
Дисперсия случайной величины
Дисперсия случайной величины характеризует меру разброса случайной величины около ее математического ожидания.
Если случайная величина имеет математическое ожидание M , то дисперсией случайной величины называется величина D = M( — M )2.
Легко показать, что D = M( — M )2= M 2 — M( )2.
Эта универсальная формула одинаково хорошо применима как для дискретных случайных величин, так и для непрерывных. Величина M 2 >для дискретных и непрерывных случайных величин соответственно вычисляется по формулам
, .
Для определения меры разброса значений случайной величины часто используется среднеквадратичное отклонение

Основные свойства дисперсии:
В теории вероятностей и математической статистике, помимо математического ожидания и дисперсии, используются и другие числовые характеристики случайных величин. В первую очередь это начальные и центральные моменты.
Начальным моментом k-го порядка случайной величины называется математическое ожидание k-й степени случайной величины , т.е. k = M k.
Центральным моментом k-го порядка случайной величины называется величина k, определяемая формулой k = M( — M )k.
Заметим, что математическое ожидание случайной величины — начальный момент первого порядка, 1 = M , а дисперсия — центральный момент второго порядка,
2 = M 2 = M( — M )2 = D .
Существуют формулы, позволяющие выразить центральные моменты случайной величины через ее начальные моменты, например:
2= 2— 12, 3 = 3 — 3 2 1 + 2 13.
Если плотность распределения вероятностей непрерывной случайной величины симметрична относительно прямой x = M , то все ее центральные моменты нечетного порядка равны нулю.
Асимметрия
В теории вероятностей и в математической статистике в качестве меры асимметрии распределения является коэффициент асимметрии, который определяется формулой ,
где 3 — центральный момент третьего порядка, — среднеквадратичное отклонение.
Эксцесс
Нормальное
распределение наиболее часто используется
в теории вероятностей и в математической
статистике, поэтому график плотности
вероятностей нормального распределения
стал своего рода эталоном, с которым
сравнивают другие распределения. Одним
из параметров, определяющих отличие
распределения случайной величины
, от нормального распределения, является
эксцесс.
Одним
из параметров, определяющих отличие
распределения случайной величины
, от нормального распределения, является
эксцесс.
Эксцесс случайной величины определяется равенством .
У нормального распределения, естественно, = 0. Если ( ) > 0, то это означает, что график плотности вероятностей p (x) сильнее “заострен”, чем у нормального распределения, если же ( ) < 0, то “заостренность” графика p (x) меньше, чем у нормального распределения.
Числовые характеристики дискретных случайных величин и их свойства
План:
1. Математическое ожидание дискретной случайной величины.
2. Свойства математического ожидания.
3. Числовые характеристики рассеяния дискретной случайной величины.
4. Свойства дисперсии.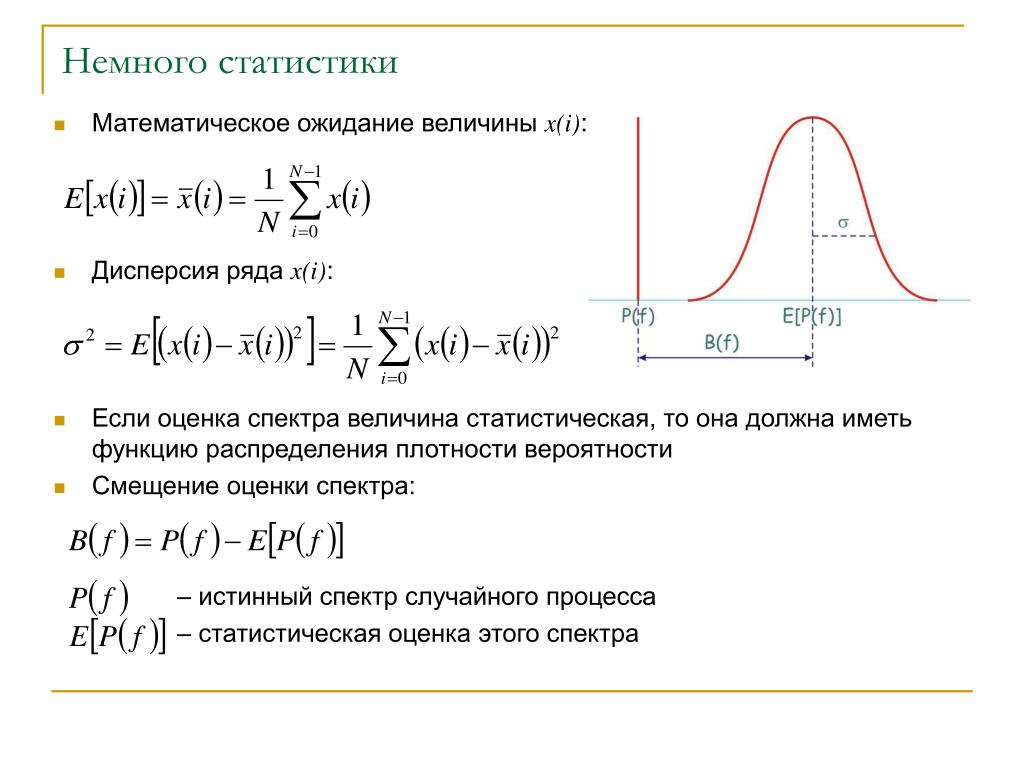
5. Другие числовые характеристики дискретных случайных величин.
К числу важных числовых характеристик относится математическое ожидание. Математическое ожидание приближенно равно среднему значению случайной величины. Для решения многих задач достаточно знать математическое ожидание. Например, если известно, что математическое ожидание числа выбиваемых очков у первого стрелка больше, чем у второго, то первый стрелок в среднем выбивает больше очков, чем второй, и, следовательно, стреляет лучше второго.
Т а б л и ц а 6.1
Теперь приведем свойства математического ожидания.
Произведением независимых случайных величин Х
и Y называется случайная величина ХY, возможные значения которой равны произведениям каждого возможного значения Х на каждое возможное значение Y; вероятности возможных значений произведения ХY равны произведениям вероятностей возможных значений сомножителей.
|
|
Суммой случайных величин Х
и Y называется случайная величина Х+Y, возможные значения которой равны суммам каждого возможного значения Х с каждым возможным значением Y; вероятности возможных значений Х+Y для независимых величин Х и Y равны произведениям вероятностей слагаемых; для зависимых величин — произведениям вероятности одного слагаемого на условную вероятность второго.
|
|
Т а б л и ц а 6. 6
6
Т а б л и ц а 6.7
Т а б л и ц а 6.8
Искомое среднее квадратическое отклонение равно:
.
Вопросы для повторения и контроля:
Опорные слова:
Числовые характеристики случайной величины, математическое ожидание, независимые случайные величины, произведение независимых случайных величин, сумма случайных величин, отклонение случайной величины, дисперсия, среднее квадратическое отклонение.
More in this category: « ТМЗ харакатининг бухгалтериядаги хисоби. Числовые характеристики непрерывных случайных величин. Виды непрерывных распределений »
back to top
3.4: Ожидаемое значение дискретных случайных величин
- Последнее обновление
- Сохранить как PDF
- Идентификатор страницы
- 12765
- Кристин Кутер
- Колледж Святой Марии
В этом и следующем разделах мы рассмотрим различные числовые характеристики дискретных случайных величин.
Ожидаемое значение дискретных случайных величин
Начнем с формального определения.
Определение \(\PageIndex{1}\)
Если \(X\) является дискретной случайной величиной с возможными значениями \(x_1, x_2, \ldots, x_i, \ldots\) и функцией массы вероятности \( p(x)\), то ожидаемое значение (или среднее ) \(X\) обозначается \(\text{E}[X]\) и задается как
$$\text{E}[X] = \sum_i x_i\cdot p(x_i).\label{expvalue}$$
Ожидаемое значение \(X\) также может обозначаться как \(\mu_X\) или просто \(\mu\), если контекст ясно.
Ожидаемое значение случайной величины имеет множество интерпретаций. Во-первых, глядя на формулу в определении 3.4.1 для вычисления ожидаемого значения (уравнение \ref{expvalue}), обратите внимание, что это, по сути, средневзвешенное значение . В частности, для дискретной случайной величины ожидаемое значение вычисляется путем «взвешивания» или умножения каждого значения случайной величины \(x_i\) на вероятность того, что случайная величина примет это значение, \(p( x_i)\), а затем суммирование всех возможных значений. Эта интерпретация ожидаемого значения как средневзвешенного объясняет, почему его также называют средним значением случайной величины.
Эта интерпретация ожидаемого значения как средневзвешенного объясняет, почему его также называют средним значением случайной величины.
Ожидаемое значение случайной величины переменная также интерпретируется как долгосрочное значение случайной величины. Другими словами, если мы повторим базовый случайный эксперимент несколько раз и возьмем среднее значение случайной величины, соответствующей результатам, мы получим приблизительно ожидаемое значение. (Примечание. Эта интерпретация ожидаемого значения аналогична аппроксимации относительной частоты для вероятности, обсуждавшейся в разделе 1.2.) Опять же, мы видим, что ожидаемое значение связано со средним значением случайной величины. Учитывая интерпретацию ожидаемого значения как среднего, «взвешенного» или «долгосрочного», ожидаемое значение часто называют мера центра случайной величины.
Наконец, математическое ожидание случайной величины имеет графическую интерпретацию. Ожидаемое значение дает центр масс функции массы вероятности, что демонстрирует следующий пример.
Ожидаемое значение дает центр масс функции массы вероятности, что демонстрирует следующий пример.
Пример \(\PageIndex{1}\)
Рассмотрим снова контекст примера 1.1.1, где мы записали последовательность орла и решки при двух подбрасываниях правильной монеты. В примере 3.1.1 мы определили дискретную случайную величину \(X\) для обозначения количества полученных решек. В примере 3.2.2 мы нашли плотность массы \(X\). Теперь мы применяем уравнение \ref{expvalue} из определения 3.4.1 и вычисляем ожидаемое значение \(X\):
\begin{align*}
\text{E}[X] &= 0\cdot p(0) + 1\cdot p(1) + 2\cdot p(2) \\
&= 0\cdot( 0.25) + 1\cdot(0.5) + 2\cdot(0.25) \\
&= 0.5 + 0.5 = 1.
\end{align*}
Таким образом, мы ожидаем, что число выпавших орлов при двух бросках честная монета будет равна 1 в долгосрочной перспективе или в среднем. На рисунке 1 показано графическое представление ожидаемого значения в виде центра масс функции массы вероятности.
Рисунок 1: Гистограмма \(X\). Красная стрелка представляет собой центр масс или ожидаемое значение \(X\) 9{th}\) бросок, для \(x=1,2,3\),
Тогда \(X\) — дискретная случайная величина с возможными значениями \(x=-1,1,2,3\), а pmf определяется следующей таблицей:
| \(x\) | \(р(х) = Р(Х=х)\) |
| \(-1\) | \(\ гидроразрыва{1}{8}\) |
| \(1\) | \(\ гидроразрыва{1}{2}\) |
| \(2\) | \(\ гидроразрыва{1}{4}\) |
| \(3\) | \(\ гидроразрыва{1}{8}\) |
Применяя определение 3.4.1, находим
\begin{align*}
\text{E}[X] &= \sum_i x_i\cdot p(x_i) \\

\end{align*}
Таким образом, ожидаемый выигрыш за одну игру составляет $1,25. Другими словами, если мы играли в игру несколько раз, мы ожидаем, что средний выигрыш составит 1,25 доллара.
Для многих распространенных распределений вероятностей ожидаемое значение задается параметром распределения. Ожидаемое значение может не быть точно равным параметру распределения вероятностей, а может быть функцией параметров. В следующей таблице приведены ожидаемые значения для каждого из распространенных дискретных распределений, включая распределение Бернулли и биномиальное распределение, которые мы представили ранее.
| Распределение | Ожидаемое значение |
| Бернулли(\(р\)) | \(р\) |
| двучлен(\(п, р\)) | \(нп\) |
| гипергеометрический(\(N, n, m\)) | \(\frac{nm}{N}\) |
| геометрический(\(р\)) | \(\frac{1}{p}\) |
| отрицательный бином(\(r, p\)) | \(\ frac{r}{p}\) |
| Пуассона (\(\лямбда\)) | \(\лямбда\) |
Ожидаемое значение функций случайных величин
Во многих приложениях нас может интересовать не значение самой случайной величины, а функция, примененная к случайной величине или набору случайных величин. 2\). Следующие теоремы, которые мы формулируем без доказательства, демонстрируют как вычислить ожидаемое значение функции случайных величин .
2\). Следующие теоремы, которые мы формулируем без доказательства, демонстрируют как вычислить ожидаемое значение функции случайных величин .
Теорема \(\PageIndex{1}\)
Пусть \(X\) — случайная величина, а \(g\) — функция с действительным знаком. Задайте случайную величину \(Y = g(X)\).
Если \(X\) является дискретной случайной величиной с возможными значениями \(x_1, x_2, \ldots, x_i, \ldots\) и функцией массы вероятности \(p(x)\), то ожидаемое значение \(Y\) задается как
$$\text{E}[Y] = \sum_i g(x_i)\cdot p(x_i).\notag$$
Проще говоря, теорема 3.4.1 утверждает что для нахождения ожидаемого значения функции случайной величины достаточно применить функцию к возможным значениям случайной величины в определении ожидаемого значения. Прежде чем сформулировать важный частный случай теоремы 3.4.1, несколько предостережений относительно порядка операций. Обратите внимание, что в целом 92\), в общем. Однако, как утверждает следующая теорема, в уравнении \ref{осторожно} есть исключения.
Частный случай теоремы 3.4.1
Пусть \(X\) — случайная величина. Если \(g\) является линейной функцией, т. е. \(g(x) = ax + b\), то
$$\text{E}[g(X)] = \text{E}[ aX + b] = a\text{E}[X] + b.\notag$$
Вышеприведенный частный случай называется линейностью ожидаемого значения, что подразумевает следующие свойства ожидаемого значения .
Линейность ожидаемого значения
Пусть \(X\) – случайная величина, \(c, c_1, c_2\) – константы, а \(g, g_1, g_2\) – функции с действительными значениями. Тогда ожидание \(\text{E}[\cdot]\) удовлетворяет следующему:
- Ожидаемое значение константы является постоянным: $$\text{E}[c] = c\notag$$
- Константы могут быть вынесены за пределы ожидаемых значений: $$\text{E}[cg(X)] = c\text{E}[g(X)]\notag$$
- Ожидаемое значение суммы равно сумме ожидаемых значений: $$\text{E}[c_1g_1(X) + c_2g_2(X)] = c_1\text{E}[g_1(X)] + c_2\ текст{E}[g_2(X)]\notag$$
- Наверх
- Была ли эта статья полезной?
- Тип изделия
- Раздел или Страница
- Автор
- Кристин Кутер
- Показать оглавление
- да
- Теги
- источник[1]-статистика-4372
- источник[2]-stats-4372
Логарифмически нормальное распределение | Свойства и доказательства
Марко Табога, доктор философии
Говорят, что случайная величина имеет логарифмически нормальное распределение, если ее естественное
логарифм имеет
нормальный
распределение.
Другими словами, экспонента нормальной случайной величины имеет логнормальный распределение.
Содержание
Определение
Отношение к нормальному распределению
Ожидаемое значение
Диазиат
- 9
- 9
- 9
. функция
Функция распределения
Решенные упражнения
Упражнение 1
Определение
Логнормальные случайные величины характеризуются следующим образом.
Определение Позволять быть непрерывным случайная переменная. Пусть это поддержка быть набор строго положительного реального номера:мы скажи это имеет логарифмически нормальное распределение с параметры и если его функция плотности вероятности
Отношение к нормальному распределению
Отношение к нормальному распределению сформулировано в следующем
предложение.
Предложение Позволять быть нормальной случайной величиной со средним значением и дисперсия . Тогда переменнаяимеет логарифмически нормальное распределение с параметрами и .
Доказательство
Если имеет нормальное распределение, то его функция плотности вероятности это функция строго возрастает, поэтому мы можем использовать формула для плотности строго возрастающей функцияВ в частности, мы иметьсо что
Ожидаемое значение
Ожидаемое значение логнормальной случайной величины
Доказательство
Это
можно вывести как
следует: где:
в ногу
мы сделали замену
переменная и
в ногу
мы использовали тот факт, что
является
функция плотности нормальной случайной величины со средним
и единичной дисперсии, и, как следствие, его интеграл равен
1.
Разница
Дисперсия логнормальной случайной величины
Доказательство
Пусть сначала выведем второй момент куда: в ногу мы сделали замену переменная и в ногу мы использовали тот факт, что является функция плотности нормальной случайной величины со средним и единичной дисперсии, и, как следствие, его интеграл равен 1. Мы можем теперь используйте формулу дисперсии
Высшие моменты
-й момент логнормального случайная переменная
Доказательство
Это можно вывести следующим образом: куда: в ногу мы сделали замену переменная и в ногу мы использовали тот факт, что является функция плотности нормальной случайной величины со средним и единичной дисперсии, и, как следствие, его интеграл равен 1.
Функция генерации момента
Логнормальное распределение не обладает
производящая момент функция.
Характеристическая функция
Замкнутая формула для характеристической функции логнормальная случайная величина неизвестна.
Функция распределения
Функция распределения логнормальной случайной величины может быть выражено как где — функция распределения стандартной нормальной случайной величины.
Доказательство
Выше мы доказали, что логнормальный переменная можно написать как где имеет нормальное распределение со средним и дисперсия . По очереди, можно написать как где — стандартная нормальная случайная величина. Как следствие,
Решенные упражнения
Ниже вы можете найти несколько упражнений с поясненными решениями.
Упражнение 1
Случайная величина
имеет логарифмически нормальное распределение со средним значением и дисперсией, равными
и
соответственно.