
Разложение вектора по базису » Аналитическая геометрия f(x)dx.Ru
п.2. Разложение вектора по базису.
Определение. Пусть – произвольный вектор, – произвольная система векторов. Если выполняется равенство
, (1)
то говорят, что вектор представлен в виде линейной комбинации данной системы векторов. Если данная система векторов является базисом векторного пространства, то равенство (1) называется разложением вектора по базису . Коэффициенты линейной комбинации называются в этом случае координатами вектора относительно базиса .
Теорема. (О разложении вектора по базису.)
Любой вектор векторного пространства можно разложить по его базису и притом единственным способом.
Доказательство. 1) Пусть L произвольная прямая (или ось) и – базис . Возьмем произвольный вектор . Так как оба вектора и коллинеарные одной и той же прямой L, то . Воспользуемся теоремой о коллинеарности двух векторов. Так как , то найдется (существует) такое число , что и тем самым мы получили разложение вектора по базису векторного пространства .
Теперь докажем единственность такого разложения. Допустим противное. Пусть имеется два разложения вектора по базису векторного пространства :
и , где . Тогда и используя закон дистрибутивности, получаем:
.
Так как , то из последнего равенства следует, что , ч.т.д.
2) Пусть теперь Р произвольная плоскость и – базис . Пусть произвольный вектор этой плоскости. Отложим все три вектора от какой-нибудь одной точки этой плоскости. Построим 4 прямых. Проведем прямую , на которой лежит вектор , прямую , на которой лежит вектор . Через конец вектора проведем прямую параллельную вектору и прямую параллельную вектору . Эти 4 прямые высекают параллелограмм. См. ниже рис. 3. По правилу параллелограмма , и , , – базис , – базис .
Теперь, по уже доказанному в первой части этого доказательства, существуют такие числа , что
и . Отсюда получаем:
и возможность разложения по базису доказана.
рис.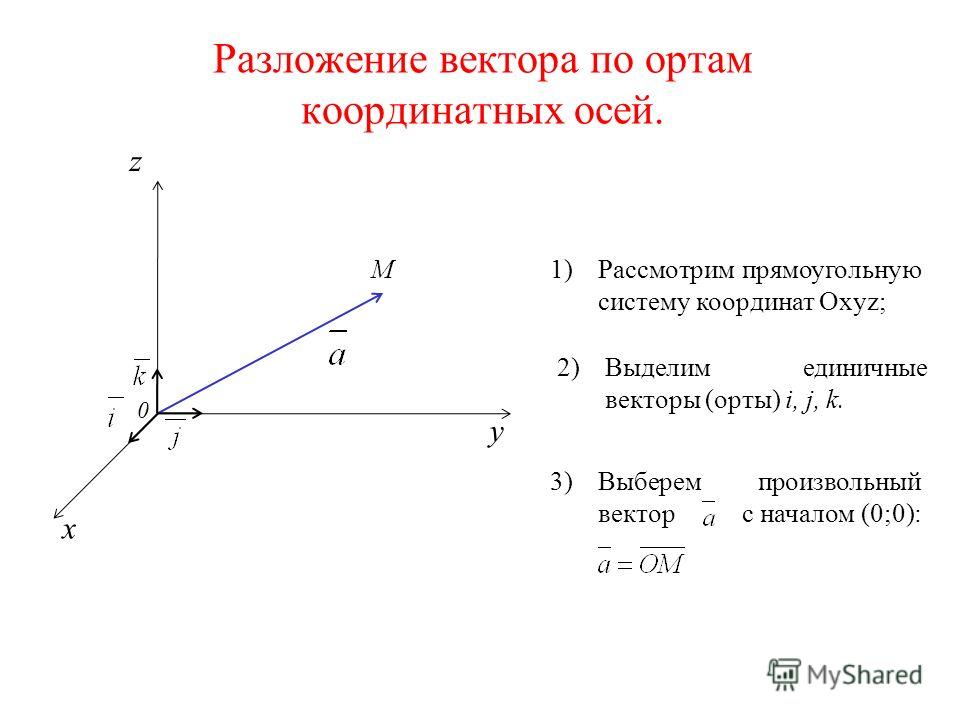 3.
3.
Теперь докажем единственность разложения по базису. Допустим противное. Пусть имеется два разложения вектора по базису векторного пространства : и . Получаем равенство
, откуда следует . Если , то , а т.к. , то и коэффициенты разложения равны: , . Пусть теперь . Тогда , где . По теореме о коллинеарности двух векторов отсюда следует, что . Получили противоречие условию теоремы. Следовательно, и , ч.т.д.
3) Пусть – базис и пусть произвольный вектор. Проведем следующие построения.
Отложим все три базисных вектора и вектор от одной точки и построим 6 плоскостей: плоскость, в которой лежат базисные векторы , плоскость и плоскость ; далее через конец вектора проведем три плоскости параллельно только что построенным трем плоскостям. Эти 6 плоскостей высекают параллелепипед:
рис.4.
По правилу сложения векторов получаем равенство:
. (1)
По построению . Отсюда, по теореме о коллинеарности двух векторов, следует, что существует число , такое что . Аналогично, и , где . Теперь, подставляя эти равенства в (1), получаем:
Отсюда, по теореме о коллинеарности двух векторов, следует, что существует число , такое что . Аналогично, и , где . Теперь, подставляя эти равенства в (1), получаем:
(2)
и возможность разложения по базису доказана.
Докажем единственность такого разложения. Допустим противное. Пусть имеется два разложения вектора по базису :
и . Тогда
. (3)
Заметим, что по условию векторы некомпланарные, следовательно, они попарно неколлинеарные.
Возможны два случая: или .
а) Пусть , тогда из равенства (3) следует:
. (4)
Из равенства (4) следует, что вектор раскладывается по базису , т.е. вектор лежит в плоскости векторов и, следовательно, векторы компланарные, что противоречит условию.
б) Остается случай , т.е. . Тогда из равенства (3) получаем или
. (5)
Так как – базис пространства векторов лежащих в плоскости, а мы уже доказали единственность разложения по базису векторов плоскости, то из равенства (5) следует, что и , ч. т.д.
т.д.
Теорема доказана.
12.3. Разложение вектора по базису Представление вектора в произвольном базисе
Пусть система векторов
является базисом, а вектор — их линейной комбинацией. Имеет место следующая теорема.
ТЕОРЕМА 2. Разложение любого вектора в базисе, если оно существует, является единственным.
Доказательство. Предположим, что вектор может быть представлен в виде линейной комбинации векторов (12.9) двумя способами:
где наборы чисел αi и βi, среди которых обязательно есть ненулевые значения, не совпадают. Вычитая одно равенство из другого, имеем
Мы получили, что
линейная комбинация векторов системы
(12.9), в которой не все коэффициенты равны
нулю (в силу несовпадения αi и βi),
равна нулю, т.
Стало быть, в произвольном базисе пространства Rn
любой вектор этого пространства обязательно представим в виде разложения по базисным векторам:
причем это разложение является единственным для данного базиса. Коэффициенты разложения
называются координатами вектора в базисе (12.10), и, как следует из сказанного, этот набор единственный для любого вектора из Rn в данном базисе.
Задача нахождения коэффициентов разложения в случае произвольного базиса (12.10) является, вообще говоря, непростой. Нужно приравнять соответствующие координаты линейной комбинации векторов слева и координаты вектора в (12.11). Пусть базисные векторы и вектор заданы в следующей координатной форме:
Выполнение
процедуры, описанной выше, приводит к системе п
линейных уравнений относительно п неизвестных координат разложения
вектора в базисе (12. 10):
10):
Такие системы уравнений и методы их решения представляют отдельные разделы линейной алгебры; они будут рассмотрены в следующих главах.
Рассмотрим базис пространства Rn, в котором каждый вектор ортогонален остальным векторам базиса:
Ортогональные базисы хорошо известны и широко используются на плоскости и в пространстве (рис. 12.2). Базисы такого вида удобны прежде всего тем, что координаты разложения произвольного вектора определяются по весьма простой процедуре, не требующей трудоемких вычислений.
Действительно, пусть требуется найти разложение произвольного вектора в ортогональном базисе (12.13). Составим разложение этого вектора с неизвестными пока координатами разложения в данном базисе:
Умножим обе части
этого равенства, представляющие собой
векторы, на вектор 1. В силу свойств 2 и 3 скалярного произведения
векторов имеем
В силу свойств 2 и 3 скалярного произведения
векторов имеем
Однако в силу взаимной ортогональности векторов базиса (12.13) все скалярные произведения векторов базиса, за исключением первого, равны нулю, т.е. коэффициент α1 определяется по формуле
Умножая поочередно равенство (12.14) на другие базисные векторы, мы получаем простую формулу для вычисления коэффициентов разложения вектора :
Нетрудно видеть, что соотношения (12.15) имеют смысл, поскольку |i| ≠ 0.
Отметим особо частный случай ортогонального базиса, когда все векторы в (12.13) имеют единичную длину (|i| = 1), или нормированы по своей длине. В таком случае базис называют ортонормированным и координаты разложения (12.15) имеют наиболее простой вид:
Обзор линейной алгебры — Вычислительная статистика в Python
Из xkcd:
texte
В 1]:
импорт ОС импорт системы импортировать глобус импортировать matplotlib.pyplot как plt импортировать matplotlib.patches как патч импортировать numpy как np импортировать панд как pd %matplotlib встроенный %точность 4 plt.style.use('ggplot') из scipy import linalg np.set_printoptions (подавить = Истина) # Студенты могут (вероятно, должны) игнорировать этот код. Это просто здесь, чтобы сделать красивые стрелки. определение plot_vectors (против): """Постройте векторы в зависимости от исходной точки (0,0)""" п = длина (против) X, Y = np.zeros ((n, 2)) U, V = np.vstack(vs).T plt.quiver(X, Y, U, V, диапазон(n), angles='xy', scale_units='xy', scale=1) xmin, xmax = np.min([U, X]), np.max([U, X]) ymin, ymax = np.min([V, Y]), np.max([V, Y]) xrng = хмакс - хмин yng = ymax - ymin xмин -= 0,05*xrng xmax += 0,05*xrng yмин -= 0,05*год ymax += 0,05*yrng plt.axis([xmin, xmax, ymin, ymax])
 pyplot как plt
импортировать matplotlib.patches как патч
импортировать numpy как np
импортировать панд как pd
%matplotlib встроенный
%точность 4
plt.style.use('ggplot')
из scipy import linalg
np.set_printoptions (подавить = Истина)
# Студенты могут (вероятно, должны) игнорировать этот код. Это просто здесь, чтобы сделать красивые стрелки.
определение plot_vectors (против):
"""Постройте векторы в зависимости от исходной точки (0,0)"""
п = длина (против)
X, Y = np.zeros ((n, 2))
U, V = np.vstack(vs).T
plt.quiver(X, Y, U, V, диапазон(n), angles='xy', scale_units='xy', scale=1)
xmin, xmax = np.min([U, X]), np.max([U, X])
ymin, ymax = np.min([V, Y]), np.max([V, Y])
xrng = хмакс - хмин
yng = ymax - ymin
xмин -= 0,05*xrng
xmax += 0,05*xrng
yмин -= 0,05*год
ymax += 0,05*yrng
plt.axis([xmin, xmax, ymin, ymax])
pyplot как plt
импортировать matplotlib.patches как патч
импортировать numpy как np
импортировать панд как pd
%matplotlib встроенный
%точность 4
plt.style.use('ggplot')
из scipy import linalg
np.set_printoptions (подавить = Истина)
# Студенты могут (вероятно, должны) игнорировать этот код. Это просто здесь, чтобы сделать красивые стрелки.
определение plot_vectors (против):
"""Постройте векторы в зависимости от исходной точки (0,0)"""
п = длина (против)
X, Y = np.zeros ((n, 2))
U, V = np.vstack(vs).T
plt.quiver(X, Y, U, V, диапазон(n), angles='xy', scale_units='xy', scale=1)
xmin, xmax = np.min([U, X]), np.max([U, X])
ymin, ymax = np.min([V, Y]), np.max([V, Y])
xrng = хмакс - хмин
yng = ymax - ymin
xмин -= 0,05*xrng
xmax += 0,05*xrng
yмин -= 0,05*год
ymax += 0,05*yrng
plt.axis([xmin, xmax, ymin, ymax])
Можно описать множество проблем статистических вычислений.
математически с помощью линейной алгебры. Эта лекция призвана служить
обзор понятий, которые вы рассмотрели в курсах линейной алгебры, так что
мы можем обсудить некоторые важные матричные разложения, используемые в статистической
анализы.
Большинство студентов на курсах элементарной линейной алгебры учатся использовать гауссовский исключение для решения систем, подобных приведенной выше. Чтобы понять больше передовые методы и матричные декомпозиции (подробнее об этом позже), нам нужно вспомнить некоторые математические понятия.
Векторные пространства
Технически, векторное пространство представляет собой поле коэффициентов \(\mathbb{F}\) вместе с коммутативной группой (над сложением) \(V\) такой, что
- Если \(c\in \mathbb{F}\) и \(v\in V\), то \(cv\in V\)
- Если \(v_1,v_2 V\) и \(c\in \mathbb{F}\), то \(с(v_1+v_2) = с v_1 + с v_2\)
- Если \(c_1,c_2\in \mathbb{F}\) и \(v\in V\), то \((c_1+c_2)v = c_1v + c_2v\)
- Если \(c_1,c_2\in \mathbb{F}\) и \(v\in V\), то \((c_1c_2)v = c_1(c_2v)\)
- Если \(1\) является мультипликативным тождеством в \(\mathbb{F}\), тогда \(1\cdot v = v\)
Это может показаться бесполезным для целей настоящего
конечно, и для многих наших целей мы можем немного упростить это. n\), т.е. точками в
\(n\) мерное пространство. «Коэффициенты» также являются действительными числами.
Это приводит к мысли, что векторы — это просто \(n\)-наборы
числа. Это хороший, конкретный способ видеть вещи, но это
немного упрощенно. Это немного затемняет необходимость в основе, и что
«координаты» на самом деле есть. Это также не очень помогает, когда мы хотим
рассмотреть векторные пространства вещей, которые не являются числами, например функции
(да, мы можем это сделать!! и это полезно даже в статистике )
n\), т.е. точками в
\(n\) мерное пространство. «Коэффициенты» также являются действительными числами.
Это приводит к мысли, что векторы — это просто \(n\)-наборы
числа. Это хороший, конкретный способ видеть вещи, но это
немного упрощенно. Это немного затемняет необходимость в основе, и что
«координаты» на самом деле есть. Это также не очень помогает, когда мы хотим
рассмотреть векторные пространства вещей, которые не являются числами, например функции
(да, мы можем это сделать!! и это полезно даже в статистике )
Поэтому, надеюсь, вы меня побалуете и сначала подумаете о «векторах» (обычно обозначаются \(u,v,w,x,y\)) и их «коэффициенты» (обычно обозначаются \(a,b,c\)) как принципиально различных объектов .
Концептуально : Думайте о векторах как о линейных комбинациях Вещи (Тм). Думайте о \(v\) как о неких объектах (функциях, яблоки, печенье) и \(c\) как числа (действительные, комплексные, кватернионы…)
Линейная независимость и базис
Набор векторов \(v_1,.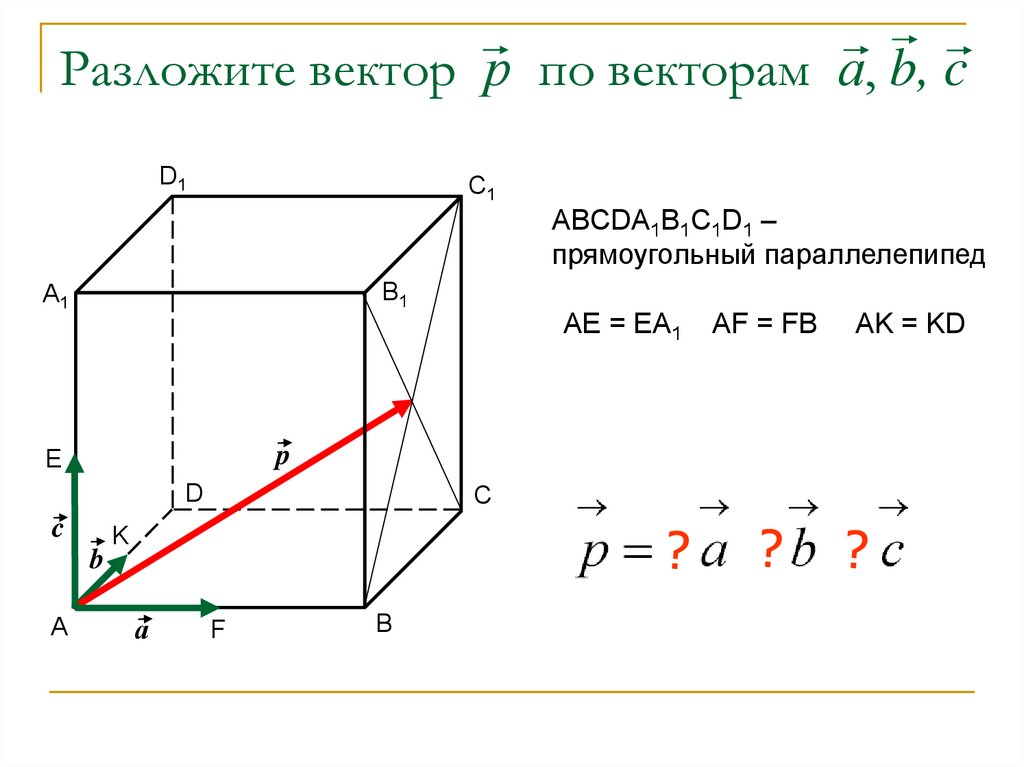 ..,v_n\) называется линейно
независимый if
..,v_n\) называется линейно
независимый if
\[c_1v_1 + \cdots c_nv_n = 0\]
\[\iff\]
\[c_1=\cdots=c_n=0\]
Другими словами, любая линейная комбинация векторов что приводит к нулевой вектор тривиален.
Другая интерпретация этого состоит в том, что ни один вектор в наборе не может быть выражается как линейная комбинация остальных. В этом смысле линейный независимость есть выражение неизбыточности в наборе векторов.
Факт : Любой линейно независимый набор \(n\) векторов охватывает \(n\)-мерное пространство. (т.е. совокупность всех возможных линейных комбинаций — это \(V\) — на самом деле это определение размерность) Такой набор векторов называется базисом пространства \(V\). Другим термином для базиса является минимальный остовный набор .
Пример
Мы можем рассмотреть векторное пространство многочленов степени \(\leq 2\) над \(\mathbb{R}\). Базис этого пространства равен 92\]
имеет координаты \((0,2,\pi)\).
Вы, вероятно, думаете о координатах с точки зрения координатной плоскости, и приравнять координаты к \(n\)-наборам, которые помечают точки. Это все верно, но пропускает шаг. Теперь, когда мы разделили нашу базисных векторов из их координат, давайте посмотрим, как это применимо в случай реальных векторных пространств, к которым вы привыкли.
Координаты изображенного вектора (ниже) равны \((2,3)\). Но что это значит? Это означает, что мы приняли стандартная основа , \(\left\{e_1,e_2\right\}\), а вектор \((2,3)\) действительно означает:
\[2e_1 + 3e_2\]
где \(e_1\) — единичный вектор (длина = 1) на горизонтальной оси и \(e_2\) — единичный вектор вдоль вертикальной оси. Это выбор координат . С таким же успехом мы могли бы выбрать основу \(\left\{v,e_2\right\}\) где \(v\) — любой вектор, линейно не зависит от \(e_2\). Тогда все векторы будут считается в виде:
\[c_1 v + c_2 e_2\]
.
В [2]:
# Опять же, этот код не предназначен для использования в качестве примера кода.
 a1 = np.array([3,0]) # ось
a2 = np.массив ([0,3])
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plot_vectors ([a1, a2])
v1 = np.массив ([2,3])
plot_vectors([a1,v1])
plt.text(2,3,"(2,3)",размер шрифта=16)
plt.tight_layout()
a1 = np.array([3,0]) # ось
a2 = np.массив ([0,3])
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plot_vectors ([a1, a2])
v1 = np.массив ([2,3])
plot_vectors([a1,v1])
plt.text(2,3,"(2,3)",размер шрифта=16)
plt.tight_layout()
Обратите внимание, что в стандартном базисе координаты \(e_1\) равны \((1,0)\). Это потому, что:
\[e_1 = 1\cdot e_1 + 0\cdot e_2\]
Точно так же координаты \(e_2\) равны \((0,1)\), потому что
\[e_2 = 0\cdot e_1 + 1\cdot e_2\]
В базисе \(\left\{v,e_1\right\}\) координаты \(e_1\) равны \((0,1)\), потому что
\[e_1 = 0\cdot v + 1\cdot e_1\]
и координаты \(v\) равны \((1 ,0)\).
Нужны эти понятия в тот момент, когда мы говорим об изменении базиса.
Матрицы и линейные преобразования
Итак, у нас есть это векторное пространство, и оно состоит из линейных комбинаций
векторы. Просто сидеть там не очень интересно. Итак, давайте сделаем
что-то с этим. 92\). Это кажется достаточно простым. Но есть еще
бесконечно много векторов. Определение преобразования звучит трудоемко.
Определение преобразования звучит трудоемко.
Ах, но мы умные. Мы определили наше пространство таким образом, что для определенных преобразований, нам нужно только определить наше преобразование на конечное множество (в случае конечномерных векторных пространств).
Линейные преобразования
Линейное преобразование \(f:V\стрелка вправо W\) является отображением из \(V\) в \(W\) такое, что
\[f(c_1 v_1+c_2v_2) = c_1f(v_1)+c_2f(v_2)\]
Теперь вспомним, что базис по существу порождает все векторное пространство через линейные комбинации. Итак, как только мы определим линейное преобразование \(f\) по базису, мы имеем его для всего пространства.
Матрицы, преобразования и геометрическая интерпретация
Вспоминая реальные векторные пространства, что делает матрица вектор? Умножение матриц имеет геометрическую интерпретацию . Когда мы
умножаем вектор, мы либо вращаем, отражаем, расширяем или какую-то комбинацию
из тех трех. Итак, умножение на матрицу преобразует один вектор в
другой вектор. Это линейных преобразований .
Итак, умножение на матрицу преобразует один вектор в
другой вектор. Это линейных преобразований .
См. ячейку ниже для примера вектора (\(v_1 = (2,3)\)) преобразуется матрицей
\[\begin{split}A = \left(\begin{matrix}2 & 1\\1&1\end{matrix}\right)\end{split}\]
так, что
\[v_2 = Av_1\]
В [3]:
a1 = np.array([7,0]) # ось
a2 = np.массив ([0,5])
A = np.array([[2,1],[1,1]]) # преобразование f в стандартном базисе
v2 =np.dot(A,v1)
plt.figure(figsize=(8,8))
plot_vectors ([a1, a2])
v1 = np.массив ([2,3])
plot_vectors([v1,v2])
plt.text(2,3,"v1 =(2,3)",размер шрифта=16)
plt.text (6,5, "Av1 = ", размер шрифта = 16)
plt.text(v2[0],v2[1],"(7,5)",размер шрифта=16)
печать (v2 [1])
9{-1}AB\] определяет такое же преобразование. Эта операция называется изменением
базис , потому что мы просто выражаем преобразование относительно
на другую основу.
Это важное понятие в матричных разложениях.
Пример.
Найти Матричное представление линейного преобразования Обратите внимание, что мы говорим найти «а» матричное представление, а не «матрицу»
представление. Это связано с тем, что представление матрицы зависит
на выбор базы . Просто чтобы мотивировать вас, почему это
важно, вспомним нашу линейную систему:
\[Ax=b\]
Некоторые формы \(A\) намного проще инвертировать. Например,
предположим, что \(A\) диагонально. Тогда мы можем легко решить каждое уравнение:
Ax =b \iff \left\{\begin{matrix}d_1 & 0& \cdots & 0\\0 & d_2 & \cdots & 0\\ \vdots & & &\vdots \\ 0 &0&\cdots &d_n
\конец{матрица}\справа\}
\left\{\begin{matrix}x_1\\ \vdots\\x_n\end{matrix}\right\}= \left\{\begin{matrix}b_1\\ \vdots\\b_n\end{matrix}\ справа\} \iff x_1 = \frac{b_1}{d_1},...,x_n=\frac{b_n}{d_n}
Итак, если бы мы могли найти базис, в котором преобразование, определяемое
\(A\) диагональна, наша система очень легко решается. Конечно, это
не всегда возможно, но мы часто можем упростить нашу систему, изменив
базиса, чтобы получившуюся систему было легче решить. (Это
«методы декомпозиции матриц», и мы поговорим о них подробно,
как только у нас будут инструменты для этого).
Теперь пусть \(f(x)\) будет линейным преобразованием, которое принимает
\(e_1=(1,0)\) в \(f(e_1)=(2,3)\) и \(e_2=(0,1)\) в
\(f(e_2) = (1,1)\). Матричное представление \(f\) будет
предоставлено: 92\), скажем \(v_1\) и \(v_2\), и предположим, что
координаты \(v_1\) в базисе \(e_1,e_2\) равны
\((1,3)\) и что координаты \(v_2\) в базисе
\(e_1,e_2\) это \((4,1)\). Сначала найдем преобразование, которое
переводит \(e_1\) в \(v_1\) и \(e_2\) в \(v_2\). А
матричное представление для этого (в базисе \(e_1, e_2\)) таково:
\[\begin{split}B = \left(\begin{matrix}1 & 4\\3&1\end{matrix}\right )\end{split}\]
Наше исходное преобразование \(f\) можно выразить относительно
базис \(v_1, v_2\) через 9{-1}\]
Вот как выглядит новая база:
В [4]:
e1 = np.массив ([1,0])
e2 = np.массив ([0,1])
B = np.массив([[1,4],[3,1]])
plt.figure(figsize=(8,4))
plt. subplot(1,2,1)
plot_vectors([e1, e2])
plt.subplot(1,2,2)
plot_vectors([B.dot(e1), B.dot(e2)])
plt.Круг((0,0),2)
#plt.show()
#plt.tight_layout()
Выход[4]:
Посмотрим, как выглядит новая матрица:
В [5]:
A = np.array([[2,1],[3,1]]) # преобразование f в стандартном базисе
e1 = np.array([1,0]) # стандартные базисные векторы e1,e2
e2 = np.массив ([0,1])
print(A.dot(e1)) # продемонстрируем, что Ae1 равно (2,3)
print(A.dot(e2)) # продемонстрируем, что Ae2 равно (1,1)
# новые базисные векторы
v1 = np.массив ([1,3])
v2 = np.массив ([4,1])
# Как v1 и v2 преобразуются с помощью A
печать("Сред.1:")
печать (A.dot (v1))
печать("Сред.2:")
печать (A.dot (v2))
# Смена базы со стандартной на v1,v2
B = np.массив([[1,4],[3,1]])
печать(Б)
B_inv = linalg.inv(B)
print("B B_inv")
print(B.dot(B_inv)) # проверка обратного
# Матрица преобразования относительно нового базиса
T = B.dot(A.dot(B_inv)) # B A B^{-1}
печать (Т)
печать (B_inv)
np. dot (B_inv, (T.dot (e1)))
[2 3]
[1 1]
Av1:
[5 6]
Av2:
[ 9 13]
[[1 4]
[3 1]]
B B_inv
[[ 1. 0.]
[ 0. 1.]]
[[ 0,0909 4,6364]
[0,2727 2,9091]]
[[-0,0909 0,3636]
[ 0,2727 -0,0909]]
Выход[5]:
массив([ 0.0909, 0. ])
Какое отношение все это имеет к линейным системам?
 Найти Матричное представление линейного преобразования
Найти Матричное представление линейного преобразования  (Это
«методы декомпозиции матриц», и мы поговорим о них подробно,
как только у нас будут инструменты для этого).
(Это
«методы декомпозиции матриц», и мы поговорим о них подробно,
как только у нас будут инструменты для этого).  subplot(1,2,1)
plot_vectors([e1, e2])
plt.subplot(1,2,2)
plot_vectors([B.dot(e1), B.dot(e2)])
plt.Круг((0,0),2)
#plt.show()
#plt.tight_layout()
subplot(1,2,1)
plot_vectors([e1, e2])
plt.subplot(1,2,2)
plot_vectors([B.dot(e1), B.dot(e2)])
plt.Круг((0,0),2)
#plt.show()
#plt.tight_layout()
 dot (B_inv, (T.dot (e1)))
dot (B_inv, (T.dot (e1)))
- Если \(A\) является матрицей \(m\times n\) и \(m>n\), если все \(m\) строк линейно независимы, то система переопределенное и несовместимое . Система не может быть решена в яблочко. Это обычный случай в анализе данных, и почему квадраты очень важны. Например, мы можем найти параметры линейной модели, где есть \(m\) точек данных и \(n\) параметры.
- Если \(A\) является матрицей \(m\times n\) и \(m
- Если \(A\) является матрицей \(m\times n\) и некоторые ее строки
линейно зависимы, то система приводима . Мы можем избавиться от
некоторые уравнения. Другими словами, в системе есть уравнения
которые не дают нам никакой новой информации.
- Если \(A\) — квадратная матрица и ее строки линейно
независимыми, система имеет единственное решение. (\(А\) есть
обратимый.) Это прекрасный случай, который происходит в основном в сфере
чистой математики и почти никогда на практике. 92}\]
Расстояние между двумя векторами равно длине их разности:
\[d(v,w) = ||v-w||\]
Примеры
В [6]:
# норма вектора # Примечание. Пакет numpy linalg импортируется вверху этой записной книжки. v = np.массив ([1,2]) линейная норма(v)
Выход[6]:
2,2361
В [7]:
# расстояние между двумя векторами ш = np.массив ([1,1]) linalg.norm(v-w)
Выход[7]:
1.0000
Внутренние продукты
Внутренние продукты тесно связаны с нормами и расстоянием. Стандарт) внутренний продукт (или скалярное произведение) двух \(n\) размерных векторов \(v\) и \(w\) определяется как:
\[
..+v_nw_n\]Т.е. внутренний продукт - это просто сумма произведения компонентов. Некоторые «специальные» матрицы также определяют внутренние продукты, и мы увидим, некоторые из них позже.
Стандартный внутренний продукт связан со стандартной нормой через: 9{\frac12}\]
Внутреннее произведение двух векторов пропорционально косинусу угол между ними. Фактически:
\[
где \(\theta\) - угол между \(v\) и \(w\).
В [8]:
e1 = np.массив ([1,0]) e2 = np.массив ([0,1]) А = np.массив([[2,3],[3,1]]) v1=А.точка(e1) v2=А.точка(e2) plt.figure(figsize=(8,4)) plt.subplot(1,2,1) plot_vectors([e1, e2]) plt.subplot(1,2,2) plot_vectors([v1,v2]) plt.tight_layout() #help(plt.Круг) plt.Circle (np.array ([0,0]), радиус = 1) plt.Circle.draw
Выход[8]:
<функция matplotlib.artist.allow_rasterization.
.draw_wrapper> Существует более абстрактная формулировка внутреннего продукта, полезная при рассмотрении более общих векторных пространств, особенно вектора функций пробелы:
Общий внутренний продукт
Мы сформулируем определение для векторных пространств над \(\mathbb{R}\), но обратите внимание, что все они могут быть расширены для любого поля коэффициентов.
Скалярный продукт на векторном пространстве \(V\) является симметричным положительным определенная, билинейная форма. Это означает, что внутренний продукт — это любая карта \(<,>_A\) (A просто для того, чтобы указать, что это другое от стандартного внутреннего продукта).
\[<,>_A: V\times V:\rightarrow \mathbb{R}\]
со следующими свойствами:
Симметричный: Для любых \(v_1,v_2\in V\times V\ ),
\[
Положительный Определенный: Для любого \(v\in V\),
\[ \begin{align}\begin{aligned}
ноль вектор ). 9{\frac12}\]
Мы обсудим это немного подробнее, когда узнаем о положительно определенных матрицы!
Общие нормы
Существует и более абстрактное определение нормы - норма есть функция из векторного пространства в действительные числа, то есть положительно определенные, абсолютно масштабируема и удовлетворяет неравенству треугольника.
В основном мы будем иметь дело с нормами, исходящими из внутренних продуктов, но Приятно отметить, что не все нормы должны исходить из внутреннего продукта. 9t\]
Обратите внимание, что я рассматриваю \(v\) и \(w\) как столбцов векторов. Результатом внутреннего продукта является скаляр . Результат внешнего продукт матрица .
Пример
В [9]:
np.outer(v,w)
Выход[9]:
массив([[1, 1], [2, 2]])Расширенный пример : ковариационная матрица является внешней матрицей.
В [10]:
# У нас есть n наблюдений p переменных п, р = 10, 4 v = np.random.random((p,n))
В [11]:
# Ковариационная матрица представляет собой матрицу p на p np.cov(v)
Выход[11]:
массив([[ 0,1212, 0,0027, -0,0452, 0,0313], [0,0027, 0,0792, 0,0045, -0,0142], [-0,0452, 0,0045, 0,0844, 0,0174], [0,0313, -0,0142, 0,0174, 0,0924]])В [12]:
# Из определения ковариационная матрица # это просто внешнее произведение нормализованного # матрица, где каждая переменная имеет нулевое среднее # разделить на количество степеней свободы w = v - v.
mean(1)[:, np.newaxis]
w.dot(w.T)/(n - 1)
Выход[12]:
массив([[ 0,1212, 0,0027, -0,0452, 0,0313], [0,0027, 0,0792, 0,0045, -0,0142], [-0,0452, 0,0045, 0,0844, 0,0174], [0,0313, -0,0142, 0,0174, 0,0924]])След и определитель матриц
След матрицы \(A\) представляет собой сумму ее диагональных элементов. Это важен по нескольким причинам:
- Это инвариант матрицы при изменении базиса (подробнее об этом потом). 9n a_{i,\sigma_i}\]
- Как и след, он также инвариантен относительно замены базиса
- \(n\times n\) матрица \(A\) обратима \(\iff\) det\((A)\neq 0\)
- Строки (столбцы) матрицы \(n\times n\) \(A\) равны линейно независимый \(\iff\) det\((A)\neq 0\)
Впрочем, не будем на этом останавливаться. Важно знать, что определитель матрицы \(2\times 2\) равен
\[\begin{split}\left|\begin{matrix}a_{11} & a_{12}\\a_{21} & a_{22} \конец{матрица}\право| = a_{11}a_{22} - a_{12}a_{21}\end{split}\]
Это может быть расширено до матрицы \(n\times n\) путем незначительного расширения. Я оставлю это для вас в Google. Будем вычислять определители используя такие инструменты, как:
np.linalg.det(A)Самое главное в определителе:
В [13]:
п = 6 M = np.
random.randint (100, размер = (n, n))
печать(М)
np.linalg.det(M)
[[23 96 78 38 47 97] [44 50 36 195 25] [61 33 91 96 5 53] [17 33 79 64 40 49] [11 74 14 79 22 74] [36 89 74 40 31 92]]
Исход[13]:
992477586.0000
Пространство столбцов, Пространство строк, Ранг и ядро
Пусть \(A\) - матрица \(m\x n\). Мы можем просмотреть столбцы \(A\) как векторы, скажем, \(\textbf{a_1},...,\textbf{a_n}\). пространство всех линейных комбинаций \(\textbf{a_i}\) являются столбцов пространства матрицы \(A\). Сейчас если \(\textbf{a_1},...,\textbf{a_n}\) равно линейно независимый , тогда пространство столбца имеет размерность \(n\). В противном случае размерность пространство столбцов - это размер максимального набора линейно независимых \(\textbf{a_i}\). Пространство строк точно аналогично, но векторы это строк \(A\).
ранг матрицы A размер пространства столбца - и - размер его строкового пространства.
Они равны для любой матрицы. Ранг может
можно рассматривать как меру невырожденности системы линейных
уравнения, в том, что это размер изображения линейного
преобразование , определяемое \(A\).Ядро матрицы A — размерность пространства, отображенного на равен нулю при линейном преобразовании, которое представляет \(A\). Размерность ядра линейного преобразования называется ничтожность .
Теорема об индексе: для матрицы \(m\times n\) \(A\),
rank(\(A\)) + nullity(\(A\)) = \(n\).
Нормы матрицы
Мы можем расширить понятие нормы вектора до нормы матрицы. Матричные нормы используются при определении 9\frac12\]
Специальные матрицы
Некоторые матрицы обладают интересными свойствами, которые позволяют либо упростить лежащей в основе линейной системы или чтобы понять больше о ней.
Квадратные матрицы
Квадратные матрицы имеют одинаковое количество столбцов (обычно обозначается \(н\)).
T\]Верхняя и нижняя треугольная
Матрица \(A\) является (верхней|нижней) треугольной, если \(a_{ij} = 0\) для всех \(i (>|<) j\)
Ленточные и разреженные матрицы
Это матрицы с большим количеством нулевых элементов. Ленточные матрицы имеют ненулевые «полосы», и эту структуру можно использовать для упрощения вычисления. Разреженные матрицы — это матрицы, в которых «мало» ненулевые записи, но нет шаблона, где ненулевые записи найденный.
Ортогональные и ортонормированные 9T\]
ВАЖНО:
- Симметричные положительно определенные матрицы имеют «квадратный корень» (в смысл)
- Любая симметричная положительно определенная матрица диагонизируема !!!
- Ковариационные матрицы симметричны и положительно определены
Теперь, когда мы знаем основы, мы можем перейти к численным методам. для решения систем — матричных разложений.
Упражнения
1 . Определите, не имеет ли следующая система уравнений решение, бесконечные решения или единственное решение без решения система
\begin{eqnarray*} х+2у-г+ш &=& 2\\ 3x-4y+2 w &=& 3\\ 2у+г &=& 4\\ 2x+2y-3z+2w&=&0\\ -2x+6y-z-w&=&-1 \end{эквнаррай*}
В [14]:
A = np.
3\) такой, что \begin{выравнивание*} f(e_1) &=& (1,1,3)\\ f(e_2) &=& (1,0,4)\\ f(e_3) &=& (0,2,1) \end{eqnarray*}
-
Найдите матричное представление для \(f\).
-
Вычислить матричное представление для \(f\) в базисе
\begin{эквнаррай*} v_1 &=& (2,3,3)\\ v_2 &=& (8,5,2)\\ v_3 &=& (1,0,5) \end{эквнаррай*}
В [ ]:
Основы линейной алгебры
Основы линейной алгебрыКраткий обзор линейной алгебры
Джон МитчеллЭтот документ представляет собой список некоторых материалов по линейной алгебре. с которыми вы должны быть знакомы. В дальнейшем мы будем считать A матрицей 3 x 4.
Я предполагаю, что вы знакомы с матричным и векторным сложением и умножением.- Все векторы будут столбцов векторов.
- Дан вектор v ,
если мы так скажем,
мы имеем в виду, что v имеет по крайней мере один ненулевой
составная часть.
- Транспонирование вектора или матрицы обозначается верхним индексом T .
Например,
- Внутреннее произведение или скалярное произведение двух векторов u и v в можно записать u T v ; это означает . Если u T v =0, то u и v являются ортогональными .
- Пустое пространство из — это множество всех решений x для матрично-векторное уравнение Ax =0.
- Чтобы решить систему уравнений Ax = b , используйте метод исключения Гаусса.
Например, если
,
то решаем х = b следующим образом:
(Мы настраиваем расширенную матрицу и уменьшаем (или поворачиваем) строку до верхней.
треугольной формы.)
Таким образом, решениями являются все векторы x формы
для любых чисел s и t . - диапазон набора векторов представляет собой набор всех линейных комбинаций векторов. Например, если а также тогда диапазон v 1 и v 2 является набором все векторы вида sv 1 + tv 2 для некоторых скаляров s и t .
- Промежуток набора векторов в дает подпространство . Любое нетривиальное подпространство можно записать как оболочку любого из несчетное множество наборов векторов.
- Набор векторов является линейно независимым если единственное решение векторного уравнения является
для всех и .
Если набор векторов не является линейно независимым,
тогда линейно зависимы от .
Например, строки A являются , а не линейно независимыми,
поскольку
Чтобы определить, является ли набор векторов линейно независимым, запишите векторы как столбцы матрицы C , скажем, и решить Cx =0. Если есть какие-то нетривиальные решения, то векторы линейно
зависимый; в противном случае они линейно независимы. - Если линейно независимый набор векторов охватывает подпространство тогда векторы образуют базис для этого подпространства. Например, v 1 и v 2 образуют основу для размаха строк A . Учитывая подпространство S , каждый базис S содержит такое же количество векторы; это число является измерением подпространства. Чтобы найти основу для промежутка набора векторов, запишите векторы в виде строк матрицы, а затем уменьшите строку матрицы.
- Промежуток строк матрицы называется пространством строк матрицы. матрица. Размерность пространства строк равна рангу матрицы.
- Диапазон столбцов матрицы называется диапазоном или место в столбце матрицы. Пространство строки и пространство столбца всегда имеют одинаковую размерность.
- Если M является матрицей m x n , то нулевое пространство и пространство строк M
являются подпространствами
и диапазон M является подпространством .
- Если u находится в пространстве строк матрицы M и v находится в пустом пространстве M , то векторы ортогональны. Размерность нулевого пространства матрицы равна недействительности матрицы. Если M имеет n столбцов, то rank( M )+nullity( M )= n . Любая основа для пространства строк вместе с любой основой для нулевого пространства дает основание для .
- Если M — квадратная матрица,
— скаляр, а x — вектор
удовлетворяющий
тогда x является собственным вектором M с соответствующим собственным значением .
Например, вектор
является собственным вектором матрицы
с собственным значением . - Собственные значения симметричной матрицы всегда действительны. Несимметричная матрица может иметь комплексные собственные значения.
- Дана симметричная матрица M ,
следующие эквивалентны:
- 1.
- 1.
 Мы можем избавиться от
некоторые уравнения. Другими словами, в системе есть уравнения
которые не дают нам никакой новой информации.
Мы можем избавиться от
некоторые уравнения. Другими словами, в системе есть уравнения
которые не дают нам никакой новой информации.

 mean(1)[:, np.newaxis]
w.dot(w.T)/(n - 1)
mean(1)[:, np.newaxis]
w.dot(w.T)/(n - 1)
 random.randint (100, размер = (n, n))
печать(М)
np.linalg.det(M)
random.randint (100, размер = (n, n))
печать(М)
np.linalg.det(M)
 Они равны для любой матрицы. Ранг может
можно рассматривать как меру невырожденности системы линейных
уравнения, в том, что это размер изображения линейного
преобразование , определяемое \(A\).
Они равны для любой матрицы. Ранг может
можно рассматривать как меру невырожденности системы линейных
уравнения, в том, что это размер изображения линейного
преобразование , определяемое \(A\). T\]
T\] 3\) такой, что
3\) такой, что 

 Если есть какие-то нетривиальные решения, то векторы линейно
зависимый; в противном случае они линейно независимы.
Если есть какие-то нетривиальные решения, то векторы линейно
зависимый; в противном случае они линейно независимы.
