
Уважаемые коллеги! 📚 Представляем.. | Ёжик в матане
Уважаемые коллеги!
Представляем вашему вниманию подборку-практикум на тему математической статистики!
Данная подборка носит прикладной характер.
Вашему вниманию предлагается:
Климов Г.П., Кузьмин А.Д. «Вероятность, процессы, статистика. Задачи с решениями»
Книга содержит 199 задач по основным разделам теории вероятностей, случайных процессов и математической статики, включаемых в начальный курс.
Перед каждой темой даётся перечень основных теоретических положений.
Кокс Д., Хинкли Д. «Задачи по теоретической статистике с решениями»
Первое на русском языке учебное пособие с упражнениями по курсу математической статистики. Оно принадлежит перу известных английских математиков и дополняет их же монографию «Теоретическая статистика». Позволяет ознакомиться как с конкретными приложениями общих статистических методов, так и с современными достижениями математической статистики.
В литературе около 150 задач с решениями. Книга рассчитана на преподавателей, аспирантов, студентов, специализирующихся в области математической статистики и ее приложений.
Содержание:
• О некоторых общих понятиях.
• Слабые критерии значимости.
• Критерии значимости: простые нулевые гипотезы.
• Критерии значимости: сложные нулевые гипотезы.
• Критерии, свободные от распределения, и критерии рандомизации.
• Интервальное оценивание.
• Точечное оценивание.
• Асимптотическая теория.
• Байсовские решения.
• Теория решений.
Микулик Н.А., Рейзина Г.Н. «Решение задач с техническим содержанием по теории вероятностей, математической статистике и случайным процессам»
Справочное пособие составлено в соответствии с программой курса математики для инженерных специальностей. В нём дано краткое изложение теоретического материала рассматриваемых тем, приведены решения типовых примеров, даны задания для аудиторной и самостоятельной работы.
Пособие предназначено для студентов технических специальностей университетов, а также может быть полезным для студентов экономических специальностей, инженерам, бакалаврам, магистрам, преподавателям вузов и колледжей.
Попов В.А., Бренерман М.Х. «Руководство к решению задач по теории вероятностей и математической статистике»
Руководство содержит более 200 задач по курсу «Теория вероятностей и математическая статистика». Большое количество задач приведено с решениями и указаниями, каждый параграф снабжен сводкой основных понятий, теорем и формул, необходимых для успешного освоения данного раздела. Это дает возможность использовать пособие как для самостоятельной работы во время семестра, так и для «срочной» подготовки к экзамену или зачету.
Просветов Г.И Статистика. «Задачи и решения»
В настоящем учебно-методическом пособии на простых примерах раскрываются следующие разделы статистики:
• теория вероятностей,
• теория статистики,
• микроэкономическая статистика,
• макроэкономическая статистика, статистика финансов.
Каждый раздел книги можно рассматривать как самостоятельный курс.
В качестве учебно-методического пособия предназначено преподавателям и студентам экономических специальностей высших учебных заведений.
Барра Ж.Р. «Основные понятия математической статистики»
В последнее время все отчетливее проявляется тенденция к формализации основных статистических понятий. Такое развитие математической статистики позволит дать строгое обоснование полуэмпирических приемов, еще нередко встречающихся в практических приложениях.
Книга Ж.-Р. Барра содержит формализованное изложение наиболее фундаментальных представлений и идей этой науки на современном математическом языке. В сравнительно небольшом объеме автору удалось изложить как начала математической статистики, так и некоторые ее актуальные проблемы, активно разрабатываемые в настоящее время.
Книга будет полезна широкому кругу математиков, желающих познакомиться с современной теорией статистики или систематизировать имеющиеся у них познания. Ее можно использовать как учебное пособие на математических отделениях университетов и пединститутов.
Ее можно использовать как учебное пособие на математических отделениях университетов и пединститутов.
Боровков А.А. «Математическая статистика»
В учебнике излагаются основания современной математической статистики, предельные теоремы для эмпирических распределений и основных типов статистик, основы теории оценок и теории проверки гипотез.
Рассматриваются методы отыскания оптимальных и асимптотически оптимальных процедур. Значительное внимание уделено статистике разнораспределенных наблюдений и, в частности, задачам однородности, задачам регрессии и дискретного анализа, распознаванию образов и задаче о разладке.
Излагается единый теоретико-игровой подход к задачам математической статистики. Изучаются статистические игры и основные принципы отыскания оптимальных и асимптотически оптимальных решающих правил.
Многие результаты теории оценивания и теории проверки гипотез обобщаются на случай произвольной функции потерь. Учебник рассчитан на студентов и аспирантов математических и физических специальностей вузов.
Подборки книг по теории вероятностей и математической статистике, которые публиковались ранее!
Учебные пособия для студентов младших курсов:
https://vk.com/wall-186208863_1914
Практикум по решению задач:
https://vk.com/wall-186208863_1918
Сборники задач:
https://vk.com/wall-186208863_1924
Базовый курс в трёх томах по теории вероятностей и математической статистики (в примерах и задачах):
https://vk.com/wall-186208863_531
Математическая статистика:
https://vk.com/wall-186208863_8474
Ещё одна подборка книг:
https://vk.com/wall-186208863_4480
#статистика
#математическая_статистика
#теория_вероятностей
Леман Э. Теория точечного оценивания
- формат djvu
- размер 14.26 МБ
- добавлен 05 декабря 2009 г.
М. : Наука, 1991. — 448 с. Имя крупного американского ученого Э.
Лемана хорошо известно читателям по классическому руководству
«Проверка статистических гипотез», выдержавшему два издания на
русском языке. Новая книга посвящается изложению теории
статистических оценок. Рассматриваются оптимальные статистические
оценки, полученные при различного рода требованиях к их качеству:
несмещенности, эквивариантности, минимаксности. Большое место
отводится асимптотическим свойствам оценок.
: Наука, 1991. — 448 с. Имя крупного американского ученого Э.
Лемана хорошо известно читателям по классическому руководству
«Проверка статистических гипотез», выдержавшему два издания на
русском языке. Новая книга посвящается изложению теории
статистических оценок. Рассматриваются оптимальные статистические
оценки, полученные при различного рода требованиях к их качеству:
несмещенности, эквивариантности, минимаксности. Большое место
отводится асимптотическим свойствам оценок.
Смотрите также
- формат djvu
- размер 8.46 МБ
М.: Финансы и статистика, 1983. — 278 с. (Серия — Математико-статистические методы за рубежом). В книге изложены основные методы современной математической статистики. Содержится большое число задач. В вып. 1 рассмотрены основные положения теории вероятностей, статистические модели, методы оценивания и сравнения оценок — теория оптимальности, доверительные интервалы и проверка гипотез, оптимальные критерии (критерий отношения правдоподобия и связ. ..
..
- формат pdf
- размер 885.79 КБ
- добавлен 12 ноября 2011 г.
Томск: Изд-во ТПУ, 2010. — 80 с. В пособии рассмотрены основные статистические процедуры для представления и предварительной обработки статистических данных, методы точечного и интервального оценивания неизвестных параметров распределений, принципы проверки статистических гипотез. В разделе «Исследование зависимостей» рассмотрены принципы проведения однофакторного, корреляционного и регрессионного анализа, условия их корректного применения для чи…
- формат djvu
- размер 10.51 МБ
- добавлен 13 декабря 2009 г.
М.: Статистика, 1976. — 598 с. Серия: «Зарубежные статистические исследования (теория и методы)». Книга охватывает все известные методы статистического оценивания, нашедшие практическое применение. Дает определение математической статистики, формулирует основные ее задачи, приводит главные понятия и законы, на которых она базируется, рассматривает символику и основные математические операции. Описывает различные статистические методы получения ст…
Книга охватывает все известные методы статистического оценивания, нашедшие практическое применение. Дает определение математической статистики, формулирует основные ее задачи, приводит главные понятия и законы, на которых она базируется, рассматривает символику и основные математические операции. Описывает различные статистические методы получения ст…
- формат pdf
- размер 5.76 МБ
- добавлен 31 августа 2011 г.
Челябинск: Изд-во ЮУрГУ, 2008. — 145 с. Пособие предназначено студентам специальностей 010101 — математика и 010200 — прикладная математика и информатика, а также студентам, обучающимся в бакалавриате соответствующих направлений подготовки. Рассмотрены основные статистические задачи — теория оценивания, статистические процедуры проверки гипотез и некоторые проблемы, связанные со статистическим исследованием зависимостей. Все утверждения и предлаг…
Все утверждения и предлаг…
- формат pdf
- размер 89.78 МБ
- добавлен 21 января 2011 г.
М.: Наука, 1979. — 528 с. До недавнего времени теория оценивания в больших выборках содержала лишь разрозненные факты о состоятельности и асимптотической нормальности некоторых конкретных оценок. Однако в результате ряда исследований последних лет ситуация изменилась — появились общие методы изучения свойств широкого класса параметрических оценок. Эти методы связаны с более широким применением теории меры и теории случайных процессов в задачах о…
- формат djvu
- размер 11.71 МБ
- добавлен 30 октября 2010 г.
М.: Наука, 1979. — 528 с. До недавнего времени теория оценивания в больших выборках содержала лишь разрозненные факты о состоятельности и асимптотической нормальности некоторых конкретных оценок.
- формат djvu
- размер 10.04 МБ
- добавлен 19 февраля 2009 г.
Книга представляет собой второй том трехтомного курса статистики М. Кендалла и А. Стьюарта, первый том которого вышел в 1966 г. под названием «Теория распределений; ». В книге содержатся сведения по теории оценивания, проверки гипотез, анализу корреляции, регрессии, непараметрическим методам, последовательному анализу.
- формат djvu
- размер 11.82 МБ
- добавлен 01 апреля 2010 г.
В книге дана сводка основных понятий и наиболее важных результатов современной математической статистики. Подробно рассмотрены теория проверки гипотез, теория оценивания, специальные главы посвящены критериям значимости, асимптотическим методам, байесовским моделям и теории статистических решений. Книга содержит большой фактический материал, изложение неформальное.
Подробно рассмотрены теория проверки гипотез, теория оценивания, специальные главы посвящены критериям значимости, асимптотическим методам, байесовским моделям и теории статистических решений. Книга содержит большой фактический материал, изложение неформальное.
- формат pdf
- размер 1.34 МБ
- добавлен 06 августа 2009 г.
Учебное пособие к практическим занятиям. 2003г. Основные понятия и задачи математической статистики. (примеры) Специальные законы распределения математической статистики. (примеры) Статистическая теория оценивания параметров распределения. (примеры) Статистическая проверка параметрических теорий. (примеры) Статистическая проверка непараметрических теорий. (примеры) Линейный регрессионный анализ. (примеры)
- формат pdf
- размер 26.41 МБ
- добавлен
25 сентября 2011 г.


М,: Эксмо, 2008 г., 434 с. В книге рассматриваются вариационные ряды, элементы комбинаторики, основные понятия и теоремы теории вероятностей, законы распределения случайных величин, закон больших чисел, представляющие значительный интерес в вопросах экономики, бизнеса, маркетинга и менеджмента. Рассматриваются и обосновываются требования, предъявляемые к организации выборки и обеспечивающие ее репрезентативность. Подробно разбираются проблемы то…
Издания | Библиотечно-издательский комплекс СФУ
- Издания(активная вкладка)
- Услуги
Все года изданияТекущий годПоследние 2 годаПоследние 5 летПоследние 10 лет
Все виды изданийУчебная литератураНаучная литератураЖурналыГазетыМатериалы конференций
Все темыЕстественные и точные наукиАстрономияБиологияГеографияГеодезия. КартографияГеологияГеофизикаИнформатикаКибернетикаМатематикаМеханикаОхрана окружающей среды. Экология человекаФизикаХимияТехнические и прикладные науки, отрасли производстваАвтоматика. Вычислительная техникаБиотехнологияВодное хозяйствоГорное делоЖилищно-коммунальное хозяйство. Домоводство. Бытовое обслуживаниеКосмические исследованияЛегкая промышленностьЛесная и деревообрабатывающая промышленностьМашиностроениеМедицина и здравоохранениеМеталлургияМетрологияОхрана трудаПатентное дело. Изобретательство. РационализаторствоПищевая промышленностьПолиграфия. Репрография. ФотокинотехникаПриборостроениеПрочие отрасли экономикиРыбное хозяйство. АквакультураСвязьСельское и лесное хозяйствоСтандартизацияСтатистикаСтроительство. АрхитектураТранспортХимическая технология. Химическая промышленностьЭлектроника. РадиотехникаЭлектротехникаЭнергетикаЯдерная техникаОбщественные и гуманитарные наукиВнешняя торговляВнутренняя торговля. Туристско-экскурсионное обслуживаниеВоенное делоГосударство и право. Юридические наукиДемографияИскусство. ИскусствоведениеИстория. Исторические наукиКомплексное изучение отдельных стран и регионовКультура.
Экология человекаФизикаХимияТехнические и прикладные науки, отрасли производстваАвтоматика. Вычислительная техникаБиотехнологияВодное хозяйствоГорное делоЖилищно-коммунальное хозяйство. Домоводство. Бытовое обслуживаниеКосмические исследованияЛегкая промышленностьЛесная и деревообрабатывающая промышленностьМашиностроениеМедицина и здравоохранениеМеталлургияМетрологияОхрана трудаПатентное дело. Изобретательство. РационализаторствоПищевая промышленностьПолиграфия. Репрография. ФотокинотехникаПриборостроениеПрочие отрасли экономикиРыбное хозяйство. АквакультураСвязьСельское и лесное хозяйствоСтандартизацияСтатистикаСтроительство. АрхитектураТранспортХимическая технология. Химическая промышленностьЭлектроника. РадиотехникаЭлектротехникаЭнергетикаЯдерная техникаОбщественные и гуманитарные наукиВнешняя торговляВнутренняя торговля. Туристско-экскурсионное обслуживаниеВоенное делоГосударство и право. Юридические наукиДемографияИскусство. ИскусствоведениеИстория. Исторические наукиКомплексное изучение отдельных стран и регионовКультура.
Все институтыВоенно-инженерный институтБазовая кафедра специальных радиотехнических системВоенная кафедраУчебно-военный центрГуманитарный институтКафедра ИТ в креативных и культурных индустрияхКафедра истории России, мировых и региональных цивилизацийКафедра культурологии и искусствоведенияКафедра рекламы и социально-культурной деятельностиКафедра философииЖелезногорский филиал СФУИнженерно-строительный институтКафедра автомобильных дорог и городских сооруженийКафедра инженерных систем, зданий и сооруженийКафедра проектирования зданий и экспертизы недвижимостиКафедра строительных конструкций и управляемых системКафедра строительных материалов и технологий строительстваИнститут архитектуры и дизайнаКафедра архитектурного проектированияКафедра градостроительстваКафедра дизайнаКафедра дизайна архитектурной средыКафедра изобразительного искусства и компьютерной графикиИнститут гастрономииБазовая кафедра высшей школы ресторанного менеджментаИнститут горного дела, геологии и геотехнологийКафедра геологии месторождений и методики разведкиКафедра геологии, минералогии и петрографииКафедра горных машин и комплексовКафедра инженерной графикиКафедра маркшейдерского делаКафедра открытых горных работКафедра подземной разработки месторожденийКафедра технической механикиКафедра технологии и техники разведкиКафедра шахтного и подземного строительстваКафедра электрификации горно-металлургического производстваИнститут инженерной физики и радиоэлектроникиБазовая кафедра «Радиоэлектронная техника информационных систем»Базовая кафедра инфокоммуникацийБазовая кафедра физики конденсированного состояния веществаБазовая кафедра фотоники и лазерных технологийКафедра нанофазных материалов и нанотехнологийКафедра общей физикиКафедра приборостроения и наноэлектроникиКафедра радиотехникиКафедра радиоэлектронных системКафедра современного естествознанияКафедра теоретической физики и волновых явленийКафедра теплофизикиКафедра экспериментальной физики и инновационных технологийКафедры физикиИнститут космических и информационных технологийБазовая кафедра «Интеллектуальные системы управления»Базовая кафедра «Информационные технологии на радиоэлектронном производстве»Базовая кафедра геоинформационных системКафедра высокопроизводительных вычисленийКафедра вычислительной техникиКафедра информатикиКафедра информационных системКафедра прикладной математики и компьютерной безопасностиКафедра разговорного иностранного языкаКафедра систем автоматики, автоматизированного управления и проектированияКафедра систем искусственного интеллектаИнститут математики и фундаментальной информатикиБазовая кафедра вычислительных и информационных технологийБазовая кафедра математического моделирования и процессов управленияКафедра алгебры и математической логикиКафедра высшей и прикладной математикиКафедра математического анализа и дифференциальных уравненийКафедра математического обеспечения дискретных устройств и системКафедры высшей математики №2афедра теории функцийИнститут нефти и газаБазовая кафедра пожарной и промышленной безопасностиБазовая кафедра проектирования объектов нефтегазового комплексаБазовая кафедра химии и технологии природных энергоносителей и углеродных материаловКафедра авиационных горюче-смазочных материаловКафедра бурения нефтяных и газовых скважинКафедра геологии нефти и газаКафедра геофизикиКафедра машин и оборудования нефтяных и газовых промысловКафедра разработки и эксплуатации нефтяных и газовых месторожденийКафедра технологических машин и оборудования нефтегазового комплексаКафедра топливообеспеченя и горюче-смазочных материаловИнститут педагогики, психологии и социологииКафедра информационных технологий обучения и непрерывного образованияКафедра общей и социальной педагогикиКафедра психологии развития и консультированияКафедра современных образовательных технологийКафедра социологииИнститут торговли и сферы услугБазовая кафедра таможенного делаКафедра бухгалтерского учета, анализа и аудитаКафедра гостиничного делаКафедра математических методов и информационных технологий в торговле и сфере услугКафедра технологии и организации общественного питанияКафедра товароведения и экспертизы товаровКафедра торгового дела и маркетингаОтделение среднего профессионального образования (ОСПО)Институт управления бизнес-процессамиБазовая кафедра Федеральной службы по финансовому мониторингу (Росфинмониторинг)Кафедра бизнес-информатики и моделирования бизнес-процессовКафедра маркетинга и международного администрированияКафедра менеджмент производственных и социальных технологийКафедра цифровых технологий управленияКафедра экономики и управления бизнес-процессамиКафедра экономической и финансовой безопасностиИнститут физ.
По релевантностиСначала новыеСначала старыеПо дате поступленияПо названиюПо автору
Текст в электронном виде
Метрология, стандартизация и сертификация
Трансфер инноваций.
 Курс лекций
Курс лекцийОбщая и неорганическая химия. Общие вопросы химии
Профессиональный английский язык для документоведов
Методология выпускной квалификационной работы магистра
Педагогика и методика преподавания истории
Педагогическая практика
Digital анализ в условиях цифровой экономики
ДинамическоемоделированиепроизводственныхпроцессовКапустина Светлана Витальевна2022 годДинамическое моделирование производственных процессов
Материаловедение. Технология конструкционных материалов
Роль плановых органов государственного управления в социально-экономическом развитии…
Буровзрывные работыКирсанов АлександрКонстантиновичВохмин Сергей АнтоновичУрбаев Денис Александрович2022 годБуровзрывные работы
Без названия
%PDF-1.6
%
1 0 объект
>
ручей
2 0 3 78 4 264 5 3526 6 3705 7 3749 8 3808 9 3943 10 4675 11 4906 12 4922 13 4942 14 4958 15 5137 16 5153 17 5173 18 5189 19 5368 20 5384 21 5404 22 5420 23 5580 24 5596 25 5616 26 5793 27 5809 28 5829 29 5845 30 6022 31 6038 32 6058 33 6074 34 6252 35 6268 36 6288 37 6304 38 6463 39 6479 40 6499 41 6676 42 6692 43 6712 44 6728 45 6905 46 6921 47 6941 48 6957 49 7136 50 7152 51 7172 52 7188 53 7348 54 7364 55 7384 56 7563 57 7579 58 759959 7615 60 7794 61 7810 62 7831 63 7847 64 8026 65 8042 66 8063 67 8079 68 8258 69 8274 70 8295 71 8311 72 8489 73 8505 74 8526 75 8542 76 8720 77 8736 78 8757 79 8773 80 8952 81 8968 82 8989 83 9005 84 9184 85 9200 86 9221 87 9237 88 9416 89 9432 90 9453 91 9469 92 9648 93 9664 94 9685 95 9701 96 9880 97 9896 98 9917 99 993 3
>
>
>
> /Тип /Страница >>
>
>
>
>
>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
>
конечный поток
эндообъект
100 0 объект
>
ручей
2019-05-10T22:20:48+00:002019-05-10T09:57:22-08:00ocrmypdf 8. 0.0 / Tesseract OCR-PDF 4.0.0-beta.1
0.0 / Tesseract OCR-PDF 4.0.0-beta.1
 548 3001 549 3022 550 3038 551 3220 552 3236 553 3257 554 3273 555 3455 556 3471 557 3492 558 3508 559 3687 560 3703 561 3724 562 3740 563 3919 564 3935 565 3956 566 3972 567 4153 568 4169 569 4190 570 4206 571 4387 572 4403 573 4424 574 4440 575 4621 576 4637 577 4658 578 4674 579 4855 580 4871 581 4892 582 4908 583 5089 584 5105 585 5127 586 5143 587 5324 588 5340 589 5362 590 5378 591 5560 592 5576 593 5598 594 5614 595 5796
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
596 0 объект
>
ручей
597 0 598 22 599 38 600 220 601 236 602 258 603 274 604 456 605 472 606 494 607 510 608 692 609 708 610 730 611 746 612 928 613 944 614 966 615 982 616 1163 617 1179 618 1201 619 1217 620 1398 621 1414 622 1436 623 1452 624 1634 625 1650 626 1672 627 1688 628 1870 629 1886 630 1908 631 1924 632 2105 633 2121 634 2143 635 2159 636 2340 637 2356 638 2378 639 2394 640 2576 641 2592 642 2614 643 2630 644 2812 645 2828 646 2850 647 2866 648 3048 649 3064 650 3086 651 3102 652 3284 653 3300 654 3322 655 3338 656 3520 657 3536 658 3558 6593574 660 3756 661 3772 662 3794 663 3810 664 3992 665 4008 666 4030 667 4046 668 4228 669 4244 670 4266 671 4282 672 4464 673 4480 674 4502 675 4518 676 4700 677 4716 678 4738 679 4754 680 4936 681 4952 682 4974 683 4990 684 5172 685 5188 686 5210 687 5226 688 5408 689 5424 690 5446 691 5462 692 5644 693 5660 694 5682
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
695 0 объект
>
ручей
696 0 697 182 698 198 699 220 700 236 701 418 702 434 703 456 704 472 705 654 706 670 707 692 708 708 709 890 710 906 711 928 712 944 713 1126 714 1142 715 1164 716 1180 717 1362 718 1378 719 1400 720 1416 721 1597 722 1613 723 1635 724 1651 725 1832 726 1848 727 1870 728 1886 729 2068 730 2084 731 2106 732 2122 733 2304 734 2320 735 2342 736 2358 737 2539 738 2555 739 2577 740 2593 741 2774 742 2790 743 2812 744 2828 745 3010 746 3026 747 3048 748 3064 749 3246 750 3262 751 3284 752 3300 753 3482 754 3498 755 3520 756 3536 757 3718 758 3734 759 3756 760 3772 761 3954 762 3970 763 3992 764 4008 765 4190 766 4206 767 4228 768 4244 769 4426 770 4442 771 4464 772 4480 773 4662 774 4678 775 4700 776 4716 777 4898 778 4914 779 4936 780 4952 781 5134 782 5150 783 5172 784 5188 785 5370 786 5386 787 5408 788 5424 789 5606 790 5622 791 5644 792 56580 793
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
794 0 объект
>
ручей
795 0 796 22 797 38 798 219 799 235 800 257 801 273 802 455 803 471 804 493 805 509 806 691 807 707 808 729 809 745 810 927 811 943 812 965 813 981 814 1163 815 1179 816 1201 817 1217 818 1399 819 1415 820 1437 821 1453 822 1635 823 1651 824 1673 825 1689 826 1871 827 1887 828 1909 829 1925 830 2107 831 2123 832 2145 833 2161 834 2343 835 2359 836 2381 837 2397 838 2579 839 2595 840 2617 841 2633 842 2814 843 2830 844 2852 845 2868 846 3049 847 3065 848 3087 849 3103 850 3284 851 3300 852 3322 853 3338 854 3519855 3535 856 3557 857 3573 858 3755 859 3771 860 3793 861 3809 862 3991 863 4007 864 4029 865 4045 866 4226 867 4242 868 4264 869 4280 870 4461 871 4477 872 4499 873 4515 874 4697 875 4713 876 4735 877 4751 878 4933 879 4949 880 4971 881 4987 882 5169 883 5185 884 5207 885 5223 886 5405 887 5421 888 5443 889 5459 890 5638 891 5654 892 5676
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
893 0 объект
>
ручей
894 0 895 179 896 195 897 217 898 233 899 415 900 431 901 453 902 469 903 651 904 667 905 689 906 705 907 886 908 902 909 924 910 940 911 1121 912 1137 913 1159 914 1175 915 1357 916 1373 917 1395 918 1411 919 1593 920 1609 921 1631 922 1647 923 1828 924 1844 925 1866 926 1882 927 2063 928 2079 929 2101 930 2117 931 2299 932 2315 933 2337 934 2353 935 2535 936 2551 937 2573 938 2589 939 2771 940 2787 941 2809 942 2825 943 3007 944 3023 945 3045 946 3061 947 3243 948 3259 949 3281 950 3297 951 3479 952 3495 953 3517 954 3533 955 3715 956 3731 957 3753 958 3769 959 3951 960 3967 961 3989 962 4005 963 4186 964 4202 965 4224 966 4240 967 4421 968 4437 969 4459 970 4475 971 4657 972 4673 973 4695 974 4711 975 4893 976 4909 977 4931 978 4947 979 5129 980 5145 981 5167 982 5183 983 5365 984 5381 985 5403 986 5419 987 5601 988 5617 989 5639 99959559595959595959595959595959595955959595595959559595955955959575959н.
548 3001 549 3022 550 3038 551 3220 552 3236 553 3257 554 3273 555 3455 556 3471 557 3492 558 3508 559 3687 560 3703 561 3724 562 3740 563 3919 564 3935 565 3956 566 3972 567 4153 568 4169 569 4190 570 4206 571 4387 572 4403 573 4424 574 4440 575 4621 576 4637 577 4658 578 4674 579 4855 580 4871 581 4892 582 4908 583 5089 584 5105 585 5127 586 5143 587 5324 588 5340 589 5362 590 5378 591 5560 592 5576 593 5598 594 5614 595 5796
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
596 0 объект
>
ручей
597 0 598 22 599 38 600 220 601 236 602 258 603 274 604 456 605 472 606 494 607 510 608 692 609 708 610 730 611 746 612 928 613 944 614 966 615 982 616 1163 617 1179 618 1201 619 1217 620 1398 621 1414 622 1436 623 1452 624 1634 625 1650 626 1672 627 1688 628 1870 629 1886 630 1908 631 1924 632 2105 633 2121 634 2143 635 2159 636 2340 637 2356 638 2378 639 2394 640 2576 641 2592 642 2614 643 2630 644 2812 645 2828 646 2850 647 2866 648 3048 649 3064 650 3086 651 3102 652 3284 653 3300 654 3322 655 3338 656 3520 657 3536 658 3558 6593574 660 3756 661 3772 662 3794 663 3810 664 3992 665 4008 666 4030 667 4046 668 4228 669 4244 670 4266 671 4282 672 4464 673 4480 674 4502 675 4518 676 4700 677 4716 678 4738 679 4754 680 4936 681 4952 682 4974 683 4990 684 5172 685 5188 686 5210 687 5226 688 5408 689 5424 690 5446 691 5462 692 5644 693 5660 694 5682
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
695 0 объект
>
ручей
696 0 697 182 698 198 699 220 700 236 701 418 702 434 703 456 704 472 705 654 706 670 707 692 708 708 709 890 710 906 711 928 712 944 713 1126 714 1142 715 1164 716 1180 717 1362 718 1378 719 1400 720 1416 721 1597 722 1613 723 1635 724 1651 725 1832 726 1848 727 1870 728 1886 729 2068 730 2084 731 2106 732 2122 733 2304 734 2320 735 2342 736 2358 737 2539 738 2555 739 2577 740 2593 741 2774 742 2790 743 2812 744 2828 745 3010 746 3026 747 3048 748 3064 749 3246 750 3262 751 3284 752 3300 753 3482 754 3498 755 3520 756 3536 757 3718 758 3734 759 3756 760 3772 761 3954 762 3970 763 3992 764 4008 765 4190 766 4206 767 4228 768 4244 769 4426 770 4442 771 4464 772 4480 773 4662 774 4678 775 4700 776 4716 777 4898 778 4914 779 4936 780 4952 781 5134 782 5150 783 5172 784 5188 785 5370 786 5386 787 5408 788 5424 789 5606 790 5622 791 5644 792 56580 793
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
794 0 объект
>
ручей
795 0 796 22 797 38 798 219 799 235 800 257 801 273 802 455 803 471 804 493 805 509 806 691 807 707 808 729 809 745 810 927 811 943 812 965 813 981 814 1163 815 1179 816 1201 817 1217 818 1399 819 1415 820 1437 821 1453 822 1635 823 1651 824 1673 825 1689 826 1871 827 1887 828 1909 829 1925 830 2107 831 2123 832 2145 833 2161 834 2343 835 2359 836 2381 837 2397 838 2579 839 2595 840 2617 841 2633 842 2814 843 2830 844 2852 845 2868 846 3049 847 3065 848 3087 849 3103 850 3284 851 3300 852 3322 853 3338 854 3519855 3535 856 3557 857 3573 858 3755 859 3771 860 3793 861 3809 862 3991 863 4007 864 4029 865 4045 866 4226 867 4242 868 4264 869 4280 870 4461 871 4477 872 4499 873 4515 874 4697 875 4713 876 4735 877 4751 878 4933 879 4949 880 4971 881 4987 882 5169 883 5185 884 5207 885 5223 886 5405 887 5421 888 5443 889 5459 890 5638 891 5654 892 5676
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
893 0 объект
>
ручей
894 0 895 179 896 195 897 217 898 233 899 415 900 431 901 453 902 469 903 651 904 667 905 689 906 705 907 886 908 902 909 924 910 940 911 1121 912 1137 913 1159 914 1175 915 1357 916 1373 917 1395 918 1411 919 1593 920 1609 921 1631 922 1647 923 1828 924 1844 925 1866 926 1882 927 2063 928 2079 929 2101 930 2117 931 2299 932 2315 933 2337 934 2353 935 2535 936 2551 937 2573 938 2589 939 2771 940 2787 941 2809 942 2825 943 3007 944 3023 945 3045 946 3061 947 3243 948 3259 949 3281 950 3297 951 3479 952 3495 953 3517 954 3533 955 3715 956 3731 957 3753 958 3769 959 3951 960 3967 961 3989 962 4005 963 4186 964 4202 965 4224 966 4240 967 4421 968 4437 969 4459 970 4475 971 4657 972 4673 973 4695 974 4711 975 4893 976 4909 977 4931 978 4947 979 5129 980 5145 981 5167 982 5183 983 5365 984 5381 985 5403 986 5419 987 5601 988 5617 989 5639 99959559595959595959595959595959595955959595595959559595955955959575959н. > /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
992 0 объект
>
ручей
993 0 994 22 995 38 996 217 997 233 998 255 999 271 1000 453 1001 469 1002 491 1003 507 1004 692 1005 708 1006 730 1007 746 1008 931 1009 947 1010 969 1011 985 1012 1170 1013 1186 1014 1208 1015 1224 1016 1409 1017 1425 1018 1447 1019 1463 1020 1648 1021 1664 1022 1686 1023 1702 1024 1887 1025 1903 1026 1925 1027 1941 1028 2126 1029 2142 1030 2164 1031 2180 1032 2365 1033 2381 1034 2403 1035 2419 1036 2604 1037 2620 1038 2642 1039 2658 1040 2843 1041 2859 1042 2881 1043 2897 1044 3081 1045 3097 1046 3119 1047 3135 1048 3319 1049 3335 1050 3357 1051 3373 1052 3558 1053 3574 1054 3596 1055 3612 1056 3797 1057 3813 1058 3835 1059 3851 1060 4036 1061 4052 1062 4074 1063 4090 1064 4275 1065 4291 1066 4313 1067 4329 1068 4514 1069 4530 1070 4552 1071 4568 1072 4753 1073 4769 1074 4791 1075 4807 1076 4991 1077 5007 1078 5029 1079 5045 1080 5229 1081 5245 1082 5267 1083 5283 1084 5467 1085 5483 1086 5505 1087 5521 1088 5705 1089 5721 1090 5743
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
1091 0 объект
>
ручей
1092 0 1093 185 1094 201 1095 223 1096 239 1097 424 1098 440 1099 462 1100 478 1101 662 1102 678 1103 700 1104 716 1105 900 1106 916 1107 1138 1108 954 1109 1138 1111111111111111111111111111111111111111111111111111111111111111111111111 111111111111111111111111111111111111111111111114 1117 1615 1118 1631 1119 1653 1120 1669 1121 1854 1122 1870 1123 1892 1124 1908 1125 2093 1126 2109 1127 2131 1128 2147 1129 2332 1130 2348 1131 2370 1132 2386 1133 2570 1134 2586 1135 2608 1136 2624 1137 2808 1138 2824 1139 2846 1140 2862 1141 3047 1142 3063 1143 3085 1144 3101 1145 3286 1146 3302 1147 3324 1148 3340 11493525 1150 3541 1151 3563 1152 3579 1153 3764 1154 3780 1155 3802 1156 3818 1157 4003 1158 4019 1159 4041 1160 4057 1161 4242 1162 4258 1163 4280 1164 4296 1165 4481 1166 4497 1167 4519 1168 4535 1169 4720 1170 4736 1171 4758 1172 4774 1173 4959 1174 4975 1175 4997 1176 5013 1177 5198 1178 5214 1179 5236.
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
992 0 объект
>
ручей
993 0 994 22 995 38 996 217 997 233 998 255 999 271 1000 453 1001 469 1002 491 1003 507 1004 692 1005 708 1006 730 1007 746 1008 931 1009 947 1010 969 1011 985 1012 1170 1013 1186 1014 1208 1015 1224 1016 1409 1017 1425 1018 1447 1019 1463 1020 1648 1021 1664 1022 1686 1023 1702 1024 1887 1025 1903 1026 1925 1027 1941 1028 2126 1029 2142 1030 2164 1031 2180 1032 2365 1033 2381 1034 2403 1035 2419 1036 2604 1037 2620 1038 2642 1039 2658 1040 2843 1041 2859 1042 2881 1043 2897 1044 3081 1045 3097 1046 3119 1047 3135 1048 3319 1049 3335 1050 3357 1051 3373 1052 3558 1053 3574 1054 3596 1055 3612 1056 3797 1057 3813 1058 3835 1059 3851 1060 4036 1061 4052 1062 4074 1063 4090 1064 4275 1065 4291 1066 4313 1067 4329 1068 4514 1069 4530 1070 4552 1071 4568 1072 4753 1073 4769 1074 4791 1075 4807 1076 4991 1077 5007 1078 5029 1079 5045 1080 5229 1081 5245 1082 5267 1083 5283 1084 5467 1085 5483 1086 5505 1087 5521 1088 5705 1089 5721 1090 5743
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
1091 0 объект
>
ручей
1092 0 1093 185 1094 201 1095 223 1096 239 1097 424 1098 440 1099 462 1100 478 1101 662 1102 678 1103 700 1104 716 1105 900 1106 916 1107 1138 1108 954 1109 1138 1111111111111111111111111111111111111111111111111111111111111111111111111 111111111111111111111111111111111111111111111114 1117 1615 1118 1631 1119 1653 1120 1669 1121 1854 1122 1870 1123 1892 1124 1908 1125 2093 1126 2109 1127 2131 1128 2147 1129 2332 1130 2348 1131 2370 1132 2386 1133 2570 1134 2586 1135 2608 1136 2624 1137 2808 1138 2824 1139 2846 1140 2862 1141 3047 1142 3063 1143 3085 1144 3101 1145 3286 1146 3302 1147 3324 1148 3340 11493525 1150 3541 1151 3563 1152 3579 1153 3764 1154 3780 1155 3802 1156 3818 1157 4003 1158 4019 1159 4041 1160 4057 1161 4242 1162 4258 1163 4280 1164 4296 1165 4481 1166 4497 1167 4519 1168 4535 1169 4720 1170 4736 1171 4758 1172 4774 1173 4959 1174 4975 1175 4997 1176 5013 1177 5198 1178 5214 1179 5236. > /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
1190 0 объект
>
ручей
1191 0 1192 22 1193 38 1194 222 1195 238 1196 260 1197 276 1198 461. 1216 1451 1217 1467 1218 1652 1219 1668 1220 1690 1221 1706 1222 1891. 1241 2899 1242 3084 1243 3100 1244 3122 1245 3138 1246 3323 1247 3339 1248 3361 1249 3377 1250 3562 1251 3578 1252 3600 1253 3616 1254 3801 1255 3817 1256 3839 1257 3855 1258 4040 1259 4056 1260 4078 1261 4094 1262 4278 1263 4294 1264 4316 1265 4332 1266 4516 1267 4532 1268 4554 1269 4570 1270 4755 1271 4771 1272 4793 1273 4809 1274 4994 1275 5010 1276 5032 1277 5048 1278 5233 1279 5249 1280 5271 1281 5287 1282 5472 1283 5488 1284 5510 1285 5526 1286 5710 1287 5726 1288 5748
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
12890 объект
>
ручей
1290 0 1291 184 1292 200 1293 222 1294 238 1295 423 1296 439 1297 461 1298 477 1299 662 1300 678 1301 700 1302 716 1303 900 1304 916 1305 938 1306 954 1307 1138 1308 1154 1309 1176 1310 1192 1311 1376 1312 1392 1313 1414 1314 1430 1315 1614 1316 1630 1317 1652 1318 1668 1319 1853 1320 1869 1321 1891 1322 1907 1323 2092 1324 2108 1325 2130 1326 2146 1327 2331 1328 2347 1329 2369 1330 2385 1331 2570 1332 2586 1333 2608 1334 2624 1335 2807 1336 2823 1337 2845 1338 2861 1339 3044 1340 3060 1341 3082 1342 3098 1343 3282 1344 3298 1345 3320 1346 3336 1347 3520 1348 3536 1349 3558 1350 3574 1351 3759 1352 3775 1353 3797 1354 3813 1355 3998 1356 4014 1357 4036 1358 4052 1359 4237 1360 4253 1361 4275 1362 4291 1363 4476 1364 4492 1365 4514 1366 4530 1367 4715 1368 4731 1369 4753 1370 4769 1371 4954.
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
1190 0 объект
>
ручей
1191 0 1192 22 1193 38 1194 222 1195 238 1196 260 1197 276 1198 461. 1216 1451 1217 1467 1218 1652 1219 1668 1220 1690 1221 1706 1222 1891. 1241 2899 1242 3084 1243 3100 1244 3122 1245 3138 1246 3323 1247 3339 1248 3361 1249 3377 1250 3562 1251 3578 1252 3600 1253 3616 1254 3801 1255 3817 1256 3839 1257 3855 1258 4040 1259 4056 1260 4078 1261 4094 1262 4278 1263 4294 1264 4316 1265 4332 1266 4516 1267 4532 1268 4554 1269 4570 1270 4755 1271 4771 1272 4793 1273 4809 1274 4994 1275 5010 1276 5032 1277 5048 1278 5233 1279 5249 1280 5271 1281 5287 1282 5472 1283 5488 1284 5510 1285 5526 1286 5710 1287 5726 1288 5748
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
12890 объект
>
ручей
1290 0 1291 184 1292 200 1293 222 1294 238 1295 423 1296 439 1297 461 1298 477 1299 662 1300 678 1301 700 1302 716 1303 900 1304 916 1305 938 1306 954 1307 1138 1308 1154 1309 1176 1310 1192 1311 1376 1312 1392 1313 1414 1314 1430 1315 1614 1316 1630 1317 1652 1318 1668 1319 1853 1320 1869 1321 1891 1322 1907 1323 2092 1324 2108 1325 2130 1326 2146 1327 2331 1328 2347 1329 2369 1330 2385 1331 2570 1332 2586 1333 2608 1334 2624 1335 2807 1336 2823 1337 2845 1338 2861 1339 3044 1340 3060 1341 3082 1342 3098 1343 3282 1344 3298 1345 3320 1346 3336 1347 3520 1348 3536 1349 3558 1350 3574 1351 3759 1352 3775 1353 3797 1354 3813 1355 3998 1356 4014 1357 4036 1358 4052 1359 4237 1360 4253 1361 4275 1362 4291 1363 4476 1364 4492 1365 4514 1366 4530 1367 4715 1368 4731 1369 4753 1370 4769 1371 4954. > /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
1388 0 объект
>
ручей
13890 1390 22 1391 38 1392 223 1393 239 1394 261 1395 277 1396 462 1397 478 1398 500 1399 516 1400 701 1401 717 1402 739 1403 755 1404 940 1405 956 1406 978 1407 994 1408 9799901 1405 1456 1406 978 1407 1408 1404 940 14405 1456 1406 978. 1456 1415 1472 1416 1657 1417 1673 1418 1695 1419 1711 1420 1896 1421 1912 1422 1934 1423 1950 1424 2134 1425 2150 1426 2172 1427 2188 1428 2372 1429 2388 1430 2410 1431 2426 1432 2611 1433 2627 1434 2649 1435 2665 1436 2850 1437 2866 1438 2888 1439 2904 1440 3089 1441 3105 1442 3127 1443 3143 1444 3328 1445 3344 1446 3366 1447 3382 1448 3566 14493582 1450 3604 1451 3620 1452 3804 1453 3820 1454 3842 1455 3858 1456 4042 1457 4058 1458 4080 1459 4096 1460 4280 1461 4296 1462 4318 1463 4334 1464 4518 1465 4534 1466 4556 1467 4572 1468 4756 1469 4772 1470 4794 1471 4810 1472 4995 1473 5011 1474 5033 1475 5049 1476 5234 1477 5250 1478 5272 1479 5288 1480 5473 1481 5489 1482 5511 1483 5527 1484 5712 1485 5728 1486 5750
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
1487 0 объект
>
ручей
1488 0 1489185 1490 201 1491 223 1492 239 1493 424 1494 440 1495 462 1496 478 1497 663 1498 679 1499 701 1500 717 1501 902 1502 918 1503 940 1504 956 1505 1140 1506 1156 1507 1178 1508 1194 1509 1357 1510 1373 1511 1395 1512 1579 1513 1595 1514 1617 1515 1633 1516 1817 1517 1833 1518 1855 1519 1871 1520 2055 1521.
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
конечный поток
эндообъект
1388 0 объект
>
ручей
13890 1390 22 1391 38 1392 223 1393 239 1394 261 1395 277 1396 462 1397 478 1398 500 1399 516 1400 701 1401 717 1402 739 1403 755 1404 940 1405 956 1406 978 1407 994 1408 9799901 1405 1456 1406 978 1407 1408 1404 940 14405 1456 1406 978. 1456 1415 1472 1416 1657 1417 1673 1418 1695 1419 1711 1420 1896 1421 1912 1422 1934 1423 1950 1424 2134 1425 2150 1426 2172 1427 2188 1428 2372 1429 2388 1430 2410 1431 2426 1432 2611 1433 2627 1434 2649 1435 2665 1436 2850 1437 2866 1438 2888 1439 2904 1440 3089 1441 3105 1442 3127 1443 3143 1444 3328 1445 3344 1446 3366 1447 3382 1448 3566 14493582 1450 3604 1451 3620 1452 3804 1453 3820 1454 3842 1455 3858 1456 4042 1457 4058 1458 4080 1459 4096 1460 4280 1461 4296 1462 4318 1463 4334 1464 4518 1465 4534 1466 4556 1467 4572 1468 4756 1469 4772 1470 4794 1471 4810 1472 4995 1473 5011 1474 5033 1475 5049 1476 5234 1477 5250 1478 5272 1479 5288 1480 5473 1481 5489 1482 5511 1483 5527 1484 5712 1485 5728 1486 5750
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
1487 0 объект
>
ручей
1488 0 1489185 1490 201 1491 223 1492 239 1493 424 1494 440 1495 462 1496 478 1497 663 1498 679 1499 701 1500 717 1501 902 1502 918 1503 940 1504 956 1505 1140 1506 1156 1507 1178 1508 1194 1509 1357 1510 1373 1511 1395 1512 1579 1513 1595 1514 1617 1515 1633 1516 1817 1517 1833 1518 1855 1519 1871 1520 2055 1521. 3063 1540 3247 1541 3263 1542 3285 1543 3301 1544 3483 1545 3499 1546 3521 1547 3537 1548 3698 1549 3714 1550 3736 1551 3900 1552 3916 1553 3938 1554 4123 1555 4139 1556 4161 1557 4177 1558 4362 1559 4378 1560 4400 1561 4416 1562 4580 1563 4596 1564 4618 1565 4800 1566 4816 1567 4838 1568 4854 1569 5036 1570 5052 1571 5074
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
1572 0 объект
>
ручей
xNAzmOU$jtcDI+D3VDCڽ`I/t\Q>dǣd}-: x18=.
5CTT]JpB1U’62aCp+@g5
3063 1540 3247 1541 3263 1542 3285 1543 3301 1544 3483 1545 3499 1546 3521 1547 3537 1548 3698 1549 3714 1550 3736 1551 3900 1552 3916 1553 3938 1554 4123 1555 4139 1556 4161 1557 4177 1558 4362 1559 4378 1560 4400 1561 4416 1562 4580 1563 4596 1564 4618 1565 4800 1566 4816 1567 4838 1568 4854 1569 5036 1570 5052 1571 5074
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
> /Тип /Страница >>
>
>
>
> /Тип /Страница >>
>
>
>
конечный поток
эндообъект
1572 0 объект
>
ручей
xNAzmOU$jtcDI+D3VDCڽ`I/t\Q>dǣd}-: x18=.
5CTT]JpB1U’62aCp+@g5Обзор статистической проверки гипотез — Статистика Джим
В этом сообщении блога я объясню, почему вам необходимо использовать статистическую проверку гипотез, и помогу вам ориентироваться в основной терминологии. Проверка гипотез — важная процедура, которую необходимо выполнить, если вы хотите сделать выводы о совокупности, используя случайную выборку. Эти выводы включают оценку свойств совокупности, таких как среднее значение, различия между средними значениями, пропорции и отношения между переменными.
Проверка гипотез — важная процедура, которую необходимо выполнить, если вы хотите сделать выводы о совокупности, используя случайную выборку. Эти выводы включают оценку свойств совокупности, таких как среднее значение, различия между средними значениями, пропорции и отношения между переменными.
В этом посте представлен обзор статистической проверки гипотез. Если вам нужно выполнить проверку гипотез, подумайте о том, чтобы приобрести мою книгу «Проверка гипотез: интуитивное руководство».
Зачем выполнять статистическую проверку гипотез
Используйте проверку гипотез, чтобы определить, являются ли различия между этими средними значениями случайной ошибкой или реальным эффектом. Проверка гипотез — это форма логической статистики, которая позволяет нам делать выводы обо всей совокупности на основе репрезентативной выборки. Вы получаете огромные преимущества, работая с образцом. В большинстве случаев просто невозможно наблюдать за всей популяцией, чтобы понять ее свойства. Единственная альтернатива — собрать случайную выборку, а затем использовать статистику для ее анализа.
Единственная альтернатива — собрать случайную выборку, а затем использовать статистику для ее анализа.
Хотя образцы гораздо более практичны и дешевле в работе, есть и компромиссы. Когда вы оцениваете свойства совокупности по выборке, маловероятно, что выборочная статистика будет точно соответствовать фактической величине совокупности. Например, среднее значение вашей выборки вряд ли будет равно среднему значению генеральной совокупности. Разница между статистикой выборки и значением генеральной совокупности является ошибкой выборки.
Различия, наблюдаемые исследователями в выборках, могут быть связаны с ошибкой выборки, а не с реальным эффектом на уровне популяции. Если ошибка выборки вызывает наблюдаемую разницу, то в следующий раз, когда кто-то проведет тот же эксперимент, результаты могут быть другими. Проверка гипотез включает оценку ошибки выборки, чтобы помочь вам принять правильное решение. Узнайте больше об ошибке выборки.
Например, если вы изучаете долю дефектов, вызванных двумя производственными методами, любая разница, которую вы заметите между пропорциями двух образцов, может быть ошибкой выборки, а не реальной разницей. Если разница не существует на уровне населения, вы не получите ожидаемых преимуществ на основе выборочной статистики. Это может дорого обойтись!
Если разница не существует на уровне населения, вы не получите ожидаемых преимуществ на основе выборочной статистики. Это может дорого обойтись!
Давайте рассмотрим некоторые основные термины проверки гипотез, которые вам необходимо знать.
Исходная информация : Разница между описательной и логической статистикой и совокупностями, параметрами и выборками в логической статистике
Проверка гипотез
Проверка гипотез — это статистический анализ, в котором используются выборочные данные для оценки двух взаимоисключающих теорий о свойствах совокупности. Статистики называют эти теории нулевой гипотезой и альтернативной гипотезой. Тест гипотез оценивает статистику вашей выборки и учитывает оценку ошибки выборки, чтобы определить, какую гипотезу поддерживают данные.
Когда вы можете отклонить нулевую гипотезу, результаты являются статистически значимыми, и ваши данные подтверждают теорию о существовании эффекта на уровне популяции.
Эффект
Эффект представляет собой разницу между значением генеральной совокупности и значением нулевой гипотезы. Эффект также известен как эффект популяции или разница. Например, средняя разница между результатами для здоровья в группе лечения и контрольной группе является эффектом.
Эффект также известен как эффект популяции или разница. Например, средняя разница между результатами для здоровья в группе лечения и контрольной группе является эффектом.
Как правило, вы не знаете размер фактического эффекта. Однако вы можете использовать проверку гипотезы, чтобы определить, существует ли эффект, и оценить его размер. Тесты гипотез преобразуют ваш эффект выборки в тестовую статистику, которую он оценивает на предмет статистической значимости. Узнайте больше о статистике тестов.
Эффект может быть статистически значимым, но это не обязательно означает, что он важен в реальном практическом смысле. Для получения дополнительной информации прочитайте мой пост о статистической и практической значимости.
Нулевая гипотеза
Нулевая гипотеза — это одна из двух взаимоисключающих теорий о свойствах совокупности при проверке гипотез. Обычно нулевая гипотеза утверждает, что эффекта нет (т. е. размер эффекта равен нулю). Нуль часто обозначается H 0 .
При проверке любой гипотезы исследователи проверяют некий эффект. Эффектом может быть эффективность новой прививки, долговечность нового продукта, доля брака в производственном процессе и так далее. Существует некоторое преимущество или различие, которое исследователи надеются выявить.
Однако возможно отсутствие эффекта или различий между экспериментальными группами. В статистике мы называем это отсутствие эффекта нулевой гипотезой. Следовательно, если вы можете отвергнуть нулевое значение, вы можете отдать предпочтение альтернативной гипотезе, утверждающей, что эффект существует (не равен нулю) на уровне популяции.
Вы можете думать о нуле как о теории по умолчанию, против которой требуются достаточно веские доказательства, чтобы отвергнуть ее.
Например, в t-критерии с двумя выборками нулевое значение часто означает, что разница между двумя средними значениями равна нулю.
Связанный пост : Более подробное понимание нулевой гипотезы
Альтернативная гипотеза
Альтернативная гипотеза — это другая теория о свойствах населения при проверке гипотез. Как правило, альтернативная гипотеза утверждает, что параметр совокупности не равен значению нулевой гипотезы. Другими словами, имеет место ненулевой эффект. Если ваша выборка содержит достаточно доказательств, вы можете отклонить нулевую гипотезу и отдать предпочтение альтернативной гипотезе. Альтернатива часто отождествляется с H 1 или H A .
Как правило, альтернативная гипотеза утверждает, что параметр совокупности не равен значению нулевой гипотезы. Другими словами, имеет место ненулевой эффект. Если ваша выборка содержит достаточно доказательств, вы можете отклонить нулевую гипотезу и отдать предпочтение альтернативной гипотезе. Альтернатива часто отождествляется с H 1 или H A .
Например, в t-критерии с двумя выборками альтернатива часто утверждает, что разница между двумя средними не равна нулю.
Вы можете указать либо одностороннюю, либо двустороннюю альтернативную гипотезу:
Если вы выполняете проверку двусторонней гипотезы, альтернатива утверждает, что параметр совокупности не равен нулевому значению. Например, когда альтернативной гипотезой является H A : μ ≠ 0, тест может обнаруживать различия как больше, так и меньше нулевого значения.
Односторонняя альтернатива имеет больше возможностей для обнаружения эффекта, но может проверять различия только в одном направлении. Например, H A : μ > 0 может проверять только различия, которые больше нуля.
Например, H A : μ > 0 может проверять только различия, которые больше нуля.
Связанные сообщения : Понимание T-тестов и односторонних и двусторонних тестов гипотез Объяснение
P-значения
P-значения — это вероятность того, что вы получите эффект, наблюдаемый в вашей выборке, или больше , если нулевая гипотеза верна. Проще говоря, p-значения говорят вам, насколько сильно ваши выборочные данные противоречат нулю. Более низкие p-значения представляют собой более сильные доказательства против нуля. Вы используете P-значения в сочетании с уровнем значимости, чтобы определить, поддерживают ли ваши данные нулевую или альтернативную гипотезу.
Связанный пост : Правильная интерпретация P-значений
Уровень значимости (альфа)
Уровень значимости, также известный как альфа или α, является доказательным стандартом, который исследователи устанавливают перед исследованием. Он указывает, насколько сильно выборочное свидетельство должно противоречить нулевой гипотезе, прежде чем вы сможете отклонить нулевое значение для всей совокупности. Этот стандарт определяется вероятностью отклонения истинной нулевой гипотезы. Другими словами, это вероятность того, что вы говорите о наличии эффекта, когда его нет. Низкие уровни значимости указывают на то, что вам требуются более веские доказательства, прежде чем вы отклоните нулевое значение.
Он указывает, насколько сильно выборочное свидетельство должно противоречить нулевой гипотезе, прежде чем вы сможете отклонить нулевое значение для всей совокупности. Этот стандарт определяется вероятностью отклонения истинной нулевой гипотезы. Другими словами, это вероятность того, что вы говорите о наличии эффекта, когда его нет. Низкие уровни значимости указывают на то, что вам требуются более веские доказательства, прежде чем вы отклоните нулевое значение.
Например, уровень значимости 0,05 означает 5-процентный риск того, что эффект существует, хотя его не существует.
Используйте p-значения и уровни значимости вместе, чтобы определить, какую гипотезу поддерживают данные. Если p-значение меньше вашего уровня значимости, вы можете отклонить нулевое значение и сделать вывод, что эффект является статистически значимым. Другими словами, доказательства в вашей выборке достаточно убедительны, чтобы можно было отвергнуть нулевую гипотезу на уровне популяции.
Похожие сообщения : Графический подход к уровням значимости и P-значениям и концептуальный подход к пониманию уровней значимости о целых популяциях. Существует два типа ошибок, связанных с неправильным выводом.
Существует два типа ошибок, связанных с неправильным выводом.
- Ложные срабатывания: вы отклоняете нулевое значение, которое является истинным. Статистики называют это ошибкой первого рода. Частота ошибок типа I равна вашему уровню значимости или альфа (α).
- Ложные отрицательные значения: вы не можете отклонить нулевое значение, которое является ложным. Статистики называют это ошибкой второго рода. Как правило, вы не знаете частоту ошибок типа II. Тем не менее, это больший риск, когда у вас небольшой размер выборки, зашумленные данные или небольшой размер эффекта. Частота ошибок типа II также известна как бета (β).
Статистическая мощность — это вероятность того, что проверка гипотезы сделает правильный вывод о наличии в генеральной совокупности эффекта выборки. Другими словами, тест правильно отклоняет ложную нулевую гипотезу. Следовательно, мощность обратно пропорциональна ошибке второго рода. Мощность = 1 – β. Узнайте больше о силе в статистике.
Похожие сообщения : Типы ошибок при проверке гипотез и оценке хорошего размера выборки для вашего исследования с использованием анализа мощности
Какой тип проверки гипотез вам подходит?
Существует множество различных процедур, которые вы можете использовать. Правильный выбор зависит от ваших целей исследования и данных, которые вы собираете. Вам нужно понять среднее значение или различия между средними значениями? Или, возможно, вам нужно оценить пропорции. Вы даже можете использовать проверку гипотез, чтобы определить, являются ли отношения между переменными статистически значимыми.
Чтобы выбрать правильную статистическую процедуру, вам необходимо оценить цели вашего исследования и собрать правильный тип данных. Это предварительное исследование необходимо, прежде чем вы начнете исследование.
Связанный пост : Тесты гипотез для непрерывных, двоичных и счетных данных
Статистические тесты имеют решающее значение, когда вы хотите использовать выборочные данные, чтобы сделать выводы о генеральной совокупности, поскольку эти тесты учитывают ошибки выборки. Использование уровней значимости и p-значений для определения того, когда следует отклонить нулевую гипотезу, повышает вероятность того, что вы сделаете правильный вывод.
Использование уровней значимости и p-значений для определения того, когда следует отклонить нулевую гипотезу, повышает вероятность того, что вы сделаете правильный вывод.
Чтобы увидеть альтернативный подход к этим традиционным методам проверки гипотез, узнайте о начальной загрузке в статистике!
Если вы хотите увидеть примеры проверки гипотез в действии, я рекомендую следующие написанные мной посты:
- Насколько эффективны прививки от гриппа? В этом примере показано, как можно использовать статистику для проверки пропорций.
- Смертность в Звездном пути. В этом примере показано, как использовать проверку гипотез с категориальными данными.
- Разрушение мифов о битве полов. Забавный пример, основанный на эпизоде «Разрушители мифов», который оценивает непрерывные данные с помощью нескольких разных тестов.
- Заразна ли зевота? Еще один забавный пример, вдохновленный эпизодом «Разрушители мифов».
Проверка гипотез
Проверка гипотез Вернуться к оглавлениюОбзор урока
- Проверка гипотез
- Ошибки типа I и типа II
- Сила теста
- Вычисление тестовой статистики
- Принятие решения по поводу H 0
- Студент t Распределение
- Степени свободы
- Таблица значений t
- Практическая значимость и статистическая значимость
- Домашнее задание
Проверка гипотез
Как только описательная статистика, комбинаторика, и дистрибутивы хорошо поняты, мы можем перейти к обширной области выводных статистика. Основная концепция называется проверка гипотез или иногда тест статистической гипотезы. Здесь у нас есть
две противоречивые теории о значении параметра населения.
Очень важно, чтобы гипотезы были противоречивыми (противоречивыми),
если одно верно, то другое должно быть ложным и наоборот. Другой способ сказать, что они взаимоисключающие и исчерпывающий, т.е. никакое перекрытие и никакие другие значения невозможны. Простые гипотезы проверяют только одно значение
параметр населения (например, 90 165 p 90 166 = ½),
тогда как 90 187 составных гипотез 90 188 проверяют диапазон значений
( р > ½).
Основная концепция называется проверка гипотез или иногда тест статистической гипотезы. Здесь у нас есть
две противоречивые теории о значении параметра населения.
Очень важно, чтобы гипотезы были противоречивыми (противоречивыми),
если одно верно, то другое должно быть ложным и наоборот. Другой способ сказать, что они взаимоисключающие и исчерпывающий, т.е. никакое перекрытие и никакие другие значения невозможны. Простые гипотезы проверяют только одно значение
параметр населения (например, 90 165 p 90 166 = ½),
тогда как 90 187 составных гипотез 90 188 проверяют диапазон значений
( р > ½). Наши две гипотезы имеют специальные названия: нулевая гипотеза представлен H 0 и альтернативой гипотеза по H a . Исторически нуль
(недействительная, недействительная, ни к чему не приводящая) гипотеза заключалась в том, что
исследователь надеялся отвергнуть. В наши дни это обычная практика не
связывать какое-либо особое значение с тем, какая гипотеза есть какая. (Но
эта обычная практика, возможно, еще не распространилась на науку о поведении. исследовательская гипотеза становится альтернативной гипотезой
и нулевая гипотеза или «соломенный человечек», который нужно сбить с ног, определяется таким образом.)
Хотя проще всего проверить простые гипотезы,
чаще иметь по одному каждого типа или, возможно, оба должны быть составными.
Если значения, указанные H a , все на одной стороне
значения, указанного H 0 , то мы имеем односторонний тест (односторонний), тогда как если Н и значения лежат по обе стороны от H 0 , то мы имеем двухсторонний тест (двусторонний).
Односторонний тест иногда называют тестом направления и
двусторонний тест иногда называют ненаправленным тестом .
В наши дни это обычная практика не
связывать какое-либо особое значение с тем, какая гипотеза есть какая. (Но
эта обычная практика, возможно, еще не распространилась на науку о поведении. исследовательская гипотеза становится альтернативной гипотезой
и нулевая гипотеза или «соломенный человечек», который нужно сбить с ног, определяется таким образом.)
Хотя проще всего проверить простые гипотезы,
чаще иметь по одному каждого типа или, возможно, оба должны быть составными.
Если значения, указанные H a , все на одной стороне
значения, указанного H 0 , то мы имеем односторонний тест (односторонний), тогда как если Н и значения лежат по обе стороны от H 0 , то мы имеем двухсторонний тест (двусторонний).
Односторонний тест иногда называют тестом направления и
двусторонний тест иногда называют ненаправленным тестом .
Результатом нашего теста относительно параметра населения будет
что мы либо отвергаем нулевую гипотезу, либо не удается отклонить нулевая гипотеза.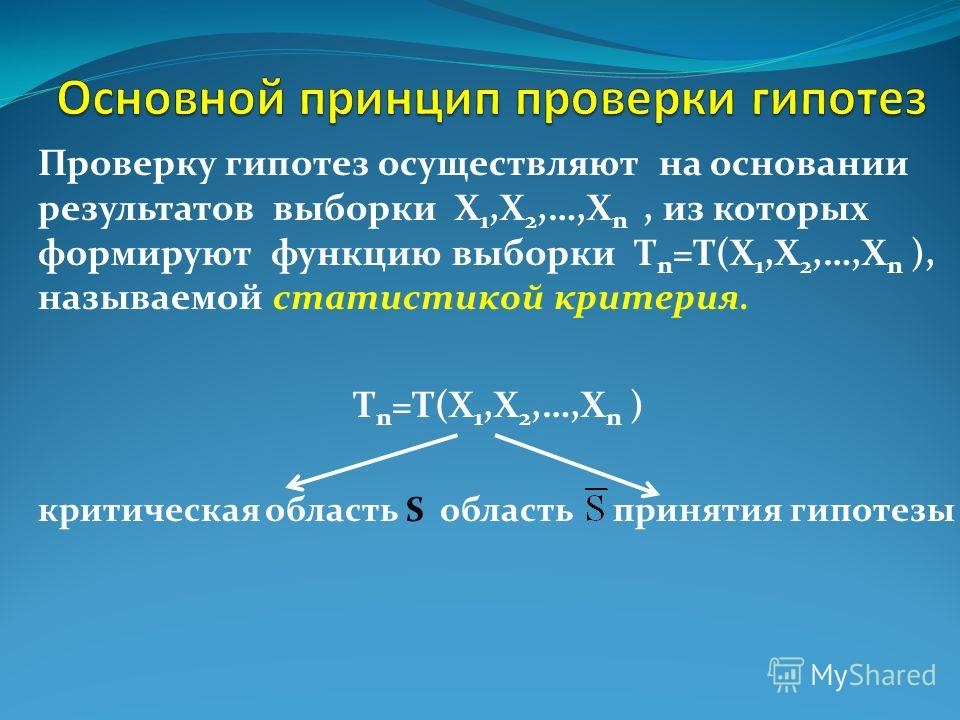 Считается
плохая форма «принять» нулевую гипотезу, хотя если мы
не в состоянии отвергнуть его, это фактически то, что мы делаем.
Когда мы отвергаем нулевую гипотезу, мы только показываем, что она
крайне маловероятно, чтобы быть правдой — мы не доказали это в
математический смысл.
Гипотеза исследования поддерживается отклонением нулевой гипотезы.
Нулевая гипотеза определяет распределение выборки, поскольку оно
(обычно) простая гипотеза, проверяющая одно конкретное значение
параметра населения.
Установление нулевой и альтернативной гипотез иногда
считается первым шагом в проверке гипотез.
Считается
плохая форма «принять» нулевую гипотезу, хотя если мы
не в состоянии отвергнуть его, это фактически то, что мы делаем.
Когда мы отвергаем нулевую гипотезу, мы только показываем, что она
крайне маловероятно, чтобы быть правдой — мы не доказали это в
математический смысл.
Гипотеза исследования поддерживается отклонением нулевой гипотезы.
Нулевая гипотеза определяет распределение выборки, поскольку оно
(обычно) простая гипотеза, проверяющая одно конкретное значение
параметра населения.
Установление нулевой и альтернативной гипотез иногда
считается первым шагом в проверке гипотез.
Ошибки типа I и типа II
Могут возникать два типа ошибок, и для них существует три схемы именования. Эти ошибки не могут возникнуть одновременно. Возможно, таблица прояснит ситуацию.| Отказ\Правда | H 0 Верно | H a Верно |
|---|---|---|
| Отклонено H a | нет ошибок | Ложноположительный, Тип II, бета = P (Отклонить H a | H a верно) |
| Отклонено H 0 | Ложноотрицательный, Тип I, альфа= P (Отклонить H 0 | H 0 верно) | нет ошибки |
Термин ложноположительный для ошибок типа II происходит, возможно, от
анализ крови, где результаты теста оказались положительными, но это не
случай (ложный), что у человека есть то, на что проверяли. Тогда термин ложноотрицательный для ошибок типа I будет означать, что
у человека действительно есть то, на что его проверяли, но тест
не нашел. При тестировании на беременность, СПИД или другие медицинские
условиях, оба типа ошибок могут быть очень серьезной проблемой.
Формально альфа = P (Принять H a | H 0 правда),
что означает вероятность того, что мы «приняли» H a , когда
на самом деле H 0 было правдой. Альфа — термин, используемый для обозначения уровня значимости мы примем. Для достоверности 95% альфа = 0,05.
Для достоверности 99% альфа = 0,01.
Эти два альфа-значения используются чаще всего.
Если наше P-значение, высокая вероятность H 0 , меньше альфа, мы можем отвергнуть нулевую гипотезу.
Альфа и бета, как правило, не могут быть сведены к минимуму — есть компромисс
между двумя. В идеале, конечно, мы бы минимизировали и то, и другое.
Тогда термин ложноотрицательный для ошибок типа I будет означать, что
у человека действительно есть то, на что его проверяли, но тест
не нашел. При тестировании на беременность, СПИД или другие медицинские
условиях, оба типа ошибок могут быть очень серьезной проблемой.
Формально альфа = P (Принять H a | H 0 правда),
что означает вероятность того, что мы «приняли» H a , когда
на самом деле H 0 было правдой. Альфа — термин, используемый для обозначения уровня значимости мы примем. Для достоверности 95% альфа = 0,05.
Для достоверности 99% альфа = 0,01.
Эти два альфа-значения используются чаще всего.
Если наше P-значение, высокая вероятность H 0 , меньше альфа, мы можем отвергнуть нулевую гипотезу.
Альфа и бета, как правило, не могут быть сведены к минимуму — есть компромисс
между двумя. В идеале, конечно, мы бы минимизировали и то, и другое. Исторически так сложилось, что фиксированный уровень значимости был
выбрано (альфа = 0,05 для социальных наук и альфа = 0,01 или альфа = 0,001
например, по естественным наукам). Это произошло из-за того, что
что нулевая гипотеза считалась «текущей теорией» и
размер Ошибки первого рода была гораздо важнее, чем ошибка Ошибки типа II. Теперь оба обычно рассматриваются вместе при определении
выборка адекватного размера. Вместо тестирования с фиксированным
уровень альфа, теперь часто сообщается значение P .
Очевидно, чем меньше значение P , тем сильнее
доказательства (более высокая значимость, меньшая альфа)
предоставленные данные относятся к H 0 .
Исторически так сложилось, что фиксированный уровень значимости был
выбрано (альфа = 0,05 для социальных наук и альфа = 0,01 или альфа = 0,001
например, по естественным наукам). Это произошло из-за того, что
что нулевая гипотеза считалась «текущей теорией» и
размер Ошибки первого рода была гораздо важнее, чем ошибка Ошибки типа II. Теперь оба обычно рассматриваются вместе при определении
выборка адекватного размера. Вместо тестирования с фиксированным
уровень альфа, теперь часто сообщается значение P .
Очевидно, чем меньше значение P , тем сильнее
доказательства (более высокая значимость, меньшая альфа)
предоставленные данные относятся к H 0 .
Пример: 14 июля 2005 г. мы взяли 10 проб.
20 пенни поставили на ребро и ударили по столу.
В результате среднее число голов составило 14,5 при стандартном отклонении 2,12.
Поскольку это небольшая выборка, и дисперсия генеральной совокупности неизвестна,
после того, как мы вычислим значение t и получим t =6,71=(14,5-10)/(2,12/
(10)),
мы применяем t -тест и находим P -значение
любого из 8,73×10 -5 или
4,36×10 -5 в зависимости от
проводим ли мы односторонний или двусторонний тест. В любом случае наши результаты статистически значимых на уровне 0,0001.
В любом случае наши результаты статистически значимых на уровне 0,0001.
| P -значение теста — это вероятность того, что тест
статистика будет принимать значение как экстремальное или более экстремальное, чем что действительно наблюдалось, если предположить, что H 0 верно. |
Сила теста
Степень в степени теста по сравнению с соответствующим правильным значением 1-бета. Это вероятность того, что ошибка II рода не допущена. Для каждого возможного правильного значения существует разное значение бета. параметра населения. Это также зависит от размера выборки ( n ), таким образом, увеличение размера выборки увеличивает мощность. Таким образом, сила важна при планировании и интерпретации тесты значимости. Легко ошибиться в мощности (1-бета) и P -значение (альфа). Мощность будет рассмотрена более подробно в урок 11 (Хинкл глава 13).
Установка уровня значимости будет соответствовать вероятности того, что мы готовы ошибаться в своем заключении, если была совершена ошибка первого рода. Эта вероятность будет соответствовать определенной области (областям) под кривой распределения вероятностей. Эти районы, известные как область отклонения ограничена критическим значением или 90 187 критических значений 90 188, которые часто вычисляются. В качестве альтернативы можно сравните тестовую статистику с соответствующей точки на кривой вероятности. Это эквивалентно способы рассмотрения проблемы, просто разные единицы измерения используются. В одностороннем тесте есть одна область, ограниченная одним критическим значением и в двустороннем тесте есть две области, ограниченные двумя критическими значениями. Какой хвост (левый или правый) рассматривается для односторонний тест зависит от направленности гипотезы.
Установление уровня значимости и соответствующих
критическое значение (я) иногда считается вторым
этап проверки гипотез. Предположительно, мы определили, как статистика
мы хотим протестировать распространяется. Эта выборка
распределение является основным распределением статистики
и определяет, какой статистический тест будет выполнен.
Предположительно, мы определили, как статистика
мы хотим протестировать распространяется. Эта выборка
распределение является основным распределением статистики
и определяет, какой статистический тест будет выполнен.
Вычисление тестовой статистики
После того, как гипотезы сформулированы и критерий отклонения Нулевая гипотеза устанавливается, мы вычисляем тестовая статистика. Тестовая статистика для проверки нулевой гипотезы относительно среднего значения населения составляет z -оценка, если известна дисперсия населения (да, верно!). Мы использовали оценку t выше, которая рассчитывается аналогичным образом, из-за небольшого размера нашей выборки и того факта, что мы не знаем дисперсии населения. Нам придется изучить другие подобные тесты статистические данные и лежащие в их основе распределения. Однако всегда применяется одна и та же основная процедура. Это рассматривается на каком-то шаге 3 при проверке гипотезы.
Принятие решения по
H 0 Последний шаг заключается в том, отклоняем ли мы или не можем отклонить нулевое значение. гипотеза. Хотя принято констатировать, что у нас небольшой вероятность того, что наблюдаемая тестовая статистика появится случайно, если нулевая гипотеза верна, технически правильнее понять, что заявление должно ссылаться на тестовую статистику этого экстремального или более экстремум , так как площадь под любой точкой на кривой вероятности равна нулю. Можно также сказать, что разница между наблюдаемыми и ожидаемая тестовая статистика слишком велика, чтобы быть объясняется случайными колебаниями выборки. это 19из 20 раз это слишком здорово — вот что 1 шанс из 20, что наша случайная выборка нас предала (учитывая альфа = 0,05). Опять же, если мы не сможем отвергнуть нулевую гипотезу, мы должны быть осторожны, чтобы сделать правильное утверждение, например: вероятность появления тестовой статистики бла случайно, если бы параметр населения был мля, больше чем 0,05. Таким образом, используемый уровень значимости
ясно, и мы не совершили еще одну распространенную ошибку
(что с 95% вероятность, H 0 верно).
Таким образом, используемый уровень значимости
ясно, и мы не совершили еще одну распространенную ошибку
(что с 95% вероятность, H 0 верно).Студент
т Распределение Часто бывает так, что нужно рассчитать размер выборки. необходимо для получения определенного уровня достоверности результатов опроса. К сожалению, этот расчет требует предварительного знания населения. стандартное отклонение (). Реально, неизвестно. Часто проводится предварительная выборка, чтобы можно сделать разумную оценку этого критического параметра популяции. Если такой предварительный образец не сделан, но доверительные интервалы для среднего значения населения равны строить с использованием неизвестного , то дистрибутив, известный как Student t дистрибутив можно использовать. Проверка гипотезы на уровне альфа=0,05 или
установление 95-процентного доверительного интервала снова существенно
тоже самое. В обоих случаях критические значения и
области отторжения одинаковы. Тем не менее, мы будем более формально развивать доверие
интервалы в уроке 9 (Хинкл, глава 9).
Тем не менее, мы будем более формально развивать доверие
интервалы в уроке 9 (Хинкл, глава 9).
Сначала немного истории о любопытном названии этого дистрибутива. Уильям Госсет (1876-1919 гг.)37) был химиком пивоварни Guinness, которому нужно было используется с небольшими образцами. Так как ирландская пивоварня не разрешила публикацию результатов исследований он опубликовал в 1908 г. под псевдонимом Студент. Мы знаем, что большие выборки приближаются к нормальному распределению. Госсет показал, что небольшие образцы, взятые практически из Нормальная популяция имеет распределение, характеризующееся размером выборки. Население не обязательно должно быть абсолютно нормальным, только одномодальным и в основном симметричный. Это часто характеризуется как куча формы или холмообразной формы.
Ниже приведены важные свойства распределения Стьюдента t .
- Распределение Student t отличается для разных выборок размеры.
- Распределение Student t обычно имеет колоколообразную форму, но
при меньших размерах выборки показывает повышенную изменчивость (более плоскую). Другими словами, распределение менее остроконечное, чем
нормальное распределение и с более толстыми хвостами (платикуртик).
По мере увеличения размера выборки распределение
приближается к нормальному распределению. Для н > 30, отличия
незначительны.
- Среднее значение равно нулю (во многом аналогично стандартному нормальному распределению).
- Распределение симметрично относительно среднего.
- Дисперсия больше единицы, но приближается к единице сверху по мере увеличения размера выборки ( 2 =1 для стандартного нормального распределения).
- Учитывается тот факт, что стандартное отклонение населения неизвестно.
- Популяция в основном нормальная (унимодальная и в основном симметричная)
 Другими словами, распределение менее остроконечное, чем
нормальное распределение и с более толстыми хвостами (платикуртик).
По мере увеличения размера выборки распределение
приближается к нормальному распределению. Для н > 30, отличия
незначительны.
Другими словами, распределение менее остроконечное, чем
нормальное распределение и с более толстыми хвостами (платикуртик).
По мере увеличения размера выборки распределение
приближается к нормальному распределению. Для н > 30, отличия
незначительны. Чтобы использовать дистрибутив Student t , который часто называют просто
распределения t , первым шагом является вычисление t -показателей.
Это очень похоже на нахождение z баллов. Формула:
Формула:
| т = ( — мк) ÷ ( с / кв.( н )) |
На самом деле, поскольку среднее значение населения, вероятно, также неизвестно, необходимо использовать выборочное среднее значение. критический t — счет можно найти на основе желаемый уровень уверенности и степеней свободы . Степени свободы — довольно технический термин, который пронизывает всю логическую статистику. Обычно его обозначают df . В данном случае это очень распространенное значение n -1.
| В общем, степеней свободы — это число значений, которые
может варьироваться после того, как на все значения были наложены определенные ограничения. |
Откуда взялся термин степени свободы? Предположим, например,
что у вас есть телефонный счет от Ameritech, в котором указано, что ваша семья должна 100 долларов. Ваши мать и отец заявляют, что 70 долларов из них
их, и что ваш младший брат должен всего 5 долларов.
Сколько это оставляет вам?
Здесь n = 3 (родители, брат, сестра, вы), но если у вас есть сумма (или среднее значение)
и еще две части информации, последний элемент данных ограничен.
То же самое и со степенями свободы, вы можете использовать любые n -1 точка данных, но последняя будет определяться для заданного среднего значения.
Другой пример: 10 тестов, в среднем 55, если вы назначаете девять человек.
случайные оценки, последняя тестовая оценка не случайна, а ограничена
общее среднее. Таким образом, для 10 тестов и среднего значения имеется девять степеней свободы.
Ваши мать и отец заявляют, что 70 долларов из них
их, и что ваш младший брат должен всего 5 долларов.
Сколько это оставляет вам?
Здесь n = 3 (родители, брат, сестра, вы), но если у вас есть сумма (или среднее значение)
и еще две части информации, последний элемент данных ограничен.
То же самое и со степенями свободы, вы можете использовать любые n -1 точка данных, но последняя будет определяться для заданного среднего значения.
Другой пример: 10 тестов, в среднем 55, если вы назначаете девять человек.
случайные оценки, последняя тестовая оценка не случайна, а ограничена
общее среднее. Таким образом, для 10 тестов и среднего значения имеется девять степеней свободы.
Если интервал требует уровня достоверности 90%,
тогда альфа = 0,10 и альфа/2 = 0,05 (для двустороннего теста).
Таблицы значений t обычно имеют столбец для степеней свободы.
а затем столбцы t значений, соответствующих различным
участки хвоста. Ниже приведена сокращенная таблица. Для получения полного набора значений обратитесь к таблице большего размера или к вашему TI-83+.
графический калькулятор. DISTR 5 дает tcdf . tcdf ожидает три аргумента,
нижнее значение t , верхнее значение t и степени свободы.
Поскольку на калькуляторе не задана функция, обратная t ,
могут быть задействованы некоторые догадки.
Обратите внимание, как tcdf(9.9,9E99,2) указывает на значение t около 9,9
для однохвостой области 0,005 с двумя степенями свободы.
Пожалуйста, найдите соответствующее значение 9,925 в таблице.
Для получения полного набора значений обратитесь к таблице большего размера или к вашему TI-83+.
графический калькулятор. DISTR 5 дает tcdf . tcdf ожидает три аргумента,
нижнее значение t , верхнее значение t и степени свободы.
Поскольку на калькуляторе не задана функция, обратная t ,
могут быть задействованы некоторые догадки.
Обратите внимание, как tcdf(9.9,9E99,2) указывает на значение t около 9,9
для однохвостой области 0,005 с двумя степенями свободы.
Пожалуйста, найдите соответствующее значение 9,925 в таблице.
Как и в случае с другими доверительными интервалами, мы используем оценку t , чтобы получить предел погрешности термин, который добавляется и вычитается из статистики представляющий интерес (в данном случае выборочное среднее), чтобы получить достоверность интервал для интересующего параметра (в данном случае среднее значение генеральной совокупности). В этом случае предел погрешности определен (поскольку у вас нет стандартное отклонение населения, которое вы используете для выборки) как:
| ME = t альфа/2 ( с ÷ sqrt( n )) |
Ваш доверительный интервал должен выглядеть так:
— МЭ < µ <
+ Я.
Таблица
t Значения Заголовки в таблице ниже, такие как .005/.01, обозначают левый/правый площадь хвоста (0,005) для один хвостовой тест или общая площадь хвоста (левый + правый = 0,01) для двухстороннего теста. В общем, если запись для желаемых степеней свободы отсутствует в таблице используйте запись для следующего меньшего значения степеней свободы. Это гарантирует консервативную оценку.| Степени свободы\1/2 хвостовика | .005/.01 | .01/.02 | .025/.05 | .05/.10 | 0.10/.10/.02.025/.05 |
|---|---|---|---|---|---|
| 1 | 63,66 | 31,82 | 12,71 | 6,314 | 3,078 |
| 2 | 9,925 | 6,965 | 4,303 | 2,920 | 1,886 |
| 3 | 5,841 | 4,541 | 3,182 | 2,353 | 1,638 |
| 4 | 4,604 | 3,747 | 2,776 | 2,132 | 1,533 |
| 5 | 4,032 | 3,365 | 2,571 | 2,015 | 1,476 |
| 10 | 3,169 | 2,764 | 2,228 | 1,812 | 1,372 |
| 15 | 2,947 | 2,602 | 2,132 | 1,753 | 1,341 |
| 20 | 2,845 | 2,528 | 2,086 | 1,725 | 1,325 |
| 25 | 2,787 | 2,485 | 2,060 | 1,708 | 1,316 |
| с | 2,576 | 2,326 | 1,960 | 1,645 | 1,282 |
Хотя процедура t довольно надежная , то есть
не сильно меняется, когда предположения процедуры
нарушены, вы всегда должны строить данные для проверки на асимметрию
и выбросы, прежде чем использовать его на небольших выборках. Здесь small можно интерпретировать как n < 15.
Если ваша выборка мала, а данные явно ненормальны или имеют выбросы
присутствуют, не используйте t .
Если ваша выборка не маленькая, а n < 40, а есть
контуры или сильный перекос, не используйте t .
Поскольку предположение о том, что выборки случайны, важнее
что нормальность распределения населения, t статистику можно безопасно использовать, даже если выборка указывает на
население явно перекошено, если n > 40.
Здесь small можно интерпретировать как n < 15.
Если ваша выборка мала, а данные явно ненормальны или имеют выбросы
присутствуют, не используйте t .
Если ваша выборка не маленькая, а n < 40, а есть
контуры или сильный перекос, не используйте t .
Поскольку предположение о том, что выборки случайны, важнее
что нормальность распределения населения, t статистику можно безопасно использовать, даже если выборка указывает на
население явно перекошено, если n > 40.
Испытания двух образцов t будут обсуждаться в урок 10.
Практическая значимость и статистическая значимость
Не все, что статистически значимо, имеет практическое значение. Выбор альфы (уровня значимости) часто довольно произволен. Р. А. Фишер использовал их в сельскохозяйственных экспериментах в начале десятилетия 1900-х годов и прошел долгий путь к объединению поле. Врач мог бы легко привести доводы в пользу меньшего альфа-канала. чем специалист по поведению. Результаты значимы при 0,10
уровень может иметь реальное значение, которое будет отклонено на уровне 0,05.
Таким образом, область исследования и характеристики исследования
нуждаются в тщательном внимании.
чем специалист по поведению. Результаты значимы при 0,10
уровень может иметь реальное значение, которое будет отклонено на уровне 0,05.
Таким образом, область исследования и характеристики исследования
нуждаются в тщательном внимании.Статистическая точность может быть определена как обратная величина стандартной ошибки для данной тестовой статистики. Таким образом, статистическая точность напрямую зависит от размера выборки. вернее, его квадратный корень. Критики назвали логическую статистику «игрой чисел». в том, что при достаточно большой выборке мы должны быть в состоянии доказать почти что угодно. Это, однако, игнорирует тщательный дизайн и другие работы, проделанные в ходе расследования, которые должны дать практические соображения относительно статистических последствий. Как только инструменты логической статистики помогают анализировать данные, эти результаты все еще нуждаются в осведомлённой интерпретации.
| НАЗАД | ДОМАШНЕЕ ЗАДАНИЕ | ДЕЯТЕЛЬНОСТЬ | ПРОДОЛЖИТЬ |
|---|
- Электронная почта: calkins@andrews.
