
Нелинейная регрессия. Парабола второго порядка
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||

 В частности, любую форму связи можно выразить уравнением общего вида у= f(х), где у рассматривают в качестве зависимой переменной, или функции от другой — независимой переменной величины х, называемой аргументом. Соответствие между аргументом и функцией может быть задано таблицей, формулой, графиком и т. д. Изменение функции в зависимости от изменений одного или нескольких аргументов называется
В частности, любую форму связи можно выразить уравнением общего вида у= f(х), где у рассматривают в качестве зависимой переменной, или функции от другой — независимой переменной величины х, называемой аргументом. Соответствие между аргументом и функцией может быть задано таблицей, формулой, графиком и т. д. Изменение функции в зависимости от изменений одного или нескольких аргументов называется  Задача исследователя сводится к тому, чтобы в каждом конкретном случае выявить форму связи и выразить ее соответствующим корреляционным уравнением, что позволяет предвидеть возможные изменения одного признака Y на основании известных изменений другого X, связанного с первым корреляционно.
Задача исследователя сводится к тому, чтобы в каждом конкретном случае выявить форму связи и выразить ее соответствующим корреляционным уравнением, что позволяет предвидеть возможные изменения одного признака Y на основании известных изменений другого X, связанного с первым корреляционно.

 Угол между ними.
Угол между ними. Матрица смежности онлайн
Матрица смежности онлайнНелинейные модели парной регрессии.
 Гиперболическое, степенное, параболическое, показательное уравнения регрессии. Эконометрика
Гиперболическое, степенное, параболическое, показательное уравнения регрессии. Эконометрика
- Параболическая регрессия
- Гиперболическая регрессия
- Показательная (экспоненциальная) регрессия)
- Степенная регрессия
Параболическая регрессия
Уравнение регрессии в форме параболы второго порядка имеет следующий вид:
Если при линейной связи
среднее изменение результативного признака на единицу фактора постоянно по всей
области вариации фактора, то при параболической корреляции изменение признака
меняется
равномерно с изменением величины фактора. В результате связь может даже
поменять знак на противоположный, из прямой превратится в обратную, из обратной в прямую. Такой характер связи присущ многим системам. Например, с увеличением дозы
удобрений урожайность сельхозкультур сначала
повышается, но если превысить оптимальную величину дозы, то при дальнейшем
росте дозы удобрения растения угнетаются и урожайность снижается.
Нормальные уравнения метода наименьших квадратов (МНК) для параболы 2-го порядка таковы:
Ввиду симметричности кривой парабола второй степени далеко не всегда пригодна в конкретных исследованиях. Чаще исследователь имеет дело лишь с отдельными сегментами параболы, а не с полной параболической формой.
Кроме того, параметры
параболической связи не всегда могут быть логически истолкованы. Поэтому если
график зависимости не демонстрирует четко выраженной параболы второго порядка
(нет смены направленности связи признаков), то она может быть заменена другой
нелинейной функцией, например степенной. В частности, в литературе часто
рассматривается парабола второй степени для характеристики зависимости
урожайности от количества внесенных удобрений. Данная форма связи мотивируется
тем, что с увеличением количества внесенных удобрений урожайность растет лишь
до достижения оптимальной дозы вносимых удобрений. Дальнейший же рост их дозы
оказывается вредным для растения, и урожайность снижается. Несмотря на несомненную
справедливость данного утверждения, следует отметить, что внесение в почву
минеральных удобрений производится на основе учета достижений агробиологической
науки. Поэтому на практике часто данная зависимость представлена лишь сегментом
параболы, что и позволяет использовать другие нелинейные функции.
Дальнейший же рост их дозы
оказывается вредным для растения, и урожайность снижается. Несмотря на несомненную
справедливость данного утверждения, следует отметить, что внесение в почву
минеральных удобрений производится на основе учета достижений агробиологической
науки. Поэтому на практике часто данная зависимость представлена лишь сегментом
параболы, что и позволяет использовать другие нелинейные функции.
Задача 1
Постройте криволинейную регрессионную модель (параболу) для следующих исходных данных.
| 1 | 2 | 3 | 4 | |
| 30 | 7 | 8 | 1 |
Решение
Если не находите примера, аналогичного вашему, если сами не успеваете выполнить работу, если впереди экзамен по предмету и нужна помощь — свяжитесь со мной:
ВКонтакте
WhatsApp
Telegram
Я буду работать с вами, над вашей проблемой, пока она не решится.
Уравнение параболической регрессии имеет вид:
Составим расчетную таблицу:
Расчетная вспомогательная таблица
| № | ||||||||||
| 1 | 1 | 30 | 1 | 1 | 1 | 30 | 30 | 28.4 | 285.61 |
342. 25 25
|
| 2 | 2 | 7 | 4 | 8 | 16 | 14 | 28 | 11.8 | 0.09 | 20.25 |
| 3 | 3 | 8 | 9 | 27 | 81 | 24 | 72 | 3.2 | 68.89 | 12.25 |
| 4 | 4 | 1 | 16 | 64 | 256 | 4 | 16 |
2. 6 6
|
79.21 | 110.25 |
| Сумма | 10 | 46 | 30 | 100 | 354 | 72 | 146 | 433.8 | 485 |
Для нахождения коэффициентов параболы необходимо решить систему уравнений:
Подставляя в систему уравнений, получаем:
Решая систему уравнений, получаем:
Уравнение параболической регрессии имеет вид:
Коэффициент детерминации:
Коэффициент эластичности:
Гиперболическая регрессия
Уравнение регрессии в форме гиперболы имеет следующий вид:
Гиперболические
зависимости характерны для связей, в которых результативный признак не может
варьировать неограниченно, его вариация имеет односторонний предел. Например,
совершенствуя двигатель, можно увеличивать его КПД, но не выше предела, допускаемого
данным видом преобразования энергии. Или таков характер связи между уровнем
душевого дохода в семье и долей семей, имеющих телевизоры – он приближен к
пределу (100%) в наиболее обеспеченной группе семей.
Например,
совершенствуя двигатель, можно увеличивать его КПД, но не выше предела, допускаемого
данным видом преобразования энергии. Или таков характер связи между уровнем
душевого дохода в семье и долей семей, имеющих телевизоры – он приближен к
пределу (100%) в наиболее обеспеченной группе семей.
Если величина положительна, то при увеличении значений факторного признака значения результативного признака уменьшаются, причем это уменьшение все время замедляется, и при средняя величина признака будет равна . Классическим примером является кривая Филлипса, характеризующая нелинейное соотношение между нормой безработицы и процентом прироста заработной платы.
Если же параметр
отрицателен,
то значения результативного признака с ростом фактора возрастают, причем их
рост замедляется, и в пределе при
. Примером может служить взаимосвязь доли
расходов на товары длительного пользования и общих сумм расходов.
Математическое описание подобного рода взаимосвязей получило название кривых Энегеля.
Примером может служить взаимосвязь доли
расходов на товары длительного пользования и общих сумм расходов.
Математическое описание подобного рода взаимосвязей получило название кривых Энегеля.
Нормальные уравнения метода наименьших квадратов (МНК) для гиперболы таковы:
Легко увидеть, что эти уравнения, по существу, те же, что для линейной связи. Линеаризация гиперболического уравнения достигается заменой на новую переменную, которую можно обозначить . Тогда уравнение гиперболической регрессии примет вид .
Задача 2
Постройте криволинейную регрессионную модель (гиперболу) для следующих исходных данных.
| 0,96 | 0,75 | 0,64 | 0,55 | 0,68 | 0,71 | 0,95 | 0,45 | 0,71 | 0,63 | |
| 1,95 | 2,6 | 4,28 | 6,52 | 4,55 | 2,91 | 1,81 | 8,21 | 2,84 | 4,38 |
Решение
Если не находите примера, аналогичного вашему, если сами не успеваете выполнить работу, если впереди экзамен по предмету и нужна помощь — свяжитесь со мной:
ВКонтакте
WhatsApp
Telegram
Я буду работать с вами, над вашей проблемой, пока она не решится.
Уравнение гиперблической регрессии имеет вид:
Составим расчетную таблицу:
Расчетная вспомогательная таблица
| № | ||||||||
| 1 | 0,96 | 1,95 | 1,042 | 1,085 | 2,031 | 1,436 | 6,598 | 4,223 |
| 2 | 0,75 | 2,6 | 1,333 | 1,778 | 3,467 | 3,105 | 0,809 | 1,974 |
| 3 | 0,64 | 4,28 | 1,563 | 2,441 | 6,688 | 4,417 | 0,169 | 0,076 |
| 4 | 0,55 | 6,52 | 1,818 | 3,306 | 11,855 | 5,880 | 3,514 | 6,325 |
| 5 | 0,68 | 4,55 | 1,471 | 2,163 | 6,691 | 3,891 | 0,013 | 0,297 |
| 6 | 0,71 | 2,91 | 1,408 | 1,984 | 4,099 | 3,535 | 0,221 | 1,199 |
| 7 | 0,95 | 1,81 | 1,053 | 1,108 | 1,905 | 1,499 | 6,279 | 4,818 |
| 8 | 0,45 | 8,21 | 2,222 | 4,938 | 18,244 | 8,192 | 17,527 | 17,682 |
| 9 | 0,71 | 2,84 | 1,408 | 1,984 | 4,000 | 3,535 | 0,221 | 1,357 |
| 10 | 0,63 | 4,38 | 1,587 | 2,520 | 6,952 | 4,559 | 0,306 | 0,141 |
| Итого | 7,03 | 40,05 | 14,905 | 23,306 | 65,932 | 40,048 | 35,658 | 38,092 |
Для нахождения коэффициентов гиперболической регрессии необходимо решить систему уравнений:
Подставляя в систему уравнений, получаем:
Решая систему уравнений, получаем:
Искомое уравнение гиперболической регрессии:
Коэффициент детерминации:
Коэффициент эластичности:
Показательная (экспоненциальная) регрессия
Уравнение регрессии в показательной форме имеет следующий вид:
Данное
уравнение является нелинейным по коэффициенту
и относится к классу моделей регрессии,
которые можно с помощью преобразований привести к линейному виду.
Показательная функция является внутренне линейной, поэтому оценки неизвестных параметров её линеаризованной формы можно рассчитать с помощью классического метода наименьших квадратов
Нормальные уравнения метода наименьших квадратов (МНК) для показательной регрессии:
Отсюда:
Задача 3
Постройте криволинейную регрессионную модель (показательная функция) для следующих исходных данных.
| 1,95 | 2,58 | 3,26 | 4,51 | 5,14 | 5,92 | 6,81 | 7,45 | 8,02 | 8,75 | |
| 6,1 | 8,51 | 10,82 | 17,92 | 24,21 | 33,1 | 45,51 | 61,21 | 72,38 | 95,24 |
Решение
Если не находите примера, аналогичного вашему, если сами не успеваете выполнить работу, если впереди экзамен по предмету и нужна помощь — свяжитесь со мной:
ВКонтакте
WhatsApp
Telegram
Я буду работать с вами, над вашей проблемой, пока она не решится.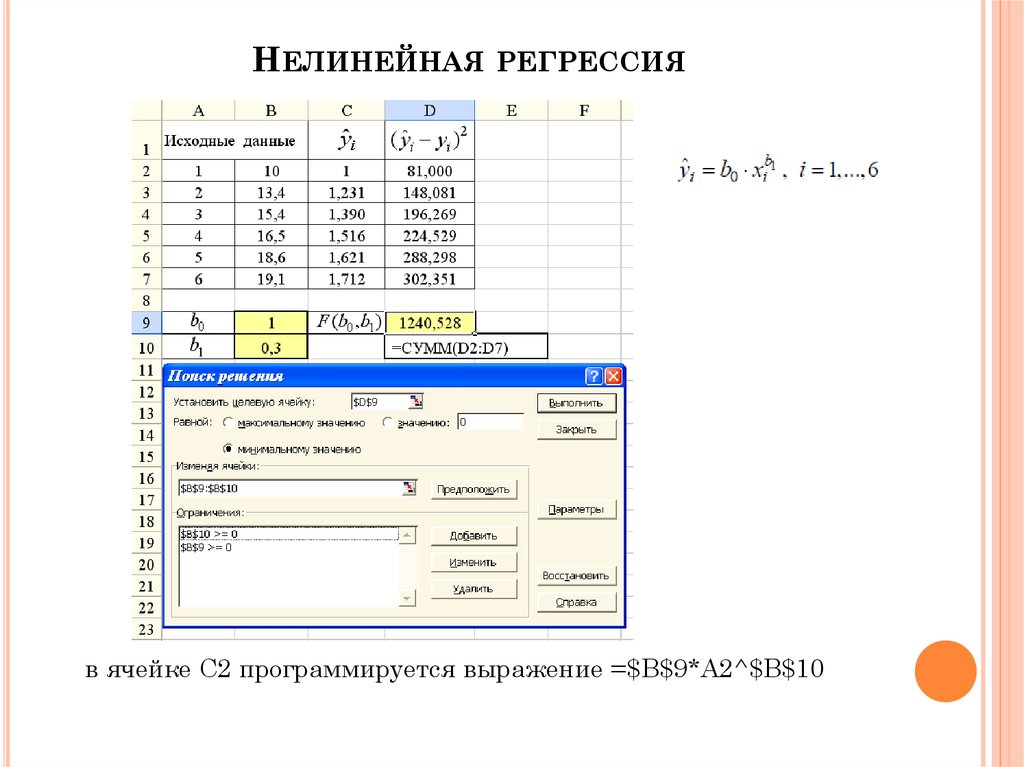
Уравнение показательной регрессии имеет вид:
Составим расчетную таблицу:
Расчетная вспомогательная таблица
| № | ||||||||
| 1 | 1,95 | 6,1 | 3,803 | 1,808 | 3,526 | 6,433 | 0,104 | 985,960 |
| 2 | 2,58 | 8,51 | 6,656 | 2,141 | 5,524 | 8,292 | 0,048 | 840,420 |
| 3 | 3,26 | 10,82 | 10,628 | 2,381 | 7,763 | 10,904 | 0,007 | 711,822 |
| 4 | 4,51 | 17,92 | 20,340 | 2,886 | 13,015 | 18,041 | 0,015 | 383,376 |
| 5 | 5,14 | 24,21 | 26,420 | 3,187 | 16,380 | 23,252 | 0,918 | 176,624 |
| 6 | 5,92 | 33,1 | 35,046 | 3,500 | 20,717 | 31,835 | 1,600 | 19,360 |
| 7 | 6,81 | 45,51 | 46,376 | 3,818 | 26,000 | 45,561 | 0,003 | 64,160 |
| 8 | 7,45 | 61,21 | 55,503 | 4,114 | 30,652 | 58,959 | 5,066 | 562,164 |
| 9 | 8,02 | 72,38 | 64,320 | 4,282 | 34,341 | 74,176 | 3,226 | 1216,614 |
| 10 | 8,75 | 95,24 | 76,563 | 4,556 | 39,869 | 99,532 | 18,423 | 3333,908 |
| Итого | 54,39 | 375 | 345,654 | 32,674 | 197,788 | 29,408 | 8294,409 |
Для нахождения коэффициентов показательной регрессии необходимо решить систему уравнений:
Подставляя в систему уравнений, получаем:
Решая систему уравнений, получаем:
Искомое уравнение показательной регрессии:
Коэффициент детерминации:
Коэффициент эластичности:
Степенная регрессия
В моделях, нелинейных по
оцениваемым параметрам, но приводимых к линейному виду, метод наименьших
квадратов и его требования применяются не к исходным данным результативного
признака, а к их преобразованным величинам.
Так, в степенной функции:
метод наименьших квадратов применяется к преобразованному уравнению:
Система линейных уравнений будет иметь вид:
Отсюда:
Степенная регрессия широко используется в исследованиях при изучении эластичности спроса от цен.
Задача 4
По данным постройте степенную регрессию:
| 2,21 | 17,45 | 8,6 | 61,05 | 5,76 | 33,38 | 16,22 | 3,88 | 0,75 | 149,3 | |
| 9,63 | 25,92 | 31,6 | 17,71 | 14,87 | 44,03 | 13,7 | 9,13 | 3,86 | 170,45 |
Решение
Если не находите примера, аналогичного вашему, если сами не успеваете выполнить работу, если впереди экзамен по предмету и нужна помощь — свяжитесь со мной:
ВКонтакте
WhatsApp
Telegram
Я буду работать с вами, над вашей проблемой, пока она не решится.
Уравнение степенной регрессии имеет вид:
Составим расчетную таблицу:
Расчетная вспомогательная таблица
| № | |||||||||
| 1 | 2,21 | 9,63 | 0,793 | 0,629 | 2,265 | 1,796 | 8,690 | 105,030 | 86,655 |
| 2 | 17,45 | 25,92 | 2,859 | 8,176 | 3,255 | 9,307 | 20,871 | 3,733 | 48,736 |
| 3 | 8,6 | 31,6 | 2,152 | 4,630 | 3,453 | 7,430 | 15,461 | 12,093 | 160,304 |
| 4 | 61,05 | 17,71 | 4,112 | 16,906 | 2,874 | 11,818 | 35,494 | 274,065 | 1,510 |
| 5 | 5,76 | 14,87 | 1,751 | 3,066 | 2,699 | 4,726 | 13,045 | 34,739 | 16,556 |
| 6 | 33,38 | 44,03 | 3,508 | 12,306 | 3,785 | 13,277 | 27,478 | 72,911 | 629,564 |
| 7 | 16,22 | 13,7 | 2,786 | 7,763 | 2,617 | 7,293 | 20,234 | 1,677 | 27,446 |
| 8 | 3,88 | 9,13 | 1,356 | 1,838 | 2,212 | 2,999 | 11,033 | 62,506 | 96,214 |
| 9 | 0,75 | 3,86 | -0,288 | 0,083 | 1,351 | -0,389 | 5,496 | 180,711 | 227,373 |
| Итого | 149,3 | 170,45 | 19,029 | 55,397 | 24,511 | 58,257 | 747,465 | 1294,358 |
Для нахождения коэффициентов степенной регрессии необходимо решить систему уравнений:
Подставляя в систему уравнений, получаем:
Решая систему уравнений, получаем:
Искомое уравнение степенной регрессии:
Коэффициент детерминации:
Коэффициент эластичности:
Нелинейная регрессия
| Команда: | Статистика Регрессия Нелинейная регрессия |
Описание
2001).
Например:
y = 1/(1+exp(a+b*x))
, где
- y — зависимая переменная
- x — независимая переменная
- a и b — параметры, определяемые программой
2007), который требует от пользователя предоставления первоначальных оценок или наилучших предположений параметров.
Требуемый ввод
- Уравнение регрессии : выберите или введите модель для подгонки, например: y = 1/(1+exp(a+b*x)) (обратите внимание, что «y=» уже отображается и вводить его не нужно). В этом примере a и b — параметры, подлежащие оценке. Уравнение нелинейной регрессии должно включать символ x, который относится к независимой переменной, выбранной в другом поле ввода (см. ниже). Различные параметры могут быть представлены отдельными символами a .. z , исключая символы x и y . Параметры также могут быть представлены более осмысленными именами, такими как, например, «наклон».
 : , ; . ( ) ‘ » [ ] { }. Кроме того, имена параметров не должны начинаться с цифры и должны отличаться от зарезервированных слов, таких как TRUE, FALSE, ROW и COLUMN.
: , ; . ( ) ‘ » [ ] { }. Кроме того, имена параметров не должны начинаться с цифры и должны отличаться от зарезервированных слов, таких как TRUE, FALSE, ROW и COLUMN. - Переменная Y : выберите зависимую переменную.
- Переменная X : выберите независимую переменную.
- Фильтр : место для дополнительного фильтра, чтобы включить в анализ подмножество данных.
- Параметры
- Получить параметры из уравнения : позволить программе извлечь имена параметров из уравнения регрессии. Если не все предполагаемые параметры извлечены, вы, вероятно, допустили некоторые ошибки в названии параметров или в уравнении регрессии.
- Список параметров и начальные значения : введите начальные значения (наилучшие оценки) для различных параметров. Чтобы ввести начальные значения, вы можете использовать различные статистические функции электронных таблиц для переменных. Эти функции могут ссылаться на выбранные переменные X и Y с помощью символов и X и и Y соответственно. Символ &FILTER может использоваться для ссылки на выбранный фильтр данных. Например: когда в качестве зависимой переменной выбрано «Отклик», то можно использовать функцию VMAX(&Y) в качестве начального значения параметра, а VMAX(&Y) вернет Максимальное значение переменной «Отклик». Примечание: &X , &Y и &FILTER можно использовать только так, как описано здесь, в контексте инициализации параметров для нелинейной регрессии. Эти символы не имеют никакого значения ни в какой другой части программы.
- Опции подгонки
- Допуск сходимости : процесс итерации завершается, когда разница между последовательными подгонками модели становится меньше этого значения. Допуск сходимости влияет на точность оценок параметров. Вы можете ввести небольшое число в E-нотации: напишите 10 -10 как 1E-10
- Максимальное количество итераций : процесс итерации останавливается, когда достигается максимальное количество итераций (когда количество итераций неожиданно велико, модель или начальные значения параметров могут быть неточными).
- Параметры графика
- Показать точечную диаграмму и аппроксимированную линию : возможность создания точечной диаграммы с аппроксимированной линией.
- Показать окно остатков : возможность создать график остатков.
 : , ; . ( ) ‘ » [ ] { }. Кроме того, имена параметров не должны начинаться с цифры и должны отличаться от зарезервированных слов, таких как TRUE, FALSE, ROW и COLUMN.
: , ; . ( ) ‘ » [ ] { }. Кроме того, имена параметров не должны начинаться с цифры и должны отличаться от зарезервированных слов, таких как TRUE, FALSE, ROW и COLUMN. Символ &FILTER может использоваться для ссылки на выбранный фильтр данных. Например: когда в качестве зависимой переменной выбрано «Отклик», то можно использовать функцию VMAX(&Y) в качестве начального значения параметра, а VMAX(&Y) вернет Максимальное значение переменной «Отклик». Примечание: &X , &Y и &FILTER можно использовать только так, как описано здесь, в контексте инициализации параметров для нелинейной регрессии. Эти символы не имеют никакого значения ни в какой другой части программы.
Символ &FILTER может использоваться для ссылки на выбранный фильтр данных. Например: когда в качестве зависимой переменной выбрано «Отклик», то можно использовать функцию VMAX(&Y) в качестве начального значения параметра, а VMAX(&Y) вернет Максимальное значение переменной «Отклик». Примечание: &X , &Y и &FILTER можно использовать только так, как описано здесь, в контексте инициализации параметров для нелинейной регрессии. Эти символы не имеют никакого значения ни в какой другой части программы.
Результаты
Итерации
В этом разделе показаны настройки допусков и итераций.
Далее указывается причина прекращения итерации:
- Критерий допуска сходимости выполнен : итерационный процесс завершен, поскольку разница между последовательными подборами модели стала меньше значения допуска сходимости.
- Превышено максимальное количество итераций : процесс итерации остановлен, поскольку достигнуто максимальное количество итераций. Это может указывать на плохое соответствие модели или плохие начальные значения параметров.
- Неверная модель или неверные начальные параметры : программе не удалось найти решение для данной модели с использованием предоставленных начальных параметров.
- Функция не определена для всех значений независимой переменной : расчет модели привел к ошибке, например, к делению на ноль.

Результаты
- Размер выборки : количество (выбранных) пар данных.
- Стандартное отклонение невязки : стандартное отклонение невязки.
Уравнение регрессии
Оценки параметров представлены со стандартной ошибкой и 95% доверительным интервалом. Доверительный интервал используется для проверки того, существенно ли отличается оценка параметра от определенного значения k . Если значение k не находится в доверительном интервале, то можно сделать вывод, что оценка параметра значительно отличается от k .
Например, когда оценка параметра составляет 1,28 с 95% ДИ от 1,10 до 1,46, тогда оценка этого параметра значительно отличается (P<0,05) от 1.
Дисперсионный анализ
Таблицы дисперсионного анализа дают модель регрессии, остаточную и общую сумму квадратов. Когда MedCalc определяет, что модель не включает точку пересечения, сообщается о «нескорректированной» сумме квадратов, которая используется для F-теста. Когда MedCalc определяет, что модель включает точку пересечения, сообщается «скорректированная» сумма квадратов, которая используется для F-теста.
Когда MedCalc определяет, что модель не включает точку пересечения, сообщается о «нескорректированной» сумме квадратов, которая используется для F-теста. Когда MedCalc определяет, что модель включает точку пересечения, сообщается «скорректированная» сумма квадратов, которая используется для F-теста.
Корреляция оценок параметров
В этой таблице представлены коэффициенты корреляции между различными оценками параметров. Когда вы обнаружите, что два или более параметра сильно коррелированы, вы можете рассмотреть возможность уменьшения количества параметров или выбора другой модели.
Диаграмма рассеяния и подобранная линия
На этом графике показана диаграмма рассеяния и подобранная линия нелинейной регрессии.
График остатков
Остатки — это разница между прогнозируемыми значениями и наблюдаемыми значениями для зависимой переменной.
График остатков позволяет визуально оценить соответствие модели. Остатки могут указывать на возможные выбросы (необычные значения) в данных или проблемы с подобранной моделью. Если остатки отображают определенный шаблон, выбранная модель может быть неточной.
Если остатки отображают определенный шаблон, выбранная модель может быть неточной.
Литература
- Гланц С.А., Слинкер Б.К. (2001) Учебник прикладной регрессии и дисперсионного анализа. 2 и изд. Макгроу-Хилл.
- Press WH, Teukolsky SA, Vetterling WT, Flannery BP (2007) Численные рецепты. Искусство научных вычислений. Третье издание. Нью-Йорк: Издательство Кембриджского университета.
См. Также
- Нелинейная регрессия. Пример: пример 4-параметрической логистической модели
- Регрессия
- Алгоритм в Википедии.
Рекомендуемая книга
Учебник по прикладной регрессии и дисперсионному анализу.
Гланц, Стэнтон, Слинкер, Брайан
Купить на Amazon
Primer of Applied Regression & Variance Analysis — это учебник, специально созданный для студентов, изучающих медицинские науки, здравоохранение, социальные науки и науки об окружающей среде, которым требуется прикладная (не теоретическая) подготовка по использованию статистических методов. Книга получила признание за удобный для пользователя стиль, который делает сложный материал понятным для читателей, не имеющих обширного математического образования. Текст наполнен учебными пособиями, которые включают в себя конспекты глав и задачи в конце глав, которые быстро оценивают усвоение материала. Для пояснения и иллюстрации ключевых моментов включены примеры из биологических наук и наук о здоровье. Обсуждаемые методы применимы к широкому кругу дисциплин, включая социальные и поведенческие науки, а также науки о здоровье и жизни. Типичные курсы, которые будут использовать этот текст, включают те, которые охватывают множественную линейную регрессию и ANOVA.
Книга получила признание за удобный для пользователя стиль, который делает сложный материал понятным для читателей, не имеющих обширного математического образования. Текст наполнен учебными пособиями, которые включают в себя конспекты глав и задачи в конце глав, которые быстро оценивают усвоение материала. Для пояснения и иллюстрации ключевых моментов включены примеры из биологических наук и наук о здоровье. Обсуждаемые методы применимы к широкому кругу дисциплин, включая социальные и поведенческие науки, а также науки о здоровье и жизни. Типичные курсы, которые будут использовать этот текст, включают те, которые охватывают множественную линейную регрессию и ANOVA.
| Имя | Описание | Аргументы | Возвращаемое значение |
| двойной getAdjustedRSquared() | Возвращает скорректированный коэффициент детерминации. | Нет. | Скорректированный R-квадрат или MissingValueCode, если модель не подходит. |
| недействительным getCoefficientPValues (двойной [число коэффициентов]) | Возвращает P-значения для оцененных коэффициентов. | Двойной выходной массив. | Нет. |
| недействительными получить коэффициенты (двойной [число коэффициентов]) | Возвращает оценочные коэффициенты. | Двойной выходной массив. | Нет. |
| void getCooksDistance(двойное c[n]) | Возвращает расстояние Кука, соответствующее каждой строке в источнике данных. | Двойной выходной массив. | Нет. |
| недействительным getDegreesOfFreedom (int df [3]) | Возвращает степени свободы, соответствующие сумме квадратов. | Двойной выходной массив. | Нет. |
| void getDFFITS(двойное d[n]) | Возвращает статистику DFFITS, соответствующую каждой строке в источнике данных. | Двойной выходной массив. | Нет. |
| двойной getDurbinWatson() | Возвращает статистику Дурбина-Ватсона. | Нет. | DW или MissingValueCode, если модель не подходит. |
| void getLeverages(double h[n]) | Возвращает кредитное плечо, соответствующее каждой строке в источнике данных. | Двойной выходной массив. | Нет. |
| double getLowerConfidenceLimit(double x[],double conflevel) | Возвращает нижний доверительный предел для среднего значения Y. | Значения X, при которых делается прогноз, и процент достоверности. | Нижний предел. |
| double getLowerPredictionLimit(double x[],double meansize,double conflevel) | Возвращает нижний предел предсказания для нового значения Y. | Значения X, при которых делается прогноз, количество наблюдений в X и процент достоверности. | Нижний предел. |
| void getMahalanobisDistance(двойное c[n]) | Возвращает расстояние Махаланобиса, соответствующее каждой строке в источнике данных. | Двойной выходной массив. | Нет. |
| двойной getMeanAbsoluteError() | Возвращает остаточную среднюю абсолютную ошибку. | Нет. | MAE или MissingValueCode, если модель не подходит. |
| двойной getMeanSquaredError() | Возвращает остаточную среднеквадратичную ошибку. | Нет. | MSE или MissingValueCode, если модель не подходит. |
| двойной getModelPValue() | Возвращает P-значение для подобранной модели. | Нет. | P-значение. |
| int getNumberOfIterations() | Возвращает количество основных итераций. | Нет. | Кол. |
| интервал getNumberOfFunctionCalls() | Возвращает число вычислений остаточной суммы квадратов. | Нет. | Кол. |
| void getPredictedValues (двойной p [n]) | Возвращает предсказанное значение Y, соответствующее каждой строке в источнике данных. | Двойной выходной массив. | Нет. |
| двойной getPrediction(двойной x[]) | Возвращает предсказанное значение Y. | Значение X, при котором делается прогноз. | Прогнозируемое значение. |
| двойной getResidualDegreesOfFreedom() | Возвращает ф.р. для члена ошибки, используемого для оценки стандартных ошибок. | Нет. | Остаточная df или 0, если модель не подходит. |
| void getResiduals(двойной r[n]) | Возвращает остаток, соответствующий каждой строке в источнике данных. | Двойной выходной массив. | Остаточный или отсутствующий код значения. |
| двойной getResidualStandardError() | Возвращает оценочное стандартное отклонение остатков. | Нет. | Стандартная ошибка оценки или MissingValueCode, если модель не может быть подобрана. |
| двойной getRSquared() | Возвращает коэффициент детерминации. | Нет. | R-squared илиmissingValueCode, если модель не подходит. |
| двойной getSampleSize() | Возвращает количество неотсутствующих значений данных. | Нет. | Размер выборки. |
| двойной getStandardErrorCoefficient(int k) | Возвращает стандартные ошибки k-го коэффициента. | Индекс. | Стандартная ошибка. |
| недействительным getStandardErrors (двойной [число коэффициентов]) | Возвращает стандартные ошибки коэффициента. | Двойной выходной массив. | Нет. |
| интервал getSuccessCode() | Возвращает код, указывающий, почему вычисления были остановлены. | Нет. | 0 для успешной сходимости, 1 если обнаружена необратимость, 4 если превышено максимальное значение параметра Марквардта, 7 если превышено максимальное количество итераций, 8 если превышено максимальное количество вызовов функции. |
| void getStudentizedResiduals(double s[n]) | Возвращает студенческий удаленный остаток, соответствующий каждой строке в источнике данных. | Двойной выходной массив. | Нет. |
| недействительным getSumsOfSquares (двойной сс [3]) | Возвращает следующие суммы квадратов: итог, модель, остаток. | Двойной выходной массив. | Нет. |
| double getUpperConfidenceLimit(double x[],double conflevel) | Возвращает верхний доверительный предел для среднего значения Y. | Значения X, при которых делается прогноз, и процент достоверности. |
