
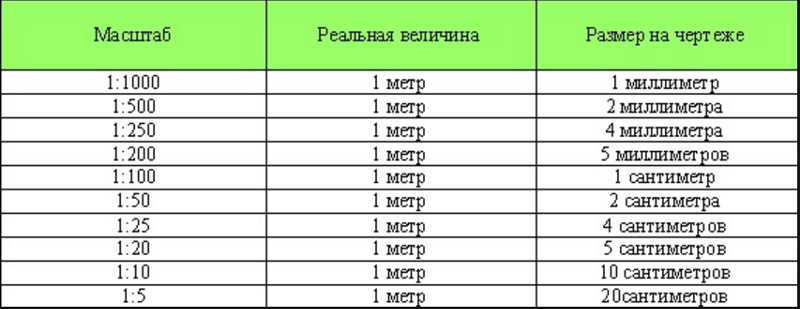
Размер кластера Atlas и выбор уровня 3
Важно
Функция недоступна в бессерверных экземплярах
Бессерверные экземпляры не поддерживают это особенность в это время. Чтобы узнать больше, см. Ограничения бессерверного экземпляра.
Выбор правильного уровня и конфигурации кластера Atlas является важный шаг в создании успешной производственной MongoDB развертывание. Вы всегда можете изменить кластер в позже, но начать работу с правильной конфигурацией возможно с помощью нескольких расчетов, основанных на размере вашего набора данных и сетевые требования.
Вы также можете настроить свой кластер на автоматическое масштабирование. уровень, емкость хранилища или и то, и другое в ответ на использование кластера, тем самым сокращение ручного обслуживания, необходимого для вашего кластера. К Дополнительные сведения см. в разделе Автомасштабирование кластера.
Рекомендовать кластеры M30 или более крупные для производственной среды
Кластеры M30 и более поздние рекомендуются для производственных сред. Вы можете использовать кластеры M10 и M20 в качестве рабочих сред для
приложения с низким трафиком, но эти уровни рекомендуются для
среды разработки.
Вы можете использовать кластеры M10 и M20 в качестве рабочих сред для
приложения с низким трафиком, но эти уровни рекомендуются для
среды разработки.
Автоматическое масштабирование кластера
Уровни кластера M10 и выше поддерживают автоматическое масштабирование кластера. Уровень кластера Автомасштабирование включено по умолчанию
при создании новых кластеров в пользовательском интерфейсе. Он отключен
по умолчанию, если вы создаете новые кластеры в API. При включенном автомасштабировании
Atlas автоматически масштабирует уровень вашего кластера, емкость хранилища или
оба в ответ на использование кластера. Автомасштабирование позволяет вашему кластеру
адаптируйтесь к вашей текущей рабочей нагрузке и уменьшите потребность в ручном
оптимизация.
Масштабирование кластерного хранилища автоматически увеличивает емкость хранилища вашего кластера, когда 90% диска емкость используется. Этот параметр включен по умолчанию, чтобы гарантировать, что ваш кластер всегда может поддерживать внезапный приток данных.
Чтобы отказаться от масштабирование хранилища кластера, снимите флажок Масштабирование хранилища установите флажок в разделе Автомасштабирование.
Масштабирование уровня кластера автоматически масштабирует уровень вашего кластера вверх или вниз в ответ на различные показатели кластера. Чтобы отказаться от автоматического масштабирования уровня кластера, снимите флажок Cluster Tier Scaling в Раздел автомасштабирования.
Чтобы контролировать, как Atlas должен автоматически масштабировать ваш кластер, вы устанавливаете:
Максимальный уровень кластера, на который ваш кластер может автоматически увеличить масштаб. По умолчанию этот параметр установлен на следующий уровень кластера. по сравнению с вашим текущим уровнем кластера.
Минимальный уровень кластера, до которого может масштабироваться ваш кластер. По умолчанию для этого параметра задан текущий уровень кластера.

Память
Память относится к общей физической оперативной памяти, доступной на каждом
узел, несущий данные вашего
Кластер Атлас. Например,
Например, M30 стандартный набор реплик
настроен с 8 ГБ ОЗУ на каждом из 3 узлов, несущих данные.
Атлас использует Механизм хранения WiredTiger.
По умолчанию для кластеров M40 и более WiredTiger выделяет 50% физическая оперативная память для кеша WiredTiger. Остальные 50% зарезервированы для операции в памяти, такие как сортировка и вычисления, лежащие в основе операционной системы и других системных служб.
По умолчанию для кластеров M30 или меньше WiredTiger выделяет 25% физическая оперативная память для кеша WiredTiger.
Дополнительные сведения об использовании памяти см. в разделе WiredTiger и использование памяти.
MongoDB использует кэш WiredTiger для хранения последних использованных данных и
индексы. Рабочий набор — это сумма всех индексов плюс набор
документы, к которым часто обращаются. Если ваш рабочий набор подходит
RAM, то MongoDB может обслуживать запросы из памяти, что обеспечивает
самое быстрое время ответа на запрос.
Чтобы оценить размер рабочего набора, вы можете либо выполнить
расчет с использованием информации, полученной из db.stats() для общего пространства индекса и предположим, что процент вашего пространства данных
будут часто использоваться, или вы можете оценить свою память
требования, основанные на обоснованных предположениях.
Пример: Наборы образцов данных Atlas
Использование Atlas выборочные наборы данных, мы рассчитаем требования к памяти для запуска всех этих баз данных в одном кластере Atlas. Следующая программа JavaScript возвращает информацию о базе данных для вашего кластера:
| вар totalIndexSize = 0; |
| var totalDataSize = 0; |
| var зарезервированоDBs = [«admin»,»config»,»local»]; |
| // Переключитесь на базу данных администратора и получите список баз данных. |
| дб = db.getSiblingDB («admin»); |
dbs = db. runCommand({ «listDatabases»: 1 }).databases; runCommand({ «listDatabases»: 1 }).databases; |
| // Перебираем каждую базу данных и получаем ее статистику. |
| dbs.forEach(функция(база данных) { |
| if (reservedDBs.includes(database.name)) |
| возврат; |
| db = db.getSiblingDB (база данных.имя ); |
| print(«Получение статистики для » + database.name); |
| var stats = db.stats(); |
| totalDataSize += (stats.dataSize / (1024*1024*1024)) ; |
| }); |
| print («Общий размер данных в ГБ: » + totalDataSize.toFixed(2)); |
| print («Общий размер индекса в ГБ: » + totalIndexSize.toFixed(2)); |
Эта программа возвращает следующие результаты: ял
Чтобы полностью запустить эти базы данных в памяти, вам потребуется как минимум
0,68 ГБ физической оперативной памяти, так как WiredTiger использует 50% физической оперативной памяти
и нам нужно не менее 0,34 ГБ, чтобы уместить рабочий набор в памяти.
Реалистичный производственный кластер будет иметь гораздо более высокие данные и индекс размер и это может быть не практично, или не бизнес или производительность Требование, чтобы запустить полный набор данных и индексы в памяти. Давайте посмотрите на другой сценарий.
Пример: мобильное приложение
Популярная мобильная игра имеет 512 ГБ данных и 32 ГБ индексов. внутренние системные данные игры занимают 16 Гб, остальное принадлежит игроку данные профиля. Профиль игрока должен находиться в памяти, пока игрок активен в игре. Около 25% всех игроков активны на любой момент времени. Системные данные используются постоянно и должны соответствовать полностью в оперативной памяти для оптимальной производительности игры. Все индексы также должны помещается в ОЗУ для самого быстрого времени ответа на запрос. Объем памяти такой следует:
Данные | Требования к оперативной памяти | ОЗУ для WiredTiger Cache |
|---|---|---|
Система: 16 ГБ | 100% в ОЗУ | 16 ГБ |
Индекс: 32 ГБ | 100% в ОЗУ | 32 ГБ |
Профили игроков: 496 ГБ | 25% в оперативной памяти | 124 ГБ |
Учитывая эти требования, вы можете ожидать среднего
рабочий набор
требуется 172 ГБ оперативной памяти.
WiredTiger выделяет 50% физической оперативной памяти для кэша WiredTiger, поэтому минимальная общая физическая оперативная память, необходимая для размещения вашего рабочего набора в два раза больше рабочего набора.
В этом примере вам потребуется не менее 344 ГБ физической памяти для разместить кеш WiredTiger и рабочий набор на 172 ГБ. В следующей таблице перечислены подходящие уровни кластера Atlas:
Поставщик услуг | Возможные уровни кластера | Примечания |
|---|---|---|
AWS |
| |
GCP |
| |
Azure |
| |
Если выбрать уровень кластера без достаточного объема оперативной памяти, например
Azure M200 с 256 ГБ ОЗУ, сегментирование
необходимый.
Сетевой трафик
Весь сетевой трафик между узлами кластера и между клиентами, потребляющими
данные из вашего кластера Atlas влияют на пропускную способность сети. Для целей
размера кластера, учитывайте максимальный трафик, который любой узел на вашем
кластер будет нести и использовать это в качестве основы для выбора адекватного
Уровень кластера Атлас.
Для целей
размера кластера, учитывайте максимальный трафик, который любой узел на вашем
кластер будет нести и использовать это в качестве основы для выбора адекватного
Уровень кластера Атлас.
Скорость передачи данных в нисходящем направлении от вашего кластера к клиентским приложениям можно рассчитать как сумму всех документов, возвращенных за период времени. Если вы читаете только с первичный узел, это единственный расчет, который вам нужно сделать. Если ваши приложения читают из вторичные узлы, вы можно разделить это число на количество узлов, которые могут обслуживать чтение операции.
Вы можете найти средний размер документа для базы данных с Метод db.stats() . Умножьте среднее
размер документа ( avgObjSize ) по количеству документов, обслуживаемых в секунду для оценки
ваши требования к пропускной способности.
Пример
Средний размер документа 10 КБ
100 000 обслуживаемых документов в секунду
10 КБ * 100 000 = 1 ГБ в секунду
ярусы. Экземпляры, которые поддерживаются
AWS обеспечивает до 10 гигабит на
второй на уровне
Экземпляры, которые поддерживаются
AWS обеспечивает до 10 гигабит на
второй на уровне M30 , а уровень M200 обеспечивает до
25 гигабит в секунду.
Соединения
Кластер Atlas может поддерживать ряд клиентских соединений, которые
определяется его уровнем кластера. Кластеры M30 поддерживают до 2000
одновременных подключений, а кластеры M200 поддерживают до 128 000
одновременные подключения.
← Примечания к производству Создание отказоустойчивого приложения с помощью MongoDB Atlas →
ATLAS.ti | Программное обеспечение №1 для качественного анализа данных
новый
Узнайте больше о нашем инновационном инструменте кодирования ИИ → Попрощайтесь с бесконечным ручным кодированием и поприветствуйте управляемую искусственным интеллектом помощь на автопилоте, подпитываемую передовой моделью GPT. С нашим программным обеспечением на базе OpenAI вы можете выполнять свои исследовательские проекты в 10 раз быстрее. Полностью автоматизированные предложения кода избавляют вас от рутинной работы, поэтому вы можете сосредоточиться на уточнении и анализе для оптимизации научной точности.
Полностью автоматизированные предложения кода избавляют вас от рутинной работы, поэтому вы можете сосредоточиться на уточнении и анализе для оптимизации научной точности.
Программное обеспечение для качественного анализа данных с лучшими оценками
G2 Crowd Score: 4,7
Capterra Score: 4,8
Оценка GetApp: 4,8
Почему ATLAS.ti
Купить сейчас Предварительный просмотр кода AIATLAS.ti доступен для Mac, Win и Web
Посмотреть полный тур по продуктуПочему наши пользователи любят ATLAS.ti
Получите универсальный доступ к нашим настольным приложениям для Windows и Mac, а также нашу веб-версию для браузеров. Воспользуйтесь нашим передовым программным обеспечением QDA уже сегодня!
Бесплатная пробная версия Купить сейчас
ATLAS.ti был отличным инструментом для моего исследования PhD, который я использовал для анализа качественных интервью из Ганы и Нигерии. Это было идеальное решение, и мы были рады узнать, что можем сотрудничать с исследователями в любой стране или учреждении без получения специальной лицензии.
Это было идеальное решение, и мы были рады узнать, что можем сотрудничать с исследователями в любой стране или учреждении без получения специальной лицензии.
Д-р Квабена Куси-Менсах
FWACP (психология), MSc.CAMH (Ib.), кандидат психиатрии, Кембриджский университет
ATLAS.ti — это самое простое и удобное программное обеспечение для кодирования качественных данных.
Светлана Полещук
Кандидат наук, исследователь в области образования, ЮНИСЕФ
Я пользуюсь ATLAS.ti более 20 лет, и все это время это программное обеспечение всегда было моим первым выбором для качественных исследований. ATLAS.ti продолжает вводить новшества и улучшаться каждый год, добавляя новые функции и преимущества для своего сообщества пользователей. Я настоятельно рекомендую его для вашего качественного исследования.
Ken Riopelle
Профессор-исследователь, Государственный университет Уэйна
#1 Программное обеспечение для качественного анализа данных
Если вы рассматриваете ATLAS. ti для качественного анализа данных, вы делаете мудрый выбор. Наше программное обеспечение QDA с самым высоким рейтингом идеально подходит для студентов, исследователей, академических учреждений и коммерческих предприятий, предлагая широкий спектр аналитических инструментов на основе ИИ, которые помогут вам добиться успеха. Вот лишь несколько причин выбрать ATLAS.ti:
ti для качественного анализа данных, вы делаете мудрый выбор. Наше программное обеспечение QDA с самым высоким рейтингом идеально подходит для студентов, исследователей, академических учреждений и коммерческих предприятий, предлагая широкий спектр аналитических инструментов на основе ИИ, которые помогут вам добиться успеха. Вот лишь несколько причин выбрать ATLAS.ti:
Интуитивно понятный интерфейс для качественных исследований
ATLAS.ti предназначен как для профессионалов, так и для начинающих. Он охватывает все, от качественного анализа текста и оценки интервью с клиентами до анализа веб-контента и конкретных задач бизнес-аналитики.
Пользователи могут собирать и анализировать данные в основных операционных системах (Windows и macOS) даже с нашей веб-версией для браузеров. Наше удобное программное обеспечение для качественного анализа данных позволяет легко загружать файлы и анализировать данные быстро и эффективно, чтобы вы могли извлечь максимальную пользу из своего исследования.
Быстрое и простое кодирование на основе ИИ
Преобразование текстовых данных в ценную информацию может занять много времени. С помощью ATLAS.ti вы можете импортировать данные из любого источника и получать более подробные сведения с помощью ИИ. Кроме того, наше качественное программное обеспечение предлагает инструменты для автоматического создания закодированных сегментов ваших данных и быстрого определения тем.
Инструменты качественного анализа данных ATLAS.ti позволяют организовать все ваши текстовые данные (т. е. из интервью с клиентами или фокус-групп) в одном месте. Таким образом, вы можете анализировать качественные данные быстрее, чем когда-либо. Кроме того, вы можете использовать иерархию кода с древовидной структурой для лучшего управления кодом.
Наша функция автоматического кодирования ИИ использует модель GPT OpenAI, которая может понимать естественный язык на человеческом уровне. Больше, чем интеллектуальный анализ текста: этот новаторский инструмент анализа расширяет возможности пользователей из всех областей деятельности, значительно сокращая общее время кодирования и анализа.
Удовлетворите все ваши потребности в качественном анализе данных
Независимо от того, полагаетесь ли вы на стенограммы фокус-групп, заметки о наблюдениях, ответы на опросы или даже на аудио- и видеофайлы, вы можете анализировать все это с помощью ATLAS.ti. В отличие от инструментов для работы с количественными данными, наше программное обеспечение поддерживает все основные формы данных, поэтому вы можете проводить качественный анализ данных в любом исследовательском проекте, включая отзывы клиентов, текстовые данные, изображения и видеозаписи.
Что бы это ни было, вы можете импортировать данные в одно центральное место в ATLAS.ti, что позволит вам использовать качественные и смешанные методы для ваших исследовательских проектов.
Мощный анализ данных на автопилоте
Наши инструменты искусственного интеллекта и машинного обучения облегчают поиск информации в вашем исследовательском проекте. Инструменты качественного анализа данных, такие как Sentiment Analysis и Opinion Mining, могут выполнять анализ текста в нескольких документах, чтобы анализировать большие проекты быстрее и глубже.
Независимо от того, хотите ли вы проанализировать данные о клиентах или определить ключевые слова из исследовательских материалов, наши инструменты искусственного интеллекта помогут вам быстро завершить работу. Независимо от того, чего вы хотите достичь: чистый качественный анализ или исследование смешанных методов, ATLAS.ti предлагает ведущее решение, которому доверяют ученые и предприятия.
Более глубокое понимание с помощью качественного анализа
Мы понимаем, что любой инструмент качественного анализа данных настолько эффективен, насколько ценна информация, которую он предоставляет вам и вашей аудитории. ATLAS.ti — это больше, чем анализатор текста. Мы разрабатываем наше программное обеспечение для визуализации вашего анализа данных в нескольких форматах:
Гистограммы, диаграммы Санки, облака слов и визуализация сетей помогают определить темы и шаблоны данных для надежного и точного понимания.
Беспрепятственное сотрудничество между группами
Качественные и смешанные методы исследования часто основаны на сотрудничестве между членами команды.