
Среднее арифметическое, мода и медиана в математической статистики с примерами
- Предмет, цели и методы математической статистики
- Метод выборочных исследований
- Средняя арифметическая, простая и взвешенная
- Мода и медиана
- Примеры
Предмет, цели и методы математической статистики
Начиная с XVIII века, в общем направлении статистических исследований начинает активно формироваться математическая статистика.
Математическая статистика – раздел математики, разрабатывающий методы регистрации, описания и анализа данных наблюдений и экспериментов с целью построения вероятностных моделей массовых случайных явлений.
В зависимости от предмета исследований математическая статистика делится на:
- статистику чисел;
- многомерный статистический анализ;
- анализ функций (процессов) и временных рядов;
- статистику объектов с нечисловыми характеристиками.
В зависимости от цели и методов исследований математическая статистика делится на: описательную статистику; теорию оценивания; теорию проверки гипотез.
| Описательная статистика | Теория оценивания | Теория проверки гипотез | |
| Цель | Обработка и систематизация эмпирических данных | Оценивание ненаблюдаемых данных и сигналов от объектов наблюдения на основе наблюдаемых данных | Обоснование предположений о виде распределения и свойствах случайной величины |
| Методы | 1. Наглядное представление в форме графиков и таблиц. 2. Количественное описание с помощью статистических показателей. | 1. Параметрические методы (наименьших квадратов, максимального правдоподобия и др.). 2. Непараметрические методы. | 1. Последовательный анализ. 2. Статистические критерии. |
Метод выборочных исследований
Статистика получила признание в различных областях человеческой деятельности благодаря заметной экономии времени и прочих ресурсов. Её основная идея: не нужно измерять всё, измерьте только часть всего и сделайте предположение об остальном.
«Всё» в статистике называется генеральной совокупностью.
«Часть всего», которую мы тщательно исследуем, называется выборкой.
Метод выборочных исследований – способ определения свойств группы объектов (генеральной совокупности) на основании статистического исследования её части (выборки).
Например, чтобы оценить средние размеры апельсина, который продаётся в магазине в декабре, необязательно денно и нощно мерить все апельсины во всех ящиках (сколько же для этого нужно времени и людей?!). Достаточно сделать выборку – мерить по одному апельсину из каждого ящика в течение месяца (тут уже и один человек справится).
Статистика предоставляет методику и оценки для того, чтобы правильно провести выборку и на основании знаний о среднем размере апельсина в выборке (выборочной средней) судить о средних размерах всех декабрьских апельсин (генеральной средней).
Средняя арифметическая, простая и взвешенная
Статистическое исследование опирается на собранные данные о каком-то признаке (рост, вес, возраст, доход и т.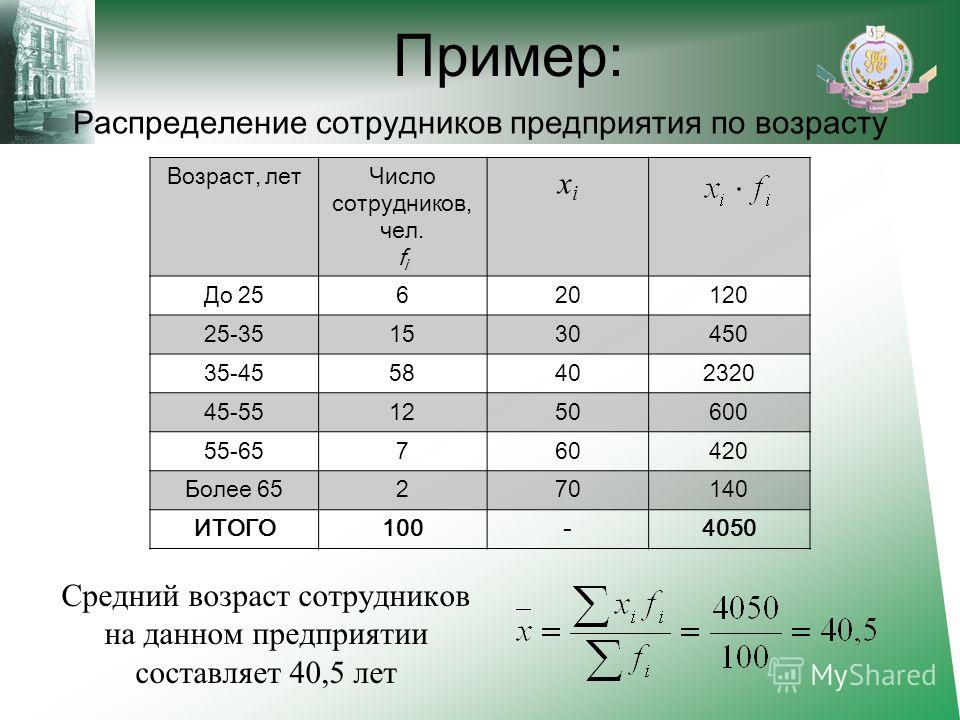 K n_i , i = \overline{1,K} $$
K n_i , i = \overline{1,K} $$
где K – количество групп с повторяющимися вариантами, $x_i$ — значение варианты в -й группе, $n_i$ – частота варианты $x_i$.
Например:
Рассматриваем тот же ряд оценок: 5,4,3,5,4,4,5,4,3,5,5,4,3,5,4,4 и составляем таблицу:
x_i
3
4
5
Σ
n_i
3
7
6
16
x_i n_i
9
28
30
67
$$ x_cp = \frac{3\cdot3+4\cdot7+5\cdot6}{3+7+6} ≈ 4,2 $$
Вычисления заметно упростились.
Мода и медиана
Мода дискретного вариационного ряда – это варианта с максимальной частотой. Мод может быть несколько. Тогда говорят, что ряд мультимодальный.
В примере с оценками по алгебре мода $M_0 = 4$ — эта оценка встречается чаще всего, её частота равна 7.
В примере с оценками по алгебре N = 16 — четное. $m = \frac{N}{2} = 8 $.
Сортируем ряд оценок по возрастанию: 3,3,3,4,4,4,4, 4,4, 4,5,5,5,5,5,5
$$ x_8 = 4, x_9 = 4 \Rightarrow M_e = \frac{4+4}{2} = 4 $$
Примеры
Пример 1.
Найдите выборочную среднюю, моду и медиану.
Почему при оценке доходов мода и медиана предпочтительней выборочной средней?
Составим таблицу:
$x_i$, дол.
100
200
300
400
1000
5000
$\sum$
$n_i$, чел.
2
2
3
1
1
1
10
$x_i n_i$
200
400
900
400
1000
5000
7900
Выборочная средняя:$ x_{cp} = \frac{7900}{10} = 790$ (дол.)
Мода: $M_o$ = 300 (дол.) – максимальная частота 3
Медиана:
100, 100, 200, 200, 300, 300, 300, 400, 1000, 5000
$$ m = \frac{10}{2} = 5, x_5 = x_6 = 300, M_e = \frac{300+300}{2} = 300 (дол.) $$
Выборочная средняя не отражает доходов большей части людей в выборке, поскольку даже один человек с большими доходами может резко сместить оценку вправо.
Пример 2. Исследовалось время решения задачи. В исследовании принимало участие 20 человек, из них двое задачу не решили. Время решения остальных участников:
$x_i$, мин
10
15
20
25
30
n_i, чел
2
5
5
4
2
Найдите выборочную среднюю, моду и медиану.
При подборе задач для контрольной работы, сколько времени следует отвести на решение подобной задачи?
Проведём вычисления:
$x_i$
10
15
20
25
30
$\sum$
$n_i$, чел
2
5
5
4
2
18
$x_i n_i$
20
75
100
100
60
355
$$x_cp = \frac{355}{18} ≈ 19,7 мин $$
В выборке 2 моды: $M_{o1}$ = 15 мин, $M_{o2}$ = 20 мин
Положение медианы: $m = \frac{N}{2} = \frac{18}{2} = 9, x_9 = x_10 = 20, Me = 20$ мин
Средняя, одна из мод и медиана равны 20 мин. Поэтому при составлении контрольной следует отвести на подобную задачу 20 мин.
Поэтому при составлении контрольной следует отвести на подобную задачу 20 мин.
Пример 3. работа по геометрии показала следующие результаты:
$x_i$
2
3
4
5
$n_i$, чел
5
22
10
2
Найдите выборочную среднюю, моду и медиану.
Что вы можете сказать об уровне понимания материала?
Проведём вычисления:
$x_i$
2
3
4
5
$\sum$
$n_i$
5
22
10
2
39
$x_i n_i$
10
66
40
10
126
$$x_cp = \frac{126}{39} ≈ 3,2$$
Мода: $M_o$ = 3 — эта оценка получена 22 раза
Положение медианы: $m = ⌈ \frac{N}{2}⌉ = ⌈\frac{39}{2}⌉ = 20, x_{20} = 3, Me = 3$
Средняя, мода и медиана равны 3.
Уровень понимания удовлетворительный, «на троечку».
Медиана как статистическая характеристика
Используй поиск, чтобы найти научные материалы и собрать список литературы
База статей справочника включает в себя статьи написанные экспертами Автор24, статьи из научных журналов и примеры студенческих работ из различных вузов страны
Содержание статьи
1. Определение медианы
Определение медианы
2. Свойства медианы
3. Примеры решения задач
Определение медианы
Понятие медианы — это одна из статистических величин, относящихся к конечному упорядоченному ряду чисел. Пусть нам дан конечный упорядоченный ряд чисел $a_1,\ a_2,\ \dots ,\ a_n$. Этот ряд может содержать как четное, так и нечетное количество чисел. Поэтому понятие медианы имеет два определения (в зависимости от количества чисел в конечном упорядоченном числовом ряду).
Определение
Медианой для конечного упорядоченного ряда чисел, имеющего нечетное число элементов, называется число, записанное в середине данного ряда.
Пример 1
Пусть дан ряд 1, 3, 5, 7, 9, 11, 13. Тогда медиана данного ряда равна 7.
Перед тем, как ввести второе определение, вспомним, что такое средне арифметическое двух чисел.
Определение
Среднее арифметическое $n$ чисел — это сумма этих чисел, поделенная на $n$.
Определение
Медианой для конечного упорядоченного ряда чисел, имеющего четное число элементов, называется среднее арифметическое двух чисел, записанных в середине данного ряда.
Пример 2
Пусть дан ряд 1, 3, 5, 7, 9, 11, 13, 15. Тогда медиана данного ряда равна
\[\frac{7+9}{2}=\frac{16}{2}=8\]
Рассмотрим теперь случай, когда ряд чисел $a_1,\ a_2,\ \dots ,\ a_n$ не упорядочен. В этом случае, перед тем как найти медиану, данный ряд сначала необходимо упорядочить, то есть расставить все числа в порядке возрастания. Только после этого мы можем применить определение понятия медианы.
Пример 3
Пусть дан ряд 3, 7, 5, 4, 11, 6, 10, 9. Вначале упорядочим данный ряд, получим:
\[3,\ 4,\ 5,\ 6,\ 7,\ 9,\ 10,\ 11\]
Вычисляем по определению 3 медиану:
\[\frac{6+7}{2}=\frac{13}{2}=6,5\]
Свойства медианы
Для понятия медианы можно выделить два следующих свойства:
- Если распределение задано непрерывно, то значение медианы совпадает с одним из решений уравнения \[F\left(x\right)=0,5\]
- Если ряд распределения имеет четное число членов и два средних члена $a_k$ и $a_{k+1}$ различны, то значение медианы принадлежит интервалу ${(a}_k,a_{k+1})$.
Напомним, что $F\left(x\right)$ — функция распределения случайной величины.
Примеры решения задач
Задача 1
Найти среднее арифметическое следующих рядов чисел.
- 3, 6, 13, 7, 3, 45, 24, 17, 8, 3.
- 10, 25, 43, 67, 13, 65, 34, 84, 46.
Решение:
- Так как данный ряд имеет 10 чисел, то среднее арифметическое равно \[\frac{3+6+13+7+3+45+24+17+8+3}{10}=\frac{129}{10}=12,9\]
- Так как данный ряд имеет 9 чисел, то среднее арифметическое равно \[\frac{10+25+43+67+13+65+34+84+46}{9}=\frac{387}{9}=43\]
Ответ: а) 12,9. б) 43.
Задача 2
Найти среднее арифметическое и медианы следующих числовых рядов:
- 2, 4, 8, 16, 32, 64, 128, 256
- 13, 24, 35, 46, 57, 68, 79
Решение:
- Так как ряд имеет 8 элементов, то среднее арифметическое равно: \[\frac{2+4+8+16+32+64+128+256}{8}=\frac{510}{8}=63,75\]
- Так как ряд имеет 7 элементов, то среднее арифметическое равно: \[\frac{13+24+35+46+57+68+79}{7}=\frac{322}{7}=46\]
Так как данный ряд чисел упорядочен и имеет нечетное число элементов, то мы сразу можем применить первое определение, получим, что медиана равна 46.
Задача 3
Найти медиану следующих рядов чисел.
- 3, 6, 13, 7, 3, 45, 24, 17, 8, 3.
- 10, 25, 43, 67, 13, 65, 34, 89, 46.
Решение:
- Вначале нам необходимо упорядочить данный ряд, получим: \[3,\ 3,\ 3,\ 6,\ 7,\ 8,\ 13,\ 17,\ 24,\ 45\]
- Вначале нам необходимо упорядочить данный ряд, получим: \[10,\ 13,\ 25,\ 34,\ 43,\ 46,\ 65,\ 67,\ 89\]
Так как данный ряд чисел упорядочен и имеет четное число элементов, то мы сразу можем применить третье определение, получим, что медиана равна:
\[\frac{7+8}{2}=\frac{13}{2}=6,5\]Так как данный ряд чисел упорядочен и имеет нечетное число элементов, то мы сразу можем применить первое определение, получим, что медиана равна 43.
Ответ: а) 6,5. б) 43.
Сообщество экспертов Автор24
Автор этой статьи Дата последнего обновления статьи: 29.01.2022
Выполнение любых типов работ по математике
Решение задач по комбинаторике на заказ Решение задачи Коши онлайн Математика для заочников Контрольная работа на тему числовые неравенства и их свойства Контрольная работа на тему умножение и деление рациональных чисел Контрольная работа на тему действия с рациональными числами Дипломная работа на тему числа Курсовая работа на тему дифференциальные уравнения Контрольная работа на тему приближенные вычисления Решение задач с инвариантами
Подбор готовых материалов по теме
Дипломные работы Курсовые работы Выпускные квалификационные работы Рефераты Сочинения Доклады Эссе Отчеты по практике Решения задач Контрольные работы
Статистика » Структурные средние величины (Мода и медиана)
- О сайте
- О себе
- Проверь себя
- Статьи
Структурные средние величины (Мода и медиана)
Четверг, Март 27th, 2008
Средние, о которых шла речь в предыдущих параграфах данной темы, являются обобщающими статистическими характеристиками изучаемого массового явления (совокупности) по тому или иному варьирующему признаку и одновременно своего рода абстракцией. Они отражают то общее, что присуще всем единицам совокупности. При этом может случиться, что величина средней не имеет точного равенства ни с одним из конкретных встречающихся в совокупности вариантов (значений единиц совокупности по признаку). Среднее число членов семьи равно 3,81. Дробного числа членов семьи не может быть. Средняя показывает некоторое центральное значение, около которого группируются реально существующие варианты.
Они отражают то общее, что присуще всем единицам совокупности. При этом может случиться, что величина средней не имеет точного равенства ни с одним из конкретных встречающихся в совокупности вариантов (значений единиц совокупности по признаку). Среднее число членов семьи равно 3,81. Дробного числа членов семьи не может быть. Средняя показывает некоторое центральное значение, около которого группируются реально существующие варианты.
Поэтому наравне со средними в качестве общих статистических характеристик изучаемого признака могут быть использованы величины конкретных вариантов, занимающих в ранжированном (построенном в прядке возрастания или убывания) ряду индивидуальных значений признака определенное положение.
В статистических исследованиях в качестве вспомогательных описательных статистических характеристик распределения варьирующего признака широко применяются мода и медиана.
Модой в статистике называется величины признака (варианта), которая чаще всего встречается в данной совокупности.
Медианой в статистике называется варианта, которая находится в середине вариационного ряда. Медиана делит ряд пополам. Обозначают медиану символом .
Определение моды и медианы в дискретном ряду, где значения признака заданы определенными числами, не представляет большой трудности.
В рассмотренном примере наиболее часто встречаются семьи, имеющие 4 члена семьи, т.е. =4 (семья имеющая 4 члена семьи).
Могут быть распределения, где все варианты встречаются одинаково часто. В этом случае моды нет. В других случаях не одна, а две варианты могут иметь наибольшие частоты. Тогда у признака будут две моды и распределение будет бимодальным.
Чтобы найти медиану в дискретном ряду, нужно сумму частот разделить пополам и к полученному результату добавить ? .
Такой номер семьи делит ряд пополам. Поскольку частоты с дробным номером не бывают, то медиана находиться посредине между 50-й и 51-й частотами. Затем по накопленным частотам (частостям) определяют величину варианта (признака), обладающего таким номером.
Однако если единиц (частот) в совокупности достаточно много и различия между величинами рядом стоящих членов ряда небольшие, то можно считать медианой (с достаточной степенью точности) один из центральных вариантов с порядковым номером n/2. Так обычно поступают, определяя медиану при четном числе членов ряда.
Рассмотрим, как определяется мода и медиана для интервального ряда.
Прежде закрывают открытые интервалы (первый и последний) и определяют интервалы, в которых находятся мода и медиана. Их называют соответственно модальным и медианным интервалом.
Модальный интервал – интервал с наибольшей частотой. В приведенном ниже примере, модальным является интервал 170-175 см.
Для расчета определенного значения модальной величины признака, заключенного в этом интервале, применяют формулу.
Смысл этой формулы заключается в следующем: величину той части модального интервала, которую нужно добавить к его минимальной границе, определяют в зависимости от величины частот предшествующего и последующего интервалов.
Posted in Структурные средние величины (Мода и медиана) | 19 Comments »
Четверг, Март 27th, 2008
Медианный интервал (содержащий частоту, который делит ряд пополам) определяется по накопленным частотам. Это будет интервал, накопленная частота которой равна или превышает половину суммы частот.
Отсюда медианным интервалом будет интервал со значением роста от 170 до 175 см. До этого интервала сумма накопленных частей составила 175. Следовательно, чтобы получить значение медианы, необходимо прибавить 75 [или 76 единиц] (250,5-75).
При определении значения медианы предполагают, что значение признака в границах этого медианного интервала распределяется равномерно.
Прибавив полученную величину к минимальной границе интервала, получим искомую величину медианы.
т.е. половина студентов имеет рост меньше 172.9 см, а вторая половина – больше.
Строго говоря, приведенная формула моды пригодна только для рядов с равными интервалами. Формула медианы применима для любого интервального ряда.
Формула медианы применима для любого интервального ряда.
Определим среднюю арифметическую для второго примера.
Для первого примера имеем: средняя = 3,81; мода = 4; медиана = 4 члена семьи.
Для второго примера: средняя = 172,85; мода равна 173.3 и медиана = 172.9 см.
Соотношение этих трех величин указывает направление и степень ассиметрии рядов распределения. Более подробно эти вопросы рассматриваются в дисциплине “Математическая статистика”.
Таким образом мода и медиана является важными дополнительными характеристиками к средней изучаемой совокупности. Особенно ценны эти показатели для характеристик небольших по численности совокупностей. При этом следует помнить, что мода и медиана являются описательными статистическими характеристиками, т.к. в них не погашаются индивидуальные отклонения, они всегда соответствуют определенной варианте.
В то же время можно привести немало примеров, когда мода или медиана являются более эффективной характеристикой, чем средняя.
Например, при статистических методах контроля качества продукции, при оценке качества передачи информации, надежности работы средств труда широкого применяются мода и медиана. Так, таксофон, почтовый ящик следует разместить не на середине улицы, а в точке, которая делит численность проживающих пополам. Используется медиана. Показатель «вероятность безотказной работы» оценивается модой.
Считается, что медиана по своему положению более определена, чем мода.
Выше было сказано, что средняя, мода и медиана совместно используются при анализе ряда распределения по структуре (на симметрию). Если , то данный ряд симметричный. Если , то в ряду имеются группы с очень высокими частотами и если таких групп нет. Если совокупность неоднородна и т.д.
Для характеристики структуры вариационного ряда кроме моды и медианы в статистике исчисляются и другие характеристики: квартили, децили, процентили.
Posted in Структурные средние величины (Мода и медиана) | 31 Comments »
Основы статистики с Python: описательная статистика
Область статистики часто понимают неправильно, однако она играет важную роль в повседневной жизни. Корректно составленная статистика позволяет извлечь знания из неопределённого и сложного реального мира, однако при неправильном применении она может нанести вред или ввести в заблуждение. Для того, чтобы отличить правду от лжи, важно чётко понимать методы статистики и значение различных статистических измерений.
Корректно составленная статистика позволяет извлечь знания из неопределённого и сложного реального мира, однако при неправильном применении она может нанести вред или ввести в заблуждение. Для того, чтобы отличить правду от лжи, важно чётко понимать методы статистики и значение различных статистических измерений.
В этой статье мы поговорим о:
- определении статистики;
- описательной статистике:
- мерах центральной тенденции;
- мерах разброса.
Нам не понадобятся глубокие знания статистики, однако понадобится хотя бы минимальное знание Python. Если вы не встречались с циклами for и списками, будет лучше сначала ознакомиться с ними.
Не знаете с какой стороны подойти к Python? Тогда почитайте о том, с чего начать изучение Python.
Загружаем данные
Мы будем обсуждать статистику, используя реальные данные, взятые с платформы Kaggle из датасета Wine Reviews. Сами данные были извлечены с сайта Wine Enthusiast.
Предположим, вы — ученик сомелье. Вы нашли интересный датасет и хотели бы сравнить различные вина, воспользовавшись статистикой для описания данных и сделав для себя несколько выводов.
Код, представленный ниже, загружает датасет wine-data.csv в переменную wines в виде списка списков. В статье мы будем вести статистику на примере этой переменной:
import csv
with open("wine-data.csv", "r", encoding="latin-1") as f:
wines = list(csv.reader(f))Давайте посмотрим на первые пять строк данных, указанных в таблице, чтобы понять, с какими значениями мы работаем:
Это вопрос с подвохом. Статистика включает в себя много всего, поэтому попытка кратко описать её неизбежно приведёт к упущению некоторых деталей. Тем не менее нам нужно с чего-то начинать.
Область статистики можно рассматривать как научную среду для работы с данными. Это определение включает все задачи, связанные со сбором, анализом и интерпретацией данных. Также статистика может относиться к отдельным измерениям, которые представляют собой сводную информацию по данным или определенные их аспекты. В этой статье мы постараемся провести грань между научной областью статистики и непосредственными измерениями.
Также статистика может относиться к отдельным измерениям, которые представляют собой сводную информацию по данным или определенные их аспекты. В этой статье мы постараемся провести грань между научной областью статистики и непосредственными измерениями.
И первым шагом будет логичный вопрос: а что такое «данные»? К счастью, это определение дать проще. Данные — это совокупность наблюдений за миром, которая может иметь множество вариаций, от качественных до количественных. Исследователи собирают данные, полученные в ходе экспериментов, предприниматели собирают данные своих клиентов, а игровые компании собирают данные о поведении игроков
Эти примеры указывают на ещё один важный аспект: наблюдения обычно связаны с генеральной совокупностью, представляющей интерес. Возвращаясь к предыдущему примеру: исследователь может рассматривать группу пациентов с определённым состоянием. Для наших данных генеральной совокупностью будет набор отзывов о винах. Чётко определив генеральную совокупность, мы можем применить методы статистики и извлечь знания из полученных результатов.
Но почему нас интересуют генеральные совокупности? Полезно иметь возможность сравнивать и противопоставлять их, чтобы проверить наши идеи. Например, мы хотели бы узнать, что пациенты, получающие новое лечение, выздоравливают быстрее тех, кто получает плацебо, но кроме того мы хотели бы доказать это количественно. Здесь на помощь приходит статистика, которая предоставляет точный подход к данным и даёт возможность принимать решения, основанные на реальных событиях, а не на догадках.
Ключевые идеи:
- статистика — наука о данных;
- данные — набор наблюдений за интересующей нас генеральной совокупностью;
- статистика предоставляет конкретный способ сравнения генеральных совокупностей с помощью чисел, а не неоднозначных описаний.
Когда у нас есть набор наблюдений, полезно свести признаки наших данных в одно определение. Этим занимается описательная статистика. Как следует из названия, описательная статистика описывает конкретное свойство данных, которые она обобщает. Такую статистику можно разделить на две категории: меры центральной тенденции и меры разброса.
Такую статистику можно разделить на две категории: меры центральной тенденции и меры разброса.
Меры центральной тенденции
Меры центральной тенденции — показатели, представляющие собой ответ на вопрос: «На что похожа середина данных?». Слово «середина» звучит неточно, так как существует множество определений для её описания. Далее мы обсудим, как каждая новая мера меняет наше определение «середины».
Среднее значение
Данная характеристика описывает среднее значение в наборе данных. Вычислить её довольно просто: сложите все значения и разделите полученную сумму на количество значений.
В случае со средним значением «серединой» датасета будет среднее арифметическое его значений. Среднее значение отражает типичный показатель в наборе данных. Если мы случайно выберем один из показателей, то, скорее всего, получим значение, близкое к среднему.
Вычислить среднее значение на Python просто. Давайте выясним, чему равна средняя оценка вина в нашем датасете:
# Извлекаем оценки из датасета scores = [float(w[4]) for w in wines] # Складываем все оценки sum_score = sum(scores) # Ищем количество оценок num_score = len(scores) # Считаем среднее значение avg_score = sum_score/num_score print(avg_score) # выводит 87.8884184721394
 8884184721394
8884184721394
Это среднее значение говорит нам, что «типичная» оценка в датасете равна примерно 87,8. Соответственно, большинство вин имеют высокий рейтинг, если предположить, что оценивают по шкале от 0 до 100. Тем не менее нужно учесть, что Wine Enthusiast не публикует отзывы с рейтингом ниже 80.
Есть разные типы среднего значения, но это — наиболее распространённая форма. Оно называется средним арифметическим, так как интересующие нас значения складываются.
Медиана
Следующая мера центральной тенденции, о которой пойдёт речь, — медиана. Медиана, как и среднее значение, нужна для определения типичного значения в наборе данных, но при этом не требует вычислений.
Чтобы найти медиану, данные нужно расположить в порядке возрастания. Медианой будет значение, которое совпадает с серединой набора данных. Если количество значений чётное, то берётся среднее двух значений, которые «окружают» середину.
Стандартной библиотекой Python не предусмотрен поиск медианы, но мы можем написать свою реализацию, следуя описанному алгоритму. Попробуем найти медиану цен на вина:
Попробуем найти медиану цен на вина:
# Извлекаем цены prices = [float(w[5]) for w in wines if w[5] != ""] # Находим их количество num_wines = len(prices) # Сортируем в порядке возрастания sorted_prices = sorted(prices) # Ищем индекс среднего элемента middle = (num_wines / 2) + 0.5 # Находим медиану print(sorted_prices[middle]) # 24
Прим.перев. С версии Python 3.4 есть встроенный способ поиска медианного значения.
Медианная цена бутылки вина составляет 24$. Это предполагает, что как минимум у половины вин в датасете цена равна или ниже 24$. Неплохо! А что насчёт среднего значения? Учитывая, что и медиана, и среднее значение отражают типичное значение, можно предположить, что они должны быть примерно одинаковы:
print(sum(prices)/len(prices)) # 33.13
Средняя цена в 33,13$ на порядок выше медианной. Как это произошло? Разница между медианой и средним значением существует из-за робастности (выбросоустойчивости).
Проблема выбросов
Как вы помните, среднее значение можно найти, сложив все значения и разделив сумму на их количество, в то время как медиана ищется простой перестановкой значений. Если в данных есть выбросы — значения, которые гораздо выше или ниже остальных, — это может негативно повлиять на среднее значение. Таким образом, среднее значение не робастно, а медиана — напротив, выбросоустойчива.
Давайте взглянем на максимальную и минимальную цену в наших данных:
min_price = min(prices) max_price = max(prices) print(min_price, max_price) # 4.0, 2300.0
Теперь мы знаем, что в данных есть выбросы. Выбросы могут отражать интересные события или ошибки в нашем наборе данных, поэтому важно уметь определять их наличие. Сравнение медианы и моды — один из способов определить наличие выбросов, хотя визуализация обычно позволяет сделать это быстрее.
Мода
Это последняя мера центральной тенденции, о которой пойдёт речь. Мода определяется как значение, которое наиболее часто встречается в наборе данных. Мода не так очевидно соответствует понятию «середины» как среднее значение или медиана, но это соответствие абсолютно обосновано: если значение появляется в данных неоднократно, оно приблизит среднее значение к моде. Чем чаще появляется значение, тем сильнее оно влияет на среднее. Таким образом, мода показывает наиболее значимый фактор, формирующий среднее значение.
Мода определяется как значение, которое наиболее часто встречается в наборе данных. Мода не так очевидно соответствует понятию «середины» как среднее значение или медиана, но это соответствие абсолютно обосновано: если значение появляется в данных неоднократно, оно приблизит среднее значение к моде. Чем чаще появляется значение, тем сильнее оно влияет на среднее. Таким образом, мода показывает наиболее значимый фактор, формирующий среднее значение.
Как и в случае с медианой, встроенной функции для поиска моды у Python нет. Зато мы можем вычислить её сами, посчитав количество повторений различных цен и выбрав самую частую:
# Создаём пустой словарь, в котором будем считать количество появлений цен
price_counts = {}
for p in prices:
if p not in price_counts:
counts[p] = 1
else:
counts[p] += 1
# Проходимся по словарю и ищем максимальное количество повторений
maxp = 0
mode_price = None
for k, v in counts. items():
if maxp < v:
maxp = v
mode_price = k
print(mode_price, maxp) # 20.0, 7860 items():
if maxp < v:
maxp = v
mode_price = k
print(mode_price, maxp) # 20.0, 7860
items():
if maxp < v:
maxp = v
mode_price = k
print(mode_price, maxp) # 20.0, 7860Прим.перев. На самом деле, с версии Python 3.4 можно найти и моду.
Мода относительно близка к медиане, поэтому можно уверенно сказать, что и мода, и медиана отражают средние значения цен на вино.
Меры центральной тенденции полезны для описания среднего значения данных. Тем не менее они не показывают, насколько большой разброс присутствует в данных. Здесь на помощь приходят меры разброса данных.
Меры разброса данных
Меры разброса отвечают на вопрос: «Как сильно варьируются мои данные?». В мире существует не так много вещей, которые остаются в одном и том же состоянии при каждом наблюдении. Эта изменчивость делает мир нечётким и неопределённым, поэтому полезно иметь показатели, которые могут обобщить эту «нечёткость».
Размах
Наша первая мера разброса — размах. Из всех измерений, которые мы рассмотрим далее, его вычислить проще всего. Для этого нужно просто вычесть из наибольшего значения в наборе данных наименьшее.
Для этого нужно просто вычесть из наибольшего значения в наборе данных наименьшее.
Мы нашли максимальную и минимальную цены, когда искали медиану, поэтому сейчас можем использовать их:
price_range = max_price - min_price print(price_range) # 2296.0
Итак, размах равен 2296, но что это значит? Когда мы рассматриваем результаты различных измерений, очень важно делать это в контексте наших данных. Наша медианная цена была 24$, а размах равен 2296$. Размах на два порядка больше медианы, что указывает на сильный разброс данных. Возможно, будь у нас ещё один винный датасет, мы могли бы сравнить размахи, чтобы понять, как они отличаются. В ином случае сам по себе размах не слишком полезен.
Мы скорее хотели бы узнать, как сильно данные отличаются от типичного значения. Здесь нам помогут стандартное отклонение и дисперсия случайной величины.
Стандартное отклонение
Стандартное отклонение тоже является мерой разброса данных. Оно помогает узнать, как сильно данные отличаются от типичного значения. Иными словами, оно говорит о том, как сильно данные отличаются от среднего арифметического. Отношение к среднему арифметическому хорошо видно при расчёте отклонения:
Иными словами, оно говорит о том, как сильно данные отличаются от среднего арифметического. Отношение к среднему арифметическому хорошо видно при расчёте отклонения:
Поговорим немного о строении уравнения. Как вы помните, среднее арифметическое рассчитывается путём сложения всех значений и деления на их количество. Уравнение стандартного отклонения похоже, но используется, чтобы найти, на сколько в среднем значения отклоняются от типичного, и включает дополнительную операцию с извлечением корня.
В некоторых источниках можно увидеть в качестве знаменателя n вместо n-1. Такие детали выходят за рамки нашей статьи, но знайте, что использование n-1 считается более корректным. Можете прочитать интуитивное объяснение коррекции Бесселя.
Мы хотим посчитать стандартное отклонение, чтобы более полно описать цены вин и их оценки, поэтому напишем свою функцию. Поиск кумулятивной суммы вручную выглядел бы довольно громоздко, но циклы for в Python всё упрощают. Мы пишем свою функцию, чтобы показать, что на Python легко заниматься такой статистикой. Тем не менее в библиотеке
Мы пишем свою функцию, чтобы показать, что на Python легко заниматься такой статистикой. Тем не менее в библиотеке numpy тоже реализовано вычисление стандартного отклонения через функцию std:
def stdev(nums):
diffs = 0
avg = sum(nums)/len(nums)
for n in nums:
diffs += (n - avg)**(2)
return (diffs/(len(nums)-1))**(0.5)
print(stdev(scores)) # 3.2223917589832167
print(stdev(prices)) # 36.32240385925089
Такие результаты вполне ожидаемы. Оценки варьируются от 80 до 100, поэтому можно предположить, что стандартное отклонение будет небольшим. С другой стороны, отклонение в ценах гораздо выше из-за выбросов. Чем больше стандартное отклонение, тем больше рассеяны данные вокруг среднего значения, и наоборот.
Далее мы увидим, что дисперсия тесно связана со стандартным отклонением.
Дисперсия
Часто стандартное отклонение и дисперсию связывают вместе и делают это не без причины. Вот уравнение дисперсии, ничего не напоминает?
Вот уравнение дисперсии, ничего не напоминает?
Дисперсия и стандартное отклонение — почти одно и то же! Дисперсия — просто квадрат стандартного отклонения. Более того, обе величины отражают одну и ту же вещь — меру разброса, хотя стоит отметить, что единицы измерения разные. В каких бы единицах ни измерялись ваши данные, единицы измерения отклонения будут такими же, а у дисперсии они будут возведены в квадрат.
Многие новички в статистике задают вопрос: «Зачем возводить отклонение в квадрат? Разве нельзя избавится от отрицательных слагаемых при помощи модуля?». Избавление от отрицательных значений — хорошая причина для возведения в квадрат, но не единственная. Как и на среднее значение, на дисперсию и стандартное отклонение влияют выбросы. Очень часто нас интересуют выбросы, поэтому возведение в квадрат позволяет выделить эту особенность. Если вы знакомы с математическим анализом, то поймете, что наличие экспоненциального выражения позволяет найти точку минимального отклонения.
Чаще всего при статистическом анализе нам понадобятся только среднее значение и стандартное отклонение, однако дисперсия по-прежнему важна в других академических областях. Меры центральной тенденции и разброса позволяют нам систематизировать данные и извлечь из них знания.
Ключевые идеи:
- описательная статистика используется для систематизации и количественного описания данных;
- среднее значение указывает на типичное значение в нашем наборе данных. Оно не робастно;
- медиана является центральным значением в ряду данных. Она робастна;
- мода — значение, которое появляется наиболее часто;
- размах — это разность между максимальным и минимальным значениями в наборе данных;
- дисперсия и стандартное отклонение являются средним расстоянием от среднего арифметического значения.
Перевод статьи «Basic Statistics in Python: Descriptive Statistics»
5.5 Мода и медиана. Их вычисление в дискретных и интервальных вариационных рядах
Мода
и медиана –
особого рода средние, которые используются
для изучения структуры вариационного
ряда. Их иногда называют структурными
средними, в отличие от рассмотренных
ранее степенных средних.
Их иногда называют структурными
средними, в отличие от рассмотренных
ранее степенных средних.
Мода – это величина признака (варианта), которая чаще всего встречается в данной совокупности, т.е. имеет наибольшую частоту.
Мода имеет большое практическое применение и в ряде случаев только мода может дать характеристику общественных явлений.
Медиана – это варианта, которая находится в середине упорядоченного вариационного ряда.
Медиана показывает количественную границу значения варьирующего признака, которой достигла половина единиц совокупности. Применение медианы наряду со средней или вместо нее целесообразно при наличии в вариационном ряду открытых интервалов, т.к. для вычисления медианы не требуется условное установление границ отрытых интервалов, и поэтому отсутствие сведений о них не влияет на точность вычисления медианы.
Медиану
применяют также тогда, когда показатели,
которые нужно использовать в качестве
весов, неизвестны. Медиану применяют
вместо средней арифметической при
статистических методах контроля качества
продукции. Сумма абсолютных отклонений
варианты от медианы меньше, чем от любого
другого числа.
Медиану применяют
вместо средней арифметической при
статистических методах контроля качества
продукции. Сумма абсолютных отклонений
варианты от медианы меньше, чем от любого
другого числа.
Рассмотрим расчет моды и медианы в дискретном вариационном ряду:
Стаж, лет, X | Число рабочих, чел, f | Накопленные частоты |
1 | 2 | 2 |
3 | 4 | 6 |
4 | 5 | (11) |
8 | 4 | 15 |
10 | 1 | 16 |
ИТОГО: | 16 | — |
Определить моду и медиану.
Мода Мо = 4 года, так как этому значению соответствует наибольшая частота f = 5.
Т.е. наибольшее число рабочих имеют стаж 4 года.
Для того, чтобы вычислить медиану, найдем предварительно половину суммы частот. Если сумма частот является числом нечетным, то мы сначала прибавляем к этой сумме единицу, а затем делим пополам:
Ме=16/2=8
Медианой будет восьмая по счету варианта.
Для того, чтобы найти, какая варианта будет восьмой по номеру, будем накапливать частоты до тех пор, пока не получим сумму частот, равную или превышающую половину суммы всех частот. Соответствующая варианта и будет медианой.
Ме = 4 года.
Т.е. половина рабочих имеет стаж меньше четырех лет, половина больше.
Если
сумма накопленных частот против одной
варианты равна половине сумме частот,
то медиана определяется как средняя
арифметическая этой варианты и
последующей.
Вычисление моды и медианы в интервальном вариационном ряду
Мода в интервальном вариационном ряду вычисляется по формуле
где ХМ0 — начальная граница модального интервала,
hм0 – величина модального интервала,
fм0, fм0-1, fм0+1– частота соответственно модального интервала, предшествующего модальному и последующего.
Модальным называется такой интервал, которому соответствует наибольшая частота.
Пример 1
Группы по стажу | Число рабочих, чел | Накопленные частоты |
1 | 2 | 3 |
До 2 | 4 | 4 |
2-4 | 23 | 27 |
4-6 | 20 | 47 |
6-8 | 35 | 82 |
8-10 | 11 | 93 |
свыше 10 | 7 | 100 |
ИТОГО: | 100 | — |
Определить
моду и медиану.
Решение.
Модальный интервал [6-8], т.к. ему соответствует наибольшая частота f = 35. Тогда:
Хм0=6, fм0=35
hм0=2, fм0-1=20
fм0+1=11
Вывод: Наибольшее число рабочих имеет стаж примерно 6,7 лет.
Для интервального ряда Ме вычисляется по следующей формуле:
где Хме – нижняя граница медиального интервала,
hме – величина медиального интервала,
– половина суммы частот,
fме – частота медианного интервала,
Sме-1 –сумма
накопленных частот интервала,
предшествующего медианному.
Медианный интервал – такой интервал, которому соответствует кумулятивная частота, равная или превышающая половину суммы частот.
Определим медиану для нашего примера.
Найдем:
т.к 82>50, то медианный интервал [6-8].
Тогда:
Хме =6, fме =35,
hме =2, Sме-1=47,
Вывод: Половина рабочих имеет стаж меньше 6,16 лет, а половина имеет стаж больше, чем 6,16 лет.
3. Структурные средние величины. Мода и медиана. Теория статистики: конспект лекций
3. Структурные средние величины. Мода и медиана. Теория статистики: конспект лекцийВикиЧтение
Теория статистики: конспект лекций
Бурханова Инесса Викторовна
Содержание
3. Структурные средние величины. Мода и медиана
Структурные средние величины. Мода и медиана
Для характеристики структуры статистической совокупности применяются показатели, которые называют структурными средними. К ним относятся мода и медиана.
Мода (Мо) – чаще всего встречающийся вариант. Модой называется значение признака, которое соответствует максимальной точке теоретической кривой распределений.
Мода представляет наиболее часто встречающееся или типичное значение.
Мода применяется в коммерческой практике для изучения покупательского спроса и регистрации цен.
В дискретном ряду мода – это варианта с наибольшей частотой. В интервальном вариационном ряду модой считают центральный вариант интервала, который имеет наибольшую частоту (частность).
В пределах интервала надо найти то значение признака, которое является модой.
где хо – нижняя граница модального интервала;
h – величина модального интервала;
fm – частота модального интервала;
fт—1 – частота интервала, предшествующего модальному;
fm+1 – частота интервала, следующего за модальным.
Мода зависит от величины групп, от точного положения границ групп.
Мода – число, которое в действительности встречается чаще всего (является величиной определенной), в практике имеет самое широкое применение (наиболее часто встречающийся тип покупателя).
Медиана (Me – это величина, которая делит численность упорядоченного вариационного ряда на две равные части: одна часть имеет значения варьирующего признака меньшие, чем средний вариант, а другая – большие.
Медиана – это элемент, который больше или равен и одновременно меньше или равен половине остальных элементов ряда распределения.
Свойство медианы заключается в том, что сумма абсолютных отклонений значений признака от медианы меньше, чем от любой другой величины.
Применение медианы позволяет получить более точные результаты, чем при использовании других форм средних.
Порядок нахождения медианы в интервальном вариационном ряду следующий: располагаем индивидуальные значения признака по ранжиру; определяем для данного ранжированного ряда накопленные частоты; по данным о накопленных частотах находим медианный интервал:
где хме– нижняя граница медианного интервала;
iMe – величина медианного интервала;
f/2 – полусумма частот ряда;
SMe—1 – сумма накопленных частот, предшествующих медианному интервалу;
fMe – частота медианного интервала.
Медиана делит численность ряда пополам, следовательно, она там, где накопленная частота составляет половину или больше половины всей суммы частот, а предыдущая (накопленная) частота меньше половины численности совокупности.
Данный текст является ознакомительным фрагментом.
Структурные продукты
Структурные продукты Блог об инвестициях с ограниченным риском –
МОДА НА ИНВЕСТИЦИИ
МОДА НА ИНВЕСТИЦИИ Все больше российских граждан открывают для себя рынок коллективных инвестиций. Главное, чтобы коррекция фондового рынка не убила в инвесторах желание вкладывать.В момент написания этой статьи российский фондовый рынок пребывал в состоянии, близком
Структурные проблемы?
Структурные проблемы?
Я убежден, что наша нынешняя система обеспечения рабочей силой необыкновенно негибка и не подготовлена к решению каких бы то ни было задач. Она не способна адекватно реагировать на возможности, которые может предложить промышленность. Это создает
Она не способна адекватно реагировать на возможности, которые может предложить промышленность. Это создает
Структурные подразделения
Структурные подразделения В небольшой организации каждый сотрудник может выполнять ту или иную функцию или совмещать несколько функций. По мере увеличения численности уже несколько работников начинают выполнять те же самые или подобные обязанности. На этом этапе
23. Средние величины и общие принципы их исчисления
23. Средние величины и общие принципы их исчисления Средние величины относятся к обобщающим статистическим показателям, которые дают сводную (итоговую) характеристику массовых общественных явлений, так как строятся на основе большого количе–ства индивидуальных
25. Мода и медиана
25. Мода и медиана
Мода – величина признака, которая чаще всего встречается в данной совокупности. Применительно к вариационному ряду модой является наиболее часто встречающееся значение ранжированного ряда. Она показывает размер признака, свойственный значи–тельной
Мода и медиана
Мода – величина признака, которая чаще всего встречается в данной совокупности. Применительно к вариационному ряду модой является наиболее часто встречающееся значение ранжированного ряда. Она показывает размер признака, свойственный значи–тельной
ЛЕКЦИЯ №5. Средние величины и показатели вариации
ЛЕКЦИЯ №5. Средние величины и показатели вариации 1. Средние величины и общие принципы их исчисления Средние величины относятся к обобщающим статистическим показателям, которые дают сводную (итоговую) характеристику массовых общественных явлений, так как строятся на
1. Средние величины и общие принципы их исчисления
1. Средние величины и общие принципы их исчисления Средние величины относятся к обобщающим статистическим показателям, которые дают сводную (итоговую) характеристику массовых общественных явлений, так как строятся на основе большого количества индивидуальных значений
59.
 Относительные и средние величины
Относительные и средние величины59. Относительные и средние величины Экономический анализ начинается по своей сути с исчисления величины относительной. Относительные величины незаменимы при анализе явлений динамики. Понятно, что эти явления можно выразить и в абсолютных величинах, но доходчивость,
4.3.1 Структурные реформы
4.3.1 Структурные реформы В перспективе для серьезного улучшения инвестиционного климата в России, роста производства и производительности исключительно важно выравнивание условий конкуренции и дальнейшая либерализация экономики. Неэффективные предприятия не должны
ЛЕКЦИЯ № 7. Средние величины
ЛЕКЦИЯ № 7. Средние величины
1. Общая характеристика
В целях анализа и получения статистических выводов по результатом сводки и группировки исчисляют обобщающие показатели – средние и относительные величины. Задача средних величин – охарактеризовать все единицы
Задача средних величин – охарактеризовать все единицы
3. Структурные средние величины. Мода и медиана
3. Структурные средние величины. Мода и медиана Для характеристики структуры статистической совокупности применяются показатели, которые называют структурными средними. К ним относятся мода и медиана.Мода (Мо ) – чаще всего встречающийся вариант. Модой называется
Мотоциклы, высокая мода и карнавал
Мотоциклы, высокая мода и карнавал Шоу Кренза 1997 года превратило освященный белыми рамами Гуггенхейм в место стоянки сотен блестящих, новеньких мотоциклов, которые представляли собой «новаторские стили» столетия[91]. Классические художественные школы были возмущены; они
18.4.5.2. Медиана репутации
18.4. 5.2. Медиана репутации
Как обсуждалось в предыдущем разделе, репутация, измеренная через среднее арифметическое (или соответствующие суммы) оценок, может быть хорошим показателем репутации. Тем не менее он все еще далек от преодоления уклона репутации, производимого
5.2. Медиана репутации
Как обсуждалось в предыдущем разделе, репутация, измеренная через среднее арифметическое (или соответствующие суммы) оценок, может быть хорошим показателем репутации. Тем не менее он все еще далек от преодоления уклона репутации, производимого
Основная мода России
Основная мода России Если вам кажется, что ситуация улучшается, значит, вы чего-то не заметили.Со страной нужно находиться в резонансе, так чтобы «быть в струе», чтобы окружающее пространство не сопротивлялась вам, а помогало, чтобы продвижение вперед происходило бы
Среднее, медиана и мода: они *все* средние..?
Purplemath
Среднее, медиана и мода — это три типа «средних». В статистике есть много «средних», но я думаю, что это три наиболее распространенных, и, безусловно, с тремя вы, скорее всего, столкнетесь на своих курсах по статистике, если эта тема вообще возникнет.
Зачем нужны различные средние значения?
Среднее значение, к которому мы привыкли, находится путем сложения всех значений в наборе данных и последующего деления суммы на количество значений в этом наборе данных; но это среднее значение может ввести в заблуждение.
Содержание продолжается ниже
MathHelp.com
Среднее значение, медиана, мода и диапазон
Типичным примером может быть случай, когда почти каждый человек в данном населении живет примерно на два доллара в день, но есть небольшая элита с доходами в миллионы. Среднее численное значение может ввести в заблуждение, предполагая, что средний (в данном случае мы имеем в виду «типичный») человек зарабатывает несколько десятков тысяч в год. Но это не совсем точно отражает то, что мы имеем в виду, когда пытаемся обсудить «средний» доход. Вот почему средний доход обычно выражается другим типом среднего.
Каковы три средних значения?
Три средних:
- «Среднее» — это «среднее», к которому вы привыкли, когда вы складываете все числа, а затем делите на количество чисел.
- «Медиана» — это «среднее» значение в списке чисел. Чтобы найти медиану, ваши числа должны быть перечислены в порядке от наименьшего к наибольшему, поэтому вам, возможно, придется переписать свой список, прежде чем вы сможете найти медиану.
- Наиболее часто встречающееся значение «mode». Если ни один номер в списке не повторяется, то для списка нет режима.

«Диапазон» списка чисел — это просто разница между наибольшим и наименьшим значениями. Он выражает «распространение», то есть насколько далеко распределены значения (или насколько они сконцентрированы).
- Найдите среднее значение, медиану, моду и диапазон для следующего списка значений:
13, 18, 13, 14, 13, 16, 14, 21, 13
Среднее значение является обычным средним, поэтому я добавлю, а затем разделю:
(13 + 18 + 13 + 14 + 13 + 16 + 14 + 21 + 13) ÷ 9 = 15
Обратите внимание, что среднее значение, в данном случае не является значением из исходного списка. Это общий результат. Вы не должны предполагать, что ваше среднее значение будет одним из ваших исходных чисел; вы не должны удивляться, когда это не так.
Это общий результат. Вы не должны предполагать, что ваше среднее значение будет одним из ваших исходных чисел; вы не должны удивляться, когда это не так.
Медиана — это среднее значение, поэтому сначала мне придется переписать список в порядке номеров:
13, 13, 13, 13, 14, 14, 16, 18, 21
В списке девять чисел, поэтому средним будет (9 + 1) ÷ 2 = 10 ÷ 2 = 5-е число:
13, 13, 13, 13, 14, 14, 16, 18, 21
13, 13, 13, 13, 14, 14, 16, 18, 21
Таким образом, медиана равна 14. мой список выше, это режим.
Наибольшее значение в списке — 21, а наименьшее — 13, поэтому диапазон равен 21 − 13 = 8.
означает: 15
медиана: 14
режим: 13
диапазон: 8
Примечание. Формула для нахождения медианы места выглядит так: «([количество точек данных] + 1) ÷ 2», но вам не обязательно использовать эту формулу. Вы можете просто считать с обоих концов списка, пока не встретитесь в середине, если хотите, особенно если ваш список короткий. В любом случае будет работать.
В любом случае будет работать.
- Найдите среднее значение, медиану, моду и диапазон для следующего списка значений:
1, 2, 4, 7
Среднее значение — это обычное среднее значение:
(1 + 2 + 4 + 7) ÷ 4 = 14 ÷ 4 = 3,5
Медиана — это среднее число. В этом примере числа уже перечислены в порядке номеров, поэтому мне не нужно переписывать список. Но «среднего» числа нет, потому что есть четное количество чисел.
Из-за этого медиана списка будет средним (то есть обычным средним) двух средних значений в списке. Средние два числа 2 и 4, поэтому:
(2 + 4) ÷ 2 = 6 ÷ 2 = 3
Таким образом, медиана этого списка равна 3, а это значение вообще отсутствует в списке.
Режим — это число, которое повторяется чаще всего, но все числа в этом списке встречаются только один раз, поэтому режима нет.
Наибольшее значение в списке — 7, наименьшее — 1, а их разница — 6, поэтому диапазон равен 6.
означает: 3,5
медиана: 3
режим: нет
диапазон: 6
Все значения в приведенном выше списке были целыми числами, но среднее значение списка было десятичным значением. Получение десятичного значения для среднего (или для медианы, если у вас четное количество точек данных) совершенно нормально; не округляйте свои ответы, чтобы попытаться соответствовать формату других чисел.
Получение десятичного значения для среднего (или для медианы, если у вас четное количество точек данных) совершенно нормально; не округляйте свои ответы, чтобы попытаться соответствовать формату других чисел.
- Найдите среднее значение, медиану, моду и диапазон для следующего списка значений:
8, 9, 10, 10, 10, 11, 11, 11, 12, 13
Среднее значение обычное среднее, поэтому я суммирую, а затем разделю:
(8 + 9 + 10 + 10 + 10 + 11 + 11 + 11 + 12 + 13) ÷ 10 = 105 ÷ 10 = 10,5
Медиана – это среднее значение. В списке из десяти значений это будет (10 + 1) ÷ 2 = 5,5-е значение; формула напоминает мне, с этим «пять десятых», что мне нужно усреднить пятое и шестое числа, чтобы найти медиану. Пятое и шестое числа — это последние 10 и первые 11, поэтому:
(10 + 11) ÷ 2 = 21 ÷ 2 = 10,5
Режим — это число, которое повторяется чаще всего. В этом списке есть два значения, которые повторяются три раза; а именно, 10 и 11, каждое из которых повторяется три раза.
Наибольшее значение равно 13, а наименьшее — 8, поэтому диапазон равен 13 − 8 = 5.
означает: 10,5
медиана: 10,5
режимы: 10 и 11
диапазон: 5
Как видите, два средних значения (в данном случае среднее и медиана) могут иметь одно и то же значение. Но это , а не обычно, и вы должны ожидать , а не .
Примечание. В зависимости от вашего текста или вашего инструктора, приведенный выше набор данных может рассматриваться как не имеющий формы, а не как имеющий две формы, потому что ни одно одиночное число не повторялось чаще, чем любое другое. Я видел книги, в которых говорится об этом в любом случае; похоже, нет единого мнения о «правильном» определении «режима» в приведенном выше случае. Поэтому, если вы не уверены, как вам следует ответить на часть «режим» в приведенном выше примере, спросите своего инструктора. до следующий тест.
Как понять, какое среднее значение какое?
Пожалуй, единственная трудность в поиске среднего, медианы и моды заключается в том, чтобы не сбиться с пути, какое «среднее» есть какое. Используйте этот список:
Используйте этот список:
- означает: обычное значение слова «средний»
- медиана: среднее значение Режим
- : чаще всего
(Выше я использовал термин «среднее» довольно небрежно. Техническое определение того, что мы обычно называем «средним», технически называется «средним арифметическим»: сложение значений и последующее деление на число значений. Поскольку вы, вероятно, лучше знакомы с понятием «среднее», чем с «мерой центральной тенденции», я использовал более удобный термин.)
- Учащийся получил следующие оценки за тесты: 87, 95, 76 и 88. Он хочет получить за курс 85 или выше. Предполагая, что все тесты имеют одинаковый вес, какую минимальную оценку он должен получить на последнем тесте, чтобы получить этот общий средний балл?
Мне нужно найти минимальный балл за последний тест. Чтобы найти среднее значение всех его оценок (известных плюс неизвестное), мне нужно сложить все оценки, а затем разделить на количество оценок. Поскольку у меня еще нет баллов за последний тест, я буду использовать переменную для обозначения этого неизвестного значения: » х «. Тогда, устанавливая выражение для среднего, равное искомому среднему, вычисляем:
Поскольку у меня еще нет баллов за последний тест, я буду использовать переменную для обозначения этого неизвестного значения: » х «. Тогда, устанавливая выражение для среднего, равное искомому среднему, вычисляем:
(87 + 95 + 76 + 88 + х ) ÷ 5 = 85
Умножая на 5 и упрощая , я получаю:
87 + 95 + 76 + 88 + х = 425
346 + х = 425
х = 79
чтобы получить общую оценку, которую он хочет (если я сомневаюсь в себе, я всегда могу подставить это значение в формулу для среднего и убедиться, что в результате я получаю 85).0005
Ему нужно получить не менее 79 баллов за последний тест.
Вы можете использовать виджет Mathway ниже, чтобы попрактиковаться в поиске медианы. Попробуйте введенное упражнение или введите свое собственное упражнение. Или попробуйте ввести любой список чисел, а затем выбрать вариант — среднее, медиана, мода и т. д. — из того, что предлагает вам виджет. Затем нажмите кнопку, чтобы сравнить свой ответ с ответом Mathway.
Пожалуйста, примите куки-файлы настроек, чтобы включить этот виджет.
(Нажмите здесь, чтобы перейти непосредственно на сайт Mathway, если вы хотите проверить их программное обеспечение или получить дополнительную информацию.)
URL: https://www.purplemath.com/modules/meanmode.htm
Медианная формула | Как рассчитать медиану (калькулятор, шаблон Excel)
Формула медианы (оглавление)
- Формула медианы
- Калькулятор формулы медианы
- Формула медианы в Excel (с шаблоном Excel)
Медиана — это среднее значение набора данных. В данном n наборе сгруппированных или разгруппированных данных в статистике медиана — это число, найденное прямо в середине набора данных. Он используется во многих реальных ситуациях.
Медиана рассчитывается по следующей формуле.
Медиана = (n + 1) / 2
Предположим, вы возьмете простой пример, 1, 2, 3, 4, 5. Среднее значение равно 3. Мы можем найти его вручную, так как это небольшой набор данные. Если вы примените тот же набор данных в приведенной выше формуле, n = 5, следовательно, медиана = (5 + 1) / 2 = 3. Таким образом, третье число является медианой. Для большого количества данных найти медиану вручную невозможно. Поэтому важно использовать формулу для большого количества наборов данных.
Среднее значение равно 3. Мы можем найти его вручную, так как это небольшой набор данные. Если вы примените тот же набор данных в приведенной выше формуле, n = 5, следовательно, медиана = (5 + 1) / 2 = 3. Таким образом, третье число является медианой. Для большого количества данных найти медиану вручную невозможно. Поэтому важно использовать формулу для большого количества наборов данных.
Давайте рассмотрим пример, чтобы лучше понять расчет формулы медианы.
Вы можете скачать этот медианный шаблон Excel здесь — Медианный шаблон Excel
Пример 1.1. Нахождение медианы для нечетного количества чисел
Рассмотрим небольшой набор данных A = 42, 21, 34, 65, 90, 45 , 109. По имеющимся данным вычислить медиану.
Решение:
Упорядочить набор данных в порядке возрастания.
Медиана рассчитывается по формуле, приведенной ниже
Здесь 4-е значение равно 45.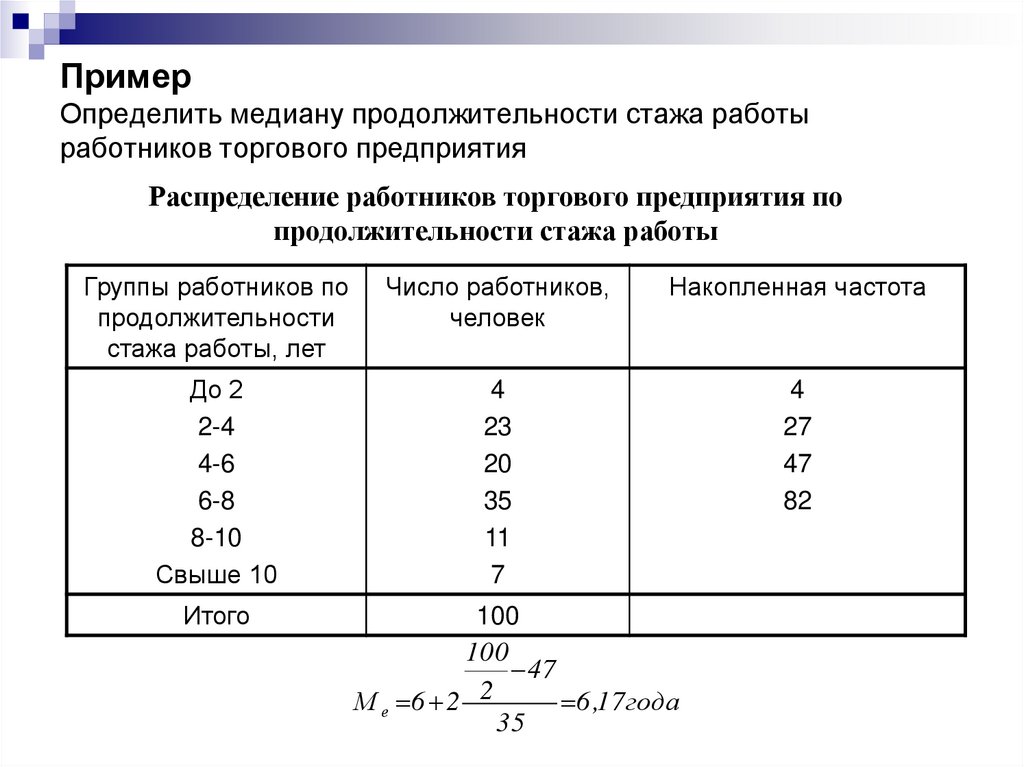 Таким образом, 45 является медианой для этого набора данных.
Таким образом, 45 является медианой для этого набора данных.
Пример #1.2
Рассмотрим большой набор данных B = 1, 2, 3 …, 51.
Здесь общее число равно 51. Таким образом, n = 51,
Медиана рассчитывается по формуле, приведенной ниже
Таким образом, число 26 th является медианным значением. Таким образом, 25 чисел должны быть ниже медианы, число 26 th является медианой, и снова 25 чисел находятся выше.
Пример 2.1. Нахождение медианы для четного количества чисел
Рассмотрим небольшой набор данных C= 2, 5, 89, 40, 66, 33, 14, 23, 90, 101. По имеющимся данным вычислите медиану.
Решение:
Расположите набор данных в порядке возрастания.
Медиана рассчитывается по формуле, приведенной ниже
5. 5 находится между 5 и 6. Поэтому нам нужно взять значение 5 th и 6 th из набора данных.
5 находится между 5 и 6. Поэтому нам нужно взять значение 5 th и 6 th из набора данных.
Из приведенного выше набора данных значения 5 th и 6 th равны 33, 40 соответственно. Сложите оба числа и разделите на 2, чтобы получить медиану. (33+40)/2 = 73/2 = 36,5. Итак, здесь среднее значение этого набора данных составляет 36,5 .
Пример №2.2:
Рассмотрим большой набор данных D = 101, 102 … 198.
Общее число в этом наборе данных равно 98.
Здесь общее число равно 98. Итак, n= 98.
Теперь разделите общее число на 2. Прибавьте, а затем вычтите 1 из полученного значения. Здесь 98/2= 49. Так как это четные числа, должно быть два средних значения. Среднее значение, которое мы получили, равно 49. Таким образом, оно должно иметь 48 чисел выше медианы и 48 чисел ниже медианы. поэтому 49-е и 50-е значения являются средними значениями.
Объяснение
Шаг 1: Сначала расположите данный набор данных в порядке возрастания. Скажем, набор данных, который у вас есть, равен 4, 2, 8 и 1. Таким образом, расположив это в порядке возрастания, вы получите 1, 2, 4, 8.
Скажем, набор данных, который у вас есть, равен 4, 2, 8 и 1. Таким образом, расположив это в порядке возрастания, вы получите 1, 2, 4, 8.
Шаг 2: Здесь n — количество элементов в заданном наборе данных. То есть, если вы рассмотрите приведенный выше примерный набор данных, 1, 2, 4 и 8, значение переменной n равно 4.
Шаг 3: Просто примените значение переменной n в формуле, чтобы получить медиану. то есть Медиана = (n + 1) / 2
Может показаться, что эту формулу очень легко увидеть, поскольку это очень небольшой набор данных. Но для большого набора данных требуется больше усилий, чтобы получить правильное значение, поскольку шаги немного различаются для четного количества чисел и НЕЧЕТНОГО количества чисел. Поэтому нужно быть очень осторожным при нахождении медианы.
Шаги для сортировки набора данных в порядке возрастания в Excel
Можно отсортировать набор данных на листе Excel следующим способом.
- Выберите диапазон ячеек, которые вы хотите отсортировать. Скажем, у вас всего 1000 значений, и они помещаются из ячейки A1 в ячейку A1000.
- Перейдите на вкладку «Данные» -> группа «Сортировка и фильтр» -> нажмите «Сортировка». Это даст вам отсортированный набор данных от наименьшего числа до наибольшего или простого, вы можете щелкнуть правой кнопкой мыши по выбранному диапазону данных и выбрать сортировку -> Нажмите на сортировку от «наименьшего к наибольшему числу».
Шаги для подсчета набора данных на листе Excel, чтобы найти значение n для большого набора данных
- Выберите диапазон ячеек (отсортированных в порядке возрастания), которые вы хотите подсчитать. В приведенном выше примере это от A1 до A1000.
- Перейдите на вкладку «Формулы» -> нажмите «Дополнительные функции» -> «Наведите курсор на статистику» и выберите функцию «СЧЕТЧИК», чтобы подсчитать непустые ячейки. Вы получите значение переменной n. В этом случае вы получите n=1000.
 В этом случае вы получите n=1000.
В этом случае вы получите n=1000.Релевантность и использование формулы медианы
Медианное значение — это статистическая мера, используемая во многих реальных сценариях, таких как медианная цена недвижимости, стоимость банкротства и т. д. Это очень полезно, когда набор данных включает очень высокие и низкие значения сгруппированные и разгруппированные наборы данных. Медиана — это просто точка, где 50% чисел выше и 50% чисел ниже. Это инстинктивная центральность, которая обозначает среднюю ценность. Это значение очень полезно в случае набора исторических данных или набора данных, который поступает с течением времени.
Калькулятор формулы медианы
Вы можете использовать следующий калькулятор медианы
| N | |
| Median Formula | |
| (n + 1) | ||
| = | ||
| 2 |
| (0 + 1) | ||
| = | 0 | |
| 2 |
Формула медианы в Excel (с шаблоном Excel)
Здесь мы сделаем еще один пример формулы медианы в Excel. Это очень легко и просто.
Это очень легко и просто.
Давайте рассмотрим пример для расчета медианы.
Расположите набор данных в порядке возрастания.
Медиан рассчитывается с использованием формулы, приведенной ниже
Медиана = (n + 1) / 2
для установки AB
- Медиан = (22 + 1) / 2
- = (22 + 1) / 2
- Медиана = 23/2
- Медиана = 11,5
- Медиана = (21 + 1) / 2
- Медиана = 22/2
- Медиана = 11
- Как рассчитать среднее значение с помощью формулы?
- Примеры формулы DPMO
- Руководство по формуле изменения портфеля
- Формула устойчивого роста
Что такое медиана?
Как найти медиану
Определение медианы с помощью статистического программного обеспечения
Почему важны медианы? И чем они отличаются от среднего?
Нахождение медианы с помощью порядковых данных
медиана — это середина ваших данных, и она отмечает 50-й процентиль.
Среднее — это среднее арифметическое ваших данных.
Режим — это значение, которое чаще всего встречается в ваших данных.
Never (0)
Monthly or less (1)
2 to 4 times a month (2)
2 to 3 times a week (3)
4 или более раз в неделю (4)
- Участник TechTarget
- Калькулятор среднего среднего режима
- 15 общих методов обработки данных, которые нужно знать и использовать
- Будущему специалисту по данным нужны бизнес, навыки глубокого обучения
- Процесс обработки и анализа данных: 6 ключевых шагов для приложений аналитики
- Разница между машинным обучением и статистикой в интеллектуальном анализе данных
Как использовать условный оператор Java?:
Автор: Кэмерон Маккензи
12 лучших городов для технических вакансий в 2021 году
Автор: Шон Кернер
- Тест
RootMetrics показывает заметные улучшения в повседневном использовании 5G
Автор: Джо О’Халлоран
блочный шифр
Автор: TechTarget Contributor
- Нулевой день Windows отменен для сентябрьского патча во вторник
В этом месяце администраторов ожидает относительно небольшая рабочая нагрузка по установке исправлений, но угроза «червя» должна увеличить чувство срочности до .
.. - Научитесь отслеживать членство в группах с помощью PowerShell
Используйте автоматизацию PowerShell для создания отчетов о членстве в локальных группах на сервере и группах безопасности в Active Directory, чтобы сохранить…
- Научитесь работать с Microsoft New Commerce Experience
Приложив дополнительные усилия на этапах планирования, можно контролировать расходы в Office 365 и Microsoft 365 с помощью нового …
- Инструменты управления затратами Azure для контроля расходов на облако
Благодаря оповещениям, панелям анализа затрат и другим функциям инструменты управления затратами Azure могут помочь администраторам более четко видеть свои …
- Сравните Фабрику данных Azure и SSIS
Узнайте о различиях между Фабрикой данных Azure и SSIS, двумя инструментами ETL.
Эти отличия включают ключевые функции управления данными… - Упростите управление пакетами с помощью этого руководства по Azure Artifacts
Расширение службы Azure DevOps, Azure Artifacts, может помочь разработчикам управлять пакетами и обмениваться ими, чтобы оптимизировать общую…
- HPE расширяет возможности Alletra за счет более низких цен и большего количества опций
Компания HPE добавила гибридную систему Alletra 5000 в свой портфель блочных систем хранения данных и GreenLake, предоставив клиентам больше емкости и больше …
- Lenovo выпускает блочные массивы хранения начального уровня
Компания Lenovo выпустила на рынок начального уровня новые флеш-массивы и гибридные массивы, которые обеспечивают компаниям преимущество по сравнению с предыдущим …
- Как настроить NAS: пошаговое руководство по настройке
Получите максимальную отдачу от стоечного устройства NAS, настроив учетные записи администратора, разрешения и доступ к сети; работает .
Для набора BC
Рекомендуемые статьи
Это руководство по формуле медианы. Здесь мы обсудим, как рассчитать медиану, а также приведем практические примеры. Мы также предоставляем калькулятор медианы с загружаемым шаблоном Excel. Вы также можете прочитать следующие статьи, чтобы узнать больше –
2.
 Среднее значение и стандартное отклонение
Среднее значение и стандартное отклонение
Медиана известна как мера местоположения; то есть он сообщает нам, где находятся данные. Как указано в , нам не нужно знать все точные значения для вычисления медианы; если бы мы сделали наименьшее значение еще меньше, а наибольшее значение еще больше, это не изменило бы значение медианы. Таким образом, медиана не использует всю информацию в данных, и поэтому можно показать, что она менее эффективна, чем среднее или среднее, которое использует все значения данных. Чтобы вычислить среднее значение, мы складываем наблюдаемые значения и делим на их количество. Сумма значений, полученных в таблице 1.1, составила 22,5, что было разделено на их количество, 15, чтобы получить среднее значение 1,5. Этот знакомый процесс
удобно выражается следующими символами:
(произносится как «x bar») означает среднее значение; х — каждое из значений содержания свинца в моче; n – количество этих значений; и σ, сигма с греческой заглавной буквы (наша «S») означает «сумма». Основным недостатком среднего является то, что оно чувствительно к удаленным точкам. Например, замена 2,2 на 22 в таблице 1.1 увеличивает среднее значение до 2,82, тогда как медиана останется неизменной.
Основным недостатком среднего является то, что оно чувствительно к удаленным точкам. Например, замена 2,2 на 22 в таблице 1.1 увеличивает среднее значение до 2,82, тогда как медиана останется неизменной.
Помимо показателей местоположения нам нужны показатели того, насколько изменчивы данные. С двумя из этих показателей, размахом и межквартильным размахом, мы познакомились в главе 19.0005
Диапазон является важным измерением, так как цифры вверху и внизу обозначают результаты, наиболее далекие от общего. Однако они не дают особых указаний на распространение наблюдений о среднем значении. Здесь на помощь приходит стандартное отклонение (SD).
Теоретическая основа стандартного отклонения сложна и не должна беспокоить обычного пользователя. Мы обсудим выборку и совокупности в главе 3. Здесь следует отметить практический момент: когда совокупность, из которой получены данные, имеет приблизительно «нормальное» (или гауссовское) распределение, то стандартное отклонение обеспечивает полезную основу для интерпретация данных с точки зрения вероятности.
Нормальное распределение представлено семейством кривых, однозначно определяемых двумя параметрами: средним значением и стандартным отклонением генеральной совокупности. Кривые всегда имеют форму симметричного колокола, но степень сжатия или уплощения колокола зависит от стандартного отклонения генеральной совокупности. Однако сам факт того, что кривая имеет форму колокола, не означает, что она представляет собой нормальное распределение, потому что другие распределения могут иметь подобную форму.
Многие биологические характеристики достаточно точно соответствуют нормальному распределению, чтобы его можно было широко использовать, например, рост взрослых мужчин и женщин, кровяное давление у здорового населения, случайные ошибки во многих типах лабораторных измерений и биохимических данных. На рис. 2.1 показана нормальная кривая, рассчитанная по диастолическому артериальному давлению 500 мужчин, среднее значение 82 мм рт.ст., стандартное отклонение 10 мм рт.ст. Отмечены диапазоны, представляющие [+-1SD, +12SD и +-3SD] относительно среднего значения. Более обширный набор значений приведен в таблице А печатного издания.
Более обширный набор значений приведен в таблице А печатного издания.
Рисунок 2.1
Причина, по которой стандартное отклонение является такой полезной мерой разброса наблюдений, заключается в следующем: если наблюдения подчиняются нормальному распределению, то диапазон охватывает одно стандартное отклонение выше среднего и одно стандартное отклонение ниже его.
включает около 68% наблюдений; диапазон двух стандартных отклонений выше и двух ниже () около 95% наблюдений; и трех стандартных отклонений выше и трех ниже () около 99,7% наблюдений. Следовательно, если мы знаем среднее значение и стандартное отклонение набора наблюдений, мы можем получить некоторую полезную информацию с помощью простой арифметики. Помещая одно, два или три стандартных отклонения выше и ниже среднего, мы можем оценить диапазоны, которые, как ожидается, будут включать около 68%, 95% и 99,7% наблюдений.
Стандартное отклонение от негруппированных данных
Стандартное отклонение — это суммарная мера различий каждого наблюдения от среднего значения. Если сложить сами разности, положительные точно уравновесят отрицательные, и поэтому их сумма будет равна нулю. Следовательно, квадраты разностей складываются. Затем сумма квадратов делится на количество наблюдений минус один, чтобы получить среднее значение квадратов, и извлекается квадратный корень, чтобы вернуть измерения к единицам, с которых мы начали. (Деление на количество наблюдений минус один вместо самого числа наблюдений для получения среднего квадрата связано с тем, что должны использоваться «степени свободы». В этих обстоятельствах они на единицу меньше, чем общее количество. Теоретическое обоснование этого не требуется. беспокоить пользователя на практике.)
Если сложить сами разности, положительные точно уравновесят отрицательные, и поэтому их сумма будет равна нулю. Следовательно, квадраты разностей складываются. Затем сумма квадратов делится на количество наблюдений минус один, чтобы получить среднее значение квадратов, и извлекается квадратный корень, чтобы вернуть измерения к единицам, с которых мы начали. (Деление на количество наблюдений минус один вместо самого числа наблюдений для получения среднего квадрата связано с тем, что должны использоваться «степени свободы». В этих обстоятельствах они на единицу меньше, чем общее количество. Теоретическое обоснование этого не требуется. беспокоить пользователя на практике.)
Чтобы получить интуитивное представление о степенях свободы, выберите шоколад из коробки с n конфетами. Каждый раз, когда мы выбираем шоколадку
, у нас есть выбор, пока мы не дойдем до последней (обычно с орехом внутри!), а затем у нас нет выбора. Таким образом, у нас есть выбор из n-1, или «степеней свободы».
Расчет дисперсии проиллюстрирован в таблице 2.1 с помощью 15 показаний предварительного исследования концентрации свинца в моче (таблица 1.2). Показания приведены в столбце (1). В столбце (2) записывается разница между каждым показанием и средним значением. Сумма разностей равна 0. В столбце (3) различия возведены в квадрат, а сумма этих квадратов указана внизу столбца.
Таблица 2.1
Сумма квадратов разностей (или отклонений) от среднего, 9,96, теперь делится на общее количество наблюдений минус один, чтобы получить дисперсию. Таким образом,
В этом случае мы находим :
Наконец, квадратный корень из дисперсии дает стандартное отклонение:
из которого мы получаем
Эта процедура иллюстрирует структуру стандартного отклонения, в частности, что два крайних значения 0,1 и 3,2 вносят наибольший вклад в сумму разницы в квадрате.
Процедура калькулятора
Большинство недорогих калькуляторов имеют процедуры, которые позволяют непосредственно вычислять среднее значение и стандартное отклонение, используя режим «SD». Например, на современных калькуляторах Casio нужно нажать SHIFT и «.», и на дисплее должен появиться маленький символ «SD». На более ранних Casios нужно нажимать INV и MODE, тогда как на Sharp 2nd следует использовать F и Stat. Данные сохраняются с помощью кнопки M+. Таким образом, переведя калькулятор в режим «SD» или «Stat», из таблицы 2.1 вводим 0,1 M+ , 0,4 M+ и т. д. Когда все данные введены, можно проверить правильность включения количества наблюдений по Shift и n, и «15» должны отображаться. Среднее значение отображается с помощью Shift и , а стандартное отклонение — с помощью Shift и . Не нажимайте Shift и AC между этими операциями, так как это очищает статистическую память. На многих калькуляторах есть еще одна кнопка. Это использует делитель n, а не n — 1 в расчете стандартного отклонения. На калькуляторе Sharp обозначается , тогда как обозначается s. Это значения «населения», и они получены в предположении, что вся совокупность доступна или что интерес сосредоточен исключительно на имеющихся данных, и результаты не будут обобщаться (см.
Например, на современных калькуляторах Casio нужно нажать SHIFT и «.», и на дисплее должен появиться маленький символ «SD». На более ранних Casios нужно нажимать INV и MODE, тогда как на Sharp 2nd следует использовать F и Stat. Данные сохраняются с помощью кнопки M+. Таким образом, переведя калькулятор в режим «SD» или «Stat», из таблицы 2.1 вводим 0,1 M+ , 0,4 M+ и т. д. Когда все данные введены, можно проверить правильность включения количества наблюдений по Shift и n, и «15» должны отображаться. Среднее значение отображается с помощью Shift и , а стандартное отклонение — с помощью Shift и . Не нажимайте Shift и AC между этими операциями, так как это очищает статистическую память. На многих калькуляторах есть еще одна кнопка. Это использует делитель n, а не n — 1 в расчете стандартного отклонения. На калькуляторе Sharp обозначается , тогда как обозначается s. Это значения «населения», и они получены в предположении, что вся совокупность доступна или что интерес сосредоточен исключительно на имеющихся данных, и результаты не будут обобщаться (см. главу 9).0062 3 для получения подробной информации о выборках и популяциях). Так как такая ситуация возникает очень редко, ее следует использовать и игнорировать, хотя даже для умеренных размеров выборки разница будет небольшой. Не забудьте вернуться в обычный режим перед возобновлением вычислений, потому что многие из обычных функций недоступны в режиме «Статистика». На современном Casio это Shift 0. На более ранних Casio и Sharps повторяется последовательность, вызывающая режим «Stat». Некоторые калькуляторы остаются в режиме «Stat»
главу 9).0062 3 для получения подробной информации о выборках и популяциях). Так как такая ситуация возникает очень редко, ее следует использовать и игнорировать, хотя даже для умеренных размеров выборки разница будет небольшой. Не забудьте вернуться в обычный режим перед возобновлением вычислений, потому что многие из обычных функций недоступны в режиме «Статистика». На современном Casio это Shift 0. На более ранних Casio и Sharps повторяется последовательность, вызывающая режим «Stat». Некоторые калькуляторы остаются в режиме «Stat»
даже в выключенном состоянии. Mullee (1) дает советы по выбору и использованию калькулятора. В формулах калькулятора используется соотношение
Правостороннее выражение легко запомнить, если вычислить среднее квадратов минус среднеквадратичное”. Выборочная дисперсия получена из
Вышеупомянутое уравнение верно, как видно из Таблицы 2.1, где сумма квадратов наблюдений , дается как 43,7l.
Таким образом, мы получаем
то же значение, что и сумма в столбце (3). Следует соблюдать осторожность, потому что эта формула включает вычитание двух больших чисел, чтобы получить меньшее, и может привести к неправильным результатам, если числа очень большие. Например, попробуйте найти стандартное отклонение 100001, 100002, 100003 на калькуляторе. Правильный ответ — 1, но многие калькуляторы дают 0 из-за ошибки округления. Решение состоит в том, чтобы вычесть большое число из каждого наблюдения (скажем, 100 000) и вычислить стандартное отклонение по остаткам, а именно 1, 2 и 3.
Стандартное отклонение от сгруппированных данных
Мы также можем рассчитать стандартное отклонение для дискретных количественных переменных. Например, помимо изучения концентрации свинца в моче 140 детей, педиатр спросил, как часто каждый из них в течение года осматривался врачом. После сбора информации он свел в таблицу данные, показанные в столбцах (1) и (2) Таблицы 2.2. Среднее значение вычисляется путем умножения столбца (1) на столбец (2), добавления продуктов и деления на общее количество наблюдений. Таблица 2.2
Таблица 2.2
Как и для непрерывных данных, для вычисления стандартного отклонения мы возводим в квадрат каждое из наблюдений по очереди. В этом случае наблюдением является количество посещений, но поскольку у нас есть несколько детей в каждом классе, показанном в столбце (2), каждый квадрат числа (столбец (4)) должен быть умножен на количество детей. Сумма квадратов дана внизу столбца (5), а именно 1697. Затем мы используем формулу калькулятора, чтобы найти дисперсию: и иметь в виду. Приблизительно 9Диапазон 5% дан за исключением двух детей без посещений и
шести детей с шестью или более посещениями. Таким образом, восемь из 140 = 5,7% находятся за пределами теоретического диапазона 95%. Обратите внимание, что для дискретных количественных переменных характерно так называемое асимметричное распределение, то есть они несимметричны. Одним из признаков отсутствия симметрии в производной статистике является то, что среднее значение и медиана значительно различаются. Другой случай, когда стандартное отклонение того же порядка, что и среднее значение, но наблюдения не должны быть отрицательными. Иногда трансформация будет
Другой случай, когда стандартное отклонение того же порядка, что и среднее значение, но наблюдения не должны быть отрицательными. Иногда трансформация будет
преобразовать асимметричное распределение в симметричное. Когда данные подсчитываются, например количество посещений врача, часто помогает преобразование квадратного корня, а если нет нулевых или отрицательных значений, логарифмическое преобразование сделает распределение более симметричным.
Преобразование данных
Анестезиолог измеряет болезненность процедуры с помощью 100-мм визуальной аналоговой шкалы у семи пациентов. Результаты приведены в таблице 2.3 вместе с логарифмическим преобразованием (кнопка ln на калькуляторе). Таблица 2.3
Данные представлены на рис. 2.2, из которого видно, что выбросы в зарегистрированных данных не выглядят столь значительными. Среднее значение и медиана составляют 10,29 и 2 соответственно для исходных данных со стандартным отклонением 20,22. Если среднее значение больше медианы, распределение имеет положительную асимметрию. Для зарегистрированных данных среднее значение и медиана составляют 1,24 и 1,10 соответственно, что указывает на то, что зарегистрированные данные имеют более симметричное распределение. Таким образом, было бы лучше проанализировать записанные преобразованные данные
Если среднее значение больше медианы, распределение имеет положительную асимметрию. Для зарегистрированных данных среднее значение и медиана составляют 1,24 и 1,10 соответственно, что указывает на то, что зарегистрированные данные имеют более симметричное распределение. Таким образом, было бы лучше проанализировать записанные преобразованные данные
в статистических тестах, чем при использовании исходной шкалы. Обратите внимание, что медиана зарегистрированных данных совпадает с журналом медианы необработанных данных, однако это неверно для среднего значения. Среднее значение зарегистрированных данных не обязательно равно журналу среднего значения необработанных данных.
Противологарифмическое значение (exp или на калькуляторе) среднего значения зарегистрированных данных известно как среднее геометрическое и часто представляет собой
лучшая сводная статистика, чем среднее значение для данных из распределений с положительной асимметрией. Для этих данных среднее геометрическое в 3,45 мм.
Стандартное отклонение между субъектами и внутри субъектов
Если проводятся повторные измерения, скажем, артериального давления у человека, эти измерения, вероятно, будут различаться. Это внутрисубъектная или внутрисубъектная изменчивость, и мы можем рассчитать стандартное отклонение этих наблюдений. Если наблюдения происходят близко друг к другу во времени, это стандартное отклонение часто называют ошибкой измерения. Измерения, сделанные на разных субъектах, различаются в зависимости от межсубъектной или межсубъектной изменчивости. Если над каждым индивидуумом производилось много наблюдений и бралось среднее, то можно считать, что внутрисубъектная изменчивость усреднена и вариация средних значений обусловлена исключительно межсубъектной изменчивостью. Отдельные наблюдения над индивидуумами явно содержат смесь межсубъектных и внутрисубъектных вариаций. Коэффициент вариации (CV%) представляет собой стандартное отклонение внутри субъекта, деленное на среднее значение, выраженное в процентах. Его часто называют мерой воспроизводимости биохимических анализов, когда анализ проводится несколько раз на одном и том же образце. Его преимущество состоит в том, что он не зависит от единиц измерения, но он также имеет многочисленные теоретические недостатки. Обычно бессмысленно использовать коэффициент вариации в качестве меры межсубъектной изменчивости.
Его часто называют мерой воспроизводимости биохимических анализов, когда анализ проводится несколько раз на одном и том же образце. Его преимущество состоит в том, что он не зависит от единиц измерения, но он также имеет многочисленные теоретические недостатки. Обычно бессмысленно использовать коэффициент вариации в качестве меры межсубъектной изменчивости.
Общие вопросы
Когда я должен использовать среднее значение и когда я должен использовать медиану для описания моих данных
?
Распространено заблуждение, что для данных с нормальным распределением используется среднее значение, а для данных с ненормальным распределением используется медиана. Увы, это не так: если данные распределены нормально, среднее значение и медиана будут близки; если данные не распределены нормально, то и среднее значение, и медиана могут дать полезную информацию. Рассмотрим переменную, которая принимает значение 1 для мужчин и 0 для женщин. Это явно не нормальное распределение. Однако среднее значение дает долю мужчин в группе, тогда как медиана просто говорит нам, в какой группе было более 50% людей. Точно так же среднее из упорядоченных категориальных переменных может быть более полезным, чем медиана, если упорядоченным категориям можно дать значимые оценки. Например, лекция может быть оценена от 1 (плохо) до 5 (отлично). Обычной статистикой для подведения итогов будет среднее значение. В ситуации, когда на одном полюсе распределения находится небольшая группа (например, годовой доход), медиана будет более «репрезентативной» для распределения. Мои данные должны иметь значения больше нуля, но среднее значение и стандартное отклонение примерно одного размера. Как это произошло? Если данные имеют очень асимметричное распределение, то стандартное отклонение будет сильно завышено и не является хорошей мерой изменчивости для использования. Как мы показали, иногда преобразование данных, такое как логарифмическое преобразование, делает распределение более симметричным. В качестве альтернативы укажите межквартильный диапазон.
Точно так же среднее из упорядоченных категориальных переменных может быть более полезным, чем медиана, если упорядоченным категориям можно дать значимые оценки. Например, лекция может быть оценена от 1 (плохо) до 5 (отлично). Обычной статистикой для подведения итогов будет среднее значение. В ситуации, когда на одном полюсе распределения находится небольшая группа (например, годовой доход), медиана будет более «репрезентативной» для распределения. Мои данные должны иметь значения больше нуля, но среднее значение и стандартное отклонение примерно одного размера. Как это произошло? Если данные имеют очень асимметричное распределение, то стандартное отклонение будет сильно завышено и не является хорошей мерой изменчивости для использования. Как мы показали, иногда преобразование данных, такое как логарифмическое преобразование, делает распределение более симметричным. В качестве альтернативы укажите межквартильный диапазон.
Список литературы
1. Мулли М. А. Как выбрать и использовать калькулятор. В: Как это сделать 2. Издательская группа BMJ
В: Как это сделать 2. Издательская группа BMJ
, 1995: 58-62.
Упражнения
Упражнение 2.1
В ходе кампании против оспы врач поинтересовался, сколько раз 150 человек в возрасте 16 лет и старше были вакцинированы в эфиопской деревне. Он получил следующие цифры: никогда, 12 человек; один раз, 24; дважды, 42; трижды, 38; четыре раза по 30; пять раз, 4. Каково среднее количество раз, когда эти люди были вакцинированы, и каково стандартное отклонение? Ответ
Упражнение 2.2
Получите среднее значение и стандартное отклонение данных в приблизительном
95% диапазоне. Какая
доля данных исключается? Ответы
Глава 2 Q3.pdfAnswer
Среднее, медиана и мода
Среднее, медиана и модаДополнение к уроку по Среднее, медиана, и режим
В этом дополнении к уроку мы рассмотрим три наиболее
общие сводки набора чисел или данных. Они называются
среднее, медиана и
режим. Среднее — красивое слово для
среднее, медиана — это среднее число, а мода — это число, которое встречается
чаще всего.
Среднее — красивое слово для
среднее, медиана — это среднее число, а мода — это число, которое встречается
чаще всего.
Нахождение среднего
Это обычное явление, когда есть несколько чисел, называемых данными, которые мы хотим чтобы понять. Большинство людей знакомы со словом «средний» и многие знают, что для нахождения среднего нужно сложить все числа и разделить на общий. Другое слово для среднего — среднее.
Чтобы найти среднее значение, просто сложите все числа и разделите на общее число. чисел. Мы можем думать об этом как о трехэтапном процессе:
Пошаговый процесс поиска среднего значения
Шаг 1. Добавьте вверх все числа. Результат называется суммой.
Шаг 2: Подсчитайте, сколько чисел. Это число называется размером выборки. Мы используем букву н для размера выборки.
Шаг 3: Среднее значение представляет собой сумму, деленную на размер выборки н.
Теперь давайте перейдем к примеру.
Пример 1
За последние пять выходных Стив отслеживал общую сумму денег, которую он потраченный.
20, 50, 70 долларов, 80$, 30$
Найдите среднюю сумму денег, которую Стив потратил за последние пять выходных.
Раствор
Шаг 1: Добавьте числа, чтобы найти их сумму.
20 + 50 + 70 + 80 + 30 = 250
Шаг 2: Сколько там цифр.
п = 5
Шаг 3: Разделите сумму чисел на размер выборки ‘n’
250
= 50
5
Следовательно, среднее этих чисел равно 50. Мы сделать вывод, что средняя сумма денег, которую Стив потратил за прошлые 5 выходных стоили 50 долларов.
Теперь попробуйте сами. Хочешь увидеть ответ, поставь мышку на желтом прямоугольнике и появится ответ.
Упражнение 1
В приведенной ниже таблице показано время в минутах, которое три бегуна
имели в своих трех испытаниях на гонке на одну милю.
| Пробная версия 1 | Пробная версия 2 | Испытание 3 | Пробная версия 4 | |
Энрике | 8 | 7 | 7 | 9 |
Моник | 9 | 6 | 6 | 7 |
Сэм | 10 | 12 | 9 | 11 |
Какое среднее время у Моник?
Ответ:
Нахождение медианы
Другой способ описания данных — посмотреть на среднее число. Когда имеется нечетное количество значений, мы можем просто найти значение так, чтобы было
такое же количество значений выше, как и ниже этого среднего значения.
Когда есть четное количество значений, там есть проблема.
одно число, которое действует как среднее значение. Вместо этого два средних числа
так что есть такое же количество значений выше, как и ниже
эти два средних числа. В качестве компромисса возьмем среднее из этих
два средних числа. Мы называем этот результат медианой
данных. Это может помочь обобщить это в трехэтапном процессе.
Когда имеется нечетное количество значений, мы можем просто найти значение так, чтобы было
такое же количество значений выше, как и ниже этого среднего значения.
Когда есть четное количество значений, там есть проблема.
одно число, которое действует как среднее значение. Вместо этого два средних числа
так что есть такое же количество значений выше, как и ниже
эти два средних числа. В качестве компромисса возьмем среднее из этих
два средних числа. Мы называем этот результат медианой
данных. Это может помочь обобщить это в трехэтапном процессе.
Пошаговый процесс нахождения медианы
Шаг 1. Поместите числа в порядке возрастания от меньшего к большему.
Шаг 2. Если нечетное количество чисел, найдите среднее число так, чтобы было равное количество значений слева и справа. Если есть даже количество чисел найдите два средних числа так, чтобы было равное число значений слева и справа от этих двух чисел.
Шаг 3. Если
есть нечетное количество чисел, это среднее число является медианой. Если
есть четное количество чисел, прибавь две средние и раздели на
2.
Результат будет медианой.
Если
есть четное количество чисел, прибавь две средние и раздели на
2.
Результат будет медианой.
Пример 2
Роза измерила вес в фунтах семи упаковок мешков с апельсинами, которые были куплены в ее фруктовом киоске. Веса показаны ниже.
|
Найдите средний вес
Раствор
Шаг 1: Сначала расставьте числа в порядке от меньшего к большему.
9, 10, 10, 11, 13, 17, 18
Шаг 2: Обратите внимание на 7 чисел. Это нечетное количество значений, поэтому мы находим среднее число. среднее число — 11. Обратите внимание, что есть равное количество (3) чисел слева от 11 и правее 11.
9, 10, 10, 11, 13, 17, 18
Шаг 3: Мы в том случае, если
есть нечетное количество значений, поэтому медиана — это среднее число. То есть медиана равна 11.
То есть медиана равна 11.
Теперь попробуйте сами. Хочешь увидеть ответ, поставь мышку на желтом прямоугольнике и появится ответ.
Упражнение 2
Пять баллов за домашнее задание Чан Хи по математике были оценены. Ее оценки показаны ниже.
|
Найдите ее средний балл за домашнее задание.
Ответ:
Вот еще один пример нахождения медианы.
Пример 3
В семье Лупе шесть братьев и сестер. Их возраст показано ниже
|
Найдите средний возраст братья и сестры в семье Лупе.
Раствор
Шаг 1: Сначала расставьте числа в порядке от меньшего к большему.
11, 11, 14, 18, 20, 22
Шаг 2: Обратите внимание на 6 чисел. Это четное число значений, поэтому мы находим два средних числа. Два средних числа 14 и 18. Обратите внимание, что их одинаковое количество (2) значений слева и справа от этих двух середин.
11, 11, 14, 18, 20, 22
Шаг 3: Мы в том случае, если есть четное количество значений, поэтому медиана — это среднее значение двух средние числа. Сложите эти два средних числа и разделите на 2.
14
+ 18
= 16
2
Таким образом, средний возраст братьев и сестер в семье Лупе составляет 16.
Теперь попробуйте сами. Хочешь увидеть ответ, поставь мышку на желтом прямоугольнике и появится ответ.
Упражнение 3
8 настольных ламп по цене Оскара. Цены указаны ниже.
|
 США,
25,00 долл. США, 30,00 долл. США, 36,00 долл. США, 52,00 долл. США, 25,00 долл. США, 90,00 долл. США
США,
25,00 долл. США, 30,00 долл. США, 36,00 долл. США, 52,00 долл. США, 25,00 долл. США, 90,00 долл. СШАКакова средняя цена?
Ответ:
Определение режима
Третье число, которое мы используем для описания данных, называется режимом данных. Мода — это число или числа, которые встречаются чаще всего. Вот двухэтапный процесс поиска режима.
Двухэтапный процесс поиска Медиана
Шаг 1. Поместите числа в порядке возрастания от меньшего к большему.
Шаг 2. Перейти вниз по списку и определить, есть ли номер, который появляется в списке больше чем любые другие числа. Если ничья для наиболее часто встречающихся число, а затем просто укажите, что оба числа являются режимом.
Пример 4
В поле ниже показано количество клиентов, которые были у ресторана в течение последние девять дней
|
Каков режим этих данных?
Раствор
Шаг 1: Сначала поставьте цифры
по размеру места, от меньшего к большему.
30, 30, 50, 50, 50, 60, 70, 80, 90
Шаг 2: Теперь пройдите вниз по списку и определите, есть ли номер, который появляется в список больше, чем любое другое число.
30, 30, 50, 50, 50, 60, 70, 80, 90
Здесь это число равно 50. Следовательно, 50 это режим.
Теперь попробуйте сами. Хочешь увидеть ответ, поставь мышку на желтом прямоугольнике и появится ответ.
Упражнение 4
Количество книжных шкафов, которые каждый из 10 рабочих произведено на мебельной фабрике по индивидуальному заказу, указано в графе ниже
|
Каков режим этих данных?
Ответ:
Теперь другой пример.
Пример 5
В рамке ниже показано количество деревьев, растущих на заднем дворе каждого дома на
отвесная улица.
|
Каков режим этих данных?
Раствор
Шаг 1: Сначала расставьте числа по размеру, от меньшего к большему.
3, 4, 7, 7, 7, 9, 9, 9, 11, 12
Шаг 2: Теперь пройдите вниз по списку и определите, есть ли число, которое появляется в списке больше, чем любой другой номер.
3, 4, 7, 7, 7, 9, 9, 9, 11, 12
Здесь мы видим, что и цифры 7, и 9появляются три раза. Следовательно, и 7 и 9 оба режимы
ПРИМЕЧАНИЕ: Для данной выборки чисел может быть режим «Нет», «ОДИН режим» или несколько режимов.
Теперь попробуйте сами. Хочешь увидеть ответ, поставь мышку на желтом прямоугольнике и появится ответ.
Упражнение 4
Сара изучала, сколько пар звездчатых сойек живет в каждом из
11 соток земли в национальном лесу. Ее данные указаны в
поле ниже
Ее данные указаны в
поле ниже
|
Каков режим этих данных?
Ответ:
Как найти медиану
В этой статье
Что такое медиана?
Медиана — это значение, которое попадает в середину набора данных, когда значения расположены в порядке возрастания. Медиана отмечает 50-й процентиль данных, отделяя нижнюю половину данных от верхней половины.
Медиана, среднее значение и мода — все это меры центра, но они не представляют одно и то же:

Как найти медиану
Чтобы найти медиану, расположите данные от наименьшего к наибольшему и найдите среднее значение. Если общее количество точек данных нечетное, будет одно число, которое находится прямо в середине вашего набора данных, и это будет ваша медиана. Если общее количество точек данных четное, найдите два средних значения и усредните их. Это среднее значение будет вашей медианой.
Пример 1. Нахождение медианы в наборе данных с нечетными номерамиДопустим, у вас есть следующий набор данных с нечетными номерами, где n=9:
115, 138, 133, 120, 117, 125, 130, 100, 112
Вы можете рассчитать медиану в 3 простых шага:
1. Упорядочить данные от наименьшего к наибольшему
1 10000 , 115, 117, 120, 125, 130, 133, 138
2. Определите положение медианы.
Определите положение медианы.
Если у вас небольшой набор данных, вы можете определить среднее положение, просто взглянув на данные. Если ваш набор данных большой, вы можете определить среднюю позицию, разделив общее количество точек данных на два и округлив до ближайшего целого числа.
n2\tfrac{n}{2}2n = 92\tfrac{9}{2}29 = 4,5
Округляя, получаем 5.
Медиана будет 5-м значением в наборе данных.
2. Найдите медиану на основе позиции, определенной на предыдущем шаге.
Из предыдущего шага мы знаем, что медиана — это 5-е значение в наборе данных. Пятое значение в данном случае равно 120. Мы можем подтвердить, что это медиана, проверив, есть ли одинаковое количество наблюдений над и под ним.
Пример 2. Нахождение медианы с четным набором данныхДопустим, у вас есть следующий четный набор данных, где n=8:
1, 11, 17, 5, 15, 10, 3, 8
Первый шаг такой же, но второй и третий шаги немного отличаются.
1. Упорядочить данные в числовом порядке от меньшего к большему
1, 3, 5, 8, 10, 11, 15, 17
2. Определите положение двух средних значений.
Когда n четно, в середине ваших данных будет два значения. Вы можете определить положение этих двух значений, используя следующие формулы:
В этом случае средние значения — это 4-е и 5-е значения:
82\tfrac{8}{2}28 = 4
82\tfrac {8}{2}28 + 1 = 5
3. Найдите медиану, усредняя два значения, расположенные в середине ваших данных.
Четвертое и пятое значения этих данных равны 8 и 10. Находим медиану путем их усреднения.
Нахождение медианы с помощью статистического программного обеспечения
Хотя полезно знать, как вычислить медиану вручную, часто проще найти медиану с помощью статистического программного обеспечения.
В таблицах Excel или Google используйте формулу =МЕДИАНА() . Список ваших данных должен быть заключен в скобки. Например, если ваши данные содержат десять значений в ячейках с A1 по A10, формула будет выглядеть так: =МЕДИАНА(A1:A10) .
Список ваших данных должен быть заключен в скобки. Например, если ваши данные содержат десять значений в ячейках с A1 по A10, формула будет выглядеть так: =МЕДИАНА(A1:A10) .
В Desmos используйте функцию median() , чтобы найти медиану. Значения в вашем наборе данных должны быть заключены в круглые скобки. Чтобы найти медиану из приведенного выше примера 1, введите: median(115, 138, 133, 120, 117, 125, 130, 100, 112) .
В R вы также можете использовать команду median() . Вы должны включить список ваших данных или имя вашей случайной переменной в круглые скобки.
Для практики попробуйте вычислить медиану из приведенных выше примеров, используя один или все эти параметры.
Почему медианы важны? И чем они отличаются от среднего?
Медиана — это мера центра, на которую не влияют выбросы или асимметрия данных.
Если у вас есть примерно симметричный набор данных, среднее и медиана будут близкими значениями, и оба будут хорошими индикаторами центра данных.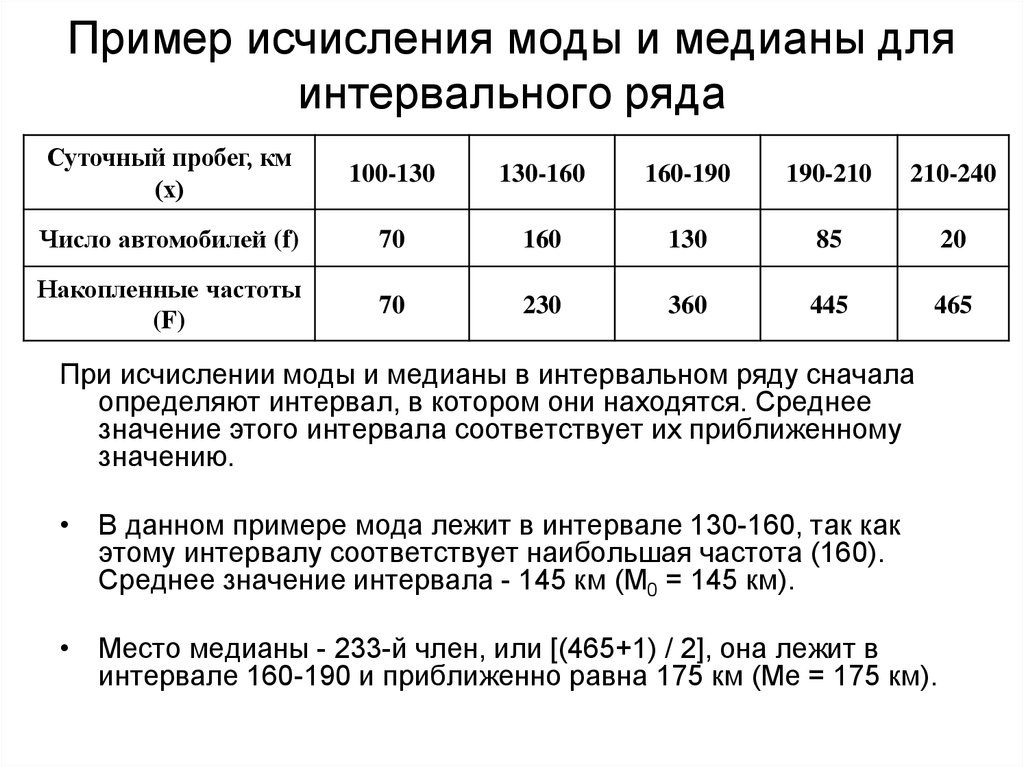 Когда распределение данных несимметрично — когда данные сильно смещены вправо или влево — предпочтительным показателем центральности является медиана. Это связано с тем, что медиана устойчива к экстремальным значениям и длинным хвостам данных, а среднее — нет.
Когда распределение данных несимметрично — когда данные сильно смещены вправо или влево — предпочтительным показателем центральности является медиана. Это связано с тем, что медиана устойчива к экстремальным значениям и длинным хвостам данных, а среднее — нет.
Чтобы продемонстрировать это, представьте десять человек, выпивающих в местной таверне. Все десять имеют одинаковый годовой доход, представленный в данных ниже.
55 тысяч долларов, 58 тысяч долларов, 62 тысячи долларов, 65 тысяч долларов, 67 тысяч долларов, 70 тысяч долларов, 73 тысячи долларов, 74 тысячи долларов, 77 тысяч долларов, 83 тысячи долларов
Средний доход этой группы составляет 68 400 долларов. Средний доход составляет 68 500 долларов. Обратите внимание, что среднее значение и медиана не так уж различаются и что оба являются хорошими индикаторами того, где сосредоточены данные.
Неожиданно появляется Опра Уинфри. Допустим, Опра зарабатывает 300 миллионов долларов в год. Что происходит со средним и медианой? Средний доход сейчас составляет 70 000 долларов. Не слишком отличается от того, что было раньше. Средний доход подскочил до 27 335 000 долларов. Доход Опры является экстремальным выбросом, и он искажает данные далеко вправо.
Что происходит со средним и медианой? Средний доход сейчас составляет 70 000 долларов. Не слишком отличается от того, что было раньше. Средний доход подскочил до 27 335 000 долларов. Доход Опры является экстремальным выбросом, и он искажает данные далеко вправо.
Если бы кто-нибудь сказал вам, что средний доход посетителей бара чуть превышает 27 миллионов долларов, вы могли бы представить себе бар, заполненный миллионерами и миллиардерами. Среднее значение больше не дает нам хорошего представления о том, где сосредоточены данные, но медиана по-прежнему дает.
Нахождение медианы с порядковыми данными
Порядковые данные — это данные, которые не совсем качественные и не совсем количественные, так как состоят из категорий с естественным порядком или заданным рангом. Хорошим примером являются данные опроса, в котором респондентов просят оценить свою удовлетворенность по шкале от 1 до 5. Несмотря на то, что порядковые данные имеют четкое ранжирование (5 лучше, чем 4, лучше, чем 3 и т. д.), шкала или расстояние между каждым ранжирование может быть неравномерным или неизвестным. 5 может быть намного лучше, чем 4, но 4 может быть лишь немного лучше, чем 3. С другой стороны, разные респонденты могут иметь субъективные интерпретации того, что представляет собой каждый рейтинг.
д.), шкала или расстояние между каждым ранжирование может быть неравномерным или неизвестным. 5 может быть намного лучше, чем 4, но 4 может быть лишь немного лучше, чем 3. С другой стороны, разные респонденты могут иметь субъективные интерпретации того, что представляет собой каждый рейтинг.
Медианы не могут быть рассчитаны для качественных данных, но вы можете вычислить медиану для набора порядковых данных с нечетными номерами. Допустим, у вас есть опрос, в котором респондентам предлагается оценить фильм по шкале от 1 до 10. В этом случае вы можете рассчитать медиану, используя тот же метод, который мы показали выше.
Если у вас есть набор порядковых данных с четными номерами, технически говоря, вы не можете вычислить медиану. Это связано с тем, что вы не можете усреднить два ранга, которые имеют неравномерную или неизвестную шкалу.
Рассмотрим следующий вопрос обследования здоровья. Каждому ответу на этот вопрос присвоен ранжированный номер:
Как часто вы употребляете спиртосодержащие напитки?
Представьте, что вы задаете этот вопрос опросу восьми человек, и в результате получаются порядковые данные: {0, 1, 2, 3, 4, 4, 4, 4}. В этом случае два средних значения данных равны 3 и 4, но нет возможности взять среднее значение «2-3 раза в неделю» и «4 или более раз в неделю».
В этом случае два средних значения данных равны 3 и 4, но нет возможности взять среднее значение «2-3 раза в неделю» и «4 или более раз в неделю».
Несмотря на технические неясности, некоторые люди считают, что вычисление медианы для порядковых данных имеет смысл и необходимо даже для данных с четными номерами. Несмотря на неоднозначные результаты, вы можете вычислить медиану порядковых данных, даже если набор данных четный. Для этого вы можете присвоить медиану наименьшему из двух средних значений или можете пойти дальше и взять среднее из двух средних значений. Если вы хотите вычислить медиану для порядкового набора данных, тщательно подумайте, что это значит, и всегда помните, что некоторые люди могут оспорить ваши расчеты.
Узнайте об отмеченных наградами курсах Outlier For-Credit Компания Outlier (от соучредителя MasterClass) собрала лучших в мире преподавателей, дизайнеров игр и кинематографистов для создания будущего онлайн-колледжа.
Ознакомьтесь со следующими родственными курсами:
Введение в статистику
Изучите курс
Введение в статистику
Как данные описывают наш мир.
Обзор курса
Введение в микроэкономику
Изучить курс
Введение в микроэкономику
Почему маленькие решения имеют большое значение.
Изучить курс
Введение в макроэкономику
Изучить курс
Введение в макроэкономику
Как деньги движут нашим миром.
Изучить курс
Введение в психологию
Изучить курс
Введение в психологию
Наука о разуме.
Изучить курс
Что такое среднее значение, медиана, мода и диапазон?
По
Термины среднее, медиана, мода и диапазон описывают свойства статистических распределений. В статистике распределение — это набор всех возможных значений терминов, представляющих определенные события. Значение терма, выраженное как переменная, называется случайной величиной.
В статистике распределение — это набор всех возможных значений терминов, представляющих определенные события. Значение терма, выраженное как переменная, называется случайной величиной.
Существует два основных типа статистических распределений. Первый тип содержит дискретные случайные величины. Это означает, что каждый термин имеет точное изолированное числовое значение. Второй основной тип распределения содержит непрерывную случайную величину. Непрерывная случайная величина — это случайная величина, данные которой могут принимать бесконечно много значений. Когда термин может принимать любое значение в пределах непрерывного интервала или диапазона, он называется функцией плотности вероятности.
ИТ-специалисты должны понимать определение среднего значения, медианы, режима и диапазона, чтобы планировать мощность и балансировать нагрузку, управлять системами, выполнять техническое обслуживание и устранять неполадки. Кроме того, понимание статистических терминов важно в растущей области науки о данных.
Понимание определения среднего, медианы, режима и диапазона важно для ИТ-специалистов по управлению центрами обработки данных. Многие соответствующие задачи требуют от администратора расчета среднего значения, медианы, режима или диапазона, а часто и некоторой комбинации, чтобы показать статистически значимую величину, тенденцию или отклонение от нормы. Поиск среднего значения, медианы, моды и диапазона — это только начало. Затем администратору необходимо применить эту информацию для исследования основных причин проблемы, точного прогнозирования будущих потребностей или установки приемлемых рабочих параметров для ИТ-систем.
При работе с большим набором данных может быть полезно представить весь набор данных одним значением, которое описывает «среднее» или «среднее» значение всего набора. В статистике это единственное значение называется центральной тенденцией, а среднее, медиана и мода — всеми способами его описания. Чтобы найти среднее значение, сложите значения в наборе данных, а затем разделите на количество добавленных значений. Чтобы найти медиану, перечислите значения набора данных в числовом порядке и определите, какое значение появляется в середине списка. Чтобы найти моду, определите, какое значение в наборе данных встречается чаще всего. Диапазон, представляющий собой разницу между наибольшим и наименьшим значением в наборе данных, описывает, насколько хорошо центральная тенденция представляет данные. Если диапазон велик, центральная тенденция не так репрезентативна для данных, как если бы диапазон был мал.
Чтобы найти среднее значение, сложите значения в наборе данных, а затем разделите на количество добавленных значений. Чтобы найти медиану, перечислите значения набора данных в числовом порядке и определите, какое значение появляется в середине списка. Чтобы найти моду, определите, какое значение в наборе данных встречается чаще всего. Диапазон, представляющий собой разницу между наибольшим и наименьшим значением в наборе данных, описывает, насколько хорошо центральная тенденция представляет данные. Если диапазон велик, центральная тенденция не так репрезентативна для данных, как если бы диапазон был мал.
Среднее
Наиболее распространенным выражением для среднего статистического распределения с дискретной случайной величиной является математическое среднее всех членов. Чтобы рассчитать его, сложите значения всех терминов, а затем разделите на количество терминов. Среднее значение статистического распределения с непрерывной случайной величиной, также называемое ожидаемым значением, получается путем интегрирования произведения переменной с ее вероятностью, определенной распределением. Ожидаемое значение обозначается строчной греческой буквой мю (µ).
Ожидаемое значение обозначается строчной греческой буквой мю (µ).
Медиана
Медиана распределения с дискретной случайной величиной зависит от того, четное или нечетное количество членов в распределении. Если количество терминов нечетное, то медианой является значение термина в середине. Это значение, при котором количество терминов, имеющих значения больше или равные ему, совпадает с количеством терминов, имеющих значения меньше или равные ему. Если количество терминов четное, то медиана является средним значением двух терминов в середине, так что количество терминов, имеющих значения больше или равные ему, совпадает с количеством терминов, имеющих значения меньше или равные к этому.
Медиана распределения с непрерывной случайной величиной — это значение m такое, что вероятность составляет не менее 1/2 (50 %) того, что случайно выбранная точка на функции будет меньше или равна m, а вероятность равна по крайней мере 1/2, что случайно выбранная точка на функции будет больше или равна m.
Режим
Модой распределения с дискретной случайной величиной является значение слагаемого, которое встречается чаще всего. Распределение с дискретной случайной величиной нередко имеет более одной моды, особенно если членов немного. Это происходит, когда два или более термина встречаются с одинаковой частотой и чаще, чем любой другой.
Распределение с двумя модами называется бимодальным. Распределение с тремя модами называется тримодальным. Модой распределения с непрерывной случайной величиной является максимальное значение функции. Как и в случае с дискретными распределениями, может быть более одной моды.
Диапазон
Размах распределения с дискретной случайной величиной – это разница между максимальным значением и минимальным значением. Для распределения с непрерывной случайной величиной диапазон представляет собой разницу между двумя крайними точками на кривой распределения, где значение функции падает до нуля. Для любого значения вне диапазона распределения значение функции равно 0,
 youtube.com/embed/ajo1noUQk50?autoplay=0&modestbranding=1&rel=0&widget_referrer=https://www.techtarget.com/searchdatacenter/definition/statistical-mean-median-mode-and-range&enablejsapi=1&origin=https://www.techtarget.com» type=»text/html» frameborder=»0″> Использование среднего значения для определения энергопотребления
youtube.com/embed/ajo1noUQk50?autoplay=0&modestbranding=1&rel=0&widget_referrer=https://www.techtarget.com/searchdatacenter/definition/statistical-mean-median-mode-and-range&enablejsapi=1&origin=https://www.techtarget.com» type=»text/html» frameborder=»0″> Использование среднего значения для определения энергопотребленияЧтобы вычислить среднее значение, сложите все числа в наборе, а затем разделите сумму на общее количество чисел. Например, в стойке центра обработки данных пять серверов потребляют 100 Вт, 98 Вт, 105 Вт, 90 Вт и 102 Вт мощности соответственно. Среднее энергопотребление этой стойки рассчитывается как (100 + 98 + 105 + 90 + 102 Вт)/5 серверов = рассчитанное среднее значение 99 Вт на сервер. Интеллектуальные блоки распределения питания сообщают о среднем использовании мощности стойки программному обеспечению управления системами.
Использование медианы для планирования мощности В центре обработки данных средние значения и медианы часто отслеживаются с течением времени для выявления тенденций, которые используются при планировании емкости или прогнозировании затрат на электроэнергию. Статистическая медиана — это среднее число в последовательности чисел. Чтобы найти медиану, упорядочите каждое число по размеру; число в середине является медианой. Для пяти серверов в стойке расположите значения энергопотребления от меньшего к большему: 90 Вт, 98 Вт, 100 Вт, 102 Вт и 105 Вт. Среднее энергопотребление стойки равно 100 Вт. чисел, усредните два средних числа. Например, если в стойке есть шестой сервер, потребляющий 110 Вт, новый набор номеров будет 9.0 Вт, 98 Вт, 100 Вт, 102 Вт, 105 Вт и 110 Вт. Найдите медиану, усредняя два средних числа: (100 + 102)/2 = 101 Вт.
Статистическая медиана — это среднее число в последовательности чисел. Чтобы найти медиану, упорядочите каждое число по размеру; число в середине является медианой. Для пяти серверов в стойке расположите значения энергопотребления от меньшего к большему: 90 Вт, 98 Вт, 100 Вт, 102 Вт и 105 Вт. Среднее энергопотребление стойки равно 100 Вт. чисел, усредните два средних числа. Например, если в стойке есть шестой сервер, потребляющий 110 Вт, новый набор номеров будет 9.0 Вт, 98 Вт, 100 Вт, 102 Вт, 105 Вт и 110 Вт. Найдите медиану, усредняя два средних числа: (100 + 102)/2 = 101 Вт.
Мода — это число, которое чаще всего встречается в наборе чисел. Для приведенных выше примеров энергопотребления сервера режим отсутствует, поскольку каждый элемент отличается. Но предположим, что администратор измерил энергопотребление всего центра управления сетью (NOC), а набор цифр — 90 Вт, 104 Вт, 98 Вт, 98 Вт, 105 Вт, 92 Вт, 102 Вт, 100 Вт, 110 Вт, 98 Вт, 210 Вт и 115 Вт. Режим 98 Вт, так как это измерение энергопотребления происходит чаще всего среди 12 серверов. Режим помогает определить наиболее распространенное или частое появление характеристики. Возможно иметь два режима (бимодальные), три режима (тримодальные) или более режимов в больших наборах чисел.
Режим 98 Вт, так как это измерение энергопотребления происходит чаще всего среди 12 серверов. Режим помогает определить наиболее распространенное или частое появление характеристики. Возможно иметь два режима (бимодальные), три режима (тримодальные) или более режимов в больших наборах чисел.
Диапазон — это разница между самым высоким и самым низким значениями в наборе чисел. Чтобы вычислить диапазон, вычтите наименьшее число из наибольшего числа в наборе. Если стойка с шестью серверами включает 90 Вт, 98 Вт, 100 Вт, 102 Вт, 105 Вт и 110 Вт, диапазон потребляемой мощности 110 Вт — 90 Вт = 20 Вт.
Диапазон показывает, насколько сильно различаются числа в наборе. Многие ИТ-системы работают в допустимых пределах; значение, превышающее этот диапазон, может вызвать предупреждение или тревогу для ИТ-персонала. Чтобы найти дисперсию в наборе данных, вычтите каждое число из среднего, а затем возведите результат в квадрат. Найдите среднее значение этих квадратов разностей, и это будет дисперсией в группе. В нашей первоначальной группе из пяти серверов среднее значение было 9.9. Сервер мощностью 100 Вт отличается от среднего на 1 Вт, сервер мощностью 105 Вт — на 6 Вт и т. д. Квадраты каждой разности равны 1, 1, 36, 81 и 9. Итак, чтобы вычислить дисперсию, прибавьте 1 + 1 + 36 + 81 + 9 и разделите на 5. Дисперсия равна 25,6. Стандартное отклонение показывает, насколько далеко друг от друга находятся все числа в наборе. Стандартное отклонение рассчитывается путем нахождения квадратного корня из дисперсии. В этом примере стандартное отклонение равно 5,1.
Найдите среднее значение этих квадратов разностей, и это будет дисперсией в группе. В нашей первоначальной группе из пяти серверов среднее значение было 9.9. Сервер мощностью 100 Вт отличается от среднего на 1 Вт, сервер мощностью 105 Вт — на 6 Вт и т. д. Квадраты каждой разности равны 1, 1, 36, 81 и 9. Итак, чтобы вычислить дисперсию, прибавьте 1 + 1 + 36 + 81 + 9 и разделите на 5. Дисперсия равна 25,6. Стандартное отклонение показывает, насколько далеко друг от друга находятся все числа в наборе. Стандартное отклонение рассчитывается путем нахождения квадратного корня из дисперсии. В этом примере стандартное отклонение равно 5,1.
Межквартильный диапазон, средние пятьдесят или середина набора чисел, удаляет выбросы — самые высокие и самые низкие числа в наборе. Если имеется большой набор чисел, разделите их поровну на меньшие и большие числа. Затем найдите медиану каждой из этих групп. Найдите межквартильный размах, вычитая нижнюю медиану из верхней медианы. Если стойка из шести серверов мощностью в ваттах расположена от меньшей к большей: 90, 98, 100, 102, 105, 110, разделите этот набор на младшие числа (90, 98, 100) и большие числа (102, 105, 110). Найдите медиану для каждого: 98 и 105. Вычтите более низкую медиану из более высокой медианы: 105 Вт — 98 Вт = 7 Вт, что является межквартильным диапазоном этих серверов.
Найдите медиану для каждого: 98 и 105. Вычтите более низкую медиану из более высокой медианы: 105 Вт — 98 Вт = 7 Вт, что является межквартильным диапазоном этих серверов.
Последнее обновление: декабрь 2020 г.
Продолжить чтение О статистическом среднем, медиане, моде и диапазонеSearchWindowsServer
 ..
..SearchCloudComputing
 Эти отличия включают ключевые функции управления данными…
Эти отличия включают ключевые функции управления данными…ПоискХранилище
