
Официальный сайт | Арбитражный суд Самарской области
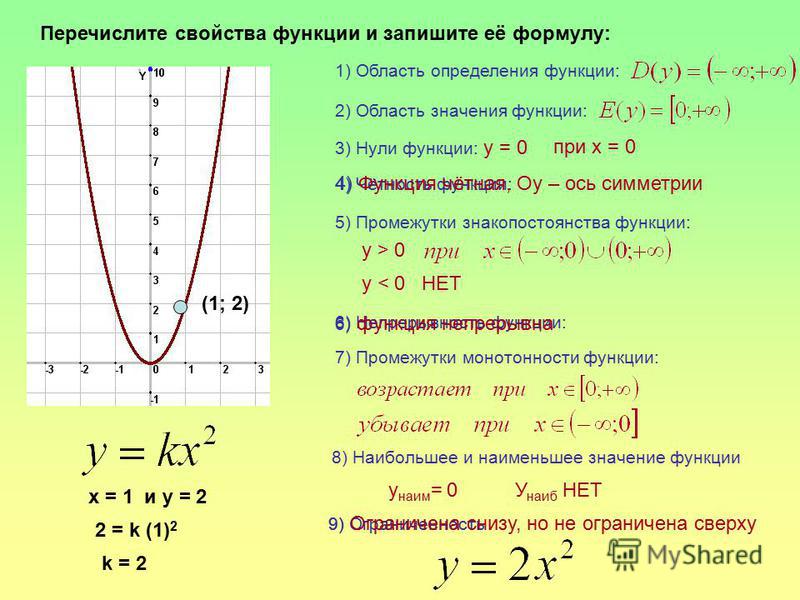
Наш суд
График проведения видеоконференций
- Январь 2023
Вс | ||||||
|---|---|---|---|---|---|---|
28 | 29 | 30 | 31 | 1 | ||
3 | 4 | 5 | 6 | 7 | 8 | |
13 | 14 | 15 | ||||
20 | 21 | 22 | ||||
27 | 28 | 29 | ||||
3 | 4 | 5 |
Сервис временно недоступен
Арбитражные суды
- Верховный Суд Российской Федерации
- Федеральные арбитражные суды
- Арбитражный суд Поволжского округа
- Одиннадцатый арбитражный апелляционный суд
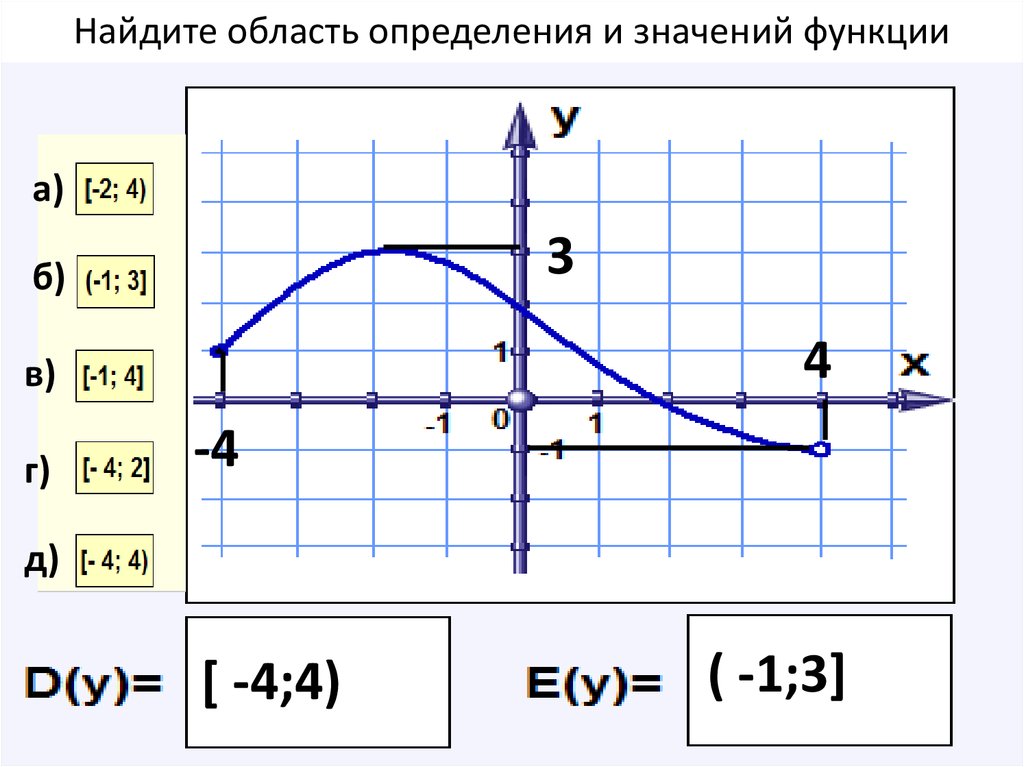
Правовые основы
Приказ Судебного департамента при Верховном Суде РФ
от 10 ноября 2015 года
Приказ Судебного департамента при Верховном Суде РФ от 10 ноября 2015 года № 355 «Об утверждении Положения о проверке достоверности и полноты сведений, представляемых гражданами, претендующими на замещение должностей в управлениях Судебного департамента в субъектах Российской Федерации, назначение на которые и освобождение от которых осуществляются Судебным департаментом при Верховном Суде Российской Федерации, и лицами, замещающими должности федеральной государственной гражданской службы в управлениях Судебного департамента в субъектах Российской Федерации, назначение на которые и освобождение от которых осуществляются Судебным департаментом при Верховном Суде Российской Федерации, и соблюдения лицами, замещающими должности федеральной государственной гражданской службы в управлениях Судебного департамента в субъектах Российской Федерации»
Письмо ЦБ РФ
от 30 июля 2012 года № 110-Т
Письмо № 110-Т Об исполнении запросов
Постановление Пленума ВАС РФ
от 11.
 07.2014 N 46
07.2014 N 46Постановление Пленума ВАС РФ от 11.07.2014 N 46
 07.2014 N 46
07.2014 N 46Приказ Судебного департамента при Верховном Суде РФ
от 31 декабря 2015 года № 412
Приказ Судебного департамента при Верховном Суде РФ от 31 декабря 2015 года № 412 «Об утверждении Положения о порядке сообщения федеральными государственными гражданскими служащими аппаратов федеральных судов общей юрисдикции и федеральных арбитражных судов, управлений Судебного департамента в субъектах Российской Федерации о получении подарка в связи с протокольными мероприятиями, служебными командировками и другими официальными мероприятиями, участие в которых связано с исполнением ими служебных (должностных) обязанностей, сдачи и оценки подарка, реализации (выкупа) и зачисления средств, вырученных от его реализации»
Приказ
от 27 июня 2012 года № 83
Приказ № 83 Об утверждении Положения о проверке достоверности и полноты сведений, представляемых гражданами
ФКЗ
от 05 февраля 2014 года № 3-ФКЗ
ФКЗ № 3-ФКЗ О Верховном Суде Российской Федерации
Архив новостей
Сейчас на сайте
- Посетителей 23
Х ВСЕРОССИЙСКИЙ СЪЕЗД СУДЕЙ
Как включить в модель знания предметной области / Хабр
Зачем это нужно?
Представьте, что вам дали размеченный набор данных, и ваша задача — предсказать новый. Что вы будете делать? Вероятно, сперва вы попробуете обучить модель машинного обучения поиску правил для разметки новых данных. А что дальше? Подробности — к старту нашего флагманского курса по науке о данных.
Что вы будете делать? Вероятно, сперва вы попробуете обучить модель машинного обучения поиску правил для разметки новых данных. А что дальше? Подробности — к старту нашего флагманского курса по науке о данных.
Модель машинного обучения удобна, но при ML сложно понять, почему модель делает именно такое предсказание. Вы также не можете использовать в такой модели знания предметной области.
Есть ли другой способ установить правила разметки данных на основе ваших знаний, кроме того, чтобы полагаться на предсказания модели машинного обучения?
Вот здесь и пригодится human-learn.
Что такое human-learn?
human-learn — это пакет Python для создания систем на основе простых в построении и совместимых со scikit-learn правил.
Чтобы установить human-learn, выполните команду:
pip install human-learn
Мы узнаем, как создать модель с помощью простой функции. Пробовать и форкать исходный код для этой статьи можно по этой ссылке:
- Интерактивный блокнот Jupyter.
Чтобы оценить эффективность модели на основе правил, начнём с предсказания набора данных с помощью модели машинного обучения.
Модель машинного обучения
В качестве примера воспользуемся набором данных Occupation Detection Dataset из репозитория UCI Machine Learning Repository.
Наша задача — спрогнозировать, занято ли помещение, помещения по температуре, влажности, освещённости и концентрации углекислого газа. Помещение свободно, если Occupancy=0, и занято, если Occupancy=1 .
После загрузки распакуйте архив и считайте данные:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Get train and test data
train = pd.read_csv("occupancy_data/datatraining.txt").drop(columns="date")
test = pd.read_csv("occupancy_data/datatest.txt").drop(columns="date")
# Get X and y
target = "Occupancy"
train_X, train_y = train.drop(columns=target), train[target]
val_X, val_y = test.
drop(columns=target), test[target]
Посмотрите на первые десять записей набора данных train:
train.head(10)
Обучите модель RandomForestClassifier [классификатор случайного леса] из scikit-learn на обучающем наборе данных и используйте эту модель для предсказания тестового набора данных:
# Train forest_model = RandomForestClassifier(random_state=1) # Preduct forest_model.fit(train_X, train_y) machine_preds = forest_model.predict(val_X) # Evalute print(classification_report(val_y, machine_preds))
Качество предсказания довольно хорошее. Однако неизвестно, как модель делает эти прогнозы. Давайте посмотрим, можно ли сделать разметку новых данных согласно простым правилам.
Модель на основе правил
Вот четыре шага создания правил разметки данных. Нужно:
- Выдвинуть гипотезу.
- Изучить данные для подтверждения гипотезы.
- Начать с простых правил, которые основаны на наблюдениях.
- Усовершенствовать правила.

Выдвигаем гипотезу
Свет в комнате — важный показатель того, занято ли помещение. Таким образом, можно предположить, что, чем светлее в помещении, тем больше вероятность того, что оно занято.
Давайте посмотрим на данные и проверим, так ли это.
Изучаем данные
Для проверки предположения воспользуемся диаграммой размаха (box plot), чтобы найти разницу между освещённостью в занятом (Occupancy=1) и пустом (Occupancy=0) помещениях.
import plotly.express as px import plotly.graph_objects as go feature = "Light" px.box(data_frame=train, x=target, y=feature)
Видно значительную разницу медианы между занятым и пустым помещениями.
Начинаем с простых правил
Теперь создадим правила определения занятости помещения по его освещенности. Например, если количество света превышает определённое значение, то Occupancy=1, в противном случае Occupancy=0.
Но какое пороговое значение выбрать? Начнём со значения 100 и посмотрим, что получится:
Чтобы создать с помощью human-learn модель на основе правил, мы:
- напишем в Python простую функцию, которая задаёт правила;
- воспользуемся
FunctionClassifier, чтобы превратить эту функцию в модель scikit-learn.

import numpy as np
from hulearn.classification import FunctionClassifier
def create_rule(data: pd.DataFrame, col: str, threshold: float=100):
return np.array(data[col] > threshold).astype(int)
mod = FunctionClassifier(create_rule, col='Light')Сделаем предсказание тестового набора данных и оценим прогноз:
mod.fit(train_X, train_y) preds = mod.predict(val_X) print(classification_report(val_y, preds))
Точность модели [на основе правил] выше точности RandomForestClassifier!
Улучшаем правила
Теперь посмотрим, сможем ли мы добиться точности выше, поэкспериментировав с пороговыми значениями. Для анализа взаимосвязи между конкретным значением освещённости и занятостью помещения используем параллельные координаты.
from hulearn.experimental.interactive import parallel_coordinates parallel_coordinates(train, label=target, height=200)
Визуализация в параллельных координатах показывает, что вероятность занятости помещения с освещённостью более 250 люксов высока.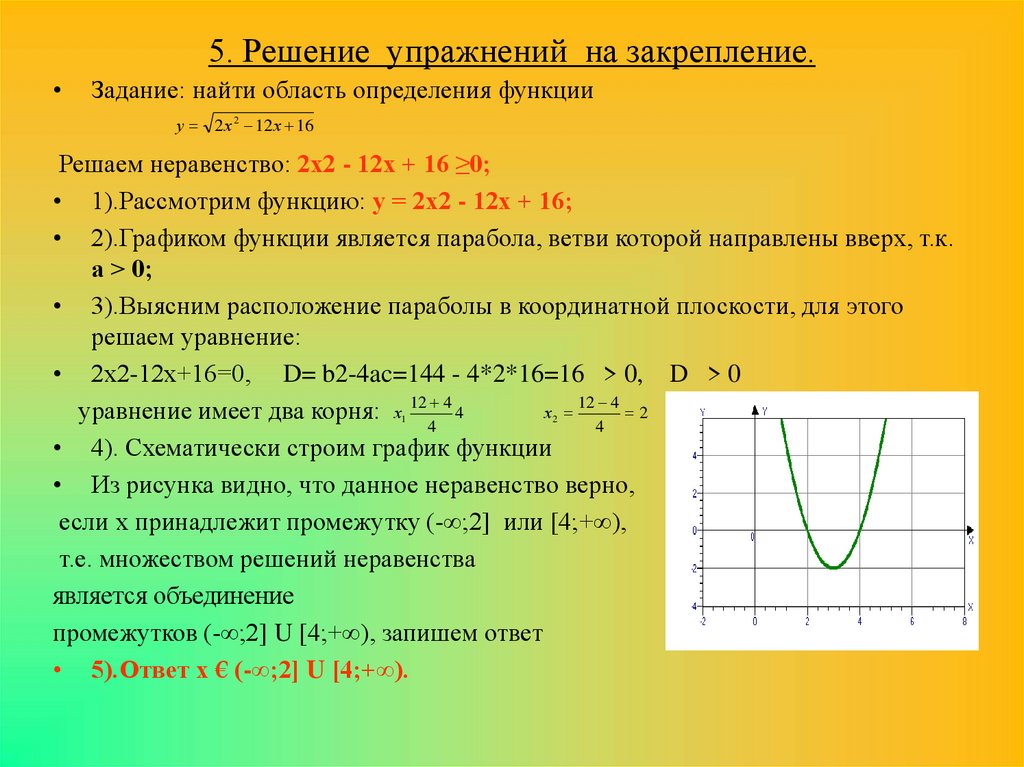 Оптимальное пороговое значение, отделяющее занятую комнату от пустой, по-видимому, находится где-то между 250 и 750 люксами.
Оптимальное пороговое значение, отделяющее занятую комнату от пустой, по-видимому, находится где-то между 250 и 750 люксами.
Найдём наилучшее пороговое значение в этом диапазоне при помощи
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(mod, cv=2, param_grid={"threshold": np.linspace(250, 750, 1000)})
grid.fit(train_X, train_y)Получаем наилучшее пороговое значение:
best_threshold = grid.best_params_["threshold"] best_threshold > 364.61461461461465
Теперь отразим это значение на диаграмме размаха:
Используем модель с наилучшим пороговым значением для прогнозирования тестового набора данных:
human_preds = grid.predict(val_X) print(classification_report(val_y, human_preds))
Пороговое значение 365 даёт точность выше, чем пороговое значение 100.
Объединение модели машинного обучения и модели на основе правил
Для создания модели на основе правил обратиться к знаниям предметной области неплохо, однако у подхода есть недостатки:
- сложно обобщать модель на недоступные данные;
- трудно придумать правила для сложных данных;
- нет обратной связи для улучшения модели.
Поэтому комбинация модели на основе правил и модели машинного обучения поможет дата-сайентистам масштабировать и улучшать модель, сохраняя при этом возможность использовать экспертные знания предметной области.
Один из простых способов объединить эти две модели — решить, нужно ли нам уменьшить ложно отрицательные прогнозы (False Negative — FN), или ложно положительные прогнозы (False Positive — FP).
Уменьшение числа ложно отрицательных прогнозов
Вероятно, вам стоит уменьшить FN в таком случае, как прогнозирование наличия у пациента рака (лучше ошибиться, сообщив пациентам, что у них рак, чем не обнаружить его, [чем наоборот: сообщить, что рака нет, когда он есть]).
Чтобы уменьшить FN, выберите положительные прогнозы, где две модели дают разные ответы:
Уменьшение числа ложно положительных прогнозов
Вероятно, вам стоит уменьшить количество FP в таких случаях, как рекомендация детям видео со сценами жестокости (лучше ошибиться, не рекомендуя детям видео для детей, чем рекомендовать детям видео для взрослых).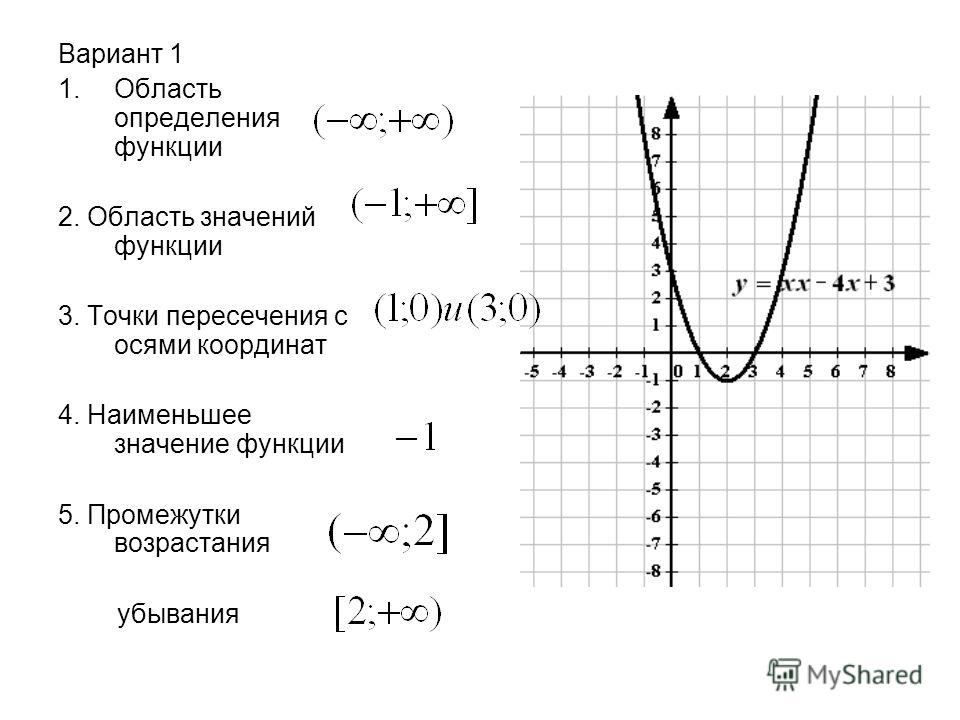
Чтобы уменьшить количество FP, выберите отрицательные прогнозы, где две модели дают разные ответы.
Для принятия решения о выборе прогноза можно использовать и другие, более сложные стратегии
Чтобы узнать подробности о том, как объединять модель машинного обучения с моделями на основе правил, рекомендую посмотреть отличное видео Джереми Джордана:
Заключение
Поздравляю! Вы только что узнали, что такое модель на основе правил и как объединить её с моделью машинного обучения. Надеюсь, что эта статья даст вам знания, необходимые для разработки вашей собственной модели на основе правил.
Добавляйте в избранное этот репозиторий, если хотите попробовать код к моим статьям.
Источник данных:
Точное определение занятости офисного помещения по данным освещённости, температуры, влажности и концентрации углекислого газа с помощью статистических моделей обучения. Luis M. Candanedo, Véronique Feldheim. Energy and Buildings.
 Том 112, 15 января 2016 г., стр. 28-39.
Том 112, 15 января 2016 г., стр. 28-39.А мы научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом.
- Профессия Data Scientist (24 месяца)
- Профессия Fullstack-разработчик на Python (16 месяцев)
Краткий каталог курсов
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия «Белый хакер»
А также
- Курс по DevOps
- Все курсы
Диапазон набора данных
Диапазон набора данных — это разница между максимальным и минимальным значениями. Он измеряет изменчивость, используя те же единицы, что и данные. Большие значения представляют большую изменчивость.
Он измеряет изменчивость, используя те же единицы, что и данные. Большие значения представляют большую изменчивость.
Диапазон — это самый простой показатель дисперсии для расчета и интерпретации в статистике, но он имеет некоторые ограничения. В этом посте я покажу вам, как найти диапазон математически и графически, интерпретировать его, объяснить его ограничения и пояснить, когда его использовать.
Формула
Чтобы найти диапазон в статистике, возьмите наибольшее значение и вычтите из него наименьшее значение.
Диапазон = наибольшее значение – наименьшее значение
Это не может быть отрицательное значение, поскольку формула берет большее значение и вычитает меньшее значение.
Связанный пост : Показатели изменчивости
Пример определения диапазона
Например, на листе ниже набор данных 1 имеет диапазон 38 – 20 = 18, а набор данных 2 – 52 – 11 = 41 Набор данных 2 имеет более широкий диапазон и, следовательно, более изменчив, чем набор данных 1.
Для удобства вы можете найти минимальные, максимальные значения и значения диапазона в описательной статистике, выводимой статистическим программным обеспечением. Функция описательной статистики Excel включает их, как показано ниже.
Связанный пост : Описательная статистика в Excel
Поиск диапазона на диаграммах
Вы можете найти диапазоны данных в нескольких типах диаграмм, включая гистограммы, ящичные диаграммы и диаграммы рассеяния. На примерах графиков ниже красные линии представляют диапазоны. Следующие графические изображения воплощают концепцию в жизнь. Если вы смотрите на диаграмму и у вас нет данных, вам придется приблизить значения визуально.
Гистограммы
В гистограмме диапазоном является ширина, которую покрывают полосы вдоль оси x. Это приблизительные значения, поскольку гистограммы отображают значения интервалов, а не необработанные значения данных.
На этих гистограммах распределение А имеет приблизительный диапазон 65 – 40 = 25, а распределение С – 90 – 20 = 70. Распределение С имеет более широкий разброс, и его обширная ширина на графике иллюстрирует это свойство.
Распределение С имеет более широкий разброс, и его обширная ширина на графике иллюстрирует это свойство.
Блок-диаграммы
Блок-диаграммы отображают диапазоны данных для групп в наборе данных. На ящичных диаграммах он равен всей длине усов для каждой группы. Минимальные и максимальные значения отображаются на концах усов, за исключением случаев, когда есть выбросы. Следовательно, диапазоны на диаграммах исключают выбросы.
На этом блочном графике оценки для метода 3 разошлись примерно от 37 до 12, что дает диапазон 25. Эта группа имеет самый большой разброс в наборе данных. И наоборот, метод 2 имеет наименьший разброс 30 – 20 = 10. Метод 2 имеет выброс (звездочку), но диаграмма удобно исключает его.
Диаграммы рассеяния
На диаграммах рассеяния вы можете одновременно найти диапазон двух переменных. Для переменной оси Y это высота данных, а для переменной оси X — ширина.
На этой диаграмме рассеяния показаны рост и вес девочек десятилетнего возраста в ходе исследования. Для этих данных вес имеет диапазон примерно 90 – 31 = 59 кг, а рост – 1,67 – 1,33 = 0,34 метра.
Для этих данных вес имеет диапазон примерно 90 – 31 = 59 кг, а рост – 1,67 – 1,33 = 0,34 метра.
Примечание. Когда вы оцениваете математические функции, а не значения данных, диапазон f(x) отображается на оси Y (выходные данные), а домен — на оси X (входные данные).
Похожие сообщения : Гистограммы, диаграммы и диаграммы рассеяния
Ограничения использования диапазона
Диапазон прост для понимания, но у него есть некоторые ограничения, которые необходимо учитывать.
К сожалению, выбросы могут существенно повлиять на него, поскольку он использует только два крайних значения. Если одно значение в наборе данных нетипично низкое или высокое, оно само изменяет весь диапазон.
Вернемся к первым двум наборам данных в этом посте. Однако я изменил нижнее число в наборе данных 1 с 18 на 102. Новый разброс равен 82. Единственное изменение привело к увеличению его с 18 до 82. Согласно новому значению, набор данных 1, по-видимому, имеет большую изменчивость, чем набор данных. 2 (г = 41). Однако все значения, кроме одного выброса в наборе данных 1, находятся в диапазоне от 20 до 34.
2 (г = 41). Однако все значения, кроме одного выброса в наборе данных 1, находятся в диапазоне от 20 до 34.
Диапазон не является надежной статистикой. Стандартное отклонение и особенно межквартильный размах более устойчивы к выбросам.
Связанный пост : Что такое надежная статистика?
Кроме того, на эту статистику влияет сам размер выборки. По мере увеличения размера выборки диапазон имеет тенденцию к увеличению. Следовательно, вы не можете сравнивать значения между образцами разных размеров.
Почему это происходит? В целом экстремальные значения имеют меньшую вероятность возникновения. Однако по мере увеличения размера выборки экстремальные значения имеют больше возможностей для появления. Следовательно, диапазон имеет тенденцию расширяться по мере увеличения размера выборки.
Если вам нужно сравнить изменчивость наборов данных разного размера, используйте другой показатель, например стандартное отклонение.
Когда использовать диапазон?
Принимая во внимание слабые стороны, когда диапазон является хорошей мерой изменчивости?
Это может быть отличным показателем, когда вам нужна интуитивно понятная статистика, показывающая степень разбросанности данных. Каждый может понять концепцию разницы между максимальными и минимальными точками данных. Также легко посчитать в уме, используя сводную статистику, когда нужна быстрая оценка.
Каждый может понять концепцию разницы между максимальными и минимальными точками данных. Также легко посчитать в уме, используя сводную статистику, когда нужна быстрая оценка.
Используйте диапазон с небольшими наборами данных, чтобы избежать выбросов и при сравнении выборок одинакового размера.
Это также отличная статистика для обнаружения ошибок ввода данных. Из-за того, что он так чувствителен к выбросам, может проявиться единственная ошибка. Вы берете слабость и используете ее для чего-то положительного! Например, если вы обнаружите, что диапазон роста людей в выборке составляет 2 метра, это ошибка!
Использование для контроля качества
Аналитики по контролю качества часто используют именно этот показатель изменчивости. Во-первых, если диапазон для партии продуктов больше, чем разброс между верхним и нижним пределами спецификации, они знают, что по крайней мере одна часть не соответствует спецификации!
Например, если диапазон длин деталей составляет 5 мм, а разброс пределов спецификации составляет 3 мм, должны быть детали, не соответствующие спецификации.
Аналитики по контролю качества также используют R-диаграммы, представляющие собой диаграммы диапазонов — разновидность контрольных диаграмм. Эти графики отслеживают изменение процесса, отслеживая диапазон во времени. Они используют R-диаграммы с небольшими (n = 2–10) партиями продукта постоянного размера из стабильного процесса, что позволяет избежать ошибок, о которых я упоминал ранее. Эти графики быстро обнаруживают нестабильную изменчивость в процессе.
На R-диаграмме точки данных представляют диапазоны для выборок, взятых с течением времени. Когда значение выборки выходит за контрольные пределы (красные линии), процесс выходит из-под статистического контроля. Этот процесс находится под контролем.
Связанный пост : Использование контрольных диаграмм с проверками гипотез
Как найти диапазон в Excel (простые формулы)
Обычно, когда я использую слово диапазон в своих учебниках по Excel, это ссылка на ячейку или коллекцию ячеек рабочего листа.
Но это руководство не об этом диапазоне.
«Диапазон» — это также математический термин, обозначающий диапазон в наборе данных (т. е. диапазон между минимальным и максимальным значением в данном наборе данных)
В этом уроке я покажу вам действительно простые способы до рассчитать диапазон в Exce л.
Что такое диапазон?
В заданном наборе данных диапазоном этого набора данных будет разброс значений в этом наборе данных.
Чтобы дать вам простой пример, если у вас есть набор данных оценок учащихся, где минимальный балл равен 15, а максимальный балл равен 9.8, то разброс этого набора данных (также называемый диапазоном этого набора данных) будет равен 73
Диапазон = 98 – 15
«Диапазон» — это не что иное, как разница между максимальным и минимальным значением этого набора данных. .
Как рассчитать диапазон в Excel?
Если у вас есть список отсортированных значений, вам просто нужно вычесть первое значение из последнего значения (при условии, что сортировка выполняется в порядке возрастания).
Но в большинстве случаев у вас будет случайный набор данных, который еще не отсортирован.
Найти диапазон в таком наборе данных также довольно просто.
В Excel есть функции для определения максимального и минимального значения диапазона (функция MAX и MIN).
Предположим, у вас есть набор данных, как показано ниже, и вы хотите рассчитать диапазон данных в столбце B.
Ниже приведена формула для расчета диапазона для этого набора данных:
=MAX(B2: B11)-MIN(B2:B11)
Приведенная выше формула находит максимальное и минимальное значение и дает нам разницу.
Довольно просто… не так ли?
Вычислить условный диапазон в Excel
В большинстве практических случаев найти диапазон будет не так просто, как просто вычесть минимальное значение из максимального значения
В реальных сценариях вам также может потребоваться учитывать некоторые условия или выбросы.
Например, у вас может быть набор данных, в котором все значения ниже 100, но есть одно значение выше 500. данные.
данные.
К счастью, в Excel есть много условных формул, которые могут помочь вам разобраться с некоторыми аномалиями.
Ниже у меня есть набор данных, в котором мне нужно найти диапазон значений продаж в столбце B.
Если вы внимательно посмотрите на эти данные, то заметите, что есть два магазина, где значения довольно низкие ( Магазин 1 и Магазин 3).
Это может быть связано с тем, что это новые магазины, или с некоторыми внешними факторами, которые повлияли на продажи в этих конкретных магазинах.
При расчете диапазона для этого набора данных может иметь смысл исключить эти новые магазины и учитывать только те магазины, в которых есть значительные продажи.
Допустим, в этом примере я хочу игнорировать все те магазины, в которых объем продаж меньше 20 000.
Ниже приведена формула, позволяющая найти диапазон с условием:
=МАКС(В2:В11)-МИНИФС(В2:В11,В2:В11,">20000")
Вместо этого в приведенной выше формуле использования функции MIN, я использовал функцию MINIFS (это новая функция в Excel 2019и Microsoft 365).
Эта функция находит минимальное значение, если выполняются упомянутые в ней критерии. В приведенной выше формуле я указал в качестве критерия любое значение, превышающее 20 000.
Итак, функция MINIFS проходит через весь набор данных, но при вычислении минимального значения учитывает только те значения, которые больше 20 000.
Это гарантирует, что значения ниже 20 000 игнорируются, а минимальное значение всегда превышает 20 000 (следовательно, выбросы игнорируются).
Обратите внимание, что MINIFS — это новая функция в Excel. доступна только в подписке Excel 2019 и Microsoft 365. Если вы используете предыдущие версии, у вас не будет этой функции (и вы можете использовать формулу, описанную позже в этом руководстве)
Если у вас нет функции MINIF в вашем Excel, используйте приведенную ниже формулу, которая использует комбинацию функций IF и MIN, чтобы сделать то же самое:
=MAX(B2:B11)-MIN(IF(B2:B11>20000,B2:B11))
Так же, как я использовал условную функцию MINIFS, вы можете также используйте функцию MAXIFS, если вы хотите избежать точек данных, которые являются выбросами в другом направлении (т.