
Т — критерий Вилкоксона | univer-nn.ru
Этот критерий также используется для связанных (зависимых) выборок, но он может применяться только для изучения количественного признака, так как учитывает не только направление сдвига, но и его выраженность. Критерий Вилкоксона является более мощным, чем критерий знаков.
Критерий Вилкоксона основан на ранжировании абсолютных значений сдвига (то есть, значений сдвига, взятых по модулю). Поэтому сдвиги должны варьироваться в достаточно широком диапазоне, иначе Т – критерий не будет отличаться от критерия знаков.
Суть метода:
- Сопоставляется выраженность по абсолютной величине сдвигов в том или ином направлении. Для этого ранжируются абсолютные величины сдвигов и суммируются полученные ранги.
- Если сдвиги в какую-либо сторону происходят случайно, то суммы рангов будут примерно равны.
- Если интенсивность сдвигов в одном направлении перевешивает, то сумма рангов противоположных по направлению сдвигов будет значительно меньше, чем это могло бы быть при случайном изменении.

Для обработки экспериментальных данных с помощью данного критерия, выполняют следующие действия:
1) записывают экспериментальные данные в таблицу (как в критерии знаков): в первый столбец – номер измерения, во второй – значения признака до воздействия фактора, в третий – после воздействия фактора;
2) в четвертый столбец таблицы записывают сдвиги (разности между значениями третьего и второго столбца), определяют типичный и нетипичный сдвиг;
3) в пятый столбец записывают модули сдвигов;
4) ранжируют модули сдвигов по возрастанию значений и записывают ранги в шестой столбец. Ранжирование – это присвоение порядковых номеров. Если в ряду значений имеются одинаковые, то каждому из них присваивается среднее арифметическое их порядковых номеров.
Пример ранжирования:
Нужно присвоить ранги следующим значениям: 5, 7, 11, 11, 12, 14, 14, 14. Пронумеруем их:
Среди значений есть одинаковые. Это число 11 (номера 3 и 4) и число 14 (номера 6, 7 и 8). Следовательно, им присваиваются ранги 3,5 и 7 (средние арифметические их порядковых номеров). Таким образом, ранги рассмотренных значений будут иметь вид:
Это число 11 (номера 3 и 4) и число 14 (номера 6, 7 и 8). Следовательно, им присваиваются ранги 3,5 и 7 (средние арифметические их порядковых номеров). Таким образом, ранги рассмотренных значений будут иметь вид:
5) суммируют ранги, соответствующие сдвигам в нетипичном направлении. Эта сумма и будет являться наблюдаемым значением критерия Тн.
6) По таблице критических точек находят значение Ткр(α;n’), где n’ — объем выборки за вычетом нулевых сдвигов.
7) осуществляют выбор одной из гипотез, учитывая, что критерий знаков является левосторонним.
Если Тн < Ткр , то гипотеза Н0 отвергается, принимается гипотеза Н1; нетипичных сдвигов немного и они невелики по абсолютному значению, преобладание типичного сдвига является неслучайным, оно обусловлено влиянием фактора.
Если Тн > Ткр, то нет оснований отвергать гипотезу Н0; нетипичных сдвигов много и они не малы по значению, преобладание типичного сдвига является случайным.
Ограничения критерия:
- выборки должны быть зависимыми и иметь одинаковый объем;
- объем выборки должен быть не менее 5 и не более 50 (при большом количестве значений затрудняется процедура ранжирования).
- Сдвиги должны варьировать в широком диапазоне
Классические методы статистики: критерий Уилкоксона
В одном из предыдущих сообщений я описал расчет критерия Стьюдента при помощи соответствующей функции, входящей в базовую комплектацию R — t.test(). Одно из важных условий корректного применения критерия Стьюдента состоит в том, что анализируемые выборки должны происходить из нормально распределенных генеральных совокупностей. В случаях, когда это условие не выполняется, вместо критерия Стьюдента следует использовать его непараметрический аналог — критерий Уилкоксона (Wilcoxon rank test). Здесь следует сразу пояснить, что создатели системы R под названием «критерий Уилкоксона» (или «тест Уилкоксона») объединяют как собственно метод, предложенный Фрэнком Уилкоксоном (Frank Wilcoxon) в 1945 г. , так и опубликованный несколько позднее (1947 г.) метод Манна-Уитни. Первый из этих методов обычно используется для сравнения двух связных выборок, тогда как второй предназначен для сравнения двух независимых выборок. Ниже я не буду разграничивать эти методы, придерживаясь подхода, принятого в системе R.
, так и опубликованный несколько позднее (1947 г.) метод Манна-Уитни. Первый из этих методов обычно используется для сравнения двух связных выборок, тогда как второй предназначен для сравнения двух независимых выборок. Ниже я не буду разграничивать эти методы, придерживаясь подхода, принятого в системе R.
Одновыборочный критерий Уилкоксона
Этот вариант критерия (Wilcoxon signed rank test) служит для проверки нулевой гипотезы о том, что анализируемая выборка происходит из симметрично распределенной генеральной совокупности с центром в точке µ
- µ0 отнимают от каждого выборочного значения;
- получившиеся величины ранжируют по возрастанию, игнорируя знак;
- ранговые номера со знаком + суммируют, получая величину V;
- критерий V сравнивают с критическим значением для заданного уровня значимости и числа степеней свободы; альтернативный подход на этом шаге заключается в нахождении вероятности случайным образом получить значение V, равное или превышающее наблюдаемое значение, при условии истинности нулевой гипотезы.

Ниже при описании теста Уилкоксона я буду использовать примеры, рассмотреные ранее для иллюстрации t-теста Стьюдента. Это позволит нам сравнить результаты, получаемые при помощи обоих методов. В частности, обратимся к данным о суточном потреблении энергии (кДж/сутки) у 11 женщин (пример заимствован из книги Altman D. G. (1981) Practical Statistics for Medical Research, Chapman & Hall, London):
d.intake <- c(5260, 5470, 5640, 6180, 6390, 6515, 6805, 7515, 7515, 8230, 8770)
Необходимо выяснить, отличается ли потребление энергии в группе обследованных женщин от рекомендованного значения 7725 кДж/сутки. Для выполнения теста Уилкоксона в системе R используется функция wilcox.test():
wilcox.test(d.intake, mu = 7725)
Wilcoxon signed rank test with continuity correction
data: d.intake
V = 8, p-value = 0.0293
alternative hypothesis: true location is not equal to 7725
Warning message:
In wilcox. test.default(d.intake, mu = 7725) :
cannot compute exact p-value with ties test.default(d.intake, mu = 7725) :
cannot compute exact p-value with ties
test.default(d.intake, mu = 7725) :
cannot compute exact p-value with ties Видим, что рассчитанное значение критерия V = 8. Вероятность получить такое (или превышающее его) значение при условии, что нулевая гипотеза верна, не превышает 0.05 (p-value = 0.0293). Это позволяет нам отклонить нулевую гипотезу о том, что суточное потребление энергии у обследованных 11 женщин не отличается от принятой нормы. Обратите внимание на выданное программой предупреждение о том, что полученное значени вероятности Р не является точным из-за наличия в данных повторяющихся значений (Warning message… cannot compute exact p-value with ties). Проблема рассчета точных Р-значений при наличии повторяющихся наблюдений в данных характерна для статистических методов, основанных на рангах, и критерий Уилкоксона здесь, увы, не исключение (но см. функцию wilcox_test() из пакета coin). При наличии повторяющихся наблюдений Р-значение рассчитывается путем аппроксимации распредения критерия Уилкоксона нормальным распределением (см.
Сравнение двух зависимых выборок
Понятие «зависимые», или «связные выборки» обсуждалось ранее в сообщении, посвященном критерию Стьюдента. Сейчас для нас более важен тот факт, что сравниваемые выборки происходят из ненормально распределенных генеральных совокупностей. Тем не менее, сравнение таких выборок при помощи критерия Уилкоксона происходит сходно с тем, как это делается при помощи парного критерия Стьюдента. В частности, находят разницу между всеми имеющимися парными выборочными наблюдениями с целью проверить нулевую гипотезу о том, что медиана полученных разностей равна нулю (либо какому-либо другому, отличному от нуля значению). (Важно упомянуть широко распространенное ошибочное представление о том, что критерий Уилкоксона применяется для сравнения выборочных медиан).
Используем рассмотренный ранее пример о суточном потреблении энергии, измеренном у одних и тех же 11 женщин до и после периода менструаций:
data(intake) # из пакета ISwR
attach(intake)
intake
pre post
1 5260 3910
2 5470 4220
3 5640 3885
4 6180 5160
5 6390 5645
6 6515 4680
7 6805 5265
8 7515 5975
9 7515 6790
10 8230 6900
11 8770 7335Сравнить два периода по потреблению энергии при помощи критерия Уилкоксона можно следующим образом (обратите внимание на использование аргумента paired = TRUE):
wilcox.
 test(pre, post, paired = TRUE)
Wilcoxon signed rank test with continuity correction
data: pre and post
V = 66, p-value = 0.00384
alternative hypothesis: true location shift is not equal to 0
Warning message:
In wilcox.test.default(pre, post, paired = T) :
cannot compute exact p-value with ties
test(pre, post, paired = TRUE)
Wilcoxon signed rank test with continuity correction
data: pre and post
V = 66, p-value = 0.00384
alternative hypothesis: true location shift is not equal to 0
Warning message:
In wilcox.test.default(pre, post, paired = T) :
cannot compute exact p-value with tiesКак видим, рассчитанное программой P-значение оказалось меньше 0.05, что позволяет нам сделать заключение о наличии статистически значимой разницы в потреблении энергии у исследованных женщин до и после менструации. (Для сравнения: Р-значение, полученное при помощи критерия Стьюдента было << 0.001). Мы можем оценить доверительный интервал, в котором с определенной вероятностью находится истинная величина эффекта, воспользовавшись аргументом conf.int (вероятность задается при помощи аргумента conf.level; по умолчанию рассчитывается 95%-ный доверительный интервал):
wilcox.test(pre, post, paired = TRUE, conf.int = TRUE) Wilcoxon signed rank test with continuity correction data: pre and post V = 66, p-value = 0.
 00384
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
1037.5 1582.5
sample estimates:
(pseudo)median
1341.332
Warning messages:
1: In wilcox.test.default(pre, post, paired = TRUE, conf.int = TRUE) :
cannot compute exact p-value with ties
2: In wilcox.test.default(pre, post, paired = TRUE, conf.int = TRUE) :
cannot compute exact confidence interval with ties
00384
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
1037.5 1582.5
sample estimates:
(pseudo)median
1341.332
Warning messages:
1: In wilcox.test.default(pre, post, paired = TRUE, conf.int = TRUE) :
cannot compute exact p-value with ties
2: In wilcox.test.default(pre, post, paired = TRUE, conf.int = TRUE) :
cannot compute exact confidence interval with ties Видим, что истинная разница уровней потребленной энергии с вероятностью 95% находится в интервале от 1037.5 до 1581.5 кДж/сутки (для сравнения: при использовании критерия Стьюдента этот интервал составил 1074.1 — 1566.8 кДж/сутки). Опять-таки, из-за наличия повторяющихся наблюдений, рассчет точных доверительных пределов оказался невозможным (см. пункт 2 в списке предупреждений Warning messages). Псевдомедиана ((pseudo)median) индивидуальных разниц между парными значениями потребления энергии была оценена в 1341.3 кДж/сутки. (Псевдомедианой распределения F называют медиану распределения (u + v) / 2, где u и v являются независимыми переменными, каждая из которых имеет распределение F. Если распределение F симметрично, псевдомедиана и медиана совпадают. Подробнее см. ?wilcox.test).
Если распределение F симметрично, псевдомедиана и медиана совпадают. Подробнее см. ?wilcox.test).
Сравнение двух независимых выборок
Если сравниваемые выборки являются независимыми (paired = FALSE), то мы имеем дело с критерием Уилкоксона, который в англоязычной литературе называют Wilcoxon rank sum test (как было отмечено выше, этот
метод называют также методом Манна-Уитни). Проверяемая с его помощью нулевая гипотеза состоит в том, что центры распределений, из которых происходят сравниваемые выборки, смещены относительно друг друга на величину µ (например, µ = 0). Алгоритм метода состоит в следующем:
- Все имеющиеся значения ранжируют, игнорируя их знак;
- Ранги значений, принадлежащих к первой группе, суммируют, получая величину W;
- Полученное W сравнивают со значением, которое можно было бы ожидать при верной нулевой гипотезе и имеющемся числе степеней свободы; альтернативный подход — находят вероятность
случайным образом получить значение W, равное или превышающее
наблюдаемое значение (при условии истинности нулевой гипотезы).

Используем рассмотренный раннее пример о суточном расходе энергии (expend) у худощавых женщин (lean) и женщих с избыточным весом (obese):
data(energy) # из пакета ISwR attach(energy) str(energy) 'data.frame': 22 obs. of 2 variables: $ expend : num 9.21 7.53 7.48 8.08 8.09 ... $ stature: Factor w/ 2 levels "lean","obese": 2 1 1 1 1 1 1 1 1 1 ...
Проверим гипотезу об отсутствии разницы в потреблении энергии у женщих из этих двух групп при помощи критерия Уилкоксона для независимых выборок:
wilcox.test(expend ~ stature, paired = FALSE) Wilcoxon rank sum test with continuity correction data: expend by stature W = 12, p-value = 0.002122 alternative hypothesis: true location shift is not equal to 0 Warning message: In wilcox.test.default(x = c(7.53, 7.48, 8.08, 8.09, 10.15, 8.4, : cannot compute exact p-value with ties
Согласно полученному Р-значению (p-value = 0. 002122),
потребление энергии у женщин из рассамтриваемых
весовых групп статистически значимо различается. Отвергая нулевую
гипотезу о равенстве потребляемой энергии, мы рискуем ошибиться с
вероятностью лишь около 0.2%.
002122),
потребление энергии у женщин из рассамтриваемых
весовых групп статистически значимо различается. Отвергая нулевую
гипотезу о равенстве потребляемой энергии, мы рискуем ошибиться с
вероятностью лишь около 0.2%.
Важно отметить одно из ограничений критерия Уилкоксона для двух выборок (зависимых или независимых): если общее количество наблюдений не превышает 6, то обнаружить разницу между выборками с уровнем ошибки в 5% просто невозможно (Dalgaard 2008).
Новые Старые
Знаковый ранговый критерий Уилкоксона
Другой популярный непараметрический критерий сопоставленных или парных данных называется знаковым ранговым критерием Уилкоксона. Как и знаковый тест, он основан на оценках различий, но в дополнение к анализу знаков различий он также принимает во внимание величину наблюдаемых различий.
Давайте воспользуемся критерием знакового ранга Уилкоксона для повторного анализа данных в примере 4 на странице 5 этого модуля. Напомним, что в этом исследовании оценивалась эффективность нового препарата, предназначенного для уменьшения повторяющегося поведения у детей, страдающих аутизмом. Всего в исследовании принимают участие 8 детей с аутизмом, и количество времени, в течение которого каждый ребенок занимается повторяющимся поведением в течение трехчасового периода наблюдения, измеряется как до лечения, так и после приема нового лекарства в течение 1 недели. Данные показаны ниже.
Всего в исследовании принимают участие 8 детей с аутизмом, и количество времени, в течение которого каждый ребенок занимается повторяющимся поведением в течение трехчасового периода наблюдения, измеряется как до лечения, так и после приема нового лекарства в течение 1 недели. Данные показаны ниже.
Ребенок | До лечения | Через 1 неделю лечения |
|---|---|---|
1 | 85 | 75 |
2 | 70 | 50 |
3 | 40 | 50 |
4 | 65 | 40 |
5 | 80 | 20 |
6 | 75 | 65 |
7 | 55 | 40 |
8 | 20 | 25 |
Сначала мы вычисляем баллы различий для каждого ребенка.
Ребенок | До лечения | Через 1 неделю лечения | Разница (до и после) |
|---|---|---|---|
1 | 85 | 75 | 10 |
2 | 70 | 50 | 20 |
3 | 40 | 50 | -10 |
4 | 65 | 40 | 25 |
5 | 80 | 20 | 60 |
6 | 75 | 65 | 10 |
7 | 55 | 40 | 15 |
8 | 20 | 25 | -5 |
Следующим шагом является ранжирование оценок разницы. Сначала мы заказываем абсолютные значения оценок различий и присваивают ранги от 1 до n до наименьшего через наибольшее абсолютные значения оценок различий, и присваивают средний ранг, когда есть связи в абсолютных значениях оценок различий.
Сначала мы заказываем абсолютные значения оценок различий и присваивают ранги от 1 до n до наименьшего через наибольшее абсолютные значения оценок различий, и присваивают средний ранг, когда есть связи в абсолютных значениях оценок различий.
Наблюдаемые различия |
| Упорядоченные абсолютные значения разностей | Ранг |
|---|---|---|---|
10 |
| -5 | 1 |
20 |
| 10 | 3 |
-10 |
| -10 | 3 |
25 |
| 10 | 3 |
60 |
| 15 | 5 |
10 |
| 20 | 6 |
15 |
| 25 | 7 |
-5 |
| 60 | 8 |
Последним шагом является добавление знаков («+» или «-») наблюдаемых различий к каждому рангу, как показано ниже.
Наблюдаемые различия |
| Упорядоченные абсолютные значения показателей разницы | Очки | Подписанные ранги |
|---|---|---|---|---|
10 |
| -5 | 1 | -1 |
20 |
| 10 | 3 | 3 |
-10 |
| -10 | 3 | -3 |
25 |
| 10 | 3 | 3 |
60 |
| 15 | 5 | 5 |
10 |
| 20 | 6 | 6 |
15 |
| 25 | 7 | 7 |
-5 |
| 60 | 8 | 8 |
Подобно критерию знаков, гипотезы для критерия знакового ранга Уилкоксона касаются медианной генеральной совокупности разностных оценок. Гипотеза исследования может быть односторонней или двусторонней. Здесь мы рассматриваем односторонний тест.
Гипотеза исследования может быть односторонней или двусторонней. Здесь мы рассматриваем односторонний тест.
H 0 : Медианная разница равна нулю по сравнению с
H 1 : Медианная разница положительна α=0,050688
Статистический показатель для знакового рангового теста Уилкоксона равен W, определяемому как меньшее из W+ (сумма положительных рангов) и W- (сумма отрицательных рангов). Если нулевая гипотеза верна, мы ожидаем увидеть одинаковые числа более низких и более высоких рангов, которые являются как положительными, так и отрицательными (т. е. W+ и W- будут одинаковыми). Если исследовательская гипотеза верна, мы ожидаем увидеть более высокие и положительные ранги (в этом примере больше детей со значительным улучшением повторяющегося поведения после лечения по сравнению с до, т. е. W+ намного больше, чем W-).
В этом примере W+ = 32 и W- = 4. Напомним, что сумма рангов (без учета знаков) всегда будет равна n(n+1)/2. В качестве проверки нашего присвоения рангов имеем n(n+1)/2 = 8(9)/2 = 36, что равно 32+4. Тестовая статистика W = 4.
В качестве проверки нашего присвоения рангов имеем n(n+1)/2 = 8(9)/2 = 36, что равно 32+4. Тестовая статистика W = 4.
Далее мы должны определить, поддерживает ли наблюдаемая тестовая статистика W нулевую или исследовательскую гипотезу. Это делается в соответствии с тем же подходом, который используется в параметрическом тестировании. В частности, мы определяем критическое значение W таким образом, что если наблюдаемое значение W меньше или равно критическому значению, мы отвергаем H 0 в пользу H 1 , а если наблюдаемое значение W превышает критическое значение, то H 0 не отвергаем.
Таблица критических значений W
Критическое значение W можно найти в таблице ниже:
Чтобы определить подходящее одностороннее критическое значение, нам нужен размер выборки (n=8) и наш односторонний уровень значимости (α=0,05). Для этого примера критическое значение W равно 6, и правилом принятия решения является отклонение H 0 , если W < 6.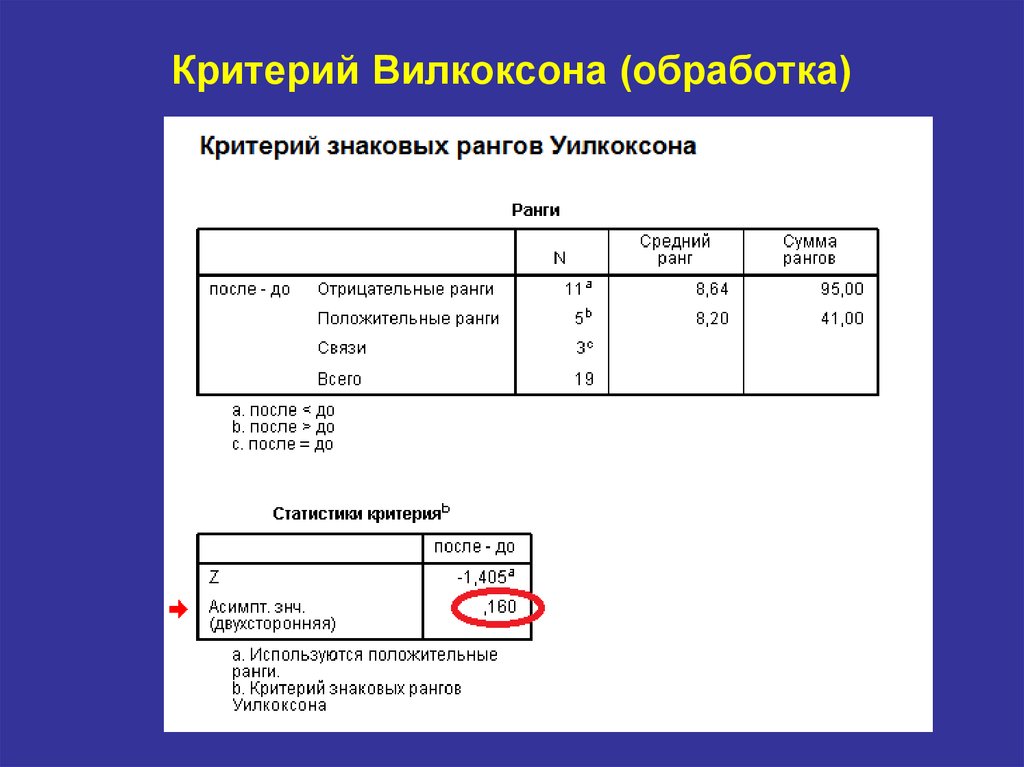 Таким образом, мы отклоняем H 0 , потому что 4 < 6. У нас есть статистически значимые доказательства при α = 0,05, показывающие, что медианная разница положительна (т. е. что повторяющееся поведение улучшается.)
Таким образом, мы отклоняем H 0 , потому что 4 < 6. У нас есть статистически значимые доказательства при α = 0,05, показывающие, что медианная разница положительна (т. е. что повторяющееся поведение улучшается.)
Обратите внимание, что когда мы анализировали данные ранее с помощью Знакового теста, нам не удалось найти статистическую значимость. Однако, когда мы используем знаковый ранговый критерий Уилкоксона, мы заключаем, что лечение приводит к статистически значимому улучшению при α = 0,05. Несоответствие результатов связано с тем, что Sign Test использует очень мало информации в данных и является менее мощным тестом.
Пример:
Исследование проводится для оценки эффективности программы упражнений для снижения систолического артериального давления у пациентов с предгипертензией (определяемой как систолическое артериальное давление в пределах 120–139 мм рт. ст. или диастолическое артериальное давление в пределах 80–89 мм рт. мм рт.ст.). Всего в исследовании принимают участие 15 пациентов с предгипертензией, и у них измеряют систолическое артериальное давление. Затем каждый пациент участвует в программе тренировок, где они изучают правильную технику и выполнение ряда упражнений. Пациентам рекомендуется выполнять программу упражнений 3 раза в неделю в течение 6 недель. Через 6 недель снова измеряют систолическое артериальное давление. Данные показаны ниже.
Затем каждый пациент участвует в программе тренировок, где они изучают правильную технику и выполнение ряда упражнений. Пациентам рекомендуется выполнять программу упражнений 3 раза в неделю в течение 6 недель. Через 6 недель снова измеряют систолическое артериальное давление. Данные показаны ниже.
Пациент | Систолическое кровяное давление Перед программой упражнений | Систолическое кровяное давление Программа после тренировки |
|---|---|---|
1 | 125 | 118 |
2 | 132 | 134 |
3 | 138 | 130 |
4 | 120 | 124 |
5 | 125 | 105 |
6 | 127 | 130 |
7 | 136 | 130 |
8 | 139 | 132 |
9 | 131 | 123 |
10 | 132 | 128 |
11 | 135 | 126 |
12 | 136 | 140 |
13 | 128 | 135 |
14 | 127 | 126 |
15 | 130 | 132 |
Есть ли разница в систолическом артериальном давлении после участия в программе упражнений по сравнению с тем, что было до?
- Шаг 1. Сформулируйте гипотезы и определите уровень значимости.
 Сформулируйте гипотезы и определите уровень значимости.
Сформулируйте гипотезы и определите уровень значимости.H 0 : Медианная разница равна нулю по сравнению с
H 1 : Медианная разница не равна нулю α=0,05
- Шаг 2. Выберите соответствующую статистику теста.
Статистический показатель для знакового рангового теста Уилкоксона равен W, определяемому как меньшее из значений W+ и W-, которые представляют собой суммы положительных и отрицательных рангов соответственно.
- Шаг 3. Установите правило принятия решения.
Критическое значение W можно найти в таблице критических значений. Чтобы определить соответствующее критическое значение из таблицы 7, нам нужен размер выборки (n = 15) и наш двусторонний уровень значимости (α = 0,05). Критическое значение для этого двустороннего теста с n = 15 и α = 0,05 равно 25, а правило принятия решений следующее: Отклонить H 0 , если W < 25.
- Шаг 4. Вычислить статистику теста.
Поскольку измерения систолического артериального давления до и после являются парными, мы рассчитываем баллы различий для каждого пациента.
Пациент | Систолическое кровяное давление Перед программой упражнений | Систолическое кровяное давление Программа после тренировки | Разница (до и после) |
|---|---|---|---|
1 | 125 | 118 | 7 |
2 | 132 | 134 | -2 |
3 | 138 | 130 | 8 |
4 | 120 | 124 | -4 |
5 | 125 | 105 | 20 |
6 | 127 | 130 | -3 |
7 | 136 | 130 | 6 |
8 | 139 | 132 | 7 |
9 | 131 | 123 | 8 |
10 | 132 | 128 | 4 |
11 | 135 | 126 | 9 |
12 | 136 | 140 | -4 |
13 | 128 | 135 | -7 |
14 | 127 | 126 | 1 |
15 | 130 | 132 | -2 |
Следующим шагом является ранжирование упорядоченных абсолютных значений оценок различий с использованием подхода, описанного в разделе 10. 1. В частности, мы присваиваем ранги от 1 до n от наименьшего до наибольшего абсолютного значения оценок различий, соответственно, и присваиваем средний ранг, когда есть связи в абсолютных значениях оценок различий.
1. В частности, мы присваиваем ранги от 1 до n от наименьшего до наибольшего абсолютного значения оценок различий, соответственно, и присваиваем средний ранг, когда есть связи в абсолютных значениях оценок различий.
Наблюдаемые различия |
| Заказанный Абсолют Значения различий | Очки |
|---|---|---|---|
7 |
| 1 | 1 |
-2 |
| -2 | 2,5 |
8 |
| -2 | 2,5 |
-4 |
| -3 | 4 |
20 |
| -4 | 6 |
-3 |
| -4 | 6 |
6 |
| 4 | 6 |
7 |
| 6 | 8 |
8 |
| -7 | 10 |
4 |
| 7 | 10 |
9 |
| 7 | 10 |
-4 |
| 8 | 12,5 |
-7 |
| 8 | 12,5 |
1 |
| 9 | 14 |
-2 |
| 20 | 15 |
Последним шагом является добавление знаков («+» или «-») наблюдаемых различий к каждому рангу, как показано ниже.
Наблюдаемые различия |
| Упорядоченные абсолютные значения разностей | Очки | Подпись Очки |
|---|---|---|---|---|
7 |
| 1 | 1 | 1 |
-2 |
| -2 | 2,5 | -2,5 |
8 |
| -2 | 2,5 | -2,5 |
-4 |
| -3 | 4 | -4 |
20 |
| -4 | 6 | -6 |
-3 |
| -4 | 6 | -6 |
6 |
| 4 | 6 | 6 |
7 |
| 6 | 8 | 8 |
8 |
| -7 | 10 | -10 |
4 |
| 7 | 10 | 10 |
В этом примере W+ = 89 и W- = 31. Напомним, что сумма рангов (без учета знаков) всегда будет равна n(n+1)/2. В качестве проверки нашего присвоения рангов имеем n(n+1)/2 = 15(16)/2 = 120, что равно 89.+ 31. Тестовая статистика W = 31.
- Шаг 5. Заключение.
Мы не отклоняем H 0 , потому что 31 > 25. Следовательно, у нас нет статистически значимых доказательств при α = 0,05, чтобы показать, что медианная разница систолического артериального давления не равна нулю (т. разница систолического артериального давления после программы упражнений по сравнению с тем, что было до нее).
вернуться наверх | предыдущая страница | следующая страница
Знаковый ранговый тест Уилкоксона: определение, как выполнять, SPSS
Содержание:
- Что такое знаковый ранговый тест Уилкоксона?
- Как выполнить ранговый тест Уилкоксона в SPSS
- Excel, R
- Как запустить тест вручную
Знаковый ранговый критерий Уилкоксона (также называемый критерием суммы знаковых рангов Уилкоксона) является непараметрическим критерием для сравнения данных. Когда в статистике используется слово «непараметрический», это вовсе не означает, что вы ничего не знаете о населении. Обычно это означает, что вы знаете, что данные о населении не имеют нормального распределения. Критерий знакового ранга Уилкоксона следует использовать, если различия между парами данных не имеют нормального распределения.
Посмотрите видео с обзором и тем, как выполнить тест подписанного ранга Уилкоксона вручную:
Знаковый ранговый тест Уилкоксона
Посмотрите это видео на YouTube.
Видео не видно? Кликните сюда.
Существуют две слегка различающиеся версии теста:
- Знаковый ранговый тест Уилкоксона сравнивает медиану вашей выборки с гипотетической медианой.
- Знаковый ранговый критерий Уилкоксона для совпадающих пар вычисляет разницу между каждым набором совпадающих пар, а затем выполняет ту же процедуру, что и знаковый ранговый критерий, для сравнения выборки с некоторой медианой.
Термин «Wilcoxon» часто используется для обоих тестов. Обычно это не сбивает с толку, так как должно быть очевидно, совпадают данные или нет.
Нулевая гипотеза для этого теста состоит в том, что медианы двух выборок равны. Обычно используется:
- В качестве непараметрической альтернативы одновыборочному t-тесту или парному t-тесту.
- Для упорядоченных (ранжированных) категориальных переменных без числовой шкалы.
Посмотрите видео, чтобы узнать, как выполнить тест Уилкоксона в SPSS:
Как выполнить ранговый тест Уилкоксона в SPSS
Посмотрите это видео на YouTube.
Видео не видно? Кликните сюда.
Excel/Open Office: Загрузите эту электронную таблицу (любезно предоставлено BioStatHandbook).
R : Вы можете найти пример кода здесь, на RCompanion.org.
Нужна помощь с формулами? Посетите нашу обучающую страницу!
Требования для проведения теста на соответствие пар:
- Данные должны совпадать.
- Зависимая переменная должна быть непрерывной (т. е. вы должны уметь различать значения в n-м десятичном разряде).
- Для максимальной точности у вас не должно быть равных рангов. Если ранги равны, есть обходной путь (см. ниже, после шага 5).
Пример вопроса: Есть ли разница между средними значениями для следующих наборов данных лечения для двенадцати групп?
Шаг 1: Вычтите лечение 2 из лечения 1, чтобы получить разницу:
Примечание : Если у вас есть только одна выборка, рассчитайте разницу между каждой переменной и нулем (гипотетическая медиана) вместо разницы между парами.
Шаг 2: Расположите различия по порядку (столбец 2 на рисунке ниже), а затем ранжируйте их. Не обращайте внимания на знак при размещении в порядке ранжирования.
Шаг 3: Создайте третий столбец и обратите внимание на знак разницы (тот, который вы проигнорировали на шаге 2!).
Следующие два шага вычисляют знаковые ранговые суммы Уилкоксона:
Шаг 4: Рассчитайте сумму рангов отрицательных разностей (со знаком минус в таблице Шага 3). Здесь вы суммируете ранги, а не фактические различия:
W — = 1 + 2 + 4 = 7
Шаг 5: Вычислите сумму рангов положительных разностей (те, которые имеют положительный знак на схеме Шаг 3).
W + = 3 + 5,5 + 5,5 + 7 + 8 + 9 + 10 + 11 + 12 = 710688
- Используйте меньшее из W + или W — для тестовой статистики. Для этого примера W stat = 7.
- Сравните статистику теста с критическим значением (см. таблицу ниже). Для этого примера наше критическое значение для N = 12 и двустороннего теста (поскольку направление не указано) составляет 13 (при уровне альфа 5%).
Наша тестовая статистика (7) меньше критического значения (13), поэтому медианы существенно различаются. Мы можем отвергнуть нулевую гипотезу.
Ссылки
Таблица: http://users.stat.ufl.edu/~winner/tables/wilcox_signrank.pdf
Breslow, N. (1970) Обобщенный критерий Крускала-Уоллиса для сравнения K выборок, подверженных неравным модели цензуры, Биометрика, 57 (3), 579–594.