Степени свободы Стьюдента распределение — Справочник химика 21
В основе статистических оценок нормально распределенных случайных величин по выборочным параметрам лежит распределение Стьюдента, связывающее три важнейших характеристики выборочной совокупности — ширину доверительного интервала, соответствующую ему доверительную вероятность и объем выборки п (или число степеней свободы выборки / = [c.833]
Распределение Стьюдента. Пусть 2 нормально распределенная случайная величина с нулевым математическим ожиданием и единичной дисперсией, а V — независимая от Г случайная величина, которая распределена по закону «хи-квадрат» с К степенями свободы. Тогда величина [c.14]
Таким образом, распределение Стьюдента зависит только от числа степеней свободы /, с которым была определена выборочная дисперсия (рис. 18). На рис. 18 приведены графики плотности t-распределения для /=1, f = 5 и нормальная кривая.
Кривые рас-пре/.еления по своей форме напоминают нормальную кривую, но [c.41]
Распределение величины I по = п—степеням свободы носит название распределения Стьюдента. Сравним его с распределением Лапласа. Если мера отклонения среднего результата измерений от математического ожидания в единицах генерального стандартного отклонения среднего о(л ), то коэффициент Стьюдента — аналогичная мера в единицах выборочного стандартного отклонения среднего результата и- = (Х — ц)/а (Г) = АХ- л/п/а-, 1- = (Х — ц)/5 (X) = АХ- / 3 . [c.833]
Попытка подставить выборочное д в изложенное выше решение задачи приводит к уменьшению по сравнению с истинными доверительных интервалов. Это объясняется тем, что величина (х — МУб распределена уже не нормально, а по распределению Стьюдента с N—1 степенью свободы. Плотность распределения Стьюдента имеет вид [c.175]
Распределением Стьюдента (или распределением) с п степенями свободы называется распределение, которым обладает с. в. [c.292]
Если число измерений мало п 20 для практических целей), то распределение Гаусса дает слишком оптимистичные оценки в этом случае применяют распределение Стьюдента. В этом распределении учитывается число степеней свободы V = га — 1. При V -> оо нормальное распределение и распределение Стьюдента совпадают. Кривая плотности распределения Стьюдента более размазана , чем кривая распределения Гаусса. [c.38]
Можно доказать, что при исходных нормальных совокупностях величина 1-) имеет расиределение Стьюдента с / = /п—2 степенями свободы. При проверке гипотезы нормальности по большому числу малых выборок из каждой выборки случайным образом отбирается по одному значению. Здесь возможно некоторое упрощение — можно отобрать только первые измерения, только вторые и т. д. Такой отбор также можно рассматривать как случайный. Если число элементов в выборках велико, например т>10, то мой- ет быть сделано несколько самостоятельных проверок гипотезы, например, по первым и последним элементам каждой выборки.
Затем, если т==4, для каждого отобранного значения по формуле (П. 131) вычисляется т, если тфА, по формуле (П. 134) т). После перехода к величинам т и т) для проверки гипотезы равномерного распределение т илп распределения Стьюдента т] (и, следовательно, нормальности исходного распределения) может быть применен любой из ра смотренных ранее критериев согласия. [c.68]
Кроме того, необходимо отметить, что при числе степеней свободы V = N — уИнормальной кривой распределения [функция Лапласа Ф(i)], а по распределению Стьюдента [141] в зависимости от V и Р. [c.275]
Здесь /р, I — квантиль распределения Стьюдента ири числе степеней свободы I = п — 1 и двухсторонней доверительной вероятности Р (значения 1р, / см. в табл. 2.3). [c.30]
Чем меньше число степеней свободы, тем менее надежной характеристикой генеральной дисперсии является выборочная дисперсия 5 . При нормальном распределении появление больших погрешностей менее вероятно, чем малых, поэтому при уменьшении числу параллельных проб вероятность появления больших погрешностей уменьшается. Неучет этого приводит к необъективному, заниженному значению погрешности. Эта ненадежность, связанная с числом определений (параллельных проб), учитывается /-распределением Стьюдента, в котором предусматривается большая вероятность появления больших погрешностей, а малых меньше, чем в нормальном распределении. [c.129]
Особенности программы доверительный интервал может быть вычислен как на основе распределения Стьюдента, так и на основе нормального распределения Гаусса. Значение доверительной вероятности не фиксировано и может произвольно изменяться оператором при переходе от обработки одной группы данных к другой. Значение коэффициента Стьюдента доверительной вероятности Р и числа степеней свободы =п— находят из табл. 7.5. Продолжительность автоматических вычислений после ввода всех исходных данных—16с (табл. 21.4).
[c.391]
Пусть теперь —нормально распределенная случайная величина, причем не зависит от . Рассмотрим случайную величину tn = % /n Xn Распределение этой случайной величины называется распределением Стьюдента с п степенями свободы. Его плотность имеет следующий вид [c.82]
Примечание Ре, — вероятность того, что случайная величина Т, распределенная по закону Стьюдента 5 (Т) с г степенями свободы, не превосходит е по абсолютному значению. [c.123]
По таблицам распределения Стьюдента для количества степеней свободы v = r7 — 1 и уровня значимости с/ можно найти такое число что интервал [c.474]
Выводим выборочное распределение этой статистики при условии, что нулевая гипотеза верна В нашем примере это будет /-распределение Стьюдента с у = и—1 степенями свободы [c.132]
Большое практическое значение имеет Ь-распределение Стьюдента. Оно очень полезно при описании малых (п Распределение Стьюдента с V степенями свободы характеризуется следующей функцией плотности вероятности [c. 426]
Можно доказать, что если X иУ — независимые величины, распределенные как ЛГ(0,1) и Хь соответственно, то величина 2 = Х1 у/ь) 1″ имеет распределение Стьюдента с V степенями свободы ( ). Поскольку, как отмечено выше, для любой нормально распределенной величины X
[c.428]
Для случая 4 строгого статистического теста сравнения двух средних до сих пор не разработано (см. Линник Ю. В. Лекции о задачах аналитической статистики. М. Наука, 1994). Приведенная в таблице тестовая статистика подчиняется распределению Стьюдента лишь весьма приближенно. При этом расчет числа степеней свободы для такого распределения по эмпирической формуле [c.443]
Двусторонние и односторонние коэффициенты -распределения Стьюдента для чисел степеней свободы (/) от 1 до 20 [c.692]
Квантили обратного распределения Стьюдента, где d определяет степени свободы (d>OHO
[c.449]
Р е П1 е и и е. Обозначим черм X результат анализа. Среднее значение трех параллельных измерений равно х = 97,8%. Ошибка воспроизводимости (выбороч-пьн 1 стандарт) х равна 0,52. Число степеней свободы ошибки воспроизводимости [ = 2. В качестве нулевой гипотезы рассмотрим гипотезу Яо пг = 99% следовательно, исследуемый реактив доброкачествен. Альтернативная гипотеза Н . гпхф =7 99. Используя распределение Стьюдента, определим вначале критическую область при двустороннем критерии. При р = 0,95 р = 0,05 и квантиль pj2 =4,30 [c.43]
Значения приведены в нриложении 3 распределения Стьюдента в зависимости от значений а и числа степеней свободы / = 1. [c.42]
В общем случае к = ip(Vi, /), где tp(Veff) — квантиль распределения Стьюдента с эффективным числом степеней свободы и доверительной вероятностью (уровнем доверия) Р, [c.262]
Если в случае нормального распределения при большом числе измерений доверительный интервал ц 2а реализовался с 95%-ной доверительной вероятностью, то при малом числе измерений заданная величина дове2ительной вероятности реализуется в доверительном интервале xd=tpjSi, где ip.
-коэффициент Стьюдента, учитывающий разницу в нормальном и /-распределении и при данной Р, зависящей от числа степеней свободы. Индекс Р у t указывает на фиксированную вероятность, f — число степеней свободы. Численные значения коэффициента tp, при различных Р и f приведены в табл. 7.1. Как видно, при Р = 95 % и f = 20 коэффициент ip,f = 2,09, т. е. близок к 2, характерному для нормального распределения. [c.130]
В основе микростатических оценок нормально распределенных случайных величин лежит распределение Стьюдента, которое связывает между собой три основные характеристики выборочной совокупности ширину доверительного интервала, соответствующую ему доверительную вероятность и объем выборки или число степеней свободы выборки = п — . Применение распределения Стьюдента для оценки неизвестного среднего ц нормальной случайной величины х основано на следующем. Пусть х, х , Хп — независимые наблюдения (результаты анализа) нормальной случайной величины X с неизвестными наблюдателю средним р, и дисперсией (т .
Вычислим соответствующие выборочные параметры j и 5 и составим дробь t — х — р,) /5. Эта Дробь имеет рас- пределение Стьюдента с = п—1 числом степеней свободы. Сравним величину I с аргументом функции Лапласа и. Если ыл — мера отклонения среднего результата анализа от математического чэжидания р, в единицах генерального стандартного отклонения [c.92]
Критическое значение критерия Стьюдента находится по таблице распределения Стьюдента. При этом задаются уровнем зна- имости сх , например 0,01 или 0,05 и учитывают величину лггветствующего числа степеней свободы/число параллельных опытов, по результатам которых определялась 6 , [c.22]
Плотность вероятносч и случайной величины Tv называется t-распределением Стьюдента с v степенями свободы и, подобно нормальной плотности, она симметрична относительно начала координат. Влияние замены а в (3 3.11) на S, как это сделано в (3 3 12), выражается в том, что изменчивость случайной величины Т возра-сгает, и, следовательно, -распределение Стьюдента более размыто, чем нормальное распределение Однако, по мере того как v увеличивается, распределение S все более и более концентрируется около а, и поэтому pa пpeдeлeниe стремится к стандартному нормальному распределению (3 2 8), как это вновь следует из центральной предельной теоремы
[c. 108]
Коэффициент распределения Стьюдента для различных уровней значимости (доверительных вероятностей) можно взять из книги В Е Гмурман Руководство к решению задач по теории вероятностей и математической статистике , приложение 6, с. 393 Следует учесть, что число степеней свободы к = I — 2 После ввода программы в ячейку О — число измерений, в ячейку 9 — [c.488]
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новых функциях см. в разделах Функция СТЬЮДЕНТ.ОБР.2Х и Функция СТЬЮДЕНТ.ОБР.
Степени_свободы Обязательный. Число степеней свободы, характеризующее распределение.
Замечания
Если любой из аргументов не является числом, то СТИФРВ возвращает #VALUE! значение ошибки #ЗНАЧ!.
Если вероятность <= 0 или вероятность > 1, то #NUM! значение ошибки #ЗНАЧ!.
Если значение «степени_свободы» не является целым, оно усекается.
Если deg_freedom < 1, то #NUM! значение ошибки #ЗНАЧ!.
Функция СТЬЮДРАСПОБР возвращает значение t, для которого P(|X| > t) = вероятность, где X — случайная величина, соответствующая t-распределению, и P(|X| > t) = P(X < -t или X > t).
Одностороннее t-значение может быть получено при замене аргумента «вероятность» на 2*вероятность. Для вероятности 0,05 и 10 степеней свободы двустороннее значение вычисляется по формуле СТЬЮДРАСПОБР(0,05;10) и равно 2,28139. Одностороннее значение для той же вероятности и числа степеней свободы может быть вычислено по формуле СТЬЮДРАСПОБР(2*0,05;10), возвращающей значение 1,812462.
Примечание: В некоторых таблицах вероятность описана как (1-p).
Если задано значение вероятности, то функция СТЬЮДРАСПОБР ищет значение x, для которого функция СТЬЮДРАСП(x, степени_свободы, 2) = вероятность. Однако точность функции СТЬЮДРАСПОБР зависит от точности СТЬЮДРАСП. В функции СТЬЮДРАСПОБР для поиска применяется метод итераций. Если поиск не закончился после 100 итераций, функция возвращает значение ошибки #Н/Д.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
T-значение t-распределения Стьюдента на основе аргументов в ячейках A2 и A3. {n-k}$$
где $\binom{n}{k} = \frac{n!}{(n-k)!k!}$ – биномиальный коэффициент.
Биномиальное распределение – это распределение числа успехов $k$ в серии из независимых $n$
опытов, при условии, что вероятность успеха в каждом опыте есть $p$.
Математическое ожидание и дисперсия, соответственно, равны
$$\mathrm{E}(X)=np$$
$$\mathrm{V}(X)=np(1−p)$$
При больших $n$ биномиальное распределение хорошо приближается нормальным.
Рис. 2 плотность вероятности и функция распределения биномиального распределения
Для вычисления биномиального распределения в Excel используется стандартная функция BINOMDIST (БИНОМРАСП):
Если cumulative=TRUE, то возвращается кумулятивная функция распределения, а если cumulative=FALSE, то возвращается плотность вероятности.
Рис. 3 Пример вычисления биномиального распределения
Равномерное распределение
Случайная величина $X$
распределена равномерно
на отрезке $[a, b]$, если ее функция распределения $U(x|a,b)$ и, соответственно, плотность
вероятности $u(x|a,b)$ имеют вид
$$U(x|a,b) = \begin{cases} 0, x≤a, \\ \frac{x-a}{b-a}, a < x ≤ b \\ 1, x > b\end{cases}$$
$$u(x|a,b) = \begin{cases} 0, x≤a, \\ \frac{1}{b-a}, a < x ≤ b \\ 0, x > b\end{cases}$$
Математическое ожидание и дисперсия, соответственно, равны
$$\mathrm{E}(X)=0. {–1}(P|N)$.
Рис.9 Функция распределения и квантиль распределения Стьюдента
Для вычисления распределения Стьюдента в Excel используется две стандартные функции: TDIST (СТЬЮДРАСП) и TINV (СТЬЮДРАСПОБР).
TDIST(x, degrees_freedom=N, tails=1|2)
Если tails=1, то функция TDIST возвращает значение $\mathrm{Pr}\{T(N) > x\}$,
а при tails=2 значение $\mathrm{Pr}\{|T(N)| > x\}$. Значения при $x<0$ не возвращаются.
Поэтому, для того, чтобы вычислить в Excel обычную кумулятивную функцию распределения
Стьюдента $T(x|N)$, приходится использовать следующую формулу
IF(x>0, 1-TDIST(x,N,1), -TDIST(-x,N,1))
Функция:
TINV(P, degrees_freedom=N)
возвращает значение $x$, для которого $\mathrm{Pr}\{|T(N)| > x\} = P$.
И в этом случае для вычисления в Excel квантиля распределения Стьюдента $T^{–1}(P|N)$,
нужно использовать следующую формулу
IF(P<0. {–1}(X)$$
имеет функцию распределения $F$.
Таким образом, если получить набор случайных величин, распределенных равномерно,
то эти случайные величины можно превратить в новые, имеющие другое, заданное распределение.
Для генерации случайных чисел в Excel имеется стандартная функция: RAND (СЛЧИС).
RAND()
Возвращает случайное число, равномерно распределенное на отрезке $[0,1]$. Новое случайное
число возвращается при каждом вычислении рабочего листа.
На листе Random рабочей книги Statistics.xls
приведен пример генерации случайных чисел для разных распределений.
Рис.13 Пример генерации случайных чисел
Распределение Стьюдента 1 —¦ 328 — Таблица
Для выборок малых объемов множитель z должен быть заменен множителем t, который находим по таблицам распределения Стьюдента. Таблицы этого распределения приведены, например, в работах [13, 17] и др. Значение t зависит от объема выборки, т. е. от величины N—1. Пользуясь этими таблицами, можно получить, например, что при 7V=20 и надежности 90% коэффициент i=l,73 при том же значении N и надежности 95%, 99%и 99,9% величина t будет соответственно равна 2,09, 2,86 и 3,88.
[c.72]
Распределение Стьюдента 328 — Таблица функции 5 (г) 334
[c.583]
Задавшись гарантией Доверительный интервал находим по формуле (10)
[c.28]
Доверительные интервалы для параметров нормальных распределений приведены в табл. 8.17. Практически для их получения необходимо использовать соответствующую оценку из табл. 8.16 и табличные значения нормированного нормального распределения ([/-распределения), распределения Стьюдента ( -распределения), или F-pa -пределения для выбранной доверительной вероятности р (уровня значимости q), фрагменты которых представлены в табл. 8. 18—8.21. Более подробные таблицы можно найти в [7, 22, 46].
[c.460]
Зная, что и = 10, Ст = 3 по таблице распределения Стьюдента можно определить требуемую вероятность Р= 0,985.
[c.83]
Коэффициент К (л, 1 - (3) называют квантилем распределения Стьюдента для доверительной вероятности (1 — (3) и числа (п — 1) степеней свободы. Этот коэффициент определяют по таблицам [11] с двумя входами пи 1 - (3.
[c.158]
По таблице распределения Стьюдента определяем t по значению /о, которое в нашем случае равно 2,228 (для уровня значимости =0,05).
[c.131]
Д в—коэффициент, соответствующий заданной вероятности Р и определяемый по таблицам распределения Стьюдента
[c.155]
Здесь tv определяется из таблиц распределения Стьюдента для заданной надежности 7 и числа степеней свободы f = N — 1.
[c.133]
Доверительными границами случайных отклонений результатов измерений называю" верхнюю и нижнюю границы интервала значений от А — Ах до X + Дх, накрывающего с заданной вероятностью случайные отклонения результатов измерений. Доверительный интервал выражается через среднее квадратическое отклонение, доверительная вероятность определяется по таблицам интеграла Лапласа (для закона нормального распределения) или, задаваясь доверительной вероятностью, определяют доверительные границы. Так, например, задаваясь 95%-ной вероятностью, считают доверительный интервал равным 4а, где а — среднее квадратическое отклонение результата измерения. При небольшом числе измерений доверительные интервалы и доверительную вероятность определяют, пользуясь распределением Стьюдента.
[c.131]
Выражение (87) показывает, что распределение Стьюдента зависит только от переменной t и числа деталей в выборке N. Поэтому, когда задана вероятность сс, то по таблицам распределения Стьюдента может быть найдено положительное число ta, которое зависит только от а и Л .
[c.113]
Полученное по результатам эксперимента значение -статистики сравнивают с критическим значением, которое при заданном уровне значимости а и числе степеней свободы — N 2 находят по таблицам распределения Стьюдента. Если полученное значение /-статистики больше критического ( > то гипотезах значимости коэффициента fx xJ генеральной совокупности не отвергается.
[c.108]
Рде —коэффициент Стьюдента, определяемый по табл. 2.1, содержащей выдержку из таблиц распределения Стьюдента г[ и
[c.43]
По таблицам t — распределения Стьюдента находят критическое значение /кр для вероятности (1—а/2) и числе степеней сво-
[c.17]
Для применения формулы (65) необходимо определить по таблицам распределения Стьюдента коэффициент к в зависимости от доверительной вероятности.
[c.239]
Таблицы распределения Стьюдента имеются в большинстве руководств по математич. статистике.
[c.351]
Задавая, например, шв = 0,95, по таблицам распределения Стьюдента с девятью степенями свободы можно найти, что / = 2,262, и поэтому в качестве предельной абс. погрешности приближенного равенства х = 18,431 следует принять
[c. 351]
Подробные таблицы функций распределения Стьюдента D (i) и х -распределения 0 ,(х) имеются в большинстве руководств по математич. статистике. Если п 20, то с удовлетворительной для большинства практич. расчетов точностью можно полагать (О = Ф (О и
[c.575]
По таблице критических точек распределения Стьюдента для л = 8 и уровня значимости 0,05 о.о5 8 = 2,31, а >2,31 поэтому размер 276,75 из расчета исключается. В результате исправления дсд и 5д
[c.277]
Таблица 3 . /-распределение Стьюдента
[c.922]
Вычислим доверительные границы е случайной погрешности измерения. Так как распределение подчиняется нормальному закону, доверительные границы вычисляем по формуле 8=ij-ffx, где ts — коэффициент, определяемый по таблице распределения Стьюдента (приложение 3).
[c.169]
Параметр i имеет распределение Стьюдента с (и - 2) степенями свободы. Если вероятность, соответствующая величине I, больше требуемой доверительной вероятности, то корреляция между х и у существует. Таблицы распределения Стьюдента приведены, например, в [2, 4].
[c.534]
Используя таблицы распределения Стьюдента для доверительной вероятности у - 0,99 и степени свободы Г = (п -1) = 4 находим, что т = 3,558.
[c.163]
Все рассмотренные выше выражения справедливы для большого числа однородных измерений, когда имеет место нормальный закон распределения ошибок. Следует заметить, что можно определить с какой-либо вероятностью границы, между которыми будет находиться значение измеряемой величины, но нельзя указать точно это значение. В этом заключается особенность измерения случайных величин. При малом числе измерений для оценки доверительной вероятности и доверительного интервала уже нельзя пользоваться интегралом вероятности. В этом случае следует пользоваться таблицами распределения Стьюдента, в которых устанавливается связь между числом измерений п и коэффициентом t , определяющим ширину доверительного интервала для различных доверительных вероятностей Р (табл. 2.2).
[c.10]
Например, для рассмотренного выше случая измерения давления будем считать, что число измерений равно 5. Определим доверительный интервал для условий, изложенных выше. Определяем 0,95 яля п—Ь по таблице распределения Стьюдента (табл. 2.2).
[c.10]
При доверительной вероятности Рд = 0,95 по таблице для распределения Стьюдента (п — 1 6) находим t 2,45.
[c.153]
При п = оо распределение Стьюдента сходится с нормальным распределением и что и видно в последней строке таблицы. На рис. 4-8 представлено изменение t в зависимости от числа наблюдений при доверительных вероятностях 0,995 и 0,950. Правые концы кривых отвечают п = оо и дают значения, со-впадаюш, ие при таких же вероятностях с z (см. приложение 1).
[c.75]
Вероятности, соответствующие отдельным значениям коэффициентов доверия 1, неодинаковы при различных объемах малой выборки ( ). Значения этих вероятностей при различных и приводятся в специальных таблицах (таблицы вероятностей по распределению Стьюдента). Так, например, вероятность того, что предельная ошибка малой выборки не превзойдет кpaтнyю среднюю ее ошибку равна (табл. 9).
[c.160]
По таблицам t — распределения Стьюдента находят критичес-кое значение /кр при уровне (1—а/2) =0, 75 и числе степеней свободы у = II /кр-= 2,201.
[c.20]
Распределение Стьюдента задается в виде таблиц значений tp, вычисленных по формулам (3.60), (3.68), для различных значений доверительной вероятности Р в пределах 0,1. .. 0,99 при к = = л— 1 = 1, 2,. .., 30. Эти значения впервые были табулированы Р. А. Фишером, который назвал рассматриваемое распределение распределением Стьюдента (псевдоним математика В. С. Госсета, предсказавшего это распределение). Значения приведены в табл. П.З (см. приложение).
[c.60]
Если случайные ошибки наблюдений подчиняются нормальному распределению, то отношения Xj — xji/sj 0 == 1, 2) распределены по закону Стьюдента. В частности, если резуль-паты наблюдений лишены систематич. ошибок, то х, = = О, и, значит, закону Стьюдента должны подчиняться отношения X, /si и iXal/sj. С помощью таблиц распределения Стьюдента с 1 — m = 8 степенями свободы можно убедиться, что если действительно х, = Хг = О, то с вероятностью 0,999 каждое пз этих отношений в отдельности не должно превосходить
[c.352]
Этот метод отбраковки недостоверной информахщи применим при больших выборках. Для малых выборок (потносительного отклонения, в котором вычисленное максимальное относительное отклонение а сравнивается с табличным его значением т, определенным для заданной доверительной вероятности у и степени свободы f. Табличное значение т определяется с использованием таблиц распределения Стьюдента.
[c.161]
На основании полученных значений т и о можно вычислить вероятность попадания случайной погрешности в заданный интервал. Для этого задаем границы интервала и по выражению (2.8) с помощью табл. 2.1 определяем вероятность нахождения случайной погрешности в заданном интервале. Таблица 2.1 предусматривает нормальный закон распредмения и бесконечно большое число измерений. Таблицей 2.1 можно пользоваться, как правило, когда число измерений более 30. При меньшем числе измерений следует пользоваться табл. 2.2, составленной для распределения Стьюдента.
[c.11]
Функция СТЬЮДРАСПОБР (TINV) - Справочник
Функция СТЬЮДРАСПОБР устаревшая с 2010-й версии Excel, оставлена для обратной совместимости с 2007 и более ранними версиями, рекомендуется воспользоваться функциями СТЬЮДЕНТ.ОБР.2Х и СТЬЮДЕНТ.ОБР. Описание функции СТЬЮДРАСПОБР
Обязательный. Число степеней свободы, характеризующее распределение.
Замечания
Если любой из аргументов не является числом, то функция СТЬЮДРАСПОБР возвращает значение ошибки #ЗНАЧ!.
Если «вероятность» 1, функция СТЬЮДРАСПОБР возвращает значение ошибки #ЧИСЛО!.
Если значение «степени_свободы» не является целым, оно усекается.
Если значение «степени_свободы»
Функция СТЬЮДРАСПОБР возвращает значение t, для которого P(|X| > t) = вероятность, где X — случайная величина, соответствующая t-распределению, и P(|X| > t) = P(X t).
Одностороннее t-значение может быть получено при замене аргумента «вероятность» на 2*вероятность. Для вероятности 0,05 и 10 степеней свободы двустороннее значение вычисляется по формуле СТЬЮДРАСПОБР(0,05;10) и равно 2,28139. Одностороннее значение для той же вероятности и числа степеней свободы может быть вычислено по формуле СТЬЮДРАСПОБР(2*0,05;10), возвращающей значение 1,812462.
Если задано значение вероятности, то функция СТЬЮДРАСПОБР ищет значение x, для которого функция СТЬЮДРАСП(x, степени_свободы, 2) = вероятность. Однако точность функции СТЬЮДРАСПОБР зависит от точности СТЬЮДРАСП. В функции СТЬЮДРАСПОБР для поиска применяется метод итераций. Если поиск не закончился после 100 итераций, функция возвращает значение ошибки #Н/Д.
Пример
т Распределение
Распределение т (также известное как t-распределение Стьюдента )
- это распределение вероятностей, которое используется для оценки совокупности
параметры, когда размер выборки невелик и / или когда совокупность
дисперсия неизвестна.
Зачем использовать t-распределение?
Согласно
центральная предельная теорема,
выборочное распределение
статистики (например, выборочного среднего) будет следовать
нормальное распределение,
при условии, что размер выборки достаточно велик.Поэтому, когда мы
знать стандартное отклонение населения, мы можем вычислить
z-счет и используйте нормальное распределение для оценки
вероятности с выборочным средним.
Но размер выборки иногда невелик, и часто мы не знаем
стандартное отклонение населения.
Когда возникает одна из этих проблем, статистики полагаются на
распространение т статистика (также известный как t оценка ), значения которых определяются по формуле:
t = [x - μ]
/ [s / sqrt (n)]
где x - выборочное среднее значение, μ
- среднее значение генеральной совокупности, s - стандартное отклонение выборки, а n -
размер образца.Распределение статистики t называется т раздача или Распределение студентов .
Распределение t позволяет нам проводить статистический анализ определенных данных.
наборы, не подходящие для анализа, с использованием нормального распределения.
Степени свободы
На самом деле существует множество различных t-распределений. Особая форма
распределения t определяется его степеней свободы . Степени свободы относятся
количеству независимых наблюдений в наборе данных.
При оценке среднего балла или доли по одной выборке,
количество независимых наблюдений равно выборке
размер минус один. Следовательно, распределение статистики t из
образцы размера 8 будут описаны t-распределением, имеющим
8 - 1 или 7 степеней свободы. Аналогично, t-распределение, имеющее
15 степеней свободы будет использоваться с образцом размером 16.
Для других приложений степени свободы могут быть вычислены.
по-другому.Мы будем описывать эти вычисления по мере их появления.
Свойства t-распределения
t-распределение имеет следующие свойства:
Дисперсия
всегда больше 1, хотя он близок к 1, когда
есть много степеней свободы. С бесконечными степенями свободы,
распределение t такое же, как и
стандартное нормальное распределение.
Когда использовать t-распределение
t-распределение можно использовать с любой статистикой, имеющей колоколообразную форму.
распространение (т.э., примерно нормально). Выборочное распределение статистики
должен иметь форму колокола, если любое из следующих
применяются условия.
Размер выборки больше 40, без выбросов.
Распределение t следует использовать , а не с небольшими выборками из
популяции, которые не являются приблизительно нормальными.
Вероятность и t-распределение Стьюдента
Когда выборка размером n отбирается из совокупности, имеющей
нормальное (или почти нормальное) распределение, выборочное среднее может быть
преобразованы в статистику t с помощью уравнения, представленного на
начало этого урока.Мы повторяем это уравнение ниже:
t = [x - μ]
/ [s / sqrt (n)]
где x - выборочное среднее значение, μ
- среднее значение генеральной совокупности, s - стандартное отклонение выборки, n -
размер выборки и степени свободы равны n - 1.
Статистика t, полученная с помощью этого преобразования, может быть связана с
уникальный
совокупная вероятность.
Эта кумулятивная вероятность представляет собой вероятность обнаружения
выборочное среднее значение меньше или равно x,
учитывая случайную выборку размером n .
Самый простой способ найти вероятность, связанную с конкретным
t статистика заключается в использовании
Калькулятор распределения T,
бесплатный инструмент, предоставляемый Stat Trek.
Калькулятор распределения T
Калькулятор распределения T решает общие статистические задачи на основе t
распределение. Калькулятор вычисляет кумулятивные вероятности на основе простых
входы. Четкие инструкции помогут вам найти точное решение, быстро и
без труда. Если что-то неясно, часто задаваемые вопросы и примеры проблем
дайте простые объяснения.В
калькулятор бесплатный. Его можно найти в Stat Trek.
главное меню на вкладке Stat Tools. Или вы можете нажать кнопку ниже.
Калькулятор распределения T
Обозначения и t Статистика
Статистики используют t α для
представляют статистику t, которая имеет
совокупная вероятность
из (1 - α).
Например, предположим, что нас интересует статистика t, имеющая
совокупная вероятность
0,95. В этом примере α будет равно (1 - 0,95)
или 0,05. Мы бы назвали t-статистику t 0.05
Конечно, значение t 0,05 зависит от количества
степеней свободы. Например,
при 2 степенях свободы t 0,05 равно 2,92;
но при 20 степенях свободы t 0,05 равно
до 1,725.
Примечание: Поскольку t-распределение симметрично относительно среднего нуля,
верно следующее.
т α = - т 1 - альфа А также t 1 - альфа = - t α
Таким образом, если t 0.05 = 2,92, тогда t 0,95 = -2,92.
Проверьте свое понимание
Проблема 1
Корпорация Acme производит лампочки. Генеральный директор утверждает, что средний Acme
лампочка длится 300 дней. Исследователь случайным образом выбирает 15 лампочек для тестирования.
Отобранные луковицы служат в среднем 290 дней со стандартным отклонением 50 дней. Если
заявление генерального директора было правдой, какова вероятность того, что 15 случайно выбранных
луковицы будут иметь средний срок службы не более 290 дней?
Примечание: Есть два способа решить эту проблему, используя T-распределение. Калькулятор.Оба подхода представлены ниже. Решение А - традиционное
подход. Это требует, чтобы вы вычислили статистику t на основе данных, представленных в
описание проблемы. Затем вы используете Калькулятор Т-распределения, чтобы найти
вероятность. Решение B проще. Вы просто вводите данные о проблеме в
Калькулятор Т-распределения. Калькулятор вычисляет t-статистику "за
сцены "и отображает вероятность. Оба подхода дают точную
тот же ответ.
Решение A
Первое, что нам нужно сделать, это вычислить статистику t на основе
по следующему уравнению:
t = [x - μ]
/ [s / sqrt (n)] t = (290–300) / [50 / sqrt (15)] t = -10 / 12.
5 = - 0,7745966
где x - выборочное среднее значение, μ
- среднее значение генеральной совокупности, s - стандартное отклонение выборки, а n -
размер образца.
Теперь мы готовы использовать Калькулятор Т-распределения.
Так как мы знаем статистику t, мы выбираем «T score» из случайной переменной.
выпадающий список. Затем вводим следующие данные:
Статистика t равна - 0,7745966.
Калькулятор отображает кумулятивную вероятность: 0,226. Следовательно, если истинное
срок службы лампы был 300 дней, есть
22.Вероятность 6%, что средний срок службы 15 случайно выбранных лампочек уменьшится.
быть меньше или равно 290 дням.
Решение B:
На этот раз мы будем работать напрямую с необработанными данными из
проблема. Мы не будем вычислять статистику t; Т
Калькулятор распределения сделает эту работу за нас. Поскольку мы будем работать
с необработанными данными мы выбираем "Среднее значение выборки" в раскрывающемся списке "Случайная переменная".
коробка. Затем мы вводим следующие данные:
Стандартное отклонение выборки составляет 50.
Калькулятор отображает кумулятивную вероятность: 0,226. Следовательно, существует
Вероятность 22,6%, что лампочка, отобранная в среднем, перегорит в течение 290 дней.
Задача 2
Предположим, что результаты теста IQ имеют нормальное распределение со средним значением 100. Предположим, случайным образом выбраны и протестированы 20 человек. Стандартное отклонение в
группа выборки - 15. Какова вероятность того, что средний результат теста в
группа выборки будет максимум 110?
Решение:
Чтобы решить эту проблему, мы будем работать напрямую с необработанными данными
от проблемы.Мы не будем вычислять статистику t; Т
Калькулятор распределения сделает эту работу за нас. Поскольку мы будем работать
с необработанными данными мы выбираем "Среднее значение выборки" в раскрывающемся списке "Случайная переменная".
коробка. Затем мы вводим следующие данные:
Стандартное отклонение выборки составляет 15.
Мы вводим эти значения в Калькулятор Т-распределения.
Калькулятор отображает кумулятивную вероятность: 0,996. Следовательно, существует
Вероятность 99,6%, что среднее значение выборки не будет больше 110.
Т-Распределение | Введение в статистику
Что такое распределение
t ?
Распределение t- описывает стандартизованные расстояния между средними значениями выборки и средними значениями генеральной совокупности, когда стандартное отклонение генеральной совокупности неизвестно, а наблюдения происходят из нормально распределенной совокупности.
Совпадает ли распределение
t- с распределением Стьюдента t ?
Да.
В чем ключевое различие между
t- и z-распределениями?
Стандартное нормальное распределение или z-распределение предполагает, что вам известно стандартное отклонение генеральной совокупности.Распределение t- основано на стандартном отклонении выборки.
т -Распределение по сравнению с нормальным распределением
Распределение t аналогично нормальному распределению. У него есть точное математическое определение. Вместо того, чтобы углубляться в сложную математику, давайте посмотрим на полезные свойства распределения t- и на то, почему оно важно для анализа.
Как и нормальное распределение, распределение t- имеет плавную форму.
Как и нормальное распределение, распределение t- является симметричным. Если вы в среднем подумаете о том, чтобы сложить его пополам, каждая сторона будет одинаковой.
Подобно стандартному нормальному распределению (или z-распределению), распределение t- имеет нулевое среднее значение.
Нормальное распределение предполагает, что стандартное отклонение генеральной совокупности известно. Распределение t- не делает этого предположения.
Распределение t- определяется степенями свободы .Это связано с размером выборки.
Распределение t- наиболее полезно для небольших размеров выборки, когда стандартное отклонение генеральной совокупности неизвестно, или для того и другого одновременно.
По мере увеличения размера выборки распределение t- становится более похожим на нормальное распределение.
Рассмотрим следующий график, сравнивающий три распределения t- со стандартным нормальным распределением:
Все распределения имеют плавную форму.Все симметричны. Все имеют нулевое среднее значение.
Форма распределения t- зависит от степеней свободы. Кривые с большим количеством степеней свободы выше и имеют более тонкие хвосты. Все три дистрибутива t- имеют «более тяжелые хвосты», чем z-распределение.
Вы можете видеть, что кривые с большим количеством степеней свободы больше похожи на z-распределение. Сравните розовую кривую с одной степенью свободы с зеленой кривой для z-распределения. Распределение t- с одной степенью свободы короче и имеет более толстые хвосты, чем z-распределение.Затем сравните синюю кривую с 10 степенями свободы с зеленой кривой для z-распределения. Эти два распределения очень похожи.
Общее практическое правило состоит в том, что для размера выборки не менее 30 можно использовать z-распределение вместо распределения t- . На рисунке 2 ниже показано распределение t- с 30 степенями свободы и z-распределением. На рисунке для z используется пунктирная зеленая кривая, так что вы можете видеть обе кривые. Это сходство является одной из причин, почему z-распределение используется в статистических методах вместо распределения t , когда размеры выборки достаточно велики.
Хвосты для проверки гипотез и
t -распределение
Когда вы выполняете тест t , вы проверяете, является ли ваша статистика теста более экстремальным значением, чем ожидалось из распределения t-.
Для двустороннего теста вы смотрите на оба хвоста распределения. На рисунке 3 ниже показан процесс принятия решения для двустороннего теста. Кривая представляет собой распределение t- с 21 степенью свободы. Значение из распределения t- с α = 0.05/2 = 0,025 равно 2,080. Для двустороннего теста вы отклоняете нулевую гипотезу, если статистика теста превышает абсолютное значение опорного значения. Если значение тестовой статистики находится либо в нижнем, либо в верхнем хвосте, вы отклоняете нулевую гипотезу. Если статистика теста находится в пределах двух контрольных линий, значит, вы не можете отклонить нулевую гипотезу.
Для одностороннего теста вы смотрите только на один хвост распределения. Например, на рисунке 4 ниже показан процесс принятия решения для одностороннего теста. Кривая снова представляет собой распределение t- с 21 степенью свободы. Для одностороннего теста значение из распределения t- с α = 0,05 составляет 1,721. Вы отклоняете нулевую гипотезу, если тестовая статистика превышает контрольное значение. Если статистика теста ниже контрольной линии, значит, вы не можете отклонить нулевую гипотезу.
Как использовать стол
t-
Большинство людей используют программное обеспечение для выполнения расчетов, необходимых для испытаний t .Но многие статистические книги по-прежнему содержат таблицы t-, поэтому понимание того, как пользоваться таблицами, может оказаться полезным. Следующие шаги описывают, как использовать типовой стол t-.
Определите, предназначена ли таблица для двусторонних или односторонних тестов. Затем решите, какой у вас тест: односторонний или двусторонний. Столбцы таблицы t- определяют разные альфа-уровни. Если у вас есть таблица для одностороннего теста, вы все равно можете использовать ее для двустороннего теста. Если вы установите α = 0.05 для двустороннего теста и иметь только одностороннюю таблицу, затем используйте столбец для α = 0,025.
Определите степени свободы ваших данных. Строки таблицы t- соответствуют разным степеням свободы. Большинство столов поднимаются до 30 степеней свободы, а затем останавливаются. Таблицы предполагают, что люди будут использовать z-распределение для больших размеров выборки.
Найдите ячейку в таблице на пересечении вашего уровня α и степеней свободы. Это значение распределения t- .Сравните свою статистику со значением распределения t- и сделайте соответствующий вывод.
Степени свободы: что это такое?
степени свободы используются при проверке гипотез.
Содержание (щелкните, чтобы перейти к этому разделу):
Что такое степени свободы?
DF: два образца
степеней свободы в ANOVA
Почему критические значения снижаются при увеличении DF?
Посмотрите видео, чтобы узнать о степенях свободы и о том, почему мы вычитаем 1: youtube.com/embed/gvOwM3Yu05A" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen=""/>
Не можете посмотреть видео? Кликните сюда.
Степени свободы в левом столбце таблицы t-распределения.
Степени свободы оценки - это количество независимых единиц информации, использованных при вычислении оценки . Это не совсем то же самое, что количество элементов в выборке. Чтобы получить df для оценки, вы должны вычесть 1 из количества элементов. Допустим, вы нашли среднюю потерю веса для низкоуглеводной диеты. Вы можете использовать 4 человека, что дает 3 степени свободы (4 - 1 = 3), или вы можете использовать сто человек с df = 99.
В математическом выражении (где «n» - количество элементов в вашем наборе):
степени свободы = n - 1
Почему мы вычитаем 1 из количества элементов?
Другой способ взглянуть на степени свободы состоит в том, что они равны - количеству значений, которые могут изменяться в наборе данных. Что означает «свободно варьироваться»? Вот пример с использованием среднего (среднего): Q . Выберите набор чисел со средним (средним) значением 10. А . Некоторые наборы чисел, которые вы можете выбрать: 9, 10, 11 или 8, 10, 12 или 5, 10, 15. После того, как вы выбрали первые два числа в наборе, третье фиксируется. Другими словами, нельзя выбрать третий элемент в наборе . Единственные числа, которые могут изменяться, - это первые два. Вы можете выбрать 9 + 10 или 5 + 15, но как только вы примете это решение, вы должны выбрать конкретное число, которое даст вам значение, которое вы ищете. Итак, степень свободы для набора из трех чисел равна ДВА.
Например: если вы хотите найти доверительный интервал для выборки, степени свободы равны n - 1. «N» также может быть количеством классов или категорий. См .: Пример критического значения хи-квадрат. В начало
Если у вас есть две выборки и вы хотите найти параметр, например среднее значение, у вас есть два «n», которые следует учитывать (выборка 1 и выборка 2). Степеней свободы в этом случае:
степени свободы (два образца): (N 1 + N 2 ) - 2.
В начало
Степени свободы становится немного сложнее в тестах ANOVA. Вместо простого параметра (например, нахождения среднего) тесты ANOVA включают сравнение известных средних в наборах данных. Например, в одностороннем дисперсионном анализе вы сравниваете два средних значения в двух ячейках. Общее среднее (среднее из средних) будет: Среднее 1 + среднее 2 = большое среднее. Что, если бы вы выбрали среднее значение 1 и знали большое среднее значение? У вас не было бы выбора относительно Среднее 2 , поэтому ваша степень свободы для двухгруппового дисперсионного анализа равна 1.
Двухгрупповой дисперсионный анализ df1 = n - 1
Для трехгруппового дисперсионного анализа вы можете варьировать два средних значения, так что степень свободы равна 2.
На самом деле немного сложнее, потому что в ANOVA есть , две степени свободы: df1 и df2. Приведенное выше объяснение относится к df1. Df2 в ANOVA - это общее количество наблюдений во всех ячейках - степени свободы, потерянные из-за того, что установлены средние значения ячеек.
Двухгрупповой дисперсионный анализ df2 = n - k
Буква «k» в этой формуле - это количество средних значений ячеек или групп / условий. Например, предположим, что у вас есть 200 наблюдений и четыре средних значения ячейки. Степени свободы в этом случае будут: Df2 = 200 - 4 = 196. Вернуться к началу
Спасибо Мохаммеду Гезму за этот вопрос.
Давайте посмотрим на формулу t-показателя при проверке гипотез:
Когда n увеличивается, t-показатель увеличивается. Это из-за квадратного корня в знаменателе: по мере увеличения дробь s / √n становится меньше, а t-оценка (результат другой дроби) увеличивается. Поскольку степени свободы определены выше как n-1, вы могли бы подумать, что критическое значение t тоже должно увеличиться, но это не так: они становятся меньше . Это кажется нелогичным.
Однако подумайте о том, что на самом деле представляет собой t-тест для . Вы используете t-тест, потому что вам неизвестно стандартное отклонение вашей совокупности и, следовательно, вы не знаете форму своего графика. У него могли быть короткие толстые хвосты. У него могли быть длинные тонкие хвосты. Вы просто не представляете.Степени свободы влияют на форму графика в t-распределении; по мере увеличения df площадь в хвостах распределения уменьшается. Когда df приближается к бесконечности, t-распределение будет выглядеть как нормальное распределение. Когда это происходит, вы можете быть уверены в своем стандартном отклонении (которое равно 1 при нормальном распределении).
Допустим, вы взяли повторную выборку веса у четырех человек, взятых из популяции с неизвестным стандартным отклонением. Вы измеряете их вес, вычисляете среднюю разницу между парами образцов и повторяете этот процесс снова и снова.Крошечный размер выборки 4 приведет к t-распределению с жирными хвостами. Жирные хвосты говорят о том, что в вашей выборке вероятнее всего будут экстремальные значения. Вы проверяете свою гипотезу на уровне альфа 5%, который отсекает последние 5% вашего распределения . На графике ниже показано t-распределение с отсечкой 5%. Это дает критическое значение 2,6. ( Примечание : я использую здесь гипотетическое t-распределение в качестве примера - CV не является точным).
Теперь посмотрим на нормальное распределение.У нас меньше шансов получить экстремальные значения при нормальном распределении. Наш альфа-уровень 5% отсекается при CV 2.
.
Вернуться к исходному вопросу «Почему критические значения снижаются, а DF увеличивается?» Вот краткий ответ:
Степени свободы связаны с размером выборки (n-1). Если df увеличивается, это также означает, что размер выборки увеличивается; график t-распределения будет иметь более узкие хвосты, что приведет к приближению критического значения к среднему.
В начало
Ссылка : Джерард Даллал.Маленький справочник по статистической практике. Получено 26 декабря 2015 г. отсюда. Алистер В. Керр, Ховард К. Холл, Стивен А. Козуб. (2002). Выполнение статистики с помощью SPSS. Публикации Sage. стр.68. Доступна здесь. Левин Д. (2014). Даже вы можете изучить статистику и аналитику: простое для понимания руководство по статистике и аналитике, 3-е издание. Пресс Pearson FT
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
6.
3: Доверительный интервал для совокупности Стандартное отклонение неизвестно, случай малой выборки
На практике мы редко знаем совокупность стандартное отклонение . В прошлом, когда размер выборки был большим, это не представляло проблемы для статистиков. Они использовали стандартное отклонение выборки s в качестве оценки для \ (\ sigma \) и, как и прежде, рассчитали доверительный интервал с достаточно близкими результатами.Это то, что мы сделали в примере 6.4 выше. Точечная оценка стандартного отклонения \ (s \) была заменена в формуле доверительного интервала для стандартного отклонения генеральной совокупности. В этом случае имеется 80 наблюдений, значительно превышающих предлагаемые 30 наблюдений, чтобы исключить любую систематическую ошибку в небольшой выборке. Однако при небольшом размере выборки статистики столкнулись с проблемами. Небольшой размер выборки вызвал неточности в доверительном интервале.
Уильям С. Госет (1876–1937) из пивоварни Guinness в Дублине, Ирландия, столкнулся с этой проблемой.Его эксперименты с хмелем и ячменем дали очень мало образцов. Простая замена \ sigma на s не дала точных результатов, когда он попытался вычислить доверительный интервал. Он понял, что не может использовать нормальное распределение для расчета; он обнаружил, что фактическое распределение зависит от размера выборки. Эта проблема привела его к тому, что он «открыл» то, что называется t-распределением Стьюдента . Название происходит от того, что Госсет писал под псевдонимом «Студент»."
Вплоть до середины 1970-х годов некоторые статистики использовали приближение нормального распределения для больших размеров выборки и использовали t-распределение Стьюдента только для размеров выборки, состоящей не более чем из 30 наблюдений.
Если вы построите простую случайную выборку из размер \ (n \) из совокупности со средним значением \ (\ mu \) и неизвестным стандартным отклонением совокупности \ (\ sigma \) и вычислить t-оценку \ (t = \ frac {\ overline {x} - \ mu} {\ left (\ frac {s} {\ sqrt {n}} \ right)} \), тогда t-баллы соответствуют t-распределению Стьюдента с \ (\ bf {n - 1} \) градусами свободы .T-оценка имеет ту же интерпретацию, что и z-оценка. Он измеряет, насколько далеко в единицах стандартного отклонения \ (\ overline x \) от среднего значения \ mu. Для каждого размера выборки \ (n \) существует различное t-распределение Стьюдента.
степеней свободы , \ (\ bf {n - 1} \), получены из расчета стандартного отклонения выборки \ (\ bf {s} \). Помните, когда мы впервые рассчитали стандартное отклонение выборки, мы разделили сумму квадратов отклонений на \ (n - 1 \), но мы использовали \ (n \) отклонения (значения \ (\ overline x \)) (\ (\ overline x \) values) для вычисления \ (\ bf {s} \).Поскольку сумма отклонений равна нулю, мы можем найти последнее отклонение, если узнаем другие \ (\ bf {n - 1} \) отклонения. Остальные \ (\ bf {n - 1} \) отклонения могут изменяться или изменяться свободно. Мы называем число \ (\ bf {n - 1} \) степенями свободы (df) в знак признания того, что одна потеряна в вычислениях. Эффект потери степени свободы состоит в том, что значение t увеличивается, а доверительный интервал увеличивается в ширину.
Свойства t-распределения Стьюдента
График t-распределения Стьюдента похож на стандартную нормальную кривую, а при бесконечных степенях свободы это нормальное распределение.Вы можете подтвердить это, прочитав нижнюю строку с бесконечными степенями свободы для знакомого уровня уверенности, например в столбце 0,05, уровень достоверности 95%, мы находим значение t 1,96 при бесконечных степенях свободы.
Среднее значение t-распределения Стьюдента равно нулю, и распределение симметрично относительно нуля, опять же, как стандартное нормальное распределение.
У t-распределения Стьюдента больше вероятность в своих хвостах, чем у стандартного нормального распределения, потому что разброс t-распределения больше, чем разброс стандартного нормального.Таким образом, график t-распределения Стьюдента будет толще в хвостах и короче в центре, чем график стандартного нормального распределения.
Точная форма t-распределения Стьюдента зависит от степеней свободы. По мере увеличения степеней свободы график t-распределения Стьюдента становится больше похожим на график стандартного нормального распределения.
Предполагается, что основная совокупность индивидуальных наблюдений имеет нормальное распределение с неизвестным средним значением для совокупности \ mu и неизвестным стандартным отклонением совокупности \ sigma .Это предположение исходит из центральной предельной теоремы, потому что отдельные наблюдения в этом случае являются \ (\ overline x \) s выборочного распределения. Размер основной популяции обычно не имеет значения, если только он не очень мал. Если это нормально, то предположение выполнено и не требует обсуждения.
Таблица вероятностей для t-распределения Стьюдента используется для вычисления t-значений при различных обычно используемых уровнях достоверности. В таблице приведены t-баллы, соответствующие уровню достоверности (столбец) и степеням свободы (строка).При использовании t-таблицы обратите внимание, что некоторые таблицы отформатированы для отображения уровня достоверности в заголовках столбцов, в то время как заголовки столбцов в некоторых таблицах могут отображать только соответствующую область в одном или обоих хвостах. Обратите внимание, что внизу таблицы будет показано значение t для бесконечных степеней свободы. Математически, когда степени свободы увеличиваются, распределение \ (t \) приближается к стандартному нормальному распределению. Вы можете найти знакомые Z-значения, посмотрев в соответствующий столбец альфа и прочитав значение в последней строке.
Таблица Стьюдента (см. Приложение A) дает t-баллы с учетом степеней свободы и правосторонней вероятности.
Распределение Стьюдента обладает одним из наиболее желательных свойств нормали: оно симметрично. Распределение Стьюдента растягивает горизонтальную ось, поэтому требуется большее количество стандартных отклонений, чтобы уловить такую же вероятность. На самом деле существует бесконечное количество t-распределений Стьюдента, по одному для каждой корректировки размера выборки.По мере увеличения размера выборки t-распределение Стьюдента становится все более и более похожим на нормальное распределение. Когда размер выборки достигает 30, обычно вместо t Стьюдента заменяется нормальное распределение, потому что они очень похожи. Эта связь между распределением Стьюдента и нормальным распределением показана на рисунке 6.8.
Рисунок 6.8
Это еще один пример одного распределения, ограничивающего другое, в этом случае нормальное распределение является предельным распределением t Стьюдента, когда степени свободы t Стьюдента стремятся к бесконечности.Этот вывод следует непосредственно из вывода г-на Госсета t-распределения Стьюдента. Он осознал, что проблема заключается в небольшом количестве наблюдений и отсутствии оценки стандартного отклонения населения. Он заменял стандартное отклонение выборки и получал нестабильные результаты. Поэтому он создал t-распределение Стьюдента как отношение нормального распределения и распределения хи-квадрат. Распределение хи-квадрат само по себе является отношением двух дисперсий, в данном случае дисперсии выборки и неизвестной дисперсии генеральной совокупности.{2}} {(n-1)}}}} \)
заменой, и, таким образом, t Стьюдента с \ (v = n - 1 \) степенями свободы составляет:
Переформулируем формулу доверительного интервала для среднего значения для случаев, когда размер выборки меньше 30 и мы не знаем стандартное отклонение генеральной совокупности, \ (\ sigma \):
Здесь точечная оценка стандартного отклонения совокупности \ (s \) заменена на стандартное отклонение совокупности, \ (\ sigma \) и \ (t _ {\ nu} \), \ (\ alpha \) имеет был заменен на \ (Z _ {\ alpha} \).Греческая буква \ (\ nu \) (произносится как ню) помещена в общую формулу в знак признания того, что существует множество распределений Стьюдента \ (t _ {\ nu} \), по одному для каждого размера выборки. \ (\ nu \) - это символ степеней свободы распределения, который зависит от размера выборки. Часто df используется для сокращения степеней свободы. Для задач этого типа степень свободы равна \ (\ nu = n-1 \), где \ (n \) - размер выборки. Чтобы найти вероятность в таблице Стьюдента, мы должны знать степени свободы в задаче.
Пример 6.5
Средняя прибыль на акцию (EPS) для 10 промышленных акций, случайно выбранных из тех, которые перечислены в промышленном индексе Доу-Джонса, оказалась равной \ (\ overline X = 1,85 \) со стандартным отклонением \ (s = 0,395 \). . Рассчитайте 99% доверительный интервал для средней прибыли на акцию всех промышленных предприятий, перечисленных в \ (DJIA \).
\ [\ overline {x} -t_ {v, \ alpha} \ left (\ frac {s} {\ sqrt {n}} \ right) \ leq \ mu \ leq \ overline {x} + t _ {\ nu , \ alpha} \ left (\ frac {s} {\ sqrt {n}} \ right) \ nonumber \]
Ответ
Чтобы визуализировать процесс вычисления доверительного интервала, мы рисуем соответствующее распределение для задачи.В данном случае это t Стьюдента, потому что мы не знаем стандартного отклонения генеральной совокупности, а выборка мала, менее 30.
Рисунок 6.9
Чтобы найти подходящее значение t, требуются две части информации: требуемый уровень достоверности и степени свободы. Вопрос задан для уровня достоверности 99%. На графике это показано, где (\ (1- \ alpha \)), уровень достоверности, находится в незатененной области. Таким образом, каждый хвост имеет вероятность 0,005, \ (\ alpha / 2 \).Степень свободы для этого типа задач равна \ (n-1 = 9 \). В таблице Стьюдента в строке с меткой 9 и столбце с меткой 0,005 указано число стандартных отклонений для определения 99% вероятности, 3,2498. Затем они помещаются на график, помня, что \ (t \) Стьюдента симметричны, и поэтому значение t равно плюс или минус с каждой стороны от среднего.
Вставка этих значений в формулу дает результат. Эти значения можно поместить на график, чтобы увидеть взаимосвязь между распределением выборочных средних \ (\ overline X \) и распределением Стьюдента.
При уровне достоверности 99% средний показатель \ (EPS \) для всех отраслей, перечисленных в \ (DJIA \), составляет от 1,44 до 2,26 доллара.
Упражнение 6.5
Вы изучаете гипнотерапию, чтобы определить, насколько она эффективна в увеличении количества часов сна, которые пациенты получают каждую ночь.Вы измерили часы сна у 12 субъектов и получили следующие результаты. Постройте 95% доверительный интервал для среднего количества часов сна для населения (предполагаемого нормальным), из которого вы взяли данные.
Распределение T, также известное как t-распределение Стьюдента, представляет собой тип распределения вероятностей, который похож на нормальное распределение с его формой колокола, но имеет более тяжелые хвосты.Распределения T имеют больше шансов получить экстремальные значения, чем нормальные распределения, следовательно, более толстые хвосты.
Ключевые выводы
T-распределение представляет собой непрерывное распределение вероятностей z-показателя, когда в знаменателе используется оценочное стандартное отклонение, а не истинное стандартное отклонение.
Распределение T, как и нормальное распределение, имеет форму колокола и симметрично, но имеет более тяжелые хвосты, что означает, что оно имеет тенденцию давать значения, которые сильно отличаются от среднего.
T-тесты используются в статистике для оценки значимости.
Что вам сообщает T-распределение?
Тяжесть хвоста определяется параметром распределения T, называемым степенями свободы, при этом меньшие значения дают более тяжелые хвосты, а более высокие значения делают распределение T похожим на стандартное нормальное распределение со средним значением 0 и стандартным отклонением 1.. Т-распределение также известно как «Т-распределение Стьюдента».
Когда выборка из n наблюдений берется из нормально распределенной совокупности, имеющей среднее значение M и стандартное отклонение D, среднее значение выборки m и стандартное отклонение выборки d будут отличаться от M и D из-за случайности выборки.
Z-показатель может быть рассчитан с использованием стандартного отклонения совокупности как Z = (x - M) / D, и это значение имеет нормальное распределение со средним 0 и стандартным отклонением 1. Но при использовании оцененного стандартного отклонения t-показатель вычисляется как T = (m - M) / {d / sqrt (n)}, разница между d и D делает распределение T-распределением с (n - 1) степенями свободы, а не нормальным распределением со средним 0 и стандартное отклонение 1.
Пример использования T-распределения
Возьмем следующий пример того, как t-распределения используются в статистическом анализе.Во-первых, помните, что доверительный интервал для среднего - это диапазон значений, рассчитанный на основе данных, предназначенный для захвата среднего «генерального». Этот интервал равен m + - t * d / sqrt (n), где t - критическое значение из распределения T.
Например, 95% доверительный интервал для средней доходности промышленного индекса Доу-Джонса за 27 торговых дней до 11.09.2001 составляет -0,33%, (+/- 2,055) * 1,07 / sqrt (27), давая (постоянную) среднюю доходность в виде некоторого числа от -0,75% до + 0,09%.Число 2,055, количество стандартных ошибок для корректировки, находится из распределения T.
Поскольку T-распределение имеет более толстые хвосты, чем нормальное распределение, его можно использовать в качестве модели для финансовой отдачи, которая демонстрирует избыточный эксцесс, что позволит более реалистично рассчитать стоимость под риском (VaR) в таких случаях.
Разница между Т-распределением и нормальным распределением
Нормальные распределения используются, когда предполагается, что распределение населения является нормальным.Распределение T похоже на нормальное распределение, только с более толстыми хвостами. Оба предполагают нормально распределенную популяцию. Т-распределения имеют более высокий эксцесс, чем нормальные распределения. Вероятность получения значений, очень далеких от среднего, больше при Т-распределении, чем при нормальном распределении.
Ограничения использования T-распределения
Т-распределение может искажать точность по сравнению с нормальным распределением. Его недостаток возникает только тогда, когда есть потребность в идеальной нормальности.Однако разница между использованием нормального распределения и Т-распределения относительно невелика.
Распределение T Стьюдента - обзор
4.4.4 Методы начальной загрузки при использовании усеченного среднего
Как указывалось ранее, усеченное 20% среднее может обеспечить лучший контроль над вероятностью ошибки типа I и более точное покрытие вероятностей , по сравнению со средним значением в различных ситуациях. Однако в некоторых случаях может потребоваться даже лучший охват вероятностей и контроль вероятностей ошибок типа I, особенно при небольшом размере выборки.Некоторый тип метода начальной загрузки может иметь существенное значение, при этом выбор метода зависит от того, сколько выполняется обрезка.
Прежде всего следует отметить, что методы начальной загрузки из разделов 4.4.1 и 4.4.2 легко применяются при использовании усеченного среднего. При использовании перцентильного метода начальной загрузки сгенерируйте выборку начальной загрузки и вычислите усеченное среднее значение выборки, дающее X¯t1⁎. Повторите этот процесс B раз, получив X¯t1⁎,…, X¯tB⁎. Тогда приблизительный доверительный интервал 1 − α для μt равен
(X¯t (ℓ + 1) ⁎, X¯t (u) ⁎),
, где снова ℓ - αB / 2, округленное до ближайшего целое число, u = B − ℓ и X¯t (1) ⁎≤ ⋯ ≤X¯t (B) ⁎ - усеченные средства начальной загрузки B , записанные в порядке возрастания.
bootstrap-t также напрямую распространяется на усеченные средства, и, чтобы быть уверенным, что детали ясны, они сведены в Таблицу 4.4. В контексте тестирования H0: μt = μ0 по сравнению с h2: μt ≠ μ0, отклонить, если Tt Tt (u) ⁎, где
Таблица 4.4. Краткое изложение метода Bootstrap-t для усеченного среднего.
Чтобы применить метод bootstrap-t (или процентиль-t) при работе с усеченным средним, действуйте следующим образом:
1.Вычислите усеченное по выборке среднее значение X¯t.
2. Сгенерируйте загрузочную выборку путем случайной выборки с заменой n наблюдений из X 1 ,…, X n , что даст X1⁎,…, Xn⁎.
3. При вычислении доверительного интервала с равными хвостами используйте выборку начальной загрузки для вычисления Tt⁎, заданного уравнением. (4.7). При вычислении симметричного доверительного интервала вычислите Tt⁎, используя уравнение. (4.8) вместо этого.
4.Повторите шаги 2 и 3, получив Tt1⁎,…, TtB⁎. B = 599, по-видимому, достаточно в большинстве ситуаций, когда n ≥ 12.
5. Поместите значения Tt1 T,…, TtB⁎ в порядке возрастания, получив Tt (1) ⁎,…, Tt (B) ⁎.
6. Установите ℓ = αB /2, c = (1 - α ) B , округлите ℓ и c до ближайшего целого числа, и пусть u = B - ℓ .
Доверительный интервал 1 - α для μ t составляет
(4.10) (X¯t − Tt (u) ⁎swn, X¯t − Tt (ℓ) ⁎swn),
, а симметричный доверительный интервал задается формулой. (4.9).
(4,7) Tt⁎ = (1−2γ) n (X¯t⁎ − X¯t) sw⁎.
Что касается симметричного двустороннего доверительного интервала, теперь используйте
(4.8) Tt⁎ = (1−2γ) n | X¯t⁎ − X¯t | sw⁎,
, и в этом случае двузначный двусторонний доверительный интервал для μt равен
(4.9) X¯t ± Tt (c) ⁎sw (1−2γ) n.
Выбор между процентильным бутстрапом и бутстрапом-t, основанный на критерии точного вероятностного покрытия, зависит от степени усечения.Без обрезки все указывает на то, что бутстрап-t предпочтительнее (например, Westfall & Young, 1993). Следовательно, ранние исследования, основанные на средствах, предлагали использовать бутстрап-t при выводе об усеченном среднем популяции, но более поздние исследования показывают, что по мере увеличения количества усечения в какой-то момент метод процентильного бутстрапа дает преимущество. В частности, исследования с помощью моделирования показывают, что, когда величина обрезки составляет 20%, следует использовать процентильный доверительный интервал начальной загрузки, а не t начальной загрузки (например,г., Wilcox, 2001a). Возможно, с немного меньшей обрезкой процентильный бутстрап продолжает давать более точное вероятностное покрытие в целом, но этот вопрос не был тщательно изучен.
Один вопрос заключается в том, может ли уравнение. (4.6) дает доверительный интервал с достаточно точным охватом вероятностей при выборке из несимметричного распределения. Чтобы решить эту проблему, снова обращаем внимание на логнормальное распределение, которое имеет μt = 1,111. Сначала подумайте, что происходит, когда bootstrap-t не используется.При n = 20 и α = 0,025 вероятность отклонения H0: μt> 1,111 при использовании уравнения. (4.4) составляет примерно 0,065, что примерно в 2,6 раза больше номинального уровня. Напротив, вероятность отклонения H0: μt <1,111 составляет приблизительно 0,010. Таким образом, вероятность отклонения H0: μt = 1,111 при тестировании на уровне 0,05 составляет примерно 0,065 + 0,010 = 0,075. Если вместо этого используется метод bootstrap-t, с B = 599, вероятность односторонней ошибки типа I теперь составляет 0,035 и 0,020, поэтому вероятность отклонения H0: μt = 1.111 составляет примерно 0,055 при тестировании на уровне 0,05. (Причина использования B = 599, а не B = 600, проистекает из результатов в Hall, 1986, показывающих, что B следует выбирать так, чтобы α было кратно (B + 1) −1. иногда эта небольшая корректировка немного улучшает ситуацию, поэтому она используется здесь.) По мере того, как мы движемся к распределению с тяжелым хвостом, как правило, фактическая вероятность ошибки типа I имеет тенденцию к уменьшению.
Для полноты, при проверке двусторонней гипотезы или вычислении двустороннего доверительного интервала, асимптотические результаты, представленные Холлом (1988a, 1988b), предлагают изменить метод bootstrap-t, заменив Tt⁎ на
(4.11) Tt⁎ = (1−2γ) n | X¯t⁎ − X¯t | sw⁎.
Теперь двусторонний доверительный интервал для μt равен
(4.12) X¯t ± Tt (c) ⁎sw (1−2γ) n,
, где c = (1 − α) B, округленное до ближайшего целое число. Это пример двустороннего доверительного интервала симметричный . То есть доверительный интервал имеет вид (X¯t − cˆ, X¯t + cˆ), где cˆ определяется с целью, чтобы охват вероятностей был как можно ближе к 1 − α. Напротив, равновернистый двусторонний доверительный интервал имеет вид (X¯t − aˆ, X¯t + bˆ), где aˆ и bˆ определяются с целью, чтобы P (μt X¯t + bˆ) ≈α / 2.Доверительный интервал, заданный формулой. (4.10) равнохвостая. С точки зрения тестирования H0: μt = μ0 по сравнению с h2: μt ≠ μ0, уравнение. (4.12) равносильно отклонению, если Tt <−1 × Tt (c) ⁎ или если Tt> Tt (c) ⁎. Когда уравнение. (4.12) применяется к логнормальному распределению с n = 20, оценка моделирования фактической вероятности ошибки типа I составляет 0,0532 по сравнению с 0,0537 с использованием (4.10). Таким образом, с точки зрения вероятностей ошибок типа I, эти два метода мало разделяют для этого особого случая, но на практике, как будет показано ниже, выбор между этими двумя методами может быть важным.
В таблице 4.5 приведены значения αˆ, оценка вероятности ошибки типа I при выполнении односторонних тестов с α = 0,025 и при оценке критического значения одним из трех методов, описанных в этом разделе. Первая оценка критического значения - t , квантиль 1 − α / 2 t-распределения Стьюдента с n − 2g − 1 степенями свободы. То есть отклонить, если Tt меньше - t или больше t в зависимости от направления теста.Вторая оценка критического значения - это Tt (ℓ) ⁎ или Tt (u) ⁎ (опять же, в зависимости от направления теста), где Tt (ℓ) ⁎ и Tt (u) ⁎ определяются с помощью равностороннего бутстрапа. -t метод. Последний метод использует Tt (c) ⁎, полученный в результате симметричного бутстрапа-t, используемого в уравнении. (4.12). Оценочные вероятности ошибок типа I представлены для четырех распределений g и h, обсуждаемых в разделе 4.2. Например, когда выборка происходит из нормального распределения (g = h = 0), α = 0,025, и когда H0 отклоняется, потому что Tt <−t, фактическая вероятность отклонения приблизительно равна 0.031. Напротив, когда g = 0,5 и h = 0, вероятность отклонения оценивается в 0,047, что примерно в два раза выше номинального уровня. (Оценки в таблице 4.5 основаны на моделировании с 1000 повторениями при использовании одного из методов начальной загрузки и 10000 повторений при использовании t Стьюдента). Если выборка происходит из логнормального распределения, не показанного в таблице 4.5, оценка увеличивается до 0,066, что в 2,64 раза больше номинального уровня 0,025. Для (g, h) = (0,5,0,0) и α = 0,05 вероятности хвоста равны 0.094 и 0,034.
Таблица 4.5. Значения αˆ соответствуют трем критическим значениям, n = 12, α = 0,025.
г
h
P ( T t & lt; - t )
P ( T t & gt; t )
P (Tt & lt; Tt (ℓ) ⁎)
P (Tt & gt; Tt (u) ⁎)
P (Tt & lt; −Tt (c) ⁎)
P (Tt & gt; Tt (c ) ⁎)
0.0
0,0
0,031
0,028
0,026
0,030
0,020
0,025
0,0
0,5
0,025
0,08 0,022 51
0,022 51 9085
0,5
0,0
0,047
0,016
0,030
0,023
0,036
0,017
0,5
0.5
0,040
0,012
0,037
0,028
0,025
0,011
Обратите внимание, что выбор между уравнениями (4.10) и уравнение. (4.12), методы равностороннего и симметричного бутстрапа, не совсем ясны на основе результатов, приведенных в таблице 4.5. Аргумент в пользу уравнения. (4.12) заключается в том, что наибольшая оценочная вероятность ошибки типа I в таблице 4.5 при выполнении двустороннего теста составляет 0,036 + 0,017 = 0,053, в то время как при использовании уравнения. (4.10) наибольшая оценка равна 0.037 + 0,028 = 0,065. Возможное возражение против уравнения. (4.12) заключается в том, что в некоторых случаях оно слишком консервативно - вероятность хвоста может быть меньше половины номинального уровня 0,025. Кроме того, если можно исключить возможность того, что выборка происходит из асимметричного распределения с очень тяжелыми хвостами, таблица 4.5 предлагает использовать уравнение. (4.10) над уравнением. (4.12), по крайней мере, на основе вероятностного покрытия.
Существуют и другие методы начальной загрузки, которые могут иметь практическое преимущество перед методом начальной загрузки, но на данный момент это не похоже на тот случай, когда γ близко к нулю.Однако обширных исследований не проводилось, поэтому дальнейшие исследования могут изменить эту точку зрения. Один из подходов заключается в использовании начальной оценки фактического вероятностного покрытия при использовании Tt с t-распределением Стьюдента, а затем корректировка уровня α так, чтобы фактическое вероятностное покрытие было ближе к номинальному уровню (Loh, 1987a, 1987b). При выборке из логнормального распределения с n = 20 односторонние тесты, рассмотренные выше, теперь имеют фактическую вероятность ошибки типа I, приблизительно равную 0.011 и 0,045, что немного хуже результатов с bootstrap-t. Вестфол и Янг (1993) отстаивают еще один метод оценки p-значения Tt. Для рассматриваемой здесь ситуации моделирования (на основе 4000 повторений и B = 1000) дают оценки вероятностей ошибок типа I, равные 0,034 и 0,017. Таким образом, по крайней мере, для логнормального распределения эти два альтернативных метода не имеют практического преимущества при γ = 0,2, но, конечно, необходимы более подробные исследования.Еще одна интересная возможность - это метод ABC, обсужденный Эфроном и Тибширани (1993). Привлекательность этого метода заключается в том, что точные доверительные интервалы могут быть возможны при значительно меньшем выборе для B , но нет результатов с малой выборкой для определения того, так ли это для рассматриваемой проблемы. Дополнительные методы калибровки кратко изложены Efron and Tibshirani (1993).
Пример
Рассмотрим снова данные закона в Таблице 4.3, где X¯t = 596.2 на основе обрезки 20%. Симметричный доверительный интервал bootstrap-t, основанный на формуле. (4.12), это (541.6,650.9), которое было вычислено с помощью функции R trimcibt, описанной в разделе 4.4.6. Как указывалось ранее, доверительный интервал для μt, основанный на распределении Стьюдента и определяемый уравнением. (4.3), это (561,8, 630,6), который является подмножеством интервала, основанного на уравнении. (4.12). Фактически, длина этой уверенности составляет 68,8 против 109,3 при использовании метода bootstrap-t. Главное здесь то, что выбор метода может существенно повлиять на длину доверительного интервала, соотношение длин составляет 68.8 / 109,3 = 0,63. Может показаться, что использование t-распределения Стьюдента предпочтительнее, потому что доверительный интервал короче. Однако, как отмечалось ранее, похоже, что выборка происходит из несимметричного распределения, и это ситуация, когда использование t-распределения Стьюдента может дать доверительный интервал, который не имеет номинального вероятностного покрытия - интервал может быть слишком коротким. . Доверительный интервал 0,95 для μ равен (577,1 623,4), что еще короче и, вероятно, очень неточно с точки зрения вероятностного покрытия.Если вместо этого используется метод равностороннего бутстрапа-t, заданный (4.10), результирующий доверительный интервал 0,95 для 20% усеченного среднего будет (523,0 626,3), что также существенно больше, чем доверительный интервал, основанный на t Стьюдента. распределение. Повторюсь, все указывает на то, что обрезка по сравнению с отсутствием обрезки обычно улучшает вероятностный охват при использовании уравнения. (4.3) и выборка производится из перекошенного распределения с легким хвостом, но метод процентильной начальной загрузки или бутстрап-t может дать даже лучшие результаты, по крайней мере, когда n мало.
т Распределение
т Распределение
Автор (ы)
Дэвид М. Лейн
Предварительные требования
Обычный
Распространение, Районы
При нормальном распределении степеней свободы
Доверительный интервал для среднего
учебных целей
Укажите разницу между формой t-распределения и нормального распределения
Укажите, в чем разница между формой t-распределения и нормального распределения.
зависит от степеней свободы
Используйте таблицу t, чтобы найти значение t для использования в доверительном интервале
Используйте калькулятор t, чтобы найти значение t для использования в качестве достоверности
интервал
Во введении к нормальным распределениям
было показано, что 95% площади нормального распределения находится в пределах
1.96 стандартных отклонений среднего. Поэтому, если вы случайно
выбрал значение из нормального распределения со средним значением 100,
вероятность того, что это будет в пределах 1,96σ от 100, равна 0,95.
Точно так же, если вы выберете N значений из генеральной совокупности, вероятность
что выборочное среднее (M) будет в пределах 1,96 σ M из 100 составляет 0,95.
Теперь рассмотрим случай, когда у вас есть нормальный
распределение, но вы не знаете стандартное отклонение.Ты
выборки значений N, вычисление среднего выборочного значения (M) и оценка
стандартная ошибка среднего (σ M )
с s M .
Какова вероятность того, что M будет в пределах 1,96 с M от среднего значения генеральной совокупности (μ)? Это сложная проблема, потому что
есть два способа, которыми M может быть больше 1,96 с M от μ: (1) M может случайно быть либо очень высоким, либо очень большим.
low и (2) s M случайно может быть
очень низкий.Интуитивно понятно, что вероятность
быть в пределах 1,96 стандартных ошибок среднего значения должно быть
меньше, чем в случае, когда известно стандартное отклонение
(и недооценивать нельзя). Но насколько меньше?
К счастью, способ решения этой проблемы был решен.
в начале 20 века У. С. Госсетом, определившим
распределение среднего деленного на оценку
стандартной ошибки.Это распределение называется Студенческим.
t распределение или иногда просто t
распределение. Госсет разработал t-распределение
и связанные с ними статистические тесты при работе на пивоварне
в Ирландии. Благодаря договорному соглашению с пивоварней,
он опубликовал статью под псевдонимом «Студент». Что
Вот почему t-критерий называется «t-критерий Стьюдента».
Распределение t очень похоже на нормальное
распределение, когда оценка дисперсии
основан на многих степенях
свободы, но имеет относительно больше очков в хвосте
когда меньше степеней свободы.На рисунке 1 показаны t-распределения с 2, 4 и 10 степенями свободы и стандартное нормальное распределение. Обратите внимание, что нормальное распределение имеет относительно больше баллов в центре распределения, а распределение t имеет относительно больше баллов в хвостах. Таким образом, t-распределение является лептокуртическим. Распределение t приближается к нормальному с увеличением степеней свободы.
Рис. 1. Сравнение t-распределений с 2, 4 и 10 df и стандартным нормальным распределением.Распределение с самым низким пиком - это распределение 2 df, следующее низкое - 4 df, самое низкое после этого - 10 df, а самое высокое - стандартное нормальное распределение.
Поскольку t-распределение лептокуртическое,
процент распределения в пределах 1,96 стандартных отклонений
среднего значения меньше 95% для нормального распределения.
В таблице 1 показано количество стандартных отклонений от среднего.
требуется, чтобы содержать 95% и 99% площади распределения t
для различных степеней свободы.Это значения t, которые
вы используете в доверительном интервале. Соответствующие значения для
нормальное распределение составляет 1,96 и 2,58 соответственно. Уведомление
что с несколькими степенями свободы значения t намного выше
чем соответствующие значения для нормального распределения и что
разница уменьшается с увеличением степеней свободы.
Значения в Таблице 1 можно получить из «Найти
t для «калькулятора доверительного интервала».
Таблица 1. Сокращенная таблица t.
df
0,95
0,99
2
4,303
9.925
3
3,182
5,841
4
2,776
4,604
5
2.571
4,032
8
2,306
3,355
10
2,228
3.169
20
2,086
2,845
50
2,009
2,678
100
1.984
2,626
Возвращаясь к проблеме, поставленной в начале этого раздела,
предположим, вы выбрали 9 значений из нормальной совокупности и оценили
стандартная ошибка среднего (σ M )
с s M . Какова вероятность того, что
M будет в пределах 1,96 с M от μ? С
размер выборки 9, имеется N - 1 = 8 df.Из Таблицы 1 вы
можно видеть, что при 8 df вероятность того, что среднее значение будет равно 0,95, будет равна 0,95.
быть в пределах 2.306 с M от μ. Вероятность того, что оно будет в пределах 1,96 с M от μ, поэтому ниже 0,95.
Как показано
на рисунке 2 "t
с помощью калькулятора распределения "можно найти, что 0,086
область t-распределения составляет более 1,96 стандартных отклонений
от среднего, поэтому вероятность того, что
M будет меньше 1.


 в. [c.292]
в. [c.292]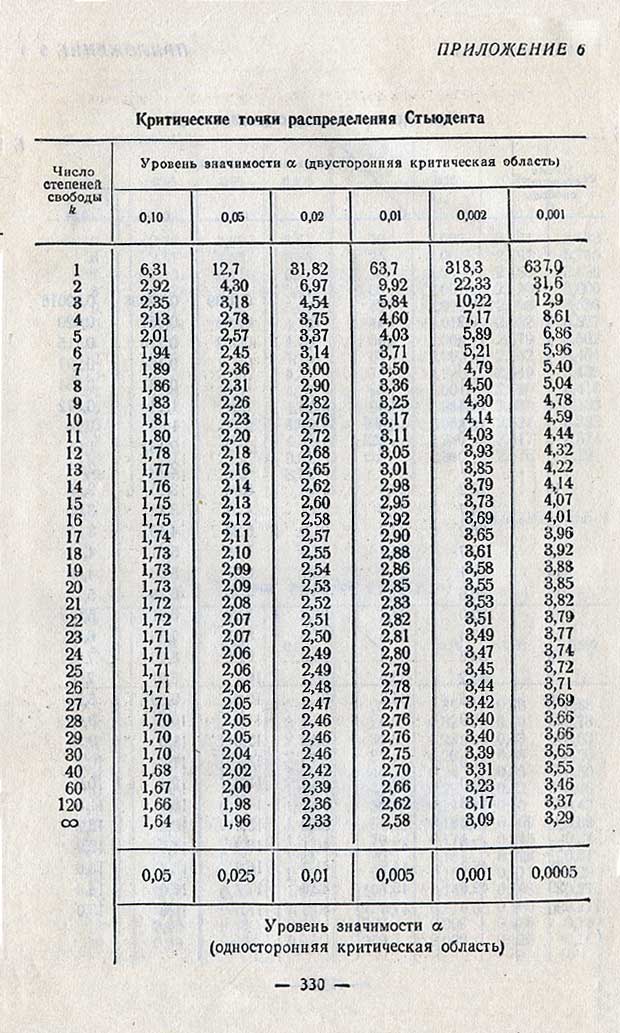
 Неучет этого приводит к необъективному, заниженному значению погрешности. Эта ненадежность, связанная с числом определений (параллельных проб), учитывается /-распределением Стьюдента, в котором предусматривается большая вероятность появления больших погрешностей, а малых меньше, чем в нормальном распределении. [c.129]
Неучет этого приводит к необъективному, заниженному значению погрешности. Эта ненадежность, связанная с числом определений (параллельных проб), учитывается /-распределением Стьюдента, в котором предусматривается большая вероятность появления больших погрешностей, а малых меньше, чем в нормальном распределении. [c.129] Рассмотрим случайную величину tn = % /n Xn Распределение этой случайной величины называется распределением Стьюдента с п степенями свободы. Его плотность имеет следующий вид [c.82]
Рассмотрим случайную величину tn = % /n Xn Распределение этой случайной величины называется распределением Стьюдента с п степенями свободы. Его плотность имеет следующий вид [c.82]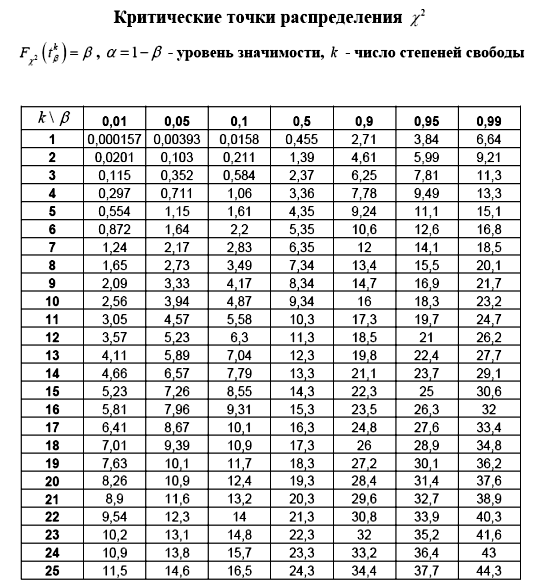 426]
426] Среднее значение трех параллельных измерений равно х = 97,8%. Ошибка воспроизводимости (выбороч-пьн 1 стандарт) х равна 0,52. Число степеней свободы ошибки воспроизводимости [ = 2. В качестве нулевой гипотезы рассмотрим гипотезу Яо пг = 99% следовательно, исследуемый реактив доброкачествен. Альтернативная гипотеза Н . гпхф =7 99. Используя распределение Стьюдента, определим вначале критическую область при двустороннем критерии. При р = 0,95 р = 0,05 и квантиль pj2 =4,30 [c.43]
Среднее значение трех параллельных измерений равно х = 97,8%. Ошибка воспроизводимости (выбороч-пьн 1 стандарт) х равна 0,52. Число степеней свободы ошибки воспроизводимости [ = 2. В качестве нулевой гипотезы рассмотрим гипотезу Яо пг = 99% следовательно, исследуемый реактив доброкачествен. Альтернативная гипотеза Н . гпхф =7 99. Используя распределение Стьюдента, определим вначале критическую область при двустороннем критерии. При р = 0,95 р = 0,05 и квантиль pj2 =4,30 [c.43]

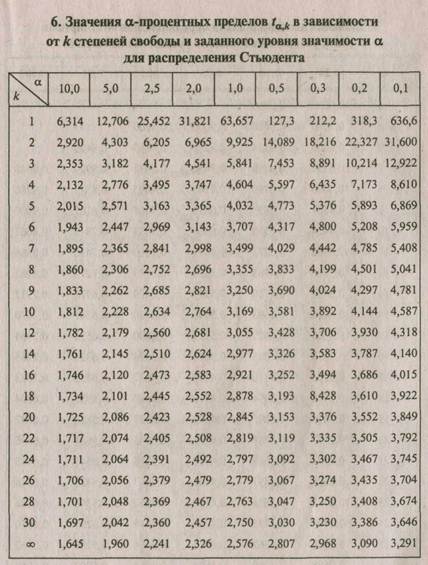 108]
108]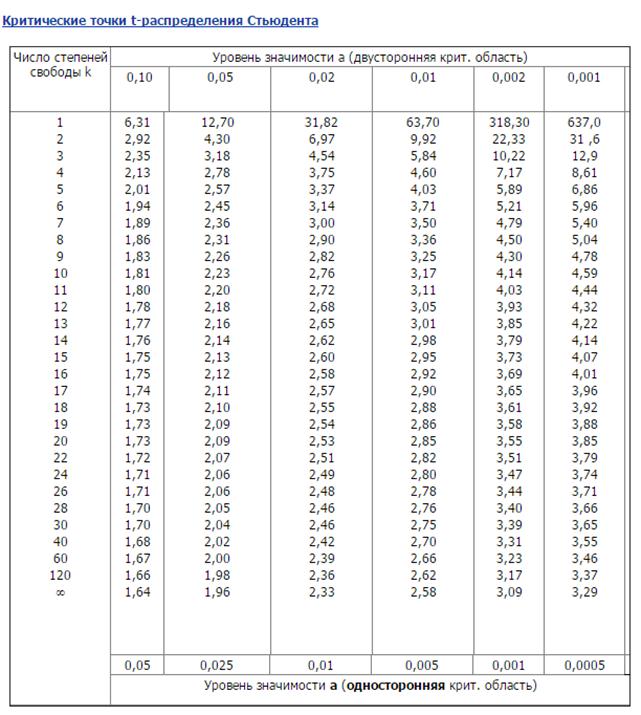
 Число степеней свободы, характеризующее распределение.
Число степеней свободы, характеризующее распределение. Число степеней свободы, характеризующее распределение.
Число степеней свободы, характеризующее распределение. Для вероятности 0,05 и 10 степеней свободы двустороннее значение вычисляется по формуле СТЬЮДРАСПОБР(0,05;10) и равно 2,28139. Одностороннее значение для той же вероятности и числа степеней свободы может быть вычислено по формуле СТЬЮДРАСПОБР(2*0,05;10), возвращающей значение 1,812462.
Для вероятности 0,05 и 10 степеней свободы двустороннее значение вычисляется по формуле СТЬЮДРАСПОБР(0,05;10) и равно 2,28139. Одностороннее значение для той же вероятности и числа степеней свободы может быть вычислено по формуле СТЬЮДРАСПОБР(2*0,05;10), возвращающей значение 1,812462. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные. {n-k}$$
{n-k}$$ {–1}(P|N)$.
{–1}(P|N)$. {–1}(X)$$
{–1}(X)$$
 Значение t зависит от объема выборки, т. е. от величины N—1. Пользуясь этими таблицами, можно получить, например, что при 7V=20 и надежности 90% коэффициент i=l,73 при том же значении N и надежности 95%, 99%и 99,9% величина t будет соответственно равна 2,09, 2,86 и 3,88.
[c.72]
Значение t зависит от объема выборки, т. е. от величины N—1. Пользуясь этими таблицами, можно получить, например, что при 7V=20 и надежности 90% коэффициент i=l,73 при том же значении N и надежности 95%, 99%и 99,9% величина t будет соответственно равна 2,09, 2,86 и 3,88.
[c.72] 18—8.21. Более подробные таблицы можно найти в [7, 22, 46].
[c.460]
18—8.21. Более подробные таблицы можно найти в [7, 22, 46].
[c.460] Доверительный интервал выражается через среднее квадратическое отклонение, доверительная вероятность определяется по таблицам интеграла Лапласа (для закона нормального распределения) или, задаваясь доверительной вероятностью, определяют доверительные границы. Так, например, задаваясь 95%-ной вероятностью, считают доверительный интервал равным 4а, где а — среднее квадратическое отклонение результата измерения. При небольшом числе измерений доверительные интервалы и доверительную вероятность определяют, пользуясь распределением Стьюдента.
[c.131]
Доверительный интервал выражается через среднее квадратическое отклонение, доверительная вероятность определяется по таблицам интеграла Лапласа (для закона нормального распределения) или, задаваясь доверительной вероятностью, определяют доверительные границы. Так, например, задаваясь 95%-ной вероятностью, считают доверительный интервал равным 4а, где а — среднее квадратическое отклонение результата измерения. При небольшом числе измерений доверительные интервалы и доверительную вероятность определяют, пользуясь распределением Стьюдента.
[c.131] Если полученное значение /-статистики больше критического ( > то гипотезах значимости коэффициента fx xJ генеральной совокупности не отвергается.
[c.108]
Если полученное значение /-статистики больше критического ( > то гипотезах значимости коэффициента fx xJ генеральной совокупности не отвергается.
[c.108] 351]
351]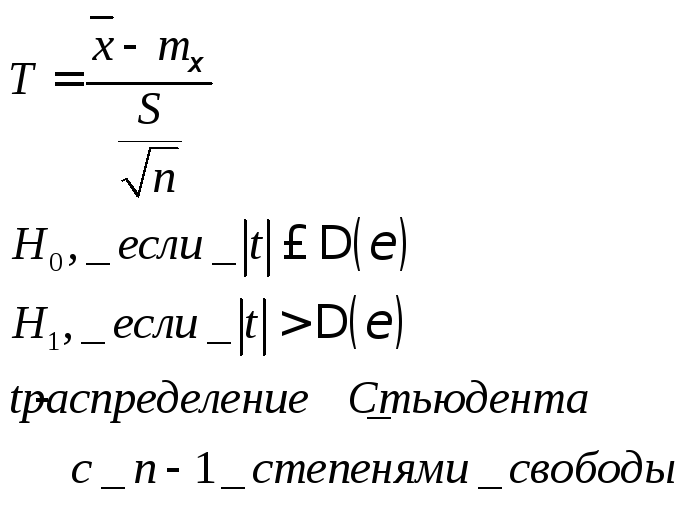 Таблицы распределения Стьюдента приведены, например, в [2, 4].
[c.534]
Таблицы распределения Стьюдента приведены, например, в [2, 4].
[c.534] 2.2).
[c.10]
2.2).
[c.10] Значения этих вероятностей при различных и приводятся в специальных таблицах (таблицы вероятностей по распределению Стьюдента). Так, например, вероятность того, что предельная ошибка малой выборки не превзойдет кpaтнyю среднюю ее ошибку равна (табл. 9).
[c.160]
Значения этих вероятностей при различных и приводятся в специальных таблицах (таблицы вероятностей по распределению Стьюдента). Так, например, вероятность того, что предельная ошибка малой выборки не превзойдет кpaтнyю среднюю ее ошибку равна (табл. 9).
[c.160]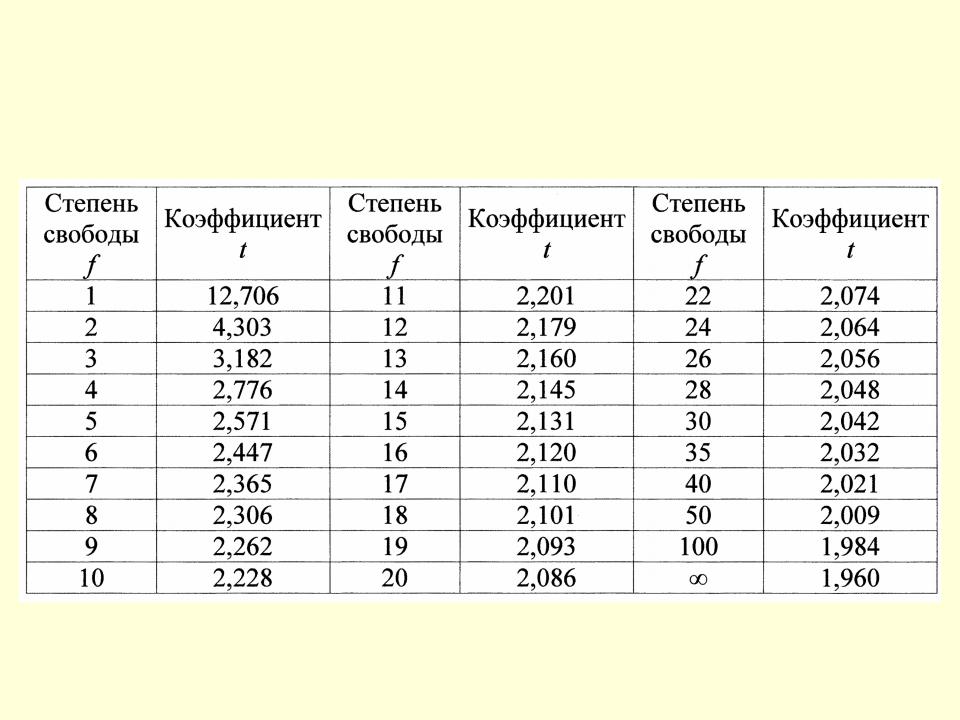 В частности, если резуль-паты наблюдений лишены систематич. ошибок, то х, = = О, и, значит, закону Стьюдента должны подчиняться отношения X, /si и iXal/sj. С помощью таблиц распределения Стьюдента с 1 — m = 8 степенями свободы можно убедиться, что если действительно х, = Хг = О, то с вероятностью 0,999 каждое пз этих отношений в отдельности не должно превосходить
[c.352]
В частности, если резуль-паты наблюдений лишены систематич. ошибок, то х, = = О, и, значит, закону Стьюдента должны подчиняться отношения X, /si и iXal/sj. С помощью таблиц распределения Стьюдента с 1 — m = 8 степенями свободы можно убедиться, что если действительно х, = Хг = О, то с вероятностью 0,999 каждое пз этих отношений в отдельности не должно превосходить
[c.352] 2.1 определяем вероятность нахождения случайной погрешности в заданном интервале. Таблица 2.1 предусматривает нормальный закон распредмения и бесконечно большое число измерений. Таблицей 2.1 можно пользоваться, как правило, когда число измерений более 30. При меньшем числе измерений следует пользоваться табл. 2.2, составленной для распределения Стьюдента.
[c.11]
2.1 определяем вероятность нахождения случайной погрешности в заданном интервале. Таблица 2.1 предусматривает нормальный закон распредмения и бесконечно большое число измерений. Таблицей 2.1 можно пользоваться, как правило, когда число измерений более 30. При меньшем числе измерений следует пользоваться табл. 2.2, составленной для распределения Стьюдента.
[c.11]





 Мы бы назвали t-статистику t 0.05
Мы бы назвали t-статистику t 0.05  Калькулятор.Оба подхода представлены ниже. Решение А - традиционное
подход. Это требует, чтобы вы вычислили статистику t на основе данных, представленных в
описание проблемы. Затем вы используете Калькулятор Т-распределения, чтобы найти
вероятность. Решение B проще. Вы просто вводите данные о проблеме в
Калькулятор Т-распределения. Калькулятор вычисляет t-статистику "за
сцены "и отображает вероятность. Оба подхода дают точную
тот же ответ.
Калькулятор.Оба подхода представлены ниже. Решение А - традиционное
подход. Это требует, чтобы вы вычислили статистику t на основе данных, представленных в
описание проблемы. Затем вы используете Калькулятор Т-распределения, чтобы найти
вероятность. Решение B проще. Вы просто вводите данные о проблеме в
Калькулятор Т-распределения. Калькулятор вычисляет t-статистику "за
сцены "и отображает вероятность. Оба подхода дают точную
тот же ответ. Затем вводим следующие данные:
Затем вводим следующие данные: Предположим, случайным образом выбраны и протестированы 20 человек. Стандартное отклонение в
группа выборки - 15. Какова вероятность того, что средний результат теста в
группа выборки будет максимум 110?
Предположим, случайным образом выбраны и протестированы 20 человек. Стандартное отклонение в
группа выборки - 15. Какова вероятность того, что средний результат теста в
группа выборки будет максимум 110?

 Кривые с большим количеством степеней свободы выше и имеют более тонкие хвосты. Все три дистрибутива t- имеют «более тяжелые хвосты», чем z-распределение.
Кривые с большим количеством степеней свободы выше и имеют более тонкие хвосты. Все три дистрибутива t- имеют «более тяжелые хвосты», чем z-распределение.
 Кривая снова представляет собой распределение t- с 21 степенью свободы. Для одностороннего теста значение из распределения t- с α = 0,05 составляет 1,721. Вы отклоняете нулевую гипотезу, если тестовая статистика превышает контрольное значение. Если статистика теста ниже контрольной линии, значит, вы не можете отклонить нулевую гипотезу.
Кривая снова представляет собой распределение t- с 21 степенью свободы. Для одностороннего теста значение из распределения t- с α = 0,05 составляет 1,721. Вы отклоняете нулевую гипотезу, если тестовая статистика превышает контрольное значение. Если статистика теста ниже контрольной линии, значит, вы не можете отклонить нулевую гипотезу. Если вы установите α = 0.05 для двустороннего теста и иметь только одностороннюю таблицу, затем используйте столбец для α = 0,025.
Если вы установите α = 0.05 для двустороннего теста и иметь только одностороннюю таблицу, затем используйте столбец для α = 0,025. youtube.com/embed/gvOwM3Yu05A" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen=""/>
youtube.com/embed/gvOwM3Yu05A" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen=""/>  Что означает «свободно варьироваться»? Вот пример с использованием среднего (среднего):
Что означает «свободно варьироваться»? Вот пример с использованием среднего (среднего):  Степеней свободы в этом случае:
Степеней свободы в этом случае:
 Поскольку степени свободы определены выше как n-1, вы могли бы подумать, что критическое значение t тоже должно увеличиться, но это не так: они становятся меньше . Это кажется нелогичным.
Поскольку степени свободы определены выше как n-1, вы могли бы подумать, что критическое значение t тоже должно увеличиться, но это не так: они становятся меньше . Это кажется нелогичным. Вы измеряете их вес, вычисляете среднюю разницу между парами образцов и повторяете этот процесс снова и снова.Крошечный размер выборки 4 приведет к t-распределению с жирными хвостами. Жирные хвосты говорят о том, что в вашей выборке вероятнее всего будут экстремальные значения. Вы проверяете свою гипотезу на уровне альфа 5%, который отсекает последние 5% вашего распределения . На графике ниже показано t-распределение с отсечкой 5%. Это дает критическое значение 2,6. ( Примечание : я использую здесь гипотетическое t-распределение в качестве примера - CV не является точным).
Вы измеряете их вес, вычисляете среднюю разницу между парами образцов и повторяете этот процесс снова и снова.Крошечный размер выборки 4 приведет к t-распределению с жирными хвостами. Жирные хвосты говорят о том, что в вашей выборке вероятнее всего будут экстремальные значения. Вы проверяете свою гипотезу на уровне альфа 5%, который отсекает последние 5% вашего распределения . На графике ниже показано t-распределение с отсечкой 5%. Это дает критическое значение 2,6. ( Примечание : я использую здесь гипотетическое t-распределение в качестве примера - CV не является точным).
 3: Доверительный интервал для совокупности Стандартное отклонение неизвестно, случай малой выборки
3: Доверительный интервал для совокупности Стандартное отклонение неизвестно, случай малой выборки