Онлайн калькулятор: Код Хаффмана
УчебаИнформатика
Построение кода Хаффмана для таблицы вероятностей.
Вот калькулятор, который рассчитывает коды Хаффмана для заданной вероятности символов.
Немного теории под калькулятором.
Код Хаффмана
Таблица вероятности символов
| Имя | Значение | ||
|---|---|---|---|
51020501001000
Таблица вероятности символов
Значение
Импортировать данныеОшибка импорта
Данные
Для разделения полей можно использовать один из этих символов: Tab, «;» или «,» Пример: Lorem ipsum;50.5
Загрузить данные из csv файла
Точность вычисления
Знаков после запятой: 2
Средняя длина символа
Энтропия
Файл очень большой, при загрузке и создании может наблюдаться торможение браузера.
Инвертировать 0 и 1
Небольшой отрывок из Википедии.
Алгоритм Хаффмана — адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных.
Этот метод кодирования состоит из двух основных этапов:
Построение оптимального кодового дерева.
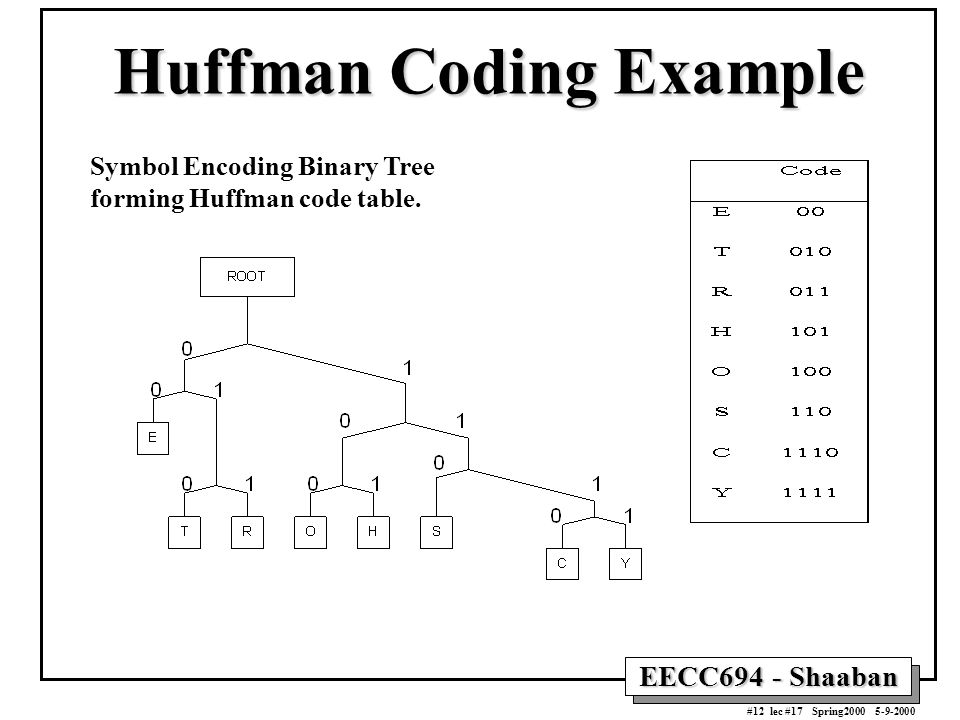
Идея алгоритма состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (т. е. ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.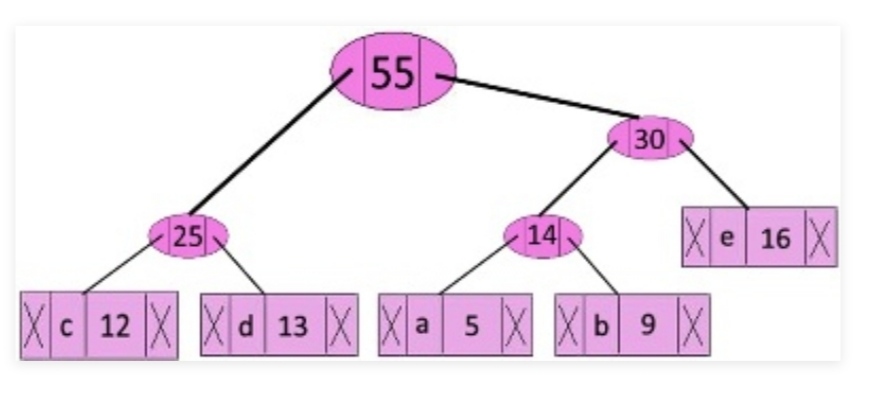
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
- Выбираются два свободных узла дерева с наименьшими весами.
- Создается их родитель с весом, равным их суммарному весу.
- Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т.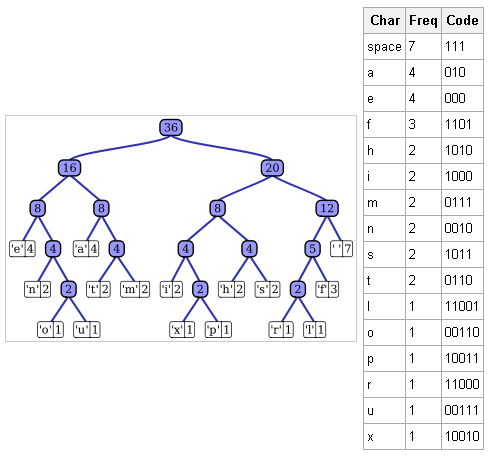 д.
д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от корня до листа дерева, соответствующего текущему символу, накапливая биты при перемещении по ветвям дерева (первая ветвь в пути соответствует младшему биту). Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Ссылка скопирована в буфер обмена
Похожие калькуляторы
- • Код Хаффмана для последовательности символов
- • Построение таблицы частот
- • Формула Шеннона
- • Частная условная энтропия
- • Условная энтропия
- • Раздел: Информатика ( 59 калькуляторов )
алгоритм Информатика код код Хаффмана Компьютеры теория информации Хаффман Шеннон энтропия
PLANETCALC, Код Хаффмана
Timur2020-11-03 14:19:30
Простой пример кодирования текстовой строки по Хаффману / Хабр
Вы, наверное, слышали о Дэвиде Хаффмане и его популярном алгоритме сжатия.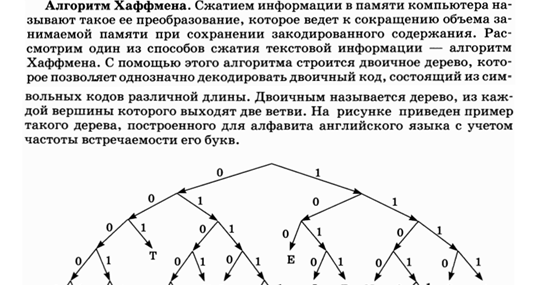 Если нет, то предлагаю вам самостоятельно поискать в интернете — в этой статье я не буду донимать вас уроками истории или математики. Я попробую показать вам на практике, как применить этот алгоритм к текстовой строке. Наше приложение просто сгенерирует значения кода для символов из введенной строки и наборот — воссоздаст оригинальную строку из представленного кода.
Если нет, то предлагаю вам самостоятельно поискать в интернете — в этой статье я не буду донимать вас уроками истории или математики. Я попробую показать вам на практике, как применить этот алгоритм к текстовой строке. Наше приложение просто сгенерирует значения кода для символов из введенной строки и наборот — воссоздаст оригинальную строку из представленного кода.
Идея кодирования по Хаффману основана на использовании частоты употребления символов в строке. Наиболее часто встречающемуся символу нужно выдать как можно более короткое кодовое значение, а наименее часто встречающемуся — как можно более длинное. Из-за того, что при архивации наиболее часто встречающиеся символы должны занимать меньше места, чем раньше, а наименее часто встречающиеся могут занимать и больше места — раз их мало, то это не сильно повлияет на результат.
Для нашего примера я решил сделать символ 8-битным, т.е. типа char. С тем же успехом можно было выбрать длину и в шестнадцать, десять или двадцать битов. Длину символа стоит выбирать в зависимости от ожидаемых входных данных. Например, для кодирования видеофайлов я бы выбрал символ того же размера, что и пиксель. Имейте в виду, что увеличение или уменьшение длины символа влияет на длину кода для каждого из символов — ведь чем больше длина, тем больше символов этой длины может существовать: способов записать единицы и нули в восемь бит гораздо меньше, чем в шестнадцать. Поэтому длину символа нужно регулировать в зависимости от задачи.
Длину символа стоит выбирать в зависимости от ожидаемых входных данных. Например, для кодирования видеофайлов я бы выбрал символ того же размера, что и пиксель. Имейте в виду, что увеличение или уменьшение длины символа влияет на длину кода для каждого из символов — ведь чем больше длина, тем больше символов этой длины может существовать: способов записать единицы и нули в восемь бит гораздо меньше, чем в шестнадцать. Поэтому длину символа нужно регулировать в зависимости от задачи.
Алгоритм Хаффмана активно задействует бинарные деревья и очереди с приоритетом, так что, если вы с ними не знакомы, придется для начала восполнить пробелы в знаниях.
Пусть у нас есть строка «beep boop beer!», которая занимает в памяти 15*8=120 битов. После кодировки по Хаффману этот размер удастся сократить до 40 битов. Если придираться к деталям, на экран мы выведем строку, состоящую из 40 элементов типа char (нули и единицы), а чтобы она занимала ровно 40 битов в памяти, эту строку нужно конвертировать в биты с использованием операций двоичной арифметики, которые мы не будем здесь рассматривать подробно.
Итак, рассмотрим строку «beep boop beer!». Чтобы сконструировать кодовые значения для всех элементов в зависимости от их частоты, нужно построить такое бинарное дерево, в котором каждый лист содержит символ из данной строки. Дерево мы будем строить от листьев к корню, чтобы элементы с меньшей частотой находились дальше от корня, а более часто встречающиеся — ближе к нему. Скоро узнаете, почему.
Для строительства такого дерева воспользуемся очередью с приоритетом, но немного модифицированной — инвертируем приоритеты, чтобы элемент с наименьшим приоритетом был самым важным. Получается, очередь сначала будет возвращать элементы с наименьшей частотой. Эта модификация поможет нам построить дерево начиная с листьев.
Для начала посчитаем частоту каждого символа:
| Символ | Частота |
|---|---|
| ‘b’ | 3 |
| ‘e’ | 4 |
| ‘p’ | 2 |
| ‘ ‘ | 2 |
| ‘o’ | 2 |
| ‘r’ | 1 |
| ‘!’ | 1 |
После этого создадим элементы бинарного дерева для каждого символа и представим их как очередь с приоритетом, в качестве которого будем использовать частоту.
Теперь возьмем первые два элемента из очереди и создадим третий, который будет их родителем. Этот новый элемент поместим в очередь с приоритетом, равным сумме приоритетов двух его потомков. Иначе говоря, равным сумме их частот.
Далее будем повторять шаги, аналогичные предыдущему:
Теперь, после объединения последних двух элементов с помощью их нового родителя, мы получим итоговое бинарное дерево:
Осталось присвоить каждому символу его код. Для этого запустим обход в глубину и каждый раз, рассматривая правое поддерево, будем записывать в код 1, а рассматривая левое поддерево — 0.
В результате соответствие символов кодовым значениям получится следующим:
| Сивол | Кодовое значение |
|---|---|
| ‘b’ | 00 |
| ‘e’ | 11 |
| ‘p’ | 101 |
| ‘ ‘ | 011 |
| ‘o’ | 010 |
| ‘r’ | 1000 |
| ‘!’ | 1001 |
Декодировать последовательность битов очень просто: нужно обходить дерево, отбрасывая левое поддерево, если встретилась единица и правое, если встретился 0. Продолжать обход нужно до тех пор, пока не встретим лист, т.е. искомое значение закодированного символа. Например, закодированной строке «101 11 101 11» и нашему дереву декодирования соответствует строка «pepe».
Продолжать обход нужно до тех пор, пока не встретим лист, т.е. искомое значение закодированного символа. Например, закодированной строке «101 11 101 11» и нашему дереву декодирования соответствует строка «pepe».
Здесь важно заметить, что ни одно кодовое значение не является префиксом никакого другого. В нашем примере 00 — код символа «b». Это значит, что 000 уже не может быть кодом ни для какого другого символа, т.к. иначе это привело бы к конфликту при декодировании. Ведь если после прохода по 00 мы пришли к листу «b», то по кодовому значению 000 мы уже не найдем никакого другого символа.
На практике после генерации дерева Хаффмана нужно сконструировать также таблицу Хаффмана. Таблица (в виде связного списка или массива) сделает процедуру кодирования более эффективной, ведь искать символ в дереве и одновременно записывать его код — неоправданно трудоемко. Поскольку мы не знаем наверняка, где находится этот символ, в худшем случае придется в его поисках перебрать все дерево.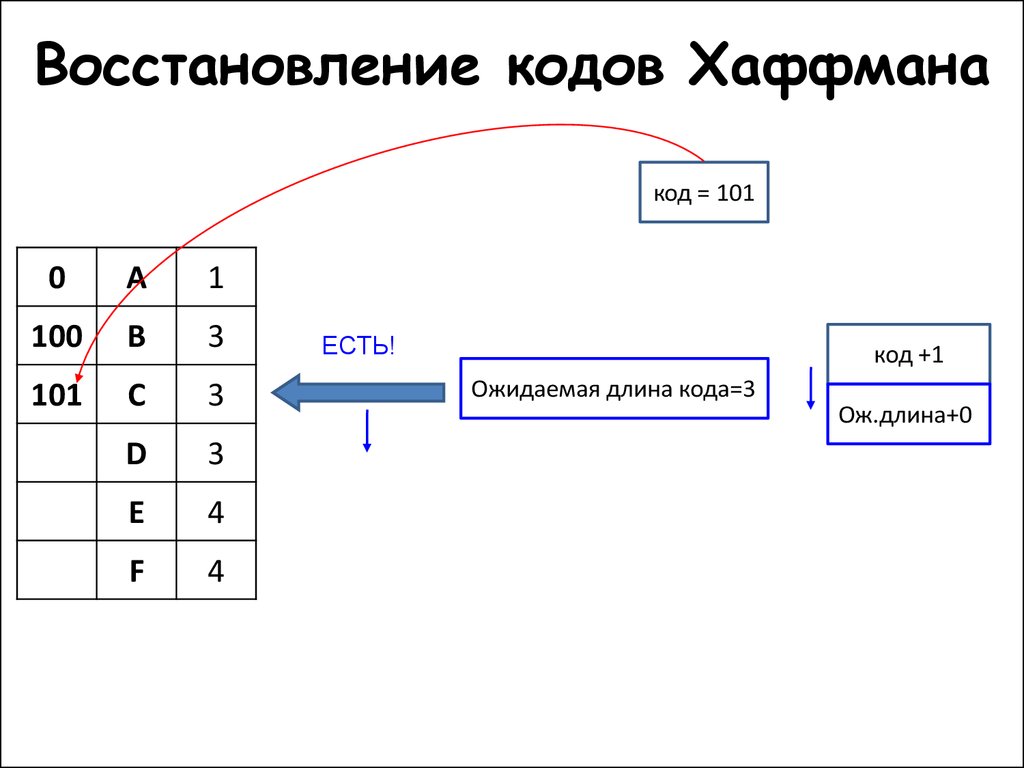 Как правило, для кодирования используют таблицу Хаффмана, а для декодирования — дерево Хаффмана.
Как правило, для кодирования используют таблицу Хаффмана, а для декодирования — дерево Хаффмана.
Входная строка: beep boop beer!
Входная строка в двоичном виде: 0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 0001
Нетрудно заметить значительную разницу между ASCII-кодировкой строки и ее же видом в коде Хаффмана.
Необходимо отметить, что статья только объясняет только принцип работы алгоритма. Для практического применения вам придется добавить дерево Хаффмана в начало или конец закодированной последовательности. Получатель сообщения должен знать, как отделить дерево от содержания и как восстановить его из текстового представления. Хороший способ для этого — обходить дерево в любом заранее выбранном порядке, записывая 0 для каждого встреченного элемента, не являющегося листом, и 1 для каждого листа. Вслед за единицей можно записать исходный символ (в нашем случае — типа char, 8 бит в кодировке ASCII). Дерево, записанное в таком виде, можно поместить в начале закодированной последовательности — тогда получатель, в самом начале разбора построив дерево, уже будет знать, как ему декодировать записанное далее сообщение и получить из него оригинал.
Вслед за единицей можно записать исходный символ (в нашем случае — типа char, 8 бит в кодировке ASCII). Дерево, записанное в таком виде, можно поместить в начале закодированной последовательности — тогда получатель, в самом начале разбора построив дерево, уже будет знать, как ему декодировать записанное далее сообщение и получить из него оригинал.
Прочитать о более продвинутой версии алгоритма вы можете в статье «Адаптивное кодирование Хаффмана».
P.S. (от переводчика)
Спасибо bobuk за то, что дал ссылку на исходную статью в своем линкблоге.
Онлайн-калькулятор: Коды Хаффмана
Профессиональные Компьютеры
Этот онлайн-калькулятор генерирует коды Хаффмана на основе набора символов и их вероятностей. Краткое описание кодирования Хаффмана находится под калькулятором.
Huffman Coding
Символы вероятности Таблица
| Имя | Значение | ||
|---|---|---|---|
51020501001000
Таблица вероятностей символов
Import dataImport error
«Один из следующих символов используется для разделения полей данных: табуляция, точка с запятой (;) или запятая (,)» Образец: Lorem ipsum;50. 5
5
Загрузить данные из файла .csv.
Перетащите файлы сюда
Точность вычислений
Знаки после запятой: 2
Взвешенная длина пути
Энтропия Шеннона
Файл очень большой. Во время загрузки и создания может происходить замедление работы браузера.
Инвертировать 0 и 1
Объяснение кодирования Хаффмана
Взято из Википедии
В компьютерных науках и теории информации кодирование Хаффмана представляет собой алгоритм энтропийного кодирования, используемый для сжатия данных без потерь. Этот термин относится к использованию таблицы кодов переменной длины для кодирования исходного символа (например, символа в файле), где таблица кодов переменной длины была получена определенным образом на основе предполагаемой вероятности появления для каждого возможного значения. исходного символа. Дэвид А. Хаффман разработал его, когда он был доктором философии. студент Массачусетского технологического института и опубликован в 1952 статья «Метод построения кодов с минимальной избыточностью».
студент Массачусетского технологического института и опубликован в 1952 статья «Метод построения кодов с минимальной избыточностью».
В кодировании Хаффмана используется особый метод выбора представления для каждого символа, в результате чего получается префиксный код (иногда называемый «беспрефиксным кодом», т. е. битовая строка, представляющая какой-либо конкретный символ, никогда не является префиксом битовой строки, представляющей любой другой символ), который выражает наиболее распространенные исходные символы с использованием более коротких строк битов, чем те, которые используются для менее распространенных исходных символов. Хаффман смог разработать наиболее эффективный метод сжатия этого типа; никакое другое преобразование отдельных исходных символов в уникальные строки битов не приведет к меньшему среднему выходному размеру, когда фактические частоты символов совпадают с теми, которые использовались для создания кода.
Кодирование Хаффмана является настолько распространенным методом создания префиксных кодов, что термин «код Хаффмана» широко используется как синоним «префиксного кода», даже если алгоритм Хаффмана не создает такой код.
Метод работает путем создания бинарного дерева узлов. Изначально все узлы являются листовыми узлами, которые содержат сам символ, вес (частоту появления) символа и, необязательно, ссылку на родительский узел, что упрощает чтение кода (в обратном порядке), начиная с листа. узел. Внутренние узлы содержат вес символа, ссылки на два дочерних узла и дополнительную ссылку на родительский узел. Согласно стандартному соглашению, бит «0» означает следование за левым дочерним элементом, а бит «1» — за правым дочерним элементом. Готовое дерево имеет до n листовых узлов и n-1 внутренних узлов. Дерево Хаффмана, в котором не используются неиспользуемые символы, дает наиболее оптимальную длину кода.
Процесс по существу начинается с листовых узлов, содержащих вероятности символа, который они представляют. Создается новый узел, дочерними узлами которого являются 2 узла с наименьшей вероятностью, так что вероятность нового узла равна сумме дочерних вероятностей. Предыдущие 2 узла объединились в один узел (таким образом, их больше не рассматривали).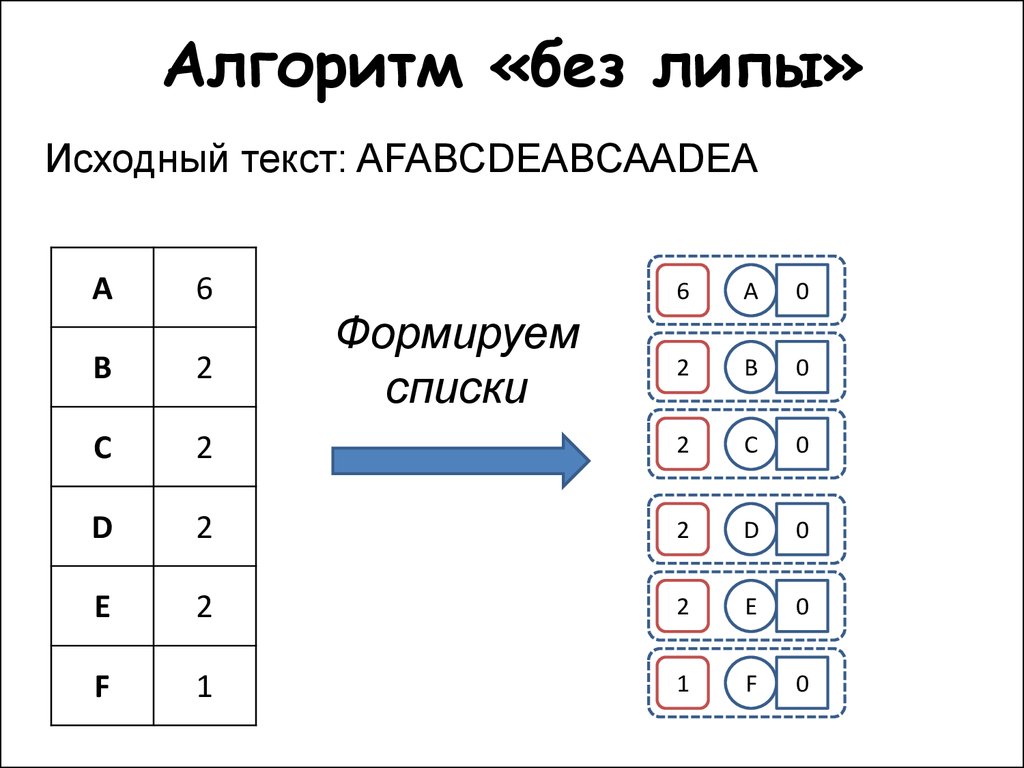 Теперь, когда рассматривается новый узел, процедура повторяется до тех пор, пока в дереве Хаффмана не останется только один узел.
Теперь, когда рассматривается новый узел, процедура повторяется до тех пор, пока в дереве Хаффмана не останется только один узел.
URL-адрес скопирован в буфер обмена
Similar calculators
- • Shannon coding
- • Shannon-Fano coding calculator
- • Shannon Entropy
- • Symbol frequencies table
- • Joint Entropy
- • Computers section ( 65 calculators )
# кодирование #энтропия #алгоритм Хаффмана код Компьютеры кодирование энтропия теория информации Хаффмана Шеннон
PLANETCALC, кодирование Хаффмана
Тимур 2021-09-30 12:08:19
Калькулятор кодирования Хаффмана — Генератор дерева сжатия
Поиск инструмента
Найдите инструмент в dCode по ключевым словам:Просмотрите полный список инструментов dCode
Кодирование Хаффмана
Инструмент для сжатия/распаковки с кодированием Хаффмана. Кодирование Хаффмана — это алгоритм сжатия данных (без потерь), который использует двоичное дерево и код переменной длины, основанный на вероятности появления.
Кодирование Хаффмана — это алгоритм сжатия данных (без потерь), который использует двоичное дерево и код переменной длины, основанный на вероятности появления.
Результаты
Кодирование Хаффмана — dCode
Теги : Сжатие
Поделиться
dCode и многое другое
dCode бесплатен, а его инструменты являются ценным подспорьем в играх, математике, геокэшинге, головоломках и задачах, которые нужно решать каждый день!
Предложение ? обратная связь? Жук ? идея ? Запись в dCode !
Декодер Хаффмана
Текст в кодировке Хаффмана110110011000111011111010010010110110110111001011000101
Использованы алфавитные и двоичные слова
Загрузка…
(если это сообщение не исчезнет, попробуйте обновить страницу)
См. также: LZW Compression
Генератор кодирования Хаффмана
Ответы на вопросы (FAQ)
Что такое кодирование Хаффмана? (Определение)
Кодирование по Хаффману — это принцип сжатия без потери данных, основанный на статистике появления символов в сообщении, что позволяет по-разному кодировать разные символы (наиболее часто используется короткий код ).
Как зашифровать с помощью шифра Хаффмана?
Код Хаффмана использует частоту появления букв в тексте, вычисляет и сортирует символы от наиболее часто встречающихся к наименее часто встречающимся.
Example: The message DCODEMESSAGE contains 3 times the letter E , 2 times the letters D and S , and 1 times the letters A , C , G , М и О .
Хаффман 9Алгоритм 0171 создаст дерево с листьями в виде найденных букв и по значению (или весу) их количества вхождений в сообщении. Чтобы создать это дерево, найдите 2 самых слабых узла (меньший вес) и соедините их с новым узлом, вес которого равен сумме двух узлов. Повторяйте процесс до тех пор, пока не останется только один узел, который станет корнем (и он будет иметь вес, равный общему количеству букв сообщения).
Затем двоичный код каждого символа получается путем просмотра дерева от корня к листьям и определения пути (0 или 1) к каждому узлу.
Пример: DCODEMOI создает дерево, в котором D и O , присутствующие чаще всего, будут иметь короткий код. ‘D = 00’, ‘O = 01’, ‘I = 111’, ‘M = 110’, ‘E = 101’, ‘C = 100’, поэтому 00100010010111001111 (20 бит)
Как расшифровать Хаффмана Код?
Расшифровка кода Хаффмана требует знания соответствующего дерева или словаря (двоичные коды символов)
Для расшифровки просмотрите дерево от корня к листьям (обычно сверху вниз), пока не найдете существующий лист (или значение в словаре).
Example: Decode the message 00100010010111001111 , search for 0 gives no correspondence, then continue with 00 which is code of the letter D , then 1 (does not exist), then 10 (не существует), затем 100 (код для C ) и т. д.
Простое сообщение «DCODEMOI»
Почему для сжатия используется алгоритм Хаффмана?
Применяя алгоритм Хаффмана , наиболее часто встречающиеся символы (с большей частотой) кодируются меньшими двоичными словами, поэтому размер, используемый для их кодирования, минимален, что увеличивает степень сжатия.
Коэффициент сжатия часто превышает 50%
Как распознать текст, закодированный по Хаффману?
Закодированное сообщение имеет двоичный формат (или шестнадцатеричное представление) и должно сопровождаться деревом или таблицей соответствия для расшифровки.
Как расшифровать код Хаффмана без дерева?
Делая предположения о длине сообщения и размере двоичных слов, можно найти вероятный список слов, используемых Хаффманом .
Затем он должен быть связан с правильными буквами, что представляет собой вторую трудность для расшифровки и, безусловно, требует автоматических методов.
Какие существуют варианты шифра Хаффмана?
Возможны варианты Хаффмана при создании дерева/словаря.
Словарь может быть статическим: каждый символ/байт имеет предопределенный код и известен или публикуется заранее (поэтому его не нужно передавать)
Словарь может быть полуадаптивным: содержимое анализируется для расчета частоты каждого символа, а для кодирования используется оптимизированное дерево (которое затем необходимо передать для декодирования).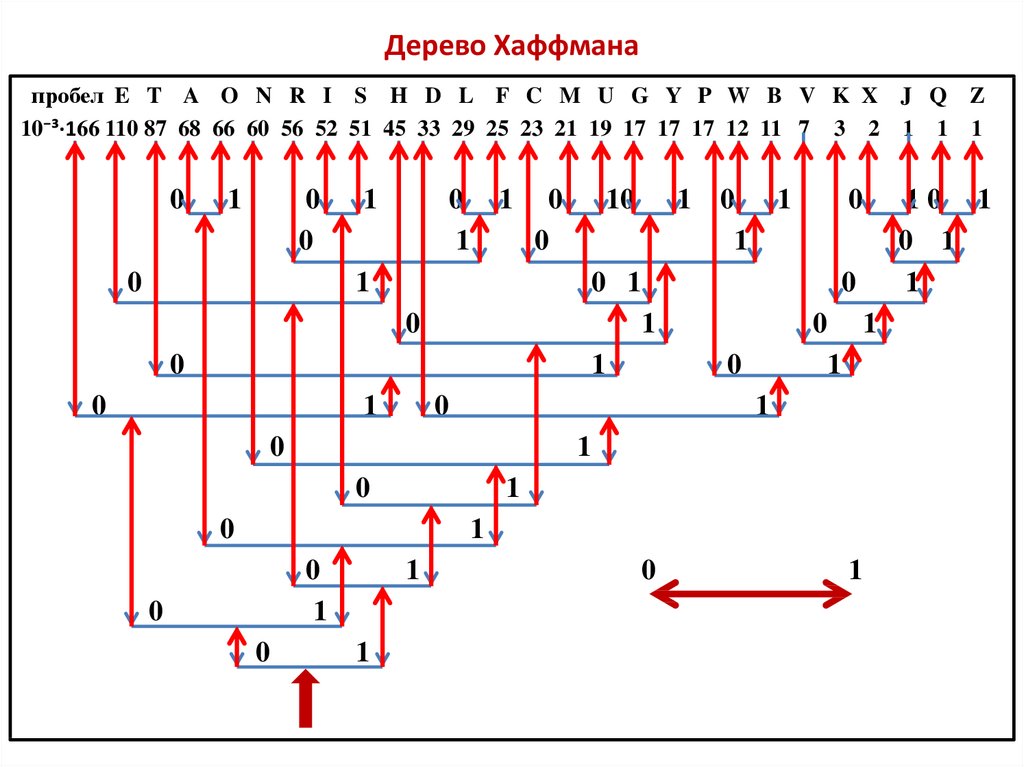 Это версия, реализованная на dCode
Это версия, реализованная на dCode
. Словарь может быть адаптивным: из известного дерева (опубликованного ранее и поэтому не передаваемого) он модифицируется при сжатии и оптимизируется как и когда. Время расчета намного больше, но часто предлагает лучшую степень сжатия.
Когда было изобретено кодирование Хаффмана?
Он был опубликован в 1952 году Дэвидом Альбертом Хаффманом .
Исходный код
dCode сохраняет за собой право собственности на исходный код «Huffman Coding». За исключением явной лицензии с открытым исходным кодом (указано Creative Commons/бесплатно), алгоритма «Кодирования Хаффмана», апплета или фрагмента (конвертер, решатель, шифрование/дешифрование, кодирование/декодирование, шифрование/дешифрование, транслятор) или «Кодирования Хаффмана». функции (вычисление, преобразование, решение, расшифровка/шифрование, расшифровка/шифрование, декодирование/кодирование, перевод), написанные на любом информационном языке (Python, Java, PHP, C#, Javascript, Matlab и т.