
Множественная линейная регрессия
Пример: множественный регрессионный анализ
Коэффициенты регрессии
Значимость эффектов предиктора
Построчный график выбросов
Расстояния Махаланобиса
Удаленные остатки
Задачей множественной линейной регрессии является построение линейной модели связи между набором непрерывных предикторов и непрерывной зависимой переменной. Часто используется следующее регрессионное уравнение:
(1)
Здесь аi — регрессионные коэффициенты, b0 — свободный член(если он используется), е — член, содержащий ошибку — по поводу него делаются различные предположения, которые, однако, чаще сводятся к нормальности распределения с нулевым вектором мат. ожидания и корреляционной матрицей .
Такой линейной моделью хорошо описываются многие задачи в различных предметных областях, например, экономике, промышленности, медицине. Это происходит потому, что некоторые задачи линейны по своей природе.
Приведем простой пример. Пусть требуется предсказать стоимость прокладки дороги по известным ее параметрам. При этом у нас есть данные о уже проложенных дорогах с указанием протяженности, глубины обсыпки, количества рабочего материала, числе рабочих и так далее.
Ясно, что стоимость дороги в итоге станет равной сумме стоимостей всех этих факторов в отдельности. Потребуется некоторое количество, например, щебня, с известной стоимостью за тонну, некоторое количество асфальта также с известной стоимостью.
Возможно, для прокладки придется вырубать лес, что также приведет к дополнительным затратам. Все это вместе даст стоимость создания дороги.
При этом в модель войдет свободный член, который, например, будет отвечать за организационные расходы (которые примерно одинаковы для всех строительно-монтажных работ данного уровня) или налоговые отчисления.
Ошибка будет включать в себя факторы, которые мы не учли при построении модели (например, погоду при строительстве — ее вообще учесть невозможно).
Пример: множественный регрессионный анализ
Для этого примера будут анализироваться несколько возможных корреляций уровня бедности и степень, которая предсказывает процент семей, находящихся за чертой бедности. Следовательно мы будем считать переменную характерезующую процент семей, находящихся за чертой бедности, — зависимой переменной, а остальные переменные непрерывными предикторами.
Коэффициенты регрессии
Чтобы узнать, какая из независимых переменных делает больший вклад в предсказание уровня бедности, изучим стандартизованные коэффициенты (или Бета) регрессии.
Рис. 1. Оценки параметров коэффициентов регрессии.
Коэффициенты Бета это коэффициенты, которые вы бы получили, если бы привели все переменные к среднему 0 и стандартному отклонению 1. Следовательно величина этих Бета коэффициентов позволяет сравнивать относительный вклад каждой независимой переменной в зависимую переменную. Как видно из Таблицы, показанной выше, переменные изменения населения с 1960 года (POP_ CHING), процент населения, проживающего в деревне (PT_RURAL) и число людей, занятых в сельском хозяйстве (N_Empld) являются самыми главными предикторами уровня бедности, т.к. только они статистически значимы (их 95% доверительный интервал не включает в себя 0). Коэффициент регрессии изменения населения с 1960 года (Pop_Chng) отрицательный, следовательно, чем меньше возрастает численность населения, тем больше семей, которые живут за чертой бедности в соответствующем округе. Коэффициент регрессии для населения (%), проживающего в деревне (Pt_Rural) положительный, т.е., чем больше процент сельских жителей, тем больше уровень бедности.
Значимость эффектов предиктора
Просмотрим Таблицу с критериями значимости.
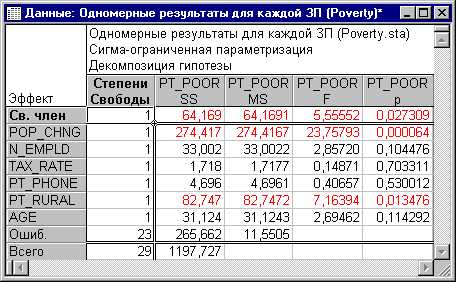
Рис. 2. Одновременные результаты для каждой заданной переменной.
Как показывает эта Таблица, статистически значимы только эффекты 2 переменных: изменение населения с 1960 года (Pop_Chng) и процент населения, проживающего в деревне (Pt_Rural), p < .05.
Анализ остатков. После подгонки уравнения регрессии, почти всегда нужно проверять предсказанные значения и остатки. Например, большие выбросы могут сильно исказить результаты и привести к ошибочным выводам.
Построчный график выбросов
Обычно необходимо проверять исходные или стандартизованные остатки на большие выбросы.
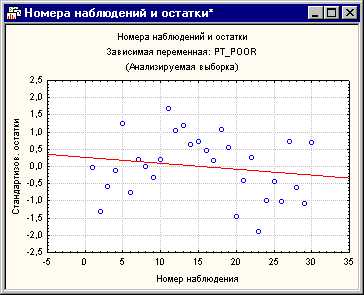
Рис. 3. Номера наблюдений и остатки.
Шкала вертикальной оси этого графика отложена по величине сигма, т.е., стандартного отклонения остатков. Если одно или несколько наблюдений не попадают в интервал ± 3 умноженное на сигма, то, возможно, стоит исключить эти наблюдения (это можно легко сделать через условия выбора наблюдений) и еще раз запустить анализ, чтобы убедится, что результаты не изменяются этими выбросами.
Расстояния Махаланобиса
Большинство статистических учебников уделяют много времени выбросам и остаткам относительно зависимой переменной. Тем не менее роль выбросов в предикторах часто остается не выявленной. На стороне переменной предиктора имеется список переменных, которые участвуют с различными весами (коэффициенты регрессии) в предсказании зависимой переменной. Можно считать независимые переменные многомерным пространством, в котором можно отложить любое наблюдение. Например, если у вас есть две независимых переменных с равными коэффициентами регрессии, то можно было бы построить диаграмму рассеяния этих двух переменных и поместить каждое наблюдение на этот график. Потом можно было отметить на этом графике среднее значение и вычислить расстояния от каждого наблюдения до этого среднего (так называемый центр тяжести) в двумерном пространстве. В этом и заключается основная идея вычисления расстояния Махаланобиса. Теперь посмотрим на гистограмму переменной изменения населения с 1960 года.
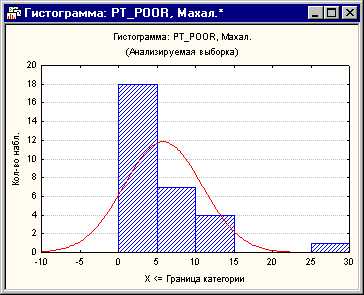
Рис. 4. Гистограмма распределения расстояний Махаланобиса.
Из графика следует, что есть один выброс на расстояниях Махаланобиса.
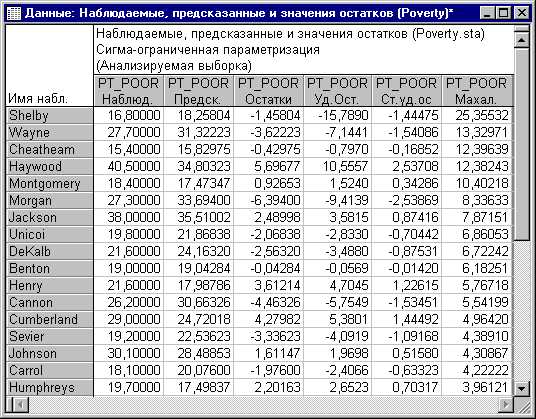
Рис. 5. Наблюдаемые, предсказанные и значения остатков.
Обратите внимание на то, что округ Shelby (в первой строке) выделяется на фоне остальных округов. Если посмотреть на исходные данные, то вы обнаружите, что в действительности округ Shelby имеет самое большое число людей, занятых в сельском хозяйстве (переменная N_Empld). Возможно, было бы разумным выразить в процентах, а не в абсолютных числах, и в этом случае расстояние Махаланобиса округа Shelby, вероятно, не будет таким большим на фоне других округов. Очевидно, что округ Shelby является выбросом.
Удаленные остатки
Другой очень важной статистикой, которая позволяет оценить серьезность проблемы выбросов, являются удаленные остатки. Это стандартизованные остатки для соответствующих наблюдений, которые получаются при удалении этого наблюдения из анализа. Помните, что процедура множественной регрессии подгоняет поверхность регрессии таким образом, чтобы показать взаимосвязь между зависимой и переменной и предиктором. Если одно наблюдение является выбросом (как округ Shelby), то существует тенденция к «оттягиванию» поверхности регрессии к этому выбросу. В результате, если соответствующее наблюдение удалить, будет получена другая поверхность (и Бета коэффициенты). Следовательно, если удаленные остатки очень сильно отличаются от стандартизованных остатков, то у вас будет повод считать, что регрессионный анализа серьезно искажен соответствующим наблюдением. В этом примере удаленные остатки для округа Shelby показывают, что это выброс, который серьезно искажает анализ. На диаграмме рассеяния явно виден выброс.
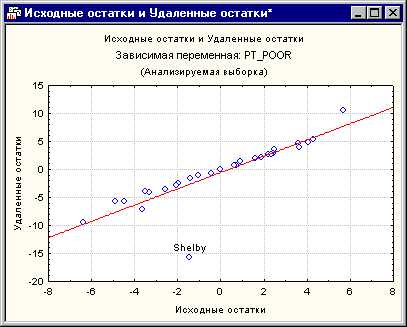
Рис. 6. Исходные остатки и Удаленные остатки переменной, означающей процент семей, проживающих ниже прожиточного минимума.
Большинство из них имеет более или менее ясные интерпретации, тем не менее обратимся к нормальным вероятностным графикам.
Как уже было упомянуто, множественная регрессия предполагает, что существует линейная взаимосвязь между переменными в уравнении и нормальное распределение остатков. Если эти предположения нарушены, то вывод может оказаться неточным. Нормальный вероятностный график остатков укажет вам, имеются ли серьезные нарушения этих предположений или нет.
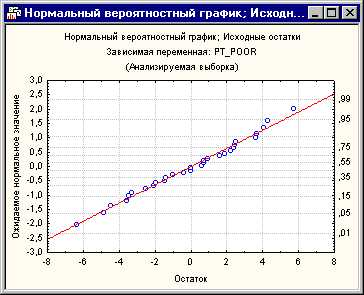
Рис. 7. Нормальный вероятностный график; Исходные остатки.
Этот график был построен следующим образом. Вначале стандартизованные остатки ранжируюся по порядку. По этим рангам можно вычислить z значения (т.е. стандартные значения нормального распределения) на основе предположения, что данные подчиняются нормальному распределению. Эти z значения откладываются по оси y на графике.
Если наблюдаемые остатки (откладываемые по оси x) нормально распределены, то все значения легли бы на прямую линию на графике. На нашем графике все точки лежат очень близко относительно кривой. Если остатки не являются нормально распределенными, то они отклоняются от этой линии. Выбросы также становятся заметными на этом графике.
Если имеется потеря согласия и кажется, что данные образуют явную кривую (например, в форме буквы S) относительно линии, то зависимую переменную можно преобразовать некоторым способом (например, логарифмическое преобразование для «уменьшения» хвоста распределения и т.д.). Обсуждение этого метода находится за пределами этого примера (Neter, Wasserman, и Kutner, 1985, pp. 134-141, представлено обсуждение преобразований, убирающих ненормальность и нелинейность данных). Однако исследователи очень часто просто проводят анализ напрямую без проверки соответствующих предположений, что ведет к ошибочным выводам.
Связанные определения:
Линейная регрессия
Матрица плана
Общая линейная модель
Регрессия
В начало
Содержание портала
statistica.ru
1.3.1 Линейное уравнение множественной регрессии
Ввиду четкой
интерпретации параметров наиболее
широко используется линейная функция.
В линейной множественной регрессии
параметры при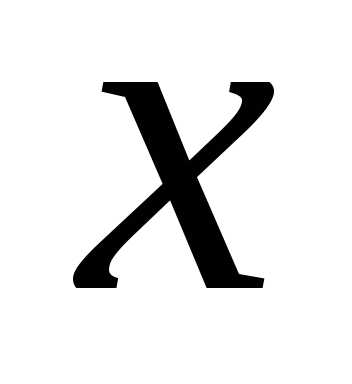 называютсякоэффициентами «чистой»
регрессии. Они характеризуют среднее
изменение результата с изменением
соответствующего фактора на единицу
при неизмененном значении других
факторов, закрепленных на среднем
уровне.
называютсякоэффициентами «чистой»
регрессии. Они характеризуют среднее
изменение результата с изменением
соответствующего фактора на единицу
при неизмененном значении других
факторов, закрепленных на среднем
уровне.
Рассмотрим линейную модель множественной регрессии
. (1.24)
Оценка параметров линейных уравнений регрессии
Классический
подход к оцениванию параметров линейной
модели множественной регрессии основан
на методе наименьших квадратов (МНК).
МНК позволяет получить такие оценки
параметров, при которых сумма квадратов
отклонений фактических значений
результативного признака  от расчетных
от расчетных минимальна:
минимальна:
. (1.25)
Как известно из курса математического анализа, для того чтобы найти экстремум функции нескольких переменных, надо вычислить частные производные первого порядка по каждому из параметров и приравнять их к нулю.
Имеем функцию 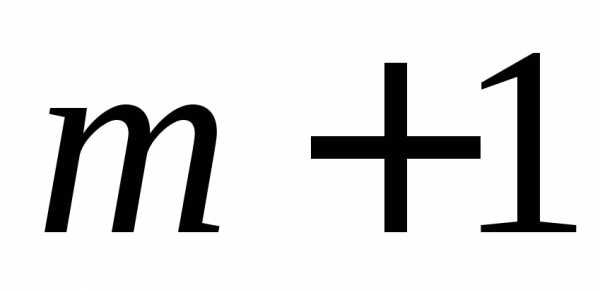 аргумента:
аргумента:
.
Находим частные производные первого порядка:
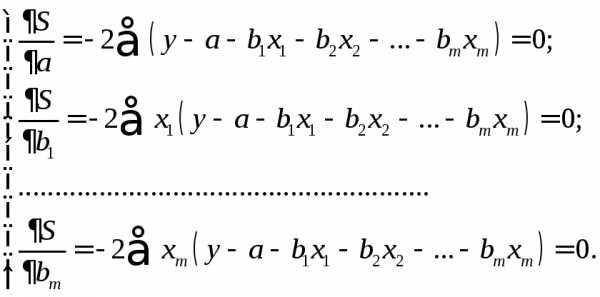
После элементарных преобразований приходим к системе линейных нормальных уравнений для нахождения параметров линейного уравнения множественной регрессии (1.24):
(1.26)
Для двухфакторной модели данная система будет иметь вид:
1.3.2 Линейное уравнение множественной регрессии с стандартизированном масштабе
Метод наименьших квадратов применим и к уравнению множественной регрессии в стандартизированном масштабе:
(1.27)
где
– стандартизированные переменные: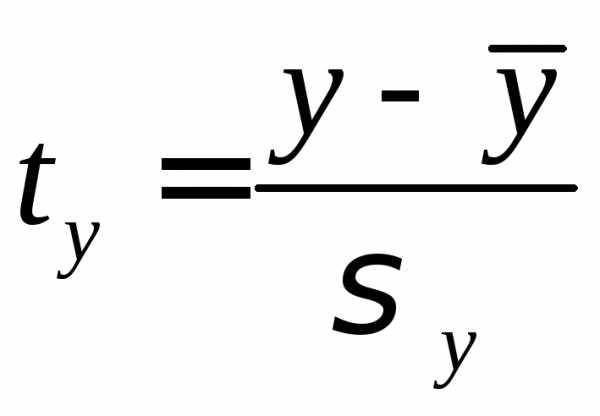 ,
,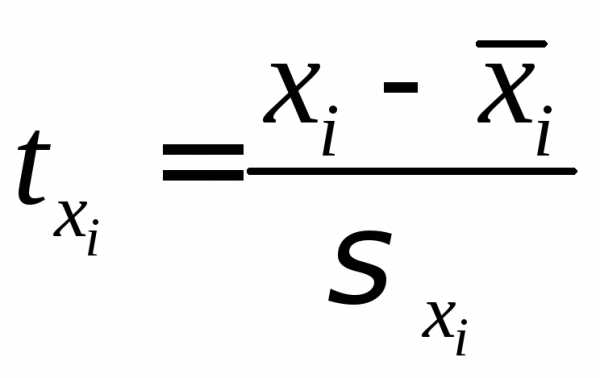 ,
для которых среднее значение равно
нулю:
,
для которых среднее значение равно
нулю: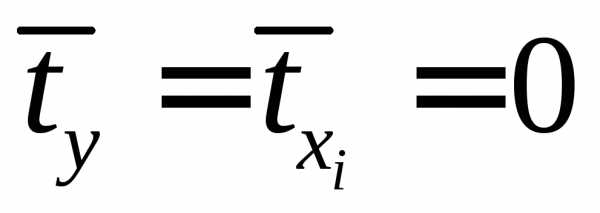 ,
а среднее квадратическое отклонение
равно единице:;
,
а среднее квадратическое отклонение
равно единице:; – стандартизированные коэффициенты
регрессии.
– стандартизированные коэффициенты
регрессии.
Стандартизованные
коэффициенты регрессии показывают, на
сколько единиц изменится в среднем
результат, если соответствующий фактор 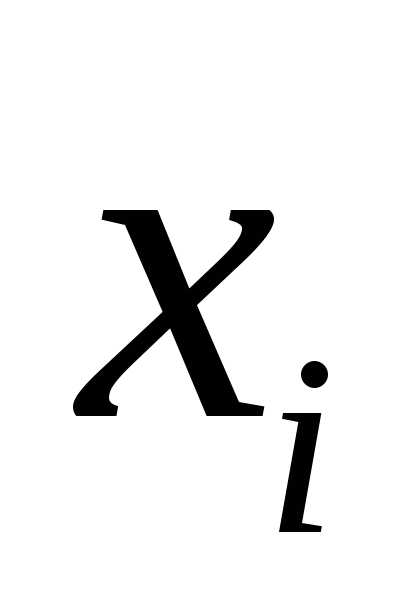 изменится на одну единицу при неизменном
среднем уровне других факторов. В силу
того, что все переменные заданы как
центрированные и нормированные,
стандартизованные коэффициенты регрессии
изменится на одну единицу при неизменном
среднем уровне других факторов. В силу
того, что все переменные заданы как
центрированные и нормированные,
стандартизованные коэффициенты регрессии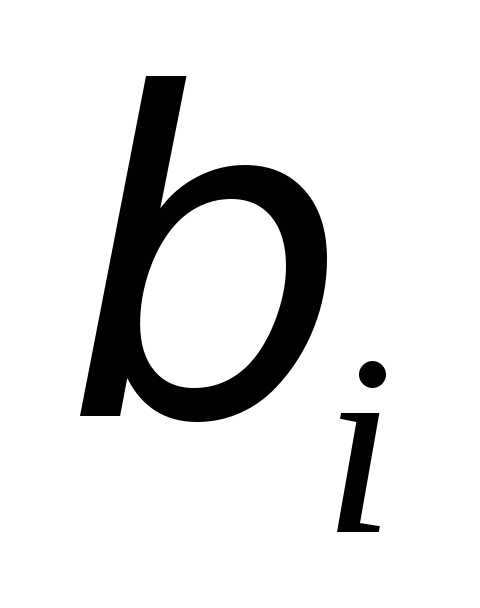 можно сравнивать между собой. Сравнивая
их друг с другом, можно ранжировать
факторы по силе их воздействия на
результат.В этом основное достоинство
стандартизованных коэффициентов
регрессии в отличие от коэффициентов
«чистой» регрессии, которые несравнимы
между собой.
можно сравнивать между собой. Сравнивая
их друг с другом, можно ранжировать
факторы по силе их воздействия на
результат.В этом основное достоинство
стандартизованных коэффициентов
регрессии в отличие от коэффициентов
«чистой» регрессии, которые несравнимы
между собой.
Применяя МНК к уравнению множественной регрессии в стандартизированном масштабе, получим систему нормальных уравнений вида
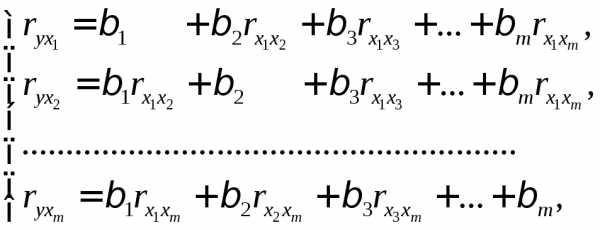 (1.28)
(1.28)
где 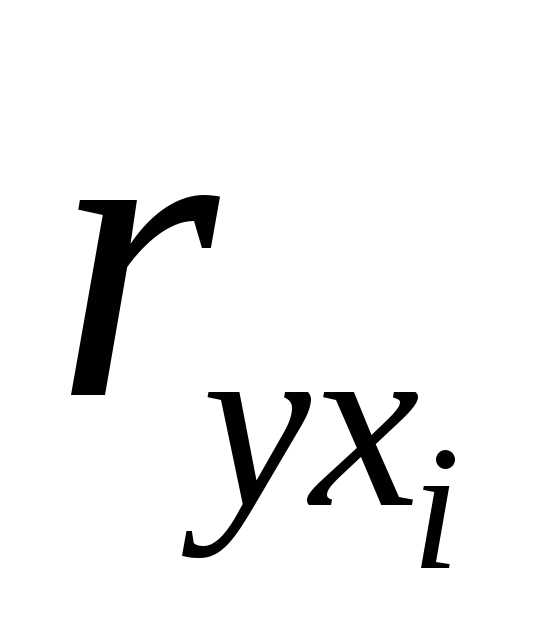 и
и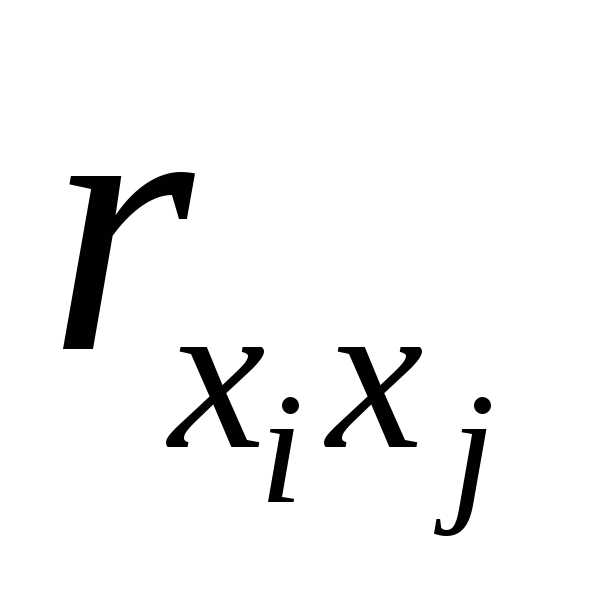 – коэффициенты парной и межфакторной
корреляции.
– коэффициенты парной и межфакторной
корреляции.
Коэффициенты
«чистой» регрессии 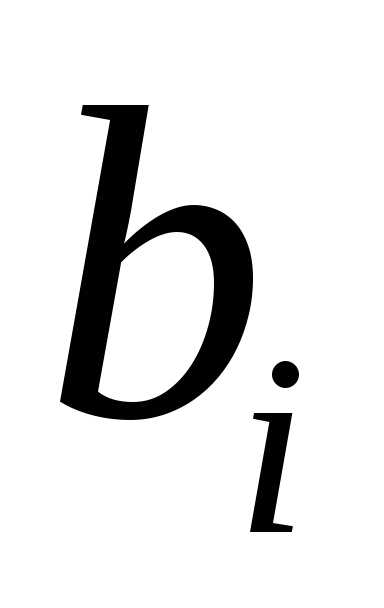 связаны со стандартизованными
коэффициентами регрессии
связаны со стандартизованными
коэффициентами регрессии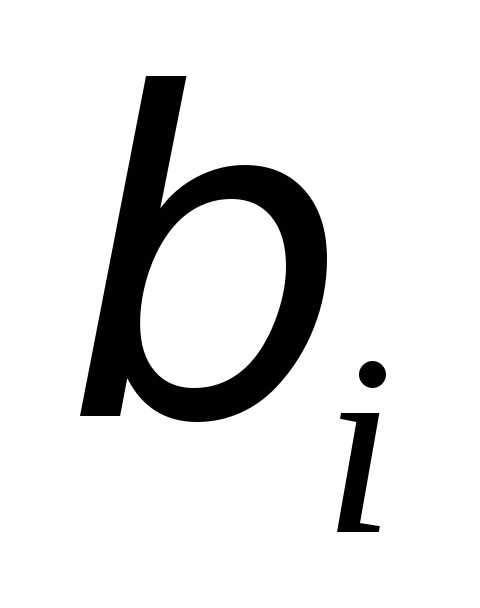 следующим образом:
следующим образом:
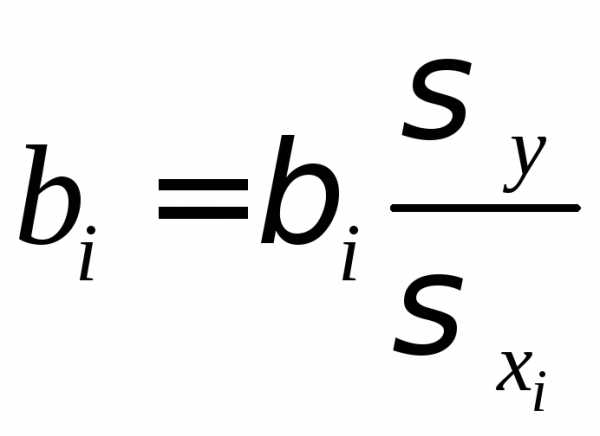 . (1.29)
. (1.29)
Поэтому можно
переходить от уравнения регрессии в
стандартизованном масштабе (1.27) к
уравнению регрессии в натуральном
масштабе переменных (1.24), при этом
параметр  определяется как
определяется как
.
Рассмотренный
смысл стандартизованных коэффициентов
регрессии позволяет их использовать
при отсеве факторов – из модели
исключаются факторы с наименьшим
значением 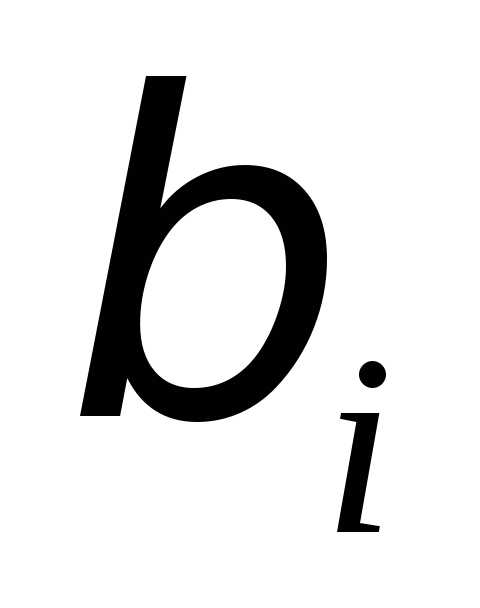 .
.
1.3.2 Частные уравнения регрессии
На основе линейного уравнения множественной регрессии
(1.30)
могут быть найдены частные уравнения регрессии:
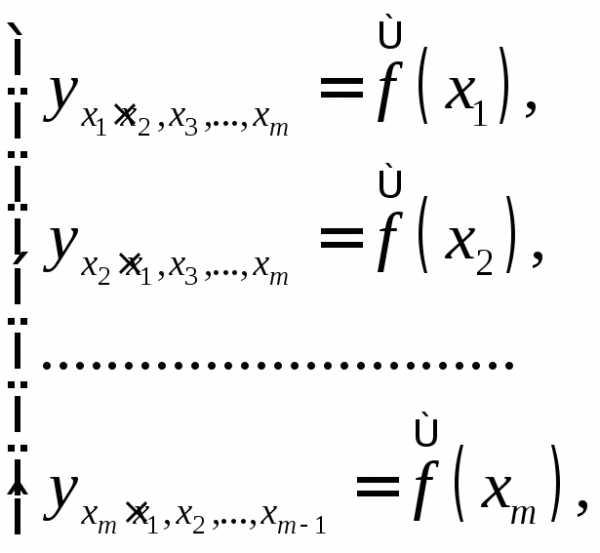 (1.31)
(1.31)
т.е.
уравнения регрессии, которые связывают
результативный признак с соответствующим
фактором 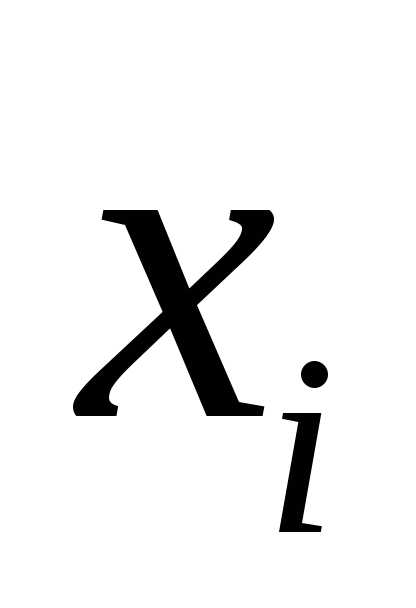 при закреплении остальных факторов на
среднем уровне. В развернутом виде
систему (1.31)
можно переписать в виде:
при закреплении остальных факторов на
среднем уровне. В развернутом виде
систему (1.31)
можно переписать в виде:
При подстановке в эти уравнения средних значений соответствующих факторов они принимают вид парных уравнений линейной регрессии, т.е. имеем
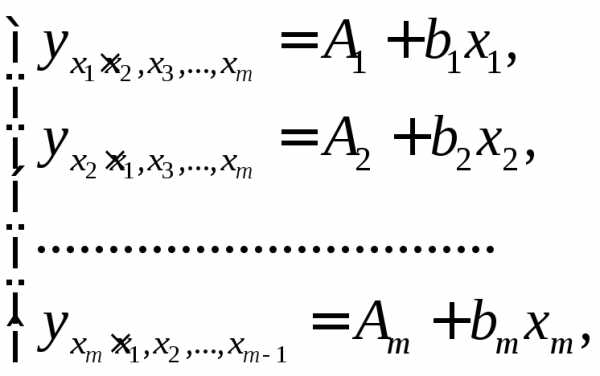 (1.32)
(1.32)
где
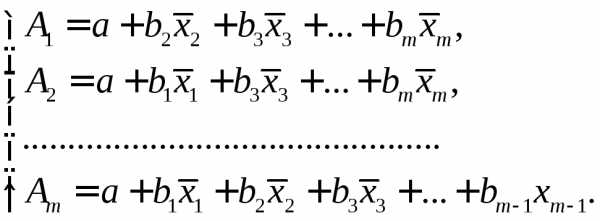
В отличие от парной регрессии частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности:
, (1.33)
где  – коэффициент регрессии для фактора
– коэффициент регрессии для фактора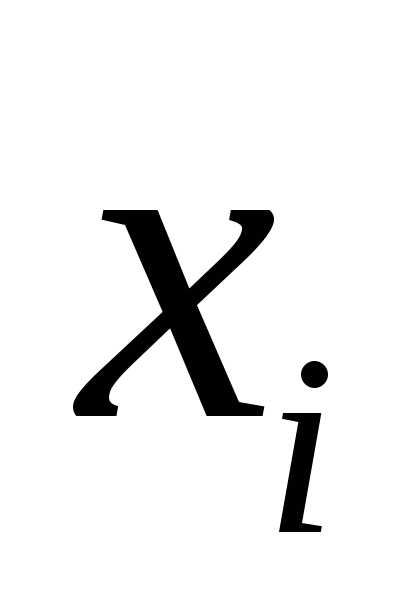 в уравнении множественной регрессии,– частное уравнение регрессии.
в уравнении множественной регрессии,– частное уравнение регрессии.
Наряду с частными коэффициентами эластичности могут быть найдены средние по совокупности показатели эластичности:
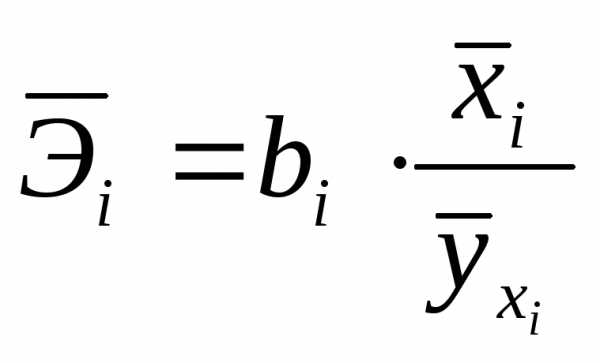 , (1.34)
, (1.34)
которые показывают, на сколько процентов в среднем изменится результат, при изменении соответствующего фактора на 1%. Средние показатели эластичности можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат.
studfiles.net
Уравнение регрессии. Уравнение множественной регрессии :: SYL.ru
Во время учебы студенты очень часто сталкиваются с разнообразными уравнениями. Одно из них – уравнение регрессии — рассмотрено в данной статье. Такой тип уравнения применяется специально для описания характеристики связи между математическими параметрами. Данный вид равенств используют в статистике и эконометрике.
Определение понятия регрессии
В математике под регрессией подразумевается некая величина, описывающая зависимость среднего значения совокупности данных от значений другой величины. Уравнение регрессии показывает в качестве функции определенного признака среднее значение другого признака. Функция регрессии имеет вид простого уравнения у = х, в котором у выступает зависимой переменной, а х – независимой (признак-фактор). Фактически регрессия выражаться как у = f (x).
Какие бывают типы связей между переменными
В общем, выделяется два противоположных типа взаимосвязи: корреляционная и регрессионная.
Первая характеризуется равноправностью условных переменных. В данном случае достоверно не известно, какая переменная зависит от другой.
Если же между переменными не наблюдается равноправности и в условиях сказано, какая переменная объясняющая, а какая – зависимая, то можно говорить о наличии связи второго типа. Для того чтобы построить уравнение линейной регрессии, необходимо будет выяснить, какой тип связи наблюдается.
Виды регрессий
На сегодняшний день выделяют 7 разнообразных видов регрессии: гиперболическая, линейная, множественная, нелинейная, парная, обратная, логарифмически линейная.
Гиперболическая, линейная и логарифмическая
Уравнение линейной регрессии применяют в статистике для четкого объяснения параметров уравнения. Оно выглядит как у = с+т*х+Е. Гиперболическое уравнение имеет вид правильной гиперболы у = с + т / х + Е. Логарифмически линейное уравнение выражает взаимосвязь с помощью логарифмической функции: In у = In с + т* In x + In E.
Множественная и нелинейная
Два более сложных вида регрессии – это множественная и нелинейная. Уравнение множественной регрессии выражается функцией у = f(х1 , х2 …хс)+E. В данной ситуации у выступает зависимой переменной, а х – объясняющей. Переменная Е — стохастическая, она включает влияние других факторов в уравнении. Нелинейное уравнение регрессии немного противоречиво. С одной стороны, относительно учтенных показателей оно не линейное, а с другой стороны, в роли оценки показателей оно линейное.
Обратные и парные виды регрессий
Обратная – это такой вид функции, который необходимо преобразовать в линейный вид. В самых традиционных прикладных программах она имеет вид функции у = 1/с + т*х+Е. Парное уравнение регрессии демонстрирует взаимосвязь между данными в качестве функции у = f (x) + Е. Точно так же, как и в других уравнениях, у зависит от х, а Е — стохастический параметр.
Понятие корреляции
Это показатель, демонстрирующий существование взаимосвязи двух явлений или процессов. Сила взаимосвязи выражается в качестве коэффициента корреляции. Его значение колеблется в рамках интервала [-1;+1]. Отрицательный показатель говорит о наличии обратной связи, положительный – о прямой. Если коэффициент принимает значение, равное 0, то взаимосвязи нет. Чем ближе значение к 1 – тем сильнее связь между параметрами, чем ближе к 0 – тем слабее.
Методы
Корреляционные параметрические методы могут оценить тесноту взаимосвязи. Их используют на базе оценки распределения для изучения параметров, подчиняющихся закону нормального распределения.
Параметры уравнения линейной регрессии необходимы для идентификации вида зависимости, функции регрессионного уравнения и оценивания показателей избранной формулы взаимосвязи. В качестве метода идентификации связи используется поле корреляции. Для этого все существующие данные необходимо изобразить графически. В прямоугольной двухмерной системе координат необходимо нанести все известные данные. Так образуется поле корреляции. Значение описывающего фактора отмечаются вдоль оси абсцисс, в то время как значения зависимого – вдоль оси ординат. Если между параметрами есть функциональная зависимость, они выстраиваются в форме линии.
В случае если коэффициент корреляции таких данных будет менее 30 %, можно говорить о практически полном отсутствии связи. Если он находится между 30 % и 70 %, то это говорит о наличии связей средней тесноты. 100 % показатель – свидетельство функциональной связи.
Нелинейное уравнение регрессии так же, как и линейное, необходимо дополнять индексом корреляции (R).
Корреляция для множественной регрессии
Коэффициент детерминации является показателем квадрата множественной корреляции. Он говорит о тесноте взаимосвязи представленного комплекса показателей с исследуемым признаком. Он также может говорить о характере влияния параметров на результат. Уравнение множественной регрессии оценивают с помощью этого показателя.
Для того чтобы вычислить показатель множественной корреляции, необходимо рассчитать его индекс.
Метод наименьших квадратов
Данный метод является способом оценивания факторов регрессии. Его суть заключается в минимизировании суммы отклонений в квадрате, полученных вследствие зависимости фактора от функции.
Парное линейное уравнение регрессии можно оценить с помощью такого метода. Этот тип уравнений используют в случае обнаружения между показателями парной линейной зависимости.
Параметры уравнений
Каждый параметр функции линейной регрессии несет определенный смысл. Парное линейное уравнение регрессии содержит два параметра: с и т. Параметр т демонстрирует среднее изменение конечного показателя функции у, при условии уменьшения (увеличения) переменной х на одну условную единицу. Если переменная х – нулевая, то функция равняется параметру с. Если же переменная х не нулевая, то фактор с не несет в себе экономический смысл. Единственное влияние на функцию оказывает знак перед фактором с. Если там минус, то можно сказать о замедленном изменении результата по сравнению с фактором. Если там плюс, то это свидетельствует об ускоренном изменении результата.

Каждый параметр, изменяющий значение уравнения регрессии, можно выразить через уравнение. Например, фактор с имеет вид с = y – тх.
Сгруппированные данные
Бывают такие условия задачи, в которых вся информация группируется по признаку x, но при этом для определенной группы указываются соответствующие средние значения зависимого показателя. В таком случае средние значения характеризуют, каким образом изменяется показатель, зависящий от х. Таким образом, сгруппированная информация помогает найти уравнение регрессии. Ее используют в качестве анализа взаимосвязей. Однако у такого метода есть свои недостатки. К сожалению, средние показатели достаточно часто подвергаются внешним колебаниям. Данные колебания не являются отображением закономерности взаимосвязи, они всего лишь маскируют ее «шум». Средние показатели демонстрируют закономерности взаимосвязи намного хуже, чем уравнение линейной регрессии. Однако их можно применять в виде базы для поиска уравнения. Перемножая численность отдельной совокупности на соответствующую среднюю можно получить сумму у в пределах группы. Далее необходимо подбить все полученные суммы и найти конечный показатель у. Чуть сложнее производить расчеты с показателем суммы ху. В том случае если интервалы малы, можно условно взять показатель х для всех единиц (в пределах группы) одинаковым. Следует перемножить его с суммой у, чтобы узнать сумму произведений x на у. Далее все суммы подбиваются вместе и получается общая сумма ху.
Множественное парное уравнение регрессии: оценка важности связи
Как рассматривалось ранее, множественная регрессия имеет функцию вида у = f (x1,x2,…,xm)+E. Чаще всего такое уравнение используют для решения проблемы спроса и предложения на товар, процентного дохода по выкупленным акциям, изучения причин и вида функции издержек производства. Ее также активно применяют в самых разнообразным макроэкономических исследованиях и расчетах, а вот на уровне микроэкономики такое уравнение применяют немного реже.
Основной задачей множественной регрессии является построение модели данных, содержащих огромное количество информации, для того чтобы в дальнейшем определить, какое влияние имеет каждый из факторов по отдельности и в их общей совокупности на показатель, который необходимо смоделировать, и его коэффициенты. Уравнение регрессии может принимать самые разнообразные значения. При этом для оценки взаимосвязи обычно используется два типа функций: линейная и нелинейная.
Линейная функция изображается в форме такой взаимосвязи: у = а0 + a1х1 + а2х2,+ … + amxm. При этом а2, am, считаются коэффициентами «чистой» регрессии. Они необходимы для характеристики среднего изменения параметра у с изменением (уменьшением или увеличением) каждого соответствующего параметра х на одну единицу, с условием стабильного значения других показателей.
Нелинейные уравнения имеют, к примеру, вид степенной функции у=ах1b1 х2b2…xmbm. В данном случае показатели b1, b2….. bm – называются коэффициентами эластичности, они демонстрируют, каким образом изменится результат (на сколько %) при увеличении (уменьшении) соответствующего показателя х на 1 % и при стабильном показателе остальных факторов.
Какие факторы необходимо учитывать при построении множественной регрессии
Для того чтобы правильно построить множественную регрессию, необходимо выяснить, на какие именно факторы следует обратить особое внимание.
Необходимо иметь определенное понимание природы взаимосвязей между экономическими факторами и моделируемым. Факторы, которые необходимо будет включать, обязаны отвечать следующим признакам:
- Должны быть подвластны количественному измерению. Для того чтобы использовать фактор, описывающий качество предмета, в любом случае следует придать ему количественную форму.
- Не должна присутствовать интеркорреляция факторов, или функциональная взаимосвязь. Такие действия чаще всего приводят к необратимым последствиям – система обыкновенных уравнений становится не обусловленной, а это влечет за собой ее ненадежность и нечеткость оценок.
- В случае существования огромного показателя корреляции не существует способа для выяснения изолированного влияния факторов на окончательный результат показателя, следовательно, коэффициенты становятся неинтерпретируемыми.
Методы построения
Существует огромное количество методов и способов, объясняющих, каким образом можно выбрать факторы для уравнения. Однако все эти методы строятся на отборе коэффициентов с помощью показателя корреляции. Среди них выделяют:
- Способ исключения.
- Способ включения.
- Пошаговый анализ регрессии.
Первый метод подразумевает отсев всех коэффициентов из совокупного набора. Второй метод включает введение множества дополнительных факторов. Ну а третий – отсев факторов, которые были ранее применены для уравнения. Каждый из этих методов имеет право на существование. У них есть свои плюсы и минусы, но они все по-своему могут решить вопрос отсева ненужных показателей. Как правило, результаты, полученные каждым отдельным методом, достаточно близки.
Методы многомерного анализа
Такие способы определения факторов базируются на рассмотрении отдельных сочетаний взаимосвязанных признаков. Они включают в себя дискриминантный анализ, распознание обликов, способ главных компонент и анализ кластеров. Кроме того, существует также факторный анализ, однако он появился вследствие развития способа компонент. Все они применяются в определенных обстоятельствах, при наличии определенных условий и факторов.
www.syl.ru
Тема 11. Оценка параметров уравнения множественной регрессии — Мегаобучалка
Пусть требуется оценить параметры линейной множественной регрессии, т.е. построить линейное уравнение множественной регрессии .
Параметры такого уравнения можно оценить с помощью МНК. При этом необходимо проверить выполнение следующих предпосылок МНК:
1) математическое ожидание случайного отклонения должно быть равно 0 для всех наблюдений;
2) должно выполняться свойство гомоспедантичности остатков, т.е. постоянство дисперсий отклонений;
3) отсутствие автокорреляции;
4) случайное отклонение должно быть независимо от объясняющих переменных;
5) модель должна быть линейной относительно параметров;
6) отсутствие мультиколлениарности факторов;
7) ошибки для каждого измерения должны иметь нормальное распределение.
В этом случае система нормальных уравнений для определения параметров множественной регрессии примет вид:
решение которой может быть выполнено с помощью метода определителей
; ; …; ,
где определитель системы нормальных уравнений , , — частные определители, получаемые из определителей системы путем замены соответствующего столбца столбцом свободным членом.
Линейное уравнение множественной регрессии может быть представлено в матричной форме:
, где
, , ,
— -мерный вектор-столбец значений результативного признака;
— матрица размерности , представляющая собой наблюдаемые значения факторов ;
— вектор-столбец параметров уравнения регрессии.
В матричной форме решение уравнения можно записать .
Уравнение множественной регрессии вида называют уравнением множественной регрессии в натуральном масштабе.
Уравнение множественной регрессии может быть представлено в стандартизированном масштабе , где — называются стандартизированными переменными, которые вычисляются по формулам
; .
При таком определении стандартизированных переменных их средние значения равны 0, т.е. , а средние квадратические отклонения – 1, т.е. .
Коэффициенты называются стандартизированными коэффициентами множественной регрессии.
Применяя МНК к уравнению множественной регрессии в стандартизированном масштабе после преобразований получают следующую систему нормальных уравнений:
решая которую находим значение стандартизованных коэффициентов .
При составлении системы уравнений использовались следующие коэффициенты парной корреляции и , причем коэффициенты называются коэффициентами межфакторной связи.
Коэффициенты парной корреляции можно найти аналогично по формулам для определения коэффициентов корреляции линейной парной регрессии.
Стандартизованные коэффициенты множественной регрессии показывают насколько изменится в среднем результат при изменении соответствующего фактора на , при изменении уровня остальных факторов. В силу того, что при составлении уравнения множественной регрессии в стандартизованном масштабе все переменные заданы как централизованные и нормированные стандартизованные коэффициенты сравнимы между собой.
Сравнивая значения коэффициентов можно определить степень воздействия каждого фактора на результативный признак, при этом необходимо отметить, что коэффициенты чистой регрессии не сравнимы между собой.
Например, если задано уравнение множественной регрессии в натуральном масштабе , то из этого уравнения следует, что при изменении фактора на 1 единицу своего измерения результат изменится на 2,1 единицы своего измерения. При этом фактор считается неизменной величиной.
Аналогично при изменении на 1 единицу при неизменном уровне фактор меняется на 3,5 единиц.
Вышесказанное не означает, что фактор сильнее влияет на результат .
Если получено уравнение множественной регрессии в стандартизованном масштабе для этой же задачи , то в этом случае можно сказать, что с ростом на при неизменном уровне результативный признак изменится на , а с ростом на при неизменном уровне увеличится на . Следовательно, в данном случае на результативный признак более сильное воздействие оказывает фактор .
Замечание
Для линейной парной зависимости стандартизованный коэффициент регрессии является линейным коэффициентом корреляции: .
Между коэффициентами «чистой регрессии» и стандартизованным коэффициентом регрессии существует соотношение: .
Последнее соотношение позволяет от уравнения множественной регрессии в стандартизованном масштабе переходить к уравнению множественной регрессии в натуральном масштабе, при чем свободный член может быть найден из формулы: .
Если задано уравнение нелинейной множественной регрессии, то аналогично нелинейной парной регрессии данное уравнение либо с помощью замены переменного, либо с помощью процедуры логарифмирования преобразовывают к линейному виду множественной регрессии, т.е. линеаризуют. Затем параметры линеаризованной линейной модели определяют с помощью МНК; после определения параметра необходимо вернуться к первоначальной нелинейной модели множественной регрессии.
megaobuchalka.ru