
Занятие 6. Проверка нормальности распределения значений признака — Основы доказательной медицины. Биомедицинская статистика. — Внауке.by
Проверка нормальности распределения значений признака
Классическим параметрическим методом, позволяющим сравнить средние значения изучаемого признака, рассчитанные на основе двух выборок, является t-тест Стьюдента (или просто «t-тест»).
Критерий Стьюдента (t-тест Стьюдента или просто «t-тест») применяется, если нужно сравнить только две группы количественных признаков с нормальным распределением (частный случай дисперсионного анализа). Но применение его является оправданным лишь примерно в 20% случаев! Этим критерием нельзя пользоваться, сравнивая попарно несколько групп, в этом случае необходимо применять дисперсионный анализ. Ошибочное использование критерия Стьюдента увеличивает вероятность «выявить» несуществующие различия. Например, вместо того, чтобы признать несколько методов лечения равно эффективными (или неэффективными), один из них объявляют лучшим.
Применение «t-теста» допустимо при наличии следующих условий:
- соответствие частотного распределения данных в каждой из сравниваемых групп закону нормального распределения;
- отсутствие статистически значимой разницы между дисперсиями сравниваемых групп (однородность дисперсий).
- наличие достаточно большого числа наблюдений в обеих сравниваемых группах (не меньше 20).
Если данные условия не соблюдать, то применение теста Стьюдента приведет к ошибочным результатам. Наиболее «опасным» является несоблюдение требования о нормальности распределения значений признака в каждой из сравниваемых группах. Существует достаточно большое число способов проверить, соответствуют ли анализируемые данные нормальному распределению. Мы рассмотрим три подхода, реализованные в программе STATISTICA.
На рисунке 1 представлены данные о количестве лейкоцитов у 50 пациентов с перитонитом.
Рисунок 1. Количество лейкоцитов у пациентов с перитонитом
В программе STATISTICA имеется специальный модуль для проверки соответствия данных тому или иному закону распределения случайных величин — Distribution Fitting (Подгонка распределений). Этот модуль можно запустить из пункта главного меню Statistics, или нажав на кнопку на дополнительной панели инструментов (ввод данной панели описан в занятии 1).
Рисунок 2. Выбор специального модуля — Distribution Fitting (Подгонка распределений)
Внешний вид окна модуля приведен на рисунке 2.
Рисунок 3. Модуль Distributions fitting программы STATISTICA

Поскольку мы хотим проверить, подчиняются ли данные о количестве лейкоцитов пациентов нормальному распределению, в списке непрерывных распределений (Continuous distributions) выбираем Normal и жмем ОК. Далее появится еще одно окошко (рисунок 4), где необходимо указать программе, какую именно переменную мы хотим проанализировать, и как. Переменная для анализа задается путем нажатия кнопки Variables. Остальные настройки можно оставить неизменными.
Рисунок 4. Окно Fitting continuous distributions (Подгонка непрерывных распределений) модуля
Distribution fittingНажав на кнопку Plot of observed and expected distributions (Изобразить наблюдаемое и ожидаемое распределения), получим гистограмму распределения данных о количестве лейкоцитов и колоколообразную красную кривую (рисунок 5), соответствующую ожидаемому нормальному распределению (у него те же средняя арифметическая и стандартное отклонение, что и в анализируемой совокупности).
Рисунок 5. Графический результат анализа, выполненного в модуле Distribution Fitting
В целом распределение значений анализируемого признака на рисунке совпадает с нормальным (столбики гистограммы примерно выстраиваются в колоколообразную фигуру). Это заключение, основанное на визуальном анализе распределения, имеет и более строгое подтверждение в виде результатов теста хи-квадрат (
Однако, следует отметить, что мощность теста хи-квадрат при проверке нормальности распределения относительно невысока. Поэтому лучше воспользоваться другими тестами.
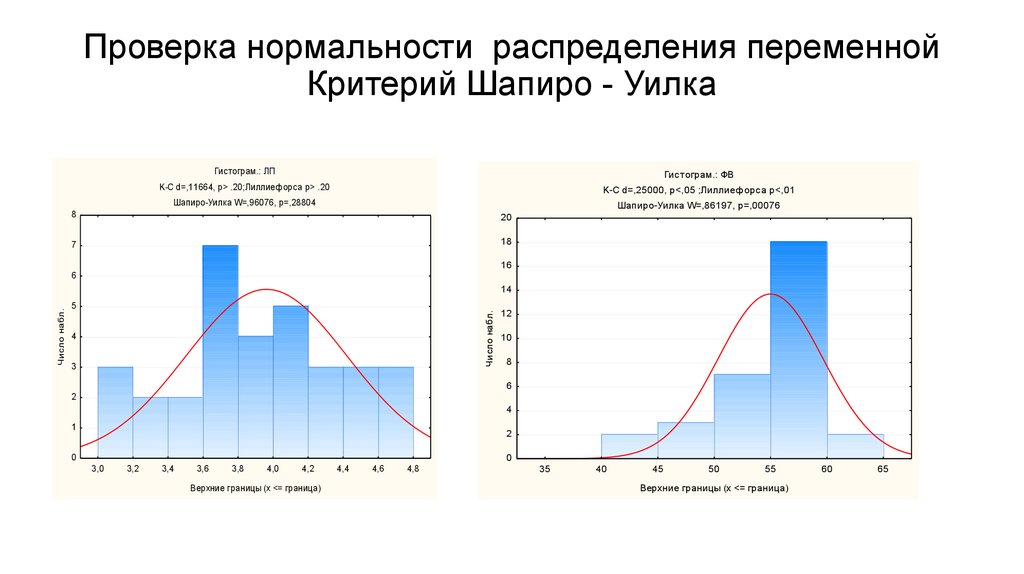
Их можно найти в модуле Descriptive Statistics (Описательная статистика), который находится здесь: Statistics > Basic Statistics/Tables. После запуска этого модуля необходимо открыть закладку Normality и в поле Distribution (Распределение) разыскать опции Kolmogorov-Smirnov and Lilliefors test for normality (Тест Колмогорова-Смирнова и Лиллиефорса на нормальность) и Shapiro-Wilk’s W test (W-тест Шапиро-Уилка) (рисунок 6).
После запуска этого модуля необходимо открыть закладку Normality и в поле Distribution (Распределение) разыскать опции Kolmogorov-Smirnov and Lilliefors test for normality (Тест Колмогорова-Смирнова и Лиллиефорса на нормальность) и Shapiro-Wilk’s W test (W-тест Шапиро-Уилка) (рисунок 6).
Рисунок 5. Окно модуля Descriptive Statistics на закладке Normality
Равно как и критерий хи-квадрат, оба эти теста проверяют гипотезу об отсутствии различий между наблюдаемым распределением признака и теоретически ожидаемым нормальным распределением. Наиболее предпочтительным является использование W-критерия Шапиро-Уилка, поскольку он обладает наибольшей мощностью в сравнении со всеми перечисленными критериями (т.е. чаще выявляет различия между распределениями в тех случаях, когда они действительно есть).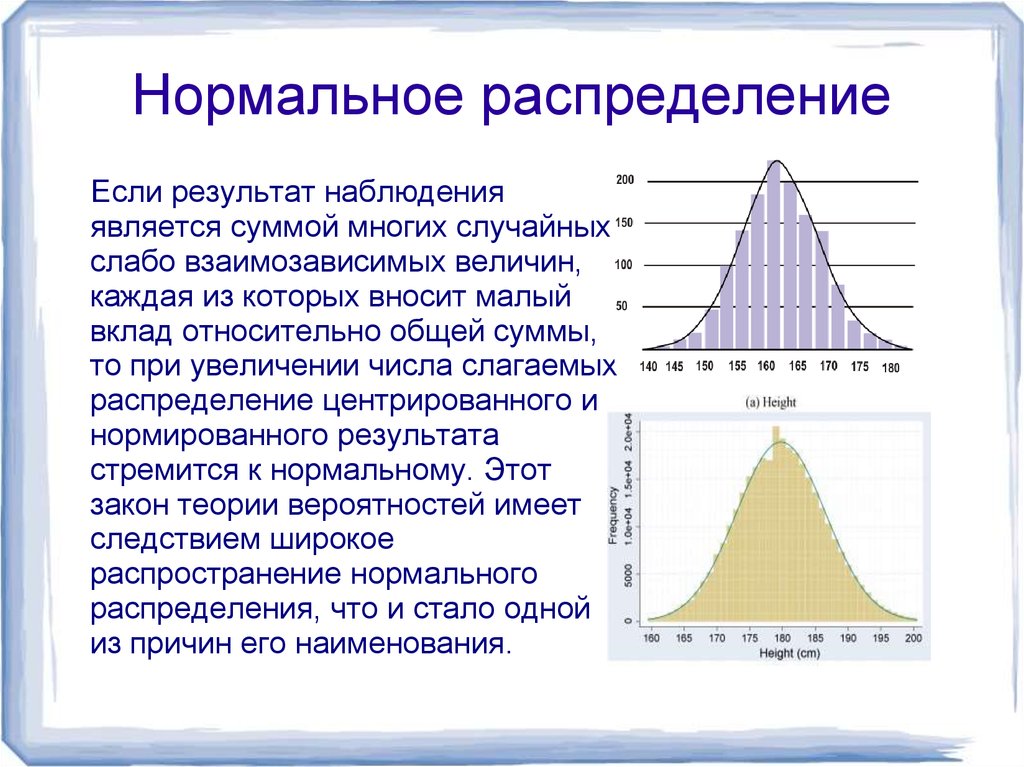
Для выбора того или иного теста, достаточно поставить флажок рядом с его названием. После выбора анализируемой переменной (кнопка Variables) и нажатия кнопки Histograms программа нарисует график с гистограммой распределения значений признака и ожидаемую нормальную кривую (рисунок 6). Результаты тестов на нормальность автоматически располагаются в заголовке этого графика. Как и ранее, при Р > 0.05 следует вывод о том, что анализируемое распределение не отличается от нормального.
Рисунок 6. Результат проверки нормальности распределения данных, выполненной при помощи модуля Descriptive Statistics
Добавление комментариев доступно только зарегистрированным пользователям
Microsoft Word — Сборник1_макет.docx
%PDF-1.4 % 1 0 obj > /OCGs [4 0 R] >> /Pages 5 0 R /Type /Catalog >> endobj 6 0 obj >> endobj 2 0 obj > /Font > >> /Fields [] >> endobj 3 0 obj > stream application/pdf
 docx
docxЧто такое нормальное распределение? – Определение TechTarget
К
- Рахул Авати
Нормальное распределение — это тип непрерывного распределения вероятностей, при котором большинство точек данных сгруппировано ближе к середине диапазона, а остальные симметрично сужаются к любому из крайних значений. Середина диапазона также известна как 9.0023 означает дистрибутива.
Середина диапазона также известна как 9.0023 означает дистрибутива.
Нормальное распределение также известно как распределение Гаусса или вероятность колоколообразная кривая . Он симметричен относительно среднего и указывает на то, что значения, близкие к среднему, встречаются чаще, чем значения, которые дальше от среднего.
Объяснение нормального распределенияГрафически нормальное распределение представляет собой колоколообразную кривую из-за ее расширяющейся формы. Точная форма может варьироваться в зависимости от распределения значений в совокупности. Совокупность — это весь набор точек данных, которые являются частью распределения.
Независимо от формы, колоколообразная кривая нормального распределения всегда симметрична относительно среднего значения. Симметричное распределение означает, что вертикальная разделительная линия, проведенная через максимальное/среднее значение, даст два зеркальных изображения по обе стороны от линии, в которых половина населения меньше среднего, а половина больше. Однако обратное не всегда верно; то есть не все симметричные распределения являются нормальными. На кривой нормального распределения пик всегда находится посередине, а среднее значение, мода и медиана одинаковы.
Однако обратное не всегда верно; то есть не все симметричные распределения являются нормальными. На кривой нормального распределения пик всегда находится посередине, а среднее значение, мода и медиана одинаковы.
Высота — это простой пример значений, которые следуют нормальному шаблону распределения. Большинство людей среднего роста — каким бы он ни был для данного населения. Если рост этих людей представлен в графическом формате вместе с ростом людей, которые выше и ниже среднего, распределение всегда будет нормальным. Это связано с тем, что люди среднего роста будут сгруппированы ближе к середине, а те, кто выше и ниже, будут дальше.
Далее, эти последние группы будут состоять из очень небольшого числа людей. Количество очень высоких или очень низких людей будет еще меньше, поэтому они будут дальше всего от среднего.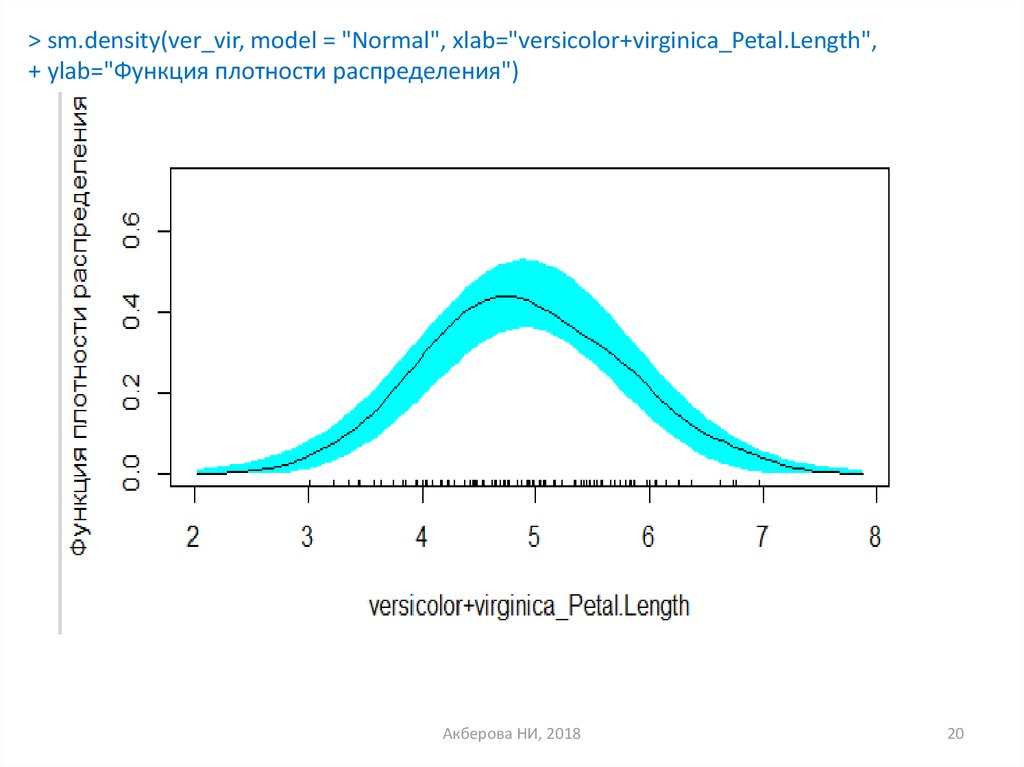
Точно так же вес может подчиняться нормальному распределению, если известен средний вес рассматриваемой совокупности. Как и в случае с ростом, отклонениями в весе будут те, кто весит больше или меньше среднего. Чем больше отклонение от среднего, тем дальше будут эти точки данных на графике распределения.
Важность нормального распределенияНормальное распределение является одним из наиболее важных распределений вероятностей для независимых случайных величин по трем основным причинам.
Во-первых, нормальное распределение описывает распределение значений многих природных явлений в широком диапазоне областей, включая биологию, физические науки, математику, финансы и экономику. Он также может точно представлять эти случайные величины.
Помимо роста и веса, нормальное распределение также используется для представления многих других величин, включая следующие:
- ошибка измерения
- кровяное давление
- балла IQ
- цены активов
- ценовое действие
Во-вторых, нормальное распределение важно, поскольку его можно использовать для аппроксимации других типов распределения вероятностей, таких как биномиальное, гипергеометрическое, обратное (или отрицательное) гипергеометрическое, отрицательное биномиальное и распределение Пуассона.
В-третьих, нормальное распределение является ключевой идеей центральной предельной теоремы, или CLT, которая утверждает, что средние значения, вычисленные из независимых, одинаково распределенных случайных величин, имеют приблизительно нормальное распределение. Это верно независимо от типа распределения, из которого отбираются переменные, если оно имеет конечную дисперсию.
Формула нормального распределения и эмпирическое правилоФормула нормального распределения представлена ниже.
Формула нормального распределения.Здесь x — значение переменной; f(x) представляет функцию плотности вероятности; мк (мю) — среднее значение; σ (сигма) — стандартное отклонение.
Эмпирическое правило нормального распределения описывает, где будет появляться большая часть данных в нормальном распределении, и утверждает следующее:
- 68,2% наблюдений появятся в пределах +/-1 стандартного отклонения от среднего;
- 95,4% наблюдений будут находиться в пределах +/-2 стандартных отклонения; и
- 99,7% наблюдений будут находиться в пределах +/-3 стандартных отклонения.


Все точки данных, выходящие за пределы трех стандартных отклонений (3σ), указывают на редкие случаи.
Параметры нормального распределенияПоскольку среднее значение, мода и медиана в нормальном распределении одинаковы, нет необходимости вычислять их отдельно. Эти значения представляют собой наивысшую точку распределения или пик. Все остальные значения в распределении затем падают симметрично вокруг среднего значения. Ширина среднего определяется стандартным отклонением.
Фактически, для описания нормального распределения требуются только два параметра: среднее значение и стандартное отклонение.
1. Среднее
Среднее значение — это центральное самое высокое значение кривой нормального распределения. Все остальные значения в распределении либо группируются вокруг него, либо находятся на некотором расстоянии от него. Изменение среднего значения на графике сдвинет всю кривую по оси X либо влево, либо вправо.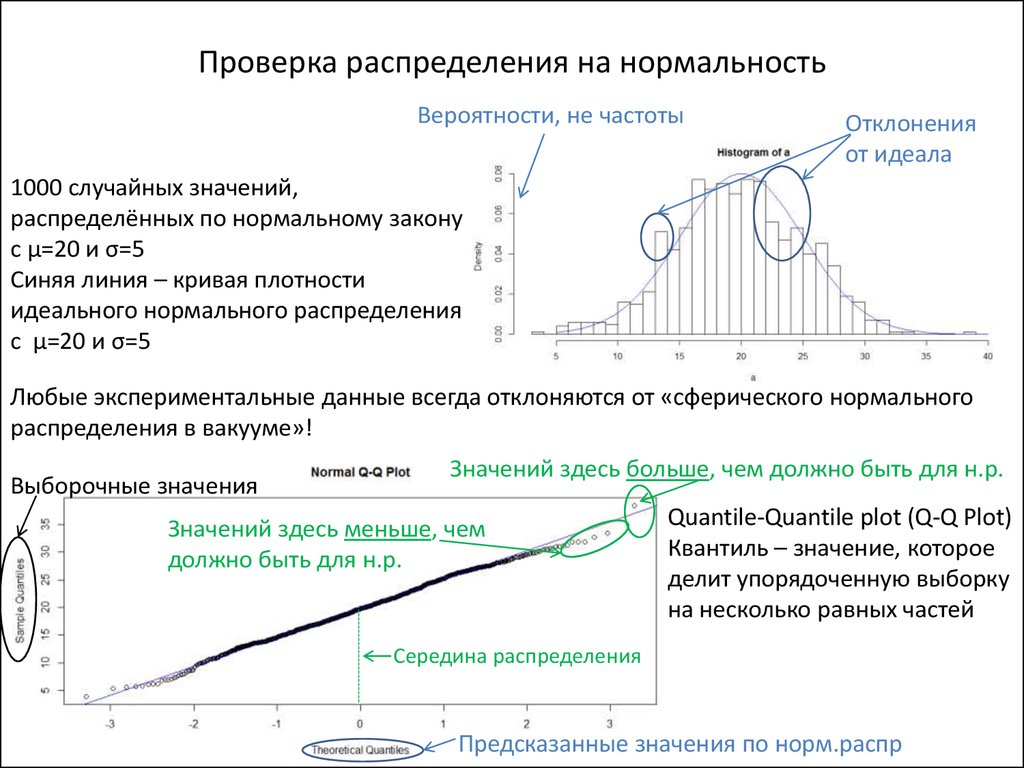 Однако его симметричность все равно будет сохраняться.
Однако его симметричность все равно будет сохраняться.
2. Стандартное отклонение
Обычно стандартное отклонение является мерой изменчивости распределения. В колоколообразной кривой он определяет ширину распределения и показывает, насколько далеко от среднего значения падают другие значения. Кроме того, он представляет типичное расстояние между средним значением и наблюдениями.
Изменение стандартного отклонения изменит распределение значений вокруг среднего значения. Меньшее отклонение уменьшит разброс — ужесточит распределение — в то время как большее отклонение увеличит разброс и создаст более широкое распределение. По мере того, как распределение становится шире, становится более вероятным, что значения будут дальше от среднего.
 techtarget.com» type=»text/html» frameborder=»0″> Асимметрия и эксцесс в нормальном распределении
techtarget.com» type=»text/html» frameborder=»0″> Асимметрия и эксцесс в нормальном распределенииАсимметрия представляет собой степень симметрии распределения. Поскольку нормальное распределение совершенно симметрично, его асимметрия равна нулю. В других распределениях с асимметрией меньше или больше нуля левый хвост (левая асимметрия) или правый хвост (правая асимметрия) будут соответственно длиннее.
Эксцесс измеряет толщину каждого хвоста распределения по отношению к хвостам нормального распределения. Для нормального распределения эксцесс всегда равен 3. В распределении с эксцессом больше 3 хвостовые данные превышают хвосты нормального распределения, что приводит к явлению, называемому курдючные . На финансовых рынках толстые хвосты описывают хвостовой риск — вероятность убытка из-за какого-то редкого события. Распределения с эксцессом менее 3 показывают более тонкие хвосты, чем хвосты нормального распределения.
См.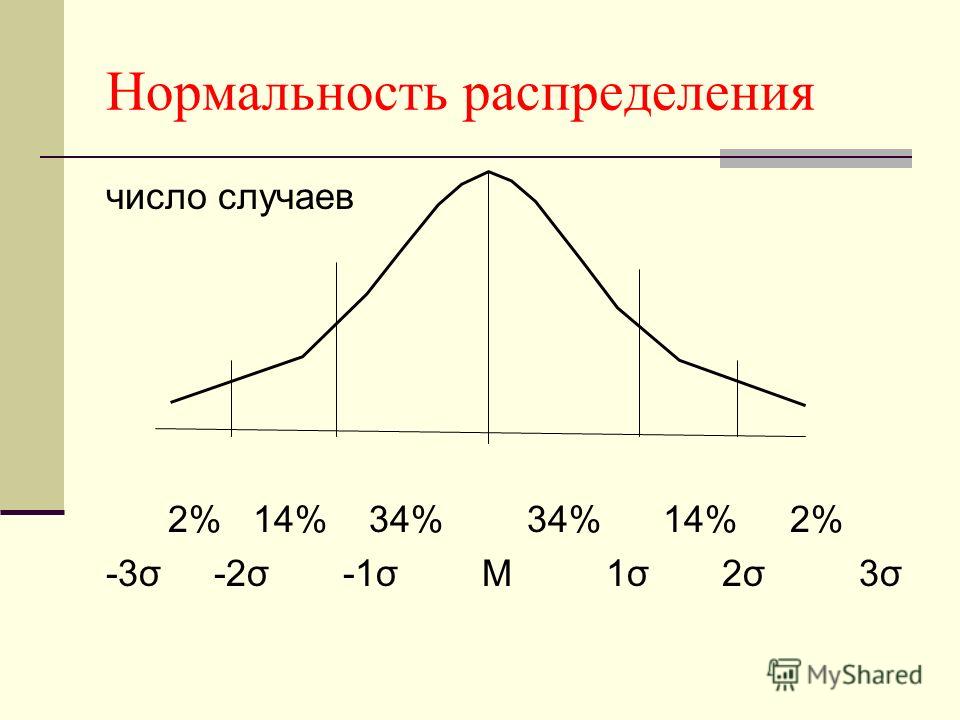 также: статистический анализ, гистограмма, зависимая переменная, данные, исследователь данных, большие данные, классификация данных, интеллектуальный анализ данных, контекст данных и анализ временных рядов в ИТ-средах.
также: статистический анализ, гистограмма, зависимая переменная, данные, исследователь данных, большие данные, классификация данных, интеллектуальный анализ данных, контекст данных и анализ временных рядов в ИТ-средах.
Последнее обновление: декабрь 2022 г.
Продолжить чтение О нормальном распределении- Общие методы обработки данных, которые необходимо знать и использовать
- Навыки работы с данными для машинного обучения и искусственного интеллекта
- Введение в типы и методы ведения журнала IoT
- Случайные процессы имеют различное практическое применение
- Специалист по данным и бизнес-аналитик: в чем разница?
распознавание образов
Распознавание изображений в контексте машинного зрения — это способность программного обеспечения идентифицировать объекты, места, людей, надписи и действия на цифровых изображениях.
Сеть
- телематика
Телематика — это термин, объединяющий слова «телекоммуникации» и «информатика» для описания использования средств связи и ИТ для …
- фильтрация пакетов
Фильтрация пакетов — это процесс пропуска или блокировки пакетов данных на сетевом интерфейсе брандмауэром на основе источника и …
- WAN (глобальная сеть)
Глобальная вычислительная сеть (WAN) — это географически распределенная частная телекоммуникационная сеть, которая соединяет между собой несколько локальных …
Безопасность
- FIDO (быстрая идентификация онлайн)
FIDO (Fast Identity Online) — это набор спецификаций безопасности, не зависящих от технологий, для строгой аутентификации.
- Альянс облачной безопасности (CSA)
Альянс по безопасности облачных вычислений (CSA) — это некоммерческая организация, которая продвигает исследования передовых методов обеспечения безопасности облачных .
.. - квантовое превосходство
Квантовое превосходство — это экспериментальная демонстрация доминирования и преимущества квантового компьютера над классическими компьютерами с помощью …
 ..
..ИТ-директор
- сделка
В вычислениях транзакция представляет собой набор связанных задач, рассматриваемых как одно действие.
- бережливое управление
Бережливое управление — это подход к управлению организацией, который поддерживает концепцию постоянного совершенствования, долгосрочного …
- идентификатор устройства (идентификация устройства)
Идентификатор устройства (идентификация устройства) — это анонимная строка цифр и букв, которая однозначно идентифицирует мобильное устройство, такое как …
HRSoftware
- вовлечения сотрудников
Вовлеченность сотрудников — это эмоциональная и профессиональная связь, которую сотрудник испытывает к своей организации, коллегам и работе.
- кадровый резерв
Кадровый резерв — это база данных кандидатов на работу, которые могут удовлетворить немедленные и долгосрочные потребности организации.
- разнообразие, равенство и инклюзивность (DEI)
Разнообразие, равенство и инклюзивность — термин, используемый для описания политики и программ, которые способствуют представительству и …

Служба поддержки клиентов
- лид, квалифицированный продуктом (PQL)
Лид, квалифицированный по продукту (PQL), — это физическое или юридическое лицо, которое получило выгоду от использования продукта в результате бесплатного …
- квалифицированный маркетолог лид (MQL)
Квалифицированный маркетолог (MQL) — это посетитель веб-сайта, уровень вовлеченности которого указывает на то, что он может стать клиентом.
- успех клиента
Успех клиента — это стратегия, направленная на то, чтобы продукция компании соответствовала потребностям клиента.
92\) — дисперсия. Распределение Z можно описать как \(N(0,1)\). Обратите внимание, что поскольку стандартное отклонение представляет собой квадратный корень из дисперсии, то стандартное отклонение стандартного нормального распределения равно 1,. Стандартное нормальное распределение 0,0 0,1 0,2 0,3 0,4 −2 −1 1 −3 3 0 2 X Стандартное нормальное распределение, N(0,1)Нахождение вероятностей стандартной нормальной случайной величины Раздел
Как мы упоминали ранее, для определения вероятностей нормальной случайной величины требуется исчисление. К счастью, у нас есть таблицы и программное обеспечение, которые могут нам помочь.
Любую нормальную случайную величину можно преобразовать в стандартную нормальную случайную величину, найдя Z-оценку . Затем мы можем найти вероятности, используя стандартные нормальные таблицы.
Большинство книг по статистике содержат таблицы для отображения площади под стандартной нормальной кривой. Найдите в приложении к учебнику стандартную нормальную таблицу. Мы включили аналогичную таблицу, Стандартную таблицу нормальной кумулятивной вероятности, чтобы вы могли распечатать ее и легко обращаться к ней при работе над домашним заданием.
Большинство стандартных нормальных таблиц содержат «вероятности меньше». Например, если \(Z\) является стандартной нормальной случайной величиной, в таблицах указано \(P(Z\le a)=P(Z
Пример 3-9: Вероятность «меньше чем» Раздел
Найдите площадь под стандартной кривой нормали слева от 0,87.
Есть два основных способа, которыми статистики находят эти числа, не требующие вычислений! Нажмите на вкладки ниже, чтобы увидеть, как отвечать с помощью таблицы и технологий.
- Метод 1: Использование таблицы
- Метод 2: Использование Minitab
Типичное число с четырьмя десятичными знаками в основной части таблицы стандартной нормальной кумулятивной вероятности дает площадь под стандартной нормальной кривой, лежащей слева от заданного значения z. Вероятность слева от z = 0,87 равна 0,8078, и ее можно найти, прочитав таблицу:
- Поскольку z = 0,87 является положительным, используйте таблицу для ПОЛОЖИТЕЛЬНЫХ значений z.
- Перейдите вниз по левой колонке, пометьте z до «0,8».
- Затем пройдитесь по этой строке до отметки «0,07» в верхней строке.
Вы должны найти значение 0,8078. Следовательно, \(P(Z<0,87)=P(Z\le 0,87)=0,8078\)
5z 9 .00 .01 .02 .03 .04 . 05.06 .07 .08 .09 0,6 .7257 .7291 .7324 .7357 .7389 .7422 .7454 .7586 .7517 .7549 0,7 .7580 .7611 .7642 .7673 .7704 .7734 .7764 .7794 .7823 .7852 0,8 .7881 .7910 .7939 .7967 .7995 .8023 .8051 .8078 .8106 .8133 0,9 .8159 .8186 .8212 .8238 .8264 .8289 .8315 .8340 .8365 .8389 Использование Minitab
Чтобы найти площадь слева от z = 0,87 в Minitab.
..- В меню Minitab выберите Calc > Распределения вероятностей > Normal .
- Выберите Суммарная вероятность .
- В поле Вводная константа введите 0,87. Нажмите ОК
Вы должны увидеть значение очень близкое к 0,8078.
Пример 3-10: Вероятность «больше» Раздел
Найдите площадь под стандартной нормальной кривой справа от 0,87.
- Метод 1: Использование таблицы
- Метод 2: Использование Minitab
Основываясь на определении функции плотности вероятности, мы знаем, что площадь под всей кривой равна единице. Поскольку нам даны вероятности «меньше» в таблице, мы можем использовать дополнения, чтобы найти вероятности «больше». Следовательно,
\(P(Z>0,87)=1-P(Z\le 0,87)\).
Используя информацию из последнего примера, мы имеем \(P(Z>0,87)=1-P(Z\le 0,87)=1-0,8078=0,1922\)
Используя Minitab
Поскольку нам дано “ «меньше чем» при использовании кумулятивной вероятности в Minitab мы можем использовать дополнения, чтобы найти «больше чем» вероятности.
Следовательно,\(P(Z>0,87)=1-P(Z\le 0,87)\).
Используя информацию из последнего примера, мы имеем \(P(Z>0,87)=1-P(Z\le 0,87)=1-0,8078=0,1922\)
Вы также можете использовать графики распределения вероятностей в Minitab, чтобы найти «больше».
- Выберите График > График распределения вероятностей > Просмотр вероятности и нажмите OK .
- Во всплывающем окне выберите нормальное распределение со средним значением 0,0 и стандартным отклонением 1,0.
- Выберите вкладку Shaded Area в верхней части окна.
- Выберите X Значение.
- Введите 0,87 для X значение .
- Выберите Правый хвост.
- Щелкните OK .
Пример 3-11: Вероятность «между» Раздел
Найдите площадь под стандартной нормальной кривой между 2 и 3.
- Метод 1: Использование таблицы
- Метод 2: Использование Minitab
Чтобы найти вероятность между этими двумя значениями, вычтите вероятность меньше 2 из вероятности меньше 3. Другими словами,
\(P(2
\(P(Z<3)\) и \(P(Z<2)\ ) можно найти в таблице, выполнив поиск 2.0 и 3.0.
Для 3.0...
z .00 .01 .02 .03 .04 .05 .06 .07 .08 .09 2,8 0,9974 0,9975 0,9976 0,9977 0,9977 0,9978 0,9979 0,9979 0,9980 0,9980 2,9 0,9981 0,9982 0,9982 0,9983 0,9984 0,9984 0,9985 0,9985 0,9986 0,9986 3,0 0,9987 0,9987 0,9987 0,9988 0,9988 0,9989 0,9989 0,9989 0,9990 0,9990 3. 10,9990 0,9991 0,9991 0,9991 0,9992 0,9992 0,9992 0,9992 0,9993 0,9993 Для 2.0...
3 5z 3 .00 .01 .02 .03 .04 .05 .06 .07 .08 .09 1,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,9706 1,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,9767 2,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,9817 2. 10,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,9857 \(P(2 < Z < 3) = P(Z < 3) - P(Z \le 2) = 0,9987 - 0,9772 = 0,0215\).
Использование Minitab
Чтобы найти область между 2,0 и 3,0, мы можем использовать метод расчета в предыдущих примерах, чтобы найти совокупные вероятности для 2,0 и 3,0, а затем вычесть.
\(P(2 < Z < 3)= P(Z < 3) - P(Z \le 2)= 0,9987 - 0,9772= 0,0215\)
Вы также можете использовать графики распределения вероятностей в Minitab, чтобы найти «между».
- Выберите График > График распределения вероятностей > Просмотр вероятности и нажмите OK .
- Во всплывающем окне выберите нормальное распределение со средним значением 0,0 и стандартным отклонением 1,0.
- Выберите вкладку Shaded Area в верхней части окна. 9{th}\) перцентиль – это значение, превышающее \(p(100\%)\) значений в наборе данных. Мы можем использовать стандартную нормальную таблицу и программное обеспечение, чтобы найти процентили для стандартного нормального распределения.
Пересечение столбцов и строк в таблице дает вероятность. Если мы поищем конкретную вероятность в таблице, мы сможем найти соответствующее значение Z.
Пример 3-12: Процентили стандартного нормального распределения Раздел
Найдите 10-й процентиль стандартной нормальной кривой.
- Метод 1: Использование таблицы
- Метод 2: Использование Minitab
Вопрос касается значения, слева от которого площадь 0,1 под стандартной кривой нормали.
Поскольку записи в Таблице стандартной нормальной кумулятивной вероятности представляют вероятности и представляют собой числа с четырьмя десятичными знаками, мы будем писать 0,1 как 0,1000, чтобы напомнить себе, что это соответствует внутренней записи таблицы.
Мы просматриваем тело таблиц и обнаруживаем, что ближайшее значение к 0,1000 — это 0,1003. Мы смотрим в крайний левый угол строки и вверх по столбцу, чтобы найти соответствующее значение z.
: Соответствующее значение z равно -1,28. Таким образом, z = -1,28.з .00 .01 .02 .03 .04 .05 .06 .07 .08 .09 -1,3 0,0968 0,0951 0,934 0,0918 0,0901 0,0885 0,0869 0,0853 0,0838 0,0823 -1,2 0,1150 0,1131 0,1112 0,1093 0,1075 0,1056 0,1038 0,1020 0,1003 00985 -1,1 0,1357 0,1335 0,1314 0,1292 0,1271 0,1251 0,1230 0,1210 0,1190 0,1170 -1,0 0,1587 0,1562 0,1539 0,1515 0,1492 0,1469 0,1446 0,1423 0,1401 0,1379
Следовательно, 10-й процентиль стандартного нормального распределения равен -1,28 .


 05
05 ..
.. Следовательно,
Следовательно,
 1
1 1
1
 Мы просматриваем тело таблиц и обнаруживаем, что ближайшее значение к 0,1000 — это 0,1003. Мы смотрим в крайний левый угол строки и вверх по столбцу, чтобы найти соответствующее значение z.
Мы просматриваем тело таблиц и обнаруживаем, что ближайшее значение к 0,1000 — это 0,1003. Мы смотрим в крайний левый угол строки и вверх по столбцу, чтобы найти соответствующее значение z. 