
Примеры использования инструмента Вычислить значение—ArcGIS Pro
Инструмент Вычислить значение – универсальный инструмент ModelBuilder, возвращающий значение из выражения Python. Инструмент поддерживает простые вычисления, встроенные функции и модули Python, функции и объекты геообработки и собственный код Python.
Выражение
Выполняйте различные вычисления, используя только параметр Выражение.
Математические вычисления
Инструмент Вычислить значение может вычислять простые математические выражения в Python. Например, посмотрите следующие выражения:
| Оператор | Объяснение | Пример | Результат |
|---|---|---|---|
x + y | x плюс y | 3 + 5 | 8 |
x — y | x минус y | 4. | 2.2 |
x * y | x умножить на y | 8 * 9 | 72 |
x / y | x разделить на y | 4 / 1.25 | 3.2 |
x // y | x разделить на y (с округлением) | 4 // 1.25 | 3 |
x % y | остаток x, разделенный на y | 4 % 1. | 0.25 |
x**y | x возвести в степень y | 2 ** 3 | 8 |
x < y | если x меньше y | 2 < 3 | 1 |
x <= y | если x меньше или равен y | 2 <=3 | 1 |
x > y | если x больше y | 2 > 3 | 0 |
x >= y | если x больше или равен y | 2 >= 3 | 0 |
| x == y | если x равен y | 2 == 3 | 0 |
x != y | если x не равен y | 2 != 3 | 1 |
 25
25Инструмент Вычислить значение позволяет использовать модуль Python math для выполнения более сложных математических операций.
Возвращает квадратный корень значения.
Expression: math.sqrt(25)
Возвращает косинус значения в радианах.
Expression: math.cos(0.5)
Константы также поддерживаются модулем math.
Возвращает постоянное значение π.
Expression: math.pi
Инструмент Вычислить значение позволяет использовать модуль random для генерирования произвольных чисел. Примеры использования модуля random:
Возвращает произвольное целое число от 0 до 10.
Expression: random.randint(0, 10)
Возвращает произвольное значение из нормального распределения со средним значением 10 и стандартным отклонением 3.
Expression: random.normalvariate(10, 3)
Пример строк
Операторы и индекс Python могут использоваться в строковых значениях.
| Пример | Объяснение | Результат |
|---|---|---|
«Input» + » » + «Name» | Конкатенация строк. | Входное имя |
«Input_Name»[6:] | Седьмой символ до последнего символа. | Имя |
«STREET».lower() | Конвертировать строковое значение в нижний регистр. | street |
«Street Name».split()[1] | Разбить строку на несколько строк по пробелу. И получить вторую возвращаемую строку. | Имя |

Инструмент Вычислить значение может заменить или удалить символы из строки. Например, если у вас имеется входное значение с десятичным числом (в данном случае – значение поля входной таблицы), и вы хотите использовать это значение в выходном имени другого инструмента посредством подстановки встроенной переменной, это десятичное число можно заменить, используя метод replace.
Например, если у вас имеется входное значение с десятичным числом (в данном случае – значение поля входной таблицы), и вы хотите использовать это значение в выходном имени другого инструмента посредством подстановки встроенной переменной, это десятичное число можно заменить, используя метод replace.
Expression:
"%Value%".replace(".", "")В строке Python обрабатывает обратную косую черту (\) как символ escape. Например, в строке «C:\temp\newProjectFolder» \n представляет собой перевод строки, а \t представляет tab. Для проверки, что строка выглядит, как ожидалось, выполните одно из следующего:
- Используйте косую черту (/) вместо обратной косой черты.
- Используйте две обратные косые черты вместо одной.
- Конвертируйте строку в строковой литерал, поставив букву r перед строкой.
Более подробно о путях настройки в Python
Тип данных
Параметр Тип данных указывает тип выходных данных инструмента Вычислить значение. Важно убедиться, что тип выходных данных инструмента Вычислить значение соответствует требуемому типу входных данных следующего инструмента.
Важно убедиться, что тип выходных данных инструмента Вычислить значение соответствует требуемому типу входных данных следующего инструмента.
Выходные данные инструмента Вычислить значение можно использовать в любых инструментах Spatial Analyst, принимающих растр или постоянное значение, например, Сложить, Больше и Меньше. Для использования выходных данных инструмента Вычислить значение измените значение Тип данных на Формализованный растр. Этот тип данных является растровой поверхностью, значения ячеек которой представлены формулой или константой.
Возвращает вычисленное значение в типе данных Формализованный растр, чтобы использовать его в качестве входных данных инструмента Больше.
Expression: %A% + 120
Значение параметра Выражение использует подстановку встроенной переменной. При запуске инструмента %A% будет заменено значением переменной A. Значение переменной A плюс 120 будет использоваться как Входной растр или постоянное значение 1 в инструменте Больше.
Блок кода
Для простых вычислений зачастую вам необходимо использовать только параметр Выражение. Для более сложных выражений, таких как мультилинейные вычисления или логические операции (if-else), также необходим параметр Блок кода. Параметр Блок кода необходимо использовать вместе с параметром Выражение.
На переменные, заданные в параметре Блок кода, может ссылаться параметр Выражение.
Например, size, заданный в Блоке кода, считает количество файлов в пути к папке. На него будет ссылаться параметр Выражение во время выполнения. Выходное значение инструмента Вычислить значение равно фактическому количеству файлов плюс пять.
Expression:
5 + size
Code Block:
import os
size = 0
folderpath = r"C:\temp\csvFiles"
for ele in os.scandir(folderpath):
size += 1Также можно использовать параметр Блок кода, чтобы определить функцию и вызвать функцию из параметра Выражение. В Python функция определяется с помощью оператора def, за которым следует имя функции. В функцию могут входить обязательные и дополнительные аргументы, или их совсем не быть. Возвращает выходное значение функции, используя выражение return.
В функцию могут входить обязательные и дополнительные аргументы, или их совсем не быть. Возвращает выходное значение функции, используя выражение return.
Время
Можно использовать параметр Блок кода для вызова модулей и методов Python. Следующий пример вызывает time метод ctime модуля.
В тех случаях, когда вам необходимо регулярно создавать резервные копии данных, добавление времени к имени папки помогает различать данные. Пример ниже показывает, как добавить врменную метку к имени папки. Функция time.ctime возвращает текущую дату и время в формате типа Tue Jun 22 16:24:08 2021. Это возвращенное значение нельзя использовать как имя папки в инструменте Создать папку, так как пробелы и знаки пунктуации здесь недопустимы. Для их удаления используется метод Python replace, путем стекинга метода для каждого элемента, который необходимо заменить. Итоговое имя папки в этом примере будет TueJun221622522021.
Expression: gettime() Code Block: import time def gettime(): # First replace removes punctuation marks.Second replace removes spaces. return time.ctime().replace(":", "").replace(" ", "")
 Second replace removes spaces.
return time.ctime().replace(":", "").replace(" ", "")
Second replace removes spaces.
return time.ctime().replace(":", "").replace(" ", "")If-then-else и встроенная подстановка
Параметр Блок кода может брать значения через входные параметры функции. Число параметров в Блоке кода должно совпадать с числом параметров в Выражении. После выполнения инструмента значение параметра передается из Выражения в Блок кода. Можно передать значение переменной модели, используя встроенную переменную как параметр Выражение, как показно ниже.
В следующем примере функция getAspectDir содержит один параметр inValue. Параметр Выражение передает значение переменной Степень ввода в Блок кода.
В следующем примере вычисляется направление экспозиции склона на основании значения Входные градусы. Если значение переменной Входные градусы равно 223, будет возвращено выходное направление экспозиции Юг.
Expression:
getAspectDir("%Input Degree%")
Code Block:
def getAspectDir(inValue):
inValue = int(inValue)
if inValue >= 45 and inValue < 135:
return "East"
elif inValue >= 135 and inValue < 225:
return "South"
elif inValue >= 225 and inValue < 315:
return "West"
else:
return "North"Несколько встроенных подстановок
Параметр Блок кода также может принимать несколько значений встроенных переменных.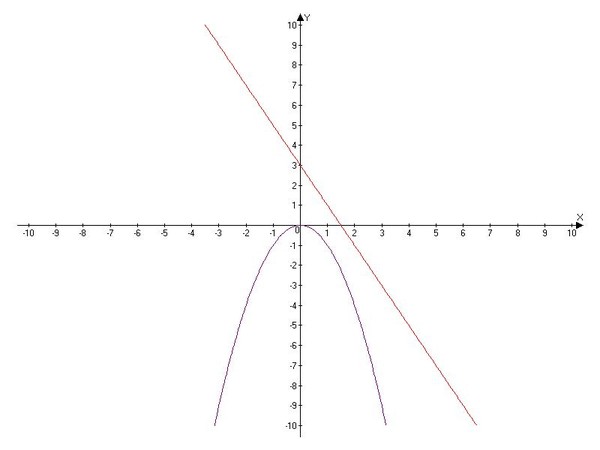
Блок кода проверяет, не превышает ли значение переменной Значение пользовательского ввода Значение по умолчанию. Если это так, выходное значение инструмента Вычислить значение – Значение пользовательского ввода. В противном случае выходным значением будет Значение по умолчанию. В данном случае Выходным значением будет 10.
Expression:
fn("%User Input Value%","%Default Value%")
Code Block:
def fn(userInputValue, defaultValue):
if float(userInputValue) > float(defaultValue):
return float(userInputValue)
else:
return float(defaultValue)Внимание:
Заключите встроенную переменную типа string в кавычки («%string variable%») в выражении. Для встроенных переменных числовых типов (double, long) кавычки не требуются (%double%).
Конкатенация пути к данным
В следующем примере демонстрируется копирование объектов по указанному пути к папке и ее имени. Параметр Блок кода принимает два значения: Путь к папке и Имя папки. Код оценивает, существует ли сочетание пути к папке и ее имени. Если такой комбинации нет, функция makedirs добавляет отсутствующие папки. Буква r в параметре Выражение предшествующая пути к папке, необходима для правильной интерпретации пути.
Если такой комбинации нет, функция makedirs добавляет отсутствующие папки. Буква r в параметре Выражение предшествующая пути к папке, необходима для правильной интерпретации пути.
Expression:
getPath(r"%Folder Path%", "%Folder Name%")
Code Block:
import os
def getPath(folderPath, folderName):
outPath = os.path.join(folderPath, folderName)
if not os.path.exists(outPath):
os.makedirs(outPath)
return outPathКонкатенация значения расстояния и единиц измерения
Для использования инструмента Вычислить значение с инструментом, принимающим линейное расстояние, например, инструментом Буфер, выполните следующее:
- Возвращает значение расстояния и линейные единицы в параметре Блок кода parameter.
- Задайте значение параметра Тип данных как Линейные единицы.
Например, инструмент Вычислить значение вернет значение 12 километров при использовании с инструментом Буфер.
Expression:
fn("%A%", "%B%")
Code Block:
def fn(a, b):
distance = int(a) * int(b)
return f"{distance} Kilometers"ArcPy
ArcPy – это пакет Esri Python который обеспечивает успешный и продуктивный анализ географических данных, конвертацию данных, управление данными и автоматизацию карт в Python. ArcPy обеспечивает доступ к инструментам геообработки, а также к дополнительным функциям, классам и модулям, которые позволяют создавать как простые, так и сложные рабочие процессы.
ArcPy обеспечивает доступ к инструментам геообработки, а также к дополнительным функциям, классам и модулям, которые позволяют создавать как простые, так и сложные рабочие процессы.
Курсор
Для работы с данными можно использовать курсор. Курсор – это объект доступа к данным, который может использоваться как для итерации набора строк в таблице, так и для вставки новых строк в таблицу. Курсоры могут быть трех форм: поиска, вставки и обновления, которые обычно используются для чтения и записи данных.
Чтобы преобразовать код вида дерева в его обычное название, можно использовать UpdateCursor для итерации по каждому дереву в таблице. На основании значения кода дерева, назначьте ему обычное имя. Например, если код дерева PIPO, назначьте ему обычное имя ponderosa pine в поле CommonName.
Expression:
fn("%trees%")
Code Block:
def fn(trees):
with arcpy.da.UpdateCursor(trees, ["Code", "CommonName"]) as cursor:
for row in cursor:
if row[0] == "PIPO":
row[1] = "ponderosa pine"
elif row[0] == "BEPA":
row[1] = "paper birch"
elif row[0] == "FAGR":
row[1] = "American beech"
cursor. updateRow(row) updateRow(row)
updateRow(row)Инструменты геообработки
ArcPy также предоставляет доступ к инструментам геообработки. Можно вызывать инструменты геообработки в параметре Блок кода.
В следующем примере инструмент Вычислить значение использует инструменты Выбрать в слое по атрибуту, Копировать объекты и Буфер. Инструменты выбирают все дороги в поле LABEL, содержащие слово HIGHWAY, создают их копию буфер вокруг дорог.
Expression:
fn("%Input Feature Class%")
Code Block:
def fn(InputFC):
# To allow overwriting outputs change overwriteOutput option to True.
arcpy.env.overwriteOutput = True
# Process: Select Layer By Attribute (Select Layer By Attribute) (management)
InputFC_Layer, Count = arcpy.management.SelectLayerByAttribute(InputFC, "NEW_SELECTION", "LABEL LIKE '%HIGHWAY%'")
# Process: Copy Features (Copy Features) (management)
copyFeaturesOutput = "C:\\temp\\Output.gdb\\copyFeaturesOutput"
arcpy.management.CopyFeatures(InputFC_Layer, copyFeaturesOutput)
# Process: Buffer (Buffer) (analysis)
bufferOutput = "C:\\temp\\Output. gdb\\bufferOutput"
arcpy.analysis.Buffer(copyFeaturesOutput, bufferOutput, "1500 Feet")
return bufferOutput gdb\\bufferOutput"
arcpy.analysis.Buffer(copyFeaturesOutput, bufferOutput, "1500 Feet")
return bufferOutput
gdb\\bufferOutput"
arcpy.analysis.Buffer(copyFeaturesOutput, bufferOutput, "1500 Feet")
return bufferOutputОтзыв по этому разделу?
еще раз и подробнее / Хабр
Введение
Некоторое время назад, во время учебы в институте, я решил понять принцип работы нейросетей. Усвоить его на уровне, необходимом, чтобы написать небольшую нейросеть самостоятельно. Начать я решил с книги Тарика Рашида «Создай свою нейросеть». Эта статья представляет из себя краткий конспект этой книги для тех, кто, как и я, столкнулся с трудностями во время изучения этой темы и этого учебника (не в последнюю очередь благодаря проблемам редактуры). В процессе я надеюсь разложить все по полочкам еще раз. Предположу, что перемножение матриц и взятие производной никого из читателей не смутят и сразу пойду дальше.
Итак, машинное обучение это незаменимый инструмент для решения задач, которые легко решаются людьми, но не классическими программами. Ребенок легко поймет, что перед ним буква А, а не Д, однако программы без помощи машинного обучения справляются с этим весьма средне.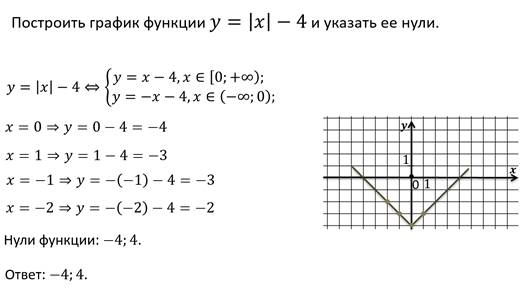 -x)
-x)
Если каждый узел обрабатывает поступивший сигнал функцией сглаживания, то можно быть полностью уверенным, что он не выйдет за пределы от 0 до 1.
Таким образом, нейрон суммирует входные сигналы, умноженные на веса связей, берет сигмоиду от результата и подает на выход.
Схема узлаЕще раз, для всего слоя:
А как это решает задачу?
Итак, как же применить нейросеть для распознавания букв на картинке?
Входным сигналом для этой картинки 28 на 28 будет последовательность из 784 чисел от 0 до 255, каждое из которых шифрует цвет соответствующего пикселя. Итак, на входном уровне должно быть 784 узла.
Информация, которую нам необходимо получить на выходе это «какая цифра скорее всего на картинке». Всего 10 вариантов. Значит, на выходном уровне будет 10 узлов. Узел, на котором сигнал будет больше и будет ответом нейросети на задачу — например, для этой картинки в идеале все узлы выходного уровня должны показывать на выходе ноль, а пятый — единицу.
Добавим еще уровень, чтобы переход не был таким резким. Допустим, нейросеть будет из трех слоев — 784, 100 и 10 узлов. Общепринятого метода выбора точного количества узлов на промежуточных слоях и количества самих промежуточных слоев не существуют — разве что проводить эксперименты, и сравнивать результаты. В нашем случае первый уровень представляет пиксели входного изображения, третий — распознанные цифры а второй каким-то трудноотслеживаемым образом представляет закономерности, подмножества пикселей, которые свойственны разным цифрам.
Добавим матрицы
Переведем правила распространения сигнала на язык математики. Задача получить сигналы нового слоя, то есть «Умножить вес каждого узла слоя 1 на его выходную связь, ведущую к узлу слоя 2 и сложить» на удивление сильно подходит на описание умножения матриц. В самом деле, расположим в каждом столбце матрицы весов веса связей, исходящих из одного узла и умножим справа на столбец входных сигналов и получим выходной сигнал этого слоя в столбце получившейся матрицы.
В строках же матрицы весов будут веса связей, ведущих в один узел нового слоя, каждый из которых умножается на вес порождающего его узла. Очень изящно! Разумеется, из-за правил перемножения матриц высота конечного столбца будет равна высоте матрицы весов, а высота матрицы входных сигналов — ширине матрицы весов. Для перехода из первого слоя (784 узла) во второй (100 узлов) в матрице весов нашей задачи понадобится таблица в 100 строк и 784 столбца.
Итак, вся загадка заключается в том, какими именно значениями заполнена матрица весов. Ее заполнение называется тренировкой нейросети. Затем останется лишь опросить нейросеть, то есть решить конкретную задачу:
Подать на вход картинку, то есть столбец из 784 сигналов.
Умножить на него справа таблицу весов 12.
Применить сигмоиду для сглаживания результатов.
На результат справа умножить таблицу весов 23.
Применить сигмоиду.
Взять номер узла с наибольшим значением.

Таким образом, из 784 значений с помощью всего лишь двух матричных умножений и сглаживаний получилось 10 чисел в диапазоне от 0 до 1. Номер узла с самым большим из них это значение цифры на картинке, как ее распознала нейросеть. Насколько это соответствует истине, зависит от тренировки нейросети.
Тренировка. Обратное распространение ошибок
Метод обратного распространения ошибок это сердце нейросети. Его суть заключается в том, чтобы после получения значения ошибки на последнем слое передать правки на предыдущие слои.
Один из основных существующих подходов — распределять ошибку пропорционально весам связей.
Обратное распространение ошибокИли то же самое, но для нескольких узлов на внешнем слое:
Ошибка, то есть e, это разница между t — желаемым значением и o — значением на выходном слое: .
Как мы видим, o1 высчитывается из узлов первого слоя с помощью связей w11 и w12, а значит, именно их и нужно корректировать с помощью ошибки этого узла. Новое значение w11 зависит от доли w11 в сумме связей, ведущих к узлу: . Конечно, для w12 нужно заменить w11 в числителе на w12.
Новое значение w11 зависит от доли w11 в сумме связей, ведущих к узлу: . Конечно, для w12 нужно заменить w11 в числителе на w12.
Теперь можно было бы приступить и к, собственно обратному распространению ошибки. Использовать данные следующего слоя для работы с предыдущим:
Однако, у нас нет целевых значений для скрытого слоя. Не беда. Просто сложим ошибки всех связей, исходящих из этого узла, и получим его ошибку!
Сложим, получим значение ошибки и просто повторим все еще раз. Пример показан ниже:
Еще раз, словами: Ошибку Oi умножаем на долю связи в сумме связи отдельного узла k со всеми узлами следующего уровня, чтобы получить ошибку узла k предыдущего слоя. Затем все ошибки связей из узла k складываем и получаем его собственную ошибку. И так далее.
Перепишем все вышесказанное в виде матриц:
Удобно. Но не до конца. Было бы здорово избавиться от всех этих отличающихся знаменателей. И деления.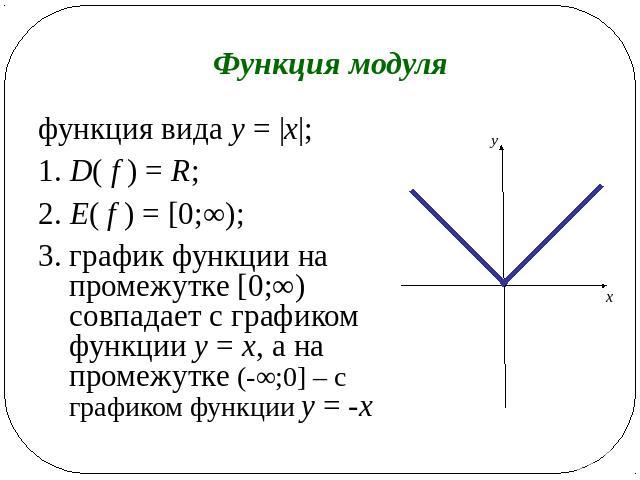 совсем не удобно делить тысячу узлов на тысячу разных сумм. Было бы здорово как-то все упростить. Тут нам поможет тот факт, что
совсем не удобно делить тысячу узлов на тысячу разных сумм. Было бы здорово как-то все упростить. Тут нам поможет тот факт, что для написания нейросети позволено забыть математику за третий класс на практике у нас будет больше двух узлов в слое. И значение числителя (например 0,2, 0,4 или 0,9) гораздо важнее, чем значение знаменателя (например 9,7, 9,3 или 8,4). Что приводит нас к моему любимому моменту в книге. Нормирующий множитель? Да зачем он нам?
Мы получили донельзя простую формулу обратного распространения ошибки с помощью матрицы весов и ошибки наружного слоя. Обратите внимание, что столбцы матрицы весов здесь поменяны местами со строками и наоборот, то есть матрица транспонирована.
Итоговая формула ОРООднако, нужно держать в уме, что это просто иллюстрация для идеального случая и понимания концепции. В нашей нейросети все немного сложнее.
Тренировка. Обновление весов
Однако, нужно напомнить, что мы дважды применяем сигмоиду по мере расчета веса узла. Кроме того, представим, что на узле ошибка 0,3. Если мы изменим одну связь, ведущую к этому узлу, то изменение других связей может снова все испортить. А так быть не должно. Интуитивно кажется, что каждая связь должна меняться сообразно своей роли в ошибке. При этом эта роль это не просто доля веса, ведь мы дважды применяли сигмоиду!
Кроме того, представим, что на узле ошибка 0,3. Если мы изменим одну связь, ведущую к этому узлу, то изменение других связей может снова все испортить. А так быть не должно. Интуитивно кажется, что каждая связь должна меняться сообразно своей роли в ошибке. При этом эта роль это не просто доля веса, ведь мы дважды применяли сигмоиду!
Итак, нам нужно свести ошибку каждого узла к нулю. Ошибка зависит от множества переменных, каждая из которых влияет на результат по разному. Звучит как задача для производной!
Здесь нам пригодится метод градиентного спуска. Если нам известно, что связь Wij влияет на общую ошибку, то просто посчитаем производную и сделаем шаг в направлении нуля.
Нам нужно минимизировать ошибку. Значит, наш шаг должен вести нас к нулевой O . Нам нужно узнать соответствующую Wij. И выполнить это для каждой связи в узле, а затем для каждого узла в слое.
Рассмотрим это для нашей многомерной функции: нам нужно узнать такие значения W (такие координаты, только не на двумерной плоскости, а во множестве измерений. Но это не сильно все осложнить), чтобы значение O было минимальным (спуститься в самую глубокую яму на карте).
Но это не сильно все осложнить), чтобы значение O было минимальным (спуститься в самую глубокую яму на карте).
Напомню, что нужно делать все более мелкие шаги, чтобы не пройти центр «ямы». Для этого нужен специальный коэфициент, убывающий во время обучения.
Также вы можете подумать, что легко можно забрести в неправильную «яму», то есть ложный минимум:
К счастью, по какой-то причине для задач, подобных нашей, большинство ложных минимумов располагаются близко от основного и почти также глубоки. Сейчас можно об этом не беспокоиться.
Самое лучшее в методе градиентного спуска, это его устойчивость к ошибкам. Если попадется несколько ошибок в тренировочных данных, последующие примеры постепенно сгладят эффект.
Как на самом деле посчитать ошибку
Для начала, вспомним, что ошибиться можно в обе стороны. А значит, значения ошибок будут как отрицательные, так и положительные. Тогда сумма ошибок может оказаться не тем больше, чем больше ошибки, а просто близкой к нулю. Значит, e = t-o как значение ошибки использовать нельзя. Приходит на ум модуль: e = |t-o|, чтобы избежать отрицательных значений. Однако тогда функция будет вести себя странно в районе нуля. Лучший вариант из всех для оценки ошибки это .
Значит, e = t-o как значение ошибки использовать нельзя. Приходит на ум модуль: e = |t-o|, чтобы избежать отрицательных значений. Однако тогда функция будет вести себя странно в районе нуля. Лучший вариант из всех для оценки ошибки это .
Теперь, когда мы исправили проблему подсчета ошибок, попробуем посчитать производную.. Это выражение представляет изменение значения ошибки при изменении веса узла.
Перепишем функцию оценки ошибки:
Е это показатель суммы всех ошибок.Получившееся выражение можно сразу упростить. Ошибка не зависит от всех значений на узлах, только от тех, что соединены с узлом k. Упростим выражение:
Упрощенное представление функцииВоспользуемся цепным правилом дифференцирования сложных функций:
Теперь мы можем работать с частями этого уравнения по отдельности:
В осталось разобраться со второй частью, а первую подставим в общее уравнение:
Перепишем выходной сигнал в явном виде:
Мы заменили выходной сигнал на сумму произведений каждой из связей, ведущих к этому узлу, на вес узла-источника.
Вот формула, по которой дифференцируется сигмоида (и как хорошо, что нам не нужно это доказывать. Это работает):
Применим это к нашей формуле и получим:
Обратите внимание на то, что в последней формуле появился сомножитель (Одна из смущающих вещей в редактуре учебника. В этой формуле j под суммой и j в остальных местах, разумеется, разные, хотя оба представляют предыдущий уровень, так что здесь я обозначу индекс под суммой i. j находится в промежутке от 0 до i.):
.
Это результат применения цепного правила дифференцирования сложной функции, то есть производная выражения в скобках сигмоиды. Возможно вы, как и я поначалу, не поняли, почему оно именно такое. Что ж, это значение представляет зависимость суммы всех связей с узлом k, умноженных на веса их узлов от веса одной связи. Поскольку производная суммы равна сумме производных, а все прочие веса кроме относительно него считаются константами, то:
.
Таким образом, окончательный вид функции для изменения узлов предпоследнего слоя это (еще раз, помните, что на картинках j под суммой это не тот же j, что и снаружи):
Чтобы таким же образом изменить узлы слоя до него, подставим нужные связи и заменим очевидную финальную ошибку на посчитанную ранее ошибку скрытого слоя
Градиент функции ошибки связей со скрытым слоемПрименим нашу формулу, отображая тот факт, что результат необходимо умножить на коэфициент обучения, а градиент по знаку противоположен изменению связей:
Перенесем W налево и покажем, как выглядят эти вычисления в матричной записи (коэфициент обучения для наглядности опущен), Е это значение ошибки узла, S это сумма произведений весов, ведущих к одному узлу, на их связь с этим узлом, на которую примененили сигмоиду, O это сигнал на выходе из предыдущего слоя:
Перепишем формулу целиком в удобном матричном виде (как можно было заметить в предыдущей формуле, последний сомножитель это транспонированная матрица выходных сигналов предыдущего слоя):
Эту формулу будет удобно использовать в коде.
Разбор примера обновления коэфициентов
Если вы не совсем поняли с первого раза, какие значения куда подставлять, то разберем такой пример:
Возьмем конкретно первый узел выходного слоя, где Мы хотим обновить весовой коэффициент для связи между последними двумя слоями. Вспомним формулу градиента ошибки:
Вместо подставим нашу ошибку
Сумма в данном случае равна (2,0*0,4) + (3,0*0,5) = 2,3.
Сигмоида
Сигнал .
Следовательно, все значение в целом составит .
Допустим, что коэффициент обучения составляет 0,1. Тогда изменение веса составит -0,1*(-0,02647)=+0,002647. Это и есть тот довесок, который нам нужно добавить в связь . Новое значение ее веса составит 2,002647.
Еще несколько тысяч таких изменений и чаша наша полна.
Пара слов о подготовке данных
График нашей сигмоидыКак мы видим, при больших значениях входного сигнала значение сигмоиды будет изменяться очень слабо, вне зависимости от знака. Это будет означать, что нейросеть почти не будет изменяться и веса останутся после обучения почти такими же. Значит, весовые коэфициенты должны располагаться поближе к нулю (но не слишком, это может вызвать проблемы с подсчетами из-за ограничений формата с плавающей точкой). Нам хорошо подойдет масштабирование входных сигналов от 0,0 до 1,0 — еще и потому, что именно такие сигналы обеспечивает сигмоида. Значение никогда не выдет за пределы (0;1).
Значит, весовые коэфициенты должны располагаться поближе к нулю (но не слишком, это может вызвать проблемы с подсчетами из-за ограничений формата с плавающей точкой). Нам хорошо подойдет масштабирование входных сигналов от 0,0 до 1,0 — еще и потому, что именно такие сигналы обеспечивает сигмоида. Значение никогда не выдет за пределы (0;1).
Для работы нейросети необходимо указать начальные значения весовых коэффициентов. Причем, это не могут быть нули или просто одинаковые значения — в таких условиях они получат одинаковые правки и останутся совпадающими после обучения, что явно не даст нам хороших результатов. Остается указать случайные значения в приемлемом диапазоне, например от -1,0 до +1,0. Однако очевидно, что если значения весов в начале обучения будут близки к максимальным, то нейросеть может быстро насытиться. Это рассуждение, подкрепленное наблюдениями, породило эмпирическое правило: весовые коэффициенты должны выбираться из диапазона, приблизительно оцененного обратной величиной корня из количества связей, ведущих к узлу. Если к узлу ведут 3 связи, его вес должен быть случайным значением в промежутке .
Если к узлу ведут 3 связи, его вес должен быть случайным значением в промежутке .
Итоги
Эта статья, представляющая конспект-пересказ книги Тарика Рашида «Создай свою нейросеть» призвана объяснить некоторые детали того, как проектируется и работает простой перцептрон и обратное распространение ошибок в нем. Я написал ее для того, чтобы охватить всю картину вместе, однако даже после столь внимательного погружения в материал и прояснения каждой его части я не уверен, что смогу написать что-то похожее, например распознавалку знаков, без заглядывания в книгу. Однако, я намного ближе к этому, чем какое-то время назад.
Я надеюсь, что эта статья поможет таким же как я новичкам в мире нейросетей, кто не понял все аспекты процесса с первого раза и забросил книгу на пару лет.
Я приветствую критику как от них, так и от всех остальных, касательно фактических ошибок, стиля подачи материала, неточностей, упущений и других проблем статьи, которые, я уверен, найдутся, поскольку раньше я ничего подобного не писал.
Спасибо вам всем!
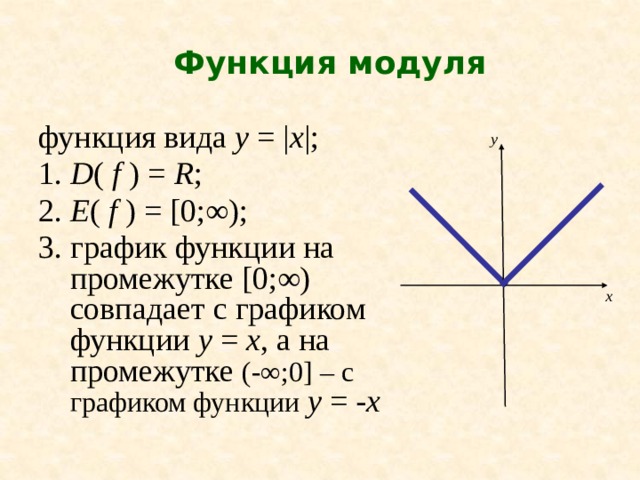
Нарисуйте график y = |x+3| и вычислить интеграл |x+3| от -6 до 0,
- #Учебник по математике, часть II для XII класса
- #NCERT
- #Математика
- #CBSE 12 Класс
- # Применение интегралов
Вопрос : 4 Нарисуйте график и оцените
Ответы (1)
y=|x+3|
данная функция модуля может быть записана как
x+3>0
x>-3
для x>-3
y=|x+3|=x+3
x+3<0
x<-3
Для x<-3
y=|x+3|=-(x+3)
Интеграл, который нужно вычислить, равен
9
Саяк
Посмотреть полный ответ 93} рефлексивно, симметрично или транзитивно.
CBSE Class 10, 12 Admit Card 2023: осталось 10 дней до экзамена, студенты все еще ждут билета в зал
Приемная карточка CBSE 2023: когда и где проверить билет в зал 10, 12 классов
Приемная карточка CBSE 2023 для классов 10, 12 скоро на cbse.nic.in
Последний вопрос
- Определите пару физических величин, которые имеют разные размерности:Вариант: 1 Волновое число и постоянная РидбергаВариант: 2 Напряжение и коэффициент упругостиВариант: 3 Коэрцитивная сила и намагниченность
- Случайная величина X имеет следующее распределение вероятностей:
Создать учетную запись
Номер мобильного телефона (+91)
Я согласен с Политикой конфиденциальности и Условиями использования Careers360
- я уже член
Ваш ответ
Создать учетную запись
Номер мобильного телефона (+91)
Я согласен с Политикой конфиденциальности и Условиями использования Careers360
- я уже член
Модульная арифметика
Модульная арифметика Модульная арифметика — способ систематического
игнорирование различий, включающих кратное целому числу. Если n является
целое число, два целых числа равны по модулю n, если они отличаются кратно
н; это как если бы кратные n «устанавливались равными 0».
Если n является
целое число, два целых числа равны по модулю n, если они отличаются кратно
н; это как если бы кратные n «устанавливались равными 0».
Определение. Пусть n, x и y — целые числа. х это конгруэнтно y mod n если . Обозначение:
Замечания. эквивалентно к следующим заявлениям:
(а) .
б) для некоторых.
в) для некоторых.
Я буду часто использовать любое из этих четырех утверждений в качестве определения .
Многие люди любят писать » » вместо » «. Я не думаю, что есть какой-либо вред в с использованием обычного знака равенства, так как » » делает смысл более понятным. Это также немного короче писать.
Пример. ( Примеры конгруэнтности с числами ) (а) Продемонстрируйте, что и .
(b) Выразите «x четно» и «x нечетно» в терминах сравнений.
(c) Что означает с точки зрения делимость?
(а)
(b) x четно тогда и только тогда, когда и x равно
странным тогда и только тогда, когда .
в) тогда и только тогда, когда . Таким образом, сравнения обеспечивают удобную запись для работа с отношениями делимости.
Следующее предложение говорит о том, что вы можете работать с модульными уравнения многими способами, которыми вы работаете с обычными уравнениями.
Предложение. Пусть .
а) Если и , то
б) Если и , то
в) Если , то
Доказательство. Две идеи для таких доказательств:
1. Вы часто можете доказать утверждения о сравнениях, приведя их к утверждениям о делимости.
2. Вы часто можете доказать утверждения о делимости, приведя их к (обычным) уравнениям.
(а) Предположим и .
средства и средства. К свойства делимости,
Поэтому, .
(б) Предположим, и .
значит, значит
для некоторых . означает , что означает для некоторых . Таким образом, , и, следовательно,
Таким образом, , и, следовательно,
Это дает , так и следовательно .
в) Предположим. Это значит, что . По свойствам делимости,
Поэтому, .
Пример. ( Решение сравнение ) Решить.
В этом случае я решу модульное уравнение, добавив или вычитая одно и то же с обеих сторон.
Решение есть.
Пример. Уменьшить до числа в диапазон , делает расчет вручную .
Обратите внимание, что
Так
Следующий результат говорит, что по модулю конгруэнтности n есть число . отношение эквивалентности .
Предложение.
(а) (Рефлексивность) для всех .
(b) (Симметрия) Пусть . Если , то .
(c) (Транзитивность) Пусть . Если и , то .
Доказательство. (а) Если , то , значит .
б) Если , то , значит . Поэтому, .
(c) Предположим и . означает ; означает . Поэтому,
Следовательно, .
Отношение эквивалентности на множестве порождает разбить множества на классы эквивалентности. В случае конгруэнтность по модулю n, класс эквивалентности состоит из целых чисел, конгруэнтных друг к другу mod n.
Определение. (читается «Z mod n») — множество эквивалентности классы по модулю конгруэнтности n.
Пример. ( Классы конгруэнтности мод 3 ) Найдите классы эквивалентности отношения конгруэнтности mod 3 на множестве целых чисел.
Относительно отношения эквивалентности конгруэнтности по модулю 3 на целые числа разбиваются на три непересекающихся наборы:
Все элементы данного множества конгруэнтны по модулю 3, и ни один элемент
в одном наборе конгруэнтна по модулю 3 элементу другого. Наборы
разделить целые числа, как три части головоломки.
Наборы
разделить целые числа, как три части головоломки.
Затруднительно писать и использовать классы эквивалентности как есть, поскольку каждый класс эквивалентности представляет собой множество (в данном случае бесконечное). Его принято выбирать представитель от каждого класса эквивалентности и использовать представителей для выполнения арифметических действий. Больной выбирать
Я буду злоупотреблять обозначениями и напишу
называется циклическим группа заказа 3 . «Циклическую» природу можно визуализировать, расположив целые числа в виде спираль, с каждым классом конгруэнтности на луче.
Когда вы делаете арифметику в , это как если бы считаешь по кругу: 0, 1, 2, потом опять до 0.
Аналогичным образом можно сформировать и другие циклические группы. Например,
Вы можете выполнять арифметические действия, добавляя и
умножая как обычно, но уменьшая мод результатов
п .
Пример. ( Операционные столы для ) Построить дополнение и таблицы умножения для .
Например, как целые числа. делю 4 на модуль 3 и получить остаток от 1. Следовательно, .
Аналогично, в .
Пример. ( Уравнения в ) Найдите в , в и -8 в .
-8 означает добавку, обратную 8. Последнее утверждение просто другой способ сказать.
Пример. ( Использование модульного арифметика в доказательстве делимости ) Докажите, что если n является целое число, то не делится на 5.
Каждое целое число n сравнимо с одним из 0, 1, 2, 3 или 4 по модулю 5. Поэтому у меня 5 дел. В каждом случае я хочу показать, что не делится на 5 — или сказать это в с точки зрения схожести, я хочу показать, что .
я поставил и
«подставить» значение в . Такая замена оправдана
свойства сравнений я обсуждал выше.
Например, если , то
Так же, . Так
По сути, я могу подключиться к , а затем уменьшить мод результата 5 до одного из 0, 1, 2, 3 или 4.
Продолжая таким образом, я получаю следующую таблицу:
Во всех пяти случаях . Следовательно, никогда не делится на 5.
Ранее я показал, как использовать алгебраические операции для решения простых задач. модульные уравнения. Как бы вы решили что-то вроде этого:
Я хотел бы разделить обе части на 6, но я умею только складывать и умножить. Я могу вычесть, но это потому что я могу сложить аддитивные инверсии. Ну деление это умножение на мультипликативная обратная; что такое мультипликативный обратный мод 25?
Определение. Пусть . а и б равны мультипликативные инверсии если (или в ).
Если a является мультипликативной инверсией b, вы можете написать .
(Вы не пишете » «, если вы находитесь в системе счисления, как рациональные числа, где дроби используются.)
Пример. ( Модульный мультипликативные обратные ) (a) Докажите, что 6 и 2 мультипликативные инверсии по модулю 11.
(b) Покажите, что число 8 не имеет обратного по модулю 12 мультипликативного числа.
(а) .
(b) Один из утомительных способов — брать кейсы:
Никакое число, умноженное на 8, не дает 1 по модулю 12.
Я мог попробовать все возможности, потому что числа были небольшими. Как Вы бы решили такую задачу, если бы числа были больше?
Один из подходов состоит в том, чтобы просто апеллировать к результату, следующему за этим. пример. Однако я могу привести доказательство и от противного.
Предположим, что 8 имеет мультипликативную обратную по модулю 12. Пусть x будет
мультипликативное обратное. Затем . Умножая обе части на 3, я получаю
Умножая обе части на 3, я получаю
Это противоречие, так как 0 и 3 не отличаются кратно 12. Следовательно, 8 не имеет мультипликативного обратного модуса 12.
Предложение. 90 109 имеет мультипликативную инверсию тогда и только тогда, когда .
Доказательство. Предположим, имеет мультипликативную инверсию, поэтому
Я могу расценивать это как заявление в:
Это означает, что и 1 отличаются на а кратное n:
Таким образом,
Это линейная комбинация m и n, которая дает 1. Следовательно, .
Наоборот, предположим. Я могу найти целые числа a и б такое, что
То есть,
Теперь рассматривается как уравнение в , это говорит
То есть m имеет мультипликативную обратную a.
Пример. ( Использование расширенного
Алгоритм Евклида для нахождения модулярных инверсий ) Найдите
мультипликативное обратное 31 в .
Обратите внимание, что . Применение расширенного евклидова Алгоритм:
Таким образом,
В и . Уравнение говорит. Таким образом, 47 является мультипликативным обратным числом 31 в.
Теорема. Если , то следующее уравнение имеет единственное решение:
Доказательство. Если , то имеет мультипликативное обратное в . Таким образом, в .
Во-первых, это означает, что это решение, поскольку
Во-вторых, если это другое решение, то . Умножая обе части на , я получаю
То есть, . Это означает, что решение уникально.
Пример. ( Решающая модульная уравнения, использующие модульные обратные ) Решить
Решение есть, т.к. Мне нужно найдите мультипликативное обратное число 13 по модулю 15.
Расширенный алгоритм Евклида говорит, что
Следовательно, , т.