
Теорема Пифагора — формула, доказательство, задачи
350.7K
Сложно представить, но в научной литературе существует 367 доказательств теоремы Пифагора. В школьной программе мы проходим гораздо меньше — в этом материале познакомимся с главными формулами и их доказательствами.
Записывайтесь на онлайн-фестиваль для родителей SmartFest!
Ждём вас 8 октября в 13:00. Вместе с педагогами, психологами и другими экспертами в образовании и воспитании ответим на главные вопросы мам и пап.
Бесплатный урок по математике
Записаться
Основные понятия
Теорема Пифагора, определение: в прямоугольном треугольнике квадрат длины гипотенузы равен сумме квадратов длин катетов.
Гипотенуза — сторона, лежащая напротив прямого угла.
Катет — одна из двух сторон, образующих прямой угол.
Формула Теоремы Пифагора выглядит так:
a2 + b2 = c2,
где a, b — катеты, с — гипотенуза.
Из этой формулы можно вывести следующее:
- a = √c2 − b2
- b = √c2 − a2
- c = √a2 + b2
Запоминаем
в любом прямоугольном треугольнике сумма квадратов длин двух катетов равна квадрату длины гипотенузы.
Для треугольника со сторонами a, b и c, где c — большая сторона, действуют следующие правила:
- если c2 < a2 + b2, значит угол, противолежащий стороне c, является острым.
- если c2 > a2 +b2, значит угол, противолежащий стороне c, является тупым.
Практикующий детский психолог Екатерина Мурашова
Бесплатный курс для современных мам и пап от Екатерины Мурашовой. Запишитесь и участвуйте в розыгрыше 8 уроков
Теорема Пифагора: доказательство
В прямоугольном треугольнике квадрат гипотенузы равен сумме квадратов катетов.
Дано: ∆ABC, в котором ∠C = 90º.
Доказать: a2 + b2 = c2.
Пошаговое доказательство:
- Проведём высоту из вершины C на гипотенузу AB, основание обозначим буквой H.
- Прямоугольная фигура ∆ACH подобна ∆ABC по двум углам:
∠ACB =∠CHA = 90º,
∠A — общий.
- Также прямоугольная фигура ∆CBH подобна ∆ABC:
∠ACB =∠CHB = 90º,
∠B — общий.
- Введем новые обозначения: BC = a, AC = b, AB = c.
- Из подобия треугольников получим: a : c = HB : a, b : c = AH : b.
- Значит a2 = c * HB, b2 = c * AH.
- Сложим полученные равенства:
a2 + b2 = c * HB + c * AH
a2 + b2 = c * (HB + AH)
a2 + b2 = c * AB
a2 + b2 = c * c
a2 + b2 = c2
Теорема доказана.
Обратная теорема Пифагора: доказательство
Если сумма квадратов двух сторон треугольника равна квадрату третьей стороны, то такой треугольник является прямоугольным.
Дано: ∆ABC
Доказать: ∠C = 90º
Пошаговое доказательство:
- Построим прямой угол с вершиной в точке C₁.
- Отложим на его сторонах отрезки C₁A₁ = CA и C₁B₁ = CB.
- Проведём отрезок A₁B₁.
- Получилась фигура ∆A₁B₁C₁, в которой ∠C₁=90º.
- В этой фигуре ∆A₁B₁C₁ применим теорему Пифагора: A₁B₁2 = A₁C₁2 + B₁C₁2.
- Таким образом получится:
- Значит, в фигурах треугольниках ∆ABC и ∆A₁B₁C₁:
- C₁A₁ = CA и C₁B₁ = CB по результату построения,
- A₁B₁ = AB по доказанному результату.
- Поэтому, ∆A₁B₁C₁ = ∆ABC по трем сторонам.
- Из равенства фигур следует равенство их углов: ∠C =∠C₁ = 90º.


Обратная теорема доказана.
Учёба без слёз (бесплатный гайд для родителей)
Пошаговый гайд от Екатерины Мурашовой о том, как перестать делать уроки за ребёнка и выстроить здоровые отношения с учёбой.
Решение задач
Задание 1. Дан прямоугольный треугольник ABC. Его катеты равны 6 см и 8 см. Какое значение у гипотенузы?
Как решаем:
Пусть катеты a = 6 и b = 8.
По теореме Пифагора c2 = a2 + b2.
Подставим значения a и b в формулу:
c2 = 62 + 82 = 36 + 64 = 100
c = √100 = 10.
Ответ: 10.
Задание 2. Является ли треугольник со сторонами 8 см, 9 см и 11 см прямоугольным?
Как решаем:
- Выберем наибольшую сторону и проверим, выполняется ли теорема Пифагора:
112 = 82 + 92
121 ≠ 145
Ответ: треугольник не является прямоугольным.
Шпаргалки по математике родителей
Все формулы по математике под рукой
как правильно выбрать диаграмму или график для годового отчета
Целевая аудитория вашей презентации либо отчета — инвесторы, руководство и просто люди — ожидают получить не ворох цифр, а уже сформулированные выводы либо понятно расставленные акценты. Возникает необходимость обратить внимание аудитории на факторы и обстоятельства, показать планы и стратегию.
Графическое отображение информации помогает донести нужную мысль, подкрепить сформулированный вывод либо подчеркнуть акцентНо есть одна проблема — восприятие положительных и отрицательных результатов. При этом разные аудитории по-разному относятся даже к положительным. Например, журналисты могут скептически комментировать достижения. Акционеры склонны болезненно реагировать на убытки. И здесь необходим тонкий продуманный подход.
Например, журналисты могут скептически комментировать достижения. Акционеры склонны болезненно реагировать на убытки. И здесь необходим тонкий продуманный подход.
О неудачах и негативе можно рассказать очень скучно и нудно, а интересный и бодрый рассказ об успехах — подкрепить наглядной демонстрацией, включающей в себя презентацию с впечатляющими графиками. При этом правильно выбранная диаграмма может в корне изменить восприятие информации: если вы просто покажете, как рос доход компании в течение года, это будет не так впечатляюще, как если рядом будет показана динамика проседания вашего конкурента.
Одна из трудностей, которая существенно замедляет составление отчетов и аналитическую работу, заключается в подборе правильного типа диаграммы. Неверный ее выбор может вызвать путаницу в голове у зрителей или привести к ошибочной интерпретации данных.
Давайте посмотрим на инфографику о мировом производстве масла.
Инфографика Top Lead для компании Baker Tilly. Посмотреть в полном размере.
Посмотреть в полном размере.
Здесь все — и объемы производства, экспорт, прогнозы, спрос, потребители и еще тонны информации. Эта инфографика вмещает в себя по сути огромный объем данных по целой отрасли. Тем не менее она проста в восприятии, и на графике четко видны определенные тенденции.
Чтобы создать диаграмму, которая объясняет и демонстрирует точную аналитику, сначала нужно понять причины, по которым вообще она может понадобиться. В этой статье мы рассмотрим пять вопросов, возникающих при выборе типа диаграммы. Затем мы дадим обзор 13 различных видов диаграмм, из которых можно выбрать самую подходящую.
5 вопросов, которые нужно задать себе при выборе диаграммы1. Вам нужно сравнивать величины?
Графики идеально подходят для сравнения одного или нескольких наборов величин, и они могут легко отображать самые низкие и высокие показатели.
Для создания сравнительной диаграммы используйте следующие типы: гистограмма, круговая диаграмма, точечная диаграмма, шкала со значениями.
2. Вы хотите показать структуру чего-либо?
Например, вы хотите рассказать о типах мобильных устройств, которые используют посетители сайта или общий объем продаж, разбитый на сегменты.
Чтобы показать структуру, используйте следующие диаграммы: круговая диаграмма, гистограмма с накоплением, вертикальный стек, областная диаграмма, диаграмма-водопад.
3. Вы хотите понять, как распределяются данные?
Таблицы с распределением помогают понять основные тенденции и отметить, что выходит за рамки.
Используйте эти диаграммы: точечная диаграмма, линейная диаграмма, гистограмма.
4. Вы заинтересованы в анализе тенденций в определенном наборе данных?
Если вы хотите узнать больше о том, как цифры ведут себя в течение конкретного временного периода, есть типы диаграмм, которые очень хорошо это отображают.
Вам пригодятся: линейная диаграмма, двойная ось (столбец и линия), гистограмма.
5. Хотите лучше понять взаимосвязь между установленными значениями?
Взаимосвязанные графики подходят для того, чтобы показать, как одна переменная относится к другой или нескольким различным переменным. Это можно использовать, чтобы показать положительное, отрицательное или нулевое влияние на другую цифру.
Это можно использовать, чтобы показать положительное, отрицательное или нулевое влияние на другую цифру.
Используйте для этого следующие диаграммы: точечная диаграмма, пузырьковая диаграмма, линейная диаграмма.
13 различных типов диаграмм для анализа и представления данныхЧтобы лучше понять каждый график и возможности его применения, рассмотрим все типы диаграмм.
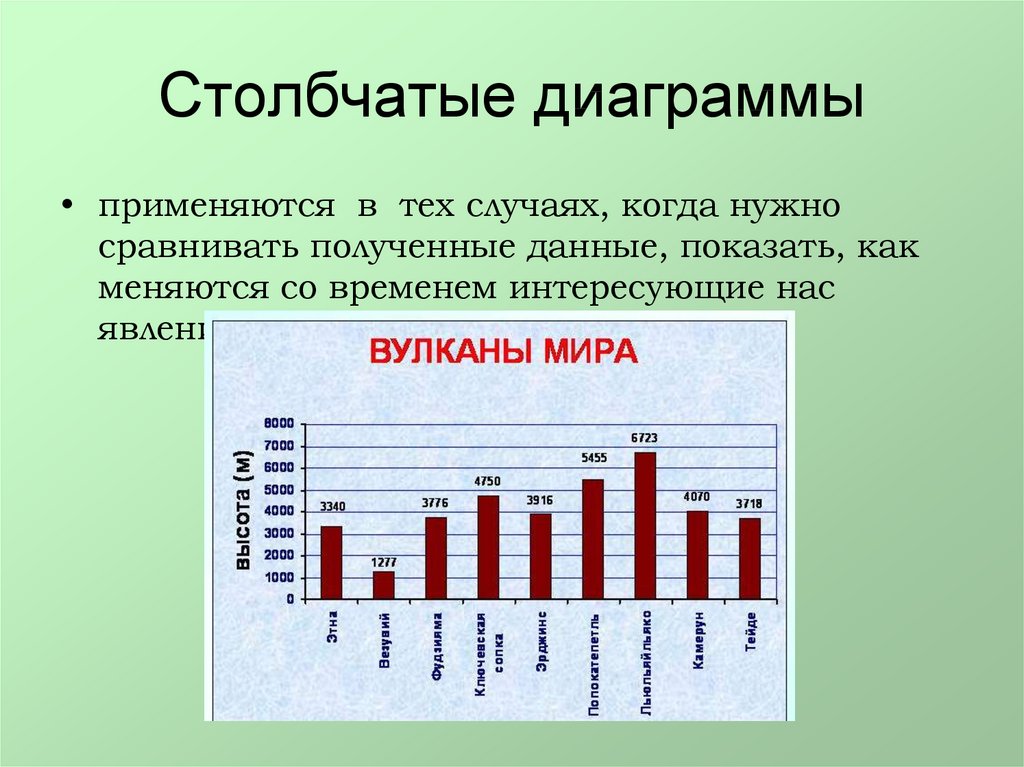
ГистограммаГистограмма используется, чтобы показать сравнение между различными элементами, также она может сравнить элементы за определенный промежуток времени. Этот формат можно использовать для отслеживания динамики переходов на лендинг или количества клиентов за определенный период.
Инфографика Top Lead для юридической компании AEQUO
Рекомендации по дизайну для столбчатых диаграмм
1. Подбирайте единую цветовую гамму и акцентируйте цветом места, которые хотите выделить как значимые моменты перелома или изменения с течением времени.
2. Используйте горизонтальные метки, чтобы улучшить читаемость.
3. Начните ось y с 0, чтобы правильно отразить значения на графике.
Горизонтальная гистограммаГистограмму — в основном горизонтальную столбчатую — следует использовать, чтобы избежать путаницы, когда одна полоска данных слишком длинная или в случае сравнения более 10 элементов. Этот вариант также может использоваться для визуализации отрицательных значений.
Инфографика Top Lead для интернет-издания Aggeek. Посмотреть в полном размере.
Рекомендации по дизайну для гистограмм
1. Подбирайте единую цветовую гамму и акцентируйте цветом места, которые хотите выделить как значимые точки перелома или изменения с течением времени.
2. Используйте горизонтальные метки, чтобы улучшить читаемость.
3. Начните ось Y с 0, чтобы правильно отразить значения на графике.
Линейная диаграммаЛинейная диаграмма отображает тенденции или прогресс и может использоваться для визуализации самых разных категорий данных. Ее следует использовать, когда вы создаете график, основанный на длительном сборе данных.
Ее следует использовать, когда вы создаете график, основанный на длительном сборе данных.
Инфографика Top Lead. Линейная диаграмма — снизу.
Рекомендации по дизайну для линейных диаграмм
1. Используйте сплошные линии.
2. Не рисуйте больше четырех линий, чтобы избежать появления визуальных отвлекающих факторов.
3. Используйте правильную высоту, чтобы линии занимали примерно 2/3 высоты оси Y.
Диаграмма с двойной осьюДвухосевая диаграмма позволяет выстраивать данные с использованием двух осей — Х и Y. Используется несколько наборов данных, один из которых, например, — данные за период, а другой — лучше подходит для группировки по категориям. Таким образом можно продемонстрировать корреляцию или ее отсутствие между разными показателями.
Инфографика Top Lead для Growth Up. Диграмма с двойной осью — вверху.
Рекомендации по дизайну для диаграмм с двумя осями
1. Используйте левую ось Y для основной переменной, потому что для людей естественно сначала смотреть влево.
Используйте левую ось Y для основной переменной, потому что для людей естественно сначала смотреть влево.
2. Используйте разные стили графиков, чтобы проиллюстрировать два набора данных.
3. Выберите контрастные цвета для сравниваемых наборов данных.
Областная диаграммаОбластная диаграмма в целом выглядит как линейная диаграмма, но пространство между осью Х и линией графика заполняется цветом или рисунком. Такой вариант подойдет для демонстрации отношений между частями одного целого, например, вклада отдельных торговых представителей в общий объем продаж за год. Это поможет проанализировать как всю картину в целом, так и информацию о тенденциях на отдельных участках.
Инфографика Top Lead для компании Baker Tilly. Сверху вниз: круговая диаграмма, две обласных диаграммы, круговые диаграммы.
Рекомендации по дизайну для диаграмм областей
1. Используйте полупрозрачные цвета.
2. Используйте не более четырех категорий, чтобы избежать путаницы.
3. Организовывайте данные с высокой частотой изменчивости в верхней части диаграммы, чтобы было легче воспринимать динамические изменения.
Штабельная диаграммаЕе можно использовать для сравнения большого количества различных составляющих. Например, частоту посещения нескольких сайтов и каждой страницы в отдельности.
Инфографика и верстка — Top Lead. Для «Нафтогаз України». Штабельная диаграмма — внизу слева. Посмотреть в полном размере.
Рекомендации по дизайну для штабельных диаграмм
1. Лучше всего использовать ее для иллюстрации отношений «часть-целое». Для большей наглядности выбирайте контрастные цвета.
2. Сделайте масштаб диаграммы достаточно большим, чтобы видеть размеры групп по отношению друг к другу.
Круговая диаграммаКруговая диаграмма отображает статическое число и то, как части складываются в целое — состав чего-либо. Круговая диаграмма показывает числа в процентах, и общая сумма всех сегментов должна равняться 100%.
Инфографика и верстка — Top Lead. Для «Нафтогаз України». Посмотреть в полном размере.
Рекомендации по дизайну для круговых диаграмм
1. Не добавляйте слишком много категорий, чтобы разница между срезами была хорошо заметна.
2. Убедитесь, что общая сумма всех частей составляет 100%.
3. Необходимо упорядочить части в соответствии с их размером.
Инфографика Top Lead для компании Baker Tilly. Посмотреть в полном размере.
Диаграмма-водопадДиаграмма-водопад используется для демонстрации того, как промежуточные значения — положительные и отрицательные — влияют на изначальное значение и приводят к окончательному результату. Примером может служить визуализация того, как общий доход компании зависит от различных отделов и превращается в конкретный объем прибыли.
Инфографика и верстка — Top Lead. Годовой отчет «Нафтогаз України». Диаграмма-водопад в верхней половине верстки. Посмотреть в полном размере.
Посмотреть в полном размере.
Рекомендации по дизайну для водопадных диаграмм
1. Используйте контрастные цвета, чтобы выделить различия в наборах данных.
2. Выбирайте теплые цвета, чтобы показать рост, и холодные цвета — для падения.
Воронкообразная диаграммаДиаграмма-воронка отображает последовательность этапов и скорость завершения каждого из них. Ее можно использовать для отслеживания процесса продаж или взаимодействия пользователей с сайтом.
Инфографика Top Lead.
Рекомендации по дизайну для воронкообразных диаграмм
1. Масштабируйте размер каждой секции, чтобы точно отобразить объем набора данных.
2. Используйте контрастные цвета или оттенки одного цвета от самого темного до самого светлого по мере сужения воронки.
Есть еще несколько видов графиков — они используются не так часто, но тоже могут пригодиться для визуализации болььших объемов данных. Среди них:
Среди них:
Точечная диаграмма показывает взаимосвязь между двумя различными переменными или демонстрирует распределяющие тенденции. Она подходит, если у вас много разных точечных данных, и вы хотите найти общее в наборе данных. Такая визуализация хорошо работает в поиске исключений или закономерности распределения данных.
Рекомендации по дизайну для точечных диаграмм
1. Включите больше переменных, таких как разные размеры, чтобы объединить больше данных.
2. Начните ось Y с 0 для точного распределения данных.
3. Если вы используете линии тенденций, необходимо ограничиться максимум двумя, чтобы график был понятен.
Пузырьковая диаграммаПузырьковая диаграмма похожа на точечный график. Но только в том смысле, что она может показывает распределение и взаимосвязь. Существует третий набор данных, который обозначается размером круга.
Рекомендации по дизайну для пузырьковых диаграмм
1. Проводите градацию пузырьков по занимаемой ими площади, а не по диаметру.
Проводите градацию пузырьков по занимаемой ими площади, а не по диаметру.
2. Убедитесь, что метки четкие и хорошо видны.
3. Используйте только круги.
Шкала со значениямиТакой график показывает прогресс в достижении цели, сравнивает его по разным критериям и отображает результат как рейтинг или производительность.
Рекомендации по разработке дизайна для шкалы со значениями
1. Используйте контрастные цвета, чтобы показать динамику.
2. Используйте один цвет в разных оттенках для оценки прогресса.
Тепловая картаТепловая карта показывает взаимосвязь между двумя элементами и предоставляет рейтинговую информацию. Информация о рейтинге отображается с использованием различных цветов или разной насыщенности.
Рекомендации по разработке дизайна для тепловой карты
1. Используйте базовый и четкий план карты, чтобы не отвлекать зрителей от данных.
2. Используйте разные оттенки одного цвета, чтобы показать изменения.
3. Избегайте использования нескольких шаблонов.
Вариантов дизайна может быть огромное количество.
Чтобы узнать больше о подготовке нефинансовых отчетов и послушать кейсы таких компаний как Coca-Cola, Kernel, Нова Пошта, 1+1 Media, Infopulse и других, регистрируйтесь на нашу онлайн-конференцию Corporate Reporting Conference 2020. Жмите на баннер, чтобы узнать подробности, а билеты покупайте прямо в Фейсбуке:
404 Страница не найдена | Образование голышмановского района
- ГЛАВНАЯ
- Структура
- НОВОСТИ
- Учредительные документы
- Объявления
- Региональный центр «Новое поколение»
- История
- Родителям
- Советы родителям школьника
- Как выбрать школьную форму
- Горячая линия» по вопросам профилактики инфекций, передающихся клещами
- Об актированных днях
- Меры социальной поддержки, предоставляемые семьям с детьми органами социальной защиты населения
- ПАМЯТКА для получения ежемесячной выплаты в связи с рождением (усыновлением) первого ребёнка
- Меры социальной поддержки, предоставляемые семьям с детьми органами социальной защиты населения 2018
- Отцы, защитите своих детей! (безопасность 0+)
- Открытое окно — опасность для ребенка
- «Скоро в школу»
- Дошкольное образование
- «Горячая Линия» по вопросам организации дошкольного образования
- Дошкольное образование в нацпроектах
- Родителям
- Об утверждении Порядка учета детей на территории Голышмановского городского округа
- Приказ Минобрнауки России от 13. 01.2014 N 8 «Об утверждении примерной формы договора об образовании по образовательным программам дошкольного образования» (Зарегистрировано в Минюсте России 27.03.2014 N 31757)
- ПРИКАЗ от 27 июня 2017 г. N 602 ОБ УТВЕРЖДЕНИИ ПОРЯДКА РАССЛЕДОВАНИЯ И УЧЕТА НЕСЧАСТНЫХ СЛУЧАЕВ С ОБУЧАЮЩИМИСЯ ВО ВРЕМЯ ПРЕБЫВАНИЯ В ОРГАНИЗАЦИИ, ОСУЩЕСТВЛЯЮЩЕЙ ОБРАЗОВАТЕЛЬНУЮ ДЕЯТЕЛЬНОСТЬ
- Об установлении родительской платы за содержание детей в дошкольных образовательных учреждениях
- Постановление №955 от 31.12. 2019 «Об утверждении Порядка распределения средств, предоставляемых в целях частичного возмещения расходов учреждений, реализующих образовательную программу дошкольного образования, на осуществление присмотра и ухода за детьми
- Об организации зачисления детей в образовательные учреждения, реализующие основную образовательную программу дошкольного образования
- О внесении изменений и дополнений в постановление Администрации Голышмановского муниципального района от 30. 06.2015 № 874 (в редакции от 18.05.2016 № 606)
- Приказ О закреплении образовательных учреждений за конкретными территориями Голыгимановского городского округа №21 от 20.01.20
- Aдминистративный регламент предоставления муниципальной услуги «Прием заявлений, постановка на учет и зачисление детей в образовательные учреждения, реализующие основную образовательную программу дошкольного образования (детские сады)»
- Постановление от 12.10.2021 № 996 Об утверждении муниципальной программы «Основные направления развития системы образования Голышмановского городского округа» на 2022-2024 годы
- МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ ПО ПРОВЕДЕНИЮ ОЦЕНКИ КАЧЕСТВА ПСИХОЛОГО-ПЕДАГОГИЧЕСКИХ УСЛОВИЙ
- Общее образование
- О проведении мониторинга качества подготовки обучающихся в 2021-2022 учебном году
- Публичный отчет Голышмановский городской округ 2020
- Об утверждении муниципальной программы «Основные направления развития системы образования в Голышмановском городском округе» на 2021-2023 годы
- Постановление ГГО Губернаторская елка 2021
- Положение о проведении Губернаторской елки
- Положение о проведении Губернаторской елки
- ПМПК
- О ПМПК
- Положение о ПМПК
- Основные направления деятельности ТПМПК
- Выбор маршрута
- Порядок осуществления обследования
- Консультации
- Запись на обследование
- Документы на ПМПК
- Вопрос — ответ
- ПМПС
- Состав ПМПС
- Положение о ПМПС 2019
- Направления работы ПМПС
- Консультации
- Защита прав детей
- Конвенция о правах ребенка
- Федеральный закон «Об основах профилактики безнадзорности и правонарушений несовершеннолетних» № 120-ФЗ от 24. 06.1999г.
- Организация питания
- НОРМАТИВНО-ПРАВОВАЯ ДОКУМЕНТАЦИЯ
- ГОРЯЧАЯ ЛИНИЯ ПО ПИТАНИЮ
- ИНФОРМАЦИЯ ДЛЯ РОДИТЕЛЕЙ
- Организация летнего отдыха
- Распоряжение № 1124-рп от 10.12.2021 г Об организации детской оздоровительной кампании в Тюменской области в 2022 году
- Реестр организации отдыха детей и их оздоровления Голышмановского городского округа на 2022г
- Постановление № 989 от 11.10.2021г Об утверждении муниципальной программы «Организация отдыха, оздоровления и занятости несовершеннолетних в Голышмановском городском округе» на 2022-2024 годы
- Постановление № 1372 30.12.2021 Об организации отдыха, оздоровления населения и занятости несовершеннолетних в Голышмановском городском округе в 2022 году
- Приказ №35 от 08.04.2022 Об организации отдыха,оздоровления и занятости детей и подростков в 2022 году
- Постановление №517 от 17.05.2022 Об утверждении Положения о порядке и условиях внесения родительской платы на организацию отдыха и оздоровления детей в лагерях с дневным пребыванием на территории Голышмановско
- Постановление №476 от 04. 05.2022
- Постановление № 523 от 17.05.2022
- Постановление №524 от 17.05.2022
- Постановление №594 от 01.06.2022
- ПРОФСОЮЗ
- Горячая линия
- ФГОС НОО ОВЗ
- НОРМАТИВНО-ПРАВОВАЯ БАЗА
- Всероссийская олимпиада школьников
- Ссылки на сайты ВсОШ
- Всероссийская олимпиада школьников 2021-2022
- Всероссийская олимпиада школьников 2020-2021
- Всероссийская олимпиада школьников 2019-2020
- «Точка опоры»
- Консультационные пункты
- Куда обратиться
- Кураторы проекта
- Навигатор для родителей
- Наши консультанты
- О проекте
- Реализация проекта в ОО ГГО
- Родительская школа
- Обратная связь
- Здоровье
- НОРМАТИВНО-ПРАВОВАЯ ДОКУМЕНТАЦИЯ
- Рекомендации по организации работы ОУ
- ИНФОРМАЦИЯ ДЛЯ РОДИТЕЛЕЙ
- Банк успешных практик
- ВНЕУРОЧНАЯ ДЕЯТЕЛЬНОСТЬ
- ДОШКОЛЬНОЕ ОБРАЗОВАНИЕ
- КЛАССНЫЙ РУКОВОДИТЕЛЬ
- МАТЕМАТИКА
- МАТЕРИАЛЫ ТЬЮТОРСКИХ СЕМИНАРОВ ПО ПОДГОТОВКЕ К ЕГЭ, ОГЭ
- МЕТОДИЧЕСКИЕ МАТЕРИАЛЫ СТАЖИРОВОЧНОЙ ПЛОЩАДКИ ПО СОВЕРШЕНСТВОВАНИЮ МАТЕМАТИЧЕСКОГО ОБРАЗОВАНИЯ
- НАЧАЛЬНЫЕ КЛАССЫ
- ОДАРЕННЫЕ И ТАЛАНТЛИВЫЕ ДЕТИ
- РУССКИЙ ЯЗЫК И ЛИТЕРАТУРА
- Оценка механизмов управления качеством образования
- 1. Образовательные результаты
- 2. Образовательная деятельность
- 1.
- МКУ «Центр развития образования»
- Структура
- Учредительные документы
- Антикоррупционная деятельность
- Консультационно-методическое обеспечение введения ФГОС НОО и ФГОС ООО
- ФГОС НОО
- ФГОС ООО
 01.2014 N 8 «Об утверждении примерной формы договора об образовании по образовательным программам дошкольного образования» (Зарегистрировано в Минюсте России 27.03.2014 N 31757)
01.2014 N 8 «Об утверждении примерной формы договора об образовании по образовательным программам дошкольного образования» (Зарегистрировано в Минюсте России 27.03.2014 N 31757) 06.2015 № 874 (в редакции от 18.05.2016 № 606)
06.2015 № 874 (в редакции от 18.05.2016 № 606) 06.1999г.
06.1999г. 05.2022
05.2022 Образовательные результаты
Образовательные результатыМинистерство просвещения Российской Федерации
Департамент образования и науки Тюменской области
ТОГИРРО
РОССИЙСКОЕ ОБРАЗОВАНИЕ ФЕДЕРАЛЬНЫЙ ПОРТАЛ
Федеральные государственные образовательные стандарты
ФЕДЕРАЛЬНЫЙ ЦЕНТР ИНФОРМАЦИОННО-ОБРАЗОВАТЕЛЬНЫХ РЕСУРСОВ
ОФИЦИАЛЬНЫЙ ИНФОРМАЦИОННЫЙ ПОРТАЛ ЕДИНОГО ГОСУДАРСТВЕННОГО ЭКЗАМЕНА
ЕГЭ.RU
Портал государственных и муниципальных услуг в сфере образования Тюменской области
Детские сады Тюменской области
Единое окно доступа к образовательным ресурсам
Электронная школа Тюменской области
Официальный интернет-портал правовой информации
Глава 1 Типы данных | Визуализация и анализ географических данных на языке R
Программный код главы
1.
 1 Типы данных
1 Типы данныхТип данных — это класс данных, характеризуемый членами класса и операциями, которые могут быть к ним применены1. С помощью типов данных мы можем представлять привычные нам сущности, такие как числа, строки и т.д. В языке R существует 5 базовых типов данных:
complex | комплексные числа |
character | символьный (строки) |
integer | целые числа |
logical | логические (булевы) |
numeric | числа с плавающей точкой |
Помимо этого есть тип Date, который позволяет работать с датами. Рассмотрим использование каждого из перечисленных типов.
1.1.1 Числа
Числа — основной тип данных в R. К ним относятся числа c плавающей точкой и целые числа. В терминологии R такие данные называются интервальными, поскольку к ним применимо понятие интервала на числовой прямой. 3
## [1] 8
2 ** 3
## [1] 8
3
## [1] 8
2 ** 3
## [1] 8
Результат деления по умолчанию имеет тип с плавающей точкой:
5 / 3 ## [1] 1.666667 5 / 2.5 ## [1] 2
Если вы хотите чтобы деление производилось целочисленным образом (без дробной части) необходимо использовать оператор %/%:
5 %/% 3 ## [1] 1
Остаток от деления можно получить с помощью оператора %%:
5 %% 3 ## [1] 2
Вышеприведенные арифметические операции являются бинарными, то есть требуют наличия двух чисел. Числа называются “операндами”. Отделять операнды от оператора пробелом или нет — дело вкуса. Однако рекомендуется все же отделять, так как это повышает читаемость кода. Следующие два выражения эквивалентны. Однако сравните простоту их восприятия:
5%/%3 ## [1] 1
5 %/% 3 ## [1] 1
Как правило, в настоящих программах числа в явном виде встречаются лишь иногда. Вместо этого для их обозначения используют переменные. В вышеприведенных выражениях мы неоднократно использовали число 3. Теперь представьте, что вы хотите проверить, каковы будут результаты, если вместо 3 использовать 4. Вам придется заменить все тройки на четверки. Если их много, то это будет утомительная работа, и вы наверняка что-то пропустите. Конечно, можно использовать поиск с автозаменой, но что если тройки надо заменить не везде? Одно и то же число может выполнять разные функции в разных выражениях. Чтобы избежать подобных проблем, в программе вводят переменные и присваивают им значения. Оператор присваивания значения выглядит как
Теперь представьте, что вы хотите проверить, каковы будут результаты, если вместо 3 использовать 4. Вам придется заменить все тройки на четверки. Если их много, то это будет утомительная работа, и вы наверняка что-то пропустите. Конечно, можно использовать поиск с автозаменой, но что если тройки надо заменить не везде? Одно и то же число может выполнять разные функции в разных выражениях. Чтобы избежать подобных проблем, в программе вводят переменные и присваивают им значения. Оператор присваивания значения выглядит как =
a = 5 b = 3
Чтобы вывести значение переменной на экран, достаточно просто ввести его:
a ## [1] 5 b ## [1] 3
Мы можем выполнить над переменными все те же операции что и над константами:
a + b ## [1] 8 a - b ## [1] 2 a / b ## [1] 1.666667 a %/% b ## [1] 1 a %% b ## [1] 2
Легко меняем значение второй переменной с 3 на 4 и выполняем код заново.
b = 4 a + b ## [1] 9 a - b ## [1] 1 a / b ## [1] 1.25 a %/% b ## [1] 1 a %% b ## [1] 1
Нам пришлось изменить значение переменной только один раз в момент ее создания, все последующие операции остались неизменны, но их результаты обновились!
Новую переменную можно создать на основе значений существующих переменных:
c = b d = a+c
Посмотрим, что получилось:
c ## [1] 4 d ## [1] 9
Вы можете комбинировать переменные и заданные явным образом константы:
e = d + 2.
 5
e
## [1] 11.5
5
e
## [1] 11.5Противоположное по знаку число получается добавлением унарного оператора - перед константой или переменной:
f = -2 f ## [1] -2 f = -e f ## [1] -11.5
Операция взятия остатка от деления бывает полезной, например, когда мы хотим выяснить, является число четным или нет. Для этого достаточно взять остаток от деления на 2. Если число является четным, остаток будет равен нулю. В данном случае c равно 4, d равно 9:
c %% 2 ## [1] 0 d %% 2 ## [1] 1
1.1.1.1 Числовые функции
Прежде чем мы перейдем к рассмотрению прочих типов данных и структур данных нам необходимо познакомиться с функциями, поскольку они встречаются буквально на каждом шагу. Понятие функции идентично тому, к чему мы привыкли в математике. Например, функция может называться Z, и принимать 2 аргумента: x и y. В этом случае она записывается как Z(x,y). Чтобы получить значение функции, необходимо подставить некоторые значения вместо x и y в скобках. Нас даже может не интересовать, как фактически устроена функция внутри, но важно понимать, что именно она должна вычислять. С созданием функций мы познакомимся позднее.
Нас даже может не интересовать, как фактически устроена функция внутри, но важно понимать, что именно она должна вычислять. С созданием функций мы познакомимся позднее.
Важнейшие примеры функций — математические. Это функции взятия корня sqrt(x), модуля abs(x), округления round(x, digits), натурального логарифма abs(x), тригонометрические функции sin(x), cos(x), tan(x), обратные к ним asin(y), acos(y), atan(y) и многие другие. Основные математические функции содержатся в пакете base, который по умолчанию доступен в среде R и не требует подключения.
В качестве аргумента функции можно использовать переменную, константу, а также выражения:
sqrt(a) ## [1] 2.236068 sin(a) ## [1] -0.9589243 tan(1.5) ## [1] 14.10142 abs(a + b - 2.5) ## [1] 6.5
Вы также можете легко вкладывать функции одна в одну, если результат вычисления одной функции нужно подставить в другую:
sin(sqrt(a)) ## [1] 0.
 7867491
sqrt(sin(a) + 2)
## [1] 1.020331
7867491
sqrt(sin(a) + 2)
## [1] 1.020331Также как и с арифметическими выражениями, результат вычисления функции можно записать в переменную:
b = sin(sqrt(a)) b ## [1] 0.7867491
Если переменной b ранее было присвоено другое значение, оно перезапишется. Вы также можете записать в переменную результат операции, выполненной над ней же. Например, если вы не уверены, что a — неотрицательное число, а вам это необходимо в дальнейших расчетах, вы можете применить к нему операцию взятия модуля:
b = sin(a) b ## [1] -0.9589243 b = abs(b) b ## [1] 0.9589243
1.1.2 Строки
Строки — также еще один важнейший тип данных. Чтобы создать строковую переменную, необходимо заключить текст строки в кавычки:
s = "В историю трудно войти, но легко вляпаться (М.Жванецкий)" s ## [1] "В историю трудно войти, но легко вляпаться (М.Жванецкий)"
Строки состоят из символов, и, в отличие от некоторых других языков, в R нет отдельного типа данных для объекта, которых хранит один символ (в C++ для этого используется тип char). Поэтому при создании строк вы можете пользоваться как одинарными, так и двойными кавычками:
Поэтому при создании строк вы можете пользоваться как одинарными, так и двойными кавычками:
s1 = "Это строка" s1 ## [1] "Это строка" s2 = 'Это также строка' s2 ## [1] "Это также строка"
Иногда бывает необходимо создать пустую строку (например, чтобы в нее далее что-то добавлять). В этом случае просто напишите два знака кавычек, идущих подряд без пробела между ними:
s1 = "" # это пустая строка s1 ## [1] "" s2 = '' # это также пустая строка s2 ## [1] "" s3 = ' ' # а это не пустая, тут есть пробел s3 ## [1] " "
Длину строки в символах можно узнать с помощью функции nchar()
nchar(s) ## [1] 56 nchar(s1) ## [1] 0 nchar(s3) ## [1] 1
Чтобы извлечь из строки подстроку (часть строки), можно использовать функцию substr(), указав ей номер первого и последнего символа:
substr(s, 3, 9) # извлекаем все символы с 3-го по 9-й ## [1] "историю"
В частности, зная длину строки, можно легко извлечь последние \(k\) символов:
n = nchar(s) k = 7 substr(s, n - k, n) ## [1] "анецкий)"
Строки можно складывать так же как и числа. Эта операция называется конкатенацией. В результате конкатенации строки состыковываются друг с другом и получается одна строка. В отличие от чисел, конкатенация производится не оператором
Эта операция называется конкатенацией. В результате конкатенации строки состыковываются друг с другом и получается одна строка. В отличие от чисел, конкатенация производится не оператором +, а специальной функцией paste(). Состыковываемые строки нужно перечислить через запятую, их число может быть произвольно
s1 = "В историю трудно войти," s2 = "но легко вляпаться" s3 = "(М.Жванецкий)"
Посмотрим содержимое подстрок:
s1 ## [1] "В историю трудно войти," s2 ## [1] "но легко вляпаться" s3 ## [1] "(М.Жванецкий)"
А теперь объединим их в одну:
s = paste(s1, s2) s ## [1] "В историю трудно войти, но легко вляпаться" s = paste(s1, s2, s3) s ## [1] "В историю трудно войти, но легко вляпаться (М.Жванецкий)"
Настоящая сила конкатенации проявляется когда вам необходимо объединить в одной строке некоторое текстовое описание (заранее известное) и значения переменных, которые у вас вычисляются в программе (заранее неизвестные). Предположим, вы нашли в программе что максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. человек. Найденный год записан у вас в переменную
Предположим, вы нашли в программе что максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. человек. Найденный год записан у вас в переменную year, а население в переменную pop. Вы их значения пока что не знаете, они вычислены по табличным данным в программе. Как вывести эту информацию на экран “человеческим” образом? Для этого нужно использовать конкатенацию строк.
Условно запишем значения переменных, как будто мы их знаем
year = 1950 pop = 1850
s1 = "Максимальная численность населения в Детройте пришлась на" s2 = "год и составила" s3 = "тыс. чел" s = paste(s1, year, s2, pop, s3) s ## [1] "Максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. чел"
Обратите внимание на то что мы конкатенировали строки с числами. Конвертация типов осуществилась автоматически. Помимо этого, функция сама вставила пробелы между строками.
Функция
paste()содержит параметрsep, отвечающий за символ, который будет вставляться между конкатенируемыми строками.sep = " ", то есть, между строками будет вставляться пробел. Подобное поведение желательно не всегда. Например, если после переменной у вас идет запятая, то между ними будет вставлен пробел. В таком случае при вызовеpaste()необходимо указатьsep = "", то есть пустую строку:paste(... sep = ""). Вы также можете воспользоваться функциейpaste0(), которая делает [почти] то же самое, что иpaste(..., sep = ""), но избавляет вас от задания параметраsep.
 По умолчанию
По умолчанию 1.1.3 Даты и длительности
Для работы с временными данными в R существуют специальные типы. Чаще всего используются даты, указанные с точностью до дня. Такие данные имеют тип Date, а для их создания используется функция as.Date(). В данном случае точка — это лишь часть названия функции, а не какой-то особый оператор. В качестве аргумента функции необходимо задать дату, записанную в виде строки. Запишем дату рождения автора (можете заменить ее на свою):
Запишем дату рождения автора (можете заменить ее на свою):
birth = as.Date('1986/02/18')
birth
## [1] "1986-02-18"Сегодняшнюю дату вы можете узнать с помощью специальной функции Sys.Date():
current = Sys.Date() current ## [1] "2022-08-23"
Даты можно вычитать. Результатом выполнения. Например, узнать продолжительность жизни в днях можно так:
livedays = current - birth livedays ## Time difference of 13335 days
Вы также можете прибавить к текущей дате некоторое значение. Например, необходимо узнать, какая дата будет через 40 дней:
current + 40 ## [1] "2022-10-02"
Имея дату, вы можете легко извлечь из нее день, месяц и год. Существуют специальные функции для этих целей (описанные в главе 8), но прямо сейчас вы можете сделать это сначала преобразовав дату в строку, а затем выбрав из нее подстроку, соответствующую требуемой компоненте даты:
cdate = as.character(current) substr(cdate, 1, 4) # Год ## [1] "2022" substr(cdate, 6, 7) # Месяц ## [1] "08" substr(cdate, 9, 10) # День ## [1] "23"
Более подробно о преобразованиях типов, аналогичных функции as., используемой в данном примере, рассказано далее в настоящей главе. character()
character()
1.1.4 Время и периоды
1.1.5 Логические
Логические переменные возникают там, где нужно проверить условие. Переменная логического типа может принимать значение TRUE (истина) или FALSE (ложь). Для их обозначения также возможны более компактные константы T и F соответственно.
Следующие операторы приводят к возникновению логических переменных:
- РАВНО (
==) — проверка равенства операндов - НЕ РАВНО (
!=) — проверка неравенства операндов - МЕНЬШЕ (
<) — первый аргумент меньше второго - МЕНЬШЕ ИЛИ РАВНО (
<=) — первый аргумент меньше или равен второму - БОЛЬШЕ (
>) — первый аргумент больше второго - БОЛЬШЕ ИЛИ РАВНО (
>=) — первый аргумент больше или равен второму
Посмотрим, как они работают:
a = 1 b = 2 a == b ## [1] FALSE a != b ## [1] TRUE a > b ## [1] FALSE a < b ## [1] TRUE
Если необходимо проверить несколько условий одновременно, их можно комбинировать с помощью логических операторов. Наиболее популярные среди них:
Наиболее популярные среди них:
- И (
&&) — проверка истинности обоих условий - ИЛИ (
||) — проверка истинности хотя бы одного из условий - НЕ (
!) — отрицание операнда (истина меняется на ложь, ложь на истину)
c = 3 (b > a) && (c > b) ## [1] TRUE (a > b) && (c > b) ## [1] FALSE (a > b) || (c > b) ## [1] TRUE !(a > b) ## [1] TRUE
Более подробно работу с логическими переменными мы разберем далее при знакомстве с условным оператором if.
1.2 Манипуляции с типами
1.2.1 Определение типа данных
Определение типа данных осуществляется с помощью функции class() (см. раздел Диагностические функции во Введении)
class(1)
## [1] "numeric"
class(0.5)
## [1] "numeric"
class(1 + 2i)
## [1] "complex"
class("sample")
## [1] "character"
class(TRUE)
## [1] "logical"
class(as.Date('1986-02-18'))
## [1] "Date"В вышеприведенном примере видно, что R по умолчанию “повышает” ранг целочисленных данных до более общего типа чисел с плавающей точкой, тем самым закладываясь на возможность точного деления без остатка. Если вы хотите, чтобы данные в явном виде интерпретировались как целочисленные, их нужно принудительно привести к этому типу. Операторы преобразования типов рассмотрены ниже.
Если вы хотите, чтобы данные в явном виде интерпретировались как целочисленные, их нужно принудительно привести к этому типу. Операторы преобразования типов рассмотрены ниже.
1.2.2 Преобразование типов данных
Преобразование типов данных осуществляется с помощью функций семейства as(d, type), где d — это входная переменная, а type — название типа данных, к которому эти данные надо преобразовать (см. таблицу в начале главы). Несколько примеров:
k = 1 print(k) ## [1] 1 class(k) ## [1] "numeric" l = as(k, "integer") print(l) ## [1] 1 class(l) ## [1] "integer" m = as(l, "character") print(m) ## [1] "1" class(m) ## [1] "character" n = as(m, "numeric") print(n) ## [1] 1 class(n) ## [1] "numeric"
Для функции as() существуют обертки (wrappers), которые позволяют записывать такие преобразования более компактно и выглядят как as.<dataype>(d), где datatype — название типа данных:
k = 1 l = as.
 integer(k)
print(l)
## [1] 1
class(l)
## [1] "integer"
m = as.character(l)
print(m)
## [1] "1"
class(m)
## [1] "character"
n = as.numeric(m)
print(n)
## [1] 1
class(n)
## [1] "numeric"
d = as.Date('1986-02-18')
print(d)
## [1] "1986-02-18"
class(d)
## [1] "Date"
integer(k)
print(l)
## [1] 1
class(l)
## [1] "integer"
m = as.character(l)
print(m)
## [1] "1"
class(m)
## [1] "character"
n = as.numeric(m)
print(n)
## [1] 1
class(n)
## [1] "numeric"
d = as.Date('1986-02-18')
print(d)
## [1] "1986-02-18"
class(d)
## [1] "Date"Если преобразовать число c плавающей точкой до целого, то дробная часть будет отброшена:
as.integer(2.7) ## [1] 2
После преобразования типа данных, разумеется, к переменной будут применимы только те функции, которые определены для данного типа данных:
a = 2.5 b = as.character(a) b + 2 ## Error in b + 2: нечисловой аргумент для бинарного оператора nchar(b) ## [1] 3
1.2.3 Проверка типов данных и пустых значений
Для проверки типа данных можно использовать функции семейства is.<datatype>:
is.integer(2.7)
## [1] FALSE
is.numeric(2.7)
## [1] TRUE
is.character('Привет!')
## [1] TRUEОсобое значение имеют функции проверки пустых переменных (имеющих значение NA — not available), которые могут получаться в результате несовместимых преобразований или соответствовать пропускам в исходных данных:
as.
 integer('Привет!')
## [1] NA
is.na(as.integer('Привет!'))
## [1] TRUE
integer('Привет!')
## [1] NA
is.na(as.integer('Привет!'))
## [1] TRUE1.3 Ввод и вывод данных в консоли
1.3.1 Ввод данных
Для ввода данных через консоль можно воспользоваться функцией readline(), которая будет ожидать пользовательский ввод и нажатие клавиши Enter, после чего вернет введенные данные в виде строки. Предположим, пользователь вызывает эту функцию и вводит с клавиатуры 1024:
a = readline()
Выведем результат на экран:
a ## [1] "1024"
Функция
readline()всегда возвращает строку, поэтому если вы ожидаете ввод числа, полученное значение необходимо явным образом преобразовать к числовому типу.
Весьма полезной особенностью readline() является возможность указания строки запроса (чтобы пользователь понимал, что от него хотят). Строку запроса можно указать при вызове функции:
lat = readline('Введите широту точки:')
## Введите широту точки:
## 54
lat
## [1] "54"1.
 3.2 Вывод данных
3.2 Вывод данныхДля вывода данных в консоль можно воспользоваться тремя способами:
- Просто напечатать название переменной с новой строки (не работает при запуске программы командой
Source) - Вызвать функцию
print() - Вызвать функцию
cat() - Заключить выражение в круглые скобки
()
Первый способ мы уже регулярно использовали ранее в настоящей главе. Следует обратить внимание на то, что он хорош для отладки программы, но выглядит некрасиво в рабочих программах, поскольку просто печатая название переменной с новой строки вы как бы явно не говорите о том, что хотите вывести ее значение в консоль, а лишь подразумеваете это. Более того, если скрипт запускается командой Source, данный метод вывода переменной просто не сработает, интерпретатор его проигнорирует.
Поэтому после отладки следует убрать из программы все лишние выводы в консоль, а оставшиеся (действительно нужные) оформить с помощью функций print() или cat(). 10))
## [1] «2 в степени 10 равно 1024»
print(paste(«Сегодняшняя дата — «, Sys.Date()))
## [1] «Сегодняшняя дата — 2022-08-23»
10))
## [1] «2 в степени 10 равно 1024»
print(paste(«Сегодняшняя дата — «, Sys.Date()))
## [1] «Сегодняшняя дата — 2022-08-23»
Функция cat() отличается от print() следующими особенностями:
-
cat()выводит значение переменной, и не печатает ее измерения и внешние атрибуты типа двойных кавычек вокруг строки. Это означает, чтоcat()можно использовать и для записи данных в файл (на практике этим мало кто пользуется, но знать такую возможность надо). -
cat()принимает множество аргументов и может осуществлять конкатенацию строк аналогично функции paste() -
cat()не возвращает никакого значений, в то время какprint()возвращает значение, переданное ей в качестве аргумента. -
cat()можно использовать только для атомарных типов данных. Для классов (таких как Date) она будет выводит содержимое объекта, которое может не совпадать с тем, что пользователь ожидает вывести
Например:
cat(a)
## 1024
cat(b)
## Fourty winks in progress
cat("2 в степени 10 равно", 2^10)
## 2 в степени 10 равно 1024
cat("Сегодняшнаяя дата -", Sys. Date())
## Сегодняшнаяя дата - 19227 Date())
## Сегодняшнаяя дата - 19227
Date())
## Сегодняшнаяя дата - 19227Можно видеть, что в последнем случае cat() напечатала отнюдь не дату в ее привычном представлении, а некое число, которое является внутренним представлением даты в типе данных Date. Такие типы данных являются классами объектов в R, и у них есть своя функция print(), которая и выдает содержимое объекта в виде, который ожидается пользователем. Поэтому пользоваться функцией cat() надо с некоторой осторожностью.
Заключительная возможность — вывод с помощью заключения выражения в круглые скобки — очень удобна на стадии отладки программы. При этом переменная, которая создается в выражении, остается доступной в программе:
(a = rnorm(5)) # сгенерируем 5 случайных чисел, запишем их в переменную a и выведем на экран ## [1] -3.740944 2.263287 -1.012359 1.370046 -1.102049 (b = 2 * a) # переменная a доступна, ее можно использовать и далее для вычислений ## [1] -7.481888 4.526573 -2.024718 2.
 740092 -2.204099
740092 -2.2040991.4 Условный оператор
Проверка условий позволяет осуществлять так называемое ветвление в программе. Ветвление означает, что при определенных условиях (значениях переменных) будет выполнен один программный код, а при других условиях — другой. В R для проверки условий используется условный оператор if — else if — else следующего вида:
if (condition) {
statement1
} else if (condition) {
statement2
} else {
statement3
}Сначала проверяется условие в выражении if (condition), и если оно истинно, то выполнится вложенный в фигурные скобки программный код statement1, после чего оставшиеся условия не будут проверяться. Если первое условие ложно, программа перейдет к проверке следующего условия else if (condition). Далее, если оно истинно, то выполнится вложенный код statement2, если нет — проверка переключится на следующее условие и так далее. Заключительный код statement3, следующий за словом else, выполнится только если ложными окажутся все предыдущие условия.
Конструкций
else ifможет быть произвольное количество, конструкцииifиelseмогут встречаться в условном операторе только один раз, в начале и конце соответственно. При этом условный оператор может состоять только из конструкцииif, аelse ifиelseне являются обязательными.
Например, сгенерируем случайное число, округлим его до одного знака после запятой и проверим относительно нуля:
(a = round(rnorm(1), 1))
## [1] -0.1
if (a < 0) {
cat('Получилось отрицательное число!')
} else if (a > 0) {
cat('Получилось положительное число!')
} else {
cat('Получился нуль!')
}
## Получилось отрицательное число!Условия можно использовать, в частности, для того чтобы обрабатывать пользовательский ввод в программе. Например, охарактеризуем положение точки относительно Полярного круга:
phi = as.numeric(readline('Введите широту вашей точки:'))Пользователь вводит 68, а мы оцениваем результат:
if (!is.
 na(phi)) { # проверяем, является ли введенное значение числом
if (abs(phi) >= 66.562 && abs(phi) <= 90) { # выполняем проверку на заполярность
cat('Точка находится в Заполярье')
} else {
cat('Точка не находится в Заполярье')
}
} else {
cat('Необходимо ввести число!') # оповещаем о некорректном вводе
}
## Точка находится в Заполярье
na(phi)) { # проверяем, является ли введенное значение числом
if (abs(phi) >= 66.562 && abs(phi) <= 90) { # выполняем проверку на заполярность
cat('Точка находится в Заполярье')
} else {
cat('Точка не находится в Заполярье')
}
} else {
cat('Необходимо ввести число!') # оповещаем о некорректном вводе
}
## Точка находится в Заполярье1.5 Оператор переключения
Оператор переключения (switch) является удобной заменой условному оператору в тех случаях, когда надо вычислить значение переменной в зависимости от значения другой переменной, которая может принимать ограниченное (заранее известное) число значений. Например:
name = readline('Введите название федерального округа:')Пользователь вводит:
Приволжский
# Определим центр в зависимости от названия:
capital = switch(name,
'Центральный' = 'Москва',
'Северо-Западный' = 'Санкт-Петербург',
'Южный' = 'Ростов-на-Дону',
'Северо-Кавказский' = 'Пятигорск',
'Приволжский' = 'Нижний Новгород',
'Уральский' = 'Екатеринбург',
'Сибирский' = 'Новосибирск',
'Дальневосточный' = 'Хабаровск')
print(capital)
## [1] "Нижний Новгород"1.
 6 Прерывание программы
6 Прерывание программыВ процессе выполнения программы могут возникнуть ситуации, при которых дальнейшее выполнение программы невозможно или недопустимо. Например, пользователь вместо числа ввёл в консоли букву. Хорошим тоном разработчика в данном случае будет не пускать ситуацию на самотёк и ждать пока программа сама споткнется и выдаст системное сообщение об ошибке, а обработать некорректный ввод сразу, сообщить об этом пользователю и остановить программу явным образом.
Прервать выполнение программы можно разными способами. Рассмотрим две часто используемые для этого функции:
-
stop(...)выводит на экран объекты, перечисленные через запятую в...и завершает выполнение программы. При ручном вызове этой функции в...целесообразно передать текстовую строку с сообщением о причине остановки программы. Вызовstop()происходит обычно после проверки некоторого условия операторомif-else. -
stopifnot(.? 2) # возведем в квадрат и выведем на экран, если все ОКВывод программы в случае ввода строки
abcбудет следующим:## Error in eval(expr, envir, enclos): Введенная строка не является числом
1.7 Технические детали
Когда вы присваиваете значение переменной другой переменной, копирования не происходит. Оба имени будут ссылаться на один и тот же объект, до тех пор, пока через одно из имен не будет предпринята попытка модифицировать объект. Это можно легко проверить с помощью функции
tracemem():a = 1 b = a cat('a:', tracemem(a), '\n') ## a: <0x7fca5b0295f0> cat('b:', tracemem(b), '\n') ## b: <0x7fca5b0295f0> a = 2 cat('a:', tracemem(a), '\n') # объект скопирован в другую область памяти ## a: <0x7fca5b0292e0> cat('b:', tracemem(b), '\n') ## b: <0x7fca5b0295f0>Подобное поведение называется copy-on-modify. Оно позволяет экономить на вычислениях в случае, когда копия и оригинал остаются неизменными.
Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019).1.8 Краткий обзор
Для просмотра презентации щелкните на ней один раз левой кнопкой мыши и листайте, используя кнопки на клавиатуре:
Презентацию можно открыть в отдельном окне или вкладке браузере. Для этого щелкните по ней правой кнопкой мыши и выберите соответствующую команду.
1.9 Контрольные вопросы и упражнения
1.9.1 Вопросы
- Какие типы данных поддерживаются в R? Каковы их англоязычные наименования?
- Что такое переменная?
- Какой оператор используется для записи значения в переменную?
- С помощью какой функции можно узнать тип переменной?
- С помощью какого семейства функций можно преобразовывать типы переменных?
- Можно ли использовать ранее созданное имя переменной для хранения новых данных другого типа?
- Можно ли записать в переменную результат выполнения выражения, в котором она сама же и участвует?
- Какая функция позволяет прочитать пользовательский ввод с клавиатуры в консоли? Какой тип данных будет иметь возвращаемое значение?
- Какую функцию можно использовать для вывода значения переменной в консоль? Чем отличается использование этой функции от случая, когда вы просто пишете название переменной в строке программы?
- Какой символ является разделителем целой и дробной части при записи чисел с плавающей точкой?
- Что такое операторы и операнды? Приведите примеры бинарных и унарных операторов. , **
- Как проверить, является ли число четным?
- Как определить количество символов в строке?
- Как называется операция состыковки нескольких строк и с помощью какой функции она выполняется? Как добиться того, чтобы при этом не добавлялись пробелы между строками?
- С помощью какой функции можно создать дату из строки?
- Как извлечь из даты год? Месяц? День?
- Какая функция позволяет получить дату сегодняшнего дня?
- Можно ли складывать даты и числа? Если да, то в каких единицах измерения будет выражен результат?
- Какова краткая форма записи логических значений
TRUEиFALSE? - Каким числам соответствуют логические значения
TRUEиFALSE? - Сколько операндов должно быть верно, чтобы оператор логического И (
&&) принял значениеTRUE? Что можно сказать в этом отношении об операторе ИЛИ (||)? - Можно ли применять арифметические операции к логическим переменным? Что произойдет, если прибавить или вычесть из числа
aзначениеTRUE? А если заменитьTRUEнаFALSE? - Что такое условный оператор и для каких сценариев обработки данных необходимы условные операторы?
- Перечислите ключевые слова, которые могут быть использованы для организации условных операторов
- При каких сценариях целесообразно использовать оператор переключения?
Запишите условие проверки неравенства чисел
aиbне менее чем тремя способами.Напишите программу, которая запрашивает в консоли целое число и определяет, является ли оно чётным или нечетным. Программа должна предварительно определить, является ли введенное число а) числом и б) целым числом.
Подсказка: результат конвертации строки в целое число и число с плавающей точкой отличается. Вы можете использовать это для проверки, является ли введенное число целым.
Напишите программу, которая считывает из консоли введенную пользователем строку и выводит в консоль количество символов в этой строке. Вывод оформите следующим образом:
"Длина введенной строки равняется ... символам", где вместо многоточия стоит вычисленная длина.В программе в виде переменных задайте координаты населенного пункта А (
x1, y1), а также дирекционный уголDи расстояниеLдо населенного пункта B. Напишите код, который определяет координаты населенного пункта B (x2, y2).Функция
atan2()позволяет найти математический азимут (полярный угол), если известны координаты вектора между двумя точками. Используя эту функцию, напишите программу, которая вычисляет географический азимут между точками А (x1, y1) и B (x2, y2). Координаты точек задайте в виде переменных непосредственно в коде.Математический азимут отсчитывается от направления на восток против часовой стрелки. Географический азимут отсчитывается от направления на север по часовой стрелке).
- Описать роль случайной выборки и случайного распределения в выводах о причинно-следственных связях
- Это 14-летнее исследование, проведенное учеными из Национального института рака.
- Результаты были опубликованы в июньском номере журнала .Медицинский журнал Новой Англии , уважаемый рецензируемый журнал.
- В ходе исследования было изучено потребление кофе более чем 402 000 человек в возрасте от 50 до 71 года из шести штатов и двух мегаполисов. В начале исследования исключались люди с раком, сердечными заболеваниями и инсультом. Потребление кофе оценивали один раз в начале исследования.
- В ходе исследования умерло около 52 000 человек.
- Люди, которые выпивали от двух до пяти чашек кофе в день, также показали более низкий риск, но степень снижения увеличилась у тех, кто выпивал шесть и более чашек.
- Размеры выборки были довольно большими, поэтому значения p довольно малы, даже несмотря на то, что процентное снижение риска было не очень большим (вероятность снизилась с 12% до примерно 10–11%).
- Независимо от того, был ли кофе с кофеином или без кофеина, это не влияло на результаты.
- Это было обсервационное исследование, поэтому нельзя сделать никаких причинно-следственных выводов между употреблением кофе и увеличением продолжительности жизни, вопреки тому впечатлению, которое создается во многих заголовках новостей об этом исследовании. В частности, возможно, что люди с хроническими заболеваниями не склонны пить кофе.
- Видео о p-значениях: P-Value Extravaganza
- Интерактивные веб-приложения для статистики преподавания и обучения
- Межуниверситетский консорциум политических и социальных исследований, где вы можете находить и анализировать данные.
- Консорциум по развитию статистики бакалавриата
- Найдите недавнюю исследовательскую статью в своей области и ответьте на следующие вопросы: Каков был основной исследовательский вопрос? Как отбирались люди для участия в исследовании? Были ли представлены сводные результаты? Насколько сильны доказательства, представленные в пользу или против вопроса исследования? Было ли использовано случайное распределение? Обобщите основные выводы исследования, касающиеся вопросов статистической значимости, статистической достоверности, обобщаемости и причины и следствия. Согласны ли вы с выводами, сделанными в этом исследовании, на основе дизайна исследования и представленных результатов?
- Разумно ли использовать случайную выборку из 1000 человек, чтобы сделать выводы обо всех взрослых в США? Объясните, почему да или почему нет.
- Расчет и интерпретация коэффициента корреляции
- Символ коэффициента корреляции населения — ρ , греческая буква «ро».
- ρ = коэффициент корреляции населения (неизвестно)
- r = выборочный коэффициент корреляции (известный; рассчитан на основе выборочных данных)
- Если r является значимым и точечная диаграмма показывает линейный тренд, линия может использоваться для прогнозирования значения y для значений x , которые находятся в пределах наблюдаемых значений x .
- Если r не является значимым ИЛИ если точечная диаграмма не показывает линейного тренда, линию не следует использовать для прогнозирования.
- Если r является значимым и если точечная диаграмма показывает линейный тренд, линия НЕ может быть подходящей или надежной для прогнозирования ВНЕ области наблюдаемых значений x в данных.
- Нулевая гипотеза: H 0 : ρ = 0
- Альтернативная гипотеза: H a : ρ ≠ 0
- Нулевая гипотеза H 0 : Коэффициент корреляции населения НЕ ОТЛИЧАЕТСЯ существенно от нуля. НЕТ существенной линейной зависимости (корреляции) между x и y в популяции.
- Альтернативная гипотеза H a : Коэффициент корреляции населения значительно ОТЛИЧАЕТСЯ ОТ нуля. СУЩЕСТВУЕТ ЗНАЧИТЕЛЬНАЯ ЛИНЕЙНАЯ ЗАВИСИМОСТЬ (корреляция) между x и y в популяции.
- Метод 1: Использование значения p
- Метод 2: Использование таблицы критических значений
- Экран вывода показывает значение p в строке, которая читается как «p =».
- (Большинство компьютерных статистических программ могут рассчитать значение p .)
 2) # возведем в квадрат и выведем на экран, если все ОК
2) # возведем в квадрат и выведем на экран, если все ОК Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019).
Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019). , **
, **1.
 9.2 Упражнения
9.2 Упражнения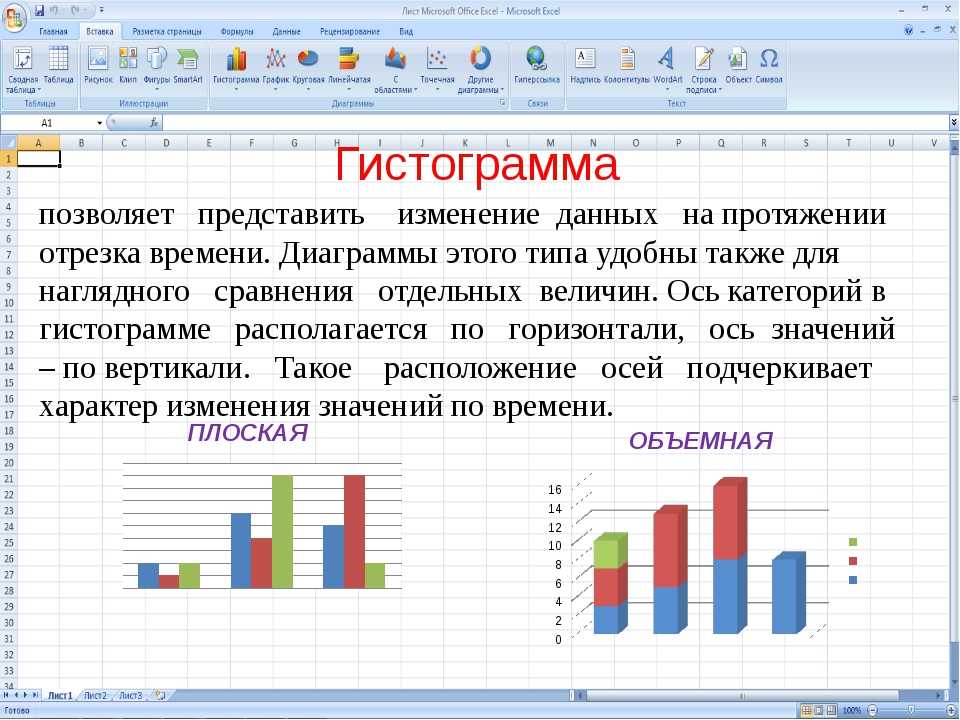 Напишите код, который определяет координаты населенного пункта B (
Напишите код, который определяет координаты населенного пункта B (| Самсонов Т.Е. Визуализация и анализ географических данных на языке R. М.: Географический факультет МГУ, 2022. DOI: 10.5281/zenodo.901911 |
Введение
2 Структуры данных
Несоответствия цифр и прописных значений в договоре
Нередко в гражданско-правовом договоре такие числовые значения как цена, срок или размер неустойки, указанные одновременно цифрами и прописью, противоречат друг другу. Любой, кто сталкивается с подобной ситуацией, задается только одним вопросом: какое значение будет приоритетным и почему? Попробуем разобраться.
Любой, кто сталкивается с подобной ситуацией, задается только одним вопросом: какое значение будет приоритетным и почему? Попробуем разобраться.
Законодательство
Действующее законодательство не имеет общего императивного правила, которое бы обязывало стороны гражданско-правового договора указывать числовые значения в договоре одновременно цифрами и прописью (в качестве исключения можно привести разве что требования к нотариальной форме договора, предусмотренные ч. 4 ст. 45.1 Основ законодательства РФ о нотариате), как и не имеет общего прямого правила на случай возникновения несоответствия между цифрами и прописными значениями в договоре.
Норму, которая бы прямо регулировала вопрос устранения несоответствия цифр и прописных значений в отечественном законодательстве можно встретить разве что в п. 6 Положения о переводном и простом векселе, утвержденном Постановлением ЦИК СССР и СНК СССР от 07.08.1937 № 104/1341, в котором указано, что если сумма переводного векселя обозначена и прописью и цифрами, то в случае разногласия между этими обозначениями вексель имеет силу на сумму, обозначенную прописью, а если в переводном векселе сумма обозначена несколько раз, либо прописью, либо цифрами, то в случае разногласия между этими обозначениями вексель имеет силу лишь на меньшую сумму.
В отношении гражданско-правовых договоров действуют правила ст. 431 ГК РФ, которых теоретически должно быть достаточно для решения вопроса несоответствия цифр и прописных значений в договоре, однако на практике данной нормой пользуются далеко не всегда.
Судебная практика
В судебной практике по вопросу несоответствия цифр и прописных значений в договоре существует две позиции судов:
Позиция № 1. Противоречие между значением, указанным в договоре цифрами и прописью, устраняется путем признания приоритета за значением, указанным прописью.
Стоит отметить, что суды по-разному мотивируют данную позицию и поэтому признаку все судебные акты можно разделить на три следующие группы:
Группа № 1
Признание числового значения, указанного прописью, в качестве приоритетного является общеизвестным и широко применяемым обычаем, которое не нуждается в доказывании.
Примечание: в одном из нижеприведенных судебных актов суд освятил историю, указав: «Обычай указывать в документах сумму прописью сложился из исторических предпосылок распространения арабских цифр, датированное периодом XIV в. То есть, данный обычай возник более 700 лет назад в связи с необходимостью затруднения ошибки/обмана/подделки, с использованием арабских цифр. Данный обычай получил широкое распространение и применяется во всех сферах, связанных с документооборотом…Таким образом, несмотря на то, что при заключении гражданско-правовых договоров стороны нормативно не обязаны указывать цену договора и прочие суммы цифрами и прописью, данный обычай укоренился в практике делового оборота и применяется повсеместно. Более 700 лет практики делового оборота сформировали в массовом сознании четкие и недвусмысленные правила написания денежных сумм и порядок разрешения несоответствия цифр и прописных значений…».
Судебная практика:
Группа № 2
Противоречия между значениями, указанными прописью и цифрами, устраняются по аналогии закона (ст. 6 ГК РФ) с применением п. 6 Положения о переводном и простом векселе, утвержденного Постановлением ЦИК и СНК СССР от 7 августа 1937 г. № 104/1341, путем признания приоритета за значением, указанным прописью.
6 ГК РФ) с применением п. 6 Положения о переводном и простом векселе, утвержденного Постановлением ЦИК и СНК СССР от 7 августа 1937 г. № 104/1341, путем признания приоритета за значением, указанным прописью.
Судебная практика:
Группа № 3
Суды никак не мотивируют свою позицию, сухо указывая на приоритет прописи перед цифрами.
Судебная практика:
Логика позиции судов, которые признают приоритет за прописью мне понятна – указывая числовое значение словами (прописью) допустить ошибку сложнее, ошибиться в цифре гораздо легче, поскольку у значений, указанных прописью, всегда больше взаимосвязанных символов, чем у значений, указанных цифрами. Кроме того, значения, указанные прописью, хуже поддаются допискам и исправлениям.
Между тем, приведенная логика, на мой взгляд, работает только тогда, когда текст договора воспроизводится человеком собственноручно чернилами на бумаге, т. е. когда человек последовательно от руки наносит числовое значение сначала цифрами, а потом словами. В этом случае действительно можно говорить о том, что определяющим значением является то, которое указано прописью.
е. когда человек последовательно от руки наносит числовое значение сначала цифрами, а потом словами. В этом случае действительно можно говорить о том, что определяющим значением является то, которое указано прописью.
Но что, если текст договора создается в электронном текстовом редакторе? Ни для кого не секрет, что сейчас тексты договоров не печатают с чистого листа, а используют заготовленные шаблоны. В таких условиях невозможно установить последовательность набора значений, а значит нельзя утверждать, что значение, указанное прописью должно иметь приоритет. В отличии от создания текста договора на бумаге от руки, текст договора в электронном виде до печати можно редактировать, составлять договор на компьютере можно в любой последовательности, копируя и вставляя отдельные слова и предложения, текст договора в электронном виде может передаваться от одной стороне другой и обратно, меняться ими, в результате чего в нем могут появиться несоответствия цифр и прописных значений. По этим причинам я полагаю, что касательно документов, созданных в электронном текстовом редакторе, вероятность ошибки одинакова как для значений, указанных цифрами, так и для значений, указанных словами, ввиду чего применение обычая, устоявшегося для рукописной формы документа, в данном случае не усметно.
Позиция № 2. Противоречие между значением, указанным в договоре цифрами и прописью, устраняется путем признания приоритета за значением, которое стороны действительно имели ввиду при заключении договора, а если действительную волю сторон установить невозможно, то соответствующее условие договора считается несогласованным.
Судебная практика:
Отдельного внимания, я считаю, заслуживает феноменальное Решение Арбитражного суда Республики Мордовия от 02.06.2015 по делу № А39-637/2015, в котором суд специфически обосновал приоритет цифрового значения над прописью:
«Как следует из пункта 4.1 договора, указанный в нем размер процентов за пользование суммой займа, а именно цифровое значение (15%) не совпадает с указанной в скобках словесной расшифровкой (восемнадцать процентов).
В силу статьи 431 ГК РФ при толковании условий договора судом должно приниматься во внимание буквальное значение содержащихся в нем слов и выражений.
Исходя из того, что указанное в договоре цифровое значение размера процентов предшествует его словесной расшифровке, суд считает необходимым применять именно первое выражение воли сторон по данному поводу- 15%».
Выводы
Важно всегда особо тщательно проверять условия договора, указанные одновременно цифрами и прописью, чтобы не допустить между ними противоречий. Также не стоит забывать, что подобные противоречия могут быть включены в текст договора намеренно одной из сторон, чтобы в будущем извлечь из этого свою выгоду.
Так, например, поставщик может намеренно указать в договоре поставки цифрами и прописью разный размер неустойки за нарушение срока поставки товаров (прописью, например укажет неустойку в значительно меньшем размере), после чего в случае спора заявит, что соглашение о неустойке не достигнуто и потому она не подлежит взысканию. В такой ситуации, при самом неблагоприятном для поставщика сценарии неустойка будет взыскана в том размере, который указан прописью, а при самом благоприятном не будет взыскана вообще.
Выводы из статистики | Введение в психологию
Цели обучения
Обобщаемость
Рисунок 1 . Обобщаемость является важным исследовательским соображением: результаты исследований с широко репрезентативными выборками с большей вероятностью будут обобщены на популяцию. [Изображение: Бюджетное жилье Barnacles]
Одним из ограничений исследования, упомянутого ранее о младенцах, выбирающих игрушку-помощника, является то, что вывод относится только к 16 младенцам, участвовавшим в исследовании. Мы мало знаем о том, как были отобраны эти 16 младенцев. Предположим, мы хотим выбрать подмножество индивидуумов (выборка ) из гораздо большей группы индивидуумов (популяция ) таким образом, чтобы выводы из выборки могли быть обобщены на большую совокупность. С этим вопросом каждый день сталкиваются социологи.
Пример 1 : Общее социальное исследование (GSS) — это исследование социальных тенденций, проводимое раз в два года в Соединенных Штатах. Основываясь на выборке из примерно 2000 взрослых американцев, исследователи делают заявления о том, какой процент населения США считает себя «либералом», какой процент считает себя «счастливым», какой процент чувствует себя «торопливым» в своей повседневной жизни и многое другое. вопросы. Ключ к этим заявлениям о большей численности всех взрослых американцев лежит в том, как отбирается выборка. Цель состоит в том, чтобы выбрать выборку, которая является репрезентативной для населения, и общий способ достижения этой цели состоит в том, чтобы выбрать случайная выборка , которая дает каждому члену совокупности равные шансы попасть в выборку. В своей простейшей форме случайная выборка включает нумерацию каждого члена населения, а затем использование компьютера для случайного выбора подмножества для обследования. Большинство опросов не работают точно так же, но они используют методы выборки, основанные на вероятности, для отбора лиц из репрезентативных на национальном уровне групп.
Большинство опросов не работают точно так же, но они используют методы выборки, основанные на вероятности, для отбора лиц из репрезентативных на национальном уровне групп.
В 2004 году СОБ сообщила, что 817 из 977 респондентов (или 83,6%) указали, что они всегда или иногда чувствуют спешку. Это явное большинство, но нам снова нужно учитывать вариацию из-за случайная выборка . К счастью, мы можем использовать ту же вероятностную модель, что и в предыдущем примере, для исследования вероятного размера этой ошибки. (Обратите внимание: мы можем использовать модель подбрасывания монеты, когда фактический размер популяции намного, намного больше, чем размер выборки, так как тогда мы все еще можем считать вероятность одинаковой для каждого человека в выборке.) Эта вероятностная модель предсказывает что результат выборки будет в пределах 3 процентных пунктов от значения генеральной совокупности (примерно 1 на квадратный корень размера выборки, погрешность ). Статистики пришли бы к выводу с уверенностью 95%, что от 80,6% до 86,6% всех взрослых американцев в 2004 году ответили бы, что они иногда или всегда чувствуют спешку.
Статистики пришли бы к выводу с уверенностью 95%, что от 80,6% до 86,6% всех взрослых американцев в 2004 году ответили бы, что они иногда или всегда чувствуют спешку.
Ключом к допустимой погрешности является то, что, когда мы используем метод вероятностной выборки, мы можем делать заявления о том, как часто (в долгосрочной перспективе, с повторной случайной выборкой) результат выборки будет находиться в пределах определенного расстояния от неизвестной совокупности. значение случайно (имеется в виду случайное отклонение выборки) в одиночку. И наоборот, неслучайные выборки часто вызывают предвзятость, что означает, что метод выборки систематически завышает некоторые сегменты населения и занижает другие. Нам также все еще необходимо учитывать другие источники предвзятости, такие как нечестные ответы отдельных лиц. Эти источники ошибок не измеряются пределом погрешности.
Попробуйте
Причина и следствие
Во многих исследованиях основной вопрос, представляющий интерес, касается различий между группами. Затем возникает вопрос, как формировались группы (например, отбирали людей, которые уже пьют кофе, и тех, кто не пьет). В некоторых исследованиях исследователи сами активно формируют группы. Но тогда у нас возникает аналогичный вопрос: могут ли любые различия, которые мы наблюдаем в группах, быть артефактом этого процесса формирования групп? Или, может быть, разница, которую мы наблюдаем в группах, настолько велика, что мы можем не принимать во внимание «случайность» в процессе формирования группы как разумное объяснение того, что мы обнаруживаем?
Затем возникает вопрос, как формировались группы (например, отбирали людей, которые уже пьют кофе, и тех, кто не пьет). В некоторых исследованиях исследователи сами активно формируют группы. Но тогда у нас возникает аналогичный вопрос: могут ли любые различия, которые мы наблюдаем в группах, быть артефактом этого процесса формирования групп? Или, может быть, разница, которую мы наблюдаем в группах, настолько велика, что мы можем не принимать во внимание «случайность» в процессе формирования группы как разумное объяснение того, что мы обнаруживаем?
Пример 2 : В психологическом исследовании изучалось, склонны ли люди проявлять больше творчества, когда они думают о внутренней (внутренней) или внешней (внешней) мотивации (Ramsey & Schafer, 2002, на основе исследования Amabile, 1985). Испытуемыми были 47 человек с большим опытом писательской деятельности. Испытуемые начали с ответов на вопросы анкеты о внутренних мотивах писательства (таких как удовольствие от самовыражения) или внешних мотивах (таких как общественное признание). Затем всем испытуемым было предложено написать хайку, и эти стихи были оценены жюри на предмет творчества. Исследователи заранее предположили, что испытуемые, которые думали о внутренних мотивах, будут проявлять больше творчества, чем испытуемые, которые думали о внешних мотивах. Показатели креативности 47 испытуемых в этом исследовании показаны на рисунке 2, где более высокие баллы указывают на большую креативность.
Затем всем испытуемым было предложено написать хайку, и эти стихи были оценены жюри на предмет творчества. Исследователи заранее предположили, что испытуемые, которые думали о внутренних мотивах, будут проявлять больше творчества, чем испытуемые, которые думали о внешних мотивах. Показатели креативности 47 испытуемых в этом исследовании показаны на рисунке 2, где более высокие баллы указывают на большую креативность.
Рисунок 2 . Оценки креативности разделены по типу мотивации.
В этом примере ключевой вопрос заключается в том, влияет ли тип мотивации на баллов креативности. В частности, имеют ли испытуемые, которых спрашивали о внутренней мотивации, более высокие показатели креативности, чем у испытуемых, которых спрашивали о внешней мотивации?
Рисунок 2 показывает, что в обеих мотивационных группах наблюдалась значительная вариабельность оценок креативности, и эти оценки в значительной степени перекрываются между группами. Другими словами, люди с внешней мотивацией не всегда обладают более высоким творческим потенциалом, чем люди с внутренней мотивацией, но статистические различия все же могут быть. 0029 тенденция в этом направлении. (Психолог Кит Станович (2013) называет трудности людей с размышлениями о таких вероятностных тенденциях «ахиллесовой пятой человеческого познания».)
0029 тенденция в этом направлении. (Психолог Кит Станович (2013) называет трудности людей с размышлениями о таких вероятностных тенденциях «ахиллесовой пятой человеческого познания».)
поддерживает гипотезу исследователей. Тем не менее, сравнение только средних значений двух групп не позволяет учитывать изменчивость оценок креативности в группах. Мы можем измерить изменчивость с помощью статистики, используя, например, стандартное отклонение: 5,25 для внешней группы и 4,40 для внутренней группы. Стандартные отклонения говорят нам о том, что большинство оценок креативности находится в пределах примерно 5 баллов от средней оценки в каждой группе. Мы видим, что средний балл для внутренней группы находится в пределах одного стандартного отклонения от среднего балла для внешней группы. Таким образом, несмотря на тенденцию к более высокому показателю креативности в группе с внутренними качествами, в среднем разница невелика.
Мы снова хотим рассмотреть возможные объяснения этой разницы. В исследовании принимали участие только люди с большим опытом творческого письма. Хотя это ограничивает популяцию, на которую мы можем обобщать, это не объясняет, почему средний балл креативности был немного выше для внутренней группы, чем для внешней группы. Может быть, женщины, как правило, получают более высокие баллы за креативность? Здесь нам нужно сосредоточиться на том, как люди были отнесены к мотивационным группам. Если бы в группе с внутренней мотивацией были только женщины, а в группе с внешней мотивацией — только мужчины, то это представляло бы проблему, потому что мы бы не знали, справилась ли группа с внутренней мотивацией лучше из-за другого типа мотивации или из-за того, что они были женщинами. Однако исследователи предохранялись от такой проблемы, случайным образом распределяя людей по мотивационным группам. Подобно подбрасыванию монеты, каждый человек с одинаковой вероятностью мог быть отнесен к любому типу мотивации. Почему это полезно? Потому что это 9Случайное назначение 0011 имеет тенденцию уравновешивать все переменные, связанные с творчеством, о которых мы можем думать, и даже те, о которых мы не думаем заранее, между двумя группами.
В исследовании принимали участие только люди с большим опытом творческого письма. Хотя это ограничивает популяцию, на которую мы можем обобщать, это не объясняет, почему средний балл креативности был немного выше для внутренней группы, чем для внешней группы. Может быть, женщины, как правило, получают более высокие баллы за креативность? Здесь нам нужно сосредоточиться на том, как люди были отнесены к мотивационным группам. Если бы в группе с внутренней мотивацией были только женщины, а в группе с внешней мотивацией — только мужчины, то это представляло бы проблему, потому что мы бы не знали, справилась ли группа с внутренней мотивацией лучше из-за другого типа мотивации или из-за того, что они были женщинами. Однако исследователи предохранялись от такой проблемы, случайным образом распределяя людей по мотивационным группам. Подобно подбрасыванию монеты, каждый человек с одинаковой вероятностью мог быть отнесен к любому типу мотивации. Почему это полезно? Потому что это 9Случайное назначение 0011 имеет тенденцию уравновешивать все переменные, связанные с творчеством, о которых мы можем думать, и даже те, о которых мы не думаем заранее, между двумя группами. Таким образом, у нас должно быть одинаковое соотношение мужчин и женщин между двумя группами; у нас должно быть одинаковое возрастное распределение между двумя группами; у нас должно быть одинаковое распределение образования между двумя группами; и так далее. Случайное распределение должно создавать максимально похожие группы, за исключением типа мотивации, который, по-видимому, исключает все эти другие переменные как возможные объяснения наблюдаемой тенденции к более высоким баллам в внутренней группе.
Таким образом, у нас должно быть одинаковое соотношение мужчин и женщин между двумя группами; у нас должно быть одинаковое возрастное распределение между двумя группами; у нас должно быть одинаковое распределение образования между двумя группами; и так далее. Случайное распределение должно создавать максимально похожие группы, за исключением типа мотивации, который, по-видимому, исключает все эти другие переменные как возможные объяснения наблюдаемой тенденции к более высоким баллам в внутренней группе.
Но всегда ли это работает? Нет, так что по «везению жеребьевки» группы могут немного отличаться до того, как они ответят на вопросы мотивационного опроса. Тогда возникает вопрос: возможно ли, что наблюдаемая разница в показателях креативности между группами вызвана неудачным случайным распределением? Другими словами, предположим, что стихотворение каждого человека должно было получить одинаковую оценку креативности, независимо от того, к какой группе они были отнесены, что тип мотивации никоим образом не влиял на их оценку. Затем, как часто один только процесс случайного распределения приводил к разнице в средних баллах креативности, которая была бы больше (или больше), чем 19?0,88 – 15,74 = 4,14 балла?
Затем, как часто один только процесс случайного распределения приводил к разнице в средних баллах креативности, которая была бы больше (или больше), чем 19?0,88 – 15,74 = 4,14 балла?
Мы снова хотим применить вероятностную модель для аппроксимации p-значения , но на этот раз модель будет немного другой. Подумайте о том, чтобы записать все оценки креативности на каталожных карточках, перетасовать каталожные карточки, а затем раздать 23 балла группе внешней мотивации и 24 группе внутренней мотивации и найти разницу в средних значениях групп. Мы (а еще лучше, компьютер) можем повторять этот процесс снова и снова, чтобы увидеть, как часто, когда оценки не меняются, случайное распределение приводит к разнице в средних значениях не менее 4,41. На рисунке 3 показаны результаты 1000 таких гипотетических случайных назначений для этих оценок.
Рисунок 3 . Различия в группе означают только случайное распределение.
Только 2 из 1000 смоделированных случайных назначений дали разницу в средних групповых значениях 4,41 или больше. Другими словами, приблизительное значение p равно 2/1000 = 0,002. Это маленькое значение p указывает на то, что было бы очень неожиданно, если бы только процесс случайного распределения привел к такой большой разнице в средних групповых значениях. Таким образом, как и в случае с Примером 2, у нас есть убедительные доказательства того, что сосредоточение внимания на внутренних мотивах приводит к повышению показателей креативности по сравнению с размышлениями о внешних мотивах.
Другими словами, приблизительное значение p равно 2/1000 = 0,002. Это маленькое значение p указывает на то, что было бы очень неожиданно, если бы только процесс случайного распределения привел к такой большой разнице в средних групповых значениях. Таким образом, как и в случае с Примером 2, у нас есть убедительные доказательства того, что сосредоточение внимания на внутренних мотивах приводит к повышению показателей креативности по сравнению с размышлениями о внешних мотивах.
Обратите внимание, что предыдущее утверждение подразумевает причинно-следственную связь между мотивацией и показателем креативности; такой сильный вывод оправдан? Да, из-за случайного распределения, используемого в исследовании. Это должно было сбалансировать любые другие переменные между двумя группами, так что теперь, когда маленькое значение р убеждает нас в том, что более высокое среднее значение в группе внутренних факторов не было простым совпадением, остается единственное разумное объяснение — это разница в типе мотивация. Можем ли мы обобщить этот вывод на всех? Не обязательно — мы могли бы осторожно распространить этот вывод на людей с большим опытом творческого письма, похожих на людей в этом исследовании, но мы все же хотели бы узнать больше о том, как эти люди были отобраны для участия.
Можем ли мы обобщить этот вывод на всех? Не обязательно — мы могли бы осторожно распространить этот вывод на людей с большим опытом творческого письма, похожих на людей в этом исследовании, но мы все же хотели бы узнать больше о том, как эти люди были отобраны для участия.
Заключение
Рисунок 4 . Исследователи используют научный метод, который включает в себя большое количество статистического мышления: сформулировать гипотезу —> спланировать исследование для проверки этой гипотезы —> провести исследование —> проанализировать данные —> сообщить о результатах. [Изображение: widdowquinn]
Статистическое мышление включает в себя тщательную разработку исследования для сбора значимых данных для ответа на конкретный исследовательский вопрос, детальный анализ закономерностей в данных и выводы, выходящие за рамки наблюдаемых данных. Случайная выборка имеет первостепенное значение для обобщения результатов нашей выборки на большую совокупность, а случайное распределение является ключом к выводам о причинно-следственных связях. С обоими видами случайности модели вероятности помогают нам оценить, сколько случайных вариаций мы можем ожидать в наших результатах, чтобы определить, могут ли наши результаты получиться случайно, и оценить допустимую погрешность.
С обоими видами случайности модели вероятности помогают нам оценить, сколько случайных вариаций мы можем ожидать в наших результатах, чтобы определить, могут ли наши результаты получиться случайно, и оценить допустимую погрешность.
Итак, что же остается нам в отношении исследования кофе, упомянутого ранее (Freedman, Park, Abnet, Hollenbeck, & Sinha, 2012 обнаружили, что мужчины, которые выпивали не менее шести чашек кофе в день, имели на 10 % меньше шансов умирают (женщин на 15% меньше), чем те, кто не пил)? Мы можем ответить на многие вопросы:
 Потребление кофе оценивали один раз в начале исследования.
Потребление кофе оценивали один раз в начале исследования. Это исследование необходимо рассматривать в более широком контексте аналогичных исследований и согласованности результатов разных исследований, с постоянным предупреждением о том, что это не был рандомизированный эксперимент.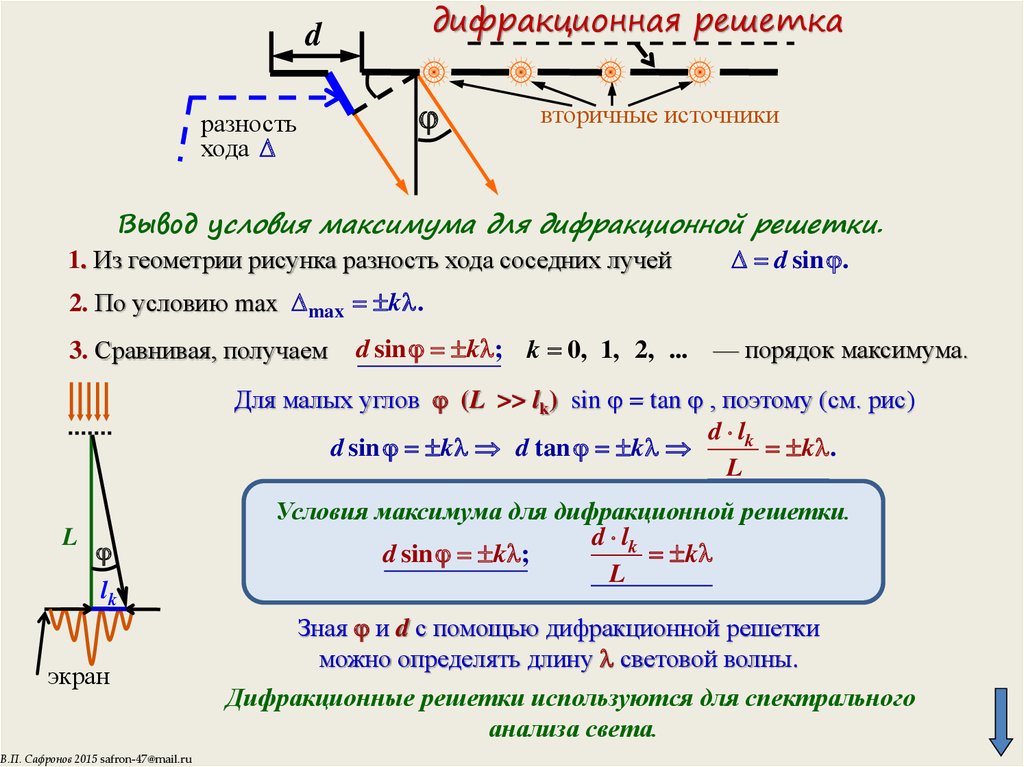 В то время как статистический анализ все еще может «приспосабливаться» к другим потенциальным вмешивающимся переменным, мы еще не убеждены, что исследователи идентифицировали их все или полностью идентифицировали, почему это снижение риска смерти очевидно. Исследователи теперь могут использовать результаты этого исследования и разрабатывать более целенаправленные исследования, направленные на решение новых вопросов.
В то время как статистический анализ все еще может «приспосабливаться» к другим потенциальным вмешивающимся переменным, мы еще не убеждены, что исследователи идентифицировали их все или полностью идентифицировали, почему это снижение риска смерти очевидно. Исследователи теперь могут использовать результаты этого исследования и разрабатывать более целенаправленные исследования, направленные на решение новых вопросов.
Подробнее
Изучите эти внешние ресурсы, чтобы узнать больше о прикладной статистике:
Подумай об этом
 Согласны ли вы с выводами, сделанными в этом исследовании, на основе дизайна исследования и представленных результатов?
Согласны ли вы с выводами, сделанными в этом исследовании, на основе дизайна исследования и представленных результатов?Глоссарий
причина и следствие: связаны с тем, говорим ли мы, что одна переменная вызывает изменения в другой переменной, по сравнению с другими переменными, которые могут быть связаны с этими двумя переменными.
обобщаемость : относится к тому, могут ли результаты выборки быть обобщены на большую совокупность.
предел погрешности : ожидаемое количество случайных изменений в статистике; часто определяется для уровня достоверности 95%.
популяция : большая коллекция особей, на которую мы хотели бы обобщить наши результаты.
p-значение : вероятность наблюдения конкретного результата в выборке или более экстремального, при предположении о большей совокупности или процессе.
случайное распределение : использование вероятностного метода для разделения выборки на лечебные группы.
случайная выборка : использование вероятностного метода для отбора подмножества лиц для выборки из населения.
образец : набор лиц, о которых мы собираем данные.
Поддержите!
У вас есть идеи по улучшению этого контента? Мы будем признательны за ваш вклад.
Улучшить эту страницуПодробнее
Проверка значимости коэффициента корреляции
Результаты обучения
Коэффициент корреляции r говорит нам о силе и направлении линейной зависимости между x и y . Однако надежность линейной модели также зависит от количества наблюдаемых точек данных в выборке. Нам нужно смотреть как на значение коэффициента корреляции х , так и на размер выборки х вместе.
Мы проводим проверку гипотезы о « значимости коэффициента корреляции », чтобы решить, достаточно ли сильна линейная связь в данных выборки, чтобы использовать ее для моделирования связи в генеральной совокупности.
Данные выборки используются для вычисления r коэффициента корреляции для выборки. Если бы у нас были данные для всего населения, мы могли бы найти коэффициент корреляции населения. Но поскольку у нас есть только выборочные данные, мы не можем рассчитать коэффициент корреляции населения. Коэффициент корреляции выборки, r , является нашей оценкой коэффициента корреляции неизвестной совокупности.
Проверка гипотезы позволяет решить, является ли значение коэффициента корреляции совокупности
ρ «близким к нулю» или «значительно отличным от нуля». Мы решаем это на основе выборочного коэффициента корреляции r и размер выборки n .
Если тест показывает, что коэффициент корреляции значительно отличается от нуля, мы говорим, что коэффициент корреляции является «значимым».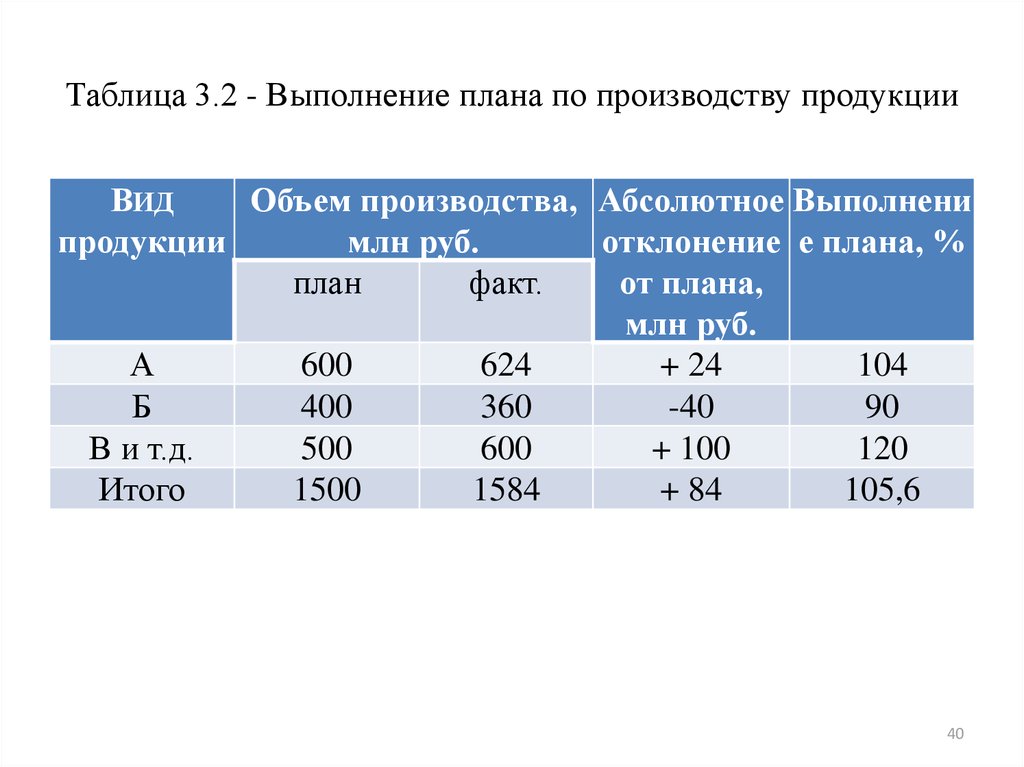
Вывод: имеется достаточно доказательств, чтобы заключить, что существует значительная линейная зависимость между x и y , поскольку коэффициент корреляции значительно отличается от нуля. Что означает вывод: существует значительная линейная зависимость между х и у . Мы можем использовать линию регрессии для моделирования линейной зависимости между x и y в популяции.
Если тест показывает, что коэффициент корреляции незначительно отличается от нуля (близок к нулю), мы говорим, что коэффициент корреляции «незначителен».
Заключение: «Недостаточно доказательств, чтобы сделать вывод о наличии значительной линейной зависимости между
x и y , потому что коэффициент корреляции незначительно отличается от нуля». Что означает вывод: нет существенной линейной зависимости между x и y . Следовательно, мы НЕ МОЖЕМ использовать линию регрессии для моделирования линейной зависимости между x и y в популяции.
Примечание
Выполнение проверки гипотез
Что означают гипотезы словами
 НЕТ существенной линейной зависимости (корреляции) между x и y в популяции.
НЕТ существенной линейной зависимости (корреляции) между x и y в популяции.Подведение итогов
Есть два способа принятия решения. Эти два метода эквивалентны и дают одинаковый результат.
В этой главе данного учебника мы всегда будем использовать уровень значимости 5%, α = 0,05
Примечание
Используя метод p -value, вы можете выбрать любой подходящий уровень значимости; вы не ограничены использованием α = 0,05. Но таблица критических значений, представленная в этом учебнике, предполагает, что мы используем уровень значимости 5%, α = 0,05. (Если бы мы хотели использовать уровень значимости, отличный от 5%, с методом критического значения, нам понадобились бы другие таблицы критических значений, которые не представлены в этом учебнике.)
(Если бы мы хотели использовать уровень значимости, отличный от 5%, с методом критического значения, нам понадобились бы другие таблицы критических значений, которые не представлены в этом учебнике.)
Метод 1: Использование значения
p для принятия решения , выделить «≠ 0»Если значение p меньше уровня значимости ( α = 0,05)
- Решение: Отклонить нулевую гипотезу.
- Заключение: «Есть достаточно доказательств, чтобы сделать вывод о наличии значительной линейной зависимости между x и y , поскольку коэффициент корреляции значительно отличается от нуля».
Если p -значение НЕ меньше уровня значимости ( α = 0,05)
- Решение: НЕ ОТКАЗЫВАТЬ нулевую гипотезу.
- Заключение: «Недостаточно доказательств, чтобы заключить, что существует значительная линейная зависимость между x и y , потому что коэффициент корреляции НЕ существенно отличается от нуля».

Примечания к расчету:
- Вы будете использовать технологию для расчета значения p . Ниже описаны расчеты для расчета тестовой статистики и p -значения:
- 999, н-2) во 2-м РАЙОНЕ.
Метод 2: Использование таблицы критических значений для принятия решения
Критические значения 95% из таблицы коэффициентов корреляции выборки можно использовать, чтобы дать вам хорошее представление о том, является ли вычисленное значение значимым или нет. Сравните r с соответствующим критическим значением в таблице. Если r не находится между положительным и отрицательным критическими значениями, то коэффициент корреляции значим. Если r является значимым, вы можете использовать линию для предсказания.
Пример
Предположим, вы вычислили r = 0,801, используя n = 10 точек данных. df = n – 2 = 10 – 2 = 8. Критические значения, связанные с df = 8, составляют -0,632 и + 0,632. Если r < отрицательное критическое значение или r > положительное критическое значение, то r равно значимому . Поскольку r = 0,801 и 0,801 > 0,632, r является значимым, и эту линию можно использовать для предсказания. Если вы посмотрите на этот пример на числовой прямой, это поможет вам.
r не имеет значения в диапазоне от -0,632 до +0,632. r = 0,801 > +0,632. Следовательно, r является значимым.
попробуйте
Для данной линии наилучшего соответствия вы вычислили, что r = 0,6501, используя n = 12 точек данных, а критическое значение равно 0,576. Можно ли использовать линию для предсказания? Почему или почему нет?
Если точечная диаграмма выглядит линейной, то да, линию можно использовать для предсказания, потому что r > положительное критическое значение.
Пример
Предположим, вы вычислили r = –0,624 с 14 точками данных. df = 14 – 2 = 12. Критические значения равны –0,532 и 0,532. Поскольку –0,624 < –0,532, r является значимым, и линию можно использовать для предсказания
r = –0,624-0,532. Следовательно, r является значимым.
попробуйте
Для заданной линии наилучшего соответствия вы вычисляете, что r = 0,5204 при использовании n = 9 точек данных, а критическое значение равно 0,666. Можно ли использовать линию для предсказания? Почему или почему нет?
Нет, эту линию нельзя использовать для предсказания, потому что r < положительное критическое значение.
Пример 3
Предположим, вы вычислили r = 0,776 и n = 6. df = 6 – 2 = 4. Критические значения –0,811 и 0,811. Поскольку –0,811 < 0,776 < 0,811, r не имеет значения, и эту линию не следует использовать для прогнозирования.
–0,811 < r = 0,776 < 0,811. Поэтому r не имеет значения.
Попробуйте
Для данной линии наилучшего соответствия вы вычисляете, что r = –0,7204, используя n = 8 точек данных, а критическое значение равно 0,707. Можно ли использовать линию для предсказания? Почему или почему нет?
Да, линию можно использовать для предсказания, потому что r < отрицательное критическое значение.
Пример
Предположим, вы вычислили следующие коэффициенты корреляции. Используя таблицу в конце главы, определите, является ли значение r значимым, и можно ли использовать линию наилучшего соответствия, связанную с каждым r , для прогнозирования значения y . Если это поможет, нарисуйте числовую линию.
- r = –0,567, а размер выборки n равен 19. df = n – 2 = 17. Критическое значение равно –0,456. –0,567 < –0,456, поэтому r имеет значение.
- r = 0,708, а размер выборки n равен девяти. df = n – 2 = 7. Критическое значение равно 0,666. 0,708 > 0,666, поэтому r является значимым.
- r = 0,134, а размер выборки n равен 14. df = 14 – 2 = 12. Критическое значение равно 0,532. 0,134 находится между –0,532 и 0,532, поэтому r не имеет значения.
- r = 0 и объем выборки н , это пять. Независимо от того, каковы dfs, r = 0 находится между двумя критическими значениями, поэтому r не имеет значения.
попробуйте
Для данной линии наилучшего соответствия вы вычисляете, что r = 0, используя n = 100 точек данных. Можно ли использовать линию для предсказания? Почему или почему нет?
Нет, линию нельзя использовать для предсказания независимо от размера выборки.
Допущения при проверке значимости коэффициента корреляции
Проверка значимости коэффициента корреляции требует выполнения определенных предположений о данных.
Предпосылка этого теста заключается в том, что данные представляют собой выборку наблюдаемых точек, взятых из большей совокупности. Мы не исследовали всю популяцию, потому что это невозможно или невозможно сделать. Мы изучаем выборку, чтобы сделать вывод о том, обеспечивает ли линейная зависимость, которую мы видим между
x и y в данных выборки, достаточно убедительные доказательства, чтобы мы могли сделать вывод о наличии линейной зависимости между x и y в популяции.Уравнение линии регрессии, которое мы вычисляем на основе выборочных данных, дает наиболее подходящую линию для нашей конкретной выборки. Мы хотим использовать эту линию наилучшего соответствия для выборки в качестве оценки линии наилучшего соответствия для генеральной совокупности. Изучение диаграммы рассеяния и проверка значимости коэффициента корреляции помогает нам определить, уместно ли это делать.
Допущения, лежащие в основе теста значимости:
- В генеральной совокупности существует линейная зависимость, которая моделирует среднее значение y для различных значений x . Другими словами, ожидаемое значение y для каждого конкретного значения лежит на прямой в генеральной совокупности. (Мы не знаем уравнения для линии для совокупности. Наша линия регрессии по выборке является нашей наилучшей оценкой этой линии в совокупности.)
- Значения и для любого конкретного значения x обычно распределяются по строке. Это означает, что их больше 9.0029 y значений разбросаны ближе к линии, чем дальше. Предположение (1) означает, что центры этих нормальных распределений находятся на прямой: средние значения этих нормальных распределений и значений лежат на прямой.
- Стандартные отклонения совокупности y значений относительно линии равны для каждого значения x . Другими словами, каждое из этих нормальных распределений значений y имеет одинаковую форму и разброс по линии.
- Остаточные ошибки взаимно независимы (нет шаблона).
- Данные получены из хорошо спланированной случайной выборки или рандомизированного эксперимента.
Значения y для каждого значения x нормально распределяются по линии с одинаковым стандартным отклонением. Для каждого значения x среднее значение значений y лежит на линии регрессии. Вблизи линии лежит больше значений и , чем разбросано дальше от линии.
Обзор концепции
Линейная регрессия — это процедура подбора прямой линии формы
[латекс]\displaystyle\hat{{y}}={a}+{b}{x}[/latex] к данным. Условия для регрессии:- Линейная: В совокупности существует линейная зависимость, которая моделирует среднее значение y для различных значений x .
- Независимый: Предполагается, что остатки независимы.
- Обычный: Значения y распределяются нормально для любого значения x .
- Равная дисперсия: Стандартное отклонение значений и одинаково для каждого значения x .
- Случайное: Данные получены из хорошо спланированной случайной выборки или рандомизированного эксперимента.
Наклон b и точка пересечения a линии наименьших квадратов оценивают наклон β и точка пересечения α популяционной (истинной) линии регрессии. Чтобы оценить стандартное отклонение совокупности y , σ , используйте стандартное отклонение остатков, s .
[латекс]\displaystyle{s}=\sqrt{{\frac{{{S}{S}{E}}}{{{n}-{2}}}}}[/latex] Переменная ρ (rho) — коэффициент корреляции населения.
Чтобы проверить нулевую гипотезу H 0 : ρ = гипотетическое значение , используйте t-критерий линейной регрессии. Самая распространенная нулевая гипотеза — 9.0029 H 0 : ρ = 0, что указывает на отсутствие линейной зависимости между x и y в популяции.
Функция калькулятора TI-83, 83+, 84, 84+ LinRegTTest может выполнять этот тест (СТАТИСТИЧЕСКИЕ ТЕСТЫ LinRegTTest).
Обзор формул
Линия наименьших квадратов или линия наилучшего соответствия: [latex]\displaystyle\hat{{y}}={a}+{b}{x}[/latex]
, где a = y — точка пересечения, b = наклон
Стандартное отклонение остатков:
[латекс]\displaystyle{s}=\sqrt{{\frac{{{S}{S}{E}}}{{{n}-{2}}}}} [/latex]
, где
SSE = сумма квадратов ошибок
n = количество точек данных
Коэффициенты корреляции
Коэффициенты корреляции Вернуться к оглавлениюОбзор урока
- Корреляция
- Момент продукта Pearson (r)
- Копьеносец Ро
- Факторы, влияющие на размер r
- Домашнее задание
Корреляция
Обычное использование слова корреляция относится к отношения между двумя или более объектами (идеями, переменными…). В статистике слово корреляция относится к отношениям между двумя переменными. Мы хотим иметь возможность количественно определить это отношение, измерить его
сила, разработайте уравнение для прогнозирования результатов, и в конечном итоге сделать проверяемый вывод о родительской популяции.
Этот урок посвящен измерению его силы,
с уравнением, которое будет на следующем уроке,
а выводы по тестированию намного позже.Примеры: одна переменная может быть числом охотники в регионе, а другой переменной может быть популяция оленей. Возможно, по мере увеличения числа охотников популяция оленей уменьшается. это пример отрицательная корреляция : как одна переменная увеличивается, другой уменьшается. положительная корреляция — это то место, где две переменные реагируют одинаково, увеличиваясь или уменьшаясь вместе. Температура в градусах Цельсия и Фаренгейта имеет положительную корреляцию.
Момент продукта Pearson
Как определить, есть ли корреляция? Наблюдая за графиками, человек может сказать, есть ли корреляция по тому, как близко данные напоминают линию. Если точки разбросаны, то
может быть нет корреляции . Если точки будут точно соответствовать
квадратное или показательное уравнение, и т. д. ,
тогда они имеют нелинейную корреляцию .
В этом курсе мы ограничимся линейными корреляциями
и, следовательно, линейная регрессия.
Поскольку данные почти линейны, данные могут быть заключены в эллипс.
Большая ось (длина) эллипса относительно малой оси (ширины) эллипса,
являются показателем степени корреляции.Как можно определить путем осмотра тип корреляции?
Если график переменных представляет собой линию с положительным наклоном, то есть положительная корреляция ( x увеличивается по мере увеличения y ). Если наклон линии отрицательный, то существует отрицательная корреляция (по мере увеличения x y уменьшается).Важным аспектом корреляции является то, насколько она сильна . Сила корреляции измеряется корреляция коэффициент r .
Другое название для r — корреляция моментов произведения Пирсона .
коэффициент в честь Карла Пирсона, разработавшего его около 1900 года.
Обычно используются как минимум три различные формулы
чтобы вычислить это число и эти разные формулы
представляют несколько разные подходы к проблеме.
Однако такое же значение для r получается
любой из различных процедур.
Сначала мы даем формула сырой оценки. n имеет обычное значение количества упорядоченных пар
есть в нашем образце. Также важно признать
разница между суммой квадратов
и квадраты сумм!г = п ху — ( х )( г )
sqrt[ n ( x 2 ) — ( x ) 2 ] · sqrt[ n ( y 2 ) — ( г ) 2 ]Далее мы представляем формулу оценки отклонения .
Эта формула ближе к истории развития
поскольку он дает среднее перекрестное произведение
стандартные оценки двух переменных, но в
вычислительно более простой формат.r = ху
sqrt( x 2 y 2 )Нам нужно сделать несколько замечаний относительно обозначений, поскольку x и y переменных в формуле выше были преобразованы из исходных переменных путем вычитания их средств.
Наконец, мы представляем формулу ковариации , что является еще одним подходом. Ковариации обычно дано между двумя переменными, и это одна из причин, почему. (Следует отметить, что размер ковариации зависит в единицах измерения, используемых для каждой переменной. Однако коэффициент корреляции — нет.)
r = с ху
с x с гr часто обозначается как r xy чтобы подчеркнуть две рассматриваемые переменные.
Для выборок коэффициент корреляции представлен как r а коэффициент корреляции для популяций обозначается
греческой буквой ро (которая может выглядеть как стр. ).
Имейте в виду, что коэффициент корреляции ро Спирмена
также использует греческую букву ро, но обычно применяется
к образцам и данным ранжирования (порядковые данные).Чем ближе r к +1, тем сильнее положительная корреляция. Чем ближе r к -1, тем сильнее отрицательная корреляция. Если | р | = 1 точно, две переменные идеально коррелированы ! Температура в градусах Цельсия и Фаренгейта идеально коррелирует.
Формальная проверка гипотезы может быть применена к r определить, насколько значим результат. Это предмет Хинкля, глава 17 и этот урок 12. Дистрибутив Student t с n -2 степени свободы.
Помните, корреляция не подразумевает причинно-следственной связи. Нулевое значение для r не означает, что корреляции нет, может быть нелинейная корреляция. Также могут быть задействованы смешанные переменные . Предположим, вы обнаружить, что майнеры имеют более высокий, чем в среднем, уровень рак легких. У вас может возникнуть соблазн немедленно заключить что их занятие является причиной, тогда как, возможно, регион имеет обильные утечки радиоактивного газа радона из подземных областей, и все люди в этой области затронуты. Или, может быть, они заядлые курильщики….
r 2 часто используется и называется коэффициент детерминации . Это доля вариации значений и . это объясняется регрессией по методу наименьших квадратов y на x . Это будет обсуждаться далее в уроке 6 после введения метода наименьших квадратов.
Коэффициенты корреляции, величина которых находится в диапазоне от 0,9 до 1,0. указывают переменные, которые можно считать очень сильно коррелированными.
Коэффициенты корреляции, величина которых находится в диапазоне от 0,7 до 0,9.указывают переменные, которые можно считать сильно коррелированными. Коэффициенты корреляции, величина которых находится в диапазоне от 0,5 до 0,7.
укажите переменные, которые можно считать умеренно коррелированными. Коэффициенты корреляции, величина которых находится в диапазоне от 0,3 до 0,5.
указывают переменные, которые имеют низкую корреляцию. Коэффициенты корреляции, величина которых меньше 0,3
имеют небольшую, если вообще имеют (линейную) корреляцию.
Мы можем легко видеть, что
0,9< |r| < 1,0 соответствует
0,81 < r 2 < 1,00;
0,7 < |r| < 0,9 соответствует
0,49 < р 2 < 0,81;
0,5 < |r| < 0,7 соответствует
0,25 < r 2 < 0,49;
0,3 < |r| < 0,5 соответствует
0,09 < г 2 < 0,25; а также
0,0 < |r| < 0,3 соответствует
0,0 < r 2 < 0,09.Копейщик Ро для ранговых/порядковых данных
Часто бывает так, что данные, которые мы хотим измерить корреляцию ибо не является интервалом или отношением уровня измерения. Был разработан коэффициент корреляции Ро Спирмена. чтобы справиться с этой ситуацией. Это досадное исключение из общего правила, Греческие буквы — параметры населения! Есть и другие.Формула расчета ро Спирмена коэффициент корреляции следующий.
ро (p) = 1 — 6 d 2
н ( н 2 -1)n – количество парных рангов и d – разница между парными разрядами. Если равных результатов нет, коэффициент корреляции Спирмена ро будет еще ближе к коэффициенту корреляции моментов произведения Пирсона. Также обратите внимание, что эту формулу легко понять, если Вы понимаете, что сумма квадратов от 1 до н можно выразить как n ( n + 1)(2 n + 1)/6.
Отсюда вы можете получить наименьшую сумму d 2 равен нулю, а наибольшая сумма d 2 равна
удвоенная сумма квадратов нечетных целых чисел до n /2, и это масштабирует такую сумму между -1 и +1.Пример: Предположим, у нас есть результаты тестов из 110, 107, 100, 96, 89, 78, 67, 66 и 49. Они соответствуют рангам с 1 по 9. Если бы были дубликаты, то нам пришлось бы найти средний рейтинг для дубликатов и подставьте это значение для наших рангов. Соответствующие общие баллы на первой странице были следующими: 29, 32, 27, 29, 25, 25, 21, 26, 22. Таким образом, эти ранги следующие: 2,5, 1, 4, 2,5, 6,5, 6,5, 9, 5, 8. (Обратите внимание, что если бы мы изменили порядок, назначив ранги от низкого к высокому, а не от высокого к низкому, в результате Коэффициент корреляции Ро Спирмена изменил бы знак.)
Мы построили таблицу ниже из информации выше. Мы добавили дополнительные столбцы d и d 2 для простоты расчета ро Спирмена.
Используя формулу Ро Спирмена, мы получаем 1-6(24)/(9(80)) = 0,80.
Мы добавили дополнительные столбцы xy , x 2 , и y 2 для облегчения расчета коэффициент корреляции моментов произведений Пирсона.Total ( x ) page 1 ( y ) x rank y rank d d 2 xy x 2 y 2 110 29 1 2.5 -1.5 2.25 3190 12100 841 107 32 2 1 1 1 3424 11449 1024 100 27 3 4 -1 1 2700 10000 7294 2700 1000000 7299700 1000000 7299700 1000000 7294 2700 1000000 7294 2700 1000000 7294 2700 1000000 729 96 29 4 2. 51.5 2.25 2784 9216 841 89 25 5 6,5 -1,5 2,25 2225 7921 625 78 25 6 6.5 -0.5 0.25 1950 6084 625 67 21 7 9 -2 4 19 7 48174 466 26 8 5 3 9 1716 9 6 1116 9099 70 415174 49 22 9 8 1 1 1078 7 9 41174 4— — —— —- —— —— —- 762 236 :суммы: 0 24 20474 9177 6 2811416 6801416 Использование формулы сырой оценки для момента продукта Пирсона
коэффициент корреляции получаем (9×20474-762×236)/кв.кв.((9×68016-762 2 )(9×6286-236 2 )
= 0,843. г 2 = 0,71
что означает 71% вариации и объясняется изменением x .
Также верно и, возможно, полезнее знать, что та же корреляция
коэффициент получается при обмене x и y .
Однако получится другое уравнение.
Возможно, имеет смысл использовать результаты первой страницы
чтобы предсказать окончательный результат теста, а не наоборот!Факторы, влияющие на размер
r Мы рассмотрели, как вычислить r , что означают различные значения, но также важно понять, какие факторы на это влияют. Во-первых, помните, имеет смысл только вычислять коэффициент корреляции, если данные парных наблюдений измерений на интервале или шкала отношений. Далее, поскольку нас здесь интересуют только линейные корреляция, момент произведения Пирсона коэффициент корреляции будет недооценивать отношения, если есть криволинейные отношения. Рекомендуется создать диаграмму рассеяния перед
расчет любых коэффициентов корреляции, а затем
действовать только в том случае, если корреляция достаточно сильна.По мере увеличения однородности группы дисперсия уменьшается, а величина коэффициент корреляции стремится к нулю. Таким образом, исследователь должен убедиться, достаточной неоднородности (изменчивости), чтобы отношения могут проявляться. В общем случае коэффициент корреляции не зависит от размера группы.
ЗАДНЯЯ ЧАСТЬ ДОМАШНЕЕ ЗАДАНИЕ ДЕЯТЕЛЬНОСТЬ ПРОДОЛЖИТЬ - электронная почта: [email protected]
- голос/почта: 269 471-6629/ BCM&S Smith Hall 106; Университет Эндрюса; Берриен Спрингс,
- класс: 269 471-6646; Smith Hall 100/ ФАКС: 269 471-3713; МИ, 49104-0140
- домашний: 269 473-2572; 610 Н. Главная улица;
Берриен Спрингс, Мичиган 49103-1013
- URL-адрес: http://www.andrews.edu/~calkins/math/edrm611/edrm05.htm
- Copyright © 1998-2005, Кит Г. Калкинс. Пересмотрено 18 июля 2005 г. или позднее.
12.5: Проверка значимости коэффициента корреляции
- Последнее обновление
- Сохранить как PDF
- r = –0,567, а размер выборки n равен 19. df = n – 2 = 17. Критическое значение равно –0,456. –0,567 < –0,456, поэтому r имеет значение.
- Идентификатор страницы
- 800
- OpenStax
- OpenStax
- Символом коэффициента корреляции населения является \(\rho\), греческая буква «rho».
- \(\rho =\) коэффициент корреляции населения (неизвестно)
- \(r =\) выборочный коэффициент корреляции (известный; рассчитан по выборочным данным)
- Заключение: имеется достаточно доказательств, чтобы заключить, что существует значительная линейная зависимость между \(x\) и \(y\), поскольку коэффициент корреляции значительно отличается от нуля.
- Что означает вывод: существует значительная линейная зависимость между \(x\) и \(y\). Мы можем использовать линию регрессии для моделирования линейной зависимости между \(x\) и \(y\) в популяции.
- Заключение: «Недостаточно доказательств, чтобы сделать вывод о наличии значительной линейной зависимости между \(x\) и \(y\), поскольку коэффициент корреляции незначительно отличается от нуля».
- Что означает заключение: между \(x\) и \(y\) нет существенной линейной зависимости. Следовательно, мы НЕ МОЖЕМ использовать линию регрессии для моделирования линейной зависимости между \(x\) и \(y\) в популяции.
- Если \(r\) является значимым, а точечная диаграмма показывает линейный тренд, линия может использоваться для прогнозирования значения \(y\) для значений \(x\), которые находятся в пределах область наблюдаемых значений \(x\).
- Если \(r\) не является значимым ИЛИ если точечный график не показывает линейный тренд, линия не должна использоваться для прогнозирования.
- Если \(r\) является значимым и если точечная диаграмма показывает линейный тренд, линия НЕ может быть подходящей или надежной для прогнозирования ВНЕ области наблюдаемых значений \(x\) в данных.
- Нулевая гипотеза: \(H_{0}: \rho = 0\)
- Альтернативная гипотеза: \(H_{a}: \rho \neq 0\)
- Нулевая гипотеза \(H_{0}\) : Коэффициент корреляции населения НЕ ОТЛИЧАЕТСЯ ДОСТОВЕРНО от нуля. НЕТ значимой линейной зависимости (корреляции) между \(x\) и \(y\) в популяции.
- Альтернативная гипотеза \(H_{a}\) : Коэффициент корреляции населения ЗНАЧИТЕЛЬНО ОТЛИЧАЕТСЯ ОТ нуля. СУЩЕСТВУЕТ ЗНАЧИТЕЛЬНАЯ ЛИНЕЙНАЯ СВЯЗЬ (корреляция) между \(x\) и \(y\) в популяции.
- Метод 1: Использование \(p\text{-значение}\)
- Метод 2: Использование таблицы критических значений
- Решение: Отклонить нулевую гипотезу.
- Заключение: «Есть достаточные доказательства, чтобы сделать вывод о наличии значительной линейной зависимости между \(x\) и \(y\), поскольку коэффициент корреляции значительно отличается от нуля».
- Решение: НЕ ОТКАЗЫВАТЬ нулевую гипотезу.
- Заключение: «Недостаточно доказательств, чтобы сделать вывод о наличии значимой линейной зависимости между \(x\) и \(y\), поскольку коэффициент корреляции НЕ существенно отличается от нуля».
- Вы будете использовать технологию для расчета \(p\text{-значение}\). Ниже описаны расчеты для расчета тестовой статистики и \(p\text{-значение}\): 999, н-2) во 2-м РАЙОНЕ.
ТРЕТИЙ ЭКЗАМЕН vs ЗАКЛЮЧИТЕЛЬНЫЙ ЭКЗАМЕН ПРИМЕР: \(p\text{-значение}\) метод
- Рассмотрим пример третьего экзамена/выпускного экзамена.
- Линия наилучшего соответствия: \(\hat{y} = -173,51 + 4,83x\) с \(r = 0,6631\) и имеется \(n = 11\) точек данных.
- Можно ли использовать линию регрессии для прогнозирования? Учитывая третий экзаменационный балл (значение \(x\) ), можем ли мы использовать эту линию, чтобы предсказать окончательный экзаменационный балл (прогнозируемое \(y\) значение)?
\(H_{0}: \rho = 0\)
\(H_{a}: \rho \neq 0\)
\(\alpha = 0.
05\)- \(p\text {-значение}\) равно 0,026 (из LinRegTTest на вашем калькуляторе или из компьютерной программы).
- \(p\text{-value}\), 0,026, меньше уровня значимости \(\alpha = 0,05\).
- Решение: отвергнуть нулевую гипотезу \(H_{0}\)
- Вывод: имеется достаточно доказательств, чтобы заключить, что существует значимая линейная зависимость между оценкой третьего экзамена (\(x\)) и итоговой оценкой экзамена (\(y\)), поскольку коэффициент корреляции значительно отличается от нуля.
Поскольку \(r\) является значимым, а точечная диаграмма показывает линейный тренд, линию регрессии можно использовать для прогнозирования результатов итоговых экзаменов.
МЕТОД 2: Использование таблицы критических значений для принятия решения
95%-е критические значения таблицы коэффициентов корреляции выборки могут быть использованы, чтобы дать вам хорошее представление о том, соответствует ли вычисленное значение \(r\) значим или нет .
Сравните \(r\) с соответствующим критическим значением в таблице. Если \(r\) не находится между положительным и отрицательным критическими значениями, то коэффициент корреляции является значимым. Если \(r\) имеет значение, вы можете использовать линию для предсказания.Пример \(\PageIndex{1}\)
Предположим, вы вычислили \(r = 0,801\), используя \(n = 10\) точек данных. \(df = n — 2 = 10 — 2 = 8\). Критические значения, связанные с \(df = 8\), равны \(-0,632\) и \(+0,632\). Если \(r<\) отрицательное критическое значение или \(r>\) положительное критическое значение, то \(r\) является значимым. Поскольку \(r = 0,801\) и \(0,801 > 0,632\), \(r\) является значимым, и линию можно использовать для прогнозирования. Если вы посмотрите на этот пример на числовой прямой, это поможет вам.
Рисунок \(\PageIndex{1}\). \(r\) не имеет значения между \(-0,632\) и \(+0,632\). \(r = 0,801 > +0,632\). Следовательно, \(r\) является значимым.Упражнение \(\PageIndex{1}\)
Для данной линии наилучшего соответствия вы вычислили, что \(r = 0,6501\) с использованием \(n = 12\) точек данных, и критическое значение равно 0,576.
Можно ли использовать линию для предсказания? Почему или почему нет?- Ответить
Если точечная диаграмма выглядит линейной, то да, линию можно использовать для предсказания, потому что \(r >\) положительное критическое значение.
Пример \(\PageIndex{2}\)
Предположим, вы вычислили \(r = –0,624\) с 14 точками данных. \(df = 14 – 2 = 12\). Критические значения равны \(-0,532\) и \(0,532\). Поскольку \(-0,624 < -0,532\), \(r\) является значимым, и линию можно использовать для прогноза
Рисунок \(\PageIndex{2}\). \(r = -0,624 — 0,532\). Следовательно, \(r\) является значимым.Упражнение \(\PageIndex{2}\)
Для данной линии наилучшего соответствия вы вычисляете, что \(r = 0,5204\), используя \(n = 9\) точек данных, а критическое значение равно \(0,666 \). Можно ли использовать линию для предсказания? Почему или почему нет?
- Ответить
Нет, линию нельзя использовать для предсказания, так как \(r <\) положительное критическое значение.
Пример \(\PageIndex{3}\)
Предположим, вы вычислили \(r = 0,776\) и \(n = 6\). \(df = 6 — 2 = 4\). Критические значения равны \(-0,811\) и \(0,811\). Поскольку \(-0,811 <0,776 <0,811\), \(r\) не имеет значения, и эту линию не следует использовать для прогнозирования.
Рисунок \(\PageIndex{3}\). \(-0,811Упражнение \(\PageIndex{3}\) Для данной линии наилучшего соответствия вы вычисляете, что \(r = -0,7204\), используя \(n = 8\) точек данных, и критическое значение равно \( = 0,707\). Можно ли использовать линию для предсказания? Почему или почему нет?
- Ответить
Да, линию можно использовать для предсказания, т.к. \(r <\) отрицательное критическое значение.
ТРЕТИЙ ЭКЗАМЕН и ЗАКЛЮЧИТЕЛЬНЫЙ ЭКЗАМЕН ПРИМЕР: метод критического значения
Рассмотрим пример третьего экзамена/выпускного экзамена.
Линия наилучшего соответствия: \(\hat{y} = -173,51 + 4,83x\) с \(r = 0,6631\) и есть \(n = 11\) точек данных. Можно ли использовать линию регрессии для предсказания? Учитывая оценку третьего экзамена ( \(x\) значение), можем ли мы использовать эту линию, чтобы предсказать окончательный результат экзамена (прогнозируемое значение \(y\) )? - \(H_{0}: \rho = 0\)
- \(H_{a}: \rho\neq 0\)
- \(\альфа = 0,05\)
- Используйте таблицу «Критическое значение 95%» для \(r\) с \(df = n — 2 = 11 — 2 = 9\).
- Критические значения: \(-0,602\) и \(+0,602\)
- Поскольку \(0,6631 > 0,602\), \(r\) является значимым.
- Решение: отвергнуть нулевую гипотезу.
- Заключение. Имеются достаточные доказательства, чтобы сделать вывод о наличии значительной линейной зависимости между оценкой третьего экзамена (\(x\)) и итоговой оценкой экзамена (\(y\)), поскольку коэффициент корреляции значительно отличается от нуля.
Поскольку \(r\) является значимым, а точечная диаграмма показывает линейный тренд, линию регрессии можно использовать для прогнозирования результатов итоговых экзаменов.
Пример \(\PageIndex{4}\)
Предположим, вы вычислили следующие коэффициенты корреляции. Используя таблицу в конце главы, определите, является ли значение \(r\) значимым, и можно ли использовать линию наилучшего соответствия, связанную с каждым r, для предсказания значения \(y\). Если это поможет, нарисуйте числовую линию.
- \(r = –0,567\), а объем выборки \(n\) равен \(19\). \(df = n — 2 = 17\). Критическое значение равно \(-0,456\). \(-0,567 <-0,456\), поэтому \(r\) является значимым.
- \(r = 0,708\), а размер выборки \(n\) равен \(9\). \(df = n — 2 = 7\). Критическое значение равно \(0,666\). \(0,708 > 0,666\), поэтому \(r\) является значимым.
- \(r = 0,134\), а размер выборки \(n\) равен \(14\). \(df = 14 — 2 = 12\). Критическое значение равно \(0,532\). \(0,134\) находится между \(-0,532\) и \(0,532\), поэтому \(r\) не имеет значения.
- \(r = 0\), а размер выборки \(n\) равен пяти. Независимо от того, каковы \(dfs\), \(r = 0\) находится между двумя критическими значениями, поэтому \(r\) не имеет значения.
Упражнение \(\PageIndex{4}\)
Для заданной линии наилучшего соответствия вы вычисляете, что \(r = 0\), используя \(n = 100\) точек данных. Можно ли использовать линию для предсказания? Почему или почему нет?
- Ответить
Нет, линию нельзя использовать для предсказания независимо от размера выборки.
Допущения при проверке значимости коэффициента корреляции
Проверка значимости коэффициента корреляции требует выполнения определенных допущений относительно данных. Предпосылка этого теста заключается в том, что данные представляют собой выборку наблюдаемых точек, взятых из большей совокупности.
Мы не исследовали всю популяцию, потому что это невозможно или невозможно сделать. Мы изучаем выборку, чтобы сделать вывод о том, обеспечивает ли линейная зависимость, которую мы видим между \(x\) и \(y\) в данных выборки, достаточно убедительные доказательства, чтобы мы могли сделать вывод о наличии линейной зависимости между \ (х\) и \(у\) в популяции.Уравнение линии регрессии, которое мы рассчитываем на основе данных выборки, дает наиболее подходящую линию для нашей конкретной выборки. Мы хотим использовать эту линию наилучшего соответствия для выборки в качестве оценки линии наилучшего соответствия для генеральной совокупности. Изучение графика рассеяния и проверка значимости коэффициента корреляции помогает нам определить, уместно ли это делать.
Предположения, лежащие в основе теста значимости:
- Существует линейная зависимость в совокупности, которая моделирует среднее значение \(y\) для различных значений \(x\). Другими словами, ожидаемое значение \(у\) для каждого конкретного значения лежит на прямой в генеральной совокупности. (Мы не знаем уравнения для линии для генеральной совокупности. Наша линия регрессии по выборке является нашей наилучшей оценкой этой линии в генеральной совокупности.)
- Значения \(y\) для любого конкретного значения \(x\) нормально распределяются по линии. Это означает, что ближе к линии разбросано больше значений \(y), чем дальше. Предположение (1) означает, что эти нормальные распределения сосредоточены на прямой: средние значения этих нормальных распределений значений \(у\) лежат на прямой.
- Стандартные отклонения значений совокупности \(y\) относительно линии равны для каждого значения \(x\). Другими словами, каждое из этих нормальных распределений значений \(y\) имеет одинаковую форму и разброс по линии.
- Остаточные ошибки взаимно независимы (нет шаблона).
- Данные получены из хорошо спланированной случайной выборки или рандомизированного эксперимента.
Для каждого значения \(x\) среднее значение \(y\) лежит на линии регрессии. Рядом с линией лежит больше значений \(y\), чем разбросанных дальше от линии.Резюме
Линейная регрессия — это процедура подбора прямой линии вида \(\hat{y} = a + bx\) к данным. Условия регрессии:
- Линейная В популяции существует линейная зависимость, которая моделирует среднее значение \(y\) для различных значений \(x\).
- Независимый Предполагается, что остатки независимы.
- Нормальный Значения \(y\) распределяются нормально для любого значения \(x\).
- Равная дисперсия Стандартное отклонение значений \(y\) одинаково для каждого значения \(x\).
- Случайная выборка Данные получены из хорошо спланированной случайной выборки или рандомизированного эксперимента.
Наклон \(b\) и точка пересечения \(a\) линии наименьших квадратов оценивают наклон \(\бета\) и точку пересечения \(\альфа\) генеральной (истинной) линии регрессии.
Чтобы оценить стандартное отклонение совокупности \(y\), \(\sigma\), используйте стандартное отклонение остатков, \(s\). \(s = \sqrt{\frac{SEE}{n-2}}\). Переменная \(\rho\) (rho) представляет собой коэффициент корреляции совокупности. Чтобы проверить нулевую гипотезу \(H_{0}: \rho =\) гипотетическое значение , используйте t-критерий линейной регрессии. Наиболее распространенной нулевой гипотезой является \(H_{0}: \rho = 0\), которая указывает на отсутствие линейной зависимости между \(x\) и \(y\) в популяции. Функция калькулятора TI-83, 83+, 84, 84+ LinRegTTest может выполнять этот тест (СТАТИСТИЧЕСКИЕ ТЕСТЫ LinRegTTest).Обзор формул
Линия наименьших квадратов или линия наилучшего соответствия:
\[\hat{y} = a + bx\]
где
\[a = y\text{-intercept}\]
\[b = \text{наклон}\]
Стандартное отклонение остатков:
\[s = \sqrt{\frac{SSE}{n-2}}\]
где
\[SSE = \text{сумма квадратов ошибок}\]
\[n = \text{количество точек данных}\]
Эта страница под названием 12.
5: Тестирование значимости коэффициента корреляции распространяется под лицензией CC BY 4.0 и была создана, изменена и/или курирована OpenStax с использованием исходного контента, который был отредактирован в соответствии со стилем и стандартами платформы LibreTexts; подробная история редактирования доступна по запросу.- Наверх
- Была ли эта статья полезной?
- Тип изделия
- Раздел или страница
- Автор
- ОпенСтакс
- Лицензия
- СС BY
- Версия лицензии
- 4,0
- Программа ООР или издатель
- ОпенСтакс
- Показать оглавление
- нет
- Теги
- Равная дисперсия
- коэффициент линейной корреляции
- источник@https://openstax. org/details/books/introductory-statistics
Дедуктивные и индуктивные аргументы | Internet Encyclopedia of Philosophy
Оценивая качество аргумента, мы спрашиваем, насколько хорошо его предпосылки подтверждают вывод. Более конкретно, мы спрашиваем, является ли аргумент либо дедуктивно достоверным , либо индуктивно сильным .
Дедуктивный аргумент — это аргумент, который, по замыслу спорящего, должен быть дедуктивно значимым, то есть предоставлять гарантию истинности вывода при условии, что посылки аргумента верны. Этот момент можно также выразить, сказав, что в дедуктивном аргументе посылки предназначены для обеспечения такой сильной поддержки вывода, что, если посылки истинны, то вывод не может быть ложным. Аргумент, в котором посылкам удается гарантировать вывод, называется (дедуктивно) допустимый аргумент . Если действительный аргумент имеет истинные предпосылки, то говорят, что аргумент также является звуком .
Все аргументы либо действительны, либо недействительны, обоснованы или несостоятельны; нет золотой середины, например, что-то действительное.Вот правильный дедуктивный аргумент:
В Сингапуре солнечно. Если в Сингапуре солнечно, то он не будет брать с собой зонт. Значит, он не будет носить зонт.
Вывод следует за словом «Итак». Две посылки этого аргумента, если они верны, гарантируют истинность вывода. Однако нам не дали никакой информации, которая позволила бы нам решить, верны ли обе посылки, поэтому мы не можем оценить, является ли аргумент дедуктивно обоснованным. То одно, то другое, но мы не знаем какое. Если выяснится, что аргумент имеет ложную предпосылку и поэтому несостоятелен, это не изменит того факта, что он действителен.
Вот умеренно сильный индуктивный аргумент:
Каждый раз, когда я проходил мимо этой собаки, она не пыталась меня укусить. Так что в следующий раз, когда я пройду мимо этой собаки, она не будет пытаться меня укусить.
Индуктивный аргумент — это аргумент, который, по замыслу спорщика, должен быть достаточно сильным, чтобы, если бы посылки были истинными, то маловероятно, что заключение ложно. Таким образом, успех или сила индуктивного аргумента зависит от степени, в отличие от дедуктивного аргумента. Не существует стандартного термина для успешного индуктивного аргумента, но в этой статье используется термин «сильный». Индуктивные аргументы, которые не являются сильными, называются слабый; нет четкой границы между сильным и слабым. Аргумент о том, что меня укусила собака, был бы сильнее, если бы мы не могли придумать никаких релевантных условий, объясняющих, почему следующий раз будет отличаться от предыдущего. Аргумент также будет тем сильнее, чем больше раз я гулял с собакой. Аргумент будет тем слабее, чем меньше раз я проходил мимо собаки. Это будет слабее, если в следующий раз релевантные условия о прошлом времени будут другими, например, в прошлом собака была за закрытыми воротами, но в следующий раз ворота будут открыты.
На индуктивный аргумент можно повлиять, приобретя новые посылки (доказательства), но на дедуктивный аргумент нельзя. Например, это достаточно сильный индуктивный аргумент:
Сегодня Джон сказал, что ему нравится Ромона.
Итак, Джону сегодня нравится Ромона., но его сила радикально меняется, когда мы добавляем эту посылку:
Сегодня Джон сказал Фелипе, что ему не очень нравится Ромона.
Различие между дедуктивной и индуктивной аргументацией впервые было замечено Аристотелем (384–322 гг. до н. э.) в Древней Греции. Разница между дедуктивными и индуктивными аргументами заключается не в словах, используемых в аргументах, а скорее в намерениях спорщика. Это происходит из отношения, которое, по мнению спорщика, существует между предпосылками и заключением. Если спорщик считает, что истинность посылок определенно устанавливает истинность вывода, тогда аргумент дедуктивен . Если спорщик считает, что истинность посылок дает только веские основания полагать, что вывод, вероятно, верен, то аргумент индуктивный .
Если мы, оценивающие качество аргумента, не располагаем информацией о намерениях спорщика, то мы проверяем и то, и другое. То есть мы оцениваем аргумент, чтобы увидеть, является ли он дедуктивно достоверным и индуктивно сильным.Концепции дедуктивной валидности можно дать альтернативные определения, которые помогут вам понять концепцию. Ниже приведены пять различных определений одного и того же понятия. Обычно слово дедуктивно отбрасывают из термина дедуктивно валидно :
- Аргумент действителен , если все посылки не могут быть истинными без того, чтобы заключение также не было истинным.
- Аргумент действителен , если истинность всех его предпосылок обуславливает истинность заключения.
- Аргумент действителен , если он несовместим, если все его посылки истинны, а его заключение ложно.
- Аргумент является действительным , если его вывод с уверенностью следует из его предпосылок.
- Аргумент является действительным , если он не имеет контрпримера, то есть возможной ситуации, которая делает все посылки истинными, а заключение ложным.
Некоторые аналитики предпочитают отличать индуктивные аргументы от «кондуктивных» аргументов; последние представляют собой аргументы, дающие явные причины за и против вывода и требующие от оценщика аргумента взвесить эти конкурирующие соображения, то есть рассмотреть все за и против. В этой статье кондуктивные аргументы рассматриваются как разновидность индуктивного аргумента.
Существительное «дедукция» относится к процессу выдвижения или установления дедуктивного аргумента или процессу рассуждения, который может быть реконструирован как дедуктивный аргумент. «Индукция» относится к процессу выдвижения индуктивного аргумента или использования рассуждений, которые можно реконструировать как индуктивный аргумент.
Хотя индуктивная сила является вопросом степени, дедуктивная достоверность и дедуктивная обоснованность — нет.
В этом смысле дедуктивное рассуждение гораздо более четкое, чем индуктивное. Тем не менее сила индуктивности не зависит от личных предпочтений; вопрос в том, является ли посылка должен способствовать большей уверенности в заключении.Поскольку дедуктивные аргументы — это аргументы, в которых истинность вывода считается полностью гарантированной а не только сделанной вероятной истинностью посылок, если аргумент здравый, то мы говорим, что вывод верный. «содержатся в» помещении; то есть вывод не выходит за рамки того, что имплицитно требуют посылки. Думайте о здравых дедуктивных аргументах как о выдавливании заключения из предпосылок, в которых оно скрыто. По этой причине дедуктивные аргументы обычно в решающей степени опираются на определения и правила математики и формальной логики.
Подумайте, как правила формальной логики применяются к этому дедуктивному аргументу:
Джон болен. Если Джон болен, то сегодня он не сможет присутствовать на нашей встрече.
Поэтому Джон не сможет сегодня присутствовать на нашей встрече.Этот аргумент действителен благодаря своей формальной или логической структуре. Чтобы понять почему, обратите внимание, что если бы слово «больной» было заменено на «счастливый», аргумент все равно был бы действителен, потому что он сохранил бы свою особую логическую структуру (называемую modus ponens 9).0030 логиками). Вот форма любого аргумента, имеющего структуру modus ponens:
P
Если P, то Q
Итак, Q
Заглавные буквы следует рассматривать как переменные, которые можно заменить повествовательными предложениями или утверждениями. , или предложения, а именно элементы, которые являются истинными или ложными. Исследование логических форм, которые включают целые предложения, а не их подлежащие, глаголы и другие части, называется логикой высказываний.
Вопрос о том, являются ли все или только большинство валидных дедуктивных аргументов валидными из-за их логической структуры, до сих пор остается спорным в области философии логики, но этот вопрос больше не исследуется в этой статье.
Индуктивные аргументы могут принимать самые разнообразные формы. Некоторые из них имеют форму утверждения о совокупности или наборе, основанном только на информации из выборки этого населения, подмножества. Другие индуктивные аргументы делают выводы, апеллируя к доказательствам, авторитету или причинно-следственным связям. Есть другие формы.
Вот несколько сильный индуктивный аргумент, имеющий форму аргумента, основанного на авторитете:
Полиция заявила, что убийство совершил Джон. Итак, Джон совершил убийство.
Вот индуктивный аргумент, основанный на доказательствах:
Свидетель сказал, что убийство совершил Джон. Итак, Джон совершил убийство.
Вот более сильный индуктивный аргумент, основанный на лучших доказательствах:
Два независимых свидетеля заявили, что убийство совершил Джон. Отпечатки пальцев Джона на орудии убийства. Джон признался в преступлении. Итак, Джон совершил убийство.
Этот последний довод, если известно, что его предпосылки верны, несомненно, достаточно хорош для того, чтобы присяжные признали Джона виновным, но ни один из этих трех доводов о том, что Джон совершил убийство, не является достаточно сильным, чтобы его можно было назвать «действительным», в по крайней мере, не в техническом смысле дедуктивной достоверности.
Тем не менее, некоторые юристы скажут своим присяжным, что это веские аргументы, поэтому мы, критически мыслящие люди, должны быть начеку в отношении того, как люди вокруг нас используют термин «действительный». Вы должны быть внимательны к тому, что они имеют в виду, а не к тому, что они говорят. Английский сыщик Шерлок Холмс ловко «выводил», кто кого убил, по малейшим уликам, но на самом деле он сделал лишь обоснованное предположение. Строго говоря, он привел индуктивный аргумент, а не дедуктивный. Чарльз Дарвин, открывший процесс эволюции, известен своей «дедукцией» о том, что круглые атоллы в океанах на самом деле являются коралловыми наростами на вершинах едва затопленных вулканов, но на самом деле он провел индукцию, а не дедукцию.Стоит отметить, что некоторые словари и тексты определяют «дедукцию» как рассуждение от общего к частному и определяют «индукцию» как рассуждение от частного к общему . Однако существует множество индуктивных аргументов, не имеющих такой формы, например: «Я видел, как она его целовала, действительно целовала его, так что я уверен, что у нее роман».
Метод математического доказательства, называемый «математической индукцией», является дедуктивным, а не индуктивным. Доказательства, использующие математическую индукцию, обычно принимают следующую форму:
Свойство P верно для натурального числа 0.
Для всех натуральных чисел n , если P верно для n , то P также верно для n + 1.
Следовательно, P истинно для всех натуральные числа.Когда такое доказательство дается математиком и когда все посылки верны, то обязательно следует заключение. Следовательно, такой индуктивный аргумент является дедуктивным. Это также дедуктивно правильно.
Поскольку разница между индуктивными и дедуктивными аргументами связана с силой доказательств, которые автор считает, что посылки обеспечивают вывод, индуктивные и дедуктивные аргументы различаются в отношении стандартов оценки, которые к ним применимы. Разница не в содержании или предмете аргумента, а также в наличии или отсутствии какого-либо конкретного слова.
Действительно, одно и то же высказывание может быть использовано для представления как дедуктивного, так и индуктивного аргумента, в зависимости от того, во что верит выдвигающий его человек. Рассмотрим для примера:Dom Perignon — это шампанское, поэтому оно должно быть сделано во Франции.
Из контекста может быть ясно, что говорящий считает, что производство в регионе Шампань во Франции является частью определяющей черты «шампанского», и поэтому вывод следует из посылки по определению. Если намерение говорящего состоит в том, чтобы доказательства были такого рода, то аргумент является дедуктивным. Однако может случиться так, что такой мысли нет в голове говорящего. Он или она может просто полагать, что почти все шампанское производится во Франции, и рассуждать вероятностно. Если это его или ее намерение, то аргумент индуктивный.
Как уже отмечалось, различие между дедуктивным и индуктивным имеет отношение к силе обоснования, что спорщик намеревается что посылки обеспечивают заключение.
Еще одна сложность в нашем обсуждении дедукции и индукции заключается в том, что спорщик может иметь в виду, что посылки обосновывают вывод, хотя на самом деле посылки вообще не дают никакого обоснования. Вот пример:Все нечетные числа являются целыми числами.
Все четные числа являются целыми числами.
Следовательно, все нечетные числа являются четными числами.Этот аргумент недействителен, потому что посылки не дают никакой поддержки заключению. Однако, если бы этот аргумент был когда-либо серьезно выдвинут, мы должны предположить, что автор поверил бы , что истинность посылок гарантирует истинность заключения. Следовательно, этот аргумент все же является дедуктивным. Он не индуктивный.
Учитывая то, как здесь определяются термины «дедуктивный аргумент» и «индуктивный аргумент», аргумент всегда является одним или другим и никогда обоими, но при решении, какой из двух он является, обычно спрашивают, является ли он соответствует как дедуктивным стандартам, так и индуктивным стандартам.
Учитывая набор предпосылок и их предполагаемый вывод, мы, аналитики, зададимся вопросом, является ли он дедуктивно достоверным, и если да, то является ли он также дедуктивно обоснованным. Если оно не является дедуктивно достоверным, то мы можем продолжить оценку того, является ли оно индуктивно сильным.Скорее всего, мы воспользуемся информацией о том, что аргумент дедуктивно недействителен, чтобы спросить себя, какие предпосылки, если бы они были допущены, сделали бы этот аргумент действительным. Тогда мы могли бы спросить, были ли эти посылки подразумеваемыми и предназначались ли они изначально. Точно так же мы могли бы спросить, какие посылки необходимы для повышения силы индуктивного аргумента, и мы могли бы спросить, были ли эти посылки изначально задуманы. Если это так, то мы меняем свое мнение о том, какой аргумент существовал еще в исходном отрывке. Так, применение дедуктивных и индуктивных стандартов используется в процессе извлечения аргумента из отрывка, в который он встроен.
Процесс выглядит следующим образом: извлеките аргумент из отрывка; оценить его с помощью дедуктивных и индуктивных стандартов; возможно, пересмотреть решение о том, какой аргумент существовал в исходном отрывке; затем переоцените этот новый аргумент, используя наши дедуктивные и индуктивные стандарты.Неявные посылки и неявные свойства явных посылок могут играть важную роль в оценке аргументов. Предположим, мы хотим знать, действительно ли Юлий Цезарь завоевал Рим. В ответ какой-нибудь историк мог бы указать, что из этих двух сведений можно с уверенностью заключить:
Генерал римских легионов Галлии пересек реку Рубикон и завоевал Рим.
Цезарь в то время был генералом римских легионов в Галлии.
Это будет правильным аргументом. Но теперь заметьте, что если бы «в то время» не было во второй части информации, то аргумент был бы недействителен. Вот почему. Возможно, Цезарь когда-то был генералом, но Тиберий был полководцем во время переправы через реку и завоевания Рима.
Если фраза «в то время» отсутствовала, вы, аналитик, должны беспокоиться о том, насколько вероятно, что эта фраза была задумана. Итак, вы столкнулись с двумя аргументами, одним действительным и одним недействительным, и вы не знаете, какой аргумент является предполагаемым.См. также статьи «Аргументы» и «Обоснованность и обоснованность» в этой энциклопедии.
Информация об авторе
Персонал IEP
IEP активно ищет автора, который напишет более сложную статью на замену.Часть II: Глава 4: Анализ количественных данных
Часть II: Глава 4: Анализ количественных данныхЧто такое качественный анализ?
Качественные режимы анализа данных позволяют различать, исследовать, сравнивать и противопоставлять, а также интерпретировать значимые закономерности или темы. Значимость определяется конкретными целями и задачами проекта: одни и те же данные могут быть проанализированы и синтезированы с разных точек зрения в зависимости от конкретных вопросов исследования или оценки.
Различные подходы, включая этнографию, нарративный анализ, анализ дискурса и текстологический анализ, соответствуют различным типам данных, дисциплинарным традициям, целям и философским ориентациям. Однако все они имеют несколько общих характеристик, которые отличают их от количественных аналитических подходов.В количественном анализе числа и то, что они обозначают, являются материалом для анализа. Напротив, качественный анализ имеет дело со словами и руководствуется меньшим количеством универсальных правил и стандартизированных процедур, чем статистический анализ.
У нас есть несколько согласованных канонов для качественного анализа данных в смысле общих основных правил для получения выводов и проверки их надежности (Майлз и Хуберман, 1984).
Это относительное отсутствие стандартизации является одновременно источником универсальности и центром значительного непонимания. Тот факт, что качественные аналитики не будут указывать единые процедуры, которым следует следовать во всех случаях, вызывает критические возражения со стороны исследователей, которые задаются вопросом, может ли анализ быть действительно строгим в отсутствие таких универсальных критериев; на самом деле, эти аналитики, возможно, способствовали возникновению этой критики, не сумев адекватно сформулировать свои стандарты оценки качественного анализа или даже отрицая, что такие стандарты возможны.
Их позиция подпитывала в корне ошибочное, но относительно распространенное представление о качественном анализе как о бессистемном, недисциплинированном и «чисто субъективном».Несмотря на то, что качественный анализ явно отличается от количественного статистического анализа как по процедурам, так и по целям, качественный анализ является систематическим и строго дисциплинированным. Качественный анализ, если он не является «объективным» в строгом позитивистском смысле, возможно, воспроизводим, поскольку другие могут быть «пройдены» мыслительными процессами и предположениями аналитика. Время также работает совсем по-другому в качественной оценке. Количественную оценку легче разделить на отдельные этапы разработки инструмента, сбора данных, обработки данных и анализа данных. Напротив, при качественной оценке сбор и анализ данных не являются дискретными во времени этапами: как только собраны первые фрагменты данных, оценщик начинает процесс осмысления информации. Кроме того, различные процессы, связанные с качественным анализом, также перекрываются во времени.
Отличительной чертой качественного анализа является петлеобразная схема многократного повторного просмотра данных по мере появления дополнительных вопросов, обнаружения новых связей и развития более сложных формулировок наряду с углублением понимания материала. Качественный анализ – это, по сути, итеративный набор процессов.На самом простом уровне качественный анализ включает в себя изучение собранных релевантных данных, чтобы определить, как они отвечают на имеющиеся вопросы оценки. Однако данные могут быть в форматах, непривычных для специалистов по количественной оценке, что усложняет эту задачу. Например, при количественном анализе результатов опроса частотное распределение ответов на конкретные пункты вопросника часто структурирует обсуждение и анализ результатов. Напротив, качественные данные чаще всего встречаются в более встроенных и менее легко поддающихся редукции или дистилляции формах, чем количественные данные. Например, релевантная «часть» качественных данных может быть перемешана с частями стенограммы интервью, несколькими выдержками из набора полевых заметок или комментарием или группой комментариев фокус-группы.
В ходе качественного анализа аналитик должен задавать и повторно задавать следующие вопросы:
- Какие закономерности и общие темы проявляются в ответах, касающихся конкретных вопросов? Как эти шаблоны (или их отсутствие) помогают осветить более широкий вопрос(ы) исследования?
- Есть ли отклонения от этих шаблонов? Если да, то есть ли какие-либо факторы, которые могли бы объяснить эти нетипичные ответы?
- Какие интересные истории появляются из ответов? Как эти истории могут помочь осветить более широкий вопрос(ы) исследования?
- Предполагает ли какая-либо из этих закономерностей или результатов, что может потребоваться сбор дополнительных данных? Нужно ли пересмотреть какие-либо из учебных вопросов?
- Подтверждают ли выявленные закономерности результаты какого-либо соответствующего качественного анализа, который был проведен? Если нет, то чем можно объяснить эти расхождения?
Будут обсуждаться две основные формы качественного анализа, практически одинаковые по своей базовой логике: анализ внутри случаев и анализ перекрестных случаев .
Случай может быть по-разному определен для разных аналитических целей. В зависимости от ситуации кейсом может быть отдельный человек, сессия фокус-группы или сайт программы (Berkowitz, 1996). С точки зрения гипотетического проекта, описанного в главе 2, случаем будет один университетский городок. Внутрикейсовый анализ исследует один объект проекта, а кросс-кейсовый анализ систематически сравнивает и противопоставляет восемь кампусов.
Процессы в качественном анализеКачественные аналитики обоснованно опасаются создания излишне редукционистской или механистической картины бесспорно сложного итеративного набора процессов. Тем не менее, оценщики выявили несколько основных общих черт в процессе осмысления качественных данных. В этой главе мы приняли структуру, разработанную Майлзом и Хуберманом (1994), для описания основных этапов анализа данных: редукция данных, отображение данных, подведение итогов и проверка.
Сокращение данныхВо-первых, масса данных должна быть организована и каким-то образом осмысленно уменьшена или реконфигурирована .
Майлз и Хуберман (1994) описывают этот первый из трех элементов качественного анализа данных как сокращение данных. «Сокращение данных относится к процессу выбора, сосредоточения, упрощения, абстрагирования и преобразования данных, которые появляются в письменных полевых заметках или транскрипциях». Данные необходимо не только сжимать для удобства управления, но и преобразовывать, чтобы сделать их понятными с точки зрения решаемых проблем.Сокращение данных часто заставляет выбирать, какие аспекты собранных данных следует выделить, свести к минимуму или полностью отложить в сторону для целей текущего проекта. Новички часто не понимают, что даже на этом этапе данные не говорят сами за себя. Обычная ошибка многих людей, совершаемых как при количественном, так и при качественном анализе, в тщетных попытках оставаться «совершенно объективными», состоит в том, чтобы представить читателю большой объем неусвоенных и неклассифицированных данных.
При качественном анализе аналитик решает, какие данные следует выделить для описания в соответствии с принципами избирательности.
Обычно это включает некоторую комбинацию дедуктивного и индуктивного анализа. В то время как первоначальные классификации формируются на основе заранее установленных вопросов исследования, качественный аналитик должен оставаться открытым для получения новых значений из доступных данных.При оценке, такой как гипотетический проект оценки в этом руководстве, сокращение данных должно основываться в первую очередь на необходимости ответить на существенный(е) вопрос(ы) оценки. Это выборочное отсеивание затруднено как потому, что качественные данные могут быть очень богатыми, так и потому, что человек, который анализирует данные, также часто играет непосредственную личную роль в их сборе. Слова, из которых состоит качественный анализ, гораздо более конкретно представляют реальных людей, места и события, чем числа в наборах количественных данных — реальность, из-за которой вырезание любого из них может быть довольно болезненным. Но лакмусовой бумажкой должна быть релевантность конкретных данных для ответа на конкретные вопросы.
Например, формирующий оценочный вопрос для гипотетического исследования может заключаться в том, подходят ли презентации для всех участников. Участники фокус-групп могли сказать много интересного о презентациях, но замечания, которые лишь косвенно касаются вопроса пригодности, возможно, придется заключить в скобки или проигнорировать. Точно так же комментарии участника о руководителе его отдела, которые не связаны с вопросами реализации программы или воздействия, какими бы интересными они ни были, не должны включаться в окончательный отчет. Подход к сокращению данных одинаков для анализа внутри и между случаями.Имея в виду гипотетический проект из главы 2, будет наглядным рассмотреть способы сокращения собранных данных для ответа на вопрос «что сделали участвующие преподаватели, чтобы поделиться знаниями с неучаствующими преподавателями?» Первым шагом в анализе проблемы внутри случая является изучение всех соответствующих источников данных, чтобы извлечь описание того, что они говорят об обмене знаниями между участвующими и неучаствующими преподавателями в одном кампусе.
Сюда может быть включена информация из фокус-групп, наблюдений и подробных интервью с ключевыми информантами, такими как заведующий кафедрой. Наиболее значимые части данных, вероятно, будут сосредоточены в определенных разделах расшифровок фокус-групп (или рецензий) и подробных интервью с заведующим кафедрой. Тем не менее, лучше также быстро просмотреть все примечания на предмет соответствующих данных, которые могут быть разбросаны повсюду.При инициировании процесса сокращения данных основное внимание уделяется уточнению предложений различных групп респондентов о мероприятиях, используемых для обмена знаниями между преподавателями, участвовавшими в проекте, и теми, кто не участвовал. Как то, что говорят участвующие преподаватели, соотносится с тем, что сообщают неучаствующие преподаватели и заведующие кафедрой об обмене знаниями и внедрении новых практик? Излагая эти различия и сходства, важно не настолько «уплощать» или уменьшать данные, чтобы они звучали как закрытые ответы на опросы.
Тенденция обращаться с качественными данными таким образом не редкость среди аналитиков, обученных количественным подходам. Неудивительно, что в результате качественный анализ выглядит как разбавленное исследование с крошечным размером выборки. Подход к качественному анализу таким образом несправедливо и излишне разбавляет богатство данных и, таким образом, непреднамеренно подрывает одну из самых сильных сторон качественного подхода.Ответ на вопрос об обмене знаниями действительно качественным образом должен выходить за рамки перечисления списка мероприятий по обмену знаниями, а также исследовать оценки респондентами относительной эффективности этих мероприятий, а также их причины полагать, что некоторые из них более эффективны, чем другие . Помимо изучения конкретного содержания взглядов респондентов, полезно также отметить относительную частоту, с которой поднимаются различные вопросы, а также интенсивность их выражения.
Дисплей данныхОтображение данных — это второй элемент или уровень в модели качественного анализа данных Майлза и Хубермана (1994).
Отображение данных выходит за рамки сокращения данных, чтобы обеспечить «организованную, сжатую сборку информации, которая позволяет делать выводы…» Отображение может быть расширенным фрагментом текста или диаграммой, диаграммой или матрицей, которая обеспечивает новый способ организации и думать о более текстовых встроенных данных. Отображение данных, будь то в словесной или диаграммной форме, позволяет аналитику экстраполировать данные достаточно, чтобы начать различать систематические закономерности и взаимосвязи. На этапе отображения из данных могут появиться дополнительные категории или темы более высокого порядка, которые выходят за рамки тех, которые впервые были обнаружены в ходе начального процесса обработки данных.С точки зрения оценки программы отображение данных может быть чрезвычайно полезным для определения того, почему система (например, данная программа или проект) работает или не работает хорошо, и что можно сделать, чтобы изменить ее. Всеобъемлющий вопрос о том, почему одни проекты работают лучше или более успешны, чем другие, почти всегда является движущей силой аналитического процесса при любой оценке.
В нашем гипотетическом примере оценки преподаватели всех восьми кампусов собираются в центральном кампусе для участия в семинарах. В этом отношении все участники подвергаются одинаковой программе. Тем не менее, реализация методов обучения, представленных на семинаре, скорее всего, будет варьироваться от кампуса к кампусу в зависимости от таких факторов, как личные характеристики участников, различные демографические характеристики студентов и различия в характеристиках университетов и факультетов (например, размер школы). студенческий состав, организация подготовительных курсов, поддержка заведующим кафедрой программных целей, восприимчивость кафедры к изменениям и инновациям). Специалисту по качественному анализу необходимо выявить модели взаимосвязей, чтобы предположить, почему проект способствовал большему изменению в одних кампусах, чем в других.Одним из методов отображения описательных данных является разработка серии блок-схем, которые отображают любые критические пути, точки принятия решений и подтверждающие данные, полученные в результате установления данных для одного сайта.
После разработки первой блок-схемы процесс можно повторить для всех остальных участков. Аналитики могут (1) использовать данные с последующих сайтов для изменения исходной блок-схемы; (2) подготовить независимую блок-схему для каждого сайта ; и/или (3) подготовьте единую блок-схему для некоторых событий (если на большинстве участков принят общий подход) и несколько блок-схем для других. Изучение данных, отображаемых в восьми кампусах, может привести к выводу о том, что внедрение проходило быстрее и эффективнее в тех кампусах, где заведующий кафедрой активно поддерживал опробование новых подходов к обучению, но препятствовал и задерживался, когда заведующие кафедрами опасались внесения изменений в проверенная временем система.Отображение данных для анализа внутри случая. В приложении 10 представлена матрица отображения данных для анализа моделей ответов, касающихся восприятий и оценок деятельности по обмену знаниями для одного кампуса. Мы предположили, что трем респондентам — участвующим преподавателям, неучаствующим преподавателям и заведующим кафедрами — были заданы аналогичные вопросы.
Глядя на столбец (а), интересно, что три группы респондентов не пришли к полному согласию даже в том, какие виды деятельности они назвали. Только участники считали электронную почту средством обмена тем, что они узнали в программе, со своими коллегами. Коллеги, не участвовавшие в обсуждении, по-видимому, смотрели на ситуацию по-другому, потому что не включили в свой список адрес электронной почты. Заведующая кафедрой — возможно, потому, что она не знала, что они происходят — не упомянула электронную почту или неформальный обмен информацией как деятельность по обмену знаниями.Столбец (b) показывает, какие виды деятельности каждая группа считает наиболее эффективным способом обмена знаниями, в порядке предполагаемой важности; в колонке (с) приведены причины, по которым респонденты считают эти конкретные виды деятельности наиболее эффективными. Глядя вниз по колонке (b), мы видим, что между группами есть некоторое совпадение — например, и участники, и заведующий кафедрой считали, что структурированные семинары были наиболее эффективным мероприятием по обмену знаниями.
Те, кто не участвовал, считали структурированные семинары более эффективными, чем встречи во время обеда, но менее эффективными, чем неформальные обмены мнениями.Экспонат 10.
Матрица данных для кампуса A: что было сделано для обмена знаниямиГруппа респондентов (а)
Виды деятельности с именем(б)
Какой самый эффективный(в)
ПочемуУчастники - Структурированные семинары
- Электронная почта
- Неофициальные обмены
- Обеденные встречи
- Структурированные семинары
- Электронная почта
- Краткий способ передачи большого объема информации
Неучастники - Структурированные семинары
- Неофициальные обмены
- Обеденные встречи
- Неформальные обмены
- Структурированные семинары
- Легче усваивать информацию в менее формальной обстановке
- Меньшие биты информации за раз
Кафедра - Структурированные семинары
- Встречи в обеденное время
- Структурированные семинары
- Самая высокая посещаемость неучастниками
- Наибольшее количество комментариев (положительных) к председателю
Простое знание того, что каждая группа респондентов считает наиболее эффективным, не зная почему, упустило бы важную часть аналитической головоломки.
Это лишило бы качественного аналитика возможности исследовать потенциально значимые вариации в основных концепциях того, что определяет эффективность образовательного обмена. Например, несмотря на то, что как участвующие преподаватели, так и заведующий кафедрой согласились с тем, что структурированные семинары являются наиболее эффективным мероприятием по обмену знаниями, они привели несколько разные причины для этого заявления. Участники сочли семинары наиболее эффективным способом краткой передачи большого объема информации. Заведующая кафедрой использовала косвенные показатели — посещаемость семинаров неучастниками, а также положительные отзывы о семинарах, организованных ей добровольцами, — чтобы сформулировать свое суждение об эффективности. Важно признать, что респонденты пришли к одним и тем же выводам на разных основаниях.Из этого относительно простого и предварительного упражнения вытекает несколько моментов, касающихся качественного анализа. Во-первых, характер межгрупповых различий можно обнаружить еще до того, как мы проанализируем ответы, касающиеся действий, которые считаются наиболее эффективными, и почему.
Открытый формат вопроса позволил каждой группе дать собственное определение «деятельности по обмену знаниями». Цель анализа состоит не только в том, чтобы определить, какие виды деятельности использовались и как часто; если бы это было основной целью постановки этого вопроса, были бы гораздо более эффективные способы (например, контрольный список или шкала оценок) для поиска ответа. С аналитической точки зрения важнее начать выявлять соответствующие групповые различия в восприятии.Различия в причинах, по которым один вид деятельности считается более эффективным, чем другой, могут также указывать на различные концепции основных целей деятельности по обмену знаниями. Некоторые из этих вариаций можно объяснить тем, что группы респондентов занимают разные структурные позиции в жизни и разные роли в данной конкретной ситуации. Хотя как участвующие, так и неучаствующие преподаватели преподают на одном и том же факультете, в этой ситуации участвующие преподаватели играют роль преподавателя по отношению к своим коллегам.
Данные в столбце (с) показывают, что участники видят свою главную цель в максимально кратком сообщении большого объема информации. Напротив, неучастники — в роли студентов — считают, что они лучше усваивают материал, когда им предоставляется меньшее количество информации в неформальной обстановке. Их разные подходы к вопросу могут отражать разные представления, основанные на этой временной перестановке их ролей. Заведующий кафедрой занимает в университете иное структурное положение, чем участвующие или неучаствующие преподаватели. Она может быть слишком удалена от повседневных обменов между преподавателями, чтобы видеть многое из того, что происходит на этом более неформальном уровне. Точно так же ее отстранение от широких масс может дать ей более широкий взгляд на эту тему.Отображение данных в перекрестном анализе. Принципы, применяемые при анализе нескольких дел, по существу аналогичны принципам, используемым при анализе внутри дела. В приложении 11 показан пример гипотетической матрицы отображения данных, которую можно использовать для анализа ответов участников программы на вопрос об обмене знаниями во всех восьми кампусах.
Глядя вниз по столбцу (а), можно увидеть различия в количестве и разнообразии мероприятий по обмену знаниями, названных участвующими преподавателями в восьми школах. К списку были добавлены обеды в коричневых пакетах, информационные бюллетени отдела, семинары и распространение письменных (распечатанных) материалов, которые для кампуса филиала А включали только структурированные семинары, электронную почту, неформальное общение и встречи во время обеда. Этот расширенный список, вероятно, охватывает большинство, если не все, такие виды деятельности в восьми кампусах. Кроме того, там, где это применимо, мы указали, было ли участие неучаствующих преподавателей в деятельности обязательным или добровольным.В Приложении 11 мы сравниваем одну и ту же группу в разных кампусах, а не разные группы в одном и том же кампусе, как в Приложении 10. Столбец (b) показывает некоторое совпадение среди участников, деятельность которых считалась наиболее эффективной: структурированные семинары были названы участниками в кампусах A и C, обеды в коричневых пакетах
Приложение 11.
Участники мнения об обмене информацией в восьми кампусахФилиал (а)
Виды деятельности с именем(б)
Какой самый эффективный(в)
ПочемуА - Структурированный семинар (добровольный)
- Электронная почта
- Неофициальные обмены
- Обеденные встречи
Структурированный семинар Электронная почта
Краткий способ передачи большого количества информации Б - Коричневые сумки
- Электронная почта
- Вестник отдела
Коричневые сумки Самый интерактивный С - Семинары (добровольные)
- Структурированный семинар (обязательный)
Структурированный семинар Обязательное Хорошо работает структурированный формат
Д - Неформальные обмены
- Распространение письменных материалов
Комбинация двух Распространение важно, но недостаточно без «личного контакта» Е - Структурированные семинары (обязательные)
- Семинары (добровольные)
Мастерские Добровольный практический подход работает лучше всего Ф - Электронная почта
- Распространение материалов
- Мастерские (обязательно)
Распространение материалов Не все регулярно пользуются электронной почтой Обязательные мастерские сопротивлялись как принудительные
Г - Структурированный семинар
- Неофициальные обмены
- Обеденные встречи
Обеденные встречи Лучшее время Н - Коричневые сумки
- Электронная почта
- Распространение материалов
Коричневые сумки Расслабленная обстановка теми, кто находится в кампусах B и H.
Однако, как и в примере 10, основные причины для названий этих видов деятельности не всегда были одинаковыми. Обед в коричневых пакетах был признан наиболее эффективным из-за его интерактивного характера (кампус B) и непринужденной обстановки, в которой он проходил (кампус H), что предполагает предпочтение менее формальным учебным ситуациям. Однако в то время как участники кампуса А считали добровольные структурированные семинары наиболее эффективным способом передачи большого объема информации, участникам кампуса С также понравилось, что структурированные семинары в их кампусе были обязательными. Участники в обоих кампусах, кажется, одобряют структуру, но могут расстаться в вопросе о том, является ли требование присутствия хорошей идеей. Было добавлено различие между добровольным и обязательным, чтобы проиллюстрировать различные аспекты эффективного обмена знаниями, которые могут оказаться аналитически релевантными.Также было бы полезно изучить причины, по которым участники считали один вид деятельности более эффективным, чем другой, независимо от вида деятельности.
Данные в столбце (c) показывают тенденцию участников кампусов B, D, E, F и H отдавать предпочтение добровольным, неформальным, практическим, личным подходам. Напротив, студенты из кампусов A и C, похоже, предпочитали более структурированную структуру (хотя они могут расходиться во мнениях относительно добровольного или обязательного подходов). Ответ, предоставленный для кампуса G («лучшее время»), неоднозначен и требует возвращения к расшифровке стенограммы, чтобы увидеть, можно ли найти дополнительные материалы для разъяснения этого ответа.Включить всю информацию об обмене знаниями от четырех разных групп респондентов во всех восьми кампусах в единую матрицу было бы довольно сложно. Поэтому для ясности мы представляем только ответы участвующих преподавателей. Тем не менее, чтобы завершить кросс-кейсовый анализ этого оценочного вопроса, необходимо следовать той же процедуре — если не в матричном формате, то концептуально — для неучаствующих заведующих кафедрами и кафедрами. Для каждой группы анализ будет смоделирован по приведенному выше примеру.
Он будет направлен на выявление важных сходств и различий в том, что респонденты говорили или наблюдали, а также на изучение возможных оснований для этих закономерностей в разных кампусах. Большая часть качественного анализа, будь то интра- или кросс-кейс, построена на том, что говорят Глейзер и Штраус (19).67) назвал «методом постоянного сравнения», интеллектуально дисциплинированным процессом сравнения и противопоставления разных случаев для установления значимых паттернов, а затем дальнейшего исследования и уточнения этих паттернов в рамках непрерывного аналитического процесса.
Заключительный чертеж и проверкаЭта деятельность является третьим элементом качественного анализа. Подведение итогов включает в себя отступление назад, чтобы рассмотреть, что означают проанализированные данные, и оценить их значение для рассматриваемых вопросов. 6 Верификация , , неразрывно связанная с подведением итогов, влечет за собой повторное рассмотрение данных столько раз, сколько необходимо для перепроверки или проверки этих возникающих выводов.
«Значения, вытекающие из данных, должны быть проверены на их правдоподобие, их надежность, их «подтверждаемость», то есть их достоверность» (Майлз и Хуберман, 1994, стр. 11). Валидность означает в этом контексте нечто иное, чем в количественной оценке, где это технический термин, относящийся весьма конкретно к тому, измеряет ли данный конструкт то, что он призван измерять. Здесь валидность включает в себя гораздо более широкую заботу о том, являются ли выводы, сделанные на основе данных, достоверными, обоснованными, обоснованными и способными противостоять альтернативным объяснениям.6 Когда качественные данные используются в качестве предварительного этапа проектирования/разработки количественных инструментов, этот этап можно отложить. Сокращение данных и поиск взаимосвязей предоставит адекватную информацию для разработки других инструментов.
Для многих качественных оценщиков именно эта третья фаза придает качественному анализу особую привлекательность.
В то же время, вероятно, именно этот аспект вызывает наибольшее беспокойство у количественных оценщиков и других специалистов, знакомых с традиционными количественными методами. Как только качественные аналитики начинают выходить за рамки осторожного анализа фактических данных, спрашивают критики, что гарантирует, что они не занимаются чисто спекулятивным полетом фантазии? Действительно, их опасения не лишены оснований. Если необработанная «куча данных» является результатом того, что вы не берете на себя ответственность за формирование «сюжетной линии» анализа, противоположная тенденция состоит в том, чтобы делать выводы, далеко выходящие за рамки того, что данные разумно подтверждают, или преждевременно делать выводы и делать выводы без надлежащей проверки данных.Хороший пример — вопрос об обмене знаниями. Основное ожидание или надежда связаны с усилиями по распространению, в которых участвующие преподаватели стимулируют инновации в преподавании математики среди своих коллег.
Взаимным выводом может быть то, что участвующие преподаватели в трех из восьми кампусов предприняли активные, постоянные усилия, чтобы поделиться своими новыми знаниями со своими коллегами в различных формальных и неформальных условиях. В двух других кампусах первоначальные попытки обмена были активными, но вскоре сошли на нет и не были продолжены. В оставшихся трех случаях один или два участника факультета делились кусочками того, что они узнали, с несколькими избранными коллегами на разовой основе, но в остальном не предпринимали никаких шагов для более широкого распространения своих новых знаний и навыков.Принимая эти выводы за чистую монету, можно сделать вывод, что проект в значительной степени не способствовал распространению новых педагогических знаний и навыков среди неучаствующих преподавателей. В конце концов, такое разделение произошло желаемым образом только в трех из восьми кампусов. Однако, прежде чем забегать вперед и делать вывод о том, что проект в этом отношении был разочаровывающим, или делать выводы за пределами этого случая о других подобных усилиях по распространению педагогических инноваций среди преподавателей, жизненно важно более внимательно изучить вероятные причины, по которым совместное использование среди участвующих и не участвующих преподавателей произошло, и где и как это произошло.
Аналитики сначала искали бы факторы, отличающие три кампуса, где постоянные организованные усилия по обмену действительно имели место, от тех, где такие усилия либо не были устойчивыми, либо происходили в значительной степени по частям. Однако также будет важно различать менее успешные сайты, чтобы выявить факторы, связанные как со степенью обмена информацией, так и со степенью устойчивости деятельности.Одной из возможных гипотез может быть то, что успешное поддержание организованных усилий по обмену на постоянной основе требует структурной поддержки на уровне департаментов и/или благоприятных условий окружающей среды в родном кампусе. При отсутствии такой поддержки большой прилив энергии и энтузиазма в начале учебного года быстро уступит место бесчисленным требованиям, как это произошло во второй группе из двух кампусов. Точно так же в большинстве случаев индивидуальная добрая воля одного или двух участвующих преподавателей в кампусе сама по себе будет недостаточна для создания типа и уровня обмена, который имел бы значение для неучаствующего факультета (третья группа кампусов).
Например, на трех «успешных» сайтах расписание преподавателей может предусматривать регулярное расписание общих периодов для обмена идеями и информацией коллег. Кроме того, участие в таких мероприятиях может поощряться заведующим кафедрой и, возможно, даже рассматриваться как фактор при принятии решений о продвижении по службе и сроках пребывания в должности. Департамент также может выделить несколько долларов на закуски, чтобы создать более неформальную и непринужденную атмосферу на этих мероприятиях. Другими словами, в кампусах, где обмен происходил по желанию, условия благоприятствовали одним или несколькими способами: новый временной интервал не нужно было вырезать из уже переполненного расписания преподавателей, заведующий кафедрой делал больше, чем просто платил «на словах». » к важности обмена (преподаватели обычно довольно проницательны в понимании того, что действительно важно в культуре факультета), и были предприняты усилия для создания непринужденной атмосферы для передачи знаний.
В некоторых других кампусах структурные условия могут быть неблагоприятными, поскольку занятия проводятся непрерывно с 8:00 до 20:00, а преподаватели приходят и уходят в разное время и в разные дни. В другом кампусе расписание может не представлять такого большого препятствия. Однако заведующая кафедрой может быть настолько занята, что, несмотря на философское согласие с важностью распространения вновь приобретенных навыков, она мало что может сделать для активного поощрения обмена между участвующими и неучаствующими преподавателями. В данном случае на пути стояли не столько структурные условия или вялая поддержка, сколько конкурирующие приоритеты и неспособность заведующей кафедрой действовать конкретно в соответствии со своими обязательствами. Напротив, в другом кампусе заведующий кафедрой может публично признать цели проекта, но на самом деле считает, что это пустая трата времени и ресурсов. Его неспособность поддержать совместную деятельность среди своих преподавателей проистекает из более глубоко укоренившихся опасений по поводу ценности и жизнеспособности проекта.
Может показаться, что это различие не имеет значения, учитывая, что результат был одинаковым в обоих кампусах (совместное использование не произошло, как хотелось бы). Однако, с точки зрения исследователя-оценщика, то, верит ли заведующий кафедрой в проект, может существенно повлиять на то, что нужно будет сделать, чтобы изменить результат.Мы начали разрабатывать достаточно последовательное объяснение межсайтовых вариаций в степени и характере обмена, происходящего между участвующими и неучаствующими преподавателями. Чтобы прийти к этому моменту, нужно было сделать шаг назад и систематически исследовать и пересматривать данные, используя множество того, что Майлз и Хуберман (1994, стр. 245-262) называют «тактикой создания смысла». Они описывают 13 таких приемов, в том числе выявление закономерностей и тем, объединение случаев в кластеры, противопоставление и сравнение, разделение переменных и подведение частностей под общее. Качественные аналитики обычно используют некоторые или все из них, одновременно и многократно, делая выводы.
Одним из факторов, который может помешать получению выводов в оценочных исследованиях, является то, что теоретические или логические допущения, лежащие в основе исследования, часто остаются невысказанными. В этом примере, как обсуждалось выше, это предположения или ожидания относительно обмена знаниями и распространения инновационных практик от участвующих преподавателей к неучаствующим и, соответственно, к их студентам. Для того чтобы аналитик мог воспользоваться возможностью сделать выводы, он или она должны уметь распознавать и учитывать эти допущения, которые часто лишь имплицитно присутствуют в оценочных вопросах. С этой целью может оказаться полезным четко сформулировать «логическую модель» или набор предположений относительно того, как программа должна достичь желаемого результата (результатов). Признание этих предположений становится еще более важным, когда возникает необходимость или желание поместить результаты одной оценки в более широкий сравнительный контекст по сравнению с другими оценками программы.
Создав, по-видимому, правдоподобное объяснение различий в степени и виде обмена, происходящего между участвующими и не участвующими преподавателями в восьми кампусах, как аналитик может проверить достоверность — или истинность — этой интерпретации данных? Майлз и Хуберман (1994, стр. 262-277) обрисовывают 13 тактик проверки или подтверждения результатов, каждая из которых направлена на необходимость включения в процесс анализа систематических «защит от самообмана» (стр. 265). Мы обсудим лишь некоторые из них, которые имеют особое значение для рассматриваемого примера, и подчеркнем критические различия между количественными и качественными аналитическими подходами. Однако с самого начала очень важно подчеркнуть два момента: некоторые из наиболее важных гарантий валидности, такие как использование нескольких источников и способов доказательства, должны быть встроены в план с самого начала; а аналитическая цель состоит в том, чтобы создать правдоподобную, эмпирически обоснованную версию, максимально отвечающую имеющимся оценочным вопросам.
Как отмечают авторы: «Вы ищете не одну версию, оставив все остальные, а лучшую из нескольких альтернативных версий» (с. 274).Один из вопросов аналитической валидности, который часто возникает, касается необходимости взвешивания доказательств, полученных из нескольких источников и основанных на различных способах сбора данных, таких как ответы на интервью, о которых сообщают сами, и данные наблюдений. Триангуляция источников данных и режимов имеет решающее значение, но результаты могут не обязательно подтверждать друг друга и даже противоречить друг другу. Например, еще один вопрос для итоговой оценки, предложенный в главе 2, касается степени, в которой неучаствующие преподаватели внедряют новые концепции и методы в свое обучение. Ответ на этот вопрос зависит от сочетания наблюдений, данных, полученных от участников фокус-групп, и подробных интервью с заведующими кафедрами и неучаствующими преподавателями. В этом случае существует вероятность того, что данные наблюдений могут расходиться с данными, полученными от одной или нескольких групп респондентов.
Например, в ходе интервью подавляющее большинство неучаствующих преподавателей могли бы сказать и действительно поверить, что они применяют инновационные принципы, связанные с проектами, в своем обучении. Однако наблюдатели могут увидеть очень мало поведенческих свидетельств того, что эти принципы действительно влияют на практику преподавания в классах этих преподавателей. Было бы легко отмахнуться от этого вывода, заключив, что неучастники спасают лицо, повторяя, как попугаи, то, что, по их мнению, они должны сказать об их обучении. Но есть и другие, более интересные с аналитической точки зрения возможности. Возможно, неучастники имеют неполное представление об этих принципах или не были должным образом обучены тому, как эффективно применять их на практике в классе.Важным моментом является то, что анализ с точки зрения нескольких групп и различных типов данных — это не просто вопрос принятия решения о том, кто прав или какие данные являются наиболее точными. Взвешивание доказательств — это более тонкий и деликатный вопрос, когда нужно выслушать точку зрения каждой группы, но при этом признавать, что любая отдельная точка зрения является частичной и соотносится с опытом и социальным положением респондента.
Более того, как отмечалось выше, представления респондентов не более и не менее реальны, чем наблюдения. На самом деле, расхождения между данными самоотчетов и данными наблюдений могут выявить полезные темы или области для дальнейшего анализа. Работа аналитика состоит в том, чтобы объединить различные голоса и источники в повествование, отвечающее на соответствующие вопросы оценки. Чем искуснее это сделано, тем проще, естественнее представляется читателю. Прилагать усилия для сбора различных типов данных и прослушивания различных голосов только для того, чтобы сложить информацию в плоскую картину, значит оказать медвежью услугу качественному анализу. Однако, если есть основания полагать, что одни данные сильнее других (некоторые респонденты хорошо осведомлены по данному вопросу, а другие нет), целесообразно придать этим ответам больший вес при анализе.Качественные аналитики также должны быть внимательны к моделям взаимосвязей в своих данных, которые отличаются от ожидаемых. Майлз и Хуберман определяют их как «последующие сюрпризы» (1994, стр.
270). Например, в одном кампусе систематическое сравнение ответов участвующих и не участвующих преподавателей на вопрос о деятельности по обмену знаниями (см. Приложение 10) может выявить несколько очевидных межгрупповых различий. Однако более внимательное изучение двух наборов расшифровок может показать значимые различия в восприятии, разделяющиеся по другим, менее ожидаемым направлениям. Для целей этой оценки молчаливо предполагалось, что соответствующие различия между преподавателями, скорее всего, будут между теми, кто участвовал и не участвовал в проекте. Однако обе группы также имеют общую историю как преподаватели одного и того же факультета. Следовательно, другие факторы, такие как предшествующие личные связи, могли перевесить различие между преподавателями-участниками и неучастниками. Одной из сильных сторон качественного анализа является его способность обнаруживать и манипулировать такого рода неожиданными закономерностями, которые часто могут быть очень информативными. Для этого требуется умение слушать и быть восприимчивым к неожиданностям.В отличие от количественных исследователей, которым необходимо объяснять отклонения или исключительные случаи, качественные аналитики также обычно радуются, когда сталкиваются с искажениями в своих данных, которые представляют свежие аналитические идеи или проблемы. Майлз и Хуберман (1994, стр. 269, 270) говорят о «проверке значения выбросов» и «использовании крайних случаев». В качественном анализе отклоняющиеся случаи или случаи, которые, по-видимому, не соответствуют шаблону или тенденции, не рассматриваются как выбросы, как это было бы в статистическом вероятностном анализе. Скорее, отклонения или исключительные случаи следует воспринимать как вызов для дальнейшей разработки и проверки развивающегося вывода. Например, если руководитель отдела решительно поддерживает цели и задачи проекта для всех успешных проектов, кроме одного, возможно, другой набор факторов выполняет ту же функцию (функции) на «отклоняющемся» сайте. Выявление этих факторов, в свою очередь, поможет более точно прояснить, что значит сильное лидерство и вера в проект, который имеет значение.
Или, развивая другой расширенный пример, предположим, что в одном кампусе, где структурные условия не способствуют обмену между участвующими и неучаствующими преподавателями, такое разделение, тем не менее, происходит, инициатором которого является один очень преданный своему делу участвующий преподаватель. Этот пример может свидетельствовать о том, что очень преданный своему делу человек, который является естественным лидером среди своих коллег по факультету, способен преодолеть структурные ограничения на обмен. В некотором смысле этот «отклоняющийся» анализ случая подкрепил бы общий вывод, показав, что необходимы исключительные обстоятельства, чтобы преобладать над ограничениями ситуации.В другом месте этого справочника мы отмечали, что итоговая и формирующая оценки часто связаны предпосылкой о том, что различия в реализации проекта, в свою очередь, повлияют на различия в результатах проекта. В гипотетическом примере, представленном в этом справочнике, все участники участвовали в одних и тех же действиях в центральном кампусе, что исключает возможность анализа влияния различий в особенностях реализации.
Однако использование другой модели и сравнение реализации и результатов в трех разных университетах с участием трех кампусов от каждого университета может дать некоторое представление о том, как может выглядеть такой анализ.Матрица отображения для межсайтовой оценки этого типа представлена на рис. 12. В верхней части матрицы показано, как три кампуса различаются по ключевым функциям реализации. Нижняя часть суммирует результаты в каждом кампусе. Хотя мы не обязательно ожидаем однозначной связи, матрица слабо связывает функции реализации с результатами, с которыми они могут быть связаны. Например, подбор персонала и проведение семинара сочетаются с мероприятиями по обмену знаниями, точность содержания семинара с изменением учебного плана. Тем не менее, ничто не мешает искать взаимосвязь между использованием соответствующих техник на семинарах (формативное обучение) и изменениями в учебных программах в кампусах (суммирующее исследование). Использование матрицы, по сути, направляет анализ в том же направлении, что и в приведенных ранее примерах.
Экспонат 12.
Матрица перекрестного анализа, связывающая реализацию и факторы результатаОсобенности реализации Филиал Семинары проведены и укомплектованы персоналом в соответствии с планом? Содержание точное/
своевременно?Используются соответствующие методы? Доступны материалы? Подходящая презентация? Кампус А Да Да Для большинства участников Да, но с задержкой В основном Кампус B № Да Да № Очень неоднозначные отзывы Кампус C В основном Да Для нескольких участников Да некоторые Характеристики результатов — участвующие кампусы Филиал Обмен знаниями с неучастниками? Изменения в учебной программе? Изменения в экзаменах и требованиях? Расходы? Студенты более заинтересованы/активны в классе? Кампус А Высокий уровень Многие некоторые № Некоторые кампусы Кампус B Низкий уровень Многие Многие Да В основном студенты участников Кампус C Средний уровень Всего несколько Мало Да Только незначительное улучшение В этом кросс-сайтовом анализе всеобъемлющий вопрос должен касаться сходства и различий между этими тремя сайтами — с точки зрения реализации проекта, результатов и связи между ними — и исследовать основы этих различий.
Был ли один из проектов заметно более успешным, чем другие, в целом или в отдельных областях, и если да, то какие факторы или сочетания факторов, по-видимому, способствовали этим успехам? Затем анализ будет продолжаться через несколько итераций, пока не будет достигнуто удовлетворительное разрешение.Резюме: оценка качества качественного анализа
Вопросы, связанные с ценностью и использованием составления выводов и проверки в качественном анализе, возвращают нас к более широким вопросам, поднятым в самом начале, о том, как судить о достоверности и качестве качественного исследования. По этим и связанным с ними вопросам идет оживленная дискуссия. Подробное обсуждение этого вопроса выходит за рамки этой главы, но стоит обобщить возникающие области согласия.
Во-первых, хотя и формулируется по-разному, существует широкий консенсус в отношении того, что качественному аналитику необходимо быть самосознательным, честным и рефлексивным в отношении аналитического процесса.
Анализ — это не только конечный продукт, но и набор процессов, используемых для достижения определенного результата. В качественном анализе нет необходимости или даже желательно, чтобы кто-то другой, проводивший аналогичное исследование, обнаружил точно такие же вещи или точно так же интерпретировал свои результаты. Однако, как только понятие анализа как набора единообразных, безличных, универсально применимых процедур отброшено, качественные аналитики обязаны описывать и обсуждать, как они выполняли свою работу способами, которые, по крайней мере, доступны другим исследователям. Открытое и честное представление аналитических процессов обеспечивает важную проверку склонности отдельного аналитика увлекаться, позволяя другим самим судить о том, заслуживают ли доверия анализ и интерпретация в свете данных.Во-вторых, качественный анализ, как и все качественные исследования, в некотором смысле является мастерством (Kvale, 1995). Там есть такая вещь, как плохо сделанный или плохой качественный анализ, и, несмотря на свое нежелание выдавать универсальные критерии, опытные качественные исследователи разных направлений все же обычно могут согласиться, когда видят пример этого.
Об аналитиках следует судить отчасти по тому, насколько искусно, искусно и убедительно они излагают аргументы или рассказывают историю. Хорошо ли проводится анализ и имеет ли он смысл по отношению к целям исследования и представленным данным? Ясна ли сюжетная линия и убедительна ли она? Является ли анализ интересным, информативным, провокационным? Объясняет ли аналитик, как и почему он или она пришли к определенным выводам, или на каком основании он или она исключили другие возможные интерпретации? Это те вопросы, которые можно и нужно задавать при оценке качества качественного анализа. В оценочных исследованиях аналитиков часто призывают перейти от выводов к рекомендациям по улучшению программ и политики. Рекомендации должны согласовываться с выводами и с пониманием аналитиками контекста или среды исследования. Часто полезно привлекать заинтересованные стороны в момент «перевода» аналитических выводов в последствия для действий.Как теперь должно быть очевидно, было бы действительно ошибкой полагать, что качественный анализ прост или может быть выполнен неподготовленными новичками.
Как Паттон (1990) комментарии:Применение рекомендаций требует здравого смысла и творческого подхода. Поскольку каждое качественное исследование уникально, используемый аналитический подход будет уникальным. Поскольку качественное исследование на каждом этапе зависит от навыков, подготовки, понимания и способностей исследователя, качественный анализ в конечном итоге зависит от аналитического интеллекта и стиля аналитика. Человеческий фактор — величайшая сила и фундаментальная слабость качественного исследования и анализа.
Практические советы по проведению качественных анализовНемедленно приступайте к анализу и постоянно ведите его учет в своих заметках: Нельзя переоценить тот факт, что анализ должен начинаться почти одновременно со сбором данных, и что это итеративный набор процессов, которые продолжаются в течение полевые работы и не только. Как правило, в полевые заметки, фокус-группы или резюме интервью полезно включать раздел, содержащий комментарии, предварительные интерпретации или возникающие гипотезы.
В конечном итоге они могут быть отменены или отвергнуты и почти наверняка будут уточнены по мере сбора дополнительных данных. Но они обеспечивают важный отчет о разворачивающемся анализе и внутреннем диалоге, который сопровождал процесс.Задействовать более одного человека: Две головы лучше, чем одна, а три еще лучше. Качественный анализ не обязательно и во многих случаях, вероятно, не должен быть изолированным процессом. Целесообразно привлекать к аналитическому процессу более одного человека, чтобы они служили перекрестной проверкой, резонирующей доской и источником новых идей и взаимного обогащения. Лучше всего, если все аналитики что-то знают о качественном анализе, а также о связанных с ним существенных вопросах. Если невозможно или нецелесообразно, чтобы второе или третье лицо играло центральную роль, его или ее навыки все же могут использоваться более ограниченным образом. Например, кто-то может просматривать только определенные части набора стенограмм.
Оставьте достаточно времени и денег для анализа и записи: Анализ и запись качественных данных почти всегда требует больше времени, размышлений и усилий, чем предполагалось.
Бюджет, предполагающий неделю анализа и неделю написания проекта, на который уходит год работы на местах, крайне нереалистичен. Наряду с выявлением непонимания природы качественного анализа, отсутствие достаточного количества времени и денег для надлежащего завершения этого процесса, вероятно, является основной причиной того, что отчеты об оценке, содержащие качественные данные, могут разочаровать.Будьте избирательны при использовании пакетов программного обеспечения для качественного анализа: В последние годы появилось большое количество пакетов программного обеспечения, которые можно использовать для помощи в анализе качественных данных. Большинство этих пакетов были рассмотрены Вейцманом и Майлзом (1995), которые сгруппировали их в шесть типов: текстовые процессоры, средства извлечения слов, менеджеры текстовой базы, программы кодирования и извлечения, средства построения теорий на основе кода и средства построения концептуальных сетей. У всех есть сильные и слабые стороны.
Вайцман и Майлз предположили, что при выборе данного пакета исследователи должны думать о количестве, типах и источниках данных, которые необходимо проанализировать, а также о типах анализов, которые будут выполняться.Необходимо сделать два предупреждения. Во-первых, пакеты компьютерного программного обеспечения для качественного анализа данных существенно помогают в манипулировании соответствующими сегментами текста. Хотя программное обеспечение помогает отмечать, кодировать и перемещать сегменты данных быстрее и эффективнее, чем вручную, оно не может определять значимые категории для кодирования и анализа или выделять важные темы или факторы. В качественном анализе, как показано выше, концепции должны преобладать над механикой: аналитическое обоснование процедур по-прежнему должно обеспечиваться аналитиком. Программные пакеты не могут и не должны использоваться как способ избежать тяжелого интеллектуального труда качественного анализа. Во-вторых, поскольку требуется время и ресурсы, чтобы научиться использовать данный программный пакет и изучить его особенности, исследователи могут захотеть подумать, действительно ли объем их проекта или их текущие потребности оправдывают инвестиции.
Ссылки
Берковиц, С. (1996). Использование качественных и смешанных подходов. Глава 4 в Оценка потребностей: творческое и практическое руководство для социологов, R. Reviere, S. Berkowitz, C.C. Картер и К. Грейвс-Фергюсон, ред. Вашингтон, округ Колумбия: Тейлор и Фрэнсис.
Глейзер, Б., и Штраус, А. (1967). Открытие Обоснованная теория. 908:24 Чикаго: Альдин.
Квале, С. (1995). Социальная конструкция достоверности. Качественный запрос, (1):19-40.
90 010 Майлз, М.Б., и Хуберман, А.М. (1984). Качественный анализ данных , 16. Ньюбери-Парк, Калифорния: Sage. 90 010 Майлз, М.Б., и Хуберман, А.М. (1994). Качественный анализ данных, 2-е изд., с. 10-12. Ньюбери-Парк, Калифорния: Сейдж.Паттон, М.К. (1990). Методы качественной оценки и исследования , 2-е изд. Ньюбери-Парк: Калифорния, Сейдж.
Вайцман, Э.А., и Майлз, М.Б.

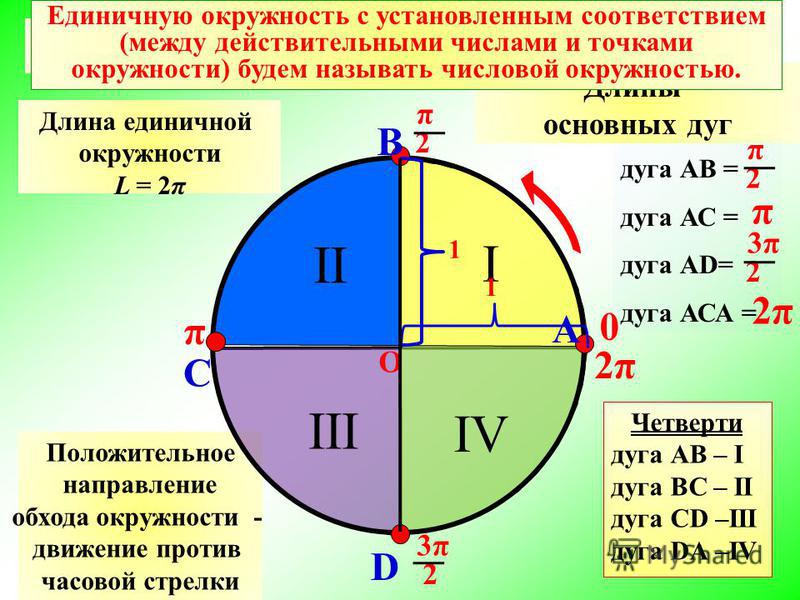


 Предпосылка этого теста заключается в том, что данные представляют собой выборку наблюдаемых точек, взятых из большей совокупности. Мы не исследовали всю популяцию, потому что это невозможно или невозможно сделать. Мы изучаем выборку, чтобы сделать вывод о том, обеспечивает ли линейная зависимость, которую мы видим между
Предпосылка этого теста заключается в том, что данные представляют собой выборку наблюдаемых точек, взятых из большей совокупности. Мы не исследовали всю популяцию, потому что это невозможно или невозможно сделать. Мы изучаем выборку, чтобы сделать вывод о том, обеспечивает ли линейная зависимость, которую мы видим между  Другими словами, ожидаемое значение y для каждого конкретного значения лежит на прямой в генеральной совокупности. (Мы не знаем уравнения для линии для совокупности. Наша линия регрессии по выборке является нашей наилучшей оценкой этой линии в совокупности.)
Другими словами, ожидаемое значение y для каждого конкретного значения лежит на прямой в генеральной совокупности. (Мы не знаем уравнения для линии для совокупности. Наша линия регрессии по выборке является нашей наилучшей оценкой этой линии в совокупности.)
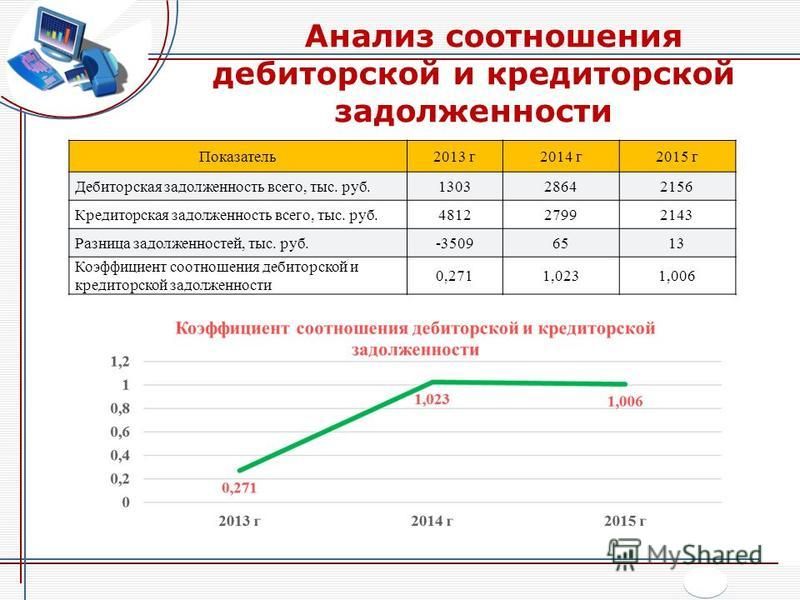

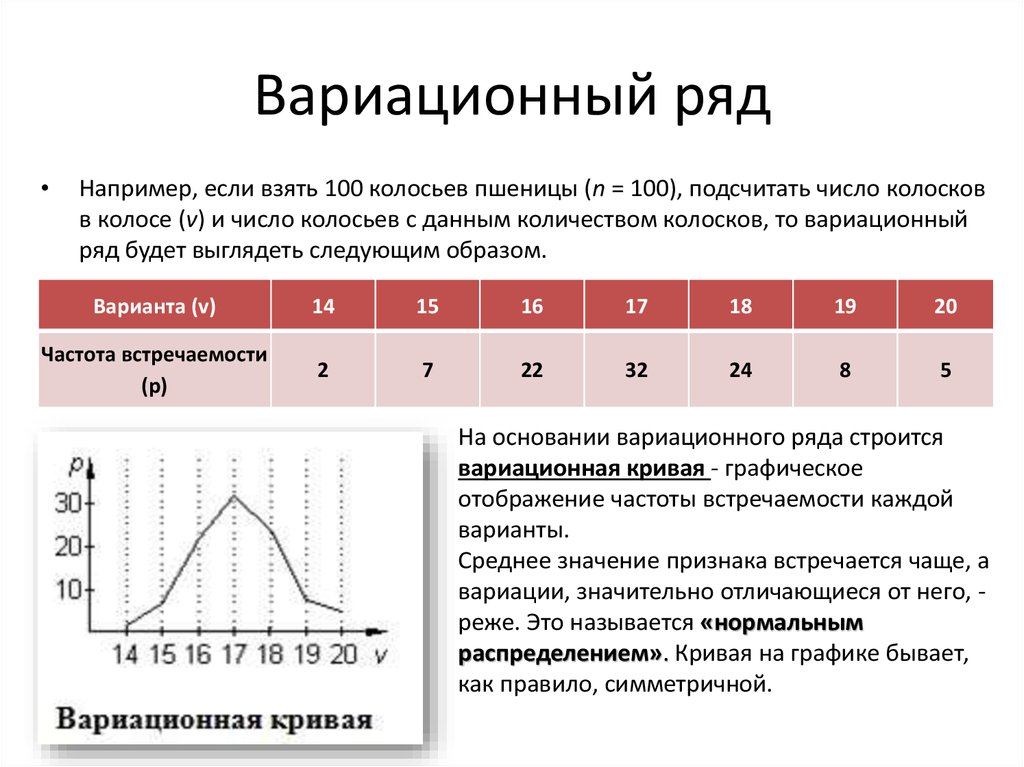 Мы хотим иметь возможность количественно определить это отношение, измерить его
сила, разработайте уравнение для прогнозирования результатов, и в конечном итоге сделать проверяемый вывод о родительской популяции.
Этот урок посвящен измерению его силы,
с уравнением, которое будет на следующем уроке,
а выводы по тестированию намного позже.
Мы хотим иметь возможность количественно определить это отношение, измерить его
сила, разработайте уравнение для прогнозирования результатов, и в конечном итоге сделать проверяемый вывод о родительской популяции.
Этот урок посвящен измерению его силы,
с уравнением, которое будет на следующем уроке,
а выводы по тестированию намного позже. Если точки разбросаны, то
может быть нет корреляции . Если точки будут точно соответствовать
квадратное или показательное уравнение, и т. д. ,
тогда они имеют нелинейную корреляцию .
В этом курсе мы ограничимся линейными корреляциями
и, следовательно, линейная регрессия.
Поскольку данные почти линейны, данные могут быть заключены в эллипс.
Большая ось (длина) эллипса относительно малой оси (ширины) эллипса,
являются показателем степени корреляции.
Если точки разбросаны, то
может быть нет корреляции . Если точки будут точно соответствовать
квадратное или показательное уравнение, и т. д. ,
тогда они имеют нелинейную корреляцию .
В этом курсе мы ограничимся линейными корреляциями
и, следовательно, линейная регрессия.
Поскольку данные почти линейны, данные могут быть заключены в эллипс.
Большая ось (длина) эллипса относительно малой оси (ширины) эллипса,
являются показателем степени корреляции. Другое название для r — корреляция моментов произведения Пирсона .
коэффициент в честь Карла Пирсона, разработавшего его около 1900 года.
Обычно используются как минимум три различные формулы
чтобы вычислить это число и эти разные формулы
представляют несколько разные подходы к проблеме.
Однако такое же значение для r получается
любой из различных процедур.
Сначала мы даем формула сырой оценки. n имеет обычное значение количества упорядоченных пар
есть в нашем образце. Также важно признать
разница между суммой квадратов
и квадраты сумм!
Другое название для r — корреляция моментов произведения Пирсона .
коэффициент в честь Карла Пирсона, разработавшего его около 1900 года.
Обычно используются как минимум три различные формулы
чтобы вычислить это число и эти разные формулы
представляют несколько разные подходы к проблеме.
Однако такое же значение для r получается
любой из различных процедур.
Сначала мы даем формула сырой оценки. n имеет обычное значение количества упорядоченных пар
есть в нашем образце. Также важно признать
разница между суммой квадратов
и квадраты сумм! Эта формула ближе к истории развития
поскольку он дает среднее перекрестное произведение
стандартные оценки двух переменных, но в
вычислительно более простой формат.
Эта формула ближе к истории развития
поскольку он дает среднее перекрестное произведение
стандартные оценки двух переменных, но в
вычислительно более простой формат. Для выборок коэффициент корреляции представлен как r а коэффициент корреляции для популяций обозначается
греческой буквой ро (которая может выглядеть как стр. ).
Имейте в виду, что коэффициент корреляции ро Спирмена
также использует греческую букву ро, но обычно применяется
к образцам и данным ранжирования (порядковые данные).
Для выборок коэффициент корреляции представлен как r а коэффициент корреляции для популяций обозначается
греческой буквой ро (которая может выглядеть как стр. ).
Имейте в виду, что коэффициент корреляции ро Спирмена
также использует греческую букву ро, но обычно применяется
к образцам и данным ранжирования (порядковые данные).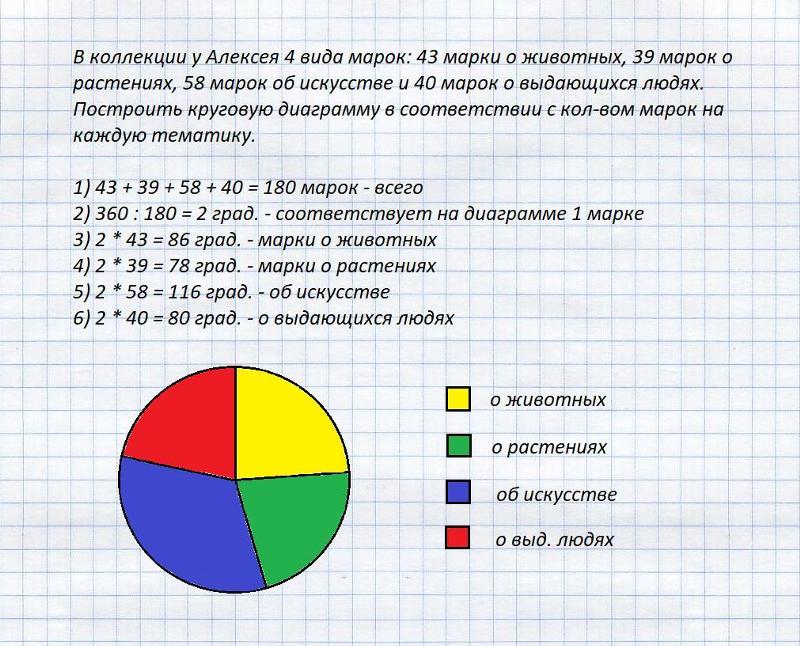
 Коэффициенты корреляции, величина которых находится в диапазоне от 0,7 до 0,9.указывают переменные, которые можно считать сильно коррелированными. Коэффициенты корреляции, величина которых находится в диапазоне от 0,5 до 0,7.
укажите переменные, которые можно считать умеренно коррелированными. Коэффициенты корреляции, величина которых находится в диапазоне от 0,3 до 0,5.
указывают переменные, которые имеют низкую корреляцию. Коэффициенты корреляции, величина которых меньше 0,3
имеют небольшую, если вообще имеют (линейную) корреляцию.
Мы можем легко видеть, что
0,9< |r| < 1,0 соответствует
0,81 < r 2 < 1,00;
0,7 < |r| < 0,9 соответствует
0,49 < р 2 < 0,81;
0,5 < |r| < 0,7 соответствует
0,25 < r 2 < 0,49;
0,3 < |r| < 0,5 соответствует
0,09 < г 2 < 0,25; а также
0,0 < |r| < 0,3 соответствует
0,0 < r 2 < 0,09.
Коэффициенты корреляции, величина которых находится в диапазоне от 0,7 до 0,9.указывают переменные, которые можно считать сильно коррелированными. Коэффициенты корреляции, величина которых находится в диапазоне от 0,5 до 0,7.
укажите переменные, которые можно считать умеренно коррелированными. Коэффициенты корреляции, величина которых находится в диапазоне от 0,3 до 0,5.
указывают переменные, которые имеют низкую корреляцию. Коэффициенты корреляции, величина которых меньше 0,3
имеют небольшую, если вообще имеют (линейную) корреляцию.
Мы можем легко видеть, что
0,9< |r| < 1,0 соответствует
0,81 < r 2 < 1,00;
0,7 < |r| < 0,9 соответствует
0,49 < р 2 < 0,81;
0,5 < |r| < 0,7 соответствует
0,25 < r 2 < 0,49;
0,3 < |r| < 0,5 соответствует
0,09 < г 2 < 0,25; а также
0,0 < |r| < 0,3 соответствует
0,0 < r 2 < 0,09.
 Отсюда вы можете получить наименьшую сумму d 2 равен нулю, а наибольшая сумма d 2 равна
удвоенная сумма квадратов нечетных целых чисел до n /2, и это масштабирует такую сумму между -1 и +1.
Отсюда вы можете получить наименьшую сумму d 2 равен нулю, а наибольшая сумма d 2 равна
удвоенная сумма квадратов нечетных целых чисел до n /2, и это масштабирует такую сумму между -1 и +1. Используя формулу Ро Спирмена, мы получаем 1-6(24)/(9(80)) = 0,80.
Используя формулу Ро Спирмена, мы получаем 1-6(24)/(9(80)) = 0,80. 5
5 Использование формулы сырой оценки для момента продукта Пирсона
коэффициент корреляции получаем (9×20474-762×236)/кв.кв.((9×68016-762 2 )(9×6286-236 2 )
= 0,843. г 2 = 0,71
что означает 71% вариации и объясняется изменением x .
Также верно и, возможно, полезнее знать, что та же корреляция
коэффициент получается при обмене x и y .
Однако получится другое уравнение.
Возможно, имеет смысл использовать результаты первой страницы
чтобы предсказать окончательный результат теста, а не наоборот!
Использование формулы сырой оценки для момента продукта Пирсона
коэффициент корреляции получаем (9×20474-762×236)/кв.кв.((9×68016-762 2 )(9×6286-236 2 )
= 0,843. г 2 = 0,71
что означает 71% вариации и объясняется изменением x .
Также верно и, возможно, полезнее знать, что та же корреляция
коэффициент получается при обмене x и y .
Однако получится другое уравнение.
Возможно, имеет смысл использовать результаты первой страницы
чтобы предсказать окончательный результат теста, а не наоборот! Рекомендуется создать диаграмму рассеяния перед
расчет любых коэффициентов корреляции, а затем
действовать только в том случае, если корреляция достаточно сильна.
Рекомендуется создать диаграмму рассеяния перед
расчет любых коэффициентов корреляции, а затем
действовать только в том случае, если корреляция достаточно сильна. Главная улица;
Берриен Спрингс, Мичиган 49103-1013
Главная улица;
Берриен Спрингс, Мичиган 49103-1013 Коэффициент корреляции \(r\) говорит нам о силе и направлении линейной зависимости между \(x\) и \(y\). Однако надежность линейной модели также зависит от количества наблюдаемых точек данных в выборке. Нам нужно смотреть как на значение коэффициента корреляции \(r\), так и на размер выборки \(n\) вместе.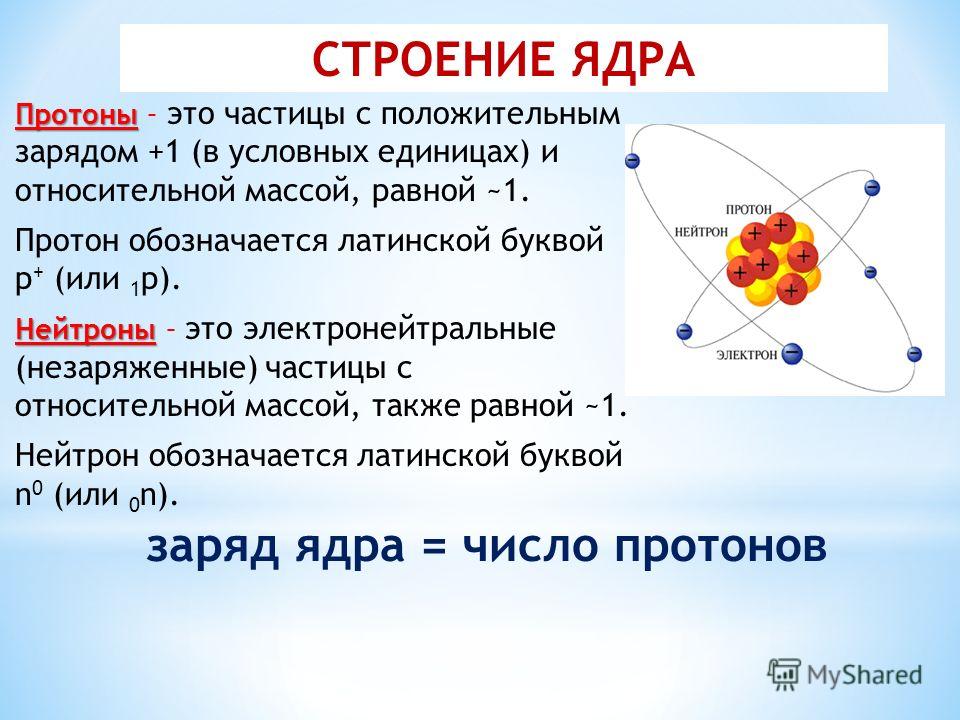 Мы проводим проверку гипотезы «значительность коэффициента корреляции» , чтобы решить, достаточно ли сильна линейная связь в данных выборки, чтобы использовать ее для моделирования связи в генеральной совокупности.
Мы проводим проверку гипотезы «значительность коэффициента корреляции» , чтобы решить, достаточно ли сильна линейная связь в данных выборки, чтобы использовать ее для моделирования связи в генеральной совокупности.
Данные выборки используются для вычисления \(r\), коэффициента корреляции для выборки. Если бы у нас были данные для всего населения, мы могли бы найти коэффициент корреляции населения. Но поскольку у нас есть только выборочные данные, мы не можем рассчитать коэффициент корреляции населения. Коэффициент корреляции выборки \(r\) является нашей оценкой коэффициента корреляции неизвестной совокупности.
Проверка гипотезы позволяет решить, является ли значение коэффициента корреляции генеральной совокупности \(\rho\) «близким к нулю» или «значительно отличным от нуля». Мы решаем это на основе коэффициента корреляции выборки \(r\) и размера выборки \(n\).
Мы решаем это на основе коэффициента корреляции выборки \(r\) и размера выборки \(n\).
Если тест показывает, что коэффициент корреляции значительно отличается от нуля, мы говорим, что коэффициент корреляции является «значимым».
Если тест показывает, что коэффициент корреляции незначительно отличается от нуля (близок к нулю), мы говорим, что коэффициент корреляции «незначителен».

ПРИМЕЧАНИЕ
ВЫПОЛНЕНИЕ ПРОВЕРКИ ГИПОТЕЗ
ЧТО ГИПОТЕЗЫ ОЗНАЧАЮТ В СЛОВАХ:
 НЕТ значимой линейной зависимости (корреляции) между \(x\) и \(y\) в популяции.
НЕТ значимой линейной зависимости (корреляции) между \(x\) и \(y\) в популяции.ПОДВЕДЕНИЕ ВЫВОДА: Существует два метода принятия решения. Эти два метода эквивалентны и дают одинаковый результат.
В этой главе данного учебника мы всегда будем использовать уровень значимости 5%, \(\alpha = 0,05\)
ПРИМЕЧАНИЕ
Используя метод \(p\text{-value}\), вы можете выберите любой подходящий уровень значимости, который вы хотите; вы не ограничены использованием \(\alpha = 0.05\). Но таблица критических значений, представленная в этом учебнике, предполагает, что мы используем уровень значимости 5%, \(\альфа = 0,05\).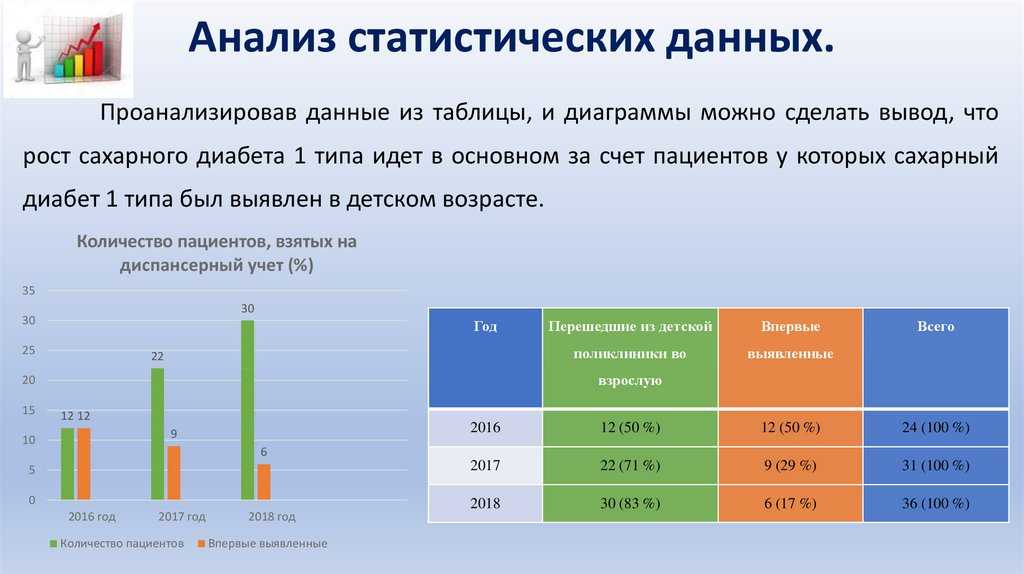 (Если бы мы хотели использовать уровень значимости, отличный от 5%, с методом критического значения, нам понадобились бы другие таблицы критических значений, которые не представлены в этом учебнике.)
(Если бы мы хотели использовать уровень значимости, отличный от 5%, с методом критического значения, нам понадобились бы другие таблицы критических значений, которые не представлены в этом учебнике.)
МЕТОД 1: Использование \(p\text{-value}\) для принятия решения
Использование КАЛЬКУЛЯТОРА TI83, 83+, 84, 84+
Для вычисления \(p\text{-value} \) с использованием LinRegTTEST:
На экране ввода LinRegTTEST в строке приглашения для \(\beta\) или \(\rho\) выделите «\(\neq 0\)»
На экране вывода отображается \ (p\text{-value}\) в строке «\(p =\)».
(Большинство компьютерных статистических программ могут вычислять \(p\text{-значение}\).)
Если \(p\text{-value}\) меньше уровня значимости ( \(\alpha = 0.05\) ):

Если \(p\text{-значение}\) НЕ меньше уровня значимости ( \(\alpha = 0.05\) )
Примечания к расчету:
 05\)
05\) Сравните \(r\) с соответствующим критическим значением в таблице. Если \(r\) не находится между положительным и отрицательным критическими значениями, то коэффициент корреляции является значимым. Если \(r\) имеет значение, вы можете использовать линию для предсказания.
Сравните \(r\) с соответствующим критическим значением в таблице. Если \(r\) не находится между положительным и отрицательным критическими значениями, то коэффициент корреляции является значимым. Если \(r\) имеет значение, вы можете использовать линию для предсказания. Можно ли использовать линию для предсказания? Почему или почему нет?
Можно ли использовать линию для предсказания? Почему или почему нет?
 Линия наилучшего соответствия: \(\hat{y} = -173,51 + 4,83x\) с \(r = 0,6631\) и есть \(n = 11\) точек данных. Можно ли использовать линию регрессии для предсказания? Учитывая оценку третьего экзамена ( \(x\) значение), можем ли мы использовать эту линию, чтобы предсказать окончательный результат экзамена (прогнозируемое значение \(y\) )?
Линия наилучшего соответствия: \(\hat{y} = -173,51 + 4,83x\) с \(r = 0,6631\) и есть \(n = 11\) точек данных. Можно ли использовать линию регрессии для предсказания? Учитывая оценку третьего экзамена ( \(x\) значение), можем ли мы использовать эту линию, чтобы предсказать окончательный результат экзамена (прогнозируемое значение \(y\) )? 
 Критическое значение равно \(0,532\). \(0,134\) находится между \(-0,532\) и \(0,532\), поэтому \(r\) не имеет значения.
Критическое значение равно \(0,532\). \(0,134\) находится между \(-0,532\) и \(0,532\), поэтому \(r\) не имеет значения. Мы не исследовали всю популяцию, потому что это невозможно или невозможно сделать. Мы изучаем выборку, чтобы сделать вывод о том, обеспечивает ли линейная зависимость, которую мы видим между \(x\) и \(y\) в данных выборки, достаточно убедительные доказательства, чтобы мы могли сделать вывод о наличии линейной зависимости между \ (х\) и \(у\) в популяции.
Мы не исследовали всю популяцию, потому что это невозможно или невозможно сделать. Мы изучаем выборку, чтобы сделать вывод о том, обеспечивает ли линейная зависимость, которую мы видим между \(x\) и \(y\) в данных выборки, достаточно убедительные доказательства, чтобы мы могли сделать вывод о наличии линейной зависимости между \ (х\) и \(у\) в популяции. (Мы не знаем уравнения для линии для генеральной совокупности. Наша линия регрессии по выборке является нашей наилучшей оценкой этой линии в генеральной совокупности.)
(Мы не знаем уравнения для линии для генеральной совокупности. Наша линия регрессии по выборке является нашей наилучшей оценкой этой линии в генеральной совокупности.) Для каждого значения \(x\) среднее значение \(y\) лежит на линии регрессии. Рядом с линией лежит больше значений \(y\), чем разбросанных дальше от линии.
Для каждого значения \(x\) среднее значение \(y\) лежит на линии регрессии. Рядом с линией лежит больше значений \(y\), чем разбросанных дальше от линии. Чтобы оценить стандартное отклонение совокупности \(y\), \(\sigma\), используйте стандартное отклонение остатков, \(s\). \(s = \sqrt{\frac{SEE}{n-2}}\). Переменная \(\rho\) (rho) представляет собой коэффициент корреляции совокупности. Чтобы проверить нулевую гипотезу \(H_{0}: \rho =\) гипотетическое значение , используйте t-критерий линейной регрессии. Наиболее распространенной нулевой гипотезой является \(H_{0}: \rho = 0\), которая указывает на отсутствие линейной зависимости между \(x\) и \(y\) в популяции. Функция калькулятора TI-83, 83+, 84, 84+ LinRegTTest может выполнять этот тест (СТАТИСТИЧЕСКИЕ ТЕСТЫ LinRegTTest).
Чтобы оценить стандартное отклонение совокупности \(y\), \(\sigma\), используйте стандартное отклонение остатков, \(s\). \(s = \sqrt{\frac{SEE}{n-2}}\). Переменная \(\rho\) (rho) представляет собой коэффициент корреляции совокупности. Чтобы проверить нулевую гипотезу \(H_{0}: \rho =\) гипотетическое значение , используйте t-критерий линейной регрессии. Наиболее распространенной нулевой гипотезой является \(H_{0}: \rho = 0\), которая указывает на отсутствие линейной зависимости между \(x\) и \(y\) в популяции. Функция калькулятора TI-83, 83+, 84, 84+ LinRegTTest может выполнять этот тест (СТАТИСТИЧЕСКИЕ ТЕСТЫ LinRegTTest). 5: Тестирование значимости коэффициента корреляции распространяется под лицензией CC BY 4.0 и была создана, изменена и/или курирована OpenStax с использованием исходного контента, который был отредактирован в соответствии со стилем и стандартами платформы LibreTexts; подробная история редактирования доступна по запросу.
5: Тестирование значимости коэффициента корреляции распространяется под лицензией CC BY 4.0 и была создана, изменена и/или курирована OpenStax с использованием исходного контента, который был отредактирован в соответствии со стилем и стандартами платформы LibreTexts; подробная история редактирования доступна по запросу. org/details/books/introductory-statistics
org/details/books/introductory-statistics Все аргументы либо действительны, либо недействительны, обоснованы или несостоятельны; нет золотой середины, например, что-то действительное.
Все аргументы либо действительны, либо недействительны, обоснованы или несостоятельны; нет золотой середины, например, что-то действительное.

 Если мы, оценивающие качество аргумента, не располагаем информацией о намерениях спорщика, то мы проверяем и то, и другое. То есть мы оцениваем аргумент, чтобы увидеть, является ли он дедуктивно достоверным и индуктивно сильным.
Если мы, оценивающие качество аргумента, не располагаем информацией о намерениях спорщика, то мы проверяем и то, и другое. То есть мы оцениваем аргумент, чтобы увидеть, является ли он дедуктивно достоверным и индуктивно сильным.
 В этом смысле дедуктивное рассуждение гораздо более четкое, чем индуктивное. Тем не менее сила индуктивности не зависит от личных предпочтений; вопрос в том, является ли посылка должен способствовать большей уверенности в заключении.
В этом смысле дедуктивное рассуждение гораздо более четкое, чем индуктивное. Тем не менее сила индуктивности не зависит от личных предпочтений; вопрос в том, является ли посылка должен способствовать большей уверенности в заключении. Поэтому Джон не сможет сегодня присутствовать на нашей встрече.
Поэтому Джон не сможет сегодня присутствовать на нашей встрече.
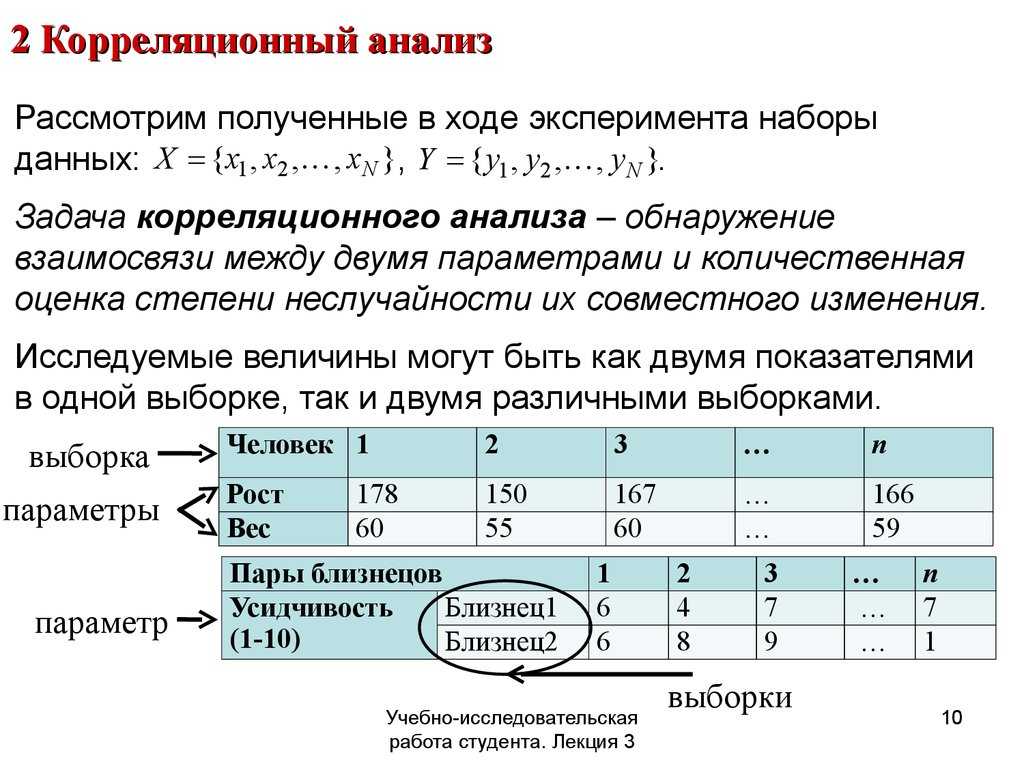 Тем не менее, некоторые юристы скажут своим присяжным, что это веские аргументы, поэтому мы, критически мыслящие люди, должны быть начеку в отношении того, как люди вокруг нас используют термин «действительный». Вы должны быть внимательны к тому, что они имеют в виду, а не к тому, что они говорят. Английский сыщик Шерлок Холмс ловко «выводил», кто кого убил, по малейшим уликам, но на самом деле он сделал лишь обоснованное предположение. Строго говоря, он привел индуктивный аргумент, а не дедуктивный. Чарльз Дарвин, открывший процесс эволюции, известен своей «дедукцией» о том, что круглые атоллы в океанах на самом деле являются коралловыми наростами на вершинах едва затопленных вулканов, но на самом деле он провел индукцию, а не дедукцию.
Тем не менее, некоторые юристы скажут своим присяжным, что это веские аргументы, поэтому мы, критически мыслящие люди, должны быть начеку в отношении того, как люди вокруг нас используют термин «действительный». Вы должны быть внимательны к тому, что они имеют в виду, а не к тому, что они говорят. Английский сыщик Шерлок Холмс ловко «выводил», кто кого убил, по малейшим уликам, но на самом деле он сделал лишь обоснованное предположение. Строго говоря, он привел индуктивный аргумент, а не дедуктивный. Чарльз Дарвин, открывший процесс эволюции, известен своей «дедукцией» о том, что круглые атоллы в океанах на самом деле являются коралловыми наростами на вершинах едва затопленных вулканов, но на самом деле он провел индукцию, а не дедукцию.
 Действительно, одно и то же высказывание может быть использовано для представления как дедуктивного, так и индуктивного аргумента, в зависимости от того, во что верит выдвигающий его человек. Рассмотрим для примера:
Действительно, одно и то же высказывание может быть использовано для представления как дедуктивного, так и индуктивного аргумента, в зависимости от того, во что верит выдвигающий его человек. Рассмотрим для примера: Еще одна сложность в нашем обсуждении дедукции и индукции заключается в том, что спорщик может иметь в виду, что посылки обосновывают вывод, хотя на самом деле посылки вообще не дают никакого обоснования. Вот пример:
Еще одна сложность в нашем обсуждении дедукции и индукции заключается в том, что спорщик может иметь в виду, что посылки обосновывают вывод, хотя на самом деле посылки вообще не дают никакого обоснования. Вот пример: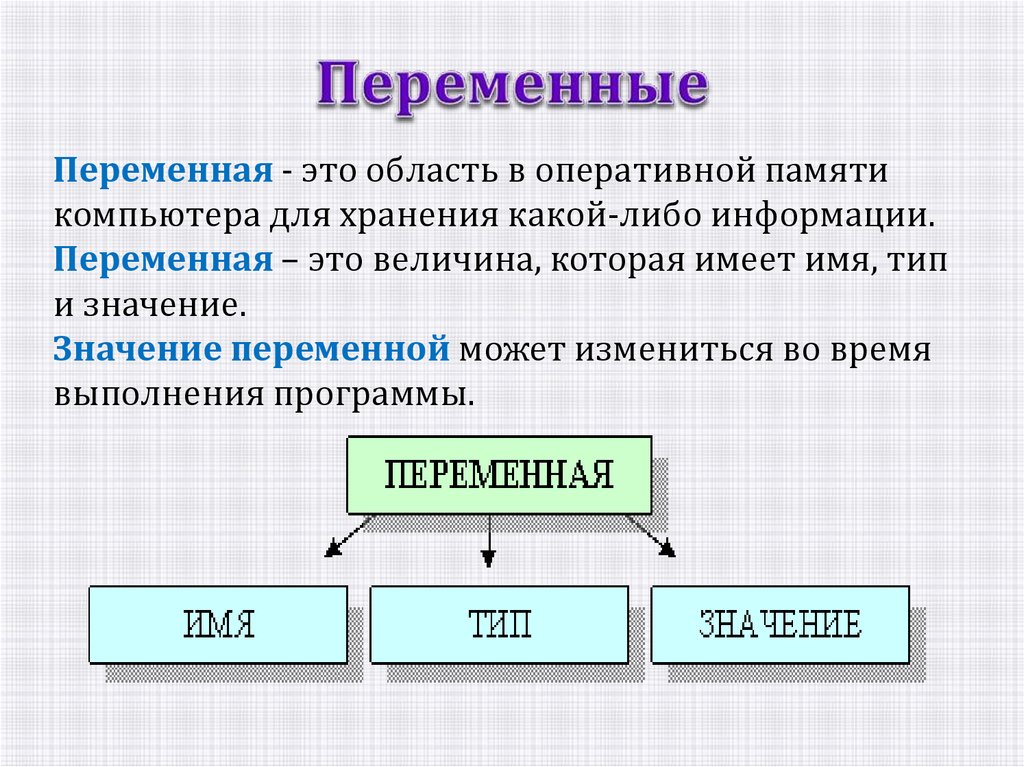 Учитывая набор предпосылок и их предполагаемый вывод, мы, аналитики, зададимся вопросом, является ли он дедуктивно достоверным, и если да, то является ли он также дедуктивно обоснованным. Если оно не является дедуктивно достоверным, то мы можем продолжить оценку того, является ли оно индуктивно сильным.
Учитывая набор предпосылок и их предполагаемый вывод, мы, аналитики, зададимся вопросом, является ли он дедуктивно достоверным, и если да, то является ли он также дедуктивно обоснованным. Если оно не является дедуктивно достоверным, то мы можем продолжить оценку того, является ли оно индуктивно сильным. Процесс выглядит следующим образом: извлеките аргумент из отрывка; оценить его с помощью дедуктивных и индуктивных стандартов; возможно, пересмотреть решение о том, какой аргумент существовал в исходном отрывке; затем переоцените этот новый аргумент, используя наши дедуктивные и индуктивные стандарты.
Процесс выглядит следующим образом: извлеките аргумент из отрывка; оценить его с помощью дедуктивных и индуктивных стандартов; возможно, пересмотреть решение о том, какой аргумент существовал в исходном отрывке; затем переоцените этот новый аргумент, используя наши дедуктивные и индуктивные стандарты. Если фраза «в то время» отсутствовала, вы, аналитик, должны беспокоиться о том, насколько вероятно, что эта фраза была задумана. Итак, вы столкнулись с двумя аргументами, одним действительным и одним недействительным, и вы не знаете, какой аргумент является предполагаемым.
Если фраза «в то время» отсутствовала, вы, аналитик, должны беспокоиться о том, насколько вероятно, что эта фраза была задумана. Итак, вы столкнулись с двумя аргументами, одним действительным и одним недействительным, и вы не знаете, какой аргумент является предполагаемым. Различные подходы, включая этнографию, нарративный анализ, анализ дискурса и текстологический анализ, соответствуют различным типам данных, дисциплинарным традициям, целям и философским ориентациям. Однако все они имеют несколько общих характеристик, которые отличают их от количественных аналитических подходов.
Различные подходы, включая этнографию, нарративный анализ, анализ дискурса и текстологический анализ, соответствуют различным типам данных, дисциплинарным традициям, целям и философским ориентациям. Однако все они имеют несколько общих характеристик, которые отличают их от количественных аналитических подходов. Их позиция подпитывала в корне ошибочное, но относительно распространенное представление о качественном анализе как о бессистемном, недисциплинированном и «чисто субъективном».
Их позиция подпитывала в корне ошибочное, но относительно распространенное представление о качественном анализе как о бессистемном, недисциплинированном и «чисто субъективном». Отличительной чертой качественного анализа является петлеобразная схема многократного повторного просмотра данных по мере появления дополнительных вопросов, обнаружения новых связей и развития более сложных формулировок наряду с углублением понимания материала. Качественный анализ – это, по сути, итеративный набор процессов.
Отличительной чертой качественного анализа является петлеобразная схема многократного повторного просмотра данных по мере появления дополнительных вопросов, обнаружения новых связей и развития более сложных формулировок наряду с углублением понимания материала. Качественный анализ – это, по сути, итеративный набор процессов.
 Случай может быть по-разному определен для разных аналитических целей. В зависимости от ситуации кейсом может быть отдельный человек, сессия фокус-группы или сайт программы (Berkowitz, 1996). С точки зрения гипотетического проекта, описанного в главе 2, случаем будет один университетский городок. Внутрикейсовый анализ исследует один объект проекта, а кросс-кейсовый анализ систематически сравнивает и противопоставляет восемь кампусов.
Случай может быть по-разному определен для разных аналитических целей. В зависимости от ситуации кейсом может быть отдельный человек, сессия фокус-группы или сайт программы (Berkowitz, 1996). С точки зрения гипотетического проекта, описанного в главе 2, случаем будет один университетский городок. Внутрикейсовый анализ исследует один объект проекта, а кросс-кейсовый анализ систематически сравнивает и противопоставляет восемь кампусов. Майлз и Хуберман (1994) описывают этот первый из трех элементов качественного анализа данных как сокращение данных. «Сокращение данных относится к процессу выбора, сосредоточения, упрощения, абстрагирования и преобразования данных, которые появляются в письменных полевых заметках или транскрипциях». Данные необходимо не только сжимать для удобства управления, но и преобразовывать, чтобы сделать их понятными с точки зрения решаемых проблем.
Майлз и Хуберман (1994) описывают этот первый из трех элементов качественного анализа данных как сокращение данных. «Сокращение данных относится к процессу выбора, сосредоточения, упрощения, абстрагирования и преобразования данных, которые появляются в письменных полевых заметках или транскрипциях». Данные необходимо не только сжимать для удобства управления, но и преобразовывать, чтобы сделать их понятными с точки зрения решаемых проблем. Обычно это включает некоторую комбинацию дедуктивного и индуктивного анализа. В то время как первоначальные классификации формируются на основе заранее установленных вопросов исследования, качественный аналитик должен оставаться открытым для получения новых значений из доступных данных.
Обычно это включает некоторую комбинацию дедуктивного и индуктивного анализа. В то время как первоначальные классификации формируются на основе заранее установленных вопросов исследования, качественный аналитик должен оставаться открытым для получения новых значений из доступных данных. Например, формирующий оценочный вопрос для гипотетического исследования может заключаться в том, подходят ли презентации для всех участников. Участники фокус-групп могли сказать много интересного о презентациях, но замечания, которые лишь косвенно касаются вопроса пригодности, возможно, придется заключить в скобки или проигнорировать. Точно так же комментарии участника о руководителе его отдела, которые не связаны с вопросами реализации программы или воздействия, какими бы интересными они ни были, не должны включаться в окончательный отчет. Подход к сокращению данных одинаков для анализа внутри и между случаями.
Например, формирующий оценочный вопрос для гипотетического исследования может заключаться в том, подходят ли презентации для всех участников. Участники фокус-групп могли сказать много интересного о презентациях, но замечания, которые лишь косвенно касаются вопроса пригодности, возможно, придется заключить в скобки или проигнорировать. Точно так же комментарии участника о руководителе его отдела, которые не связаны с вопросами реализации программы или воздействия, какими бы интересными они ни были, не должны включаться в окончательный отчет. Подход к сокращению данных одинаков для анализа внутри и между случаями. Сюда может быть включена информация из фокус-групп, наблюдений и подробных интервью с ключевыми информантами, такими как заведующий кафедрой. Наиболее значимые части данных, вероятно, будут сосредоточены в определенных разделах расшифровок фокус-групп (или рецензий) и подробных интервью с заведующим кафедрой. Тем не менее, лучше также быстро просмотреть все примечания на предмет соответствующих данных, которые могут быть разбросаны повсюду.
Сюда может быть включена информация из фокус-групп, наблюдений и подробных интервью с ключевыми информантами, такими как заведующий кафедрой. Наиболее значимые части данных, вероятно, будут сосредоточены в определенных разделах расшифровок фокус-групп (или рецензий) и подробных интервью с заведующим кафедрой. Тем не менее, лучше также быстро просмотреть все примечания на предмет соответствующих данных, которые могут быть разбросаны повсюду. Тенденция обращаться с качественными данными таким образом не редкость среди аналитиков, обученных количественным подходам. Неудивительно, что в результате качественный анализ выглядит как разбавленное исследование с крошечным размером выборки. Подход к качественному анализу таким образом несправедливо и излишне разбавляет богатство данных и, таким образом, непреднамеренно подрывает одну из самых сильных сторон качественного подхода.
Тенденция обращаться с качественными данными таким образом не редкость среди аналитиков, обученных количественным подходам. Неудивительно, что в результате качественный анализ выглядит как разбавленное исследование с крошечным размером выборки. Подход к качественному анализу таким образом несправедливо и излишне разбавляет богатство данных и, таким образом, непреднамеренно подрывает одну из самых сильных сторон качественного подхода. Отображение данных выходит за рамки сокращения данных, чтобы обеспечить «организованную, сжатую сборку информации, которая позволяет делать выводы…» Отображение может быть расширенным фрагментом текста или диаграммой, диаграммой или матрицей, которая обеспечивает новый способ организации и думать о более текстовых встроенных данных. Отображение данных, будь то в словесной или диаграммной форме, позволяет аналитику экстраполировать данные достаточно, чтобы начать различать систематические закономерности и взаимосвязи. На этапе отображения из данных могут появиться дополнительные категории или темы более высокого порядка, которые выходят за рамки тех, которые впервые были обнаружены в ходе начального процесса обработки данных.
Отображение данных выходит за рамки сокращения данных, чтобы обеспечить «организованную, сжатую сборку информации, которая позволяет делать выводы…» Отображение может быть расширенным фрагментом текста или диаграммой, диаграммой или матрицей, которая обеспечивает новый способ организации и думать о более текстовых встроенных данных. Отображение данных, будь то в словесной или диаграммной форме, позволяет аналитику экстраполировать данные достаточно, чтобы начать различать систематические закономерности и взаимосвязи. На этапе отображения из данных могут появиться дополнительные категории или темы более высокого порядка, которые выходят за рамки тех, которые впервые были обнаружены в ходе начального процесса обработки данных. В нашем гипотетическом примере оценки преподаватели всех восьми кампусов собираются в центральном кампусе для участия в семинарах. В этом отношении все участники подвергаются одинаковой программе. Тем не менее, реализация методов обучения, представленных на семинаре, скорее всего, будет варьироваться от кампуса к кампусу в зависимости от таких факторов, как личные характеристики участников, различные демографические характеристики студентов и различия в характеристиках университетов и факультетов (например, размер школы). студенческий состав, организация подготовительных курсов, поддержка заведующим кафедрой программных целей, восприимчивость кафедры к изменениям и инновациям). Специалисту по качественному анализу необходимо выявить модели взаимосвязей, чтобы предположить, почему проект способствовал большему изменению в одних кампусах, чем в других.
В нашем гипотетическом примере оценки преподаватели всех восьми кампусов собираются в центральном кампусе для участия в семинарах. В этом отношении все участники подвергаются одинаковой программе. Тем не менее, реализация методов обучения, представленных на семинаре, скорее всего, будет варьироваться от кампуса к кампусу в зависимости от таких факторов, как личные характеристики участников, различные демографические характеристики студентов и различия в характеристиках университетов и факультетов (например, размер школы). студенческий состав, организация подготовительных курсов, поддержка заведующим кафедрой программных целей, восприимчивость кафедры к изменениям и инновациям). Специалисту по качественному анализу необходимо выявить модели взаимосвязей, чтобы предположить, почему проект способствовал большему изменению в одних кампусах, чем в других. После разработки первой блок-схемы процесс можно повторить для всех остальных участков. Аналитики могут (1) использовать данные с последующих сайтов для изменения исходной блок-схемы; (2) подготовить независимую блок-схему для каждого сайта ; и/или (3) подготовьте единую блок-схему для некоторых событий (если на большинстве участков принят общий подход) и несколько блок-схем для других. Изучение данных, отображаемых в восьми кампусах, может привести к выводу о том, что внедрение проходило быстрее и эффективнее в тех кампусах, где заведующий кафедрой активно поддерживал опробование новых подходов к обучению, но препятствовал и задерживался, когда заведующие кафедрами опасались внесения изменений в проверенная временем система.
После разработки первой блок-схемы процесс можно повторить для всех остальных участков. Аналитики могут (1) использовать данные с последующих сайтов для изменения исходной блок-схемы; (2) подготовить независимую блок-схему для каждого сайта ; и/или (3) подготовьте единую блок-схему для некоторых событий (если на большинстве участков принят общий подход) и несколько блок-схем для других. Изучение данных, отображаемых в восьми кампусах, может привести к выводу о том, что внедрение проходило быстрее и эффективнее в тех кампусах, где заведующий кафедрой активно поддерживал опробование новых подходов к обучению, но препятствовал и задерживался, когда заведующие кафедрами опасались внесения изменений в проверенная временем система. Глядя на столбец (а), интересно, что три группы респондентов не пришли к полному согласию даже в том, какие виды деятельности они назвали. Только участники считали электронную почту средством обмена тем, что они узнали в программе, со своими коллегами. Коллеги, не участвовавшие в обсуждении, по-видимому, смотрели на ситуацию по-другому, потому что не включили в свой список адрес электронной почты. Заведующая кафедрой — возможно, потому, что она не знала, что они происходят — не упомянула электронную почту или неформальный обмен информацией как деятельность по обмену знаниями.
Глядя на столбец (а), интересно, что три группы респондентов не пришли к полному согласию даже в том, какие виды деятельности они назвали. Только участники считали электронную почту средством обмена тем, что они узнали в программе, со своими коллегами. Коллеги, не участвовавшие в обсуждении, по-видимому, смотрели на ситуацию по-другому, потому что не включили в свой список адрес электронной почты. Заведующая кафедрой — возможно, потому, что она не знала, что они происходят — не упомянула электронную почту или неформальный обмен информацией как деятельность по обмену знаниями.