
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. Но наиболее информативными и часто используемыми явлются: дисперсия, среднеквадратичное отклонение и коэффициент вариации.
Напомню, что среднее линейное отклонение отражает среднее абсолютное отклонение значений от их средней величины. При расчете этого показателя, чтобы избежать взаимопогашения положительных и отрицательных отклонений, используется модуль, то есть каждое отклонение от средней берется с положительным знаком. Та же идея лежит в расчете другого известного в статистике показателя, только отклонения берутся не по модулю, а возводятся в квадрат. Квадрат любого числа, как известно, всегда будет положительным.
Дисперсия
Речь идет о дисперсии случайной величины. Это очень важный показатель, который активно используется в различных методах статистического анализа (проверка гипотез, анализ причинно-следственных связей и др.). Как и среднее линейное отклонение, дисперсия также отражает меру разброса данных вокруг средней величины.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое.
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Примечание. Для расчета дисперсии в Excel предусмотрена специальная функция.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. В то же время не все так плохо. При увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной. Поэтому при работе с большими размерами выборок можно использовать формулу выше.
Язык знаков полезно перевести на язык слов. Получится, что дисперсия — это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Разгадка заключается всего в трех словах.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который необходим для других видов статистического анализа. У нее даже единицы измерения нормальной нет. Судя по формуле, это квадрат единицы измерения исходных данных. Без бутылки, как говорится, не разберешься.
Среднеквадратичное отклонение
{module 111}
Дабы вернуть дисперсию в реальность, то есть использовать в более приземленных целей, из нее извлекают квадратный корень. Получается так называемое среднеквадратичное отклонение (СКО). Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквы). Формула стандартного отклонения имеет вид:
Для получения этого показателя по выборке используют формулу:
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Но и этот показатель в чистом виде не очень информативен, так как в нем заложено слишком много промежуточных расчетов, которые сбивают с толку (отклонение, в квадрат, сумма, среднее, корень). Тем не менее, со среднеквадратичным отклонением уже можно работать непосредственно, потому что свойства данного показателя хорошо изучены и известны. К примеру, есть такое правило трех сигм, которое гласит, что у нормально распределенных данных 997 значений из 1000 находятся в пределах ±3 сигмы от средней арифметической. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Коэффициент вариации
Среднее квадратическое отклонение дает абсолютную оценку меры разброса. Поэтому чтобы понять, насколько разброс велик относительно самих значений (т.е. независимо от их масштаба), требуется относительный показатель. Такой показатель называется коэффициентом вариации и рассчитывается по следующей формуле:
Коэффициент вариации измеряется в процентах (если умножить на 100%). По этому показателю можно сравнивать однородность самых разных явлений независимо от их масштаба и единиц измерения. Данный факт и делает коэффициент вариации столь популярным.
В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. Мне здесь трудно что-то прокомментировать. Не знаю, кто и почему так определил, но это считается аксиомой.
Чувствую, что я увлекся сухой теорией и нужно привести что-то наглядное и образное. С другой стороны все показатели вариации описывают примерно одно и то же, только рассчитываются по-разному. Поэтому разнообразием примеров блеснуть трудно, Отличаться могут лишь значения показателей, но не их суть. Вот и сравним, как отличаются значения различных показателей вариации для одной и той же совокупности данных. Возьмем пример с расчетом среднего линейного отклонения (из предыдущей статьи). Вот исходные данные:
И график для напоминания.
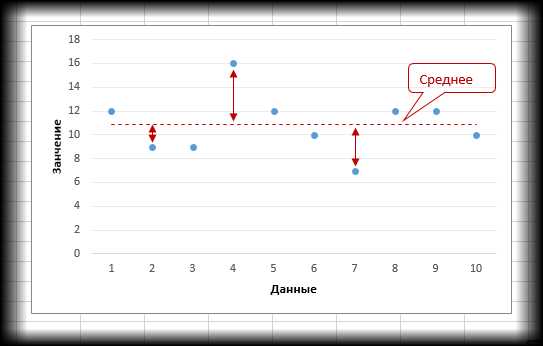
По этим данным рассчитаем различные показатели вариации.
Среднее значение – это обычная средняя арифметическая.
Размах вариации – разница между максимумом и минимумом:
Среднее линейное отклонение считается по формуле:
Дисперсия:
Стандартное отклонение:
Расчет сведем в табличку.
Как видно, среднее линейное и среднеквадратичное отклонение дают похожие значения степени вариации данных. Дисперсия – это сигма в квадрате, поэтому она всегда будет относительно большим числом, что, собственно, ни о чем не говорит. Размах вариации – это разница между крайними значениями и может говорить о многом.
Подведем некоторые итоги.
Вариация показателя отражает изменчивость процесса или явления. Ее степень может измеряться с помощью нескольких показателей.
1. Размах вариации – разница между максимумом и минимумом. Отражает диапазон возможных значений.
2. Среднее линейное отклонение – отражает среднее из абсолютных (по модулю) отклонений всех значений анализируемой совокупности от их средней величины.
3. Дисперсия – средний квадрат отклонений.
4. Среднеквадратичное отклонение – корень из дисперсии (среднего квадрата отклонений).
5. Коэффициент вариации – наиболее универсальный показатель, отражающий степень разброса значений независимо от их масштаба и единиц измерения. Коэффициент вариации измеряется в процентах и может быть использован для сравнения вариации различных процессов и явлений.
Таким образом, в статистическом анализе существует система показателей, отражающих однородность явлений и устойчивость процессов. Часто показатели вариации не имеют самостоятельного смысла и используются для дальнейшего анализа данных (расчет доверительных интервалов, проверка статистических гипотез и др.). Исключением является коэффициент вариации, который характеризует однородность данных, что является ценной статистической характеристикой.
Про дисперсию можно много чего еще рассказать. Например, у нее есть ряд полезных свойств. Но на сегодня все. До скорых встреч.
Поделиться в социальных сетях:
statanaliz.info
16. Дисперсия и ее основные свойства.
Дисперсия в статистике определяется как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. Распространенный способ расчета квадратов отклонений вариантов от средней с их последующим усреднением.
(1)
В экономически-статистическом анализе вариацию признака принято оценивать чаще всего с помощью среднего квадратического отклонения, оно представляет собой корень квадратный из дисперсии.
(3)
Характеризует абсолютную колеблемость значений варьирующего признака выражается в тех же единицах измерения, что и варианты. В статистике часто возникает необходимость сравнения вариации различных признаков. Для таких сравнений используется относительный показатель вариации, коэффициент вариации.
V(4)
Свойства дисперсии:
1)если из всех вариант вычесть какое-либо число, то дисперсия от этого не изменится;
2) если все значения вариант разделить на какое-либо число b, то дисперсия уменьшится в b^2 раз, т.е.
3) если исчислить средний квадрат отклонений от какого-либо числа с неравного средней арифметической, то он будет больше дисперсии . При этом на вполне определенную величину на квадрат разности между средней величиной поc.
C = 0
Дисперсию можно определить как разницу между средним квадратом и средней в квадрате.
-)
17. Групповая и межгрупповая вариации. Правило сложения дисперсии
Если статистическая совокупность разбита на группы или части по изучаемому признаку, то для такой совокупности могут быть исчислены следующие виды дисперсии: групповые (частные), средне групповые (частных), и межгрупповая.
Общая дисперсия – отражает вариацию признака за счет всех условий и причин, действующих в данной статистической совокупности.
Групповая дисперсия — равна среднему квадрату отклонений отдельных значений признака внутри группы от средней арифметической этой группы, называемой групповой средней. При этом групповая средняя не совпадает с общей средней для всей совокупности.
Групповая дисперсия отражает вариацию признака только за счет условий и причин, действующих внутри группы.
Средняя групповых дисперсий — определяется как среднее взвешенное арифметическое из дисперсий групповых, причем весами являются объемы групп.
Межгрупповая дисперсия — равна среднему квадрату отклонений групповых средних от общей средней.
Межгрупповая дисперсия характеризует вариацию результативного признака за счет группировочного признака.
Между рассмотренными видами дисперсий существует определенное соотношение: общая дисперсия равна сумме средней групповой и межгрупповой дисперсии.
Это соотношение называется правилом сложения дисперсии.
18. Динамический ряд и его составные элементы. Виды динамических рядов.
Ряд в статистике — это цифровые данные, показывающие, изменение явления во времени или в пространстве и дающие возможность производить статистическое сравнение явлений как в процессе их развития во времени, так и по различным формам и видам процессов. Благодаря этому можно обнаружить взаимную зависимость явлений.
Процесс развития движения социальных явлений во времени в статистике принято называть динамикой. Для отображения динамики строят ряды динамики (хронологические, временные), которые представляют собой ряды изменяющихся во времени значений статистического показателя (например, число осуждённых за 10 лет), расположенных в хронологическом порядке. Их составными элементами являются цифровые значения данного показателя и периоды или моменты времени, к которым они относятся.
Важнейшая
характеристика рядов динамики — их размер (объём, величина) того или
иного явления, достигнутых в определённых
период или к определённому моменту.
Соответственно, величина членов ряда
динамики — его уровень.
Ещё одна важная характеристика динамического ряда — время, прошедшее от начального до конечного наблюдения, или число таких наблюдений.
Существуют различные виды рядов динамики, их можно классифицировать по следующим признакам.
1) В зависимости от способа выражения уровней ряды динамики подразделяются на ряды абсолютных и производных показателей (относительных и средних величин).
2) В зависимости от того, как выражают уровни ряда состояние явления на определённые моменты времени (на начало месяца, квартала, года и т.п.) или его величину за определённые интервалы времени (например, за сутки, месяц, год и т.п.), различают соответственно моментные и интервальные ряды динамики. Моментные ряды в аналитической работе правоохранительных органов используются сравнительно редко.
В теории статистики выделяют рады динамики и по ряду других классификационных признаков: в зависимости от расстояния между уровнями — с равностоящими уровнями и неравностоящими уровнями во времени; в зависимости от наличия основной тенденции изучаемого процесса — стационарные и не стационарные. При анализе динамических рядов исходят из следующего уровни ряда представляют в виде составляющих :
Yt = TP + Е (t)
где ТР – детерминированная составляющая определяющая общую тенденцию изменения во времени или тренд.
Е (t) – случайная компонента, вызывающая колеблимость уровней.
Дисперсия и стандартное отклонение
Обратная связь
ПОЗНАВАТЕЛЬНОЕ
Сила воли ведет к действию, а позитивные действия формируют позитивное отношение
Как определить диапазон голоса — ваш вокал
Как цель узнает о ваших желаниях прежде, чем вы начнете действовать. Как компании прогнозируют привычки и манипулируют ими
Целительная привычка
Как самому избавиться от обидчивости
Противоречивые взгляды на качества, присущие мужчинам
Тренинг уверенности в себе
Вкуснейший «Салат из свеклы с чесноком»
Натюрморт и его изобразительные возможности
Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д.
Как научиться брать на себя ответственность
Зачем нужны границы в отношениях с детьми?
Световозвращающие элементы на детской одежде
Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия
Как слышать голос Бога
Классификация ожирения по ИМТ (ВОЗ)
Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека — Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
Отёска стен и прирубка косяков — Когда на доме не достаёт окон и дверей, красивое высокое крыльцо ещё только в воображении, приходится подниматься с улицы в дом по трапу.
Дифференциальные уравнения второго порядка (модель рынка с прогнозируемыми ценами) — В простых моделях рынка спрос и предложение обычно полагают зависящими только от текущей цены на товар.
Дисперсия случайной величины — мера разброса данной случайной величины, то есть её отклонения от математического ожидания. В статистике для обозначения дисперсии часто употребляется обозначение (сигма в квадрате). Квадратный корень из дисперсии , равный , называется
Хотя для оценки всей выборки очень удобно использовать лишь одно значение (такое как среднее значение или моду и медиану), этот подход легко может привести к неправильным выводам. Причина такого положения лежит не в самой величине, а в том, что одна величина никак не отражает разброс значений данных.
Например, в выборке:
среднее значение равно 5.
Однако, в самой выборке нет ни одного элемента со значением 5. Возможно, Вам потребуется знать степень близости каждого элемента выборки к ее среднему значению. Или, другими словами, вам потребуется знать дисперсию значений. Зная степень изменения данных, Вы можете лучше интерпретировать среднее значение
, медиану и моду. Степень изменения значений выборки определяется путем вычисления их дисперсии и стандартного отклонения.Дисперсия и квадратный корень из дисперсии, называемый стандартным отклонением, характеризуют среднее отклонение от среднего значения выборки. Среди этих двух величин наибольшее значение имеет стандартное отклонение. Это значение можно представить как среднее расстояние, на котором находятся элементы от среднего элемента выборки.
Дисперсию трудно интерпретировать содержательно. Однако, квадратный корень из этого значения является стандартным отклонением и хорошо поддается интерпретации.
Стандартное отклонение вычисляется путем определения сначала дисперсии и затем вычисления квадратного корня из дисперсии.
Например, для массива данных, приведенных на рисунке, будут получены следующие значения:
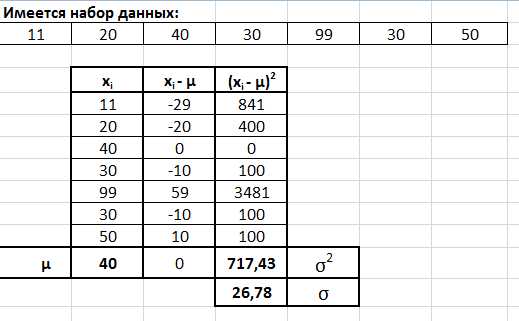
Здесь среднее значение квадратов разностей равно 717,43. Для получения стандартного отклонения осталось лишь взять квадратный корень из этого числа.
Результат составит приблизительно 26,78.
Следует помнить, что стандартное отклонение интерпретируется как среднее расстояние, на котором находятся элементы от среднего значения выборки.
Стандартное отклонение показывает, насколько хорошо среднее значение описывает всю выборку.
Допустим, Вы являетесь руководителем производственного отдела по сборке ПК. В квартальном отчете говорится, что выпуск за последний квартал составил 2500 ПК. Плохо это или хорошо? Вы попросили (или уже в отчете есть эта графа) в отчете отобразить стандартное отклонение по этим данным. Цифра стандартного отклонения, например, равна 2000. Становится понятным для Вас, как руководителя отдела, что производственная линия требует лучшего управления (слишком большие отклонения по количеству собираемых ПК).
Вспомним: при большой величине стандартного отклонения данные широко разбросаны относительно среднего значения, а при маленькой – они группируются близко к среднему значению.
Четыре статистические функции ДИСП(), ДИСПР(), СТАНДОТКЛОН() и СТАНДОТКЛОНП() – предназначены для вычисления дисперсии и стандартного отклонения чисел в интервале ячеек. Перед тем как вычислять дисперсию и стандартное отклонение набора данных, нужно определить, представляют ли эти данные генеральную совокупность или выборку из генеральной совокупности. В случае выборки из генеральной совокупности следует использовать функции ДИСП() и СТАНДОТКЛОН(), а в случае генеральной совокупности – функции ДИСПР() и СТАНДОТЛОНП():
| Генеральная совокупность | Функция |
 | ДИСПР() |
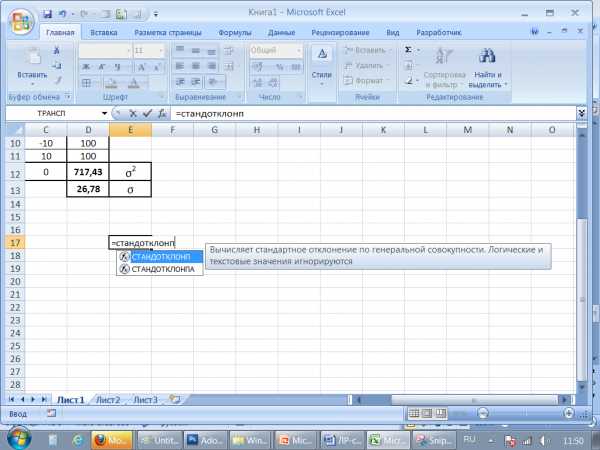 | СТАНДОТЛОНП() |
| Выборка | |
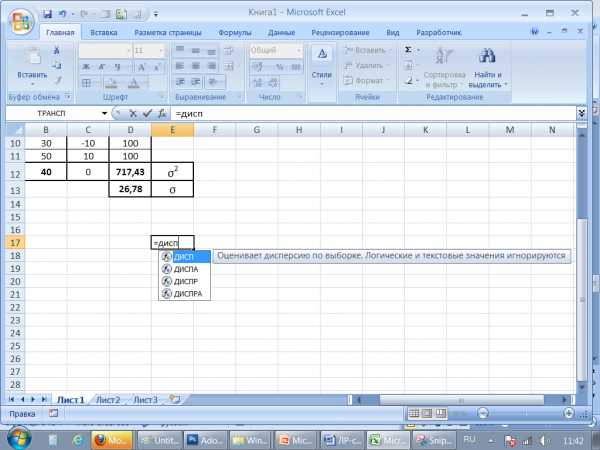 | ДИСП() |
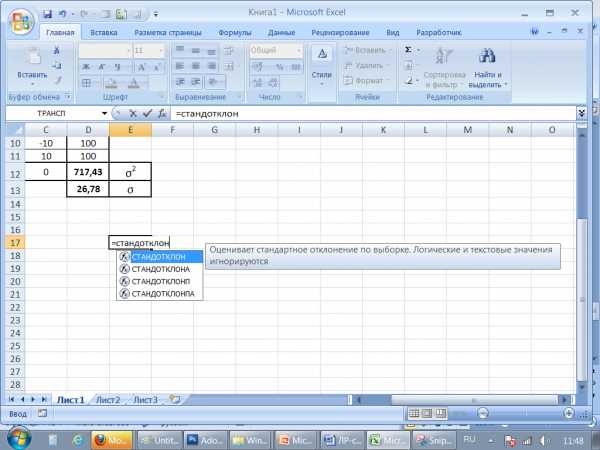 | СТАНДОТКЛОН() |
Дисперсия (а так же стандартное отклонение), как мы отмечали, свидетельствуют о том, в какой степени входящие в набор данных величины разбросаны вокруг среднего арифметического.
Малое значение дисперсии или стандартного отклонения говорит о том, что все данные сосредоточены вокруг среднего арифметического, а большое значение этих величин – о том, что данные разбросаны в широком диапазоне значений.
Дисперсию достаточно трудно интерпретировать содержательно (что значит малое значение, большое значение?). Выполнение Задания 3позволит визуально, на графике, показать смысл дисперсии для набора данных.
Задания
· Задание 1.
· 2.1. Дать понятия: дисперсия и стандартное отклонение; их символьное обозначение при статистической обработке данных.
· 2.2. Оформить рабочий лист в соответствии с рисунком 1 и произвести необходимые расчеты.
· 2.3. Привести основные формулы, используемые при расчетах
· 2.4. Пояснить все обозначения ( , , , )
· 2.5. Пояснить практическое значение понятия дисперсия и стандартное отклонение.
Задание 2.
1.1. Дать понятия: генеральная совокупность и выборка; математическое ожидание и среднее арифметическое их символьное обозначение при статистической обработке данных.
1.2. В соответствии с рисунком 2 оформить рабочий лист и произвести расчеты.
1.3. Привести основные формулы, используемые при расчетах (для генеральной совокупности и выборке).
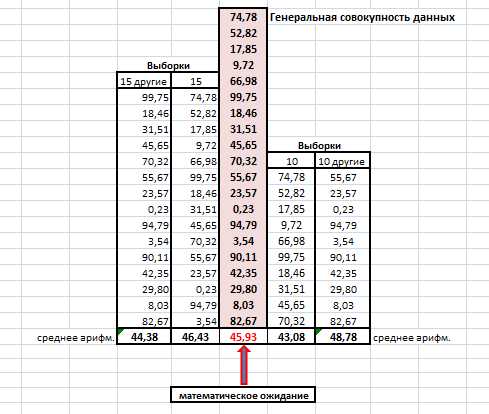
Рисунок 2
1.4. Объяснить, почему возможны получения таких значений средних арифметических в выборках как 46,43 и 48,78 (см. файл Приложение). Сделать выводы.
Задание 3.
Имеется две выборки с различным набором данных, но среднее для них будет одинаковым:
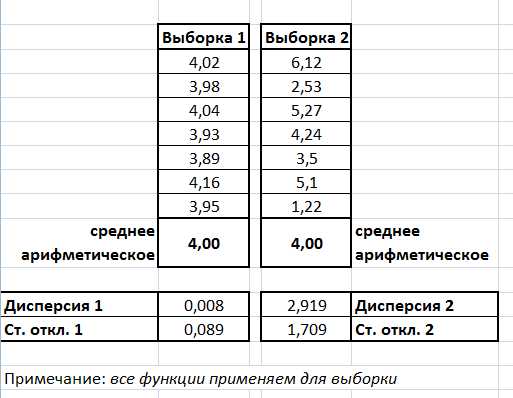
Рисунок 3
| Рисунок 4 | Рисунок 5 |
| Видно, что практически разброса нет. Значение дисперсии 0,008 и стандартного отклонения – 0,089. Все очень наглядно. | Разброс данных явный, что подтверждает значение дисперсии – 2,19 и стандартного отклонения – 1,709 |
3.1. Оформить рабочий лист в соответствии с рисунком 3 и произвести необходимые расчеты.
3.2. Приведите основные формулы расчета.
3.3. Постройте графики в соответствии с рисунками 4, 5.
3.4. Поясните полученные зависимости.
3.5. Аналогичные вычисления проведите для данных двух выборок.
Исходная выборка 11119999
Значения второй выборки подбираете так, что бы среднее арифметическое для второй выборки было таким же, например,:
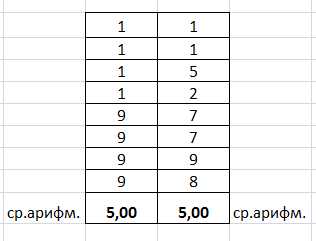
Подберите значения для второй выборки самостоятельно. Оформите вычисления и построения графиков подобно рисункам 3, 4, 5. Покажите основные формулы, которые использовали при вычислениях.
Сделайте соответствующие выводы.
Все задания оформить в виде отчета со всеми необходимыми рисунками, графиками, формулами и краткими пояснениями.
Примечание: построение графиков обязательно пояснить с рисунками и краткими пояснениями.
megapredmet.ru