
Критерий Вальда
- ◄
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- ►
Глава 2. Принятие решений в условиях неопределенности
Критерий Вальда является самым «осторожным». Согласно ему, оптимальной альтернативой будет та, которая обеспечивает наилучший исход среди всех возможных альтернатив при самом плохом стечении обстоятельств.
Если исходы отражают подлежащие минимизации показатели (убытки, расходы, потери и т.д.), то критерий Вальда ориентируется на «минимакс» (минимум среди максимальных значений потерь всех альтернатив).
Если в качестве исходов альтернатив фигурируют показатели прибыли, дохода и других показателей, которые надо максимизировать (по принципу «чем больше, тем лучше»), то ищется  Здесь и далее для всех критериев в тексте мы будем рассматривать именно такой случай, когда исход показывает некий выигрыш.
Здесь и далее для всех критериев в тексте мы будем рассматривать именно такой случай, когда исход показывает некий выигрыш.
По критерию Вальда оценкой i-й альтернативы является ее наименьший выигрыш:
Wi = min(xij), j = 1..M
Оптимальной признается альтернатива с максимальным наихудшим выигрышем:
Х* = Хk, Wk = max(Wi), i = 1..N
Пример применения критерия Вальда
Есть два проекта Х1 и Х2, которые при трех возможных сценариях развития региона (j=1..3) обеспечивают разную прибыль. Значения прибыли приведены в таблице 2.2. Необходимо выбрать проект для реализации.
| Альтернативы (Xi) | Состояния природы (j) | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| Х1 | 45 | 25 | 50 |
| X2 | 20 | 60 | 25 |
Среди возможных проектов нет доминирующих ни абсолютно, ни по состояниям. Поэтому решение придется принимать по критериям.
Поэтому решение придется принимать по критериям.
Если выбор оптимального проекта осуществляется по критерию Вальда, то ЛПР должен выполнить следующие действия:
1. Найти минимальные исходы для каждой альтернативы. Это и будут значения критерия Вальда:
W1 = min( x1j ), j = 1..3 => W1 = min(45, 25, 50) = 25
W2 = min( x2j ), j = 1..3 => W2 = min(20, 60, 25) = 20
2. Сравнить значения критерия Вальда и найти наибольшую величину. Альтернатива с максимальным значением критерия будет считаться оптимальной:
25 > 20 => W1 > W2 => X* = X1
Если бы решение принималось только по критерию Вальда, ЛПР выбрал для реализации проект Х1, поскольку прибыль, которую обеспечит данный проект при самом плохом развитии ситуации, выше.
Выбрав оптимальную альтернативу по критерию Вальда, ЛПР гарантирует себе, что при самом плохом стечении обстоятельств он не получит меньше, чем значение критерия. Поэтому данный показатель еще называют критерием гарантированного результата.
Поэтому данный показатель еще называют критерием гарантированного результата.
Основной проблемой критерия Вальда является его излишняя пессимистичность, и, как следствие, не всегда логичный результат. Так, например, при выборе по данному критерию между альтернативами А{100; 500} и В{90; 1000} следует остановиться на варианте А. Однако в жизни логичнее было бы выбрать В, так как в худшем случае В лишь немного хуже А, тогда как при хорошем стечении обстоятельств В обеспечивает гораздо больший выигрыш.
Наверх
- ◄
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- ►
Дата обновления: 25.09.2014
Примеры решения задач — Математическое программирование — Исследование операций — ЭММ
Условие задачи
Фермер
может посеять на данном участке одну из трех культур
. Урожайность каждой из
культур во многом зависит от погоды, которая может быть засушливой, нормальной или дождливой
(влияние других факторов не учитывается). Известна цена
одного центнера культуры
, а также урожайности
(ц/га) каждой культуры
– урожайность при засушливой погоде,
–урожайность при нормальной погоде,
– урожайность при дождливой погоде.
Многолетние наблюдения за погодой данного района показывают, что вероятности
засушливой, нормальной и дождливой погоды составляют соответственно
.
Урожайность каждой из
культур во многом зависит от погоды, которая может быть засушливой, нормальной или дождливой
(влияние других факторов не учитывается). Известна цена
одного центнера культуры
, а также урожайности
(ц/га) каждой культуры
– урожайность при засушливой погоде,
–урожайность при нормальной погоде,
– урожайность при дождливой погоде.
Многолетние наблюдения за погодой данного района показывают, что вероятности
засушливой, нормальной и дождливой погоды составляют соответственно
.
Требуется:
- придать описанной ситуации игровую схему и составить платежную матрицу;
- пользуясь критериями Бейеса, Вальда, Сэвиджа и Гурвица (величина параметра для критерия Гурвица задается) выяснить, какую культура следует сеять, чтобы обеспечить наибольший доход.
Решение задачи
Игровая схема
Игра
парная, статистическая.
— посадить 1-ю культуру
— посадить 2-ю культуру
— посадить 3-ю культуру
Второй игрок — природа. Под природой мы понимаем совокупность внешних условий, определяющих урожайность. Стратегии природы будут следующими:
– погода будет засушливая
– погода будет нормальная
– погода будет дождливая
Платежная матрица
Составляем платежную матрицу. Элементы этой матрицы – цена реализации выращенного урожая.
Или
| 6 | 9 | 3 | |
| 5 | 10 | 30 | |
| 8 | 12 | 4 |
Критерий Байеса
При известных вероятностях
воспользуемся критерием Байеса.
Определяем средние выигрыши:
Оптимальной является стратегия
Критерий Вальда
Оптимальной является стратегия .
Критерий Сэвиджа
Составляем матрицу рисков:
| 2 | 3 | 27 | 27 | |
| 3 | 2 | 0 | 3 | |
| 0 | 0 | 26 | 26 |
Оптимальной является стратегия
Критерий Гурвица
Согласно критерию Гурвица, наилучшим решением является чистая стратегия, соответствующая условию:
Оптимальной является стратегия
В
соответствии со всеми критериями фермеру необходимо выращивать 2-ю культуру.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная оплата переводом на карту СберБанка.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Обобщенная оценка и тесты Вальда
На этой странице
АннотацияВведениеПриложениеСсылкиАвторское правоСтатьи по теме
Обобщенная оценка и тесты Вальда описаны и связаны с их необобщенными версиями. Обсуждаются два интересных приложения. В первом выводится новый тест для задачи Беренса-Фишера. Во-вторых, проверяется однородность отклонений от нескольких одномерных нормальных популяций.
1. Введение
Этот документ предназначен в качестве учебного пособия для тех, кто хочет получить информацию об обобщенном балле и тестах Вальда. Он расширяет содержание [1] и имеет аналогичные цели; то есть он фокусируется на использовании этих тестов, а не на их свойствах. Он предназначен быть очень доступным. Читателям нужны лишь некоторые предварительные знания о секционированных матрицах, оценках и критериях Вальда, см., например, [1] и [2, глава 3].
Он расширяет содержание [1] и имеет аналогичные цели; то есть он фокусируется на использовании этих тестов, а не на их свойствах. Он предназначен быть очень доступным. Читателям нужны лишь некоторые предварительные знания о секционированных матрицах, оценках и критериях Вальда, см., например, [1] и [2, глава 3].
Тест на баллы особенно ценен, когда оценка максимального правдоподобия (ML) в полной модели не предпочтительна, а оценка ML в нулевой модели предпочтительнее. Обратное верно для теста Вальда. Таким образом, когда оценка ML по одной из нулевой и полной моделей не является предпочтительной, тест отношения правдоподобия проблематичен, а один из критериев оценки и теста Вальда — нет. Здесь под нежеланием имеется в виду, что, например, оценки могут быть рассчитаны по какой-либо итерационной схеме с сомнительной сходимостью. Другие возможности заключаются в том, что оценки могут иметь особенно запутанное выражение или свойства конечной выборки (например, большое смещение) могут быть неподходящими для интересующей проблемы.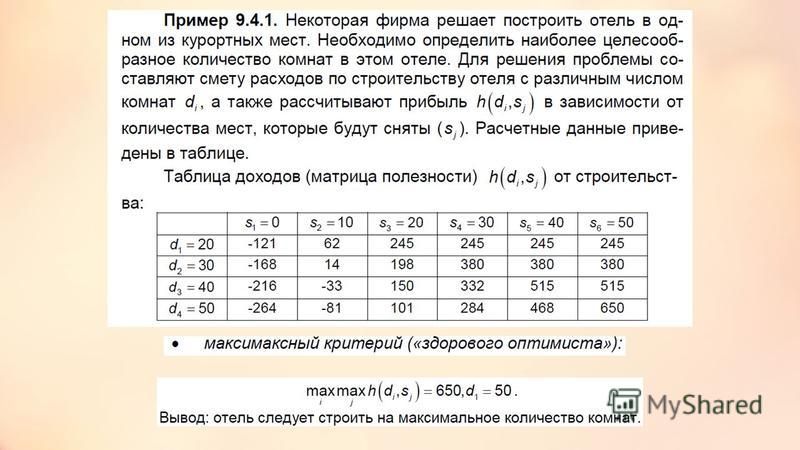
Когда оценка машинного обучения как в нулевой, так и в полной моделях нежелательна, нам нужен другой путь вперед. Это обеспечивается обобщенной оценкой и тестами Вальда. Эти тесты особенно ценны, когда модель может быть неправильно определена, но здесь мы не об этом.
В Разделе 2 описаны обобщенная оценка и тесты Вальда. В разделе 3 этот материал применяется для получения нового теста для задачи Беренса-Фишера, а в разделе 4 рассматривается проверка равенства дисперсий из нескольких независимых нормальных выборок.
2. М-оценщики и обобщенные оценочные тесты
Класс М-оценщиков включает как МО, так и метод моментных оценок. M-оценка удовлетворяет
в котором независимы, но не обязательно одинаково распределены, является известной функцией, не зависящей от или , является -мерным параметром и вообще обозначает вектор нулей. Оценочная функция должна быть достаточно «гладкой». В частности, должны существовать ее производные до второго порядка и их математические ожидания. Следовательно, матрицы и определенные далее предполагаются существующими. Кроме того, ожидание производных второго порядка должно быть ограничено по вероятности. Дополнительные технические подробности о М-оценках можно найти в [3, глава 5].
Следовательно, матрицы и определенные далее предполагаются существующими. Кроме того, ожидание производных второго порядка должно быть ограничено по вероятности. Дополнительные технические подробности о М-оценках можно найти в [3, глава 5].
В нашей настройке мы предполагаем, что и что мы хотим проверить : против альтернативы : с вектором основного интереса, с вектором мешающих параметров и с . Обобщенный балльный тест основан на частичной М-оценке, которая удовлетворяет
где разбивается аналогично , так что , и где в которой находится М-оценка при нулевой гипотезе. Определять в котором обозначает математическое ожидание при нулевой гипотезе. Вот и есть и есть. Заметим, что не обязательно симметричный while есть. Это означает, что форму обобщенных тестов, приведенную, например, в [4], необходимо немного видоизменить. Обобщенная статистическая оценка теста определяется выражением
в котором, как легко показать, и аргументы в , и опущены; здесь все такие. Точно так же обобщенная статистика теста Вальда определяется выражением
в котором все аргументы . В изложении [4] параметры оцениваются ML, но данные не поступают из параметрической модели: это ML при неправильной спецификации. В [5] даны определения Кента, но вместо ML-оценок разрешены любые M-оценки. В [4] также отмечается, что и на практике могут быть заменены любыми непротиворечивыми оценками.
В изложении [4] параметры оцениваются ML, но данные не поступают из параметрической модели: это ML при неправильной спецификации. В [5] даны определения Кента, но вместо ML-оценок разрешены любые M-оценки. В [4] также отмечается, что и на практике могут быть заменены любыми непротиворечивыми оценками.
Альтернативный, более удобный для расчета вид приведен в [2], где он применяется для построения обобщенных гладких критериев согласия. Эта форма дает
в котором Эквивалентность двух форм требует рутинной, но утомительной матричной алгебры и здесь не рассматривается. Асимптотическое распределение обоих и ниже равно .
Если — производная логарифма вероятности, которая является обычной функцией оценки, то — обычная (симметричная) информационная матрица, и . Если используется оценка ML, то обычная статистика критерия Вальда и обычная статистика критерия оценки. Оба приведены в таком виде в [1]. Подробнее см. [5, 6].
В [5, стр. 328] рекомендуется заменить обратную асимптотическую ковариационную матрицу на обобщенную обратную непротиворечивой оценки. Хотя это может показаться тривиальным, при вычислении любого обычного или обобщенного показателя или статистики критерия Вальда мы находим где по крайней мере асимптотически многомерная норма и по крайней мере асимптотически ковариационная матрица полного ранга . Очень иногда бывает удобнее найти точную ковариационную матрицу, а не асимптотически эквивалентную. Если это так, то в приведенных выше выражениях можно использовать точную ковариационную матрицу; аналогичным образом, когда это уместно, может использоваться обобщенная обратная точная или асимптотически эквивалентная ковариационная матрица.
Хотя это может показаться тривиальным, при вычислении любого обычного или обобщенного показателя или статистики критерия Вальда мы находим где по крайней мере асимптотически многомерная норма и по крайней мере асимптотически ковариационная матрица полного ранга . Очень иногда бывает удобнее найти точную ковариационную матрицу, а не асимптотически эквивалентную. Если это так, то в приведенных выше выражениях можно использовать точную ковариационную матрицу; аналогичным образом, когда это уместно, может использоваться обобщенная обратная точная или асимптотически эквивалентная ковариационная матрица.
3. Проблема Беренса-Фишера
В задаче Беренса-Фишера — случайная выборка из совокупности и независимая случайная выборка из совокупности. Желательно протестировать : против : , со стандартными отклонениями и мешающими параметрами. В [2, Пример 3.3.2] получены отношение правдоподобия, оценка и критерии Вальда. Тест на оценку требует решения неудобного кубического уравнения; так что это одна из ситуаций, в которой статистика Вальда выглядит явно более привлекательной, чем как отношение правдоподобия, так и статистика тестов.
Когда оценочной функцией является обычная функция оценки, обобщенный тест оценки является обычным тестом оценки. Чтобы соответствовать нашим обозначениям положить , , и . Мы тестируем против , с неприятными параметрами и . Логарифм вероятности равен
. и, следовательно, функция оценки имеет следующие компоненты: Это частные производные логарифма вероятности. При нулевой гипотезе оценочные уравнения имеют вид . Это приводит к неудобному кубическому уравнению, упомянутому ранее. Если мы продолжим эту модель, кубическое должно быть решено, чтобы найти , и, следовательно, и . Мы также находимоткуда
а обобщенная статистика тестовой оценки равна . Это просто обычная статистика тестов.
Хотя решение кубика не представляет большой трудности, если мы изменим его так, чтобы он стал
можно найти, возможно, менее эффективную, но определенно более удобную оценку общего среднего при нулевой гипотезе. Эта оценка является решением , а именно . Если мы также изменим так, чтобы
оставляя два других уравнения без изменений, тест на обобщенную оценку основан на
Оценки и немного отличаются от тех, которые были найдены ранее, будучи и . Изменение предыдущего вывода дает
откуда
Изменение предыдущего вывода дает
откуда
а статистика обобщенного теста равна
. Можно показать, что статистика теста Вальда является функцией один-один от этого , так что эти два теста эквивалентны. Однако, если использовать асимптотические критические значения, тест с обобщенной оценкой имеет фактические размеры тестов, намного более близкие к номинальным размерам, чем тест Вальда. При использовании смоделированных критических значений, которые практически точны, мощность теста с обобщенной оценкой находится в пределах 1% от укоренившегося теста из-за Уэлча [7]. Таким образом, по этому критерию тест Уэлча и обобщенный балльный тест практически неотличимы.
Тест Уэлча очень похож на тест Вальда. Использование приближения Саттертуэйта к нулевому распределению критерия Уэлча дает превосходное соответствие между номинальным и фактическим размерами теста. Однако приближение Саттертуэйта не так хорошо работает для . Следовательно, с точки зрения соответствия между номинальным и фактическим тестовыми размерами с использованием аппроксимаций и асимптотических критических значений предпочтение следует отдавать критерию Уэлча. Поддержка этих утверждений и дополнительные численные детали доступны в [8].
Поддержка этих утверждений и дополнительные численные детали доступны в [8].
4. Проверка равенства дисперсий
Предположим, что у нас есть независимые случайные выборки с th, , размером и из нормальной совокупности. Общий размер выборки составляет . Мы стремимся проверить равенство отклонений: : скажем против альтернативы : не . Популярные тесты включают тест отношения правдоподобия, часто называемый тестом Бартлетта, и тест Левена. Известно, что первый ненадежен, а второй более надежен в том смысле, что его фактические уровни ближе к номинальным уровням. Тест Левена менее эффективен, чем тест Бартлетта, когда данные согласуются с нормой.
Теперь мы построим тест Вальда против . Мы могли бы использовать построение обобщенного критерия Вальда с производной логарифма вероятности, но мы оставляем это в качестве упражнения для заинтересованного читателя. Мы могли бы также вычислить одну из форм асимптотической ковариационной матрицы, но это тот случай, когда проще вычислить точную ковариационную матрицу. Более того, точная ковариационная матрица включает неудобную обратную; поэтому вместо этого мы используем обратную модель Мура-Пенроуза. Это определено в приложении вместе с некоторыми соответствующими полезными результатами. Этот подход приводит к более простой тестовой статистике.
Более того, точная ковариационная матрица включает неудобную обратную; поэтому вместо этого мы используем обратную модель Мура-Пенроуза. Это определено в приложении вместе с некоторыми соответствующими полезными результатами. Этот подход приводит к более простой тестовой статистике.
В этом примере, поскольку мы вычисляем статистику теста Вальда, все оценки являются ML. Как следствие, оценки обозначаются шляпами () вместо тильд (). Мы также используем несмещенные версии выборочных дисперсий (с делителями вместо ). Они асимптотически эквивалентны обычным оценкам ML, а соответствующая статистика теста асимптотически эквивалентна обычной статистике теста Вальда.
Прежде чем приступить к построению, обратите внимание, что если является несмещенной выборкой дисперсии случайной выборки размера из распределения, то имеет распределение. Как известно, , так что
Из теоремы Рао-Блэквелла оптимальная оценка , будучи единственной оценкой с минимальной дисперсией в классе несмещенных оценок . Эта оптимальность определяется при оценке . Запись для несмещенной оценки дисперсии генеральной совокупности , оптимальная оценка для .
Эта оптимальность определяется при оценке . Запись для несмещенной оценки дисперсии генеральной совокупности , оптимальная оценка для .
Если нулевая гипотеза верна, несмещенной оценкой общей дисперсии генеральной совокупности является дисперсия объединенной выборки, где для . Обратите внимание, что поскольку , . Теперь определите Затем . Это ноль тогда и только тогда, когда для всех . Следовательно, проверка на равенство дисперсий эквивалентна проверке : против : . Непредвзятая оценка есть и поскольку симметрична, имеет ковариационную матрицу, оцениваемую где теперь . Теперь CDC не имеет полного ранга, и для использования результатов о квадратичных формах многомерных нормальных случайных величин требуются обобщенные или псевдообратные. Здесь мы используем обратную матрицу Мура-Пенроуза M. См. приложение.
Поскольку это идемпотент, обратная функция Мура-Пенроуза для CDC задается формулой
Статистика теста Вальда для тестирования : против : есть
Так как , следует сравнивать с распределением для оценки значимости. Если тест показывает значимость на соответствующем уровне, можно провести грубые попарные сравнения, как при сравнении средних в дисперсионном анализе. Чтобы увидеть, как это сделать, сначала обратите внимание, что, как и выше, имеет распределение, которое для больших примерно равно . Отсюда приблизительно и при нулевой гипотезе равенства дисперсий для любого разность приблизительно равна , и может быть оценена как . Наименее значимое различие может быть построено обычным способом.
Если тест показывает значимость на соответствующем уровне, можно провести грубые попарные сравнения, как при сравнении средних в дисперсионном анализе. Чтобы увидеть, как это сделать, сначала обратите внимание, что, как и выше, имеет распределение, которое для больших примерно равно . Отсюда приблизительно и при нулевой гипотезе равенства дисперсий для любого разность приблизительно равна , и может быть оценена как . Наименее значимое различие может быть построено обычным способом.
Приложение
Обратное Мура-Пенроуза
Одной из нескольких псевдообратных или обобщенных обратных является обратная Мура-Пенроуза: см., например, [9, раздел 8.11]. Единственная обратная Мура-Пенроуза вещественной симметричной матрицы B удовлетворяет Привычно показывать следующее.
(i) Если
, то
. (ii) Если H ортогонален, то
. (iii) Если A идемпотент, то
. (iv) Если последующие матричные произведения определены, то
(iv) Если последующие матричные произведения определены, то
и
.
Хорошо известно, что если с рангом , то имеет распределение где является псевдообратным . Для сценария здесь разумно протестировать использование тестовой статистики.
Ссылки
JCW Rayner, «Асимптотически оптимальные тесты», Journal of the Royal Statistical Society Series D , vol. 46, нет. 3, стр. 337–346, 1997.
Посмотреть по адресу:
Сайт издателя | Академия Google
J. C. W. Rayner, O. Thas, and D. J. Best, Smooth Tests of Goodness of Fit: Using R , John Wiley & Sons, Сингапур, 2-е издание, 2009 г.
A. W. van der Vaart, 90symotic Статистика , том. 3 of Cambridge Series in Statistical and Probabilistic Mathematics , Cambridge University Press, Cambridge, UK, 1998.0101 Биометрика , том.
 69, нет. 1, стр. 19–27, 1982.
69, нет. 1, стр. 19–27, 1982.Посмотреть по адресу:
Google Scholar | Zentralblatt МАТЕМАТИКА | MathSciNet
Д. Боос, «Об обобщенных тестах оценки», The American Statistician , vol. 47, стр. 327–333, 1992.
Посмотреть по адресу:
Google Scholar
Х. Уайт, «Оценка максимального правдоподобия неверно заданных моделей», Econometrica , vol. 50, нет. 1, стр. 1–25, 1982.
Посмотреть по адресу:
Сайт издателя | ученый Google | Zentralblatt МАТЕМАТИКА | MathSciNet
Б. Л. Уэлч, «Значение разницы между двумя средними значениями, когда дисперсии совокупности не равны», Biometrika , vol. 29, pp. 350–362, 1937.
Посмотреть по адресу:
Google Scholar
П.
Риппон, Дж. Рейнер и О. Тас, «Конкурент теста Уэлча в задаче Беренса-Фишера. », Неопубликованный отчет, 2008 г.Посмотреть по адресу:
Google Scholar
Дж. Л. Голдберг, Matrix Theory with Applications , McGraw-Hill, New York, NY, USA, 1991.
 69, нет. 1, стр. 19–27, 1982.
69, нет. 1, стр. 19–27, 1982. Риппон, Дж. Рейнер и О. Тас, «Конкурент теста Уэлча в задаче Беренса-Фишера. », Неопубликованный отчет, 2008 г.
Риппон, Дж. Рейнер и О. Тас, «Конкурент теста Уэлча в задаче Беренса-Фишера. », Неопубликованный отчет, 2008 г.Это статья в открытом доступе, распространяемая под Лицензия Creative Commons Attribution, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии надлежащего цитирования оригинальной работы.
12.1 — Логистическая регрессия | СТАТ 462
Логистическая регрессия моделирует взаимосвязь между предикторными переменными и категориальной переменной отклика. Например, мы могли бы использовать логистическую регрессию для моделирования взаимосвязи между различными измерениями изготовленного образца (такими как размеры и химический состав), чтобы предсказать, произойдет ли трещина более 10 мил (бинарная переменная: либо да, либо нет). Логистическая регрессия помогает нам оценить вероятность попадания в определенный уровень категориального ответа с учетом набора предикторов. Мы можем выбрать один из трех типов логистической регрессии в зависимости от характера категориальной переменной отклика:
Логистическая регрессия помогает нам оценить вероятность попадания в определенный уровень категориального ответа с учетом набора предикторов. Мы можем выбрать один из трех типов логистической регрессии в зависимости от характера категориальной переменной отклика:
Двоичная логистическая регрессия :
Используется, когда ответ является бинарным (т. е. имеет два возможных результата). В приведенном выше примере взлома будет использоваться бинарная логистическая регрессия. Другие примеры бинарных ответов могут включать прохождение или непрохождение теста, ответ «да» или «нет» в опросе и наличие высокого или низкого артериального давления.
Номинальная логистическая регрессия :
Используется при наличии трех или более категорий без естественного порядка уровней. Примеры номинальных ответов могут включать в себя отделы компании (например, маркетинг, продажи, отдел кадров), тип используемой поисковой системы (например, Google, Yahoo!, MSN) и цвет (черный, красный, синий, оранжевый).
Порядковая логистическая регрессия :
Используется при наличии трех или более категорий с естественным порядком уровней, но ранжирование уровней не обязательно означает, что интервалы между ними равны. Примерами порядковых ответов могут быть то, как учащиеся оценивают эффективность курса обучения в колледже (например, «хорошо», «средне», «плохо»), уровень вкуса горячих крылышек и состояние здоровья (например, «хорошее», «стабильное», «серьезное», «критическое»).
Особые проблемы с моделированием категориальной переменной отклика включают ненормальные условия ошибки, непостоянную дисперсию ошибки и ограничения на функцию отклика (т. е. ответ находится в диапазоне от 0 до 1). Здесь мы исследуем способы решения этих проблем в условиях бинарной логистической регрессии. Номинальная и порядковая логистическая регрессия в этом курсе не рассматриваются.
Множественная бинарная логистическая регрессионная модель выглядит следующим образом:
\[\begin{align}\label{logmod}
\pi(\textbf{X})&=\frac{\exp(\beta_{0 }+\beta_{1}X_{1}+\ldots+\beta_{k}X_{k})}{1+\exp(\beta_{0}+\beta_{1}X_{1}+\ldots+\ beta_ {k} X_ {k})} \ notag \\
и
= \ frac {\ exp (\ textbf {X} \ beta)} {1+ \ exp (\ textbf {X} \ beta)} \\
и
=\frac{1}{1+\exp(-\textbf{X}\beta)},
\end{align}\]
, где здесь \(\pi\) обозначает вероятность, а — нет иррациональное число 3. 14….
14….
- \(\pi\) — это вероятность того, что наблюдение относится к определенной категории двоичной Y переменной, обычно называемой «вероятностью успеха».
- Обратите внимание, что модель описывает вероятность события как функцию X переменных. Например, он может предоставить оценки вероятности того, что у пожилого человека есть болезнь сердца.
- В логистической модели оценки $\pi$ из уравнений, подобных приведенному выше, всегда будут находиться в диапазоне от 0 до 1. Причины:
- Числитель \(\exp(\beta_{0}+\beta_{1}X_{1}+\ldots+\beta_{k}X_{k})\) должен быть положительным, так как это степень положительное значение ( e ).
- Знаменатель модели равен (1 + числитель), поэтому ответ всегда будет меньше 1.
- С одной переменной X теоретическая модель для \(\pi\) имеет вытянутую форму «S» (или сигмоидальную форму) с асимптотами в точках 0 и 1, хотя в выборочных оценках мы можем не увидеть эту форму «S» если диапазон 9{n}[y_{i}\textbf{X}_{i}\beta-\log(1+\exp(\textbf{X}_{i}\beta))].
\end{align*}\]Максимизация правдоподобия (или логарифмического правдоподобия) не имеет решения в закрытой форме, поэтому для нахождения оценки коэффициентов регрессии $\hat{\ бета}$.
Для иллюстрации рассмотрим данные, опубликованные о n = 27 больных лейкемией. Данные (leukemia_remission.txt) содержат переменную ответа о том, имела ли место ремиссия лейкемии (REMISS), которая определяется числом 1,9.0003
Прогностические переменные: клеточность среза костного мозга (CELL), дифференциальный процент бластов в мазке (SMEAR), процент абсолютного лейкозно-клеточного инфильтрата (INFIL), процентный индекс мечения клеток лейкоза костного мозга (LI), абсолютный количество бластов в периферической крови (BLAST) и самая высокая температура до начала лечения (TEMP).
Следующие выходные данные показывают оценочное уравнение логистической регрессии и связанные с ним тесты значимости
Коэффициенты
Термин Coef SE Coef 95% CI Z-значение P-значение VIF
Константа 64,3 75,0 (-82,7, 211,2) 0,86 0,391 90 2 52,1 (-71,4, 133,0) 0,59 0,554 62,46
МАЗОК 24,7 61,5 (-95,9 , 145,3) 0,40 0,688 434,42
INFIL -25,0 65,3 (-152,9, 103,0) -0,38 0,702 471,10
LI 5, 4,36 9,57) 1,64 0,101 4,43
ВЗРЫВ -0,01 2,27 ( -4,45, 4,43) -0,01 0,996 4,18
TEMP -100,2 77,8 (-252,6, 52,2) -1,29 0,198 3,01Критерий Вальда
используем т -тесты в линейной регрессии).
Для оценок максимального правдоподобия отношение })}
\end{equation*}\]можно использовать для проверки $H_{0}: \beta_{i}=0$. Стандартная нормальная кривая используется для определения значения $p$ теста. Кроме того, доверительные интервалы могут быть построены как
\[\begin{equation*}
\hat{\beta}_{i}\pm z_{1-\alpha/2}\textrm{s.e.}(\hat{\beta}_{i}).
\end{equation*}\]Оценки коэффициентов регрессии, $\hat{\beta}$, приведены в таблице коэффициентов в столбце с надписью «Coef». В этой таблице также приведены значения коэффициента p , основанные на критериях Вальда. Индекс клеток лейкемии костного мозга (LI) имеет наименьшее значение p и, таким образом, оказывается наиболее близким к достоверному прогностическому признаку наступления ремиссии. Изучив различные подмножества данных, мы обнаруживаем, что хорошей моделью является та, которая включает только индекс маркировки в качестве предиктора:
Коэффициенты. ( 0,57, 5,22) 2,44 0,015 1,00
Уравнение регрессии
P(1) = exp(Y’)/(1 + exp(Y’))
Y’ = -3,78 + 2,90 LIвизуализировать сигмоидальную форму подобранной кривой логистической регрессии:
Шансы, логарифм шансов и отношение шансов
Существуют алгебраически эквивалентные способы записи модели логистической регрессии: pi}{1-\pi}=\exp(\beta_{0}+\beta_{1}X_{1}+\ldots+\beta_{k}X_{k}),
\end{уравнение}\], которое представляет собой уравнение, описывающее шансы попасть в текущую интересующую категорию.
По определению, 90 189 шансов 90 190 для события составляют 90 225 π 90 226 / (1 — π ), так что P — это вероятность события. Например, если вы находитесь на ипподроме и есть вероятность 80%, что определенная лошадь выиграет скачки, то ее шансы равны 0,80 / (1 — 0,80) = 4, или 4:1.Второй
\[\begin{equation}\label{logmod2}
\log\biggl(\frac{\pi}{1-\pi}\biggr)=\beta_{0}+\beta_{ 1}X_{1}+\ldots+\beta_{k}X_{k},
\end{equation}\], в котором утверждается, что (натуральный) логарифм шансов является линейной функцией X переменных (и часто называется логарифмическими шансами ). Это также называется логит-преобразованием вероятности успеха, \(\pi\).
отношение шансов (которое мы запишем как $\theta$) между шансами для двух наборов предикторов (скажем, $\textbf{X}_{(1)}$ и $\textbf{X}_{ (2)}$) задается как
\[\begin{equation*}
\theta=\frac{(\pi/(1-\pi))|_{\textbf{X}=\textbf{X }_{(1)}}}{(\pi/(1-\pi))|_{\textbf{X}=\textbf{X}_{(2)}}}.
\end{equation*}\]Для бинарной логистической регрессии шансы на успех составляют:
\[\begin{equation*}
\frac{\pi}{1-\pi}=\exp(\ textbf{X}\бета).
\end{equation*}\]Подставив это в формулу для $\theta$ выше и установив $\textbf{X}_{(1)}$ равным $\textbf{X}_{(2 )}$ за исключением одной позиции (т. е. только один предиктор отличается на одну единицу), мы можем определить связь между этим предиктором и ответом. Отношение шансов может быть любым неотрицательным числом. Отношение шансов, равное 1, служит базой для сравнения и указывает на отсутствие связи между ответом и предиктором. Если отношение шансов больше 1, то шансы на успех выше для более высоких уровней непрерывного предиктора (или для указанного уровня фактора). В частности, шансы мультипликативно увеличиваются на $\exp(\beta_{j})$ при каждом увеличении $\textbf{X}_{j}$ на одну единицу. Если отношение шансов меньше 1, то шансы на успех меньше для более высоких уровней непрерывного предиктора (или для указанного уровня фактора).
Значения дальше от 1 представляют более сильные степени ассоциации.Например, когда имеется только один предиктор \(X\), шансы на успех составляют:
\[\begin{equation*}
\frac{\pi}{1-\pi}=\ exp(\beta_0+\beta_1X).
\end{equation*}\]Если мы увеличим \(X\) на одну единицу, отношение шансов составит
\[\begin{equation*}
\theta=\frac{\exp(\beta_0+\ beta_1(X+1))}{\exp(\beta_0+\beta_1X)}=\exp(\beta_1).
\end{equation*}\]Чтобы проиллюстрировать это, соответствующие выходные данные примера с лейкемией:
Отношения шансов для непрерывных предикторов 9{\textrm{th}}$ процентиль от стандартного нормального распределения. Интерпретация отношения шансов заключается в том, что при каждом увеличении LI на 1 единицу расчетные шансы ремиссии лейкемии умножаются на 18,1245. Однако, поскольку LI находится между 0 и 2, может быть, имеет смысл сказать, что на каждые 0,1 единицы увеличения L1 расчетные шансы ремиссии умножаются на $\exp(2,89726\times 0,1)=1,336$.
Тогда- При LI=0,9 предполагаемый шанс ремиссии лейкемии составляет $\exp\{-3,77714+2,89726*0,9\}=0,310$.
- При LI=0,8 предполагаемая вероятность ремиссии лейкемии составляет $\exp\{-3,77714+2,89726*0,8\}=0,232$.
- Полученное отношение шансов составляет $\frac{0,310}{0,232}=1,336$, что представляет собой отношение шансов на ремиссию при LI=0,9 по сравнению с шансами при L1=0,8.
Обратите внимание, что $1,336\times 0,232=0,310$, что демонстрирует мультипликативный эффект $\exp(0,1\hat{\beta_{1}})$ на шансы.
Тест отношения правдоподобия (или отклонения)
тест отношения правдоподобия используется для проверки нулевой гипотезы о том, что любое подмножество $\beta$ равно 0. Количество $\beta$ в полной модели равно k +1 , в то время как количество $\beta$ в сокращенной модели равно r +1 . (Помните, что сокращенная модель — это модель, которая получается, когда $\beta$ в нулевой гипотезе установлены равными 0.
) Таким образом, количество $\beta$, проверяемых в нулевой гипотезе, равно \((k +1)-(г+1)=к-г\). Тогда статистика теста отношения правдоподобия определяется как: 92$ = отклонение (уменьшенное) – отклонение (полное).Эта процедура тестирования аналогична общей процедуре линейного F-теста для множественной линейной регрессии. Однако обратите внимание, что при тестировании одного коэффициента критерий Вальда и критерий отношения правдоподобия будут , а не , в целом дадут идентичные результаты.
Чтобы проиллюстрировать это, соответствующие выходные данные программного обеспечения для примера с лейкемией:9 8,299 8,30 0,004
LI 1 8,299 8,299 8,30 0,004
Ошибка 25 25 2 26,073 3 1,04 34,372Поскольку в этом примере имеется только один предиктор, эта таблица просто предоставляет информацию о тесте отношения правдоподобия для LI ( p — значение 0,004), что похоже, но не идентично более раннему результату теста Вальда ( p — значение 0,015).
Таблица отклонений включает следующее:- 9009{2}$ распределение с \(2-1=1\) степенями свободы.

 Для оценок максимального правдоподобия отношение })}
Для оценок максимального правдоподобия отношение })}  По определению, 90 189 шансов 90 190 для события составляют 90 225 π 90 226 / (1 — π ), так что P — это вероятность события. Например, если вы находитесь на ипподроме и есть вероятность 80%, что определенная лошадь выиграет скачки, то ее шансы равны 0,80 / (1 — 0,80) = 4, или 4:1.
По определению, 90 189 шансов 90 190 для события составляют 90 225 π 90 226 / (1 — π ), так что P — это вероятность события. Например, если вы находитесь на ипподроме и есть вероятность 80%, что определенная лошадь выиграет скачки, то ее шансы равны 0,80 / (1 — 0,80) = 4, или 4:1.
 Значения дальше от 1 представляют более сильные степени ассоциации.
Значения дальше от 1 представляют более сильные степени ассоциации. Тогда
Тогда ) Таким образом, количество $\beta$, проверяемых в нулевой гипотезе, равно \((k +1)-(г+1)=к-г\). Тогда статистика теста отношения правдоподобия определяется как: 92$ = отклонение (уменьшенное) – отклонение (полное).
) Таким образом, количество $\beta$, проверяемых в нулевой гипотезе, равно \((k +1)-(г+1)=к-г\). Тогда статистика теста отношения правдоподобия определяется как: 92$ = отклонение (уменьшенное) – отклонение (полное). Таблица отклонений включает следующее:
Таблица отклонений включает следующее:При использовании теста отношения правдоподобия (или отклонения) для более чем одного коэффициента регрессии мы можем сначала подобрать «полную» модель, чтобы найти отклонение (полное), которое показано в строке «Ошибка» в результирующей полной модели. Отклонение Стол. Затем подгоните «урезанную» модель (соответствующую модели, которая получается, если нулевая гипотеза верна), чтобы найти отклонение (уменьшенное), которое показано в строке «Ошибка» в результирующей таблице отклонений сокращенной модели. Например, соответствующие таблицы отклонений для примера вспышки заболевания на страницах 581–582 из 9.0225 Прикладные модели линейной регрессии (4-е изд.) Катнера и др.:
Полная модель:
Источник DF Adj Dev Adj Среднее значение хи-квадрат P-значение 0217 Ошибка 88 93,996 1,06813
Всего 97
Регрессия 054 1,0866 92 = 101,054-93,996 = 7,058\), которое сравнивается с распределением хи-квадрат с \(10-5=5\) степенями свободы, чтобы найти p -значение = 0,216 > 0,05 (что означает, что условия взаимодействия равны не имеет значения при уровне значимости 5%). 2\). Например, соответствующая таблица отклонений для примера вспышки заболевания: 9
2\). Например, соответствующая таблица отклонений для примера вспышки заболевания: 9
Регрессия 7,40 0,007 1 1,804 1,8040 1,80 0,179
7 Сектор 1 10,448 10,4481 10,45 0,001
Возраст*Средний 1 4,570 4,5697 4,57 0,033
Возраст*Младший 1 1,015 1,0152 1,02 0,314 92 = 4,570+1,015+1,120+0,000+0,353 = 7,058\), то же, что и в первом расчете.
Тесты на соответствие
Общие характеристики подобранной модели можно измерить с помощью нескольких различных тестов на соответствие. Двумя тестами, требующими повторных данных (множество наблюдений с одинаковыми значениями для всех предикторов), являются критерий согласия хи-квадрат Пирсона и критерий согласия отклонения (аналогичный множественной линейной регрессии). F-критерий несоответствия). Оба этих теста имеют статистику, приблизительно распределенную по принципу хи-квадрат с c — k — 1 степеней свободы, где c – количество различных комбинаций переменных-предикторов. Когда тест отклоняют, имеет место статистически значимое несоответствие. В противном случае нет никаких признаков несоответствия.
Когда тест отклоняют, имеет место статистически значимое несоответствие. В противном случае нет никаких признаков несоответствия.
Напротив, критерий согласия Хосмера-Лемешова полезен для нереплицированных наборов данных или для наборов данных, содержащих лишь несколько повторяющихся наблюдений. Для этого теста наблюдения группируются на основе их предполагаемых вероятностей. Результирующая тестовая статистика приблизительно распределена по хи-квадрат с c — 2 степеней свободы, где c – количество групп (обычно выбирается от 5 до 10, в зависимости от размера выборки).
Чтобы проиллюстрировать это, соответствующие выходные данные программного обеспечения для примера с лейкемией: 23,93 0,523
Хосмер-Лемешоу 7 6,87 0,442
Поскольку для этого примера нет реплицированных данных, критерий отклонения и согласия Пирсона недействителен, поэтому первые две строки этой таблицы следует игнорировать. Однако тест Хосмера-Лемешоу не требует дублирования данных, поэтому мы можем интерпретировать его высокие 9{2} = \ frac {\ ell (\ hat {\ beta_ {0}}) — \ ell (\ hat {\ beta})} {\ ell (\ hat {\ beta_ {0}}) — \ ell_ { S}(\beta)},
Однако тест Хосмера-Лемешоу не требует дублирования данных, поэтому мы можем интерпретировать его высокие 9{2} = \ frac {\ ell (\ hat {\ beta_ {0}}) — \ ell (\ hat {\ beta})} {\ ell (\ hat {\ beta_ {0}}) — \ ell_ { S}(\beta)},
\end{equation*}\]
где $\ell(\hat{\beta_{0}})$ — логарифмическая вероятность модели, когда включен только отрезок и $ \ell_{S}(\beta)$ — логарифмическая вероятность насыщенной модели (т. е. когда модель идеально соответствует данным). Этот R 2 действительно идет от 0 до 1, где 1 идеально подходит. Для нереплицированных данных $\ell_{S}(\beta)=0$, поэтому формула упрощается до: 9{2}=1-\фракция{26,073}{34,372}=0,2414.
\end{equation*}\]
Необработанный остаток
Необработанный остаток представляет собой разницу между фактическим ответом и расчетной вероятностью из модели. Формула для исходного остатка:
\[\begin{equation*}
r_{i}=y_{i}-\hat{\pi}_{i}.
\end{equation*}\]
Остаток Пирсона
Остаток Пирсона корректирует неравную дисперсию необработанных остатков путем деления на стандартное отклонение. Формула остатков Пирсона равна 9.0003
Формула остатков Пирсона равна 9.0003
\[\begin{equation*}
p_{i}=\frac{r_{i}}{\sqrt{\hat{\pi}_{i}(1-\hat{\pi}_{i })}}.
\end{equation*}\]
Остатки отклонения
Остатки отклонения также популярны, потому что сумма квадратов этих остатков является статистикой отклонения. Формула для остатка отклонения:
\[\begin{equation*}
d_{i}=\pm\sqrt{2\biggl[y_{i}\log\biggl(\frac{y_{i}}{ \шляпа{\pi}_{i}}\biggr)+(1-y_{i})\log\biggl(\frac{1-y_{i}}{1-\шляпа{\pi}_{i }}\biggr)\biggr]}.
\end{equation*}\]
Вот графики остатков Пирсона и остатков отклонения для примера лейкемии. На этих графиках нет тревожных закономерностей, указывающих на серьезную проблему с моделью.
Шляпные значения
Шляпная матрица служит той же цели, что и в случае линейной регрессии — для измерения влияния каждого наблюдения на общее соответствие модели — но интерпретация не столь ясна из-за ее более сложная форма. Значения шляпы (рычаги) даны 9{\ textrm {T}} \ textbf {W} \ textbf {X}) \ textbf {x} _ {i},
\ end {equation *} \]
, где W — это $ n \ раз n $ диагональная матрица со значениями $\hat{\pi}_{i}(1-\hat{\pi}_{i})$ при $i=1 ,\ldots,n$ на диагонали.