
Определение доверительного интервала косвенного измерения
Пусть искомая величина y является известной функцией величин х1,х2, …, xn, каждую из которых находят в результате прямых измерений:
(1.12)
Ставится задача: зная доверительные интервалы для величин, входящих в эту формулу, рассчитать доверительный интервал для величины y.
Для того, чтобы найти среднее значение результата косвенных измерений, следует в формулу (1.12) подставить средние значения величинх1, х2, …, xn:
. (1.13)
Полуширину доверительного интервала Δу находят по формуле:
(1.14)
где Δхi – полуширина доверительного интервала
(абсолютная погрешность) величины х
Если является степенной функцией вида:
(1.15)
где k,l,…,m – целые или дробные числа, то формулу (1.13) можно привести к виду:
(1.16)
Расчет погрешности при измерении плотности
В данной работе плотность древесины, из которой изготовлен брусок в форме прямоугольного параллелепипеда, измеряется косвенно, то есть вычисляется по формуле, следующей из формул (1.3) и (1.4):
. (1.17)
Вначале производятся прямые измерения массы, длины, ширины и высоты бруска и рассчитываются соответствующие доверительные интервалы при одинаковых значениях доверительной вероятности:
.
Остается рассчитать доверительный интервал, в котором с заданной доверительной вероятностью лежит истинное значение плотности
.
Среднее значение плотности, как следует из формулы (1.13), таково
. (1.18)
Абсолютная погрешность плотности, как следует из формул (1.14) и (1.17),
(1.19)
где ;
;
аналогично
Используя эти выражения для частных производных в формуле (1.19), и подставляя в них средние значения величин, получаем:
,
(1.20)
где – относительные погрешности прямых измерений массы и линейных размеров (рассчитанные по формулам (1.2)).
Единица измерения
плотности в СИ 1 кг/м
Порядок выполнения работы
1. Ознакомиться с
устройством штангенциркуля и способом
измерения линейных размеров с его
помощью (Приложение). Определить и
записать приборную погрешность для
штангенциркуля – половину цены деления
нониуса.
Определить и
записать приборную погрешность для
штангенциркуля – половину цены деления
нониуса.
2. Измерить каждый из линейных размеров тела в пяти точках образца, данные занести в таблицу, образец которой (таблица 1.2) дан для измерений длины a. Таблицы для b и c аналогичны.
Таблица 1.2 – Результаты измерения длины
№ | а i, мм | , мм | Δаi, мм | (Δаi)2, мм2 | Δа, мм | δa |
1. | ||||||
… | ||||||
5. |

3. С помощью преподавателя выполнить однократное взвешивание тела на технических весах. Определить приборную погрешность весов Δ
4. Измерения линейных размеров тела являются прямыми, поэтому для их обработки применить алгоритм, описанный в пункте «Порядок обработки результатов многократных прямых измерений» теоретического введения. Доверительную вероятность принять равной 0,95. Результаты представить в виде:мм,мм,мм.
5. По формуле (1.18)
рассчитать среднее значение плотности
. Так
как измерение плотности является
косвенным, то для расчета погрешности
измерения плотности, то есть полуширины
доверительного интерваланужно использовать формулу (1.20).
Так
как измерение плотности является
косвенным, то для расчета погрешности
измерения плотности, то есть полуширины
доверительного интерваланужно использовать формулу (1.20).
6. Результат записать в виде г/см3 , а также выразить его в единицах СИ. Определить, из какой древесины изготовлено тело, используя таблицу 1.3.
Таблица 1.3 – Плотность различных пород дерева
Древесная порода | , кг/м3 | Древесная порода | , кг/м3 |
Бакаут(«железное дерево») | 1100-1400 | Тополь | 480 |
Дуб | 760 | Осина | 465 |
Клен | 750 | Ель | 450 |
Ясень | 750 | Липа | 450 |
Береза | 650 | Бамбук | 400 |
Сосна | 520 | Бальза | 100-120 |
Погрешность и доверительный интервал: в чем разница?
Часто в статистике мы используем доверительные интервалы для оценки значения параметра совокупности с определенным уровнем достоверности.
Каждый доверительный интервал принимает следующий вид:
Доверительный интервал = [нижняя граница, верхняя граница]
Погрешность равна половине ширины всего доверительного интервала.
Например, предположим, что у нас есть следующий доверительный интервал для среднего значения генеральной совокупности:
95% доверительный интервал = [12,5, 18,5]
Ширина доверительного интервала составляет 18,5 – 12,5 = 6. Допустимая погрешность равна половине ширины, которая будет равна 6/2 = 3 .
В следующих примерах показано, как рассчитать доверительный интервал вместе с погрешностью для нескольких различных сценариев.
Пример 1: Доверительный интервал и допустимая погрешность для среднего значения генеральной совокупностиМы используем следующую формулу для расчета доверительного интервала для среднего значения генеральной совокупности:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: z-критическое значение
- s: стандартное отклонение выборки
- n: размер выборки
Пример: Предположим, мы собираем случайную выборку дельфинов со следующей информацией:
- Размер выборки n = 40
- Средний вес выборки x = 300
- Стандартное отклонение выборки s = 18,5
Мы можем подставить эти числа в калькулятор доверительного интервала , чтобы найти 95% доверительный интервал:
95% доверительный интервал для истинного среднего веса популяции черепах составляет [294,267, 305,733] .
Погрешность будет равна половине ширины доверительного интервала, который равен:
Погрешность: (305,733 – 294,267) / 2 = 5,733 .
Пример 2: Доверительный интервал и допустимая погрешность для доли населенияМы используем следующую формулу для расчета доверительного интервала для доли населения:
Доверительный интервал = p +/- z * (√ p (1-p) / n )
куда:
- p: доля выборки
- z: выбранное значение z
- n: размер выборки
Пример: Предположим, мы хотим оценить долю жителей округа, поддерживающих определенный закон. Мы выбираем случайную выборку из 100 жителей и спрашиваем их об их отношении к закону. Вот результаты:
- Размер выборки n = 100
- Доля в пользу закона p = 0,56
Мы можем подставить эти числа в доверительный интервал для калькулятора пропорций , чтобы найти 95% доверительный интервал:
95% доверительный интервал для истинной доли населения составляет [0,4627, 0,6573] .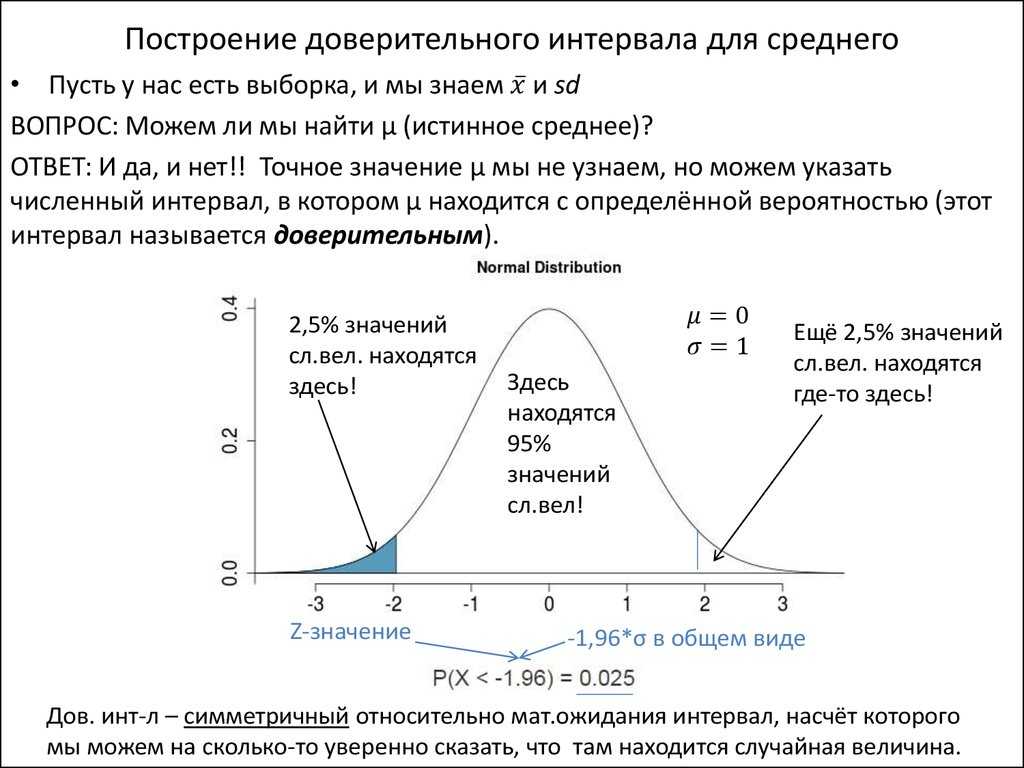
Погрешность будет равна половине ширины доверительного интервала, который равен:
Погрешность: (0,6573 – 0,4627) / 2 = 0,0973 .
Дополнительные ресурсыПогрешность и стандартная ошибка: в чем разница?
Как найти погрешность в Excel
Как найти погрешность на калькуляторе TI-84
5.4.5 — Расчет размера выборки
Расчет размера выборки для среднего доверительного интервала генеральной совокупности Раздел
Напомним, что \((1-\alpha)\)100% доверительный интервал для \(\mu\) равен \(\bar{x}\pm t_{\alpha/2}\dfrac{s}{\ sqrt{n}}\), где множитель \(t\) имеет t-распределение с \(df = n — 1\). Таким образом, погрешность E равна:
\(E=t_{\alpha/2}\dfrac{s}{\sqrt{n}}\) 92\) Затем округлить до следующего целого числа.
Пример 5-8: Весенние каникулы Раздел
Маркетинговая исследовательская фирма хочет оценить среднюю сумму, которую студент тратит во время весенних каникул. 2\). Мы знаем, что \(z_{\alpha/2}=1,645\) (для 92=31,99\)
2\). Мы знаем, что \(z_{\alpha/2}=1,645\) (для 92=31,99\)
Если мы используем \(n = 32\), результат будет таким же. Таким образом, более точным ответом на пример будет выборка из 32 учащихся.
S.2 Доверительные интервалы | СТАТ ОНЛАЙН
Давайте рассмотрим основную концепцию доверительного интервала.
Предположим, мы хотим оценить фактическое среднее значение генеральной совокупности \(\mu\). Как вы знаете, мы можем получить только \(\bar{x}\), среднее значение выборки, случайно выбранной из интересующей совокупности. Мы можем использовать \(\bar{x}\) для поиска диапазона значений:
\[\text{Нижнее значение} < \text{среднее значение}\;\; \mu < \text{Верхнее значение}\]
, в котором мы можем быть уверены, содержится среднее значение генеральной совокупности \(\mu\). Диапазон значений называется « доверительный интервал ».
Должно ли использование сотового телефона в руке во время вождения быть незаконным? Раздел
Нет никаких сомнений в том, что на протяжении многих лет вы видели многочисленные доверительные интервалы для долей населения, о которых сообщалось в газетах.
Например, в газетном сообщении (опрос ABC News, 16-20 мая 2001 г.) был вопрос о том, считают ли взрослые США использование портативного мобильного телефона за рулем незаконным. Из 1027 взрослых американцев, случайно выбранных для участия в опросе, 69% считали, что это должно быть незаконным. Репортер заявил, что «погрешность » опроса составила 3%. Следовательно, доверительный интервал для (неизвестной) доли населения p составляет 69% ± 3%. То есть мы можем быть уверены, что от 66% до 72% всех взрослых американцев считают, что использование мобильного телефона во время вождения автомобиля должно быть незаконным.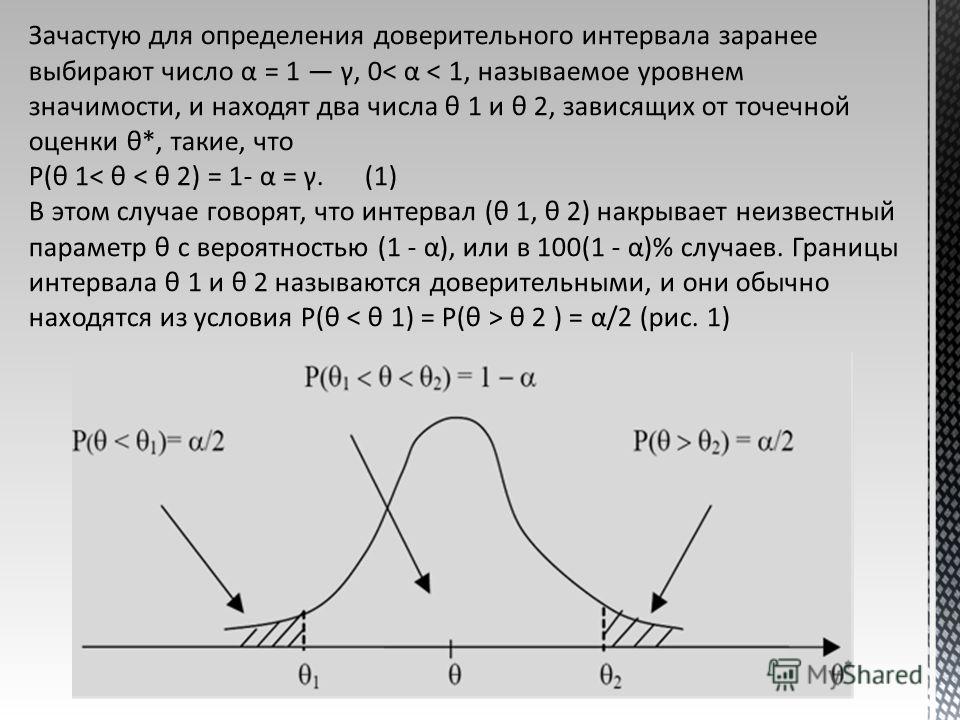
Общая форма (наиболее) доверительных интервалов Раздел
Предыдущий пример иллюстрирует общий вид большинства доверительных интервалов, а именно:
$\text{Выборочная оценка} \pm \text{погрешность}$
Нижний предел получается по формуле:
$\text{ нижний предел L интервала} = \text{оценка} — \text{погрешность}$
Верхний предел получается:
$\text{верхний предел U интервала} = \text{ оценка} + \text{погрешность}$
Как только мы получили интервал, мы можем утверждать, что мы действительно уверены, что значение параметра совокупности находится где-то между значением L и значением U .
До сих пор мы обсуждали расчет и интерпретацию доверительных интервалов в общих чертах. Чтобы быть более конкретным в отношении их использования, давайте рассмотрим конкретный интервал, а именно « t — интервал для среднего значения генеральной совокупности µ ».
(1-α)100%
t -интервал для среднего значения совокупности \(\mu\)Если нас интересует оценка среднего значения совокупности \(\mu\), весьма вероятно, что мы используйте t -интервал для среднего значения совокупности \(\mu\).
- t -Интервал для среднего значения совокупности
- Формула доверительного интервала для слов:
$\text{Выборочное среднее} \pm (\text{t-множитель} \times \text{стандартная ошибка})$
- , и вы, возможно, помните, что формула для доверительного интервала в записи:
- $\bar{x}\pm t_{\alpha/2, n-1}\left(\dfrac{s}{\sqrt{n}}\right)$
Обратите внимание, что:
- « t -множитель «, который мы обозначаем как \(t_{\alpha/2, n-1}\), зависит от размера выборки через n — 1 (называется « степеней свободы «) и уровень достоверности \((1-\alpha)\times100%\) через \(\frac{\alpha}{2}\).
- «стандартная ошибка », которая равна \(\frac{s}{\sqrt{n}}\), количественно определяет, насколько значение выборки \(\bar{x}\) варьируется от выборки к выборке.
 То есть стандартная ошибка — это просто другое название предполагаемого стандартного отклонения всех возможных выборочных средних.
То есть стандартная ошибка — это просто другое название предполагаемого стандартного отклонения всех возможных выборочных средних. - количество справа от знака ±, т. е. , « t — множитель × стандартная ошибка «, — это просто более конкретная форма погрешности. То есть предел погрешности оценки среднего значения генеральной совокупности µ вычисляется путем умножения множителя t на стандартную ошибку выборочного среднего.
- формула подходит только в том случае, если выполняется определенное допущение, а именно, что данные нормально распределены.
 То есть стандартная ошибка — это просто другое название предполагаемого стандартного отклонения всех возможных выборочных средних.
То есть стандартная ошибка — это просто другое название предполагаемого стандартного отклонения всех возможных выборочных средних.Очевидно, что выборочное среднее \(\bar{x}\) , выборочное стандартное отклонение s и размер выборки n легко получить из выборочных данных. Теперь нам просто нужно просмотреть, как получить значение множителя t , и все будет готово.
Как определяется множитель t?
Как показано на следующем графике, мы поместили доверительный уровень $1-\alpha$ в центр распределения t . Затем, поскольку вся вероятность, представленная кривой, должна равняться 1, вероятность α должна быть поровну разделена между двумя «хвостами» распределения. То есть вероятность левого хвоста равна $\frac{\alpha}{2}$, а вероятность правого хвоста равна $\frac{\alpha}{2}$. Если мы сложим вероятности различных частей $(\frac{\alpha}{2} + 1-\alpha + \frac{\alpha}{2})$, мы получим 1. t -множитель, обозначаемый \(t_{\alpha/2}\), представляет собой t -значение такое, что вероятность «справа от него» равна $\frac{\alpha}{2}$:
Затем, поскольку вся вероятность, представленная кривой, должна равняться 1, вероятность α должна быть поровну разделена между двумя «хвостами» распределения. То есть вероятность левого хвоста равна $\frac{\alpha}{2}$, а вероятность правого хвоста равна $\frac{\alpha}{2}$. Если мы сложим вероятности различных частей $(\frac{\alpha}{2} + 1-\alpha + \frac{\alpha}{2})$, мы получим 1. t -множитель, обозначаемый \(t_{\alpha/2}\), представляет собой t -значение такое, что вероятность «справа от него» равна $\frac{\alpha}{2}$:
Неудивительно, что мы хотим быть максимально уверенными, когда оцениваем параметр генеральной совокупности. Вот почему уровни доверия обычно очень высоки. Наиболее распространенными уровнями достоверности являются 90%, 95% и 99%. Следующая таблица содержит сводку значений \(\frac{\alpha}{2}\), соответствующих этим общим уровням достоверности. (Обратите внимание, что « коэффициент достоверности «это просто уровень достоверности, представленный в виде доли, а не в процентах. )
)
| Коэффициент доверия $(1-\alpha)$ | Уровень достоверности $(1-\alpha) \times 100$ | $(1-\dfrac{\alpha}{2})$ | $\dfrac{\alpha}{2}$ |
|---|---|---|---|
| 0,90 | 90% | 0,95 | 0,05 |
| 0,95 | 95% | 0,975 | 0,025 |
| 0,99 | 99% | 0,995 | 0,005 |
Хорошая новость заключается в том, что статистическое программное обеспечение, такое как Minitab, рассчитает для нас большинство доверительных интервалов.
Давайте возьмем в качестве примера исследователей, которые интересуются средней частотой сердечных сокращений студентов мужского пола. Предположим, что для исследования была выбрана случайная выборка из 130 студентов мужского пола.
Ниже приведены выходные данные Minitab для одновыборочного t -интервального вывода с использованием этих данных.
Одновыборочный T: ЧСС
Описательная статистика
| N | Среднее значение | СтДев | SE Среднее значение | 95% ДИ для $\mu$ |
|---|---|---|---|---|
| 130 | 73,762 | 7.062 | 0,619 | (72.536, 74.987) |
$\mu$: среднее значение ЧСС
В этом примере исследователей интересовала оценка \(\mu\), частоты сердечных сокращений. Выходные данные показывают, что среднее значение для выборки из n = 130 учащихся мужского пола равно 73,762. Стандартное отклонение выборки (StDev) составляет 7,062, а расчетная стандартная ошибка среднего значения (SE Mean) составляет 0,619. 95% доверительный интервал для среднего $\mu$ населения составляет (72,536, 74,987). Мы можем быть на 95% уверены, что средняя частота сердечных сокращений всех студентов мужского пола составляет от 72,536 до 74,9. 87 ударов в минуту.
87 ударов в минуту.
Факторы, влияющие на ширину t-интервала для среднего $\mu$ Раздел
Подумайте о ширине интервала в предыдущем примере. В целом, как вы думаете, нам нужны узкие доверительные интервалы или широкие доверительные интервалы? Если вы не уверены, рассмотрите следующие два интервала:
- Мы на 95% уверены, что средний средний балл всех студентов колледжа находится между 1,0 и 4,0.
- Мы на 95% уверены, что средний средний балл всех студентов колледжей составляет от 2,7 до 2,9.
Какой из этих двух интервалов более информативен? Конечно, более узкий дает нам лучшее представление о величине истинного неизвестного среднего среднего балла. В целом, чем уже доверительный интервал, тем больше информации мы имеем о значении параметра совокупности. Поэтому мы хотим, чтобы все наши доверительные интервалы были как можно более узкими. Итак, давайте исследуем, какие факторы влияют на ширину t -интервал для среднего \(\mu\).
Итак, давайте исследуем, какие факторы влияют на ширину t -интервал для среднего \(\mu\).
Конечно, чтобы найти ширину доверительного интервала, мы просто берем разницу в двух пределах:
Ширина = Верхний предел — Нижний предел
Какие факторы влияют на ширину доверительного интервала? Мы можем исследовать этот вопрос, используя формулу для доверительного интервала и наблюдая, что произойдет, если допустить изменение одного из элементов формулы.
\[\bar{x}\pm t_{\alpha/2, n-1}\left(\dfrac{s}{\sqrt{n}}\right)\]
Какова ширина t -интервала для среднего? Если вычесть нижний предел из верхнего предела, вы получите:
\[\text{Ширина}=2 \times t_{\alpha/2, n-1}\left(\dfrac{s}{\sqrt{ n}}\right)\]
Теперь давайте исследуем факторы, влияющие на длину этого интервала. Убедитесь, что каждое из следующих утверждений верно:
- По мере увеличения среднего значения выборки длина остается неизменной. То есть выборочное среднее не влияет на ширину интервала.
- По мере уменьшения стандартного отклонения выборки с ширина интервала уменьшается. Поскольку s является оценкой того, насколько данные изменяются естественным образом, у нас мало контроля над s , кроме как убедиться, что мы делаем наши измерения как можно тщательнее.
- По мере уменьшения доверительного уровня множитель t уменьшается, и, следовательно, ширина интервала уменьшается. На практике мы не хотели бы устанавливать уровень уверенности ниже 9.0%.
- По мере увеличения размера выборки ширина интервала уменьшается. Это фактор, который мы можем изменить с наибольшей гибкостью, единственным ограничением являются наши временные и финансовые ограничения.
 То есть выборочное среднее не влияет на ширину интервала.
То есть выборочное среднее не влияет на ширину интервала.При закрытии
В нашем обзоре доверительных интервалов мы сосредоточились только на одном доверительном интервале. Важно понимать, что темы, обсуждаемые здесь — общая форма интервалов, определение множителей t и факторы, влияющие на ширину интервала, — обычно распространяются на все доверительные интервалы, с которыми мы столкнемся в этом курсе.