
2.2.2 Квадратичная регрессия
Разумеется, нередко встречаются ситуации, несводимые к уравнению линейной регрессии, пожалуй, самым распространенным таким случаем является ситуация, когда между объясняемой и объясняющей переменной наблюдается квадратичная зависимость. Рассмотрим этот вариант.
Вполне аналогично случаю линейной зависимости, мы располагаем на старте некоторыми наборами значений {xi,yi} (или геометрически – набором точек {Pi}). При этом как минимум одна переменная yi содержит случайную составляющую ui. Поэтому точная запись нашего соотношения будет иметь вид:
yi = 1 + 2 xi + 3 xi2 + ui (2.12)
Вполне аналогично линейной ситуации, наша цель провести на плоскости (X,Y) параболу таким образом, чтобы она была максимально близка к нашему набору точек.
Пусть уравнение такой параболы
имеет вид:
– здесь мы через
обозначили значения на модельной
параболе.
Как только мы проведем любую параболу, у нас в каждой точке появятся отклонения εi = yi – , наша задача состоит теперь в том, чтобы так подобрать коэффициенты модели b1 , b2 и b3, чтобы минимизировать отклонения в совокупности; используя МНК мы будем стремиться минимизировать сумму квадратов отклонений εi.
Соответственно получим задачу:
(2.13)
Чтобы найти оптимальные значения искомых параметров регрессии следует продифференцировать функцию по этим трем переменным и каждую из производных приравнять нулю – получим следующую систему трех уравнений с тремя неизвестными:
(2.14 а)
(2.14 б)
(2.14 в)
Нетрудно обнаружить, что,
несмотря на видимую сложность, система
организована очень закономерно. Степень
иксов, которые суммируются для вычисления
коэффициентов системы вырастает на
единицу при смещении на единицу сверху
вниз (в первом уравнении первый коэффициент
и правая часть содержат переменную x
в нулевой степени, суммирование этих
единиц и породило коэффициент (1,1), равный
n).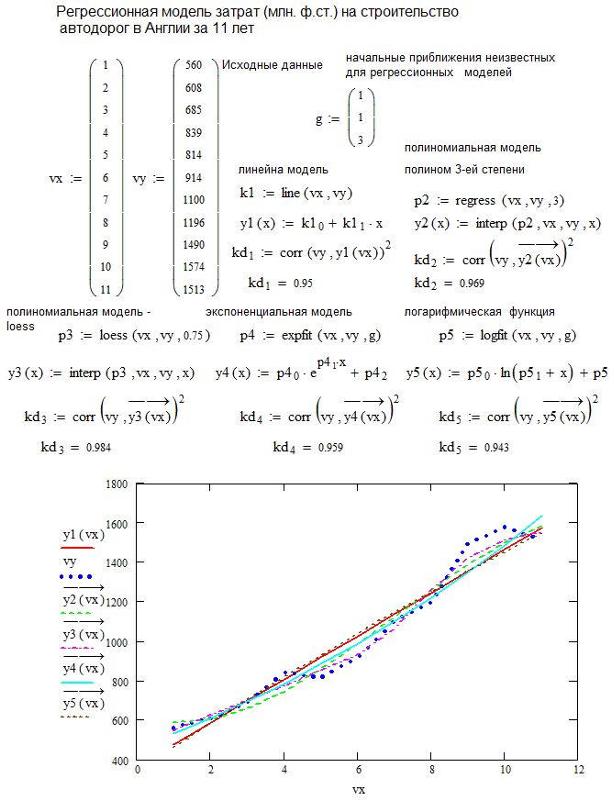
В отличие от линейного случая, общее решение системы (2.14) имеет слишком сложный вид, неудобный как для записи, так и для непосредственных вычислений. Обычно просто вычисляют коэффициенты системы как числа, а потом решают получившуюся систему методом Гаусса.
Общую схему решения задачи квадратичной регрессии можно представить в виде следующей таблицы:
xi | yi | xi2 | xi3 | xi4 | xi yi | xi2 yi | εi | |
x1 | y1 | x12 | x13 | x14 | x1 y1 | x12 y1 | ε1 = y1– | |
x2 | y2 | x22 | x23 | x24 | x1 y1 | x12 y1 | ε2 = y2– | |
… | … | … | … | … | … | … | … | … |
xn | yn | xn2 | xn3 | xn4 | xn yn | xn2 yn | εn =yn– | |
Используя исходные данные заполняем
первые два столбца таблицы. Потом
вычисляем и заполняем следующие пять
столбцов. Далее, для первых семи столбцов
вычисляем элементы последней строки:
суммы по столбцам.
Потом
вычисляем и заполняем следующие пять
столбцов. Далее, для первых семи столбцов
вычисляем элементы последней строки:
суммы по столбцам.
Теперь мы располагаем всеми коэффициентами и правыми частями системы уравнений (2.14) и можем ее решить. Решая систему, находим набор неизвестных коэффициентов квадратичного уравнения регрессии b1 , b2 и b3.
Теперь, зная все коэффициенты, мы можем вычислить все значения , после этого вычисляем отклонения εi и вычисляем величину стандартной ошибки аппроксимации σ.
1 Это т.н. статистическое определение вероятности по сути представляет собой одну из форм закона больших чисел.
2
Здесь и далее
3 Согласно Плутарху, солдаты двух легионов, бежавшие от Спартака, бросив оружие, были подвергнуты децимации по распоряжению Марка Красса
4
От английского random – случайный ( отсюда:
рандомизация – «ослучайнивание»).
5 Музыка на CD-диске записана в цифровом формате. Громкость звука имеет обычно двухбайтовое представление, т.е. может принимать примерно 65 000 различных дискретных значений, мы на слух не замечаем того факта, что амплитуда записана дискретно.
6 Некоторые методы обработки данных требуют определенного минимального числа вариант в группе, например не менее 5-ти для применения метода χ-квадрат (см. далее).
7 О вычислении см. ниже.
8 Напомним, что для вычисления вероятности попадания нормально распределенной случайной величины в интервал (а , b) необходимо пересчитать этот интервал в нормированный интервал ( , ) по формулам: , после чего искомая вероятность вычисляется по формуле Р = Ф() – Ф(). При таком преобразовании точка µ–σ превращается в (–1), а точка µ+σ превращается в +1; вообще, точка µ–сσ превращается просто в –с, а точка µ+сσ соответственно просто в с.
9
Обратите внимание, вопрос поставлен
именно так «можно ли считать?», а не
«является ли?», это объясняется как раз
тем, что мы можем утверждать «у нас нет
оснований отвергнуть нулевую гипотезу»,
но не можем утверждать «тем самым мы
доказали, что».
10 Т.е. полученные в результате обработки данных наблюдений.
11 Число степеней свободы для данного типа распределения определяется как число интервалов классификации k минус число параметров, которые необходимо задать, чтобы вычислить величины для данного распределения. Для нормального распределения необходимо задать 3 таких параметра: N, и σ. Потому для нормального распределения формула и принимает вид:
12 Например, можно считать, что {xi} и {yj} это список размеров и ростов верхней одежды, а опыт состоит в подборе этих параметров для одного человека.
13 Т.е. матожидание этих оценок не совпадает с оцениваемой величиной
14 Напомним, что запись M[…] означает математическое ожидание для выражения (…).
15
Напомним, что здесь как обычно символ
означает
дисперсию случайной величины Х.
16 Нетрудно заметить, что в выражении для коэффициента корреляции множитель входит и в числитель и в знаменатель и, следовательно, сокращается. Теперь если интерпретировать величины и как координаты соответствующих векторов, то получится, что Cov(x,y) есть скалярное произведение этих векторов, а есть произведение их длин. Тогда получим, что выражение превращается в известную формулу для косинуса угла между векторами: .
Разумеется, отсюда вытекает, что возможные значения коэффициента корреляции принадлежат отрезку [–1, 1]
17
Обратите внимание: при использовании
критерия Фишера, как и при использовании
параметра
,
в качестве нулевой гипотезы принимается
гипотеза о случайности совпадений,
а не о случайности различий. Соответственно,
чем больше значение параметра критерия
F, тем вероятнее,
что наблюдаемая близость между
объясняемыми величинами yi и модельными величинами
носит не случайный, а закономерный
характер.
18 Напомним, что здесь 2 гипотетический, а — полученный из уравнения регрессии коэффициент пропорциональности между объясняемой и объясняющей переменными.
19 Функции такого типа также широко используются как модели производственных функций (функция Кобба-Дугласа для одной инструментальной переменной).
20 Строгая монотонность f(X) необходима для того, чтобы связь между двумя объясняющими переменными: исходной X и модифицированной Z= f(X) – была взаимно однозначной; каждому значению X соответствует одно и только одно значение Z. И обратно: каждому значению Z соответствует одно и только одно значение X.
33
Как выполнить квадратичную регрессию в Excel
Регрессия — это статистический метод, который мы можем использовать для объяснения взаимосвязи между одной или несколькими переменными-предикторами и переменной-откликом. Наиболее распространенным типом регрессии является линейная регрессия , которую мы используем, когда связь между переменной-предиктором и переменной-откликом является линейной .
Наиболее распространенным типом регрессии является линейная регрессия , которую мы используем, когда связь между переменной-предиктором и переменной-откликом является линейной .
То есть, когда предикторная переменная увеличивается, переменная отклика также имеет тенденцию к увеличению. Например, мы можем использовать модель линейной регрессии для описания взаимосвязи между количеством часов обучения (переменная-предиктор) и оценкой, которую студент получает на экзамене (переменная-ответ).
Однако иногда связь между переменной-предиктором и переменной-ответом нелинейна.Одним из распространенных типов нелинейных отношений является квадратичная зависимость , которая может выглядеть как U или перевернутая U на графике.
То есть, когда переменная-предиктор увеличивается, переменная-отклик также имеет тенденцию к увеличению, но после определенного момента переменная-отклик начинает уменьшаться, поскольку переменная-предиктор продолжает расти.
Например, мы можем использовать модель квадратичной регрессии, чтобы описать взаимосвязь между количеством часов, потраченных на работу, и уровнями счастья человека. Возможно, чем больше человек работает, тем более удовлетворенным он себя чувствует, но как только он достигает определенного порога, большая работа на самом деле приводит к стрессу и уменьшению счастья. В этом случае модель квадратичной регрессии будет соответствовать данным лучше, чем модель линейной регрессии.
Давайте рассмотрим пример выполнения квадратичной регрессии в Excel.
Квадратичная регрессия в ExcelПредположим, у нас есть данные о количестве отработанных часов в неделю и сообщаемом уровне счастья (по шкале от 0 до 100) для 16 разных людей:
Во-первых, давайте создадим диаграмму рассеяния, чтобы увидеть, является ли линейная регрессия подходящей моделью для соответствия данным.
Выделите ячейки A2:B17.Затем щелкните вкладку «ВСТАВИТЬ» на верхней ленте, затем нажмите « Разброс » в области « Диаграммы ». 2 в ячейку B2. Это дает значение 36.Затем щелкните в правом нижнем углу ячейки B2 и перетащите формулу вниз, чтобы заполнить оставшиеся ячейки в столбце B.
2 в ячейку B2. Это дает значение 36.Затем щелкните в правом нижнем углу ячейки B2 и перетащите формулу вниз, чтобы заполнить оставшиеся ячейки в столбце B.
Далее мы подгоним модель квадратичной регрессии.
Нажмите «ДАННЫЕ» на верхней ленте, затем нажмите « Анализ данных» справа. Если вы не видите эту опцию, то вам сначала нужно установить бесплатный Analysis ToolPak .
После того, как вы нажмете « Анализ данных» , появится всплывающее окно. Нажмите «Регрессия», а затем нажмите «ОК» .
Затем заполните следующие значения в появившемся окне Регрессия.Затем нажмите ОК .
Будут отображены следующие результаты:
Вот как интерпретировать различные числа из вывода:
Квадрат R: также известный как коэффициент детерминации, это доля дисперсии переменной отклика, которая может быть объяснена предикторными переменными. В этом примере R-квадрат равен 0,9092 , что указывает на то, что 90,92% дисперсии зарегистрированных уровней счастья можно объяснить количеством отработанных часов и количеством отработанных часов^2.
Стандартная ошибка: Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 9,519 единиц .
F-статистика : F-статистика рассчитывается как регрессия MS/остаточная MS. Эта статистика показывает, обеспечивает ли регрессионная модель лучшее соответствие данным, чем модель, которая не содержит независимых переменных. По сути, он проверяет, полезна ли регрессионная модель в целом. Как правило, если ни одна из переменных-предикторов в модели не является статистически значимой, общая F-статистика также не является статистически значимой. В этом примере статистика F равна 65,09 , а соответствующее значение p <0,0001. Поскольку это p-значение меньше 0,05, регрессионная модель в целом является значимой.
Коэффициенты регрессии. Коэффициенты регрессии в последней таблице дают нам числа, необходимые для написания оценочного уравнения регрессии:
у шляпа = б 0 + б 1 х 1 + б 2 х 1 2
В этом примере расчетное уравнение регрессии имеет вид:
сообщаемый уровень счастья = -30,252 + 7,173 (отработанные часы) -0,106 (отработанные часы) 2
Мы можем использовать это уравнение для расчета ожидаемого уровня счастья человека на основе количества отработанных часов. Например, ожидаемый уровень счастья человека, который работает 30 часов в неделю, составляет:
Например, ожидаемый уровень счастья человека, который работает 30 часов в неделю, составляет:
сообщаемый уровень счастья = -30,252 + 7,173(30) -0,106(30) 2 = 88,649 .
Дополнительные ресурсыКак добавить квадратную линию тренда в Excel
Как читать и интерпретировать таблицу регрессии
Что такое хорошее значение R-квадрата?
Понимание стандартной ошибки регрессии
Простое руководство по пониманию F-теста общей значимости в регрессии
Квадратичная регрессия — Voxco
ПОДЕЛИТЕСЬ СТАТЬЕЙ ПО
Содержание
Что такое квадратичная регрессия?
Квадратичная регрессия — это статистический метод, используемый для нахождения уравнения параболы, которое наилучшим образом соответствует набору данных. Этот тип регрессии является расширением простой линейной регрессии, которая используется для поиска уравнения прямой линии, которое лучше всего соответствует набору данных.
На точечной диаграмме квадратное уравнение образует U-образную форму, которая либо вогнута вниз, либо вогнута вверх. Линейную регрессию можно выполнить даже с двумя точками, в то время как для квадратичной регрессии требуется гораздо больше точек данных. Это связано с тем, что для квадратичной регрессии требуется больше точек данных, чтобы данные попадали в форму буквы «U».
Преобразуйте процесс получения информации
Создайте действенный процесс сбора отзывов.
Подробнее
R-квадрат в квадратичной регрессии
В квадратичной регрессии R-квадрат является коэффициентом детерминации и показывает степень, в которой изменение y может быть объяснено x-переменными. Таким образом, значение r-квадрата позволяет нам оценить, как различия в одной переменной могут быть объяснены различием во второй переменной. R-квадрат может принимать значения от 0 до 1, где 0 соответствует 0% вариации, а 1 соответствует 100% вариации.
Загрузить набор инструментов для исследования рынка
Получить руководство по тенденциям исследования рынка, руководство по онлайн-опросам, руководство по гибким исследованиям рынка и шаблон 5 исследования рынка
y = ax 2 + bx + c
Для расчета значений a, b и c можно использовать следующие формулы:
a = { [ Σ x 2 y * Σ xx ] – [Σ xy * Σ xx 2 ] } / { [ Σ xx * Σ x 2 x 2 ] — [σ xx 2 ] 2 }
B = {[σ xy * σ x 2 x 2 ] — x 2 ] — x 2 ] — x 2 ] — x 2 ] — x 2 ]. y * Σ xx 2 ] } / { [ Σ xx * Σ x 2 x 2 ] – [Σ хх 2 ] 2 }
y * Σ xx 2 ] } / { [ Σ xx * Σ x 2 x 2 ] – [Σ хх 2 ] 2 }
с = [ Σ у / п ] – { б * [ 9 х 4 а ] 2 / n ] }
Где
- x и y: переменные
- a, b и c: коэффициенты квадратного уравнения = сумма первых оценок
- Σ y = сумма вторых оценок
- Σ x2 = сумма квадратов первых оценок
- Σ x 3 = сумма куба первых оценок
- Σ x 4 = сумма степени четырех первых оценок
- Σ xy = сумма произведения первой и второй оценок
- Σ x2y = сумма квадратов первых оценок
- Σ x x = [ Σ x 2 ] – [ ( Σ x )2 / n ]
- Σ x y = [ Σ x y ] – [ ( Σ x * Σ y ) / n ]
- Σ x x2 = [ Σ x 3 ] – [ ( Σ x 2 * Σ x ) / n ]
- Σ x2 y = [ Σ x 2 y] – [ ( Σ x 2 * Σ y ) / n ]
- Σ x2 x2 = [ Σ х 4 ] – [ ( Σ х 2 )2 / п ]
Часто задаваемые вопросы о квадратичной регрессии
Что такое квадратичная регрессия?
Квадратичная регрессия — это разновидность статистического метода, используемого для нахождения уравнения параболы, которое наилучшим образом соответствует набору данных.
В чем разница между квадратичной регрессией и простой линейной регрессией?
Простая линейная регрессия используется для нахождения уравнения прямой линии, которое лучше всего соответствует набору данных, а квадратичная регрессия используется для нахождения уравнения параболы, которое лучше всего соответствует набору данных.
Что такое уравнение квадратичной регрессии?
Уравнение квадратичной регрессии:
y = ax 2 + bx + c
Где
a ≠ 0
Почему используется квадратичная регрессия?
Квадратичная регрессия используется для моделирования взаимосвязи между двумя наборами переменных, чтобы модель можно было использовать для объяснения или прогнозирования определенных результатов.
Получить БЕСПЛАТНУЮ демоверсию
Узнайте, как Voxco может преобразовать ваши исследования в области опросов за 30 минут.
company
Select CountryAfghanistanAland IslandsAlbaniaAlgeriaAmerican SamoaAndorraAngolaAnguillaAntarcticaAntigua and BarbudaArgentinaArmeniaArubaAustraliaAustriaAzerbaijanBahamasBahrainBangladeshBarbadosBelarusBelauBelgiumBelizeBeninBermudaBhutanBoliviaBonaire, Saint Eustatius and SabaBosnia and HerzegovinaBotswanaBouvet IslandBrazilBritish Indian Ocean TerritoryBritish Virgin IslandsBruneiBulgariaBurkina FasoBurundiCambodiaCameroonCanadaCape VerdeCayman IslandsCentral African RepublicChadChileChinaChristmas IslandCocos (Keeling) IslandsColombiaComorosCongo (Brazzaville)Congo (Kinshasa)Cook IslandsCosta RicaCroatiaCubaCuraçaoCyprusCzech RepublicDenmarkDjiboutiDominicaDominican RepublicEcuadorEgyptEl SalvadorEquatorial GuineaEritreaEstoniaEthiopiaFalkland IslandsFaroe IslandsFijiFinlandFranceFrench ГвианаФранцузская ПолинезияФранцузские южные территорииГабонГамбияГрузияГерманияГанаГибралтарГрецияГренландияГренадаГваделупаГуамГватемалаГернсиГвинеяГвинея-БисауГайан aHaitiHeard Island and McDonald IslandsHondurasHong KongHungaryIcelandIndiaIndonesiaIranIraqIrelandIsle of ManIsraelItalyIvory CoastJamaicaJapanJerseyJordanKazakhstanKenyaKiribatiKosovoKuwaitKyrgyzstanLaosLatviaLebanonLesothoLiberiaLibyaLiechtensteinLithuaniaLuxembourgMacao S. A.R., ChinaMacedoniaMadagascarMalawiMalaysiaMaldivesMaliMaltaMarshall IslandsMartiniqueMauritaniaMauritiusMayotteMexicoMicronesiaMoldovaMonacoMongoliaMontenegroMontserratMoroccoMozambiqueMyanmarNamibiaNauruNepalNetherlandsNew CaledoniaNew ZealandNicaraguaNigerNigeriaNiueNorfolk IslandNorth KoreaNorthern Mariana IslandsNorwayOmanPakistanPalestinian TerritoryPanamaPapua New GuineaParaguayPeruPhilippinesPitcairnPolandPortugalPuerto RicoQatarReunionRomaniaRussiaRwandaSão Tomé and PríncipeSaint BarthélemySaint HelenaSaint Kitts and NevisSaint LuciaSaint Martin (Dutch part)Saint Martin (French part)Saint Pierre and MiquelonSaint Vincent and the ГренадиныСамоаСан-МариноСаудовская АравияСенегалСербияСейшелыСьерра-ЛеонеСинг aporeSlovakiaSloveniaSolomon IslandsSomaliaSouth AfricaSouth Georgia/Sandwich IslandsSouth KoreaSouth SudanSpainSri LankaSudanSurinameSvalbard and Jan MayenSwazilandSwedenSwitzerlandSyriaTaiwanTajikistanTanzaniaThailandTimor-LesteTogoTokelauTongaTrinidad and TobagoTunisiaTurkeyTurkmenistanTurks and Caicos IslandsTuvaluUgandaUkraineUnited Arab EmiratesUnited Kingdom (UK)United States (US)United States (US) Minor Outlying IslandsUnited States (US) Virgin IslandsUruguayUzbekistanVanuatuVaticanVenezuelaVietnamWallis and FutunaWestern SaharaYemenZambiaZimbabwe
A.R., ChinaMacedoniaMadagascarMalawiMalaysiaMaldivesMaliMaltaMarshall IslandsMartiniqueMauritaniaMauritiusMayotteMexicoMicronesiaMoldovaMonacoMongoliaMontenegroMontserratMoroccoMozambiqueMyanmarNamibiaNauruNepalNetherlandsNew CaledoniaNew ZealandNicaraguaNigerNigeriaNiueNorfolk IslandNorth KoreaNorthern Mariana IslandsNorwayOmanPakistanPalestinian TerritoryPanamaPapua New GuineaParaguayPeruPhilippinesPitcairnPolandPortugalPuerto RicoQatarReunionRomaniaRussiaRwandaSão Tomé and PríncipeSaint BarthélemySaint HelenaSaint Kitts and NevisSaint LuciaSaint Martin (Dutch part)Saint Martin (French part)Saint Pierre and MiquelonSaint Vincent and the ГренадиныСамоаСан-МариноСаудовская АравияСенегалСербияСейшелыСьерра-ЛеонеСинг aporeSlovakiaSloveniaSolomon IslandsSomaliaSouth AfricaSouth Georgia/Sandwich IslandsSouth KoreaSouth SudanSpainSri LankaSudanSurinameSvalbard and Jan MayenSwazilandSwedenSwitzerlandSyriaTaiwanTajikistanTanzaniaThailandTimor-LesteTogoTokelauTongaTrinidad and TobagoTunisiaTurkeyTurkmenistanTurks and Caicos IslandsTuvaluUgandaUkraineUnited Arab EmiratesUnited Kingdom (UK)United States (US)United States (US) Minor Outlying IslandsUnited States (US) Virgin IslandsUruguayUzbekistanVanuatuVaticanVenezuelaVietnamWallis and FutunaWestern SaharaYemenZambiaZimbabwe
Предоставляя эту информацию, вы соглашаетесь с тем, что мы можем обрабатывать ваши персональные данные в соответствии с нашей Политикой конфиденциальности.
Исследуйте все типы вопросов
опроса, возможные на Voxco
Подробнее
Voxco Survey Software расширяет команду руководителей и нанимает директора по маркетингу и вице-президента по маркетингу для усиления управления клиентским опытом и опытом сотрудников
9 июня 2020 г. Комментариев нет
— ветеран Voice of Customer Джонатан Левитт нанят на должность директора по маркетингу — Эбхи Рана нанят на должность вице-президента по маркетингу роста МОНРЕАЛЬ, 3 марта 2020 г. — Voxco объявила сегодня о
Подробнее »
Корреляция и причинность
15 декабря 2021 г. Комментариев нет
Корреляция и причинно-следственная связь ПОДЕЛИТЬСЯ СТАТЬЕЙ В Поделиться на facebook Поделиться в Twitter Поделиться на linkedin Содержание Определения Корреляция В статистике, когда два
Подробнее »
Исследовательский опрос
2 ноября 2021 г. Комментариев нет
Комментариев нет
Типы опросов Методы исследования ПОДЕЛИТЕСЬ СТАТЬЕЙ ПО Оглавлению В современном мире, где компании полностью зависят от того, что и как их
Подробнее »
Все, что вам нужно знать о пожизненной ценности клиента
16 марта 2021 г. Комментариев нет
Все, что вам нужно знать о ценности жизни клиента Скачать бесплатно: повысить показатели NPS с помощью наших шаблонов опросов NPS Загрузить сейчас ПОДЕЛИТЬСЯ СТАТЬЕЙ ПО
Подробнее »
Шкала оценок
19 августа 2021 г. Комментариев нет
Использование рейтинговых шкал в опросах Преобразуйте процесс получения информации Используйте наше подробное онлайн-руководство по проведению опросов, чтобы создать действенный процесс сбора отзывов.
Подробнее »
BPMS
25 марта 2022 г. Комментариев нет
BPMS ПОДЕЛИТЬСЯ СТАТЬЕЙ В Поделиться на facebook Поделиться в Twitter Поделиться на linkedin Содержание BPMS — это аббревиатура от «Управление бизнес-процессами»
Подробнее »
Квадратичная регрессия
Горячая математика А
квадратичный
регрессия – это процесс нахождения уравнения
парабола
который лучше всего соответствует набору данных. В результате получаем уравнение вида:
В результате получаем уравнение вида:
у знак равно а Икс 2 + б Икс + с куда а ≠ 0 .
Лучший способ найти это уравнение вручную — использовать метод наименьших квадратов. То есть нам нужно найти значения а , б , а также с таким образом, что квадрат вертикального расстояния между каждой точкой ( Икс я , у я ) и квадратичная кривая у знак равно а Икс 2 + б Икс + с минимален.
Матричное уравнение для квадратичной кривой имеет вид:
[ ∑ Икс я 4 ∑ Икс я 3 ∑ Икс я 2 ∑ Икс я 3 ∑ Икс я 2 ∑ Икс я ∑ Икс я 2 ∑ Икс я н ] [ а б с ] знак равно [ ∑ Икс я 2 у я ∑ Икс я у я ∑ у я ]
Относительная предсказательная сила квадратичной модели обозначается
р
2
.
Это можно получить по формуле:
р 2 знак равно 1 − ССЭ SST куда ССЭ знак равно ∑ ( у я − а Икс я 2 − б Икс я − с ) 2 а также SST знак равно ∑ ( у я − у ¯ ) 2
Значение р 2 варьируется между 0 а также 1 . Чем ближе значение к 1 , тем точнее модель.
Но это очень утомительные расчеты. Итак, мы будем использовать графический калькулятор для автоматического расчета кривой.
Пример 1:
Рассмотрим набор данных. Определите квадратичную регрессию для множества.
( − 3 , 7,5 ) , ( − 2 , 3 ) , ( − 1 , 0,5 ) , ( 0 , 1 ) , ( 1 , 3 ) , ( 2 , 6 ) , ( 3 , 14 )
Введите Икс -координаты и у -координаты в вашем калькуляторе и сделать квадратичную регрессию. Уравнение параболы, которое лучше всего аппроксимирует точки, имеет вид
у
знак равно
1.