
ЕСЛИ (функция ЕСЛИ) — Служба поддержки Майкрософт
Формулы и функции
-
Общие сведения о формулах в Excel
Статья -
ПРОСМОТРX
Статья -
ВПР
Статья -
Функция СУММ
Статья -
Функция СЧЁТЕСЛИ
Статья -
Функция ЕСЛИ
Статья -
ЕСЛИМН
Статья -
СУММЕСЛИ
Статья -
СУММЕСЛИМН
Статья -
ПОИСКПОЗ
Статья
Далее: Использование функций
Функция ЕСЛИ — одна из самых популярных функций в Excel. Она позволяет выполнять логические сравнения значений и ожидаемых результатов.
Она позволяет выполнять логические сравнения значений и ожидаемых результатов.
Поэтому у функции ЕСЛИ возможны два результата. Первый результат возвращается в случае, если сравнение истинно, второй — если сравнение ложно.
Например, функция =ЕСЛИ(C2=»Да»;1;2) означает следующее: ЕСЛИ(С2=»Да», то вернуть 1, в противном случае вернуть 2).
Функция ЕСЛИ, одна из логических функций, служит для возвращения разных значений в зависимости от того, соблюдается ли условие.
ЕСЛИ(лог_выражение; значение_если_истина; [значение_если_ложь])
Например:
|
Имя аргумента |
Описание |
|---|---|
|
лог_выражение (обязательно) |
Условие, которое нужно проверить. |
|
значение_если_истина (обязательно) |
Значение, которое должно возвращаться, если лог_выражение имеет значение ИСТИНА. |
|
значение_если_ложь (необязательно) |
Значение, которое должно возвращаться, если лог_выражение имеет значение ЛОЖЬ. |

Простые примеры функции ЕСЛИ
-
=ЕСЛИ(C2=»Да»;1;2)
В примере выше ячейка D2 содержит формулу: ЕСЛИ(C2 = Да, то вернуть 1, в противном случае вернуть 2)
В этом примере ячейка D2 содержит формулу: ЕСЛИ(C2 = 1, то вернуть текст «Да», в противном случае вернуть текст «Нет»). Как видите, функцию ЕСЛИ можно использовать для сравнения и текста, и значений. А еще с ее помощью можно оценивать ошибки. Вы можете не только проверять, равно ли одно значение другому, возвращая один результат, но и использовать математические операторы и выполнять дополнительные вычисления в зависимости от условий. Для выполнения нескольких сравнений можно использовать несколько вложенных функций ЕСЛИ.
Как видите, функцию ЕСЛИ можно использовать для сравнения и текста, и значений. А еще с ее помощью можно оценивать ошибки. Вы можете не только проверять, равно ли одно значение другому, возвращая один результат, но и использовать математические операторы и выполнять дополнительные вычисления в зависимости от условий. Для выполнения нескольких сравнений можно использовать несколько вложенных функций ЕСЛИ.
В примере выше функция ЕСЛИ в ячейке D2 означает: ЕСЛИ(C2 больше B2, то вернуть текст «Превышение бюджета», в противном случае вернуть текст «В пределах бюджета»)
На рисунке выше мы возвращаем не текст, а результат математического вычисления. Формула в ячейке E2 означает: ЕСЛИ(значение «Фактические» больше значения «Плановые», то вычесть сумму «Плановые» из суммы «Фактические», в противном случае ничего не возвращать).
В этом примере формула в ячейке F7 означает: ЕСЛИ(E7 = «Да», то вычислить общую сумму в ячейке F5 и умножить на 8,25 %, в противном случае налога с продажи нет, поэтому вернуть 0)
Примечание: Если вы используете текст в формулах, заключайте его в кавычки (пример: «Текст»). Единственное исключение — слова ИСТИНА и ЛОЖЬ, которые Excel распознает автоматически.
Единственное исключение — слова ИСТИНА и ЛОЖЬ, которые Excel распознает автоматически.
Распространенные неполадки
|
Проблема |
Возможная причина |
|---|---|
|
0 (ноль) в ячейке |
Не указан аргумент значение_если_истина или значение_если_ложь. Чтобы возвращать правильное значение, добавьте текст двух аргументов или значение ИСТИНА/ЛОЖЬ. |
|
#ИМЯ? в ячейке |
Как правило, это указывает на ошибку в формуле. |
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Функция ЕСЛИ — вложенные формулы и типовые ошибки
Функция УСЛОВИЯ
Использование ЕСЛИ с функциями И, ИЛИ и НЕ
СЧЁТЕСЛИ
Рекомендации, позволяющие избежать появления неработающих формул
Общие сведения о формулах в Excel
Знакомство с R (молниеносное и поверхностное).
- О курсе
- Презентации и данные
- Полезности
Собственно, сам R
RStudio — среда для разработки (IDE) на R
Онлайн IDE для R — на тот случай, если у вас не установлен R:
- https://rstudio.
 cloud
cloud
 cloud
cloud- Создайте папку, где будут храниться ВСЕ материалы курса. Например: Мы будем ее называть рабочей директорией. В эту папку помещайте ВСЕ файлы с кодом (с расширением .R).
- Внутри папки
linmodrсоздайте папкуdata, где будут храниться все файлы с данными для анализа.
В итоге у вас должно получиться примерно это:
C:\linmodr\ C:\linmodr\data\
Настройка RStudio
Все настройки RStudio находятся в меню Tools -> Global Options
- Восстановление рабочего пространства из прошлого сеанса — это лучше
отменить, т.к. обычно переменные-призраки очень мешают. На вкладке
Generalубираем галочкуRestore .RData into workspace at startup, и меняемSave workspace to .RData on exit—Never - Перенос длинных строк в окне кода — это удобно. На вкладке
Codeставим галочку рядом с опциейSoft-wrap R source files
Комментарии в текстах программ обозначаются символом #
# это комментарии, они не будут выполняться
Ctrl + Shift + C— закомментировать/раскомментировать выделенный фрагмент кодаCtrl + Enter— отправляет активную строку из текстового редактора в консоль, а если выделить несколько строк, то будет выполнен этот фрагмент кода.TabилиCtrl + Space— нажмите после того как начали набирать название функции или переменной, и появится список автоподстановки. Это помогает печатать код быстро и с меньшим количеством ошибок.

- В RStudio можно поставить курсор на слово
setwdи нажатьF1 - Перед названием функции можно напечатать знак вопроса и выполнить
эту строку
?setwd - Можно воспользоваться функцией
help()
help("setwd")## [1] 4
1024/2
## [1] 512
## [1] 1 2 3 4 5 6 7 8 9 10
## [1] 136
## [1] 16
sqrt(27)
## [1] 5.196152
Оператор присваивания это символ стрелочки <-. Он
работает справа налево, это значит, что значение выражения в его правой
части присваивается объекту в левой части.
Переменные — это такие контейнеры, в которые можно положить разные
данные и даже функции.
Имена переменных могут содержать латинские буквы обоих регистров, символы точки . и подчеркивания _ , а так же цифры. Имена переменных должны начинаться с латинских букв. Создавайте понятные и “говорящие” имена переменных.
var_1 <- 1024 / 2 1238 * 3 -> var_2 var_2
## [1] 3714
Как выбрать название переменной?
a— плохо, и дажеb,с, илих. Но в некоторых случаях допустимо:)var1— плохо, но уже лучшеvar_1— плохо, но уже лучшеshelllength— говорящее, но плохо читаетсяshell_length,wing_colourилиleg_num— хорошие говорящие и читабельные названия
Данные в R можно хранить в виде разных объектов.
В результате выполнения следующих команд числа. Одно выражение — одно значение.
## [1] 23
sqrt(25)
## [1] 5
На самом деле, эти величины — просто векторы единичной длины
Векторы — один объект, внутри которого несколько
значений.
Некоторые способы создания векторов:
- Оператор: используется для создания целочисленных векторов, где значения следуют одно за другим без пропусков
1:10 # от одного до 10
## [1] 1 2 3 4 5 6 7 8 9 10
-5:3 # от -5 до 3
## [1] -5 -4 -3 -2 -1 0 1 2 3
- Функция
seq()создает последовательности из чисел
seq(from = 1, to = 5, by = 0.5)
## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
- Функция
c()— от англ. concatenate. Следите, чтобы было английское си, а не русское эс:).
?c # посмотрите хелп к функции
Функция c принимает несколько (произвольное количество)
аргументов, разделенных запятыми. Она собирает из них вектор.
c(2, 4, 6)
## [1] 2 4 6
c(-9.3, 0, 2.17, 21.3)
## [1] -9.30 0.00 2.17 21.30
Векторы можно хранить в переменных для последующего использования
vect_num <- -11:12 # численный вектор от -11 до 12 сохранен в переменной vect_num vect_num_1 <- c(1.
 3, 1.7, 1.2, 0.9, 1.6, 1.4) # численный вектор, сохранен в переменной vect_num_1
3, 1.7, 1.2, 0.9, 1.6, 1.4) # численный вектор, сохранен в переменной vect_num_1Адресация внутри векторов
При помощи оператора [], можно обратится к некоторым
элементам вектора. В квадратных скобках вам нужно указать один или
несколько порядковых номеров элементов
vect_num[1] # первый элемент в векторе vect_num
## [1] -11
vect_num[10] # 10-й элемент
## [1] -2
vect_num[22]
## [1] 10
Если вам нужно несколько элементов, то их нужно передать квадратным скобкам в виде вектора. Например, нам нужны элементы с 3 по 5. Вот вектор, который содержит значения 3, 4 и 5.
## [1] 3 4 5
Если мы его напишем в квадратных скобках, то добудем элементы с такими порядковыми номерами
vect_num[3:5]
## [1] -9 -8 -7
Аналогично, если вам нужны элементы не подряд, то передайте вектор с номерами элементов, который вы создали при помощи функции c() c(2, 4, 6) # это вектор содержащий 2, 4 и 6, поэтому
vect_num[c(2, 4, 6)] # возвращает 2-й, 4-й и 6-й элементы
## [1] -10 -8 -6
vect_num[c(1, 10, 20)] # возвращает 1-й, 10-й и 20-й элементы
## [1] -11 -2 8
Вектор — одномерный объект. У его элементов только один порядковый
номер (индекс). Поэтому при обращении к элементам вектора нужно
указывать только одно число или один вектор с адресами.
У его элементов только один порядковый
номер (индекс). Поэтому при обращении к элементам вектора нужно
указывать только одно число или один вектор с адресами.
Правильно:
vect_num[c(1, 2, 5)] # возвращает 1-й, 3-й и 5-й элементы
## [1] -11 -10 -7
Но R выдаст ошибку, если при обращении к вектору, вы не создавали вектор, а просто перечислили номера элементов через запятую.
vect_num[1, 3, 5] # ошибка vect_num[15, 9, 1] # ошибка
vect_num[c(15, 9, 1)] # правильно
## [1] 3 -3 -11
При помощи функции c() можно объединять несколько векторов в один вектор
c(1, 1, 5:9)
## [1] 1 1 5 6 7 8 9
c(vect_num, vect_num)
## [1] -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 ## [20] 8 9 10 11 12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 ## [39] 3 4 5 6 7 8 9 10 11 12
c(100, vect_num)
## [1] 100 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 ## [20] 7 8 9 10 11 12
Добываем 1, 3, 5 и с 22 по 24 элементы
vect_num[c(1, 3, 5, 22:24)]
## [1] -11 -9 -7 10 11 12
Числовые данные
Уже видели в прошлом разделе.
Текстовые данные
Каждый текстовый элемент (говорят “строка” — string или character) должен быть окружен кавычками — двойными или одинарными.
"это текст"
## [1] "это текст"
'это тоже текст'
## [1] "это тоже текст"
Текстовые значения можно объединять в вектора.
Это текстовый вектор
rainbow <- c("red", "orange", "yellow", "green", "blue", "violet")
rainbow # весь вектор## [1] "red" "orange" "yellow" "green" "blue" "violet"
Добываем первый и последний элементы
В данном случае я точно знаю, что их 6, мне нужны 1 и 6.
rainbow[c(1, 6)]
## [1] "red" "violet"
Добываем элементы с 3 по 6
Если у вас вдруг слишком короткий вектор в этом задании, то можно склеить новый из двух
double_rainbow <- c(rainbow, rainbow) double_rainbow
## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"
rainbow[3:6] # элементы с 3 по 6
## [1] "yellow" "green" "blue" "violet"
Логические данные
TRUE # истина
## [1] TRUE
FALSE # ложь
## [1] FALSE
Для ленивых — можно сокращать первыми заглавными буквами. Но
лучше так не делать, чтобы читать программы было легче.
Но
лучше так не делать, чтобы читать программы было легче.
c(T, T, T, T, F, F, T, T)
## [1] TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE
Логический вектор
c(TRUE, TRUE, TRUE, FALSE, FALSE, TRUE)
## [1] TRUE TRUE TRUE FALSE FALSE TRUE
Еще логический вектор
short_logical_vector <- c(FALSE, TRUE)
Создаем длинный логический вектор.
Чтобы создавать длинные вектора из повторяющихся элементов, можно использовать функцию rep()
?rep
rep(x = 1, times = 3) # 1 повторяется 3 раза
## [1] 1 1 1
rep(x = "red", times = 5) # "red" повторяется 5 раз
## [1] "red" "red" "red" "red" "red"
rep(x = TRUE, times = 2) # TRUE повторяется 2 раза
## [1] TRUE TRUE
В R названия аргументов функций можно не указывать, если вы используете аргументы в том же порядке, что прописан в help к этой функции.
rep(TRUE, 5) # TRUE повторяется 5 раз, аргументы без названий
## [1] TRUE TRUE TRUE TRUE TRUE
Создаем логический вектор, где TRUE повторяется 3 раза, FALSE 3 раза
и TRUE 4 раза. Результат сохраняем в переменной vect_log
Результат сохраняем в переменной vect_log
vect_log <- c(rep(TRUE, 3), rep(FALSE, 3), rep(TRUE, 4)) vect_log
## [1] TRUE TRUE TRUE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
Применение логических векторов для фильтрации данных
Логические векторы создаются при проверке выполнения каких либо
условий, заданных при помощи логических операторов (>, <, ==, !=, >=, <=, !, &, |).
Такие векторы можно использовать для фильтрации данных
Вспомните, у нас был вот такой текстовый вектор
double_rainbow
## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"
Задача 1. Допустим, мы хотим из этого вектора извлечь только желтый цвет.
Мы можем создать логический вектор, в котором TRUE будет только для 3-го и 9-го элементов
f_yellow <- double_rainbow == "yellow" f_yellow
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
Этот логический вектор-фильтр мы можем использовать для извлечения
данных из double_rainbow
double_rainbow[f_yellow]
## [1] "yellow" "yellow"
Задача 2. Допустим, мы хотим извлечь из double_rainbow желтый и синий
Желтый фильтр у нас уже есть, поэтому мы создадим фильтр для синего.
Допустим, мы хотим извлечь из double_rainbow желтый и синий
Желтый фильтр у нас уже есть, поэтому мы создадим фильтр для синего.
f_blue <- double_rainbow == "blue"
Выражение “желтый или синий” можно записать при помощи логического
“или” (|)
f_yellow | f_blue
## [1] FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSE
Задача решена, мы извлекли желтый и синий цвета.
double_rainbow[f_yellow | f_blue]
## [1] "yellow" "blue" "yellow" "blue"
То же самое можно было бы записать короче.
В одну строку — совершенно нечитабельно:
double_rainbow[double_rainbow == "yellow" | double_rainbow == "blue"]
## [1] "yellow" "blue" "yellow" "blue"
Фильтр отдельно — читается лучше:
f_colours <- double_rainbow == "yellow" | double_rainbow == "blue" double_rainbow[f_colours]
## [1] "yellow" "blue" "yellow" "blue"
У нас был числовой вектор
vect_num
## [1] -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 ## [20] 8 9 10 11 12
Задача 3. Давайте извлечем из числового вектора
Давайте извлечем из числового вектора vect_num только значения больше 0
vect_num[vect_num > 0]
## [1] 1 2 3 4 5 6 7 8 9 10 11 12
Задача 4. Давайте извлечем из вектора vect_num все
числа, которые либо меньше или равны -8, либо больше или равны 8
f_5_8 <- (vect_num <= -8) | (vect_num >= 8) vect_num[f_5_8]
## [1] -11 -10 -9 -8 8 9 10 11 12
Факторы
Факторы — это способ хранения дискретных (=категориальных данных). Например, если вы поймали 10 улиток и посмотрели их цвет. У большого количества улиток небольшое счетное количество возможных цветов.
snail_colours <- c("red", "green", "green", "green", "yellow", "yellow", "yellow", "yellow")
snail_colours # это текстовый вектор.## [1] "red" "green" "green" "green" "yellow" "yellow" "yellow" "yellow"
Но цвет “желтый” обозначает одно и то же для каждой из улиток.
Поэтому в целях экономии места можно записать цвета этих улиток в виде
вектора, в котором численным значениям будут сопоставлены “этикетки”
(называются “уровни” — levels) — названия цветов. Мы можем создать
“фактор” цвет улиток.
Мы можем создать
“фактор” цвет улиток.
factor(snail_colours)
## [1] red green green green yellow yellow yellow yellow ## Levels: green red yellow
уровни этого фактора
- 1 — green,
- 2 — red,
- 3 — yellow
По умолчанию, R назначает порядок уровней по алфавиту. Можно изменить
порядок (см. help("factor")). Нам это пригодится позже
double_rainbow # текстовый вектор
## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"
Создаем фактор из текстового вектора и складываем его в переменную
f_double_rainbow <- factor(double_rainbow)
Как узнать, что за данные хранятся в переменной?
Чтобы узнать, что за данные хранятся в переменной, используйте
функцию class()
class(f_double_rainbow)
## [1] "factor"
class(vect_log)
## [1] "logical"
class(vect_num)
## [1] "integer"
class(rainbow)
## [1] "character"
Встроенные константы в R: NA, NULL, NAN, Inf
- NA — англ “not available”. Когда объект был, но его свойство не
измерили или не записали.
- NULL — пусто — просто ничего нет
- NaN — “not a number”
- Inf — “infinity” — бесконечность
 Когда объект был, но его свойство не
измерили или не записали.
Когда объект был, но его свойство не
измерили или не записали.Вот текстовый вектор с пропущенным значением
rainbow_1 <- c("red", "orange", NA, "green", "blue", "violet")Кстати, если попросили добыть из вектора номер элемента, которого там точно нет, то R выдаст NA, потому, что такого элемента нет
rainbow_1[198]
## [1] NA
Поэкспериментируем с векторами. Проверим, как работают арифметические операции
vect_num + 2
## [1] -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
vect_num * 2
## [1] -22 -20 -18 -16 -14 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 14 ## [20] 16 18 20 22 24
vect_num * (-2)
## [1] 22 20 18 16 14 12 10 8 6 4 2 0 -2 -4 -6 -8 -10 -12 -14 ## [20] -16 -18 -20 -22 -24
vect_num ^2
## [1] 121 100 81 64 49 36 25 16 9 4 1 0 1 4 9 16 25 36 49 ## [20] 64 81 100 121 144
Теперь посмотрим на встроенные константы в действии.
Создаем новый вектор для экспериментов
NAs_NANs <- c(1, 3, NA, 7, 0, 22:24)
Вот так он выглядит
NAs_NANs
## [1] 1 3 NA 7 0 22 23 24
Что произойдет с NA?
NAs_NANs + 2 # останется NA
## [1] 3 5 NA 9 2 24 25 26
NAs_NANs * 0 # останется NA
## [1] 0 0 NA 0 0 0 0 0
NAs_NANs / 0 # останется NA
## [1] Inf Inf NA Inf NaN Inf Inf Inf
Но в последнем случае вы увидите
- Inf при делении чисел на ноль
- NaN при делении нуля на ноль
NaN получится, если взять корень из отрицательного числа
sqrt(-1)
## Warning in sqrt(-1): NaNs produced
## [1] NaN
Вы уже видели массу функций, их легко узнать по скобкам после ключевого слова. Познакомимся еще с несколькими и научимся писать пользовательские функции. Пользовательские функции позволяют автоматизировать повторяющиеся действия и делают код легко читаемым.
Вот наш вектор
NAs_NANs
## [1] 1 3 NA 7 0 22 23 24
Длину вектора можно вычислить при помощи функции length()
length(NAs_NANs)
## [1] 8
Сумму элементов вектора при помощи функции sum()
sum(NAs_NANs)
## [1] NA
Упс! Почему-то получилось NA
Чтобы узнать, почему и как это исправить — посмотрите в help("sum"). Выяснится, что у функции
Выяснится, что у функции sum() есть аргумент na.rm, который по умолчанию принимает
значение FALSE, то есть NA не учитываются при
подсчете суммы.
Если мы передадим функции sum аргумент na.rm = TRUE, то получится правильная сумма
sum(NAs_NANs, na.rm = TRUE)
## [1] 80
Та же история с функцией mean
mean(NAs_NANs, na.rm = TRUE)
## [1] 11.42857
Попробуем написать пользовательскую функцию mmean(),
которая будет по умолчанию считать среднее значение элементов в векторе
с учетом пропущенных значений (NA)
mmean <- function(x){
mean(x, na.rm = TRUE)
}В этом коде: — mmean — переменная, название функции. В эту переменную
мы складываем функцию, которую создает функция function() — function() — функция, которая делает функции. В скобках
перечисляются аргументы (названия переменных, которые мы передаем в
функцию, чтобы она что-то сделала с ними) — { } — в
фигурных скобках тело функции — последовательность действий, которую
нужно сделать с аргументами
У больших функций бывает еще инструкция return(),
которая сообщает, что именно должна возвращать наша функция. Вот как
выглядела бы наша функция с этой инструкцией
Вот как
выглядела бы наша функция с этой инструкцией
mmean <- function(x){
res <- mean(x, na.rm = TRUE)
return(res)
}Проверим нашу функцию при помощи встроенной функции
mean(vect_num, na.rm = TRUE)
## [1] 0.5
mmean(vect_num)
## [1] 0.5
Работает
Датафрейм — один из способов хранения табличных данных в R. Создадим датафрейм.
Для этого, для начала, создадим векторы с данными для переменных.
len <- 1:9 # числовой
col <- c(rep("green", 4), rep("red", 5)) # текстовый
wid <- seq(from = 2, by = 2, to = 18) # числовойТеперь сложим эти векторы в датафрейм
my_worms <- data.frame(Length = len, Width = wid, Colour = col)
Можно проверить, действительно мы создали объект класса data.frame
class(my_worms) # смотрим, действительно датафрейм
## [1] "data.frame"
Содержимое датафрейма можно просмотреть несколькими способами
my_worms # печать датафрейма
## Length Width Colour ## 1 1 2 green ## 2 2 4 green ## 3 3 6 green ## 4 4 8 green ## 5 5 10 red ## 6 6 12 red ## 7 7 14 red ## 8 8 16 red ## 9 9 18 red
View(my_worms) # просмотр в RStudio head(my_worms)
## Length Width Colour ## 1 1 2 green ## 2 2 4 green ## 3 3 6 green ## 4 4 8 green ## 5 5 10 red ## 6 6 12 red
tail(my_worms)
## Length Width Colour ## 4 4 8 green ## 5 5 10 red ## 6 6 12 red ## 7 7 14 red ## 8 8 16 red ## 9 9 18 red
# fix(my_worms) # ручное редактирование.
 осторожно! избегайте его использовать, никаких документов о нем не останется
осторожно! избегайте его использовать, никаких документов о нем не останетсяАдресация внутри датафреймов
Вывод столбца-переменной при помощи оператора $ и имени переменной
my_worms$Length
## [1] 1 2 3 4 5 6 7 8 9
my_worms$Width
## [1] 2 4 6 8 10 12 14 16 18
У каждой ячейки в датафрейме есть координаты вида [строка, столбец]
my_worms[2, 3] # вторая строка в 3 столбце
## [1] "green"
my_worms[2, ] # вторая строка целиком
## Length Width Colour ## 2 2 4 green
my_worms[1:9, 2] # строки с 1 по 9 во втором столбце
## [1] 2 4 6 8 10 12 14 16 18
my_worms[, 2] # второй столбец целиком
## [1] 2 4 6 8 10 12 14 16 18
Базовые графики
Скаттерплот (точечный график) — по оси х и y непрерывные числовые величины
plot(x = my_worms$Width, y = my_worms$Length)
Боксплот — по оси х дискретная величина, по оси y значение
непрерывной величины. Черта — медиана, коробка — 25 и 75 перцентили, усы
— либо размах варьирования, либо 1.5 интерквартильных расстояния (1.5
высоты коробки), если есть “выбросы”.
Черта — медиана, коробка — 25 и 75 перцентили, усы
— либо размах варьирования, либо 1.5 интерквартильных расстояния (1.5
высоты коробки), если есть “выбросы”.
plot(x = as.factor(my_worms$Colour), y = my_worms$Length)
Для настройки внешнего вида см graphical parameters в help
На самом деле, мы не будем пользоваться этой системой графики, но об этом в следующих сериях
Графики из пакета ggplot2
В R есть более удобный (но, может быть, более многословный) пакет для рисования графиков — ggplot2. Чтобы использовать функции из пакета ggplot2, нужно его сначала установить.
Установка пакета в локальную библиотеку делается один раз. Поэтому
строку с install.packages() не нужно включать в финальную
версию кода.
install.packages('ggplot2')В текущей сессии работы в R пакет нужно активировать перед
использованием. Когда вы в следующий раз начнете работать с R, нужные
пакеты придется снова активировать. Поэтому строки с загрузкой пакетов
при помощи library() обязательно должны остаться в
финальной версии кода.
library(ggplot2)
Нарисуем те же самые графики при помощи пакета ggplot2.
ggplot(data = my_worms) + geom_point(aes(x = Width, y = Length))
ggplot(data = my_worms) + geom_boxplot(aes(x = Colour, y = Length))
Добавляем для точек эстетику цвет (colour) из переменной Colour
ggplot(data = my_worms) + geom_point(aes(x = Width, y = Length, colour = Colour))
Графики можно сохранять в переменных, и использовать потом
gg <- ggplot(data = my_worms) + geom_point(aes(x = Width, y = Length, colour = Colour))
Чтобы вывести график, нужно напечатать название переменной.
Можно менять темы оформления графика. Если тема нужна только один раз, то прибавляем ее к графику
gg + theme_dark()
gg + theme_light()
gg + theme_classic()
Можно установить нужную тему до конца сессии.
theme_set(theme_bw()) gg
Подписи осей и легенд задает функция labs()
gg + labs(x = "Ширина", y = "Длина", colour = "Цвет")
Графики можно делить на фасетки при помощи facet_wrap или facet_grid
gg + facet_wrap(~Colour, nrow = 1)
Чтобы изменить подписи цветов, нужно изменить уровни соотв. фактора.
фактора.
my_worms$col_rus <- factor(my_worms$Colour, levels = c("green", "red"), labels = c("Зеленый", "Красный"))
ggplot(data = my_worms) +
geom_point(aes(x = Width, y = Length, colour = col_rus)) +
labs(x = "Ширина", y = "Длина", colour = "Цвет") +
facet_wrap(~col_rus, nrow = 1)Больше или равно (>=) — JavaScript
Оператор больше или равен ( >= ) возвращает true , если
левый операнд больше или равен правому операнду, и ложь в противном случае.
х >= у
Операнды сравниваются по тому же алгоритму, что и оператор «Меньше», с инвертированием результата. x >= y обычно эквивалентно !(x < y) , за исключением двух случаев, когда x >= y и x < y оба равны false :
- выдает синтаксическую ошибку при передаче в
BigInt()). - Если один из операндов преобразуется в
NaN. (Например, строки, которые нельзя преобразовать в числа, или undefined.)
 (Например, строки, которые нельзя преобразовать в числа, или
(Например, строки, которые нельзя преобразовать в числа, или х >= у обычно эквивалентно x > y || x == y , за исключением нескольких случаев:
- Когда одно из
xилиyравноnull, а другое не являетсяnullи становится 0 при приведении к числовому (включая 9 0004 0 ,0n,false,"","0",new Date(0)и т. д.):x >= yistrue, аx > y || х == уравноложь. - Когда одно из
xилиyравноundefined, а другое является одним изnullилиundefined:x >= yравноfalse, аx == yравноправда. - Когда
xиyявляются одним и тем же объектом, который становитсяNaNпосле первого шага Меньше чем (например,new Date(NaN)):x >= yравноfalse, аx == yравноtrue. - Когда
xиyявляются разными объектами, которые становятся одним и тем же значением после первого шага Меньше чем:x >= yравноtrue, аx > y || x == yравноfalse.

Сравнение строк
"a" >= "b"; // ЛОЖЬ "а" >= "а"; // истинный "а" >= "3"; // истинный
Сравнение строки с числом
"5" >= 3; // истинный "3" >= 3; // истинный "3" >= 5; // ЛОЖЬ "привет" >= 5; // ЛОЖЬ 5 >= "привет"; // ЛОЖЬ
Сравнение номеров
5 >= 3; // истинный 3 >= 3; // истинный 3 >= 5; // ЛОЖЬ
Сравнение числа с BigInt
5n >= 3; // истинный 3 >= 3н; // истинный 3 >= 5н; // ЛОЖЬ
Сравнение логических значений, null, undefined, NaN
true >= false; // истинный правда >= правда; // истинный ложь >= истина; // ЛОЖЬ правда >= 0; // истинный правда >= 1; // истинный ноль >= 0; // истинный 1 >= ноль; // истинный не определено >= 3; // ЛОЖЬ 3 >= не определено; // ЛОЖЬ 3 >= NaN; // ЛОЖЬ NaN >= 3; // ЛОЖЬ
| Спецификация |
|---|
| Спецификация языка ECMAScript # sec-relational-operators |
BCD загружаются только в браузере с включенным JavaScript. Включите JavaScript для просмотра данных.
Включите JavaScript для просмотра данных.
- Больше, чем оператор
- Меньше, чем оператор
- Оператор меньше или равно
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Посмотреть исходный код на GitHub.
Хотите принять более активное участие?
Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
Если еще и Вложенные, если еще
Операторы If-Else являются важной частью программирования R. В этом руководстве мы увидим различные способы применения условных операторов (If..Else вложенный IF) в R. В R есть много мощных пакетов для манипулирования данными. В более поздней части этого руководства мы увидим, как операторы IF ELSE используются в популярных пакетах.
Образец данных
Давайте создадим образец данных, чтобы показать, как выполнять функцию ЕСЛИ ИНАЧЕ. Этот фрейм данных будет использоваться далее в примерах.
| x1 | x2 | х3 |
|---|---|---|
| 1 | 129 | А |
| 3 | 178 | Б |
| 5 | 140 | С |
| 7 | 186 | Д |
| 9 | 191 | Э |
| 11 | 104 | Ф |
| 13 | 150 | Г |
| 15 | 183 | Х |
| 17 | 151 | я |
| 19 | 142 | Дж |
Запустите программу ниже, чтобы создать приведенную выше таблицу в R.
сет.сид(123)
mydata = data.frame(x1 = seq(1,20,by=2),
x2 = выборка (100:200,10,ЛОЖЬ),
x3 = БУКВЫ [1:10])
x1 = seq(1,20,by=2) : Переменная 'x1' содержит альтернативные числа от 1 до 20. Всего это 10 числовых значений.
x2 = выборка(100:200,10,FALSE) : Переменная 'x2' представляет собой 10 неповторяющихся случайных чисел в диапазоне от 100 до 200.
x3 = БУКВЫ[1:10] : Переменная 'x3' содержит 10 алфавитов, начиная с A до Z.
Синтаксис функции ifelse() :
Функция ifelse() в R работает аналогично функции MS Excel ЕСЛИ. Синтаксис см. ниже:
. ifelse(условие, значение, если условие истинно, значение, если условие ложно)
Пример 1: простой оператор IF ELSE
Предположим, вас попросили создать двоичную переменную — 1 или 0 на основе переменной «x2». Если значение переменной 'x2' больше 150, присвойте 1, иначе 0.
Если значение переменной 'x2' больше 150, присвойте 1, иначе 0.
mydata$x4 = если еще (mydata$x2>150,1,0)
В этом случае он создает переменную x4 в том же фрейме данных «mydata». Результат показан на изображении ниже:
| ifelse : Output |
Создать переменную в новом фрейме данных
Предположим, вам нужно добавить созданную выше бинарную переменную в новый фрейм данных. Вы можете сделать это, используя приведенный ниже код -
х = если еще (мои данные $ х2> 150,1,0) новые данные = cbind (х, мои данные)
cbind() используется для объединения двух векторов, матриц или фреймов данных по столбцам.
Применить ifelse() к символьным переменным
Если переменная 'x3' содержит символьные значения - 'A', 'D', то переменная 'x1' должна быть умножена на 2. В противном случае она должна быть умножена на 3.
В противном случае она должна быть умножена на 3.
mydata$y = ifelse(mydata$x3 %in% c("A","D") ,mydata$x1*2,mydata$x1*3)
Результат показан в таблице ниже
х1 х2 х3 у 1 129 А 2 3 178 Б 9 5 140 С 15 7 186 Д 14 9191 Э 27 11 104 Ф 33 13 150 Г 39 15 183 Н 45 17 151 я 51 19 142 Дж 57
Пример 2. Вложенный оператор If ELSE в R
Несколько операторов If Else можно написать аналогично функции If в Excel. В этом случае мы говорим R умножить переменную x1 на 2, если переменная x3 содержит значения «A», «B». Если значения «C», «D», умножьте на 3. В противном случае умножьте на 4.
mydata$y = ifelse(mydata$x3 %in% c("A","B"), mydata$x1*2,
ifelse(mydata$x3 %in% c("C","D"), mydata$x1*3,
моиданные$x1*4))
Вы ненавидите указывать фрейм данных несколько раз для каждой переменной?
Вы можете использовать функцию with() , чтобы каждый раз не упоминать фрейм данных. Это ускоряет написание кода R.
Это ускоряет написание кода R.
mydata$y = with(mydata, ifelse(x3 %in% c("A","B") , x1*2,
ifelse(x3 %in% c("C","D"), x1*3, x1*4)))
Специальные темы, связанные с IF ELSE
В этом разделе мы рассмотрим следующие темы -
- Как обрабатывать отсутствующие (NA) значения в IF ELSE.
- Как использовать операторы ИЛИ и И в IF ELSE
- Агрегированные или сводные функции и оператор IF ELSE
Обработка отсутствующих значений
Неверный метод
x = NA
ifelse(x==NA,1,0)
Результат: NA
Должно было быть возвращено 1.
Правильный метод 901 58
х = нет данных
ifelse( is.na(x) ,1,0)
Результат: 1
Функция is. na() проверяет, является ли значение NA или нет.
na() проверяет, является ли значение NA или нет.
Использование операторов ИЛИ и И
Символ & используется для выполнения условий И
ifelse(mydata$x1<10 & mydata$x2>150,1,0)
Результат: 0 1 0 1 1 0 0 0 0 0
| символ используется для выполнения условий ИЛИ
ifelse(mydata$x1<10 | mydata$x2>150,1,0)
Результат: 1 1 1 1 1 0 0 1 1 0
Подсчет случаев, когда условие выполняется 900 11
В этом примере , мы можем подсчитать количество записей, в которых выполняется условие.
sum(ifelse(mydata$x1<10 | mydata$x2>150,1,0))
Результат: 7
Оператор If Else: Другой стиль
Есть еще один способ определить if.. оператор else в R. Этот стиль написания If Else в основном используется, когда мы используем условные операторы в циклах и функциях R. Другими словами, он используется, когда нам нужно выполнить различные действия на основе условия.
Другими словами, он используется, когда нам нужно выполнить различные действия на основе условия.
Синтаксис -
если (состояние) да иначе нет
k = 99
if(k > 100) 1 else 0
Результат: 0
If..Else If..Else Операторы
k = 100
if (k > 100){
print("Больше 100")
} else if (k < 100){
print("Меньше 100")
} else 9 0199 {
печать ("Равно 100")
}
Результат: "Равно 100"
If Else в популярных пакетах
1. dplyr package
if_else( условие, значение, если условие истинно, значение, если условие ложно, значение, если нет данных)
Следующая программа проверяет, является ли значение кратным 2
библиотека (dplyr) х=с(1,Н/Д,2,3) if_else(x%%2==0, "Кратно 2", "Не кратно 2", "Отсутствует")
Результат : Не кратное 2 Отсутствующий Кратность 2 Не кратное 2
Символ %% возвращает остаток после деления значения на делитель.
 Ученик выполняет эти действия для записи ответа или облегчения расчетов. Но нельзя превратить неправильную дробь в правильную и наоборот. Это два разных вида чисел, которые между собой никак не связаны.
Ученик выполняет эти действия для записи ответа или облегчения расчетов. Но нельзя превратить неправильную дробь в правильную и наоборот. Это два разных вида чисел, которые между собой никак не связаны.
 Поделите числитель на знаменатель
Поделите числитель на знаменатель






 При вычислениях со смешанными числами может быть намного проще выполнить необходимые арифметические действия, если смешанные числа будут преобразованы в неправильные дроби.
При вычислениях со смешанными числами может быть намного проще выполнить необходимые арифметические действия, если смешанные числа будут преобразованы в неправильные дроби.
 Включает рассуждения и прикладные вопросы.
Включает рассуждения и прикладные вопросы.

 Выберите дробь, которая равна 5 \frac{3}{7}?
Выберите дробь, которая равна 5 \frac{3}{7}?

 .. или 0,142857142857… Это отличает такие дроби от непериодических десятичных дробей, которые заканчиваются после определенного числа цифр, например, 0,5 или 0,75.
.. или 0,142857142857… Это отличает такие дроби от непериодических десятичных дробей, которые заканчиваются после определенного числа цифр, например, 0,5 или 0,75. .. или 3,(3)
.. или 3,(3) 02+17.19
02+17.19 Целые числа, целые числа, натуральные числа, рациональные и иррациональные числа и т. д. являются примерами чисел. Система счисления — это стандартизированный метод выражения чисел во многих форматах, включая цифры и язык. Он содержит много видов чисел, таких как простые числа, нечетные числа, четные числа, рациональные числа, целые числа и так далее. Эти числа могут быть представлены несколькими способами в зависимости от используемой системы счисления.
Целые числа, целые числа, натуральные числа, рациональные и иррациональные числа и т. д. являются примерами чисел. Система счисления — это стандартизированный метод выражения чисел во многих форматах, включая цифры и язык. Он содержит много видов чисел, таких как простые числа, нечетные числа, четные числа, рациональные числа, целые числа и так далее. Эти числа могут быть представлены несколькими способами в зависимости от используемой системы счисления. Натуральные числа состоят исключительно из целых чисел, включая ноль. Числа 0, 1, 2, 3, 4, 5,… обозначают подмножество. Подмножество исключает дроби, десятичные числа и отрицательные целые числа.
Натуральные числа состоят исключительно из целых чисел, включая ноль. Числа 0, 1, 2, 3, 4, 5,… обозначают подмножество. Подмножество исключает дроби, десятичные числа и отрицательные целые числа. Числитель — это целое число, а знаменатель — 1. Например, если целое число равно 5, числитель дроби равен 5, а знаменатель — 1. В результате 5/1.
Числитель — это целое число, а знаменатель — 1. Например, если целое число равно 5, числитель дроби равен 5, а знаменатель — 1. В результате 5/1. Каждая дробь состоит из двух частей: числителя и знаменателя.
Каждая дробь состоит из двух частей: числителя и знаменателя.



 ..++Cn-1n-1+Cn-1n-2·a·bn-1+Cn-1n-1·bn
..++Cn-1n-1+Cn-1n-2·a·bn-1+Cn-1n-1·bn
 ..+Cnn-2+2·n)
..+Cnn-2+2·n) Введите выражение
Введите выражение  2+3x-12.
2+3x-12.
 е. значения функции на его концах имеют противоположные знаки.
е. значения функции на его концах имеют противоположные знаки.
 (3.16)
(3.16)
 18)
18)
 .. >xn>xn+1>ε. Следовательно, существует .
.. >xn>xn+1>ε. Следовательно, существует .

 009
009
 Практикуйте свои математические навыки и учитесь шаг за шагом с помощью нашего математического решателя. Ознакомьтесь со всеми нашими онлайн-калькуляторами здесь.
Практикуйте свои математические навыки и учитесь шаг за шагом с помощью нашего математического решателя. Ознакомьтесь со всеми нашими онлайн-калькуляторами здесь. {5}$ 9{2}+405x+243$
{5}$ 9{2}+405x+243$  Указаны шаги расчета.
Указаны шаги расчета. Вычислить онлайн количество расположения p элементов множества из n элементов.
Вычислить онлайн количество расположения p элементов множества из n элементов.

 11.16
11.16  jpg»>
jpg»>
 Просто введите выражение в соответствии с x функции, которую нужно построить, используя обычные математические операторы.
9Построитель кривых 0236 особенно подходит для изучения функции ,
позволяет получить графическое представление функции из уравнения кривой,
его можно использовать для определения вариации, минимума, максимума функции.
Просто введите выражение в соответствии с x функции, которую нужно построить, используя обычные математические операторы.
9Построитель кривых 0236 особенно подходит для изучения функции ,
позволяет получить графическое представление функции из уравнения кривой,
его можно использовать для определения вариации, минимума, максимума функции. (абсолютное значение),
график абсолютного значения
(абсолютное значение),
график абсолютного значения



 Сделать это,
используйте область в правом нижнем углу графиков.
Сделать это,
используйте область в правом нижнем углу графиков.
 01.2021 года
01.2021 года ruВсе новости
ruВсе новости Как беспилотники атаковали Москву и Подмосковье — видео
Как беспилотники атаковали Москву и Подмосковье — видео Чем хорош новый китайский полноприводный кроссовер: рассказы владельцев
Чем хорош новый китайский полноприводный кроссовер: рассказы владельцев 04.2023
04.2023 (b) Девять крор пять лакхов сорок один. одна тысяча триста два. (d) Пятьдесят восемь миллионов четыреста двадцать три тысячи двести два. (e) Двадцать три лакха тридцать тысяч десять.
(b) Девять крор пять лакхов сорок один. одна тысяча триста два. (d) Пятьдесят восемь миллионов четыреста двадцать три тысячи двести два. (e) Двадцать три лакха тридцать тысяч десять.

 ..
.. Разрешите получать регулярные обновления!
Разрешите получать регулярные обновления! Например, число «0,23» часто говорят как «двадцать три сотых», а не как «двадцать одна сотая и три десятых» (хотя, строго говоря, в этом нет ничего плохого)
Например, число «0,23» часто говорят как «двадцать три сотых», а не как «двадцать одна сотая и три десятых» (хотя, строго говоря, в этом нет ничего плохого) Изучите, как сгруппированы следующие числа:
Изучите, как сгруппированы следующие числа: Рассмотрим следующее (я буду выделять каждый отдельный элемент списка в основном списке, используя другой цвет, а также нумеруя их, тогда как каждому элементу во вторичных списках будет присвоено либо «a», либо «b»):
Рассмотрим следующее (я буду выделять каждый отдельный элемент списка в основном списке, используя другой цвет, а также нумеруя их, тогда как каждому элементу во вторичных списках будет присвоено либо «a», либо «b»): д., их можно далее подразделить на сотни и единицы измерения.
д., их можно далее подразделить на сотни и единицы измерения.
 S.) — Ссылка (Гюнтера; Сюрвейерская)LNK (RE) — Ссылка (Рамсденская; Инженерная)LS — Световая секундаLY — Световая- yearM — метр (базовая единица СИ)MIL — мил (Швеция и Норвегия)MILE DATA — мили (тактические или данные)MK — MickeyNAIL — гвоздь (ткань)NL — морская лигаNM — нанометрNMI — морская миляNMI I — морская миляP — PalmPC — ParsecPICA — PicaPM — пикометр (бикрон, клеймо) POINT — точка (американский, английский) PT — PaceQUART — QuarterSHAKU — Shaku (японский) SPT — SpatTH — Mil (тыс.)TWP — TwipUM — микрометр (стар.: микрон)XU — единица X; siegbahnABA — Электромагнитная единица AbampereAMP — Ампер (базовая единица Si)ESU — Esu в секунду Статампер (CgsABC — Абкулон Электромагнитная единицаATU — Атомная единица зарядаCLM — КулонFRD — ФарадейMAH — Миллиампер-часSTT — Статкулон Франклин ЭлектростABV — Абвольт (единица Cgs)STV — Статвольт ( Cgs Unit)VLT — Вольт (Si Unit)ACF — Акр-футыACI — Акры-дюймыBIB — Баррели (нефтяные)BII — Баррели (британские)BIU — Баррели (Us Dry)BKT — Ведра (британские)BRO — Галлоны (пивные)BUD — Бушели (Us Dry Level)BUI — Бушели (Imperial)BUU — Бушели (Us Dry Heaped)CMB — CoombsCMI — Cubic MilesCP — CupsCRF — Cord-FootsCRW — Cords (Дрова)CUF — Cubic FathomsCUI — Cubic InchsCUT — Cubic FootsCUY — Cubic ЯрдыDSI — тире (имперские фунты)DSS — десертные ложки (имперские фунты)DSU — тире (США)FBM — борд-футыFFT — пятые FID — жидкие драхмы (имперские)FIS — жидкие скрукле (имперские)FLB — бочки (США, жидкие)FLU — жидкие драмы ( Us) Us FluidramFRK — FirkinsGAI — галлоны (имперские единицы)GAU — галлоны (Us Dry)GAW — галлоны (Us Fluid Wine)GLU — Teacups (gills)GTT — DropsHDI — Hogsheads (Imperial)HHU — Hogsheads (Us)JGR — Jiggers ( Bartending)KLD — KilderkinsLMD — LambdasLOD — LoadsLST — LastsM3 — Кубические метры (Si Unit)MII — Minims (Imperial)MIU — Minims (Us)OZF — Унции (Fluid Us Food NutritioPER — PerchsPKI — Pecks (Imperial)PKU — Pecks (Us) Сухой)PNI — пинчи (британские)PNU — пинчи (американские)PON — PonysPOT — Pottle QuartersPP — стыковые трубыPTI — пинты (британские)PUD — пинты (Us Dry)PUF — пинты (Us Fluid)QRF — Quart S (Us Fluid) QRT — Кварталы QTI — Кварты (британские)QTU — Кварты (Us Dry)RGS — Реестр TonsSCI — Мешки (британские) BagsSCU — Мешки(Us)SHT — Shots (Us)SM — SeamsSTK — Забастовки (Imperial)STU — Забастовки (Us) )TBC — столовые ложки (канадские)TBF — столовые ложки (обычные в США)TBM — столовые ложки (метрические)TBS — столовые ложки (в австралийских единицах измеренияTCA — чайные ложки (канадские) TFD — столовые ложки (Us Food NutritionTIM — чайные ложки (британские)TMF — Timber FootsTMT — чайные ложки ( Метрическая система)TND – тонны (водоизмещение)TNT – тонны (воды)TNW – тонны (фрахт)TSC – чайные ложки (стандарт США)TSF – чайные ложки (США Food Nutrition) WEY — Wey (Us)ACM — Атмосфера-кубический фут в минутуACS — Атмосфера-кубический фут в секунду SecoATC — Атмосфера-кубический сантиметр PeATH — Атмосфера-кубический фут в часBTJ — BTU (Международная таблица) В расчете на BTN — BTU (Международная таблица) В расчете на BTS — БТЕ (международная таблица) по CAS — Калория (международная таблица) ERS — Эрг в секундуFMF — Фут-фунт-сила в минутуFT — Фут-фунт-сила в часFTO — Фут-фунт-сила в секундуHPS — Лошадиная силаLAM — Литр-атмосфера в час MinuteLSC — LusecLTS — Литр атмосферы в секундуPNC — PonceletSQL — Прямой эквивалент квадратного фута TC — Тонна кондиционирования воздухаTMS — Атмосфера-кубический сантиметр PeTRM — Тонна охлаждения (ImperialTRR — Тонна охлаждения (It)ACR — AcresCMK — Квадратные сантиметрыFTK — Квадратные футыHAR — ГектарыINK — Квадратные дюймыKMK — Квадратные километрыMIK — Квадратные милиMTK — Квадратные метрыYDK — Квадратные ярдыAMU — Унифицированная атомная единица массыAT — Тонна анализа (краткая)ATS — Тонна анализа (длинная)BAC — Мешок (Кофе)BDM — Мешок (портландцемент)BRG — BargeCLV — CloveCRT — CrithCT — Carat (Metric)DA — DaltonDRT — Dram (Apothecary Troy)DWT — PennyweightGAM — GammaGR — GrainGV — GraveKIP — KipLB — Pound (Metric)LBA — PoundLBT — Pound (Troy)LBV — Pound (Avoirdupois)ME — Атомная единица массы Электрон RMRK — MarkMTE — MiteMTM — Клещ (метрический) OZ — Унция (этикетка питания США OZT — Унция (аптечная Троя) OZZ — Унция (Avoirdupois) PNN — PointQ — Квинтал (метрический) QR — Квартал (неофициальный) QRI — Quarter (Imperial)QRL — Quarter Long (Informal)SAP — Scruple (Apothecary)SH — Ton ShortSLG — Slug Geepound HylSLH — SheetST — StoneSWT — Hundredweight (центум веса oTON — Ton LongWY — WeyZTR — ZentnerANN — YearsDAY — DaysHUR — HoursMCS — MicrosecondsMIN — MinutesMLS — MillisecondsMON — MonthsSEC — SecondsWEE — WeeksARE — AresBD — BoardsBHE — эквивалент мощности котла DBR — BarnsBRN — BaronysCDA — Cuerda Pr SurveysCRD — CordsCRI — Circular InchsCRM — Circular MilsDNM — DunamsGNT — GunthasHD — HidesRO — RoodsSCT — SectionsSHD — Сараи SII — Square Link Gunters InternatiSLR — Square Link RamsdensSQC — Square Chains InternationalSQM — Square Mil Square ThousSQR — Square Rod/Pole/PerchsSRR — Square RoofingsSTR — StremmasTWN — TownshipsYLN — YardlandsARM — Arcminute MoaARS — ArcsecondCNS — Centesimal Second Of ArcCNT — Centesimal Minute Of ArcDOA — Degree (Дуги)GRA — Grad Gradian GonOCT — OctantQRD — QuadrantSGN - SignSXT — Sextantµ — Угловой MilATA — Атмосфера (Техническая)ATM — Атмосфера (Стандартная)BAR — BarBRY — Бари (единица Cgs)CMH — Сантиметр ртутного столбаCMW — Сантиметр водяного столба ( 4 °C)FTH — фут ртутного столба (условный)FTW — фут водяного столба (392 °F)IMC — дюйм ртутного столба (условный)INW — дюйм водяного столба (392 °F)KM — килограмм-сила на квадратный метр KSI — кип на квадратный дюймLTP — длинная тонна на квадратный футMHG — микрометр ртутного столбаMMH — миллиметр ртутного столбаMMW — Миллиметр воды (398 °C)PA — Паскаль (единица Си)PD — Фунт на квадратный футPSF — Фунт на квадратный футPSI — Фунт на квадратный дюймPZ — Пьез (единица МТС)STP — Короткая тонна на квадратный футTOR — ТоррATN — Атомная единица ForceDYN — Dyne (Cgs Unit)KFF — Килограмм-сила Kilopond Grave-KI — Kip Kip-ForceMGF — Milligrave-Force Gravet-ForceOZC — Унция-силаPDL — PoundalSN — Sthene (единица Mts)TNF — Long Ton-ForceTNL — Short Ton- ForceAUC — атомная единица времениCTN — CenturyCYC — каллипический циклDEC — DecadeFN — FortnightHEL — HelekHIP — гиппархический циклJFF — JiffyKEH — Ke (четверть часа) LSR — Luster LustrumMD — MillidayMLL — MillenniumMMN — MomentMOF — Month (Full)MOG — Month (Greg) Av)MOH — месяц (полый)MOS — месяц (синодический)MTN — метонический цикл EnneadecaeterisOC — OctaeterisPLN — планковское времяSGM — SigmaSHK — ShakeSTH — сотический циклSVD — SvedbergYR — год (общий)YRG — год (григорианский)YRJ — год (юлианский) YRL – год (високосный)YRM – год (среднетропический)B39- Британская термальная единица (39 °F)B59 — Британская термальная единица (59 °F)B60 — Британская термальная единица (60 °F)B63 — Британская термальная единица (63 °F)BOE — эквивалент барреля нефтиBRT — Британская термальная единица ( Iso)BTI — Британская термальная единица (InternatBTM — Британская термальная единица (средняя)BTT — Британская термальная единица (ThermochC15 — Калория (15 °C)C20 — Калория (20 °C)C98 — Калория (398 °C)CAM — Калория ( Среднее значение)CFT — Кубический фут атмосферы CHU — Тепловая единица ЦельсияCL — Калория (Us Fda)CLTH — Калория (термохимическая)CN — Кубический фут природного газаCTA — Кубический сантиметр атмосферыCYD — Кубический ярд атмосферы StandEH — Атомная единица энергии ХартриFTD — Foot-PoundalIMG — Галлон-атмосфераKCA — Большая килокалорияKWH — Киловатт-час Board Of Trade ULTM — Литр-атмосфераQD — QuadRDB — Therm (Ec)RY — RydbergTCE — Тонна угольного эквивалентаTHR — Therm (Us)THU — ThermieTN — Тонна TntTOE — Tone Of Oil EquivalentBAN — Ban HartleyBSH — Bit ShannonCD — Candela (Si Base Unit) CandleCPD — Candlepower (New)JK — Si UnitNAT — Nat Nip NepitNBL — NibbleBIT — BitsBYT — BytesEBI — ExabitsEBY — ExabytesGBI — GigabitsGBY — GigabytesKBI — KilobitsKBY — KilobytesMBI — МегабитыMBY — МегабайтыPBI — ПетабитыPBY — ПетабайтыTBI — ТерабитыTBY — ТерабайтыBLL — Баррели (нефть)CMQ — Кубические сантиметрыFTQ — Кубические футыGLI — Галлоны (Великобритания)GLL — Галлоны (жидкости США)LTR — ЛитрыMLT — МиллилитрыMTQ — Кубические метрыOZI — Унции UKBQ — Беккерели ( Si Unit)CI — КюриRD — Резерфорд (H)BTU — BTUCAL — КалорииERG — ErgEVL — Электрон ВольтFPD — Фут-фунтHPH — Лошадиная сила-часIPD — Дюйм-фунтJOU — ДжоульC — Скорость света в вакуумеFPF — Фарлонг в две неделиFPH — Фут в часIPH — Inch Per HourIPM — Inch Per MinuteIPS — Inch Per SecondMCH — Mach NumberMPM — Mile Per MinuteMPS — Mile Per SecondMS — Метр в секунду (Si Unit)SPS — Скорость звука в AirCDF — Candela Per Square FootCDI — Candela Per Square InchCDM — Candela Per Квадратный метр (Si UFL — FootlambertLMB — LambertSB — Stilb (Cgs Unit)CEL — ЦельсийDDE — Градус DelisleDNE — Градус НьютонаFAN — ФаренгейтGMR — Регулирующий газ MarkKEL — Kelvin’sRAN — RankineREA — ReaumurRME — Градус RømerCFM — Кубический фут в минутуFTS — Кубический фут в минуту SecondGPD — галлон (жидкость США) в суткиGPH — галлон (жидкость США) в часGPM — галлон (жидкость США) в минутуINM — кубический дюйм в минутуINS — кубический дюйм в секундуLPM — литр в минутуMQS — кубический метр в секунду (Si UniCM — кулоновый метрDB — DebyeEA0 — атомная единица электрического диполя CMT — сантиметр DMT — дециметрыFOT — футыINH — дюймыKMT — километрыMMT — миллиметрыMTR — метрыSMI — милиYRD — ярдыCTM — каратыGRM — граммыKGM — килограммыLBR — фунтыMGM — миллиграммыONZ — унции TNE — тонны (метрические)DEG — градусыGRD — градыRAD - RadiansFC — Фут-канд Люмен на квадрат FoLMN — Люмен на квадратный дюймLX — Люкс (Единица Si)PH — Фот (Единица Cgs)FHP — Фут в час в секундуFMS — Фут в минуту в секундуFP — Фут в секунду в квадратеdG — Стандартная сила тяжестиGAL — Gal GalileoIP — Дюйм в минуту в секундуIP2 — дюйм в секунду в квадратеKNS — узел в секундуMM — миля в минуту в секундуMP — миля в час в секундуMP2 — миля в секунду в квадратеMSA — метр в секунду в квадрате (Si UFPM — футы/минутыFPS — футы/секундыKMH — километры/ ЧасKMS — Километры/секундыKNT — УзлыMPH — Мили/часMTS — Метры/секундыFT2 — Квадратный фут в секундуM2S — Квадратный метр в секунду (Si UnSTX — Стокс (единица Cgs)FTP — Foot-PoundalMKG — Метр Килограмм-силаNEM — Ньютон-метр (Единица Si )GCC — граммы/кубический сантиметрKCC — килограммы/кубический сантиметрKLI — килограммы/литрKMC — килограммы/кубический метрOCI — унции/кубический дюймOGL — унции/галлонPCF — фунты/кубический футPCI — фунты/кубический дюймPGL — фунты/галлонGML — грамм на миллилитрLAB — фунт (Avoirdupois) Per GallonLBF — фунт (Avoirdupois) на кубический LBI — фунт (Avoirdupois) на кубический LBL — фунт (Avoirdupois) на галлонOFT — унция (Avoirdupois) на кубический OG — унция (Avoirdupois) на галлонOGA — унция (Avoirdupois) на галлонOIN — Унция (Avoirdupois) на кубический SFT — Слаг на кубический футGSS — Гаусс (единица Cgs)TSL — Тесла (единица Si)GY — Грей (единица Si)RDD — RadJCM — Джоули/сантиметрKGF — Килограмм-силаNWN — НьютоныPFC — Фунт силыLBH — Фунт Per Foot HourLBS — Фунт на фут-секундуLFT — Фунт-сила-секунда на квадрат LIN — Фунт-сила-секунда на квадрат PAS — Паскаль-секунда (единица Si)PSU — Пуаз (единица Cgs)MX — Максвелл (единица Cgs)WB — Вебер (Si) Единица)REM — Рентген-эквивалент ManSV — Зиверт (Единица Si)
S.) — Ссылка (Гюнтера; Сюрвейерская)LNK (RE) — Ссылка (Рамсденская; Инженерная)LS — Световая секундаLY — Световая- yearM — метр (базовая единица СИ)MIL — мил (Швеция и Норвегия)MILE DATA — мили (тактические или данные)MK — MickeyNAIL — гвоздь (ткань)NL — морская лигаNM — нанометрNMI — морская миляNMI I — морская миляP — PalmPC — ParsecPICA — PicaPM — пикометр (бикрон, клеймо) POINT — точка (американский, английский) PT — PaceQUART — QuarterSHAKU — Shaku (японский) SPT — SpatTH — Mil (тыс.)TWP — TwipUM — микрометр (стар.: микрон)XU — единица X; siegbahnABA — Электромагнитная единица AbampereAMP — Ампер (базовая единица Si)ESU — Esu в секунду Статампер (CgsABC — Абкулон Электромагнитная единицаATU — Атомная единица зарядаCLM — КулонFRD — ФарадейMAH — Миллиампер-часSTT — Статкулон Франклин ЭлектростABV — Абвольт (единица Cgs)STV — Статвольт ( Cgs Unit)VLT — Вольт (Si Unit)ACF — Акр-футыACI — Акры-дюймыBIB — Баррели (нефтяные)BII — Баррели (британские)BIU — Баррели (Us Dry)BKT — Ведра (британские)BRO — Галлоны (пивные)BUD — Бушели (Us Dry Level)BUI — Бушели (Imperial)BUU — Бушели (Us Dry Heaped)CMB — CoombsCMI — Cubic MilesCP — CupsCRF — Cord-FootsCRW — Cords (Дрова)CUF — Cubic FathomsCUI — Cubic InchsCUT — Cubic FootsCUY — Cubic ЯрдыDSI — тире (имперские фунты)DSS — десертные ложки (имперские фунты)DSU — тире (США)FBM — борд-футыFFT — пятые FID — жидкие драхмы (имперские)FIS — жидкие скрукле (имперские)FLB — бочки (США, жидкие)FLU — жидкие драмы ( Us) Us FluidramFRK — FirkinsGAI — галлоны (имперские единицы)GAU — галлоны (Us Dry)GAW — галлоны (Us Fluid Wine)GLU — Teacups (gills)GTT — DropsHDI — Hogsheads (Imperial)HHU — Hogsheads (Us)JGR — Jiggers ( Bartending)KLD — KilderkinsLMD — LambdasLOD — LoadsLST — LastsM3 — Кубические метры (Si Unit)MII — Minims (Imperial)MIU — Minims (Us)OZF — Унции (Fluid Us Food NutritioPER — PerchsPKI — Pecks (Imperial)PKU — Pecks (Us) Сухой)PNI — пинчи (британские)PNU — пинчи (американские)PON — PonysPOT — Pottle QuartersPP — стыковые трубыPTI — пинты (британские)PUD — пинты (Us Dry)PUF — пинты (Us Fluid)QRF — Quart S (Us Fluid) QRT — Кварталы QTI — Кварты (британские)QTU — Кварты (Us Dry)RGS — Реестр TonsSCI — Мешки (британские) BagsSCU — Мешки(Us)SHT — Shots (Us)SM — SeamsSTK — Забастовки (Imperial)STU — Забастовки (Us) )TBC — столовые ложки (канадские)TBF — столовые ложки (обычные в США)TBM — столовые ложки (метрические)TBS — столовые ложки (в австралийских единицах измеренияTCA — чайные ложки (канадские) TFD — столовые ложки (Us Food NutritionTIM — чайные ложки (британские)TMF — Timber FootsTMT — чайные ложки ( Метрическая система)TND – тонны (водоизмещение)TNT – тонны (воды)TNW – тонны (фрахт)TSC – чайные ложки (стандарт США)TSF – чайные ложки (США Food Nutrition) WEY — Wey (Us)ACM — Атмосфера-кубический фут в минутуACS — Атмосфера-кубический фут в секунду SecoATC — Атмосфера-кубический сантиметр PeATH — Атмосфера-кубический фут в часBTJ — BTU (Международная таблица) В расчете на BTN — BTU (Международная таблица) В расчете на BTS — БТЕ (международная таблица) по CAS — Калория (международная таблица) ERS — Эрг в секундуFMF — Фут-фунт-сила в минутуFT — Фут-фунт-сила в часFTO — Фут-фунт-сила в секундуHPS — Лошадиная силаLAM — Литр-атмосфера в час MinuteLSC — LusecLTS — Литр атмосферы в секундуPNC — PonceletSQL — Прямой эквивалент квадратного фута TC — Тонна кондиционирования воздухаTMS — Атмосфера-кубический сантиметр PeTRM — Тонна охлаждения (ImperialTRR — Тонна охлаждения (It)ACR — AcresCMK — Квадратные сантиметрыFTK — Квадратные футыHAR — ГектарыINK — Квадратные дюймыKMK — Квадратные километрыMIK — Квадратные милиMTK — Квадратные метрыYDK — Квадратные ярдыAMU — Унифицированная атомная единица массыAT — Тонна анализа (краткая)ATS — Тонна анализа (длинная)BAC — Мешок (Кофе)BDM — Мешок (портландцемент)BRG — BargeCLV — CloveCRT — CrithCT — Carat (Metric)DA — DaltonDRT — Dram (Apothecary Troy)DWT — PennyweightGAM — GammaGR — GrainGV — GraveKIP — KipLB — Pound (Metric)LBA — PoundLBT — Pound (Troy)LBV — Pound (Avoirdupois)ME — Атомная единица массы Электрон RMRK — MarkMTE — MiteMTM — Клещ (метрический) OZ — Унция (этикетка питания США OZT — Унция (аптечная Троя) OZZ — Унция (Avoirdupois) PNN — PointQ — Квинтал (метрический) QR — Квартал (неофициальный) QRI — Quarter (Imperial)QRL — Quarter Long (Informal)SAP — Scruple (Apothecary)SH — Ton ShortSLG — Slug Geepound HylSLH — SheetST — StoneSWT — Hundredweight (центум веса oTON — Ton LongWY — WeyZTR — ZentnerANN — YearsDAY — DaysHUR — HoursMCS — MicrosecondsMIN — MinutesMLS — MillisecondsMON — MonthsSEC — SecondsWEE — WeeksARE — AresBD — BoardsBHE — эквивалент мощности котла DBR — BarnsBRN — BaronysCDA — Cuerda Pr SurveysCRD — CordsCRI — Circular InchsCRM — Circular MilsDNM — DunamsGNT — GunthasHD — HidesRO — RoodsSCT — SectionsSHD — Сараи SII — Square Link Gunters InternatiSLR — Square Link RamsdensSQC — Square Chains InternationalSQM — Square Mil Square ThousSQR — Square Rod/Pole/PerchsSRR — Square RoofingsSTR — StremmasTWN — TownshipsYLN — YardlandsARM — Arcminute MoaARS — ArcsecondCNS — Centesimal Second Of ArcCNT — Centesimal Minute Of ArcDOA — Degree (Дуги)GRA — Grad Gradian GonOCT — OctantQRD — QuadrantSGN - SignSXT — Sextantµ — Угловой MilATA — Атмосфера (Техническая)ATM — Атмосфера (Стандартная)BAR — BarBRY — Бари (единица Cgs)CMH — Сантиметр ртутного столбаCMW — Сантиметр водяного столба ( 4 °C)FTH — фут ртутного столба (условный)FTW — фут водяного столба (392 °F)IMC — дюйм ртутного столба (условный)INW — дюйм водяного столба (392 °F)KM — килограмм-сила на квадратный метр KSI — кип на квадратный дюймLTP — длинная тонна на квадратный футMHG — микрометр ртутного столбаMMH — миллиметр ртутного столбаMMW — Миллиметр воды (398 °C)PA — Паскаль (единица Си)PD — Фунт на квадратный футPSF — Фунт на квадратный футPSI — Фунт на квадратный дюймPZ — Пьез (единица МТС)STP — Короткая тонна на квадратный футTOR — ТоррATN — Атомная единица ForceDYN — Dyne (Cgs Unit)KFF — Килограмм-сила Kilopond Grave-KI — Kip Kip-ForceMGF — Milligrave-Force Gravet-ForceOZC — Унция-силаPDL — PoundalSN — Sthene (единица Mts)TNF — Long Ton-ForceTNL — Short Ton- ForceAUC — атомная единица времениCTN — CenturyCYC — каллипический циклDEC — DecadeFN — FortnightHEL — HelekHIP — гиппархический циклJFF — JiffyKEH — Ke (четверть часа) LSR — Luster LustrumMD — MillidayMLL — MillenniumMMN — MomentMOF — Month (Full)MOG — Month (Greg) Av)MOH — месяц (полый)MOS — месяц (синодический)MTN — метонический цикл EnneadecaeterisOC — OctaeterisPLN — планковское времяSGM — SigmaSHK — ShakeSTH — сотический циклSVD — SvedbergYR — год (общий)YRG — год (григорианский)YRJ — год (юлианский) YRL – год (високосный)YRM – год (среднетропический)B39- Британская термальная единица (39 °F)B59 — Британская термальная единица (59 °F)B60 — Британская термальная единица (60 °F)B63 — Британская термальная единица (63 °F)BOE — эквивалент барреля нефтиBRT — Британская термальная единица ( Iso)BTI — Британская термальная единица (InternatBTM — Британская термальная единица (средняя)BTT — Британская термальная единица (ThermochC15 — Калория (15 °C)C20 — Калория (20 °C)C98 — Калория (398 °C)CAM — Калория ( Среднее значение)CFT — Кубический фут атмосферы CHU — Тепловая единица ЦельсияCL — Калория (Us Fda)CLTH — Калория (термохимическая)CN — Кубический фут природного газаCTA — Кубический сантиметр атмосферыCYD — Кубический ярд атмосферы StandEH — Атомная единица энергии ХартриFTD — Foot-PoundalIMG — Галлон-атмосфераKCA — Большая килокалорияKWH — Киловатт-час Board Of Trade ULTM — Литр-атмосфераQD — QuadRDB — Therm (Ec)RY — RydbergTCE — Тонна угольного эквивалентаTHR — Therm (Us)THU — ThermieTN — Тонна TntTOE — Tone Of Oil EquivalentBAN — Ban HartleyBSH — Bit ShannonCD — Candela (Si Base Unit) CandleCPD — Candlepower (New)JK — Si UnitNAT — Nat Nip NepitNBL — NibbleBIT — BitsBYT — BytesEBI — ExabitsEBY — ExabytesGBI — GigabitsGBY — GigabytesKBI — KilobitsKBY — KilobytesMBI — МегабитыMBY — МегабайтыPBI — ПетабитыPBY — ПетабайтыTBI — ТерабитыTBY — ТерабайтыBLL — Баррели (нефть)CMQ — Кубические сантиметрыFTQ — Кубические футыGLI — Галлоны (Великобритания)GLL — Галлоны (жидкости США)LTR — ЛитрыMLT — МиллилитрыMTQ — Кубические метрыOZI — Унции UKBQ — Беккерели ( Si Unit)CI — КюриRD — Резерфорд (H)BTU — BTUCAL — КалорииERG — ErgEVL — Электрон ВольтFPD — Фут-фунтHPH — Лошадиная сила-часIPD — Дюйм-фунтJOU — ДжоульC — Скорость света в вакуумеFPF — Фарлонг в две неделиFPH — Фут в часIPH — Inch Per HourIPM — Inch Per MinuteIPS — Inch Per SecondMCH — Mach NumberMPM — Mile Per MinuteMPS — Mile Per SecondMS — Метр в секунду (Si Unit)SPS — Скорость звука в AirCDF — Candela Per Square FootCDI — Candela Per Square InchCDM — Candela Per Квадратный метр (Si UFL — FootlambertLMB — LambertSB — Stilb (Cgs Unit)CEL — ЦельсийDDE — Градус DelisleDNE — Градус НьютонаFAN — ФаренгейтGMR — Регулирующий газ MarkKEL — Kelvin’sRAN — RankineREA — ReaumurRME — Градус RømerCFM — Кубический фут в минутуFTS — Кубический фут в минуту SecondGPD — галлон (жидкость США) в суткиGPH — галлон (жидкость США) в часGPM — галлон (жидкость США) в минутуINM — кубический дюйм в минутуINS — кубический дюйм в секундуLPM — литр в минутуMQS — кубический метр в секунду (Si UniCM — кулоновый метрDB — DebyeEA0 — атомная единица электрического диполя CMT — сантиметр DMT — дециметрыFOT — футыINH — дюймыKMT — километрыMMT — миллиметрыMTR — метрыSMI — милиYRD — ярдыCTM — каратыGRM — граммыKGM — килограммыLBR — фунтыMGM — миллиграммыONZ — унции TNE — тонны (метрические)DEG — градусыGRD — градыRAD - RadiansFC — Фут-канд Люмен на квадрат FoLMN — Люмен на квадратный дюймLX — Люкс (Единица Si)PH — Фот (Единица Cgs)FHP — Фут в час в секундуFMS — Фут в минуту в секундуFP — Фут в секунду в квадратеdG — Стандартная сила тяжестиGAL — Gal GalileoIP — Дюйм в минуту в секундуIP2 — дюйм в секунду в квадратеKNS — узел в секундуMM — миля в минуту в секундуMP — миля в час в секундуMP2 — миля в секунду в квадратеMSA — метр в секунду в квадрате (Si UFPM — футы/минутыFPS — футы/секундыKMH — километры/ ЧасKMS — Километры/секундыKNT — УзлыMPH — Мили/часMTS — Метры/секундыFT2 — Квадратный фут в секундуM2S — Квадратный метр в секунду (Si UnSTX — Стокс (единица Cgs)FTP — Foot-PoundalMKG — Метр Килограмм-силаNEM — Ньютон-метр (Единица Si )GCC — граммы/кубический сантиметрKCC — килограммы/кубический сантиметрKLI — килограммы/литрKMC — килограммы/кубический метрOCI — унции/кубический дюймOGL — унции/галлонPCF — фунты/кубический футPCI — фунты/кубический дюймPGL — фунты/галлонGML — грамм на миллилитрLAB — фунт (Avoirdupois) Per GallonLBF — фунт (Avoirdupois) на кубический LBI — фунт (Avoirdupois) на кубический LBL — фунт (Avoirdupois) на галлонOFT — унция (Avoirdupois) на кубический OG — унция (Avoirdupois) на галлонOGA — унция (Avoirdupois) на галлонOIN — Унция (Avoirdupois) на кубический SFT — Слаг на кубический футGSS — Гаусс (единица Cgs)TSL — Тесла (единица Si)GY — Грей (единица Si)RDD — RadJCM — Джоули/сантиметрKGF — Килограмм-силаNWN — НьютоныPFC — Фунт силыLBH — Фунт Per Foot HourLBS — Фунт на фут-секундуLFT — Фунт-сила-секунда на квадрат LIN — Фунт-сила-секунда на квадрат PAS — Паскаль-секунда (единица Si)PSU — Пуаз (единица Cgs)MX — Максвелл (единица Cgs)WB — Вебер (Si) Единица)REM — Рентген-эквивалент ManSV — Зиверт (Единица Si)


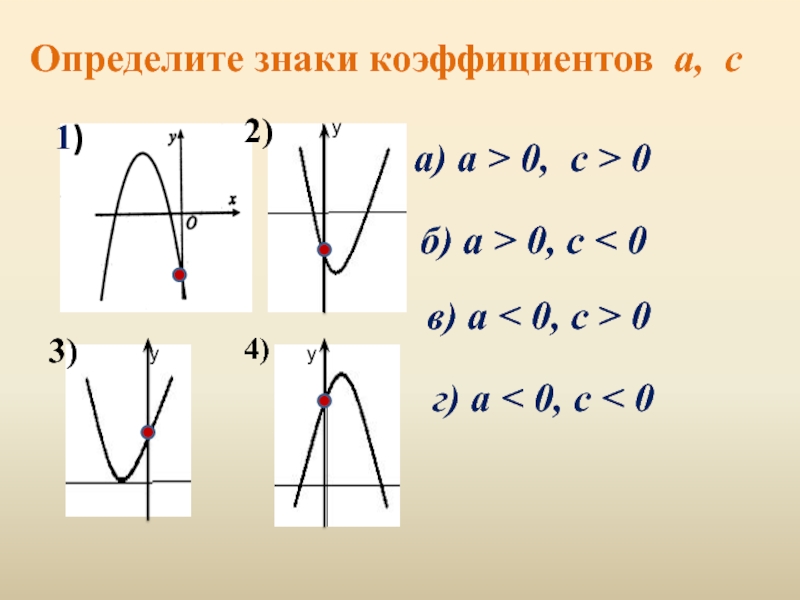
 Пружины вертикальны. Верхний конец пружины жёсткостью 3k и нижний конец пружины жёсткостью k закреплены. Известно, что нижняя пружина сжата на a=5 см. Ускорение свободного падения g=10 Н/кг.
Пружины вертикальны. Верхний конец пружины жёсткостью 3k и нижний конец пружины жёсткостью k закреплены. Известно, что нижняя пружина сжата на a=5 см. Ускорение свободного падения g=10 Н/кг. ВОКАЛЬНЫЕ ЖАНРЫ:
ВОКАЛЬНЫЕ ЖАНРЫ: какая электрическая величина меняется в цепи при изменении длины включенного реохорда
какая электрическая величина меняется в цепи при изменении длины включенного реохорда ..
..  pdx.edu › ~atkinsdb › учить › NAOH
pdx.edu › ~atkinsdb › учить › NAOH




 ) + Ca 2+ (водн.) + 2OH – (водн.) = CaSO 3 (т) + 2 H 2 O (л)
) + Ca 2+ (водн.) + 2OH – (водн.) = CaSO 3 (т) + 2 H 2 O (л) 
 Это непрямой кислый буфер, так как сульфит кальция образуется в результате реакции слабой кислоты и сильного основания.
Это непрямой кислый буфер, так как сульфит кальция образуется в результате реакции слабой кислоты и сильного основания. 


 И., Пантелеев А.В., 2015» для чтения, скачивания и покупки
И., Пантелеев А.В., 2015» для чтения, скачивания и покупки ..
.. .. — PDF Drive
.. — PDF Drive .. — PDF Drive
.. — PDF Drive ..
..

 Наука, изучающая численные методы, называется также численным анализом, или вычислительной математикой.
Наука, изучающая численные методы, называется также численным анализом, или вычислительной математикой. litres.ru
litres.ru
 Учебное пособие…
Учебное пособие…
 .
.




 Конвертировать (EPUB, MOBI) Отправлено на электронную почту Отправлено в Kindle Report.
Конвертировать (EPUB, MOBI) Отправлено на электронную почту Отправлено в Kindle Report. Описание этого курса может измениться. Окончательная версия будет опубликована 1 июня.
Описание этого курса может измениться. Окончательная версия будет опубликована 1 июня.

 Поскольку в этом случае вы рискуете ничему не научиться в процессе выполнения работы. Самый лучший вариант – это подробные методические рекомендации, следуя которым можно легко справиться с работой самостоятельно.
Поскольку в этом случае вы рискуете ничему не научиться в процессе выполнения работы. Самый лучший вариант – это подробные методические рекомендации, следуя которым можно легко справиться с работой самостоятельно. После этого он сможет сделать вывод об эффективности своей работы, о необходимости проведения дополнительных занятий по какой-либо теме, о качестве заданий.
После этого он сможет сделать вывод об эффективности своей работы, о необходимости проведения дополнительных занятий по какой-либо теме, о качестве заданий.

 Иначе, велика вероятность возврата на доработку или получения заниженной оценки, потому что некоторые преподаватели требуют точного следования всем инструкциям. Подробнее про оформление контрольной работы здесь.
Иначе, велика вероятность возврата на доработку или получения заниженной оценки, потому что некоторые преподаватели требуют точного следования всем инструкциям. Подробнее про оформление контрольной работы здесь. Если же время поджимает или задание оказалось слишком сложным – лучше заказать работу у профессионалов. Только обязательно потом изучите решение. А самое главное – любая контрольная работа помогает вам повысить уровень своей квалификации.
Если же время поджимает или задание оказалось слишком сложным – лучше заказать работу у профессионалов. Только обязательно потом изучите решение. А самое главное – любая контрольная работа помогает вам повысить уровень своей квалификации. Как правило, преподаватели проводят такие проверочные несколько раз за семестр, и оценки за контрольную существенно повлияют на итоговый балл. Чтобы контрольную работу оценили высоко, она должна иметь правильную структуру.
Как правило, преподаватели проводят такие проверочные несколько раз за семестр, и оценки за контрольную существенно повлияют на итоговый балл. Чтобы контрольную работу оценили высоко, она должна иметь правильную структуру.
 Представители гуманитарных специальностей обычно анализируют материал по теме работы, будущие инженеры производят расчёты или делают чертежи.
Представители гуманитарных специальностей обычно анализируют материал по теме работы, будущие инженеры производят расчёты или делают чертежи. Каждый элемент нумеруется в алфавитном порядке.
Каждый элемент нумеруется в алфавитном порядке. Они в краткие сроки подготовят любую учебную работу: контрольную, лабораторную, самостоятельную, практическую.
Они в краткие сроки подготовят любую учебную работу: контрольную, лабораторную, самостоятельную, практическую. На их выполнение уходит несколько часов, и ваш ученик справится с ними за один присест (конечно, с перерывом или двумя).
На их выполнение уходит несколько часов, и ваш ученик справится с ними за один присест (конечно, с перерывом или двумя). Баллы также могут быть использованы для определения суммы, которую ваш учащийся получает от некоторых форм финансовой помощи, таких как стипендии. И даже если желаемая школа вашего ученика не требует оценок, ваш ученик может захотеть представить их в любом случае, если он наберет действительно хороший балл, поскольку это только увеличит его шансы на поступление.
Баллы также могут быть использованы для определения суммы, которую ваш учащийся получает от некоторых форм финансовой помощи, таких как стипендии. И даже если желаемая школа вашего ученика не требует оценок, ваш ученик может захотеть представить их в любом случае, если он наберет действительно хороший балл, поскольку это только увеличит его шансы на поступление. Один из лучших вариантов — купить книгу для подготовки к экзамену, который собирается сдавать ваш ученик. Вы можете найти их на Amazon, и они дадут вашему ученику действительно хорошее представление о том, чего ожидать на экзамене, а также помогут им подготовиться к нему. Ваш ученик также должен пройти тест достаточно рано, чтобы у него было время пересдать его, если он не сдаст экзамен так хорошо, как хотел бы, с первого раза.
Один из лучших вариантов — купить книгу для подготовки к экзамену, который собирается сдавать ваш ученик. Вы можете найти их на Amazon, и они дадут вашему ученику действительно хорошее представление о том, чего ожидать на экзамене, а также помогут им подготовиться к нему. Ваш ученик также должен пройти тест достаточно рано, чтобы у него было время пересдать его, если он не сдаст экзамен так хорошо, как хотел бы, с первого раза. Например, чего пытается добиться ваш преподаватель, проводя для вас контрольный опрос в первый день занятий? Чем цель этого теста может отличаться от цели, скажем, пробной викторины, проводимой перед промежуточным экзаменом? И какова цель промежуточного периода?
Например, чего пытается добиться ваш преподаватель, проводя для вас контрольный опрос в первый день занятий? Чем цель этого теста может отличаться от цели, скажем, пробной викторины, проводимой перед промежуточным экзаменом? И какова цель промежуточного периода?
 Формирующее оценивание помогает преподавателю лучше удовлетворить ваши потребности как учащегося.
Формирующее оценивание помогает преподавателю лучше удовлетворить ваши потребности как учащегося. Например, в тесте с закрытой книгой испытуемый обычно должен полагаться на память, чтобы отвечать на определенные вопросы. Однако в тесте с открытой книгой испытуемый может использовать один или несколько дополнительных ресурсов, например, справочник или заметки. Тестирование по открытой книге может использоваться для предметов, по которым требуется много технических терминов или формул, чтобы эффективно отвечать на вопросы, например, по химии или физике.
Например, в тесте с закрытой книгой испытуемый обычно должен полагаться на память, чтобы отвечать на определенные вопросы. Однако в тесте с открытой книгой испытуемый может использовать один или несколько дополнительных ресурсов, например, справочник или заметки. Тестирование по открытой книге может использоваться для предметов, по которым требуется много технических терминов или формул, чтобы эффективно отвечать на вопросы, например, по химии или физике. Давайте посмотрим, какие вещи вы должны будете выполнить в каждом типе теста.
Давайте посмотрим, какие вещи вы должны будете выполнить в каждом типе теста. Но при умеренном использовании вопросы «верно/неверно» могут быть эффективными.
Но при умеренном использовании вопросы «верно/неверно» могут быть эффективными.
 Эти задачи измеряют физические способности, такие как сила, мышечная гибкость и выносливость. Ниже приведен пример тестов на физические способности на рабочем месте:
Эти задачи измеряют физические способности, такие как сила, мышечная гибкость и выносливость. Ниже приведен пример тестов на физические способности на рабочем месте: Они хотят знать, что вы достигаете целей, которые они перед вами поставили. Их цели могут относиться к когнитивным навыкам, таким как запоминание, понимание, применение, анализ, оценка и создание. (Дополнительную информацию о таксономии Блума и когнитивной области обучения см. в разделе «Модели мышления».) Кроме того, ваши преподаватели всегда рады хорошей грамматике, вдумчивости, творчеству, точности и надежным ссылкам.
Они хотят знать, что вы достигаете целей, которые они перед вами поставили. Их цели могут относиться к когнитивным навыкам, таким как запоминание, понимание, применение, анализ, оценка и создание. (Дополнительную информацию о таксономии Блума и когнитивной области обучения см. в разделе «Модели мышления».) Кроме того, ваши преподаватели всегда рады хорошей грамматике, вдумчивости, творчеству, точности и надежным ссылкам./Dopolnitelnye%20zadaniya/8%20klass/Kontrolnye%20raboty%20ris/Kontrolnaya%20rabota%20(8kl)%208.jpg)