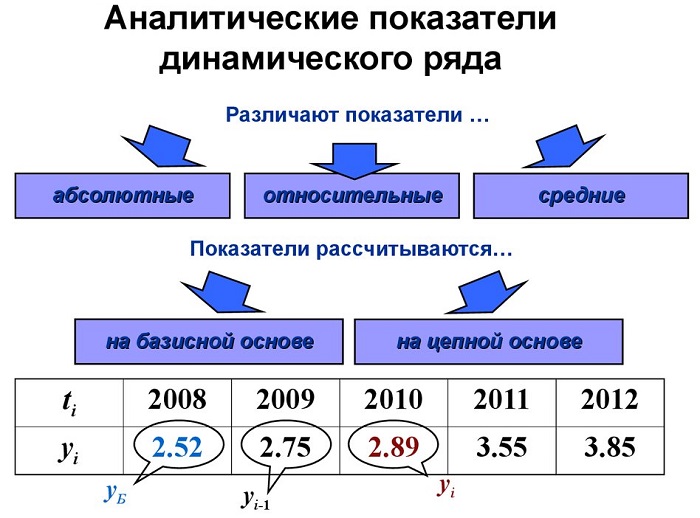
Примеры решения задач — Статистика
Условие задачи
Определить вид ряда динамики. Для полученного ряда рассчитать: цепные и базисные абсолютные приросты, темпы роста, темпы прироста, средний уровень ряда, средний темп роста, средний темп прироста. Проверить взаимосвязь абсолютных приростов и темпов роста. По расчетам сделать выводы. Графически изобразить полученный ряд динамики.
| Годы | Объем производства, млн.р. |
| 2011 | 12 |
| 2012 | 10 |
| 2013 | 11 |
| 2014 | 10 |
| 9 |
Решение задачи
Данный
ряд динамики – интервальный, так как значение показателя заданы за определенный
интервал времени.
Определяем цепные и базисные показатели ряда динамики
|
Абсолютные приросты цепные:
|
Абсолютные приросты базисные:
|
|
Темпы роста цепные:
|
Темпы роста базисные:
|
|
Темпы прироста цепные:
|
Темпы прироста базисные:
|
Показатели динамики объема производства 2011-2015 гг
| Годы |  р. р.
|
Абсолютные приросты, млн.р. | Темпы роста, % | Темпы прироста, % | |||
| цепные | базисные | цепные | базисные | цепные | базисные | ||
| 2011 | 12 | —— | —— | 100.0 | 100.0 | —— | —— |
| 2012 | 10 | -2 | -2 |
83. 3 3
|
83.3 | -16.7 | -16.7 |
| 2013 | 11 | 1 | -1 | 110.0 | 91.7 | -8.3 | |
| 2014 | 10 | -1 | -2 | 90.9 | 83.3 | -9.1 | -16.7 |
| 2015 | 9 | -1 | -3 |
90. 0 0
|
75.0 | -10.0 | -25.0 |
Определяем средние показатели ряда динамики
Средний уровень исследуемого динамического ряда найдем по формуле средней арифметической:
Среднегодовой абсолютный прирост:
Среднегодовой темп роста:
Среднегодовой темп прироста:
Строим график
График динамики объема производства 2011-2015 гг
Таким образом на протяжении всего исследуемого периода за исключением 2013 года объем производства продукции на предприятиях снижался. В среднем предприятия производили продукции на 10,4 млн.р. в год. В среднем показатель снижался на 0,75 млн.р. в год или на 6,9% в относительном выражении.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная оплата переводом на карту СберБанка.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача по статистике S-7
Изменение численности работающих характеризуется следующими данными:
1.Определить вид динамического ряда.
2.Определить аналитические показатели динамики: абсолютный прирост, темп роста и прироста (цепные и базисные), абсолютное содержание 1% прироста. Результаты оформить таблицей.
3.Определить динамические средние за период.
4.Для определения тенденции изменения численности работающих произведите аналитическое выравнивание и выразите общую тенденцию соответствующим математическим уравнением.
5.Определить выровненные (теоретические) уровни ряда динамики и нанести их на график – с фактическими данными.
6.Предполагая, что выявленная тенденция сохранится в будущем, определить ожидаемую численность работающих на ближайшие 5 лет.
Решение:
Для наглядности построим гистограмму.
Имеем дело с моментным рядом динамики с равноотстоящими уровнями.
Абсолютные приросты определяются как разность между двумя уровнями динамического ряд и показывают, насколько данный уровень превышает уровень, принятый за базу сравнения.
Базисные абсолютные приросты определяются при сравнении с переменной базой (базисный период), по формуле:
Цепные абсолютные приросты определяются при сравнении с переменной базой, по формуле:
Рассчитываем базисные абсолютные приросты, за базисный период принимаем 1 год (1983) и соответствующее ему значение численности 746
Определим среднегодовой темп роста.
Относительные величины динамики принято называть темпами роста – темпами динамики (Т).
Цепные темпы роста
Базисные темпы роста — за основу принимается постоянная база сравнения, т.е. начальный уровень ряда динамики.
Вычислим темпы динамики. Результаты запишем в таблицу.
Темп прироста в рядах динамики характеризует относительную скорость изменения уровня ряда в единицу времени и рассчитывается отношением абсолютного прироста к уровню, принятому за базу сравнения.
Для вычисления темпов прироста воспользуемся формулой:
Средний уровень вычислим по средней хронологической.
Вывод: Средняя численность работающих за рассматриваемый период = 97,27.
Результирующая таблица.
Вычислим средние величины.
Среднегодовой абсолютный прирост – характеризует среднюю скорость изменения уровня ряда в единицу времени и рассчитывается делением цепных абсолютных приростов на их число, т.е.
Вывод: В рассматриваемый период численность падает в среднем на 11,64 чел.
Определим среднегодовой темп роста.
Среднегодовой темп роста рассчитывается по формуле средней геометрической из цепных темпов роста
Определим среднегодовой темп прироста.
Вывод: За период численность рабочих ежегодно падает на 1,75%
Построим поле корреляции.
Можем предположить о линейной зависимости показателя численности от времени.
Проведем аналитическое выравнивание ряда методом наименьших квадратов.
Линейная модель имеет вид:
Методом наименьших квадратов вычислим параметры линейной регрессии:
Получили уравнение линейной регрессии:
По найденной формуле вычислим теоретические значения численности и прогнозные значения численности рабочих на ближайшие 5 лет. Для этого вместо переменной t будем подставлять значения от 1 до 20.
Для этого вместо переменной t будем подставлять значения от 1 до 20.
Вынесем значения на график.
Прогнозирование временных рядов: варианты использования и примеры
Время чтения: 13 минут
Прогнозирование временных рядов вряд ли является новой проблемой в науке о данных и статистике. Этот термин говорит сам за себя и уже несколько десятилетий находится в повестке дня бизнес-аналитиков: самые первые примеры анализа временных рядов и прогнозирования восходят к началу 1920-х годов.
Хотя стажер-аналитик сегодня может работать с временными рядами в Excel, рост вычислительной мощности и инструментов обработки данных позволяет использовать временные ряды для решения гораздо более сложных задач, чем раньше, для достижения более высокой точности прогнозирования.
В этой статье мы подробно рассмотрим, как используется прогнозирование временных рядов, обсудим несколько методов и назовем ключевые инструменты, которые помогают специалистам по данным использовать эту технику.
Что такое прогнозирование и анализ временных рядов?
Прогнозирование временных рядов — это набор методов в статистике и науке о данных для прогнозирования некоторых переменных, которые развиваются и изменяются с течением времени. Основная цель прогнозирования временных рядов заключается в определении того, как целевые переменные будут изменяться в будущем, путем наблюдения за историческими данными с точки зрения времени, определения закономерностей и получения краткосрочных или долгосрочных прогнозов того, как происходят изменения, с учетом зафиксированных закономерностей.
Вариантов использования этого подхода множество: от прогнозов продаж и спроса до узкоспециализированных научных работ по бактериальным экосистемам.
Что такое анализ временных рядов?
Анализ временных рядов направлен на понимание зависимостей данных по мере их изменения во времени. В отличие от прогнозирования, он пытается ответить на вопросы , что происходит? и почему так происходит? Прогнозирование, с другой стороны, соответствует выяснению того, что произойдет .
При этом анализ предшествует прогнозированию и помогает специалистам по данным подготавливать данные для обучения моделей машинного обучения.
Тенденции, сезоны, циклы и нерегулярности
Многие задачи машинного обучения и интеллектуального анализа данных работают с наборами данных, которые имеют один отрезок времени или вообще не учитывают временной аспект. Обработка естественного языка, распознавание изображений или звуков, а также многочисленные задачи классификации и регрессии могут быть решены вообще без временных переменных. Например, решение по распознаванию звука, с которым мы работали, включало в себя улавливание характерных звуков скрежета зубов пациентов, когда они спали. Итак, нас интересовало не то, как эти звуки меняются со временем, а то, как отличить их от окружающих звуков.
Проблемы временных рядов, с другой стороны, всегда зависят от времени, и мы обычно рассматриваем четыре основных компонента: сезонность, тенденции, циклы и нерегулярные компоненты.
Источник: Прогнозирование: принципы и практика, Роб Дж. Хайндман, 2014 г. Приведенный выше график является наглядным примером того, как работают тренды и времена года. Тренды. Компонент тренда описывает, как переменная – в данном случае продажи наркотиков – изменяется в течение длительных периодов времени. Мы видим, что выручка от продажи противодиабетических препаратов существенно увеличилась за период с 19с 90-х по 2010-е годы. Времена года. Сезонный компонент демонстрирует волнообразные изменения моделей продаж каждый год. Продажи то увеличивались, то уменьшались в зависимости от сезона. Сезонные ряды могут быть привязаны к любому измерению времени, но эти периоды времени всегда имеют фиксированную длину и последовательность. Мы можем учитывать месячные или квартальные модели продаж в средней или небольшой электронной коммерции или отслеживать микровзаимодействия в течение дня. Циклы. Циклы — это долгосрочные паттерны, которые имеют форму волны и повторяющийся характер, похожие на сезонные паттерны, но с переменной продолжительностью, они не имеют фиксированного периода времени. Например, деловые циклы имеют узнаваемые элементы роста, спада и восстановления. Но сами циклы растягиваются во времени по-разному для данной страны на протяжении всей ее истории. Неисправности. Нерегулярные компоненты появляются из-за неожиданных событий, таких как катаклизмы, или просто представляют шум в данных. Прогнозирование временных рядов, возможно, является одной из наиболее распространенных областей применения машинного обучения в бизнесе. Давайте обсудим некоторые варианты использования из нашего опыта и других предприятий. Прогнозирование потребительского спроса является краеугольным камнем для компаний, которые управляют поставками и закупками. Как консалтинговая компания в области технологий для путешествий, у нас был опыт работы с японским гигантом розничной торговли Rakuten, у которого также есть свой филиал в сфере гостеприимства. Мы использовали данные временных рядов Rakuten о продажах гостиничных номеров, а также данные, полученные от конкурирующих отелей. Эти данные помогли определить наиболее вероятные цены, которые помогут увеличить доход. Переменные сезонности рассматривали цены в зависимости от будних дней, праздников и… ну, сезонов. Прогнозы также учитывали общие тенденции рынка гостеприимства. Прогноз цен в прогнозировании временных рядов также дает большие возможности для улучшения и персонализации взаимодействия с пользователем. Одним из таких случаев является наш клиент Fareboom. Источник: Fareboom.com Двигатель имеет 75-процентную уверенность в том, что тарифы скоро вырастут которые соединяют людей с поставщиками конечных услуг. Если у вас есть сезонные или трендовые данные об отелях, которые нравятся людям на Рождество, почему бы не превратить их в рекомендации? Ознакомьтесь с подробной статьей о нашем опыте прогнозирования цен на авиабилеты здесь. Анализ временных рядов и прогнозирование стали ключевым методом, применяемым в здравоохранении для прогнозирования распространения Covid-19. Помимо этого, очевидно, подходящего набора вариантов использования, анализ временных рядов и прогнозирование нашли свое применение почти во всех областях здравоохранения, от генетики до диагностики и лечения. Значительный прогресс как в краткосрочном, так и в долгосрочном прогнозировании заболеваний. Например, прогнозирование временных рядов используется для прогнозирования возможной смерти после сердечных приступов для применения профилактических мер. Управление циклом доходов и выставление счетов за медицинские услуги находятся на другом конце спектра лечения. Одним из вариантов использования прогнозов временных рядов является прогнозирование расходов на прописанные лекарства. Обнаружение аномалий — одна из распространенных задач машинного обучения, которая ищет выбросы в том, как точки данных обычно распределяются. Поиск аномалий в данных временных рядов. Источник: Neptune.ai Выявление мошенничества является критически важной деятельностью для любой отрасли, связанной с платежами и другими финансовыми операциями. PayPal — центр машинного обучения, когда речь идет об обнаружении мошенничества, — применяет анализ временных рядов для отслеживания нормальной частоты операций каждой учетной записи, чтобы найти нерегулярные всплески количества транзакций. Эти результаты также проверяются на наличие других подозрительных действий, таких как недавние изменения адреса доставки или массовое снятие средств, чтобы выделить данную транзакцию как вероятную мошенническую. Эти методы работают в целях кибербезопасности. Помимо кибербезопасности, данные временных рядов датчиков закладывают основу для диагностического обслуживания, политики прогнозирования отказа оборудования до того, как он действительно произойдет, чтобы снизить затраты на ремонт и время простоя. Обнаружив малозаметные аномалии в текущих показаниях датчиков, такие системы могут предвидеть более драматические события, ведущие к отказу. Был опубликован ряд исследовательских работ, посвященных использованию прогнозирования временных рядов для профилактического обслуживания, включая морскую отрасль, добычу угля, работу банкоматов и многое другое. «Предсказывать очень сложно, особенно если речь идет о будущем». Нильс Бор, лауреат Нобелевской премии по физике Сегодня задачи временных рядов обычно решаются с помощью традиционных статистических (например, ARIMA) и методов машинного обучения, включая искусственные нейронные сети (ANN), методы опорных векторов (SVM), и некоторые другие. Итак, давайте рассмотрим главное, что происходит в поле. Традиционные методы прогнозирования стремятся привнести во временные ряды стационарность, т. е. сделать так, чтобы ряд статистических свойств постоянно повторялся во времени. Необработанные данные обычно не обеспечивают достаточную стационарность для получения надежных прогнозов. Например, к приведенному выше графику продаж противодиабетических препаратов мы должны применить несколько математических преобразований, чтобы сделать нестационарные временные ряды хотя бы приблизительно стационарными. Источник: Forecasting: Principles & Practice, Rob J Hyndman, 2014 Стационарность данных наши усилия, так как слишком много нерегулярных факторов которые влияют на изменения. Посмотрите на сбои в поездках, особенно на те, которые случаются во время войн и пандемий. Потоки путешественников меняются, пункты назначения меняются, а авиакомпании корректируют свои цены по-разному, что делает наблюдения годичной давности практически устаревшими. Или цены на сырую нефть, которые имеют решающее значение для прогнозирования для игроков во многих отраслях, не позволили нам построить алгоритмы временных рядов, которые были бы достаточно точными. Традиционный подход к машинному обучению заключается в разделении доступного исторического набора данных на два или три меньших набора для обучения модели и дальнейшей проверки ее производительности по сравнению с данными, которые машина раньше не видела. Основное отличие временных рядов состоит в том, что специалисту по данным необходимо использовать проверочный набор, который точно соответствует обучающему набору на временной оси, чтобы убедиться, что обученная модель достаточно хороша. Проблема с нестационарными записями заключается в том, что данные в обучающей выборке могут не быть однородными с проверочной выборкой, поскольку свойства временных рядов существенно меняются в течение периода, охватываемого обучающей и проверочной выборками. Вот когда мы можем использовать метод потокового обучения. Потоковое обучение предполагает постепенное изменение алгоритма — по сути, его переобучение. По мере поступления новой записи или небольшого их набора он обновляет модель, а не обрабатывает весь набор данных. Горизонт данных. Сколько новых обучающих экземпляров необходимо для обновления модели? Например, Шуан Гао и Ялин Лэй из Китайского университета геонаук применили потоковое обучение для повышения точности прогнозирования в таких нестационарных временных рядах, как упомянутые выше цены на сырую нефть. Они установили горизонт данных как можно меньше, чтобы каждое обновление цен на нефть немедленно обновляло алгоритм. Устаревание данных. Сколько времени нужно, чтобы начать считать исторические данные или некоторые их элементы неактуальными? Ответ на этот вопрос может быть довольно сложным, так как он требует доли предположений, основанных на предметной области, по сути, понимания того, как меняется рынок, с которым вы работаете, и сколько нестационарных факторов его бомбардирует. Если ваш бизнес электронной коммерции значительно вырос с прошлого года как с точки зрения клиентской базы, так и с точки зрения разнообразия продуктов, данные за тот же квартал предыдущего года могут считаться устаревшими. Хотя прогнозы сырой нефти, основанные на изучении потока, в конечном итоге работают лучше, чем обычные методы, они по-прежнему показывают результаты, которые лишь немного лучше, чем у подброшенной монеты, и остаются на уровне 60-процентной достоверности. Они также более сложны в разработке, развертывании и требуют предварительного бизнес-анализа для определения горизонта данных и устаревания. Еще один способ борьбы с нестационарностью — ансамблевые модели. Ансамблирование использует несколько методов машинного обучения и интеллектуального анализа данных для дальнейшего объединения их результатов и повышения точности прогнозов. Этот метод не имеет ничего общего с новыми подходами в науке о данных, но имеет решающее значение с точки зрения бизнес-решений, связанных с инициативами в области науки о данных. В принципе, несмотря на то, что построение надежного прогнозирования является дорогостоящим и трудоемким, оно не сводится к созданию и проверке одной или двух моделей с дальнейшим выбором лучшего исполнителя. Что касается временных рядов, то нестационарные компоненты, такие как различная продолжительность циклов, низкая предсказуемость погоды и другие нерегулярные явления, влияющие на несколько отраслей, еще больше усложняют ситуацию. Это было проблемой для команды Google, которая создавала инфраструктуру прогнозирования временных рядов для анализа бизнес-динамики своей поисковой системы и YouTube с дальнейшей дезагрегацией этих прогнозов по регионам и небольшим временным рядам, таким как дни и недели. Когда инженеры Google раскрыли свой подход, стало ясно, что даже на Олимпе технологий, управляемых ИИ, предпочтение отдается более простым методам, чем сложным. Они еще не используют потоковое обучение и довольствуются ансамблевыми методами. Но главное, что они выражают, это то, что вам нужно как можно больше методов, чтобы получить наилучшие результаты: “ Итак, какие модели мы включаем в наш ансамбль? Практически любая разумная модель, которую мы можем получить! Конкретные модели включают варианты многих известных подходов, таких как модель диффузии Басса, модель Theta, логистические модели, bsts, STL, модели Холта-Винтерса и другие модели экспоненциального сглаживания, сезонные и другие модели на основе ARIMA, годовые модели. Путем усреднения прогнозов многих моделей, которые по-разному работают в разных ситуациях временных рядов, они добились большей предсказуемости, чем могли бы с одной моделью. В то время как некоторые модели лучше работают со своими конкретными нестационарными данными, другие блестят со своими. Среднее значение, которое они дают, действует как мнение эксперта и оказывается очень точным. Источник: Наше стремление к надежному прогнозированию временных рядов в масштабе , Эрик Тассоне и Фарзан Рохани, 2017 г., Процедура прогнозирования в Google 
Прогнозирование и анализ временных рядов: примеры и варианты использования
Прогнозирование спроса для розничной торговли, закупок и динамического ценообразования
 Еще одним распространенным приложением является прогнозирование цен и тарифов на продукты и услуги, которые динамически корректируют цены в зависимости от спроса и целевых доходов.
Еще одним распространенным приложением является прогнозирование цен и тарифов на продукты и услуги, которые динамически корректируют цены в зависимости от спроса и целевых доходов. Прогноз цен для клиентских приложений и улучшение пользовательского опыта
 com. Fareboom — это служба бронирования авиабилетов, которая успешно находит для своих клиентов самые низкие тарифы на авиабилеты. Проблема с ценами на авиабилеты в том, что они меняются быстро и без видимых причин. Если вы не покупаете билеты прямо перед поездкой, информация о будущих ценах будет полезной. Отличным UX-решением было предсказать, упадут или вырастут цены в ближайшем или отдаленном будущем, и предоставить эту информацию клиентам. Это побуждает клиентов возвращаться и делает Fareboom их платформой для оптимизации их бюджетов на поездки.
com. Fareboom — это служба бронирования авиабилетов, которая успешно находит для своих клиентов самые низкие тарифы на авиабилеты. Проблема с ценами на авиабилеты в том, что они меняются быстро и без видимых причин. Если вы не покупаете билеты прямо перед поездкой, информация о будущих ценах будет полезной. Отличным UX-решением было предсказать, упадут или вырастут цены в ближайшем или отдаленном будущем, и предоставить эту информацию клиентам. Это побуждает клиентов возвращаться и делает Fareboom их платформой для оптимизации их бюджетов на поездки. Прогнозирование распространения пандемии, диагностика и планирование лекарств в здравоохранении
 Он использовался для прогнозирования передачи, коэффициентов смертности, распространения эпидемии и многого другого.
Он использовался для прогнозирования передачи, коэффициентов смертности, распространения эпидемии и многого другого. Обнаружение аномалий для обнаружения мошенничества, кибербезопасности и профилактического обслуживания
 Хотя это не обязательно должны быть данные временных рядов, обнаружение аномалий часто идет рука об руку с ними. Обнаружение аномалий во временных рядах влечет за собой обнаружение нерегулярных всплесков или впадин, которые значительно отклоняются от того, как выглядят сезоны и тренды.
Хотя это не обязательно должны быть данные временных рядов, обнаружение аномалий часто идет рука об руку с ними. Обнаружение аномалий во временных рядах влечет за собой обнаружение нерегулярных всплесков или впадин, которые значительно отклоняются от того, как выглядят сезоны и тренды. Например, в ряде исследовательских работ сообщается об эффективном использовании анализа временных рядов данных датчиков IoT для выявления атак вредоносных программ.
Например, в ряде исследовательских работ сообщается об эффективном использовании анализа временных рядов данных датчиков IoT для выявления атак вредоносных программ. Подходы к прогнозированию временных рядов
 Пока эти подходы доказали свою эффективность, меняются задачи, их объем и наши возможности решения проблем. И простой набор вариантов использования временных рядов сегодня может быть расширен. По мере того, как статистика вступает в эру обработки больших данных с Интернетом вещей, предоставляющим неограниченное количество отслеживаемых устройств и анализом социальных сетей, специалисты по данным ищут новые подходы к обработке этих данных и преобразованию их в прогнозы.
Пока эти подходы доказали свою эффективность, меняются задачи, их объем и наши возможности решения проблем. И простой набор вариантов использования временных рядов сегодня может быть расширен. По мере того, как статистика вступает в эру обработки больших данных с Интернетом вещей, предоставляющим неограниченное количество отслеживаемых устройств и анализом социальных сетей, специалисты по данным ищут новые подходы к обработке этих данных и преобразованию их в прогнозы. Тогда мы сможем находить закономерности и делать прогнозы.
Тогда мы сможем находить закономерности и делать прогнозы. Традиционные методы машинного обучения
 Если мы применим машинное обучение без фактора временных рядов, специалист по данным может выбрать наиболее релевантные записи из доступных данных и подогнать к ним модель, оставив после себя зашумленные и противоречивые записи.
Если мы применим машинное обучение без фактора временных рядов, специалист по данным может выбрать наиболее релевантные записи из доступных данных и подогнать к ним модель, оставив после себя зашумленные и противоречивые записи. Потоковое обучение
 Этот подход требует понимания двух основных вещей:
Этот подход требует понимания двух основных вещей: С другой стороны, если страна переживает экономический спад, новые краткосрочные данные могут быть менее информативными, чем данные о предыдущей рецессии.
С другой стороны, если страна переживает экономический спад, новые краткосрочные данные могут быть менее информативными, чем данные о предыдущей рецессии. Ансамбльные методы

 Годовые модели роста, пользовательские модели и многое другое. », — говорят Эрик Тассоне и Фарзан Рохани.
Годовые модели роста, пользовательские модели и многое другое. », — говорят Эрик Тассоне и Фарзан Рохани. Таким образом, если вы не работаете с множеством местоположений или большим набором различных источников данных, ансамблевые модели могут вам не подойти. Но если вы отслеживаете закономерности временных рядов по странам или бизнес-подразделениям в разных регионах, это может быть лучшим вариантом.
Таким образом, если вы не работаете с множеством местоположений или большим набором различных источников данных, ансамблевые модели могут вам не подойти. Но если вы отслеживаете закономерности временных рядов по странам или бизнес-подразделениям в разных регионах, это может быть лучшим вариантом.
Инструменты и службы, используемые для прогнозирования временных рядов
Мы опубликовали обзор платформ MLaaS для полу- и полностью автоматизированных задач машинного обучения, к которым могут подойти организации с ограниченным доступом к науке о данных и аналитике.
Проблема с автоматизацией операций прогнозирования и машинного обучения заключается в том, что эти технологии все еще находятся в зачаточном состоянии. Полностью автоматизированные решения страдают от недостатка гибкости, поскольку они выполняют множество операций «под капотом» и могут либо выполнять простые и общие задачи (например, распознавание объектов на изображениях), либо не учитывать специфику бизнеса. С другой стороны, на ранних стадиях вашей аналитической инициативы наем полноценных групп по анализу данных может быть чувствительным к затратам. Золотая середина здесь — такие инструменты, как TensorFlow, которые по-прежнему требуют некоторого инженерного таланта, но обеспечивают достаточную автоматизацию и удобные инструменты, чтобы не изобретать велосипед.
С другой стороны, на ранних стадиях вашей аналитической инициативы наем полноценных групп по анализу данных может быть чувствительным к затратам. Золотая середина здесь — такие инструменты, как TensorFlow, которые по-прежнему требуют некоторого инженерного таланта, но обеспечивают достаточную автоматизацию и удобные инструменты, чтобы не изобретать велосипед.
Prophet от Facebook
Великий вклад в операционализацию предсказания временных рядов вносит Prophet, один из самых популярных продуктов с открытым исходным кодом от Facebook с эпическим названием. Facebook был довольно щедр в открытом исходном коде инструментов, которые они используют, вспомните React Native, который был выпущен для публичного использования в 2013 году. Но на этот раз они раздают симпатичный пакет для конкретной задачи.
Prophet позиционируется как «Прогнозирование в масштабе», что, по мнению авторов, означает в основном 3 вещи:
1. Пакетом могут пользоваться самые разные люди. Потенциальными пользователями являются как специалисты по данным, так и люди, обладающие знаниями предметной области для настройки источников данных и интеграции Prophet в свои аналитические инфраструктуры. Вы можете работать с Prophet с R и Python, двумя наиболее распространенными языками программирования, применяемыми для задач обработки данных.
Потенциальными пользователями являются как специалисты по данным, так и люди, обладающие знаниями предметной области для настройки источников данных и интеграции Prophet в свои аналитические инфраструктуры. Вы можете работать с Prophet с R и Python, двумя наиболее распространенными языками программирования, применяемыми для задач обработки данных.
2. Можно решить широкий спектр проблем. Facebook использовал инструмент для прогнозирования временных рядов социальных сетей, но модель можно настроить в соответствии с различными бизнес-обстоятельствами. Пророк не только хорошо работает с данными, имеющими ярко выраженную сезонность, но и может автоматически подстраиваться под изменения тренда.
3. Оценка производительности автоматизирована. А вот и самое приятное. Оценка и ряд поверхностных проблем автоматизированы, и аналитики-люди должны просто визуально проверять прогнозы, выполнять моделирование и реагировать на ситуации, когда машина считает, что прогнозы имеют высокую вероятность ошибки.
Источник: Масштабное прогнозирование, Шон Дж. Тейлор и Бенджамин Летам, 2017 г. Например, вы можете ввести данные о размере рынка или другую информацию о возможностях, чтобы алгоритм учитывал эти факторы и адаптировался к ним. Как вы знаете, когда вы собираетесь внедрить какие-то революционные обновления, такие как редизайн сайта или какую-то умопомрачительную функцию, вы также можете сообщить об этом алгоритму. И, в конце концов, вы можете определить соответствующую шкалу сезонности и даже добавить праздники в качестве повторяющихся шаблонов в свой временной ряд. Все ритейлеры знают, насколько Черная пятница или Рождество отличаются от остального года.
TensorFlow, BigQuery и Vertex AI от Google
Google предлагает надежный и богатый набор облачных сервисов с различными возможностями машинного обучения прямо из коробки. Если вы придерживаетесь Google, вы можете либо использовать автоматизированные инструменты, либо выбрать индивидуальный подход, чтобы лучше адаптировать его набор инструментов к уникальным бизнес-потребностям. Google предлагает три основных инструмента для доступа к возможностям временных рядов.
Google предлагает три основных инструмента для доступа к возможностям временных рядов.
ТензорФлоу. TensorFlow — это популярная универсальная платформа машинного обучения, специально предназначенная для нейронных сетей. Это также инструмент с открытым исходным кодом, предназначенный для специалистов по данным и инженеров машинного обучения, которые могут либо использовать его готовые возможности, либо углубиться и настроить модели, работающие под капотом. TensorFlow можно использовать как отдельный инструмент для обучения моделей и развертывания их там, где вам нужно, но он также хорошо интегрирован с облачной инфраструктурой Google.
BigQuery и Vertex AI. Если вы используете платформу Google Cloud, вы можете получить доступ к прогнозированию временных рядов с помощью инструмента autoML под названием Vertex AI. Он поставляется с предварительно настроенными моделями с инструментами настройки. По своей сути Vertex AI использует возможности TensorFlow, но требует гораздо меньше знаний в области обработки данных для работы, обслуживая средних инженеров-программистов.
Кроме того, вы можете исследовать, визуализировать и подготавливать данные для задач временных рядов с помощью инструмента облачного хранилища данных Google BigQuery, поскольку он интегрирован с Vertex AI.
Вот руководство Google по прогнозированию временных рядов с помощью Google.
Amazon Forecast
Amazon Forecast — еще один управляемый инструмент для прогнозирования временных рядов с помощью AWS. Система способна автоматически анализировать данные, находить в них ключевые переменные и выбирать наиболее подходящий алгоритм для применения. Однако, если у вас есть достаточный опыт работы с данными, вы можете выбрать один из шести встроенных алгоритмов в зависимости от ваших конкретных потребностей.
Алгоритмы прогнозирования временных рядов Amazon, сравните. Источник: AWS
Алгоритмы различаются по своим возможностям и вычислительной мощности, что напрямую влияет на стоимость. Они варьируются от более мощных сверточных нейронных сетей до более традиционных методов, таких как ARIMA и ETS.
Azure Time Series Insights для данных IoT
Наконец, давайте упомянем инструмент Microsoft, Time Series Insights, предназначенный исключительно для поддержки анализа временных рядов, но не для прогнозирования. Решение для аналитики ориентировано на потоковые данные IoT, что означает, что оно может собирать и визуализировать аналитику в масштабе с миллиардами событий, передаваемых в систему в течение нескольких секунд.
Insights предварительно интегрированы с инфраструктурой Azure, в частности с IoT Hub и Events Hub. Облачный сервис позволяет хранить данные JSON и CSV до 400 дней, запрашивать их и визуализировать.
Прогнозирование временных рядов в будущем станет более автоматизированным
Как автоматизация временных рядов, так и рост объема доступных данных с оконечных устройств определяют основную тенденцию в прогнозировании временных рядов. Аналитика становится все более доступной и, в конечном счете, все более важной для успеха бизнеса. Мы можем не только отслеживать прогресс в бизнесе, но и фиксировать очень специфические нестационарные и иногда зависящие от времени события, которые раньше отсутствовали. А растущая мощь посреднических услуг позволяет более широкой группе профессионалов, не имеющих опыта работы с данными, использовать прогнозы временных рядов.
А растущая мощь посреднических услуг позволяет более широкой группе профессионалов, не имеющих опыта работы с данными, использовать прогнозы временных рядов.
Систематические решения для прогнозирования временных рядов в реальных бизнес-задачах | Алина Чжан
Опубликовано в
·
Чтение: 7 мин.
·
13 октября 2018 г.
Интернет-ресурсы и учебные пособия по прогнозированию временных рядов в основном делятся на 2 категории: демонстрация кода для определенной модели прогнозирования, и академический стиль объяснение теории математических формул. Оба эти подхода полезны для учебных целей. Однако для решения реальных бизнес-задач в отрасли важно иметь систематическое и хорошо структурированное решение, которое специалисты по данным могут использовать в качестве руководства и применять в практических случаях.
Цель этой статьи — предоставить сквозное систематическое решение для прогнозирования временных рядов с практической точки зрения, показав:
- общий вид полных процессов прогнозирования
- как применить решение непосредственно к решить вашу бизнес-проблему, шаг за шагом следуя приведенной ниже блок-схеме методологии
Начните с вопроса
На какой вопрос мы хотим ответить с помощью данных? Например,
- Каковы ожидаемые объемы продаж сотен групп продуктов питания в продуктовых магазинах в следующем квартале?
- Какова стоимость перепродажи автомобилей после их аренды на 3 года?
- Каково количество пассажиров на каждом крупном международном авиамаршруте и для каждого класса пассажиров (эконом-класс, бизнес-класс и первый класс)?
- Каковы ожидаемые сроки спроса клиентов в ближайшие 3 месяца в индустрии продуктов питания и напитков?
Начните с мозгового штурма вопросов, которые вас интересуют и на которые вы ожидаете получить ответы с вашими наборами данных.
Предсказуемость
Важно определить предсказуемость вашей проблемы, потому что не все прогнозы лучше, чем подбрасывание монеты. Предсказуемость события или значения зависит от нескольких факторов. Вы можете обратиться к моей предыдущей статье «Основы прогнозирования, которые вы должны знать перед созданием прогностических моделей» для получения более подробной информации.
Доступность данных
Когда полностью отсутствуют исторические данные (т. е. новый продукт, новая политика, новый конкурент), или данные неполны, или данные становятся доступными только после некоторой задержки, Оценочное прогнозирование является единственным Вариант для этих случаев.
Когда наборы данных содержат числовую информацию о прошлом, а также разумно предположить, что некоторые аспекты прошлой модели сохранятся в будущем, мы можем построить Прогнозирование временных рядов моделей, чтобы сделать прогноз.
Отсутствующие значения и выбросы
Обычный способ работы с отсутствующими значениями заключается в замене их оценками с использованием методов интерполяции. Например, для этой цели предназначен метод pandas.DataFrame.interpolate .
- Для несезонных данных можно использовать простую линейную интерполяцию для заполнения отсутствующих разделов, т.е. соединить значения, т.е.
interpolate(method=’spline’, order=2)
Самый простой способ справиться с выбросами — заполнить их медианным значением переменной. Например, если значение переменной «Возраст» больше 80, мы заменяем его медианой, df["Возраст"] = np.where(df["Возраст"] >80, median,df["Возраст "]).
Очевидно, что эти методы интерполяции следует использовать только тогда, когда мы предполагаем, что пропущенное значение и выброс являются действительно ошибками. Просто заменять их, не задумываясь о том, почему они произошли, опасно, потому что они могут предоставить полезную информацию, которую нам нужно принять во внимание.
Декомпозиция
Декомпозиция в первую очередь полезна для изучения данных временных рядов путем разделения временного ряда на три компонента, каждый из которых представляет базовую категорию шаблона.
- Компонент цикла тренда
- Сезонный компонент
- Остаточный компонент (содержащий что-либо еще во временном ряду)
Сезонная корректировка (опционально)
Экономические ряды обычно корректируются с учетом сезонных колебаний. Сезонная корректировка означает удаление сезонного компонента из наблюдений.
Например, данные об уровне безработицы среди гражданского населения обычно корректируются с учетом сезонных колебаний, чтобы выделить колебания, обусловленные основным состоянием экономики, а не сезонные колебания.
- Для аддитивного разложения сезонно скорректированные данные рассчитываются путем вычитания сезонной составляющей из наблюдений,
Сезонная составляющая наблюдения - Для мультипликативной декомпозиции сезонно скорректированные значения получаются путем деления наблюдения на сезонную составляющую,
Наблюдение/сезонная составляющая
Корреляционный анализ (дополнительно)
900 04 Корреляция не подразумевает причинно-следственную связь . Теория предотвращения конфликтов «Золотые арки» является примером теории, основанной на неправильно понятой корреляции. Понимание и определение причинно-следственного механизма имеет решающее значение для построения хорошей модели прогнозирования. На практике график рассеяния можно легко использовать для определения корреляции между переменными.
Теория предотвращения конфликтов «Золотые арки» является примером теории, основанной на неправильно понятой корреляции. Понимание и определение причинно-следственного механизма имеет решающее значение для построения хорошей модели прогнозирования. На практике график рассеяния можно легко использовать для определения корреляции между переменными.Контрольный показатель (необязательно)
Существуют контрольные показатели прогнозирования, которые можно сравнивать с любыми разработанными нами методами, чтобы убедиться, что новый метод лучше, чем эти простые альтернативы. Новый метод не стоит рассматривать, если он работает хуже, чем эталонные тесты. Четыре общих метода прогнозирования ориентиров:
- Метод среднего : установите для всех прогнозов среднее значение исторических данных. Например, установите объем продаж в ноябре равным среднему объему продаж с января по октябрь.
- Наивный метод : установить прогнозы всех будущих значений равными последнему наблюдению.
 Например, установите продажи в ноябре равными продажам в октябре.
Например, установите продажи в ноябре равными продажам в октябре. - Сезонный наивный метод : установите каждый прогноз равным последнему наблюдаемому значению того же сезона года. Например, установите продажи в ноябре этого года равными продажам в ноябре прошлого года.
- Метод дрейфа : увеличение или уменьшение средней величины изменения во времени (так называемый дрейф). Например, если месячный рост продаж с января по октябрь составляет 10 000 (дрейф), установите продажи в ноябре равными продажам в октябре плюс 10 000.
 Например, установите продажи в ноябре равными продажам в октябре.
Например, установите продажи в ноябре равными продажам в октябре.Преобразование и корректировка (дополнительно)
Как правило, чем проще структура исторических данных, тем точнее прогноз будущих значений. Преобразование и корректировка исходных данных могут исключить некоторые известные вариации и сделать скрытые закономерности в наборах данных более согласованными с течением времени. Существует 4 распространенных типа корректировок:
- Корректировка календаря : учет разного количества дней в каждом месяце
- Корректировка численности населения : устранение последствий изменений численности населения
- Корректировка инфляции : устранение последствий инфляции
- Математическое преобразование : сезонные колебания, которые увеличиваются или уменьшаются с уровнем временного ряда
Выберите и модели поездов
Модели прогнозирования, широко используемые в промышленности Исследования по прогнозированию временных рядов проводятся уже почти столетие. Вы можете себе представить, сколько алгоритмов было разработано и оптимизировано в этой конкретной области. Выбор методов прогнозирования зависит от доступных данных, точности прогнозирования моделей и способа использования модели прогнозирования. В настоящее время лучшими и наиболее широко используемыми моделями прогнозирования в отрасли являются регрессия прогнозирования временных рядов, экспоненциальное сглаживание, ARIMA, динамическая регрессия, а также несколько передовых методов, включая нейронные сети.
Вы можете себе представить, сколько алгоритмов было разработано и оптимизировано в этой конкретной области. Выбор методов прогнозирования зависит от доступных данных, точности прогнозирования моделей и способа использования модели прогнозирования. В настоящее время лучшими и наиболее широко используемыми моделями прогнозирования в отрасли являются регрессия прогнозирования временных рядов, экспоненциальное сглаживание, ARIMA, динамическая регрессия, а также несколько передовых методов, включая нейронные сети.
Оценка
Чтобы выбрать лучшую модель, необходимо измерить и оценить точность прогноза. На практике обычно используются следующие методы оценки:
- Средняя абсолютная ошибка: MAE
- Среднеквадратическая ошибка: RMSE
- Средняя абсолютная ошибка в процентах: MAPE
- Средняя абсолютная масштабированная ошибка: MASE 90 293 Критерий Байеса-Шварца : BIC
- Критерий Акаике: AIC
- Исправленный информационный критерий Акаике: AICc
- Критерий Ханнана-Куинна: HQC
Иногда разные методы оценки могут выбирать разные модели прогнозирования. Рекомендуемый подход состоит в том, чтобы найти модель с наименьшим RMSE , вычисленным с использованием перекрестной проверки временных рядов, или модель с наименьшим значением AICc .
Рекомендуемый подход состоит в том, чтобы найти модель с наименьшим RMSE , вычисленным с использованием перекрестной проверки временных рядов, или модель с наименьшим значением AICc .
Остаток (необязательно)
Остаток можно использовать для проверки того, использует ли метод прогнозирования всю доступную информацию. Остаток хорошей модели прогнозирования должен удовлетворять следующим условиям:
- Среднее значение остатков равно 0; если нет, то прогноз необъективен
- Остатки не коррелированы; если нет, в данных остается другая информация, которую следует использовать при расчете прогнозов
- Остатки имеют постоянную дисперсию (необязательно)
- Остатки имеют нормальное распределение (необязательно)
Любой метод прогнозирования, который не удовлетворяет первому два условия можно улучшить. Настоятельно рекомендуется визуализировать остатки:
- Временной график: показывает, можно ли считать дисперсию постоянной или нет.
- Гистограмма: нормальное распределение или нет
- ACF (автокорреляция): корреляция между значениями ряда; если остатки выглядят как белый шум, это говорит о том, что метод прогнозирования верен.
Объединить прогнозы (необязательно)
Лаплас сказал: «Объединяя результаты этих двух методов, можно получить результат, закон вероятности ошибки которого будет уменьшаться быстрее».
Роберт Клемент написал: «Результаты были практически единодушны: объединение нескольких прогнозов приводит к повышению точности прогнозов. Во многих случаях можно значительно улучшить производительность, просто усредняя прогнозы».
Я бы рекомендовал использовать несколько разных методов, предложенных на предыдущем шаге Выбрать и обучить модели на одном и том же временном ряду и усреднить полученные прогнозы. Объединение прогнозов с использованием простого среднего значения в большинстве случаев трудно превзойти.
Целью написания этой статьи является описание комплексного систематического решения, которое специалисты по данным могут применять непосредственно в своей повседневной работе для решения реальных бизнес-задач.