
Столтенберг назвал задачей НАТО предотвращение выхода военных действий за пределы Украины — Газета.Ru
Столтенберг назвал задачей НАТО предотвращение выхода военных действий за пределы Украины — Газета.Ru | Новости
Размер текста
А
А
А
close
100%
Генеральный секретарь НАТО Йенс Столтенберг рассказал о задаче Североатлантического альянса, связанной с конфликтом на Украине. Об этом сообщает ТАСС.
«Задача НАТО — поддержать Украину и предотвратить войну за пределами Украины», — заявил генсек.
По его словам, именно с этой целью альянс посылает России четкие сигналы о том, что блок готов защищать каждого союзника.
Также Столтенберг в очередной раз отметил, что НАТО не является стороной украинского конфликта и не будет вовлекаться в него.
«Мы стоим на стороне Украины и помогаем ей в ее праве защищать себя», — заключил он.
До этого командующий армией США в Европе и Африке генерал Дэррил Уильямс рассказал, что армии США и НАТО обучаются ведению боевых действий за счет помощи Украине и в целом конфликту в этой стране. По его словам, если верить заявлениям альянса, все идет «хорошо» в вопросе помощи Киеву.
В настоящее время на Украине продолжается специальная операция Вооруженных сил РФ. О ее начале 24 февраля объявил президент России Владимир Путин. По его словам, цель военных действий заключается в демилитаризации соседней страны и денацификации ее властей.
Решение о проведении операции стало причиной новых санкций против России со стороны США и их союзников.
«Газета.Ru» следит за хроникой событий.
Все новости на тему:
Операция на Украине
Подписывайтесь на «Газету.
Чтобы сообщить об ошибке, выделите текст и нажмите Ctrl+Enter
Новости
Дзен
Telegram
Владимир Трегубов
Разворот на Восток
О переформатировании внешнеторговых отношений России
Дмитрий Самойлов
Пока светится ель
О важности маленьких радостей
Мария Дегтерева
Битвы при оливье
О том, почему важно правильно приготовить главный новогодний салат
Иван Глушков
Вокруг света за выходные
О главных праздничных блюдах разных стран
Георгий Бовт
Мир без людей
О том, что будет, когда всем начнет править искусственный разум
Найдена ошибка?
Закрыть
Спасибо за ваше сообщение, мы скоро все поправим.
Продолжить чтение
Пределы(задачи)
I. ПРЕДЕЛЫ
Понятие предела функции в точке. Теорема о переходе к пределу в неравенствах.
Понятие непрерывности функции.
Первый замечательный предел .
Понятие бесконечно малой функции. Теорема о связи между функцией, ее пределом и бесконечно малой.
Теорема о сумме бесконечно малых функций.
Теорема о произведении бесконечно малой функции на ограниченную функцию.
Теорема об отношении бесконечно малой функции к функции, имеющей предел, отличный от нуля.
Теорема о пределе суммы.
Теорема о пределе произведения.

Теорема о пределе частного.
Понятие бесконечно большой функции. Теоремы о связи бесконечно больших функций с бесконечно малыми.
Сравнение бесконечно малых функций.
Эквивалентные бесконечно малые функции. Теорема о замене бесконечно малых функций эквивалентными.
Условие эквивалентности бесконечно малых функций.

Задача 9. Вычислить пределы функций.
9.1. 9.2.
9.3. 9.4.
9.5. 9.6.
9.7. 9.8.
9.9. 9.10.
9.11. 9.12.
9.13. 9.14.
9.15. 9.16.
9.17. 9.18.
9.19. 9.20.
9.21. 9.22.
9.23. 9.24.
9.24.
9.25. 9.26.
9.27. 9.28.
9.29. 9.30.
9.31.
Задача 10. Вычислить пределы функций.
10.1 10.2.
10.3 10.4
10.5 10.6
10.7 10.8
10.9 10.10
10.11 10.12
10.13 10.14
10.15 10.16
10.17 10.18
10.19 10.20
10.21 10.22
10.23 10.24
10.25 10.26
10.27 10.28
10.29 10.30
10.31
4
Соседние файлы в папке Математика Геологи(1 курс)
- #
30.03.2015947.2 Кб54Вектора(задачи).doc
- #
30.
03.2015245.76 Кб29Графики(задачи).doc - #
30.03.2015561.15 Кб49Интегралы(задачи).doc
- #
30.03.2015184.83 Кб215Пределы(задачи).doc
- #
30.03.2015491.01 Кб183Производные(задачи).doc
- #
30.03.2015334.85 Кб18Тема_01_ВЕКТОРЫ В ЛИНЕЙНОМ ПРОСТРАНСТВЕ.DOC
- #
30.03.2015271.87 Кб22Тема_02_СКАЛЯРНОЕ ПРОИЗВЕДЕНИЕ.DOC
- #
30.03.2015254.46 Кб16Тема_03_ВЕКТОРНОЕ И СМЕШАННОЕ ПРОИЗВЕДЕНИЕ.DOC
- #
30.03.2015343.55 Кб29Тема_09_ПРЕДЕЛ ФУНКЦИИ.DOC
 03.2015245.76 Кб29Графики(задачи).doc
03.2015245.76 Кб29Графики(задачи).docНастройка ресурсов задач — Flyte
Изменить эту страницуПереключить боковую панель оглавления
Теги: Развертывание, Инфраструктура, Базовый
Одной из причин использования размещенной среды Flyte является потенциал использования ресурсов ЦП, памяти и хранилища, намного превышающий то, что доступно локально.
В этом примере объем памяти, требуемый функцией, увеличивается по мере увеличения размера набора данных. Большие наборы данных могут не работать локально, поэтому мы хотели бы предоставить подсказки серверной части Flyte, чтобы запросить больше памяти. Это делается путем украшения задачи подсказками, как показано в следующем примере кода.
Задачи могут иметь запросов и ограничений , которые отражают нативные эквиваленты в Kubernetes.
Задаче может быть выделено больше ресурсов, чем она запрашивает, но не больше ее предела.
Запросы рассматриваются как подсказки для планирования задач на узлах с доступными ресурсами, в то время как ограничения
являются жесткими ограничениями.
Информацию о запросе или ограничении см. в документации flytekit.Resources .
Для ресурса можно указать следующие атрибуты .
процессорпамятьGPU
Чтобы обычные задачи, не требующие использования графических процессоров, не планировались на узлах графического процессора, можно настроить отдельную группу узлов для узлов графического процессора с пометками.
Чтобы убедиться, что задачи, требующие использования графических процессоров, получают необходимые допуски в своих модулях, настройте FlytePropeller, используя следующую конфигурацию. Убедитесь, что эта конфигурация допуска соответствует конфигурации taint, которую вы настроили для защиты узлов, предоставляющих GPU, от работы с обычными рабочими нагрузками (модулями), не связанными с GPU.
Фактические значения соответствуют соглашению Kubernetes. Давайте рассмотрим пример, чтобы понять, как настроить ресурсы.
Импорт зависимостей.
Определите задачу и настройте выделяемые для нее ресурсы.
@task(запросы=ресурсы(cpu="1", mem="100Mi"), лимиты=ресурсы(cpu="2", mem="150Mi")) def count_unique_numbers(x: typing.
 List[int]) -> int:
с = установить ()
для я в х:
с.добавить(я)
вернуть линзы
List[int]) -> int:
с = установить ()
для я в х:
с.добавить(я)
вернуть линзы
Определите задачу, которая вычисляет квадрат числа.
@задача
квадрат защиты (x: int) -> int:
вернуть х * х
Вы можете использовать задачи, украшенные подсказками памяти и хранилища, как обычные задачи в рабочем процессе.
@рабочий процесс
def my_workflow(x: typing.List[int]) -> int:
возвращаемый квадрат (x = count_unique_numbers (x = x))
Вы можете выполнить рабочий процесс локально.
если __name__ == "__main__":
печать (count_unique_numbers (x = [1, 1, 2]))
печать (мой_рабочий процесс (х = [1, 1, 2]))
Примечание
Чтобы изменить ограничения конфигурации платформы по умолчанию, измените конфигурацию администратора и квоту уровня пространства имен в кластере.
Вы можете использовать метод with_overrides для динамического переопределения ресурсов, выделенных задачам. Давайте разберемся, как можно инициализировать ресурсы на примере.
Давайте разберемся, как можно инициализировать ресурсы на примере.
Импорт зависимостей.
ввод импорта # noqa: E402 from flytekit import Resources, task, workflow # noqa: E402
Определите задачу и настройте выделяемые для нее ресурсы. Вы можете использовать задачи, украшенные подсказками памяти и хранилища, как обычные задачи в рабочем процессе.
@task(запросы=ресурсы(cpu="2", mem="200Mi"), лимиты=ресурсы(cpu="3", mem="350Mi"))
def count_unique_numbers_1(x: typing.List[int]) -> int:
с = установить ()
для я в х:
с.добавить(я)
вернуть линзы
Определите задачу, которая вычисляет квадрат числа.
@задача
def Square_1(x: int) -> int:
вернуть х * х
Метод with_overrides переопределяет старые распределения ресурсов.
@рабочий процесс
def my_pipeline(x: typing.List[int]) -> int:
вернуть Square_1 (x = count_unique_numbers_1 (x = x)). with_overrides (
лимиты = Ресурсы (ЦП = "6", мем = "500Ми")
)
Вы можете выполнить рабочий процесс локально.
если __name__ == "__main__":
печать (count_unique_numbers_1 (x = [1, 1, 2]))
печать (мой_конвейер (х = [1, 1, 2]))
Ниже показано распределение памяти. Предел памяти составляет 500Mi , а не 350Mi , а
Ограничение ЦП — 4, тогда как должно было быть 6, как указано с помощью with_overrides .
Это связано с тем, что квота ЦП платформы по умолчанию для каждого модуля равна 4.
Ресурс, выделенный с помощью метода with_overrides
Общее время работы сценария: ( 0 минут 0,000 секунды)
Загрузите исходный код Python: customizing_resources.py
Загрузите блокнот Jupyter: customizing_resources.ipynb
Галерея, созданная Sphinx-Gallery
Tasks — Prefect 2 — Координация мировых потоков данных
Задача — это функция, представляющая дискретную единицу работы в рабочем процессе Prefect. Задачи не требуются — вы можете определить рабочие процессы Prefect, состоящие только из потоков, используя обычные операторы и функции Python. Задачи позволяют инкапсулировать элементы логики вашего рабочего процесса в наблюдаемые единицы, которые можно повторно использовать в потоках и подпотоках.
Задачи позволяют инкапсулировать элементы логики вашего рабочего процесса в наблюдаемые единицы, которые можно повторно использовать в потоках и подпотоках.
Обзор задач
Задачи — это функции: они могут принимать входные данные, выполнять работу и возвращать выходные данные. Задача Prefect может делать почти все, что может делать функция Python.
Задачи являются особенными, поскольку они получают метаданные о зависимостях восходящего потока и состоянии этих зависимостей перед запуском, даже если они не получают от них никаких явных входных данных. Это дает вам возможность, например, дождаться завершения другой задачи перед выполнением.
Задачи также используют преимущества автоматического ведения журнала Prefect для сбора сведений о выполнении задач, таких как время выполнения, теги и конечное состояние.
Вы можете определить свои задачи в том же файле, что и ваше определение потока, или вы можете определить задачи в модулях и импортировать их для использования в ваших определениях потока. Все задачи должны вызываться из потока. Задачи не могут вызываться из других задач.
Все задачи должны вызываться из потока. Задачи не могут вызываться из других задач.
Вызов задачи из потока
Используйте декоратор @task , чтобы обозначить функцию как задачу. Вызов задачи из функции потока создает новый запуск задачи:
из потока импорта префекта, задача
@задача
определить мою_задачу():
print("Привет, я задача")
@поток
определить мой_поток():
моя задача()
Задачи однозначно идентифицируются по ключу задачи, который представляет собой хэш, состоящий из имени задачи, полного имени функции и любых тегов. Если у задачи не указано имя, имя берется из функции задачи.
Насколько большой должна быть задача?
Префект поощряет «небольшие задачи» — каждая из них должна представлять собой один логический шаг вашего рабочего процесса. Это позволяет Prefect лучше сдерживать сбои задач.
Для ясности: ничто не мешает вам поместить весь ваш код в одну задачу — Prefect с радостью ее запустит! Однако в случае сбоя какой-либо строки кода произойдет сбой всей задачи, и ее придется повторить с самого начала. Этого можно избежать, разделив код на несколько зависимых задач.
Этого можно избежать, разделив код на несколько зависимых задач.
Вызов функции задачи из другой задачи
Prefect не позволяет запускать задачи из других задач. Если вы хотите напрямую вызвать функцию своей задачи, вы можете использовать задача.fn() .
из потока импорта префекта, задача
@задача
защита my_first_task(msg):
print(f"Здравствуйте, {msg}")
@задача
Def my_second_task (сообщение):
my_first_task.fn(msg)
@поток
определить мой_поток():
my_second_task("Триллиан")
Обратите внимание, что в приведенном выше примере вы вызываете только функцию задачи, фактически не создавая запуск задачи. Prefect не будет отслеживать выполнение задачи в вашем бэкэнде Prefect, если вы вызываете функцию задачи таким образом. Вы также не сможете использовать такие функции, как повторные попытки с этим вызовом функции.
Аргументы задачи
Задачи допускают большую настройку с помощью аргументов. Примеры включают поведение при повторных попытках, имена, теги, кэширование и многое другое. Задачи принимают следующие необязательные аргументы.
Задачи принимают следующие необязательные аргументы.
| Аргумент | Описание |
|---|---|
| название | Необязательное имя задачи. Если не указано, имя будет выведено из имени функции. |
| описание | Необязательное строковое описание задачи. Если он не указан, описание будет взято из строки документации декорированной функции. |
| ярлыки | Необязательный набор тегов, связанных с выполнением этой задачи. Эти теги объединяются с любыми тегами, определенными контекстом prefect.tags во время выполнения задачи. |
| cache_key_fn | Необязательный вызываемый объект, который с учетом контекста запуска задачи и параметров вызова создает строковый ключ. Если ключ соответствует предыдущему завершенному состоянию, результат этого состояния будет восстановлен вместо повторного запуска задачи. |
| срок действия кеша | Необязательное количество времени, указывающее, как долго кэшированные состояния для этой задачи должны быть восстанавливаемыми; если не указано, кэшированные состояния никогда не истечет. |
| повторных попыток | Необязательное количество повторных попыток при сбое выполнения задачи. |
| retry_delay_seconds | Необязательное количество секунд ожидания перед повторной попыткой выполнения задачи после сбоя. Это применимо только в том случае, если повторных попыток не равно нулю. |
| версия | Необязательная строка, указывающая версию определения этой задачи. |
Например, для задачи можно указать значение имя . Здесь мы также использовали необязательный аргумент description .
@task(name="hello-task",
description="Эта задача передает привет.")
определить мою_задачу():
print("Привет, я задача")
Теги
Теги — это необязательные строковые метки, которые позволяют идентифицировать и группировать задачи, отличные от имени или потока. Теги полезны для:
- Задача фильтрации запускается по тегу в пользовательском интерфейсе и через Orion REST API.
- Установка ограничений параллелизма для запуска задач по тегу.

Теги могут быть указаны в качестве аргумента ключевого слова в декораторе задач.
@task(name="hello-task", tags=["test"])
определить мою_задачу():
print("Привет, я задача")
Вы также можете предоставить теги в качестве аргумента диспетчеру контекста тегов , указав теги при вызове задачи, а не в ее определении.
из потока импорта префекта, задача
из тегов префекта импорта
@задача
определить мою_задачу():
print("Привет, я задача")
@поток
определить мой_поток():
с тегами("тест"):
моя задача()
повторных попыток
Задачи Prefect могут автоматически повторяться в случае сбоя. Чтобы включить повторы, передайте в задачу параметры retries и retry_delay_seconds :
запросов на импорт
# эта задача будет повторяться до 3 раз, ожидая 1 минуту между каждой повторной попыткой
@task(повторных попыток=3, retry_delay_seconds=60)
защита get_page (url):
страница = запросы. get(url)
 get(url)
get(url)
Повторные попытки не создают новых запусков задач
Новый запуск задачи не создается при повторной попытке задачи. Новое состояние добавляется в историю состояний исходного запуска задачи.
Кэширование
Кэширование относится к способности выполнения задачи отражать завершенное состояние без фактического запуска кода, определяющего задачу. Это позволяет эффективно повторно использовать результаты задач, выполнение которых может быть дорогостоящим при каждом запуске потока, или повторно использовать кэшированные результаты, если входные данные для задачи не изменились.
Чтобы определить, должен ли запуск задачи извлекать кэшированное состояние, мы используем «ключи кэша». Ключ кэша — это строковое значение, указывающее, следует ли считать один запуск идентичным другому. Когда задача, запущенная с ключом кеша, завершается, мы привязываем этот ключ кеша к состоянию. При запуске каждой задачи Prefect проверяет состояния с соответствующим ключом кэша.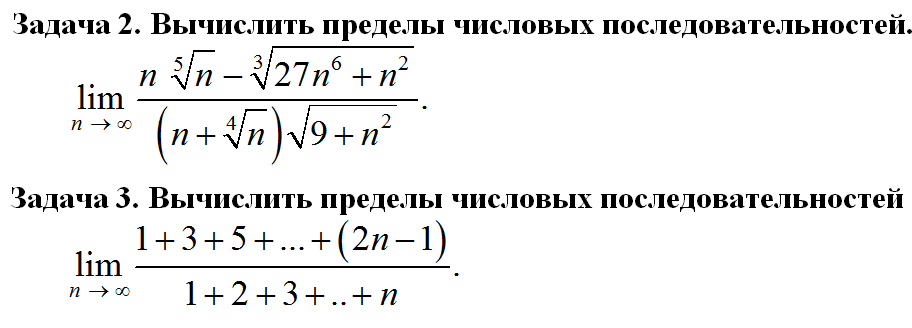 Если будет найдено состояние с идентичным ключом, Prefect будет использовать кэшированное состояние вместо повторного запуска задачи.
Если будет найдено состояние с идентичным ключом, Prefect будет использовать кэшированное состояние вместо повторного запуска задачи.
Чтобы включить кэширование, укажите cache_key_fn — функция, возвращающая ключ кеша — на вашу задачу. Вы можете дополнительно указать cache_expiration timedelta, указывающую, когда истекает срок действия кеша. Если вы не укажете cache_expiration , срок действия ключа кэша не истекает.
Вы можете определить задачу, которая кэшируется на основе ее входных данных, используя Prefect task_input_hash . Это реализация ключа кэша задач, которая хэширует все входные данные для задачи с помощью сериализатора JSON или cloudpickle. Если входные данные задачи не изменяются, используются кэшированные результаты, а не выполнение задачи до истечения срока действия кэша.
Обратите внимание: если какие-либо аргументы не сериализуемы в формате JSON, в качестве запасного варианта используется сериализатор pickle.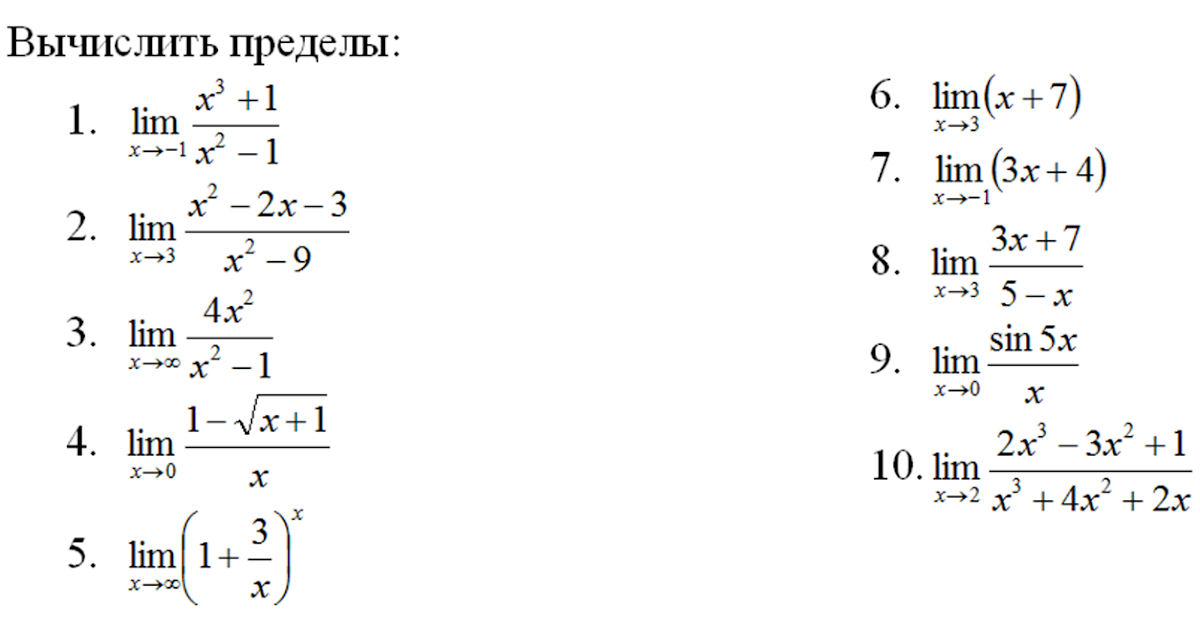 В случае сбоя cloudpickle
В случае сбоя cloudpickle task_input_hash возвращает нулевой ключ, указывающий, что ключ кэша не может быть сгенерирован для заданных входных данных.
В этом примере до тех пор, пока не закончится время cache_expiration , пока входные данные для hello_task() остаются неизменными при вызове, возвращается кэшированное возвращаемое значение. В этом случае задача не перезапускается. Однако, если значение входного аргумента изменяется, hello_task() запускается с использованием нового ввода.
из даты и времени импорта timedelta
из потока префекта импорта, задача
из prefect.tasks импортировать task_input_hash
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(дни=1))
определение hello_task (name_input):
# Делаем какую-то работу
print("Привет")
вернуть "привет" + name_input
@поток
определение hello_flow (name_input):
hello_task (имя_ввод)
Кроме того, вы можете предоставить свою собственную функцию или другой вызываемый объект, который возвращает ключ строкового кэша.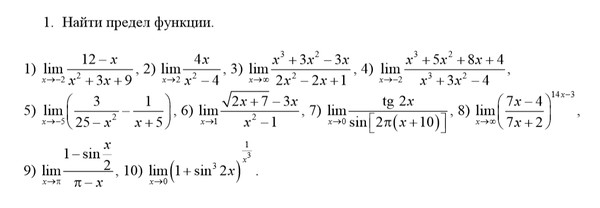 Общий
Общий cache_key_fn — это функция, которая принимает два позиционных аргумента:
- Первый аргумент соответствует
TaskRunContext, в котором хранятся метаданные запуска задачи в атрибутахtask_run_id,flow_run_idиtask. - Второй аргумент соответствует словарю входных значений задачи. Например, если ваша задача определена сигнатурой
fn(x, y, z), то словарь будет иметь ключи"x","y"и"z"с соответствующими значениями, которые можно использовать для вычисления ключа кэша.
Обратите внимание, что cache_key_fn — это , а не , определенный как @task .
из задачи импорта префекта, поток
def static_cache_key (контекст, параметры):
# вернуть константу
вернуть "статический ключ кеша"
@task(cache_key_fn=static_cache_key)
определение cached_task():
print('выполняется дорогостоящая операция')
вернуться 42
@поток
определение test_caching():
cached_task()
cached_task()
cached_task()
В этом случае у ключа кэша нет срока действия и нет логики для изменения ключа кэша, поэтому cached_task() запускается только один раз.
>>> test_caching() проведение дорогостоящей операции >>> test_caching() >>> test_caching()
Когда каждое выполнение задачи запрашивало переход в состояние Выполняется , оно предоставляло свой ключ кэша, вычисленный из cache_key_fn . Серверная часть Orion определила, что с этим ключом связано состояние COMPLETED, и дала указание запуску немедленно перейти в то же состояние COMPLETED, включая те же возвращаемые значения.
Реальный пример может включать идентификатор запуска потока из контекста в ключ кэша, чтобы кэшировались только повторяющиеся вызовы в одном и том же запуске потока.
def cache_within_flow_run (контекст, параметры):
return f"{context.task_run.flow_run_id}-{task_input_hash(контекст, параметры)}"
@task(cache_key_fn=cache_within_flow_run)
определение cached_task():
print('выполняется дорогостоящая операция')
вернуться 42
Результаты задачи, повторные попытки и кэширование
Результаты задачи кэшируются в памяти во время выполнения потока и сохраняются в месте, указанном параметром Параметр PREFECT_LOCAL_STORAGE_PATH . В результате кэширование задач между запусками потока в настоящее время ограничено запусками потока с доступом к этому локальному пути к хранилищу.
В результате кэширование задач между запусками потока в настоящее время ограничено запусками потока с доступом к этому локальному пути к хранилищу.
Тайм-ауты
Тайм-ауты задач используются для предотвращения непреднамеренных длительных задач. Когда продолжительность выполнения задачи превышает продолжительность, указанную в тайм-ауте, будет возбуждено исключение тайм-аута, и задача будет помечена как невыполненная. В пользовательском интерфейсе задача будет обозначена как TimedOut 9.0016 . С точки зрения потока задача с истекшим временем ожидания будет рассматриваться как любая другая невыполненная задача.
Продолжительность тайм-аута указывается с помощью ключевого аргумента timeout_seconds .
из задачи импорта префекта, get_run_logger
время импорта
@задача(timeout_seconds=1)
определение show_timeouts():
регистратор = get_run_logger()
logger.info("Я выполню")
время сна(5)
logger.info("Я не буду выполнять")
Результаты задания
В зависимости от того, как вы вызываете задачи, они могут возвращать различные типы результатов и при необходимости использовать средство запуска задач.
Любая задача может вернуть:
- Данные , такие как
int,str,dict,listи т. д. — это поведение по умолчанию каждый раз, когда вы вызываетеyour_task(). -
PrefectFuture— достигается вызовомyour_task.submit().PrefectFutureсодержит данные и State - Префект
Штат— каждый раз, когда вы вызываете свою задачу или поток с аргументомreturn_state=True, он напрямую вернет состояние, которое вы можете использовать для создания пользовательского поведения на основе интересующего вас изменения состояния, такого как сбой или повторная попытка задачи или потока.
Чтобы запустить задачу с помощью средства запуска задач, вы должны вызвать задачу с помощью .submit() .
Примеры см. в возвращаемых значениях состояния.
Исполнители задач необязательны.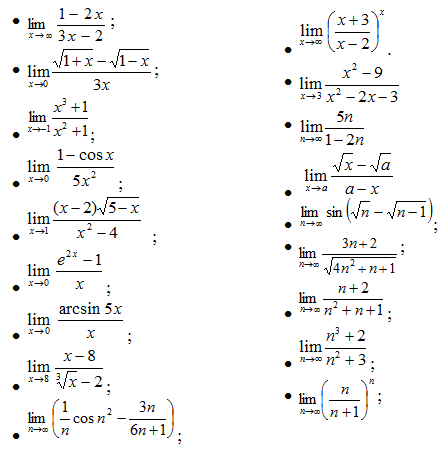
Если вам просто нужен результат задачи, вы можете просто вызвать задачу из своего потока. Для большинства рабочих процессов поведение по умолчанию — прямой вызов задачи и получение результата — это все, что вам нужно.
Подождите
Чтобы создать зависимость между двумя задачами, которые не обмениваются данными, но одна из которых должна дождаться завершения другой, используйте специальный аргумент ключевого слова wait_for :
@задача
определить задачу_1():
проходят
@задача
определение задачи_2():
проходят
@поток
определить мой_поток():
х = задача_1 ()
# задача 2 будет ждать завершения задачи_1
у = задача_2 (ожидание_для = [х])
Карта
Prefect предоставляет реализацию .map() , которая автоматически создает запуск задачи для каждого элемента входных данных. Сопоставленные задачи представляют собой вычисления множества отдельных дочерних задач.
Простейшая карта Prefect берет задачи и применяет их к каждому элементу своих входов.
из потока импорта префекта, задача
@задача
определение print_nums (числа):
для n в цифрах:
печать (н)
@задача
определение квадрат_номер (число):
вернуть число**2
@поток
определение map_flow (числа):
print_nums (числа)
квадратные_числа = квадратные_числа.карта(числа)
print_nums (квадратные_числа)
map_flow([1,2,3,5,8,13])
Prefect также поддерживает несопоставленных аргументов , что позволяет передавать статические значения, которые не отображаются.
из потока импорта префекта, задача
@задача
определение add_together (х, у):
вернуть х + у
@поток
def sum_it (числа, статическое_значение):
фьючерсы = add_together.map (числа, статическое_значение)
возврат фьючерсов
сумма_ит ([1, 2, 3], 5)
Если ваш статический аргумент является итерируемым, вам нужно обернуть его несопоставленным , чтобы сообщить Prefect, что его следует рассматривать как статическое значение.
из префекта потока импорта, задача, несопоставленная
@задача
def sum_plus(x, static_iterable):
вернуть x + сумму (static_iterable)
@поток
def sum_it (числа, static_iterable):
фьючерсы = sum_plus. map (числа, static_iterable)
возврат фьючерсов
sum_it([4, 5, 6], несопоставленный([1, 2, 3]))
 map (числа, static_iterable)
возврат фьючерсов
sum_it([4, 5, 6], несопоставленный([1, 2, 3]))
map (числа, static_iterable)
возврат фьючерсов
sum_it([4, 5, 6], несопоставленный([1, 2, 3]))
Асинхронные задачи
Prefect также по умолчанию поддерживает определения асинхронных задач и потоков. Применяются все стандартные правила асинхронности:
асинхронный импорт
из задачи импорта префекта, поток
@задача
асинхронное определение print_values (значения):
для значения в значениях:
await asyncio.sleep(1) # выход
распечатать (значение, конец = "")
@поток
асинхронное определение async_flow():
await print_values([1, 2]) # выполняется немедленно
coros = [print_values ("abcd"), print_values ("6789")]
# асинхронно собираем задачи
ожидание asyncio.gather(*coros)
asyncio.run(async_flow())
Обратите внимание: если вы не используете asyncio.gather , вызов .submit() требуется для асинхронного выполнения в ConcurrentTaskRunner .
Ограничения одновременного запуска задач
Существуют ситуации, в которых вы хотите активно предотвращать одновременный запуск слишком большого количества задач. Например, если многие задачи в нескольких потоках предназначены для взаимодействия с базой данных, которая допускает только 10 подключений, вы хотите убедиться, что в любой момент времени выполняется не более 10 задач, которые подключаются к этой базе данных.
Например, если многие задачи в нескольких потоках предназначены для взаимодействия с базой данных, которая допускает только 10 подключений, вы хотите убедиться, что в любой момент времени выполняется не более 10 задач, которые подключаются к этой базе данных.
Prefect имеет встроенную функциональность для достижения этой цели: ограничение одновременности задач.
Ограничения параллелизма задач используют теги задач. Вы можете указать необязательный предел параллелизма как максимальное количество одновременных запусков задач в состоянии Running для задач с заданным тегом. Указанный предел параллелизма применяется к любой задаче, к которой применяется тег.
Если задача имеет несколько тегов, она будет выполняться только в том случае, если все теги имеют доступный параллелизм.
Теги без явных ограничений считаются имеющими неограниченный параллелизм.
0 предел параллелизма прерывает запуск задачи
В настоящее время, если предел параллелизма установлен на 0 для тега, любая попытка запустить задачу с этим тегом будет прервана, а не отложена.
Поведение при выполнении
Пределы тегов задачи проверяются всякий раз, когда выполнение задачи пытается перейти в состояние Выполняется .
Если ни для одного из тегов вашей задачи нет доступных слотов параллелизма, переход на Состояние Running будет задержано, и клиенту будет предложено снова попытаться войти в состояние Running через 30 секунд.
Ограничения параллелизма в подпотоках
Использование ограничений параллелизма для выполнения задач в подпотоках может привести к взаимоблокировкам. Рекомендуется настраивать теги и ограничения параллелизма, чтобы не устанавливать ограничения на выполнение задач в подпотоках.
Настройка ограничений параллелизма
Вы можете установить ограничения параллелизма для нескольких или любого количества тегов по своему усмотрению. Вы можете установить лимиты через:
- Префект CLI
- Prefect API с использованием
OrionClientклиента Python - Пользовательский интерфейс сервера Prefect Orion или Prefect Cloud
CLI
Вы можете создавать, перечислять и удалять ограничения параллелизма с помощью команд Prefect CLI concurrency-limit .
$ prefect concurrency-limit [команда] [аргументы]
| Команда | Описание |
|---|---|
| создать | Создайте ограничение параллелизма, указав тег и ограничение. |
| удалить | Удалить ограничение параллелизма, установленное для указанного тега. |
| осмотр | Просмотр сведений об ограничении параллелизма, установленном для указанного тега. |
| лс | Просмотрите все определенные ограничения параллелизма. |
Например, чтобы установить ограничение параллелизма 10 для тега small_instance:
$ prefect concurrency-limit create small_instance 10
Чтобы удалить ограничение параллелизма для тега small_instance:
$ prefect concurrency-limit удалить small_instance
Чтобы просмотреть сведения об ограничении параллелизма для тега small_instance:
$ prefect concurrency-limit проверяет small_instance
клиент Python
Чтобы программно обновить лимиты параллелизма тегов, используйте OrionClient. . create_concurrency_limit
create_concurrency_limit
create_concurrency_limit принимает два аргумента:
-
тегуказывает тег задачи, для которого вы устанавливаете ограничение. -
concurrency_limitуказывает максимальное количество одновременных запусков задач для этого тега.
Например, чтобы установить ограничение параллелизма 10 для тега small_instance:
из импорта prefect.client get_client
async с get_client() в качестве клиента:
# установить ограничение параллелизма 10 для тега 'small_instance'
limit_id = ожидание client.create_concurrency_limit(
тег = "маленький_экземпляр",
concurrency_limit=10
)
Чтобы удалить все ограничения параллелизма для тега, используйте OrionClient.delete_concurrency_limit_by_tag , передав тег:
асинхронно с get_client() в качестве клиента: # удалить ограничение параллелизма для тега 'small_instance' ожидайте client.
