
Тиунчик М.Ф. Примеры решения задач по теории вероятностей и математической статистике
- формат rtf
- размер 19.07 МБ
- добавлен 24 августа 2011 г.
Учебное пособие. — Хабаровская государственная академия экономики и права, 2002. — 135с.
Предлагаемое пособие содержит как необходимые теоретические
сведения, так и практикум с разбором решений. Задачи с решениями, а
также задачи для самостоятельной работы рассматриваются на
протяжении всего изложения учебного материала, и приводятся в конце
каждого параграфа. Пособие оснащено статистическо-математическими
таблицами, которые применяются к решению задач.
Данное пособие составлено таким образом, чтобы содержащегося в нем
материала было достаточно для успешной сдачи экзамена или зачета по
дисциплине.
Дополнительные знания Вы можете получить из литературы,
рекомендованной в пособии, любой другой доступной Вам научной и
учебно-методической литературы по теории вероятностей и
математической статистике, а также из всевозможных сайтов в
Inteet, содержащих материалы по данной дисциплине.
Похожие разделы
- Академическая и специальная литература
- Математика
- Задачники и решебники
- Академическая и специальная литература
- Математика
- Теория вероятностей и математическая статистика
- Математическая статистика
- Задачники по математической статистике
- Академическая и специальная литература
- Математика
- Теория вероятностей и математическая статистика
- Теория вероятностей
- Задачники по теории вероятностей
Смотрите также
- формат djvu, htm
- размер 6.
 53 МБ
53 МБ - добавлен 02 февраля 2009 г.
 53 МБ
53 МБСерия или Выпуск: Учебник для вузов. От издателя Перед вами — расширенный учебник по теории вероятностей и математической статистике. Традиционный материал пополнен такими вопросами, как вероятности комбинаций случайных событий, случайные блуждания, линейные преобразования случайных векторов, численное нахождение нестационарных вероятностей состояний дискретных марковских процессов, применение методов оптимизации для решения задач математической…
- формат tif, jpg
- размер 76.76 МБ
- добавлен 16 марта 2010 г.
Москва: Высш. школа, 1991, 157 с. Формат jpg. Задачи по математической статистике, по теории вероятностей, математическая статистика, случайные величины, случайные события, теория вероятностей. Элементы теории вероятностей. Математическая статистика. Приложение: распределение Пуассона, функция плотности вероятности нормального распределения, распределения Пирсона, Стьюдента и Фишера.rn
Элементы теории вероятностей. Математическая статистика. Приложение: распределение Пуассона, функция плотности вероятности нормального распределения, распределения Пирсона, Стьюдента и Фишера.rn
Справочник
- формат djvu
- размер 4.14 МБ
- добавлен 25 августа 2011 г.
Авт.: В.С. Королюк, Н.И. Портенко, А.В. Скороход, А.Ф. Турбин. — М.: Наука. Главная редакция физико-математической литературы, 1985. — 640 с. Справочник представляет собой расширенное и переработанное издание книги «Справочник по теории вероятностей и математической статистике» под редакцией В.С. Королюка, вышедшей в 1978 г. в издательстве «Наукова думка». По широте охвата основных идей, методов и конкретных результатов современной теории вероятн…
- формат djvu
- размер 3. 78 МБ
- добавлен 30 ноября 2011 г.
 78 МБ
78 МБУчебное пособие для студентов вузов. Москва, изд-во «Статистика», 1975. — 199 с. В сборнике даны подробные решения типовых задач по теории вероятностей и математической статистики. Большинство задач носит конкретный характер, при их составлении использован фактический материал. Сборник содержит сквозные задачи, решение которых развивает у студентов способность анализировать явления с помощью математических методов. Для их решения используются как…
- формат djvu
- размер 1.41 МБ
- добавлен 30 июня 2008 г.
М.: Айрис-пресс, 2004. -256 с. Настоящая книга представляет собой курс лекций по теории вероятностей математической статистике. Первая часть книги содержит основные понятия и теоремы теории вероятностей, такие как случайные события, вероятность, случайные функции, корреляция, условная вероятность, закон больших чисел и предельные теоремы.
- формат djvu
- размер 3.78 МБ
- добавлен 19 апреля 2011 г.
М.: Айрис-пресс, 2008. -288 с. Настоящая книга представляет собой курс лекций по теории вероятностей математической статистике. Первая часть книги содержит основные понятия и теоремы теории вероятностей, такие как случайные события, вероятность, случайные функции, корреляция, условная вероятность, закон больших чисел и предельные теоремы. В отдельной главе приведены основные понятия теории случайных процессов. Вторая часть книги посвящена матем…
Контрольная работа
- формат rtf
- размер 1.67 МБ
- добавлен
14 марта 2011 г.

Решения 17 задач по теории вероятностей и матстатистике Решебник содержит задачи по теории вероятностей и математической статистике и примеры их решения. В решебник вошли 17 задач по способам определения вероятности происхождения события с помощью формулы Бейеса на примере задач о вынимании шарика определенного цвета из урны, попадании стрелком в мишень, о выпадении герба монеты, передачи сообщения по средствам связи без помех.
- формат djvu
- размер 3.71 МБ
- добавлен 18 января 2009 г.
-249с. Содержит собрание неожиданных выводов и утверждений из теории вероятностей, математической статистике и теории случайных процессов. Классические парадоксы теории вероятностей. Парадоксы в математической статистике. Парадоксы случайных процессов. Парадоксы в основаниях теории вероятностей. Разные парадоксы. Парадоксология.
Разные парадоксы. Парадоксология.
Решение задач по статистике в колледже
Проведение любого вида анализа, как оперативного, так и ретроспективного, требует грамотного использования статистических приемов. Они помогают оценить наличие достоверной связи между явлениями, выводят усредненные показатели, которые важны для факторной оценки.
Особенности решения задач по статистике в колледжах и вузах
На современном этапе развития общества применение методов статистической обработки материала позволяет:
- проанализировать те или иные явления, определив характер и выявив закономерности;
- спрогнозировать ситуацию на близкую либо отдаленную перспективу;
- спланировать перечень мероприятий для корректировки выявленной тенденции.
Статистика применяется в экономике, здравоохранении, педагогическом анализе, бизнесе, социальных науках и общественных явлениях.
В учебных программах колледжей и вузов обязательно присутствует курс статистики, целью которого является научить студентов статистической методологии, правилам применения статистических выводов в практической деятельности специалиста.
Статистика является целостной системой, затрагивающей как социально-экономическое, так и отраслевое направление, часто имеет международный характер.
Решение задач по статистике в учебных заведениях среднего и высшего звена опирается на утвержденные алгоритмы, смыслом которых является четкое следование оговоренным этапам.
- Сбор данных. При этом в работу берутся не все показатели. Исключение составляют, например, годы, когда действовали факторы непреодолимой силы (стихийные бедствия, эпидемии и т.п.). Таким образом, формируются выборки показателей, каждая из которых предназначена для определенной статистической обработки.
- Обобщение выбранных данных – преподаватель дает студенту характеристику существующих методов и способов получения показательного результата, выведения закономерностей и подтверждения их графически.
- Анализ. Устанавливаются связи между явлениями или факторами, наблюдается наличие взаимосвязи между количественными и качественными показателями.
- Итог. Определение динамики того или иного процесса, характеристика демографических процессов среди населения либо прочих анализируемых факторов.

Формируя определенную совокупность для статистической обработки, обращают внимание на частоту встречаемости того или иного признака или варианта. Тот из них, который встречается чаще других, статистически обозначает «моду». Благодаря ему формируется обобщающая характеристики величины признака. Обозначается мода Мо. При рассмотрении дискретного ряда (т.е. ряда, образованного числами) мода выделяет то значение, которое встречается чаще остальных.
Существует еще одна характеристика выстроенного динамического ряда. Это медиана. Она находится в середине вариационного ряда, построенного по принципу возрастания или убывания, и делит его на две половины.
Мода и медиана в математике называются распределительными средними. Их основное назначение сводится к формированию общей характеристики выбранного варьирующего признака какой-то величины.
Их основное назначение сводится к формированию общей характеристики выбранного варьирующего признака какой-то величины.
Методы расчета ошибки выборки
Задачи со статистическими методами решений имеют в своей основе генеральную совокупность. Под этим термином понимается суммарное количество предметов наблюдения, которые имеют тот или иной общий признак.
Пример
Населенный пункт можно охарактеризовать численностью населения, количеством имеющихся на территории промышленных предприятий, учреждений образования, здравоохранения и т.д.
Выбрав нужный признак, его характеристики отбираются и объединяются в выборку (выборочную совокупность). Однако необходимо помнить, что для обеспечения полноценного действия полученного в результате анализа вывода, каждая выборка должна быть репрезентативной.
Репрезентативность выборки можно продемонстрировать на следующем примере. Отобрав значения показателей детей, посещающих детские дошкольные учреждения в Москве и получив выводы, его нельзя применить ко всей Московской области либо ко всей стране.
Кроме репрезентативности, каждая выборка может иметь ошибку. Ошибка выборки может возникнуть по причине недостаточного количества ее размера. Другими словами, в изучаемом процессе недостаточный доверительный интервал.
Ошибки можно дифференцировать на:
- статистическую;
- систематическую.
Именно статистическая определяется размером выборки. С увеличением числа наблюдений она уменьшается.
Систематическая ошибка не математического характера. Она зависит от воздействия определенных факторов, которые могут сместить результаты наблюдения в ту или иную нетипичную сторону.
В математике, когда говорят об ошибке выборки, имеют ввиду статистическую.
Рассмотрим расчет ошибки выборки для обобщения результатов опроса респондентов. Обычно такие социальные исследования носят выборочный характер, т.е. опрашиваются не 100% людей, а некоторая часть. Именно поэтому нельзя быть уверенным в полученном результате на 100%.
Определить ошибку выборки можно по следующим формулам:
1. \(\Delta=Ζ\surd(p\times g\div n)\)
\(\Delta=Ζ\surd(p\times g\div n)\)
Она применяется для тех ситуаций, когда размер выборки намного меньше чем сама генеральная совокупность.
2. Для случаев с незначительной разницей между объемом выборки и генеральной совокупностью рекомендуется формула:
\(\Delta=Ζ\surd(p\times q\div n\times((N-n)\div(N-1))\)
Условные обозначения:
Δ — предельная ошибка
Ζ — коэффициент доверительного уровня
N — величина генеральной совокупности
n — объем выборки
p — часть опрошенных, у которых есть исследуемый признак
q = 1−p — те опрошенные, которые не имеют исследуемого признака
Статистическая сводка и группировка
Источник: works.doklad.ruПосле этапа статистического наблюдения следует составление статистической сводки. Его цель – систематизация имеющейся информации, составление общей характеристики для рассматриваемой совокупности.
Алгоритм операций, начиная с первичной обработки имеющихся данных, имеющий своей целью выделение типичных свойств описывающих изучаемое явление, называется статистической сводкой. Он включает подсчет групповых и обобщенных результатов, группировку сведений и составление табличной формы анализа.
Он включает подсчет групповых и обобщенных результатов, группировку сведений и составление табличной формы анализа.
Дифференцируют простую и сложную сводку. При простой в качестве результата анализа имеют общие итоги. При сложной – итоги в виде анализов по группам, возможно, объединенных в таблицы.
Основными этапами составления сводки являются:
- отбор признака, по которому будет проводиться группировка;
- обозначение последовательности, которая ляжет в основу формирования каждой группы;
- определение системы показателей, которые будут статистически характеризовать каждую группу и совокупность;
- составление таблиц с целью наглядной демонстрации полученных результатов.
Метод статистической обработки путем группировки применяется, когда вся исследуемая генеральная совокупность может быть разделена на группы по выбранному признаку. Этот признак называется группировочным.
Таким образом, группировка – это один из способов выделения в совокупности данных, характеризующих выбранный признак. Такое изучение имеет своей целью изучить структуру совокупности, выявить возможную взаимосвязь между изучаемыми признаками. Например, применяя группировку, легко выделить в большой организации участки с высоким выполнением запланированных показателей.
Такое изучение имеет своей целью изучить структуру совокупности, выявить возможную взаимосвязь между изучаемыми признаками. Например, применяя группировку, легко выделить в большой организации участки с высоким выполнением запланированных показателей.
В экономической отрасли группировка применяется если нужно проанализировать трудовые ресурсы, наличие средств труда, материальные ресурсы и т.п.
Сегодня выделяют следующие виды группировок:
- простая;
- сложная;
- типологическая;
- структурная;
- аналитическая и др.
При структурной группировке могут исследоваться состав и структура имеющегося статистического материала. При аналитической – исследуются связи, возникающие между отдельными элементами и их группами. В таких случаях могут выделяться обобщающие значения, результативные или те, которые определенным образом влияют на обобщающие.
Ряды распределения и статистические таблицы
При проведении статистического анализа пользуются построением рядов распределения. Их целью является определение самых характерных признаков и присутствующих закономерностей, действующих в совокупности. Вид рядов распределения определяется тем, какой признак лежит в основе группировки. Принимая за основу качественные показатели, получают атрибутивные группировки. Делая акцент на количественном признаке, ряд называется вариационным. В свою очередь, вариационный ряд может быть ранжированным, дискретным, интервальным.
Их целью является определение самых характерных признаков и присутствующих закономерностей, действующих в совокупности. Вид рядов распределения определяется тем, какой признак лежит в основе группировки. Принимая за основу качественные показатели, получают атрибутивные группировки. Делая акцент на количественном признаке, ряд называется вариационным. В свою очередь, вариационный ряд может быть ранжированным, дискретным, интервальным.
В ранжированном ряду элементы совокупности располагаются в порядке возрастания или убывания. Так легко выявить наибольшее либо наименьшее значения. В дискретном ряду присутствует признак прерывающихся изменений. Он может выглядеть двухграфной таблицей, в которой одна графа – признак, вторая – частота его встречаемости.
Если анализируемый признак претерпевает постоянные изменения, строится интервальный вариационный ряд. В таком случае в графе для количественных показателей указывается не одно значение, а интервал от и до.
Типовые примеры с решениями и выводами для студентов
К типовым задачам по статистике в программах колледжей и вузов относятся:
- Определение моды динамического ряда.

В динамическом ряду 1, 5, 6, 4, 8, 4, 3, 4, 9 найти моду. Так как число 4 встречается чаще других, оно и является модой. Легко определить моду с помощью гистограммы.
Источник: statanaliz.infoНа предложенной гистограмме изображено бимодальное распределение признака.
При интервальных данных задача решается чуть труднее. Допустим, даны исходные материалы:
Источник: statanaliz.infoНа графике модальный интервал с наибольшей частотой – 301-400 (самый высокий столбик).
Моду рассчитываем по формуле:
\(Mo=Xo+h(ƒMo-ƒMo-1)\div((ƒMo-ƒMo-1)+(ƒMo-ƒMo1)\)
где Mo-мода
Xo— начало модального интервала
h — Размер модального интервала
ƒ – частота модального интервала
ƒMo-1 – частота интервала перед модальным
ƒ Mo– частота интервала после модального
В результате расчета для данного примера Мода равна 334,3 руб
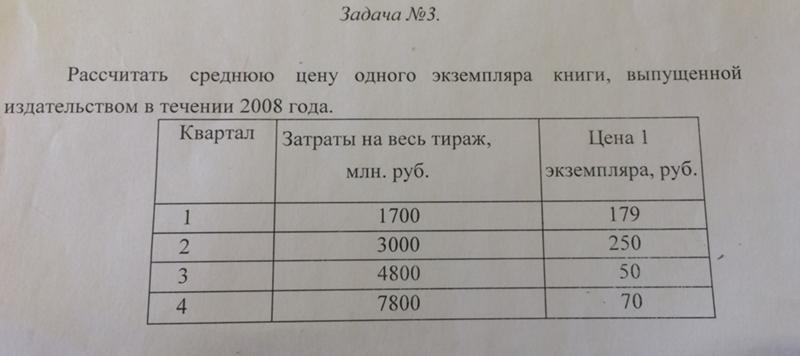
Задача № 2
Студенческой библиотекой пользуются 40 человек.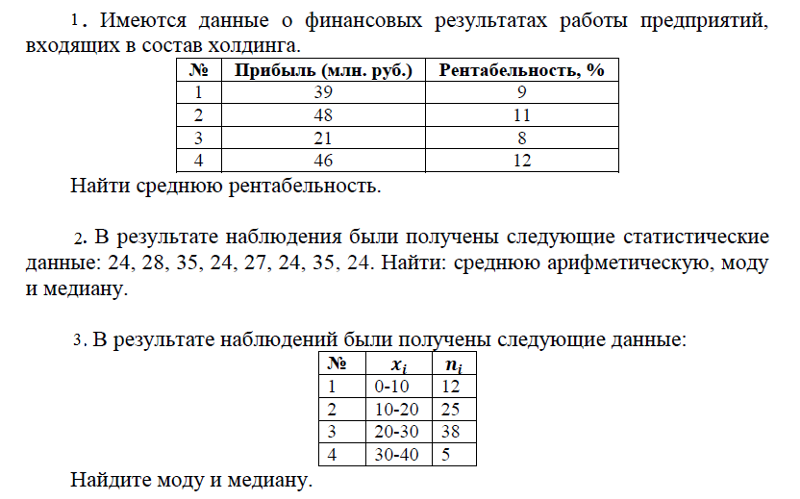 Было выписано, сколько книг взял за год каждый из них. Получился результат:
Было выписано, сколько книг взял за год каждый из них. Получился результат:
Строим ранжированный и дискретный вариационные ряды в таблице:
Источник: ekonomika-st.ruПостроению таблицы предшествовало обозначение элементов ряда. Полученная совокупность содержит в себе много вариантов для анализа, как пользуются студенты библиотечным фондом.
Статистика – дисциплина, позволяющая на результатах конкретного анализа выявить наиболее проблемные либо успешные организационные моменты и провести коррекцию того или иного типового направления работы. Если нужна помощь с учебными заданиями по статистике, обращайтесь в ФениксХелп.
Начало работы — Руководство по исследованию данных и статистики
Начало работы
Это руководство поможет вам разработать стратегию, найти, цитировать и работать с данными, статистикой и соответствующим программным обеспечением.
На этой странице:
Что такое данные?
Данные представляют собой набор значений качественных или количественных переменных, собранных вместе для справки или анализа. Необработанные или «необработанные данные» часто требуют некоторой очистки перед анализом. Исследователи во многих дисциплинах, от химиков до политологов и цифровых гуманитариев, делают выводы на основе результатов анализа своих данных.
Необработанные или «необработанные данные» часто требуют некоторой очистки перед анализом. Исследователи во многих дисциплинах, от химиков до политологов и цифровых гуманитариев, делают выводы на основе результатов анализа своих данных.
В данных в виде электронной таблицы переменные представлены столбцами, а записи или случаи представлены строками. Интерпретация или анализ данных требует надлежащей документации, что часто достигается путем создания кодовых книг и словарей данных. Они описывают коды и значения, используемые для маркировки наблюдений. Например, в наборе данных может быть переменная для пола, где «1» означает «мужской», а «2» — женский. Эта информация будет указана в кодовой книге, чтобы мы могли читать и интерпретировать данные в переменной Gender. Кроме того, столбцы могут называться сокращенно, без документации никто не узнает значение «здоровье2» или «здоровье3» и так далее.
Источник: NYU Data Services — Introduction to SPSS
Данные поступают в файлы различных форматов. Некоторые файлы могут быть открыты только определенным программным обеспечением, в то время как другие могут быть открыты многими программами. По возможности выбирая популярные открытые стандарты, вы будете более независимы от дорогостоящего программного обеспечения и с большей вероятностью сможете получить доступ к своему файлу через много лет (например, .CSV вместо .XLS). Посмотрите это руководство из Стэнфорда, если хотите узнать больше.
Некоторые файлы могут быть открыты только определенным программным обеспечением, в то время как другие могут быть открыты многими программами. По возможности выбирая популярные открытые стандарты, вы будете более независимы от дорогостоящего программного обеспечения и с большей вероятностью сможете получить доступ к своему файлу через много лет (например, .CSV вместо .XLS). Посмотрите это руководство из Стэнфорда, если хотите узнать больше.
Определение данных исследований из Конкордата по открытым данным исследований
Данные исследования — это доказательства, лежащие в основе ответа на вопрос исследования, и могут использоваться для проверки результатов независимо от их формы (например, печатной, цифровой или физической). Это может быть количественная информация или качественные утверждения, собранные исследователями в ходе их работы с помощью экспериментов, наблюдений, моделирования, интервью или других методов, или информация, полученная из существующих данных.
 Данные могут быть необработанными или первичными (например, полученными непосредственно в результате измерения или сбора), либо полученными из первичных данных для последующего анализа или интерпретации (например, очищенными или извлеченными из более крупного набора данных), либо полученными из существующих источников, на которые могут принадлежать права. другими. Данные могут быть определены как «реляционные» или «функциональные» компоненты исследования, тем самым сигнализируя о том, что их идентификация и ценность зависят от того, используют ли их исследователи в качестве доказательства для утверждений и если да, то каким образом. (См. полный текст Конкордата по открытым исследовательским данным.)
Данные могут быть необработанными или первичными (например, полученными непосредственно в результате измерения или сбора), либо полученными из первичных данных для последующего анализа или интерпретации (например, очищенными или извлеченными из более крупного набора данных), либо полученными из существующих источников, на которые могут принадлежать права. другими. Данные могут быть определены как «реляционные» или «функциональные» компоненты исследования, тем самым сигнализируя о том, что их идентификация и ценность зависят от того, используют ли их исследователи в качестве доказательства для утверждений и если да, то каким образом. (См. полный текст Конкордата по открытым исследовательским данным.)
Что такое статистика?
Статистические данные представляют собой обработанную информацию, полученную путем математических расчетов необработанных данных. Часто это быстрые факты и цифры, представленные в таблицах и диаграммах, не дающие пользователям достаточной свободы для настройки и расчета по своему усмотрению.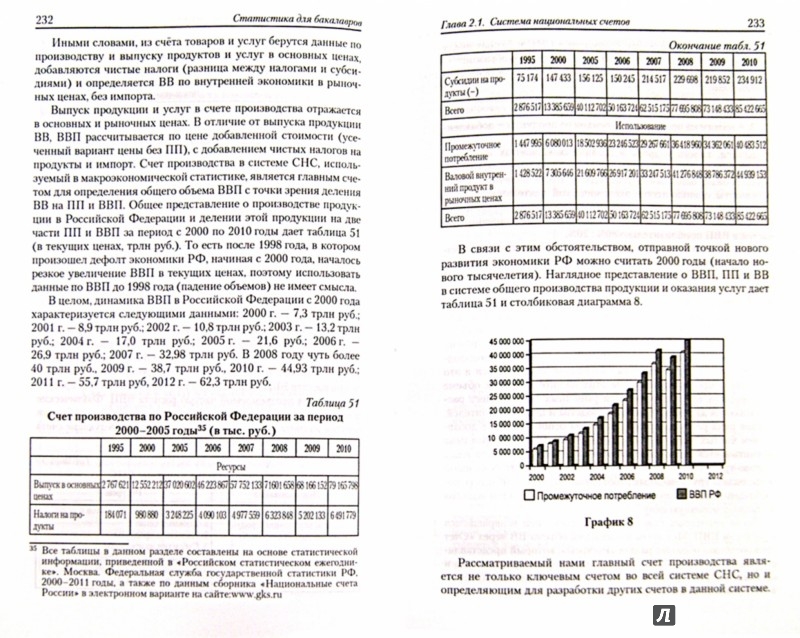
Другими словами, статистика суммирует данные. Примерами статистики могут быть графические представления (такие как диаграммы и таблицы), которые обычно можно увидеть в статьях и популярных СМИ.
Источник: Netflix в Statista
Узнайте больше о данных и статистике
Источники
Информация для этого исследовательского руководства была с благодарностью адаптирована из:
Руководство по данным и статистике Нью-Йоркского университета
Руководство по данным и статистике МГУ
Домашняя страница — Статистика и данные
- Об этом руководстве
- Статистика и данные: в чем разница?
- Передовой опыт: замедлитесь и задавайте вопросы!
- Глоссарий
В этом руководстве приведены отправные точки для поиска статистической информации и наборов данных. Некоторые предоставленные ресурсы ограничены использованием сообщества Университета Святой Марии. Другие источники данных, перечисленные здесь, находятся в открытом доступе и находятся в свободном доступе в Интернете.
Некоторые предоставленные ресурсы ограничены использованием сообщества Университета Святой Марии. Другие источники данных, перечисленные здесь, находятся в открытом доступе и находятся в свободном доступе в Интернете.
Поговорите с нами! Мы можем помочь вам ориентироваться в различных статистических данных и инструментах данных, таких как коллекции Статистического управления Канады, источники данных об эффективности отрасли и компании и многое другое. Загляните в нашу службу поддержки исследований или назначьте встречу, чтобы обсудить ваш проект и требования к данным.
Библиотека участвует в Инициативе Статистического управления Канады по освобождению данных (DLI) и может предоставить доступ в исследовательских целях к файлам микроданных общего пользования (PUMF) из многих программ опросов Статистического управления Канады. Исследователям, которым требуется доступ к PUMF, базам данных и географическим файлам StatCan, следует связаться с представителем DLI библиотеки, Джойс Томсон, по телефону Teams или по электронной почте joyce. [email protected]
[email protected]
. Термины «статистика» и «данные» часто используются как синонимы. Хотя есть некоторые общепринятые различия, есть и серые зоны: статистика — это своего рода данные, а данные используются для создания статистики. Между этими двумя терминами есть некоторые различия:
Статистика часто бывает: | Данные обычно можно использовать для: |
|---|---|
|
|
Размышляя об использовании данных, подумайте, какой тип данных вам может понадобиться — микроданные или агрегированные данные. Микроданные — это исходная (в основном) необработанная информация*, такая как уровень образования каждого члена семьи, высота и порода каждого дерева в парке. Совокупные данные обобщаются и каким-то образом объединяются: средний уровень образования в городе, количество дубов в городском парке.
Микроданные — это исходная (в основном) необработанная информация*, такая как уровень образования каждого члена семьи, высота и порода каждого дерева в парке. Совокупные данные обобщаются и каким-то образом объединяются: средний уровень образования в городе, количество дубов в городском парке.
*(микроданные немного обработаны для защиты конфиденциальности участников, но ответы респондентов практически не изменены)
Содержание адаптировано с разрешения библиотеки Университета Брока
Что происходит с этими номерами?
Перво-наперво: помедленнее . Не сосредотачивайтесь сразу на цифрах в таблице. Вместо этого внимательно просмотрите детали по краям: какую информацию дает заголовок или заголовок? Что такое метки строк и столбцов? Есть ли сноски или ссылки под таблицей? Вся эта информация может помочь вам понять контекст чисел, которые находятся внутри таблицы.
Вопросы, которые нужно задать (и ответить!) при просмотре числовых данных или статистики:
- Что подсчитывается или суммируется?
- Какие единицы измерения используются: тысячи долларов (CAD? USD?), отдельные зрители, процентное изменение (от чего?), процент от суммы и т. д.
- Кто собирал и/или обобщал данные?
- Какие вопросы задавались или какие источники использовались для поиска, запроса, компиляции, сбора, создания данных?
- Какова была цель сбора данных в первую очередь?
- Как все это согласуется с тем, что ВЫ хотите сделать с этими числами?
Ограничения, о которых следует помнить
Многие факторы могут влиять на то, какие данные собираются и почему, а другие факторы влияют на то, чем можно делиться с другими. Несколько общих проблем, возникающих с опубликованными данными и статистикой, включают (1) необходимость защиты конфиденциальности, 2. усилия по контролю точности и достоверности, 3. обязательные измерения (например, перепись) и 4. ранее существовавшие категории. с помощью которого можно организовать данные.
обязательные измерения (например, перепись) и 4. ранее существовавшие категории. с помощью которого можно организовать данные.
- Защита конфиденциальности :
- Из-за соображений конфиденциальности некоторые данные могут быть ограничены, поскольку подсчитываемое население настолько мало, что можно было бы идентифицировать отдельного человека или компанию.
- Усилия по контролю точности и прецизионности
- Данные могут быть недоступны, если есть сомнения относительно методов сбора данных или когда невозможно подтвердить точность данных. Некоторые статистические расчеты требуют определенных критериев, чтобы считаться действительными: например, если количество точек данных слишком мало или если метод получения данных был непоследовательным, статистический расчет не считается точным и не может быть опубликован. .
- Сравнение во времени часто невозможно
- Многие обследования, включая национальную перепись, требуются по закону или постановлению; в некоторых случаях собранные конкретные вопросы и ответы прямо изложены государственным органом или постановлением. Эти правила могут меняться со временем, поэтому вопросы, заданные 10 или 20 лет назад, могут отличаться от тех, которые задают сегодня. Следовательно, сравнение данных во времени может быть сложным или невозможным.
- Многие обследования, включая национальную перепись, требуются по закону или постановлению; в некоторых случаях собранные конкретные вопросы и ответы прямо изложены государственным органом или постановлением.
- Стандартные категории и методы могут не соответствовать вашим требованиям
- Стандартные методы и категории часто используются многими группами для облегчения обмена и сравнения наборов данных и статистики. Эти стандарты удобно использовать, но они могут не полностью соответствовать вашему конкретному вопросу.
- Например, коды NAICS (коды Североамериканской отраслевой классификации) обычно используются в Канаде и США для сбора экономической и трудовой статистики по отраслям.
- Каждая специализированная отрасль будет иметь единый код NAICS, который является подмножеством более крупной категории, которая, в свою очередь, является частью еще более крупной категории и т. д.
- Иерархическая структура, определенная NAICS, может не всегда соответствовать тому, как вы хотели бы классифицировать отрасль.
- Эти коды также могут меняться со временем, о чем следует помнить, если вы просматриваете статистику за разные десятилетия: в NAICS 1997 было 3 кода для отраслей, связанных с Интернетом. НАИКС 2012 имеет 57,
- Например, коды NAICS (коды Североамериканской отраслевой классификации) обычно используются в Канаде и США для сбора экономической и трудовой статистики по отраслям.
- Стандартные методы и категории часто используются многими группами для облегчения обмена и сравнения наборов данных и статистики. Эти стандарты удобно использовать, но они могут не полностью соответствовать вашему конкретному вопросу.
 Эти правила могут меняться со временем, поэтому вопросы, заданные 10 или 20 лет назад, могут отличаться от тех, которые задают сегодня. Следовательно, сравнение данных во времени может быть сложным или невозможным.
Эти правила могут меняться со временем, поэтому вопросы, заданные 10 или 20 лет назад, могут отличаться от тех, которые задают сегодня. Следовательно, сравнение данных во времени может быть сложным или невозможным.
После 20/20 :
- Программное обеспечение, которое позволяет пользователю манипулировать сводной таблицей для создания и изменения формы файла данных.
Данные :
- Данные представляют собой числовые файлы, созданные и организованные для обработки и анализа. Существует два типа данных: совокупные данные и микроданные. Агрегированные данные и микроданные предлагают пользователю больший контроль над переменными, предлагаемыми для анализа.
DLI :
- Инициатива по освобождению данных — партнерство между Статистическим управлением Канады и канадскими высшими учебными заведениями для продвижения и облегчения доступа Статистического управления Канады и других канадских данных для образовательных и академических исследовательских целей.

Геопространственные данные :
- Определяет географическую область и ее размеры. Они имеют форму точек, линий, многоугольников или пикселей.
Основные файлы :
- «Чистый» или «Набор необработанных данных, состоящий из всех ответов респондентов на вопросы опроса. [Почти] все переменные и случаи доступны для анализа в основном файле. Основной файл недоступен всем пользователям.
Метаданные :
- Метаданные – это документация, которая сопровождает пользователей и помогает им в интерпретации микроданных, агрегированных данных и географических файлов.
Микроданные :
- Необработанные или минимально обработанные данные исследования (также известные как данные опроса). Каждая строка в файле содержит информацию о человеке (или другом объекте наблюдения). Обычно он используется в SPSS, Stata, R или других статистических программах.
