
Нормальные алгоритмы Маркова как основание языка программирования / Хабр
В этой статье хотелось бы поделиться мыслями о применении Нормальных Алгоритмов Маркова (далее по тексту: НАМ) в качестве основания для языка программирования.
Заранее скажу, что представленный концепт ЯП не претендует на решение каких-либо «мировых» проблем программирования, не представляет собой замену существующим инструментам, это результат моих скромных исследований в области проектирования ЯП.
К истории вопроса
20 век ознаменовался становлением и бурным развитием компьютерной индустрии. Пока практики — инженеры и программисты совершенствовали компьютеры и программы для них, теоретики — математики, а позже и специалисты в области компьютерных наук, совершенствовали формальное основание всего этого.
На заре вычислительной эры, когда объёмы памяти измерялись не гигабайтами, а за клавиатурами сидели не любители булочек, а электрики и учёные, одной из важнейших задач теоретической информатики была формализация понятия «алгоритм». Решения этой задачи были найдены, и как следует из моих слов, этих решений было несколько.
Решения этой задачи были найдены, и как следует из моих слов, этих решений было несколько.
Первой, и самой очевидной для нас сейчас, формализацией алгоритма была машина Тьюринга (а также её собратья: машина Поста и машина Минского). Машина представляла собой устройство, последовательно читающее ленту с командами и выполняющее их. Всё просто и понятно: алгоритм в данном случае являлся последовательностью шагов, которые приводят к какому-либо результату.
Иной, «более математический» вариант предложил Алонзо Чёрч: разработанная им теория лямбда-исчисления представляла алгоритм как совокупность аппликации — применения функции к аргументу и абстракции — создания новой функции.
Наконец, третью составляющую важность для нас теорию предложил советский математик Андрей Андреевич Марков. Нормальный алгоритм, введённый Марковым состоял из трёх частей:
Алфавита, с которым работает алгоритм.
Правил подстановки.
Начального состояния.
Алфавит представляет собой множество символов которые алгоритм будет распознавать. К алфавиту применяются правила подстановки. Правила подстановки есть правила вида:
К алфавиту применяются правила подстановки. Правила подстановки есть правила вида: A → B, означающее, что всякое A мы заменяем на B. Для наглядности рассмотрим пример:
Алфавит = A, B, C
Правила = A → B,
B → CC,
C → ø
Исходное состояние = ABC
Шаг 0. ABC
Шаг 1. BBC
Шаг 2. CCBC
Шаг 3. øCBC
Шаг 4. øøBC
Шаг 5. øøCCC
Шаг 6. øøøCC
Шаг 7. øøøøC
Шаг 8. øøøøøВ кратце, именно в этом и состоит суть НАМ.
Так что же с языками программирования? — спросит читатель, порядком уставший от заунывных теоретических выкладок, — Доколе бюрократией мы будем заниматься?
Не унывать! — отвечу я, — переходим ближе к делу.
Итак, мы имеем три основных формализации алгоритмов — в основу каких парадигм и языков программирования они легли? Машина Тьюринга стала базой для императивного программирования, в лоне лямбда-исчисления сформировался функциональный подход. Что же с НАМ? А они стали основой для продукционной парадигмы, о которой ни то, что статьи в Википедии, но и в обозримой части Интернета материалов нет (соглашусь, если Вы скажете, что есть, но они очень низкого качества).
Перейдём же теперь от теории к практике.
LN — язык, основанный на нормальных алгоритмах
LN (Language of Normal Markov algorithms, знаю, сокращение необычное) — это язык, основанный на НАМ, который навязывает их так же, как C — императивный подход, а Haskell — доску, мел и учебник по теории категорий.
В отличие от других «Марковских» ЯП — Thue и MarkovJunior, LN работает не с отдельными символами, а со словами и последовательностями, то бишь, в нём возможно создать правило типа python → shit, c_coding → Segmentation fault, best language → lisp или maybe vim? → no, emacs better.
Словом будем называть любую совокупность символов, ограниченную пробелами, последовательностью — слова ограниченные специальными словами [ и ]. Таким образом JS — слово, JS is evil — 3 разных слова, [ JS is evil ] — последовательность слов.
Основу языка составляет единственное ключевое слово: rule, посредством которого создаются новые правила подстановки, имеет оно следующий синтаксис:
rule .word .word (выполняем подстановку типа слово → слово) rule .word .seq (выполняем подстановку типа слово → последовательность) rule .seq .word (выполняем подстановку типа последовательность → слово) rule .seq .seq (выполняем подставноку типа последовательность → последовательность)
Учитывая это, приведённые выше холиварные примеры можно переписать так:
rule python shit rule c_coding [ Segmentation fault ] rule [ Best language ] Lisp rule [ maybe vim? ] [ no, Emacs better ]
Теперь, имея правила, неплохо было бы их применять. Условимся всё, что не является вызовом ключевого слова, считать исходным состоянием. Тогда нашу одиозную программу выше можно дополнить так:
Условимся всё, что не является вызовом ключевого слова, считать исходным состоянием. Тогда нашу одиозную программу выше можно дополнить так:
python c_coding [ Best language ] [ maybe vim? ]
После ряда подстановок мы получим следующий код:
shit [ Segmentation fault ] Lisp no, emacs better
После этого интерпретатор попытается вычислить этот код, у него ничего не получится, и мы получим ошибку. Но так как пока это лишь концепт, и интерпретатор не ограничивает нашу фантазию, то мы можем побаловаться, не обращая внимания на работоспособность программ.
Важно отметить тот факт, что представленный выше результат работы программы весьма условен: на самом деле сначала интерпретатор прочтёт слово python, обнаружит, что для него существует правило, выполнит подстановку и придёт к ошибке.
Создание простейших программ
Как можно использовать такой необычный язык программирования? Ну, например, он может решать задачи по готовым формулам, т. е. выполнять роль мощного калькулятора. Приведём пример:
е. выполнять роль мощного калькулятора. Приведём пример:
Задача. Воде, массой 5 кг и теплоёмкостью 4200 Дж/кг×°C, сообщили теплоту. В результате её температура изменилась на 20°C. Какую теплоту сообщили воде? Теплообменом с сосудом и окружающей средой пренебречь.
Для решения этой задачи достаточно написать простейшую программу:
rule Q [ * C m dT ] rule C 4200 rule m 5 rule dT 20 print Q
Из приведённого выше примера можно сделать следующие выводы:
В языке используется префиксная нотация для записи выражений.
Функция
printреализует вывод на экран.Программа написана в декларативном стиле, т.е. мы лишь описали саму задачу, решение же её возложено на компьютер.
Кроме того, такой язык «из коробки» может решать системы уравнений методом подстановки, достаточно лишь задать саму систему и выразить одну из переменных.
Ну а что же с реальными задачами? — спросит неутомимый практик, — Уравнения решать и энергию расчитывать это одно, а скажем ветвления, циклы? Как их реализовать в таком ЯП?
Создаём управляющие конструкции: начало
Ну что же, давайте смотреть. Начнём с ветвлений. Для начала добавим в язык новое ключевое слово —
Начнём с ветвлений. Для начала добавим в язык новое ключевое слово — atom, оно сообщит интерпретатору, что, то или иное слово атомарно, пытаться вычислять его не нужно. Зная это, можно реализовать ветвление следующим образом:
atom simple-if rule [ simple-if 1 ] [ print "True" ] rule [ simple-if 0 ] [ print "False" ] [ simple-if some-condition ]
some-condition в данном случае, это некоторое условие, результатом которого становится 1 — истина, и 0 — ложь. Так же можно заметить, что каждый раз, когда требуется ввести условие, потребуется вводить два правила (при условии, что атом simple-if уже введён, ибо его можно использовать повторно). Исправить это можно, но мы сделаем это чуть позже, сейчас же заострим внимание на другой детали: зачем нам simple-if?
Сначала может показаться что это вещь совсем ненужная, результат работы твердолобого теоретика, который спит и видит, как бы ввести новую бесполезную абстракцию, насолить бравым программистам.
simple-if выполняет очень важную роль: он позволяет отделить выражения ветвлений от всего остального, это в некотором смысле маяк, увидев который интерпретатор понимает, что перед не очередное баловство программиста, а самое обыкновенное ветвление. Впредь такие, с виду бесполезные атомы, мы и будем называть маяками.Переходим к циклам. Здесь, уже набившего оскомину инструментария atom и rule будет не достаточно, нам потребуются некоторые абстракции — введём их. Пусть слово .word обозначает любое корректное слово, а .seq — любую корректную последовательность. Внимательный читатель подметит мою забывчивость, и действительно, мы уже встречались с этими word и seq, однако тогда, я так и не дал им объяснения, да и использовал в другом контексте. Условимся .word и .seq называть заполнителями. Теперь с их помощью мы можем реализовать цикл while:
atom simple-while rule [ simple-while 1 .seq ] [ simple-while cond [ some data ] print "Hello, world" ] [ simple-while cond print "Hello, world!" ]
 seq ]
[ simple-while
cond [ some data ]
print "Hello, world" ]
[ simple-while
cond
print "Hello, world!" ]
seq ]
[ simple-while
cond [ some data ]
print "Hello, world" ]
[ simple-while
cond
print "Hello, world!" ]Как видно, заполнитель .seq в данном случае мы используем, чтобы сократить первую часть правила.
С виду может показаться, что наш язык совершенно не пригоден для использования на практике. И действительно, представленные реализации if и while крайне ограничены и просты. Однако, позже мы дополним их, сделаем их мощь сопоставимой с таковой в императивных ЯП. Сейчас же отойдём в сторону, поговорим о переменных и функциях.
Переменные и функции
Что же, перейдём к… переменным? Сначала значит, мы рассуждаем о циклах и ветвлениях, а тут вдруг о переменных вспомнили. Странно, не правда ли? В свою защиту могу сказать, что переменные в LN вещь более сложная, чем простейшие управляющие конструкции. Почему? — Спросите вы. Потому что их нет! — Отвечу я.
Действительно, при детальном рассмотрении окажется, что реализовать переменные при помощи rule нельзя. Наоборот, переменные в LN, в том смысле, в котором они есть например в C, не существуют. В языках императивных переменная — как мы помним из детского сада — это некоторая именованная область памяти, контейнер куда мы можем что-то положить. В LN же, мы можем лишь создать правило, согласно которому
Наоборот, переменные в LN, в том смысле, в котором они есть например в C, не существуют. В языках императивных переменная — как мы помним из детского сада — это некоторая именованная область памяти, контейнер куда мы можем что-то положить. В LN же, мы можем лишь создать правило, согласно которому the-best-coder будет заменяться на "you, my dear ❤️". Да, это будет похоже на переменные, но ими являться не будет. Не возможны потому и указатели.
С точки зрения типов наш язык будет очень близок к Common Lisp — переменные, которых нет, типов иметь не будут, типизированы будут данные. Как и CL, концептуальный язык обладает сильной динамической типизацией. Судить о том, хорошо это или плохо не берусь, ибо совсем не являюсь экспертом в данной теме. Сами основные типы таковы:
seq— последовательности (например:[ a b c ])word— слова (например:peace)numeric— необычный тип, описывающий «что-то числовое» (необязательно число), представляет собой слово, состоящее из числовых символов — цифр,. ). Данный тип позволяет описывать как числа, так и различные совокупности чисел: коды, номера, даты, время и т.п. Пример: 7,3.14,2/3,12.45.6,--34/56.89:1||15.complex— комплексные числа (например:89|12)rational— рациональные числа (например:6.626e-34)integer— целые числа (например:9)fraction— обыкновенные дроби (например:8/9)symbolic— тип, сходныйnumeric, описывает «что-то символьное».character— UTF-8 символstring— UTF-8 строка
 ). Данный тип позволяет описывать как числа, так и различные совокупности чисел: коды, номера, даты, время и т.п. Пример:
). Данный тип позволяет описывать как числа, так и различные совокупности чисел: коды, номера, даты, время и т.п. Пример: Представленные типы имеют следующую иерархию:
seq
└── word
├── numeric
│ └── complex
│ ├── rational
│ │ └── integer
│ └── fraction
└── symbolic
├── character
└── stringТеперь, введём для наших типов пару простых правил:
Типы, находящиеся в иерархии на одном уровне будем называть равноправными.
Например, numericиsymbolic— равноправны,rationalиfraction— равноправны,complexиcharacter— равноправны, а вотstringиrationalуже не равноправны.Равноправные типы не заменяемы. Это означает, что в следующее правило:
rule [ + .integer .integer ]... передатьcharacterилиstring нельзя.Типы, могут иметь подтипы, т.е. такие типы, которые находятся в иерархии на более низком уровне. Например,
word— подтипseq,numeric— подтипword,complex— подтипnumeric.Типы заменяемы подтипами, но не наоборот. Другими словами, типу
numericможно передать значение любого его подтипа:complex,rational,integer,fraction— это не вызовет ошибок. Например, в следующее правило:rule [ example .можно передать не только слова, но и любые числа, символы и строки. word .word ] ...
 Например,
Например,  word .word ] ...
word .word ] ...Всем типам соответствуют заполнители, имена которых, это имя типа с точкой в начале (типу seq соответствует .seq, word — .word и т.д.).
Учитывая природу переменных в LN (а природа их исходит из rule), они будут глобальными и независящими от контекста создания: объявите переменную хоть в глобальной области видимости, хоть в теле функции — она будет видна везде.
А будут ли переменные, которых нет, переменными? Что с иммутабельностью? Чёткого ответа у меня нет. Вполне допустима как переписываемость правил:
rule best-poet Homer rule best-poet John-Milton print best-poet (John-Milton)
так и константность их:
rule best-poet Homer rule best-poet John-Milton (ошибка)
На данный момент моё мнение состоит в следующем: правила должны быть мутабельны, обратное сделает язык менее гибким.
Хорошо, с переменными мы разобрались, перейдём к функциям.
Здесь читатель догадливо заметит, что и их нет в таком ЯП, и он окажется прав. Функций в LN нет, есть лишь правила, используемые в качестве таковых, несмотря на это, далее по тексту, слово «функция» будет повсеместно использоваться, сделано так для большей простоты и лёгкости материала.
Однако, для введения функций нам нужны параметры, а текущая версия rule позволяет определить лишь подстановки без параметризации. Что же, давайте изменим это. Условимся следующую запись заполнителя: .placeholder:name называть именованным заполнителем, где placeholder — тип заполнителя (.seq, .word и др.), а name — имя заполнителя. Учитывая это мы можем написать две классические функции — сумму аргументов, и приветствие:
rule [ sum .rational:a .rational:b ]
[ + a b ]
rule [ greeting .string:name ]
[ print [ "Hello, " name "!" ] ]
[ sum 6 9 ] → 15
[ greeting "Sasha" ] → "Hello, Sasha!"В последний раз обратим своё внимание на типизацию. Ранее было сказано, что она динамическая и сильная, однако, не вооружённым глазом видно, что в объявлении «функции» чётко заданы типы аргументов. Поэтому, правильнее наверное будет сказать, что наш язык имеет типизацию близкую к динамической сильной.
Ранее было сказано, что она динамическая и сильная, однако, не вооружённым глазом видно, что в объявлении «функции» чётко заданы типы аргументов. Поэтому, правильнее наверное будет сказать, что наш язык имеет типизацию близкую к динамической сильной.
Не трудно заметить, что в силу своей природы «функции» могут использовать собственный синтаксис. Например, математические операции в LN работают в префиксной форме, но это легко исправить (другой вопрос надо ли, ибо префикс совершенней инфикса, как мне кажется):
rule [ .rational:a my+ .rational:b ]
[ + a b ]
[ 4 my+ 5 ] → 9В этом примере мы пользуемся тем фактом, что функции — это правила, а потому, порядок следования элементов правила мы можем задать любой. Здесь, однако, следует сделать оговорку: правила не должны выглядеть одинаково, создание двух одинаковых правил означает создание одного, которое мы просто переписываем (или вообще получаем ошибку, если правила иммутабельны).
Так же правила могут порождать другие правила (или, если вам будет понятнее: «функции» могут порождать «функции»). Такие правила (функции) мы будем называть конструкторами. Например, ниже представлен простейший конструктор — синтаксический сахар для «переменных».
Такие правила (функции) мы будем называть конструкторами. Например, ниже представлен простейший конструктор — синтаксический сахар для «переменных».
rule [ var .word:name .word:value ]
[ rule name value ]
var pastille "very tasty stuff"Заметьте, что здесь мы используем 4-е правило типизации: «функция» определена для двух слов, но мы спокойно можем передавать и строки и числа, а вот передача последовательности в качестве аргумента вызовет ошибку.
Создаём управляющие конструкции: продолжение
Итак, после того, как мы изучили лжепеременные, лжефункции и типизацию, можно возвратиться к конструированию ветвлений и циклов.
Начнём с ветвлений. Используя именованные заполнители, мы можем написать следующее:
atom if
rule [ if 1 .seq:true-body .seq:false-body ]
true-body
rule [ if 0 .seq:true-body .seq:false-body ]
false-body
[ if [ - 1 0 ]
[ print "- 1 0 == 1" ]
[ print "- 1 0 == 0" ] ] → [ print "- 1 0 == 1" ] → "- 1 0 == 1"
[ if [ - 1 1 ]
[ print "- 1 1 == 1" ]
[ print "- 1 1 == 0" ] ] → [ print "- 1 1 == 0" ] → "- 1 1 == 0"С виду, этот код может показаться лёгким и понятным. Однако, эта простота обманчива, и потому советую вам сделать попытку самостоятельно решить поставленную задачу.
Однако, эта простота обманчива, и потому советую вам сделать попытку самостоятельно решить поставленную задачу.
Поясняя же работу этой реализации ветвлений скажу, что устроены они так: мы определили маяк if. Далее задали два правила, пока не обращайте на них внимания. Далее написали 2 ветвления. Как они будут вычисляться? if является атомом, он будет пропущен, а вот выражение стоящее за ним будет вычислено и заменено своим результатом — нулём или единицей. Тут-то правила и выходят на сцену: последовательность if 1 .seq будет заменена на код if-ветки, соответственно if 0 .seq — на else-ветку.
Здесь некоторые вспомнят известную шутку про троллейбус из буханки хлеба и спросят: зачем вообще нужен ЯП на котором простые, базовые конструкции реализуются так сложно, в котором программист, будто человек эпохи первобытности, должен всё делать сам, бегать за мамонтом ногами, а не послать за ним робота. На этот сложный, и действительно важный вопрос я отвечу позже. Сейчас же вернёмся к делу.
Сейчас же вернёмся к делу.
И так, нашей задачей было улучшить цикл while, как же это сделать? Прежде всего, надо указать, что в языке, построенном на НАМ, цикл (а равно и рекурсия, ибо ни того, ни другого в чистом виде в нашем ЯП нет) есть правило, которое вычисляется в само себя с некоторыми отличиями (или без них). Легко понять, что под каждый цикл придётся писать отдельное правило, это не удобно, потому, как и в прошлый раз воспользуемся конструктором.
atom while
rule [ while .seq:cond .seq:body ]
[ rule [ while 1 .seq ]
[ while cond body ] ]
[ while [ some-condition ] [ print "Hi" ] ]Устроен этот листинг достаточно просто: конструктор создаёт правило, согласно которому, истина условия в цикле порождает этот же цикл.
Зачем? Кому?
Этими вопросами любой здравомыслящий читатель задумался при прочтении статьи уже не единожды, пришло время ответить на них.
Для начала повторяя себя скажу, что изначально никакой практической цели перед ЯП не ставилось, а потому вопрос "Зачем?" не очень уместен. Однако, спрашивающий прав в некоторой степени, ибо любая технология имеет какое-то применение и цель. Зачем же может понадобиться LN? Приведу список своих мыслей по этому поводу:
Однако, спрашивающий прав в некоторой степени, ибо любая технология имеет какое-то применение и цель. Зачем же может понадобиться LN? Приведу список своих мыслей по этому поводу:
LN интересен с точки зрения фундаментальной информатики. С одной стороны, он сочетает в себе простоту и минимализм возможностей и синтаксиса, а с другой — чрезвычайную мощь и выразительность. Может в будущем продукционное программирование приобретёт популярность, а LN будет известен как один из языков, где данная парадигма получила своё воплощение.
Обработка текстов и данных. Вы возможно заметили, что весь LN построен на идее анализа последовательностей. Это свойство можно применять и для обработки текстов (например для расстановки знаков препинания) где имеет место некоторая шаблонность и структурируемость. То же самое и с данными, хотя честно скажу, с Data Science я не знаком, и моя оценка может быть неверна.
LN так же может применяться для автоматического решения математических, физических и логических задач различного типа.
Достаточно лишь задать условия и начальное состояние — далее система будет действовать сама.
 Достаточно лишь задать условия и начальное состояние — далее система будет действовать сама.
Достаточно лишь задать условия и начальное состояние — далее система будет действовать сама.В завершение этого скромного раздела скажу одно: пока судить о том, где такой ЯП можно применять сложно. Сейчас мы имеем лишь формальное описание, фантазию скрупулёзного теоретика, В перспективе, когда я таки сделаю интерпретатор (есть у меня таковое намерение) можно будет говорить более конкретно.
Заключение
Наконец, подводя итог нужно сказать, что я прошёлся по верхам своих мыслей, бегло рассказал о своей задумке. Однако, этого ознакомления, по моему мнению, достаточно для первого знакомства с языком. В будущем я намерен развивать эту тему, надеюсь, что читателям будет интересно.
Не относитесь к представленному слишком строго или снисходительно, это лишь скромное исследование не претендующие на оригинальность или новизну. Я лишь хотел исследовать ещё одну грань информатики.
Исследуйте новые технологии, учите новые языки, и конечно, «Sapere aude»! До встречи, читатель.
Спасибо моему другу Александру, без него этой статьи не было бы.
Полезные ссылки
Нормальные алгоритмы Маркова: Википедия
Язык программирования РЕФАЛ: Википедия, Содружество РЕФАЛ/Суперкомпиляция
Язык программирования Thue: Википедия, Github
Язык программирования MarkovJunior: Github
Нормальные алгорифмы МарковаЧто это такое?
Тренажёр «Нормальные алгорифмы Маркова» — это учебная модель
универсального исполнителя, предложенного в 1940-х годах
А.А. Марковым для
уточнения понятия алгоритма.
Марков предположил, что любой алгоритм может быть записан в виде
нормального «алгорифма» (учёный считал, что правильно произносить это
иностранное слово именно так). Позднее было доказано, что нормальные
алгорифмы Маркова эквивалентны по своим возможностям другим универсальным исполнителям:
машине Тьюринга и машине Поста. Нормальный алгорифм задает метод преобразования строк с помощью системы подстановок. Каждая подстановка состоит из слова-образца и слова-замены, разделенных цепочкой символов «->». На каждом шаге замены подстановки просматриваются по порядку сверху вниз, и выполняется первая из них, которая подошла: первое найденное слово-образец рабочей строки заменяется на слово-замену.
Слова слева и справа от знака «->» могут быть (а могут и не быть) заключены
в апострофы или двойные кавычки. Следующие подстановки равносильны и определяют замену буквы «а»
на сочетание «бв»: Левая часть (слово-образец) может отсутствовать, в этом случае слово-замена ставится в самое начало рабочего слова. Обычно такая замена должна стоять последней в списке подстановок (иначе происходит зацикливание).
Правая часть подстановки тоже может отсутствовать (при стирании образца).
Символ «.» после слова-замены обозначает терминальную подстановку,
после которой выполнение алгоритма заканчивается. Например: Где почитать ещё?
Что с этим делать?
В верхней части программы находится поле редактора, в которое можно ввести условие задачи в свободной форме. Система подстановок, задающая нормальный алгорифм Маркова, набирается в виде таблице в нижней части окна программы. Программа может выполняться непрерывно (F9) или по шагам (F8). Команда, которая сейчас будет выполняться, подсвечивается зеленым фоном. Скорость выполнения регулируется с помощью меню Скорость. Задачи можно сохранять в файлах и загружать из файлов. Сохраняется условие задачи, исходное слово и система подстановок. Протокол работы алгоритма, в котором показаны все последовательные замены, вызывается при нажатии клавиш Ctrl+P. Если вы заметили ошибку или у вас есть предложения, замечания, жалобы, просьбы и заявления, пишите. Технические требованияПрограмма работает под управлением операционных систем линейки Windows на любых современных компьютерах. Лицензия
Программа является бесплатной для некоммерческого использования. Программа поставляется «as is», то есть, автор не несет никакой ответственности за всевозможные последствия ее использования, включая моральные и материальные потери, вывод оборудования из строя, физические и душевные травмы. При размещении программы на других веб-сайтах ссылка на первоисточник обязательна. Без письменного согласия автора ЗАПРЕЩАЕТСЯ:
Использование и скачивание материалов означает, что вы приняли условия этого лицензионного соглашения. Скачать
Пароль к архиву — kpolyakov.spb.ru В архив включены следующие файлы:
После распаковки архива программа находится в работоспособном состоянии и не требует никаких дополнительных установок. |
Программная среда для управления исполнителями (Робот, Чертежник, Черепаха) с помощью Си-подобного языка. HTML-редактор «HEFS» — удобное средство
ручного создания Web-страниц для начинающих. Электронный учебник-самоучитель по Delphi с практическими заданиями. Тренажер «Setup» позволяет на практике освоить все этапы инсталляции современных программ. |



 Исходные тексты программы не распространяются.
Исходные тексты программы не распространяются.


Алгоритм Маркова
Определение
Алгоритм Маркова — вариант системы перезаписи, изобретенный математиком Андреем Андреевичем Марковым-младшим в 1960 году. Как и система перезаписи, алгоритм Маркова состоит из алфавита и набора продукций. Кроме того, переписывание выполняется путем применения постановок по одному, если таковые имеются. Однако, в отличие от системы рерайтинга, применение продукции регулируется в следующем смысле:
- •
P заказан таким образом, что среди всех применимых производств на одном этапе перезаписи должен использоваться первый применимый x→y;
- •
среди всех вхождений, где может иметь место перезапись относительно x→y, должно применяться самое левое вхождение.

Формально алгоритм Маркова представляет собой четверку ℳ=(Σ,P,F,T), где
- 1.
Σ — алфавит;
- 2.
P — непустое конечное упорядоченное множество (упорядоченное, скажем, по ≤) пар слов над Σ, элементы которого называются произведениями и обычно записываются x→y, а не (x,y);
- 3.
F является подмножеством P, элементы которого называются конечными произведениями ; и
- 4.
T — это подмножество Σ, называемое терминальным алфавитом.
Процесс перезаписи
Далее мы опишем процесс перезаписи для ℳ. Произведение x→y применимо к паре (u,v) слов над Σ, если существуют два слова p,q такие, что u=pxq и v=pyq.
Бинарное отношение⇒ на Σ*, называемое переписывая ступенчатое отношение , определяется следующим образом: u⇒v тогда и только тогда, когда существует продукция x→y такая, что
- 1.
u=pxq и v=pyq для некоторых слов p,q над Σ,
- 2.
если (r,s)<(x,y), то r→s неприменимо к (u,v),
- 3.
, если u=p′xq′ и v=p′yq′, то px является префиксом p′x.

Первое условие гарантирует, что существует производство (x→y в данном случае), применимое к (u,v), второе условие говорит, что x→y является первым доступным производством, которое может быть применено, а последнее условие говорит что вхождение x в u самое левое.
Согласно приведенному выше определению, каждый шаг перезаписи u⇒v определяет уникальную продукцию x→y, называемую ассоциированной продукцией u⇒v.
Слово u над Σ называется терминальным , если нет слов v таких, что u⇒v.
Шаг перезаписи называется final , если связанное с ним производство является окончательным (в F).
Вычисление
Возьмем рефлексивное транзитивное замыкание ⇒* слова ⇒. Если u⇒*v, мы говорим, что v может быть вычислено из u, или что v является вычислением из u.
Для любого слова u над Σ мы можем итеративно применять шаги перезаписи к u, используя методы, описанные выше. Возможны три сценария:
- •
Процесс завершается: u⇒*v, где v — терминальное слово;
- •
Процесс достигает финального шага перезаписи: u⇒*v, где последний шаг перезаписи un-1⇒un=v является окончательным; или
- •
Процесс никогда не достигает финального шага перезаписи и продолжается бесконечно.
Если происходит третий сценарий, мы говорим, что ℳ зацикливает на u. В противном случае ℳ останавливает на u. В любом случае получаем уникальную последовательность
| u=u0⇒u1⇒⋯⇒un⇒⋯ |
шагов перезаписи ui→ui+1. В первом сценарии последовательность конечна, а в третьем сценарии последовательность бесконечна. Во втором сценарии последовательность может быть конечной или бесконечной, в зависимости от того, следует ли продолжать перезапись после достижения последнего шага перезаписи (если v не является терминальным словом, то перезапись может продолжаться). Составляем правило:
Составляем правило:
, когда достигнута окончательная перезапись, дальнейшая перезапись производиться не будет.
Таким образом, последовательность конечна тогда и только тогда, когда ℳ останавливается на u. Когда ℳ останавливается на u, конечная последовательность
| u=u0⇒u1⇒⋯⇒un=v |
дает уникальное слово v. Слово v считается словом, вычисленным с помощью ℳ от u. Обратите внимание, что v является либо конечным словом, либо вычисляется из конечной продукции un-1→v. В любом случае никакие более ранние произведения ui→ui+1 не являются окончательными.
Таким образом, вычисление по алгоритму Маркова можно представить как частичную функцию
| мℳ:Σ*→Σ*, |
, где mℳ(u) определяется тогда и только тогда, когда ℳ останавливается на u, а значение mℳ(u) устанавливается равным уникальному слову v, вычисленному ℳ из u.
Адаптер языка
ℳ можно рассматривать как акцептор языка, что является целью терминального алфавита T: набор
| L(ℳ):={u∈T*∣mℳ(u)=λ} |
называется языком , принятым ℳ. Частичная функция mℳ определена в предыдущем разделе.
Примечание. Оказывается, алгоритм Маркова — это просто еще одна форма машины Тьюринга. Можно показать, что язык рекурсивно перечислим тогда и только тогда, когда он может быть принят марковским алгоритмом.
Эквивалентность машине Тьюринга можно переформулировать с точки зрения функциональной вычислимости. Прежде чем формализовать это понятие, нам нужно сначала закодировать наборы натуральных чисел словами. Предположим, что (n1,…,nm) — m-набор натуральных чисел. Набор
| E(n1,…,nm):=abn1abn2a⋯abnma, |
слово в алфавите {a,b}. Если вместо этого разрешены неотрицательные целые числа, мы можем вместо этого использовать слово E(n1+1,…,nm+1).
Мы говорим, что m-мерная теоретико-числовая частичная функция f:ℕm→ℕ является марковски-вычислимой , если существует марковский алгоритм ℳ такой, что f(n1,…,nm) определено тогда и только тогда, когда mℳ(E( n1,…,nm)) определено и равно E(f(n1,…,nm)).
Можно показать, что частичная функция вычислима по Тьюрингу тогда и только тогда, когда она вычислима по Маркову.
Ссылки
- 1 А. Саломаа Вычисления и автоматы, Энциклопедия математики и ее приложений, Vol. 25. Кембридж (1985).
- 2 Н. Катленд, Вычислимость: Введение в теорию рекурсивных функций. Издательство Кембриджского университета, (1980).
- 3 JD Monk, Mathematical Logic , Springer, New York (1976).
Алгоритм Маркова Онлайн
Алгоритм Маркова
цитата из википедии:
Правила — это последовательность пары строк, обычно представленная в виде шаблона → замена .
Учитывая строку ввода :
- Просмотрите правила в порядке сверху вниз, чтобы увидеть, можно ли найти какой-либо из шаблонов в ввод строки .
- Если ничего не найдено, алгоритм останавливается.
- Если один (или несколько) найден, используйте первый из них, чтобы заменить крайнее левое вхождение совпавшего текста во входной строке его заменой . Если только что примененное правило было завершающим, алгоритм останавливается.
- Перейти к шагу 1.
Обратите внимание, что после каждого применения правила поиск начинается с первого правила.
 Каждое правило может быть как обычным, так и завершающим.
Каждое правило может быть как обычным, так и завершающим.Синтаксис и ограничения
| Шаблон : замена | Это обычное правило. Замените первое вхождение шаблона на замену . Замените первое вхождение шаблона на замену . |
| образец :: замена | Это завершающее правило. Замените первое вхождение шаблона на замену , и алгоритм остановится. |
| пустой узор | Пустая строка соответствует началу строки. |
| комментарии | Строки, не содержащие : , считаются комментариями. |
| мест | Начальные/конечные пробелы в шаблоне /, заменяющем , игнорируются. |
| ограничение шага | Количество замен не должно быть 50000 раз. |
| ограничение длины строки | Длина строки ввода не должна превышать 500 в любой момент.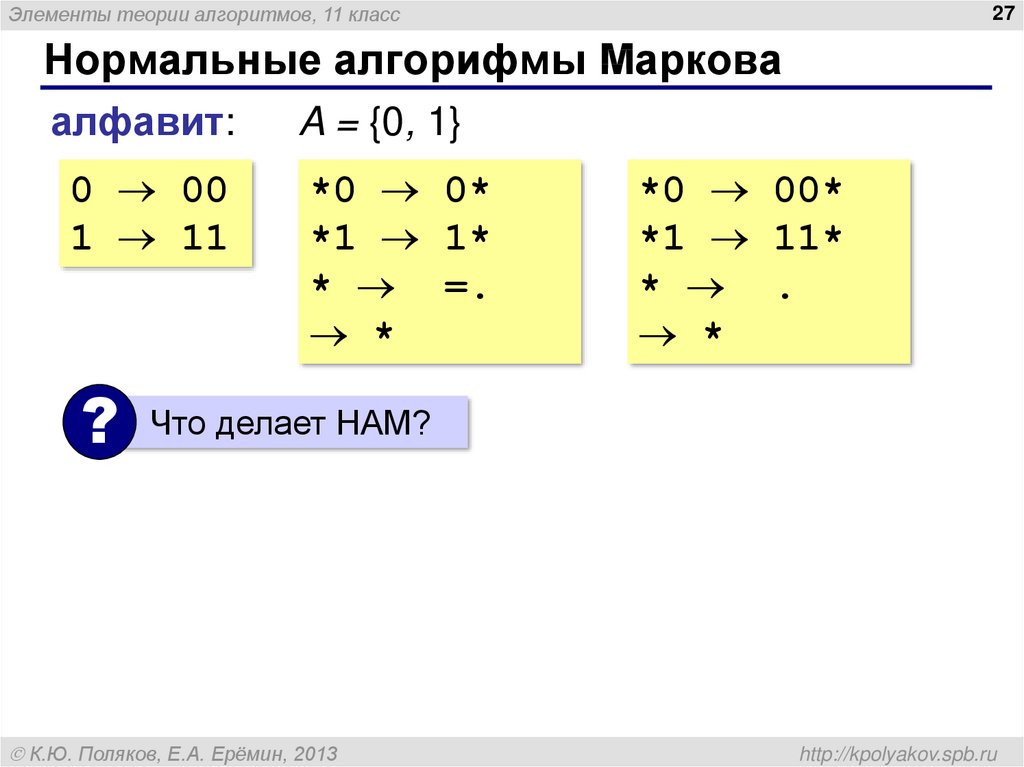 |