
Красоту можно расчитать
Самая красивая женщина в мире — Эмбер Херд (бывшая жена Джонни Деппа). По результатам измерений пропорций лица знаменитости западные эксперты назвали ее почти эталоном. Список состоит из многих известных красавиц, среди которых Мэрилин Монро, Хелен Миррен, Ким Кардашьян, Дженнифер Лоуренс и др.
Древнегреческий философ Пифагор рассчитал, что все прекрасное в мире подходит под формулу «золотого сечения» и соответствует определенным пропорциям, в том числе женское лицо. Джулиан де Сильва (британский пластический хирург) составил список знаменитых женщин, чьи черты лица максимально близки к эталону красоты. По результатам вычислений греческого философа коэффициент привлекательности составляет 1,618. Высота лица, деленная на ширину лица, составляет 1,618; ширина рта, деленная на ширину носа, составляет 1,618; расстояние между зрачками, деленное на расстояние между бровями, составляет 1,618 и так далее все отношения расстояний.
По итогам вычислений по формуле «золотого сечения» доктор Сильва определил, что лицо Эмбер Херд подходит под идеальные параметры на 91,85%. Второе место досталось Ким Кардашьян с коэффициентом соответствующим 91,39%. На третьем, четвертом и пятом местах оказались Кейт Мосс (91,06%), Эмили Ратайковски (90,08%) и Кендалл Дженнер (90,18%) соответствующе.
Доктор Сильва также произвел расчеты и по отдельным параметрам. Самый красивый нос оказался у Мэрилин Монро, Эмили Ратайковски, Эмбер Херд, Хелен Миррен и Скарлетт Йоханссон. Самые красивые глаза принадлежат Мэрилин Монро, актриса Скарлетт Йоханссон, модель Кейт Мосс, певица Рианна и модель Кара Делевинь. Мэрилин Монро, Натали Портман, Кайли Дженнер и Анджелина Джоли – получили первенство за самые красивые губы. Брови Ким Кардашьян, Селены Гомес, Эмбер Херд, Хелен Миррен и Кейт Мосс признаны лучшими по расчетам пластического хирурга. Скарлетт Йоханссон, Эмбер Херд, Анджелина Джоли, Эмили Ратайковски и Рианна.
Чтобы узнать, насколько вы близки к идеальным параметрам, нужно сделать селфи, распечатать его на листе бумаги A4 и произвести следующие вычисления:
Измерьте длину носа от перносицы до ноздрей
Измерьте самую широкую часть носа
Разделите длину носа на его ширину
Если получившееся число больше 1.
 618, то разделите 1.618 на него, если получилось меньше 1.618, то разделите получившееся число на 1.618
618, то разделите 1.618 на него, если получилось меньше 1.618, то разделите получившееся число на 1.618Итоговый результат — это и есть % идеальности вашего носа
Измерьте бровь от переносицы до изгиба (длина арки)
Измерьте условную прямую линию от начала брови до ее кончика (полная длина)
Разделите полную длину на длину арки
Если получившееся число больше 1.618, то разделите 1.618 на него, если получилось меньше 1.618, то разделите получившееся число на 1.618
Итоговый результат — это и есть % идеальности ваших бровей
Измерьте длину ваших губ от одного уголка рта до другого
Разделите длину губ на ширину носа (чем ближе получившееся число к 1,618, тем лучше)
 618, то разделите 1.618 на него, если получилось меньше 1.618, то разделите получившееся число на 1.618
618, то разделите 1.618 на него, если получилось меньше 1.618, то разделите получившееся число на 1.618Как рассчитать расход грунтовки на 1 м2 стены: нормы, пропорции
Содержание
- Факторы, влияющие на расход грунта
- Норма расхода грунтовки
- Грунтовка глубокого проникновения
- Акриловый грунт
Грунтование – важный этап отделки любого помещения. Перед поклейкой обоев, работ с гипсокартонном, нанесением штукатурки поверхность обязательно нужно загрунтовать. Чтобы правильно нанести грунтовку, важно точно рассчитать пропорции этого материала.
Перед поклейкой обоев, работ с гипсокартонном, нанесением штукатурки поверхность обязательно нужно загрунтовать. Чтобы правильно нанести грунтовку, важно точно рассчитать пропорции этого материала.
Факторы, влияющие на расход грунта
Количество грунтовки на 1 м2 зависит от следующих факторов:
- Вид обрабатываемой поверхности. Грунтовку можно наносить на дерево, сталь, гипсокартон и т.д. Большое значение имеет структура поверхности.
- Способ нанесения. При нанесении валиком или кистью требуется больше грунта, чем при распылении пульверизатором.
- Вид грунта. Разновидность грунта и его назначение определяют необходимый объем материала.
- Количество слоев. Чем больше слоев вы наносите, тем больше грунта понадобится.
- Влажность и температура. В сухом помещении при комнатной температуре вы израсходуете меньше грунта.
На каждой упаковке с грунтовкой производитель указывает, какое количество материала понадобится для нанесения на 1 м2. Однако реальный расход грунтовки будет зависеть от вышеперечисленных факторов.
Однако реальный расход грунтовки будет зависеть от вышеперечисленных факторов.
Норма расхода грунтовки
Как уже было сказано выше, количество грунтовки во многом зависит от материала, из которого изготовлена поверхность.
Так, на один квадратный метр металла понадобится 80-90 гр грунтовки. Точное количество зависит от вида используемого материала. Стоит отметить, что в сравнении с остальными для нанесения на металл требуется меньше грунтовки. Это связано с тем, что этот материал не впитывает грунт.
Для обработки гипсокартона используют универсальные грунты, которые нужно наносить в один слой. На один квадратный метр понадобится 95-115 гр смеси.
Оштукатуренные стены отличаются повышенной пористостью, поэтому их нужно грунтовать в два слоя. Для нанесения на один квадратный метр необходимо 180-200 гр грунта.
Древесину и древесностружечные и древесноволокнистые поверхности обрабатывают акриловым грунтом.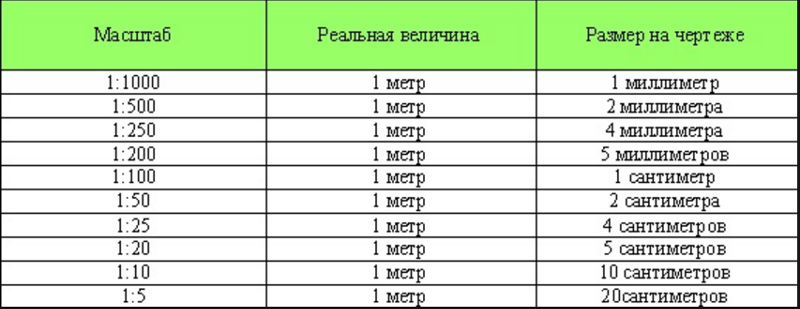 Для этих материалов необходимо 120-150 гр на один квадратный метр. Точное количество зависит от влажности и структуры поверхности.
Для этих материалов необходимо 120-150 гр на один квадратный метр. Точное количество зависит от влажности и структуры поверхности.
После пробного покрытия вы поймете, сколько точно понадобится грунтовки.
Количество грунта на 1 м2 зависит также от вида и назначения этого строительного материала:
- грунтовка бесконтакт – 400 гр;
- грунт глубокого проникновения – 160 гр;
- алкидный грунт – 150 гр;
- водно-дисперсионная грунтовка, которая наносится перед покраской – до 100 гр;
- специальный грунт под декоративную штукатурку – 200 гр;
- акриловый грунт – 120-140 гр;
- антикоррозионный грунт для защиты металла – 8 гр;
- влагоизоляционный грунт – 100 гр.
Грунтовка глубокого проникновения
Применение глубоко проникающей грунтовки требует значительно меньше клея, краски и штукатурки, предназначенных для покрытия пористой основы.
При повышенном поглощении грунта основой на один квадратный метр понадобится 180 гр. Этого хватит на один слой.
Акриловый грунт
Грунтовку на акриловой основе используют как для внутренней, так и для внешней отделки. Ее наносят на стены перед оштукатуриванием. На один квадратный метр понадобится примерно 130-150 гр акрилового грунта. При этом материал, из которого изготовлена поверхность, не имеет значения.
Зная, сколько грунта нужно на 1 м2 стены, вы сможете точно рассчитать необходимое количество этого строительного материала. Специалисты советуют не экономить на грунтовке: от этого покрытия зависит качество чистовой отделки стены.
Возможно вас заинтересует
Грунтовки
Грунт-Эмали
Шпатлевки
Сравнение пропорций с относительным риском и отношением шансов
Классическая таблица «два на два» отображает количество так называемых «успехов» и «неуспехов» в сравнении с некоторой двухуровневой группирующей переменной, такой как пол (мужской и женский) или лечение (плацебо и активный препарат). Пример одной такой таблицы приведен в книге «Введение в анализ категорийных данных» (Агрести, 1996, стр. 20). В таблице инфаркт миокарда классифицирован (да/нет) по группам (плацебо/аспирин). Данные были «взяты из отчета о взаимосвязи между употреблением аспирина и инфарктом миокарда (сердечными приступами) Исследовательской группы по изучению здоровья врачей Гарвардской медицинской школы».
Пример одной такой таблицы приведен в книге «Введение в анализ категорийных данных» (Агрести, 1996, стр. 20). В таблице инфаркт миокарда классифицирован (да/нет) по группам (плацебо/аспирин). Данные были «взяты из отчета о взаимосвязи между употреблением аспирина и инфарктом миокарда (сердечными приступами) Исследовательской группы по изучению здоровья врачей Гарвардской медицинской школы».
Давайте воспроизведем таблицу в R и отобразим ее.
# Таблица 2.3, стр. 20
MI <- матрица (c (189, 104, 10845, 10933), nrow = 2)
dimnames(MI) <- list("Группа" = c("Плацебо","Аспирин"), "MI" = c("Да","Нет"))
Ми
## МИ
## Группа Да Нет
## Плацебо 189 10845
## Аспирин 104 10933
Первая строка создает таблицу как матричный объект и присваивает ей имя «MI». Поскольку мы предоставляем 4 числа и указываем «nrow = 2», мы получаем таблицу 2 x 2. (Обратите внимание, что R по умолчанию заполняет матрицу по столбцам.) В следующей строке указаны имена измерений таблицы. Третья строка печатает таблицу.
Третья строка печатает таблицу.
На первый взгляд мы видим относительно небольшое количество врачей, перенесших инфаркт миокарда, который мы будем называть «ИМ». Мы можем рассчитать пропорции в R, используя функцию prop.table :
prop.table (MI, маржа = 1) ## МИ ## Группа Да Нет ## Плацебо 0,01712887 0,9828711 ## Аспирин 0,00942285 0,9905771
Мы указываем «margin = 1», поэтому пропорции рассчитываются построчно. Мы видим, что доля ИМ («Да») для обеих групп не только мала, но и довольно близка. Группа плацебо составила около 2%, а группа аспирина — около 1%.
Давайте теперь поработаем с этой таблицей и посмотрим, как мы можем сравнить эти пропорции. Мы рассмотрим многое из того, что представлено на страницах 20–25 Agresti, но мы предоставим код R, чтобы показать, как выполнять вычисления.
Разница пропорций
Обычный подход к сравнению пропорций состоит в том, чтобы вычесть одну из другой и посмотреть на разницу. Конечно, если наши данные являются выборкой, рассчитанная разница в пропорциях является всего лишь оценкой. Если бы мы взяли другую выборку и вычислили разницу в пропорциях, то получили бы другую оценку. Поэтому нам нужно рассчитать стандартную ошибку для разницы в пропорциях, чтобы дать нам некоторое представление о ее изменчивости. Затем мы можем использовать эту стандартную ошибку для формирования доверительного интервала. Чтобы узнать подробности, мы отсылаем вас к любой вводной книге по статистике или к Google. Пока давайте просто сделаем это в R.
Конечно, если наши данные являются выборкой, рассчитанная разница в пропорциях является всего лишь оценкой. Если бы мы взяли другую выборку и вычислили разницу в пропорциях, то получили бы другую оценку. Поэтому нам нужно рассчитать стандартную ошибку для разницы в пропорциях, чтобы дать нам некоторое представление о ее изменчивости. Затем мы можем использовать эту стандартную ошибку для формирования доверительного интервала. Чтобы узнать подробности, мы отсылаем вас к любой вводной книге по статистике или к Google. Пока давайте просто сделаем это в R.
Самый простой способ — использовать функцию prop.test. Если мы дадим ему таблицу 2 x 2, она проверит нулевую гипотезу о том, что пропорции в обеих группах одинаковы. Кроме того, он обеспечит доверительный интервал для разницы в пропорциях. Если мы прочитаем документацию для prop.test, там говорится, что для этого требуется «двумерная таблица (или матрица) с двумя столбцами, дающая количество успехов и неудач соответственно».
Если мы думаем о «Да» как об успехе, а «Нет» — как о неудаче, то это именно то, что мы имеем с нашей матрицей ИМ.
проп.тест(MI) ## ## 2-выборочный тест на равенство пропорций с непрерывностью ## исправление ## ## данные: МИ ## X-квадрат = 24,429, df = 1, p-значение = 7,71e-07 ## альтернативная гипотеза: двусторонняя ## 95-процентный доверительный интервал: ## 0,004597134 0,010814914 ## примерные оценки: ## реквизит 1 реквизит 2 ## 0,01712887 0,00942285
Сообщается, что 95-процентный доверительный интервал составляет около (0,005, 0,011). Он не пересекается с 0, и поэтому мы можем быть уверены, что между пропорциями есть разница. Фактическая оценочная разница не приводится, но мы можем достаточно легко ее рассчитать следующим образом:
p.out <- prop.test(MI) # разница в пропорциях p.out$оценка[1] - p.out$оценка[2] ## предложение 1 ## 0.007706024
Выше мы сохранили вывод prop. test в объект с именем «p.out». Затем мы получили доступ к элементу «оценка» объекта, который содержал обе оценочные пропорции, и вычислили разницу.
test в объект с именем «p.out». Затем мы получили доступ к элементу «оценка» объекта, который содержал обе оценочные пропорции, и вычислили разницу.
Сейчас разница небольшая (менее 1%) и выборка довольно большая. У нас может возникнуть соблазн отмахнуться от этой разницы как от непрактичной, а просто из-за большого размера нашей выборки. Стандартные ошибки и, следовательно, p-значения зависят от размера выборки, поэтому действительно большие выборки почти всегда приводят к неперекрывающимся доверительным интервалам 0,9.0005
Но разница между двумя пропорциями, близкими к 0 или 1, может быть более заметной, чем разница между двумя пропорциями, которые находятся ближе к середине диапазона [0,1].
Чтобы исследовать это, мы обратимся к относительным рискам и отношениям шансов.
Относительный риск
Относительный риск обычно определяется как отношение двух пропорций «успеха». В нашем случае это группа «Да». Мы можем рассчитать относительный риск в R «вручную», сделав что-то вроде этого:
prop.
 out <- prop.table (MI, маржа = 1)
# относительный риск плацебо по сравнению с аспирином
проп.выход[1,1]/проп.выход[2,1]
## [1] 1.817802
out <- prop.table (MI, маржа = 1)
# относительный риск плацебо по сравнению с аспирином
проп.выход[1,1]/проп.выход[2,1]
## [1] 1.817802
В первой строке мы сохраняем результат в объект с именем prop.out. Он содержит построчные пропорции. В следующей строке мы берем пропорцию «Плацебо/Да» (строка 1, столбец 1) и делим ее на пропорцию «Аспирин/Да» (строка 2, столбец 1). Результат 1,82 можно интерпретировать как «доля случаев ИМ у врачей, принимавших плацебо, примерно в 1,82 раза превышала долю случаев ИМ у врачей, принимавших аспирин». Другими словами, выборочная доля случаев ИМ была примерно на 82% выше в группе плацебо.
Таким образом, хотя разница в пропорциях была незначительной (всего около 0,008), относительный риск говорит о другом. Как пишет Агрести на стр. 22, «использование одной только разницы в пропорциях для сравнения двух групп может ввести в заблуждение, когда обе пропорции близки к нулю».
Как и разница в пропорциях, относительный риск является лишь оценкой при работе с выборкой. Рекомендуется рассчитать доверительный интервал для относительного риска, чтобы определить диапазон правдоподобных значений. Мы снова позволим R сделать это за нас, но на этот раз воспользуемся пакетом epitools, который предоставляет функции для анализа в эпидемиологии. Нам нужна функция
Рекомендуется рассчитать доверительный интервал для относительного риска, чтобы определить диапазон правдоподобных значений. Мы снова позволим R сделать это за нас, но на этот раз воспользуемся пакетом epitools, который предоставляет функции для анализа в эпидемиологии. Нам нужна функция коэффициент риска .
# install.packages("epitools")
библиотека (эпитулы)
rr.out <- коэффициент риска (MI)
rr.out$мера
## отношение рисков с 95% ДИ
## Групповая оценка нижняя верхняя
## Плацебо 1.00000 NA NA
## Аспирин 1.00784 1.004759 1.010931
Сначала мы загружаем пакет epitools, чтобы получить доступ к его функциям, затем передаем MI функции Riskratio и сохраняем результаты в объект с именем «rr.out». Объект «rr.out» представляет собой объект списка с 4 элементами. Мы получаем доступ к элементу с именем «мера», который содержит относительный риск, помеченный как «коэффициент риска». Но обратите внимание, что расчет 1,00784 отличается от того, что мы вычислили выше. Что произошло? ну
Что произошло? ну Функция Riskratio любит таблицы, построенные иначе, чем функция prop.test . Если мы просмотрим документацию ( ?riskratio ), то увидим, что функция ожидает количество «успехов» в правом столбце. Автор epitools называет это «болезнью = 1». У нас есть «успех» в левой колонке. Таким образом, функция, взяв нашу таблицу ИМ, вернула отношение риска доли «Нет ИМ» в каждой группе. Это не то, чего мы хотим. К счастью, функция Riskratio имеет аргумент под названием «rev», который позволяет вам легко переключать (или обращать) порядок столбцов, строк или того и другого. Используем:
rr.out <- коэффициент риска (MI, rev="c") rr.out$мера ## отношение рисков с 95% ДИ ## Групповая оценка нижняя верхняя ## Плацебо 1.000000 NA NA ## Аспирин 0,550115 0,4336731 0,6978217
«rev=c» означает обратный порядок столбцов. Хорошо, мы получили что-то другое, но все же не то, что рассчитали вручную. В чем дело? На самом деле результат дает нам подсказку. Обратите внимание, что в первой строке указано плацебо с оценкой отношения рисков, равной 1. Это означает, что это контрольный уровень или, другими словами, знаменатель в расчете отношения рисков. Итак, мы видим
Обратите внимание, что в первой строке указано плацебо с оценкой отношения рисков, равной 1. Это означает, что это контрольный уровень или, другими словами, знаменатель в расчете отношения рисков. Итак, мы видим Riskratio функция ожидает, что первая строка будет контрольной группой, или «exposed=0», как это называется в документации. На самом деле это то, что мы имеем в матрице ИМ, но мы рассчитали отношение риска, как если бы аспирин был референтной группой, а не плацебо. Здесь произошло то, что плацебо рассматривалось как эталонный уровень, и, таким образом, отношение рисков было рассчитано как 0,55. Это означает, что «врачи, принимающие аспирин, имели в 0,55 раза больший риск инфаркта миокарда по сравнению с врачами в группе плацебо». Это не неправильный ответ, это просто другой способ суммировать нашу таблицу. Если мы хотим воспроизвести то, что вычислили вручную, нам нужно изменить порядок строк и столбцов, например, так (rev="b" означает "оба"):
rr.out <- коэффициент риска (MI, rev="b") rr.
 out$мера
## отношение рисков с 95% ДИ
## Групповая оценка нижняя верхняя
## Аспирин 1.000000 NA NA
## Плацебо 1,817802 1,433031 2,305884
out$мера
## отношение рисков с 95% ДИ
## Групповая оценка нижняя верхняя
## Аспирин 1.000000 NA NA
## Плацебо 1,817802 1,433031 2,305884
Теперь мы получаем тот же ответ, который мы рассчитали вручную вместе с 95% доверительным интервалом (1,43, 2,31). В то время как мы хотели бы, чтобы доверительный интервал для разницы не перекрывался с 0, здесь мы хотели бы видеть, чтобы доверительный интервал не перекрывал 1. Это не так, и мы делаем вывод, что пропорции разные. Используя нижнюю границу интервала, мы можем сказать, что «риск инфаркта миокарда как минимум на 43% выше в группе плацебо». Обычно коэффициент риска выражается в процентах увеличения, когда отношение рисков больше 1, и в процентах уменьшения, когда отношение рисков меньше 1. Формулы для определения процента увеличения или уменьшения следующие:0005
Увеличение в процентах = (нижняя граница коэффициента риска – 1) x 100
Снижение в процентах = (1 – верхняя граница коэффициента риска) x 100
Стоит еще раз отметить: при сравнении двух пропорций, близких к 1 или 0, отношение рисков равно обычно лучшее резюме, чем необработанная разница.
Отношения шансов
Теперь обратимся к отношениям шансов как к еще одному способу подытожить таблицу 2 x 2. Шансы — это еще один способ выразить вероятность «успеха». Можно сказать, что вероятность события составляет 75%. Это вероятность 0,75. Чтобы преобразовать это в шансы, мы делим 0,75 на (1 – 0,75 = 0,25) и получаем 3. Шансы на успех равны 3 к 1. Мы ожидаем 3 успеха на каждую 1 неудачу. Используя наш объект prop.out, который мы создали ранее, который содержит пропорции MI по строкам, мы можем рассчитать шансы MI в каждой группе:
# вероятность ИМ в группе плацебо проп.выход[1,1]/проп.выход[1,2] ## [1] 0,01742739 # вероятность инфаркта миокарда при приеме аспирина проп.выход[2,1]/проп.выход[2,2] ## [1] 0,009512485
Расчетные шансы не сильно отличаются от расчетной вероятности (или пропорций). Это происходит с вероятностями, близкими к 0. Используя функцию фракций, которая поставляется с пакетом MASS (входит в состав базы R), мы можем получить рациональную аппроксимацию этих значений.
MASS::fractions(prop.out[1,1]/prop.out[1,2]) ## [1] 21/1205 MASS::fractions(prop.out[2,1]/prop.out[2,2]) ## [1] 8/841
В группе плацебо ожидается 21 сердечный приступ на каждые 1205 человек, у которых не было сердечного приступа. Точно так же в группе аспирина мы ожидаем наблюдать 8 сердечных приступов на каждые 841 человек, у которых не было сердечного приступа.
Точно так же, как мы взяли отношение вероятностей, чтобы получить относительный риск, мы можем взять отношение шансов, чтобы получить отношение шансов. Еще раз обратимся к пакету epitools за его функцией odsratio . К соотношению шансов применяются те же самые требования к расположению таблицы, что и к 9.0013 коэффициент риска : Наш ответ (Да/Нет) включает столбцы с «Да» (успех) в правом столбце, а наша группирующая переменная (Плацебо/Аспирин) включает строки с «Плацебо» (контроль) в первом ряду. Это означает, что нам нужно снова поменять местами строки и столбцы. Как и Riskratio , коэффициент шансов имеет аргумент «оборот», облегчающий эту задачу. Давай сделаем это.
Давай сделаем это.
or.out <- отношение шансов (MI, rev="b") или.вне$меры ## отношение шансов с 95% ДИ ## Групповая оценка нижняя верхняя ## Аспирин 1.000000 NA NA ## Плацебо 1,830705 1,442201 2,336797
Как и прежде, мы сохраняем результаты отношения шансов в объект, на этот раз с именем or.out. Это тоже объект-список с элементом под названием «мера», который содержит отношение шансов и доверительный интервал 95%.
Отношение шансов составляет 1,83 с доверительным интервалом (1,44, 2,34). Как и в случае с относительным риском, мы могли бы посмотреть на нижнюю границу и сделать такое утверждение, как «шансы инфаркта миокарда по крайней мере на 44% выше для субъектов, принимающих плацебо, чем для субъектов, принимающих аспирин». Или мы можем сказать, что «оценочная вероятность инфаркта миокарда была на 83% выше в группе плацебо».
Вы могли заметить, что отношение шансов и относительный риск в этом случае очень похожи. Это происходит, когда сравниваемые пропорции близки к 0. Какой из них вы решите использовать, зависит от личных предпочтений и, возможно, вашей аудитории.
Какой из них вы решите использовать, зависит от личных предпочтений и, возможно, вашей аудитории.
С вопросами или разъяснениями относительно этой статьи обращайтесь в StatLab библиотеки UVA: [email protected]
Просмотрите всю коллекцию статей StatLab библиотеки UVA.
Клэй ФордКонсультант по статистическим исследованиям
Библиотека Университета Вирджинии
8 января 2016 г.
Вычисление процентов в Excel для Mac
В Excel предусмотрены различные способы вычисления процентов. Например, вы можете использовать Excel для расчета налога с продаж для покупок, процента правильных ответов на тест или процента изменения между двумя значениями.
Используйте предоставленные образцы данных и следующие процедуры, чтобы научиться вычислять проценты.
Вычислите процент, если вы знаете итог и сумму
Допустим, вы правильно ответили на 42 вопроса из 50 в тесте. Каков процент правильных ответов?
 org/ItemList">
org/ItemList">Щелкните любую пустую ячейку.
Введите = 42/50 и нажмите RETURN.
Результат 0,84.
Выберите ячейку, содержащую результат шага 2.
На вкладке Главная нажмите Процентный стиль .
Результат 84%, это процент правильных ответов на тест.
Примечание: Чтобы изменить количество знаков после запятой, отображаемых в результате, нажмите Увеличить десятичный разряд или Уменьшить десятичный разряд .
Подсчитайте сумму, если вы знаете сумму и процент
Предположим, что распродажная цена рубашки составляет 15 долларов, что на 25 % меньше первоначальной цены. Какова первоначальная цена? В этом примере вы хотите найти 75% от числа, равного 15.
Щелкните любую пустую ячейку.
Тип = 15/0,75 , а затем нажмите RETURN .
Результат 20.
Выберите ячейку, содержащую результат шага 2.
 org/ListItem">
org/ListItem">На вкладке Home нажмите Формат номера счета
Результат равен $20.00, что является исходной ценой рубашки.
Рассчитайте сумму, если знаете сумму и процент
Допустим, вы хотите купить компьютер за 800 долларов и должны заплатить дополнительно 8,9% налога с продаж. Сколько нужно платить налога с продаж? В этом примере вы хотите найти 8,9% от 800.
Щелкните любую пустую ячейку.
Тип = 800*0,089 , а затем нажмите RETURN .
Результат 71,2.
На вкладке Home нажмите Формат номера счета
Результат равен 71,20 доллара США, что является суммой налога с продаж для компьютера.
 org/ListItem">
org/ListItem">Выберите ячейку, содержащую результат шага 2.
Вычислить разницу между двумя числами в процентах
Допустим, ваш заработок составляет 2342 доллара в ноябре и 2500 долларов в декабре. Каков процент изменения вашего заработка за эти два месяца? Затем, если ваш заработок в январе составил 2425 долларов, каков процент изменения вашего заработка в период с декабря по январь? Вы можете рассчитать разницу, вычитая новый доход из исходного дохода, а затем разделив результат на исходный доход.
Рассчитать процент увеличения
 org/ItemList">
org/ItemList">Щелкните любую пустую ячейку.
Введите = (2500-2342)/2342 и нажмите RETURN .
Результат равен 0,06746.
Выберите ячейку, содержащую результат шага 2.
На вкладке Главная нажмите Процентный стиль .
Результат равен 7%, что является процентом увеличения заработка.
Рассчитать процент уменьшения
 org/ItemList">
org/ItemList">Щелкните любую пустую ячейку.
Тип = (2425-2500)/2500 , а затем нажмите RETURN.
Результат -0,03.
Выберите ячейку, содержащую результат шага 2.
На вкладке Главная нажмите Процентный стиль .
Результат -3%, что является процентом уменьшения заработка.
Увеличить или уменьшить число на процент
Допустим, вы тратите в среднем 113 долларов в неделю на еду и хотите увеличить свои еженедельные расходы на еду на 25%. Сколько вы можете потратить? Или, если вы хотите уменьшить свое еженедельное пособие на питание в размере 113 долларов США на 25%, каково ваше новое недельное пособие?
Сколько вы можете потратить? Или, если вы хотите уменьшить свое еженедельное пособие на питание в размере 113 долларов США на 25%, каково ваше новое недельное пособие?
Увеличить число на процент
Щелкните любую пустую ячейку.
Введите = 113*(1+0,25) и нажмите RETURN .
Результат 141,25.
Выберите ячейку, содержащую результат шага 2.
На вкладке Home нажмите Формат номера счета
Результат равен 141,25 доллара, что на 25% больше недельных расходов на продукты питания.
