
просто о сложных формулах / Хабр
Статистика вокруг нас
Статистика и анализ данных пронизывают практически любую современную область знаний. Все сложнее становится провести границу между современной биологией, математикой и информатикой. Экономические исследования и регрессионный анализ уже практически неотделимы друг от друга. Один из известных методов проверки распределения на нормальность — критерий Колмогорова-Смирнова. А вы знали, что именно Колмогоров внес огромный вклад в развитие математической лингвистики?
Еще будучи студентом психологического факультета СПбГУ, я заинтересовался когнитивной психологией. Кстати, Иммануил Кант не считал психологию наукой, так как не видел возможности применять в ней математические методы. Мои текущие исследования посвящены моделированию психических процессов, и я надеюсь, что такие направления в современной когнитивной психологии, как вычислительные и коннективисткие модели, смягчили бы его отношение!
Конечно, статистика применяется далеко за пределами научных лабораторий: в рекламе, маркетинге, бизнесе, медицине, образовании и т.
Распределение имеет явно выраженную асимметрию: очень состоятельных людей заметно меньше, чем представителей среднего класса. Это приводит к тому, что в данном случае банкротство одного из миллионеров может значительно повлиять на этот показатель.
Черный ящик статистического анализа
Как мы уже выяснили, чем бы вы ни планировали заниматься, вероятность столкнуться с курсом «математическая статистика в вашей области» постепенно приближается к единице. Однако, часто занятия по введению в статистику не вызывают восторга у студентов нетехнических факультетов. Через несколько занятий выясняется, что такие базовые понятия, как, например, корреляция представляют собой нечто следующее:
И, отчаявшись досконально разобраться с происхождением этих сумм и квадратных корней, студент может начать воспринимать статистику следующим образом: «если r > 0, то положительная связь, а если меньше 0, то отрицательная»; «если p уровень значимости меньше 0. 05 — то хорошо, если от 0.05 до 0.1 — то не очень хорошо, а если больше 0.1 — то плохо». Помогая студентам готовиться к экзамену, не раз сталкивался с такими заклинаниями! Также, разумеется, никто не рассчитывает все эти показатели вручную, и используя, например, SPSS, можно за секунду загуглить пошаговую инструкцию «как сравнить два средних».
05 — то хорошо, если от 0.05 до 0.1 — то не очень хорошо, а если больше 0.1 — то плохо». Помогая студентам готовиться к экзамену, не раз сталкивался с такими заклинаниями! Также, разумеется, никто не рассчитывает все эти показатели вручную, и используя, например, SPSS, можно за секунду загуглить пошаговую инструкцию «как сравнить два средних».
- Жмем сюда
- Снимаем/ставим галочки тут
- p < 0.05 —> profit
Статистический анализ начинает напоминать черный ящик: на вход подаются данные, на выход — таблица основных результатов и значение p-уровня значимости (p-value), который и расставит все точки над i.
О чем нам, собственно, говорит p-value?
Предположим, мы решили выяснить, существует ли взаимосвязь между пристрастием к кровавым компьютерным играм и агрессивностью в реальной жизни. Для этого были случайным образом сформированы две группы школьников по 100 человек в каждой (1 группа — фанаты стрелялок, вторая группа — не играющие в компьютерные игры).
А теперь несколько примеров про p-value
Итак, мы сравнили две группы школьников между собой по уровню агрессивности при помощи стандартного t-теста (или непараметрического критерия Хи — квадрат более уместного в данной ситуации) и получили, что заветный p-уровень значимости меньше 0.
- Компьютерные игры — причина агрессивного поведения с вероятностью 96%.
- Вероятность того, что агрессивность и компьютерные игры не связаны, равна 0.04.
- Если бы мы получили p-уровень значимости больше, чем 0.05, это означало бы, что агрессивность и компьютерные игры никак не связаны между собой.
- Вероятность случайно получить такие различия равняется 0.04.
- Все утверждения неверны.
Если вы выбрали пятый вариант, то абсолютно правы! Но, как показывают многочисленные исследования, даже люди со значительным опытом в анализе данных часто некорректно интерпретируют значение p-value (например, можно посмотреть эту интересную статью).
Давайте разберем все ответы по порядку:
- Первое утверждение — пример ошибки корреляции: факт значимой взаимосвязи двух переменных ничего не говорит нам о причинах и следствиях. Может быть, это более агрессивные люди предпочитают проводить время за компьютерными играми, а вовсе не компьютерные игры делают людей агрессивнее.
- Это уже более интересное утверждение. Все дело в том, что мы изначально принимаем за данное, что никаких различий на самом деле нет. И, держа это в уме как факт, рассчитываем значение p-value. Поэтому правильная интерпретация: «Если предположить, что агрессивность и компьютерные игры никак не связаны, то вероятность получить такие или еще более выраженные различия составила 0.04».
- А что делать, если мы получили незначимые различия? Значит ли это, что никакой связи между исследуемыми переменными нет? Нет, это означает лишь то, что различия, может быть, и есть, но наши результаты не позволили их обнаружить.
- Это напрямую связано с самим определением p-value.
 0.04 — это вероятность получить такие или еще более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
0.04 — это вероятность получить такие или еще более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
 0.04 — это вероятность получить такие или еще более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
0.04 — это вероятность получить такие или еще более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!Вот такие подводные камни могут скрываться в интерпретации такого показателя, как p-value. Поэтому очень важно понимать механизмы, заложенные в основании методов анализа и расчета основных статистических показателей.
Онлайн-курс по основам статистики: сложные формулы несложным языком
Сейчас я пишу диссертацию на факультете психологии СПбГУ и преподаю статистику биологам в Институте биоинформатики. Основываясь на курсе читаемых лекций и собственного исследовательского опыта, возникла идея создать онлайн-курс по введению в статистику на русском языке для всех желающих, необязательно биоинформатиков или биологов.
Существует много хороших онлайн-курсов по анализу данных и статистике (например, такой, такой, или такой), но практически все они на английском языке. Надеюсь, что курс будет полезен для тех, кто только знакомится с основами статистики. В нем я стараюсь в максимально доступной форме разобрать основные идеи и методы анализа данных, уделяя особое внимание самой идее статистической проверки гипотез и интерпретации получаемых результатов. В качестве примеров будут задачи из различных областей: от биоинформатики до социологии. Курс бесплатный и все его материалы останутся открытыми после окончания, начинается 15 февраля.
Надеюсь, что курс будет полезен для тех, кто только знакомится с основами статистики. В нем я стараюсь в максимально доступной форме разобрать основные идеи и методы анализа данных, уделяя особое внимание самой идее статистической проверки гипотез и интерпретации получаемых результатов. В качестве примеров будут задачи из различных областей: от биоинформатики до социологии. Курс бесплатный и все его материалы останутся открытыми после окончания, начинается 15 февраля.
Полезные материалы
Если вы знаете какие-либо полезные курсы или материалы по введению в статистику — делитесь в комментариях!
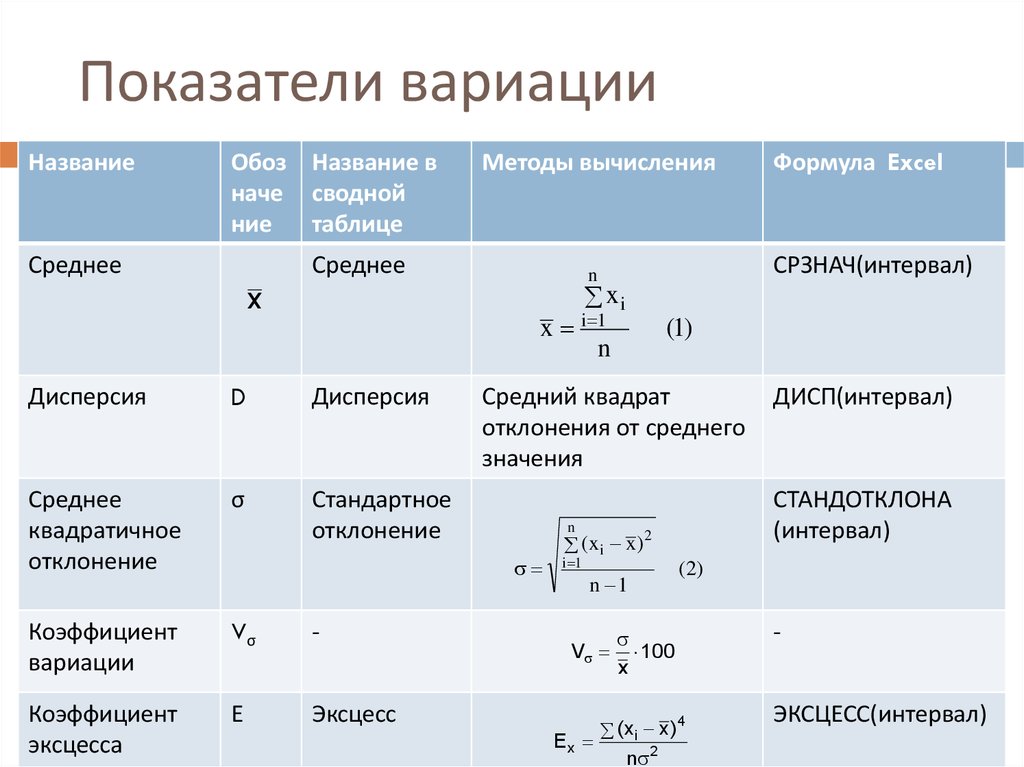
Основные статистические функции в Excel: использование, формулы
Зная статистические формулы и приемы можно обработать, проанализировать и упорядочить большое количество информации. В Эксель инструменты статистики выведены в отдельную категорию функций. Давайте посмотрим, как их найти, а также, какие из них являются наиболее популярными среди пользователей.
- Использование статистических функций
- СРЗНАЧ
- МАКС
- МИН
- СРЗНАЧЕСЛИ
- МЕДИАНА
- НАИБОЛЬШИЙ
- НАИМЕНЬШИЙ
- МОДА.ОДН
- СТАНДОТКЛОН
- СРГЕОМ
- Заключение
Использование статистических функций
Смотрите также: “Основные математические функции в Excel: использование, формулы”
Формулы функций в Excel можно вводить вручную непосредственно в той ячейке, где планируется выполнить соответствующие расчеты. Это легко применимо к таким простым действиям, как сложение, вычитание, умножение и деление. Но запомнить формулы сложных функций уже непросто, поэтому проще воспользоваться специальным помощником, который встроен в программу.
Но запомнить формулы сложных функций уже непросто, поэтому проще воспользоваться специальным помощником, который встроен в программу.
Итак, чтобы вставить функцию в ячейку, выполняем одно из следующих действий:
- Находясь в любой вкладке программы щелкаем по значку “Вставить функцию” (fx), которая находится с левой стороны от строки формул.
- Переходим во вкладку “Формулы”, где видим в левом углу ленты инструментов кнопку “Вставить функцию”.
- Используем сочетание клавиш Shift+F3.
Независимо от выбранного способа выше перед нами появится окно вставки функций. Щелкаем по текущей категории и из раскрывшегося списка выбираем пункт “Статистические”.
Далее будет предложен на выбор один из статистических операторов. Отмечаем нужный и жмем OK.
На экране отобразится окно с аргументами выбранной функции, которые нужно заполнить.
Примечание: существует еще один способ выбора требуемой функции. Находясь во вкладке “Формулы” в блоке инструментов “Библиотека функций” щелкаем по значку “Другие функции”, затем выбираем пункт “Статистические” и, наконец, в открывшемся перечне (который можно листать вниз) – нужный оператор.
Находясь во вкладке “Формулы” в блоке инструментов “Библиотека функций” щелкаем по значку “Другие функции”, затем выбираем пункт “Статистические” и, наконец, в открывшемся перечне (который можно листать вниз) – нужный оператор.
Давайте теперь рассмотрим наиболее популярные функции.
СРЗНАЧ
Смотрите также: “Как посчитать среднее значение в Excel: формула, функции, инструменты”
Оператор вычисляет среднее арифметическое значение из указанных значений (диапазона). Формула функции выглядит таким образом:
=СРЗНАЧ(число1;число2;…)
В качестве аргументов функции можно указать:
- конкретные числа;
- ссылки на ячейки, которые можно указать как вручную (напечатать с помощью клавиатуры), так и находясь в соответствующем поле щелкнуть по нужному элементу в самой таблице;
- диапазон ячеек – указывается вручную или путем выделения в таблице.
- переход к следующему аргументу происходит путем щелчка по соответствующему полю напротив него или просто нажатием клавиши Tab.

МАКС
Функция помогает определить максимальное значение из заданных чисел (диапазона). Формула оператора следующая:
=МАКС(число1;число2;…)
В аргументах функции, также, как и в случае с оператором СРЗНАЧ можно указать конкретные числа, ссылки на ячейки или диапазоны ячеек.
МИН
Функция находит минимальное число из указанных значений (диапазона ячеек). В общем виде синтаксис выглядит так:
=МИН(число1;число2;…)
Аргументы функции заполняются так же, как и для оператора МАКС.
СРЗНАЧЕСЛИ
Функция позволяет найти среднее арифметическое значение, но при выполнении заданного условия. Формула оператора:
=СРЗНАЧЕСЛИ(диапазон;условие;диапазон_усреднения)
В аргументах указываются:
- Диапазон ячеек – вручную или с помощью выделения в таблице;
- Условие отбора значений из заданного диапазона (больше, меньше, не равно) – в кавычках;
- Диапазон_усреднения – не является обязательным аргументом для заполнения.

МЕДИАНА
Оператор находит медиану заданного диапазона значений. Синтаксис функции:
=МЕДИАНА(число1;число2;…)
В аргументах указываются: конкретные числа, ссылки на ячейки или диапазоны элементов.
НАИБОЛЬШИЙ
Функция позволяет найти из указанного диапазона значений с заданной позицией (по убыванию). Формула оператора:
=НАИБОЛЬШИЙ(массив;k)
Аргумента функции два: массив и номер позиции – K.
Допустим, имеется ряд чисел 4, 6, 12, 24, 15, 9. Если мы укажем в качестве аргумента “K” число 2, результатом будет значение, равное 15, т.к. оно второе по величине в выбранном диапазоне.
НАИМЕНЬШИЙ
Функция также, как и оператор НАИБОЛЬШИЙ, выполняет поиск из указанного диапазона значений. Правда, в данном случае счет идет по возрастанию. Синтаксис оператора следующий:
=НАИМЕНЬШИЙ(массив;k)
МОДА.ОДН
Функция пришла на замену более старому оператору “МОДА” (теперь находится в категории “Полный алфавитный перечень”). Позволяет определять число, которое повторяется чаще остальных в выбранном диапазоне. Работает функция по формуле:
Позволяет определять число, которое повторяется чаще остальных в выбранном диапазоне. Работает функция по формуле:
=МОДА.ОДН(число1;число2;…)
В значениях аргументов указываются конкретные числовые значения, отдельные ячейки или их диапазоны.
Для вертикальных массивов, также, используется функция МОДА.НСК.
СТАНДОТКЛОН
Функция СТАНДОТКЛОН также устарела (но ее все еще можно найти, выбрав алфавитный перечень) и теперь представлена двумя новыми:
- СТАДНОТКЛОН.В – находит стандартное отклонение выборки
- СТАДНОТКЛОН.Г – определяет стандартное отклонение по генеральной совопкупности
Формулы функций выглядят следующим образом:
- =СТАДНОТКЛОН.В(число1;число2;…)
- =СТАДНОТКЛОН.Г(число1;число2;…)
СРГЕОМ
Оператор находит среднее геометрическое значение для заданного массива или диапазона. Формула функции:
Формула функции:
=СРГЕОМ(число1;число2;…)
Заключение
В программе Excel более 100 статистических функций. Мы лишь рассмотрели те, которые используются пользователями чаще других, а также, где их можно найти и как заполнить аргументы для получения корректного результата.
Смотрите также:
- Почему Эксель не считает формулу: что делать
- Сортировка и фильтрация данных в Excel
Формулы статистики
На этой веб-странице перечислены формулы статистики, используемые в Stat Trek учебники. Каждая формула ссылается на веб-сайт страница, которая объясняет, как использовать формулу.
Параметры
- Среднее значение населения = μ = ( Σ X i ) / N
- Стандартное отклонение населения = σ = sqrt [ Σ ( X i — мк) 2 /Н]
- Дисперсия населения = о 2 = Σ ( X i — мк) 2 / N
- Дисперсия доли населения = σ P 2 = PQ / n
- Стандартизированная оценка = Z = (X — μ) / σ
- Коэффициент корреляции населения = ρ = [ 1 / N ] * Σ { [ (X i — μ X ) / σ x ] * [ (Y i — μ Y ) / σ г ] }
Статистика
Если не указано иное, в этих формулах предполагается
простая случайная выборка.
- Среднее значение выборки = х = ( Σ х i ) / n
- Стандартное отклонение выборки = s = sqrt [ Σ ( x i — х) 2 / (n-1)]
- Выборочная дисперсия = с 2 = Σ ( х i — х) 2 / (п-1)
- Дисперсия доли выборки = с р 2 = pq / (n — 1)
- Доля объединенной выборки = p = (p 1 * n 1 + p 2 * n 2 ) / (n 1 + n 2 )
- Стандартное отклонение объединенной выборки = с р = sqrt [ (n 1 — 1) * s 1 2 + (п 2 — 1) * с 2 2 ] / (n 1 + n 2 — 2) ]
- Коэффициент корреляции выборки = г = [ 1 / (п — 1) ] * Σ { [ (х я — х) / с x ] * [ (у я — у) / с г ] }
Корреляция
- Корреляция Пирсона продукт-момент = r = Σ (xy) / sqrt [ ( Σ x 2 ) * ( Σ y 2 ) ]
- Линейная корреляция (выборочные данные) = r = [ 1 / (n — 1) ] * Σ { [ (x i — x) / с x ] * [ (y i — y) / с y ] }
- Линейная корреляция (данные населения) = ρ = [ 1 / N ] * Σ { [ (X i — μ X ) / σ x ] * [ (Y i — μ Y ) / σ y ] 1 }
Простая линейная регрессия
- Линия простой линейной регрессии: ŷ = b 0 + b 1 x
- Коэффициент регрессии = б 1 = Σ [ (х i — х) (у я — у) ] / Σ [ (х я — х) 2 ]
- Пересечение наклона регрессии = б 0 = у — б 1 * х
- Коэффициент регрессии = б 1 = г * (с у / с х )
- Стандартная ошибка наклона регрессии = с б 1 = sqrt [ Σ(y i — ŷ i ) 2 / (п — 2) ] / sqrt [ Σ(x я — х) 2 ]
Подсчет
- п факториал:
н! = п * (п-1) * (п — 2) * . . . * 3 * 2 * 1. По соглашению,
0! = 1,
- Перестановки n вещей, взятых r за один раз: n P r = n! / (н — р)!
- Комбинации из n вещей, взятых r за один раз: n C r = n! / г!(п — г)! = n P r / r!
 . . * 3 * 2 * 1. По соглашению,
0! = 1,
. . * 3 * 2 * 1. По соглашению,
0! = 1,Вероятность
- Правило добавления: Р (А ∪ В) = Р(А) + Р(В) — Р(А ∩ В)
- Правило умножения: Р (А ∩ В) = Р(А) Р(В|А)
- Правило вычитания: P(A’) = 1 — P(A)
Случайные величины
В следующих формулах X и Y являются случайными величинами, а a и b являются константами.
- Ожидаемое значение X = E (X) = μ x = Σ [ x i * P (x i ) ]
- Дисперсия X = Var(X) = σ 2 = Σ [ х i — E(x) ] 2 * P(x i ) = Σ [ x i — μ x ] 2 * P(x i )
- Нормальная случайная величина = z-оценка = z = (X — μ)/σ
- Статистика хи-квадрат = Χ 2 = [ ( n — 1 ) * с 2 ] / σ 2
- f статистика = ф = [ с 1 2 /σ 1 2 ] / [ с 2 2 /σ 2 2 ]
- Ожидаемое значение суммы случайных величин = Е(Х + Y) = Е(Х) + Е(Y)
- Ожидаемое значение разницы между случайными величинами = Е(Х — У) = Е(Х) — Е(У)
- Дисперсия суммы независимых случайных величин = Вар(Х + Y) = Вар(Х) + Вар(Y)
- Дисперсия разности между независимыми случайными величинами = Вар(Х — Y) = Вар(Х) + Вар(Y)
Распределение проб
- Среднее выборочное распределение среднего = μ x = мк
- Среднее выборочное распределение доли = мк р = Р
- Стандартное отклонение пропорции = σ р = sqrt[P * (1 — P)/n] = sqrt(PQ/n)
- Стандартное отклонение среднего = σ x = σ/sqrt(n)
- Стандартное отклонение разности выборочных средних = σ d = sqrt[ (σ 1 2 / n 1 ) + (σ 2 2 / п 2 ) ]
- Стандартное отклонение разницы пропорций выборки = σ d = sqrt{ [P 1 (1 — P 1 ) / номер 1 ] + [P 2 (1 — P 2 ) / № 2 ] }
Стандартная ошибка
- Стандартная ошибка пропорции = SE p = с р = sqrt[p * (1 — p)/n] = sqrt(pq/n)
- Стандартная ошибка разности пропорций = SE p = с р = sqrt{ p * ( 1 — p ) * [ (1/n 1 ) + (1/n 2 ) ] }
- Стандартная ошибка среднего = SE x = с х = с/кв (n)
- Стандартная ошибка разности выборочных средних = SE д = с д = sqrt[ (s 1 2 / п 1 ) + (с 2 2 / номер 2 ) ]
- Стандартная ошибка разности парных выборочных средних = SE д = с д = { квт [ (Σ(d i — d) 2 / (n — 1) ] } / sqrt(n)
- Стандартная ошибка объединенной выборки = с объединено = sqrt [ (n 1 — 1) * s 1 2 + (n 2 — 1) * с 2 2 ] / (n 1 + n 2 — 2) ]
- Стандартная ошибка разности пропорций выборки = с д = sqrt{ [p 1 (1 — p 1 ) / п 1 ] + [p 2 (1 — p 2 ) / номер 2 ] }
Дискретные распределения вероятностей
- Биномиальная формула: P(X = x) = б( х ; н, Р ) = n C x * P x * (1 — P) n — x = n C x * P x * Q n — x
- Среднее биномиального распределения = μ x = n * P
- Дисперсия биномиального распределения = σ x 2 = n * P * ( 1 — P )
- Отрицательная биномиальная формула: P(X = x) = b*( x ; r, P ) = x-1 C r-1 * Р р * (1 — Р) х — р
- Среднее отрицательного биномиального распределения = μ x = rQ / P
- Дисперсия отрицательного биномиального распределения = σ x 2 = р * К/П 2
- Геометрическая формула: P(X = x) = g( x ; P ) = P * Q x — 1
- Среднее геометрическое распределение = мк х = Q / P
- Дисперсия геометрического распределения = σ x 2 = В/П 2
- Гипергеометрическая формула: P(X = x) = ч( x ; N , н , к ) = [ k C x ] [ N-k C n-x ] / [ Н С Н ]
- Среднее значение гипергеометрического распределения = мк х = n * k / N
- Дисперсия гипергеометрического распределения = σ x 2 = п * к * ( Н — к ) * ( Н — п ) / [Н 2 * ( Н — 1 ) ]
- Формула Пуассона: P( x; µ ) = (e -µ ) (µ x ) / x!
- Среднее значение распределения Пуассона = мк х = мк
- Дисперсия распределения Пуассона = σ x 2 = μ
- Полиномиальная формула: P = [ n! / ( п 1 !
* п 2 ! * . .. п к ! )]
* ( стр. 1 п 1 * p 2 n 2 * . . .
* p k n k )
 .. п к ! )]
* ( стр. 1 п 1 * p 2 n 2 * . . .
* p k n k )
.. п к ! )]
* ( стр. 1 п 1 * p 2 n 2 * . . .
* p k n k )Линейные преобразования
Для следующих формул предположим, что Y является линейное преобразование случайной величины X, определяемой уравнением: Y = aX + b.
- Среднее линейного преобразования = E(Y) = У = аХ + б.
- Дисперсия линейного преобразования = Var(Y) = а 2 * Вар(Х).
- Стандартизированная оценка = z = (x — μ x ) / σ x .
- t статистика = t = (x — μ x ) / [s/sqrt(n)].
Оценка
- Доверительный интервал: Выборочная статистика + Критическое значение * Стандартная ошибка статистики
- Погрешность = (Критическое значение) * (Стандартное отклонение статистики)
- Погрешность = (Критическое значение) * (Стандартная ошибка статистики)
Проверка гипотез
- Стандартизированная тестовая статистика = (Статистика — Параметр) / (Стандартное отклонение статистики)
- Одновыборочный z-тест для пропорций: z-оценка = z = (p — P 0 ) / sqrt (p * q / n)
- Двухвыборочный z-тест для пропорций: z-оценка = z = z = [(p 1 — p 2 ) — d ] / SE
- Одновыборочный t-критерий для средних: t статистика = t = (x — μ) / SE
- Двухвыборочный t-критерий для средних: t статистика = t = [ (x 1 — х 2 ) — д ] / SE
- Стьюдентный критерий с согласованной выборкой для средних значений: t статистика = t = [ (x 1 — х 2 ) — Д ] / SE = (д — Д) / SE
- Статистика критерия хи-квадрат = Χ 2 = Σ[ (Наблюдается — Ожидается) 2 / Ожидается ]
Степени свободы
Правильная формула для степеней свободы (DF) зависит от ситуации
(характер тестовой статистики, количество образцов,
исходные предположения и др.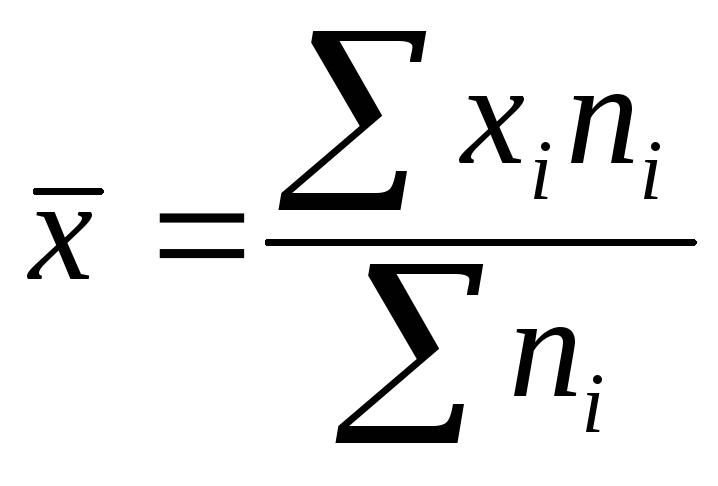 ).
).
- Одновыборочный t-критерий: ДФ = п — 1
- Двухвыборочный t-критерий: ДФ = (s 1 2 /n 1 + с 2 2 /n 2 ) 2 / { [ (с 1 2 / п 1 ) 2 / (n 1 — 1) ] + [ (с 2 2 / п 2 ) 2 / (n 2 — 1) ] }
- Двухвыборочный t-критерий, объединенная стандартная ошибка: ДФ = п 1 + п 2 — 2
- Простая линейная регрессия, тестовый наклон: ДФ = n — 2
- Хи-квадрат критерия согласия: ДФ = к — 1
- Критерий хи-квадрат на однородность: ДФ = (г — 1) * (с — 1)
- Тест хи-квадрат на независимость: ДФ = (г — 1) * (с — 1)
Размер выборки
Ниже первые две формулы находят наименьшие размеры выборки. требуется для достижения фиксированной погрешности, используя простой
случайная выборка. Третья формула
распределяет выборку по стратам на основе пропорционального плана.
четвертая формула, распределение Неймана, использует стратифицированную выборку для
минимизировать дисперсию при фиксированном размере выборки. И последняя формула,
оптимальное распределение, использует стратифицированную выборку для минимизации дисперсии,
при фиксированном бюджете.
требуется для достижения фиксированной погрешности, используя простой
случайная выборка. Третья формула
распределяет выборку по стратам на основе пропорционального плана.
четвертая формула, распределение Неймана, использует стратифицированную выборку для
минимизировать дисперсию при фиксированном размере выборки. И последняя формула,
оптимальное распределение, использует стратифицированную выборку для минимизации дисперсии,
при фиксированном бюджете.
- Среднее значение (простая случайная выборка): n = {z 2 * σ 2 * [Н/(Н-1)]} / {МЕ 2 + [ z 2 * σ 2 / (N — 1) ] }
- Доля (простая случайная выборка): n = [(z 2 * p * q) + ME 2 ] / [ME 2 + з 2 * п * к/н ]
- Пропорциональная стратифицированная выборка: п ч = ( N ч / N ) * n
- Распределение Неймана (стратифицированная выборка): n ч = n * ( N ч * σ ч ) / [ Σ ( N я * σ я ) ]
- Оптимальное распределение (стратифицированная выборка):
n h = n * [( N h * σ h ) / sqrt( c h ) ] / [ Σ ( N я * σ я ) / кврт( с и )]
Базовые формулы статистики — Cuemath
Статистика — это раздел математики, который имеет дело с числами и анализом данных. Статистика — это наука о сборе, анализе, интерпретации, представлении и организации данных.
Статистика — это наука о сборе, анализе, интерпретации, представлении и организации данных.
Короче говоря, статистика имеет дело со сбором, классификацией, упорядочиванием и представлением собранных числовых данных простыми и понятными способами. Статистика интерпретирует различные результаты и возможности прогноза. Существуют различные основные формулы статистики, которые помогают нам иметь дело с фактами, наблюдениями и информацией, которые представлены только в виде числовых данных. С помощью статистики мы можем найти различные меры центральных тенденций и отклонения значений данных от центра. Давайте изучим основные формулы статистики вместе с несколькими решенными примерами. 9{2}}{н}} \\
\хлайн
\end{массив}\)
где
x = данные наблюдений
\(\bar{x}\) = Среднее
n = общее количество наблюдений
Решенные примеры с использованием формулы базовой статистики
Пример 1: Возраст учащихся = {14,15,16,15,17,15,18}Найдите режим.
