
Как научиться решать алгоритмические задачи?
Перед вами руководство для того, чтобы научиться быстро и без труда решать алгоритмические задачи. Готовьтесь к собеседованиям правильно.
Если хочешь подтянуть свои знания, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в решение практических задач;
- узнаешь все про сложные алгоритмы, сортировки, сжатие данных и многое другое.
Ты также будешь на связи с преподавателем и другими студентами.
В итоге будешь браться за сложные проекты и повысишь чек за свою работу 🙂
Интересно, хочу попробовать
Для начала, если вы думаете, что изучения основ компьютерных наук хватит для того, чтобы вам посыпались предложения от разных компаний, вы можете закончить читать здесь. Это руководство предназначено для тех, кто хочет обеспечить себя необходимыми навыками для того, чтобы без проблем пройти собеседование с помощью LeetCode.
Оттачивать навыки написания кода на LeetCode — это не просто запоминать ответы.
В этом руководстве предполагается, что вы по крайней мере слышали об основных вещах, таких как двойные указатели и манипулирование битами. Вам не нужно знать их в совершенстве, но хотя бы базовые знания о том, что это такое, помогут вам более эффективно практиковаться решать задачи на LeetCode. Если вы изучали только основы компьютерных наук, вам может понадобиться обратиться к некоторым книгам, чтобы немного подтянуться.
Легкие алгоритмические задачи на LeetCode
Легкие задачи призваны помочь вам ознакомиться с основными приёмами. Обычно у них есть грубые тривиальные решения. Вам нужно научиться применять эти приёмы, чтобы лёгкие задачи не вызывали у вас никаких проблем.
Если случайно открывая несколько простых задач из структур данных или алгоритмов вы можете легко и быстро придумать оптимальное решение, после чего реализовать его, вы можете переходить к следующему пункту. Если же нет, то вам очевидно придётся задержаться и больше тренироваться решать лёгкие задачи.
Если же нет, то вам очевидно придётся задержаться и больше тренироваться решать лёгкие задачи.
Как тренироваться
- Отсортируйте задачи по убыванию рейтинга принятия (англ. acceptance rate). Обычно задачи с более высоким рейтингом принятия немного легче.
- Старайтесь решать лёгкие задачи без подсказок.
- Как ни странно, злоупотреблять кнопкой «run» не очень полезно. Попробуйте написать решение лёгких задач так, чтобы они были приняты с первого раза. Такой подход имитирует ситуацию, когда вы пишете код на доске, что позволит вам научиться рассматривать все варианты сразу в голове.
- Иногда следует приглядываться к решениям в топе на предмет применения каких-то интересных приёмов. Часто решения попадают в топ, когда они короткие и недостаточно документированы. Также читайте комментарии и не стесняйтесь просить пояснить какие-то моменты.
- Как только вы чувствуете что изучили достаточно шаблонов решений простых задач, вернитесь к пункту 1 и решите, готовы ли вы двигаться дальше.

Средние алгоритмические задачи на LeetCode
Средние задачи предназначены для того, чтобы вы научились видеть суть. Чаще всего они представляют собой различные комбинации лёгких задач. Но решения «в лоб» часто могут привести к ошибке времени выполнения. Вам нужно уметь определять, какой именно шаблон решения требует та или иная задача.
Пункт 2: Распознавание шаблонов задачЕсли случайно открывая несколько средних задач из структур данных или алгоритмов, вы можете определить, какой вид задач в них представлен, и реализовать близкое к оптимальному решение в течение получаса, то смело переходите к более высокому уровню.
Как тренироваться
- Внимательно читайте сам текст задачи и ищите в нём подсказки по поводу реализации. Например, количество подзадач может указывать на динамическое программирование, строковое преобразование с помощью dictionary указывает на поиск в ширину, поиск в длину или префиксное дерево, поиск повторяющихся или уникальных элементов указывает на хеширование или манипулирование битами и т. д. Если вам требуется более полный список приёмов, то следует обратить внимание на книгу-руководство для программистов.
- Когда есть приблизительное представление о решении — это уже полпути. Попытайтесь реализовать его, даже если оно не совсем оптимальное. Это нормально, ведь обычно люди тратят гораздо больше времени на оптимизацию, чем на само решение.
- Когда вы реализовали своё неидеальное решение, посмотрите на топовые решения этой же задачи, чтобы посмотреть, как вы можете улучшить своё.
- Затем попытайтесь хорошо понять основную мысль и реализовать более оптимальное решение, не используя подсказки.
- Как только вы чувствуете, что можете больше, чем просто применять шаблоны, настало время перейти к сложным задачам.
 д. Если вам требуется более полный список приёмов, то следует обратить внимание на книгу-руководство для программистов.
д. Если вам требуется более полный список приёмов, то следует обратить внимание на книгу-руководство для программистов.Сложные алгоритмические задачи на LeetCode
Сложные задачи предназначены для того, чтобы заставить вас напрячься. Обычно 45 минут достаточно для того, чтобы вы могли придумать рабочее решение. Чтобы научиться их решать, нужно научиться видеть какие-то более изящные пути, чем тривиальное решение «в лоб».
В сложных задачах обычно есть ограничения, которые не позволят вам получить решения, используя привычные шаблоны. Если вы можете модифицировать обычные приёмы для решения сложных задач, то ваша подготовка завершена. Время здесь не так важно, вы должны научиться видеть связь между привычными шаблонами решений и этими ограничениями.
Как тренироваться
- В этом случае решение задачи важнее, чем нахождение оптимального решения. Если вы можете решить задачу «в лоб», жертвуя ограничениями по времени и/или месту, делайте это.
- И только после нужно определить, как оптимизировать решение, чтобы оно соответствовало ограничениям.
- Если у вас не получается оптимизировать решение, то самое время обратить внимание на топовые варианты реализации. Здесь очень важно понять ход решения. Вы должны научиться подбирать правильный алгоритм и использовать нужные структуры данных, а также уметь учитывать все случаи.
- Как только вы научитесь находить решения одних сложных задач, переходите к другим видам задач и старайтесь делать ваши решения более оптимальными.

Спасибо, что прочитали. Надеюсь вы нашли для себя что-то полезное.
Гайд по алгоритмам для тех, кому сложно решать задачи
Рассказываем, какие алгоритмы учить к собеседованиям и что делать, если решать алгоритмические задачи вам просто скучно.
Это адаптированный перевод статьи Grokking LeetCode: A Smarter Way to Prepare for Coding Interviews, автор — Арслан Ахмад. Повествование ведется от имени автора.
Эта статья — для разработчиков, которые частично уже знают алгоритмы, а сейчас готовятся к собеседованиям с алгоритмами. В ближайшее время мы выпустим похожую статью для новичков в программировании.
Грокать алгоритмы или не грокать? Что делать, если вам не хочется решать сто задач к вашему следующему собеседованию?
Часть меня ненавидит технические собеседования, в первую очередь из-за того, что мне нужно повторять много материала. Кроме того, в процессе самого собеседования мне часто приходится предлагать какое-то особенное решение, а не то, которое я бы выбрал в своей будничной практике.
Кроме того, в процессе самого собеседования мне часто приходится предлагать какое-то особенное решение, а не то, которое я бы выбрал в своей будничной практике.
Несмотря на это, я люблю алгоритмы и люблю решать задачки по программированию. Для меня это веселое времяпровождение и хорошая тренировка для мозга. Учитывая все это, хочу рассказать вам о моей собственной технике подготовки к собеседованиям, которая намного интереснее и волнительнее, чем обычная подготовка.
Коротко расскажу о себе, чтобы вы убедились в моей экспертности. Я программирую уже 20 лет, за это время я много раз менял место работы. Всего я прошел около 30 воронок найма — больше 120 собеседований. Плюс к этому у меня есть опыт с той стороны баррикад: я провел около 300 технических собеседований и больше 200 собеседований по системному дизайну.
Где мы грокаем алгоритмы
Если вы когда-нибудь искали работу, то знаете, что есть ресурсы, которые собирают задачи с собеседований. Один из них — LeetCode, это самый популярный сайт, где очень много задач. Плюс вокруг него сложилось развитое сообщество, где можно обсуждать задачки с другими инженерами. Если выдается свободная минутка, я всегда не прочь провести ее на LeetCode. Там я решаю задачи или читаю чужие решения, после чего сравниваю со своими.
Один из них — LeetCode, это самый популярный сайт, где очень много задач. Плюс вокруг него сложилось развитое сообщество, где можно обсуждать задачки с другими инженерами. Если выдается свободная минутка, я всегда не прочь провести ее на LeetCode. Там я решаю задачи или читаю чужие решения, после чего сравниваю со своими.
Самая большая проблема LeetCode в том, что сайту не хватает продуманной системы обучения. У него много разных задач, в которых легко потеряться. Сколько нужно таких задач, чтобы подготовиться к собеседованию? Я бы предпочел двигаться по продуманной программе, в конце которой я смогу ощутить уверенность в собственных знаниях. Но системы нет, а я ленивый, и вообще — не хочу решать 500+ задач.
Одно из популярных решений для этой проблемы — решать задачи, которые относятся к одной структуре данных (например, прорешать несколько задач с деревьями). Какая-то система обучения появляется, но это решение меня все равно не устраивает. Например, что делать, если задачу можно решить при помощи разных структур данных?
Какую систему обучения придумал я
Я бы предпочел такую систему, в которой задачи распределены по паттернам, а не по структурам данных. Мои любимые паттерны — скользящее окно, нахождение цикла и топологическая сортировка. Когда я научился пользоваться этими методами, я стал решать незнакомые задачи по аналогии с задачами, которые решал до этого. Благодаря этому весь процесс подготовки к собеседованиям стал более интересным и веселым. Ну и конечно же, более систематичным.
Мои любимые паттерны — скользящее окно, нахождение цикла и топологическая сортировка. Когда я научился пользоваться этими методами, я стал решать незнакомые задачи по аналогии с задачами, которые решал до этого. Благодаря этому весь процесс подготовки к собеседованиям стал более интересным и веселым. Ну и конечно же, более систематичным.
Я обнаружил 25 паттернов, которые лежат в основе решения большинства задач. Думаю, эти паттерны помогут кому угодно показывать на собеседованиях красивые и элегантные решения. Вся фишка этих паттернов в том, что понимая один из них, вы научитесь решать сразу несколько задач, десятки задач.
Самые распространенные паттерны для решения задач
- Метод скользящего окна
- Метод двух указателей
- Нахождение цикла
- Интервальное слияние
- Цикличная сортировка
- In-place Reversal для LinkedList
- Поиск в ширину
- Поиск в глубину
- Двоичная куча
- Подмножества
- Усовершенствованный бинарный поиск
- Побитовое исключающее ИЛИ
- Top K Elements
- K-образное слияние
- Задача о рюкзаке 0-1
- Задача о неограниченном рюкзаке
- Числа Фибоначчи
- Наибольшая последовательность-палиндром
- Наибольшая общая подстрока
- Топологическая сортировка
- Чтение префиксного дерева
- Задача: количество островов в матрице
- Метод проб и ошибок
- Система непересекающихся множеств
- Задача: найти уникальные маршруты
Читайте также: Это снова я, резиновая уточка: что такое метод Фейнмана и почему с его помощью так просто изучать программирование
Метод скользящего окна
Контекст: Мы используем этот метод, когда у нас есть входные данные с заданным размером окна.
Задачи для этого паттерна:
- Longest Substring with K Distinct Characters
- Fruits into Baskets
- Permutation in a String
Метод двух указателей
Контекст: Мы используем два указателя, чтобы перебрать все входные данные. Обычно два указателя движутся в противоположных направлениях с фиксированным интервалом.
Задачи для этого паттерна:
- Squaring a Sorted Array
- Dutch National Flag Problem
- Minimum Window Sort
Нахождение цикла
Контекст: Еще этот алгоритм называют алгоритмом черепахи и зайца. В отличие от предыдущего метода, два указателя тут движутся с разной скоростью.
Задачи для этого паттерна:
- Middle of the LinkedList
- Happy Number
- Cycle in a Circular Array
Интервальное слияние
Контекст: Этот метод применяют, если есть пересекающиеся интервалы. Например, на этом изображении мы видим, что интервалы a и b могут пересекаться шестью разными способами:
Например, на этом изображении мы видим, что интервалы a и b могут пересекаться шестью разными способами:
- Intervals Intersection
- Conflicting Appointments
- Minimum Meeting Rooms
Цикличная сортировка
Контекст: Если входные данные лежат в заданном интервале, используйте цикличную сортировку.
Задачи для этого паттерна:
- Find all Missing Numbers
- Find all Duplicate Numbers
- Find the First K Missing Positive Numbers
Читайте также: Виталий Емельянцев: Как создать самый популярный чат об эмиграции для разработчиков «Релокейти» и что теперь будет с IT в России
In-place Reversal для LinkedList
Техника: Эта техника описывает эффективный способ перевернуть связи между узлами в LinkedList (класс Java). Часто мы ограничены in-place, то есть мы должны использовать исходные узлы.
Задачи для этого паттерна:
- Reverse every K-element Sub-list
- Rotate a LinkedList
Поиск в ширину
Контекст: Это метод для решения задач с деревьями.
Задачи для этого паттерна:
- Binary Tree Level Order Traversal
- Minimum Depth of a Binary Tree
- Connect Level Order Siblings
Поиск в глубину
Контекст: Тот же, что для предыдущего метода.
Задачи для этого паттерна:
- Path With Given Sequence
- Count Paths for a Sum
Двоичная куча
Контекст: Во многих задачах у нас есть набор элементов, который можно разделить на две части. Тогда мы могли бы выяснить, какой элемент является наименьшим в первой куче и какой является наибольшим во второй куче.
Задачи для этого паттерна:
- Find the Median of a Number Stream
- Next Interval
Подмножества
Контекст: Если задача требует перестановки или комбинаций элементов, используйте подмножества.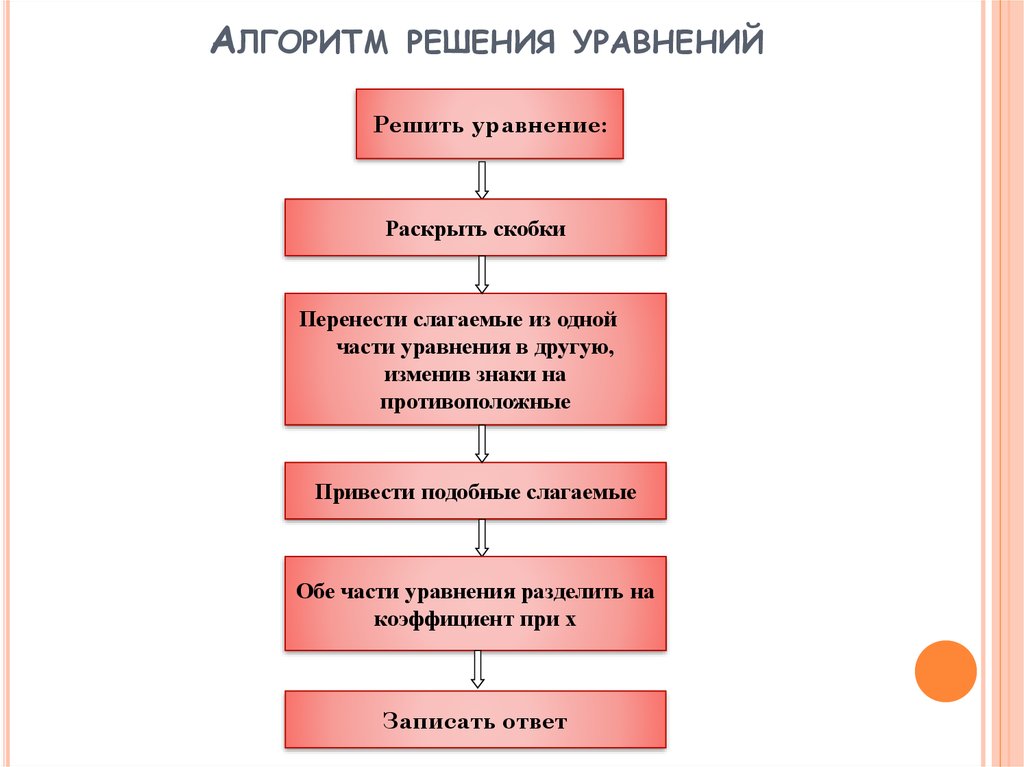
Задачи для этого паттерна:
- String Permutations by changing case
- Unique Generalized Abbreviations
Усовершенствованный бинарный поиск
Контекст: Эта техника использует логический оператор для наиболее эффективного поиска элементов.
Задачи для этого паттерна:
- Two Single Numbers
- Flip and Invert an Image
Наибольшее
K элементовКонтекст: Эта техника используется, чтобы найти наибольший/наименьший или наиболее часто встречающийся набор k-элементов в коллекции.
Задачи для этого паттерна:
- ‘K’ Closest Points to the Origin
- Maximum Distinct Elements
Читайте также: Как решить задачу, если непонятно, с чего вообще начать: советы от Хекслета
K-образное слияние
Контекст: Используйте эту технику, если у вас есть список отсортированных массивов.
Задачи для этого паттерна:
- Kth Smallest Number in M Sorted Lists
- Kth Smallest Number in a Sorted Matrix
Рюкзак 0-1
Контекст: Этот паттерн используют для задач на оптимизацию. Используйте эту технику, чтобы выбирать элементы, которые дают максимум выгоды в данном наборе ограничений по вместимости. Учитывая то, что каждый элемент может быть выбран лишь единожды.
Задачи для этого паттерна:
- Equal Subset Sum Partition
- Minimum Subset Sum Difference
Неограниченный рюкзак
Контекст: То же самое, что в предыдущем паттерне, но только каждый элемент может быть выбран повторно сколько угодно раз.
Задачи для этого паттерна:
- Rod Cutting
- Coin Change
Числа Фибоначчи
Контекст: Как очевидно из названия, это паттерн для чисел Фибоначчи. Это последовательность, в которой каждое последующее число равно сумме двух предыдущих чисел.
Задачи для этого паттерна:
- Staircase
- House Thief
Наибольшая последовательность — палиндром
Контекст: Имеется в виду задача, которая может быть использована как для последовательности, так и для строк. По сути это задача на оптимизацию.
Задачи для этого паттерна:
- Longest Palindromic Subsequence
- Minimum Deletions in a String to make it a Palindrome
Наибольшая общая подстрока
Контекст: Как понятно из названия, это паттерн для работы со строками или другими последовательностями, а также для работы с наборами строк или последовательностей.
Задачи для этого паттерна:
- Maximum Sum Increasing Subsequence
- Edit Distance
Чтение префиксного дерева
Контекст: Это специфичная для структуры данных техника, с помощью которой читают или создают префиксное дерево.
Задачи для этого паттерна:
- Longest Word in Dictionary
- Palindrome Pairs
Читайте также: Обзор на книгу «Грокаем алгоритмы» Адитья Бхаргава
Острова в матрице
Контекст: Этот паттерн подходит для чтения любого двумерного массива, где нам нужно обнаружить связанные между собой элементы.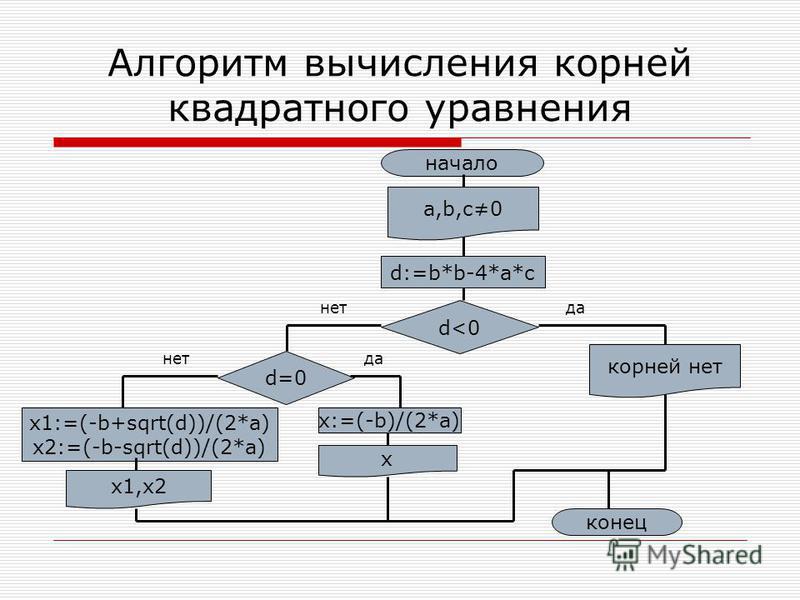
Задачи для этого паттерна:
- Number of Distinct Islands
- Maximum Area of Island
Путь проб и ошибок
Контекст: Этот паттерн подойдет для того, чтобы пройтись по массиву в поисках подходящего под требования элемента.
Задачи для этого паттерна:
- Find Kth Smallest Pair Distance
- Minimize Max Distance to Gas Station
Система непересекающихся множеств
Контекст: Если данные раскиданы по непересекающимся множествам, то они решаются одним и тем же способом.
Задачи для этого паттерна:
- Number of Provinces
- Bipartite Graph
Поиск уникального маршрута
Контекст: Этот паттерн подойдет для прохождения по любому многомерному массиву.
Задачи для этого паттерна:
- Find Unique Paths
- Dungeon Game
Никогда не останавливайтесь: В программировании говорят, что нужно постоянно учиться даже для того, чтобы просто находиться на месте.
 Развивайтесь с нами — на Хекслете есть сотни курсов по разработке на разных языках и технологиях
Развивайтесь с нами — на Хекслете есть сотни курсов по разработке на разных языках и технологияхЧтобы решать «нерешаемые» задачи, нужно знать алгоритмы / Хабр
Артём Мурадов — Senior Software Development Engineer в Amazon и автор курса «Алгоритмы: roadmap для работы и собеседований». Уже больше 14 лет он использует алгоритмы для решения рабочих задач и прохождения собеседований. С помощью алгоритмов он повышал производительность приложений, побеждал в спорах с коллегами и ускорял исследование ДНК. Даже попасть в Amazon ему помогло знание алгоритмов.
Мы пообщались с Артёмом, чтобы узнать о его опыте. Он подробно рассказал, как изучал алгоритмы и как они помогали ему в работе.
Ускорил приложение в 600 раз с помощью алгоритма
2012 год. Я прихожу на работу и узнаю, что система, которую мы писали, медленно запускается. Настолько медленно, что мы даже не можем выпустить релиз.
Ситуацию спас один человек. Он увидел, что в задаче поиска, которая запускается на старте приложения, используется квадратичный алгоритм. Алгоритм работал хорошо на малом объёме данных. Но когда данных стало много, его скорость быстро деградировала. Это стало причиной блокера для релиза.
Он увидел, что в задаче поиска, которая запускается на старте приложения, используется квадратичный алгоритм. Алгоритм работал хорошо на малом объёме данных. Но когда данных стало много, его скорость быстро деградировала. Это стало причиной блокера для релиза.
Тогда меня это поразило: человек просто поменял квадратичный алгоритм на линейный, и всё снова стало прекрасно.
Прошло 5 лет, я оказался в другой компании, где отвечал за приложение, которое сравнивало объекты. Представьте, у вас есть объект №1 с полями, и объект №2 с полями. Вам нужно понять, чем они отличаются. Вы открываете форму, и она показывает разницу между объектами: какие поля добавились или удалились.
В какой-то момент приложение начало долго открываться, что было критично. Невозможно работать, если у тебя обычная форма сравнения объектов открывается 30 минут.
Припоминая историю спасённого релиза, я уже догадывался, в чём может быть дело, и начал смотреть код. Причина оказалась та же — неэффективный алгоритм. Когда приложение создавалось, полей было около 200, алгоритм справлялся. Прошло 10 лет, и количество полей возросло до десятков тысяч. Такие объёмы алгоритму были уже не под силу: он начал работать очень медленно.
Когда приложение создавалось, полей было около 200, алгоритм справлялся. Прошло 10 лет, и количество полей возросло до десятков тысяч. Такие объёмы алгоритму были уже не под силу: он начал работать очень медленно.
Я произвёл ту же замену, что и мой коллега когда-то, — заменил квадратичный алгоритм на линейный. На всё это ушёл один день, и время открытия формы уменьшилось с 30 минут до 3 секунд. Скорость выросла в 600 раз.
За 2 дня сделал то, на что ушло 2 года
Я всегда читал много разных книг по алгоритмам. Особенно меня поразили «Жемчужины программирования» Джона Бентли. По большому счёту, это сборник историй и рассказов о том, как помогают алгоритмы. Одна из историй рассказывала о сортировке подсчётом. Обычно, если ты хочешь отсортировать какие-то вещи, ты предварительно сравниваешь их друг с другом. А особенность сортировки подсчётом в том, что тебе не нужно ничего сравнивать.
В то время я даже не мог представить, что существует такой алгоритм. Мозг взрывался от нового знания, и я пошёл решать задачи.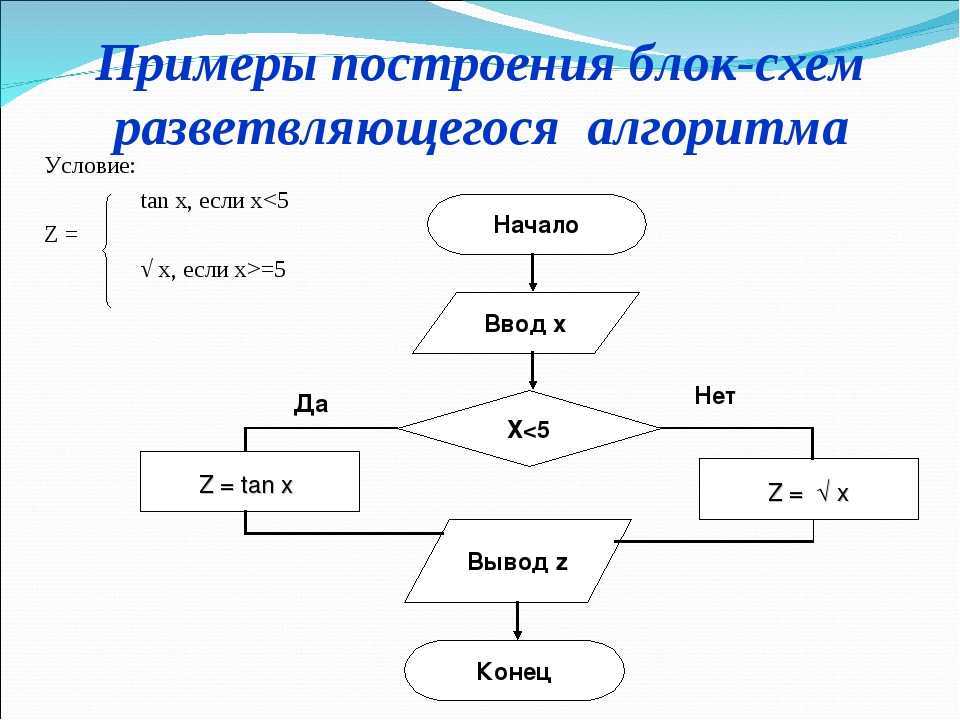 Какие-то давались легко, какие-то сложнее. Наконец, на одной платформе попалась такая, которую никак не получалось решить. Точнее моё решение работало, но было слишком медленным, что, конечно, меня не устраивало.
Какие-то давались легко, какие-то сложнее. Наконец, на одной платформе попалась такая, которую никак не получалось решить. Точнее моё решение работало, но было слишком медленным, что, конечно, меня не устраивало.
Шли месяцы, я всё пытался «одолеть» задачу, но она упорно не поддавалась. Теоретически, можно было бы подсмотреть решение в интернете, но я был слишком горд для этого.
В 2014 года я попал на онлайн-курс от Западного университета, где рассказывали про определённую структуру данных и её использование. К тому моменту про структуру данных я уже знал, но никогда не применял её на практике.
Открылась простая истина: недостаточно просто знать алгоритм, нужно понимать, когда его применить.
На курсе рассказали, что «структура данных» — это префиксное дерево, и показали, как с ним работать. Я начал решать примеры, и тут в голове щёлкнуло: «Это ведь та самая задача!». Я потратил ещё 2 дня и наконец-то справился с ней. Проблема была в теоретический базе — как только я её получил, сразу смог найти решение.
Естественно, я бы никому не советовал 2 года решать одну задачу. В то время я был немножко упоротый по алгоритмам — это и помогло не бросить всё на полпути. Но чтобы не тратить столько времени на поиск правильного решения, нужны проверенные источники для обучения.
Пранк вышел из-под контроля: решил нерешаемую задачу
В 2016 году меня пригласили работать в Польшу. Хорошо помню первую задачу в новой компании. Она касалась блоттера.
Блоттер — грид по типу Excel с двумя особенностями. Первая особенность в том, что он держит в памяти только те данные, которые показывает. Предположим, есть таблица с миллионом элементов, из которых видны только 100. Эта сотня — то, что есть прямо сейчас. Всех остальных элементов нет. Когда крутишь блоттер, он начинает запрашивать новые пачки данных, чтобы отображать их.
Вторая особенность — все данные изменяются в реальном времени. Это значит, что в любой момент какие-то строчки могут пропасть, или, наоборот, добавиться.
Мне нужно было сделать так, чтобы, когда пользователь выделял какую-то область в блоттере, а после этого проматывал вверх или вниз, выделенная область сохранялась в памяти. Проблема заключалась в том, что строки постоянно добавлялись, удалялись и обновлялись. Всё это было очень динамично и, разумеется, не сохранялось. Если что-то промотал, всё тут же исчезало.
Проблема заключалась в том, что строки постоянно добавлялись, удалялись и обновлялись. Всё это было очень динамично и, разумеется, не сохранялось. Если что-то промотал, всё тут же исчезало.
Я понял, что нужен хитрый алгоритм, который бы находил строчки, которые были выделены, и показывал их, даже когда данные блоттера уже изменились. Провозился с задачей примерно неделю и все-таки решил её.
Но самое интересно дальше — начинаю рассказывать обо всём коллегам, а они только удивляются. Я, естественно, ничего не понимаю, спрашиваю, в чём дело. Тут выясняется, что надо мной просто пошутили. Все в команде уже пытались решить эту задачу, но ни у кого не получилось. И когда пришёл новичок, они просто хотели посмотреть, что он будет делать, столкнувшись с нерешаемой задачей. Правда, шутка вышла из-под контроля. И даже, когда спустя 4 года я уходил из компании, коллеги всё ещё вспоминали эту историю.
Ускорил исследование ДНК в 4000 раз
У меня около 900 ответов на Stack Overflow, из которых больше сотни по алгоритмам. В потоке вопросов я хорошо запомнил один, связанный с ДНК.
В потоке вопросов я хорошо запомнил один, связанный с ДНК.
ДНК — молекула, которая обеспечивает хранение и передачу информации. Она состоит из нуклеотидов. Каждый нуклеотид содержит сахарную и фосфатную группу, а также азотистые основания. Эти азотистые основания делятся на 4 типа: аденин, тимин, гуанин и цитозин.
Эти же азотистые основания — 4 буквы, отвечающие за определённые позиции в ДНК. А сама ДНК выглядит как последовательность букв, алфавит которых ограничен 4 значениями. Для исследования нужно было обрабатывать миллионы таких последовательностей. Делать это автору вопроса приходилось в полуручном режиме. На то было две причины.
Первая — рабочее приложение принимало только 10 тысяч последовательностей, каждая не длиннее 10 символов. Вторая — это было лицензированное ПО, которое стояло на старом компьютере. Из-за ограничения лицензии его нельзя было перенести не более мощное устройство.
У меня родилась идея, как решить проблему. Если взять две последовательности, которые одинаковы на всех позициях, кроме одной, их можно смёржить в одну. Нужен только специальный символ, который скажет, что это не одна последовательность, а две.
Нужен только специальный символ, который скажет, что это не одна последовательность, а две.
Объясню на примере. У нас есть два имени: «Артем» и «Артём». Пускай, «е» и «ё» — это какая-нибудь спецбуква, например «у». Мы берём «Артём» и «Артем» и мёржим в «Артум». Теперь все, кто будет смотреть на слово «Артум», будут знать, что это два имени, но обрабатывать его смогут как одно.
Благодаря такому варианту сжатия можно было сократить количество последовательностей ДНК до нужного уровня. Допустим, на входе 600 элементов, а на выходе 17. На входе 3 миллиона, а на выходе 150 тысяч.
Я закончил писать алгоритм под свою идею, и автор вопроса опробовал его в действии. Он установил приложение с моим алгоритмом на новый компьютер и запустил обработку 4 миллионов последовательностей по 11 символов. Это было в 450 раз больше, чем могла посчитать его старая программа. Операция заняла 7 секунд. Производительность выросла в 4000 раз.
Я не делал никаких сложных распараллеленных вычислений. Только реализовал одну идею в простом алгоритме, который написал за пару дней. Всё.
Только реализовал одну идею в простом алгоритме, который написал за пару дней. Всё.
История попадания в Amazon
Скажу сразу, Amazon — не единственная крупная компания, куда я пытался устроиться. Я ходил на собеседование в Microsoft, дважды участвовал в отборе в Google. Каждый раз я добирался до финального этапа, но выбор делали в пользу другого кандидата.
Признаюсь, три неудачных собеседования дают повод усомниться в реальности попадания в компанию уровня FAANG. Хотя я и готовился ко встрече с представителем Amazon, шёл туда больше по фану: на других посмотреть, себя показать и шутеечки пошутить.
Прихожу, меня спрашивают: «Ну, что, готов?».
Отвечаю: «Да, погнали. Давай мне алгоритмы, сейчас всё разберём!».
Возможно, дело было в том, что я два раза готовился к собеседованию в Google, два раза участвовал в чемпионате внутри моей компании и вообще был адово нагретый по алгоритмам. Но когда мне задавали задачу, я даже не дослушивал её до конца. Говорил: «Всё, стоп. Я знаю, как решать». И начинал решать. Для некоторых задач даже код не писал — просто объяснял, что нужно сделать.
Я знаю, как решать». И начинал решать. Для некоторых задач даже код не писал — просто объяснял, что нужно сделать.
Когда уходил с собеседования, был в состоянии типа: «А что это было вообще? А где настоящее собеседование? Почему меня не разносят задачами?».
Вскоре со мной связались и сказали, что я прошёл, да ещё и назвали senior. Я тогда удивился, но сейчас понимаю, что это закономерно. Каждое новое собеседование добавляло мне опыта и развивало.
Я шёл трудным путём: сам составлял себе программу обучения, сам всё учил, сам выбирал задачи и решал их без помощи извне. В Microsoft я подался в 2012 году, а работать в Amazon начал только в 2020 году. За 8 лет у меня было 4 собеседования в FAANG, 3 из которых прошли неуспешно.
Когда я рассказал на прошлой работе, что прошёл собеседование в Amazon, меня сразу стали спрашивать, что там и как. И спрашивали так часто, что пришлось сделать шпаргалку, которую я просто копипастил и отправлял всем интересующимся. Но это было не напрасно — те, кто воспользовался моими рекомендациями, теперь работают там, где мечтали.
Всех, кто хочет погрузиться в тему алгоритмов, приглашаем на экспресс-курс «Алгоритмы: roadmap для работы и собеседований». Вы узнаете, как алгоритмы помогают в работе и на собеседованиях и получите проверенные ресурсы для их изучения.
Вам не придётся читать десятки ненужных книг — вы сразу начнете с правильной базы и сможете решать задачи, которые не под силу другим программистам.
Дисклеймер: всё, что Артем рассказывает на курсе — его личное мнение, которое никак не связано с позицией компании Amazon
Стратегии решения проблем с алгоритмами — Сообщество разработчиков 👩💻👨💻
Головоломки с алгоритмами — это, к сожалению, распространенный способ отсеять кандидатов в процессе подачи заявок. Однако, когда вы не беспокоитесь о поиске работы, это на самом деле очень весело, как кроссворды для программистов.
При их решении возникают уникальные проблемы, с которыми вы не столкнетесь при запуске приложения Yet Another Crud, и вы познакомитесь с концепциями, с которыми вы, возможно, еще не знакомы.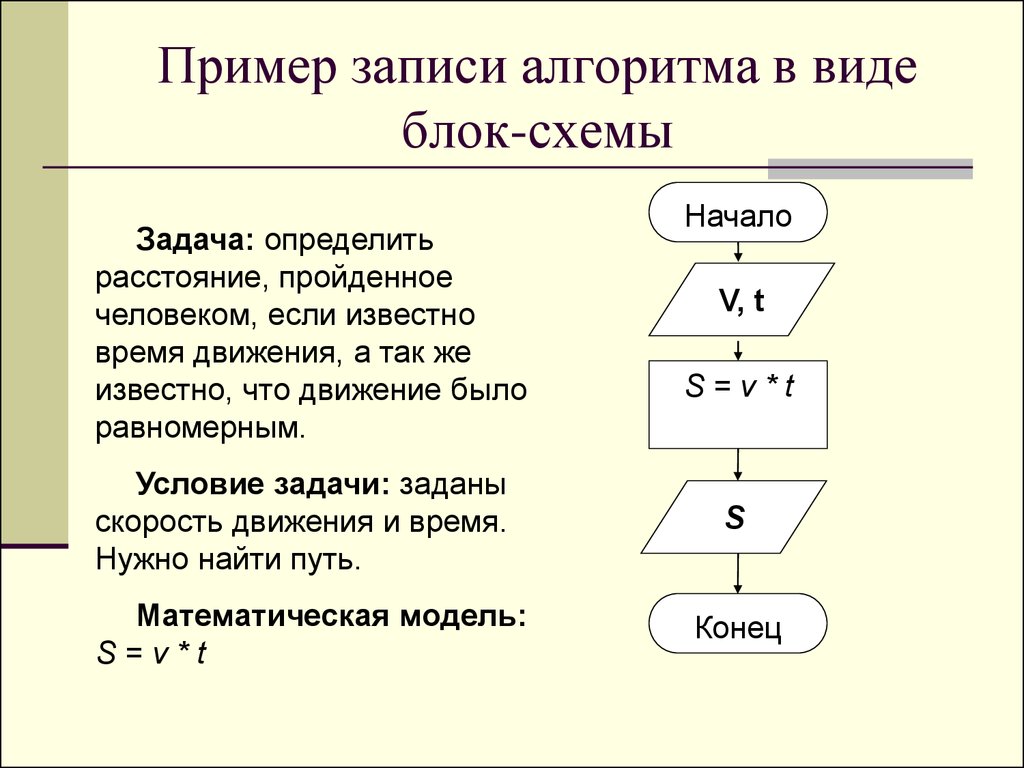 Практика алгоритмических задач улучшит ваши более широкие способности решения проблем, а также укрепит процесс решения проблем, который будет более полезным в целом.
Практика алгоритмических задач улучшит ваши более широкие способности решения проблем, а также укрепит процесс решения проблем, который будет более полезным в целом.
Как и в случае с другими типами головоломок, существуют стратегии, которые дают вам раннее понимание проблемы и способ разбить ее на более мелкие, более доступные части. В настоящей головоломке вы можете рассортировать кусочки по согласованным группам схожих цветов или характеристик, найти очевидные совпадения и расти дальше. С сапером вы можете начать со случайного щелчка, а затем перемещаться по открытым краям, отмечая очевидные мины и обнажая очевидные чистые области, щелкая случайным образом еще раз только тогда, когда вы исчерпали все возможности.
Несмотря на то, что существуют стратегии для работы с подобными типами алгоритмов, я бы порекомендовал вам начать с более широкой стратегии решения проблем, которую вы принимаете как общую привычку, а не только когда вы шлифуете LeetCode в качестве подготовки к собеседованию.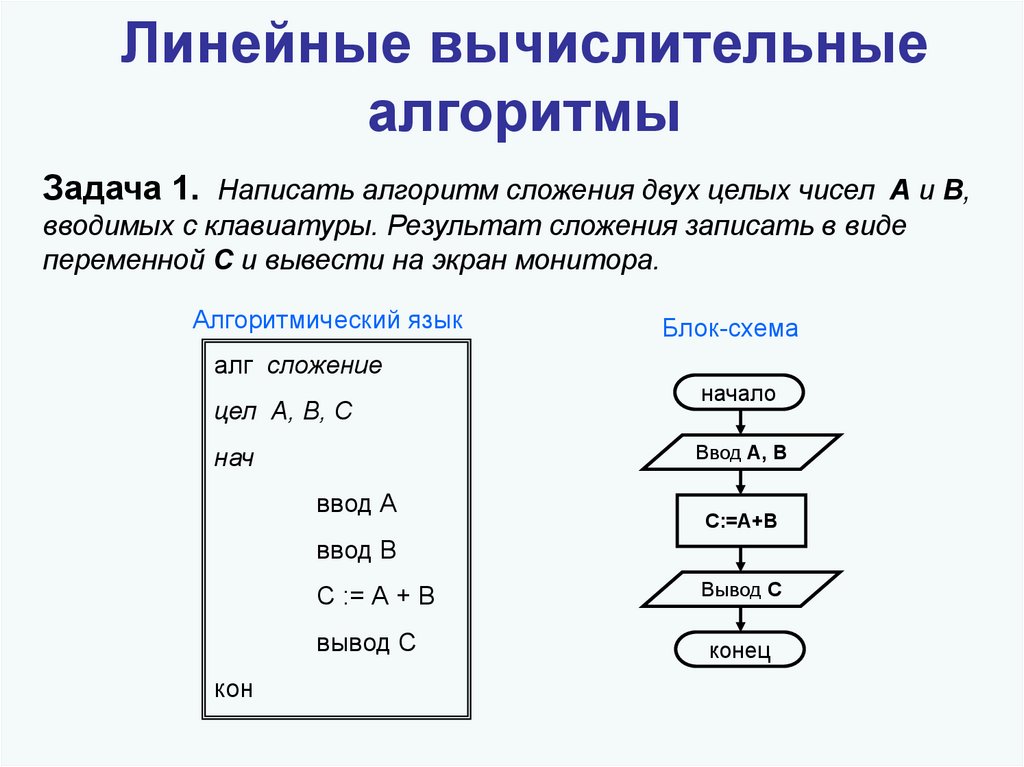
Вместо того, чтобы углубляться в проблему, подойдите к проблеме поэтапно:
Подумайте:
- Проанализируйте проблему
- Переформулируйте проблему
- Запишите примеры ввода и вывода
- Разбейте проблему на составные части
- Обрисовать решение в псевдокоде
- Пройдитесь по данным вашего примера с вашим псевдокодом
Выполнить
- Закодировать
- Проверьте свое решение на своих примерах
- Рефакторинг
(Если вы знакомы с этим подходом, перейдите к шаблонам алгоритмов)
Проанализируйте проблему
Возможно, вас осенило, когда вы впервые увидели проблему. Как правило, это ваш ум, соединяющийся с каким-то предыдущим опытом. Держитесь за это понимание! Тем не менее, вы все равно должны потратить некоторое время на изучение проблемы, особенно на то, как ваше понимание отличается от фактического вопроса.
Любая хорошо написанная головоломка содержит компоненты, необходимые для решения задачи, содержащейся в одном-двух предложениях. Однако то, что вы читаете задачу, не означает, что вы ее понимаете. И если вы не понимаете проблемы, вы будете бесцельно спотыкаться или решать то, что, как вы предполагали, было проблемой.
Однако то, что вы читаете задачу, не означает, что вы ее понимаете. И если вы не понимаете проблемы, вы будете бесцельно спотыкаться или решать то, что, как вы предполагали, было проблемой.
Найдите ключевые слова, которые определяют форму задачи.
Определите ввод.
Определите желаемый результат.
Определите критические ключевые слова и фразы.
Например, LeetCode #26
Учитывая [отсортированный] [массив] nums, [удалить дубликаты] [на месте], чтобы каждый элемент появлялся только один раз, и [возвратить новую длину].
Не выделяйте дополнительное пространство для другого массива, это необходимо сделать, изменив входной массив на месте с [O(1) дополнительной памяти].
Ввод:
- массив. Итак, мы знаем, что, вероятно, собираемся сделать какую-то итерацию.
- массив чисел. Это больше подразумевается, чем конкретно указано, и на самом деле не так важно, как мы можем использовать тот же набор условных выражений.

Возврат:
- длина измененного массива
- побочный эффект: модифицированный массив
Критические слова и фразы:
- отсортировано: повторяющиеся элементы будут рядом друг с другом
- удалить… дубликаты
- на месте: сам массив должен быть деструктивно изменен. Это ограничение определяет, какие методы массива мы можем использовать.
- Дополнительная память O(1): мы ограничены пространственной сложностью O(1), что позволяет нам определять переменные, но не создавать копию массива.
Переформулируйте проблему
Теперь, своими словами, перефразируйте это так, чтобы оно имело смысл для нас самих. Если вы находитесь на собеседовании, вы можете пересказать интервьюеру, как для того, чтобы запомнить его, так и для того, чтобы убедиться, что вы правильно его услышали и поняли.
Пересчитано:
При наличии отсортированного массива чисел, переданного по ссылке, деструктивно изменить исходный массив на месте, удалив дубликаты, чтобы каждое значение появлялось только один раз.
 Возвращает длину измененного массива.
Возвращает длину измененного массива.Запишите пример входных данных и ожидаемых результатов
Все, что мы делаем, это сопоставляем входы с выходами. Задача состоит в том, чтобы выяснить, как добраться из A в B, однако сначала нам нужно установить, что A и B представляют собой . Даже если вам дали тест-кейсы, напишите свои. Глядя на что-то, не создается почти такого же понимания, как если бы вы делали это для себя.
Это также прекрасное время, чтобы изучить свое понимание проблемы и найти особенности, которые могут сбить с толку наивное решение. Это включает в себя крайние случаи, такие как пустые входные данные, массив, заполненный дубликатами одного и того же значения, массивный набор данных и т. д. Нам не нужно беспокоиться ни о чем, кроме ограничений задачи 9.0003
Запишите не менее 3-х примеров:
[] -> [], возврат 0 [1] -> [1], вернуть 1 [1, 1, 2, 3, 4, 4, 4, 5] -> [1, 2, 3, 4, 5], вернуть 5 [1, 1, 1, 1, 1] -> [1], вернуть 1
Учитывая входные данные, достаточно ли у вас информации для сопоставления с результатом? Если вы этого не сделаете, сделайте шаг назад и продолжите изучение проблемы, прежде чем продолжить. Если вы проводите собеседование, не стесняйтесь просить разъяснений.
Если вы проводите собеседование, не стесняйтесь просить разъяснений.
Ищите простой и последовательный процесс, который можно применять независимо от ценности для достижения результата. Если вы получите запутанную серию шагов и исключений, вы, вероятно, зашли слишком далеко и пропустили более простое решение.
Разбейте проблему на мелкие части
Начиная с простейшего возможного примера, просто сведите задачу к основной головоломке и развивайте ее. В данном случае это массив из трех элементов, два из которых дублируются, например. [1, 1, 2] . Сведение проблемы к такому небольшому случаю делает ее более доступной и проясняет первый шаг, который вам нужно сделать. Ваша задача состоит в том, чтобы разработать процедуру, которая решает этот простой случай и , справедливый для всех других случаев в наборе задач.
Итак, мы знаем, что нам нужно сделать пару вещей:
- Перебрать массив
- Следите за тем, где в массиве мы находимся
- Проверить соседние значения на равенство
- Деструктивно удалить все повторяющиеся значения после первого вхождения
- Получить окончательную длину массива и вернуть ее
Это относительно простой пример задачи, однако в ней скрывается подвох : многие итерационные методы плохо работают с удалением элементов из массива , в то время как вы перебираете массив, потому что значения индекса меняются. Вы можете в конечном итоге пропустить дубликат, потому что указатель увеличился над ним.
Вы можете в конечном итоге пропустить дубликат, потому что указатель увеличился над ним.
Эта ошибка указывает на то, что мы хотим использовать подход, который дает нам явное управление итерацией.
В более сложной задаче мы могли бы рассматривать некоторые или все эти компоненты как вспомогательные функции, что позволит нам написать ясное и краткое решение, а также проверить правильность каждой из наших подчастей по отдельности.
Псевдокод решения
Если мы ясно поняли проблему, определили основные задачи и, надеюсь, заметили недостатки в наших собственных предположениях и любые подводные камни, мы записываем понятное для человека описание того, каким будет наш подход. Надеюсь, когда мы это сделаем, мы сможем аккуратно преобразовать его в работающий код.
То, как вы пишете псевдокод, зависит от вас. Ваши обозначения не обязательно должны быть идеально написаны и грамматически правильны. Это может быть жестовая комбинация кода и слов, предназначенная для передачи значения. Ваш псевдокод предоставит содержательную дорожную карту, к которой вы сможете вернуться, если обнаружите, что глубоко заблудились в деталях реализации, поэтому убедитесь, что вы записали достаточно, чтобы быть полезными позже.
Ваш псевдокод предоставит содержательную дорожную карту, к которой вы сможете вернуться, если обнаружите, что глубоко заблудились в деталях реализации, поэтому убедитесь, что вы записали достаточно, чтобы быть полезными позже.
Если вы проводите собеседование, это отличная возможность рассказать интервьюеру о ваших намерениях. И если у вас мало времени, у вас по крайней мере будет что-то на доске, демонстрирующее ваш подход к решению проблем.
Рекомендации:
- начать с сигнатуры функции:
removeDuplicates :: (массив) -> номер - при использовании интерактивной доски оставьте достаточно места для написания фактического кода
- , если вы используете IDE, пишите комментарии и храните их отдельно от кода, чтобы вы могли ссылаться на них позже.
- напишите это как серию шагов и используйте маркеры
Поскольку мы ищем дубликаты, это означает, что нам нужно выполнить сравнение. Мы можем смотреть вперед на нашу текущую позицию в массиве или мы можем смотреть назад.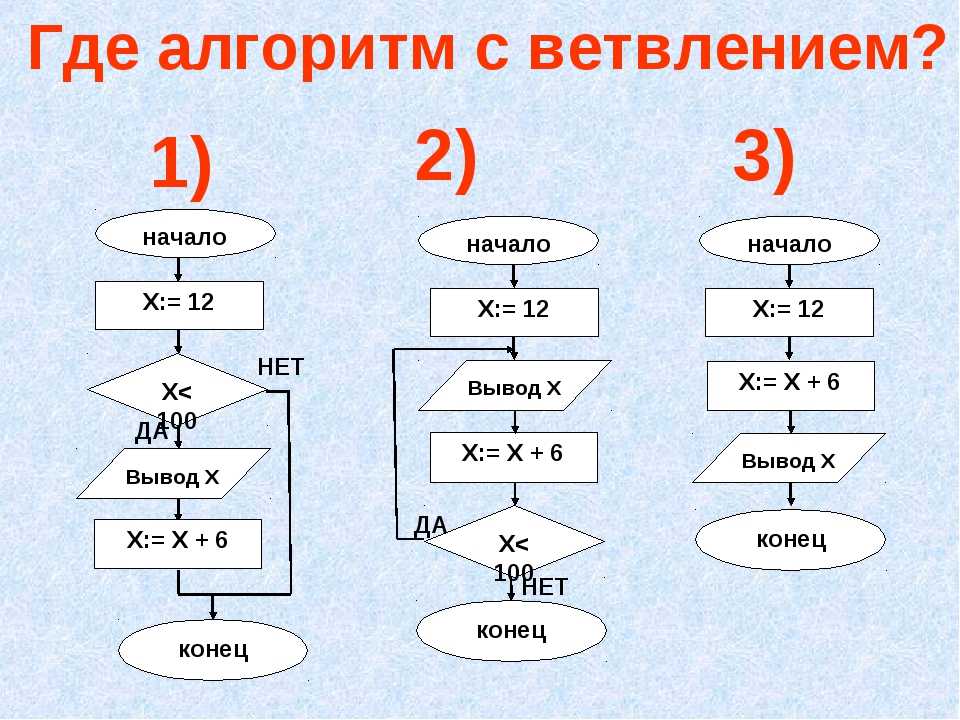
// удалить дубликаты :: (массив) -> число // если массив пуст или содержит 1 элемент, вернуть длину массива и выйти // итерация по массиву // сравниваем каждый элемент со следующим элементом // // повторяем до false: // если следующий элемент совпадает с текущим элементом // удаляем следующий элемент // // переходим к следующему элементу массива // остановимся, как только будет достигнут предпоследний элемент // возвращаем длину массива
Мы начинаем с выхода, если наш массив имеет размер всего 0 или 1 элемент, отчасти потому, что эти случаи удовлетворяют условиям задачи: нет возможных дубликатов, а отчасти потому, что они сломают наш код, если мы попытаемся сравнить первое значение со вторым, которого не существует.
Мы также устанавливаем условие выхода из итерации, и, поскольку мы будем использовать просмотр вперед, мы обязательно остановим до того, как мы достигнем последнего элемента.
Потому что мы не перемещаем позицию указателя до после мы разобрались с любыми дубликатами, мы должны быть свободны от проблемы смещения индексов.
Пройдитесь по образцу данных
Уделите немного времени и мысленно запустите некоторые образцы данных через наш псевдокод:
[] -> [], верните 0 [1] -> [1], вернуть 1 [1, 1, 2, 3, 4, 4, 4, 5] -> [1, 2, 3, 4, 5], вернуть 5 [1, 1, 1, 1, 1] -> [1], вернуть 1
Мы что-то упустили?
Может возникнуть проблема с последним примером: [1, 1, 1, 1, 1] . Что произойдет, если мы удалим все дубликаты, а затем попытаемся перейти к следующему элементу в нашем массиве, не проверяя, есть ли они?
Мы хотим убедиться, что наше конечное условие улавливает любые изменения длины массива.
Код это
Пора резине встретить дорогу. Здесь у вас есть все предположения, о которых вы даже не подозревали, что они вернулись, чтобы преследовать вас. Чем лучше вы смогли спланировать, тем меньше их будет.
функция удалить дубликаты (обр) {
если (arr.length < 2) вернуть arr.length
обратная длина приб.
}
Лично мне нравится сначала вводить возвращаемые значения.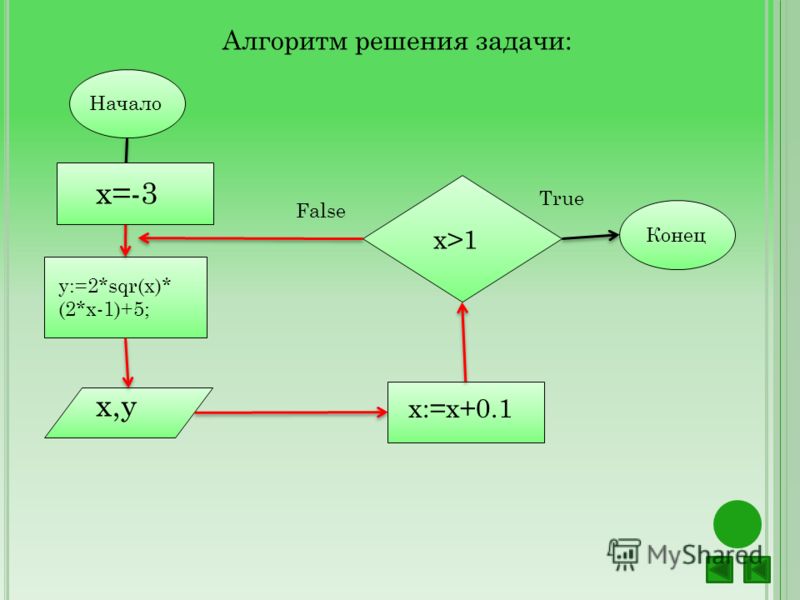 Таким образом, я ясно понимаю, какова моя цель, и я также зафиксировал первый случай пустых или одноэлементных массивов.
Таким образом, я ясно понимаю, какова моя цель, и я также зафиксировал первый случай пустых или одноэлементных массивов.
функция удаления дубликатов (обр) {
если (arr.length < 2) вернуть arr.length
for(пусть i = 0; i < arr.length; arr++) {}
обратная длина приб.
}
Да, мы используем стандартный цикл for. Я предпочитаю не использовать их, если есть более подходящий или более чистый синтаксис, но для этой конкретной проблемы нам нужна возможность контролировать нашу итерацию.
функция удаления дубликатов (обр) {
если (arr.length < 2) вернуть arr.length
for(пусть i = 0; i < arr.length; i++) {
в то время как (arr[i + 1] && arr[i] === arr[i + 1]) arr.splice(i + 1, 1)
}
обратная длина приб.
}
И это работает из коробки, кроме:
removeDuplicates([0,0,1,1,1,2,2,3,3,4]) //> 6, должно быть 5
Оказывается, проверка существования, которую я пробрался в цикле while, разрешается как ложная, если значение массива равно 0 . Спасибо JavaScript! Так что давайте просто переработаем это очень быстро и посмотрим назад, а не вперед, что на самом деле также немного очищает код:
Спасибо JavaScript! Так что давайте просто переработаем это очень быстро и посмотрим назад, а не вперед, что на самом деле также немного очищает код:
function removeDuplicates(arr) {
если (arr.length < 2) вернуть arr.length
for(пусть i = 0; i < arr.length; i++) {
в то время как (arr[i] === arr[i - 1]) arr.splice(i, 1)
}
обратная длина приб.
}
И это проходит. Это эффективное решение для памяти, мы определили только 1 переменную, кроме ссылки на массив. И это средняя скорость, которую мы могли бы улучшить.
Но в основном это был простой пример процесса:
- Анализ
- Переформулировать
- Примеры записи
- Разберитесь с мелкими проблемами
- Контур в псевдокоде
- Шаг по псевдокоду с примерами
- Код
- Тест
- Рефакторинг
Помимо определенных структур данных и алгоритмов, которые имеют известные и довольно стандартизированные подходы, проблемы с алгоритмами, как правило, делятся на категории, которые предполагают аналогичные подходы к решению. Изучение этих подходов дает вам точку опоры в проблеме.
Изучение этих подходов дает вам точку опоры в проблеме.
Несколько указателей
Когда мы впервые учимся перебирать коллекцию, обычно массив, мы делаем это с помощью одного указателя с индексом, идущим от наименьшего значения к наибольшему. Это работает для некоторых операций и просто для рассмотрения и кода. Однако для задач, связанных со сравнением нескольких элементов, особенно тех, где важна их позиция в коллекции, поиск соответствующего значения с помощью одного указателя требует повторения массива по крайней мере один раз для каждого значения, O(n 2) операция.
Если вместо этого мы используем несколько множественных точек, мы потенциально можем сократить вычисление до операции O(n).
Существуют две общие стратегии: два указателя и скользящее окно
Два указателя
Почему бы не начать с обоих концов и не двигаться дальше? Или начните со значения или пары значений и расширяйтесь наружу. Это отличный подход для поиска самой большой последовательности в коллекции.
Поскольку вы работаете с двумя точками, вам необходимо определить правило, чтобы гарантировать, что они не пересекаются друг с другом.
// Временная сложность O(n)
// Пространственная сложность O(1)
функция sumZero(arr) {
пусть слева = 0;
пусть право = массив.длина - 1;
в то время как (слева < справа) {
пусть сумма = обр [слева] + обр [право];
если (сумма === 0) вернуть [обр [слева], обр [право]];
иначе если (сумма > 0) право--;
иначе осталось++;
}
}
Раздвижное окно
Вместо размещения двух точек на внешних границах мы можем пройтись по нашему массиву, последовательно перемещая два указателя параллельно. Ширина нашего окна может увеличиваться или уменьшаться в зависимости от набора задач, но оно продолжает перемещаться по коллекции, захватывая моментальный снимок любой последовательности, которая лучше всего соответствует желаемому результату.
функция maxSubarraySum(массив, n) {
если (array.length < n) n = array. length;
пусть сумма = 0;
для (пусть i = 0; i < n; i++) {
сумма = сумма + массив [i];
}
пусть maxSum = сумма;
// сдвиг окна по массиву
for (пусть я = n; я < array.length; я ++) {
сумма = сумма + массив [i] - массив [i - n];
если (сумма > maxSum) maxSum = сумма;
}
вернуть максимальную сумму;
}
 length;
пусть сумма = 0;
для (пусть i = 0; i < n; i++) {
сумма = сумма + массив [i];
}
пусть maxSum = сумма;
// сдвиг окна по массиву
for (пусть я = n; я < array.length; я ++) {
сумма = сумма + массив [i] - массив [i - n];
если (сумма > maxSum) maxSum = сумма;
}
вернуть максимальную сумму;
}
length;
пусть сумма = 0;
для (пусть i = 0; i < n; i++) {
сумма = сумма + массив [i];
}
пусть maxSum = сумма;
// сдвиг окна по массиву
for (пусть я = n; я < array.length; я ++) {
сумма = сумма + массив [i] - массив [i - n];
если (сумма > maxSum) maxSum = сумма;
}
вернуть максимальную сумму;
}
Разделяй и властвуй
Разделяй и властвуй часто используется рекурсивный подход: применение одного и того же правила для разделения коллекции до тех пор, пока вы не разбьете ее на мельчайшие компоненты и не определите ответ.
Двоичный поиск и сортировка слиянием являются прекрасными примерами рекурсивного подразделения, ведущего к решению.
O(1) Поиск: Объект/Словарь/Хэш
Хешированный ключ: Хранилища значений, называемые объектами, словарями или хэшами в зависимости от вашего языка кодирования, являются невероятно полезными инструментами для хранения информации при подсчете частоты, проверке на наличие дубликатов или дополнении ответа. Как там
Как там
Вы можете сохранить значение, или вместо этого вы можете сохранить значение, которое вы ищете. Например, при поиске пар с нулевой суммой в массиве мы можем сохранить дополнение, а не само значение.
Ресурсы:
Основы алгоритмического решения задач (видео)
Алгоритмическое решение задач для программистов
10 лучших алгоритмов в вопросах на собеседовании
Улучшение навыков работы с алгоритмами и структурами данных
Как использовать алгоритмы для решения задач?
Алгоритм — это процесс или набор правил, которым необходимо следовать для выполнения конкретной задачи. Это в основном пошаговая процедура для выполнения любой задачи. Все задачи выполняются по определенному алгоритму, от приготовления чашки чая до создания масштабируемого программного обеспечения. Это способ разделить задачу на несколько частей. Если мы нарисуем алгоритм выполнения задачи, то задачу будет легче выполнить.
Алгоритм используется для,
- Для разработки основы для обучения компьютеров.
- Введены обозначения основных функций для выполнения основных задач.
- Для определения и описания большой проблемы небольшими частями, чтобы ее было очень легко выполнить.

Характеристики алгоритма
- Алгоритм должен быть четко определен.
- Алгоритм должен выдавать хотя бы один результат.
- Алгоритм должен иметь ноль или более входных данных.
- Алгоритм должен быть выполнен и завершен за конечное число шагов.
- Алгоритм должен быть простым и простым в исполнении.
- Каждый шаг начинается с определенного отступа, например, «Шаг-1»,
- Должен быть «Начало» в качестве первого шага и «Конец» в качестве последнего шага алгоритма.
Возьмем в качестве примера приготовление чая,
Шаг 1: Запуск
Шаг 2: Набери немного воды в миске.
Шаг 3: Поставьте воду на газовую горелку .
Шаг 4: Включите газовую горелку
Шаг 5: Подождите некоторое время, пока вода не закипит.
Шаг 6: Добавьте в воду несколько листьев чая в соответствии с требованиями.
Шаг 7: Затем снова подождите некоторое время, пока вода не станет цвета чая.
Шаг 8: Затем добавьте немного сахара по вкусу.
Шаг 9: Снова подождите некоторое время, пока сахар не растает.
Шаг 10: Выключите газовую горелку и подавайте чай в чашках с печеньем.
Шаг 11: Конец
Вот алгоритм приготовления чашки чая. То же самое и с задачами по информатике.
Есть несколько основных шагов для создания алгоритма:
- Старт – Запуск алгоритма
- Вход — Принять входные данные для значений, при которых будет выполняться алгоритм.
- Условия — Выполните некоторые условия на входах, чтобы получить желаемый результат.
- Вывод – Печать выводов.
- Конец — Завершить выполнение.

Давайте рассмотрим несколько примеров алгоритмов для задач информатики.
Пример 1. Поменять местами два числа с третьей переменной
Шаг 1: Запуск
Шаг 2: Возьмите 2 числа в качестве входных данных.
Шаг 3: Объявите другую переменную как «temp».
Шаг 4: Сохраните первую переменную в «temp».
Шаг 5: Сохраните вторую переменную в первой переменной.
Шаг 6: Сохраните переменную «temp» во вторую переменную.
Шаг 7: Распечатайте первую и вторую переменные.
Шаг 8: Конец
Пример 2. Найдите площадь прямоугольника
Найдите площадь прямоугольника
Шаг 1: Запустите
Шаг 2: В качестве входных данных возьмите высоту и ширину прямоугольника.
Шаг 3: Объявить переменную как «площадь»
Шаг 4: Умножить высоту и ширину )
Шаг 6: Напечатать «площадь»;
Шаг 7: Конец
Пример 3. Найдите наибольшее из 3 чисел.
Шаг 1: Запустить
Шаг 2: В качестве входных данных принять 3 числа, скажем A, B и C.
Шаг 3: Проверить, если (A>B и A>C3)
Шаг 4: Тогда A больше
Шаг 5: Распечатать A
Шаг 6 : Иначе
Шаг 7: Проверить, если (B>A и B>C)
Шаг 8: , затем B превышает
Шаг 9: Печать B
Шаг 10: ELS
Преимущества алгоритма
- Алгоритм использует определенную процедуру.
- Это легко понять, потому что это пошаговое определение.
- Алгоритм легко отладить, если произойдет какая-либо ошибка.
- Не зависит ни от какого языка программирования.
- Программисту легче преобразовать ее в настоящую программу, потому что алгоритм делит задачу на более мелкие части.
Недостатки алгоритмов
- Алгоритм требует много времени, для разных алгоритмов существует определенная временная сложность.
- Большие задачи трудно решать в алгоритмах, потому что временная сложность может быть выше, поэтому программисты должны найти хороший эффективный способ решения этой задачи.
- Циклы и ветвления трудно определить в алгоритмах.
5 Должен знать алгоритм, методы решения проблем или подходы для программиста
Задумывались ли вы когда-нибудь о том, «как работает netflix» или «как работает поиск Google». Ответ: Алгоритм. В реальном мире мы используем алгоритм для методов решения проблем.
1. Пример: Создайте пример алгоритма
Прежде чем думать о логике алгоритма, мы должны четко понять вопрос. Напишите не менее двух примеров с указанием ввода и вывода. Эта двухминутная первоначальная работа устранит неуверенность, связанную с непониманием вопроса и мыслями в неправильном направлении.
Например,
Вопрос: найти первый неповторяющийся символ в строкеЗатем, перед написанием алгоритма, выполните эти шаги
Пример 1:
Ввод: аливазоть
Выход: L (Small L)Пример 2:
Ввод: Loveyourself
Выход: VЭто один из в основном используемых методы решения задач для алгоритмов.
Читайте также: Как стать хорошим программистом: что нужно, чтобы выделиться среди остальных
2. Сопоставление с образцом
Мы должны рассмотреть, на какие задачи похож алгоритм, нам нужно выяснить, можем ли мы изменить решение, чтобы разработать алгоритм для данной задачи.Например:
Вопрос: Отсортированный массив был повернут таким образом, что элементы могут располагаться в порядке 3 4 5 6 7 1 2 . Как найти минимальный элемент.
Аналогичные задачи:
1. Найдите минимальный элемент в массиве.
2.Найти определенный элемент в массиве (например, бинарный поиск).Поиск минимального элемента в массиве здесь вряд ли будет полезен, так как он не использует предоставленную информацию (о том, что массив отсортирован).
Двоичный поиск может быть очень полезен. Мы знаем, что массив отсортирован, но повернут. Таким образом, он должен действовать в порядке возрастания, затем сбрасываться и снова увеличиваться.Сравнивая первый и средний элементы (3 и 6), мы знаем, что диапазон все еще увеличивается. Это указывает на то, что точка сброса должна быть после 6 (или 3 — это минимальный элемент, а массив никогда не вращался). Мы можем продолжать применять уроки бинарного поиска, чтобы точно определить эту точку сброса, ища диапазоны, где ЛЕВОЕ > ПРАВОЕ. То есть для конкретной точки, если ВЛЕВО < ВПРАВО, то диапазон не содержит сброс. Если ВЛЕВО > ВПРАВО, то да.
Мы часто практикуемся в написании алгоритмов. Если мы напишем алгоритм , то у нас не может быть алгоритма
3. Упростить и обобщить
Изменение ограничения (например, размер, длина, тип данных) для упрощения задачи. Например, изменение типа данных с double на int , make проблема меньше. Напишите алгоритм для типа данных int, а затем обобщите его для double.
Например,
Вопрос в том, чтобы обрезать пробелы в строке пароля или сжать строку
Решите следующим образом
1.
2. Обрезка справа (удаление пробелов в крайнем правом углу)
3. Удаление пробелов между строкой4. Базовый случай и Сборка
Этот подход наиболее широко используется в рекурсивном алгоритме.
Сначала решите алгоритм для базового случая (например, только один элемент). Затем попытайтесь решить его для элементов один и два, предполагая, что у нас есть ответ для элемента один. Затем попытайтесь решить его для элементов один, два и три, предполагая, что у нас есть ответ на элементы один и два.Например,
Вопрос заключается в том, чтобы найти все возможные перестановки строки, предполагая, что все символы в строке уникальны.Входная строка: "abcdef"
Процедура решения:
Извлекать по одному символу из входной строки
Базовый случай
a(первый элемент входной строки): a(возможная перестановка)9 9 Сборка
ab : ab,ba
abc : abc,acb,bac,bca,cba,cab
abcd.
abcde...
abcdef...
5. Структура данных Мозговой штурмЭто утомительный метод, основанный на методе проб и ошибок. Просто просмотрите список структур данных и попытайтесь применить каждую из них.
Например,
Вопрос: Числа генерируются случайным образом и сохраняются в (расширяющемся) массиве. Как мы будем отслеживать медиану (нечетное количество элементов: среднее число, но если четное количество элементов, то среднее значение двух средних элементов)?Структура данных Мозговой штурм:
1. Связанный список: Связанные списки не очень хорошо подходят для доступа и сортировки чисел. Поэтому лучше его избегать.
2. Массив . Не уверен, так как у нас уже есть массив. Сортировка элементов в массиве может быть дорогостоящей. Мы оставим этот вариант на удержании и вернемся к нему, если он понадобится.
3. Двоичное дерево. Это может быть жизнеспособным вариантом, поскольку бинарные деревья довольно хорошо справляются с упорядочением.
4. Куча: куча действительно хороша для базового упорядочения и отслеживания максимального и минимального значений. Предположим, у нас есть две кучи, и мы можем отслеживать самую большую половину и самую маленькую половину элементов. Самая большая половина хранится в куче min, так что самый маленький элемент в самой большой половине находится в корне. Наименьшая половина хранится в максимальной куче, так что самый большой элемент наименьшей половины находится в корне. Теперь, с этими структурами данных, у нас есть потенциальные срединные элементы в корнях. Если кучи больше не одного размера, мы можем быстро «перебалансировать» кучи, выталкивая элемент из одной кучи и помещая его в другую.

 Важность алгоритма нельзя недооценивать. Алгоритм несет исключительную ответственность за техническую революцию в последнее десятилетие. Алгоритм зависит от времени и пространственной сложности. Хорошие алгоритмы требуют меньше времени и памяти для выполнения задачи. Если вам нужно создать свой собственный алгоритм, вы можете использовать эти пять методов решения проблем.
Важность алгоритма нельзя недооценивать. Алгоритм несет исключительную ответственность за техническую революцию в последнее десятилетие. Алгоритм зависит от времени и пространственной сложности. Хорошие алгоритмы требуют меньше времени и памяти для выполнения задачи. Если вам нужно создать свой собственный алгоритм, вы можете использовать эти пять методов решения проблем.
 Минимальный элемент – это точка «сброса».
Минимальный элемент – это точка «сброса». Обрезка слева (удаление пробелов в крайнем левом углу)
Обрезка слева (удаление пробелов в крайнем левом углу)  ..
..  Как мы знаем, вершина идеально сбалансированного бинарного дерева поиска является медианой, если в бинарном дереве поиска присутствует нечетное количество элементов. Но если есть четное количество элементов, медиана на самом деле является средним значением двух средних элементов. Средние два элемента не могут быть оба наверху. Это, наверное, нам нужно посмотреть, давайте воздержимся от этого.
Как мы знаем, вершина идеально сбалансированного бинарного дерева поиска является медианой, если в бинарном дереве поиска присутствует нечетное количество элементов. Но если есть четное количество элементов, медиана на самом деле является средним значением двух средних элементов. Средние два элемента не могут быть оба наверху. Это, наверное, нам нужно посмотреть, давайте воздержимся от этого.