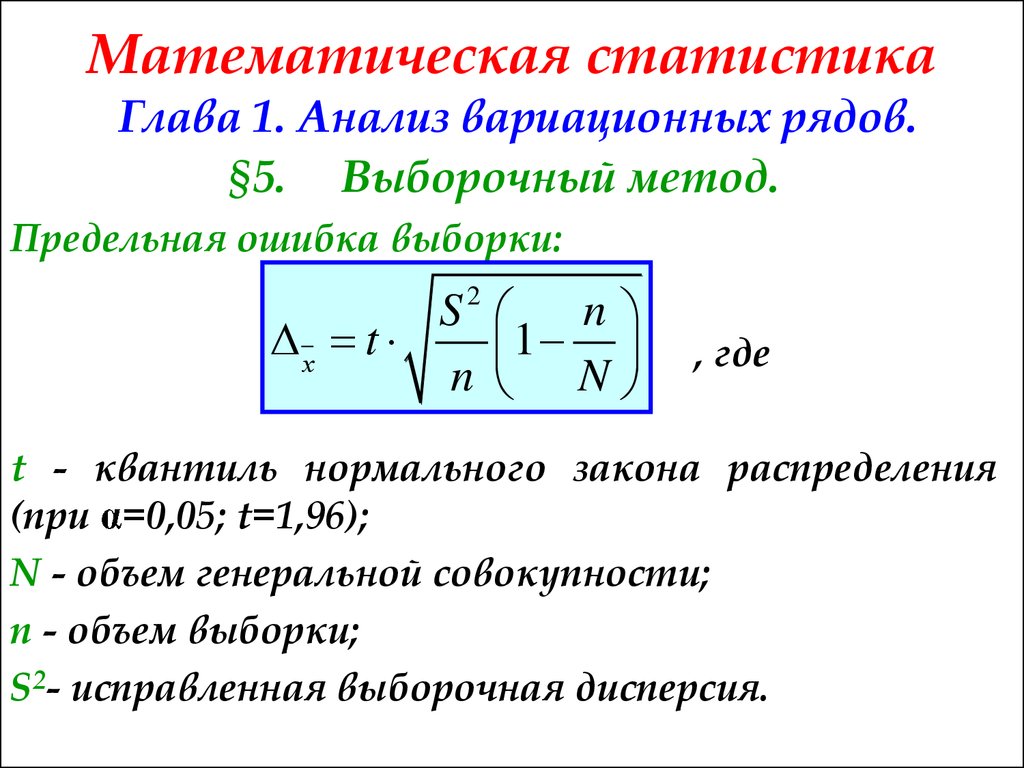
Медиан рассчитывается с использованием формулы, приведенной ниже
(n + 1) TH /2 Срок
Медиан = (19 + 1)/ 2 = 10 TH Термин
- Median = 100014 TH -й срок, 19, 21, 21, 22, 24, 25, 27, 27, 27, 29, 30, 31, 34, 36, 38, 39, 43, 45, 45
- Медиана = 29
Мода рассчитывается по приведенной ниже формуле
Мода = Значение в наборе данных, которое встречается наиболее часто , 27, 29, 30, 31, 34, 36, 38, 39, 43, 45, 45 Дисперсия рассчитывается по формуле, приведенной ниже0002 Следовательно, среднее значение, медиана, мода и дисперсия данного набора данных равны 30,7, 29, 27 и 65,5 соответственно. Теперь давайте возьмем пример набора данных с четным числом переменных и вычислим формулу статистики: 82, 76, 62, 78, 83, 89, 61, 76, 72 , 71, 91, 76, 62, 69, 77, 76, 85, 89, 71, 63, 68, 82. Количество переменных, N = 22. Вычисляет среднее значение, медиану, моду и дисперсию вышеуказанного набора данных. . Solution: Mean is calculated using the formula given below Mean x̄ = Σxi / N Медиана рассчитывается по формуле, приведенной ниже0014 th term ] / 2 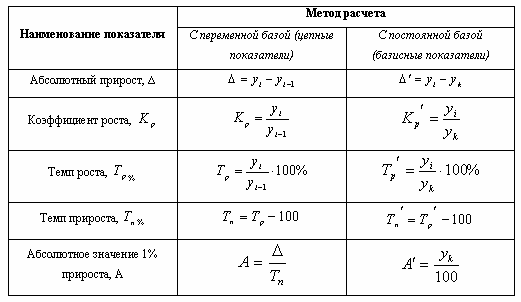
Формула статистики – пример №2
Медиана = (22/2 + (22/2 + 1)) / 2. Теперь расположите набор данных в порядке возрастания (или убывания), чтобы определить медиану, 11 -й -й терм 12 -й -й терм 61, 62, 62, 63, 68, 69, 71, 71, 72, 76, 76, 76, 76, 77, 78, 82, 82, 83, 85, 89, 89 , 91
- Медиана = (76 + 76) / 2
- Медиана = 76
Режим рассчитывается по приведенной ниже формуле
Режим = Значение в наборе данных, которое встречается чаще всего
- Режим = Набор данных равен 76, что встречается наиболее часто (4 раза) в этом наборе данных.
- Режим = 76
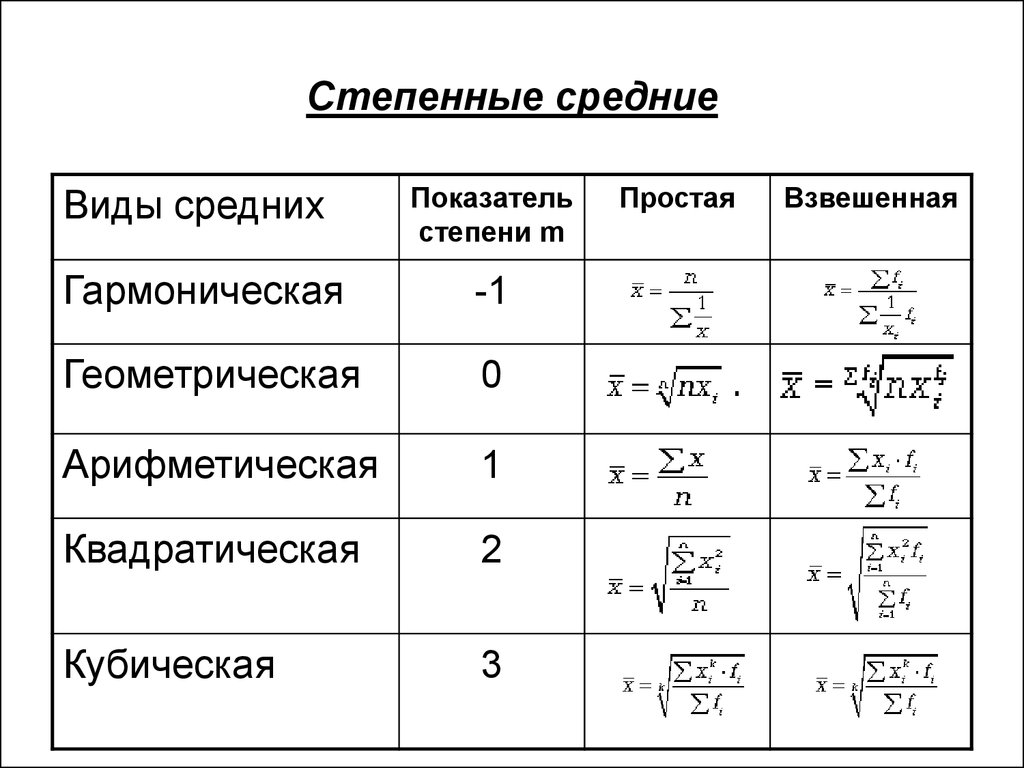
Дисперсия рассчитывается с использованием формулы, приведенной ниже
Дисперсия = σ (xi — x̄) 2 / n
- . ) 2 + (62 – 75,4) 2 + (78 – 75,4) 2 + (83 – 75,4) 2 + (89 – 75,4) 2 + (61 – 75,4) 2 + (76 – 90,14) 2 90 72 – 75,4) 2 + (71 – 75,4) 2 + (91 – 75,4) 2 + (76 – 75,4) 2 + (62 – 75,4) 2 19 – 015 + (6,4 ) 904 2 + (77 – 75,4) 2 + (76 – 75,4) 2 + (85 – 75,4) 2 + (89 – 75,4) 2 + (71 – 75,4)4 2 – 75.4) 2 + (68 – 75,4) 2 + (82 – 75,4) 2 } / 22
- Отклонение = 78,5
Следовательно, среднее значение, медиана, мода и дисперсия данного набора данных равны 75,4, 76, 76 и 78,5 соответственно.
Объяснение
Формулу для статистики можно рассчитать, выполнив следующие шаги:
- Среднее значение: Это среднее значение всех чисел, доступных в наборе данных.
- Медиана: Если расположить в порядке возрастания или убывания, это точно середина набора данных. Например, если в наборе данных 100 чисел, то 50 -й -й и 51-й -й -й термины являются средними числами.
- Режим: Это число в наборе данных, которое встречается максимальное количество раз.
- Дисперсия: Он измеряет, насколько разбросаны числа в наборе данных, т. е. насколько далеко каждое число разбросано от среднего значения набора данных.
Актуальность и использование формулы статистики
С точки зрения статистика очень важно понимать концепцию формулы статистики, поскольку она помогает организовывать и анализировать большие объемы данных. Эти статистические методы также используются в различных инструментах для принятия решений, особенно для получения выводов на основе данных, собранных в ходе обследований.
Калькулятор формулы статистики
Вы можете использовать калькулятор формулы статистики
| xi | |
| N | |
| Statistics Formula | |
| Statistics Formula = | Σxi / N | |
| Σ0 / 0 = | 0 |
Рекомендуемые статьи
Это руководство по формуле статистики. Здесь мы обсуждаем, как рассчитать статистику вместе с практическими примерами. Мы также предоставляем калькулятор статистики с загружаемым шаблоном Excel. Вы также можете прочитать следующие статьи, чтобы узнать больше:
- Пример формулы среднего арифметического
- Как рассчитать медиану?
- Расчет формулы режима
- Что такое статистика Z-теста?
Статистические функции (справочник)
Чтобы получить подробную информацию о функции, щелкните ее имя в первом столбце.
Примечание. Маркеры версии указывают версию Excel, в которой была введена функция. Эти функции недоступны в более ранних версиях. Например, маркер версии 2013 указывает, что эта функция доступна в Excel 2013 и всех более поздних версиях.
Функция | Описание |
функция АВЕДЕВ | Возвращает среднее абсолютных отклонений точек данных от их среднего значения |
СРЕДНЯЯ функция | Возвращает среднее значение своих аргументов |
Функция СРЗНАЧА | Возвращает среднее значение аргументов, включая числа, текст и логические значения. |
СРЗНАЧЕСЛИ функция | Возвращает среднее (среднее арифметическое) всех ячеек в диапазоне, соответствующих заданным критериям |
Функция СРЗНАЧЕСЛИ | Возвращает среднее (среднее арифметическое) всех ячеек, соответствующих нескольким критериям |
БЕТА.РАСП | Возвращает кумулятивную функцию бета-распределения |
БЕТА.ОБР функция | Возвращает обратную интегральную функцию распределения для указанного бета-распределения |
БИНОМ. | Возвращает вероятность биномиального распределения отдельного термина |
Функция БИНОМ.РАСП.ДИАПАЗОН | Возвращает вероятность результата испытания с использованием биномиального распределения |
БИНОМ.ОБР функция | Возвращает наименьшее значение, для которого кумулятивное биномиальное распределение меньше или равно значению критерия |
Функция ХИ.РАСП. | Возвращает кумулятивную функцию плотности бета-вероятности |
Функция ХИ. | Возвращает одностороннюю вероятность распределения хи-квадрат |
Функция ХИ.ОБР. | Возвращает кумулятивную функцию плотности бета-вероятности |
Функция ХИСК.ОБР.ПХ | Возвращает обратную одностороннюю вероятность распределения хи-квадрат |
Функция CHISQ.ТЕСТ | Возвращает тест на независимость |
УВЕРЕННОСТЬ. | Возвращает доверительный интервал для среднего значения генеральной совокупности. |
УВЕРЕННОСТЬ.T функция | Возвращает доверительный интервал для среднего значения генеральной совокупности с использованием распределения Стьюдента |
КОРРЕЛ функция | Возвращает коэффициент корреляции между двумя наборами данных |
СЧЕТ функция | Подсчитывает количество чисел в списке аргументов |
Функция СЧЁТ | Подсчитывает количество значений в списке аргументов |
СЧИТАТЬ ПУСТОТЫ | Подсчитывает количество пустых ячеек в диапазоне |
СЧЁТЕСЛИ функция | Подсчитывает количество ячеек в диапазоне, соответствующих заданным критериям |
СЧЁТЕСЛИМН функция | Подсчитывает количество ячеек в диапазоне, соответствующих нескольким критериям |
Функция КОВАРИАЦИЯ. | Возвращает ковариацию, среднее значение произведений парных отклонений |
Функция КОВАРИАЦИЯ.S | Возвращает выборочную ковариацию, среднее значение отклонений произведений для каждой пары точек данных в двух наборах данных |
Функция DEVSQ | Возвращает сумму квадратов отклонений |
Функция ЭКСП.РАСП. | Возвращает экспоненциальное распределение |
Функция F. | Возвращает F-распределение вероятностей |
Функция F.РАСП.ВП | Возвращает F-распределение вероятностей |
Функция F.ОБР. | Возвращает обратное F-распределение вероятностей |
Функция F.ОБР.ПХ | Возвращает обратное F-распределение вероятностей |
Функция F. | Возвращает результат F-теста |
функция ФИШЕР | Возвращает преобразование Фишера |
функция РЫБАЛОБР | Возвращает обратное преобразование Фишера |
ПРОГНОЗ | Возвращает значение по линейному тренду Примечание. В Excel 2016 эта функция заменена на FORECAST.LINEAR как часть новых функций прогнозирования, но она по-прежнему доступна для совместимости с более ранними версиями. |
ПРОГНОЗ.ETS функция | Возвращает будущее значение на основе существующих (исторических) значений с использованием версии AAA алгоритма экспоненциального сглаживания (ETS) |
ПРОГНОЗ.ETS.CONFINT функция | Возвращает доверительный интервал для значения прогноза на указанную целевую дату |
ПРОГНОЗ.ETS.СЕЗОННОСТЬ функция | Возвращает длину повторяющегося шаблона, обнаруженного Excel для указанного временного ряда |
ПРОГНОЗ. | Возвращает статистическое значение в результате прогнозирования временных рядов |
ПРОГНОЗ.ЛИНЕЙНАЯ функция | Возвращает будущее значение на основе существующих значений |
функция ЧАСТОТА | Возвращает частотное распределение в виде вертикального массива |
ГАММА-функция | Возвращает значение гамма-функции |
ГАММА. | Возвращает гамма-распределение |
Функция ГАММА.ОБР | Возвращает обратное суммарное гамма-распределение |
Функция ГАММАЛН | Возвращает натуральный логарифм гамма-функции, Γ(x) |
ГАММАЛЬН.ТОЧНАЯ функция | Возвращает натуральный логарифм гамма-функции, Γ(x) |
Функция ГАУССА | Возвращает на 0,5 меньше стандартного нормального кумулятивного распределения |
Функция ГЕОМЕАН | Возвращает среднее геометрическое |
функция РОСТА | Возвращает значения по экспоненциальному тренду |
функция ХАРМАНА | Возвращает среднее гармоническое |
Функция ГИПЕРГЕОМ. | Возвращает гипергеометрическое распределение |
ПЕРЕХВАТ | Возвращает точку пересечения линии линейной регрессии |
КУРТ функция | Возвращает эксцесс набора данных |
БОЛЬШАЯ функция | Возвращает k-е наибольшее значение в наборе данных |
Функция ЛИНЕЙН | Возвращает параметры линейного тренда |
Функция ЛИНЕЙН | Возвращает параметры экспоненциального тренда |
Функция ЛОГНОРМ. | Возвращает кумулятивное логнормальное распределение |
функция ЛОГНОРМ.ОБР | Возвращает обратное логарифмически нормальное кумулятивное распределение |
Функция МАКС. | Возвращает максимальное значение в списке аргументов |
Функция МАКСА | Возвращает максимальное значение в списке аргументов, включая числа, текст и логические значения |
Функция МАКСИФМН | Возвращает максимальное значение среди ячеек, заданных заданным набором условий или критериев |
МЕДИАННАЯ функция | Возвращает медиану заданных чисел |
Функция МИН. | Возвращает минимальное значение в списке аргументов |
Функция МИНИФС | Возвращает минимальное значение среди ячеек, заданных заданным набором условий или критериев. |
Функция МИНА | Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения |
РЕЖИМ.МУЛЬТФУНКЦИЯ | Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных |
Функция MODE. | Возвращает наиболее распространенное значение в наборе данных |
ОТРБИНОМ.РАСП | Возвращает отрицательное биномиальное распределение |
Функция НОРМ.РАСП. | Возвращает нормальное кумулятивное распределение |
НОРМ.ОБР функция | Возвращает обратное нормальное кумулятивное распределение |
Функция НОРМ. | Возвращает стандартное нормальное кумулятивное распределение |
Функция НОРМ.С.ОБР. | Возвращает обратное стандартному нормальному кумулятивному распределению |
Функция ПИРСОН | Возвращает коэффициент корреляции момента продукта Пирсона |
ПРОЦЕНТИЛЬ.ИСКЛ функция | Возвращает k-й процентиль значений в диапазоне, где k находится в диапазоне от 0 до 1, исключая. |
ПРОЦЕНТИЛЬ.ВКЛ функция | Возвращает k-й процентиль значений в диапазоне |
Функция ПРОЦЕНТРАНГ.ИСКЛ. | Возвращает ранг значения в наборе данных в процентах (0..1, исключая) набора данных |
Функция ПРОЦЕНТРАНГ.ВКЛ. | Возвращает процентный ранг значения в наборе данных |
ПЕРЕСТАВИТЬ функцию | Возвращает количество перестановок для заданного количества объектов |
функция ПЕРЕСТАНОВКА | Возвращает количество перестановок для заданного количества объектов (с повторениями), которые можно выбрать из общего количества объектов |
функция PHI | Возвращает значение функции плотности для стандартного нормального распределения |
Функция ПУАССОН. | Возвращает распределение Пуассона |
ПРОБ функция | Возвращает вероятность того, что значения в диапазоне находятся между двумя пределами |
КВАРТИЛЬ.ИСКЛ функция | Возвращает квартиль набора данных на основе значений процентиля от 0 до 1, исключая |
КВАРТИЛЬ.ВКЛ функция | Возвращает квартиль набора данных |
РАНГ. | Возвращает ранг числа в списке чисел |
Функция РАНГ.ЭКВ. | Возвращает ранг числа в списке чисел |
Функция RSQ | Возвращает квадрат коэффициента корреляции момента произведения Пирсона |
Функция СКОС | Возвращает асимметрию распределения |
Функция СКОС. | Возвращает асимметрию распределения на основе генеральной совокупности: характеристика степени асимметрии распределения относительно его среднего значения |
НАКЛОН функция | Возвращает наклон линии линейной регрессии |
МАЛЕНЬКАЯ функция | Возвращает k-е наименьшее значение в наборе данных |
СТАНДАРТНАЯ функция | Возвращает нормализованное значение |
Функция СТАНДОТКЛОН. | Вычисляет стандартное отклонение на основе всей совокупности |
Функция СТАНДОТКЛОН.С | Оценивает стандартное отклонение на основе выборки |
СТАНДОТКЛОН функция | Оценивает стандартное отклонение на основе выборки, включая числа, текст и логические значения |
Функция СТАНДОТКЛОНПА | Вычисляет стандартное отклонение на основе всей совокупности, включая числа, текст и логические значения |
Функция СТЕЙКС | Возвращает стандартную ошибку предсказанного значения y для каждого x в регрессии |
Функция Т. | Возвращает процентные пункты (вероятность) для t-распределения Стьюдента |
Функция Т.РАСП.2T | Возвращает процентные пункты (вероятность) для t-распределения Стьюдента |
Функция Т.РАСП.ВП | Возвращает t-распределение Стьюдента |
Функция Т.ОБР. | Возвращает t-значение распределения Стьюдента как функцию вероятности и степеней свободы |
Функция Т. | Возвращает обратное распределение Стьюдента |
Функция Т.ТЕСТ | Возвращает вероятность, связанную с критерием Стьюдента |
Функция ТРЕНД | Возвращает значения по линейному тренду |
функция ОБРЕЗАТЬСРЕДНЕЕ | Возвращает среднее значение внутренней части набора данных |
Функция VAR. | Вычисляет дисперсию на основе всего населения |
Функция VAR.S | Оценивает дисперсию на основе выборки |
Функция ВАРА | Оценивает дисперсию на основе выборки, включая числа, текст и логические значения |
Функция ВАРПА | Вычисляет дисперсию на основе всей совокупности, включая числа, текст и логические значения |
Функция WEIBULL. | Возвращает распределение Вейбулла |
Функция Z.ТЕСТ | Возвращает одностороннее значение вероятности z-критерия |

 РАСП функция
РАСП функция  РАСП.ВП
РАСП.ВП  НОРМ функция
НОРМ функция  P
P  РАСП
РАСП  ТЕСТ
ТЕСТ 
 ETS.СТАТ функция
ETS.СТАТ функция  РАСП
РАСП  РАСП.
РАСП. РАСП
РАСП 
 SNGL
SNGL  СТ.РАСП
СТ.РАСП 
 РАСП
РАСП  СРЕДНЯЯ функция
СРЕДНЯЯ функция  П
П  П
П  РАСП
РАСП  ОБР.2Т
ОБР.2Т  P
P  DIST
DIST Важно: Результаты расчетов формул и некоторых функций рабочего листа Excel могут незначительно отличаться на ПК с Windows с архитектурой x86 или x86-64 и ПК с Windows RT с архитектурой ARM. Узнайте больше о различиях.
Функции Excel (по категориям)
функций Excel (по алфавиту)
Выучить формулы для среднего, медианы и моды
- Автор: Ритеш Кумар Гупта
- Последнее изменение 20-07-2022
- Автор Ритеш Кумар Гупта
- Последнее изменение 20-07-2022
Статистические формулы : Статистика — это раздел математики, который занимается сбором, организацией, анализом, интерпретацией и представлением данных. Это позволяет нам понимать различные результаты и предвидеть широкий спектр возможностей. Статистика связана с фактами, наблюдениями и информацией, которые являются просто числовыми данными. Формулы статистики делают арифметические вычисления быстрыми, менее подверженными ошибкам и облегчают задачу.
Это позволяет нам понимать различные результаты и предвидеть широкий спектр возможностей. Статистика связана с фактами, наблюдениями и информацией, которые являются просто числовыми данными. Формулы статистики делают арифметические вычисления быстрыми, менее подверженными ошибкам и облегчают задачу.
Используя статистику, мы можем получить несколько показателей центральной тенденции и отклонения отдельных значений от центра. Мы можем использовать статистику для изучения данных в различных областях, чтобы отслеживать развивающиеся закономерности, а затем использовать результаты для разработки выводов и прогнозов. Давайте узнаем о формулах статистики класса 10 на их примерах.
Статистика — это дисциплина математики, которая занимается анализом данных и числами. Изучение сбора, анализа, интерпретации, представления и организации данных известно как статистика.
Статистика связана со сбором, классификацией, организацией и представлением числовых данных в заданном контексте. Это позволяет нам анализировать ряд данных. Классификация статистики приведена ниже:
Это позволяет нам анализировать ряд данных. Классификация статистики приведена ниже:
Изучение концепций экзамена на Embibe
Основные понятия среднего, медианы, моды, дисперсии и стандартного отклонения являются ступеньками практически для всех статистических вычислений. Давайте подробно рассмотрим базовую статистику всех формул класса 10. 9n {{f_i} = } \)Общее количество частот
Практические экзаменационные вопросы
Медиана
Среднее число или центральное значение в наборе данных называется медианой. Середина множества также известна как медиана. Чтобы найти медиану, расположите данные в порядке возрастания/убывания от наименьшего к наибольшему или от наибольшего к наименьшему значению. Медиана — это число, которое разделяет верхнюю и нижнюю половины выборки данных, генеральной совокупности или распределения вероятностей.
9{{\rm{th}}}}{\rm{term}}}}{2}\) Аналогично, для сгруппированных данных:
Медиана \( = l + \left( {\frac {{\frac {N}{2} – c}}{f}} \right) \times h\)
Где,
\(l = \)нижний предел среднего класса
\(c = \)кумулятивная частота класса, предшествующего среднему классу
\(f = \)частота среднего класса
\(N = \)общее количество частота
\(h=\)высота медианного класса
Попытка пробных тестов
Режим
В наборе данных режим данных — это наблюдение с наибольшей частотой. Но невозможно рассчитать режим сгруппированного частотного распределения, просто взглянув на частоту. В таких обстоятельствах модальный класс используется для определения режима данных. Модальный класс содержит свойство режима. Формула для определения режима данных
Но невозможно рассчитать режим сгруппированного частотного распределения, просто взглянув на частоту. В таких обстоятельствах модальный класс используется для определения режима данных. Модальный класс содержит свойство режима. Формула для определения режима данных
Режим \( = l + \left( {\ frac {{{f_1} – {f_0}}}{{2\,{f_1} – {f_0} – {f_2}}}} \right) \times h\ )
Где,
\(l = \)нижняя граница модального класса
\({f_0} = \)частота класса, предшествующего модальному классу
\({f_1} = \)частота модального класса
\( {f_2} = \) частота класса, следующего за модальным классом
\(h = \)высота модального класса
Существует одна эмпирическая формула среди среднего, медианы и моды:
\({\rm{Mean}} — {\rm{Mode}} = 3\left( {{\rm{Mean}} — {\rm{Median}}} \right)\)
Изучите все концепции статистики
Диапазон
Разница между самым высоким и самым низким значением среди заданного набора данных называется диапазоном. n {\left| {{x_i} — A} \right|} }}{п}\)
n {\left| {{x_i} — A} \right|} }}{п}\)
Где,
\(MD\left( A \right) = \) Среднее отклонение относительно \(A\)
\(A = \) Среднее/медиана/мода
\(n = \) количество данных или наблюдений
Дисперсия
Дисперсия точек данных является мерой того, насколько они отличаются от среднего. Чем выше значение дисперсии, тем больше разброс данных от среднего, а чем меньше значение дисперсии, тем меньше разброс данных от среднего. Ожидание случайного набора квадратов отклонений данных от их среднего значения называется дисперсией. 92}} }}{N}} \)
\(N = \)Общее количество частот
Применение статистики в реальной жизни
Вот несколько примеров использования статистики в повседневной жизни.
1. Все медицинские исследования опираются на статистику. Врачи используют статистику, чтобы отслеживать, где должен быть младенец с точки зрения умственного развития. Врачи также используют статистику для оценки эффективности лечения.
2. Для моделей наблюдения, анализа и математического прогнозирования статистика имеет решающее значение. Чтобы прогнозировать будущие погодные условия, модели прогноза погоды строятся с использованием данных, которые сравнивают предыдущие погодные условия с текущими погодными условиями.
Для моделей наблюдения, анализа и математического прогнозирования статистика имеет решающее значение. Чтобы прогнозировать будущие погодные условия, модели прогноза погоды строятся с использованием данных, которые сравнивают предыдущие погодные условия с текущими погодными условиями.
3. Ежедневно корпорация производит тысячи товаров и следит за тем, чтобы продавались только самые качественные вещи. Корпорация не может протестировать каждый продукт. В результате организация применяет статистически обоснованное тестирование качества.
4. Для анализа акций фондовый рынок также использует статистические компьютерные модели. Биржевые аналитики используют статистические методы для сбора информации об экономике.
5. Розничные торговцы используют статистику для отслеживания всего, что они продают, и для отслеживания своих запасов. Ведущие ритейлеры по всему миру используют аналитику, чтобы определить, какие товары поставляются в какие магазины и когда. 9{{\rm{th}}}}{\rm{наблюдение}}}}{2} = \frac{{2 + 3}}{2} = 2,5\)
Следовательно, медиана данных равна \( 2. 5.\)
5.\)
Q.4. Вычислите среднее отклонение от среднего для следующих данных:
4,7,8,9,10,12,13,17
Ответ: среднее значение заданных данных.
\(\overline x = \frac{{4 + 7 + 8 + 9 + 10 + 12 + 13 + 17}} {8} = 10\)
| \({x_i}\) | \(\left| {{d_i}} \right| = \left| {{x_i} – \overline x } \right|\) | ||||||||||||
| \(4\) | \(6\) | ||||||||||||
| \(7\) | \(3\) | ||||||||||||
| \(8\) | \(2\) | ||||||||||||
| \(9\) | \(1\) | ||||||||||||
| \(10\) | \(0\) | ||||||||||||
| \(12\) | \(2\) | ||||||||||||
| \(13\) | 2 1 3 9132 \(3\) 9133 (17\)\(7\) | 9п {\ слева | {{d_i}} \right|} \)
| \(x:\) | \(3\) | \(8\) | \(13\) | \(18\) | \(23\) | (f:\) | \(7\) | \(10\) | \(15\) | \(10\) | \(6\) |
Подведение итогов
В этой статье мы узнали о статистике, формулах и решенных примерах и их применении в реальной жизни. Статистика играет важную роль в нашей повседневной жизни. Мы можем помочь людям с задачами по статистике, чтобы они могли понять важность статистики в повседневной жизни.
Статистика играет важную роль в нашей повседневной жизни. Мы можем помочь людям с задачами по статистике, чтобы они могли понять важность статистики в повседневной жизни.
Статистика широко используется в области медицинских исследований, прогнозов погоды, проверки качества, фондового рынка и т. д. Мы можем узнать о том, что произошло в прошлом и что может произойти в будущем, используя статистику.
Изучение показателей центральной тенденции
Часто задаваемые вопросы по формулам статистики
Вот некоторые из часто задаваемых вопросов о формулах статистики:
Q.1: Как запомнить формулы статистики?
Ответ: Чтобы запомнить формулы статистики, нам нужно продолжать практиковаться в ежедневном решении множества вопросов. Регулярное решение множества задач поможет запомнить формулы статистики.
Q.2: Что такое формула моды в статистике?
Ответ: В наборе данных модой данных является наблюдение с наибольшей частотой.