
Как линейная алгебра используется в машинном обучении?
В предыдущей статье речь шла о математическом анализе. Продолжая серию публикаций к запуску авторского «Онлайн-курса по математике в Data Science Lite», поговорим о применении линейной алгебры в машинном обучении (завершит цикл статья о теории вероятностей и статистике – прим. ред.). За примерами далеко ходить не нужно: напротив, очень трудно найти такую сферу машинного обучения, в которой не используется линейная алгебра. Причем не только ее основные методы, вроде операций с векторами и матрицами, но и продвинутые вроде сингулярного разложения матрицы (Singular Value Decomposition, SVD), метода главных компонент (Principal Component Analysis, PCA) и метода опорных векторов (Support Vector Machines, SVM). Последний – один из основных алгоритмов машинного обучения.
Далеко не каждый курс линейной алгебры, даже на математических факультетах, рассматривает все ее приложения в машинном обучении. (То же самое можно сказать и о статистике, которая также является одной из основ Data Science и машинного обучения). Это обусловливает необходимость специальных курсов математики для Data Science.
(То же самое можно сказать и о статистике, которая также является одной из основ Data Science и машинного обучения). Это обусловливает необходимость специальных курсов математики для Data Science.
Основы
Линейная алгебра работает с векторами и матрицами – а точнее, с их линейными комбинациями, также являющимися векторами и матрицами. Математически вектор можно представить набором действительных чисел:
Такой набор может представлять очень разные сущности: например, геометрический вектор в некоторой системе координат (при этом числа ai умножаются на векторы базиса), полином (числа ai умножаются на xi) и вообще любую линейную комбинацию каких-либо элементов. Матрица – это такой же набор действительных чисел, но организованный в виде прямоугольника. Матрицу тоже можно представить в виде длинного вектора, если поставить ее столбцы друг на друга.
Что в машинном обучении можно представить в виде векторов и матриц? Практически всё! Например, одна строка из набора данных – это вектор, каждый элемент которого представляет значение некоторого признака. Весь тренировочный набор данных (или, в случае нейронной сети, один batch из этого набора) – это матрица. Изображение, которое будет распознавать сверточная нейронная сеть – тоже матрица чисел, соответствующих отдельным пикселям. Градиент функции потерь – это вектор, и так далее.
Произведение векторов, умножение матрицы на вектор и произведение матриц – все это используется в машинном обучении. Например, модель линейной регрессии с вектором весов w и вектором признаков x можно записать в виде произведения векторов, если добавить в вектор признаков x[0] = 1:
Поскольку результат линейной регрессии – произведение векторов, произведение матрицы тренировочного набора данных на вектор весов дает вектор предсказаний модели. Если вычесть из него вектор истинных значений, получится вектор ошибок, который можно передать в функцию потерь.
Если вычесть из него вектор истинных значений, получится вектор ошибок, который можно передать в функцию потерь.
В качестве примера перемножения матриц представим, что у нас есть набор изображений для обучения сверточной нейронной сети, и мы хотим дополнить этот набор поворотами этих изображений, чтобы сеть могла распознавать изображения независимо от их наклона. Поворот изображения – это частный случай умножения матрицы векторов координат на матрицу трансформации, которую также изучает линейная алгебра. Матрица трансформации для поворота координат на угол theta выглядит так:
Измерения
Норма вектора – это термин линейной алгебры, определяющий длину вектора и расстояние между векторами (как длину разности между ними). Существуют нормы различных порядков, но обычно используются только первые два:
Геометрическое место точек, у которых норма равна единице: L1 (слева) и L2 (справа)Норма L2(x-y) – это расстояние между векторами x и y. Обе нормы используются в машинном обучении для регуляризации функции потерь: лассо-регуляризация использует L1, регуляризация Тихонова – L2, а эластичная сеть – и ту, и другую.
Обе нормы используются в машинном обучении для регуляризации функции потерь: лассо-регуляризация использует L1, регуляризация Тихонова – L2, а эластичная сеть – и ту, и другую.
Косинус угла между двумя векторами x и y линейная алгебра определяет так:
Эта формула – самый популярный метод оценки сходства двух векторов. Если косинус угла близок к единице, то угол между векторами минимален, то есть векторы направлены почти одинаково. Если он близок к минус единице, векторы направлены почти противоположно. Наконец, если косинус близок к нулю, то векторы перпендикулярны (ортогональны), то есть, совершенно не зависят друг от друга.
Измерение меры сходства используется в машинном обучении очень широко – например, рекомендательные системы часто измеряют сходство векторов пользователей по их предпочтениям, и на основании этого сходства принимается решение, что похожим пользователям можно рекомендовать продукты, которые уже понравились одному из них.
Разумеется, оценка сходства широко применяется и в моделях кластеризации – например, метод k-Nearest Neighbors размечает кластеры именно по степени сходства элементов друг с другом.
Сингулярное разложение матриц (SVD)
Квадратная матрица называется ортогональной, если все ее столбцы ортонормальны – норма каждого из них равна единице, и все они попарно ортогональны, то есть образуют ортонормальный базис. Ортогональные матрицы обладают следующими свойствами:
Сингулярное разложение матрицы вводится следующей теоремой линейной алгебры: любую невырожденную прямоугольную матрицу Am*n можно представить в виде произведения трех матриц Um*m, Em*n и Vn*n, где U и V – ортогональные матрицы, а E – прямоугольная матрица, в которой все элементы, кроме диагональных, равны нулю.
Сингулярное разложение широко используется в рекомендательных системах. Оно позволяет найти базисы пространства строк и пространства столбцов, то есть элементарные признаки обоих пространств. Например, если строки матрицы соответствуют читателям, столбцы – книгам, а сама матрица содержит оценки, которые пользователи поставили книгам, то сингулярное разложение матрицы выделит «типичных читателей» и «типичные книги». Каждого реального читателя и каждую реальную книгу можно представить линейной комбинацией «типичных», после чего будет достаточно легко рассчитать ожидаемую оценку любой книги любым читателем.
Методов, позволяющих современным компьютерам обрабатывать огромные разреженные матрицы пользовательских оценок за приемлемое время, очень мало, так что сингулярное разложение матриц применяется очень широко.
Метод главных компонент (PCA)
Метод главных компонент – один из основных методов сокращения размерности данных, используемых в машинном обучении. Сокращение размерности применяется как при анализе данных, чтобы найти наиболее важные переменные и сконструировать новые признаки на их основе, так и при моделировании, если количество признаков очень велико, и большинство из них слабо влияют на результат. Метод главных компонент находит такую проекцию данных на пространство меньшей размерности, которая максимально сохраняет дисперсию данных.
Сокращение размерности применяется как при анализе данных, чтобы найти наиболее важные переменные и сконструировать новые признаки на их основе, так и при моделировании, если количество признаков очень велико, и большинство из них слабо влияют на результат. Метод главных компонент находит такую проекцию данных на пространство меньшей размерности, которая максимально сохраняет дисперсию данных.
Продемонстрируем работу метода главных компонент на примере двухмерного набора данных, который мы будем проецировать на одномерное подпространство (линию). Метод состоит из нескольких шагов:
- Вычитаем среднее значение, чтобы набор данных имел среднее значение 0. Это сокращает риск возникновения числовых проблем.
- Стандартизируем. Делим элементы данных на стандартное отклонение sigmad по каждому измерению d.
 Теперь данные не имеют единиц измерения, а их дисперсия по каждой оси равна 1, что отмечено на рис. в) голубыми стрелками.
Теперь данные не имеют единиц измерения, а их дисперсия по каждой оси равна 1, что отмечено на рис. в) голубыми стрелками. - Выполняем спектральное разложение матрицы ковариации. Вычисляем матрицу ковариации данных, ее собственные векторы и собственные значения. На рис. г) собственные векторы масштабированы соответствующими собственными значениями (голубые стрелки), и более длинный вектор соответствует подпространству главных компонент. Матрица ковариации данных изображена в виде эллипса.
- Проецируем данные в подпространство. Рисунок е) показывает итоговую проекцию, перенесенную в исходное пространство данных.
 Теперь данные не имеют единиц измерения, а их дисперсия по каждой оси равна 1, что отмечено на рис. в) голубыми стрелками.
Теперь данные не имеют единиц измерения, а их дисперсия по каждой оси равна 1, что отмечено на рис. в) голубыми стрелками.Из описания метода главных компонент видно, что в нем используются понятия не только линейной алгебры, но и статистики (среднее значение, дисперсия, отклонение, матрица ковариации). Тем не менее, основные операции выполняются методами линейной алгебры, ведь именно она описывает проекции из одного пространства в другое, собственные векторы и собственные значения, а также спектральное разложение матриц.
Метод опорных векторов (SVM)
Один из основных методов построения моделей машинного обучения – это метод опорных векторов (Support Vector Machine). Этот метод основан на построении гиперплоскости, максимально разделяющей объекты разных классов – то есть, обеспечивающей максимальное расстояние между граничными точками. Мы не будем вдаваться в детали его реализации, поскольку они достаточно сложны и выходят за рамки нашей статьи. Метод очень подробно, с примерами кода и анимацией, описан в статье на Хабре, откуда взята следующая иллюстрация:
Метод опорных векторов широко используется для задач бинарной классификации, а также сегментации изображений и многих других задач. Существует множество различных вариаций этого метода, причем он позволяет задать спрямляющее ядро, при правильном выборе которого результирующая модель зачастую оказывается более точной, чем модели на основе нейронных сетей – однако это ядро невозможно подобрать автоматически, так что его выбор представляет собой искусство Data Scientist’а.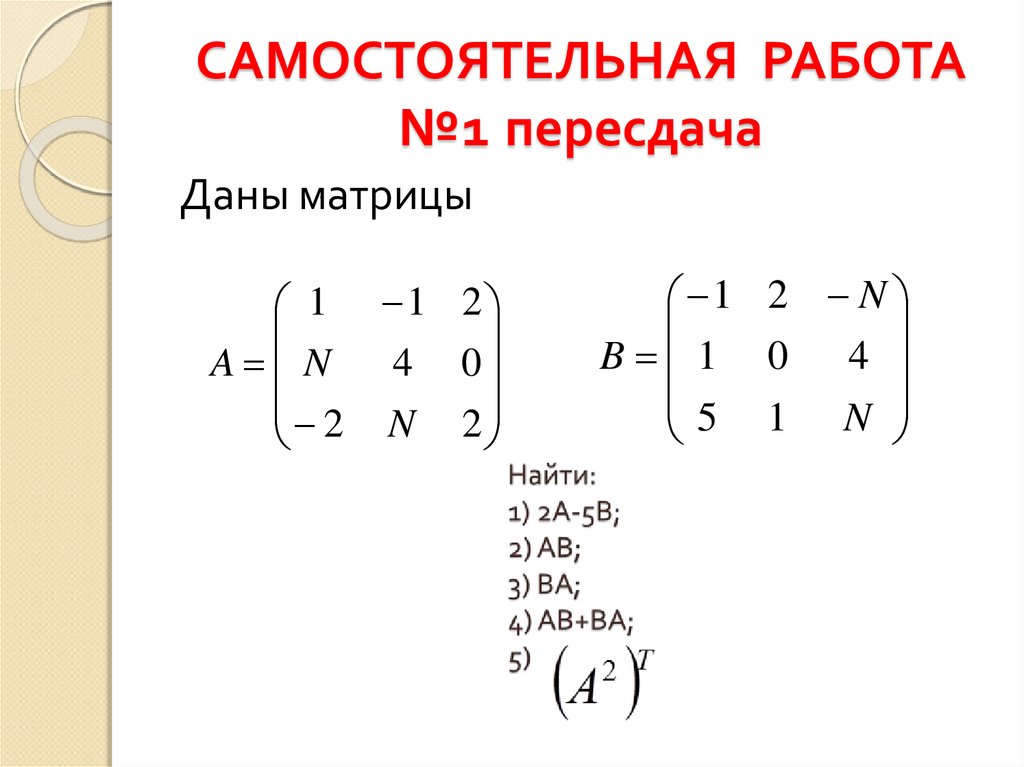 Метод хорошо работает с данными небольшого объема и с данными, имеющими большое количество признаков.
Метод хорошо работает с данными небольшого объема и с данными, имеющими большое количество признаков.
Для нас главное – то, что векторы и гиперплоскости относятся к линейной алгебре, как и весь метод в целом, и для его успешного применения, а также для правильной интерпретации его результатов, хорошее знание линейной алгебры просто необходимо.
Заключение
Мы рассмотрели только самые важные и очевидные приложения линейной алгебры в машинном обучении, но из приведенных примеров понятно, насколько широко она применяется, и насколько глубоко требуется ее знать для уверенного понимания хотя бы основных методов. Разумеется, для реальной работы в области машинного обучения придется изучить намного больше, чем описано в этой статье (предыдущая публикация была посвящена приложениям математического анализа, а в следующей речь пойдет о теории вероятностей и статистике – прим. ред.).
ред.).
Надеюсь, что вы по-настоящему любите математику, или, по крайней мере, она вас не пугает.
***
Если вы хотите наработать необходимую для изучения Data Science математическую базу и подготовиться к углубленным занятиям в «Школе обработки данных» или Computer Science Center, обратите внимание на онлайн-курс «Библиотеки программиста». С помощью опытных преподавателей из ведущих вузов страны сделать это будет намного проще, чем самостоятельно по книгам.
Интересно, хочу попробовать
Линейная алгебра для Data Science и Machine Learning / Хабр
Линейная алгебра в Data Science и Machine Learning является основополагающей. Новички, начинающие свой путь обучения в области Data Science, а также признанные практики должны развить хорошее понимание основных понятий линейной алгебры.
Специально к новому старту курса математика и Machine Learning для Data Science делимся переводом статьи Бенджамина Оби Тайо — физика, кандидата наук и преподавателя Data Science — о том, что нужно знать, чтобы лучше понимать Data Science и Machine Learning.
Линейная алгебра — это раздел математики, который чрезвычайно полезен в Data Science и машинном обучении. Владение линейной алгеброй — это также самый важный математический навык в машинном обучении. Большинство моделей машинного обучения могут быть выражены в матричном виде. Сам набор данных часто представляется в виде матрицы. Линейная алгебра используется при предварительной обработке данных, в преобразовании данных и оценке моделей. Вот темы, с которыми вы должны быть знакомы:
Векторы.
Матрицы.
Транспонирование матрицы.
Обратная матрица.
Определитель матрицы.
След матрицы.
Скалярное произведение.
Собственные значения.
Собственные векторы.
В этой статье мы проиллюстрируем применение линейной алгебры в Data Science и Machine Learning с использованием набора данных рынка технологических акций, который можно найти здесь.
Линейная алгебра для предварительной обработки данных
Мы начнём с иллюстрации того, как линейная алгебра применяется для предварительной обработки данных.
Импорт необходимых библиотек линейной алгебры
import numpy as np import pandas as pd import pylab import matplotlib.pyplot as plt import seaborn as sns
Чтение набора данных и отображение признаков
data = pd.read_csv("tech-stocks-04-2021.csv")
data.head()Таблица 1. Цены на акции за первые 16 дней апреля 2021 года.print(data.shape) output = (11,5)
Функция data.shape позволяет нам узнать размерность нашего набора данных. В этом случае набор данных содержит 5 признаков (date, AAPL, TSLA, GOOGL и AMZN) и каждый содержит 11 наблюдений. Дата (date) относится к торговым дням в апреле 2021 года (до 16 апреля). AAPL, TSLA, GOOGL и AMZN — это цены закрытия акций Apple, Tesla, Google и Amazon соответственно.
Визуализация данных
Чтобы выполнить визуализацию данных, нужно определить столбцовые матрицы визуализируемых признаков:
x = data['date'] y = data['TSLA'] plt.plot(x,y) plt.xticks(np.array([0,4,9]), ['Apr 1','Apr 8','Apr 15']) plt.Рисунок 1. Цена акций Tesla за первые 16 дней апреля 2021 года.
 title('Tesla stock price (in dollars) for April 2021',size=14)
plt.show()
title('Tesla stock price (in dollars) for April 2021',size=14)
plt.show()Ковариационная матрица
Ковариационная матрица является одной из наиболее важных матриц в Data Science и Machine Learning. Она предоставляет информацию о совместном движении (корреляции) между признаками. Предположим, у нас есть матрица признаков с 4 признаками и n наблюдениями, как показано в таблице 2:
Таблица 2. Матрица признаков с 4 переменными и n наблюдениямиЧтобы визуализировать корреляции между признаками, мы можем сгенерировать диаграмму рассеяния:
cols=data.columns[1:5] print(cols) output = Index(['AAPL', 'TSLA', 'GOOGL', 'AMZN'], dtype='object') sns.pairplot(data[cols], height=3.0)Рисунок 2. Парная диаграмма рассеяния для выбранных технологических акций.
где μ и σ — среднее значение и стандартное отклонения признака соответственно. Это уравнение указывает, что при нормализации признаков матрица ковариации представляет собой просто точечное произведение между признаками.
Эта матрица может быть преобразована в диагональную путём выполнения унитарного преобразования, также называемого преобразованием анализа главных компонентов (PCA), чтобы получить следующее:
Поскольку след матрицы при унитарном преобразовании остаётся инвариантным, мы наблюдаем, что сумма собственных значений диагональной матрицы равна общей дисперсии, содержащейся в признаках X1, X2, X3 и X4.
Вычисление ковариационной матрицы для технологических акций
from sklearn.preprocessing import StandardScaler stdsc = StandardScaler() X_std = stdsc.fit_transform(data[cols].iloc[:,range(0,4)].values) cov_mat = np.cov(X_std.T, bias= True)
Обратите внимание, что при этом используется транспонирование нормализованной матрицы.
Визуализация ковариационной матрицы
plt.figure(figsize=(8,8)) sns.set(font_scale=1.2) hm = sns.Рисунок 3. График ковариационной матрицы для выбранных технологических акций
 heatmap(cov_mat,
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 12},
yticklabels=cols,
xticklabels=cols)
plt.title('Covariance matrix showing correlation coefficients')
plt.tight_layout()
plt.show()
heatmap(cov_mat,
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 12},
yticklabels=cols,
xticklabels=cols)
plt.title('Covariance matrix showing correlation coefficients')
plt.tight_layout()
plt.show()Из рисунка 3 видно, что AAPL сильно коррелирует с GOOGL и AMZN и слабо с TSLA. TSLA обычно слабо коррелирует с AAPL, GOOGL и AMZN, в то время как AAPL, GOOGL и AMZN сильно коррелируют друг с другом.
Вычисление собственных значений ковариационной матрицы
np.linalg.eigvals(cov_mat) output = array([3.41582227, 0.4527295 , 0.02045092, 0.11099732]) np.sum(np.linalg.eigvals(cov_mat)) output = 4.000000000000006 np.trace(cov_mat) output = 4.000000000000001
Мы наблюдаем, что, как и ожидалось, след ковариационной матрицы равен сумме собственных значений.
Вычисление кумулятивной дисперсии
Поскольку след матрицы остаётся инвариантным при унитарном преобразовании, мы наблюдаем, что сумма собственных значений диагональной матрицы равна общей дисперсии, содержащейся в признаках X1, X2, X3 и X4. Следовательно, мы можем определить следующие величины:
Следовательно, мы можем определить следующие величины:
Обратите внимание, что когда p = 4, кумулятивная дисперсия, как и ожидалось, становится равной 1.
eigen = np.linalg.eigvals(cov_mat) cum_var = eigen/np.sum(eigen) print(cum_var) output = [0.85395557 0.11318237 0.00511273 0.02774933] print(np.sum(cum_var)) output = 1.0
Из кумулятивной дисперсии (cum_var) мы видим, что 85 % дисперсии содержатся в первом собственном значении и 11 % — во втором. Это означает, что при реализации PCA могут использоваться только первые два основных компонента, поскольку 97 % общей дисперсии приходятся на эти 2 компонента. Это может существенно уменьшить размерность пространства признаков (с 4 до 2), когда реализован PCA.
Матрица линейной регрессии
Предположим, у нас есть набор данных, который имеет 4 признака предиктора и n наблюдений, как показано ниже.
Таблица 3. Матрица признаков с 4 переменными и n наблюдениями. Столбец 5 — целевая переменная (y)Мы хотели бы построить модель множественной регрессии для прогнозирования значений y (столбец 5). Таким образом, наша модель может быть выражена так:
Таким образом, наша модель может быть выражена так:
.
В матричном виде это уравнение можно записать так:
где X — матрица признаков (n x 4), w — матрица (4 x 1), представляющая определяемые коэффициенты регрессии, и y — матрица (n x 1), содержащая n наблюдений целевой переменной y.
Обратите внимание, что X является прямоугольной матрицей, поэтому мы не можем решить приведённое выше уравнение, взяв обратную X величину.
Чтобы преобразовать X в квадратную матрицу, мы умножаем левую и правую части нашего уравнения на транспонирование из X, то есть:
Это уравнение можно записать так:
Где
является матрицей регрессии (4×4). Мы наблюдаем, что R — это вещественная и симметричная матрица. Обратите внимание, что в линейной алгебре транспонирование произведения двух матриц подчиняется следующему соотношению:
Теперь, когда мы сократили нашу задачу регрессии и выразили её в терминах (4×4) вещественной, симметричной и обратимой матрицы регрессии R, легко показать, что точное решение уравнения регрессии выглядит так:
.
Примеры регрессионного анализа для прогнозирования непрерывных и дискретных переменных приведены ниже:
Матрица линейного дискриминантного анализа
Другим примером реальной и симметричной матрицы в Data Science является матрица линейного дискриминантного анализа (LDA). Эта матрица может быть выражена так:
Где SW — матрица рассеяния в пределах признака (the within-feature scatter matrix), а SB — матрица рассеяния между признаками. Поскольку обе матрицы SW и SB вещественны и симметричны, из этого следует, что L также вещественна и симметрична. Диагонализация L создаёт подпространство признаков, которое оптимизирует раздельность классов и уменьшает размерность. Следовательно, LDA является алгоритмом обучения с учителем, а PCA — нет.
Чтобы узнать больше о реализации LDA, пожалуйста, ознакомьтесь со следующими ссылками:
Репозиторий GitHub для реализации LDA с использованием набора данных Iris.
Машинное обучение Python от Себастьяна Рашки, 3-е изд.
(глава 5).
 (глава 5).
(глава 5).Резюме
Итак, мы обсудили несколько применений линейной алгебры в Data Science и машинном обучении. Используя набор данных рынка технологических акций, мы проиллюстрировали важные понятия, такие как размер матрицы, столбцовые матрицы, квадратные матрицы, ковариационные матрицы, транспонирование матрицы, собственные значения, точечные произведения и т. д.
Линейная алгебра является важным инструментом в Data Science и машинном обучении. Таким образом, новички, интересующиеся Data Science, должны ознакомиться с основными понятиями линейной алгебры.
Чтобы в деталях разобраться с внутренней механикой Data Science, не оставив без внимания машинное обучение, вы можете присмотреться к нашему курсу математика и Machine Learning для Data Science, где опытные менторы и эксперты в своём деле ответят на сложные вопросы, устранят неясности и правильно направят ваши размышления, чтобы в дальнейшем вы решали сложные проблемы самостоятельно.
Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Профессия Data Scientist
Профессия Data Analyst
Курс по Data Engineering
ПРОФЕССИИ
Профессия Fullstack-разработчик на Python
Профессия Java-разработчик
Профессия QA-инженер на JAVA
Профессия Frontend-разработчик
Профессия Этичный хакер
Профессия C++ разработчик
Профессия Разработчик игр на Unity
Профессия Веб-разработчик
Профессия iOS-разработчик с нуля
Профессия Android-разработчик с нуля
КУРСЫ
Курс по Machine Learning
Курс «Machine Learning и Deep Learning»
Курс «Математика для Data Science»
Курс «Математика и Machine Learning для Data Science»
Курс «Python для веб-разработки»
Курс «Алгоритмы и структуры данных»
Курс по аналитике данных
Курс по DevOps
Линейная алгебра: Что на самом деле представляют собой матрицы
Большинство старшеклассников в США узнают о матрицах и умножении матриц, но их часто не учат почему умножение матриц работает именно так. Добавлять матрицы легко: вы просто добавляете соответствующие записи. Однако умножение матриц так не работает, и для того, кто не понимает теории матриц, этот способ умножения матриц может показаться чрезвычайно надуманным и странным. Чтобы по-настоящему понять матрицы, мы рассматриваем их как представление части более широкой картины. Матрицы представляют функций между пробелами, называемых векторными пространствами, и не просто любых функций, а линейных функций. Именно поэтому линейная алгебра фокусируется на матрицах. Два фундаментальных факта о матрицах состоят в том, что каждая матрица представляет некоторую линейную функцию и каждая линейная функция представлена матрицей . Поэтому на самом деле между матрицами и линейными функциями существует взаимно однозначное соответствие. Мы покажем, что умножение матриц соответствует составлению функций, которые они представляют. Попутно мы рассмотрим, для чего нужны матрицы и почему вообще возникла линейная алгебра.
Добавлять матрицы легко: вы просто добавляете соответствующие записи. Однако умножение матриц так не работает, и для того, кто не понимает теории матриц, этот способ умножения матриц может показаться чрезвычайно надуманным и странным. Чтобы по-настоящему понять матрицы, мы рассматриваем их как представление части более широкой картины. Матрицы представляют функций между пробелами, называемых векторными пространствами, и не просто любых функций, а линейных функций. Именно поэтому линейная алгебра фокусируется на матрицах. Два фундаментальных факта о матрицах состоят в том, что каждая матрица представляет некоторую линейную функцию и каждая линейная функция представлена матрицей . Поэтому на самом деле между матрицами и линейными функциями существует взаимно однозначное соответствие. Мы покажем, что умножение матриц соответствует составлению функций, которые они представляют. Попутно мы рассмотрим, для чего нужны матрицы и почему вообще возникла линейная алгебра.
Скорее всего, если вы изучали алгебру в старшей школе, вы видели что-то вроде следующего:
Ваш школьный учитель алгебры, вероятно, сказал вам, что это «матрица». Затем вы узнали, как работать с матрицами. Например, вы можете сложить две матрицы, и операция довольно интуитивно понятна:
Вы также можете вычесть матрицы, что работает аналогично. Вы можете умножить матрицу на число:
Потом, когда вас учили умножать матрицы, все казалось неправильным:
То есть, чтобы найти запись в -й строке, -м столбце произведения, вы смотрите на -ю строку первой матрицы, -й столбец второй матрицы, вы перемножаете их соответствующие числа, а затем вы суммируете результаты, чтобы получить запись в этой позиции. В приведенном выше примере запись 1-й строки и 2-го столбца равна a, потому что 1-я строка первой матрицы равна , 2-й столбец второй матрицы равен , и у нас есть . Более того, это означает, что умножение матриц даже не является коммутативным! Если мы поменяем порядок умножения выше, мы получим
Почему матричное умножение работает не так, как сложение и вычитание? И если умножение работает таким образом, как, черт возьми, работает деление? Цель этого поста — ответить на эти вопросы.
Чтобы понять, почему умножение матриц работает таким образом, необходимо понять, что такое матрицы на самом деле. Но прежде чем мы перейдем к этому, давайте кратко рассмотрим, почему мы вообще заботимся о матрицах. Самое основное применение матриц — решение систем линейных уравнений. Линейное уравнение — это уравнение, в котором все переменные появляются сами по себе без степеней; они не умножаются ни друг на друга, ни на самих себя, и никаких забавных функций тоже. Примером системы линейных уравнений является
Решение этой системы . Такие уравнения кажутся простыми, но они легко возникают в жизни. Например, предположим, что у меня есть два друга Алиса и Боб, которые пошли в магазин за конфетами. Алиса купила 2 плитки шоколада и 1 пакет кеглей и потратила 3 доллара, тогда как Боб купил 4 плитки шоколада и 3 пакета кеглей и потратил 7 долларов. Если мы хотим выяснить, сколько стоят шоколадные батончики и кегли, пусть это будет цена плитки шоколада и цена пакета кеглей, а переменные будут удовлетворять приведенной выше системе линейных уравнений. Следовательно, мы можем сделать вывод, что плитка шоколада стоит 1 доллар, как и пакет кеглей. Эту систему было особенно легко решить, потому что можно угадать и проверить решение, но в целом с переменными и уравнениями вместо 2 это намного сложнее. Вот где на помощь приходят матрицы! Обратите внимание, что путем матричного умножения приведенная выше система линейных уравнений может быть переписана как
Следовательно, мы можем сделать вывод, что плитка шоколада стоит 1 доллар, как и пакет кеглей. Эту систему было особенно легко решить, потому что можно угадать и проверить решение, но в целом с переменными и уравнениями вместо 2 это намного сложнее. Вот где на помощь приходят матрицы! Обратите внимание, что путем матричного умножения приведенная выше система линейных уравнений может быть переписана как
Если бы мы только могли найти матрицу, обратную матрице , так что, если бы мы умножили обе части уравнения (слева) на мы получили бы
Применение матриц простирается далеко помимо этой простой проблемы, но сейчас мы будем использовать это в качестве нашей мотивации. Вернемся к пониманию того, что такое матрицы. Чтобы понять матрицы, мы должны знать, что такое векторы. Векторное пространство является набором с определенной структурой, а вектор — это просто элемент векторного пространства. На данный момент, для технической простоты, мы будем использовать векторные пространства над действительными числами, также известные как вещественных векторных пространств . Реальное векторное пространство — это в основном то, о чем вы думаете, когда думаете о пространстве. Числовая прямая представляет собой одномерное вещественное векторное пространство, плоскость x-y представляет собой двумерное вещественное векторное пространство, трехмерное пространство представляет собой трехмерное вещественное векторное пространство и так далее. Если вы узнали о векторах в школе, то вы, вероятно, привыкли думать о них как о стрелках, которые можно сложить, умножить на действительное число и так далее, но умножение векторов работает по-другому. Это звучит знакомо? Должно. Именно так работают матрицы, и это не случайно.
Реальное векторное пространство — это в основном то, о чем вы думаете, когда думаете о пространстве. Числовая прямая представляет собой одномерное вещественное векторное пространство, плоскость x-y представляет собой двумерное вещественное векторное пространство, трехмерное пространство представляет собой трехмерное вещественное векторное пространство и так далее. Если вы узнали о векторах в школе, то вы, вероятно, привыкли думать о них как о стрелках, которые можно сложить, умножить на действительное число и так далее, но умножение векторов работает по-другому. Это звучит знакомо? Должно. Именно так работают матрицы, и это не случайно.
Самый важный факт о векторных пространствах заключается в том, что они всегда имеют основу. базис векторного пространства — это набор векторов, такой, что любой вектор в пространстве может быть записан как линейная комбинация этих базисных векторов. Если ваши базисные векторы, то это линейная комбинация, если это действительные числа. Конкретный пример следующий: основой для плоскости x-y являются векторы . Любой вектор имеет форму, которую можно записать как
Конкретный пример следующий: основой для плоскости x-y являются векторы . Любой вектор имеет форму, которую можно записать как
, так что у нас действительно есть основа! Это не единственное возможное основание. На самом деле векторы в нашем базисе даже не обязательно должны быть перпендикулярны! Например, векторы образуют основу, так как мы можем написать
.
Теперь линейное преобразование является просто функцией между двумя векторными пространствами, которая оказывается линейной . Быть линейным — чрезвычайно приятное свойство. Функция является линейной, если выполняются следующие два свойства:
Например, функция, определенная на реальной линии, не является линейной, поскольку тогда как . Теперь мы соединяем воедино все идеи, о которых мы говорили до сих пор: матрицы, базис и линейные преобразования. Связь в том, что 9Матрицы 0007 представляют собой линейные преобразования , и вы можете понять, как записать матрицу, увидев, как она действует на основе. Чтобы понять первое утверждение, нам нужно понять, почему верно второе. Идея состоит в том, что любой вектор представляет собой линейную комбинацию базисных векторов, поэтому вам нужно только знать, как линейное преобразование влияет на каждый базисный вектор. Это потому, что, поскольку функция линейна, если у нас есть произвольный вектор, который можно записать в виде линейной комбинации , то
Чтобы понять первое утверждение, нам нужно понять, почему верно второе. Идея состоит в том, что любой вектор представляет собой линейную комбинацию базисных векторов, поэтому вам нужно только знать, как линейное преобразование влияет на каждый базисный вектор. Это потому, что, поскольку функция линейна, если у нас есть произвольный вектор, который можно записать в виде линейной комбинации , то
Обратите внимание, что значение полностью определяется значениями , так что это вся информация, необходимая для полного определения линейного преобразования. При чем здесь матрица? Что ж, как только мы выберем основу как для домена, так и для цели линейного преобразования, столбцы матрицы будут представлять изображения базисных векторов под функцией. Например, предположим, что у нас есть линейное преобразование, которое отображается на , что означает, что оно принимает трехмерные векторы и выдает двумерные векторы. Прямо сейчас это просто какая-то абстрактная функция, которую мы не можем записать на бумаге. Давайте выберем основу как для нашей области (3-пространство), так и для нашей цели (2-пространство или плоскость). Хороший выбор будет для первого и для второго. Все, что нам нужно знать, это то, как влияет на , а основой для цели является конкретное запись значений. Матрица для нашей функции будет матрицей 2 на 3, где 3 столбца проиндексированы , а 2 строки проиндексированы . Все, что нам нужно записать, это значения. Для конкретности, скажем,
Давайте выберем основу как для нашей области (3-пространство), так и для нашей цели (2-пространство или плоскость). Хороший выбор будет для первого и для второго. Все, что нам нужно знать, это то, как влияет на , а основой для цели является конкретное запись значений. Матрица для нашей функции будет матрицей 2 на 3, где 3 столбца проиндексированы , а 2 строки проиндексированы . Все, что нам нужно записать, это значения. Для конкретности, скажем,
Тогда соответствующая матрица будет
Причина, по которой это работает, заключается в том, что умножение матриц было разработано таким образом, что если вы умножаете матрицу на вектор со всеми нулями, кроме 1 в -й записи, то результат это просто -й столбец матрицы. Вы можете проверить это сами. Итак, мы знаем, что матрица работает правильно, когда применяется к базисным векторам (умножается на них). Но также матрицы удовлетворяют тем же свойствам, что и линейные преобразования, а именно и , где — векторы и — действительное число. Поэтому работает для всех векторов, так что это правильное представление . Обратите внимание, что если бы мы выбрали разные векторы для базисных векторов, матрица выглядела бы иначе. Следовательно, матрицы не являются естественными в том смысле, что они зависят от того, какие основания мы выбираем.
Поэтому работает для всех векторов, так что это правильное представление . Обратите внимание, что если бы мы выбрали разные векторы для базисных векторов, матрица выглядела бы иначе. Следовательно, матрицы не являются естественными в том смысле, что они зависят от того, какие основания мы выбираем.
Теперь, наконец, ответ на поставленный в начале вопрос. Почему умножение матриц работает именно так? Давайте посмотрим на две матрицы, которые у нас были в начале: и . Мы знаем, что они соответствуют линейным функциям на плоскости, обозначим их и соответственно. Умножение матриц соответствует составлению их функций. Поэтому делать то же самое, что и для любого вектора. Чтобы определить, как должна выглядеть матрица, мы можем посмотреть, как она влияет на базисные векторы. У нас есть
, поэтому первый столбец должен быть , и
, поэтому второй столбец должен быть . Действительно, это согласуется с ответом, который мы получили в начале путем умножения матриц! Хотя это вовсе не строгое доказательство, поскольку это всего лишь пример, оно улавливает идею о том, почему умножение матриц такое, какое оно есть.
Теперь, когда мы понимаем, как и почему работает умножение матриц, как работает деление матриц? Вы, вероятно, знакомы с функциональными инверсиями. обратная функция — это такая функция, что для всех . Поскольку умножение матриц соответствует композиции функций, имеет смысл только то, что мультипликативная обратная матрица является композиционной обратной соответствующей функции. Вот почему не все матрицы имеют мультипликативные обратные. Некоторые функции не имеют композиционных инверсий! Например, линейная функция, отображаемая на определенную, не имеет обратной, поскольку многие векторы отображаются на одно и то же значение (что будет? ? ?). Это соответствует тому факту, что матрица 1 × 2 не имеет мультипликативной обратной. Таким образом, деление на матрицу — это просто умножение на , если оно существует. Существуют алгоритмы вычисления обратных матриц, но мы оставим их для другого поста.
Нравится:
Нравится Загрузка…
линейная алгебра — Что такое матрица?
1. Определение матрицы.
Определение матрицы.
Вопрос о том, что такое матрица , точнее , возник у меня давно, когда я был старшеклассником. Потребовалось много попыток, чтобы получить прямой ответ, потому что люди склонны путать «матрицу» с «линейным преобразованием». Они тесно связаны, но НЕ одно и то же. Итак, позвольте мне начать со строгого определения матрицы:
Матрица размером $m$ на $n$ является функцией двух переменных, первая из которых имеет область определения $\{1,2,\dots,m\}$, а вторая имеет область определения $\{1,2 ,\точки,n\}$.
Это формальное определение матриц, но мы обычно о них не думаем. У нас есть специальное обозначение для матриц — «ящик чисел», с которым вы знакомы, где значение функции в $(1,1)$ помещается в верхний левый угол, значение в $(2,1)$ помещается в верхний левый угол. )$ ставится прямо под ним и т. д. Обычно мы думаем о матрице просто как об этом прямоугольнике и забываем, что это функция. Однако иногда вам нужно помнить, что матрица имеет более формальное определение, например, при реализации матриц на компьютере (большинство языков программирования имеют встроенные матрицы).
Дело в том, что матрицу можно использовать для многих вещей. Однако одно использование преобладает как наиболее распространенное и представляет линейных преобразований . Распространенность этого использования является причиной того, что люди часто объединяют эти два понятия. Линейное преобразование — это функция $f$ векторов, обладающая следующими свойствами:
- $f(x+y) = f(x) + f(y)$ для любых векторов $x$ и $y$.
- $f(ax) = af(x)$ для любого вектора $x$ и любого скаляра $a$.
Эти свойства гарантируют, что функция $f$ не имеет кривизны. Так что это похоже на прямую линию, но, возможно, в более высоких измерениях.
Связь между матрицами и линейными преобразованиями проистекает из того факта, что линейное преобразование полностью определяется значениями, которые оно принимает на основе для своего домена. T$. Таким образом, матрица $M$ полностью кодирует линейное преобразование $f$, а умножение матриц говорит вам, как его декодировать, т.е. как использовать матрицу для получения значений $f$.
T$. Таким образом, матрица $M$ полностью кодирует линейное преобразование $f$, а умножение матриц говорит вам, как его декодировать, т.е. как использовать матрицу для получения значений $f$.
3. Геометрическая интуиция.
На мой взгляд, самая важная теорема для понимания матриц и линейных преобразований — это теорема о разложении по сингулярным числам. Это говорит о том, что любое линейное преобразование можно записать как последовательность трех простых преобразований: поворот, растяжение и еще один поворот. Обратите внимание, что операция растяжения может растягиваться на разную величину в разных ортогональных направлениях. Это говорит вам о том, что все линейные преобразования представляют собой некоторую комбинацию вращения и растяжения.
Другие свойства матриц также часто имеют прямую геометрическую интерпретацию. Например, определитель говорит вам, как линейное преобразование изменяет объемы. С помощью разложения по сингулярным числам линейное преобразование превращает куб в своего рода растянутый и повернутый параллелограмм. Определитель — это отношение объема полученного параллелограмма к объему куба, с которого вы начали.
Определитель — это отношение объема полученного параллелограмма к объему куба, с которого вы начали.
Однако не все свойства матрицы можно легко связать со знакомыми геометрическими понятиями. Например, я не знаю хорошей геометрической картины для следа. Однако это не означает, что трассировка менее полезна или с ней легко работать!
4. Прочее имущество.
Почти все «свойства» и «операции» для матриц исходят из свойств линейных отображений и теорем о них. Например, стандартное умножение матриц разработано специально для получения значений линейных карт, как описано выше. Это НЕ единственный тип умножения, который может быть определен на матрицах, и на самом деле существуют другие типы умножения для матриц (например, произведение Адамара и произведение Кронекера). Эти другие типы умножения иногда полезны, но, как правило, не так полезны, как обычное матричное умножение, поэтому люди часто не знают (или не заботятся) о них.
5.