Вы искали y корень x 2? На нашем сайте вы можете получить ответ на любой математический вопрос здесь. Подробное
решение с описанием и пояснениями поможет вам разобраться даже с самой сложной задачей и y корень из x 2, не
исключение. Мы поможем вам подготовиться к домашним работам, контрольным, олимпиадам, а так же к поступлению
в вуз.
И какой бы пример, какой бы запрос по математике вы не ввели — у нас уже есть решение.
Например, «y корень x 2».
Применение различных математических задач, калькуляторов, уравнений и функций широко распространено в нашей
жизни. Они используются во многих расчетах, строительстве сооружений и даже спорте. Математику человек
использовал еще в древности и с тех пор их применение только возрастает. Однако сейчас наука не стоит на
месте и мы можем наслаждаться плодами ее деятельности, такими, например, как онлайн-калькулятор, который
может решить задачи, такие, как y корень x 2,y корень из x 2,корень из x 2 y 2,постройте график функции y 2 корень x,постройте график функции y корень x 2. На этой странице вы найдёте калькулятор,
который поможет решить любой вопрос, в том числе и y корень x 2. Просто введите задачу в окошко и нажмите
«решить» здесь (например, корень из x 2 y 2).
Где можно решить любую задачу по математике, а так же y корень x 2 Онлайн?
Решить задачу y корень x 2 вы можете на нашем сайте https://pocketteacher.ru. Бесплатный
онлайн решатель позволит решить онлайн задачу любой сложности за считанные секунды. Все, что вам необходимо
сделать — это просто
ввести свои данные в решателе. Так же вы можете посмотреть видео инструкцию и узнать, как правильно ввести
вашу задачу на нашем сайте. А если у вас остались вопросы, то вы можете задать их в чате снизу слева на странице
калькулятора.
Mathway | Популярные задачи
1
Упростить
квадратный корень s квадратный корень s^7
2
Упростить
кубический корень 8x^7y^9z^3
3
Упростить
arccos(( квадратный корень 3)/2)
4
Risolvere per ?
sin(x)=1/2
5
Упростить
квадратный корень s квадратный корень s^3
6
Risolvere per ?
cos(x)=1/2
7
Risolvere per x
sin(x)=-1/2
8
Преобразовать из градусов в радианы
225
9
Risolvere per ?
cos(x)=( квадратный корень 2)/2
10
Risolvere per x
cos(x)=( квадратный корень 3)/2
11
Risolvere per x
sin(x)=( квадратный корень 3)/2
12
График
g(x)=3/4* корень пятой степени x
13
Найти центр и радиус
x^2+y^2=9
14
Преобразовать из градусов в радианы
120 град. 2+n-72)=1/(n+9)
Функция КОРЕНЬ — Служба поддержки Office
В этой статье описаны синтаксис формулы и использование функции КОРЕНЬ в Microsoft Excel.
Описание
Возвращает положительное значение квадратного корня.
Синтаксис
КОРЕНЬ(число)
Аргументы функции КОРЕНЬ описаны ниже.
Замечание
Если число отрицательное, то SQRT возвращает #NUM! значение ошибки #ЗНАЧ!.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Данные
-16
Формула
Описание
Результат
=КОРЕНЬ(16)
Квадратный корень числа 16.
4
=КОРЕНЬ(A2)
Квадратный корень -16. Так как число отрицательное, #NUM! возвращается сообщение об ошибке.
#ЧИСЛО!
=КОРЕНЬ(ABS(A2))
Старайтесь не #NUM! сообщение об ошибке: сначала с помощью функции ABS можно найти абсолютное значение -16, а затем найти квадратный корень.
4
Как найти область определения функции?
Для того, чтобы понять, что такое область определения функции, необходимо знать области определения основных элементарных функций. Для этого нужно углубить знания данной статьей. Будут рассмотрены различные сложнейшие комбинации функций вида y=x+x-2 или y=5·x2+1·x3, y=xx-5 или y=x-15-3. Рассмотрим теорию и решим несколько примеров с подобными заданиями.
Что значит найти область определения
После того, как функция задается, указывается ее область определения. Иначе говоря, без области определения функция не рассматривается. При задании функции вида y=f(x) область определения не указывается, так как ее ОДЗ для переменной x будет любым. Таким образом, функция определена на всей области определения.
Ограничение области определения
Область определения рассматривается еще в школьной курсе. у действительных чисел она может быть (0, +∞) или такой [−3, 1)∪[5, 7). Еще по виду функции можно визуально определить ее ОДЗ. Рассмотрим, на что может указывать наличие области определения:
Определение 1
при имеющемся знаменателе необходимо производить деление такого типа функции как y=x+2·xx4-1;
при наличии переменной под знаком корня необходимо обращать внимание на корень четной степени типа y=x+1 или y=23·x+3x;
при наличии переменной в основании степени с отрицательным или нецелым показателем такого типа, как y=5·(x+1)-3, y=-1+x113, y=(x3-x+1)2, которые определены не для всех чисел;
при наличии переменной под знаком логарифма или в основании вида y=lnx2+x4 или y=1+logx-1(x+1) причем основание является числом положительным, как и число под знаком логарифма;
при наличии переменной, находящейся под знаком тангенса и котангенса вида y=x3+tg2·x+5 или y=ctg(3·x3-1), так как они существуют не для любого числа;
при наличии переменной, расположенной под знаком арксинуса или арккосинуса вида y=arcsin(x+2)+2·x2, y=arccosx-1+x, область определения которых определяется ни интервале от -1 до 1.
При отсутствии хотя бы одного признака, область определения приходится искать другим образом. Рассмотрим пример функции вида y=x4+2·x2-x+12+223·x. Видно, что никаких ограничений она не имеет, так как в знаменателе нет переменной.
Правила нахождения области определения
Для примера рассмотрим функцию типа y=2·x+1. Для вычисления ее значения можем определить x. Из выражения 2·x+1 видно, что функция определена на множестве всех действительных чисел. Рассмотрим еще один пример для подробного определения.
Если задана функция типа y=3x-1, а необходимо найти область определения, тогда понятно, что следует обратить внимание на знаменатель. Известно, что на ноль делить нельзя. Отсюда получаем, что 3x-1знаменатель равняется нулю при х=1, поэтому искомая область определения данной функции примет вид (−∞, 1)∪(1, +∞) и считается числовым множеством.
На рассмотрении примера y=x2-5·x+6 видно, что имеется подкоренное выражение, которое всегда больше или равно нулю. Значит запись примет вид x2−5·x+6≥0. После решения неравенства получим, что имеются две точки, которые делят область определения на отрезки, которые записываются как (−∞, 2]∪[3, +∞).
При подготовке ЕГЭ и ОГЭ можно встретить множество комбинированных заданий для функций, где необходимо в первую очередь обращать внимание на ОДЗ. Только после его определения можно приступать к дальнейшему решению.
Область определения суммы, разности и произведения функций
Перед началом решения необходимо научиться правильно определять область определения суммы функций. Для этого нужно, чтобы имело место следующее утверждение:
Когда функция ff считается суммой n функций f1, f2, …, fn, иначе говоря, эта функция задается при помощи формулы y=f1(x)+f2(x)+…+fn(x), тогда ее область определения считается пересечением областей определения функций f1, f2, …, fn. Данное утверждение можно записать как:
D(f)=D(f1)D(f2)…D(fn)
Поэтому при решении рекомендуется использование фигурной скобки при записи условий, так как это является удобным способом для понимания перечисления числовых множеств.
Пример 1
Найти область определения функции вида y=x7+x+5+tgx.
Решение
Заданная функция представляется как сумма четырех: степенной с показателем 7,степенной с показателем 1, постоянной, функции тангенса.
По таблице определения видим, что D(f1)=(−∞, +∞), D(f2)=(−∞, +∞), D(f3)=(−∞, +∞), причем область определения тангенса включает в себя все действительные числа, кроме π2+π·k, k∈Z.
Областью определения заданной функции f является пересечение областей определения f1, f2, f3 и f4. То есть для функции существует такое количество действительных чисел, куда не входит π2+π·k, k∈Z.
Ответ: все действительные числа кроме π2+π·k, k∈Z.
Для нахождения области определения произведения функций необходимо применять правило:
Определение 2
Когда функция f считается произведением n функций f1, f2, f3 и fn, тогда существует такая функция f, которую можно задать при помощи формулы y=f1(x)·f2(x)·…·fn(x), тогда ее область определения считается областью определения для всех функций.
Запишется D(f)=D(f1)D(f2)…D(fn)
Пример 2
Найти область определения функции y=3·arctg x·ln x.
Решение
Правая часть формулы рассматривается как f1(x)·f2(x)·f3(x), где за f1является постоянной функцией, f2является арктангенсом,f3– логарифмической функцией с основанием e. По условию имеем, что D(f1)=(−∞, +∞), D(f2)=(−∞, +∞) и D(f3)=(0, +∞). Мы получаем, что
Ответ: область определения y=3·arctg x·ln x – множество всех действительных чисел.
Необходимо остановиться на нахождении области определения y=C·f(x), где С является действительным числом. Отсюда видно, что ее областью определения и областью определения f совпадающими.
Функция y=C·f(x)– произведение постоянной функции и f. Область определения – это все действительные числа области определения D(f). Отсюда видим, что область определения функции y=C·f(x)является -∞, +∞D(f)=D(f).
Получили, что область определения y=f(x) и y=C·f(x), где C является некоторое действительное число, совпадают. Это видно на примере определения корня y=x считается [0, +∞), потому как область определения функции y=-5·x — [0, +∞).
Области определения y=f(x) и y=−f(x)совпадают , что говорит о том, что его область определения разности функции такая же, как и область определения их суммы.
Пример 3
Найти область определения функции y=log3x−3·2x.
Решение
Необходимо рассмотреть как разность двух функций f1 и f2.
f1(x)=log3x и f2(x)=3·2x. Тогда получим, что D(f)=D(f1)D(f2).
Область определения записывается как D(f1)=(0, +∞). Приступим к области определения f2 . в данном случае она совпадает с областью определения показательной, тогда получаем, что D(f2)=(−∞, +∞).
Для нахождения области определения функции y=log3x−3·2xполучим, что
D(f)=D(f1)D(f2)=(0, +∞)-∞, +∞
Ответ: (0, +∞).
Необходимо озвучить утверждение о том, что областью определения y=anxn+an-1xn-1+…+a1x+a0 является множество действительных чисел.
Рассмотрим y=anxn+an-1xn-1+…+a1x+a0, где в правой части имеется многочлен с одной переменной стандартного вида в виде степени n с действительными коэффициентами. Допускается рассматривать ее в качестве суммы (n+1)-ой функции. Область определения для каждой из таких функций включается множество действительных чисел, которое называется R.
Пример 4
Найти область определения f1(x)=x5+7×3-2×2+12.
Решение
Примем обозначение f за разность двух функций, тогда получим, что f1(x)=x5+7×3-2×2+12 и f2(x)=3·x-ln 5. Выше было показано, что D(f1)=R. Область определения для f2 является совпадающей со степенной при показателе –ln5, иначе говоря, что D(f2)=(0, +∞).
Получаем, что D(f)=D(f1)D(f2)=-∞, +∞(0, +∞)=(0, +∞).
Ответ: (0, +∞).
Область определения сложной функции
Для решения данного вопроса необходимо рассмотреть сложную функцию вида y=f1(f2(x)).Известно, что D(f)является множеством всех x из определения функции f2, где область определения f2(x)принадлежит области определения f1.
Видно, что область определения сложной функции вида y=f1(f2(x)) находится на пересечении двух множеств таких, где x∈D(f2)и f2(x)∈D(f1). В стандартном обозначении это примет вид
x∈D(f2)f2(x)∈D(f1)
Рассмотрим решение нескольких примеров.
Пример 5
Найти область определения y=ln x2.
Решение
Данную функцию представляем в виде y=f1(f2(x)), где имеем, что f1 является логарифмом с основанием e, а f2 – степенная функция с показателем 2.
Для решения необходимо использовать известные области определения D(f1)=(0, +∞) и D(f2)=(−∞, +∞).
Искомая область определения найдена. Вся ось действительных чисел кроме нуля является областью определения.
Ответ: (−∞, 0)∪(0, +∞).
Пример 6
Найти область определения функции y=(arcsin x)-12.
Решение
Так как дана сложная функция, необходимо рассматривать ее как y=f1(f2(x)), где f1 является степенной функцией с показателем -12, а f2 функция арксинуса, теперь необходимо искать ее область определения. Необходимо рассмотреть D(f1)=(0, +∞) и D(f2)=[−1, 1]. Теперь найдем все множества значений x, где x∈D(f2) и f2(x)∈D(f1). Получаем систему неравенств вида
Для решения arcsin x>0 необходимо прибегнуть к свойствам функции арксинуса. Его возрастание происходит на области определения [−1, 1], причем обращается в ноль при х=0, значит, что arcsin x>0 из определения x принадлежит промежутку (0, 1].
Преобразуем систему вида
x∈-1, 1arcsin x>0⇔x∈-1, 1x∈(0, 1]⇔x∈(0, 1]
Область определения искомой функции имеет интервал равный (0, 1].
Ответ: (0, 1].
Постепенно подошли к тому, что будем работать со сложными функциями общего вида y=f1(f2(…fn(x)))). Область определения такой функции ищется из x∈D(fn)fn(x)∈D(fn-1)fn-1(fn(x))∈D(fn-2)…f2(f3(…(fn(x)))∈D(f1).
Пример 7
Найти область определения y=sin(lg x4).
Решение
Заданная функция может быть расписана, как y=f1(f2(f3(x))), где имеем f1 – функция синуса, f2 – функция с корнем 4 степени, f3– логарифмическая функция.
Имеем, что по условию D(f1)=(−∞, +∞), D(f2)=[0, +∞), D(f3)=(0, +∞). Тогда областью определения функции – это пересечение множеств таких значений, где x∈D(f3), f3(x)∈D(f2), f2(f3(x))∈D(f1). Получаем, что
При решении примеров были взяты функции, которые были составлены при помощи элементарных функций, чтобы детально рассмотреть область определения.
Область определения дроби
Рассмотрим функцию вида f1(x)f2(x). Стоит обратить внимание на то, что данная дробь определяется из множества обеих функций, причем f2(х) не должна обращаться в ноль. Тогда получаем, что область определения f для всех x записывается в виде x∈D(f1)x∈D(f2)f2(x)≠0.
Запишем функцию y=f1(x)f2(x) в виде y=f1(x)·(f2(x))-1. Тогда получим произведение функций вида y=f1(x)с y=(f2(x))-1. Областью определения функции y=f1(x)является множество D(f1), а для сложной y=(f2(x))-1 определим из системы вида x∈D(f2)f2(x)∈(-∞, 0)∪(0, +∞)⇔x∈D(f2)f2(x)≠0.
Заданная функция дробная, поэтому f1 – сложная функция, где y=tg(2·x+1) и f2 – целая рациональная функция, где y=x2−x−6, а область определения считается множеством всех чисел. Можно записать это в виде
x∈D(f1)x∈D(f2)f2(x)≠0
Представление сложной функции y=f3(f4(x)), где f3–это функция тангенс, где в область определения включены все числа, кроме π2+π·k, k∈Z, а f4– это целая рациональная функция y=2·x+1 с областью определения D(f4)=(−∞, +∞). После чего приступаем к нахождению области определения f1:
Ответ: множество действительных чисел, кроме -2, 3 и π4-12+π2·k, k∈Z.
Область определения логарифма с переменной в основании
Определение 3
Определение логарифма существует для положительных оснований не равных 1. Отсюда видно, что функция y=logf2(x)f1(x) имеет область определения, которая выглядит так:
x∈D(f1)f1(x)>0x∈D(f2)f2(x)>0f2(x)≠1
А аналогичному заключению можно прийти, когда функцию можно изобразить в таком виде:
y=logaf1(x)logaf2(x), a>0, a≠1. После чего можно приступать к области определения дробной функции.
Область определения логарифмической функции – это множество действительных положительных чисел, тогда области определения сложных функций типа y=logaf1(x) и y=logaf2(x) можно определить из получившейся системы вида x∈D(f1)f1(x)>0 и x∈D(f2)f2(x)>0. Иначе эту область можно записать в виде y=logaf1(x)logaf2(x), a>0, a≠1, что означает нахождение y=logf2(x)f1(x) из самой системы вида
Обозначить область определения функции y=log2·x(x2-6x+5).
Решение
Следует принять обозначения f1(x)=x2−6·x+5 и f2(x)=2·x, отсюда D(f1)=(−∞, +∞) и D(f2)=(−∞, +∞). Необходимо приступить к поиску множества x, где выполняется условие x∈D(f1), f1(x)>0, x∈D(f2), f2(x)>0, f2(x)≠1. Тогда получаем систему вида
Отсюда видим, что искомой областью функции y=log2·x(x2-6x+5) считается множнство, удовлетворяющее условию 0, 12∪12, 1∪(5, +∞).
Ответ: 0, 12∪12, 1∪(5, +∞).
Область определения показательно-степенной функции
Показательно-степенная функция задается формулой вида y=(f1(x))f2(x). Ее область определениявключает в себя такие значения x, которые удовлетворяют системе x∈D(f1)x∈D(f2)f1(x)>0.
Эта область позволяет переходить от показательно-степенной к сложной вида y=aloga(f1(x))f2(x)=af2(x)·logaf1(x), где где a>0, a≠1.
Пример 10
Найти область определения показательно-степенной функции y=(x2-1)x3-9·x.
Решение
Примем за обозначение f1(x)=x2−1и f2(x)=x3-9·x.
Функция f1определена на множестве действительных чисел, тогда получаем область определения вида D(f1)=(−∞, +∞). Функция f2является сложной, поэтому ее представление примет вид y=f3(f4(x)), а f3 – квадратным корнем с областью определения D(f3)=[0, +∞), а функция f4 – целой рациональной,D(f4)=(−∞, +∞). Получаем систему вида
Значит, область определения для функции f2имеет вид D(f2)=[−3, 0]∪[3, +∞). После чего необходимо найти область определения показательно-степенной функции по условию x∈D(f1)x∈D(f2)f1(x)>0.
Получаем систему вида x∈-∞, +∞x∈-3, 0∪[3, +∞)x2-1>0⇔x∈-∞, +∞x∈-3, 0∪[3, +∞)x∈(-∞, -1)∪(1, +∞)⇔⇔x∈-3, -1∪[3, +∞)
Ответ: [−3, −1)∪[3, +∞)
В общем случае
Для решения обязательным образом необходимо искать область определения, которая может быть представлена в виде суммы или разности функций, их произведений. Области определения сложных и дробных функций нередко вызывают сложность. Благодаря выше указанным правилам можно правильно определять ОДЗ и быстро решать задание на области определения.
Таблицы основных результатов
Весь изученный материал поместим для удобства в таблицу для удобного расположения и быстрого запоминания.Ф
Функция
Ее область определения
Сумма, разность, произведение функций
f1, f2,…, fn
Пересечение множеств
D(f1), D(f2), …, D(fn)
Сложная функция
y=f1(f2(f3(…fn(x))))
В частности,
y=f1(f2(x))
Множество всех x, одновременно удовлетворяющих условиям
Множество всех x, которые одновременно удовлетворяют условиям x∈D(f1), x∈D(f2), f2(x)≠0
f2(x)≠0
y=f(x)n, где n — четное
x∈D(f1), f(x)≥0
y=logf2(x)f1(x)
В частности, y=logaf1(x)
В частности, y=logf2(x)a
x∈D(f1), f1(x)>0,x∈D(f2), f2(x)>0, f2(x)≠1
x∈D(f1), f1(x)>0
x∈D(f2), f2>0, f2(x)≠1
Показательно-степенная y=(f1(x))f2(x)
x∈D(f1), x∈D(f2), f1(x)>0
Отметим, что преобразования можно выполнять, начиная с правой части выражения. Отсюда видно, что допускаются тождественные преобразования, которые на область определения не влияют. Например, y=x2-4x-2 и y=x+2 являются разными функциями, так как первая определяется на (−∞, 2)∪(2, +∞), а вторая из множества действительных чисел. Из преобразования y=x2-4x-2=x-2x+2x-2=x+2 видно, что функция имеет смысл при x≠2.
Как найти область определения функции
После этого экскурса в важную составную матанализа многие согласятся, что найти
область определения функции не очень сложно. Ненамного сложнее, чем Московскую область на карте.
Во-первых, нужно различать виды функций (корень, дробь, синус и др.). Во-вторых,
решать уравнения и неравенства с учетом вида функции (например, на что нельзя делить, какое выражение
не может быть под знаком корня и тому подобное). Согласитесь, не так уж много и не так сложно.
Итак, чтобы находить области определения распространённых функций, порешаем
уравнения и неравенства с одной переменной. А в конце урока обобщим понятие на уровне теории. Пока же —
краткое определение. Область определения функции y=f(x)
— это множество значений X, для которых существуют значения Y.
Будут и задачи для самостоятельного решения, к которым можно
посмотреть ответы.
Приступаем к практике. На рисунке изображён график функции .
Знаменатель дроби не может быть равен нулю, так как на нуль делить нельзя. Поэтому, приравнивая знаменатель
нулю, получаем значение, не входящее в область определения функции: 1. То есть, область определения заданной функции —
это все значения «икса» от минус бесконечности до единицы и от единицы до плюс бесконечности. Это хорошо
видно на графике. Приведённый здесь пример функции относится к виду дробей. На уроке разберём решения
всех распространённых видов функций.
Пример 0. Как найти область
определения функции игрек равен квадратному корню из икса минус пять (подкоренное выражение икс минус пять)
()? Нужно всего лишь
решить неравенство
x — 5 ≥ 0,
так как для того, чтобы мы получили действительное значение игрека, подкоренное
выражение должно быть больше или равно нулю. Получаем решение: область определения функции — все значения икса
больше или равно пяти (или икс принадлежит промежутку от пяти включительно до плюс бесконечности).
На чертеже сверху — фрагмент числовой оси. На ней область опредения рассмотренной функции
заштрихована, при этом в «плюсовом» направлении штриховка продолжается бесконечно вместе с самой осью.
Постоянная (константа) определена при любых действительных
значениях x, следовательно, данная функция определена на всём
множестве R действительных чисел. Это можно записать и так:
областью определения данной функции является вся числовая прямая ]- ∞; + ∞[.
Пример 1. Найти область определения функцииy = 2.
Решение. Область определения функции не указана, значит, в силу выше приведённого
определения имеется в виду естественная область определения. Выражение
f(x) = 2 определено при любых действительных
значениях x, следовательно, данная функция определена на всём
множестве R действительных чисел.
Поэтому на чертеже сверху числовая прямая заштрихована на всём протяжении от минус
бесконечности до плюс бесконечности.
В случае, когда функция задана формулой и n — натуральное число:
Пример 2. Найти область определения функции
.
Решение. Как следует из
определения, корень чётной степени имеет смысл, если подкоренное выражение неотрицательно, то есть,
если — 1 ≤ x ≤ 1.
Следовательно, область определения данной функции — [- 1; 1].
Заштрихованная область числовой прямой на чертеже сверху — это область определения
данной функции.
Область определения степенной функции с целым показателем степени
В случае, когда функция задана формулой :
если a — положительное, то областью определения функции является множество
всех действительных чисел, то есть ]- ∞; + ∞[;
если a — отрицательное, то областью определения функции является
множество ]- ∞; 0[ ∪ ]0 ;+ ∞[,
то есть вся числовая прямая за исключением нуля.
На соответствующем чертеже сверху вся числовая прямая заштрихована, а точка,
соответствующая нулю, выколота (она не входит в область определения функции).
Пример 3. Найти область определения функции
.
Решение. Первое слагаемое целой степенью икса, равной 3, а степень икса во втором
слагаемом можно представить в виде единицы — так же целого числа.
Следовательно, область определения данной функции — вся числовая прямая, то есть
]- ∞; + ∞[.
Область определения степенной функции с дробным показателем степени
В случае, когда функция задана формулой :
если
— положительное, то областью определения функции является множество [0; + ∞[;
если
— отрицательное, то областью определения функции является множество ]0; + ∞[.
Пример 4. Найти область определения функции
.
Решение. Оба слагаемых в выражении функции — степенные функции с положительными
дробными показателями степеней. Следовательно, область определения данной функции —
множество [0; + ∞[.
На чертеже сверху заштрихована часть числовой прямой от нуля (включительно) и больше,
причём штриховка продолжается вместе с самой прямой до плюс бесконечности.
Пример 5. Найти область определения функции
.
Решение. Дробный показатель степени данной степенной функции — отрицательный.
Поэтому решим строгое неравенство, когда квадратный трёхчлен в скобках строго больше нуля::
.
Дикриминант получился отрицательный. Следовательно сопряжённое неравенству
квадратное уравнение не имеет корней. А это значит, что квадратный трёхчлен ни при каких значениях
«икса» не равен нулю. Таким образом, область определения данной функции — вся числовая ось, или,
что то же самое — множество R действительных чисел, или,
что то же самое — ]- ∞; + ∞[.
Область определения показательной функции
В случае, когда функция задана формулой ,
областью определения функции является вся числовая прямая, то есть
]- ∞; + ∞[.
Область определения логарифмической функции
Логарифмическая функция
определена при условии, если её аргумент положителен, то есть, областью её определения является множество
]0; + ∞[.
Найти область определения функции самостоятельно, а затем посмотреть решение
Область определения функции y = cos(x) —
так же множество R действительных чисел.
Область определения функции y = tg(x) —
множество R действительных чисел, кроме чисел
.
Область определения функции y = ctg(x) —
множество R действительных чисел, кроме чисел
.
Пример 8. Найти область определения функции
.
Решение. Внешняя функция — десятичный логарифм и на область её определения
распространяются условия области определения логарифмической функции вообще. То есть, её аргумент
должен быть положительным. Аргумент здесь — синус «икса». Поворачивая воображаемый циркуль по
окружности, видим, что условие sin x > 0
нарушается при «иксе» равным нулю, «пи», два, умноженном на «пи» и вообще равным произведению числа «пи»
и любого чётного или нечётного целого числа.
Таким образом, область определения данной функции задаётся выражением
,
где k — целое число.
Область определения обратных тригонометрических функций
Область определения функции y = arcsin(x) —
множество [-1; 1].
Область определения функции y = arccos(x) —
так же множество [-1; 1].
Область определения функции y = arctg(x) —
множество R действительных чисел.
Область определения функции y = arcctg(x) —
так же множество R действительных чисел.
Пример 9. Найти область определения функции
.
Решение. Решим неравенство:
Таким образом, получаем область определения данной функции — отрезок
[- 4; 4].
Пример 10. Найти область определения функции
.
Решение. Решим два неравенства:
Решение первого неравенства:
Решение второго неравенства:
Таким образом, получаем область определения данной функции — отрезок
[0; 1].
Если функция задана дробным выражением, в котором переменная находится в знаменателе
дроби, то областью определения функции является множество R действительных чисел,
кроме таких x, при которых знаменатель дроби обращается в нуль.
Пример 11. Найти область определения функции
.
Решение. Решая равенство нулю знаменателя дроби, находим область определения данной функции — множество
]- ∞; — 2[ ∪ ]- 2 ;+ ∞[.
Пример 12. Найти область определения функции
.
Решение. Решим уравнение:
Таким образом, получаем область определения данной функции —
]- ∞; — 1[ ∪ ]- 1 ; 1[ ∪ ]1 ;+ ∞[.
Пример 13. Найти область определения функции
.
Решение. Область определения первого слагаемого — данной функции — множество
R действительных чисел, второго слагаемого — все
действительные числа, кроме -2 и 2 (получили, решая равенство нулю знаменателя, как в предыдущем примере). В этом случае область определения функции должна удовлетворять
условиями определения обоих слагаемых. Следовательно, область определения данной функции — все
x, кроме -2 и 2.
Пример 14. Найти область определения функции
.
Решение. Решим уравнение:
Уравнение не имеет действительных корней. Но функция определена только на действительных
числах. Таким образом, получаем область определения данной функции — вся числовая прямая или, что
то же самое — множество R действительных чисел или,
что то же самое — ]- ∞; + ∞[.
То есть, какое бы число мы не подставляли вместо «икса», знаменатель никогда не
будет равен нулю.
Пример 15. Найти область определения функции
.
Решение. Решим уравнение:
Таким образом, получаем область определения данной функции —
]- ∞; — 1[ ∪ ]- 1 ; 0[ ∪ ]0 ; 1[ ∪ ]1 ;+ ∞[.
Пример 16. Найти область определения функции
.
Решение. Кроме того, что знаменатель не может быть равным нулю, ещё и выражение под
корнем не может быть отрицательным. Сначала решим уравнение:
График квадратичной функции под корнем представляет собой параболу, ветви которой
направлены вверх. Как следует из решения квадратного уравнения, парабола пересекает ось Ox в точках
1 и 2. Между этими точками линия параболы находится ниже оси Ox, следовательно значения
квадратичной функции между этими точками отрицательное. Таким образом, исходная функция не определена
на отрезке [1; 2].
Найти область определения функции самостоятельно, а затем посмотреть решение
Если функция задана формулой вида y = kx + b,
то область определения функции — множество
R действительных чисел.
А теперь обобщим решения рассмотренных примеров. Каждой точке графика функции соответствуют:
определённое значение «икса» — аргумента функции;
определённое значение «игрека» — самой функции.
Верны следующие факты.
От аргумента — «икса» — вычисляется «игрек» — значения функции.
Область определения функции — это множества всех значений «икса», для которых существует, то есть может
быть вычислен «игрек» — значение функции. Иначе говоря, множество значений аргумента, на котором
«функция работает».
Весь раздел «Исследование функций»
Урок 21. показательная функция — Алгебра и начала математического анализа — 10 класс
Алгебра и начала математического анализа, 10 класс
Урок №21. Показательная функция.
Перечень вопросов, рассматриваемых в теме:
— какая функция называется показательной;
— какие свойства имеет показательная функция в зависимости от ее основания;
— какой вид имеет график показательной функции в зависимости от ее основания;
Функция вида , a>0, а≠1 называется показательной функцией с основанием а.
Функция называется монотонно возрастающей на промежутке <a; b>, если (чем больше аргумент, тем больше значение функции).
Функция называется монотонно убывающей на промежутке <a; b>, если (чем больше аргумент, тем меньше значение функции).
Основная литература:
Колягин Ю.М., Ткачёва М.В., Фёдорова Н.Е., Шабунин М.И. под ред. Жижченко А.Б. Алгебра и начала математического анализа. 10 класс: учеб.для общеобразоват. учреждений: базовый и профил. уровни 2-е изд. – М.: Просвещение, 2010. – 336 с.: ил. – ISBN 978-5-09-025401-4, сс.310-314, сс. 210-216.
Открытые электронные ресурсы:
http://fcior.edu.ru/ — Федеральный центр информационно-образовательных ресурсов
http://school-collection.edu.ru/ — Единая коллекция цифровых образовательных ресурсов
Теоретический материал для самостоятельного изучения
1. Определение, свойства и график показательной функции
Определение:
Функция вида y=ах, a>0, а≠1 называется показательной функцией с основанием а.
Такое название она получила потому, что независимая переменная стоит в показателе. Основание а – заданное число.
Для положительного основания значение степени ах можно найти для любого значения показателя х – и целого, и рационального, и иррационального, то есть для любого действительного значения.
Сформулируем основные свойства показательной функции.
1. Область определения.
Как мы уже сказали, степень ах для a>0 определена для любого действительного значения переменной х, поэтому область определения показательной функции D(y)=R.
2. Множество значений.
Так как основание степени положительно, то очевидно, что функция может принимать только положительные значения.
Множество значений показательной функции Е(y)=R+, или Е(y)=(0; +∞).
3. Корни (нули) функции.
Так как основание a>0, то ни при каких значениях переменной х функция не обращается в 0 и корней не имеет.
4. Монотонность.
При a>1 функция монотонно возрастает.
При 0<a<1 функция монотонно убывает.
5. При любом значении а значение функции y (0) = а0 =1.
6. График функции.
При a>1
Рисунок 1 – График показательной функции при a>1
При 0<a<1
Рисунок 2 – График показательной функции при 0<a<1
Независимо от значения основания а график функции имеет горизонтальную асимптоту y=0. Для 0<a<1 при х стремящемся к плюс бесконечности, для a>1 при х стремящемся к минус бесконечности.
2. Рассмотрим пример исследования функции y=–3х+1.
Решение:
1) Область определения функции – любое действительное число.
2) Найдем множество значений функции.
Так как 3х>0, то –3х<0, значит, –3х+1<1, то есть множество значений функции y=–3х+1 представляет собой промежуток (-∞; 1).
3) Так как функция y=3х монотонно возрастает, то функция y=–3х монотонно убывает. Значит, и функция y=–3х+1 также монотонно убывает.
4) Эта функция будет иметь корень: –3х+1=0, 3х=1, х=0.
5) График функции
Рисунок 3 – График функции y=–3х+1
6) Для этой функции горизонтальной асимптотой будет прямая y=1.
3. Примеры процессов, которые описываются показательной функцией.
1) Рост различных микроорганизмов, бактерий, дрожжей и ферментов описывает формула: N= N0·akt, N– число организмов в момент времени t, t – время размножения, a и k – некоторые постоянные, которые зависят от температуры размножения, видов бактерий. Вообще это закон размножения при благоприятных условиях (отсутствие врагов, наличие необходимого количества питательных веществ и т.п.). Очевидно, что в реальности такого не происходит.
2) Давление воздуха изменяется по закону: P=P0·a-kh, P– давление на высоте h, P0 – давление на уровне моря, h – высота над уровнем моря, a и k – некоторые постоянные.
3) Закон роста древесины: D=D0·akt, D– изменение количества древесины во времени, D0 – начальное количество древесины, t – время, a и k – некоторые постоянные.
4) Процесс изменения температуры чайника при кипении описывается формулой: T=T0+(100– T0)e-kt.
5) Закон поглощения света средой: I=I0·e-ks, s– толщина слоя, k – коэффициент, который характеризует степень замутнения среды.
6) Известно утверждение, что количество информации удваивается каждые 10 лет. Изобразим это наглядно.
Примем количество информации в момент времени t=0 за единицу. Тогда через 10 лет количество информации удвоится и будет равно 2. Еще через 10 лет количество информации удвоится еще раз и станет равно 4 и т. д.
Если предположить, что поток информации изменялся по тому же закону до того года, который принят за начальный, то будем двигаться по оси абсцисс влево от начала координат и над значениями аргумента -10, -20 и т.д. будем наносить на график значения функции уже в порядке убывания — уменьшая каждый раз вдвое.
Рисунок 4 – График функции y=2х – изменение количества информации
Закон изменения количества информации описывается показательной функцией y=2х.
Примеры и разбор решения заданий тренировочного модуля
Пример 1.
Выберите показательные функции, которые являются монотонно убывающими.
y=3x-1
y=(0,4)x+1
y=(0,7)-х
y=
y=3-2х
y=102x +1
Решение:
Монотонно убывающими являются показательные функции, основание которых положительно и меньше единицы. Такими функциями являются: 2) и 4) (независимо от того, что коэффициент в показателе функции 4) равен 0,5), заметим, что функцию 4) можно переписать в виде: , используя свойство степеней.
Также монотонно убывающей будет функция 5). Воспользуемся свойством степеней и представим ее в виде:
2) 4) 5)
Пример 2.
Найдите множество значений функции y=3x+1– 3.
Решение:
Рассмотрим функцию.
Так как 3x+1>0, то 3x+1– 3>–3, то есть множество значений:
(– 3; +∞).
Пример 3.
Найдите множество значений функции y=|2x– 2|
Рассмотрим функцию.
2x–2>–2, но, так как мы рассматриваем модуль этого выражения, то получаем: |2x– 2|0.
Урок алгебры по теме»Функция y=√x «
Донецкая общеобразовательная школа-интернат
І-ІІІ ступеней №3
Открытый урок по алгебре в 8 классе.
Тема:
«Функция у=, её свойства и график».
Разработала и провела
учитель I категории
Плахотник Н. С.
Цель урока:
1. Обучающая
— познакомить учащихся с функцией квадратного корня и ее графиком, научить использовать график функции квадратного корня при решении иррациональных уравнений.
2. Развивающие
— развивать логическое мышление, внимание, математическую речь учащихся, самосознание, самооценку
3. Воспитательная
— воспитывать личностные качества: ответственность, добросовестность, самостоятельность, умение слушать друг друга
Ход урока.
Добрый день, ребята! Я рада вас видеть.
«День прожит не зря, если вы узнали что-то новое» — так сказал ученый Дэвид Эддингс.
Вот и сегодня на уроке вы познакомитесь с новой функцией, функцией у=√х; научитесь изображать график этой функции, изучите её свойства. В конце урока мы проверим ваши знания с помощью теста.
Откройте тетради и запишите тему урока:
А сейчас повторим изученный вами ранее материал, который пригодиться вам при изучении новой темы
І. Актуализация опорных знаний.
Сформулируйте определение арифметического квадратного корня.
При каких значениях a выражение √aимеет смысл? √100, √81, √0, √-25
Имеет ли уравнение x2 = aкорни при а > 0, a = 0, a < 0, и если имеет, то сколько?
Решите уравнения: x2 = 4, x2 =5, x2= = 4, = 5, =
Сократите дробь: , , ,
Найдите площадь фигуры.
Задачи, приводящие к понятию функции y = √x.
а) сторона квадрата а = √S;
б) радиус круга r =
– Что особенного в этих заданиях? (Зависимость задана формулой y = с которой мы еще не встречались).
ІІ. Изложение новой темы.
Для построения графика функции у=√х, дадим как обычно, независимой переменной х несколько конкретных значений и вычислим соответствующие значения переменной у. Как вы думаете, могу ли я взять для вычислений, отрицательные значения х? (нет, так как квадратный корень из отрицательного числа не существует.)
Мы будем давать переменной х такие значения, для которых известно точное значение квадратного корня.
Итак: если х=0, то у= √0=0
Если х=1, то у= √1=1
Если х=4, то у= √4=2
Если х=6,25 то у= √6,25=2,5
Если х=9, то у= √9=3
Составим таблицу значений функций.
Запишите её.
Построим найденные точки на координатной плоскости. Они располагаются на некоторой линии, начертите её. Мы построили график функции у = √х.
Работа по графику функции:
-найдите значение у, если х = 1,5; 5,5; 7,2; 15. — найдите значение х, если у = 1,5; 1,8; 2,5.
Принадлежат ли графику функции точки: А(64; 8), B(100; 10), С(-81; 9), D(25; -5).
С помощью графика сравнить числа: √0,5 и √0,8; √4,2 и √5,7; √7 и √8.
Свойства функции:
область определения: луч [0;+∞) или х≥0;
если х=0, то у=0;
у>0 при х>0;
f(х) возрастает при х принадлежащем [0;+∞);
у наим.=0 (при х=0), у наиб. не существует.
ІІІ. Первичное закрепление.А сейчас вы будете работать с тестом.Задания выполняйте по порядку, выписывая те буквы, под которыми находятся правильные ответы. Если задания будут выполнены верно, то вы получите фамилию математика. (ДЕКАРТ).
Тест
1) Какой из графиков соответствует графику функции у=√х ? (чертежи подготовить учителю)
В) Г) Д) Б)
2) Какая из заданных точек принадлежит графику функции у=√х ?
К) (-1; 1) Л) (0; 5) М) (2; 4) Е) (4; 2).
3) Наименьшее значение функции у=√х равно :
А) 0,001 К) 0 В) 1 Г) не существует.
4) Область определения функции у= √х :
А) х ≥ 0 Н) х > 0 П) х < 0 О) х ≤ 0.
5) Корнем уравнения √х = 2-х является число, равное
П) 4; К) 0; С) 3; Р) 1.
6) Между какими целыми числами заключено число √27
В) 26 и 28; Т) 5 и 6; М) 13 и 14; К) 0 и 7
Что вы знаете об этом математике?
IV. Домашнее задание: §15 прочитать, выучить свойства функции, решить № 355, 356, 363. Разгадать кроссворд.
V. Подведение итогов, выставление оценок.
VI. Рефлексия. Ребята, выберите смайлик, который больше всего подходит вашему настроению.
Функция, обратная квадратному корню
Чтобы найти обратную функцию квадратного корня, очень важно сначала набросать или изобразить данную проблему, чтобы четко определить, что такое область и диапазон. Я буду использовать домен и диапазон исходной функции, чтобы описать область и диапазон обратной функции, поменяв их местами. Если вам нужна дополнительная информация о том, что я имел в виду под «обменом домена и диапазона» между функцией и ее обратной, см. Мой предыдущий урок об этом.
Примеры того, как найти обратную функцию квадратного корня
Пример 1: Найдите обратную функцию, если она существует. Укажите его домен и диапазон.
Каждый раз, когда я сталкиваюсь с функцией извлечения квадратного корня с линейным членом внутри радикального символа, я всегда думаю о ней как о «половине параболы», нарисованной сбоку. Поскольку это положительный случай функции квадратного корня, я уверен, что ее диапазон будет становиться все более положительным, проще говоря, стремительно увеличиваясь до положительной бесконечности.
Эта конкретная функция извлечения квадратного корня имеет этот график с определенными областью и диапазоном.
С этого момента мне придется решать обратную алгебру, следуя предложенным шагам. По сути, замените \ color {red} f \ left (x \ right) на \ color {red} y, поменяйте местами x и y в уравнении, решите для y, которое вскоре будет заменено соответствующей обратной записью, и, наконец, укажите домен и диапазон.
Не забудьте использовать методы решения радикальных уравнений для решения обратной задачи.Возведение квадратного корня в квадрат или во вторую степень должно устранить радикал. Однако вы должны сделать это с обеими сторонами уравнения, чтобы сохранить баланс.
Убедитесь, что вы проверили домен и диапазон обратной функции из исходной функции. Они должны быть «противоположны друг другу».
Размещение графиков исходной функции и обратной к ней по одной координатной оси.
Вы видите их симметрию вдоль линии y = x? Посмотрите на зеленую пунктирную линию.2} = 1. Его домен и диапазон будут замененной «версией» исходной функции.
Пример 3: Найдите обратную функцию, если она существует. Укажите его домен и диапазон.
Это график исходной функции, показывающий ее домен и диапазон.
Определение дальности обычно является сложной задачей. Лучший способ найти это — использовать график данной функции с ее областью определения. Проанализируйте, как функция ведет себя по оси Y, учитывая значения x из области.
Вот шаги, чтобы решить или найти обратное значение данной функции квадратного корня.
Как видите, все очень просто. Убедитесь, что вы делаете это осторожно, чтобы избежать ненужных алгебраических ошибок.
Пример 4: Найдите обратную функцию, если она существует. Укажите его домен и диапазон.
Эта функция составляет 1/4 (четверть) окружности с радиусом 3, расположенной в Квадранте II. С другой стороны, это половина полукруга, расположенная над горизонтальной осью.
Я знаю, что он пройдет проверку горизонтальной линии, потому что ни одна горизонтальная линия не пересечет ее более одного раза. Это хороший кандидат на обратную функцию.
Опять же, я могу легко описать диапазон, потому что потратил время на его построение. Что ж, я надеюсь, что вы понимаете важность наличия наглядного пособия, которое поможет определить этот «неуловимый» диапазон.
Присутствие члена в квадрате внутри радикального символа говорит мне, что я буду применять операцию извлечения квадратного корня к обеим сторонам уравнения, чтобы найти обратное. Поступая так, у меня будет плюс или минус. Это ситуация, когда я приму решение, какую из них выбрать в качестве правильной обратной функции. Помните, что обратная функция уникальна, поэтому я не могу позволить получить два ответа.
Как я решу, какой выбрать? Ключевым моментом является рассмотрение домена и диапазона исходной функции. Я поменяю их местами, чтобы получить домен и диапазон обратной функции. Используйте эту информацию, чтобы определить, какая из двух функций-кандидатов удовлетворяет требуемым условиям.
Хотя у них один и тот же домен, диапазон здесь — решающий фактор! Диапазон говорит нам, что обратная функция имеет минимальное значение y = -3 и максимальное значение y = 0.
Случай положительного квадратного корня не соответствует этому условию, так как он имеет минимум при y = 0 и максимум при y = 3. Отрицательный случай должен быть очевидным выбором, даже после дальнейшего анализа.
Пример 5: Найдите обратную функцию, если она существует. Укажите его домен и диапазон.
Полезно увидеть график исходной функции, потому что мы можем легко определить ее домен и диапазон.
Отрицательный знак функции квадратного корня означает, что он находится ниже горизонтальной оси. Обратите внимание, что это похоже на Пример 4. Это также одна четверть круга, но с радиусом 5. Область вынуждает четверть круга оставаться в Квадранте IV.
Вот как мы алгебраически находим обратное.
Вы выбрали правильную обратную функцию из двух возможных? Ответ — случай с положительным знаком.
Практика с рабочими листами
Возможно, вас заинтересует:
Инверсия матрицы 2 × 2
Функция, обратная абсолютному значению
Функция, обратная постоянной
Обратная экспоненциальная функция
Функция, обратная линейной
Обратная логарифмическая функция
Обратная квадратичная функция
Обратная рациональная функция
9.
1: Функция квадратного корня
В этом разделе мы обратим наше внимание на функцию квадратного корня, функцию, определяемую уравнением
\ [\ begin {массив} {c} {f (x) = \ sqrt {x}} \\ \ end {array} \]
Мы начинаем раздел с рисования графика функции, затем обращаемся к домену и диапазону.После этого мы исследуем ряд различных преобразований функции.
График функции квадратного корня
Давайте создадим таблицу точек, которая удовлетворяет уравнению функции, а затем нанесем точки из таблицы в декартовой системе координат на миллиметровую бумагу. Мы продолжим создавать и наносить точки, пока не убедимся в окончательной форме графика.
Мы знаем, что не можем извлечь квадратный корень из отрицательного числа. Поэтому мы не хотим помещать в нашу таблицу отрицательные значения x .Чтобы еще больше упростить наши вычисления, давайте использовать числа, квадратный корень которых легко вычисляется. Это напоминает идеальные квадраты, такие как 0, 1, 4, 9 и так далее. Мы поместили эти числа как значения x в таблицу на рис. , рис. 1, (b), а затем вычислили квадратный корень из каждого значения. На рис. 1 (a) каждая точка из таблицы изображена сплошной точкой. Если мы продолжим добавлять точки в таблицу, наносим их на график, график в конечном итоге заполнится и примет форму сплошной кривой, показанной на , рис. 1, (c).2 \), \ (x \ ge 0 \), что изображено на рис. 2 (c). Обратите внимание на точное совпадение с графиком функции квадратного корня в Рисунок 1 (c).
Последовательность графиков на рис. 2 также помогает нам определить область и диапазон функции квадратного корня.
В рис. 2 (а) парабола открывается наружу неограниченно, как влево, так и вправо. Следовательно, доменом является \ (D_ {f} = (- \ infty, \ infty) \) или все действительные числа. Кроме того, граф имеет вершину в начале координат и неограниченно открывается вверх, поэтому диапазон равен \ (R_ {f} = [0, \ infty) \). {−1}} = [0, \ infty) \).
Конечно, мы также можем определить область и диапазон функции квадратного корня, проецируя все точки на графике на оси x и y , как показано на рисунках 3 (a) и ( б) соответственно.
Рис. 3.} \ text {Спроецируйте на оси, чтобы найти домен и диапазон}} \\ \ nonumber \ end {array} \]
Кто-то может возразить против диапазона, спросив: «Откуда мы знаем, что график изображение функции квадратного корня в Рисунок 3 (b) растет бесконечно? » Опять же, ответ кроется в последовательности графиков на рис. 2 .2 \), \ (x \ ge 0 \), открывается бесконечно вправо по мере того, как график уходит в бесконечность. Следовательно, после отражения этого графика по линии y = x результирующий график должен бесконечно подниматься вверх при движении вправо. Таким образом, диапазон функции квадратного корня равен \ ([0, \ infty) \).
Переводы
Если мы сдвинем график \ (y = \ sqrt {x} \) вправо и влево или вверх и вниз, это затронет домен и / или диапазон.
Пример \ (\ PageIndex {4} \)
Нарисуйте график \ (f (x) = \ sqrt {x − 2} \).Используйте свой график, чтобы определить домен и диапазон.
Мы знаем, что основное уравнение \ (y = \ sqrt {x} \) имеет график, показанный на Рисунках 1 (c). Если мы заменим x на x — 2, основное уравнение \ (y = \ sqrt {x} \) станет \ (f (x) = \ sqrt {x − 2} \). Из нашей предыдущей работы с геометрическими преобразованиями мы знаем, что это сдвинет график на две единицы вправо, как показано на Рисунках 4, (a) и (b).
Рисунок 4. Чтобы нарисовать график \ (f (x) = \ sqrt {x − 2} \), сдвиньте график \ (y = \ sqrt {x} \) на две единицы вправо.
Чтобы найти область, мы проецируем каждую точку графика f на ось x, как показано на рис. 4 (a). Обратите внимание, что все точки справа от 2 или включая 2 заштрихованы на оси абсцисс. Следовательно, область определения f равна
Домен = \ ([2, \ infty) \) = {x: \ (x \ ge 0 \)}
Поскольку сдвига в вертикальном направлении не произошло, диапазон остается прежним. Чтобы найти диапазон, мы проецируем каждую точку графика на ось y, как показано на рис. , рис. , , 4, (b).Обратите внимание, что все точки, равные нулю и выше, заштрихованы на оси ординат. Таким образом, диапазон f равен
Мы можем найти область определения этой функции алгебраически, исследуя ее определяющее уравнение \ (f (x) = \ sqrt {x − 2} \). Мы понимаем, что нельзя извлекать квадратный корень из отрицательного числа. Следовательно, выражение под радикалом должно быть неотрицательным (положительным или нулевым). То есть
\ (х — 2 \ ge 0 \).
Решение этого неравенства для x ,
\ (х \ ge 2 \).
Таким образом, область определения f — это Domain = \ ([2, \ infty) \), что соответствует графическому решению, приведенному выше.
Давайте посмотрим на другой пример.
Пример \ (\ PageIndex {5} \)
Нарисуйте график \ (f (x) = \ sqrt {x + 4} + 2 \). Используйте свой график, чтобы определить домен и диапазон f.
Опять же, мы знаем, что основное уравнение \ (y = \ sqrt {x} \) имеет график, показанный на рис. 1 (c). Если мы заменим x на x +4, основное уравнение \ (y = \ sqrt {x} \) станет \ (y = \ sqrt {x + 4} \).Из нашей предыдущей работы с геометрическими преобразованиями мы знаем, что это сдвинет график \ (y = \ sqrt {x} \) на четыре единицы влево, как показано на , рис. 5, (a).
Если мы знаем, что прибавляем 2 к уравнению \ (y = \ sqrt {x + 4} \), чтобы получить уравнение \ (y = \ sqrt {x + 4} + 2 \), это сдвинет график \ ( y = \ sqrt {x + 4} \) на две единицы вверх, как показано на рис. 5 (b).
Рис. 5. Перевод исходного уравнения \ (y = \ sqrt {x} \) для получения графика \ (y = \ sqrt {x + 4} + 2 \)
. Идентификация области \ (f (x ) = \ sqrt {x + 4} + 2 \), мы проецируем все точки на графике f на ось x, как показано на , рис. 6, (a).Обратите внимание, что все точки справа от — 4 или включая его заштрихованы на оси x . Таким образом, область определения \ (f (x) = \ sqrt {x + 4} + 2 \) равна
Рис. 6. Спроецируйте точки f на оси, чтобы определить область и диапазон
. Аналогичным образом, чтобы найти диапазон f , спроецируйте все точки на графике f на ось y , как показано в . Рисунок 6 (б). Обратите внимание, что все точки на оси y больше или включают 2 затенены.Следовательно, диапазон f равен
Мы также можем найти область определения f алгебраически, исследуя уравнение \ (f (x) = \ sqrt {x + 4} + 2 \). Мы не можем извлечь квадратный корень из отрицательного числа, поэтому выражение под корнем должно быть неотрицательным (нулевым или положительным). Следовательно,
\ (х + 4 \ ge 0 \).
Решение этого неравенства для x ,
\ (х \ ge −4 \).
Таким образом, область определения f — это Domain = \ ([- 4, \ infty) \), что соответствует графическому решению, представленному выше.
Отражения
Если мы начнем с основного уравнения \ (y = \ sqrt {x} \), а затем заменим x на −x, тогда график полученного уравнения \ (y = \ sqrt {−x} \) будет захвачен путем отражения график \ (y = \ sqrt {x} \) (см. , рис. 1, (c)) по горизонтали поперек оси y. График \ (y = \ sqrt {−x} \) показан на Рисунке 7 (a).
Точно так же график \ (y = — \ sqrt {x} \) будет вертикальным отражением графика \ (y = \ sqrt {x} \) по оси x, как показано на , рис. (б).
Рис. 7. Отражение графика \ (y = \ sqrt {x} \) по осям x и y.
Чаще всего вам будет предложено выполнить отражение и перевод.
Пример \ (\ PageIndex {6} \)
Нарисуйте график \ (f (x) = \ sqrt {4− x} \). Используйте полученный график, чтобы определить домен и диапазон f.
Сначала перепишите уравнение \ (f (x) = \ sqrt {4− x} \) следующим образом:
\ (f (x) = \ sqrt {- (x − 4)} \)
Определение
Первые размышления .Обычно более интуитивно понятно выполнять размышления перед переводом.
Помня об этом, мы сначала нарисуем график \ (f (x) = \ sqrt {−x} \), который является отражением графика \ (f (x) = \ sqrt {x} \ ) по оси y . Это показано на рис. 8 (а).
Теперь в \ (f (x) = \ sqrt {−x} \) замените x на x — 4, чтобы получить \ (f (x) = \ sqrt {- (x − 4)} \). Это сдвигает график \ (f (x) = \ sqrt {−x} \) на четыре единицы вправо, как показано на , рис. 8, (b).
Рисунок 8. Отражение с последующим переводом.
Чтобы найти область определения функции \ (f (x) = \ sqrt {- (x − 4)} \) или, что эквивалентно, \ (f (x) = \ sqrt {4 − x} \), спроецируйте каждый точка на графике f на оси x , как показано на рис. 9 (a). Обратите внимание, что все действительные числа, меньшие или равные 4, заштрихованы на оси x . Следовательно, домен f равен
Аналогичным образом, чтобы получить диапазон f, спроецируйте каждую точку на графике f на их ось, как показано на рис. 9 (b).Обратите внимание, что все действительные числа, большие или равные нулю, заштрихованы на оси ординат. Следовательно, диапазон f равен
Мы также можем найти область определения функции f , исследуя уравнение \ (f (x) = \ sqrt {4 − x} \). Мы не можем извлечь квадратный корень из отрицательного числа, поэтому выражение под корнем должно быть неотрицательным (нулевым или положительным). Следовательно,
\ (4 — х \ ge 0 \).
Рисунок 9. Определение области и диапазона \ (f (x) = \ sqrt {4 − x} \)
Решите это последнее неравенство для x . Сначала вычтите 4 из обеих частей неравенства, затем умножьте обе части полученного неравенства на — 1. Конечно, умножение на отрицательное число меняет символ неравенства на противоположное.
\ (- х \ ge −4 \)
\ (х \ ле 4 \)
Таким образом, область определения f равна {x: \ (x \ le 4 \)}. В обозначении интервалов Domain = \ ((- \ infty, 4] \). Это хорошо согласуется с приведенным выше графическим результатом.
Чаще всего требуется сочетание вашего графического калькулятора и небольших алгебраических манипуляций, чтобы определить область определения функции квадратного корня.
Пример \ (\ PageIndex {7} \)
Нарисуйте график \ (f (x) = \ sqrt {5−2x} \) Используйте график и алгебраический метод, чтобы определить область определения функции.
Загрузите функцию в Y1 в меню Y = вашего калькулятора, как показано на рис. 10 (a). Выберите 6: ZStandard в меню ZOOM, чтобы построить график, показанный на рис. 10 (b).
Рисунок 10. Построение графика f (x) = \ sqrt {5−2x} на графическом калькуляторе.
Внимательно посмотрите на график , рис. 10, (b) и обратите внимание, что трудно сказать, идет ли график полностью вниз, чтобы «коснуться» оси x около \ (x \ приблизительно 2.5 \). Однако наш предыдущий опыт использования функции извлечения квадратного корня заставляет нас думать, что это всего лишь артефакт недостаточного разрешения калькулятора, который не позволяет графику «касаться» оси x в точке \ (x \ приблизительно 2,5 \).
Алгебраический подход разрешит проблему. Мы можем определить область определения f, исследуя уравнение \ (f (x) = \ sqrt {5 — 2x} \). Следовательно, Мы не можем извлечь квадратный корень из отрицательного числа, поэтому выражение под радикалом должно быть неотрицательным (нулевым или положительным).
\ (5 — 2x \ ge 0 \).
Решите это последнее неравенство для x . Сначала вычтем 5 из обеих частей неравенства.
\ (- 2x \ ge −5 \).
Затем разделите обе части этого последнего неравенства на −2. Помните, что мы должны обратить неравенство в тот момент, когда делим на отрицательное число.
\ (\ frac {−2x} {- 2} \ le \ frac {−5} {- 2} \).
\ (х \ le \ frac {5} {2} \).
Таким образом, область определения f равна {x: \ (x \ le \ frac {5} {2} \)}. В интервальной записи Домен = \ ((- \ infty, \ frac {5} {2}] \).Это хорошо согласуется с приведенным выше графическим результатом.
Дальнейшее самоанализ показывает, что этот аргумент также решает вопрос о том, «касается» ли граф оси x в точке \ (x = \ frac {5} {2} \). Если вас это не убедило, замените \ (x = \ frac {5} {2} \) на \ (f (x) = \ sqrt {5−2x} \) , чтобы увидеть
Таким образом, график f «касается» оси x в точке \ ((\ frac {5} {2}, 0) \).
В упражнении Exercise 1-10 выполните все следующие задачи:
Установите систему координат на миллиметровой бумаге. Обозначьте и масштабируйте каждую ось.
Заполните таблицу баллов по данной функции. Постройте каждую точку в своей системе координат, а затем используйте их, чтобы нарисовать график данной функции.
Используйте карандаши разных цветов, чтобы спроецировать все точки на оси x и y , чтобы определить область и диапазон.Используйте интервальную нотацию для описания области данной функции.
Упражнение \ (\ PageIndex {1} \)
\ (f (x) = — \ sqrt {x} \)
Ответ
х
0
1
4
9
ф (х)
0
– 1
– 2
– 3
Отметьте точки в таблице и используйте их для построения графика.
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([0, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ((- \ infty, 0] \).
Упражнение \ (\ PageIndex {2} \)
\ (f (x) = \ sqrt {−x} \)
Упражнение \ (\ PageIndex {3} \)
\ (f (x) = \ sqrt {x + 2} \)
Ответ
х
– 2
– 1
2
7
f ( x )
0
1
2
3
Отметьте точки в таблице и используйте их для построения графика.
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([ — 2, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([0, \ infty) \).
Упражнение \ (\ PageIndex {4} \)
\ (f (x) = \ sqrt {5 − x} \)
Упражнение \ (\ PageIndex {5} \)
\ (f (x) = \ sqrt {x} +2 \)
Ответ
Нанесите точки в таблицу и используйте их для построения графика f .
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([0, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([2, \ infty) \).
Упражнение \ (\ PageIndex {6} \)
\ (f (x) = \ sqrt {x} −1 \)
Упражнение \ (\ PageIndex {7} \)
\ (f (x) = \ sqrt {x + 3} +2 \)
Ответ
х
– 3
– 2
1
6
ф (х)
2
3
4
5
Постройте точки в таблице и используйте их для построения графика f .
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([ — 3, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([2, \ infty) \).
Упражнение \ (\ PageIndex {8} \)
\ (f (x) = \ sqrt {x − 1} +3 \)
Упражнение \ (\ PageIndex {9} \)
\ (f (x) = \ sqrt {3 − x} \)
Ответ
х
– 6
– 1
2
3
f ( x )
3
2
1
0
Постройте точки в таблице и используйте их для построения графика f .
Спроецируйте все точки на графике на ось x, чтобы определить домен: Domain = \ (( — \ infty, 3] \). Спроецируйте все точки на графике на ось y, чтобы определить диапазон: Диапазон = \ ([0, \ infty) \).
Упражнение \ (\ PageIndex {10} \)
\ (f (x) = — \ sqrt {x + 3} \)
В Exercises 11 — 20 выполните каждую из следующих задач.
Установите систему координат на миллиметровой бумаге.Обозначьте и масштабируйте каждую ось. Не забудьте нарисовать все линии линейкой.
Используйте геометрические преобразования, чтобы нарисовать график данной функции в вашей системе координат без использования графического калькулятора. Примечание. Вы можете проверить свое решение с помощью калькулятора, но вы сможете построить график без использования калькулятора.
Используйте карандаши разных цветов, чтобы спроецировать точки графика функции на оси x и y . Используйте обозначение интервала для описания области и диапазона функции.
Упражнение \ (\ PageIndex {11} \)
\ (f (x) = \ sqrt {x} +3 \)
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a). Затем добавьте 3, чтобы получить уравнение \ (y = \ sqrt {x} + 3 \). Это сдвинет график \ (y = \ sqrt {x} \) вверх на 3 единицы, как показано в (b).
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([0, \ infty) \).Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([3, \ infty) \).
Упражнение \ (\ PageIndex {12} \)
\ (f (x) = \ sqrt {x + 3} \)
Упражнение \ (\ PageIndex {13} \)
\ (f (x) = \ sqrt {x − 2} \)
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a). Затем замените x на x — 2, чтобы получить уравнение \ (y = \ sqrt {x − 2} \). Это сдвинет график \ (y = \ sqrt {x} \) вправо на 2 единицы, как показано в (b).
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([2, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([0, \ infty) \).
Упражнение \ (\ PageIndex {14} \)
\ (f (x) = \ sqrt {x} −2 \)
Упражнение \ (\ PageIndex {15} \)
\ (f (x) = \ sqrt {x + 5} +1 \)
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a).Затем замените x на x + 5, чтобы получить уравнение \ (y = \ sqrt {x + 5} \). Затем добавьте 1, чтобы получить уравнение \ (f (x) = \ sqrt {x + 5} +1 \). Это сдвинет график \ (y = \ sqrt {x} \) влево на 5 единиц, а затем вверх на 1 единицу, как показано в (b).
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([- 5, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([1, \ infty) \).
Упражнение \ (\ PageIndex {16} \)
\ (f (x) = \ sqrt {x − 2} −1 \)
Упражнение \ (\ PageIndex {17} \)
\ (y = — \ sqrt {x + 4} \)
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a).Затем инвертируйте, чтобы получить \ (y = — \ sqrt {x} \). Это отразит график \ (y = \ sqrt {x} \) по оси x, как показано в (b). Наконец, замените x на x + 4, чтобы получить уравнение \ (y = — \ sqrt {x + 4} \). Это сдвинет график \ (y = — \ sqrt {x} \) на четыре единицы влево, как показано в (c).
Спроецируйте все точки на графике на ось x, чтобы определить домен: Domain = \ ([- 4, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ((- \ infty, 0] \).
Упражнение \ (\ PageIndex {18} \)
\ (f (x) = — \ sqrt {x} +4 \)
Упражнение \ (\ PageIndex {19} \)
\ (f (x) = — \ sqrt {x} +3 \)
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a). Затем инвертируйте, чтобы получить \ (y = — \ sqrt {x} \). Это отразит график \ (y = \ sqrt {x} \) по оси x, как показано в (b). Наконец, добавьте 3, чтобы получить уравнение \ (y = — \ sqrt {x} +3 \).Это сдвинет график \ (y = — \ sqrt {x} \) на три единицы вверх, как показано в (c).
Спроецируйте все точки графика на ось x, чтобы определить домен: Domain = \ ([0, \ infty) \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ((- \ infty, 3] \).
Упражнение \ (\ PageIndex {20} \)
\ (f (x) = — \ sqrt {x + 3} \)
Упражнение \ (\ PageIndex {21} \)
Чтобы построить график функции \ (f (x) = \ sqrt {3 − x} \), выполните последовательно каждый из следующих шагов без помощи калькулятора.
Настройте систему координат и нарисуйте график \ (y = \ sqrt {x} \). Обозначьте график соответствующим уравнением.
Установите вторую систему координат и нарисуйте график \ (y = \ sqrt {−x} \). Обозначьте график соответствующим уравнением.
Установите третью систему координат и нарисуйте график \ (y = \ sqrt {- (x — 3)} \). Обозначьте график соответствующим уравнением. Это график \ (y = \ sqrt {3 − x} \). Используйте обозначение интервала, чтобы указать домен и диапазон этой функции.
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a).Затем замените x на — x , чтобы получить уравнение \ (y = \ sqrt {−x} \). Это будет отражать график \ (y = \ sqrt {x} \) по оси y , как показано на (b). Наконец, замените x на x — 3, чтобы получить уравнение \ ( y = \ sqrt { — ( x — 3)} \). Это сдвинет график \ (y = \ sqrt {−x} \) на три единицы вправо, как показано в (c).
Спроецируйте все точки на графике на ось x, чтобы определить домен: Domain = \ ((- \ infty, 3] \). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([0, \ infty) \).
Упражнение \ (\ PageIndex {22} \)
Чтобы построить график функции \ (f (x) = \ sqrt {−x − 3} \), последовательно выполните каждый из следующих шагов.
Настройте систему координат и нарисуйте график \ (y = \ sqrt {x} \). Обозначьте график соответствующим уравнением.
Установите вторую систему координат и нарисуйте график \ (y = \ sqrt {−x} \).Обозначьте график соответствующим уравнением.
Установите третью систему координат и нарисуйте график \ (y = \ sqrt {- (x + 3)} \). Обозначьте график соответствующим уравнением. Это график \ (y = \ sqrt {−x − 3} \). Используйте обозначение интервала, чтобы указать домен и диапазон этой функции.
Упражнение \ (\ PageIndex {23} \)
Чтобы построить график функции \ (f (x) = \ sqrt {−x − 3} \), выполните последовательно каждый из следующих шагов без помощи калькулятора.
Настройте систему координат и нарисуйте график \ (y = \ sqrt {x} \).Обозначьте график соответствующим уравнением.
Установите вторую систему координат и нарисуйте график \ (y = \ sqrt {−x} \). Обозначьте график соответствующим уравнением.
Установите третью систему координат и нарисуйте график \ (y = \ sqrt {- (x + 1)} \). Обозначьте график соответствующим уравнением. Это график \ (y = \ sqrt {−x − 1} \). Используйте обозначение интервала, чтобы указать домен и диапазон этой функции.
Ответ
Сначала постройте график \ (y = \ sqrt {x} \), как показано на (a).Затем замените x на −x, чтобы получить уравнение \ (y = \ sqrt {−x} \). Это будет отражать график \ (y = \ sqrt {x} \) по оси y, как показано в (b). Наконец, замените x на x + 1, чтобы получить уравнение \ (y = \ sqrt {- (x + 1)} \). Это сдвинет график \ (y = \ sqrt {−x} \) на одну единицу влево, как показано в (c).
Спроецируйте все точки на графике на ось x, чтобы определить область: Domain = \ ((- \ infty, −1] \). Спроецируйте все точки на графике на ось y, чтобы определить диапазон: Range = \ ([0, \ infty) \).
Упражнение \ (\ PageIndex {24} \)
Чтобы построить график функции \ (f (x) = \ sqrt {1 − x} \), последовательно выполните каждый из следующих шагов.
Настройте систему координат и нарисуйте график \ (y = \ sqrt {x} \). Обозначьте график соответствующим уравнением.
Установите вторую систему координат и нарисуйте график \ (y = \ sqrt {−x} \). Обозначьте график соответствующим уравнением.
Установите третью систему координат и нарисуйте график \ (y = \ sqrt {- (x − 1)} \).Обозначьте график соответствующим уравнением. Это график \ (y = \ sqrt {1 − x} \). Используйте обозначение интервала, чтобы указать домен и диапазон этой функции.
В упражнениях 25 — 28 выполните каждую из следующих задач.
Нарисуйте график данной функции с помощью графического калькулятора. Скопируйте изображение из окна просмотра на свою домашнюю работу. Обозначьте и масштабируйте каждую ось с помощью xmin, xmax, ymin и ymax. Обозначьте свой график его уравнением.Используйте график, чтобы определить область определения функции и описать область с помощью интервальной записи.
Используйте чисто алгебраический подход, чтобы определить область определения данной функции. Для описания результата используйте обозначение интервалов. Согласен ли он с графическим результатом из части 1?
Упражнение \ (\ PageIndex {25} \)
\ (f (x) = \ sqrt {2x + 7} \)
Ответ
Мы используем графический калькулятор, чтобы построить следующий график \ (f (x) = \ sqrt {2x + 7} \)
По нашим оценкам, домен будет состоять из всех действительных чисел справа от примерно — 3 . 5. Чтобы найти алгебраическое решение, обратите внимание, что вы не можете извлечь квадратный корень из отрицательного числа. Следовательно, выражение под корнем в \ (f (x) = \ sqrt {2x + 7} \) должно быть больше или равно нулю.
Мы используем графический калькулятор, чтобы построить следующий график \ (f (x) = \ sqrt {12−4x} \).
По нашим оценкам, область будет состоять из всех действительных чисел справа от приблизительно 3. Чтобы найти алгебраическое решение, обратите внимание, что вы не можете извлечь квадратный корень из отрицательного числа. Следовательно, выражение под корнем в \ (f (x) = \ sqrt {12−4x} \) должно быть больше или равно нулю.
\ (12−4x \ ge 0 \)
\ (- 4x \ ge −12 \)
\ (х \ ле 3 \)
Следовательно, домен равен \ ((- \ infty, 3] \).
Упражнение \ (\ PageIndex {28} \)
\ (f (x) = \ sqrt {12 + 2x} \)
В упражнениях 29 — 40 найдите область определения заданной функции алгебраически.
Упражнение \ (\ PageIndex {29} \)
\ (f (x) = \ sqrt {2x + 9} \)
Ответ
Четный корень отрицательного числа не считается действительным числом. Таким образом, 2x + 9 должно быть больше или равно нулю. Поскольку \ (2x + 9 \ ge 0 \) означает, что \ (x \ ge — \ frac {9} {2} \), область представляет собой интервал \ ([- \ frac {9} {2}, \ infty ) \).
Упражнение \ (\ PageIndex {30} \)
\ (f (x) = \ sqrt {−3x + 3} \)
Упражнение \ (\ PageIndex {31} \)
\ (f (x) = \ sqrt {−8x − 3} \)
Ответ
Четный корень отрицательного числа не считается действительным числом.Таким образом, −8x − 3 должно быть больше или равно нулю. Поскольку \ (- 8x − 3 \ ge 0 \) означает, что \ (x \ le — \ frac {3} {8} \), область представляет собой интервал \ ((- \ infty, — \ frac {3} { 8}] \).
Упражнение \ (\ PageIndex {32} \)
\ (f (x) = \ sqrt {−3x + 6} \)
Упражнение \ (\ PageIndex {33} \)
\ (f (x) = \ sqrt {−6x − 8} \)
Ответ
Четный корень отрицательного числа не считается действительным числом. Таким образом, −6x − 8 должно быть больше или равно нулю.Поскольку \ (- 6x − 8 \ ge 0 \) влечет, что \ (x \ le — \ frac {4} {3} \), область представляет собой интервал \ ((- \ infty, \ frac {4} {3 }] \).
Упражнение \ (\ PageIndex {34} \)
\ (f (x) = \ sqrt {8x − 6} \)
Упражнение \ (\ PageIndex {35} \)
\ (f (x) = \ sqrt {−7x + 2} \)
Ответ
Четный корень отрицательного числа не считается действительным числом. Таким образом, −7x + 2 должно быть больше или равно нулю. Поскольку \ (- 7x + 2 \ ge 0 \) означает, что \ (x \ le \ frac {2} {7} \), область представляет собой интервал \ ((- \ infty, \ frac {2} {7} ] \).
Упражнение \ (\ PageIndex {36} \)
\ (f (x) = \ sqrt {8x − 3} \)
Упражнение \ (\ PageIndex {37} \)
\ (f (x) = \ sqrt {6x + 3} \)
Ответ
Четный корень отрицательного числа не считается действительным числом. Таким образом, 6x + 3 должно быть больше или равно нулю. Поскольку \ (6x + 3 \ ge 0 \) означает, что \ (x \ ge — \ frac {1} {2} \), область представляет собой интервал \ ([- \ frac {1} {2}, \ infty ) \).
Упражнение \ (\ PageIndex {38} \)
\ (f (x) = \ sqrt {x − 5} \)
Упражнение \ (\ PageIndex {39} \)
\ (f (x) = \ sqrt {−7x − 8} \)
Ответ
Четный корень отрицательного числа не считается действительным числом. 2} = \ pm xx2 = ± x
Почему некоторые люди говорят, что это правда: Это именно то, чему меня учили в школе: когда вы извлекаете квадратный корень, ответ всегда будет «плюс-минус» некоторого значения.
Почему некоторые люди говорят, что это ложь: Когда вы возводите в квадрат x, x, x, оно становится положительным, независимо от того, что было раньше; тогда, когда вы извлечете квадратный корень, он все равно будет положительным. Следовательно, ответ будет просто ∣x∣ | x | ∣x∣, а не ± x \ pm x ± x.
Выявите правильный ответ: \ color {# 20A900} {\ text {Выявите правильный ответ:}} Выявите правильный ответ:
Утверждение ложно \ color {# D61F06} {\ textbf {false}} ложно.
Пояснение:
В своей стандартной области неотрицательных действительных чисел x \ sqrt {x} x определяется как «неотрицательное действительное число, которое в квадрате равно x.x.x. «Например, 25 = 5 \ sqrt {25} = 525 = 5 , а не ± 5 \ pm 5 ± 5. x \ sqrt {x} x определяется таким образом, поэтому это функция.
Функция — это отношение или карта между набором входных значений (домен) и набором выходных значений (диапазон), которая имеет свойство, что каждый принятый вход соответствует точно одному выходу. Это свойство широко известно как «прохождение теста вертикальной линии».
Чтобы x \ sqrt {x} x была функцией, ее оценка на любом входе должна быть единственным четко определенным выходом.Парабола 2×2 не пройдет проверку вертикальной линии и не будет функцией.
Расширение домена до всех действительных чисел и диапазона до комплексных чисел:
Поведение функции извлечения квадратного корня при расширении на область всех действительных чисел (положительные действительные числа, отрицательные действительные числа и 0) в точности отражает приведенный выше аргумент. Квадратный корень отрицательного числа — это комплексное число. Но даже с расширенной областью определения x \ sqrt {x} x аналогичным образом определяется, так что это все еще функция.2}} {| x |} + 1, ∣x∣x2 +1,
, где xxx — ненулевое действительное число.
См. Также
Функция квадратного корня Python — настоящий Python
Вы пытаетесь решить квадратное уравнение? Возможно, вам нужно рассчитать длину одной стороны прямоугольного треугольника. Для этих и других типов уравнений функция квадратного корня Python sqrt () может помочь вам быстро и точно вычислить решения.
К концу этой статьи вы узнаете:
Что такое квадратный корень
Как использовать функцию квадратного корня Python, sqrt ()
Когда sqrt () может быть полезен в реальном мире
Погрузимся!
Python Pit Stop: Это руководство представляет собой quick и практический способ найти нужную информацию, так что вы вернетесь к своему проекту в кратчайшие сроки!
Квадратные корни в математике
В алгебре квадрат , x , является результатом умножения числа n на само себя: x = n²
Вы можете вычислить квадраты с помощью Python:
>>>
>>> п = 5
>>> х = п ** 2
>>> х
25
Оператор Python ** используется для вычисления степени числа.В этом случае 5 в квадрате или 5 в степени 2 дает 25.
Таким образом, квадратный корень — это число n , которое при умножении само на себя дает квадрат x .
В этом примере n , квадратный корень, равен 5.
25 — это пример полного квадрата . Совершенные квадраты — это квадраты целых чисел:
>>>
>>> 1 ** 2
1
>>> 2 ** 2
4
>>> 3 ** 2
9
Возможно, вы запомнили некоторые из этих совершенных квадратов, когда выучили свои таблицы умножения на уроках элементарной алгебры.
Если вам дан маленький точный квадрат, может быть достаточно просто вычислить или запомнить его квадратный корень. Но для большинства других квадратов это вычисление может быть немного более утомительным. Часто оценки бывает достаточно, когда у вас нет калькулятора.
К счастью, у вас, как у разработчика Python, есть калькулятор, а именно интерпретатор Python!
Функция квадратного корня Python
Модуль
Python math в стандартной библиотеке может помочь вам работать с математическими задачами в коде.Он содержит множество полезных функций, таких как restder () и factorial () . Он также включает функцию квадратного корня Python sqrt () .
Вы начнете с импорта math :
Вот и все, что нужно! Теперь вы можете использовать math.sqrt () для вычисления квадратных корней.
sqrt () имеет простой интерфейс.
Требуется один параметр, x , который (как вы видели ранее) обозначает квадрат, для которого вы пытаетесь вычислить квадратный корень.В предыдущем примере это будет 25 .
Возвращаемое значение sqrt () — это квадратный корень из x в виде числа с плавающей запятой. В примере это 5,0 .
Давайте рассмотрим несколько примеров того, как (и как не использовать) использовать sqrt () .
Квадратный корень положительного числа
Один из типов аргументов, который вы можете передать функции sqrt () , — это положительное число. Сюда входят типы int и float .
Например, вы можете найти квадратный корень из 49 , используя sqrt () :
Возвращаемое значение — 7,0 (квадратный корень из 49 ) в виде числа с плавающей запятой.
Наряду с целыми числами вы также можете передавать значения с плавающей запятой :
>>>
>>> math.sqrt (70.5)
8,396427811873332
Вы можете проверить точность этого квадратного корня, вычислив его обратную величину:
>>>
>>> 8.396427811873332 ** 2
70,5
Квадратный корень нуля
Даже 0 — правильный квадрат для передачи функции квадратного корня Python:
Хотя вам, вероятно, не придется часто вычислять квадратный корень из нуля, вы можете передать переменную в sqrt () , значение которой вы на самом деле не знаете. Итак, хорошо знать, что в таких случаях он может обрабатывать ноль.
Квадратный корень отрицательных чисел
Квадрат любого действительного числа не может быть отрицательным.Это потому, что отрицательный результат возможен только в том случае, если один фактор положительный, а другой отрицательный. Квадрат по определению является произведением числа и самого себя, поэтому получить отрицательный действительный квадрат невозможно:
Если вы попытаетесь передать отрицательное число в sqrt () , вы получите ValueError , потому что отрицательные числа не входят в область возможных действительных квадратов.Вместо этого квадратный корень отрицательного числа должен быть сложным, что выходит за рамки функции квадратного корня Python.
Квадратных корней в реальном мире
Чтобы увидеть реальное применение функции квадратного корня Python, давайте обратимся к теннису.
Представьте, что Рафаэль Надаль, один из самых быстрых игроков в мире, только что ударил справа из заднего угла, где базовая линия пересекается с боковой линией теннисного корта:
Теперь предположим, что его противник нанес контратакующий удар (тот, который закроет мяч с небольшим ускорением вперед) в противоположный угол, где другая боковая линия встречается с сеткой:
Как далеко Надаль должен бежать, чтобы дотянуться до мяча?
Из нормативных размеров теннисного корта можно определить, что длина базовой линии составляет 27 футов, а длина боковой линии (на одной стороне сетки) — 39 футов.Итак, по сути, это сводится к решению гипотенузы прямоугольного треугольника:
Используя ценное геометрическое уравнение, теорему Пифагора, мы знаем, что a² + b² = c² , где a и b — катеты прямоугольного треугольника, а c — гипотенуза.
Таким образом, мы можем рассчитать расстояние, которое Надаль должен пробежать, переписав уравнение, чтобы найти c :
Вы можете решить это уравнение, используя функцию квадратного корня Python:
>>>
>>> a = 27
>>> b = 39
>>> математика.sqrt (а ** 2 + b ** 2)
47.434164569
Итак, Надаль должен пробежать около 47,4 фута (14,5 метра), чтобы дотянуться до мяча и сохранить точку.
Заключение
Поздравляем! Теперь вы знаете все о функции квадратного корня Python.
Вы покрыли:
Краткое введение в квадратные корни
Особенности функции квадратного корня Python, sqrt ()
Практическое применение sqrt () на реальном примере
Умение пользоваться sqrt () — это только половина дела.Другое дело — понять, когда его использовать. Теперь вы знаете и то, и другое, так что примените свое новое мастерство в использовании функции извлечения квадратного корня Python!
Поиск производной квадратного корня от x — стенограмма видео и урока
Решение
Формула показывает, что производная квадратного корня из x равна (1/2) x -1/2. Это можно записать в нескольких разных формах:
Проверка вашей работы
Есть несколько различных способов, с помощью которых мы можем проверить нашу работу при работе с производными финансовыми инструментами.Первый касается определения производной с использованием лимитов.
Мы можем использовать это определение, чтобы проверить нашу работу. При этом мы должны получить тот же результат, что и при использовании формулы. Мы начинаем с того, что позволяем f ( x ) = sqrt ( x ) и подключаемся соответственно.
Теперь мы хотим найти предел, поскольку h приближается к 0.Один из способов оценки предела — подставить число, которое приближается к h , на h . Однако в этом случае мы бы вставили 0 для h . Вы понимаете, почему мы не можем этого сделать? Если вы думаете, что мы не можем подставить 0 вместо h , потому что это приведет к нулевому знаменателю, то вы правы! Следовательно, мы собираемся манипулировать лимитом, чтобы преобразовать его в форму, в которой мы можем вставить 0 для h без создания неопределенного выражения.Умножим все это на версию числа 1:
Помните, мы не меняли предел, поскольку в конечном итоге мы просто умножили его на единицу. Также обратите внимание, что теперь мы можем подставить ноль для h без создания нулевого знаменателя или неопределенного выражения. Давайте сделаем это, чтобы найти предел и, в процессе, найти производную квадратного корня из x . Как только мы подставим 0 для h , наше уравнение станет:
Видите ли, производная квадратного корня из x равна (1/2) x -1/2, и это именно то, что мы получили, когда использовали формулу.Уф! Это хорошие новости! Значит, мы сделали свою работу правильно.
Интегралы
Другой способ проверить нашу работу — использовать интегралы. Интегралы называются антипроизводными, и они в основном отменяют производные. То есть, если a является производной от b , то интеграл от a равен b + C , где C — константа.
Это говорит нам о том, что в нашем примере, поскольку производная sqrt ( x ) равна (1/2) x -1/2, интеграл от (1/2) x -1/2 — это sqrt ( x ) + C , где C — постоянная.Возможно, вы еще не знакомы с интегралами, но это нормально. Нам посчастливилось иметь два простых факта, которые позволят нам найти интеграл от (1/2) x -1/2.
1.) Интеграл от постоянной, умноженной на функцию, равен этой константе, умноженной на интеграл функции.
2.) Формула для интеграла x n равна:
Используя эти два правила, мы можем найти интеграл (1/2) x -1/2 и проверить, что это sqrt ( x ) + C , где C — это постоянный.Это позволит нам проверить, правильно ли мы сделали свою работу.
Как мы и надеялись, мы видим, что интеграл от (1/2) x -1/2 равен sqrt ( x ) + C , где C — константа. Большой! И снова наша работа проходит проверку.
При работе с производными функции производных с использованием пределов и интегралов чрезвычайно полезны для проверки правильности нашей работы.
Результаты обучения
Тщательно изучите урок и запомните достаточно информации, чтобы уверенно:
Найдите производную квадратного корня x
Использовать интегралы для проверки своей работы
Как нарисовать график функций квадратного корня, (f (x) = √ x)
В этой статье будет показано, как рисовать графики функции квадратного корня, используя только три различных значения для ‘x’, а затем находя точки через который строится график уравнений / функций, а также будет показано, как график перемещается по вертикали (перемещается вверх или вниз), перемещается по горизонтали (перемещается влево или вправо) и как график одновременно выполняет оба перевода.
Уравнение функции квадратного корня имеет вид … y = f (x) = A√x, где (A) не должно быть равно нулю (0). Если (A) больше нуля ( 0), то есть (A) является положительным числом, тогда форма графика функции квадратного корня аналогична верхней половине буквы «C». Если (A) меньше нуля (0), то есть (A) является отрицательным числом, форма графика аналогична форме нижней половины буквы «C». Пожалуйста, нажмите на изображение для лучшего просмотра.
Чтобы нарисовать график уравнения, … y = f (x) = A√x, мы выбираем три значения для ‘x’, x = (-1), x = (0) и x = (1 ). Мы подставляем каждое значение «x» в уравнение … y = f (x) = A√x и получаем соответствующее соответствующее значение для каждого «y».
Учитывая y = f (x) = A√x, где (A) — вещественное число и (A) не равно нулю (0), и подставив x = (-1) в уравнение, мы получаем y = f (-1) = A√ (-1) = i (мнимое число). Таким образом, первая точка не имеет реальных координат, следовательно, через эту точку нельзя построить никакой график.Теперь подставив x = (0), мы получаем y = f (0) = A√ (0) = A (0) = 0. Итак, вторая точка имеет координаты (0,0). Подставив x = (1), мы получим y = f (1) = A√ (1) = A (1) = A. Итак, третья точка имеет координаты (1, A). Поскольку первая точка имела координаты, которые не были реальными, теперь мы ищем четвертую точку и выбираем x = (2). Теперь подставим x = (2) в y = f (2) = A√ (2) = A (1.41) = 1.41A. Итак, четвертая точка имеет координаты (2,1.41A). Теперь мы нарисуем кривую через эти три точки. Пожалуйста, нажмите на изображение для лучшего просмотра.
Учитывая уравнение y = f (x) = A√x + B, где B — любое вещественное число, график этого уравнения будет преобразовывать единицы измерения по вертикали (B). Если (B) — положительное число, график будет двигаться вверх (B) единиц, а если (B) — отрицательное число, график будет двигаться вниз (B) единиц. Чтобы нарисовать графики этого уравнения, мы следуем инструкциям и используем те же значения «x» из шага №3. Пожалуйста, нажмите на изображение, чтобы лучше рассмотреть.
Дано уравнение y = f (x) = A√ (x — B), где A и B — любые действительные числа, и (A) не равно нулю (0), и x ≥ B.График этого уравнения будет преобразовывать единицы по горизонтали (B). Если (B) — положительное число, график переместится в правые (B) единицы, а если (B) — отрицательное число, график переместится в левые (B) единицы. Чтобы нарисовать графики этого уравнения, мы сначала устанавливаем выражение «x — B», которое находится под радикальным знаком Больше или равно нулю, и решаем относительно «x». То есть … x — B ≥ 0, тогда x ≥ B.
Теперь мы будем использовать следующие три значения для ‘x’, x = (B), x = (B + 1) и x = (B + 2).Мы подставляем каждое значение «x» в уравнение … y = f (x) = A√ (x — B) и получаем соответствующее соответствующее значение для каждого «y».
Дано y = f (x) = A√ (x — B), где A и B — действительные числа, и (A) не равно нулю (o), где x ≥ B. Подставляя x = (B) в Уравнение получаем y = f (B) = A√ (BB) = A√ (0) = A (0) = 0. Значит, первая точка имеет координаты (B, 0). Теперь подставив x = (B + 1), мы получим y = f (B + 1) = A√ (B + 1 — B) = A√1 = A (1) = A. Итак, вторая точка имеет координаты ( B + 1, A), и подставив x = (B + 2), мы получим y = f (B + 2) = A√ (B + 2-B) = A√ (2) = A (1.41) = 1,41 А. Итак, Третья Точка имеет координаты (B + 2,1,41A). Теперь мы нарисуем кривую через эти три точки. Пожалуйста, нажмите на изображение для лучшего просмотра.
Дано y = f (x) = A√ (x — B) + C, где A, B, C — действительные числа и (A) не равны нулю (0) и x ≥ B. Пронумеруйте, затем График в ШАГЕ №7 будет преобразовывать единицы измерения по вертикали (C). Если (C) — положительное число, график будет двигаться вверх (C) единиц, а если (C) — отрицательное число, график будет двигаться вниз (C) единиц.2 + x. Функция (f * g) (x) определена для x = все действительные числа, кроме интервала a, b 1. вычислить значение a и b 2. найти диапазон o
f (x) = √ (x — 2)
г (х) = х 2 + х
Область — это набор значений x, в которых определена функция.
Для f (x) у нас не может быть отрицательного числа под квадратным корнем. Таким образом, домен — это все действительные числа, большие или равные 2.
В интервальном обозначении: [2, ∞)
g (x) — парабола. Парабола содержит все действительные числа.
Поскольку f (x) имеет ограничение, (f * g) (x) определено для всех действительных чисел, кроме интервала -∞, 1,99.
а = -∞
b = 1,99 (цифра 9 повторяется)
Чтобы найти диапазон, мы оцениваем f (x), когда x приближается к бесконечности, начиная с x = 2.Диапазон — это предел f (x).
f (2) = √ (2 — 2)
= 0
f (20) = √ (20-2)
= √18
f (100) = √ (100-2)
= √98
f (500) = √ (500-2)
= √498
f (2000) = √ (2000 — 2)
= √1998
f (10000) = √ (10000 — 2)
= √9998
Как видите, когда x приближается к бесконечности, значение f (x) не достигает постоянного значения.Следовательно, предел не существует, и диапазон f (x) находится в интервале [0, ∞).
г (х) действительно имеет диапазон. Помещая g (x) в форме вершины, вершина даст нам диапазон. g (x) в вершинной форме —
г (x) = (x 2 + x + 1/4) — 1/4
г (x) = (x + 1/2) (x + 1/2) — 1/4
г (x) = (x + 1/2) 2 — 1/4
Вершина g (x) равна (-1/2, -1/4).Координата Y вершины сообщает нам диапазон. Поскольку парабола открывается вверх, диапазон значений g (x) находится в интервале (-1/4, ∞).
Следовательно, диапазон (f * g) (x) в обозначении интервала равен
Решение задач линейного программирования в MS Excel
1. Решение задач линейного программирования в MS Excel
LOGO Общая задача линейного программирования решается симплексным методом Симплекс (лат. simplex — простой) – простейший выпуклый многогранник в n-мерном пространстве с n+1 вершиной (например, тетраэдр в 3-мерном пространстве) На рисунке: оптимальное решение находится в одной из вершин многоугольника решений А, В, С, D Если задача линейного программирования имеет оптимальное решение, то оно соответствует хотя бы одной угловой точке многогранника решений (и совпадает с одним из допустимых базисных решений системы ограничений) Геометрический смысл симплексного метода состоит в последовательном переходе от одной вершины многогранника ограничений к соседней, в которой целевая функция принимает лучшее (по крайней мере, не худшее) значение Впервые симплексный метод был предложен американским ученым Дж. Данцигом в 1949 г. Джордж Бернард Данциг (1914-2005) – американский математик, разработал симплексный алгоритм, считается основоположником методов линейного программирования Идеи симплексного метода были разработаны в 1939 г. российским ученым Л.В.Канторовичем Леонид Витальевич Канторович (1912-1986) – советский математик и экономист, лауреат Нобелевской премии по экономике 1975 года «за вклад в теорию оптимального распределения ресурсов». Один из создателей линейного программирования Симплексный метод позволяет решить любую задачу линейного программирования В настоящее время он используется для компьютерных расчетов Рассмотрим решение задачи линейного программирования в MS Excel В MS Excel для решения задачи линейного программирования используется надстройка ПОИСК РЕШЕНИЯ Сначала надстройку Поиск решения необходимо подключить (до первого использования) В MS Excel 2003: Сервис / Надстройки / Поиск решения / OK После этого команда Поиск решения включена в меню Сервис В MS Excel 2007: 1) Кнопка Office (левый верхний угол окна программы) 2) Кнопка Параметры Excel (внизу окна меню) 3) Надстройки 1 2 3 В MS Excel 2007: 4) Кнопка Перейти (внизу окна Параметры Excel) 3 4 В окне Надстройки установить флажок и нажать ОК В MS Excel 2007 кнопка Поиск решения появится во вкладке Данные В MS Excel 2007 кнопка Поиск решения появится во вкладке Данные Решим в MS Excel задачу линейного программирования 1 2 Решим в MS Excel задачу линейного программирования 3 4 СРС СРС Ответы: 1 2 3 4 Решим в MS Excel задачу линейного программирования 1. Создадим область переменных Ячейки В2:В6 будут играть роль переменных (пока они пусты) Решим в MS Excel задачу линейного программирования 2. Введем формулу вычисления значений целевой функции Например, в ячейку А8 Решим в MS Excel задачу линейного программирования 3. Создадим область ограничений В ячейках А11:А13 будем вычислять левые части ограничений в системе В ячейках В11:В13 введем правые части ограничений системы Решим в MS Excel задачу линейного программирования 3. Создадим область ограничений В ячейках А11:А13 будем вычислять левые части ограничений в системе Первое ограничение Решим в MS Excel задачу линейного программирования 3. Создадим область ограничений В ячейках А11:А13 будем вычислять левые части ограничений в системе Второе ограничение Решим в MS Excel задачу линейного программирования 3. Создадим область ограничений В ячейках А11:А13 будем вычислять левые части ограничений в системе Третье ограничение Решим в MS Excel задачу линейного программирования 4. Вызовем окно диалога Поиск решения При этом удобно, если активной ячейкой является ячейка со значением целевой функции Решим в MS Excel задачу линейного программирования 1) Устанавливаем целевую ячейку А8 (там где вычисляется значение целевой функции) 2) Указываем направление оптимизации – минимизация (по условию) 3) В поле Изменяя ячейки указываем ячейки переменных В2:В6 Решим в MS Excel задачу линейного программирования Укажем ограничения 4) Нажимаем кнопку Добавить Появится окно Добавление ограничения Решим в MS Excel задачу линейного программирования Укажем ограничения 5) Неотрицательность переменных: Нажать кнопку Добавить 6) Остальные ограничения: Нажать OK Решим в MS Excel задачу линейного программирования Осталось нажать кнопку Выполнить Решим в MS Excel задачу линейного программирования Результаты Ответ: Литература 1. Кремер Н.Ш., Путко Б. А. Исследование операций в экономике. — М.: ЮНИТИ, 2003. 407 с. 2. Красс М.С., Чупрынов Б.П. Математика для экономистов. — СПб.: Питер, 2005. — 464 с.
«Решение задач оптимизации симплекс методом» | Методическая разработка на тему:
Пояснительная записка
Методическая разработка практической работы по теме «Решение задач оптимизации симплекс методом» по профессиональному модулю МДК 06-03 «Методы оптимизации систем автоматизации» предназначена для студентов 5-го курса специальности 15.02.07 «Автоматизация технологических процессов и производств по отраслям».
Студентам предлагаются типовые задачи оптимизации (оптимальное использование ограниченных ресурсов, раскрой промышленных материалов, смеси и т.п.). В примерах приводится подробное описание технологии получения оптимального решения симплекс методом и средствами Ms Excel.
Цель практической работы:
закрепить теоретические знания по теме;
приобретение навыков компьютерной реализации оптимизационных моделей симплекс методом;
сформировать у обучающихся умение работать самостоятельно и в сотрудничестве в группе.
Порядок выполнения работы:
Изучить теоретический материал.
Ответить на вопросы по теме.
Выполнить задания.
Оформить отчет по практическим занятиям.
Задача линейного программирования. Симплекс метод.
Составьте оптимальный план производства продукции, дающий максимальную прибыль. Предприятие выпускает продукцию четырех видов П1, П2, П3, П4 с использованием для этого ресурсов, виды и нормы расхода по которым, а также уровень получаемой от их реализации прибыли, приведены в таблице.
Вид ресурса
Запас
ресурса
П1
П2
П3
П4
Трудовые
1
1
1
1
16
Сырье
6
5
4
3
110
Оборудование
4
6
10
13
100
Прибыль
60
70
120
130
Экономико-математическая модель задачи запишется следующим образом:
x1+x2+x3+x4≤16
6×1+5×2+4×3+3×4≤110
4×1+6×2+10×3+13×4≤100
xj≥0 (j=1, 2, 3, 4)
Решение
Запустить табличный процессор Ms Excel.
Укажем адреса ячеек, в которые будет помещен результат решения (изменяемые ячейки). Значения компонент Х(x1,x2,x3,x4) поместим в ячейках В3:Е3, оптимальное значение целевой функции – в ячейку F4.
Введем исходные данные задачи в созданную форму-таблицу
Введем зависимость для целевой функции:
Установить курсор в ячейку F4, кликнуть по кнопке Мастер Функций (fx). Выберите категорию Математические и функцию СУММПРОИЗВ. На экране появится диалоговое окно СУММПРОИЗВ. В строку Массив 1 введем В$3:Е$3, в строку Массив 2 введем В4:Е4 и ОК.
Ввести зависимости для ограничений:
— курсор в ячейку F4: кнопка Копировать;
— вставить в ячейки F7, F8, F9.
В строке Меню установить указатель мыши на имя Сервис. В развернутом меню выбрать команду Поиск решения.
— кнопка Добавить. Появляется диалоговое окно Добавление ограничения;
— в строке Ссылка на ячейку введем адрес $F$7:$F$9, (или укажем на листе, т.е. щелкнуть на маленькой красной стрелке рядом с этим полем, выйти в таблицу и выделить ячейки F7: F9, нажать клавишу F4, при этом ссылка станет абсолютной $F$7:$F$9, щелкнуть на красной стрелке и вернуться в блок Поиска решения, при этом нужный адрес будет введен).
— выберем знак ограничения ≤;
— в строке Ограничения введем адрес $Н$7:$Н$9, ОК.
8. Введем параметры для решения задачи линейного программирования:
— в диалоговом окне Поиск решения →Параметры;
— в окне Параметры решения установить флажки — Линейная модель (симплекс метод), Неотрицательные значения →ОК→в окне Поиск Решения нажать кнопку Выполнить.
— в окне Результаты поиска решения выбрать Сохранить найденное решение →ОК.
На экране отразится таблица с заполненными ячейками В3:Е3 для значений х и ячейка F4 с максимальным значением целевой функции.
Максимальный доход 1320 денежных единиц предприятие может получить при объемах выпуска продукции первого вида -10 единиц, третьего вида 6 единиц. Продукцию второго и четвертого вида выпускать невыгодно.
Задача целочисленного линейного программирования. Симплекс метод.
Организация арендует баржу грузоподъёмностью 200 тонн. На барже предполагается перевозить груз 4-ех типов. Вес и стоимость единицы груза соответственно равны 20, 15, 20, 14 и 100, 80, 40, 30. Необходимо погрузить груз максимальной стоимости.
Экономико-математическая модель.
Пусть xj≥0 (j=1, 2, 3, 4) – число предметов , которое следует погрузить на баржу. Тогда задача о подборе для баржи допустимого груза максимальной стоимости запишется следующим образом:
max f(x1, x2, x3, x4)=100 x1+80 x2+40 x3+30 x4
20 x1+15 x2+20 x3+14 x4≤200 xj ≥ (j=1, 2, 3, 4)
Решение
Создать таблицу и ввести исходные данные
Ввести зависимость для целевой функции:
Установить курсор в ячейку F4, кликнуть по кнопке Мастер Функций (fx). Выберите категорию Математические и функцию СУММПРОИЗВ. На экране появится диалоговое окно СУММПРОИЗВ. В строку Массив 1 введем В$3:Е$3, в строку Массив 2 введем В4:Е4 и ОК.
Ввести зависимость для ограничений:
— скопировать полученную формулу в ячейку F8.
В строке Меню установить указатель мыши на имя Сервис. В развернутом меню выбрать команду Поиск решения.
— кнопка Добавить. Появится окно Добавление ограничения; в строке Ссылка на ячейку введем адрес $F$8;
— выберем знак ≤; в строке Ограничение введем адрес $H$8 → кнопка Добавить;
— в строке Ссылка на ячейку введем адрес $В$3: $Е$3;
— выберем значение цел→ ОК. На экране появится окно Поиск решения с введенными условиями.
Введем параметры для решения задачи:
— кнопка Параметры; в окне Параметры поиска решения установить флажки Линейная модель (симплекс метод), Неотрицательные значения →ОК→в окне Поиск Решения нажать кнопку Выполнить.
— в окне Результаты поиска решения выбрать Сохранить найденное решение →ОК.
Получим решение.
Таким образом, рекомендуемое управленческое решение с позиций принятого критерия оптимизации – следует погрузить 1 предмет первого типа и 12 предметов второго типа. В этом случае стоимость груза составит 1060 денежных единиц, и грузоподъемность будет использована полностью.
Михеева Е.В. Информационные технологии в профессиональной деятельности – М.: Издательский центр «Академия», 2014. -384с.
К вопросу использования надстройки Excel «Поиск решения» в задачах линейного программирования Текст научной статьи по специальности «Компьютерные и информационные науки»
ФГБОУ ВПО «Национальный исследовательский университет (МИЭТ)» 2
Москва, Россия Кандидат педагогических наук
Доцент
E-mail: fedotova-e2007@yandex. ru
К вопросу использования надстройки Excel «поиск решения» в задачах линейного программирования
1 105005, г. Москва, ул. Радио, 22
2 124460, г. Москва, Филаретовская ул., корп. 1134, кв. 165 1
Аннотация. Существует насущная необходимость принятия эффективных управленческих решений.
В условиях полной определенности широко используются задачи линейного программирования, где требуется найти оптимальное решение. При этом оптимальность принимаемого решения во многом зависит от количества существующих альтернатив и их научно-технической обоснованности. В некоторых случаях существует несколько альтернативных оптимальных решений одной задачи. Их поиск в задачах линейного программирования процесс весьма трудоёмкий.
Обычно для решения задач линейного программирования используется надстройка Excel «поиск решения». Однако не все предлагаемые ей методы равнозначны при поиске альтернативных оптимальных решений. Кроме того, эффективность поиска зависит от начального приближения целевой функции. Поэтому целью настоящей работы являются выбор наиболее эффективного метода поиска альтернативных оптимальных решений задач линейного программирования с помощью надстройки Excel «поиск решения» и задание наилучших начальных приближений целевой функции.
В работе проведено сравнение эффективности симплексного метода и метода обобщенного приведенного градиента надстройки Excel «поиск решения» при нахождении альтернативных оптимальных решений задач линейного программирования и предложен эвристический способ задания начальных приближений целевой функции, позволяющий сократить время поиска.
Барышев А.В., Федотова Е.Л. К вопросу использования надстройки Excel «поиск решения» в задачах линейного программирования // Интернет-журнал «НАУКОВЕДЕНИЕ» Том 7, №3 (2015) http://naukovedenie.ru/PDF/54TVN315.pdf (доступ свободный). Загл. с экрана. Яз. рус., англ. DOI: 10.15862/54TVN315
Менеджеру любого ранга повседневно приходится принимать целый ряд решений связанных с экономикой и управлением. При этом, с точки зрения эффективности, принятое решение должно быть оптимальным. Выполнить это требование бывает очень трудно, особенно если математическая модель задачи является негладкой и нелинейной или сама задача плохо структурирована.
Существует много методов принятия управленческих решений [1]. Здесь же мы остановимся на принятии управленческих решений в задачах линейного программирования [2, 3], а именно на использовании надстройки поиск решения Excel в задачах линейного программирования [4].
Как известно, эффективность принимаемого решения во многом зависит от количества существующих альтернатив и их научно-технической обоснованности [5, 6]. При решении задач линейного программирования, в некоторых случаях, найденное оптимальное решение оказывается не единственным [7]. Поэтому, с целью обеспечения большей свободы выбора управленческого воздействия, необходимо выявить все оптимальные альтернативные решения.
В работе предлагается эвристический способ задания начальных приближений целевой функции, позволяющий сократить время поиска.
Этим обусловлена актуальность и практическая ценность настоящей работы.
Существуют различные признаки, указывающие на наличие оптимальных альтернативных решений. При использовании надстройки поиск решения Excel в задачах линейного программирования в качестве таких признаков является наличие в отчете по устойчивости нулей «в таблице «Изменяемые ячейки» в столбцах «Допустимое увеличение» и «Допустимое уменьшение». ..» (отчет получают при использовании симплексного метода решения) [8]. Однако, найти эти оптимальные альтернативные решения не так просто, поскольку результат поиска решения зависит от начального приближения и не только. Рассмотрим этот вопрос подробнее. Для этого возьмем несколько конкретных примеров.
Пример 1 [7]. Найти максимум целевой функции
Внесем данные на лист Excel (см. рисунок 1).
В ячейки B2:D2 названия переменных, а в ячейки B3:D3 — коэффициенты при целевой функции F(x).
В ячейки B2:D2 диапазона (B5:D5; B7:D7) запишем коэффициенты при неизвестных в ограничениях.
В ячейки B10:D10, первоначально подставляются начальные условия, например, все единицы или нули.
В ячейках E5,E6,E7 записываются формулы вычисления левой части ограничений, а в ячейки G5,G6,G7 — значения правой части.
В ячейку E10 записывается формула вычисления целевой функции.
Р(х) =Х1+Х2+Хз
(1)
при ограничениях
(2).
AI
A В С D Е F G
1 перем лев часть знак прав часть
2 наименование Xl х2 ¡(3
3 коэф в цел.функции 1 1 1
4
5 коэф в 1 огранич -1 3 2 =СУ М М П РОИ ЗВ[ В5: D5; В10: D1 s &
S коэф в 2 ограним 2 4 2 =СУ М М П РО ШВ( В 6: D6; В10: D1 s а
7 коэф в 3 огранич 3 2 -1 =СУ М М П Р О И ЗВ( В 7: D7; В10: D1 £ 4
S
9 XI1 х2′ хЗг т
10 оптим значение 0 0 0 =СУММПРОИЗВ(ВЗ:ОЗ;В10: max
Рисунок 1. Фрагмент листа Excel, заполненный данными из формул (1) и (2)
(произведен авторами)
Теперь можно непосредственно перейти к использованию «надстройки поиск решения».
Через меню «данные» и «поиск решения» входим в таблицу «параметры поиска решения» (см. рис. 2).
Параметры поиска решения I
Оптимизировать целевою функцию:
До: Максимум Минимум
Изменяя ячейки переменных:
шш
Значения:
Ш
Б соответствии с ограничениями:
ÎEÎUO >= 0
$C$U0 >= 0
IDE 10 >= □
ÎE$5 <= ÎG$5
$E$6 <= SGSo
SES7 <= $G$7
«W
Добавить
Изменить
Удалить
Сбросить
Загрузит ь/оохранить
Сделать переменные без ограничений неотрицательными Выберите
Поиск решения линейных задач симплекс-методом
Параметры
метод решения: Метод решения
Для гладких нелинейных задач используйте поиск решения нелинейных задач методом ОПГ, для линейных задач — поиск решения линейных задач симплекс-методом, а для негладких задач — эволюционный поиск решения.
Справка
Найти решение
Закрыть
Рисунок 2. Окно параметры поиска решения MS Excel
В неё вводим указание на ячейку со значением целевой функции ($E$10). Указываем, что ищем максимум целевой функции, и указываем диапазон изменяемых ячеек ($B$10:$D$10). Затем через пункт таблицы «добавить» вводим указания на ограничения, предварительно установив параметры поиска:
1. Точность ограничения — 0.001.
2. Максимальное время (в секундах) — 100.
3. Число итераций — 100.
4. Максимальное число допустимых решений (установим, например) — 4.
При необходимости устанавливаем метки на такие пункты как «Использовать автоматическое масштабирование» и «Показывать результаты итераций» и др.
Минько А.А. рекомендует использовать автоматическое масштабирование во всех случаях [8]. Кроме того, многие авторы, например [4, 8] рекомендуют для решения задач линейного программирования использовать симплексный метод решения. Это же рекомендуется в самом окне «параметры поиска решения» MS Excel. Однако это, также как и использование автоматического масштабирования, как это будет показано ниже, не всегда оказывается целесообразным.
Теперь, нажав кнопку «найти решение» находим искомое решение. Максимум целевой функции будет помещен в ячейку E10. В ячейки В10, С10, D10 будут записаны соответственно Х1, Х2, хз.
В качестве начального приближения используем значения переменных Х1, х2, хз= 0.
После найденного оптимального решения убедимся, что существуют альтернативные оптимальные решения. Для этого создадим «отчет об устойчивости».
На рис. 3. поместим фрагмент отчета об устойчивости.
Ячейки переменных
Окончательное Приведенн. Целевая функция Допустимое Допустимое
Ячейка Имя Значение Стоимость Коэффициент Увеличение Уменьшение
$В$10 оптим значение xl1 2 0 1 1Е+30 0
$С$10 оптим значение х2′ 0 -1 1 1 1Е4-30
$D$10 оптим значение хЗ’ 2 0 1 0 1
Рисунок 3. Фрагмент отчета об устойчивости (получен авторами)
Как следует из рисунка, в двух крайних столбцах имеются нули. Это указывает на наличие альтернативных оптимальных решений.
Исследуем возможности надстройки «поиск решения» для получения оптимальных альтернативных решений. С этой целью будем различным образом задавать начальное приближение целевой функции (методом случайного поиска и предлагаемым способом), а также будем изменять сам метод поиска (с симплексного на метод обобщенного приведенного градиента (ОПТ) [9]). Результаты поместим в таблицы 1 и 2.
Таблица 1
Поиск альтернативных решений целевой функции (1) симплексным методом
(составлено авторами)
Метод решения Способ задание начального приближения Начальное приближение Значение целевой функции Значение переменных
Симплекс ный метод решения Случайный поиск Х1,Х2,Х3= 0 4. 00 Х1= 2.00; Х2=0.00; хз= 2.00
Как следует из данных таблицы 1, при использовании различных способов задания начальных приближений симплексный метод не обеспечивает поиск альтернативных оптимальных решений. Изменим симплексный метод решения на метод обобщенного приведенного градиента (ОПТ). Результаты поместим в таблицу 2.
Как следует из данных таблицы 2, предлагаемый способ задания начальных приближений обеспечил поиск 4 альтернативных решений, если же использовать автоматическое масштабирование, то можно найти только два альтернативных решения.
Таблица 2
Поиск альтернативных решений целевой функции (1) методом ОПГ
(составлено автором)
Метод решения Способ задания начального приближения Начальное приближение Значение целевой функции Значение переменных
Метод решения нелинейных задач методом ОПГ Способ перестановки ограничений (без масштабирова ния) Х1,Х2,Х3= 0 4.00 Х1= 1.90; Х2= 0.00; хз= 2.10
Произведем поиск альтернативных решений, используя метод решения нелинейных задач ОПГ и предлагаемый способ задания начальных приближений. Результаты поиска поместим в таблицу 3.
Как видим из данных таблицы 3, найдено 3 альтернативных оптимальные решения, при этом мы избежали случайного поиска начальных значений.
Таблица 3
Поиск альтернативных решений целевой функции (3) методом ОПГ
(составлено авторами)
Метод решения Метод задания начального приближения Начальное приближение Значение целевой функции Значение переменных
Метод решения нелинейных задач методом ОПГ Способ перестановки ограничений (без масштабирова ния) Х1,Х2,Х3= 0 10.00 Х1= 0,71; х2= 1,43; хз= 2,14
На основании изложенного материала можно сделать следующие выводы:
1. Начинать решение задачи линейного программирования с помощью надстройки Excel «поиск решения» следует с помощью симплексного метода, получив при этом отчет об устойчивости. Если в отчете по устойчивости «в таблице «Изменяемые ячейки» в столбцах «Допустимое увеличение» и «Допустимое уменьшение»…» есть нули, то необходимо искать альтернативные оптимальные решения.
2. Симплексный метод решения не обеспечивает поиск альтернативных оптимальных решений.
3. Поиск альтернативных оптимальных решений следует производить методом обобщенного приведенного градиента (ОПГ) без автоматического масштабирования, используя задание начальных приближений с помощью
предлагаемого способа перестановки ограничений. Это позволит сократить затраченное время.
ЛИТЕРАТУРА
1. Орлов А.И. Организационно-экономическое моделирование: теория принятия решений: учебник. — М.: КНОРУС, 2011. — 568 с.
2. Титов В.В. Оценка эффективности оптимизационного планирования деятельности промышленного предприятия / Регион: экономика и социология. 2007. №1. С. 241-250.
3. Созонов С.В. Разработка моделей оптимизации производственной программы промышленного предприятия на основе формулирования целевых функций / Экономические науки. 2010. Т. 67. №6. С. 231-235.
4. Урубков А.Р., Федотов И.В. Методы и модели оптимизации управленческих решений: учебное пособие. — М.: Издательство «Дело» АНХ, 2009. — 240 с.
5. Баллод Б. А., Елизарова Н.Н. Методы и алгоритмы принятия решений в экономике: учебное пособие. — М.: Финансы и статистика; ИНФРА-М, 2009. -224 с.
6. Барышев А.В., Федотова Е.Л. К вопросу формирования творческих способностей выпускников вузов // Интернет-журнал «НАУКОВЕДЕНИЕ» 2014. №4 http:// http://naukovedenie.ru/PDF/80PVN414.pdf (доступ свободный). Загл. с экрана. Яз. рус.
7. Агальцов В.П. Математические методы в программировании: учебник. — М.: ИД «ФОРУМ», 2010. — 240 с.
8. Минько А.А. Принятие решений с помощью Excel. Просто как дважды два. -М.: Эксмо, 2007. — 240 с.
9. Метод обобщенного приведенного градиента. http://iasa.org.Ua/lections/iso/6/6.7.h tm.
10. Палий И.А. Линейное программирование. Учебное пособие. — М.: Эксмо, 2008. 256 с.
Рецензент: Ключников Анатолий Васильевич, доцент, кандидат технических наук, Национальный исследовательский университет «МИЭТ».
Barushev Alexsandr Vladimirowich
NOU VPO «Russian new University» Russia, Moscow E-mail: [email protected]
Vedotova Elena Leonidovha
National Research University of Electronic Technology
Finding optimal solutions for linear programming decision problems using Microsoft Excel Solver Add-in.
Abstract. The vital necessity does exist for making effective management decisions.
Linear programming approach is widely used in case of the full certainty where an optimal decision must be found. The optimality of a found decision mostly depends on the number of existing alternatives and their scientific feasibility. In some cases there can be several alternative optimal solutions for a single decision problem. Finding the best one of these alternatives is a quite difficult and hard-working process.
Often Microsoft Excel Solver Add-in is used to solve linear programming decision problems. However not all of its techniques are equal when finding an optimal solution for a decision problem. Further, the efficiency of finding a solution depends on initial approximation of the objective function. Therefore, the aim of this paper is to choose the most efficient method for finding optimal solutions of linear programming problems using Microsoft Excel Solver Add-in by providing the best input approximation for objective function.
This paper compares the efficiency of simplex and generalized reduced gradient methods in Microsoft Excel for finding alternative optimal solutions of linear programming problems. ита! «NAUKOVEDENIE» 2014. №4 http:// http://naukovedenie.ru/PDF/80PVN414.pdf (dostup svobodnyy). Zagl. s екгапа. Yaz. rus.
7. Agal’tsov У.Р. Matematicheskie metody V programmirovanii: иЛеЬшк. — М.: ID «FORUM», 2010. — 240 s.
8. Мт’ко А.А. Prinyatie resheniy s pomoshch’yu Ехсе1. Prosto как dvazhdy dva. — М.: Eksmo, 2007. — 240 s.
9. Metod obobshchennogo privedennogo gradienta. http://iasa.org.Ua/lections/iso/6/6.7.htm.
10. Paliy 1.А. Lineynoe programmirovanie. Uchebnoe posobie. — М.: Eksmo, 2008. 256 s.
Учебные задачи для Excel
Учебные задачи для Excel Электронные таблицы MS Excel — очень удобный инструмент для вычислений.
При вычислениях длинных выражений Excel удобнее любого калькулятора, особенно тем, что легко править ошибки во введённой формуле или изменять часть формулы
в Excel удобно решать уравнения с одним неизвестным при помощи «подбора параметра»
несложно решать системы линейных алгебраических уравнений (СЛАУ)
можно решать задачи оптимизации (линейного, целочисленного программирования)
. .. и многие другие задачи. Некоторые задачи сопротивления материалов, решённые с помощью Excel можно найти
здесь
Построение графика функции и решение уравнений с одним неизвестным
Численное интегрирование
Решение систем линейных алгебраических уравнений
Решение задач линейного программирования (Л.П.)
Тема 1. Практикуемся в построении математической модели. Методичка, описание решений
(скачать 3 документа Word в RAR-архиве — 100кб)
Тема 2. Формы записи задачи линейного программирования (общая задача Л.П., основная форма, каноническая форма, допустимый план, оптимальный план). Методичка, описание решений (скачать 3 документа Word в RAR-архиве — 100кб)
Тема 3. Графический метод решения задачи Л.П. Методичка, описание решений, документ Excel с решениями (скачать 2 документа Word и 1 док. Excel в RAR-архиве — 100кб)
Графический метод (с использованием Excel)
Тема 4. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ СИМПЛЕКСНОГО МЕТОДА РЕШЕНИЯ ЗАДАЧ Л.П.
Методичка, описание решения (скачать 2 документа Word в RAR-архиве — 50кб)
Тема 5. СИМПЛЕКСНЫЙ МЕТОД РЕШЕНИЯ ЗАДАЧ Л.П. (скачать методичку, описание решений, решения в Excel RAR-архив — 200кб)
Тема 6. МЕТОД ИСКУССТВЕННОГО БАЗИСА. ДВУХЭТАПНЫЙ СИМПЛЕКС-МЕТОД РЕШЕНИЯ ЗАДАЧ Л.П. (скачать методичку, описание решений, решения в Excel RAR-архив — 200кб)
Тема 7. ДВОЙСТВЕННЫЙ СИМПЛЕКС-МЕТОД (Р-МЕТОД) (скачать методичку, описание решений, решения в Excel RAR-архив — 100кб)
Тема 8. Задача целочисленного Л.П. (скачать методичку, описание решений, решения в Excel RAR-архив — 450кб)
Тема 9. РЕШЕНИЕ ЗАДАЧ Л.П. С ПОМОЩЬЮ MS EXCEL (скачать методичку, описание решений, решения в Excel RAR-архив — 350кб)
1. Численное интегрирование
Для численного интегрирования функции одной переменной применяют методы:
прямоугольников, трапеций, Симпсона. Подробнее об этих методах можно прочесть в «Справочнике по высшей математике М.Я. Выгодского»
( см библиотеку)
Метод прямоугольников
Метод трапеций
Метод Симпсона
Все эти методы заключаются в:
Разбиении интервала (отрезка) интегрирования на n равных более мелких отрезков
Замене на каждом таком мелком отрезке исходной функции (её графика) соответственно:
— горизонтальной прямой
— наклонной прямой
— параболой
Вычислении площади полученной фигуры, которая приблизительно равна площади
под графиком функции, т е искомому интегралу.
Лист MS Excel с решением задачи
(Точное значение вычисляемого интеграла равно 30)
Скачать документ Excel
с этим примером (в виде RAR-архива LAB1_win.rar — 22kB)
Решение игровых задач с нулевой суммой с помощью Microsoft Excel
Библиографическое описание:
Захарова, Т. Н. Решение игровых задач с нулевой суммой с помощью Microsoft Excel / Т. Н. Захарова. — Текст : непосредственный // Актуальные задачи педагогики : материалы I Междунар. науч. конф. (г. Чита, декабрь 2011 г.). — Чита : Издательство Молодой ученый, 2011. — С. 176-181. — URL: https://moluch.ru/conf/ped/archive/20/1343/ (дата обращения: 12.06.2021).
Рассмотрим
общий случай игровой задачи m
x
n
с нулевой суммой, когда модель задачи не имеет седловой точки. Такую
модель можно представить в виде матрицы (табл.1):
Таблица 1. Общая таблица стратегий
Стратегии
В1
В2
…
Вn
A1
a11
a12
a1n
A2
a21
a22
a2n
….
Am
am1
am2
amn
Оптимальное
решение необходимо искать в области смешанных стратегий. Обозначим
вероятности применения стратегий первого игрока (игрока А) через
,
а цену игры — через v.
Оптимальная смешанная стратегия игрока А определяется из условия
Пусть
Поскольку при
оптимальной стратегии средний выигрыш не меньше v
при любой стратегии противника, то справедлива система n
неравенств:
Или
(1)
Тогда задача отыскания
оптимальной смешанной стратегии игрока А может быть сформулирована в
виде задачи линейного программирования.
Для этого
необходимо максимизировать целевую функцию F
=v
при ограничениях
(2)
Введем новые
неизвестные:
Поскольку
Разделим левую и
правую части неравенств (1) и (2) на v, получим:
(3)
В силу того что
max
v
= min
1/v
= min{x1+x2+…+xm}.
задача принимает вид
F=
x1+x2+…+xm
→
min
(4)
при ограничениях
(5)
Для
второго игрока (игрока В) оптимальная стратегия определяется из
условия:
при условии
q1+q2+…+qn
= 1
Эта задача
записывается как симметричная двойственная задача линейного
программирования к задаче игрока A
(4), (5):
L=
y1
+y2+…
+yn
→
max
(6)
при ограничениях
(7)
Задачи игроков A
и В решают симплекс-методом.
Использование
возможностей Microsoft
Excel
позволяет существенно облегчить и ускорить решение этой задачи.
Сначала нужно создать исходную таблицу:
Затем, на основе этой таблицы записать
формулы для нахождения решения:
Для нахождения
решения используется надстройка Поиск решения. Нужно выделить ячейку,
в которой вычисляется значение функции F
и вызвать надстройку Поиск решения. Заполнить окно поиска решения:
В поле Ограничения
нужно задать формулы для всех ограничений. Затем нажать кнопку
Параметры и отметить поля Линейная модель и Неотрицательные значения.
Нажать кнопку ОК, затем Выполнить.
Чтобы найти значения вероятностей и цену
игры нужно записать формулы:
Решение задачи для
игрока В выполняется по аналогичной схеме согласно формулам (6), (7).
Рассмотрим пример
решения задачи. Найдем
решение игры, заданной матрицей
.
Проверим наличие седловой точки.
В режиме отображения
формул эта запись имеет вид:
Поскольку нижняя цена
игры (минимальный выигрыш игрока А) и верхняя цена игры (максимальный
проигрыш игрока В) не равны, то модель данной задачи не имеет
седловой точки. Поэтому решение следует искать в смешанных
стратегиях. Составим задачи линейного программирования для нахождения
решений игроков А (согласно формулам (4), (5)) и В(согласно формулам
(6), (7)):
для игрока А и
для игрока В.
Для решения этих систем используем
надстройку «Поиск решения». Сначала оформим задачу для
поиска решения игрока А:
В режиме отображения формул:
Затем нужно активировать ячейку В7 и
запустить надстройку Поиск решения. Далее заполнить окно Поиска
решения:
Затем нажать кнопку Параметры и отметить
поля Линейная модель и Неотрицательные значения. Нажать кнопку ОК,
затем Выполнить.
Получим результат:
Вероятности применения смешанных
стратегий и цену игры найдем по формулам: pi=xi/F,
v=1/F.
В режиме отображения формул:
Аналогично найдем решение для игрока В:
В режиме отображения формул:
Литература:
1. Акулич И.Л. Математическое
программирование в примерах и задачах. М. «Высшая школа»,
1993г.
2. Агальцов В.П., Волдайская И.В.
Математические методы в программировании М. ИД «Форум» -
ИНФРА-М, 2006г.
3. Бережная Е.В., Бережной В.И.
Математические методы моделирования экономических систем М. «Финансы
и статистика», 2003г.
4. Партыка Т.Л., Попов И.И.
Математические методы М. ИД «Форум» — ИНФРА-М, 2007г.
Основные термины(генерируются автоматически): игрок А, Поиск решения, режим отображения формул, игрок В, линейное программирование, цена игры, кнопка ОК, Линейная модель, оптимальная смешанная стратегия, оптимальная стратегия.
Похожие статьи
Создание и использование программы для статистического…
стратегия, игра, игрок, матричная игра, ценаигры, решениеигры, нулевая сумма, участник, верхняя ценаигры, платежная матрица. Поискрешения как средство решения задач оптимизации…
Теория
игр: основные понятия, типы игр, примеры
Для второго игрока самой оптимальнойсмешаннойстратегией является стратегия . Запишем ценуигры
Алгоритм. Иначе ценаигры находится в промежутке и решениеигры находится в смешанныхстратегиях.
Поискрешения как средство решения задач оптимизации…
Получится запись как на рис.1. В диалоговом окне Поискрешения нажать кнопку Параметры, установить флажок Линейнаямодель и задать условия неотрицательности переменных, установив флажок
Нажать кнопкуОК и перейти в диалоговое окно Поискрешения.
Математическое моделирование
оптимальныхстратегий…
‒ аспект оптимальныхрешений — теория математических моделей принятия оптимальныхрешений вусловиях конфликтов.
Аналогичным образом с помощью интеграла Стильтьеса находится цена непрерывной игры и оптимальнаясмешаннаястратегия для обоих игроков-стратегов. Предположим, что есть платежная функция (или функция выигрыша)…
Целочисленное
решение задач линейногопрограммирования…
Оптимальноерешение в примере, в принципе, не может быть получено каким-либо округлением решения соответствующей задачи линейногопрограммирования.
Метод линейногопрограммирования при решении текстовых задач графически имеет следующий алгоритм
Литература: 1. Шикин Е. В., Чхартишвили А. Г. Математические методы и модели.
Линейноепрограммирование | Статья в журнале «Молодой…»
Модельлинейногопрограммирования имела бы множество переменных решений
Решение задач оптимального раскроя средствами MS Excel. Симплекс-метод, основанный на идеях Л. В. Канторовича, был описан и детально разработан рядом ученых из США в середине 20 века.
Решение задач линейного программирования » Привет Студент!
Факультет экономики и управления
Кафедра математических методов и моделей в экономике
ОТЧЕТ
по лабораторной работе
по курсу «Исследование операций»
на тему: «Решение задач линейного программирования»
Постановка задачи
На предприятии имеются три группы станков. Нужно изготовить два вида изделий – А и В. Фонд рабочего времени по первой группе станков составляет 400 часов, по второй- 360 часов, по третьей- 1320 часов. Время на обработку одного изделия вида А составляет для первой группы станков- 0,4 час., для второй – 0,84 час., для третьей- 8,0 часов. Соответственно для одного изделия группы В- 2,0; 1,2; 4,0 час. Каждое изделие вида А при его реализации дает прибыль предприятию в 1,2 ед., а изделие В- 4,8 ед. Найти план при котором прибыль будет максимальна.
Решить задачу:
Симплекс- методом с помощью программного обеспечения DV SIMP;
В МПП Excel с помощью надстройки «Поиск решения».
1 Обоснование симплекс- метода
Симплекс метод — это характерный пример итерационных вычислений, используемых при решении большинства оптимизационных задач. В вычислительной схеме симплекс-метода реализуется упорядоченный процесс, при котором, начиная с некоторой исходной допустимой угловой точки (обычно начало координат), осуществляются последовательные переходы от одной допустимой экстремальной точки к другой до тех пор, пока не будет найдена точка, соответствующая оптимальному решению.
Пусть имеется задача линейного программирования в канонической форме:
и трактовать следующим образом: из всех разложений вектора b по векторам с неотрицательными коэффициентами, требуется выбрать хотя бы одно такое, коэффициенты xi которого доставляют целевой функции F оптимальной значение. Не ограничивая общности, считаем ранг матрицы А: r=m и n>m.
Ненулевое допустимое решение называется опорным, если вектора , соответствующие отличным от нуля координатам , линейно независимы.
Ненулевое опорное решение называется невырожденным, если оно имеет m- положительных координат.
Если число положительных координат опорного решения меньше m, то оно называется вырожденным.
Упорядоченный набор из m- линейно независимых векторов , соответствующих положительным координатам опорного решения, назовем базисом.
Теорема: вектор тогда и только тогда является опорным решением задачи, когда точка является вершиной допустимого множества. Таким образом, задача нахождения вершины допустимого множества свелась к задаче нахождения опорного решения, а, следовательно, к нахождению базиса.
Будем считать, что исходный базис Ai1,…,Aim, тогда вектор b разложим по этому базису:
b==
.
Аналогично можно представить любой вектор :
В частности, в качестве исходного базиса могут быть взяты вектора, образующие единичную матрицу:
если они присутствуют в канонической форме задачи; в противном случае, исходный базис нужно строить, то есть имеет место задача с искусственным базисом.
Используя разложение вектора по базису векторами можно сформулировать утверждения:
Если для данного базиса все оценки
неотрицательны, то опорное решение является оптимальной точкой задачи;
Если для данного базиса существует хотя бы одна оценка для нее все то это означает, что целевая функция данной задачи линейного программирования не ограничена сверху на допустимом множестве;
Если для данного базиса есть такая отрицательная оценка что среди координат вектора в данном базисе
координаты все векторов в новом базисе могут быть найдены через координаты векторов в старом базисе по формулам:
Алгоритм решения задачи симплекс методом.
Исходные данные:
Вычисляем координаты разложения векторов по базису ;
Рассчитываем оценки по формулам (1) и проверяем, являются ли они положительными. Если да, то алгоритм заканчивает свою работу, опорное решения является оптимальным, если нет, то проверяем, существуют ли такие , что все . Если существуют, то алгоритм заканчивает свою работу, задача неразрешима. Если нет, находим и находим
Далее производим замену в базисе вектора на вектор и снова выполняем разложение по новому базису.
В случае небольшого числа ограничений переменных указанный алгоритм легко реализовать без помощи ЭВМ, оформляя решение в виде симплекс-таблиц.
Пусть дана задача в канонической форме и найден исходный базис . Находим разложение всех векторов по базису. Результат оформляем в виде таблицы.
№
Базис
В
…
…
1
…
2
…
…
…
…
…
…
…
…
…
M
…
…
2 Практическая часть
Представим данную задачу в виде таблицы 1.
Таблица 1- Исходные данные
Группа станков
Фонд рабочего времени, час.
Время на реализацию ед. продукции
А
В
1
400
0,4
2
2
360
0,84
1,2
3
1320
8
4
Обозначим:
х1— количество произведенных изделий вида А;
х2 – количество произведенных изделий вида В.
Таким образом, целевая функция имеет следующий вид:
F=1,2*x1+4,8*x2→max;
Система ограничений запишется в виде:
0,4*х1+2*х2 ≤ 400;
0,84*х1+1,2*х2 ≤ 360;
8*х1+4*х2 ≤ 1320;
х1 ≥ 0, х2 ≥ 0.
Решим задачу с помощью программы DV SIMP. Введем исходные данные (рисунок 1).
Рисунок 1- Исходные данные
На следующем шаге необходимо привести систему к каноническому виду (рисунок 2).
Рисунок 2- Приведение к каноническому виду
После чего в целевой функции появятся переменные х3, х4, х5, и коэффициенты системы ограничений имеют следующий вид (рисунок 3):
Рисунок 3- Коэффициенты
Видим, что начальный базис можно указать. Он будет состоять из векторов А3, А4, А5 , которые образуют единичную матрицу.
Таким образом, на начальном этапе симплекс-таблица имеет следующий вид (рисунок 4):
Рисунок 4- Симплекс таблица
Для данной таблицы рассчитали оценки, среди которых оказались отрицательные, следовательно, решение не оптимально.
Так как решение не найдено, продолжаем решение, определяем новый базис (рисунок 5).
Рисунок 5- Определение базиса
По рисунку 5 видно, что ввести в базис нужно вектор А2, так как ему минимальная оценка.
Для определения вектора, который нужно вывести из базиса, рассчитаем ϴ для каждого вектора текущего базиса.
ϴ1=400/2=200;
ϴ2=360/1,2=300;
ϴ3=1320/4=330.
Минимальное значение ϴ соответствует вектору А3, следовательно, его выводим из базиса.
Для нового базиса симплекс- таблица представлена на рисунке 6.
Рисунок 6- Симплекс-таблица
Среди оценок текущей симплекс- таблицы есть отрицательная, следовательно, оптимальное решение не найдено, и нужно продолжать решение.
Минимальное значение оценки соответствует вектору А1, который введем в базис. Рассчитаем ϴ:
ϴ1=200/0,2=1000;
ϴ2=120/0,6=200;
ϴ3=520/7,2=72.222.
Минимальное значение ϴ соответствует вектору А5, следовательно, его выводим из базиса.
Для нового базиса симплекс- таблица представлена на рисунке 7.
Рисунок 7- Симплекс-таблица
Видим, что среди оценок нет отрицательных, а значит, оптимальное решение найдено (рисунок 8).
Рисунок 8- Решение задачи
В базис вошли вектора А2, А4, А1. Оптимальное значение целевой функции F=977,333. Соответственно оптимальные значения х1= 72,222; х2= 185,556.
Найдем решение данной задачи с помощью функции «Поиск решения» в МПП Excel.
Результат представлен на рисунке 9.
Рисунок 9- Решение задачи в МПП Excel
Получили аналогичный результат, то есть оптимально производить 72 изделия вида А и 185 изделий вида В. При этом максимальная прибыть будет равна 977,333 ед.
Скачать: У вас нет доступа к скачиванию файлов с нашего сервера. КАК ТУТ СКАЧИВАТЬ
Лабораторная работа №4. Реализация пошагового алгоритма решения задачи линейного программирования табличным симплекс-методом средствами Excel при выполнении всех условий
Задание.
Реализуйте все нижеприведенные шаги в
табличном процессоре Excel,
необходимые для решения задачи ЛП.
Поясним
последовательность действий при решения
задачи ЛП табличным симплекс-методом
на примере.
Следующая
строка таблицы соответствует первому
ограничению. Базисная переменная,
найденная в первом ограничении, свободный
член, коэффициенты при переменных
соответствующего ограничения. Аналогичным
образом заполняются 2 и 3 строки.
Последняя
строка – это строка целевой функции,
которая заполняется следующим образом,
свободный член без изменения знака, а
коэффициенты при переменных с
противоположным (рис. 26).
Рис.
26. Исходная
симплекс таблица.
Проконтролируйте
правильность заполнения таблицы. Так
как
,,- базисные переменные, то на пересечении(5
строка)
с
(столбецD)
должна
стоять 1
(ячейка
D5),
а в соответствующем столбце ниже –
нули, на пересечении
(6 строка)
с
(столбецE)
должна
стоять 1 (ячейка
E6),
а в соответствующем столбце ниже –
нули,
(7 строка)
с
(столбецH)
должна
стоять 1 (ячейка
H7),
а в соответствующем столбце ниже –
нули.
Запишите
значение целевой функции, начальный
опорный план, опираясь на столбец
свободных членов (рис. 27).
Рис.
27. Значение
целевой функции и начальный опорный
план.
III. Нахождение оптимального плана и оптимального значения целевой функции.
Так
в индексной строке есть отрицательные
коэффициенты при переменных, то опорный
план не является оптимальным. Организуйте
процесс улучшения плана, выполнив
предложенные шаги.
Среди
отрицательных элементов индексной
строки выберите наибольший по модулю
элемент. Соответствующий столбец
назовите ведущим. Данный столбец
показывает, какую переменную необходимо
включить в базис (рис. 28).
Рис.
28. Выбор
ведущего столбца.
Теперь
необходимо определить какую переменную
исключить из базиса. Для этого составьте
отношения для всех элементов столбца
свободных членов ()
к соответствующим элементам ведущего
столбца ().
Например, в ячейку I5
введите
формулу =B5/C5.
Растяните формулы для ячеек I6,
I7,
исключая ячейку индексной строки (рис.
29).
Рис.
29. Составление
отношений.
Определите
результат отношений (таблица 5), учитывая,
что в результате может получиться
число, отличное от нуля, 0 или бесконечность
(рис. 30).
Рис.
30. Результат
отношений.
Выберите
наименьшее из отношений. Строку, в
которой получился наименьший результат,
назовите ведущей (рис. 31). Данная
строка показывает, какую переменную
необходимо исключить из базиса.
Рис.
31. Выбор
ведущей строки.
На
пересечении ведущей строки и ведущего
столбца получается ведущий элемент
(рис. 32).
Рис.
32. Ведущий
элемент.
Постройте
новую симплексную таблицу. Выведите
переменную
из базиса, на ее место запишите ту
переменную, которой соответствует
ведущий столбец (рис. 33). В нашем
случае – это переменная.
Рис.
33. Новый
базис.
Так
как теперь
— базисная переменная, то на пересечении(13
строка)
с
(столбецC)
должна
стоять 1
(ячейка
С13),
а в соответствующем столбце ниже –
нули. С помощью элементарных преобразований
сделайте ведущий столбец базисным.
Для
получения 1 в ячейке С13 необходимо каждый
элемент ведущей строки поделить на
ведущий элемент.
Рис.
35. Первая
строка второй симплексной таблицы.
Затем получите
нуль в ячейке С14.
Для
этого во второй симплексной таблице 1
(ячейка С13) умножьте на элемент предыдущей
таблицы, соответствующий элементу
ячейки С14, взятый с противоположным
знаком и сложите с этим же элементом.
Так
как элемент, соответствующий элементу
ячейки С14 равен 1 (ячейка С6), то это
означает, что все элементы первой строки
второй симплексной таблицы умножаются
на (-1) и складывается с соответствующими
элементами первой симплексной ьаблицы.
Запишите
в ячейку С14 формулу =C13*(-1)+C6 (рис. 36).
Рис.
36. Элемент
С14 второй симплексной таблицы.
Аналогичным
образом получите остальные элементы
базисного столбца (рис. 37 и рис. 38).
Рис.
37. Элемент
С15 второй симплексной таблицы.
Рис.
38. Элемент
С16 второй симплексной таблицы.
Растяните
формулы базисного столбца по строкам,
получите вторую симплексную таблицу
(рис. 39).
Рис.
39. Первая и
вторая симплексные таблицы.
Так
в индексной строке есть отрицательные
коэффициенты при переменных, то опорный
план не является оптимальным.
Запишите
значение целевой функции, найденный
новый опорный план, опираясь на столбец
свободных членов (рис. 40). Проконтролируйте,
что значение целевой функции
максимизируется.
Рис.
40. Значение
целевой функции и опорного плана второй
симплексной таблицы.
Организуйте
процесс улучшения плана, выполнив
предложенные шаги, начиная с пункта 5,
до тех пор пока не будет выполняться
какой-нибудь из критериев остановки.
Получите третью симплексную таблицу
(рис. 41).
Рис.
41. Первая,
вторая и третья симплексные таблицы.
В
индексной строке нет отрицательных
элементов, поэтому план
оптимален,.
Задание. Воспользуйтесь
материалами лабораторной работы №3.
Выполните проверку, используя программу
MathCad.
Симплексный метод регрессии LAD | Реальная статистика с использованием Excel
Используя симплексный метод, мы решаем задачу нахождения минимума абсолютных отклонений между наблюдаемыми значениями y и предсказанными значениями y.
в задачу минимизации линейного программирования с учетом ограничений
для всех i = 1,…, n .
Мы можем использовать Excel Solver для решения этой задачи линейного программирования, применяя метод Simplex Linear Programming , где каждый элемент данных приводит к двум ограничениям.
Пример 1 : Повторите пример 1 наименьших квадратов для множественной регрессии с использованием регрессии LAD.
Мы повторяем данные из Примера 1 в диапазоне A3: E14 на Рисунке 1 вместе с настройкой, необходимой для использования симплексного метода Excel Solver.
Рисунок 1. Данные и настройка для симплекс-метода
Здесь ячейка D4 содержит формулу = $ F $ 15 + MMULT (A4: B4, $ F $ 16: $ F $ 17), E4 содержит = C4- D4, G4 содержит = -F4, а F19 содержит = СУММ (F4: F14). Ячейки в диапазоне F4: F14, которые представляют собой, установлены на начальное предположение 1, как и коэффициенты регрессии в диапазоне F15: F17.Мы могли бы заменить эти догадки какими-то другими значениями. Обратите внимание, что мы размещаем ячейки коэффициентов прямо под ячейками, чтобы у нас был непрерывный диапазон ячеек, который будет изменен во время работы алгоритма решателя.
Теперь мы выбираем Data> Analysis | Solver и заполняем диалоговое окно, которое появляется, как показано на рисунке 2.
Рисунок 2 — диалоговое окно Solver
Обратите внимание, что мы хотим минимизировать значение в ячейке F19, который будет содержать сумму абсолютного значения отклонения между наблюдаемыми значениями y (столбец C) и значениями, предсказанными регрессионной моделью (столбец D).Минимизация осуществляется путем изменения значений в диапазоне F4: F14, который содержит абсолютные отклонения, а также в диапазоне F15: F17, который содержит коэффициенты регрессии.
Мы указываем ограничения для процесса оптимизации обычным способом, за исключением того, что на этот раз мы объединяем такие ограничения, как E4 <= F4, E5 <= F5, E6 <= F6,…, E14 <= F14, используя неравенство диапазона E4: E14 <= F4: F14. Наконец, мы просим использовать метод Simplex LP . Когда мы нажимаем кнопку OK , мы получаем результаты, показанные на рисунке 3.
Рисунок 3 — Результаты регрессии LAD
Модель регрессии LAD —
Цена = 7,667 + 4,333 * Цвет + 2,778 * Качество
Поскольку у нас есть две независимые переменные, как отмечалось ранее, по крайней мере, три элемента данных будет иметь нулевой остаток, а именно строки 8, 10 и 11.
Одна проблема с использованием симплексного метода в Excel заключается в том, что он ограничен 100 ограничениями, что означает, что он будет поддерживать только модели LAD с не более чем 50 элементами данных .
3.3a. Решение стандартных задач максимизации с помощью симплекс-метода
В предыдущем разделе мы обнаружили, что графический метод решения задач линейного программирования, хотя и требует много времени, позволяет нам видеть области решения и определять угловые точки. Однако это невозможно при наличии нескольких переменных. Мы можем визуализировать до трех измерений, но даже это может быть сложно, когда есть множество ограничений.
Для решения задач линейного программирования, содержащих более двух переменных, математики разработали то, что теперь известно как симплекс-метод .Это эффективный алгоритм (набор механических шагов), который «переключает» угловые точки, пока не найдет ту, которая максимизирует целевую функцию. Хотя это заманчиво, есть несколько вещей, на которые нам нужно обратить внимание, прежде чем использовать его.
Прежде чем приступить к математическим деталям, давайте рассмотрим пример задачи линейного программирования, для которой соответствует симплекс-методу:
Пример 1
С помощью симплекс-метода можно решить следующую систему:
Цель Функция: P = 2 x + 3 y + z
При соблюдении ограничений:
3 x + 2 y ≤ 5
2 x + y — z ≤ 13
z ≤ 4
х, у, z≥0
Стандартная задача максимизации
С математической точки зрения, чтобы использовать симплексный метод для решения задачи линейного программирования, нам нужна стандартная задача максимизации:
,
— целевая функция, а
—
одно или несколько ограничений вида a 1 x 1 + a 2 x 2 +… a n x n le В
Все числа a представляют собой коэффициенты с действительными числами, а
x номер представляет соответствующие переменные.
V — неотрицательное (0 или большее) действительное число
Наличие ограничений с верхними пределами должно иметь смысл, поскольку при максимизации количества у нас, вероятно, есть ограничения на то, что мы можем сделать. Если бы у нас не было ограничений, мы могли бы продолжать увеличивать, скажем, прибыль, бесконечно! Это противоречит тому, что мы знаем о реальном мире.
Чтобы использовать симплексный метод, технологически или вручную, мы должны настроить исходную симплексную таблицу , которая представляет собой матрицу, содержащую информацию о задаче линейного программирования, которую мы хотим решить.
Во-первых, матрицы плохо справляются с неравенством. Во-первых, у матрицы нет простого способа отслеживать направление неравенства. Уже одно это препятствует использованию неравенств в матрицах. Как же нам этого избежать?
Поскольку мы знаем, что левые части обоих неравенств будут величинами, меньшими, чем соответствующие значения справа, мы можем быть уверены, что добавление «чего-то» к левой части сделает их в точности равными.То есть:
2 x + 3 y + с 1 = 6
3 x + 7 y + s 2 = 12
Например, предположим, что x = 1, y = 1, тогда
2 + 3 + s 1 = 6 или s 1 = 1
3 + 7 + s 2 = 12 или s 2 = 2
Важно отметить, что эти две переменные, s 1 и s 2 , не обязательно одинаковы.Они просто действуют на неравенство, подбирая «слабину», которая не дает левой стороне выглядеть как правая. Следовательно, мы называем их резервными переменными . Это устраняет неравенство за нас. Поскольку расширенные матрицы содержат все переменные слева и константы справа, мы перепишем целевую функцию в соответствии с этим форматом:
–7 x — 12 y + P = 0
Теперь мы можем написать исходную систему уравнений :
2 x + 3 y + s 1 = 6
3 x + 7 y + s 2 = 12
–7 x — 12 y + P = 0
Для этого нам потребуется матрица, которая может обрабатывать x , y , s 1 , s 2 и P .Мы разместим это в таком порядке. Наконец, симплексный метод требует, чтобы целевая функция была указана в нижней строке матрицы, чтобы мы имели:
Мы создали исходную симплексную таблицу . Обратите внимание, что горизонтальные и вертикальные линии используются просто для отделения коэффициентов ограничения от констант и коэффициентов целевой функции. Также обратите внимание, что столбцы переменных резервов вместе с выходными данными целевой функции образуют единичную матрицу.
Мы представим алгоритм решения, однако отметим, что он не совсем интуитивно понятен. Мы сосредоточимся на этом методе для одного примера, а затем перейдем к использованию технологий для выполнения процесса за нас.
1. Выберите столбец поворота
Сначала мы выбираем сводный столбец, который будет столбцом, содержащим наибольший отрицательный коэффициент в строке, содержащей целевую функцию. Обратите внимание, что наибольшее отрицательное число принадлежит члену, который больше всего влияет на целевую функцию.Это сделано намеренно, поскольку мы хотим сосредоточиться на значениях, которые делают вывод как можно большим.
Таким образом, наша точка поворота — это столбец и .
2. Выберите сводную строку
Сделайте это, вычислив отношение каждой константы ограничения к соответствующему коэффициенту в сводном столбце — это называется тестовым отношением . Выберите строку с наименьшим тестовым соотношением.
Поскольку тестовое соотношение для строки 2 меньше, мы выбираем ее в качестве сводной строки. Штучное значение теперь называется нашей опорной точкой . Чтобы объяснить, почему мы это делаем, заметим, что 2 и 1.7 — это просто вертикальные пересечения двух неравенств. Мы выбираем меньшее, чтобы убедиться, что угловая точка находится в допустимой области:
3. Используя метод исключения Гаусса, удалите строки 1 и 3
Умножьте R2 на (1/7), чтобы преобразовать 7 в 1.
Затем используйте 1, чтобы удалить 3 в R1: -3R 2 + R 1 → R 1
И используйте 1, чтобы удалить -12 в R3: 12R 2 + R 3 → R 3
Получаем следующую матрицу (возможно, дроби)
Что мы сделали? Во-первых, мы максимально увеличили вклад 2-2 входного коэффициента y -значение в целевую функцию. Оптимизировали ли мы функцию? Не совсем так, поскольку мы все еще видим, что в первом столбце есть отрицательное значение.Это говорит нам о том, что все еще может вносить вклад в целевую функцию. Чтобы устранить это, мы сначала находим сводную строку, получая тестовые отношения:
Чтобы идентифицировать набор решений, мы сосредотачиваемся только на столбцах с ровно одной ненулевой записью — они называются базовыми переменными (столбцы с более чем одной ненулевой записью, таким образом, называются небазовыми переменными ) .
Мы замечаем, что оба столбца x any являются базовыми переменными. Нас действительно не волнуют переменные резервов, так же как мы игнорируем неравенство, когда находим пересечения. Теперь мы видим, что
Таким образом, x = 1,2, y = 1,2, P = 22,8 — это решение задачи линейного программирования. То есть входные данные x = 1,2 и y = 1,2 дадут максимальное значение целевой функции 22,8
.
Хотя этот процесс несколько интуитивно понятен, за ним стоит больше, чем мы предполагаем. И вместо того, чтобы проходить эти изнурительные шаги до тошноты, мы позволим нашей технологии следовать этим шагам. Для этого нам понадобится специальная программа, которая будет распространяться в классе
.
Для выполнения симплекс-метода с помощью графического калькулятора необходимы следующие программы:
Поворот,
Pivot1 и
Симплекс
Pivot и Pivot1 напрямую не используются.Вместо этого программа Simplex обращается к этим двум приложениям, чтобы помочь ей с помощью довольно длинного и утомительного кода. Как работает код? Используя инструкции, он находит сводные столбцы, сводные строки, выполняет гауссовское исключение, проверяет наличие негативов в строке целевой функции и повторяет этот процесс по мере необходимости, пока все негативы не будут удалены.
Теперь, когда мы проиллюстрировали, что на самом деле симплекс-метод работает даже с двумя входными переменными, давайте покажем ситуацию, в которой этот метод особенно полезен.
Пример 2
Новая авиакомпания решила выйти на рынок. Он рассматривает возможность предложения рейсов из Феникса, штат Аризона, и первоначально хотел бы отправиться в три разных места: Сан-Диего, Сан-Франциско и Лас-Вегас. Расстояния каждого рейса туда и обратно, вылетающего из Феникса, составляют (приблизительно): 720 миль, 1500 миль и 1140 миль соответственно. Компания хотела бы использовать слоган: «Средняя цена за рейс никогда не превышает 200 долларов». Что касается затрат, ожидается, что полеты в Сан-Диего будут составлять около 10% от стоимости авиабилетов.Точно так же на Сан-Франциско будет приходиться 12%, а на Лас-Вегас — 14% авиаперевозок. Компания хочет, чтобы общая средняя стоимость не превышала 10% от заработанных авиабилетов. Недавнее исследование рынка позволяет компании сделать вывод, что она могла бы продать около 1900 билетов в Сан-Диего, 700 билетов в Сан-Франциско и 1000 билетов в Лас-Вегас. В этих условиях и при условии, что все проданные билеты являются рейсами в оба конца, какую сумму компания должна взимать за билет, чтобы максимизировать свой общий доход?
Решение
Мы хотим знать стоимость авиабилетов в каждый пункт назначения.Пусть,
x = цена билета в оба конца до Сан-Диего
y = цена билета в оба конца до Сан-Франциско
z = цена за билет в оба конца до Лас-Вегаса
Компания хочет максимизировать общий доход. Это основано на сумме количества проданных билетов, умноженной на цену за билет, которая составляет:
.
R = 1900 x + 700 y + 1000 z
При соблюдении ограничений:
Средняя цена за рейс не превышает 200 долларов США
Средняя стоимость авиабилетов не более 10% от общей суммы
Математически,
Добавьте цены и разделите на 3 [латекс] \ displaystyle \ frac {{{x} + {y} + {z}}} {{3}} \ le {200} [/ latex]
Или x + y + z ≤ 600
Общий доход от билетов в Сан-Диего составит 10% от этой суммы.То есть Стоимость = 0,10 (1900 x ) = 190 x . Точно так же имеем 0,12 (700 y ) = 84 y и 0,14 (1000 z ) = 140 z . Мы хотим, чтобы сумма этих затрат была меньше или равной 10% от общего дохода, что составляет 0,10 (1900 x + 700 y + 1000 z ) = 190 x + 70 y . + 100 z .
190 x + 84 y + 140 z ≤ 190 x + 70 y + 100 z
или 14 y + 40 z ≤ 0
Поскольку оба ограничения имеют правильную форму, мы можем приступить к настройке исходной симплексной таблицы.В качестве примечания будьте очень осторожны при использовании симплексного метода, поскольку невыполненные требования делают полученные результаты недействительными.
Переписанная целевая функция:
–1900 x — 700 y — 1000 z + R = 0
И упрощенные ограничения:
x + y + z ≤ 600 (умножить обе стороны на 3)
14 y + 40 z ≤ 0
х, y≥0
Для каждого из двух ограничений потребуется переменная Slack, поэтому мы перепишем их следующим образом:
x + y + z + s 1 = 600
14 y + 40 z + s 2 = 0
У нас будут следующие столбцы переменных: x , y , z, s 1 , s 2 , R и постоянный столбец, всего 7 столбцы.Всего у нас есть два ограничения и одна целевая функция для трех строк. Теперь напишем исходную симплексную таблицу:
Поскольку базовым будет только столбец x , мы можем видеть, что x = 600 является решением.Поскольку y и z не являются базовыми переменными, мы устанавливаем y = z = 0. То есть они не способствуют максимизации дохода. Кроме того, R является активной переменной, поэтому мы видим, что R = 1 140 000 долларов США — это максимальный доход, который компания может получить с учетом ограничений. Им следует продавать билеты в Сан-Диего за 600 долларов и не продавать рейсы в другие города. Как нетрудно догадаться, компания, вероятно, немного ошеломлена. Мы рассмотрим это в следующем примере.
Интересно, что поездки в Сан-Диего сами по себе приносят наибольший доход, исходя из данных ограничений. Почему это? Если мы посмотрим на ограничения, то увидим, что компания вполне уверена, что сможет продать 1900 рейсов в Сан-Диего. Компания также несколько озадачена тем, что предполагается продавать билеты по 600 долларов за штуку. На этом этапе он может решить добавить к модели некоторые дополнительные ограничения.
Пример 3
Предположим, что авиалайнер в Примере 2 решает, что он может взимать не более 150 долларов за билет до Сан-Диего, чтобы быть конкурентоспособным по сравнению с другими авиалайнерами, которые летают в тот же пункт назначения.Если предположить, что все остальные ограничения все еще будут использоваться, как это повлияет на цены на билеты и максимальный доход?
Решение
Мы используем ту же исходную таблицу, но мы должны иметь дело со следующим новым ограничением:
x ≤ 150
Добавляя третью переменную slack, получаем
x + с 3 = 150
Это добавляет один столбец и одну строку в нашу таблицу:
Кейтеринговая компания приготовит обед к деловой встрече.Здесь подают бутерброды с ветчиной, легкие бутерброды с ветчиной и вегетарианские бутерброды. Сэндвич с ветчиной состоит из 1 порции овощей, 4 ломтиков ветчины, 1 ломтика сыра и 2 ломтиков хлеба. Легкий бутерброд с ветчиной состоит из 2 порций овощей, 2 ломтиков ветчины, 1 ломтика сыра и 2 ломтиков хлеба. Вегетарианский бутерброд состоит из 3 порций овощей, 2 ломтиков сыра и 2 ломтиков хлеба. Всего доступно 10 пакетов ветчины, в каждой по 40 ломтиков; Доступно 18 буханок хлеба, каждая по 14 ломтиков; Доступно 200 порций овощей и 15 пакетов сыра, по 60 ломтиков в каждом.Учитывая ресурсы, сколько бутербродов можно произвести, если цель состоит в том, чтобы максимально увеличить количество бутербродов?
Решение
Мы хотим увеличить количество бутербродов, поэтому давайте:
x = количество бутербродов с ветчиной
y = Количество легких бутербродов с ветчиной
z = количество вегетарианских бутербродов
Общее количество бутербродов равно
.
S = x + y + z
Ограничения будут даны с учетом общего количества доступных ингредиентов.То есть у компании ограниченное количество ветчины, овощей, сыра и хлеба.
Всего у компании есть 10 (40) = 400 ломтиков ветчины, 18 (14) = 252 ломтика хлеба, 200 порций овощей и 15 (60) = 900 ломтиков сыра. Максимум, компания может использовать вышеуказанные суммы.
Есть два бутерброда с ветчиной: для первого требуется 4 ломтика ветчины, а для второго — только 2 на бутерброд. То есть 4 x + 2 y ≤ 400
То есть общее количество ломтиков ветчины не может превышать 400.
Для каждого бутерброда требуется 2 ломтика хлеба, поэтому 2 x + 2 y + 2 z ≤ 252
В бутербродах с ветчиной 1 и 2 порции овощей соответственно, а в вегетарианском бутерброде 3 порции овощей. Итак, 1 x + 2 y + 3 z ≤ 200
Для обоих бутербродов с ветчиной требуется один ломтик сыра, а для вегетарианского бутерброда — два ломтика сыра, поэтому 1 x + 1 y + 2 z ≤ 900 Ниже представлена законченная модель линейного программирования для этого примера.
Развернуть: S = x + y + z
Субъект Кому: 4 x + 2 y ≤ 400
2 x + 2 y + 2 z ≤ 252
x + 2 y + 3 z ≤ 200
1 x + 1 y + 2 z ≤ 900
х, у, z≥0
Эти ограничения удовлетворяют требованиям симплекс-метода, поэтому продолжаем.
Поскольку наибольшее отрицательное число в нижней строке одинаково для трех столбцов, мы можем использовать любой столбец.Можно также использовать первый столбец. Наименьшее частное получается путем деления 4 на 400, так что строка 1 является сводным столбцом. Разворот на «4» в R1C1 дает доход.
Примечание: мы увеличили S с 0 до 200, но у нас все еще есть отрицательный знак в нижней строке.Поскольку «-1» более отрицательное значение, чем «-1/2», мы будем вращаться по столбцу 3. После деления положительных чисел выше «-1» на константы, мы получим наименьшее частное в строке 2. Вращаемся по «2». ”В выходах R2C3.
Конечно, нас действительно интересуют: x = 100, y = 0, z = 26, S = 126
Мы обнаружили, что необходимо приготовить 100 бутербродов с ветчиной, 26 вегетарианских бутербродов и 0 легких бутербродов с ветчиной, чтобы увеличить общее количество приготовленных бутербродов.
Переменные резерва не важны в решении. Просто в достижении решения.
Дополнительные примеры см. В следующем разделе. Во многих задачах используются переменные с индексами, такие как x 1 , x 2 , x 3 и т. Д. Это особенно полезно, если у вас есть несколько переменных. Вы увидите это в следующих примерах.
Дополнительные ресурсы перечислены ниже:
Milos Podmanik, By the Numbers, «Решение стандартных задач максимизации с помощью симплекс-метода», лицензия CC BY-NC-SA 3.0 лицензия.
MathIsGreatFun, «MAT217 HW 2.2 # 1», под лицензией Standard YouTube.
MathIsGreatFun, «MAT217 2.2 # 2» под стандартной лицензией YouTube.
MathIsGreatFun, «MAT217 2.2 # 3» под стандартной лицензией YouTube.
MathIsGreatFun, «MATh317 2.2 # 4» под стандартной лицензией YouTube.
Excel Solver — что может и чего не может Solver
Основная цель решателя
— найти решение , то есть значения для переменных решения в вашей модели, которое удовлетворяет всем ограничениям и максимизирует или минимизирует цель значение ячейки (если есть).Тип , тип решения, которого вы можете ожидать, и сколько вычислительного времени может потребоваться для поиска решения, в первую очередь зависит от трех характеристик вашей модели:
Размер вашей модели (количество переменных решения и ограничений, общее количество формул )
Математические отношения (например, линейные или нелинейные) между целью и ограничениями и переменными решения
Использование целочисленных ограничений для переменных в вашей модели
Другие проблемы, такие как плохое масштабирование , также могут повлиять на решение время и качество, но указанные выше характеристики влияют на внутреннюю разрешимость вашей модели.Хотя более быстрые алгоритмы и более быстрые процессоры могут помочь, для решения некоторых невыпуклых или негладких моделей могут потребоваться годы или десятилетия, чтобы добиться оптимальности на самых быстрых компьютерах, которые только можно себе представить.
Общий размер вашей модели и использование целочисленных ограничений относительно легко оценить, когда вы исследуете свою модель. Математические отношения, которые определяются формулами в вашей модели, может быть труднее оценить, но они часто имеют решающее влияние на время и качество решения — как далее объясняется, начиная с этой темы.
Подводя итог:
Если ваша цель и ограничения — это линейные функции переменных решения, вы можете быть уверены, что достаточно быстро найдете глобально оптимальное решение , учитывая размер вашей модели. Это задача линейного программирования ; это также задача оптимизации выпуклых (поскольку все линейные функции выпуклые). Для этих задач разработан метод Simplex LP Solving.
Если ваша цель и ограничения — это гладких нелинейных функций переменных решения, время решения будет больше.Если проблема выпуклый , вы можете быть уверены, что найдете глобально оптимальное решение , но если это невыпуклый , вы можете ожидать только локально оптимальное решение — и даже это может быть трудно найти . Метод нелинейного решения GRG разработан для этих задач.
Если ваша цель и ограничения — это негладкие и невыпуклые функции переменных решения (например, если вы используете функции ЕСЛИ, ВЫБРАТЬ и ПРОСМОТР, аргументы которых зависят от переменных решения), лучшее, на что вы можете надеяться является «хорошим» решением (лучше, чем начальные значения переменных), а не локально или глобально оптимальным решением.Метод эволюционного решения предназначен для этих задач.
Вы можете использовать целочисленные, двоичные и любые другие ограничения для переменных со всеми тремя методами решения. Однако эти ограничения значительно усложняют решение задачи невыпуклых и .
С помощью метода Simplex LP Solving вы можете найти глобально оптимальное решение за достаточно времени, но, возможно, вам придется довольствоваться решением, которое «близко к оптимальному», найденным за более разумный промежуток времени.От методов нелинейного и эволюционного решения GRG следует ожидать «хорошего», но не доказуемо оптимального решения.
Excel Solver: какой метод решения мне выбрать?
Если вы когда-либо заходили в надстройку Excel Solver, вы, вероятно, замечали, что есть много вариантов, и это может быть немного подавляющим. В этом посте я хотел бы предоставить некоторую практическую информацию, которая поможет вам выбрать правильный метод решения в Excel, чтобы эффективно найти оптимальное решение вашей проблемы.
Одна из вещей, которую вы должны выбрать при настройке Solver в Excel, — это метод решения. На выбор есть три метода или алгоритма:
GRG Нелинейный
эволюционный
Симплекс LP
GRG Нелинейный и эволюционный лучше всего подходят для нелинейных задач, в то время как симплексный LP ограничивается только линейными задачами.
GRG означает «Обобщенный уменьшенный градиент». В своей основной форме этот метод решателя смотрит на градиент или наклон целевой функции при изменении входных значений (или переменных решения) и определяет, что он достиг оптимального решения, когда частные производные равны нулю.
Из двух методов нелинейного решения GRG Nonlinear является самым быстрым. Однако такая скорость идет с компромиссом.
Обратной стороной является то, что решение, которое вы получаете с помощью этого алгоритма, сильно зависит от начальных условий и может не быть глобальным оптимальным решением. Решающая программа, скорее всего, остановится на локальном оптимальном значении, ближайшем к начальным условиям, предоставив вам решение, которое может или не может быть оптимизировано глобально.
Еще одно требование к нелинейному решателю GRG для получения хорошего решения состоит в том, чтобы функция была гладкой.Любые нарушения непрерывности, вызванные, например, функциями IF, VLOOKUP или ABS, вызовут проблемы для этого алгоритма.
Эволюционный алгоритм более надежен, чем GRG Nonlinear, потому что он с большей вероятностью найдет глобально оптимальное решение. Однако этот метод решения также ОЧЕНЬ медленный.
Позвольте мне объяснить, почему:
Эволюционный метод основан на теории естественного отбора, который хорошо работает в данном случае, потому что оптимальный результат был определен заранее.
Проще говоря, решатель начинает со случайной «совокупности» наборов входных значений. Эти наборы входных значений вставляются в модель, и результаты оцениваются относительно целевого значения.
Наборы входных значений, которые приводят к решению, наиболее близкому к целевому значению, выбираются для создания второй популяции «потомков». Потомство — это «мутация» наилучшего набора входных значений из первой популяции.
Затем оценивается вторая популяция и выбирается победитель для создания третьей популяции.
Надеюсь, что приведенная ниже диаграмма проясняет ситуацию.
Так продолжается до тех пор, пока целевая функция не меняется очень мало от одной популяции к другой.
Что делает этот процесс настолько трудоемким, так это то, что каждый член населения должен оцениваться индивидуально. Кроме того, последующие «поколения» заполняются случайным образом вместо использования производных и наклона целевой функции для поиска следующего наилучшего набора значений.
Теперь Excel дает вам некоторый контроль над алгоритмом через окно параметров решателя.Например, вы можете выбрать частоту мутаций и размер популяции, чтобы потенциально сократить время решения.
Однако это имеет убывающую отдачу, потому что уменьшение размера популяции и / или увеличение скорости мутаций может потребовать еще большего количества популяций для достижения конвергенции.
Хороший компромисс между скоростью нелинейного алгоритма GRG и надежностью эволюционного алгоритма — это GRG Nonlinear Multistart. Вы можете включить эту опцию в окне Solver Options на вкладке GRG Nonlinear.
Алгоритм создает случайно распределенную совокупность начальных значений, каждое из которых оценивается с использованием традиционного нелинейного алгоритма GRG.
При многократном запуске с разных начальных условий существует гораздо большая вероятность, , что найденное решение является глобальным оптимумом.
Из трех методов решения я меньше всего использую Simplex LP. Его применение ограничено, поскольку его можно применять только к задачам, содержащим только линейные функции.
Часто задачи, которые я решаю, нелинейны. А когда они линейны, я предпочитаю решать их как матричное уравнение.
Однако он очень надежен, потому что, если проблема, которую вы решаете, является линейной, вы можете быть уверены, что решение, полученное методом Simplex LP, всегда является глобально оптимальным решением.
Линейное программирование с помощью электронных таблиц
Линейное программирование с помощью электронных таблиц
Линейное программирование с помощью электронных таблиц
Представлено в Интернете
В стадии строительства
Обзор
Модуль 1.Что такое линейное программирование?
Введение.
Аспекты линейного программирования.
История линейного программирования.
Линейное программирование и электронные таблицы.
Проблема узких мест в производстве.
Решение уравнения.
Упражнения.
Литература.
Модуль 2. Простая модель и ее составление в виде электронной таблицы.
Введение.
Производство чизкейков для гурманов.
Алгебраическая формулировка.
Формулировка действия в среде электронной таблицы.
Представление модели чизкейка с помощью числового графика.
Построение графика модели чизкейка.
Особые случаи.
Безграничное решение.
Нет подходящего решения.
Множественные оптимальные решения.
Вырожденное решение.
Упражнения.
Литература
Модуль 3. Оптимизация на основе электронных таблиц.
Введение.
Оптимизация электронных таблиц с помощью What’sBest.
Самая лучшая установка и команды.
Постановка задачи.
Расчет и результаты.
Неограниченное решение.
Нет подходящего решения.
Составы с верхними границами.
Оптимизация электронных таблиц с помощью функции «Что, если».
Присоединение надстройки.
Формулировка задачи «Что, если».
Решение проблемы.
Сохранение настроек Whatif.
Оригинальный состав WhatIf.
Выбор симплекс-метода.
Оптимизация электронных таблиц с Quattro Pro.
Оптимизация электронных таблиц с помощью Excel.
Упражнения.
Литература.
Модуль 4. Симплексный метод.
Введение.
Простое возможное решение.
Итерация симплекс-метода.
Выбор новой базовой переменной.
Выбор выходной базовой переменной.
Преобразование системы уравнений.
Пример симплекс-метода.
Геометрия симплекс-метода.
Выполнение симплекс-метода.
Упражнения.
Литература.
Модуль 5. Что поесть в McDonald’s?
Введение.
Лучшая покупка в гамбургер-меню.
Большая проблема.
Полное ежедневное питание.
Упражнения.
Литература.
Модуль 6. Смешивание и смешивание моделей.
Введение.
Купля-продажа.
Структура купли-продажи.
Совокупность видов деятельности.
Модель с раздельной продажей и покупкой.
Проблема минимизации затрат.
Проблема кормов.
Проблема смешивания кормов для крупного рогатого скота.
Смешение бензина.
Переменное производство и продажа бензина.
Смешивание ряда бензиновых продуктов.
Прочие проблемы при смешивании и смешивании.
Упражнения.
Литература.
Модуль 7. Анализ чувствительности.
Введение.
Изменение количества труда.
Изменения констант ограничений.
Изменение коэффициентов целевой функции.
Анализ чувствительности для ограничений с WB.
Анализ чувствительности для переменных решения с WB.
Анализ чувствительности с помощью Excel Solver.
Вырожденные решения.
Множественные оптимальные решения.
Одновременные изменения.
Упражнения.
Литература.
Модуль 8. Двойная проблема.
Введение.
Двойная оценка.
Двойная проблема для простого случая.
Двойная задача для примера с чизкейком.
Общая постановка первичных и двойственных задач.
Отношения между первичным и двойственным решениями.
Первичная и двойная задачи для примера с чизкейком.
Проблема минимизации.
Двойственность транспонированием.
Упражнения.
Литература.
Модуль 9. Параметрическое программирование.
Введение.
Параметрическое программирование ограничений с WB.
Чистый доход и двойная переменная труда.
Первичные переменные и доход от продукта для различного количества рабочей силы.
Стоимость ресурсов для различного количества рабочей силы.
Доходы трудовых коллективов.
Параметрическое программирование коэффициентов целевой функции с помощью Excel Solver.
Переменные решения и их доходы для различных доходов от природных ресурсов.
Стоимость ресурсов для различных доходов от природных ресурсов.
Упражнения.
Литература.
Модуль 10. Транспортные модели.
Введение.
Транспортные модели
Проблемы с назначением.
Упражнения.
Модуль 11. Целочисленное программирование и задачи присваивания.
Введение.
Целочисленное программирование.
Пример инвестиций в недвижимость.
Фиксированные затраты на деятельность.
Проблемы с расположением.
Упражнение.
Задания.
Проблема местоположения.
Проблема с выбором программного обеспечения.
Модуль 12. Анализ охвата данных.
Введение.
Проблема Исполнительного совета факультета.
Графическое определение эффективности.
Формулировка линейного программирования для случая с одним входом.
Несколько входов и выходов.
Ценностный подход.
Упражнения.
Модуль 13. Линейное программирование и экономический анализ.
Руководство по решению Excel с пошаговыми примерами
В руководстве объясняется, как добавить и где найти Solver в разных версиях Excel, с 2016 по 2003 год.Пошаговые примеры показывают, как использовать Excel Solver для поиска оптимальных решений для линейного программирования и других проблем.
Всем известно, что Microsoft Excel содержит множество полезных функций и мощных инструментов, которые могут сэкономить вам часы расчетов. Но знаете ли вы, что в нем также есть инструмент, который может помочь вам найти оптимальные решения проблем, связанных с принятием решений?
В этом руководстве мы рассмотрим все основные аспекты надстройки Excel Solver и предоставим пошаговое руководство по ее наиболее эффективному использованию.
Что такое Excel Solver?
Excel Solver принадлежит к специальному набору команд, часто называемому инструментами анализа «что, если». В первую очередь он предназначен для моделирования и оптимизации различных бизнес-моделей и инженерных моделей.
Надстройка Excel Solver особенно полезна для решения задач линейного программирования, так называемых задач линейной оптимизации, и поэтому иногда называется решателем линейного программирования . Кроме того, он может решать гладкие нелинейные и негладкие задачи.Дополнительные сведения см. В разделе «Алгоритмы решения Excel».
Хотя Solver не может решить все возможные проблемы, он действительно полезен при решении всех видов задач оптимизации, когда вам необходимо принять наилучшее решение. Например, он может помочь вам максимизировать возврат инвестиций, выбрать оптимальный бюджет для вашей рекламной кампании, составить оптимальный график работы для ваших сотрудников, минимизировать затраты на доставку и так далее.
Как добавить решатель в Excel
Надстройка Solver включена во все версии Microsoft Excel, начиная с 2003 года, но по умолчанию она не включена.
Чтобы добавить Solver в Excel, выполните следующие действия:
В Excel 2010 , Excel 2013 , Excel 2016 и Excel 2019 щелкните Файл > Параметры . В Excel 2007 нажмите кнопку Microsoft Office , а затем щелкните Параметры Excel .
В диалоговом окне Excel Options нажмите Add-Ins на левой боковой панели, убедитесь, что Excel Add-ins выбран в поле Manage внизу окна, и нажмите Go .
В диалоговом окне Надстройки установите флажок Надстройка Solver и нажмите ОК :
Чтобы получить Решатель на Excel 2003 , перейдите в меню Инструменты и щелкните Надстройки . В списке надстроек доступных установите флажок Solver Add-in и нажмите ОК .
Примечание. Если Excel отображает сообщение о том, что надстройка Solver в настоящее время не установлена на вашем компьютере, щелкните Да , чтобы установить ее.
Где находится решатель в Excel 2019, 2016, 2013, 2010 или 2007?
В современных версиях Excel кнопка Solver отображается на вкладке Data в группе Analysis :
Где находится решатель в Excel 2003?
После загрузки надстройки Solver в Excel 2003 ее команда добавляется в меню инструментов :
Теперь, когда вы знаете, где найти Solver в Excel, откройте новый рабочий лист и приступим!
Примечание. В примерах, обсуждаемых в этом руководстве, используется Решатель в Excel 2013. Если у вас другая версия Excel, снимки экрана могут не совпадать с вашей версией, хотя функциональность Решателя в основном такая же.
Как использовать Solver в Excel
Перед запуском надстройки Excel Solver сформулируйте модель, которую вы хотите решить, на листе. В этом примере давайте найдем решение следующей простой задачи оптимизации.
Проблема . Предположим, вы владелец салона красоты и планируете предоставить своим клиентам новую услугу.Для этого нужно купить новое оборудование стоимостью 40 000 долларов, которое необходимо оплатить в рассрочку в течение 12 месяцев.
Цель : Рассчитать минимальную стоимость услуги, которая позволит вам оплатить новое оборудование в указанные сроки.
Для этой задачи я создал следующую модель:
А теперь давайте посмотрим, как Excel Solver может найти решение этой проблемы.
1. Запустите Excel Solver
На вкладке Data в группе Analysis нажмите кнопку Solver .
2. Определите проблему
Откроется окно параметров решателя , в котором необходимо настроить 3 основных компонента:
Ячейка объектива
Переменные ячейки
Ограничения
Что именно делает Excel Solver с указанными выше параметрами? Он находит оптимальное значение (максимальное, минимальное или заданное) для формулы в ячейке Цель , изменяя значения в ячейках Переменная и с учетом ограничений в ячейках Ограничения .
Цель
Ячейка Цель (ячейка Цель в более ранних версиях Excel) — это ячейка , содержащая формулу , которая представляет цель или цель проблемы. Целью может быть максимальное, минимальное или достижение некоторого целевого значения.
В этом примере целевой ячейкой является B7, в которой срок платежа рассчитывается по формуле = B3 / (B4 * B5) , а результат формулы должен быть равен 12:
.
Переменные ячейки
Ячейки переменных ( Изменение ячеек или Регулируемые ячейки в более ранних версиях) — это ячейки, которые содержат переменные данные, которые можно изменять для достижения цели.Excel Solver позволяет указать до 200 ячеек переменных.
В этом примере у нас есть пара ячеек, значения которых можно изменять:
Предполагаемое количество клиентов в месяц (B4), которое должно быть меньше или равно 50; и
Стоимость услуги (B5), которую мы хотим, чтобы вычислить Excel Solver.
Наконечник. Если переменные ячейки или диапазоны в вашей модели несмежные , выберите первую ячейку или диапазон, а затем нажмите и удерживайте клавишу Ctrl при выборе других ячеек и / или диапазонов.Или введите диапазоны вручную через запятую.
Ограничения
Excel Solver Ограничения — это ограничения или пределы возможных решений проблемы. Другими словами, ограничения — это условия, которые должны выполняться.
Чтобы добавить ограничение (я), выполните следующие действия:
Нажмите кнопку Добавить справа от поля « с учетом ограничений ».
В окне Ограничение введите ограничение.
Нажмите кнопку Добавить , чтобы добавить ограничение в список.
Продолжайте вводить другие ограничения.
После того, как вы ввели окончательное ограничение, нажмите OK , чтобы вернуться в главное окно Solver Parameters .
Excel Solver позволяет указать следующие отношения между ячейкой, на которую указывает ссылка, и ограничением.
Меньше или равно , равно и больше или равно .Вы устанавливаете эти отношения, выбирая ячейку в поле Ссылка на ячейку , выбирая один из следующих знаков: <= , =, или > = , а затем вводя число, ссылку на ячейку / имя ячейки, или формулу в поле Ограничение (см. снимок экрана выше).
Целое число . Если указанная ячейка должна быть целым числом, выберите int , и слово целое число появится в поле Ограничение .
Разные значения . Если каждая ячейка в указанном диапазоне должна содержать разные значения, выберите dif , и в поле Constraint появится слово AllDifferent .
Двоичный . Если вы хотите ограничить указанную ячейку 0 или 1, выберите bin , и двоичное слово появится в поле Constraint .
Примечание. Отношения int , bin и diff могут использоваться только для ограничений ячеек переменных.
Чтобы изменить или удалить существующее ограничение, выполните следующие действия:
В диалоговом окне Solver Parameters щелкните ограничение.
Чтобы изменить выбранное ограничение, щелкните Изменить и внесите нужные изменения.
Чтобы удалить ограничение, нажмите кнопку Удалить .
В этом примере ограничения:
B3 = 40000 — стоимость нового оборудования 40 000 долларов США.
B4 <= 50 - количество планируемых пациентов в месяц в возрасте до 50 лет.
3. Решаем проблему
После того, как вы настроили все параметры, нажмите кнопку Solve в нижней части окна Solver Parameters (см. Снимок экрана выше) и позвольте надстройке Excel Solver найти оптимальное решение для вашей проблемы.
В зависимости от сложности модели, памяти компьютера и скорости процессора это может занять несколько секунд, несколько минут или даже несколько часов.
Когда Solver завершит обработку, отобразится диалоговое окно Solver Results , в котором вы выбираете Keep the Solver Solution и нажимаете OK :
Окно Solver Result закроется, и решение сразу же появится на рабочем листе.
В этом примере в ячейке B5 отображается 66,67 доллара, что является минимальной стоимостью услуги, которая позволит вам оплатить новое оборудование в течение 12 месяцев при условии, что в месяц есть не менее 50 клиентов:
Советы:
Если программа Excel Solver слишком долго обрабатывала определенную проблему, вы можете прервать процесс, нажав клавишу Esc.Excel пересчитает лист с последними значениями, найденными для ячеек переменной .
Чтобы получить более подробную информацию о решенной проблеме, щелкните тип отчета в поле Отчеты , а затем щелкните ОК . Отчет будет создан на новом листе:
Теперь, когда у вас есть основное представление о том, как использовать Solver в Excel, давайте подробнее рассмотрим еще пару примеров, которые могут помочь вам лучше понять.
Примеры решения Excel
Ниже вы найдете еще два примера использования надстройки Excel Solver.Сначала мы найдем решение известной головоломки, а затем решим реальную задачу линейного программирования.
Excel Solver, пример 1 (магический квадрат)
Я считаю, что все знакомы с головоломками «магический квадрат», в которых вы должны поместить набор чисел в квадрат так, чтобы все строки, столбцы и диагонали в сумме давали определенное число.
Например, знаете ли вы решение для квадрата 3×3, содержащего числа от 1 до 9, где каждая строка, столбец и диагональ в сумме дают 15?
Вероятно, нет ничего страшного в том, чтобы решить эту головоломку методом проб и ошибок, но я уверен, что Решатель найдет решение быстрее.Наша часть работы — правильно определить проблему.
Для начала введите числа от 1 до 9 в таблицу, состоящую из 3 строк и 3 столбцов. Решателю Excel эти числа на самом деле не нужны, но они помогут нам визуализировать проблему. Что действительно нужно надстройке Excel Solver, так это формулы СУММ, суммирующие каждую строку, столбец и 2 диагонали:
После ввода всех формул запустите Solver и настройте следующие параметры:
Комплект Объектив .В этом примере нам не нужно устанавливать какую-либо цель, поэтому оставьте это поле пустым.
Ячейки переменных . Мы хотим заполнить числа в ячейках от B2 до D4, поэтому выберите диапазон B2: D4.
Ограничения . Должны быть соблюдены следующие условия:
$ B $ 2: $ D $ 4 = AllDifferent — все ячейки переменных должны содержать разные значения.
$ B $ 2: $ D $ 4 = целое число — все ячейки переменных должны быть целыми числами.
$ B $ 5: $ D $ 5 = 15 — сумма значений в каждом столбце должна равняться 15.
$ E $ 2: $ E $ 4 = 15 — сумма значений в каждой строке должна равняться 15.
$ B $ 7: $ B $ 8 = 15 — сумма обеих диагоналей должна равняться 15.
Наконец, нажмите кнопку Решить , и решение есть!
Excel Solver, пример 2 (задача линейного программирования)
Это пример простой задачи оптимизации транспортировки с линейной целью. Многие компании используют более сложные модели оптимизации такого типа, чтобы ежегодно экономить тысячи долларов.
Проблема : Вы хотите минимизировать стоимость доставки товаров с 2 разных складов 4 разным покупателям. На каждом складе есть ограниченное предложение, и у каждого покупателя есть определенный спрос.
Цель : Свести к минимуму общую стоимость доставки, не превышая количества, доступного на каждом складе, и удовлетворить потребности каждого клиента.
Исходные данные
Вот как выглядит наша задача по оптимизации перевозок:
Формулировка модели
Чтобы определить нашу задачу линейного программирования для Excel Solver, давайте ответим на 3 основных вопроса:
Какие решения необходимо принять? Мы хотим рассчитать оптимальное количество товаров для доставки каждому покупателю с каждого склада.Это ячеек переменной (B7: E8).
Какие ограничения? Запасы, имеющиеся на каждом складе (I7: I8), не могут быть превышены, и количество, заказанное каждым клиентом (B10: E10), должно быть доставлено. Это ограниченных ячеек.
Какова цель? Минимальная общая стоимость доставки. А это наша ячейка Objective (C12).
Следующее, что вам нужно сделать, это вычислить общее количество, отгруженное с каждого склада (G7: G8), и общее количество товаров, полученных каждым клиентом (B9: E9).Вы можете сделать это с помощью простых формул Sum, показанных на скриншоте ниже. Кроме того, вставьте формулу СУММПРОИЗВ в C12, чтобы рассчитать общую стоимость доставки:
Чтобы упростить понимание нашей модели оптимизации транспортировки, создайте следующие именованные диапазоны:
Название диапазона
Ячейки
Параметр решателя
Отгружено товаров
B7: E8
Переменные ячейки
В наличии
I7: I8
Ограничение
Всего отгружено
G7: G8
Ограничение
Заказано
B10: E10
Ограничение
Всего_получено
B9: E9
Ограничение
Стоимость доставки
C12
Объектив
Последнее, что вам осталось сделать, это настроить параметры Excel Solver:
Цель: Стоимость доставки установлена на Мин.
Ячейки с переменными: Products_shipped
Ограничения: Total_received = Заказано и Total_shipped <= Доступно
Обратите внимание, что в этом примере мы выбрали метод решения Simplex LP , потому что мы имеем дело с задачей линейного программирования.Если вы не уверены, что это за проблема, вы можете оставить метод решения GRG Nonlinear по умолчанию. Дополнительные сведения см. В разделе «Алгоритмы решения Excel».
Решение
Нажмите кнопку Solve внизу окна Solver Parameters , и вы получите свой ответ. В этом примере надстройка Excel Solver рассчитала оптимальное количество товаров для доставки каждому покупателю с каждого склада с минимальной общей стоимостью доставки:
Как сохранять и загружать сценарии Excel Solver
При решении определенной модели вы можете захотеть сохранить значения ячейки Variable в качестве сценария, который вы можете просмотреть или повторно использовать позже.
Например, при расчете минимальной стоимости услуги в самом первом примере, обсуждаемом в этом руководстве, вы можете попробовать разное количество прогнозируемых клиентов в месяц и посмотреть, как это повлияет на стоимость услуги. При этом вы можете сохранить наиболее вероятный сценарий, который вы уже рассчитали, и восстановить его в любой момент.
Сохранение сценария Excel Solver сводится к выбору диапазона ячеек для сохранения данных. Загрузка модели Solver — это просто вопрос предоставления Excel диапазона ячеек, в котором сохраняется ваша модель.Подробные инструкции приведены ниже.
Сохранение модели
Чтобы сохранить сценарий Excel Solver, выполните следующие действия:
Откройте рабочий лист с рассчитанной моделью и запустите Excel Solver.
В окне параметров решателя нажмите кнопку Загрузить / сохранить .
Excel Solver сообщит вам, сколько ячеек необходимо для сохранения вашего сценария. Выделите столько пустых ячеек и нажмите Сохранить :
Excel сохранит вашу текущую модель, которая может выглядеть примерно так:
В то же время появится окно Solver Parameters , где вы можете изменить свои ограничения и попробовать разные варианты «что, если».
Загрузка сохраненной модели
Когда вы решите восстановить сохраненный сценарий, сделайте следующее:
В окне параметров решателя нажмите кнопку Загрузить / сохранить .
На листе выберите диапазон ячеек, содержащих сохраненную модель, и щелкните Загрузить :
В диалоговом окне Загрузить модель нажмите кнопку Заменить :
Откроется главное окно Excel Solver с параметрами ранее сохраненной модели.Все, что вам нужно сделать, это нажать кнопку Решить , чтобы пересчитать его.
Алгоритмы решателя Excel
При определении проблемы для Excel Solver вы можете выбрать один из следующих методов в раскрывающемся списке Выберите метод решения :
ГРГ Нелинейный. Обобщенный нелинейный алгоритм с редуцированным градиентом используется для задач, которые являются гладкими нелинейными, то есть в которых по крайней мере одно из ограничений является гладкой нелинейной функцией переменных решения.Более подробную информацию можно найти здесь.
LP Simplex . Метод Simplex LP Solving основан на алгоритме Simplex, созданном американским ученым-математиком Джорджем Данцигом. Он используется для решения так называемых задач Linear Programming — математических моделей, требования которых характеризуются линейными отношениями, т.е. состоят из единственной цели, представленной линейным уравнением, которое должно быть максимизировано или минимизировано. Для получения дополнительной информации посетите эту страницу.
Эволюционный . Он используется для негладких задач, которые являются наиболее сложным типом задач оптимизации для решения, поскольку некоторые функции негладкие или даже прерывистые, и поэтому трудно определить направление, в котором функция увеличивается или уменьшается. Для получения дополнительной информации посетите эту страницу.
Чтобы изменить способ поиска решения, нажмите кнопку Options в диалоговом окне Solver Parameters и настройте любые или все параметры на вкладках GRG Nonlinear , All Methods и Evolutionary .
Вот как вы можете использовать Solver в Excel, чтобы найти наилучшие решения для ваших проблем принятия решений. А теперь вы можете загрузить примеры решения Excel, обсуждаемые в этом руководстве, и перепроектировать их для лучшего понимания. Благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе.
Трехмерные графики. Анимация — Решение математических задач в Maple
График
поверхности, заданной явной функцией.
График
функции z = f(x, y) можно нарисовать, используя команду plot3d(f(x,y), x=x1…x2, y=y1…y2, options). Параметры этой команды частично совпадают с параметрами команды plot. К
часто используемым параметрам команды plot3d относится light=[angl1,
angl2, c1, c2, c3] – задание подсветки поверхности, создаваемой источником
света из точки со сферическими координатами (angl1, angl2). Цвет
определяется долями красного (c1), зеленого (c2) и синего (c3) цветов, которые находятся в интервале [0,1]. Параметр style=opt задает
стиль рисунка: POINT –точки, LINE – линии, HIDDEN – сетка
с удалением невидимых линий, PATCH – заполнитель (установлен по
умолчанию), WIREFRAME – сетка с выводом невидимых линий, CONTOUR – линии уровня, PATCHCONTOUR – заполнитель и линии уровня. Параметр shading=opt задает функцию интенсивности заполнителя, его значение равно xyz – по
умолчанию, NONE – без раскраски.
В качестве примера построим график функции f=sin(x)+cos(y).
График
поверхности, заданной параметрически.
Если
требуется построить поверхность, заданную параметрически: x=x(u,v), y=y(u,v),
z=z(u,v), то эти функции перечисляются в квадратных скобках в команде: plot3d([x(u,v), y(u,v), z(u,v)], u=u1..u2, v=v1..v2).
График
поверхности, заданной неявно.
Трехмерный
график поверхности, заданной неявно уравнением F(x, y,z) =c, строится с помощью
команды пакета plot: implicitplot3d(F(x,y,z)=c, x=x1..x2, y=y1. 2=4.
График
пространственных кривых.
В пакете
plot имеется команда spacecurve для построения пространственной кривой,
заданной параметрически: x = x(t), y = y(t),z = z(t). Параметры команды:
Maple
позволяет выводить на экран движущиеся изображения с помощью команд animate (двумерные) и animate3d (трехмерные) из пакета plot. Среди параметров
команды animate3d есть frames – число кадров анимации (по
умолчанию frames=8).
Трехмерные изображения
удобнее настраивать не при помощи опций команды plot3d, а используя
контекстное меню программы. Для этого следует щелкнуть правой кнопкой мыши по
изображению. Тогда появится контекстное меню настройки изображения. Команды
этого меню позволяют изменять цвет изображения, режимы подсветки, устанавливать
нужный тип осей, тип линий и управлять движущимся изображением.
Что такое 3D графика?
Вступление
Вопрос о том, что же является двигателем всей компьютерной индустрии, давно заботит многих пользователей. То ли это фирма Intel, которая, не переставая, выпускает и выпускает новые процессоры. Но кто тогда заставляет их покупать? Может, во всем виноват Microsoft, который непрерывно делает свои окна больше и краше? Да нет, можно ведь довольствоваться старыми версиями программ — тем более спектр их возможностей практически не изменяется. Вывод напрашивается сам собой — во всем виноваты игры. Да, именно игры стремятся все более и более уподобиться реальному миру, создавая его виртуальную копию, хотят все более мощных ресурсов.
Вся история компьютерной графики на PC является тому подтверждением. Вспомните, в начале были тетрисы, диггеры, арканоиды. Вся графика заключалась в перерисовке небольших участков экрана, спрайтов, и нормально работала даже на XT. Но прошли те времена. Взошла звезда симуляторов.
С выходом таких игр, как F19, Formula 1 и т. п., в которых приходилось уже перерисовывать весь экран, предварительно заготавливая его в памяти, всем нам пришлось обзавестись, по крайней мере, 286 процессором. Но прогресс на этом не остановился. Желание уподобить виртуальный мир в игре реальному миру усилилось, и появился Wolf 3D.
Это, можно сказать, первая 3D-игра, в которой был смоделирован какой-никакой, но все же реалистичный мир. Для его реализации пришлось использовать верхнюю (более 640 Кб) память и загнать программу в защищенный режим. Для полноценной игры пришлось установить процессор 80386. Но и мир Wolf 3D страдал недостатками. Хотя стены и были не просто одноцветными прямоугольниками, но для их закраски использовались текстуры с небольшим разрешением, поэтому поверхности смотрелись прилично лишь на расстоянии. Конечно, можно было пойти по пути наращивания разрешения текстур, вспомним, например, DOOM. Тогда нам пришлось снова перейти на более новый процессор и увеличить количество памяти. Правда, все равно, хотя изображение и улучшилось, но ему были присущи все те же недостатки. Да и плоские объекты и монстры — кому это интересно. Тут то и взошла звезда Quake. В этой игре был применен революционный подход — z-буфер, позволивший придать объемность всем объектам. Однако вся игра все равно работала в невысоком разрешении и не отличалась высокой реалистичностью.
Назревало новое аппаратное решение. И решение это оказалось, в общем-то, лежащим на поверхности. Раз пользователи хотят играть в трехмерном виртуальном мире, то процесс его создания (вспомним минуты ожидания, проведенные за 3D Studio перед появлением очередной картинки) надо кардинально ускорить. А раз центральный процессор с этой задачей справляется из рук вон плохо, было принято революционное решение — сделать специализированный.
Тут то и вылез производитель игровых автоматов 3Dfx, сделавший эту сказку былью с помощью своего графического процессора Voodoo. Человечество сделало еще один шаг в виртуальный мир.
А поскольку операционной системы на PC с текстурными окнами, уплывающими назад, в туман, пока нет, и не предвидится, весь аппарат трехмерной графики можно пока применить только к играм, что успешно делает все цивилизованное человечество.
Модель
Для изображения трехмерных объектов на экране монитора требуется проведение серии процессов (обычно называемых конвейером) с последующей трансляцией результата в двумерный вид. Первоначально, объект представляется в виде набора точек, или координат, в трехмерном пространстве. Трехмерная система координат определяется тремя осями: горизонтальной, вертикальной и глубины, обычно называемых, соответственно осями x, y и z. Объектом может быть дом, человек, машина, самолет или целый 3D мир и координаты определяют положение вершин (узловых точек), из которых состоит объект, в пространстве. Соединив вершины объекта линиями, мы получим каркасную модель, называемую так из-за того, что видимыми являются только края поверхностей трехмерного тела. Каркасная модель определяет области, составляющие поверхности объекта, которые могут быть заполнены цветом, текстурами и освещаться лучами света.
Рис. 1: Каркасная модель куба
Даже при таком упрощенном объяснении конвейера 3D графики становится ясно, как много требуется вычислений для прорисовки трехмерного объекта на двумерном экране. Можно представить, насколько увеличивается объем требуемых вычислений над системой координат, если объект движется.
Рис. 2: Модель самолета с закрашенными поверхностями
Роль API
Программируемый интерфейс приложений (API) состоит из функций, управляющих 3D конвейером на программном уровне, но при этом может использовать преимущества аппаратной реализации 3D, в случае наличия этой возможности. Если имеется аппаратный ускоритель, API использует его преимущества, если нет, то API работает с оптимальными настройками, рассчитанными на самые обычные системы. Таким образом, благодаря применению API, любое количество программных средств может поддерживаться любым количеством аппаратных 3D ускорителей.
Для приложений общего и развлекательного направления, существуют следующие API:
Microsoft Direct3D
Criterion Renderware
Argonaut BRender
Intel 3DR
Компания Apple продвигает свой собственный интерфейс Rave, созданный на основе их собственного API Quickdraw 3D.
Для профессиональных приложений, работающих под управлением WindowsNT доминирует интерфейс OpenGL. Компания Autodesk, крупнейший производитель инженерных приложений, разработала свой собственный API, называемый Heidi. Свои API разработали и такие компании, как Intergraph — RenderGL, и 3DFX — GLide.
Существование и доступность 3D интерфейсов, поддерживающих множество графических подсистем и приложений, увеличивает потребность в аппаратных ускорителях трехмерной графике, работающих в режиме реального времени. Развлекательные приложения, главный потребитель и заказчик таких ускорителей, но не стоит забывать и о прфессиональных приложениях для обработки 3D графики, работающих под управлением Windows NT, многие из которых переносятся с высокопроизводительных рабочих станций, типа Silicon Graphics, на PC платформу. Интернет приложения сильно выиграют от невероятной маневренности, интуитивности и гибкости, которые обеспечивает применение трехмерного графического интерфейса. Взаимодействие в World Wide Web будет гораздо проще и удобнее, если будет происходить в трехмерном пространстве.
Графический ускоритель
Рынок графических подсистем до появления понятия малтимедиа был относительно прост в развитии. Важной вехой в развитии был стандарт VGA (Video graphics Array), разработанный компанией IBM в 1987 году, благодаря чему производители видеоадаптеров получили возможность использовать более высокое разрешение (640х480) и большую глубину представления цвета на мониторе компьютера. С ростом популярности ОС Windows, появилась острая потребность в аппаратных ускорителях двумерной графики, чтобы разгрузить центральный процессор системы, вынужденный обрабатывать дополнительные события. Отвлечение CPU на обработку графики существенно влияет на общую производительность GUI (Graphical User Interface) — графического интерфеса пользователя, а так как ОС Windows и приложениям для нее требуется как можно больше ресурсов центрального процессора, обработка графики осуществлялась с более низким приоритетом, т.е. делалась очень медленно. Производители добавили в свои продукты функции обработки двумерной графики, такие, как прорисовка окон при открытии и свертовании, аппаратный курсор, постоянно видимый при перемещении указателя, закраска областей на экране при высокой частоте регенерации изображения. Итак, появился процессор, обеспечивающий ускорение VGA (Accelerated VGA — AVGA), также известный, как Windows или GUI ускоритель, который стал обязательным элементом в современных компьютерах.
Внедрение малтимедиа создало новые проблемы, вызванные добавлением таких компонентов, как звук и цифровое видео к набору двумерных графических функций. Сегодня легко заметить, что многие продукты AVGA поддерживают на аппаратном уровне обработку цифрового видео. Следовательно, если на Вашем мониторе видео проигрывается в окне, размером с почтовую марку — пора установить в Вашей машине малтимедиа ускоритель. Малтимедиа ускоритель (multimedia accelerator) обычно имеет встроенные аппаратные функции, позволяющие масштабировать видеоизображение по осям x и y, а также аппаратно преобразовывать цифровой сигнал в аналоговый, для вывода его на монитор в формате RGB. Некоторые малтимедиа акселлераторы могут также иметь встроенные возможности декомпресси цифрового видео.
Разработчики графических подсистем должны исходить из требований, частично диктуемых размерами компьютерного монитора, частично под влиянием GUI, и частично под влиянием графического процессора. Первичный стандарт VGA с разрешением 640х480 пикселов был адекватен 14″ мониторам, наиболее распространенных в то время. Сегодня наиболее предпочтительны мониторы с размером диагонали трубки 17″, благодаря возможности выводить изображения с разрешением 1024х768 и более.
Основной тенденцией при переходе от VGA к малтимедиа ускорителям была возможность размещения как можно больше визуальной информации на мониторе компьютера. Использование 3D графики является логичным развитием этой тенденции. Огроммные объемы визуальной информации могут быть втиснуты в ограниченное пространство экрана монитора, если она представляется в трехмерном виде. Обработка трехмерной графики в режиме реального времени дает возможность пользователю легко оперировать представляемыми данными.
Игровые двигатели (Games engines)
Первое правило компьютерных игр — нет никаких правил. Традиционно, разработчики игр больше заинтересованы в крутой графике своих программ, чем следованию рекомендаций технарей. Не взирая на то, что в распоряжении разработчиков имеется множество трехмерных API, например — Direct3D, некоторые программисты идут по пути создания собственного 3D игрового интерфейса или двигателя. Собственные игровые двигатели — один из путей для разработчиков добиться невероятной реалистичности изображения, фактически на пределе возможностей графического программирования.
Нет ничего более желанного для разработчика, чем иметь прямой доступ к аппаратным функциям компонентов системы. Несколько известных разработчиков создали свои собственные игровые двигатели, работающие с оптимальным использованием аппаратных ускорителей графики, которые принесли им известность и деньги. Например, двигатели Interplay для Descent II и id Software для Quake, обеспечивают истинную трехмерность действия, используя наполную аппаратные функции 3D, если они доступны.
Графика без компромисов
Разговоры, ведущиеся уже довольно долгое время, о перспективах применения трехмерной графики в таких областях, как развлечения и бизнес, допредела подогрели интерес потенциальных пользователей, на рынке уже появился новый тип продуктов. Эти новые технологические решения, совмещают в себе великолепную поддержку 2D графики, соответствующую сегодняшним требованиям к Windows акселлераторам, аппаратную поддержку функций 3D графики и проигрывают цифровое видео с требуемой частотой смены кадров. В принципе, эти продукты можно смело отнести к новому поколению графических подсистем, обеспечивающих графику без компромиссов, занимающих достойное место стандартного оборудования в настольных вычислительных системах. Среди представителей нового поколения можно назвать, в качестве примера, следующие продукты:
процессор Ticket-To-Ride компании Number Nine Visual Technologies
серия процессоров ViRGE компании S3 Inc.
процессор RIVA128, разработанный совместно компаниями SGS Thomson и nVidia
Технология 3D-графики
Пусть нам все-таки удалось убедить Вас попробовать трехмерную графику в действии (если Вы до сих пор не сделали это), и Вы решили сыграть в одну из трехмерных игр, предназначенных для применения 3D-видеокарты. Допустим, такой игрой оказался симулятор автомобильных гонок, и Ваша машина уже стоит на старте, готовая устремиться к покорению новых рекордов. Идет предстартовый обратный отсчет, и Вы замечаете, что вид из кабины, отображаемый на экране монитора, немного отличается от привычного. Вы и прежде участвовали в подобных гонках, но впервые изображение поражает Вас исключительным реализмом, заставляя поверить в действительность происходящего. Горизонт, вместе с удаленными объектами, тонет в утренней дымке. Дорога выглядит необычайно ровно, асфальт представляет собой не набор грязно-серых квадратов, а однотонное покрытие с нанесенной дорожной разметкой. Деревья вдоль дороги действительно имеют лиственные кроны, в которых, кажется, можно различить отдельные листья. От всего экрана в целом складывается впечатление как от качественной фотографии с реальной перспективой, а не как от жалкой попытки смоделировать реальность.
Попробуем разобраться, какие же технические решения позволяют 3D-видеокартам передавать виртуальную действительность с такой реалистичностью. Каким образом изобразительным средствам PC удалось достигнуть уровня профессиональных студий, занимающихся трехмерной графикой.
Часть вычислительных операций, связанных с отображением и моделированием трехмерного мира переложено теперь на 3D-акселератор, который является сердцем 3D-видеокарты. Центральный процессор теперь практически не занят вопросами отображения, образ экрана формирует видеокарта. В основе этого процесса лежит реализация на аппаратном уровне ряда эффектов, а также применение несложного математического аппарата. Попробуем разобраться, что же конкретно умеет графический 3D-процессор.
Возвращаясь к нашему примеру с симулятором гонок, задумаемся, каким образом достигается реалистичность отображения поверхностей дороги или зданий, стоящих на обочине. Для этого применяется распространенный метод, называемый текстурирование (texture mapping). Это самый распространенный эффект для моделирования поверхностей. Например, фасад здания потребовал бы отображения множества граней для моделирования множества кирпичей, окон и дверей. Однако текстура (изображение, накладываемое на всю поверхность сразу) дает больше реализма, но требует меньше вычислительных ресурсов, так как позволяет оперировать со всем фасадом как с единой поверхностью. Перед тем, как поверхности попадают на экран, они текстурируются и затеняются. Все текстуры хранятся в памяти, обычно установленной на видеокарте. Кстати, здесь нельзя не заметить, что применение AGP делает возможным хранение текстур в системной памяти, а ее объем гораздо больше.
Очевидно, что когда поверхности текстурируются, необходим учет перспективы, например, при отображении дороги с разделительной полосой, уходящей за горизонт. Перспективная коррекция необходима для того, чтобы текстурированные объекты выглядели правильно. Она гарантирует, что битмэп правильно наложится на разные части объекта — и те, которые ближе к наблюдателю, и на более далекие. Коррекция с учетом перспективы очень трудоемкая операция, поэтому нередко можно встретить не совсем верную ее реализацию.
При наложении текстур, в принципе, также можно увидеть швы между двумя ближайшими битмэпами. Или, что бывает чаще, в некоторых играх при изображении дороги или длинных коридоров заметно мерцание во время движения. Для подавления этих трудностей применяется фильтрация (обычно Bi- или tri-линейная).
Билинейная фильтрация — метод устранения искажений изображения. При медленном вращении или движении объекта могут быть заметны перескакивания пикселов с одного места на другое, что и вызывает мерцание. Для снижения этого эффекта при билинейной фильтрации для отображения точки поверхности берется взвешенное среднее четырех смежных текстурных пикселов.
Трилинейная фильтрация несколько сложнее. Для получения каждого пиксела изображения берется взвешенное среднее значение результатов двух уровней билинейной фильтрации. Полученное изображение будет еще более четкое и менее мерцающее.
Текстуры, с помощью которых формируется поверхность объекта, изменяют свой вид в зависимости от изменения расстояния от объекта до положения глаз зрителя. При движущемся изображении, например, по мере того, как объект удаляется от зрителя, текстурный битмэп должен уменьшаться в размерах вместе с уменьшением размера отображаемого объекта. Для того чтобы выполнить это преобразование, графический процессор преобразует битмэпы текстур вплоть до соответствующего размера для покрытия поверхности объекта, но при этом изображение должно оставаться естественным, т.е. объект не должен деформироваться непредвиденным образом.
Для того, чтобы избежать непредвиденных изменений, большинство управляющих графикой процессов создают серии предфильтрованных битмэпов текстур с уменьшенным разрешением, этот процесс называется mip mapping. Затем, графическая программа автоматически определяет, какую текстуру использовать, основываясь на деталях изображения, которое уже выведено на экран. Соответственно, если объект уменьшается в размерах, размер его текстурного битмэпа тоже уменьшается.
Но вернемся в наш гоночный автомобиль. Сама дорога уже выглядит реалистично, но проблемы наблюдаются с ее краями! Вспомните, как выглядит линия, проведенная на экране не параллельно его краю. Вот и у нашей дороги появляются «рваные края». И для борьбы с этим недостатком изображения применяется anti-aliasing.
Рваные края
Ровные края
Это способ обработки (интерполяции) пикселов для получения более четких краев (границ) изображения (объекта). Наиболее часто используемая техника — создание плавного перехода от цвета линии или края к цвету фона. Цвет точки, лежащей на границе объектов определяется как среднее цветов двух граничных точек. Однако в некоторых случаях, побочным эффектом anti-aliasing является смазывание (blurring) краев.
Мы подходим к ключевому моменту функционирования всех 3D-алгоритмов. Предположим, что трек, по которому ездит наша гоночная машина, окружен большим количеством разнообразных объектов — строений, деревьев, людей. Тут перед 3D-процессором встает главная проблема, как определить, какие из объектов находятся в области видимости, и как они освещены. Причем, знать, что видимо в данный момент, недостаточно. Необходимо иметь информацию и о взаимном расположении объектов. Для решения этой задачи применяется метод, называемый z-буферизация. Это самый надежный метод удаления скрытых поверхностей. В так называемом z-буфере хранятся значения глубины всех пикселей (z-координаты). Когда рассчитывается (рендерится) новый пиксел, его глубина сравнивается со значениями, хранимыми в z-буфере, а конкретнее с глубинами уже срендеренных пикселов с теми же координатами x и y. Если новый пиксел имеет значение глубины больше какого-либо значения в z-буфере, новый пиксел не записывается в буфер для отображения, если меньше — то записывается.
Z-буферизация при аппаратной реализации сильно увеличивает производительность. Тем не менее, z-буфер занимает большие объемы памяти: например даже при разрешении 640×480 24-разрядный z-буфер будет занимать около 900 Кб. Эта память должна быть также установлена на 3D-видеокарте.
Разрешающая способность z-буфера — самый главный его атрибут. Она критична для высококачественного отображения сцен с большой глубиной. Чем выше разрешающая способность, тем выше дискретность z-координат и точнее выполняется рендеринг удаленных объектов. Если при рендеринге разрешающей способности не хватает, то может случиться, что два перекрывающихся объекта получат одну и ту же координату z, в результате аппаратура не будет знать какой объект ближе к наблюдателю, что может вызвать искажение изображения. Для избежания этих эффектов профессиональные платы имеют 32-разрядный z-буфер и оборудуются большими объемами памяти.
Кроме вышеперечисленных основ, трехмерные графические платы обычно имеют возможность воспроизведения некоторого количества дополнительных функций. Например, если бы Вы на своем гоночном автомобиле въехали бы в песок, то обзор бы затруднился поднявшейся пылью. Для реализации таких и подобных эффектов применяется fogging (затуманивание). Этот эффект образуется за счет комбинирования смешанных компьютерных цветовых пикселов с цветом тумана (fog) под управлением функции, определяющей глубину затуманивания. С помощью этого же алгоритма далеко отстоящие объекты погружаются в дымку, создавая иллюзию расстояния.
Реальный мир состоит из прозрачных, полупрозрачных и непрозрачных объектов. Для учета этого обстоятельства, применяется alpha blending — способ передачи информации о прозрачности полупрозрачных объектов. Эффект полупрозрачности создается путем объединения цвета исходного пиксела с пикселом, уже находящимся в буфере. В результате цвет точки является комбинацией цветов переднего и заднего плана. Обычно, коэффициент alpha имеет нормализованное значение от 0 до 1 для каждого цветного пиксела. Новый пиксел = (alpha)(цвет пиксела А) + (1 — alpha)(цвет пиксела В).
Очевидно, что для создания реалистичной картины происходящего на экране необходимо частое обновление его содержимого. При формировании каждого следующего кадра, 3D-акселератор проходит весь путь подсчета заново, поэтому он должен обладать немалым быстродействием. Но в 3D-графике применяются и другие методы придания плавности движению. Ключевой — Double Buffering. Представьте себе старый трюк аниматоров, рисовавших на уголках стопки бумаги персонаж мультика, со слегка изменяемым положением на каждом следующем листе. Пролистав всю стопку, отгибая уголок, мы увидим плавное движение нашего героя. Практически такой же принцип работы имеет и Double Buffering в 3D анимации, т.е. следующее положение персонажа уже нарисовано, до того, как текущая страница будет пролистана. Без применения двойной буферизации изображение не будет иметь требуемой плавности, т.е. будет прерывистым. Для двойной буферизации требуется наличие двух областей, зарезервированных в буфере кадров трехмерной графической платы; обе области должны соответствовать размеру изображения, выводимого на экран. Метод использует два буфера для получения изображения: один для отображения картинки, другой для рендеринга. В то время как отображается содержимое одного буфера, в другом происходит рендеринг. Когда очередной кадр обработан, буфера переключаются (меняются местами). Таким образом, играющий все время видит отличную картинку.
В заключение обсуждения алгоритмов, применяемых в 3D-графических акселераторах, попробуем разобраться, каким же образом применение всех эффектов по отдельности позволяет получить целостную картину. 3D-графика реализуется с помощью многоступенчатого механизма, называемого конвейером рендеринга. Применение конвейерной обработки позволяет еще ускорить выполнение расчетов за счет того, что вычисления для следующего объекта могут быть начаты до окончания вычислений предыдущего.
Конвейер рендеринга может быть разделен на 2 стадии: геометрическая обработка и растеризация.
На первой стадии геометрической обработки выполняется преобразование координат (вращение, перенос и масштабирование всех объектов), отсечение невидимых частей объектов, расчет освещения, определение цвета каждой вершины с учетом всех световых источников и процесс деления изображения на более мелкие формы. Для описания характера поверхности объекта она делится на всевозможные многоугольники. Наиболее часто при отображении графических объектов используется деление на треугольники и четырехугольники, так как они легче всего обсчитываются и ими легко манипулировать. При этом координаты объектов переводятся из вещественного в целочисленное представление для ускорения вычислений.
На второй стадии к изображению применяются все описанные эффекты в следующей последовательности: удаление скрытых поверхностей, наложение с учетом перспективы текстур (используя z-буфер), применение эффектов тумана и полупрозрачности, anti-aliasing. После этого очередная точка считается готовой к помещению в буфер со следующего кадра.
Из всего вышеуказанного можно понять, для каких целей используется память, установленная на плате 3D-акселератора. В ней хранятся текстуры, z-буфер и буфера следующего кадра. При использовании шины PCI, использовать для этих целей обычную оперативную память нельзя, так как быстродействие видеокарты существенно будет ограничено пропускной способностью шины. Именно по этому для развития 3D-графики особенно перспективно продвижение шины AGP, позволяющее соединить 3D-чип с процессором напрямую и тем самым организовать быстрый обмен данными с оперативной памятью. Это решение, к тому же, должно удешевить трехмерные акселераторы за счет того, что на борту платы останется лишь немного памяти собственно для кадрового буфера.
Заключение
Повсеместное внедрение 3D-графики вызвало увеличение мощности компьютеров без какого-либо существенного увеличения их цены. Пользователи ошеломлены открывающимися возможностями и стремятся попробовать их у себя на компьютерах. Множество новых 3D-карт позволяют пользователям видеть трехмерную графику в реальном времени на своих домашних компьютерах. Эти новые акселераторы позволяют добавлять реализм к изображениям и ускорять вывод графики в обход центрального процессора, опираясь на собственные аппаратные возможности.
Хотя в настоящее время трехмерные возможности используются только в играх, думается, деловые приложения также смогут впоследствии извлечь из них выгоду. Например, средства автоматизированного проектирования уже нуждаются в выводе трехмерных объектов. Теперь создание и проектирование будет возможно и на персональном компьютере благодаря открывающимся возможностям. Трехмерная графика, возможно, сможет также изменить способ взаимодействия человека с компьютером. Использование трехмерных интерфейсов программ должно сделать процесс общения с компьютером еще более простым, чем в настоящее время.
При подготовке материала использовалась информация из Diamond White Papers
Что такое 3D-графика – База знаний Timeweb Community
Под понятие 3D-графики можно отнести двухмерные изображения с элементами объема, который придается за счет работы с освещением и другими элементами, создающими на экране визуальную иллюзию. Еще к 3D-графике относятся полноценные трехмерные модели, создаваемые в специальных программах и применяемые в играх, кинематографе и мультипликации.
Далее я предлагаю детальнее остановиться на этом типе графики, разобраться во всех ее тонкостях, характеристиках и принципах создания при помощи современных технологий.
Что такое 3D-изображение
Для начала остановимся на 3D-изображениях и поймем, что вообще делает их трехмерными и какие типы картинок можно отнести к этой категории. Если при просмотре изображения вы можете описать ширину и высоту, но не наблюдаете глубины, значит, это двухмерная графика. Значки на рабочем столе и указатели на улицах – все это относится к 2D-графике (за некоторым исключением, когда художник использует тень или другие приемы, чтобы сделать картинку объемной). 3D-изображение обязательно обладает глубиной, то есть является объемным. Простой пример такой графики вы видите на следующем изображении:
Если нарисовать квадрат, представив только основные его четыре линии, это будет двухмерная модель. Но если немного повернуть квадрат, дорисовать грани и вершины, получится куб, являющийся объемным элементом, а значит, к нему относится характеристика 3D-модели.
История развития 3D
Полноценное представление 3D-элементов на экране мир увидел в короткометражном фильме «A Computer Animated Hand», вышедшем в 1972 году. На скриншоте ниже вы видите то, как аниматоры смогли спроектировать человеческую руку и анимировать ее на экране.
Это дало сильный толчок в развитии анимационных технологий и применении подобных эффектов в кинематографе. Одним из первых фильмов, в котором зритель мог увидеть анимацию человеческого лица, считается «Futureworld», вышедший в 1976 году. Сразу после этого трехмерная графика начала прогрессировать очень быстро. Появились специальные программы, кинокомпании стали набирать сотрудников соответствующих должностей и реализовывали самые разные эффекты в своих проектах. Обладатели персональных компьютеров уже в начале 80-х годов могли скачать программу под названием 3D Art Graphics, которая включала в себя набор различных трехмерных объектов и эффектов.
Создание трехмерной графики
Как же работает трехмерная графика на компьютерах и на какие этапы делится ее создание?
3D-моделирование. На компьютере создается модель, в точности передающая форму объекта, который нужно представить. Это может быть любой предмет, животное или человек. В общем, все, что нас окружает. Существует несколько видов трехмерного моделирования, каждый из которых имеет свои особенности и принципы, но сейчас не будем вдаваться в эту тему. Если хотите, можете ознакомиться с такими программами, как Blender или 3Ds Max, чтобы узнать, как трехмерные объекты рисуются при помощи программ.
Сценарий и анимация. Модели всегда размещены на сцене и необходимы для выполнения определенного действия: перемещения, разрушения или передачи любого другого эффекта. Для расположения объектов на сцене и их анимирования может использоваться та же программа, которая применялась и для моделирования, но иногда разработчики обращаются к другому софту. Анимации тоже бывают разными, например, сейчас особо популярен захват движения (когда программа считывает движения человека и передает их на трехмерную фигуру).
Рендеринг. Завершающий процесс работы над проектом. Подразумевает обработку цветов, типов поверхности, освещения и всех других параметров сцены. Для обработки необходим мощный компьютер, способный быстро считывать кадры и выдавать на экран необходимый результат.
3D-моделирование
В рамках этой статьи остановимся только на 3D-моделировании, поскольку именно этот процесс и является основной трехмерной графики. Вы уже знаете, что для выполнения данной операции используется специальный софт. Аниматор может взаимодействовать как с отдельными геометрическими фигурами и точками, преобразовывая их в необходимый объект, так и с одной болванкой, доводя ее до необходимой формы (как скульптор в реальной жизни).
Изначально модель имеет серый цвет, поэтому обязательным этапом является наложение текстур и материалов. В крупных компаниях этим занимается специально обученный человек, получивший заготовку от 3D-моделировщика. Он по эскизам или специальным шаблонам накладывает на модель различные элементы, имитирующие волосы, ткань или типы поверхностей. Это и делает 3D-модель похожей на настоящую.
Тему можно развивать бесконечно, поскольку 3D-графика обладает огромным множеством интересных особенностей, которые делают индустрию такой сложной и высокооплачиваемой. Кинокомпании тратят миллионы долларов на создание моделей и эффектов, которые в реальной жизни повторить проблематично и еще более затратно. Сейчас при помощи 3D-графики создаются практически все современные игры и мультфильмы.
Построение графиков — Sage Tutorial in Russian v9.3
Sage может строить двумерные и трехмерные графики.
Двумерные графики
В двумерном пространстве Sage может отрисовывать круги, линии и
многоугольники; графики функций в декартовых координатах; также графики
в полярных координатах, контурные графики и изображения векторных полей.
Некоторые примеры будут показаны ниже. Для более исчерпывающей информации
по построению графиков см. Решение дифференциальных уравнений и Maxima,
а также документацию
Sage Constructions.
Данная команда построит желтую окружность радиуса 1 с центром в начале:
Можно создавать окружность и задавать ее какой-либо переменной.
Данный пример не будет строить окружность:
sage: c = circle((0,0), 1, rgbcolor=(1,1,0))
Чтобы построить ее, используйте c.show() или show(c):
c.save('filename.png') сохранит график в файл.
Теперь эти „окружности“ больше похожи на эллипсы, так как оси имеют
разный масштаб. Это можно исправить следующим образом:
sage: c.show(aspect_ratio=1)
Команда show(c, aspect_ratio=1) выполнит то же самое. Сохранить
картинку можно с помощью c.save('filename.png', aspect_ratio=1).
Строить графики базовых функций легко:
sage: plot(cos, (-5,5))
Graphics object consisting of 1 graphics primitive
Как только имя переменной определено, можно создать параметрический график:
sage: x = var('x')
sage: parametric_plot((cos(x),sin(x)^3),(x,0,2*pi),rgbcolor=hue(0. 3),(x,0,2*pi),rgbcolor=hue(0.6))
sage: show(p1+p2+p3, axes=false)
Хороший способ создания заполненных фигур — создание списка точек (L в следующем примере), а затем использование команды polygon для
построения фигуры с границами, образованными заданными точками. К
примеру, создадим зеленый дельтоид:
sage: L = [[-1+cos(pi*i/100)*(1+cos(pi*i/100)),
....: 2*sin(pi*i/100)*(1-cos(pi*i/100))] for i in range(200)]
sage: p = polygon(L, rgbcolor=(1/8,3/4,1/2))
sage: p
Graphics object consisting of 1 graphics primitive
Напечатайте show(p, axes=false), чтобы не показывать осей на графике.
Можно добавить текст на график:
sage: L = [[6*cos(pi*i/100)+5*cos((6/2)*pi*i/100),
....: 6*sin(pi*i/100)-5*sin((6/2)*pi*i/100)] for i in range(200)]
sage: p = polygon(L, rgbcolor=(1/8,1/4,1/2))
sage: t = text("hypotrochoid", (5,4), rgbcolor=(1,0,0))
sage: show(p+t)
Учителя математики часто рисуют следующий график на доске: не одну
ветвь arcsin, а несколько, т. е. график функции \(y=\sin(x)\)
для \(x\) между \(-2\pi\) и \(2\pi\), перевернутый по
отношению к линии в 45 градусов. Следующая команда Sage построит
вышеуказанное:
sage: v = [(sin(x),x) for x in srange(-2*float(pi),2*float(pi),0.1)]
sage: line(v)
Graphics object consisting of 1 graphics primitive
Так как функция тангенса имеет больший интервал, чем синус, при
использовании той же техники для перевертывания тангенса требуется
изменить минимальное и максимальное значения координат для оси x:
sage: v = [(tan(x),x) for x in srange(-2*float(pi),2*float(pi),0.01)]
sage: show(line(v), xmin=-20, xmax=20)
Sage также может строить графики в полярных координатах, контурные
построения и изображения векторных полей (для специальных видов функций).
Далее следует пример контурного чертежа:
sage: f = lambda x,y: cos(x*y)
sage: contour_plot(f, (-4, 4), (-4, 4))
Graphics object consisting of 1 graphics primitive
Трехмерные графики
Sage также может быть использован для создания трехмерных графиков. 2 — 1)
sage: implicit_plot3d(f, (x, -0.5, 0.5), (y, -1, 1), (z, -1, 1))
Graphics3d Object
3D графика — основа 3Д графики лежит геометрическая проекция отличием от 2Д
3D графика — разработка и создание 3д дизайна
3D графика «трехмерная графика» — это особая разновидность компьютерной графики, предназначенная для созданий трехмерных моделей. В их основе лежит геометрическая проекция, которая выступает ключевым отличием между 3D и 2D. Создание геометрической проекции сопровождается использованием специализированного программного обеспечения. Конечным результатом выступает высокоточная копия реального объекта.
Наша компания предлагает комплексные услуги по разработке 3D графики и дизайну с использованием современного технического оснащения. Специалисты руководствуются полученным опытом и знаниями. Регулярное повышение квалификации позволяет справиться с задачами любой сложности.
Разработка 3D графики
Разработка 3D графики осуществляется в несколько последовательных этапов. От правильного соблюдения установленного алгоритма зависит качество конечного результата. Специалисты нашей компании проводят комплексную работу по разработке 3D графики в несколько этапов:
Оценка проекта — специалисты занимаются изучением предоставленного материала, объема работ
Старт проекта — после согласования основных этапов, а также обсуждения финансовых вопросов, специалисты приступают к реализации проекта
Выполнение работ — основная часть осуществляется в специальных программах, где дизайнер делает основные наброски. После утверждения подходящего варианта, он дорабатывается до совершенства
Закрытие проекта — на данном этапе клиент получает готовый заказ
Специалисты компании «МирСео24» работают по-готовому техническому заданию «ТЗ», что исключает развитие непредвиденных ситуаций. Все этапы разработки с указанием общей стоимости содержаться в договоре, который подписывается между клиентом и исполнителем.
Технологии применения 3D графики
Технологии применения 3D графики необходимы во многих сферах жизни человека. Примечательно, что они доставляют визуальное наслаждение, и при этом приносят реальную прибыль. Встретить трехмерные изображения можно на телевидение, в кино, в играх, на рекламных щитах и т.д. Современная 3D графика, это:
3D графика в видеофильмах и мультфильмах — все персонажи, а также реалистичные спецэффекты создаются с помощью комплексной работы по разработке и созданию 3D графики в специальных 3D программных обеспечениях.
3D графика рекламных объектов — способности графики неисчерпаемы, благодаря уникальной модели можно создать рекламу продукта, и тем самым, побудить клиента к его приобретению
3D графический дизайн интерьеров — перед укладкой плитки или поклейкой обоев, клиент желает увидеть 3D модель и расставить все объекты согласно собственным предпочтениям. Сегодня, такая услуга предоставляется во всех строительных и мебельных магазинах
В скором времени, графика затронет и другие сферы жизни и станет неотъемлемой частью повседневной рутины. А пока, остается лишь заказывать качественный визуал и тем самым повышать узнаваемость бренда!
Образец 3D модели «Задвижка» «Autodesk 3ds Max 2020»
Образец 3D модели «Музыкальный центр» «Autodesk 3ds Max 2020»
Образец 3D модели «Червяк испанский» «Autodesk 3ds Max 2020»
Создание 3D графики
Наша компания специализируется на создании 3D графики для любых сфер жизни. Веб дизайнеры проводят разработку по созданию 3D графики любого объекта с использованием современного технического оснащения. В основе создания уникальной модели лежат следующие этапы:
3D Моделирование — модель будущего объекта создается в специальном редакторе. Наиболее продвинутыми программами являются 3Ds Max и Adobe After Effects
Текстурирование — на данном этапе осуществляется наложение текстур на ранее разработанную модель. Дополнением выступает настройка материалов и придание моделям реалистичности
Освещение — на данном этапе создается и устанавливается направление и настройка источников освещения. Это действие осуществляется в графических редакторах, с использованием установленных источников света
3D Анимация — движущие объекты подчеркивают реалистичность любой модели. Создание анимации осуществляется в современных редакторах, оснащенных множеством инструментов
Рендеринг — на заключительном этапе трехмерная модель проходит через процесс преобразования. Итогом работы является «плоское» изображение
Описанные этапы разработки являются ключевыми, они следуют друг за другом в четко установленной последовательности.
Интересны услуги по созданию 3D графики Оформляйте заказ на официальной странице компании «МирСео24». Консультации и квалифицированная помощь предоставляются на бесплатной основе.
Видео пример 3D модели «Задвижка»
Видео пример 3D модели «Музыкальный центр»
Видео пример 3D модели «Червяк испанский»
Виды 3D графики
Существует несколько разновидностей 3D моделирования. Наиболее востребованными вариантами выступают: полигональное и сплайновое.
Полигональное моделирование — полигональный вид 3D графики появился несколько десятков лет назад. На тот момент для создания объемной модели приходилось вручную вводить координаты по осям. Это значительно увеличивало длительность работы и отражалось на корректности конечного результата.
В основе полигонального вида лежит использование трех или четырех вершин, в зависимости от требуемого результата. Большинство изображений созданы посредством трех вершин. Для каждого полигона характерен определенный оттенок и текстура. Все полигоны соединяются между собой, создавая тем самым полигональную сетку или объект. При необходимости дальнейшего увеличения объекта необходимо заранее создавать несколько полигонов.
Методика полигонального моделирования используется повсеместно, особенно для создания компьютерных игр.
Сплайновое моделирование — в основе сплайнового моделирования лежит использование специальных сплайнов. Их линии задаются посредством трехмерного набора контрольных точек, которые и определяют гладкость кривой. Все сплайны подводятся к сплайновому каркасу, на основе которого в дальнейшем создается огибающая трехмерная геометрическая поверхность.
Указанная методика моделирования используется повсеместно, для создания персонажей игр, моделей для рекламных компаний, персонажей фильмов и мультфильмов.
Услуги по созданию и разработке 3D графики
Наша компания предоставляет комплексные услуги по созданию и разработке 3D графики. Специалисты оказывают качественный сервис по объемному моделированию для заказчиков из любой сферы деятельности. Полный спектр услуг по разработке 3D графики включает:
Подготовка 3D модели, которая будет полностью оптимизирована под требования потенциального заказчика (с учетом конечной цели)
Создание трехмерной модели с последующей печатью объекта
Проведение консультаций относительно последующей реализации и процесса подготовки
Специалисты работают по установленному алгоритму, начиная с момента проектирования и заканчивая полной сдачей объекта. Услуги по моделированию решают ряд задач клиентов:
демонстрация заказа в реалистичном виде (для застройщиков)
наглядная презентация коммерческой недвижимости (для арендодателей)
яркие презентации с целью реализации продукта/услуги (для маркетинга и рекламных компаний)
Виртуальная проекция позволяет увидеть ошибки и объективно оценить конечный результат. Это качественный инструмент, который является визуалом любого бизнеса. Для оформления услуг по 3D графике, звоните по указанным номерам телефонов или обращайтесь через форму обратной связи.
Программное обеспечение для создания 3D графики
Моделирование сопровождается использованием установленного программного обеспечения. Для получения броской трехмерной графики используются различные коммерческие продукты, в частности:
Autodesk 3ds Max
Autodesk Maya
Autodesk Softimage
Blender
Наша компания активно использует несколько программ среди которых две программы считаются самыми приоритетными: «Autodesk 3ds Max 2020» и специальный плагин «3D Element» для популярной программы по созданию видео и видео эффектов «Adobe After Effects». Программа 3Ds Max используется во многих сферах, в частности:
визуализация объектов
дизайн интерьера
3D моделирование
Профильный 3Д дизайн
Рекламная анимация
3D анимация
3D WEB-дизайн
Компьютерная графика
Программа действительно многопрофильная, и указанными сферами использования не ограничивается. В 3Ds Max можно свободно создать фотореалистичную трехмерную модель. Разнообразный инструментарий позволяет разрабатывать уникальные объекты. Посредством анализа и настройки освещенности они обретают новые очертания и «оживают». Благодаря встроенному фотореалистичному визуализатору удалось добиться высокого уровня правдоподобности.
Ключевое достоинство программы – возможность установления дополнительных плагинов, что благотворно отражается на количестве инструментов и значительно расширяет стандартные возможности. 3Ds Max позволяет гибко управлять частицами, а также создавать разнообразные эффекты.
3D Element специальный плагин для Adobe After Effects – это универсальная программа (плагин — «plugin»), которая пользуется не меньшей популярностью. Главное достоинство – возможность редактирования любого видео, создание визуальных эффектов и анимации любой сложности. Программу часто используются в кинематографе для создания постпродакшна. Более того, она свободно функционирует как обычный редактор нелинейного типа, звуковой редактор и транскодер. Посредством программного обеспечения можно создавать модели с несколькими слоями в трехмерном пространстве.
Примечательно, что несмотря на расширенный функционал, программа очень простая в работе. Но при этом она позволяет создавать нереальные модели, подобий которым не существует.
Требуется качественный визуал? Планируете создание уникальных 3D моделей? Обращайтесь за помощью к специалистам компании «МирСео24».
Мы гарантируем комплексный подход и быстрое решение задач любой сложности.
Стоимость услуг по созданию 3D графики
Интересует стоимость услуг по созданию 3D графики? Фиксированный прайс-лист представлен на официальной странице компании «МирСео24». Но, стоимость способна варьироваться в зависимости от сложности графики и установленных сроков. На конечную цену влияют:
Сложность объекта
Наличие дополнительной анимации
Наличие дополнительных спецэффектов
Сроки выполнения
Проконсультироваться по любым вопросам вы можете по указанным номерам телефонов. Звоните прямо сейчас и получайте бесплатный расчет прямо сейчас!
Matplotlib. Урок 5. Построение 3D графиков. Работа с mplot3d Toolkit
До этого момента все графики, которые мы строили были двумерные, Matplotlib позволяет строить 3D графики. Этой теме посвящен данный урок.
Импортируем необходимые модули для работы с 3D:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
В библиотеке доступны инструменты для построения различных типов графиков. Рассмотрим некоторые из них более подробно.
Линейный график
Для построения линейного графика используется функция plot().
z координаты. Если передан скаляр, то он будет присвоен всем точкам графика.
zdir: {‘x’, ‘y’, ‘z’}
Определяет ось, которая будет принята за z направление, значение по умолчанию: ‘z’.
**kwargs
Дополнительные аргументы, аналогичные тем, что используются в функции plot() для построения двумерных графиков.
x = np.linspace(-np.pi, np.pi, 50)
y = x
z = np.cos(x)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot(x, y, z, label='parametric curve')
Точечный график
Для построения точечного графика используется функция scatter().
Координаты точек по оси z. Если передан скаляр, то он будет присвоен всем точкам графика. Значение по умолчанию: 0.
zdir: {‘x’, ‘y’, ‘z’, ‘-x’, ‘-y’, ‘-z’}, optional
Определяет ось, которая будет принята за z направление, значение по умолчанию: ‘z’
s: скаляр или массив, optional
Размер маркера. Значение по умолчанию: 20.
c: color, массив, массив значений цвета, optional
Цвет маркера. Возможные значения:
Строковое значение цвета для всех маркеров.
Массив строковых значений цвета.
Массив чисел, которые могут быть отображены в цвета через функции cmap и norm.
2D массив, элементами которого являются RGB или RGBA.
depthshade: bool, optional
Затенение маркеров для придания эффекта глубины.
**kwargs
Дополнительные аргументы, аналогичные тем, что используются в функции scatter() для построения двумерных графиков.
np.random.seed(123)
x = np.random.randint(-5, 5, 40)
y = np.random.randint(0, 10, 40)
z = np.random.randint(-5, 5, 40)
s = np.random.randint(10, 100, 20)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z, s=s)
Каркасная поверхность
Для построения каркасной поверхности используется функция plot_wireframe().
plot_wireframe(self, X, Y, Z, *args, **kwargs)
X, Y, Z: 2D массивы
Данные для построения поверхности.
rcount, ccount: int
Максимальное количество элементов каркаса, которое будет использовано в каждом из направлений. Значение по умолчанию: 50.
rstride, cstride: int
Параметры определяют величину шага, с которым будут браться элементы строки / столбца из переданных массивов. Параметры rstride, cstride и rcount, ccount являются взаимоисключающими.
**kwargs
Дополнительные аргументы, определяемые Line3DCollection.
u, v = np.mgrid[0:2*np.pi:20j, 0:np.pi:10j]
x = np.cos(u)*np.sin(v)
y = np.sin(u)*np.sin(v)
z = np.cos(v)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z)
ax.legend()
Поверхность
Для построения поверхности используйте функцию plot_surface().
plot_surface(self, X, Y, Z, *args, norm=None, vmin=None, vmax=None, lightsource=None, **kwargs)
X, Y, Z : 2D массивы
Данные для построения поверхности.
rcount, ccount : int
rstride, cstride : int
color: color
Цвет для элементов поверхности.
cmap: Colormap
Colormap для элементов поверхности.
facecolors: массив элементов color
Индивидуальный цвет для каждого элемента поверхности.
norm: Normalize
Нормализация для colormap.
vmin, vmax: float
Границы нормализации.
shade: bool
Использование тени для facecolors. Значение по умолчанию: True.
lightsource: LightSource
Объект класса LightSource – определяет источник света, используется, только если shade = True.
**kwargs
Дополнительные аргументы, определяемые Poly3DCollection.
u, v = np.mgrid[0:2*np.pi:20j, 0:np.pi:10j]
x = np.cos(u)*np.sin(v)
y = np.sin(u)*np.sin(v)
z = np.cos(v)
fig = plt.figure()
ax = fig. add_subplot(111, projection='3d')
ax.plot_surface(x, y, z, cmap='inferno')
ax.legend()
P.S.
Вводные уроки по “Линейной алгебре на Python” вы можете найти соответствующей странице нашего сайта. Все уроки по этой теме собраны в книге “Линейная алгебра на Python”.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. Для начала вы можете познакомиться с вводными уроками. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Использование 3D-графики в 2D-анимации — Кино и сериалы на DTF
В 2D мультипликации уже давно применяется 3D графика. Иногда это практически незаметно, иногда бьет по глазам. Знали ли вы, что диснеевская «Принцесса и лягушка» и короткометражка от этой же студии «Paperman» созданы с применением компьютерной графики? Даже в фильмах студии Гибли используются 3D-технологии!
1604 просмотров
3D технологии в Paperman
Для чего совмещать 2D и 3D
Есть ряд причин, прагматических и эстетических.
Во-первых, экономия. 2D-анимация — дорогостоящий и трудоемкий процесс. Анимировать некоторые сцены в 3D дешевле — например, сделать окружение или массовку.
Во-вторых, ускорение и упрощение процесса. Это связано с первой причиной: чем больше времени и сил аниматоров затрачено, тем дороже мультфильм. Многие рутинные операции можно автоматизировать. Например, морфинг, где программа сама отрисовывает промежуточные кадры.
В «Принцессе Мононоке» при помощи 3D были созданы некоторые бэкграунды. На CG модель местности «натянули» вручную нарисованные кадры.
Фон здесь создан при помощи 3D
CG позволяет создавать особо сложные сцены. 3D-анимация дает более точные ощущения пространства и объема. рисование разных углов конкретного объекта в 2D-областях может быть сложным и трудоемким по сравнению с 3D-моделями.
Освещение и перспективу, требующие сложных расчетов, тоже часто делают с применением 3D-технологий.
Освещение в «Клаусе» создано при помощи 3D
В каких сценах применяют 3D-графику
Окружение и задники. Нередко окружение моделируют в 3D, а персонажей в 2D. Это позволяет не рисовать огромное количество ракурсов одной локации, а просто перемещать по ней камеру.
Пример 3D окружения
Миядзаки и сотрудники Studio Ghibli давно (начиная с «Принцессы Мононоке») экспериментируют с компьютерной анимацией. Они использовали Softimage 3D при создании задних планов, сцен с движущейся камерой в «Унесенных призраками» и «Ходячем замке». Компьютерная анимация в 2D-фильмах Гибли применяется с большой осторожностью, чтобы не разрушить магию традиционной анимации.
Работа с софтом при создании Ходячего замка
Динамичные сцены. Помните в диснеевском «Тарзане» сцену, где Тарзан скользит по лианам? Она выполнена при помощи технологии «виртуальной съемки». Аниматоры создавали виртуальную съемочную площадку, которую можно было крутить, как угодно. Камеры выписывали виражи, как в игровом кино, что придавало динамики. Эта сцена до сих пор выглядит впечатляюще.
Транспорт и техника, фоновые объекты. Часто в 2D-анимации используют метод импорта 3D-объектов. Это помогает при рисовании автомобилей и сложной техники в перспективе. Модель рендерят (в программах типа Toon Boom это делается автоматически), и так она более органично вписывается в 2D-сцену. В «Ходячем замке» сам замок и некоторые его интерьеры были созданы в 3D и анимированы в Softimage.
Массовка. В сценах, где есть массовка, прорисовывать каждую фигуру в толпе — лишняя трата сил и средств. Во многих проектах массовку создают в 3D. Анимируют одну или несколько моделек и клонируют. Этим приемом пользовались, например, в диснеевском «Горбуне из Нотр-Дама», где многие сцены показывают толпу. Тем же методом сделана массовка в «Мулан».
Присмотритесь к массовке: это 3D
Освещение. В мультфильме «Клаус» при помощи 3D-технологий выстроено освещение. Для этого был создан специальный инструмент под названием «Клаус Свет и Тень».
Движение камеры. Создав сцену в 3D, можно перемещать камеру по этой сцене и масштабировать, что существенно упрощает работу. В аниме «Волчьи дети Амэ и Юки» в отдельных сценах окружение было выполнено в 3D, чтобы эффектно показать движение героев при помощи пролета камеры, создать иллюзию живой съемки. 2D персонажи были нарисованы поверх.
Лес смоделировали в компьютерной графике
Отрендерили и наложили анимацию 2D персонажа
Перспектива. В анимационном клипе «Freak of the Week» на песню группы Freak Kitchen сначала смоделировали персонажей в 3D, а потом отрисовали поверх моделек мимику и детали вручную. Это позволило играть с перспективой и масштабом, показывать сложные ракурсы.
Стилизация. В мультсериале «Удивительный мир Гамболла» комбинируются всевозможные виды анимации. Есть персонажи, созданные в 2D (Гамболл, Дарвин и др.), в технике фотомонтажа, в технике стоп-моушена. Есть здесь и 3D-персонажи: робот Боберт, воздушный шарик Алан и др. Такое разнообразие технологий позволяет создать уникальный, безумный мир, населенный разношерстными существами.
Боберт создан в 3D
Сложные эффекты. Некоторые эффекты практически невозможно создать при помощи ручной анимации, и тут на помощь приходит 3D. В «Принцессе Мононоке» в сцене атаки разъяренного татаригами кабан был нарисован вручную, но каждый из червей, покрывающих его, был сделан при помощи 3D.
В «Ходячем замке», чтобы создать атмосферу военного патриотизма, Миядзаки показывает развевающиеся флаги. Это трехмерные каркасные модели, анимированные так, будто их толкает невидимая масса воздуха.
Эксперимент. В диснеевской короткометражке «Paperman» художники рисовали ключевую анимацию поверх CG рендера. По словам создателей, этот способ мог бы определить будущее 2D-анимации.
Disney для фильма «Paperman» разработали уникальную в своем роде программу под названием Meander. Эта программа — анимационный редактор, который представляет из себя гибрид между векторной и растровой графикой.
Почему 3D-графика в 2D-мультипликации часто плохо смотрится
Низкий бюджет и нехватка времени прямым образом влияет на качество анимации. Многие аниме-сериалы грешат халтурными 3D-сценами. Яркий пример — кривая массовка в аниме «Оверлорд». Сравните с 3D-толпой в диснеевских рисованных мультфильмах, о которых говорилось выше.
Эта армия так и просит поскорее прикончить ее.
Не последнюю роль играет и развитие технологий. Например, в диснеевской «Планете сокровищ» 3D-объекты довольно заметно выделяются на фоне 2D, хотя все выполнено на высшем уровне для того времени (тем более, работали над мультфильмом лучшие профессионалы). Так, металлическая рука киборга Сильвера анимирована в 3D.
Один из лучших современных примеров совмещения 2D и 3D анимации — мультфильм «Человек-паук: через вселенные». Здесь на компьютерные модели накладывали изображение, выполненное вручную. В результате получился уникальный визуальный стиль, приближенный к комиксу.
Какие трудности возникают при совмещении 3D и 2D
Если в 3D сделано окружение, сложно бывает показать, как 2D-персонаж с ним взаимодействует. В таких случаях окружение и анимацию персонажа делают в разных программах. Потом изображение из одной программы импортируют в другую. Иногда 2D анимацию делают поверх 3D-окружения. Чтобы лучше показать взаимодействие, аниматор на черновом этапе работы намечает в 3D-окружении линии, по которым должен двигаться 2D-персонаж.
Вспомогательные линии
Объекты, выполненные в 2D и 3D должны быть похожи друг на друга, не выбиваться из общего визуального стиля. Во многом это зависит от уровня детализации и того, как деталь ведет себя на движущейся поверхности.
Кроме того, между 2D и 3D не должно быть разрыва в частоте кадров в секунду. Их должно быть не менее 24 в секунду.
Применение компьютерной графики в 2D-анимации — это прием, который может сделать сцену глубже и красивее, облегчить работу аниматору. Но этим приемом надо пользоваться грамотно и не злоупотреблять, иначе можно испортить сцену.
Справка в Интернете — Справка Origin
Создать 3D-график
Трехмерные графики находят широкое применение в науке, технике и финансах. Origin включает в себя широкий спектр типов трехмерных графиков, в том числе трехмерный разброс, трехмерные полосы и трехмерные поверхности. Создание этих графиков в Origin выполняется быстро и легко: вы можете просто выбрать данные и щелкнуть нужную кнопку графика или команду меню, чтобы создать график. После создания вы можете изменять и манипулировать графиком различными способами, включая вращение, изменение размера, построение пересечения нескольких поверхностей, изменение отображения метки оси и т. Д.Вы можете вращать и изменять размер 3D-графиков графически или вводя точные числа в текстовые поля. Как правило, вы можете изменить внешний вид любого элемента графика, дважды щелкнув по нему, открыв диалоговое окно и изменив настройки. Здесь мы видим три примера трехмерных графиков:
3D-разброс из матрицы с «в 3D-плоскости»
Заголовки осей и метки делений
3D-вектор
Несколько поверхностей с пересечением
Origin поддерживает OpenGL для всех трехмерных графиков. Ниже приведены минимальные системные требования для Origin 9.0 для построения графиков OpenGL, особенно требования к видеокарте и драйверам:
Процессор: Inter celeron processor 900MHz
Память (RAM): 512 МБ
Видеопамять: SiS 300/305 (32 МБ)
Жесткий диск: 80 ГБ
ОС: EXP SP3
Типы трехмерных графиков
Типы графиков перечислены ниже вместе с форматами данных, которые можно использовать для создания каждого типа. Для определения виртуальной матрицы см. Создание трехмерных и контурных графиков на основе виртуальной матрицы.
Тип графика
столбцов XYZ на листе
столбцов XYY на листе
Окно матрицы
Виртуальная матрица
на листе
3D-разброс
Поверхность цветной карты
Проволочная рама
Поверхность провода
3D стержни
Поверхность цветовой карты с выступом
Проволочная рама
Поверхность провода
Трехмерная поверхность трехкомпонентной карты цветов
Да
(для поверхности трехмерной тройной цветовой карты требуются столбцы XYZZ)
Нет
Да
Да
Да
Нет
Да
Нет
3D траектория
3D вектор XYZ XYZ
3D вектор XYZ dXdYdZ
Да
Нет
Нет
Нет
3D стены
3D ленты
Планки XYY 3D
Нет
Да
Нет
Нет
Константа X с базой
Константа Y с основанием
Нет
Нет
Да
Да
Поверхность заливки цветом с полосой ошибок
Поверхность цветовой карты с полосой ошибок
Многоцветная заливка поверхностей
Несколько поверхностей цветовой карты
Нет
Нет
Да
Нет
Примечание: Алгоритм контурной триангуляции, который строит необработанные данные X и Y, был реализован для Origin 2016. Предыдущие версии выполняли некоторую нормализацию данных X и Y перед построением графика. Таким образом, контурные и трехмерные поверхностные графики данных рабочего листа XYZ, созданные в версии 2016 и выше, могут отличаться от графиков тех же данных, созданных в более ранних версиях. Это изменение будет наиболее заметно, если между значениями X и Y имеются большие различия в диапазоне шкалы. См. FAQ-822 для получения дополнительной информации.
Как создавать и настраивать 3D-графики
Чтобы создать трехмерный график из данных матрицы или рабочего листа, вы выбираете данные и нажимаете соответствующую кнопку графика на панели инструментов 3D и Контурные графики .В качестве альтернативы вы можете выбрать график в меню Plot . Чтобы создать график из виртуальной матрицы, вы должны нажать кнопку графика на панели инструментов 3D и Contour Graphs , чтобы открыть диалоговое окно, которое поможет вам указать данные X, Y, Z и создать график. Дополнительные сведения о создании графиков из виртуальных матриц см. В Создание трехмерных и контурных графиков из виртуальных матриц . Мы подробно представили каждый тип трехмерных графиков в Приложение 2 — Типы графиков , вы можете обратиться к нему для получения более подробной информации.
Настройка трехмерных графиков в основном выполняется в диалоговых окнах Axis и Plot Details . Вы можете узнать больше о диалоговом окне Axis и узнать, как настроить оси графика в Graph Axes . Для получения дополнительной информации о диалоговом окне Plot Details см. Customizing Your Graph .
3D-график в Excel | Как создать трехмерный график поверхности (диаграмму) в Excel?
3D-графики также известны как графики поверхностей в Excel, которые используются для представления трехмерных данных. Чтобы создать трехмерный график в Excel, нам необходимо иметь трехмерный диапазон данных, что означает, что у нас есть трехмерные данные. x, y и z, трехмерные графики или графики поверхности можно использовать на вкладке вставки в Excel.
Excel Трехмерная диаграмма
Прежде чем мы начнем создавать 3D-график в Excel, мы должны знать, что такое сюжет. Графики — это диаграммы в Excel, которые визуально представляют заданные данные. В Excel есть различные типы диаграмм, которые используются для описания данных. Но в основном данные представлены в виде 2D-диаграмм, что означает, что данные или таблица находятся в двух сериях, то есть по оси X и оси Y. Но как насчет того, чтобы построить эту диаграмму, если у нас есть три переменные X, Y и Z. Это то, что мы узнаем об этом 3D-графике в теме Excel.
У нас есть постановка задачи, что у нас есть данные по трем осям последовательностей, то есть X, Y и Z. Как нам нанести эти данные на диаграммы. Диаграмма, которую мы используем для представления этих данных, в Excel называется трехмерным графиком или графиком поверхности. 3D-графики представляют трехмерные данные; здесь есть три переменные. Одна переменная зависит от двух других, а две другие переменные не зависят. Двумерные диаграммы полезны для представления данных, а трехмерные данные полезны при анализе данных.Такие как CO-отношение и регресс. Диаграмма этого типа строится по осям X, Y и Z, где две оси горизонтальны, а одна — вертикальна. Какая ось должна оставаться основной осью, зависит от пользователя диаграммы. Какие данные, независимые или одна из двух зависимых, могут быть первичной осью.
Где в Excel можно найти трехмерный график или поверхностную диаграмму? На вкладке «Вставка» в разделе диаграмм мы можем найти вариант для поверхностных диаграмм.
Выделенные диаграммы являются поверхностными или трехмерными графиками в Excel.
Как создать трехмерный график в Excel?
А теперь сделаем поверхность, то есть трехмерные графики в excel, с помощью пары примеров.
Пример # 1
Давайте сначала выберем несколько случайных данных, как показано ниже,
У нас есть несколько случайных чисел, сгенерированных в столбцах Excel X, Y и Z, и мы построим эти данные на трехмерных графиках.
Выберите данные, в которых мы хотим построить трехмерную диаграмму.
Теперь на вкладке «Вставка» в разделе диаграмм щелкните поверхностную диаграмму.
Типичный трехмерный график поверхности в Excel показан ниже, но на данный момент мы не можем многое прочитать из этого графика.
Как видим, работа поверхностной карты осуществляется в цветах. Диапазоны показаны цветами.
В настоящее время эта диаграмма не так удобна для чтения, поэтому щелкните карту правой кнопкой мыши и выберите «Форматировать область диаграммы».
Появится панель инструментов форматирования диаграммы, затем нажмите «Эффекты».В «Эффектах» нажмите «Поворот 3D-изображения», как показано ниже.
Измените значения для поворота X и Y и перспективы, что изменит диаграмму, и ее будет легче читать.
Вот так теперь выглядит диаграмма после изменения поворота по умолчанию.
Теперь мы должны назвать ось. Мы можем дать название оси, нажав на кнопку, предоставленную Excel.
Приведенная выше поверхностная диаграмма представляет собой трехмерный график для случайных данных, выбранных выше.Давайте использовать 3D-графики поверхности в Excel для некоторых сложных ситуаций.
Пример # 2
Предположим, у нас есть данные по региону, продажи которого осуществляются за шесть месяцев, и мы хотим отобразить эти данные в виде диаграммы. Взгляните на данные ниже,
Теперь мы хотим показать это на трехмерной диаграмме, поскольку у нас есть три переменные, с которыми нужно определить. Один — это месяц, другой — прибыль или убыток, понесенные компанией, а третий — общий объем продаж, выполненных за этот период месяца.Выполните следующие шаги:
Выберите данные, в которых мы хотим построить трехмерную диаграмму.
На вкладке «Вставка» под диаграммами в разделе щелкните поверхностную диаграмму.
В настоящее время трехмерная диаграмма выглядит так, как показано ниже:
Цвета показывают диапазоны значений на диаграмме, и они находятся в диапазоне от -20000 до 60000, но наши данные в прибылях / убытках находятся только в диапазоне от 7000 до -5000 и от 30000 до 40000, поэтому нам нужно изменить их.Щелкните диаграмму правой кнопкой мыши и выберите область чата «Форматировать».
Появится панель инструментов форматирования диаграммы. Щелкните эффекты, а в нижней части эффектов снимите флажок автомасштабирования.
Параметр «Проверки» на панели инструментов диаграммы в Excel изменяет перспективу до точки, в которой мы можем правильно просматривать диаграмму.
В настоящее время наш график выглядит следующим образом:
Теперь на вкладке «Дизайн» есть различные другие параметры форматирования диаграмм, например, для добавления элемента диаграммы.
Добавьте заголовок к диаграмме как «Данные о продажах».
Почему мы используем 3D Plot в Excel? Чтобы ответить на этот вопрос, мы можем обратиться к примеру два. Данные были в трех сериях, т.е. мы должны были представить данные в трех осях.
Это было невозможно с двухмерными диаграммами, поскольку двухмерные диаграммы могут представлять данные только по двум осям. Поверхность 3D-графиков в Excel работает с цветовым кодированием. Цвет представляет диапазоны данных, в которых они определены.
Например, посмотрите на снимок экрана ниже из примера 2:
Каждый диапазон значений представлен разным набором цветов.
Что нужно помнить
3D-графики поверхности в Excel полезны, но их очень сложно использовать, поэтому они используются не очень часто.
Из трех осей на трехмерном графике одна расположена вертикально, а две другие — горизонтально.
На трехмерном поверхностном графике в Excel необходимо отрегулировать трехмерное вращение в соответствии с диапазоном данных, так как может быть сложно читать с графика, если перспектива неправильная.
Ось должна быть названа, чтобы избежать путаницы, какая ось является осью X, Y или Z для пользователя.
Рекомендуемые статьи
Это руководство по 3D-графику в Excel. Здесь мы обсудим, как создать трехмерный поверхностный график (диаграмму) в Excel, а также практические примеры и загружаемый шаблон Excel. Вы можете узнать больше об Excel из следующих статей —
Пакет All in One Excel VBA (35 курсов с проектами)
35+ курсов
120+ часов
Полный пожизненный доступ
Свидетельство о завершении
ПОДРОБНЕЕ >>
Основы визуализации данных
Трехмерные графики довольно популярны, в частности, в бизнес-презентациях, а также среди ученых.Они также почти всегда используются ненадлежащим образом. Я редко вижу трехмерный график, который нельзя улучшить, превратив его в обычную двухмерную фигуру. В этой главе я объясню, почему у трехмерных графиков возникают проблемы, почему они обычно не нужны и в каких ограниченных обстоятельствах трехмерные графики могут быть подходящими.
Избегайте беспричинного 3D
Многие программы для визуализации позволяют украсить графики, превращая графические элементы графиков в трехмерные объекты. Чаще всего мы видим, как круговые диаграммы превращаются в диски, повернутые в пространстве, столбчатые диаграммы превращаются в столбцы, а линейные диаграммы — в полосы.Примечательно, что ни в одном из этих случаев третье измерение не передает никаких реальных данных. 3D используется просто для украшения и украшения сюжета. Я считаю такое использование 3D неоправданным. Это однозначно плохо, и его следует стереть из визуального словаря специалистов по данным.
Проблема с беспричинным 3D заключается в том, что проекция 3D-объектов в двух измерениях для печати или отображения на мониторе искажает данные. Человеческая зрительная система пытается исправить это искажение, отображая двумерную проекцию трехмерного изображения обратно в трехмерное пространство.Однако это исправление может быть только частичным. В качестве примера возьмем простую круговую диаграмму с двумя срезами, один из которых представляет 25% данных, а другой — 75%, и повернем эту круговую диаграмму в пространстве (рисунок 26.1). По мере того как мы меняем угол, под которым смотрим на круговую диаграмму, кажется, что изменяется и размер ломтиков. В частности, 25% -ный срез, расположенный в передней части пирога, выглядит намного больше, чем 25%, когда мы смотрим на пирог под прямым углом (рис. 26.1a).
Рисунок 26.1: Та же трехмерная круговая диаграмма, показанная под четырьмя разными углами.Вращение пирога в третьем измерении заставляет кусочки пирога спереди казаться больше, чем они есть на самом деле, а кусочки пирога сзади — меньше. Здесь, в частях (a), (b) и (c), синий срез, соответствующий 25% данных, визуально занимает более 25% площади, представляющей круговую диаграмму. Только часть (d) является точным представлением данных.
Подобные проблемы возникают и для других типов трехмерных графиков. На рис. 26.2 показано распределение пассажиров «Титаника» по классам и полу с использованием трехмерных полос.Из-за того, как стержни расположены относительно осей, все стержни выглядят короче, чем они есть на самом деле. Например, всего 322 пассажира путешествовали в 1-м классе, однако рисунок 26.2 предполагает, что их было меньше 300. Эта иллюзия возникает из-за того, что столбцы, представляющие данные, расположены на расстоянии от двух задних поверхностей, на которых серые горизонтальные линии нарисованы. Чтобы увидеть этот эффект, рассмотрите возможность расширения любого из нижних краев одного из столбцов, пока он не достигнет самой нижней серой линии, которая представляет собой 0.Затем представьте, что вы проделываете то же самое с любым верхним краем, и вы увидите, что все столбцы выше, чем кажется на первый взгляд. (См. Рисунок 6.10 в главе 6, где представлена более разумная двухмерная версия этого рисунка.)
Рисунок 26.2: Количество пассажиров-мужчин и женщин на Титанике, путешествующих 1-м, 2-м и 3-м классами, показано в виде трехмерной гистограммы. Общее количество пассажиров 1-го, 2-го и 3-го классов составляет 322, 279 и 711 соответственно (см. Рис. 6.10). Однако на этом графике полоса 1-го класса, по-видимому, представляет менее 300 пассажиров, полоса 3-го класса, кажется, представляет менее 700 пассажиров, а полоса 2-го класса кажется ближе к 210–220 пассажирам, чем фактические 279 пассажиров.Кроме того, планка 3-го класса визуально доминирует над фигурой и заставляет количество пассажиров 3-го класса казаться больше, чем оно есть на самом деле.
Избегайте трехмерных шкал положения
В то время как визуализации с беспричинным 3D можно легко отклонить как плохие, менее ясно, что думать о визуализациях, использующих три подлинных шкалы положения ( x , y и z ) для представления данных. В этом случае использование третьего измерения служит реальной цели.Тем не менее, полученные графики часто трудно интерпретировать, и, на мой взгляд, их следует избегать.
Рассмотрим трехмерный график разброса топливной эффективности в зависимости от рабочего объема и мощности для 32 автомобилей. Мы видели этот набор данных ранее в главе 2, рисунок 2.5. Здесь мы наносим смещение по оси x , мощность по оси y и топливную экономичность по оси z и представляем каждую машину точкой (рис. 26.3). Несмотря на то, что эта трехмерная визуализация показана с четырех разных точек зрения, трудно представить, как именно точки распределяются в пространстве.Я нахожу часть (d) рисунка 26.3 особенно запутанной. Кажется, что это почти другой набор данных, хотя ничего не изменилось, кроме угла, под которым мы смотрим на точки.
Рисунок 26.3: Топливная эффективность в зависимости от рабочего объема и мощности для 32 автомобилей (модели 1973–74). Каждая точка представляет одну машину, а цвет точки представляет количество цилиндров машины. На четырех панелях (a) — (d) показаны одни и те же данные, но используются разные точки зрения. Источник данных: Motor Trend, 1974.
Основная проблема таких 3D-визуализаций заключается в том, что они требуют двух отдельных последовательных преобразований данных. Первое преобразование отображает данные из пространства данных в пространство трехмерной визуализации, как обсуждалось в главах 2 и 3 в контексте шкал положения. Второй отображает данные из пространства 3D-визуализации в 2D-пространство окончательной фигуры. (Это второе преобразование, очевидно, не происходит для визуализаций, показанных в истинной трехмерной среде, например, когда они показаны как физические скульптуры или объекты, напечатанные на 3D-принтере.Мое основное возражение здесь — против 3D-визуализаций, отображаемых на 2D-дисплеях.) Второе преобразование необратимо, потому что каждая точка на 2D-дисплее соответствует строке точек в пространстве 3D-визуализации. Следовательно, мы не можем однозначно определить, где в трехмерном пространстве находится какая-либо конкретная точка данных.
Наша визуальная система, тем не менее, пытается преобразовать 3D в 2D. Однако этот процесс ненадежен, чреват ошибками и сильно зависит от соответствующих реплик в изображении, которые передают некоторое ощущение трехмерности.Когда мы убираем эти реплики, инверсия становится совершенно невозможной. Это можно увидеть на рисунке 26.4, который идентичен рисунку 26.3, за исключением того, что все признаки глубины удалены. В результате получается четыре случайных расположения точек, которые мы вообще не можем интерпретировать и которые даже нелегко связать друг с другом. Не могли бы вы сказать, какие точки в части (а) соответствуют точкам в части (б)? Я, конечно, не могу.
Рисунок 26.4: Топливная эффективность в зависимости от рабочего объема и мощности для 32 автомобилей (модели 1973–74).Четыре панели (a) — (d) соответствуют тем же панелям на рисунке 26.3, только все линии сетки, обеспечивающие глубину, были удалены. Источник данных: Motor Trend, 1974.
Вместо применения двух отдельных преобразований данных, одно из которых необратимо, я думаю, что обычно лучше просто применить одно подходящее обратимое преобразование и отобразить данные непосредственно в 2D-пространство. Редко бывает необходимо добавлять третье измерение в качестве шкалы положения, поскольку переменные также могут быть отображены на шкале цвета, размера или формы.Например, в главе 2 я построил сразу пять переменных набора данных о топливной эффективности, но при этом использовал только две шкалы положения (рис. 2.5).
Здесь я хочу показать два альтернативных способа построения графиков именно тех переменных, которые показаны на рис. 26.3. Во-первых, если мы в первую очередь заботимся о топливной эффективности как переменной отклика, мы можем построить ее дважды: один раз в зависимости от рабочего объема, а второй — от мощности (рисунок 26.5). Во-вторых, если нас больше интересует, как рабочий объем двигателя и мощность соотносятся друг с другом, а топливная эффективность является второстепенной переменной, представляющей интерес, мы можем построить график зависимости мощности от рабочего объема и сопоставить топливную эффективность с размером точек (рис.6). Оба рисунка более полезны и менее запутаны, чем рисунок 26.3.
Рисунок 26.5: Топливная эффективность в зависимости от рабочего объема (а) и мощности (б). Источник данных: Motor Trend, 1974.
Рисунок 26.6: Зависимость мощности от рабочего объема для 32 автомобилей, топливная эффективность представлена размером точки. Источник данных: Motor Trend, 1974.
Вы можете задаться вопросом, заключается ли проблема с трехмерными диаграммами рассеяния в том, что фактическое представление данных, точки, сами по себе не передают никакой трехмерной информации.Что произойдет, например, если вместо этого мы будем использовать трехмерные стержни? На рис. 26.7 показан типичный набор данных, который можно визуализировать с помощью трехмерных столбцов, уровней смертности в Вирджинии 1940 года, стратифицированных по возрастным группам, полу и местоположению жилья. Мы видим, что трехмерные полосы действительно помогают нам интерпретировать график. Маловероятно, что можно принять полосу на переднем плане за полосу на заднем плане или наоборот. Тем не менее проблемы, обсуждаемые в контексте рисунка 26.2, существуют и здесь. Трудно точно судить о высоте отдельных столбиков, а также трудно проводить прямые сравнения.Например, был ли уровень смертности городских женщин в возрастной группе 65–69 лет выше или ниже, чем у городских мужчин в возрастной группе 60–64 лет?
Рисунок 26.7: Показатели смертности в Вирджинии в 1940 году, визуализированные в виде трехмерной гистограммы. Показатели смертности показаны для четырех групп населения (городских и сельских женщин и мужчин) и пяти возрастных категорий (50–54, 55–59, 60–64, 65–69, 70–74), и они указаны в единицах смертей на 1000 человек. Этот рисунок отмечен как «плохой», потому что трехмерная перспектива затрудняет чтение сюжета.Источник данных: Молино, Гиллиам и Флоран (1947).
В общем, лучше использовать графики Trellis (Глава 21) вместо трехмерных визуализаций. Для набора данных о смертности в Вирджинии требуется только четыре панели, если они представлены в виде решетки (рис. 26.8). Считаю эту цифру понятной и легко интерпретируемой. Сразу становится очевидным, что уровень смертности среди мужчин был выше, чем среди женщин, а также что у городских мужчин уровень смертности был выше, чем у сельских мужчин, тогда как среди городских и сельских женщин такой тенденции не наблюдается.
Рисунок 26.8: Показатели смертности в Вирджинии в 1940 году, представленные в виде графика Trellis. Показатели смертности показаны для четырех групп населения (городских и сельских женщин и мужчин) и пяти возрастных категорий (50–54, 55–59, 60–64, 65–69, 70–74), и они указаны в единицах смертей на 1000 человек. Источник данных: Молино, Гиллиам и Флоран (1947).
Надлежащее использование 3D-визуализаций
Однако иногда могут быть уместны визуализации
с использованием трехмерных координатных шкал.Во-первых, проблемы, описанные в предыдущем разделе, вызывают меньшее беспокойство, если визуализация является интерактивной и может вращаться зрителем, или, альтернативно, если она отображается в среде виртуальной реальности или дополненной реальности, где ее можно рассматривать с разных сторон. Во-вторых, даже если визуализация не интерактивна, отображение ее медленно вращающегося, а не статического изображения с одной точки зрения, позволит зрителю различить, где в трехмерном пространстве находятся различные графические элементы. Человеческий мозг очень хорошо восстанавливает трехмерную сцену из серии изображений, снятых под разными углами, и медленное вращение графики обеспечивает именно эти изображения.
Наконец, имеет смысл использовать 3D-визуализацию, когда мы хотим показать реальные 3D-объекты и / или данные, отображенные на них. Например, отображение топографического рельефа гористого острова — разумный выбор (рис. 26.9). Точно так же, если мы хотим визуализировать сохранение эволюционной последовательности белка, нанесенного на его структуру, имеет смысл показать эту структуру как трехмерный объект (рис. 26.10). Однако в любом случае эти визуализации все равно было бы легче интерпретировать, если бы они отображались как вращающиеся анимации.Хотя это невозможно в традиционных печатных публикациях, это можно легко сделать при размещении рисунков в Интернете или при проведении презентаций.
Рисунок 26.9: Рельеф острова Корсика в Средиземном море. Источник данных: Служба мониторинга земель Коперник.
Рисунок 26.10: Паттерны эволюционной изменчивости белка. Цветная трубка представляет собой остов протеина экзонуклеазы III из бактерии Escherichia coli (идентификатор банка данных протеина: 1AKO).Окраска указывает на эволюционную консервацию отдельных участков в этом белке, при этом темная окраска указывает на консервативные аминокислоты, а светлая окраска указывает на вариабельные аминокислоты. Источник данных: Marcos and Echave (2015).
3D-график
Трехмерный график в общем записывается: z = f ( x , y ). То есть значение z- находится путем подстановки как значения x- , так и значения y- .
Первый пример, который мы видим ниже, — это график z = sin ( x ) + sin ( y ). Это функция x и y .
Вы можете использовать следующий апплет, чтобы исследовать трехмерные графики и даже создавать свои собственные, используя переменные x и y . Вы также можете переключаться между режимом 3D Grapher и контурным режимом.
Развлечения
1. Выберите любой из предустановленных трехмерных графиков в раскрывающемся списке вверху.
2. Вы можете ввести свою собственную функцию из x и y , используя простые математические выражения (допустимый синтаксис см. Ниже на графике).
3. Выберите режим Contour с помощью флажка. В этом режиме вы смотрите на трехмерный график сверху, а цветные линии представляют собой равные высоты (это похоже на контурную карту в географии). Синие линии самые низкие, а красные — самые высокие.
4. Вы можете изменить нижний и верхний пределы x- и y- , используя ползунки под графиком.
5. Вы можете изменять , масштаб z- (изменяя высоту каждого пика) и количество сегментов (которое изменяет частоту дискретизации) с помощью ползунков под графиком.
6. Увеличивайте и уменьшайте масштаб с помощью колесика мыши (или сжимания двумя пальцами, если на мобильном устройстве). Также используйте ползунок z-Scale , чтобы увидеть основные характеристики графика
7. Переместите весь график влево и вправо с помощью правой кнопки мыши и перетаскивания (или смахивания тремя пальцами на мобильном устройстве)
Этот апплет должен нормально работать на мобильных устройствах.y ) и логарифм ( ln (x + y) для натурального логарифма и log (x + y) для логарифма с основанием 10)
Абсолютное значение : используйте «абс», например: абс (x + y)
Знак (1, если знак положительный, -1, если знак функции отрицательный). Например, попробуйте sign (sin (x))
Фактически, вы можете использовать большинство математических функций JavaScript, включая
потолок: потолок (x) и круглый : круглый (x)
квадратный корень: sqrt (y)
Вы также можете использовать любые комбинации вышеперечисленного, например ln (abs (x-y)) .
Если ваш график не работает: Попробуйте использовать скобки! Например, «загар 2x» не сработает. Надо поставить tan (2x) .
Дополнительная информация
Кредит: Вышеупомянутый 3D-график основан на примерах Ли Стемкоски Three.js.
3D-графики
3D-графики создаются на основе данных, определенных как Z = f (X, Y). Что касается 2D-графиков, есть два способа получить 3D-график в зависимости от способа определения значений (X, Y, Z):
Вы можете иметь свои Z-значения в матрице.SciDAVis будет считать, что все данные, представленные в матрице, являются значениями Z, а значения X и Y могут быть определены как функция номеров столбцов и строк.
Данные в матрицу можно вводить несколькими способами:
по одному с клавиатуры,
путем чтения файла ascii в таблице и преобразования таблицы в матрицу,
по установка значений с помощью функции.
Если вы хотите построить график функции, матрица не нужна.Вы можете использовать непосредственно команду New -> New Surface 3D Plot . Это откроет соответствующее диалоговое окно, и вы сможете определить математическое выражение вашей функции.
Можно выбрать несколько видов трехмерных графиков. Список доступных графиков см. В разделе меню Plot3d в справочной главе.
Рисунок 2-8. Пример 3D-графиков.
3D-графики используют OpenGL, поэтому вы можете легко вращать, масштабировать и сдвигать их с помощью мыши.В диалоговом окне настроек 3D-графика или с помощью панели инструментов Surface 3D вы можете изменить все предопределенные настройки трехмерного графика: сетки, масштабы, оси, заголовок, легенду и цвета для различных элементов.
Есть несколько типов графиков, которые можно построить из матрицы. Они представлены в меню Plot3d.
Это самый простой способ получить трехмерный график. Это делается с помощью команды New -> New Surface 3D Plot из меню File или напрямую с помощью Ctrl-Alt-Z.Откроется следующее диалоговое окно:
Рисунок 2-9. Определение нового трехмерного графика поверхности
Вы можете ввести функцию z = f (x, y) и диапазоны для X, Y и Z. Затем SciDAVis создаст трехмерный график по умолчанию:
Рисунок 2-10. 3D-график поверхности, созданный по умолчанию
Затем вы можете настроить этот график, открыв диалоговое окно «Параметры графика поверхности». Вы можете изменить диапазоны и параметры оси, добавить заголовок, изменить цвета различных элементов и изменить соотношение сторон графика.Кроме того, вы можете использовать различные команды панели инструментов 3D-графика, чтобы добавить сетки на стены или изменить стиль графика. После некоторых изменений вы можете получить следующий график:
Рисунок 2-11. Трехмерный график поверхности после настроек
Если вы хотите изменить саму функцию, вы можете использовать команду поверхность … , которую можно активировать из контекстного меню, щелкнув правой кнопкой мыши на трехмерном графике. Это повторно откроет диалоговое окно определения функции поверхности.
Второй способ получить трехмерный график — использовать матрицу. Поэтому первым делом нужно заполнить матрицу, задав функцию.
Команда New -> New Matrix создает пустую матрицу по умолчанию с ячейками 32×32. Затем используйте команду Set Dimensions … , чтобы изменить количество строк и столбцов матрицы. Это диалоговое окно также используется для определения диапазонов X и Y.
Затем используйте команду Set Values … , чтобы заполнить ячейки числами.Диапазоны X и Y, определенные на предыдущем шаге, не известны этому диалоговому окну, тогда функция определяется с номерами строки и столбца (i и j) в качестве параметров ввода (подробности см. В разделе «Установочные значения»).
Другой способ получить матрицу — импортировать файл ASCII в таблицу с помощью команды Импорт ASCII -> Один файл … из меню Файл. Затем таблица может быть преобразована в матрицу с помощью команды Convert to Matrix command из меню Table.
Затем эту матрицу можно использовать для построения трехмерного графика с помощью одной из команд меню «График».
График Dewesoft 3D показывает трехмерные массивы или массивы с историей. С помощью этого графика мы можем показать историю БПФ, порядок и водопад БПФ из математики отслеживания порядка, подсчет дождевых потоков из модуля анализа усталости и даже данные тепловизионного зрения.
При выборе 3D-графика в левой и правой части экрана появятся следующие настройки:
Свойства элемента управления — для получения подробной информации о свойствах элемента управления: группировка, количество столбцов, добавление / удаление, прозрачность.
Параметры чертежа — выбирает, какие параметры будут отображаться на графике.
Селектор каналов
Входные данные для 3D-графика могут быть:
Математика БПФ на основе блоков (история БПФ во времени)
STFT математика
Математика CPB на основе блоков (CPB со временем)
Каскад заказов и БПФ из модуля отслеживания заказов
Зависимость водопада заказов от времени
3D дождь и счет Маркова
Тепловизор FLIR (требуется специальный модуль).
Обратите внимание, что 3D-просмотр может быть недоступен на компьютерах, на которых не установлен DirectX или графическая карта не поддерживает 3D-функции, требуемые для графика.
Недвижимость
Автоматическое масштабирование автоматически масштабирует ось z.
Тип оси Z может быть установлен на линейный, логарифмический, 0 дБ, уровень звука в дБ от Ref.dB. Минимум и максимум каждой шкалы можно определить, щелкнув минимальное и максимальное значение, как на любом графике. Это также работает для шкалы z, которая находится в левой части дисплея.
Палитра оси Z
может быть как в цвете радуги, так и в оттенках серого.
Проекцию оси можно изменить. Первый (2D (X, Y)) представляет собой планарный вид и в основном используется, когда данные, основанные на времени, отображаются, например, как история БПФ. Второй (2D (Y, X)) полезен при отображении матричных каналов, таких как количество дождевых потоков или тепловизионное изображение. Отслеживание заказов находится посередине, некоторые пользователи предпочитают первый, а другие — второй вариант. Также есть трехмерный вид (3D (X, Y)).
Трехмерный вид можно повернуть, нажав и удерживая левую кнопку мыши, чтобы повернуть его. Прокрутка колеса мыши или нажатие клавиши Shift и левой кнопки увеличивает или уменьшает масштаб изображения при перемещении мыши вверх и вниз. Щелкните правой кнопкой мыши и перемещайте мышь, чтобы вращать график вокруг плоскости отображения.
Маркеры
Перемещение кнопки мыши по графику поместит курсор в виде перекрестия в ближайшую точку на графике.
Нажав на точку правой кнопкой мыши, вы можете добавить маркер в направлении X или Y.В приведенном ниже примере канал, назначенный трехмерному графику, — это водопад заказов из математики отслеживания заказов. Канал в направлении X — это заказы, а канал по оси Y — это скорость. Имя оси X и оси Y читается из имени канала. Все курсоры можно удалить, щелкнув правой кнопкой мыши и выбрав «Удалить маркер».
Когда курсор будет добавлен, вы увидите плоскость, указывающую на «Снятие заказов». Маркер «Срез по порядку» создает канал, который можно отобразить на 2D-графике.
При щелчке по кнопке «Вырезать заказы» появится стрелка.С помощью этой опции вы можете вручную перемещать маркер в спектре.
При ручном перемещении маркера обновляется также канал «Отрезка заказов», отображаемый на 2D графике — отсечение рассчитывается и обновляется автоматически.
Те же свойства применяются также для добавления маркера в направлении Y (Speed cut).
Когда на 2D-графике отображается разрез в направлении Y, на этом же 2D-графике также виден маркер в направлении X. Разрез в направлении X виден в виде линии в положении маркеров, что указывает на разрез Одерса.
Добавление нескольких маркеров
На трехмерный график можно добавить несколько маркеров в обоих направлениях. Каждый из них создаст канал, который можно отобразить на 2D-графике.
При наличии нескольких маркеров на одном трехмерном графике вы можете изменить их цвет для облегчения идентификации.
Идентификатор, тип, цвет, положение по оси X и положение по оси Y могут отображаться в таблице маркеров.
вастуриано / 3d-force-graph: компонент трехмерного графика, направленного по силе, с использованием ThreeJS / WebGL
linkLabel ([ str or fn ])
Ссылка на функцию доступа к объекту или атрибут для имени (показано на этикетке).Поддерживает простой текст или HTML-контент. Обратите внимание, что этот метод внутренне использует innerHTML , поэтому не забудьте предварительно очистить любой вводимый пользователем контент, чтобы предотвратить уязвимости XSS.
наименование
linkVisibility ([ boolean , str or fn ])
Функция доступа к объекту ссылки, атрибут или логическая константа для отображения строки ссылки. Значение false поддерживает силу ссылки без ее рендеринга.
правда
linkColor ([ str or fn ])
Ссылка на функцию доступа к объекту или атрибут для цвета линии.
цвет
linkAutoColorBy ([ str or fn ])
Свяжите функцию доступа к объекту ( fn (ссылка) ) или атрибут (например, 'type' ) для автоматической группировки цветов. Влияет только на ссылки без атрибута цвета.
linkOpacity ([ num ])
Получатель / установщик для непрозрачности строк ссылок между [0,1].
0,2
linkWidth ([ num , str or fn ])
Функция доступа к объекту ссылки, атрибут или числовая константа для ширины линии ссылки. При нулевом значении будет отображаться линия ThreeJS с постоянной шириной ( 1px ) независимо от расстояния. Для индексации значения округляются до ближайшего десятичного знака.
0
ссылка Разрешение ([ число ])
Получатель / установщик геометрического разрешения каждого звена, выраженного в количестве радиальных сегментов, на которые нужно разделить цилиндр. Более высокие значения дают более гладкие цилиндры. Применимо только к ссылкам с положительной шириной.
6
linkCurvature ([ num , str or fn ])
Функция доступа к объекту ссылки, атрибут или числовая константа для радиуса кривизны линии связи.Изогнутые линии представлены как трехмерные кривые Безье, и допускается любое числовое значение. Значение 0 отображает прямую линию. 1 указывает радиус, равный половине длины линии, в результате чего кривая приближается к полукругу. Для саморегулирующихся ссылок ( исходный равен целевой ) кривая представлена в виде петли вокруг узла с длиной, пропорциональной значению кривизны. Линии изогнуты по часовой стрелке для положительных значений и против часовой стрелки для отрицательных значений.Обратите внимание, что визуализация изогнутых линий является чисто визуальным эффектом и не влияет на поведение основных сил.
0
linkCurveRotation ([ num , str or fn ])
Свяжите функцию доступа к объекту, атрибут или числовую константу для поворота вдоль оси линии, применяемого к кривой. Не влияет на прямые линии. При повороте на 0 кривая ориентирована в направлении пересечения с плоскостью XY .Угол поворота (в радианах) будет вращать изогнутую линию по часовой стрелке вокруг оси «от начала до конца» от этой исходной ориентации.
0
linkMaterial ([ Material , str or fn ])
Функция или атрибут доступа к объекту ссылки для указания настраиваемого материала для стилизации ссылок графа. Должен возвращать экземпляр ThreeJS Material. Если возвращается значение falsy , для этой ссылки будет использоваться материал по умолчанию.
Материал ссылки
по умолчанию — MeshLambertMaterial, стилизованный в соответствии с цветом и непрозрачностью .
linkThreeObject ([ Object3d , str or fn ])
Функция или атрибут доступа к объекту ссылки для создания пользовательского 3D-объекта для визуализации в виде ссылок на график. Должен возвращать экземпляр ThreeJS Object3d. Если возвращается значение falsy , для этой ссылки будет использоваться тип трехмерного объекта по умолчанию.
Объект ссылки
по умолчанию представляет собой линию или цилиндр, размер которого соответствует ширине и оформлен в соответствии с материалом .
linkThreeObjectExtend ([ bool , str or fn ])
Функция доступа к объекту ссылки, атрибут или логическое значение, указывающее, следует ли заменить ссылку по умолчанию при использовании настраиваемого объекта linkThreeObject ( false ) или расширить его ( true ).
Получатель / установщик для пользовательской функции, вызывающей обновление позиции ссылок на каждой итерации рендеринга. Он получает соответствующую ссылку ThreeJS Object3d , координаты начала и конца ссылки ( {x, y, z} каждая) и данные ссылки . Если функция возвращает истинное значение, обычная функция обновления позиции не будет запускаться для этой ссылки.
linkDirectionalArrowLength ([ num , str or fn ])
Функция доступа к объекту ссылки, атрибут или числовая константа для длины стрелки, указывающей направление ссылки. Стрелка отображается непосредственно над линией связи и указывает в направлении источник > цель . Значение 0 скрывает стрелку.
0
linkDirectionalArrowColor ([ str or fn ])
Ссылка на функцию доступа к объекту или атрибут цвета стрелки.
цвет
linkDirectionalArrowRelPos ([ num , str or fn ])
Функция доступа к объекту ссылки, атрибут или числовая константа для продольного положения наконечника стрелки вдоль линии связи, выраженная как отношение между 0 и 1 , где 0 указывает непосредственно рядом с узлом источника , 1 рядом с целевым узлом и 0.5 прямо посередине.
0,5
linkDirectionalArrowResolution ([ число ])
Геттер / сеттер для геометрического разрешения острия стрелки, выраженного в количестве сегментов среза, чтобы разделить окружность основания конуса. Более высокие значения дают более гладкие стрелки.
8
linkDirectionalParticles ([ num , str or fn ])
Функция доступа к объекту ссылки, атрибут или числовая константа для количества частиц (маленьких сфер), отображаемых над линией связи.Частицы распределяются с равным интервалом вдоль линии, движутся в направлении источник > цель и могут использоваться для указания направленности линии связи.
0
linkDirectionalParticleSpeed ([ num , str or fn ])
Функция доступа к объекту Link, атрибут или числовая константа для скорости направленных частиц, выраженная как отношение длины ссылки к перемещению за кадр.Значения выше 0,5 не приветствуются.
0,01
linkDirectionalParticleWidth ([ num , str or fn ])
Ссылка на функцию доступа к объекту, атрибут или числовую константу для ширины направленных частиц. Для индексации значения округляются до ближайшего десятичного знака.
0,5
linkDirectionalParticleColor ([ str or fn ])
Ссылка на функцию доступа к объекту или атрибут для цвета направленных частиц.
цвет
linkDirectionalParticleResolution ([ число ])
Геттер / сеттер для геометрического разрешения каждой направленной частицы, выраженного в количестве сегментов среза, чтобы разделить окружность. Более высокие значения дают более гладкие частицы.
4
emitParticle ( ссылка )
Альтернативный механизм для генерации частиц, этот метод испускает нециклическую одиночную частицу в пределах определенного звена.Испускаемая частица имеет тот же стиль (скорость, ширина, цвет), что и обычные свойства частицы. Допустимый объект link , который включен в graphData , должен быть передан как единственный параметр.
lim (1 + х)х =е , при х стремящемся к бесконечности -первый замечательный предел. lim sinx/x=1 при х стремящемся к бесконечности — второй замечательный предел . Замечательные пределы- пределы стремящиеся к бесконечности.
Второй замечательный предел замечателен не только тем. что он суще-ствует, но и тем. что его величина — это знаменитое неперово числое = 2.71828… . Что касается первого замечательного предела, то. как известно, он равен единице, но при условии, что угол х измеряется в радианах. А это значит, что и он связан с другим не ме-нее замечательным числом — архимедовым числом тг (тг — отношениедлины любой окружности к ее диаметру, одно и то же для всех окруж-ностей по соображениям подобия). илона варкки 11с http://www.finmath.ru/vocabulary/90/ http://ru.wikipedia.org/ http://209. m-1/x}=m
Они замечательны тем, что помогают вычислению многих других пределов.
Так, с помощью первого замечательного предела можно установить важную для приложений эквивалентность при стремлении х к нулю следующих бесконечно малых величин: ax, sinax, tgax, arcsinax, arctgax(эквивалентность означает, что их отношение стремится к 1 при стремлении х к нулю). Отметим, что аргументы тригонометрических и обратных тригонометрических функций здесь измеряются в радианах, как это обычно бывает при рассмотрении подобных функций.
Так называют следующие равенства: lim sin x/x=1 -первый замечательный предел; lim(1+x)1/x=lim(1+1/x)x=e=2,718281… -второй замечательный предел. Они замечательны тем, что помогают вычислению многих других пределов. x = exp Они замечательны тем, что помогают вычислению многих других пределов.
Так, с помощью первого замечательного предела можно установить важную для приложений эквивалентность при стремлении х к нулю следующих бесконечно малых величин: ax, sinax, tgax, arcsinax, arctgax Второй замечательный предел служит для раскрытия неопределенности
http://www.tstu.tver.ru/faculties/civil/vm/math_on_line/topic/funczija/lect_1/lect_1_8.html Анна Фадеева 11b
28 сентября 2009 г., 12:06
cjgray1
комментирует…
Уважаемые блоггеры! Кто ни будь знает кто дал название замечательным пределам? Если есть информация по этому вопросу, поделитесь пожалуйста…
7 декабря 2009 г., 21:27
Расчет
— Как доказать, что $ \ lim \ limits_ {x \ to0} \ frac {\ sin x} x = 1 $?
Это новый пост на старой пиле, потому что это одна из тех вещей, где я могу видеть, как это, к сожалению, то, как мы структурировали текущую учебную программу по математике, действительно не позволяет делать справедливость, которую они заслуживают, и я думаю, что в конечном итоге это оказывает медвежью услугу многим учащимся.
По правде говоря, этот предел не может быть честным доказательством без честного определения синусоидальной функции.И это , а не так просто, как кажется. Даже если мы рассмотрим простое понятие из многих тригонометрических трактовок, что синус равен «длине противоположной стороны прямоугольного треугольника, деленной на длину его гипотенузы», это не решит проблему, потому что на самом деле существует едва уловимый недостающий элемент, и это то, что синус не является функцией «прямоугольного треугольника» (хотя вы могли бы определить это, если бы захотели, и это было бы легко!), а от угловой меры .И на самом деле выяснение того, что означает «угловая мера», по сути, эквивалентно определению синусоидальной функции в первую очередь, так что этот подход является круговым! (каламбур наблюдается после написания, несмотря на то, что изначально не предназначался!)
Итак, как мы определяем синус или угловую меру? К сожалению, любой подход к этому таков, что должен включать в себя исчисление. Это связано с тем, что используемая нами угловая мера является «гладкой и устойчивой», что означает, что, по сути, если у нас есть некоторый угол, мы хотели бы разделить эту угловую меру, чтобы разделить угол таким же образом, как при разрезании кусков пирога: если у меня есть угол с заданной угловой мерой $ \ theta $, то для того, чтобы система измерения работала, я должен иметь возможность получить угол с мерой $ \ frac {\ theta} {n} $, должен быть углом, который геометрически $ n $ -сечение угла на $ n $ конгруэнтных меньших углов, которые в сумме составляют полный угол.
Но уже сейчас мы видим, что это нетривиально: рассмотрим $ n = 3 $. Затем у нас есть знаменитая «невозможная» проблема «троекратного угла», которая раздражала даже древних греков и которую люди продолжали пытаться разгадывать, пока Пьер Ванцель, наконец, не доказал, что ее невозможно решить более двух тысяч лет спустя. Мы просим математический виджет, который может не только разделять на три части, но и углы, составляющие 5, 629 и т. Д., И в порядке систематически !
Действительно, синусоидальная функция не только не является тривиальной, мы можем утверждать, что даже экспоненциальную функцию значительно легче обрабатывать, чем синусоидальную, хотя я не буду здесь приводить такую трактовку.
Итак, как мы это делаем? Что ж, ключевое наблюдение состоит в том, что наша «устойчивая» угловая мера фактически определяется длиной дуги сегмента круга, пересекаемого углом, когда он нарисован в центре круга и спроецирован наружу. В частности, это должно быть «очевидно» из геометрической формулы
(вводимой по кругу).
$$ \ mbox {Длина дуги окружности} = r \ theta $$
Поскольку это всего лишь тривиальное умножение, вся нетривиальность должна заключаться либо в определении $ \ theta $ в терминах геометрических углов, образованных линиями, либо в определении «длины дуги окружности» и, более того, в этих двух задачах. должно быть одинаково сложно.Следовательно, мы сначала начнем с вопроса о дуге, и вы увидите, что в этом ответе будет использована изрядная часть материала Исчисления II, чтобы ответить на этот вопрос уровня Исчисления I о математическом объекте , предположительно , предшествующем исчислению. В самом деле, это и есть вся «радианная мера»: это мера углов в терминах длины дуги части, которую они вырезают из единичной окружности (то есть $ r = 1 $). «Градусы» — это просто странная кратная единица фактической длины, равная $ \ frac {2 \ pi} {360} $ (или лучше $ \ frac {\ tau} {360} $) какой-то другой единицы длины. .
Если вы воспользуетесь книгой по тригонометрии , несколько более , вы увидите кое-что о том, что синус и косинус определяются как в основном координаты на единичной окружности, когда угловая мера $ \ theta $ была размещена из $ x ось $:
$$ C (\ theta): = (\ cos (\ theta), \ sin (\ theta)) $$
Теперь, как сказано выше, $ \ theta $ — это длина дуги . Таким образом, то, что у нас есть выше, называется параметризацией длины дуги круга — и это говорит нам, как нам нужно действовать.{-1} (\ theta) $$
.
Наконец, на этом этапе, имея в руках полное, герметичное определение $ \ sin (x) $, мы готовы оценить предел:
Поскольку «реальная» или базовая функция здесь на самом деле является обратной функцией , то есть $ \ arcsin $, мы сначала выполняем замену переменных: вместо этого мы рассматриваем предел в терминах $ y $, где $ y (х): = \ arcsin (x) $. Обратите внимание, что тривиально $ \ arcsin (0) = 0 $ из определения интеграла, поэтому мы получаем
Теперь что касается правого предела, нам нужно только рассмотреть поведение $ \ arcsin (y) $, когда $ y $ мало.{y} 1 \ d \ xi $$
, когда $ y \ приблизительно 0 $, и тогда правый интеграл приблизительно равен $ y $, следовательно, $ \ arcsin (y) \ приблизительно y $, когда $ y \ приблизительно 0 $ и
Тем не менее, как я уже упоминал ранее, это не решает требований вопроса, который, хотя я уверен, что его первоначальный вопрос давно ушел, тем не менее, все еще актуален для студентов, изучающих математику, за студентами, изучающими математику, вплоть до сегодняшнего дня: ограничить использование только методов Calculus I / pre-Calculus. Я говорю о том, что на самом деле это не совсем возможно и показывает слабость учебной программы в том, что она на самом деле не соответствует правильному логическому построению математической конструкции.
На самом деле должно быть сделано, чтобы оставить триггер для более позднего , то есть пропустить триггер и сначала перейти к исчислению. Когда я изучал математику самостоятельно, я именно так и поступил. На самом деле, как предполагали многие преподаватели, я бы сказал, что большинству людей они не нужны, но им действительно нужно больше статистики.2} $, который является очень хорошим примером отношения площади к интеграции, и это может, если будет подчеркнуто более сильно, потенциально побудить к более тонкому размышлению об интегралах, помимо просто «вставки и исправления правил интеграции». В частности, с более ограниченным набором функций, мы можем подумать о других способах, которыми мы могли бы подойти к ним, и / или о различных способах интерпретации интеграла, которые, как я думаю, могут быть полезны только для разработки более творческих думать о проблемах и меньше углубляться в методы с небольшим полученным реальным пониманием (а механическое измельчение интегралов еще менее актуально с программным обеспечением для компьютерной алгебры; более важным является действительно способность понять проблему и то, как ее части сочетаются друг с другом и приводят к решение. -} \ sin (x) = 0 $$
Я хотел бы иметь возможность проводить доказательство без ссылки на сложные теоремы (теорема о среднем значении, ряды и т. Д.).У меня есть геометрический подход к нахождению предела справа, но мне нужна аналогичная помощь при приближении к нулю слева.
Спасибо.
Обновление : я собираюсь доказать, что синус непрерывен при любом значении $ a $, но сначала мне нужно доказать, что
$$ \ lim _ {\ theta \ to0} \ sin \ theta = 0 \ quad \ text {и} \ quad \ lim _ {\ theta \ to0} \ cos \ theta = 1. $$
Я уже показал, что $ f $ непрерывно в $ a $, если
$$ \ lim_ {h \ to 0} f (a + h) = f (a), $$
так что тогда я могу показать
$$ \ lim_ {h \ to0} \ sin (a + h) = \ sin (a), $$
откуда следует, что синус непрерывен в любой точке $ a $.-} \ sin \ theta = 0 $.
Обновление: Благодаря всей полученной мною хорошей помощи оказалось, что если $ 0 \ le \ theta \ le \ pi / 2 $, то
$$ \ sin \ theta \ le \ theta $$
что, поскольку $ \ sin \ theta $ и $ \ theta $ положительны на $ 0 \ le \ theta \ le \ pi / 2 $, эквивалентно
$$ | \, \ sin \ theta \, | <| \, \ theta \, |. $$
Во-вторых, если $ — \ pi / 2 \ le \ theta \ le0 $, то $ 0 \ le- \ theta \ le \ pi / 2 $. Следовательно, мы можем подставить $ — \ theta $ в последнее неравенство, что приведет к:
$$ \ begin {align *}
| \ sin (- \ theta) \, | & \ le | — \ theta \, | \\
| — \ sin (\ theta) \, | & \ le | — \ theta \, | \\
| \ sin (\ theta) \, | & \ le | \, \ theta \, |
\ end {align *} $$
Следовательно, если $ — \ pi / 2 \ le \ theta \ le \ pi / 2 $, то
$$ | \ sin (\ theta) \, | \ le | \, \ theta \, |.$$
Последний шаг связан с тем, что $ | -x | = | x | $ для всех действительных чисел $ x $. Последнее неравенство эквивалентно
$$ — | \, \ theta \, | \ le \ sin \ theta \ le | \, \ theta \, |, $$
и по теореме сжатия, поскольку оба конца стремятся к нулю при $ \ theta \ to0 $, я показал, что
$$ \ lim _ {\ theta-> 0} \ sin \ theta = 0. $$
Калькулятор
— limit_calculator (sin (x) / x; x) — Solumaths
Сводка:
Калькулятор пределов позволяет вычислить предел функции с подробностями и шагами вычисления.
limit_calculator онлайн
Описание:
Калькулятор пределов находит, существует ли предел в любой точке: предел в 0, предел в «+ oo» и предел в «-oo» функции.
Вычисление предела функции a
Можно вычислить предел в функции , где a представляет действительное число:
Если предел существует и калькулятор может рассчитать, он возвращается.2 + х; х; а`)
Вычисление предела функции 0
Можно вычислить предел при 0 функции :
Если предел существует и калькулятор может рассчитать, он возвращается.
Для результата вычисления предела, например следующего: `lim_ (x-> 0) sin (x) / x`, введите:
limit_calculator (`sin (x) / x; x`)
Вычисление предела функции на плюс бесконечности
Можно вычислить предел на + infini функции :
Если предел существует и калькулятор может рассчитать, он возвращается.
Для результата вычисления предела, например следующего: `lim_ (x -> + oo) sin (x) / x`, введите:
limit_calculator (`sin (x) / x`)
Вычисление предела функции на минус бесконечности
Можно вычислить предел в — infini функции :
Если предел существует и калькулятор может рассчитать, он возвращается.
Для результата вычисления предела, например следующего: `lim_ (x -> — oo) sin (x) / x`, введите:
limit_calculator (`sin (x) / x`)
Калькулятор пределов позволяет вычислить предел функции с подробными сведениями и шагами вычисления.
Синтаксис:
limit_calculator (функция; переменная; значение),
Примеры:
Чтобы вычислить предел sin (x) / x при 0 относительно x, введите :
Калькулятор возвращает 1
Расчет онлайн с помощью limit_calculator (предел функции)
Тригонометрические пределы
Базовый тригонометрический предел —
\ [\ lim \ limits_ {x \ to 0} \ frac {{\ sin x}} {x} = 1. \]
Используя этот предел, можно получить ряд других тригонометрических ограничений:
Далее мы предполагаем, что углы измеряются в радианах.
Решенные проблемы
Щелкните или коснитесь проблемы, чтобы увидеть решение.
Пример 1
Найдите предел \ (\ lim \ limits_ {x \ to 0} {\ large {\ frac {{4x}} {{\ sin 3x}}} \ normalsize} \).2}}} \ normalsize} \).
Пример 3
Найдите предел \ (\ lim \ limits_ {x \ to 0} {\ large \ frac {{\ sin5x — \ sin 3x}} {{\ sin x}} \ normalsize} \).
Пример 4
Вычислить предел \ (\ lim \ limits_ {x \ to 0} {\ large {\ frac {{\ cos \ left ({x + a} \ right) — \ cos \ left ({x — a} \ right) }} {x}} \ normalsize}. \)
Пример 5
Вычислите предел \ (\ lim \ limits_ {x \ to 0} {\ large \ frac {{\ sin ax}} {{\ sin bx}} \ normalsize} \).
Пример 6
Найдите предел \ (\ lim \ limits_ {x \ to b} {\ large \ frac {{\ sin x — \ sin b}} {{x — b}} \ normalsize} \).2}}} {{\ arcsin \ left ({1 — 2x} \ right)}} \ normalsize} \).
Пример 9
Найдите предел \ (\ lim \ limits_ {x \ to 0 + 0} {\ large \ frac {{\ sqrt {1 — \ cos x}}} {x} \ normalsize} \).
Пример 1.
Найдите предел \ (\ lim \ limits_ {x \ to 0} {\ large {\ frac {{4x}} {{\ sin 3x}}} \ normalsize} \).
Решение.
\ [L = {\ lim \ limits_ {x \ to 0} \ frac {{4x}} {{\ sin 3x}}} = {\ lim \ limits_ {x \ to 0} \ frac {{3 \ cdot 4x}} {{3 \ sin 3x}}} = {\ frac {4} {3} \ lim \ limits_ {x \ to 0} \ frac {{3x}} {{\ sin 3x}}} = {\ frac {4} {3} \ lim \ limits_ {x \ to 0} \ frac {1} {{\ large \ frac {{\ sin 3x}} {{3x}} \ normalsize}}} = {\ frac {4} {3} \ frac {{\ lim \ limits_ {x \ to 0} 1}} {{\ lim \ limits_ {x \ to 0} \ large \ frac {{\ sin 3x}} {{3x}} \ normalsize}}.2}}}} = {- 2 \ lim \ limits_ {x \ to 0} \ frac {{\ sin x}} {x} \ cdot \ lim \ limits_ {x \ to 0} \ frac {{\ sin 2x}} {x}} = {- 2 \ cdot 1 \ cdot \ lim \ limits_ {2x \ to 0} \ frac {{2 \ sin 2x}} {{2x}}} = {- 2 \ cdot 2 \ lim \ limits_ {2x \ to 0} \ frac {{\ sin 2x}} {{2x}} = — 4. } \]
Пример 3.
Найдите предел \ (\ lim \ limits_ {x \ to 0} {\ large \ frac {{\ sin5x — \ sin 3x}} {{\ sin x}} \ normalsize} \).
Решение.
Мы используем следующую тригонометрическую идентичность:
\ [{\ sin x — \ sin y} = {2 \ sin \ frac {{x — y}} {2} \ cos \ frac {{x + y}} {2}.} \]
Тогда получаем
\ [{\ lim \ limits_ {x \ to 0} \ frac {{\ sin5x — \ sin 3x}} {{\ sin x}}} = {\ lim \ limits_ {x \ to 0} \ frac { {2 \ sin \ large \ frac {{5x — 3x}} {2} \ normalsize \ cos \ large \ frac {{5x + 3x}} {2} \ normalsize}} {{\ sin x}}} = {\ lim \ limits_ {x \ to 0} \ frac {{2 \ sin x \ cos 4x}} {{\ sin x}}} = {\ lim \ limits_ {x \ to 0} \ left ({2 \ cos 4x} \ right).} \]
Так как \ (\ cos {4x} \) — непрерывная функция в \ (x = 0, \), то
\ [{\ lim \ limits_ {x \ to 0} \ left ({2 \ cos 4x} \ right)} = {2 \ lim \ limits_ {x \ to 0} \ cos 4x} = {2 \ cdot \ cos \ left ({4 \ cdot 0} \ right) = 2 \ cdot 1 = 2. } \]
Пределы формул тригонометрических функций
Подсказка: поиск некоторых тригонометрических идентификаторов может помочь вам. Я использовал delta-epilson, чтобы доказать это государственным деятелям … Сеть обмена стеками Сеть обмена стеками состоит из 176 сообществ вопросов и ответов, включая самое большое и самое большое надежное интернет-сообщество, в котором разработчики могут учиться, делиться своими знаниями и строить свою карьеру.
Какое из следующих утверждений о молекуле воды верно_ quizlet
Введены основные формулы дифференцирования для каждой из тригонометрических функций.Только производная синусоидальной функции вычисляется непосредственно из определения предела. Производные всех остальных триггерных функций выводятся с использованием общих правил дифференцирования.
Формулы составных углов
: https://www.youtube.com/watch?v=SOLnFGvXKAk&list=PLJ-ma5dJyAqozLeG-y7ixDhMFEq0deC7F&index=3 Непрерывность триггерных функций по пределам: . ..
базовый предел x. 0 sinx x = 1. Используя этот предел, можно получить ряд других тригонометрических пределов: lim x → 0 tanx x = 1, lim x → 0 arcsinx x = 1, lim x → 0 arctanx x = 1.
Тригонометрические функции обратных тригонометрических функций приведены в таблице ниже. Быстрый способ получить их — рассмотреть геометрию прямоугольного треугольника, одна сторона которого равна 1, а другая — длина x, а затем применить теорему Пифагора и определения тригонометрических соотношений.
Предел тригонометрической функции, важные пределы, примеры и решения. 11 июня 2018 г. · Раздел 7-3: Подтверждение триггерных пределов. В этом разделе мы собираемся предоставить доказательство двух ограничений, которые используются при выводе производной синуса и косинуса в разделе «Производные триггерных функций» главы «Производные».
Уроки тригонометрии в старших классах подробно знакомят учащихся с различными тригонометрическими тождествами, свойствами и функциями. Студенты обычно изучают тригонометрию после завершения предыдущего курса по алгебре и геометрии, но перед тем, как пройти предварительное исчисление и исчисление.
B mod shock package
Уроки тригонометрии в старших классах подробно знакомят учащихся с различными тригонометрическими идентичностями, свойствами и функциями.Студенты обычно изучают тригонометрию после завершения предыдущего курса по алгебре и геометрии, но перед тем, как пройти предварительное исчисление и исчисление.
21 декабря 2020 г. · Обратные тригонометрические функции. Из их графиков мы знаем, что ни одна из тригонометрических функций не является взаимно однозначной во всей своей области определения. Однако мы можем ограничить эти функции подмножествами их областей, где они взаимно однозначны. Например, \ (y = \ sin \; x \) взаимно однозначно на интервале \ (\ left [- \ frac {\ pi} {2}, \ frac {\ pi} {2} \ right . ..
Тригонометрия — это изучение треугольников, которые, конечно же, содержат углы. Познакомьтесь с некоторыми особыми правилами для углов и различных других важных функций, определений и переводов. Синусы и косинусы — это две тригонометрические функции, которые сильно влияют на любое изучение тригонометрии; у них есть свои формулы и правила, которые вы захотите понять, если […]
Глава пятая Цели TRIG 1. Напишите выражение в терминах триггерной функции или функций. 2. Разложите на множители и упростите триггерные выражения.3. Найдите значение каждой триггерной функции с учетом значения одной из функций. 4. Проверьте идентификационные данные триггеров. 5. Используйте тождества суммы и разности косинуса, синуса и тангенса, чтобы найти значения функции. 6.
5 ноября 2020 г. · Изучите периодическое свойство триггерных функций. Все триггерные функции являются периодическими, что означает, что они возвращаются к одному и тому же значению после поворота в течение одного периода. Примеры: Функция f (x) = sin x имеет период 2Pi. Функция f (x) = tan x имеет период Pi. Функция f (x) = sin 2x имеет период Pi.
Если числитель не равен нулю, называется a, тогда a / 0 не определено (деление на 0 не определено), поэтому его предел не существует. В пределе a / 0 = ± ∞ зависит от знака. Когда предел равен ± ∞, он называется бесконечным пределом или неограниченным пределом. В бесконечном пределе предела не существует, потому что мы не рассматриваем ± ∞ как число. Пределы функций mc-TY-limits-2009-1 В этом разделе мы объясняем, что означает стремление функции к бесконечности , до минус бесконечности или до реального предела, поскольку x стремится к бесконечности или к минус бесконечности.Мы также объясняем, что означает стремление функции к действительному пределу, когда x стремится к заданному действительному числу. В каждом случае мы приводим пример класса
средней школы по тригонометрии, который подробно знакомит учащихся с различными тригонометрическими тождествами, свойствами и функциями. Студенты обычно изучают тригонометрию после завершения предыдущего курса по алгебре и геометрии, но перед тем, как пройти предварительное исчисление и исчисление.
Solving Trig Equations 1 — Cool Math предлагает бесплатные уроки математики онлайн, классные математические игры и забавные математические задания.Действительно понятные уроки математики (предварительная алгебра, алгебра, предварительное вычисление), классные математические игры, графические онлайн-калькуляторы, геометрическое искусство, фракталы, многогранники, области для родителей и учителей.
Средний счет за воду в Детройте
Avanti derma
Тригонометрия в современном понимании началась с греков. Гиппарх (около 190–120 гг. До н. Э.) Был первым, кто построил таблицу значений для тригонометрической функции. Он считал, что каждый треугольник — плоский или сферический — вписанный в круг, так что каждая сторона становится хордой (т. Е. прямая линия, соединяющая две точки на кривой или поверхности, как показано вписанным треугольником ABC в. {-1} $ или $ \ arcsin $ («арксинус») и часто записывается asin на различных языках программирования.
Очевидно, что, когда h приближается к 0, координата P приближается к соответствующей координате B. Но по определению мы знаем, что sin (0) = 0 и cos (0) = 1. Значения функций совпадают. с теми из пределов, когда x стремится к 0 (напомните определение непрерывности, которое у нас есть).lim x → 0 sin (x) = sin (0) = 0 lim x → 0 cos (x) = cos (0) = 1
калькулятор тригонометрических пределов. специальные тригонометрические пределы. два специальных тригонометрических предела. пределы с использованием тригонометрических тождеств. пределы и непрерывность тригонометрических функций. пределы тригонометрических функций на бесконечности. ограничение триггера с использованием тождества двойного угла. пределы тригонометрических функций на бесконечности pdf. предельные примечания к лекциям. пределы триггеров без l hopital.lim 1-cosx / (sinx). два специальных тригонометрические пределы. особые пределы …
Гидролизует ли e coli крахмал Новый шаблон водительских прав в Иллинойсе
Викторина Chemthink по ионному связыванию Номер телефона запасной зоны
Fm20 лучший директор футболаS10 подвеска грузовика
Портал компании Microsoft intune приложение не wo rking
Это позволяет им выходить за рамки прямоугольных треугольников, где углы могут иметь любую величину, даже за 360 °, и могут быть как положительными, так и отрицательными. Подробнее об этом см. Функции тригонометрии для больших и отрицательных углов. Идентичности — замена функции другими Тригонометрические идентичности — это просто способы написания одной функции с использованием других.
Дизайн спринклерной системы Загрузка файла в angularjs w3schools
Напольное покрытие Mapei
Стихи с днем рождения для парня в тюрьме
Элитный симулятор полета
9045 определенный момент времени, когда норма финансовых сбережений является тригонометрической функцией.Производные тригонометрических функций. Показывает, что предел (cos (x) -1) / x = 0 за счет использования того факта, что limit (sin x) / x = 1. Также есть три производные тригонометрические задачи с решениями. формулы сложения тригонометрических тождеств, формулы двойного угла, формулы половинного угла, формулы для удаления квадрата и куба из sin и cos —— оставляйте свои комментарии ниже —— указатель отказа от ответственности по математическим задачам:
Тормозная жидкость утечка из бачка главного цилиндра Sherman red yoder part 2 sbar
тюрьма округа Ланкастер
Coco annotator
Trx250r club
Интеграция тригонометрических функций. При интегрировании функции, если в подынтегральном выражении присутствуют тригонометрические функции, мы можем использовать тригонометрические тождества, чтобы упростить функцию и упростить ее интегрирование. Некоторые формулы интегрирования тригонометрических функций приведены ниже: Sin2x = \ [\ frac {1-cos2x} {2} \] cos2x = \ [\ frac {1 + cos2x} {2} \] MATH 1910-Тригонометрические пределы и сжатие Теорема. Нахождение пределов, связанных с тригонометрическими функциями. Двумя важными ограничениями, связанными с тригонометрическими функциями, являются 1. lim x → 0 sinx x 1 2. lim x → 0 1 −cosx x 0 Первый из них мы рассмотрели ранее.Это можно доказать с помощью геометрии. Давайте выведем вторую из первой.
График церемонии натурализации Колумбус, Огайо, 2019 Программа для покупателей Fannie mae, готовая
Лотерея NC 3, дневное время
Заработная плата руководителей Nv energy
Коммутационная плата C11g
Синометрические функции Trigon произношение, перевод тригонометрических функций, английское словарное определение тригонометрических функций. тригонометрическая функция В прямоугольном треугольнике три основные тригонометрические функции: синус θ = противоположный / гипотенуза, косинус θ = смежный / гипотенуза … Чтобы найти пределы функций, в которых задействованы тригонометрические функции, вы должны изучить как тригонометрические тождества, так и пределы тригонометрических функций. формулы функций. Вот список решаемых простых и сложных задач тригонометрических пределов с пошаговыми решениями в различных методах оценки тригонометрических пределов в исчислении.
Google home несколько сетей Wi-Fi Студент прикладывает силу 72n
City of Heroes mastermind builds
Itunes не может сделать резервную копию iphone
Fs19 john deere x9
, 2019 · 6.Интегрирование: обратные тригонометрические формы. М. Борна. Используя наши знания о производных обратных тригонометрических тождеств, которые мы узнали ранее, и обращая эти процессы дифференцирования, мы можем получить следующие интегралы, где `u` является функцией` x`, то есть `u = f (x) `.
Ограничения по весу оси в Джорджии Antzle Community Edition
Разархивировать rar онлайн 823871 переключатель
37 недель беременных в Интернете
37 недель беременных в Интернете движение
9045 Proxy commander deck
Бухгалтерский баланс Федерального резерва в процентах от ввп
• используйте тригонометрические тождества для интеграции sin2 x, cos2 x и функций форм in3x cos4x.• интегрировать произведения синусов и косинусов, используя смесь тригонометрических тождеств и интегрирования путем подстановки • использовать тригонометрические замены для оценки интегралов Содержание 1. Введение 2 2.
Автогрейдер Gradescope не смог выполнить Toddo hells angels
Заполнить меню с помощью json
Команды Ragebot 3
Иллинойс выберите 3 результата за прошлую неделю
Гиперболические тригонометрические функции расширяют понятие параметрических уравнений для единичной окружности (x = cos t (x = \ cos t (x = cos t и y = sin t) y = \ sin t) y = sin t) параметрическим уравнениям для гиперболы, которые дают следующие два основных гиперболических уравнения:
Двигатель Cat 924g Sheeko wasmo iyo raaxo 2
Преобразование почтальона в powershell
Нумерация узлов Abaqus Настройки телевизора Jvc
Таймер 30 секунд громко
Корки в носу Лучший портативный воздушный компрессор 110 В
Подобные цифры викторины ответы
MSI Dragon Center Shift Sport 6
Любимая беспроводная игровая мышь 9463
Пользовательский интервал сетки Matplotlib Части рабочего листа химической реакции
Spn 520372 fmi 16
Имена злоумышленников для instagram Пигмент Super Chameleon
Свойства серого чугуна
Свойства серого чугуна
Ссылка Лист — Список основных личностей и правил. pdf doc; Триггер (часть I) — Толкование триггерных функций и практика с инверсиями. pdf doc; Триггер (часть II) — Больше практики. pdf doc; Дениз и Чад — Иллюстрация эффектов изменения амплитуды и периода. pdf doc Гиперболические тригонометрические функции расширяют понятие параметрических уравнений для единичной окружности (x = cos t (x = \ cos t (x = cos t и y = sin t) y = \ sin t) y = sin t) параметрическим уравнениям для гиперболы, которые дают следующие два фундаментальных гиперболических уравнения:
Diablo 3 new Season 21 best builds8tb hyperspin жесткий диск
50 Эта функция триггера поможет найти график и конкретные характеристики (период, частота, амплитуда, фазовый сдвиг и вертикальный сдвиг) более сложных тригонометрических функций, таких как \ (f (x) = 3 \ cos (\ pi (x-2) +3) — \ frac {\ pi} {4} \) Этот график имеет дело только с тригонометрическими функциями.
Sonarr remove seriesUc berkeley accept rate by major 2018
Совместимость с оригинальным xbox sata с жестким диском Fite tv soccer
Content Dictionary 100 круглый барабан
Oculus rift s gun stock reddit
Как заменить dremel 300 bit 2
Тест по главе 3 по математике 1
Городское вождение автомобиля 1.038 mod apk
Используйте серию Тейлора для оценки калькулятора пределов
Бесплатный калькулятор расчетов — шаг за шагом вычисляйте пределы, интегралы, производные и ряды Этот веб-сайт использует файлы cookie, чтобы обеспечить максимальное удобство. У разработчиков было 31 декабря 2020 г. · РУКОВОДСТВО ПО РЕШЕНИЯМ Trim: MATH 1010 — Applied Finite Mathematics by D.W. Руководство по решениям для учащихся для прикладного исчисления Уонера / Костенобля, 7-е, 7-е издание, Стефан Ванер (автор), Стивен Костенобль (автор) ISBN-13: 978-1337291293. Решения в формате PDF.Конечная математика и прикладное исчисление (6-е издание), ответы на главу 0 — Раздел 0.1 — Действительные числа — Упражнения — Страница 7 1, включая рабочий шаг по …
Низкий поршень Холли с промежуточным охладителем
Первое обозначение единичной дроби не использовалось в Классической Греции. Бесконечный ряд, преобразованный в рациональное число 4/3, должен был быть суммирован с площадью параболы. Бесконечный ряд, возможно, сообщил об историческом методе исчисления «исчерпания исчерпания».Ряд Тейлора с одной и несколькими переменными • Ряд Тейлора с одной переменной: пусть f — бесконечно дифференцируемая функция в некотором открытом интервале вокруг x = a. е (Икс) знак равно X∞ К знак равно 0 е (К) (а) К! (Х-а) К знак равно е (а) + е ‘(а) (х-а) + е’ ‘(а) 2! (x − a) 2 + ··· • Линейное приближение по одной переменной: возьмите постоянные и линейные члены из . ..
Код ошибки 105 samsung tv
series. Кроме того, эта статья покажет, как мы можем использовать Mathematica для поддержки и информирования нашего исследования серий.2) $, что означает, что предел равен 216, но как рассчитать это разложение Тейлора?
Арбалетные болты Lumenok 22 дюйма
3E: Как бы вы приблизились к e? 0,6, используя, например, серию Тейлора? Уильям Л. Бриггс, Лайл Кокран, Бернард Джиллет 9780321570567 Исчисление: ранние трансцендентальные методы 1-е издание 6.4.2. Распознайте разложения общих функций в ряды Тейлора. 6.4.3 Распознавать и применять методы нахождения ряда Тейлора для функции.6.4.4 Используйте ряды Тейлора для решения дифференциальных уравнений. 6.4.5 Используйте ряды Тейлора для вычисления неэлементарных интегралов.
Рейчел Мэддоу оценок на этой неделе
Использование калькулятора. Как и калькулятор комбинаций, калькулятор перестановок находит количество подмножеств, которые могут быть взяты из большего набора. 22 января 2020 г. · В нашем предыдущем уроке «Ряд Тейлора» мы узнали, как создать полином Тейлора (ряд Тейлора), используя наш центр, что, в свою очередь, помогает нам сгенерировать радиус и интервал сходимости, производные и факториалы.Мы также узнали, что существует пять основных формул разложения Тейлора / Маклорена.
Крейсерская скорость Cessna 182 и расход топлива
Расчет расширения любой дифференцируемой функции в серии Тейлора; Чтобы вычислить разложение Тейлора в 0 для `f: x-> cos (x) + sin (x) / 2`, в порядке 4, просто введите taylor_series_expansion (` cos (x) + sin (x) / 2; x; 0; 4`) после расчета возвращается результат. Калькулятор рядов Тейлора позволяет вычислить разложение Тейлора функции.Оценивайте выражения с произвольной точностью. Выполните алгебраические манипуляции с символическими выражениями. Выполняйте основные вычислительные задачи (пределы, дифференцирование и интегрирование) с символьными выражениями. Решайте полиномиальные и трансцендентные уравнения. Решите некоторые дифференциальные уравнения.
Ck2 theocracy vassal limit
Derivative Calculator. Рассчитывайте производные онлайн — с помощью шагов и графиков! Калькулятор производных поддерживает вычисление первой, второй,…, пятой производных, а также в противном случае применяется вероятностный алгоритм, который оценивает и сравнивает обе функции в случайно выбранных местах.Ряд Тейлора — это умный способ аппроксимировать любую функцию как многочлен с бесконечным числом членов. Каждый член полинома Тейлора происходит от производных функции в одной точке.
Wilson combat p320 compact обзор
Хотелось бы оценить гауссиан, но есть одна проблема: нет элементарной первообразной e x2. Это означает, что мы не можем полагаться на фундаментальную теорему исчисления для вычисления интеграла.Но используя ряд Тейлора, мы можем приблизить значение этого интеграла. Пример 1.2. Приблизительно Z 1 3 0 e x2dxto в пределах 10 6 от его …
T = taylor (f, var) приближает f с расширением ряда Тейлора f до пятого порядка в точке var = 0. var, тогда Тейлор использует переменную по умолчанию, определяемую symvar (f, 1).
Как разблокировать iphone без пароля после перезапуска
Калькулятор заработной платы покажет вам ежемесячный или годовой заработок с учетом налогов Великобритании, государственного страхования и студенческой ссуды.Обратите внимание: несмотря на то, что мы делаем все возможное, чтобы информация, предоставляемая Калькулятором заработной платы, была верной, она не является безошибочной.
Оцените предел, используя ряд Тейлора: 2 4 16 lim ln (3) x x x → — -. MATH 1C Cembellin 2. Рассмотрим дифференциальное уравнение ‘() 4 8, (0) 0 y t y y + = (a) Найдите решение степенного ряда для задачи начального значения, указанной выше.
Устойчивое развитие туризма означает
Японская коробка конфет
Land Cruiser Cummins Diesel конверсия
Magpul Magpul Magpul песочного цвета
Vw t5 Apple Carplay Radio
Длина бедренной кости
Subaru тип жидкости переднего дифференциала для записи
первые три ненулевых члена и общий член ряда Тейлора для f около x = 0.(b) Используйте ряд Тейлора для f относительно x = 0, найденный на панели (a), чтобы определить, имеет ли f относительный максимум, относительный минимум или ни один из них при x = 0. Обоснование вашего ответа. (c) Напишите многочлен Тейлора пятой степени для g около x …
Этот рабочий лист выполняет множество вещей, связанных с теоремой Грина для бесконечно малого треугольника. Используя ряд Тейлора, он показывает, как вычислить линейный интеграл векторного поля по отрезку прямой до второго порядка. Отчасти здесь интересно отметить, насколько легко этот метод обобщается для получения формул более высокого порядка.{- 1}} x $$ с помощью функции расширения ряда Маклорена. Рассмотрим функцию вида \ [f \ left
] Часто бывает полезно представлять функции степенными рядами. Так, например, можно показать, что тригонометрическая функция sin (x) представлена рядом. Мы выведем формулу разложения Маклаурина и ее обобщение, разложение Тейлора для произвольных функций.
Is ut austin a good school reddit
Scary stories to copy and paste
Проверить статус дрос онлайн
Используйте правила мощности для степеней, чтобы упростить выражение
Вы искали 2 делить на 3 корня из 2? На нашем сайте вы можете получить ответ на любой математический вопрос здесь. Подробное
решение с описанием и пояснениями поможет вам разобраться даже с самой сложной задачей и 2 корня из 3 делить на 2, не
исключение. Мы поможем вам подготовиться к домашним работам, контрольным, олимпиадам, а так же к поступлению
в вуз.
И какой бы пример, какой бы запрос по математике вы не ввели — у нас уже есть решение.
Например, «2 делить на 3 корня из 2».
Применение различных математических задач, калькуляторов, уравнений и функций широко распространено в нашей
жизни. Они используются во многих расчетах, строительстве сооружений и даже спорте. Математику человек
использовал еще в древности и с тех пор их применение только возрастает. Однако сейчас наука не стоит на
месте и мы можем наслаждаться плодами ее деятельности, такими, например, как онлайн-калькулятор, который
может решить задачи, такие, как 2 делить на 3 корня из 2,2 корня из 3 делить на 2,3 корень из 2 поделить на 2,3 корня из 2 делить на 2. На этой странице вы найдёте калькулятор,
который поможет решить любой вопрос, в том числе и 2 делить на 3 корня из 2. Просто введите задачу в окошко и нажмите
«решить» здесь (например, 3 корень из 2 поделить на 2).
Где можно решить любую задачу по математике, а так же 2 делить на 3 корня из 2 Онлайн?
Решить задачу 2 делить на 3 корня из 2 вы можете на нашем сайте https://pocketteacher.ru. Бесплатный
онлайн решатель позволит решить онлайн задачу любой сложности за считанные секунды. Все, что вам необходимо
сделать — это просто
ввести свои данные в решателе. Так же вы можете посмотреть видео инструкцию и узнать, как правильно ввести
вашу задачу на нашем сайте. А если у вас остались вопросы, то вы можете задать их в чате снизу слева на странице
калькулятора.
правила, методы, примеры как делить квадратные корни
Наличие квадратных корней в выражении усложняет процесс деления, однако существуют правила, с помощью которых работа с дробями становится значительно проще.
Единственное, что необходимо все время держать в голове — подкоренные выражения делятся на подкоренные выражения, а множители на множители. В процессе деления квадратных корней мы упрощаем дробь. Также, напомним, что корень может находиться в знаменателе.
Метод 1. Деление подкоренных выражений
Алгоритм действий:
Записать дробь
Если выражение не представлено в виде дроби, необходимо его так записать, потому так легче следовать принципу деления квадратных корней.
Пример 1
144÷36, это выражение следует переписать так: 14436
Использовать один знак корня
В случае если и в числителе, и знаменателе присутствует квадратные корни, необходимо записать их подкоренные выражения под одним знаком корня, чтобы сделать процесс решения проще.
Напоминаем, что подкоренным выражением (или числом) является выражением под знаком корня.
Пример 2
14436. Это выражение следует записать так: 14436
Разделить подкоренные выражения
Просто разделите одно выражение на другое, а результат запишите под знаком корня.
Пример 3
14436=4, запишем это выражение так: 14436=4
Упростить подкоренное выражение (если необходимо)
Если подкоренное выражение или один из множителей представляют собой полный квадрат, упрощайте такое выражение.
Напомним, что полным квадратом является число, которое представляет собой квадрат некоторого целого числа.
Пример 4
4 — полный квадрат, потому что 2×2=4. Из этого следует:
4=2×2=2. Поэтому 14436=4=2.
Метод 2. Разложение подкоренного выражения на множители
Алгоритм действий:
Записать дробь
Перепишите выражение в виде дроби (если оно представлено так). Это значительно облегчает процесс деления выражений с квадратными корнями, особенно при разложении на множители.
Пример 5
8÷36, переписываем так 836
Разложить на множители каждое из подкоренных выражений
Число под корнем разложите на множители, как и любое другое целое число, только множители запишите под знаком корня.
Пример 6
Упростить числитель и знаменатель дроби
Для этого следует вынести из-под знака корня множители, представляющие собой полные квадраты. Таким образом, множитель подкоренного выражения станет множителем перед знаком корня.
Пример 7
2266×62×2×2, из этого следует: 836=226
Рационализировать знаменатель (избавиться от корня)
В математике существуют правила, по которым оставлять корень в знаменателе — признак плохого тона, т.е. нельзя. Если в знаменателе присутствует квадратный корень, то избавляйтесь от него.
Умножьте числитель и знаменатель на квадратный корень, от которого необходимо избавиться.
Пример 8
В выражении 623 необходимо умножить числитель и знаменатель на 3, чтобы избавиться от него в знаменателе:
623×33=62×33×3=669=663
Упростить полученное выражение (если необходимо)
Если в числителе и знаменателе присутствуют числа, которые можно и нужно сократить. Упрощайте такие выражения, как и любую дробь.
Пример 9
26 упрощается до 13; таким образом 226упрощается до 123=23
Нужна помощь преподавателя?
Опиши задание — и наши эксперты тебе помогут!
Описать задание
Метод 3. Деление квадратных корней с множителями
Алгоритм действий:
Упростить множители
Напомним, что множители представляют собой числа, стоящие перед знаком корня. Для упрощения множителей понадобится разделить или сократить их. Подкоренные выражения не трогайте!
Пример 10
432616. Сначала сокращаем 46: делим на 2 и числитель, и знаменатель: 46=23.
Упростить квадратные корни
Если числитель нацело делится на знаменатель, то делите. Если нет, то упрощайте подкоренные выражения, как и любые другие.
Пример 11
32 делится нацело на 16, поэтому: 3216=2
Умножить упрощенные множители на упрощенные корни
Помним про правило: не оставлять в знаменателе корни. Поэтому просто перемножаем числитель и знаменатель на этот корень.
Пример 12
Рационализировать знаменатель (избавиться от корня в знаменателе)
Пример 13
4327. Следует умножить числитель и знаменатель на 7, чтобы избавиться от корня в знаменателе.
437×77=43×77×7=42149=4217
Метод 4. Деление на двучлен с квадратным корнем
Алгоритм действий:
Определить, находится ли двучлен (бином) в знаменателе
Напомним, что двучлен представляет собой выражение, которое включает 2 одночлена. Такой метод имеет место быть только в случаях, когда в знаменателе двучлен с квадратным корнем.
Пример 14
15+2— в знаменателе присутствует бином, поскольку есть два одночлена.
Найти выражение, сопряженное биному
Напомним, что сопряженный бином является двучленом с теми же одночленами, но с противоположными знаками. Чтобы упростить выражение и избавиться от корня в знаменателе, следует перемножить сопряженные биномы.
Пример 15
5+2и 5-2 — сопряженные биномы.
Умножить числитель и знаменатель на двучлен, который сопряжен биному в знаменателе
Такая опция поможет избавиться от корня в знаменателе, поскольку произведение сопряженных двучленов равняется разности квадратов каждого члена биномов: (a-b)(a+b)=a2-b2
Пример 16
15+2=1(5-2)(5-2)(5+2)=5-2(52-(2)2=5-225-2=5-223.
Из этого следует: 15+2=5-223.
Советы:
Если вы работаете с квадратными корнями смешанных чисел, то преобразовывайте их в неправильную дробь.
Отличие сложения и вычитания от деления — подкоренные выражения в случае деления не рекомендуется упрощать (за счет полных квадратов).
Никогда (!) не оставляйте корень в знаменателе.
Никаких десятичных дробей или смешанных перед корнем — необходимо преобразовать их в обыкновенную дробь, а потом упростить.
В знаменателе сумма или разность двух одночленов? Умножьте такой бином на сопряженный ему двучлен и избавьтесь от корня в знаменателе.
Почему нельзя делить на ноль?
«Делить на ноль нельзя!» — большинство школьников заучивает это правило наизусть, не задаваясь вопросами. Все дети знают, что такое «нельзя» и что будет, если в ответ на него спросить: «Почему?» А ведь на самом деле очень интересно и важно знать, почему же нельзя.
Всё дело в том, что четыре действия арифметики — сложение, вычитание, умножение и деление — на самом деле неравноправны. Математики признают полноценными только два из них — сложение и умножение. Эти операции и их свойства включаются в само определение понятия числа. Все остальные действия строятся тем или иным образом из этих двух.
Рассмотрим, например, вычитание. Что значит 5 – 3? Школьник ответит на это просто: надо взять пять предметов, отнять (убрать) три из них и посмотреть, сколько останется. Но вот математики смотрят на эту задачу совсем по-другому. Нет никакого вычитания, есть только сложение. Поэтому запись 5 – 3 означает такое число, которое при сложении с числом 3 даст число 5. То есть 5 – 3 — это просто сокращенная запись уравнения: x + 3 = 5. В этом уравнении нет никакого вычитания. Есть только задача — найти подходящее число.
Точно так же обстоит дело с умножением и делением. Запись 8 : 4 можно понимать как результат разделения восьми предметов по четырем равным кучкам. Но в действительности это просто сокращенная форма записи уравнения 4 · x = 8.
Вот тут-то и становится ясно, почему нельзя (а точнее невозможно) делить на ноль. Запись 5 : 0 — это сокращение от 0 · x = 5. То есть это задание найти такое число, которое при умножении на 0 даст 5. Но мы знаем, что при умножении на 0 всегда получается 0. Это неотъемлемое свойство нуля, строго говоря, часть его определения.
Такого числа, которое при умножении на 0 даст что-то кроме нуля, просто не существует. То есть наша задача не имеет решения. (Да, такое бывает, не у всякой задачи есть решение.) А значит, записи 5 : 0 не соответствует никакого конкретного числа, и она просто ничего не обозначает и потому не имеет смысла. Бессмысленность этой записи кратко выражают, говоря, что на ноль делить нельзя.
Самые внимательные читатели в этом месте непременно спросят: а можно ли ноль делить на ноль? В самом деле, ведь уравнение 0 · x = 0 благополучно решается. Например, можно взять x = 0, и тогда получаем 0 · 0 = 0. Выходит, 0 : 0=0? Но не будем спешить. Попробуем взять x = 1. Получим 0 · 1 = 0. Правильно? Значит, 0 : 0 = 1? Но ведь так можно взять любое число и получить 0 : 0 = 5, 0 : 0 = 317 и т. д.
Но если подходит любое число, то у нас нет никаких оснований остановить свой выбор на каком-то одном из них. То есть мы не можем сказать, какому числу соответствует запись 0 : 0. А раз так, то мы вынуждены признать, что эта запись тоже не имеет смысла. Выходит, что на ноль нельзя делить даже ноль. (В математическом анализе бывают случаи, когда благодаря дополнительным условиям задачи можно отдать предпочтение одному из возможных вариантов решения уравнения 0 · x = 0; в таких случаях математики говорят о «раскрытии неопределенности», но в арифметике таких случаев не встречается.)
Вот такая особенность есть у операции деления. А точнее — у операции умножения и связанного с ней числа ноль.
Ну, а самые дотошные, дочитав до этого места, могут спросить: почему так получается, что делить на ноль нельзя, а вычитать ноль можно? В некотором смысле, именно с этого вопроса и начинается настоящая математика. Ответить на него можно только познакомившись с формальными математическими определениями числовых множеств и операций над ними. Это не так уж сложно, но почему-то не изучается в школе. Зато на лекциях по математике в университете вас в первую очередь будут учить именно этому.
Ответил: Александр Сергеев
Чиcло пи. π, 2π, 1/π, π/2, π/3, π/4, π/180, (π/180)2, π2, π3, π4 и др.
Навигация по справочнику TehTab.ru: главная страница / / Техническая информация / / Математический справочник / / Таблицы численных значений. (Таблица квадратов, кубов, синусов ….) + Таблицы Брадиса / / Чиcло пи. π, 2π, 1/π, π/2, π/3, π/4, π/180, (π/180)2, π2, π3, π4 и др.
Чиcло пи. π, 2π, 1/π, π/2, π/3, π/4, π/180, (π/180)2, π2, π3, π2, корень квадратный из π, ln π, lg π, πe, eπ, e-π, e1/(2π) , ii , e-1/(2π) и др..
Обращаем ваше внимание на то, что данный интернет-сайт носит исключительно информационный характер. Информация, представленная на сайте, не является официальной и предоставлена только в целях ознакомления. Все риски за использование информаци с сайта посетители берут на себя. Проект TehTab.ru является некоммерческим, не поддерживается никакими политическими партиями и иностранными организациями.
Таблица синусов.
Таблица синусов.
Таблица синусов от 1 до 360 градусов. Значения синусов сведены в таблицу. На другой странице размещена тригонометрическая таблица с корнями для школьников.
Тригонометрическая таблица синусов начинается со значения угла альфа равного единице. Синус угла ноль градусов sin 0 равен нулю. Точно такое же значение имеет синус 360 градусов sin 360 или синус 2пи радиан, который можно найти в таблице синусов.
синус угла 0 градусов = синус угла 0 радиан = 0
sin 0 = 0
sin 360 = sin 2pi = 0
Синус 30 градусов sin 30 равен 0,5 или 1/2. В радианной мере мере углов это значение синуса соответствует синусу пи/6. В таблице синусов это значение тригонометрической функции sin можно найти напротив угла в 30 градусов.
Тригонометрическая таблица синусов, помимо широко распространнехых значений синуса, содержит так же следующие значения: синус 5, sin 6, синус 10 градусов в градусной мере углов, а так же sin 12, синус 15, sin 20 градусов.
Синус 45 градусов sin 45 равняется 0,7071 или корень из двух деленный на два. В радианах это соответствует синусу пи/4 радиан.
Другие значения синуса, которые представлены в таблице для углов больше 90 градусов, можно получить так же при помощи формул приведения тригонометрических функций
Если вам понравилась публикация и вы хотите знать больше, помогите мне в работе над другими материалами.
Как извлечь корень в Эксель: квадратный, кубический, в степени
Среди базовых математических вычислений помимо сложения, вычитания, умножения и деления можно выделить возведение в степень и обратное действие – извлечение корня. Давайте посмотрим, каким образом можно выполнить последнее действие в Эксель разными способами.
Метод 1: использование функции КОРЕНЬ
Множество операций в программе реализуется с помощью специальных функций, и извлечение корня – не исключение. В данном случае нам нужен оператор КОРЕНЬ, формула которого выглядит так:
=КОРЕНЬ(число)
Для выполнения расчета достаточно написать данную формулу в любой свободной ячейке (или в строке формул, предварительно выбрав нужную ячейку). Слово “число”, соответственно, меняем на числовое значение, корень которого нужно найти.
Когда все готово, щелкаем клавишу Enter и получаем требуемый результат.
Вместо числа можно, также, указать адрес ячейки, содержащей число.
Указать координаты ячейки можно как вручную, прописав их с помощью клавиш на клавиатуре, так и просто щелкнув по ней, когда курсор находится в положенном месте в формуле.
Вставка формулы через Мастер функций
Воспользоваться формулой для извлечения корня можно через окно вставки функций. Вот, как это делается:
Выбрав ячейку, в которой мы хотим выполнить расчеты, щелкаем по кнопке “Вставить функцию” (fx).
В окне мастера функций выбираем категорию “Математические”, отмечаем оператор “КОРЕНЬ” и щелкаем OK.
Перед нами появится окно с аргументом функции для заполнения. Как и при ручном написании формулы можно указать конкретное число или ссылку на ячейку, содержащую числовое значение. При этом, координаты можно указать, напечатав их с помощью клавиатуры или просто кликнуть по нужному элементу в самой таблице.
Щелкнув кнопку OK мы получим результат в ячейке с функцией.
Вставка функции через вкладку “Формулы
Встаем в ячейку, в которой хотим произвести вычисления. Щелкаем по кнопке “Математические” в разделе инструментов “Библиотека функций”.
Пролистав предложенный перечень находим и кликаем по пункту “КОРЕНЬ”.
На экране отобразится уже знакомое окно с аргументом, который нужно заполнить, после чего нажать кнопку OK.
Метод 2: нахождение корня путем возведения в степень
Описанный выше метод позволяет с легкостью извлекать квадратный корень из числа, однако, для кубического уже не подходит.(1/3).
Нажав Enter, получаем результат вычислений.
Аналогично работе с функцией КОРЕНЬ, вместо конкретного числа можно указать ссылку на ячейку.
Заключение
Таким образом, в Excel можно без особых усилий извлечь корень из любого числа, и сделать это можно разными способами. К тому же, возможности программы позволяют выполнять расчеты для извлечения не только квадратного, но и кубического корня. В редких случаях требуется найти корень n-степени, но и эта задача достаточно просто выполняется в программе.
Глава МИД Венгрии назвал свой народ самым коренным на Украине
https://ria.ru/20210708/ukraina-1740418928.html
Глава МИД Венгрии назвал свой народ самым коренным на Украине
Глава МИД Венгрии назвал свой народ самым коренным на Украине — РИА Новости, 08.07.2021
Глава МИД Венгрии назвал свой народ самым коренным на Украине
Принятый на Украине закон о коренных народах не способствует улучшению ситуации с венгерским меньшинством, заявил глава МИД Венгрии Петер Сийярто в интервью… РИА Новости, 08.07.2021
МОСКВА, 8 июл — РИА Новости. Принятый на Украине закон о коренных народах не способствует улучшению ситуации с венгерским меньшинством, заявил глава МИД Венгрии Петер Сийярто в интервью «Известиям».По мнению министра, именно его народ можно считать самым коренным на территории Украины.»Я не могу представить на Украине более коренного народа, чем венгры. Это, конечно, некоторое преувеличение, но тем не менее эти люди живут на этой территории на протяжении веков. Там даже есть люди, которые, не покидая одного города, могли быть гражданами аж пяти стран — СССР, Украины, Чехословакии, Словакии, Венгрии. Менялась принадлежность территории, но не проживающий на ней народ», — подчеркнул Сийярто.Ранее Верховная рада приняла закон «О коренных народах Украины», в перечень которых, в частности, не включены русские. При этом в тексте отдельно прописаны как коренные народы те, что сформировались на территории Крыма: крымские татары, караимы и крымчаки. Документ должен подписать Владимир Зеленский, который и был его инициатором.Проект встретил критику как в России, так и на Украине. Так, глава региональной национально-культурной автономии крымских татар Эйваз Умеров назвал его клоунадой. А украинская партия «Оппозиционная платформа — За жизнь» планирует обратиться в Конституционный суд страны. Владимир Путин, в свою очередь, напомнил, что русские испокон веков жили на территории Украины и решение объявить их «некоренными» продиктовано недружественной позицией, которую заняли в Киеве. Ранее российский лидер подчеркивал, что идея делить народы на коренные и нет напоминает теорию и практику нацистской Германии.
россия, мид венгрии, петер сийярто, верховная рада украины, владимир зеленский, владимир путин, словакия, киев, в мире
12:48 08.07.2021 (обновлено: 13:16 08.07.2021)
Глава МИД Венгрии назвал свой народ самым коренным на Украине
Рационализировать знаменатель
«Рационализация знаменателя» — это когда мы перемещаем корень (например, квадратный корень или кубический корень) из нижней части дроби в верхнюю.
О нет! Иррациональный знаменатель!
Нижняя часть дроби называется знаменателем . Такие числа, как 2 и 3, являются рациональными. Но многие корни, такие как √2 и √3, иррациональны.
Пример: имеет иррациональный знаменатель
Чтобы быть в «простейшей форме», знаменатель не должен быть иррациональным!
Исправление (путем рационального использования знаменателя) называется « Рационализация знаменателя »
Примечание: нет ничего неправильного с иррациональным знаменателем, все равно работает. Но это не самая простая форма, поэтому может стоить марок.
А их удаление может помочь вам решить уравнение, поэтому вам следует узнать, как это сделать.
Итак … как мы это делаем?
1. Умножьте верх и низ на корень
Иногда можно просто умножить верх и низ на корень:
Пример: имеет иррациональный знаменатель. Давай исправим.
Умножьте верхнюю и нижнюю часть на квадратный корень из 2, потому что: √2 × √2 = 2:
Теперь в знаменателе есть рациональное число (= 2).Сделанный!
Примечание. Иррациональное число в верхней части (числителе) дроби — это нормально.
2. Умножьте верх и низ на конъюгат
Есть еще один особый способ переместить квадратный корень из нижней части дроби в верхнюю часть … мы умножаем верхний и нижний на , сопряженное знаменателю .
Сопряжение — это где мы меняем знак в середине двух членов:
Пример выражения
Его конъюгат
x 2 — 3
х 2 + 3
Другой пример
Его конъюгат
а + б 3
а — б 3
Это работает, потому что, когда мы умножаем что-то на его сопряжение, мы получаем квадратов , как это:
(a + b) (a − b) = a 2 — b 2
Вот как это сделать:
Пример: вот дробь с «иррациональным знаменателем»:
1 3 − √2
Как мы можем переместить квадратный корень из 2 вверх?
Мы можем умножить верхнюю и нижнюю части на 3 + √2 (сопряжение 3 − √2) , что не изменит значение дроби:
1 3 − √2 × 3 + √2 3 + √2 знак равно 3 + √2 3 2 — (√2) 2 знак равно 3 + √2 7
(Вы видели, что мы использовали (a + b) (a − b) = a 2 — b 2 в знаменателе?)
Используйте свой калькулятор, чтобы вычислить значение до и после… это то же самое?
Есть еще один пример на странице Оценка пределов (расширенная тема), где я перемещаю квадратный корень сверху вниз.
Полезный
Так что постарайтесь запомнить эти маленькие уловки, они могут однажды помочь вам решить уравнение!
Конъюгаты и деление на радикалы
Purplemath
Иногда вам нужно умножать многочленные выражения, содержащие только радикалы.Это ситуация, в которой вертикальное умножение является прекрасным подспорьем.
Упростить
Это упражнение выглядит некрасиво, но оно вполне выполнимо, если я аккуратен и точен в своей работе.
Сначала я выполняю умножение, используя вертикальный метод, чтобы все было прямо:
MathHelp.com
Затем я устанавливаю исходное выражение, равное последней строке из приведенного выше умножения, и завершаю вычисления, упрощая каждый член:
Упростить:
Сначала делаю умножение:
А потом упрощаю:
Обратите внимание на последний пример выше, как я получил все целые числа.(Хорошо, технически они целые числа, но дело в том, что члены , а не включают какие-либо радикалы.) Я перемножил два радикальных бинома и получил ответ, в котором не было радикалов. Вы также могли заметить, что два «бинома» были одинаковыми, за исключением знака посередине: у одного был «плюс», а у другого — «минус».
Эта пара факторов, где второй фактор отличается только одним знаком посередине, очень важна; по сути, этот «тот же самый, за исключением знака посередине» второй фактор имеет собственное название:
Учитывая радикальное выражение
, «конъюгат» является выражением.
Конъюгат (KAHN-juh-ghitt) имеет те же числа, но с противоположным знаком посередине. Таким образом,
не только является конъюгатом, но и является конъюгатом.
Кроме того, конъюгаты не обязательно должны быть двухчленными выражениями с радикалами в каждом из терминов. Фактически, любое двухчленное выражение может иметь конъюгат:
1 + sqrt [2] является конъюгатом 1 — sqrt [2]
sqrt [7] — 5 sqrt [6] является конъюгатом sqrt [7] + 5 sqrt [6] x + sqrt [y] является конъюгатом x — sqrt [y]
Чтобы создать конъюгат, все, что вам нужно сделать, это перевернуть знак посередине.Все остальное остается прежним.
Что такое спряжение 3 + sqrt [5]?
В этом случае я нахожу сопряжение для выражения, в котором только один из терминов имеет радикал. Это хорошо. Независимо от этого, процесс тот же; а именно я переворачиваю знак посередине. Поскольку они дали мне выражение со знаком «плюс» в середине, спряжение — это те же два термина, но с «минусом» посередине:
Найдите конъюгат –7 sqrt [3] — 2
На этот раз радикал находится в первом из двух членов, и перед первым термином стоит «минус».Это хорошо. Я оставлю первый «минус» в покое, потому что ничего не меняю, кроме среднего знака; Переверну второй «минус» посередине на «плюс»:
Когда мы умножаем конъюгаты, мы делаем нечто похожее на то, что происходит, когда мы умножаем на разность квадратов; а именно:
a 2 — b 2 = ( a + b ) ( a — b )
Когда мы умножаем множители a + b и a — b , средние члены « ab » сокращаются:
То же самое происходит, когда мы умножаем конъюгаты:
Мы вскоре увидим, почему это важно.Чтобы понять это, давайте сначала взглянем на дроби, в знаменателях которых есть радикалы.
Деление на квадратные корни
Точно так же, как мы можем переключаться между умножением радикалов и радикалом, содержащим умножение, мы можем переключаться между делением корней и одним корнем, содержащим деление.
Упростить:
Я могу упростить это, работая внутри, а затем извлекая квадратный корень:
…. или, в противном случае, разделив разделение на два радикала, упрощение и исключение:
В любом случае, мой окончательный ответ такой же.
Упростить:
Я вижу, что в знаменателе есть полный квадрат, а в числителе — простое число.Так что упрощение будет легче, если я разделю радикал, содержащий фракцию, на фракцию, содержащую радикалы:
Когда вы впервые узнали о числах в квадрате, таких как 3 2 , 5 2 и x 2 , вы, вероятно, узнали об обратной операции возведения в квадрат числа, то есть о квадратном корне.Эта обратная связь между возведением чисел в квадрат и квадратными корнями важна, потому что на простом английском языке это означает, что одна операция отменяет действие другой. Это означает, что если у вас есть уравнение с квадратными корнями в нем, вы можете использовать операцию «возведения в квадрат» или экспоненты, чтобы удалить квадратные корни. Но есть некоторые правила, как это сделать, а также потенциальная ловушка ложных решений.
TL; DR (слишком долго; не читал)
Чтобы решить уравнение с квадратным корнем, сначала выделите квадратный корень на одной стороне уравнения.Затем возведите обе части уравнения в квадрат и продолжайте поиск переменной. Не забудьте в конце проверить свою работу.
Простой пример
Прежде чем рассматривать некоторые потенциальные «ловушки» решения уравнения с квадратными корнями в нем, рассмотрим простой пример: Решите следующее уравнение для x :
\ sqrt {x } + 1 = 5
Используйте арифметические операции, такие как сложение, вычитание, умножение и деление, чтобы выделить выражение квадратного корня на одной стороне уравнения.2
x = 16
Вы удалили знак квадратного корня и , у вас есть значение x , так что ваша работа здесь сделана. Но подождите, есть еще один шаг:
Проверьте свою работу, подставив найденное вами значение x в исходное уравнение:
\ sqrt {16} + 1 = 5
4 + 1 = 5
5 = 5
Поскольку это вернуло допустимый оператор (5 = 5, в отличие от недопустимого оператора, такого как 3 = 4 или 2 = -2, решение, которое вы нашли на шаге 2, является действительным.В этом примере проверка вашей работы кажется тривиальной. Но этот метод устранения радикалов иногда может давать «ложные» ответы, которые не работают в исходном уравнении. Так что лучше иметь привычку всегда проверять свои ответы, чтобы убедиться, что они возвращают действительный результат, начиная с этого момента.
Немного сложнее
Что делать, если у вас есть более сложное выражение под знаком корня (квадратный корень)? Рассмотрим следующее уравнение. Вы по-прежнему можете применить тот же процесс, что и в предыдущем примере, но это уравнение выделяет пару правил, которым вы должны следовать.2
y — 4 = 576
Теперь, когда вы исключили радикальный или квадратный корень из уравнения, вы можете изолировать переменную. Чтобы продолжить пример, добавив 4 к обеим сторонам уравнения, вы получите:
y = 580
Как и раньше, проверьте свою работу, подставив найденное вами значение y обратно в исходное уравнение. Это дает вам:
\ sqrt {580 — 4} + 5 = 29
\ sqrt {576} + 5 = 29
Упрощение радикала дает:
24 + 5 = 29
29 = 29
истинное утверждение, указывающее на действительный результат.
Умножение квадратного корня: 3 простых метода [с примерами]
Ваши ученики знают, как умножать экспоненты, но теперь пришло время научить их умножению квадратного корня и удивительному миру предалгебры. Но вы опасаетесь, что они могут подумать: «На уроке математики мы больше узнали об алгебре, например, X + 10 = Y, но почему меня это должно волновать?»
Вы хотите, чтобы они поняли, что французский математик Жан де Ронд д’Аламбер сказал знаменитую фразу: «алгебра щедра; она часто дает больше, чем от нее просят.
То, что вы не видите X и Y, не означает, что вы не используете алгебру каждый день. Умение умножать квадратные корни — это один из камней на живописном пути к пониманию актуальности алгебры в реальной жизни.
Преподаватели, подобные вам, знают, что не всегда легко сделать эти абстрактные и сложные концепции интересными и увлекательными.
Этот пост в блоге, разделенный на три части, призван изменить это!
Что такое квадратные корни
Как умножить квадратные корни
Привлечение способов закрепить знания учащихся о квадратном корне
Часть первая: Что такое «квадратный корень»?
Квадратный корень из числа относится к множителю, который вы можете умножить само на себя, чтобы получить это число.Другими словами, нахождение квадратного корня — это процесс, противоположный возведению числа в квадрат.
Извлечь квадратный корень можно только из неотрицательных чисел — даже тех, которые не дают целых чисел. Это потому, что любое число раз само по себе является положительным или нулевым — вы никогда не получите отрицательный продукт, возведя в квадрат отрицательное число. Как вы видели выше, квадратный корень отменяет возведение в квадрат, поэтому отрицательные числа не могут иметь квадратные корни.
Тем не менее, точные квадратные числа являются наиболее эффективными при обучении студентов умножению квадратных корней.
На рисунке ниже мы видим, что квадратный корень из 16 равен 4, потому что 4 в квадрате, или 42, равно 16.
В математическом классе это уравнение будет выглядеть так:
Учащиеся видят это Впервые наверняка возникнут вопросы: Что это за символ в виде галочки? Почему на нем крошечная цифра?
Бретт Берри, основатель Math Hacks, в своей статье о понимании логарифмов и корней создала ясный и лаконичный образ со всей терминологией root .
Многие вопросы о нахождении квадратного корня не включают корневой индекс. Однако корневые индексы необходимы при вычислении более высоких индексированных корней, таких как кубические, четвертые или пятые корни.
Когда мне когда-нибудь понадобится умножать квадратные корни?
Независимо от того, насколько хорошо вы преподаете эти алгебраические концепции, студенты всегда будут задавать этот вопрос. ☝️
И вы должны быть готовы предоставить им законные ответы. Например, умножение квадратного корня может быть важно для:
Знание площади их будущих домов
Архитекторов
Художников
Плотников
Строителей
Дизайнеров
Инженеров
Есть еще кое-что! В то время как некоторым придется вычислять уравнения каждый день, другие будут использовать эти концепции для составления оценок.Одно можно сказать наверняка — люди этих профессий изучали математику в школе в детстве и используют ее до сих пор!
Часть вторая: 3 простых метода умножения квадратных корней
Умножение квадратных корней без коэффициентов
1. Умножьте каждое корневое и так же, как и без радикала или символа квадратного корня.
2. Упростите подкоренное выражение, вычленив все полные квадраты. Если в подкоренном выражении нет полных квадратов, значит, оно уже упрощено.В этом случае вы можете упростить √98 до √2, а √49 — до полного квадрата.
3. Извлеките квадратный корень из полного квадрата. В этом примере упростите √49 до 7 и поместите его перед оставшимся выражением √2.
Умножение квадратных корней на коэффициенты
1. Умножение коэффициентов перед знаками корня , если они есть.
2. Умножьте каждое подкоренное выражение так же, как и без радикала или символа квадратного корня.
3. Упростите подкоренное выражение, вычленив все полные квадраты. В этом примере вы можете упростить √40 до √4 и √10.
4. Извлеките квадратный корень из полного квадрата и умножьте его на коэффициент . В этом примере упростите √4 до 2 и умножьте его на 6.
Умножение квадратных корней с переменными
Помимо чисел, радикалы могут содержать другие вещи, такие как переменные и показатели степени.Упрощение радикалов с помощью переменных следует тем же правилам, что и упрощение радикалов с числами.
1. Умножьте подкоренные выражения . Если есть коэффициенты, их тоже умножьте.
Примечание : для умножения радикалов, содержащих переменные,:
Корневой индекс должен быть таким же
Значение x — вместе с любыми другими переменными — должно быть больше или равно нулю
2. Найдите разложения на простые множители, чтобы определить точные квадратные множители. Для этого вы можете использовать дерево факторов, как на изображении ниже.
Например, 2 и 9 равны 18, а 9 упрощается до 3 и 3. Таким образом, разложение на простые множители и квадратные множители для 18 будут 2, 3 и 3. Разложение на простые множители 30 равно 2, 3 и 5. Вы также можете разбить и переставить переменные экспоненты — вы можете переписать x3 как x2 и x .
Часть третья: Действия по закреплению знаний учащихся о квадратном корне
Создайте радикальные башни чисел
Лиза Тарман, педагог из Пенсильвании, создала сотни учебных материалов.Ее «Лабиринт упрощающих радикалов» — это освежающий и увлекательный подход к традиционным рабочим листам.
Попросите учащихся начать с левого верхнего угла. Им придется упростить радикалы, чтобы добраться до конца лабиринта. Получите доступ к бесплатной рабочей таблице Тармана и ответьте на него здесь.
Если вы хотите лабиринт умножающих радикалов, посмотрите этот от Teachers Pay Teachers!
Play Prodigy
Prodigy — бесплатная адаптивная математическая игра, которой пользуются полтора миллиона учителей и более 50 миллионов студентов по всему миру! Он предлагает контент по всем основным математическим темам и охватывает 1-8 классы, в том числе инструкции:
Оценивать идеальные корни
Переписывать показатели степени как корни
Использование Prodigy в вашем классе поможет ученикам развить беглость математики и уверенность в себе. будущая средняя школа и курсы математики на уровне колледжа.Ваш класс будет исследовать мир, наполненный захватывающими квестами, которые предоставляют персонализированный, согласованный с учебной программой контент и данные об учениках в реальном времени.
Помня об этих методах и упражнениях, вы поймете, что умножение квадратных корней не должно оставаться неуместным или пугающим для вас или ваших учеников.
При эффективном использовании упражнения, подобные приведенным выше, могут помочь укрепить понимание учащимися и повысить уровень вовлеченности учителей, которые редко становятся свидетелями на уроках математики.
Вы педагог? Настройте вопросы по математике, чтобы дополнить учебный материал и дифференцировать обучение, обращая внимание на проблемные места каждого учащегося.
Prodigy также предлагает мощные инструменты для немедленной подготовки отчетов как для учителей, так и для родителей. От отчетов о прогрессе до отчетов об использовании и т. Д. Используйте данные своего ученика или ребенка, чтобы определить, где они преуспевают или испытывают трудности, чтобы вы могли настроить для них контент в игре.
Нажмите здесь или на баннер ниже, чтобы начать работу менее чем за пять минут!
Сводка: В алгебре вы тратите много времени на решение многочлена
уравнения или факторизации многочленов (что одно и то же).Было бы легко потеряться во всех техниках, но эта статья
связывает их все вместе в единое целое.
Генеральный план
Убедитесь, что вас не смущает терминология. Все это
то же:
Решение полиномиального уравнения p ( x ) = 0
Нахождение корней полиномиального уравнения p ( x ) = 0
Нахождение нулей полиномиальной функции p ( x )
Факторизация полиномиальной функции p ( x )
Есть коэффициент для каждого корня, и наоборот. ( x — r ) является множителем тогда и только тогда, когда r является корнем. Это Теорема о факторах : поиск корней или факторов
по сути то же самое. (Основное различие заключается в том, как вы относитесь к
постоянный коэффициент.)
точное или приблизительное значение?
Чаще всего, когда мы говорим о решении уравнения или факторизации
многочлен, мы имеем в виду точное (или аналитическое) решение . В
другой тип, приближенное (или числовое) решение ,
всегда возможно, а иногда и единственная возможность.
Когда найдешь, точное решение лучше .
Вы всегда можете найти численное приближение к точному решению,
но пойти другим путем гораздо труднее. Эта страница тратит больше всего
своего времени на методы точных решений, но также расскажет, что нужно
делать, когда аналитические методы терпят неудачу.
Шаг за шагом
Как найти множители или нули многочлена (или корни
полиномиального уравнения)? В основном вам сточить . Каждый раз
вы вычеркиваете множитель или корень из многочлена, у вас остается
полином на одну степень проще.Используйте этот новый уменьшенный
полином, чтобы найти оставшиеся факторы или корни.
На любом этапе процедуры, если вы доберетесь до кубическое или четвертое уравнение (степень 3 или 4), у вас есть выбор
продолжения факторинга или использования
кубические или четвертичные формулы. Этих формул много
работы, поэтому большинство людей предпочитают продолжать факторинг.
Выполните эту процедуру, шаг за шагом:
Если вы решаете уравнение, запишите его в стандартную форму с 0
с одной стороны и упрощают .[ подробности ]
Знайте , сколько корней ожидать.
[ подробности ]
Если у вас есть линейное или квадратное уравнение (степень 1 или 2), решите осмотром или по формуле корней квадратного уравнения.
[ подробности ] Затем переходите к шагу 7.
Найдите один рациональный множитель или корень. Это самая сложная часть,
но есть много методов, которые могут вам помочь.
[ подробности ] Если вы можете найти фактор или корень, перейдите к шагу 5 ниже; если
не можете, переходите к шагу 6.
Разделите на множитель . Это оставляет вас с новым приведенный многочлен , степень которого на 1 меньше.
[ подробности ] Для остальной части задачи вы будете работать с уменьшенным
многочлен, а не оригинал. Продолжите с шага 3.
Если вы не можете найти множитель или корень , обратитесь к
численные методы.
[ подробности ] Затем переходите к шагу 7.
Если это уравнение нужно было решить, запишите корни .
Если это был многочлен для факторизации, запишите его в факторизованной форме ,
включая любые постоянные факторы, которые вы вывели на шаге 1.
Это пример алгоритма , набор шагов
что приведет к желаемому результату за конечное количество операций.
Это итеративная стратегия , потому что средние шаги
повторять столько, сколько необходимо.
Кубические и четвертые формулы
Приведенные здесь методы находят рациональный корень и
использовать синтетическое деление проще всего.
Но если вы не можете найти рациональный корень, есть специальные методы для
кубические уравнения (степень 3) и
уравнения четвертой степени (степень 4), оба в Mathworld.Альтернативный подход предоставляется
Дик Никаллс в PDF для
кубический
а также
четвертичная
уравнения.
Шаг 1. Стандартная форма и упрощение
К сожалению, это легко не заметить.
Если у вас есть полиномиальное уравнение , отложите все члены в одну сторону.
и 0 с другой.
И независимо от того, является ли это проблема факторинга или уравнение, которое нужно решить, положите
ваш многочлен в стандартной форме от до самой низкой степени .
Например, вы, , не можете решить это уравнение в такой форме:
x + 6 x + 12 x = −8
Вы должны изменить его на эту форму:
x + 6 x + 12 x + 8 = 0
Также убедитесь, что вы упростили, исключив любые общие факторы .Это может включать в себя вычитание −1
так что наивысшая степень имеет положительный коэффициент. Пример: в коэффициент
7-6 x -15 x —
2 х
начнем с того, что приведем его в стандартную форму:
−2 x -15 x -6 x + 7
, а затем вычтите −1
— (2 x + 15 x + 6 x -7)
или же
(−1) (2 x + 15 x + 6 x -7)
Если вы решаете уравнение, вы можете выбросить любых
общий постоянный множитель.Но если вы факторизуете многочлен, вы должны сохранить общий множитель .
Пример: решить
8 x + 16 x + 8 = 0, вы можете
разделите левую и правую на общий множитель 8. Уравнение х + 2 х + 1 = 0 имеет те же корни, что и исходное уравнение .
Пример: Фактор
8 x + 16 x + 8, вы узнаете
общий множитель 8 и перепишем многочлен в виде
8 ( x + 2 x + 1), что является идентичен исходному многочлену .(Хотя это правда, что вы
сосредоточит ваши дальнейшие усилия по факторингу на x + 2 x + 1, это будет ошибкой написать, что исходный многочлен равен х + 2 х + 1.)
Ваш общий фактор может быть
дробь, потому что вы должны вычесть любые дроби, чтобы
полином имеет целочисленных коэффициентов .
Пример: решить
(1/3) x + (3/4) x — (1/2) x + 5/6 = 0,
вы узнаете общий множитель 1/12 и разделите обе стороны на 1/12.Это в точности то же самое, что и распознавание и умножение на наименьший общий знаменатель из 12. В любом случае вы получите
4 x + 9 x -6 x + 10 = 0,
которое имеет те же корни, что и исходное уравнение .
Пример: Фактор
(1/3) x + (3/4) x — (1/2) x + 5/6,
вы узнаете общий множитель 1/12 (или наименьший общий
знаменатель 12) и вычитаем 1/12. Ты получаешь
(1/12) (4 x + 9 x -6 x + 10),
что идентично исходному многочлену .
Шаг 2. Сколько корней?
Многочлен степени n будет иметь n корней, некоторые из которых могут быть
множественные корни.
Как узнать, что это правда? В Основная теорема алгебры говорит вам, что многочлен
имеет хотя бы один корень. Теорема о факторах говорит вам, что если r является корнем, тогда ( x — r ) является множителем. Но если разделить многочлен
степени n на множитель ( x — r ), степень которого равна 1, вы получите
полином степени n −1.Неоднократно применяя Фундаментальную
Теорема и теорема о множителях дают вам n корней и n факторов.
Правило знаков Декарта
Правило знаков Декарта может сказать вам, сколько положительных и сколько отрицательных действительных нулей многочлен. Это
большое трудосберегающее устройство, особенно когда вы решаете, какой
возможные рациональные корни, которые нужно искать.
Чтобы применить Правило знаков Декарта, вам необходимо понимать термин изменение знака .Когда многочлен расположен в
стандартная форма, вариация в
Знак возникает, когда знак коэффициента отличается от знака
предыдущего коэффициента. (Нулевой коэффициент игнорируется.) Для
пример,
p ( x ) = x 5 —
2 x 3 + 2 x 2 — 3 x + 12
имеет четыре варианта знака.
Правило знаков Декарта:
Число положительных корней из p ( x ) = 0 либо равно
количество вариаций знака p ( x ), или меньше, чем на четное
номер.
Число отрицательных корней из p ( x ) = 0 либо равно
количество вариаций знака p (- x ), или меньше, чем на четное
номер.
Пример: рассмотрим p ( x ) выше. Поскольку у него четыре варианта
в знаке должно быть либо четыре положительных корня, либо два положительных корня,
или нет положительных корней.
Теперь сформируйте p (- x ), заменив x на (- x ) в
выше:
p (- x ) = (- x ) 5 — 2 (- x ) 3 + 2 (- x ) 2 — 3 (- x ) + 12
p (- x ) = — x 5 + 2 x 3 + 2 x 2 + 3 x + 12
p (- x ) имеет один вариант знака, поэтому
оригинал p ( x ) имеет один негатив
корень.Поскольку вы знаете, что p ( x ) должен иметь отрицательный корень, но он может
или может не иметь положительных корней, сначала ищите отрицательные
корнеплоды.
p ( x ) — полином пятой степени, поэтому он должен иметь пять нулей.
Поскольку x не является множителем, вы знаете, что x = 0 не является
нуль полинома. (Для полинома с действительными коэффициентами, например
в этом случае комплексные корни встречаются парами.)
Следовательно, есть три возможности:
количество нулей , которые являются
положительным
отрицательным
комплексным нереальным
первая возможность
4
1
0
вторая возможность 2
1
2
третий вариант
0
1
4
Сложные корни
Если полином имеет действительных коэффициентов , то либо все
корни настоящие или есть четное число невещественных комплексных корней в сопряженных парах .
Например, если 5 + 2i является нулем многочлена с вещественными
коэффициентов, то 5−2i также должен быть нулем этого многочлена.
Также верно и то, что если ( x −5−2i) является множителем, то
( x −5 + 2i) также является фактором.
Почему это правда? Потому что, когда у вас есть фактор с воображаемым
часть и умножьте ее на комплексное сопряжение, вы получите реальную
результат:
( x −5−2i) ( x −5 + 2i) = x −10 x + 25−4i = х −10 х +29
Если ( x −5−2i) было фактором, но
( x −5 + 2i) не было, тогда многочлен будет иметь
воображение в его коэффициентах, независимо от других факторов
возможно.Если многочлен имеет только действительные
коэффициентов, то любые комплексные корни должны входить в сопряженные пары.
Иррациональные корни
По тем же причинам, если многочлен имеет рациональных коэффициентов то иррациональные корни, содержащие
квадратный
корни встречаются (если вообще встречаются) в сопряженных парах.
Если ( x −2 + √3) является множителем многочлена с рациональными
коэффициентов, то ( x −2 − √3) также должно быть
фактор. Чтобы понять почему, вспомните, как вы рационализируете бином
знаменатель; или просто проверьте, что происходит, когда вы умножаете эти два
факторы.(1/3) и два
сложные корни.
Интересная проблема, нет ли иррациональности
с четными корнями порядка ≥4 также должны встречаться в сопряженных
пары. У меня нет немедленного ответа. Я работаю над
доказательство, как я успеваю.
Множественные корни
Когда данный множитель ( x — r ) встречается m раз в полиноме, r равно
называется кратным корнем или корнем с кратностью м .
Если кратность м — четное число, график касается
Ось x при x = r , но не пересекает ее.
Если кратность m — нечетное число, график пересекает
Ось x при x = r . Если кратность 3, 5, 7 и т. Д., График
горизонтально в точке пересечения оси.
Примеры: сравните эти два многочлена и их графики:
f ( x ) =
( x −1) ( x −4) 2 = x 3 — 9 x 2 +
24 х — 16
г ( x ) =
( x −1) 3 ( x −4) 2 = x 5 -11 x 4 + 43 x 3 — 73 x 2 + 56 x — 16
Эти многочлены имеют одинаковые нули, но корень 1 встречается
с разной кратностью.Посмотрите на графики:
Оба полинома имеют нули только в точках 1 и 4. f ( x ) имеет степень 3,
что означает три корня. Из факторов видно, что 1 является корнем
кратность 1 и 4 является корнем из кратности 2. Следовательно, граф
пересекает ось в точке x = 1 (но не горизонтально там) и касается в точке х = 4 без пересечения.
Напротив, г ( x ) имеет степень 5. ( г ( x ) = f ( x ) раз
( x −1) 2 .) Из пяти корней 1 встречается с
кратность 3: график пересекает ось при x = 1 и является горизонтальным
там; 4 встречается с кратностью 2, и график касается
ось при x = 4 без пересечения.
Шаг 3. Квадратичные множители
Когда у вас есть квадратичные множители (Ax + Bx + C), он может или не может
можно будет их дополнительно проанализировать.
Иногда вы можете просто увидеть факторы, как в случае с x — x −6 = ( x +2) ( x −3).В других случаях не так очевидно,
квадратичный можно разложить на множители. Вот когда квадратная формула (показан справа) ваш друг.
Например, предположим, что у вас есть коэффициент
12 x — x −35. Можно ли это еще раз проанализировать? Судом и
ошибка вам придется перепробовать много комбинаций! Вместо этого используйте факт
что коэффициенты соответствуют корням , и примените формулу к
найти корни из 12 x — x −35 = 0, например:
x = [- (- 1) √1 — 4 (12) (- 35)] / 2 (12)
x = [1 √1681] / 24
√1681 = 41, следовательно,
x = [1 41] / 24
x = 42/24 или -40/24
x = 7/4 или -5/3
Если 7/4 и −5/3 — корни, то ( x −7/4) и ( x +5/3)
факторы.Следовательно,
12 x — x −35 =
(4 x −7) (3 x +5)
А как насчет x −5 x +7? Этот выглядит как лучший,
но как ты можешь быть уверен? Снова применим формулу:
x = [- (- 5) √25 — 4 (1) (7)] / 2 (1)
x = [5 √ − 3] / 2
Что с этим делать, зависит от исходной проблемы. Если это
должен был разложить на множители действительные числа, тогда x −5 x +7 простое число.Но если
этот фактор был частью уравнения, и вы должны были найти все
сложные корни, у вас их два:
x = 5/2 + (√3 / 2) i, x = 5/2 — (√3 / 2) i
Поскольку исходное уравнение имело действительные коэффициенты, эти
сложные корни встречаются в сопряженной паре.
Шаг 4. Найдите один фактор или корень
Этот шаг является сердцем факторизации многочлена или решения
полиномиальное уравнение. Есть много методов, которые могут вам помочь
найти фактор.
Иногда можно найти факторы путем осмотра (см. Первые два
следующие разделы). Это отличный способ быстрого доступа, поэтому проверьте
легкие факторы, прежде чем начинать более напряженные
методы.
Мономиальные множители
Всегда начинайте с поиска любых мономиальных множителей, которые вы видите. Например,
если ваша функция
f ( x ) = 4 x 6 + 12 x 5 + 12 x 4 + 4 x 3
, вы должны немедленно разложить его на
f ( x ) = 4 x 3 ( x 3 + 3 x 2 + 3 x + 1)
Получение 4 из оттуда упрощает оставшиеся числа, x 3 дает вам корень x = 0 (с кратностью
3), и теперь у вас есть только кубический многочлен (степени 3) вместо
sextic (степень 6).Фактически, теперь вы должны распознать эту кубику как
особый продукт, идеальный куб
( x +1) 3 .
Когда вы вычитаете общий переменный множитель, убедитесь, что вы
помните об этом в конце, когда перечисляете фактор или корни. x +3 x +3 x +1 = 0 имеет определенные корни, но x ( x +3 x +3 x +1) = 0 имеет те же корни и
также корень при x = 0 (с кратностью 3).
Особые продукты
Будьте внимательны к применению специальных продуктов .Если вы сможете применить их, ваша задача станет намного проще. Специальный
Продукты
полный квадрат (2 формы): A 2 A B + B = ( A B )
сумма квадратов: A + B нельзя разложить на множители на действительные числа, как правило (для исключительных случаев см. Как разложить на множители сумму квадратов)
разность квадратов: A — B = ( A + B ) ( A — B )
идеальный куб (2 формы): A 3 A B + 3 A B B = ( A B )
сумма кубов: A + B = ( A + B ) ( A — A B + B )
разность кубов: A — B = ( A — B ) ( A + A B + B )
Выражения для суммы или разности двух кубов выглядят так:
хотя они должны учитывать дополнительные факторы, но они этого не делают. A A B + B является простым над реалами.
Рассмотрим
p ( x ) = 27 x — 64
Вы должны узнать это как
p ( x ) = (3 x ) — 4
Вы умеете множить разницу двух кубов:
p ( x ) = (3 x −4) (9 x +12 x +16)
Бинго! Как только вы дойдете до квадратичной, вы можете применить
Квадратичная формула, и все готово.
Вот другой пример:
q ( x ) = x 6 + 16 x 3 + 64
Это просто идеальный квадратный трехчлен, но вместо x 3 х . Вы учитываете это точно так же:
q ( x ) = ( x 3 ) 2 + 2 (8) ( x 3 ) + 8 2
q ( x ) = ( x 3 + 8) 2
И вы можете легко разложить ( x 3 +8) 2 как
( x +2) 2 ( x 2 −2 x +4) 2 .
Рациональные корни
Предполагая, что вы уже учли легкое
мономиальные факторы и
специальные продукты, что вы будете делать, если
у вас все еще есть многочлен степени 3 или выше?
Ответ — Rational Root Test .
Он может показать вам некоторые корни кандидатов
когда вы не видите, как разложить полином на множители, как показано ниже.
Рассмотрим многочлен стандартной формы, записанный с высшей степени.
до самого низкого и всего с целочисленными коэффициентами :
f ( x ) = a n x n +… + a o
Теорема о рациональном корне говорит вам, что , если многочлен имеет рациональный нуль , затем , это должна быть дробь p / q ,
где p — коэффициент концевой константы a o и q — множитель старшего коэффициента a n .
Пример:
p ( x ) = 2 x 4 — 11 x 3 — 6 x 2 + 64 x + 32
Коэффициенты старшего коэффициента (2) равны 2 и 1.В
коэффициенты постоянного члена (32) равны 1, 2, 4, 8, 16 и 32.
Следовательно, возможные рациональные нули: 1, 2, 4, 8, 16 или
32 разделить на 2 или 1:
любой из 1/2, 1/1, 2/2, 2/1, 4/2, 4/1, 8/2, 8/1, 16/2, 16/1, 32/2, 32/1
уменьшенный: любой из, 1, 2, 4, 8, 16, 32
Что мы имеем в виду, когда говорим, что это список всех возможных рациональных корней ? Мы имеем в виду, что никакое другое рациональное число,
как или 32/7, может быть нулем этого конкретного многочлена.
Осторожно : Не делайте Rational Root Test
больше, чем есть.Это не означает, что рациональные числа являются корнями , просто
что никакие другие рациональные числа не могут быть корнями. И это не говорит
вы что-нибудь о том, какие иррациональные или даже сложные корни
существовать. Rational Root Test — это только отправная точка.
Предположим, у вас есть многочлен с нецелыми коэффициентами.
Вы застряли? Нет, вы можете исключить наименее распространенные
знаменатель (LCD) и получите многочлен с целыми коэффициентами, которые
способ. Пример:
(1/2) x — (3/2) x + (2/3) x — 1/2
ЖК-дисплей 1/6.Выносим за скобки 1/6 получаем многочлен
.
(1/6) (3 x — 9 x + 4 x — 3)
Две формы эквивалентны, и поэтому имеют одинаковые
корнеплоды. Но вы не можете применить Rational Root Test к первой форме,
только ко второму. Тест говорит вам, что единственно возможное рациональное
корни — любые из 1/3, 1, 3.
После того, как вы определили возможных рациональных нулей, как
вы можете их проверить? Метод грубой силы заключался бы в том, чтобы взять каждый
возможное значение и замените его на x в полиноме: если
результат равен нулю, тогда это число является корнем.Но есть лучше
способ.
Используйте Synthetic Division, чтобы узнать,
кандидат делает полином равным нулю. Это лучше на троих
причины. Во-первых, это проще в вычислительном отношении, потому что вам не нужно
вычислить высшие степени чисел. Во-вторых, в то же время он сообщает
независимо от того, является ли данное число корнем, он производит сокращенный многочлен , который вы будете использовать, чтобы найти оставшийся
корнеплоды. Наконец, результаты синтетического деления могут дать вам
верхняя или нижняя граница, даже если число
тестирование оказывается не рутом.
Иногда правило знаков Декарта может
поможет вам в дальнейшем выявить возможные рациональные корни. Например,
Rational Root Test сообщает, что если
q ( x ) = 2 x 4 + 13 x 3 + 20 x 2 + 28 x + 8
имеет какие-то рациональные корни, они должны быть из списка
любой из, 1, 2, 4, 8. Но не начинайте с замены или
синтетическое разделение. Поскольку нет изменений знака, нет
положительные корни.Есть ли отрицательные корни?
q (- x ) = 2 x 4 -13 x 3 + 20 x 2 -28 x + 8
имеет четыре смены знака. Следовательно, может быть целых четыре
отрицательные корни. (Также может быть два отрицательных корня или ни одного.)
Нет гарантии, что какой-либо из корней является рациональным, но любой корень
рациональное должно происходить из списка -, −1,
−2, −4, −8.
(Если у вас
графического калькулятора, вы можете предварительно просмотреть рациональные корни, построив график
полином и увидеть, где он, кажется, пересекает ось x .Но ты
по-прежнему необходимо проверить корень алгебраически, чтобы увидеть, что f ( x )
там ровно 0, а не почти 0.)
Помните, Rational Root Test гарантирует нахождение всех рациональных корней. Но он полностью упустит настоящие корни, которых нет.
рациональные, как корни x −2 = 0, которые
√2, или корни из x + 4 = 0, которые
2i.
Наконец, помните, что Rational Root Test работает, только если все
коэффициенты — целые числа.Посмотрите еще раз на эту функцию, которая
На графике справа:
p ( x ) = 2 x 4 — 11 x 3 — 6 x 2 + 64 x + 32
Теорема о рациональном корне говорит вам, что единственно возможный рациональный
нули — это 1, 2, 4, 8, 16, 32. Но предположим, что вы
вычтите 2 (как я когда-то сделал в классе), написав эквивалент
функция
p ( x ) = 2 ( x 4 — (11/2) x 3 — 3 x 2 + 32 x + 16)
Эта функция аналогична предыдущей, но вы не можете
дольше применять Rational Root Test, потому что коэффициенты не
целые числа.По сути — это ноль р ( х ), но это не так.
появляются, когда я (незаконно) применил Rational Root Test к
вторая форма. Моя ошибка заключалась в том, что я забыл, что применима теорема о рациональном корне.
только когда все коэффициентов многочлена равны
целые числа.
Графические подсказки
Построение графика функции вручную или с помощью графика
Вы можете понять, где находятся корни,
примерно, и сколько существует настоящих корней.
Пример: Если Rational Root Test
говорит вам, что 2 возможных рациональных корня, вы можете посмотреть на
график, чтобы увидеть, пересекает ли он (или касается) оси x в точках 2 или
−2.Если да, используйте синтетическое деление, чтобы
убедитесь, что предполагаемый корень на самом деле является корнем. Да ты всегда
нужно проверить по графику, вы никогда не можете быть уверены
является ли точка пересечения на ваш возможный рациональный корень или
просто около это.
Границы корней
Некоторые методы не сообщают вам конкретное значение корня, но
скорее, что корень существует между двумя значениями или что все корни
меньше определенного числа больше определенного числа. Этот
помогает сузить область поиска.
Теорема о промежуточном значении
Эта теорема говорит вам, что если график многочлена находится выше
ось x для одного значения x и ниже оси x для
другое значение x , оно должно пересекать ось x где-то посередине.
(Если вы можете построить график функции, пересечения
обычно будет очевидным.)
Пример:
p ( x ) = 3 x + 4 x -20 x −32
Рациональные корни
(если есть) должны быть из списка
любой из 1/3, 2/3, 1, 4/3, 2, 8/3, 4, 16/3, 8, 32/3, 16, 32.Естественно, сначала вы посмотрите на целые числа, потому что арифметика
Полегче. Пробуя синтетическое деление, вы
найти p (1) = −45, p (2) = −22 и p (4) = 144. Поскольку p (2) и p (4) имеют противоположные знаки, вы
знайте, что график пересекает ось между x = 2 и x = 4, поэтому
хотя бы один корень между этими числами. Другими словами, либо 8/3 — это
корень или корень от 2 до 4 иррациональны. (По факту,
синтетическое деление показывает, что 8/3 — это корень.)
Теорема о промежуточном значении может сказать вам, где находится
root, но он не может сказать вам, где нет root. Например,
считать
q ( x ) = 4 x -16 x + 15
q (1) и q (3) оба положительны, но это вам не говорит
может ли график касаться или пересекать ось между ними. (Это на самом деле
дважды пересекает ось, при x = 3/2 и х = 5/2.)
Верхняя и нижняя границы
Одним из побочных эффектов синтетического деления является
что даже если число, которое вы тестируете, окажется не корневым, оно может
сказать вам, что все корни меньше или больше этого
номер:
Если вы выполните синтетическое деление на положительное число a , и каждые
число в нижней строке положительное или нулевое, тогда a — верхняя граница для корней, что означает, что все действительные корни
≤ — .
Если вы делаете синтетическое деление на отрицательное число b , а числа в нижнем ряду чередуются
знак, тогда b — это нижняя граница для корней, что означает, что все
действительные корни ≥ b .
Что делать, если нижняя строка содержит нули? Более полный
Утверждение состоит в том, что чередуются неотрицательные и неположительные знаки ,
после синтетического деления на отрицательное число показать нижнюю границу
корень. Следующие два примера поясняют это.
(Кстати, правило для нижних оценок следует
из правила для верхних оценок.
Нижние пределы корней p ( x ) равны верхним пределам
корни p (- x ), и деление на (- x + r ) такое же, как
деление на — ( x — r ).)
Пример:
q ( x ) = x 3 + 2 x 2 — 3 x — 4
Использование Rational Root
Тест, вы определяете единственно возможные рациональные корни как
4, 2 и 1.Вы решаете попробовать −2 как
возможный корень, и вы тестируете его с синтетическим делением:
−2 не является корнем уравнения f ( x ) = 0.
В третьей строке чередуются знаки, и вы делили на
отрицательное число; однако этот ноль все портит.
Напомним, что у вас есть нижняя граница, только если знаки в нижнем ряду
чередовать неположительный и неотрицательный.1 положительный
(неотрицательный), и 0 может считаться неположительным, но
−3 не считается неотрицательным. Чередование
битая, а ты не знаешь есть ли корни
меньше -2. (Фактически, графический или
численные методы покажут корень около -2,5.)
Следовательно, вам нужно попробовать нижний возможный рациональный корень, −4:
−3 не является корнем, но знаки здесь чередуются, так как
первый 0 считается неположительным, а второй — неотрицательным.Следовательно, −3 — это нижняя граница корней, а это означает, что
уравнение не имеет вещественных корней ниже −3.
Коэффициенты и корни
Существует интересная взаимосвязь между коэффициентами
многочлен и его нули. Я упоминаю об этом в последнюю очередь, потому что это больше подходит
для формирования многочлена, который имеет нули с желаемыми свойствами,
вместо нахождения нулей существующего многочлена. Однако если вы
знать все корни многочлена, кроме одного или двух, вы можете легко использовать это
техника, чтобы найти оставшийся корень.
Рассмотрим многочлен
f ( x ) = a n x n + а n −1 x n −1 + a n −2 x n −2 + … + а 2 x 2 + а 1 х + а или
Существуют следующие отношения:
— a n −1 a n = сумма всех корней
+ a n − 2 a n = сумма произведений корней
взяты по два за раз
— a n −3 a n = сумма произведений корней
взято по три за раз
и так далее, пока
(−1) n a 0 a n = произведение всех корней
Пример: f ( x ) = x 3 — 6 x 2 —
7 x — 8 имеет степень 3 и, следовательно, не более трех действительных нулей.Если
записываем действительные нули как r 1 , r 2 , r 3 , тогда сумма корней равна r 1 + r 2 + r 3 = — (- 6) = 6; в
сумма произведений корней, взятых по два за раз, равна r 1 r 2 + r 1 r 3 + r 2 r 3 =
−7, а произведение корней равно r 1 r 2 r 3 =
(-1) 3 (-8) = 8.
Пример: Учитывая, что многочлен
г ( x ) = x 5 — 11 x 4 + 43 x 3 — 73 x 2 + 56 x — 16
имеет тройной корень x = 1, найдите два других корня.
Решение: Пусть два других корня будут c и d .
Тогда вы знаете, что сумма всех корней равна 1 + 1 + 1 + c + d =
— (- 11) = 11, или c + d = 8.Ты
также знайте, что продукт всех корней
111 c d =
(−1) 5 (−16) = 16, или c d = 16. c + d = 8, c d = 16; поэтому c = d =
4, поэтому оставшиеся корни представляют собой двойной корень с размером x = 4.
Дополнительные коэффициенты и корни
Есть еще несколько теорем о соотношении
между коэффициентами и корнями.
Статья в Википедии
Свойства корней полиномов
дает хорошее, хотя и несколько краткое резюме.
Шаг 5. Разделите на множитель
Помните, что r является корнем тогда и только тогда, когда x — r является множителем;
это факторная теорема. Так что если ты хочешь
чтобы проверить, является ли r корнем, вы можете разделить многочлен на x — r и посмотрите, выходит ли ровным (остаток от 0).
Элизабет Стапель имеет хороший
пример деления многочленов делением в столбик.
Но делать синтетическое деление проще и быстрее.Если твой
синтетическое деление немного заржавело, вы можете взглянуть на Dr.
Математика короткая
Учебное пособие по Synthetic Division;
если вам нужен более длинный учебник, Элизабет Стейплс
Синтетический дивизион отличный.
(У доктора Мата также есть страница о
почему работает Synthetic Division.)
Синтетическое подразделение также имеет некоторые побочные преимущества. Если вы подозреваете
корень на самом деле является корнем, синтетическое деление дает вам приведенный многочлен . А иногда и тебе везет, и
синтетическое деление показывает вам верхнюю или нижнюю
привязаны к корням.
Вы можете использовать синтетическое деление при делении на
бином вида x — r для константы r . Если вы делите на x −3, вы проверяете, является ли 3 корнем, и вы синтетическое деление
на 3 (не на −3). Если вы делите на x +11, вы тестируете
является ли −11 корнем, и вы синтетически делите на −11 (не
11).
Пример:
p ( x ) = 4 x 4 — 35 x 2 — 9
Вы подозреваете, что x −3 может быть фактором, и проверяете это с помощью
синтетическое деление, например:
Поскольку остаток равен 0, вы знаете, что 3 является корнем p ( x ) = 0, а x −3 является множителем p ( x ).Но ты знаешь
более. Поскольку 3 положительно и нижняя строка синтетического деления
все положительные или нулевые, вы знаете, что все корни p ( x ) = 0 должно быть ≤ 3. И вы также знаете
что
p ( x ) = ( x −3) (4 x 3 + 12 x 2 + x + 3)
4 x 3 + 12 x 2 + x + 3
— это приведенный полином .Все его факторы также
коэффициентов исходного p ( x ), но его степень на единицу ниже , поэтому его
с ним легче работать.
Шаг 6. Численные методы
Когда у вашего уравнения больше нет рациональных корней (или ваша
многочлен не имеет более рациональных множителей) можно перейти к числовым
методы нахождения приблизительного значения иррациональных корней:
Статья в Википедии
Алгоритм поиска корней
имеет достойное резюме с указателями на конкретные методы.
Многие графические калькуляторы имеют
Команда Root или Zero, которая поможет вам найти
приблизительные корни. Например, на TI-83 или TI-84 вы
график
функцию, а затем выберите [2nd] [Calc] [zero].
Полный пример
Решить для всех сложных корней:
4 x + 15 x — 36 = 0
Шаг 1. Уравнение уже в стандартной форме, с
только ноль с одной стороны и степени x от наибольшего к наименьшему.Там
нет общих факторов.
Шаг 2. Поскольку уравнение имеет степень 3, будет 3
корнеплоды. Есть одна вариация знака, а от
Правило знаков Декарта, которое, как вы знаете, должно
быть одним положительным корнем. Изучите многочлен с заменой — x x :
−4 x -15 x -36
Нет изменений в знаке, а значит, нет
отрицательные корни. Следовательно, два других корня должны быть сложными,
и конъюгаты друг друга.
Шаги 3 и 4. Возможные рациональные корни
к сожалению, довольно много: любые из 1, 2, 3, 4, 6, 9, 12, 18, 36
делится на любое из 4, 2, 1. (перечислены только положительные корни, потому что вы
уже определили, что для этого нет отрицательных корней
уравнение.) Вы решаете сначала попробовать 1:
Увы, 2 тоже не рут.Но обратите внимание, что f (1) = −17 и f (2) = 26. У них противоположные
знаки, что означает, что график пересекает ось x между x = 1
и x = 2, а корень находится между 1 и 2. (В данном случае это единственный
root, поскольку вы определили, что существует один положительный корень и
нет отрицательных корней.)
Единственно возможный рациональный корень между 1 и 2 — 3/2, и
следовательно, либо 3/2 является корнем, либо корень иррационален. Вы пытаетесь 3/2
по синтетическому разделению:
Ура! 3/2 — это корень.Приведенный полином равен
4 x + 6 x + 24. Другими словами,
(4 x + 15 x — 36)
( х −3/2) =
4 х + 6 х + 24
Приведенный многочлен имеет степень 2,
так что нет необходимости в большем
методом проб и ошибок, и вы переходите к шагу 5.
Шаг 5. Теперь вы должны решить
4 x + 6 x + 24 = 0
Сначала разделите общий делитель 2:
2 x + 3 x + 12 = 0
Нет смысла пытаться множить этот квадратичный коэффициент, потому что
вы определили, используя Правило знаков Декарта, что больше нет
настоящие корни.Итак, вы используете квадратичный
формула:
x = [−3 √9 — 4 (2) (12)] / 2 (2)
x = [−3 √ − 87] / 4
x = −3/4 (√87 / 4) i
Шаг 6. Помните, что вы нашли корень в
более ранний шаг! Полный список корней —
3/2, −3/4 + (√87 / 4) я,
−3/4 — (√87 / 4) я
Что нового
19 октября 2020 г. : преобразовано в HTML5. Переменные, выделенные курсивом и
имена функций; выделил мнимое i.
3 ноя 2018 : Некоторые изменения форматирования для ясности,
особенно с радикалами. Здесь отметили, что 0
является тройным корнем в этом примере.
(промежуточные изменения подавлены)
15 февраля 2002 г. : первая публикация.
Калькулятор преобразования кубического корня
$ \ epsilon = 8 $ — это слишком большая тень, но намного ближе, чем $ \ epsilon = 7 $, поэтому ответ — оттенок ниже 378. Если бы мы хотели продолжить, мы могли бы взять $ \ epsilon = 8 $ и вычислим величину, на которую квадратный корень должен быть меньше 378, или мы могли бы взять $ \ epsilon = 7 $ и вычислить величину, на которую квадратный корень должен превышать 377.
Квадратный корень из 3 равен. То, что 5 — это. И особенно квадратный корень из 1. Другими словами, равно. знак равно Точно так же, поскольку куб степени будет показателем степени, умноженным на 3 (куб из n равен 3n), кубический корень из степени будет показателем степени, деленным на 3. Кубический корень из 6 равен 2; что из 2 — это а. И …
Чтобы извлечь кубический корень с помощью SPSS, просто возведите переменную в степень 1/3. В коде это будет выглядеть так: wkincome **. 333 Я полагаю, что коды преобразования указаны на стр.(1/3) используется, чтобы найти кубический корень 216, который равен 6. Вычислить корни мнимых чисел.
Онлайн-калькулятор — это простое веб-приложение, которое позволяет выполнять расширенные вычисления, строить двухмерные и трехмерные графики и выполнять символьные вычисления, такие как дифференцирование. Введите функции в стандартной математической записи, используя x как независимую переменную.
28 января 2016 г. · Графики сдвига функций квадратного корня. Построить график функций квадратного корня с помощью графического калькулятора. Решайте реальные проблемы, используя функции извлечения квадратного корня.Вступление. В этой главе вы узнаете о другом виде функции, называемой функцией извлечения квадратного корня. Вы заметили, что извлечение квадратного корня очень полезно при решении квадратичных …
19 ноября 2018 г. · Чтобы получить кубический корень в графических калькуляторах серии TI-83, у вас есть несколько вариантов. Уравнения для нахождения куба или кубического корня из любого числа просты. Когда вы нажимаете все правильные клавиши для выполнения уравнения, калькулятор TI-83 мгновенно генерирует ответ.
Разделение растений — Могу ли я разделить растение?
Разделение растений включает выкапывание растений и разделение их на две или более секции. Это обычная практика, которую проводят садоводы, чтобы сохранить растения здоровыми и создать дополнительный запас. Давайте посмотрим, как и когда делить растения.
Могу ли я разделить растение?
Не знаете, как ответить на вопрос: «Могу ли я разделить растение?» Поскольку деление растений включает в себя расщепление или разделение кроны и корневого комка, его использование должно быть ограничено растениями, которые распространяются от центральной кроны и имеют привычку к комковатому росту.
Подходящими кандидатами для разделения являются многочисленные виды многолетних растений и луковиц. Однако растения с стержневыми корнями обычно размножают черенками или семенами, а не дроблением.
Когда делить садовые растения
Когда и как часто делят растение, зависит от типа растения и климата, в котором оно выращивается. Как правило, большинство заводов разделяют каждые три-пять лет или когда они становятся переполненными.
Большинство растений делятся ранней весной или осенью; однако некоторые растения можно разделить в любое время, например лилейники.Обычно весной и летом цветущие растения разделяются осенью, а остальные — весной, но это не всегда так.
Конвертировать PPTX в JPG онлайн, бесплатно преобразовать .pptx в .jpg
Расширение файла
.jpg
Категория файла
images
Описание
JPG – популярный графический формат, отличающийся высокой степенью сжатия, что приводит к снижению качества изображения. Использует технологию кодирования плавных цветовых переходов, предоставляя возможность многократно сократить объем данных в процессе записи изображения.
Из-за малых размеров востребован у владельцев веб-сайтов, позволяя реально экономить трафик. Также нередко применяется в картах памяти цифровых видеокамер. Алгоритм JPG оптимально подходит для сжатия фотографий и картин, в которых присутствуют реалистичные сюжеты с незначительной контрастностью цветов. Не рекомендуется использовать этот формат для сжатия чертежей и различных видов графики, так как сильный контраст между рядом находящимися пикселами провоцирует появление видимых артефактов.
Технические детали
Процедура сжатия цифровых изображений в формате JPG осуществляется в несколько этапов. Сначала фотография преобразуется в цветовое пространство YCbCr, затем она делится на квадраты для определения верхнего диапазона цветового спектра. В завершение производится кодирование цветов и яркости.
JPEG использует систему сжатия «с потерями» и технологию дискретного косинусного преобразования. Формат выступает одновременно стандартом ИСО и Международного союза электросвязи. Пропорция сжатия файла находится в диапазоне от 10:1 до 100:1. При этом снижение качества изображения может варьироваться от незначительного до существенного.
Программы
Microsoft Windows Photo Gallery Viewer
Adobe Photoshop
Adobe Suite
Apple Preview
Corel Paint Shop Pro
Most web browsers
Разработчик
The JPEG Committee
MIME type
image/jpeg
onlineconvertfree.com
Конвертировать PPTX в JPEG онлайн, бесплатно преобразовать .pptx в .jpeg
Расширение файла
.jpeg
Категория файла
images
Описание
JPEG – популярный графический формат, отличающийся высокой степенью сжатия, что приводит к снижению качества изображения. Использует технологию кодирования плавных цветовых переходов, предоставляя возможность многократно сократить объем данных в процессе записи изображения. Из-за малых размеров востребован у владельцев веб-сайтов, позволяя реально экономить трафик. Также нередко применяется в картах памяти цифровых видеокамер. Алгоритм JPEG оптимально подходит для сжатия фотографий и картин, в которых присутствуют реалистичные сюжеты с незначительной контрастностью цветов. Не рекомендуется использовать этот формат для сжатия чертежей и различных видов графики, так как сильный контраст между рядом находящимися пикселами провоцирует появление видимых артефактов.
Технические детали
Процедура сжатия цифровых изображений в формате JPEG осуществляется в несколько этапов. Сначала фотография преобразуется в цветовое пространство YCbCr, затем она делится на квадраты для определения верхнего диапазона цветового спектра. В завершение производится кодирование цветов и яркости. JPEG использует систему сжатия «с потерями» и технологию дискретного косинусного преобразования. Формат выступает одновременно стандартом ИСО и Международного союза электросвязи. Пропорция сжатия файла находится в диапазоне от 10:1 до 100:1. При этом снижение качества изображения может варьироваться от незначительного до существенного.
Программы
Adobe Photoshop
Apple Preview
Corel Paint Shop Pro
Основная программа
MS Paint
Разработчик
The JPEG Committee
MIME type
image/jpeg
onlineconvertfree.com
PPT в PPTX | Zamzar
Расширение файла
.pptx
Категория
Document File
Описание
Как часть пакета Microsoft 2007, был представлен другой тип документа open XML. В сфере PowerPoint, PPTX является форматом презентации, который хранит слайды, используемые для слайд-шоу или презентаций. Он сходен с форматом PPT, который может включать текст, изображения и другие средства; однако, PPTX основан на формате Open XML и ZIP-архивирован для меньшего размера.
Действия
Convert PPTX file View other document file formats
Технические детали
Файл PPTX является совершенно уникальным. Индивидуальные параметры для PPTX хранятся в стандарте ECMA-376 для Office Open XML. Вы можете создать файл PPTX путем архивации директории, но материалы в директории должны соответствовать структуре OPC, в том числе вложенные папки, содержащие формат XML. Любое приложение, поддерживающее XML, может получить доступ и работать с данными в новом формате. Так же, как формат DOCX файла, PPTX оптимизирует файл, осуществляет управление и восстановление данных.
Существуют следующие свойства модуля действительных чисел:
1) |a + b| ≤ |a| + |b|;
2) |ab| = |a| × |b|;
3) , a ≠ 0;
4) |a – b| ≥ |a| – |b|.
Проведем доказательства, рассматривая различные случаи значений a и b.
Доказательство 1) |a + b| ≤ |a| + |b|:
Если a и b – положительные числа, то их модули совпадают с их значениями: |a| = a, |b| = b. Из этого следует, что |a + b| = |a| + |b|.
Если a – отрицательное число, а b – положительное число, то выражение |a + b| можно записать как |b – a|. Выражение же |a| + |b| равно сумме абсолютных значений a и b, что больше, чем b – a. Поэтому |a + b| < |a| + |b|.
Если b – отрицательное число, а a – положительное, то |a + b| принимает вид |a – b|, что также меньше суммы модулей |a| + |b|.
Если a и b – отрицательные числа, то получим |–a – b|. Результат этого выражения равен |a + b| (т. к. |–a – b| = |–(a + b)| = |a + b|). Но уже было доказано, что |a + b| = |a| + |b|, следовательно и |–a – b| = |a| + |b|.
Доказательство 2) |ab| = |a| × |b|: Здесь, в отличие от сложения, рассматривать все случаи особо не требуется, т. к. абсолютное значение произведения любых чисел (положительных ли, отрицательных ли) не зависит от знаков множителей. В выражении |ab| мы сначала перемножаем числа, а потом «отбрасываем» знак (отрицательный, если он есть), в выражении |a| × |b| сначала избавляемся от знаков, а потом перемножаем. Но от того, в какой момент был взят модуль (до или после умножения), не зависит абсолютное значение произведения.
Доказательство 3) , a ≠ 0:
Если a – положительное число, то |a| = a и, следовательно, доказываемое равенство верно, т. к. и правая и левая части равны 1/a.
Если a – отрицательное число, то имеем . Взятие модуля в обоих выражениях приведет к делению единицы на абсолютное значение a. 2-1}{4}d$. Равенство в нем достигается, когда $a_1 = \ldots = a_m \lt a_{m+1} = \ldots = a_{2m+1}$.
Поделиться ссылкой:
Похожее
Внеклассный урок — Модуль числа
Модуль числа
Модулем числа называется само это число, если оно неотрицательное, или это же число с противоположным знаком, если оно отрицательное.
Например, модулем числа 5 является 5, модулем числа –5 тоже является 5.
То есть под модулем числа понимается абсолютная величина, абсолютное значение этого числа без учета его знака.
Обозначается так: |5|, |х|, |а| и т.д.
Правило:
|а| = а, если а ≥ 0.
|а| = –а, если а < 0.
Пояснение:
|5| = 5 Читается так: модулем числа 5 является 5.
|–5| = –(–5) = 5 Читается так: модулем числа –5 является 5.
|0| = 0 Читается так: модулем нуля является ноль.
Свойства модуля:
1) Модуль числа есть неотрицательное число:
|а| ≥ 0
2) Модули противоположных чисел равны:
|а| = |–а|
3) Квадрат модуля числа равен квадрату этого числа:
|а|2 = a2
4) Модуль произведения чисел равен произведению модулей этих чисел:
|а · b| = |а| · |b|
6) Модуль частного чисел равен отношению модулей этих чисел:
|а:b| = |а| : |b|
7) Модуль суммы чисел меньше или равен сумме их модулей:
|а + b| ≤ |а| + |b|
8) Модуль разности чисел меньше или равен сумме их модулей:
|а – b| ≤ |а| + |b|
9) Модуль суммы/разности чисел больше или равен модулю разности их модулей:
|а ± b| ≥ ||а| – |b||
10) Постоянный положительный множитель можно вынести за знак модуля:
|m · a| = m · |а|, m >0
11) Степень числа можно вынести за знак модуля:
|аk| = |а|k, если аk существует
12) Если |а| = |b|, то a = ± b
Геометрический смысл модуля.
Модуль числа – это величина расстояния от нуля до этого числа.
Для примера возьмем снова число 5. Расстояние от 0 до 5 такое же, что и от 0 до –5 (рис.1). И когда нам важно знать только длину отрезка, то знак не имеет не только значения, но и смысла. Впрочем, не совсем верно: расстояние мы измеряем только положительными числами – или неотрицательными числами. Пусть цена деления нашей шкалы составляет 1 см. Тогда длина отрезка от нуля до 5 равна 5 см, от нуля до –5 тоже 5 см.
На практике часто расстояние отмеряется не только от нуля – точкой отсчета может быть любое число (рис.2). Но суть от этого не меняется. Запись вида |a – b| выражает расстояние между точками а и b на числовой прямой.
Пример 1. Решить уравнение |х – 1| = 3.
Решение.
Смысл уравнения в том, что расстояние между точками х и 1 равно 3 (рис.2). Поэтому от точки 1 отсчитываем три деления влево и три деления вправо – и наглядно видим оба значения х: х1 = –2, х2 = 4.
Можем и вычислить.
│х – 1 = 3 │х – 1 = –3
↕
│х = 3 + 1 │х = –3 + 1
↕
│х = 4 │ х = –2.
Ответ: х1 = –2; х2 = 4.
Пример 2. Найти модуль выражения:
3√5 – 10.
Решение.
Сначала выясним, является ли выражение положительным или отрицательным. Для этого преобразуем выражение так, чтобы оно состояло из однородных чисел. Не будем искать корень из 5 – это довольно сложно. Поступим проще: возведем в корень 3 и 10. Затем сравним величину чисел, составляющих разность:
3 = √9. Следовательно, 3√5 = √9 · √5 = √45
10 = √100.
Мы видим, что первое число меньше второго. Значит, выражение отрицательное, то есть его ответ меньше нуля:
3√5 – 10 < 0.
Но согласно правилу, модулем отрицательного числа является это же число с противоположным знаком. У нас отрицательное выражение. Следовательно, надо поменять его знак на противоположный. Выражением, противоположным 3√5 – 10, является –(3√5 – 10). Раскроем в нем скобки – и получим ответ:
–(3√5 – 10) = –3√5 + 10 = 10 – 3√5.
Ответ:
|3√5 – 10| = 10 – 3√5.
Модуль — сумма — Большая Энциклопедия Нефти и Газа, статья, страница 1
Модуль — сумма
Cтраница 1
Модуль суммы не может превзойти сумму модулей слагаемых.
[1]
Модуль суммы двух или нескольких комплексных чисел не превосходит суммы модулей этих чисел.
[2]
Модуль суммы двух или нескольких чисел меньше или равен сумме модулей этих чисел.
[3]
Модуль суммы индексов всех особых точек невырожденного векторного поля v степени т ( обозначается Ind v) не превосходит числа Петровского — — Олейник II ( т) и сравним по модулю 2 с числом и. Никаких других ограничений на Irul v не существует.
[4]
Заменим модуль суммы в правой части ( 20) суммой модулей и потребуем выполнения полученного неравенства. В этом случае ( 20) будет выполняться автоматически.
[5]
Докажите, что модуль суммы двух перемещений не превосходит суммы модулей составляющих перемещений. В каком случае модуль суммы равен сумме модулей слагаемых перемещений.
[6]
Известно, что модуль суммы меньше или равен сумме модулей слагаемых.
[7]
Доказать, что модуль суммы двух комплексных чисел не превосходит суммы модулей этих чисел.
[8]
Установим теперь свойства модуля суммы и разности двух комплексных чисел.
[9]
Теорема о том, что модуль суммы не больше суммы модулей слагаемых, легко распространяется на случай абсолютно сходящихся рядов.
[10]
Теорема о том, что модуль суммы не больше суммы модулей слагаемых, легко распространяется на случай абсолютно сходящихся рядов.
[11]
Поскольку разложить в ряд Фурье модуль суммы гармоник в общем виде нельзя, укажем, что при незначительных искажениях несущей выходной сигнал будет подобен детектированному.
[12]
Принципиальный интерес представляет способ выделения модуля суммы и разности входных — величин, предложенный в.
[13]
Установим теперь важные для дальнейшего свойства модуля суммы и разности двух комплексных чисел.
[14]
Такое отображение, фактически представляющее собой натягивание модуля суммы гауссовскнх полей на параболоиды в направлении внешней нормали, переведет гладкие параболоиды в некоторые случайные геометрические тела. {2}}\Leftrightarrow \\xy>\left| x \right|\cdot \left| y \right|\Leftrightarrow \\xy>\left| xy \right|,\end{array}\)
а это противоречит определению модуля.
Следовательно, таких \( x;y\in \mathbb{R}\) не существует, а значит, при всех \( x,\text{ }y\in \mathbb{R}\) выполняется неравенство \( \left| x+y \right|\le \left| x \right|+\left| y \right|.\)
Примеры для самостоятельного решения:
1) Докажите свойство №6.
2) Упростите выражение \( \left| \frac{31}{8}-\sqrt{15} \right|+\left| \frac{15}{4}-\sqrt{15} \right|\).
Ответы:
1) Воспользуемся свойством №3: \( \left| c\cdot x \right|=\left| c \right|\cdot \left| x \right|\), а поскольку \( c>0\text{ }\Rightarrow \text{ }\left| c \right|=c\), тогда
\( \left| cx \right|=c\cdot \left| x \right|\), ч.т.д.
Мы уже рассматривали уравнения, равные нулю (типа «произведение равно нулю»). К виду «произведение равно нулю» сводятся многие уравнения из разных разделов алгебры.
Если в уравнении сумма равна нулю, в некоторых случаях его можно решить, применяя следующее свойство функций:
Сумма нескольких неотрицательных функций равна нулю тогда и только тогда, когда каждая из функций равна нулю.
Таким образом, уравнение
где
равносильно системе уравнений
В частности,
где 2n — чётное натуральное число
Примеры уравнений, решение которых основано на этом свойстве функций.
ОДЗ: x∈R.
Сумма модулей равна нулю, если каждое из слагаемых равно нулю. Поэтому данное уравнение равносильно системе
Найдём корни каждого уравнения:
Оба модуля обращаются в нуль при x=2.
Ответ: 2.
ОДЗ: x∈[-4;2].
Сумма корней чётной степени равна нулю, если каждое из слагаемых рано нулю. Следовательно, это уравнение равносильно системе
Решаем каждое уравнение:
Оба слагаемых обращаются в нуль при x= -4.
Ответ: -4.
Для нахождения корней достаточно решить только одно из уравнений и проверить, удовлетворяют ли полученные корни остальным уравнениям системы.
ОДЗ: x∈(-∞; 1]U[9; ∞).
Сумма неотрицательных функций равна нулю, если каждая каждая из функций равна нулю:
Корень третьего уравнения — x=9 — удовлетворяет также 1-му и 2-му уравнениям системы.
Ответ: 9.
ОДЗ: x∈[-1; 1].
Правая часть уравнений — сумма неотрицательных функций. Соответственно, уравнение равносильно системе
Корни второго уравнения
x=1 и x= -1. Оба корня удовлетворяют и первому уравнению.
Ответ: ±1.
Как в другие уравнения из курса алгебры, решаемые с применением свойств функций, уравнения, в которых сумма неотрицательных функций равна нулю, при первом рассмотрении могут производить впечатление сложных. На самом деле, решить их достаточно просто, если помнить соответствующий теоретический материал.
Сумма модулей отклонений — Студопедия
плюсы:
— нечувствительность к выбросам.
минусы:
— сложность вычислительной процедуры;
— возможность больших отклонений между фактическими и проектными функциями;
— неоднозначность значений параметров и т.д.
Исходя из этих преимуществ и недостатков, обычно в качестве меры близости выбирают сумму квадратов и выбирают такую функцию y=f(x), у которой эта сумма квадратов достигает минимума.
Для того, чтобы лучше понять сущность метода наименьших квадратов, необходимо вначале вспомнить математические основы определения экстремума функции нескольких переменных.
В первую очередь, введем некоторые определения:
Определение 1.Функция Z = ƒ (x, y)имеет максимум в точке М0 (х0, у0), если значение функции в этой точке больше значений ее в точках, достаточно близких к точке М0 (х0, у0), т.е.
ƒ (х0, у0) > ƒ (х0 + Δх, у0 + Δу).
Это означает, что полное приращение функции Z = ƒ (х, у), вызванное переходом от точки (х0, у0) к соседней точке, будет величиной отрицательной:
ΔZ = ƒ (х0 + Δх, у0 + Δу) — ƒ (х0, у0) < 0. (2.1)
Определение 2.Функция Z = ƒ (x, y)имеет минимум в точке М0 (х0, у0), если значение функции в этой точке меньше значений ее в точках, достаточно близких к точке М0 (х0, у0), т. е.
ƒ (х0, у0) < ƒ (х0 + Δх, у0 + Δу).
Это означает, что полное приращение функции Z = ƒ (х, у), будет величиной положительной:
ΔZ = ƒ (х0 + Δх, у0 + Δу) — ƒ (х0, у0) > 0. (2.2)
Допустим, что функция Z = ƒ (х, у) имеет в точке М0 (х0, у0) максимум или минимум (экстремум).Тогда для функции должно выполняться одно из неравенств (3.1) или (3.2) при любых, достаточно малых Δх, Δу.
Предположим, что Δу = 0; тогда функция Z = ƒ (х, у) сделается функцией только одной переменной х. Эта функция по условию имеет экстремум.
Таким образом, условия обращения в нуль частных производных функции или несуществование хотя бы одной из них являются необходимыми условиями, но недостаточными условиями экстремума функции.
Имеем систему:
. (2.4)
Условия (2. 4) являются необходимыми для существования экстремума функции. Но может случиться, что эти условия в некоторых обстоятельствах невыполнимы.
Достаточные условия существования экстремума функции нескольких переменных имеют более сложный вид.
Пусть в точке М0 (х0, у0) частные производные обращаются в нуль, т.е.
, .
Подсчитаем значения частных производных второго порядка функции
Z = ƒ (х, у) в этой точке и обозначим их соответственно буквами: А, В, С:
тогда:
1. Если АС — В2 > 0, то функция Z = ƒ (х, у) имеет в точке М0 (х0, у0) экстремум, а именно:
при А < 0 максимум,
при А > 0 минимум.
2. Если АС — В2 < 0, то функция Z = ƒ (х, у) не имеет в точке М0 (х0, у0) экстремума.
3. Если АС — В2 = 0, то вопрос о существовании экстремума функции в точке М0 (х0, у0) остается открытым и требуются дополнительные исследования.
Метод наименьших квадратов является одним из важных применений теории экстремума функции нескольких переменных.
Предположим, что в результате некоторого опыта или наблюдения установлена зависимость между переменными величинами х и у, выражаемая в виде таблицы:
х
х1
х2
…
хn
у
у1
у2
…
уn
Пусть требуется перейти от табличного метода задания функции к аналитическому (т.е. выраженному в виде формулы), причем, если это нельзя сделать точно, постараемся получить аналитическую связь приближенно.
Теперь обратимся к графическому изображению данной системы. Рассматривая значения х и у как координаты точек в прямоугольной системе координат, наносим эти точки на график. Пусть, например, построенные точки расположены достаточно близко к некоторой прямой. Поэтому можно приблизительно считать, что между х и у существует линейная зависимость, выражаемая формулой,
у = ах + b.
Поставим задачу аналитического определения неизвестных коэффициентов а и b.
В основе аналитического метода определения а и b лежит метод наименьших квадратов. Точки, полученные на основании опытных данных, вообще говоря, не лежат на искомой прямой. Если бы некоторая точка (хi, уi) лежала на прямой, то ее координаты удовлетворяли бы уравнению прямой, т.е. имело бы место равенство:
уi = axi + b или axi + b — yi = 0
Однако в общем случае подстановка координат точки в уравнение прямой дала бы:
axi + b — yi = εi,
где εi ─ какая то малая величина.
Прямая сумма модулей — Примеры задач
В абстрактной алгебре прямая сумма — это конструкция, которая объединяет несколько модулей в новый, более крупный. В некотором смысле прямая сумма модулей — это «самый общий» модуль, который содержит данные модули как подпространства.
Наиболее известные примеры этой конструкции встречаются при рассмотрении векторных пространств (модулей над полем) и абелевых групп (модулей над кольцом Z целых чисел). Конструкция также может быть расширена для покрытия банаховых и гильбертовых пространств.
Конструкция векторных пространств и абелевых групп
Мы даем конструкцию первой в этих двух случаях в предположении, что у нас есть только два объекта. Затем мы обобщаем на произвольное семейство произвольных модулей. Ключевые элементы общей конструкции более четко определяются при более глубоком рассмотрении этих двух случаев.
Конструкция для двух векторных пространств
Предположим, что V и W — векторные пространства над полем K .Мы можем превратить декартово произведение V × W в векторное пространство над K , определив операции покомпонентно:
( v 1 , w 1 ) + ( v 2 , w 2 ) = ( v 1 + v 2 , ш 1 + ш 2 )
α ( v , w ) = (α v , α w )
для v , v 1 , v 2 дюймов V , w , w 1 , w 2 в W и α в K .
Результирующее векторное пространство называется прямой суммой V и W и обычно обозначается знаком плюса внутри круга:
V⊕W {\ displaystyle V \ oplus W}
Подпространство V × {0} V ⊕ W изоморфно V и часто идентифицируется с V ; аналогично для {0} × W и W . (См. Внутреннюю прямую сумму ниже.) При такой идентификации верно, что каждый элемент V ⊕ W может быть записан одним и только одним способом как сумма элемента V и элемента W . Размер V ⊕ W равен сумме размеров V и W .
Эта конструкция легко обобщается на любое конечное число векторных пространств.
Конструкция для двух абелевых групп
Для абелевых групп G и H , которые записываются аддитивно, прямое произведение также называется прямой суммой.Таким образом, мы превращаем декартово произведение G × H в абелеву группу, определяя операции покомпонентно:
( г 1 , ч 1 ) + ( г 2 , ч 2 ) = ( г 1 + г 2 , h 1 + h 2 )
для г 1 , г 2 дюймов G и h 1 , h 2 дюймов Н .
Обратите внимание, что мы также можем расширить операцию взятия целых кратных до прямой суммы:
для г в G , h в H и n целое число. Это аналогично расширению скалярного произведения векторных пространств до указанной выше прямой суммы.
Результирующая абелева группа называется прямой суммой из G и H и обычно обозначается знаком плюса внутри круга:
G⊕H {\ displaystyle G \ oplus H}
Подпространство G × {0} из G ⊕ H изоморфно G и часто идентифицируется с G ; аналогично для {0} × H и H .(См. Внутреннюю прямую сумму ниже.) С этой идентификацией верно, что каждый элемент G ⊕ H может быть записан одним и только одним способом как сумма элемента G и элемента из H . Ранг G ⊕ H равен сумме рангов G и H .
Эта конструкция легко обобщается на любое конечное число абелевых групп.
Построение произвольного семейства модулей
Следует заметить явное сходство между определениями прямой суммы двух векторных пространств и двух абелевых групп.Фактически каждый из них является частным случаем построения прямой суммы двух модулей. Кроме того, изменяя определение, можно учесть прямую сумму бесконечного семейства модулей. Точное определение выглядит следующим образом.
Предположим, что R — некоторое кольцо, а { M i : i in I } — семейство левых модулей R , индексированных набором I . Прямая сумма для { M i } затем определяется как набор всех функций α с областью I , таких что α ( i ) ∈ M i для все i ∈ I и α ( i ) = 0 для всех, кроме конечного числа индексов i .
Две такие функции α и β можно добавить, записав (α + β) ( i ) = α ( i ) + β ( i ) для всех i (обратите внимание, что это снова ноль для все, кроме конечного числа индексов), и такая функция может быть умножена на элемент r из R , записав ( r α) ( i ) = r (α ( i )) для все и . Таким образом, прямая сумма становится левым модулем R . Обозначим его через
При правильной идентификации мы снова можем сказать, что каждый элемент x прямой суммы может быть записан одним и только одним способом как сумма конечного числа элементов M i .
Если M i на самом деле являются векторными пространствами, то размерность прямой суммы равна сумме размеров M i . То же верно и для ранга абелевых групп и длины модулей.
Каждое векторное пространство над полем K изоморфно прямой сумме достаточно большого количества копий K , поэтому в определенном смысле следует учитывать только эти прямые суммы. Это неверно для модулей над произвольными кольцами.
Тензорное произведение распределяется по прямым суммам в следующем смысле: если N — некоторый правильный R -модуль, то прямая сумма тензорных произведений N на M i (что являются абелевыми группами) естественно изоморфно тензорному произведению N на прямую сумму M i .
Прямые суммы также коммутативны и ассоциативны, что означает, что не имеет значения, в каком порядке формируется прямая сумма.
Группа линейных гомоморфизмов R из прямой суммы в некоторую левую R -модуль L естественно изоморфна прямому произведению групп R -линейных гомоморфизмов из M i до L .
Внутренняя прямая сумма
Предположим, что M — это некий модуль R , а M i — это подмодуль M для каждых i в I .Если каждое x в M может быть записано одним и только одним способом как сумма конечного числа элементов M i , то мы говорим, что M — это внутренняя прямая сумма субмодулей M i . В этом случае M естественно изоморфна (внешней) прямой сумме M i , как определено выше.
Прямое слагаемое из M — это подмодуль N , такой, что есть другой подмодуль N ‘ из M , такой, что M является внутренней внутренней прямой суммой N и N ′ .
Категориальная интерпретация
На языке теории категорий прямая сумма является копроизведением и, следовательно, копределом в категории левых R -модулей, что означает, что она характеризуется следующим универсальным свойством. Для каждых i в I учитывайте естественное вложение
, который отправляет элементы M i к тем функциям, которые равны нулю для всех аргументов, кроме i .Если f i : M i → M являются произвольными линейными картами R для каждого i , то существует ровно одна линейная карта R
f: ⨁i∈IMi → M {\ displaystyle f: \ bigoplus _ {i \ in I} M_ {i} \ rightarrow M}
, так что f o j i = f i для всех i .
Прямая сумма модулей с дополнительной структурой
Если рассматриваемые нами модули несут некоторую дополнительную структуру (например,грамм. норма или внутренний продукт), то прямая сумма модулей часто также может содержать эту дополнительную структуру. В этом случае мы получаем копродукт в соответствующей категории всех объектов, несущих дополнительную структуру. Два наиболее ярких примера относятся к банаховым и гильбертовым пространствам.
Прямая сумма банаховых пространств
Прямая сумма двух банаховых пространств X и Y является прямой суммой X и Y , рассматриваемых как векторные пространства, с нормой || ( x , y ) || = || x || X + || y || Y для всех x дюймов X и y дюймов Y .
Как правило, если X i , где i пересекает набор индексов I , представляет собой набор банаховых пространств, то прямая сумма ⊕ i ∈ I X i состоит из всех функций x с доменом I , так что x ( i ) ∈ X i для всех i ∈ I и
∑i∈I‖x (i) ‖Xi конечно. {\ displaystyle \ sum _ {i \ in I} \ | x (i) \ | _ {X_ {i}} {\ mbox {конечно.}}}
Норма определяется суммой выше. Прямая сумма с этой нормой снова является банаховым пространством.
Например, если мы возьмем набор индексов I = N и X i = R , то прямая сумма ⊕ i ∈ N будет пробелом l 1 , который состоит из всех последовательностей ( a i ) вещественных чисел с конечной нормой || a || = ∑ i | a i |.
Прямая сумма гильбертовых пространств
Если дано конечное число гильбертовых пространств H 1 , …, H n , можно построить их прямую сумму, как указано выше (поскольку они являются векторными пространствами), а затем повернуть прямую сумму в гильбертово пространство, определив внутренний продукт как:
Это превращает прямую сумму в гильбертово пространство, которое содержит данные гильбертовы пространства как взаимно ортогональные подпространства.
Если дано бесконечно много гильбертовых пространств H i для i в I , мы можем провести такое же построение; обратите внимание, что при определении внутреннего продукта только конечное число слагаемых будет отличным от нуля. Однако результатом будет только внутреннее пространство продукта, и оно не будет полным.Затем мы определяем прямую сумму гильбертовых пространств H i как завершение этого внутреннего пространства продукта.
В качестве альтернативы и эквивалентно, можно определить прямую сумму гильбертовых пространств H i как пространство всех функций α с областью I , так что α ( i ) является элементом H i для каждых i в I и:
∑i‖α (я) ‖2 <1 {\ displaystyle \ sum _ {i} \ left \ | \ alpha _ {(i)} \ right \ | ^ {2} <{\ mathcal {1}} }
Тогда скалярное произведение двух таких функций α и β определяется как:
Это пространство заполнено, и мы получаем гильбертово пространство. {2}}. Сравнивая это с примером для банаховых пространств, мы видим, что прямая сумма банахова пространства и прямая сумма гильбертова пространства не обязательно совпадают. Но если имеется только конечное число слагаемых, то прямая сумма банахова пространства изоморфна прямой сумме гильбертова пространства.
Каждое гильбертово пространство изоморфно прямой сумме достаточно большого числа копий основного поля (либо R , либо C ).
de: Direkte Summe
es: Suma directa
fr: somme directe
он: סכום ישר
ja: 直 和
(PDF) Подмодули типов и разложение модулей по прямой сумме
98 J.DAUNS AND Y. ZHOU
(4) ⇒ (2). Пусть K — естественный класс. Чтобы показать (2), достаточно показать
, что для любых подмодулей X и Y из M, если X и Yare в K, тогда
будет X + Y. По лемме Цорна существует подмодуль Pmaximal
относительно X⊆P∈K и подмодуль Qmaximal относительно
до Y⊆Q∈K. Тогда P и Q дополняют подмодули M,
P∩Q≤eP и P∩Q ≤eQ. Таким образом, P и Q оба являются замыканиями
P∩Qin M. Если P = Q, по (4) существует 0– = X⊆P + Q, например
P∩X = 0 и X → P∩Q.Тогда X∈K и P⊂P⊕X∈K, противоречие
. Итак, P = Q и, значит, X + Y⊆P∈K.
(5) ⇒ (1). Предположим, что (1) не выполняется. Тогда существуют подмодули типа
T1- = T2 Mof типа K для естественного класса K. Отсюда следует
, что T1∩T2- = 0, T1∩T2≤eTifor i = 1,2, и T1∩T2 не является существенным
. в T1 + T2. Таким образом, существует 0 = A⊆T1 + T2, такое что
T1∩T2∩A = 0. Отсюда следует, что Ti∩A = 0fori = 1,2. Поскольку
каждый Ti является подмодулем типа M, мы имеем TiTA. Мы знаем, что
A = A / (T1∩A) ∼
= (A + T1) / T1⊆ (T2 + T1) / T1∼
= Т2 / (Т1∩Т2).Тогда
A∼
= B / (T1∩T2) для некоторого B с T1∩T2≤eB⊆T2. Обратите внимание, что B⊥A,
и поэтому B∩A = 0 иB⊕A⊆M.
(3) ⇒ (5). Предположим, что существует вложение X⊕ (X / Y) α
→ M
, где Y — собственный существенный подмодуль X и X⊥ (X / Y). Возьмем
x∈X, но x / ∈Y, и пусть m1 = α (x) и m2 = α (x + Y). Тогда m1R⊥
m2R. Чтобы в этом убедиться, пусть m1aR ∼
= m2bR для некоторых a, b ∈R. Отсюда следует, что
α (xaR) ∼
= α ((x + Y) bR). Это дает xaR ∼
= (x + Y) bR.Должно быть
xaR = 0, поскольку X⊥ (X / Y). Итак, m1aR = 0. Таким образом, m1R⊥m2R.
Кроме того, m⊥
1⊆m⊥
2 и m⊥
2 / m⊥
1≤eR / m⊥
1.Wenextprovem2 = 0,
, что дает противоречие. Определим β: m1R → m2R по β (m1r) = m2r,
r∈R. Тогда β является гомоморфизмом и ker (β) = m1m⊥
2. Пусть L будет замыканием типа
для ker (β) inm1R. Определим f: m1R → m1R⊕m2R (⊆M)
как f (x) = x + β (x), x∈m1R. Тогда это мономорфизм. Поскольку L
является замыканием типа ker (β) inm1R, f (ker (β)) параллельно f (L).Это
дает, что ker (β) параллельно f (L). Пусть Ltc и f (L) tc — замыкания типа
Земли f (L) inM соответственно. Тогда и Ltc, и f (L) tc
являются замыканиями типа ker (β) в M. По (3) Ltc = f (L) tc. Отсюда следует, что
L + f (L) является параллельным расширением L.ПримечаниеL — это подмодуль типа
m1R. Так как m1R⊥m2R, Lis — подмодуль типа для m1R⊕m2R. Это
означает, что L = L + f (L), т. Е. F (L) .L. Отсюда следует, что β (L) ⊆L.
прямая сумма в nLab
Прямые суммы и слабые прямые произведения
Контекст
Пределы и пределы
пределы и коллимиты
1-категориальный
предел и копредел
лимитов и копределов на примере
Коммутативность пределов и копределов
малый лимит
отфильтрованный colimit
колимит просеянный
подключенный лимит, широкий откат
сохраненный лимит, отраженный лимит, созданный лимит
продукт, продукт волокна, изменение базы, сопродукт, откат, выталкивание, изменение базы, эквалайзер, коэквалайзер, соединение, встреча, конечный объект, исходный объект, прямой продукт, прямая сумма
конечный предел
Канский добавочный номер
взвешенный лимит
конец и коэнда
2-категоричный
(∞, 1) -категория
Модельно-категориальная
Идея
Понятие прямой суммы или слабого прямого произведения — это понятие из алгебры, которое действительно имеет смысл в любой категории CC с нулевыми морфизмами (то есть любой категории, обогащенной над замкнутой моноидальной категорией заостренных множеств), поскольку пока существуют необходимые (со) лимиты.
Базовый и знакомый пример — прямая сумма V1⊕V2V_1 \ oplus V_2 двух векторных пространств V1V_1 и V2V_2 над некоторым полем или, в более общем смысле, двух модулей над некоторым кольцом. Как правило, для II — множество и {Vi} i∈I \ {V_i \} _ {i \ in I} — индексируемое II семейство векторных пространств или модулей, их прямая сумма ∈i∈IVi \ bigoplus_ {i \ in I } V_i — это набор формальных линейных комбинаций элементов в каждом из ViV_i. Это может частично мотивировать терминологию: элемент в прямой сумме — это сумма элементов , по крайней мере, в этих случаях.
Это обобщает двумя разными способами, которые мы называем прямой суммой и слабым прямым произведением . Во многих случаях (как в примере выше) они совпадают, но не всегда. Также во многих случаях прямые суммы будут такими же, как и сопутствующие продукты. В любом случае конечные слабые прямые продукты такие же, как и продукты, но бесконечные версии (почти всегда) разные.
Терминология
Название «слабый прямой продукт» происходит от понятия прямого продукта в алгебре для продукта в конкретной категории, созданного с помощью функтора забывчивости; слабый прямой продукт будет подобъектом прямого продукта (и всего прямого продукта в конечных случаях). Но здесь мы не будем ограничиваться контекстом такой конкретной категории.
Термин «прямая сумма» происходит от конечного побочного продукта (одновременно продукта и сопутствующего продукта) в аддитивных категориях. Аддитивный характер этих побочных продуктов распространяется в бесконечном случае (где побочные продукты обычно больше не появляются) на побочные продукты, а не на продукт. Даже когда прямая сумма не совпадает с побочным продуктом, он все равно сохраняет часть этого аромата.
В классических примерах CC прямая сумма и слабое прямое произведение совпадают.Однако приведенные ниже общие определения различают их в некоторых случаях, и мы используем термины «прямая сумма» и «слабый прямой продукт», чтобы лучше всего вызвать ощущения «как сопутствующий продукт» и «часть продукта».
Определения
Пусть 𝒞 \ mathcal {C} — категория с произведениями и копроизведениями, а также с нулевыми морфизмами. Пусть II — множество, и пусть (Ai) i∈I (A_i) _ {i \ in I} — II-индексированное семейство объектов в 𝒞 \ mathcal {C}, следовательно, функция A: I → Obj ( 𝒞) A: I \ to Obj (\ mathcal {C}).
Теперь мы определим как прямую сумму, так и слабое прямое произведение этого семейства.AiA_i будем называть прямыми слагаемыми или (слабыми) прямыми множителями .
Прямая сумма
Здесь мы должны предположить, кроме того, что 𝒞 \ mathcal {C} — обычная категория (или иначе имеет хорошее представление об изображении).
Определение
Пусть rr — морфизм копроизведения ∐iAi \ coprod_i A_i в произведение ∏iAi \ prod_i A_i, характеризующийся наличием следующих компонентов
(Ai → ∐A → r∏A → Aj) = {IdAiifi = j0ijifi ≠ j,
\оставил(
A_i \ to \ coprod A \ stackrel {r} {\ to} \ prod A \ to A_j
\верно)
знак равно
\оставил\{
\множество{
Id_ {A_i} & if \; я = j
\\
0_ {ij} & если \; я \ neq j
,}
\верно.\,
, где 0ij0_ {ij} — нулевой морфизм от AiA_i к AjA_j.
Прямая сумма по семейству {Ai} \ {A_i \} — это изображение
∐iAi → coimr⨁iAI → imriAi
\ coprod_i A_i \ overset {\ coim r} \ to \ bigoplus_i A_I \ overset {\ im r} \ to \ prod_i A_i
морфизма рр.
Слабое прямое произведение
Здесь мы рассматриваем финишные изделия
∏i∈FAi \ prod_ {i \ in F} A_i
, поскольку FF изменяется на конечных подмножествах индексного множества II. (В конструктивной математике используйте здесь «конечно индексированные» или «конечные по Куратовски» … хотя если II имеет разрешимое равенство, как это имеет место в обычных примерах, то каждое конечно индексированное подмножество II на самом деле конечно в самом строгом смысле.)
Эти конечные произведения образуют прямую систему, индексируемую направленным множеством 𝒫finI \ mathcal {P} _ {fin} I конечных подмножеств II (упорядоченных по включению) с отображением
∏i∈FAi → ∏i∈GAi, \ prod_ {i \ in F} A_i \ to \ prod_ {i \ in G} A_i,
, где F⊆GF \ substeq G, заданная формулой
∏i∈FAi≅∏i∈FAi × ∏i∈G ∖ F1 → (id, 0) ∏i∈FAi × ∏i∈G ∖ FAi≅∏i∈GAi. \ prod_ {i \ in F} A_i \ cong \ prod_ {i \ in F} A_i \ times \ prod_ {i \ in G \ setminus F} 1 \ stackrel {(id, 0)} {\ to} \ prod_ { i \ in F} A_i \ times \ prod_ {i \ in G \ setminus F} A_i \ cong \ prod_ {i \ in G} A_i. wk_i A_i определяется как направленный копредел этой прямой системы.
Примеры
Пример
В категориях Grp или Ab (абелевых) групп прямая сумма и слабое прямое произведение согласуются. Для конечного числа объектов это то же самое, что и прямой продукт, который является продуктом в обеих категориях.
Предложение
В этих примерах прямая сумма также может быть описана в более элементарных терминах как подгруппа прямого произведения:
, где «ess∀ess \ forall» означает «для всех, кроме конечного множества».Это проясняет, что прямая сумма равна прямому продукту, когда задействовано только конечное число объектов.
Для 𝒞 = \ mathcal {C} = Ab, RRMod это группа формальных линейных комбинаций элементов в слагаемых.
Пример
Для RR кольца прямые суммы в категории RRMod или модулей над RR даются суммами на нижележащих абелевых группах.
Пример
В категории заостренных множеств прямая сумма и слабое прямое произведение различаются.p прямых сумм для 1≤p≤∞1 \ leq p \ leq \ infty, хотя я не знаю, каким универсальным свойствам они все удовлетворяют.) В этом случае прямая сумма совпадает с копроизведением, а слабое прямое произведение — то же самое, что и произведение даже для бесконечно большого числа объектов. См. Прямую сумму банаховых пространств.
Внутренние прямые суммы
Дан объект BB и семейство подобъектов? AiA_i группы BB (или, в более общем смысле, семейство морфизмов Ai → BA_i \ to B, или эквивалентно отображение ∐iAi → B \ coprod_i A_i \ to B), предположим, что существует прямая сумма ⨁iAi \ bigoplus_i A_i.Предположим далее, что отображение ∐iAi → B \ coprod_i A_i \ в B факторизуется через отображение ∐iAi → ⨁iAi \ coprod_i A_i \ в \ bigoplus_i A_i (что означает, что оно уникально множится, если ∐iAi → ⨁iAi \ coprod_i A_i \ to \ bigoplus_i A_i эпично, так как должно быть в обычной категории). Наконец, предположим, что (или) фактор-отображение ⨁iAi → B \ bigoplus_i A_i \ to B является изическим. Затем мы говорим, что BB — это внутренняя прямая сумма AiA_i.
Напротив, абстрактно определенная прямая сумма ⨁iAi \ bigoplus_i A_i может называться внешней прямой суммой .Эти термины обычно используются с конкретными категориями, где AiA_i может быть задан независимо (для внешней прямой суммы) или как подмножество некоторого окружающего пространства (либо BB, либо что-то из того, что BB является подмножеством) для внутренней прямой суммы. В слишком абстрактном контексте разницы нет: с одной стороны, любая внутренняя прямая сумма тем более изоморфна любой внешней прямой сумме; с другой стороны, для внешней прямой суммы существует естественное отображение ∐iAi → ⨁iAi \ coprod_i A_i \ to \ bigoplus_i A_i, относительно которого внешняя прямая сумма является внутренней прямой суммой.3 | y \ in \ mathbb {F} \} \), то уравнение (4.4.2) остается в силе.
Если \ (U = U_1 + U_2 \), то для любого \ (u \ in U \) существуют \ (u_1 \ in U_1 \) и \ (u_2 \ in U_2 \) такие, что \ (u = u_1 + u_2. \)
Если так получилось, что \ (u \) можно однозначно записать как \ (u_1 + u_2 \), то \ (U \) называется прямой суммой \ (U_1 \) и \ (U_2. \)
Определение 4.4.3: Прямая сумма
Предположим, что каждое \ (u \ in U \) может быть однозначно записано как \ (u = u_1 + u_2 \) для \ (u_1 \ in U_1 \) и \ (u_2 \ in U_2 \).{2m + 1} \}. \] Тогда \ (\ mathbb {F} [z] = U_1 \ oplus U_2. \)
Предложение 4.4.6 . Пусть \ (U_1, U_2 \ subset V \) — подпространства. Тогда \ (V = U_1 \ oplus U_2 \) тогда и только тогда, когда выполняются следующие два условия:
\ (V = U_1 + U_2; \)
Если \ (0 = u_1 + u_2 \) с \ (u_1 \ in U_1 \) и \ (u_2 \ in U_2 \), тогда \ (u_1 = u_2 = 0. \)
Доказательство. \ ((«\ Rightarrow») \) Предположим, \ (V = U_1 \ oplus U_2 \).Тогда по определению выполняется условие 1. Конечно, \ (0 = 0 + 0 \), и, поскольку по уникальности это единственный способ записать \ (0 \ in V \), мы имеем \ (u_1 = u_2 = 0 \).
\ ((«\ Leftarrow») \) Предположим, что выполнены условия 1 и 2. По условию 1 для всех \ (v \ in V \) существуют \ (u_1 \ in U_1 \) и \ (u_2 \ in U_2 \) такие, что \ (v = u_1 + u_2 \). Предположим, \ (v = w_1 + w_2 \) с \ (w_1 \ in U_1 \) и \ (w_2 \ in U_2 \). Вычитая два уравнения, получаем
\ [0 = (u_1 — w_1) + (u_2 — w_2), \]
, где \ (u_1 — w_1 \ in U_1 \) и \ (u_2 — w_2 \ in U_2 \).По условию 2 это подразумевает \ (u_1 — w_1 = 0 \) и \ (u_2 — w_2 = 0 \), или, что эквивалентно, \ (u_1 = w_1 \) и \ (u_2 = w_2 \), как требуется.
Предложение 4.4.7. Пусть \ (U_1, U_2 \ subset V \) будут подпространствами. Тогда \ (V = U_1 \ oplus U_2 \) тогда и только тогда, когда выполняются следующие два условия:
\ (V = U_1 + U_2; \)
\ (U_1 \ cap U_2 = \ {0 \}. \)
Доказательство. \ ((«\ Rightarrow») \) Предположим, \ (V = U_1 \ oplus U_2 \).Тогда по определению выполняется условие 1. Если \ (u \ in U_1 \ cap U_2 \), то \ (0 = u + (−u) \) с \ (u \ in U_1 \) и \ (- u \ in U_2 \) (почему?). По предложению 4.4.6 имеем \ (u = 0 \) и \ (- u = 0 \), так что \ (U_1 \ cap U_2 = \ {0 \}. \)
\ ((«\ Leftarrow») \) Предположим, что выполнены условия 1 и 2. Чтобы доказать, что выполняется \ (V = U_1 \ oplus U_2 \), предположим, что
\ [0 = u_1 + u_2, \ rm {~ где ~} u_1 \ в U_1 \ rm {~ и ~} u_2 \ в U_2. \ tag {4.3} \]
По предложению 4.4.6 достаточно показать, что \ (u_1 = u_2 = 0 \).3 \ neq U_1 \ oplus U_2 \ oplus U_3 \), поскольку, например,
Но \ (U_1 \ cap U_2 = U_1 \ cap U_3 = U_2 \ cap U_3 = \ {0 \} \), так что аналог предложения 4.4.7 не выполняется.
Авторы
Версии этого учебника в твердом и мягком переплете доступны на сайте WorldScientific. com.
О. В. Камловский, “Сумма модулей коэффициентов Уолша для некоторых сбалансированных булевых функций”, Матем.Вопр. Криптогр., 8: 4 (2017), 75–98
Эта статья цитируется в научной статье 1 (всего в статье 1 )
Сумма модулей коэффициентов Уолша для некоторых сбалансированных булевых функций
О.В. Камловский
ООО «Центр Сертификационных Исследований», Москва
Аннотация: Мы рассматриваем следующие сбалансированные булевы функции: а) построенные из нормальной бент-функции методом Доббертина, б) мажоритарная функция, в) функции, значения единиц которых последовательно расположены в таблице истинности. Получены точные формулы и оценки сумм модулей коэффициентов Уолша.
Полный текст: PDF-файл (225 kB) Ссылки :
PDF файл HTML файл
Библиографические базы данных:
УДК: 519.12 + 519.719.2 Поступила 11.V.2017
Образец цитирования: О. В. Камловский, “Сумма модулей коэффициентов Уолша для некоторых сбалансированных булевых функций”, Матем. Вопр. Криптогр., 8: 4 (2017), 75–98
Цитирование в формате AMSBIB
\ RBibitem {Kam17} \ by О. ~ В. ~ Камловский \ paper Сумма модулей коэффициентов Уолша для некоторых сбалансированных булевых функций \ jour Матем. Вопр. Криптогр. \ год 2017 \ vol 8 \ issue 4 \ pages 75--98 \ mathnet {http://mi. mathnet.ru/mvk240} \ crossref {https://doi.org/10.4213/mvk240 } \ mathscinet {http://www.ams.org/mathscinet-getitem?mr=3770676} \ elib {https://elibrary.ru/item.asp?id=32641310}
Варианты соединения:
http://mi.mathnet.ru/eng/mvk240
https://doi.org/10.4213/mvk240
http://mi.mathnet.ru/eng/mvk/v8/i4/p75
Цитирующие статьи в Google Scholar: Русские цитаты,
Цитаты на английском языке Статьи по теме в Google Scholar: Русские статьи,
Английские статьи
Эта публикация цитируется в следующих статьях:
О.А. Логачев, С. Н. Федоров, В. В. Ященко, “О $ \ Delta $ -эквивалентности булевых функций”, Дискретная математика. Appl., 30: 2 (2020), 93–101
Количество просмотров:
Эта страница:
295
Полный текст:
143
Ссылки:
38
Первая страница:
прямой перевод% 20sum% 20of% 20modules — английский французский перевод прямого% 20sum% 20of% 20modules
Ваш поиск не дал результатов
EN
Слова, похожие на прямые% 20sum% 20of% 20modules
отстранение
,
Därstetten
,
du reste
,
Drust IX des Pictes
,
Друк Цендхен
,
Drucat
,
Дроге де Травейл
,
Дроге-де-Травей
,
Дроэда
,
Driss Jettou
,
Дрезденко
,
Дрезднер Банк
,
Дрезден
,
Дрезде
FR
Слова, похожие на прямые% 20sum% 20of% 20modules
Därstetten
,
Дурресский район
,
Сухих дрожжей
,
Стены из сухого камня
,
Стена из сухого камня
,
Сухой камень
,
галантерея
,
Друст IX пиктов
,
Друк Цендхен
,
аптека
,
Торговля наркотиками
,
Наркотуризм
,
Дизайн лекарств
,
наркозависимый
,
наркозависимость
Прямая сумма — go2kanid
Прямые суммы определены для ряда различных видов математических объектов,
включая подпространства, матрицы, модули и группы.
Прямая сумма матрицы определяется как
(Ayres 1962, стр. 13-14).
Прямая сумма двух подпространств и представляет собой сумму подпространств, в которых и имеют общий только нулевой вектор (Розен 2000, стр. 357).
Важным свойством прямой суммы является то, что она является копродуктом в категории модулей (т. Е. Прямой суммой модулей). Это общее определение как следствие дает определение прямой суммы абелевых групп и (поскольку они являются -модулями, т.е., модули над целыми числами) и прямую сумму векторных пространств (поскольку они являются модулями над полем). Обратите внимание, что прямая сумма абелевых групп такая же, как прямое произведение группы, но термин прямая сумма не используется для неабелевых групп.
Обратите внимание, что прямые продукты и прямые суммы различаются для бесконечных индексов. Элемент прямой суммы равен нулю для всех элементов, кроме конечного, в то время как элемент прямого произведения может иметь все ненулевые элементы.
СМОТРИ ТАКЖЕ: Abelian Group, Direct Product, Direct Summand, Group Direct Product, Group Direct Sum, Matrix Direct Sum, Module, Module Direct Sum
Части этой записи предоставлены Тоддом Роулендом
ССЫЛКИ:
Ayres , Ф.Jr. Очерк теории и проблем матриц Шаума. New York: Schaum, 1962.
Rosen, K.H. (Ed.). Справочник по дискретной и комбинаторной математике. Boca Raton, FL: CRC Press, 2000.
Прямая сумма двух подпространств и является суммой подпространств, в которых и имеют общий только нулевой вектор (Rosen 2000, стр. 357).
Важным свойством прямой суммы является то, что она является сопутствующим продуктом в категории модулей (т.е., модульная прямая сумма). Это общее определение как следствие дает определение прямой суммы абелевых групп и (поскольку они являются -модулями, т. Е. Модулями над целыми числами) и прямой суммы векторных пространств (поскольку они являются модулями над полем).
{\frac{1}{2}}}=\sqrt{4}=2\)), а вот \( \displaystyle {{\log }_{-4}}2\) не существует.
Поэтому и отрицательные основания проще выбросить, чем возиться с ними.
Ну а поскольку основание a у нас бывает только положительное, то в какую бы степень мы его ни возводили, всегда получим число строго положительное.
Значит, аргумент должен быть положительным.
Например, \( \displaystyle {{\log }_{2}}\left( -4 \right)\) не существует, так как \( 2\) ни в какой степени не будет отрицательным числом (и даже нулем, поэтому \( \displaystyle {{\log }_{2}}0\) тоже не существует).
В задачах с логарифмами первым делом нужно записать ОДЗ.
Вспомним определение: логарифм \( \displaystyle {{\log }_{x}}\left( x+2 \right)\) – это степень, в которую надо возвести основание \( x\), чтобы получить аргумент \( \displaystyle \left( x+2 \right)\).
И по условию, эта степень равна \( 2\): \( \displaystyle {{x}^{2}}=x+2\).{2}}-x-2=0\).
Решим его с помощью теоремы Виета: сумма корней равна \( 1\), а произведение \( -2\). Легко подобрать, это числа \( 2\) и \( -1\).
Но если сразу взять и записать оба этих числа в ответе, можно получить 0 баллов за задачу на ЕГЭ.
Почему?
Давайте подумаем, что будет, если подставить эти корни в начальное уравнение?
\( \displaystyle x=-1\text{: }{{\log }_{-1}}\left( -1+2 \right)=2\) – это явно неверно, так как основание не может быть отрицательным, то есть корень \( x=-1\) – «сторонний».
Чтобы избежать таких неприятных подвохов, нужно записать ОДЗ еще до начала решения уравнения:
Теперь вспоминаем, что такое логарифм: в какую степень нужно возвести основание \( \displaystyle x+1\), чтобы получить аргумент \( \displaystyle 2x+5\)?
Хотите читать учебник без ограничений? Зарегистрируйтесь:
Казалось бы, меньший корень равен \( \displaystyle -2\). Но это не так: согласно ОДЗ корень \( \displaystyle x=-2\) – сторонний, то есть это вообще не корень данного уравнения. Таким образом, уравнение имеет только один корень: \( \displaystyle x=2\).
Ответ: \( \displaystyle x=2\).
Урок 27. логарифмические уравнения — Алгебра и начала математического анализа — 10 класс
Алгебра и начала математического анализа, 10 класс
Урок № 27. Логарифмические уравнения.
Перечень вопросов, рассматриваемых в теме
1) Понятие простейшего логарифмического уравнения
2) Основные способы решения логарифмический уравнений
3) Общие методы в решении логарифмических уравнений
Глоссарий по теме
Простейшее логарифмическое уравнение. Уравнение вида , где, a > 0, a ≠ 1.
Основные способы решения логарифмических уравнений
1. , где, a > 0, a ≠ 1, то , при условии, что
2. .
Общие методы для решения логарифмических уравнений
Разложение на множители.
Введение новой переменной.
Графический метод.
Основная литература:
Колягин Ю.М., Ткачева М.В., Фёдорова Н.Е. и др. Математика: алгебра и начала математического анализа, геометрия. Алгебра и начала математического анализа. 10 класс. Базовый и углублённый уровни. – М.: Просвещение, 2014.–384с.
Открытые электронные ресурсы:
http://fipi.ru/
Теоретический материал для самостоятельного изучения
Уравнение вида , где, a > 0, a ≠ 1 называют простейшимлогарифмическим уравнением.
Данное уравнение имеет единственное решение, которое мы можем получить графически или по определению логарифма: .
Способы решения логарифмических уравнений:
Если , то (где, a > 0, a ≠ 1,
Пример 1.
.
Воспользуемся определением логарифма
;
.
Оба корня удовлетворяют неравенству
Ответ: – 8; 1.
Если
Если ,
Пример 2.
.
;
;
;
;
Ответ: 1.
Пример 3.
.
В данном уравнении систему с ограничивающими условиями можно не составлять, сделав в конце проверку о существовании логарифмов для конкретных значений х.
Сумму логарифмов в левой части заменим логарифмом произведения:
.
Подставим каждый корень в исходное уравнение, получаем верные числовые равенства.
Ответ: 3; 4.
Встречаются уравнения, когда нельзя сразу использовать 1 или 2 правило. В этом случае сначала используют общие методы решения уравнений.
Разложение на множители.
Пример 4.
Перенесем все в левую часть:
Можно увидеть общий множитель: .
Для этого приведем к основанию первый логарифм:
.
Вынесем за скобку общий множитель:
Имеем произведение равное нулю. (Произведение равно нулю тогда и только тогда, когда один из множителей равен нулю)
, два простейших логарифмических уравнения.
;
Выполняем проверку. Оба числа являются корнями уравнения.
Ответ: 3; 5.
Введение новой переменной.
Пример 5.
Замена: тогда
Обратная замена:
Оба числа являются корнями уравнения.
Ответ: ; 5.
Графический способ решения.
Строим графики левой и правой частей уравнения, определяем абсциссы точек пересечения графиков.
Примеры и разбор решения заданий тренировочного модуля
№1. Решите уравнение:
Решение.
Дважды используем определение логарифма:
Ответ: 6.
№2 Укажите промежуток, содержащий нули функции
.
Возможные варианты ответа:
Решение: Чтобы найти нули функции, приравниваем ее к нулю.
Приведем логарифмы к основанию 5: .
Две равные дроби с равными знаменателями, следовательно, равны и числители. Т. е. Слева и справа логарифмы по одинаковому основанию, значит .
Ответ: 4
Логарифмические уравнения. 10-11 класс
Стоит напомнить всем, что логарифмическими называют уравнения, в которых переменная или функция от «икс» находится под знаком логарифма. При равносильных преобразованиях справедливая формула перехода от логарифмического до простого уравнения logaf(x)=c⇔f(x)=ac. ОДЗ: основание логарифма должно быть больше нуля и не равняться единице, функция – положительной {x>0, x≠1, f(x)>0}. Важно знать частные случаи простейших логарифмических уравнений: правая сторjна равна нулю (с=0) или единицы (с=1): логарифм основания равен единице c=1⇔logaa=1⇔f(x)=a. логарифм единицы равен нулю c=1⇔loga1=0⇔f(x)=1. Эти формулы Вы должны знать на память, поскольку их чаще всего применяют при сведении логарифмов до простейшего типа. С целью научить Вас раскрывать логарифмические уравнения, а также подготовить к ВНО тестированию нами решены 40 примеров, которые в полной мере охватывают все известные методы решения логарифмических уравнений, которые Вас учат в 10-11 классе школьной программы, и дальше на первых курсах в ВУЗ-ах.
Схема вычисления логарифмических уравнений
если возможно, выписать область допустимых значений логарифмов и функций, которые в него входят.
свести уравнение к простейшему типу путем элементарных преобразований, которые заключаются в вынесении степени из основания логарифма (или наоборот), логарифмированию и потенцированию (возведение в степень по основанию (экспонента, основы =10, 2, π)
в случаях сложных уравнений вводят замену переменных и сводят к квадратным или другим известным уравнениям.
Вычисление уравнений с логарифмом
Пример 16.1 Решить уравнение logax=c.
Решение: Имеем простейшее логарифмическое уравнение, которое решается методом сведения к одному основанию логарифмов: logax=c (здесь a>0, a≠1), logax=c•1, logax=c•logaa, logax= logaac Здесь использовали свойства логарифма, единицу расписали как логарифм основания, после чего множитель c внесли под логарифм. Далее опустили основы и приравняли выражения в логарифмах: x=ac. ОДЗ: x>0. Ответ: ac – Г.
Пример 16.2 Решить уравнение log1/2(x)=-4.
А
Б
В
Г
Д
ø
-16
1/16
1/16; 16
16
Решение: ОДЗ функции под логарифмом: x>0. Сводим уравнение к одному основанию логарифмов
При равных основах приравниваем выражения под логарифмами: x=(1/2)-4, x=24, x=16. Ответ: 16 – Д.
Пример 16.3 Решить уравнение log2(-x)=5.
А
Б
В
Г
Д
ø
32
-32
1/32
-1/32
Решение: Выполняем раскрытия логарифмов по данной в начале инструкции: ОДЗ – -x>0,x<0. Упростим уравнения log2(-x)=5 log2(-x)=5•1 log2(-x)=5• log22 log2(-x)= log225 опустим основы и приравняем логарифмические выражения: -x=25, -x=32, x=-32. Ответ: -32 – У.
x∈(-∞;1)∪(1;+∞). На этом множестве значений и ищем решение уравнения, сперва сведя к одной основе логарифмы
по теореме Виета: x1+x2=1, x1•x2=-2. x1=-1, x2=2. Оба корня принадлежат ОДЗ. Ответ: -1; 2 – Д.
ОДЗ неравенства могут быть сложнее, чем сами уравнения, тогда достаточно сами корни уравнения подставить в неравенство (или систему неравенств) и определить, принадлежат ли корни области допустимых значений логарифмческого уравнения.
Пример 16.5 Сколько корней имеет уравнение lg(x4-10x2)=lg3x3?
А
Б
В
Г
Д
Ни одного
один
два
три
четыре
Решение: В логарифме имеем биквадратное выражение, которое при условиях на ОДЗ требует вычислений.2)=lg3x3 имеет один корень. Ответ: один – Б.
Пример 16.6 Решить уравнение log6(x-2)+log6(x-1)=1 и указать промежуток, которому принадлежит его корень.
Решение: Выпишем систему неровностей для ОДЗ:
По правилу, что сумма логарифмов чисел равна логарифму их произведения ln(a)+ln(b)=ln(a•b) и свойству log66=1, сведем логарифмы к общему основанию:
При преобразованиях получили квадратное уравнение, корни которого находим по теореме Виета: x1+x2=3 x1•x2=-4. x1=-1<2 (не принадлежит ОДЗ) x2=4. x=4 – единственный корень заданного уравнения, он принадлежит промежутку (3,9;4,1). Ответ: (3,9;4,1) – Б.
Пример 16.9 Решить уравнение (log2x)2-2log2x-3=0 и указать сумму его корней.
Решение: ОДЗ: x>0. логарифмическое уравнение (log2x)2-2log2x-3=0 сведем к квадратному заменой log2x=t. t2-2•t-3=0 По формулам Виета имеем: t1+t2=2 – сумма корней уравнения; t1•t2=3 – их произведение, тогда t1=-1 и t2=3 – корни квадратного уравнения. Возвращаемся к замене, и вычисляем простые логарифмические уравнения
Оба корня принадлежат ОДЗ, по условию найдем их сумму: x1+x2=0,5+8=8,5. Ответ: 8,5 – Д.
С простых примеров на раскрытие логарифмических уравнений Вы увидели, что достаточно знать несколько формул и базовые свойства логарифма и уже можно самостоятельно решать уравнения. Для простых условий это работает, но напоминаем, что курс ВНО подготовки содержит 40 примеров, причем ряд задач сочетают в себе не только логарифмы, но и корни, модули, показательные выражения. Вы научитесь сводить уравнения к квадратным, логарифмировать и еще много чего нового.
Алгебра 10 класс — Личный сайт учителя Чендевой Ю.А.
Логарифмы
Логарифм числа b по основанию а – это показатель степени, в которую нужно возвести число а, чтобы получить число b.
Формула
Примеры
loga b = c (при a > 0, a ≠ 1, b > 0).
Это означает, что ac = b.
log525 = 2
Читается так: логарифмом числа 25 по основанию 5 является 2. Число 2 является показателем степени. Это означает, что 52 = 25.
log464 = 3
Логарифмом числа 64 по основанию 4 является 3. Это означает, что 43 = 64
Говоря иначе, логарифмирование – это действие, обратное возведению в степень.
Логарифм по основанию 10 называют десятичным логарифмом.
Примеры десятичного логарифма:
log10 100
log10 5
log10 0,01
Десятичный логарифм обозначают символом lg. Таким образом:
вместо log10 100 следует писать lg 100;
вместо log10 5 пишем lg 5;
вместо log10 0,01 пишем lg 0,01.
Логарифмирование и потенцирование.
Логарифмирование – это нахождение логарифмов заданных чисел или выражений.
b Пример: Найдем логарифм x = a2 · — . c
Решение.
Последовательно воспользуемся сразу всеми тремя основными свойствами логарифмов, которые изложены выше (логарифм произведения, логарифм частного и логарифм степени): b lg x = lg (a2 · —) = lg a2 + lg b – lg c = 2lg a + lg b – lg c. c
Потенцирование – это нахождение чисел или выражений по данному логарифму числа (выражения).
Потенцировать – значит освобождаться от значков логарифмов в процессе решения логарифмического выражения.
Например, надо решить уравнение log2 3x = log2 9.
Убираем значки логарифмов – то есть потенцируем:
3х = 9.
В результате получаем простое уравнение, которое решается за несколько секунд:
х = 9 : 3 = 3.
Но потенцирование не сводится к простому и произвольному убиранию значков логарифмов. Для этого в обоих частях уравнения как минимум должно быть одинаковое значение основания (в нашем случае это число 2). Подробнее о потенцировании и его правилах – в следующем разделе.
Урок по математике на тему «Решение логарифмических уравнений» (10 класс)
Тема: Решение логарифмических уравнений (10 класс)
Цель урока: повторить понятие и свойства логарифма; повторить способы решения логарифмических уравнений и закрепить их при выполнении упражнений.
Задачи:
— обучающие: повторить определение и основные свойства логарифмов, уметь применять их в вычислении логарифмов, в решении логарифмических уравнений;
-воспитательные: воспитывать настойчивость, самостоятельность; прививать интерес к предмету
Тип урока: урок повторения и закрепления ранее изученного материала.
Ход урока:
Организационный момент.
Проверка готовности обучающихся и кабинета к занятию. Объявление темы.
Устная работа.
Повторение понятия логарифма, повторение его основных свойств и свойств логарифмической функции:
Разминка по теории:
1. Дайте определение логарифма.
2. От любого ли числа можно найти логарифм?
3. Какое число может стоять в основании логарифма?
4. Функция y=log0,8 x является возрастающей или убывающей? Почему?
5. Какие значения может принимать логарифмическая функция?
6. Какие логарифмы называют десятичными, натуральными?
7. Назовите основные свойства логарифмов.
8. Можно ли перейти от одного основания логарифма к другому? Как это сделать?
Работа по карточкам:
Карточка №1:
Вычислить: а) log64 + log69 =
б) log1/336 – log1/312 =
Решить уравнение:
log5х = 4 log53 – 1/3 log527
Карточка №2:
Вычислить: а) log211 – log244 =
б) log1/64 + log1/69 =
Решить уравнение:
log7х = 2 log75 + 1/2 log736 – 1/3log7125.
Фронтальный опрос класс
Вычислить:
log216
lоg3 √3
log71
log5 (1/625)
log211 — log 244
log814 + log 832/7
log35 ∙ log53
5 log5 49
8 lоg 85 — 1
25 –log 510
Сравнить числа:
log½ е и log½π;
log2 √5/2 и log2√3/2.
Выяснить знак выражения log0,83 · log62
Повторение решения логарифмических уравнений.
Класс делится на группы по 4 человека. Каждый из четырех членов группы выбирает один из способов решения, разбирается с ним (при затруднении можно обратиться к учителю), проводит взаимообучение с остальными тремя товарищами. Далее вместе прорешивают четыре примера, ответы проверяются учителем.
Решение уравнений на основании определения логарифма.
имеет решение .
На основе определения логарифма решаются уравнения, в которых:
по данным основаниям и числу определяется логарифм,
по данному логарифму и основанию определяется число,
по данному числу и логарифму определяется основание.
Ответ: 7
Ответ: 8
Ответ: 3
2.Метод потенцирования.
Под потенцированием понимается переход от равенства, содержащего логарифмы, к равенству, не содержащему их т.е. , то , при условии, что .
Пример: Решите уравнение
3
— неверно
Ответ: решений нет.
ОДЗ:
3.Уравнения, решаемые с помощью применения основного логарифмического тождества.
Пример: Решите уравнение
– не принадлежит ОДЗ
– принадлежит ОДЗ
Ответ: х=2
ОДЗ:
Домашнее задание: Решить задание на карточке.
Подведение итогов, рефлексия
Музыка может возвышать или умиротворять душу
Живопись – радовать глаз,
Поэзия – пробуждать чувства,
Философия – удовлетворять потребности разума,
Инженерное дело – совершенствовать материальную сторону жизни,
А математика способна достичь всех этих целей.
Конспект урока по Математике «Способы решения логарифмических уравнений» 10 класс
Тема: «Способы решения логарифмических уравнений».
Предмет
Алгебра и начала математического анализа
Класс
10
Тема урока
«Способы решения логарифмических уравнений», 2 часа
Базовый учебник
Ш.А. Алимов, Ю.М. Колягин и др. / М. Просвещение 2014
Цель урока: повторить знания учащихся о логарифме числа, его свойствах; изучить способы решения логарифмических уравнений и закрепить их при выполнении упражнений.
Задачи:
— обучающие: повторить определение и основные свойства логарифмов, уметь применять их в вычислении логарифмов, в решении логарифмических уравнений;
— Здравствуйте, садитесь! Сегодня тема нашего урока «Решение логарифмических уравнений», на котором мы познакомимся со способами их решения, используя определение и свойства логарифмов. (слайд № 1)
Устная работа.
Закрепление понятия логарифма, повторение его основных свойств и свойств логарифмической функции:
1. Разминка по теории:
1. Дайте определение логарифма. (слайд № 2)
2. От любого ли числа можно найти логарифм?
3. Какое число может стоять в основании логарифма?
4. Функция y=log0,8x является возрастающей или убывающей?Почему?
5. Какие значения может принимать логарифмическая функция?
6. Какие логарифмы называют десятичными, натуральными?
7. Назовите основные свойства логарифмов. (слайд № 3)
8. Можно ли перейти от одного основания логарифма к другому? Как это сделать? (слайд № 4)
Рязановский, А.Р. Математика. 5 – 11 кл.: Дополнительные материалы к уроку математики/ А.Р.Рязановский, Е.А.Зайцев. – 2-е изд., стереотип. – М.: Дрофа,2002
Математика. Приложение к газете «Первое сентября». 1997. № 1, 10, 46, 48; 1998. № 8, 16, 17, 20, 21, 47.
Скоркина, Н.М. Нестандартные формы внеклассной работы. Для средних и старших классов/ Н.М. Скоркина. – Волгоград: Учитель, 2004
Зив, Б.Г., Гольдич,В.А. Дидактические материалы по алгебре и началам анализа для 10 класса./Б.Г.Зив, В.А.Гольдич. – 3-е изд., исправленное. – СПб.: «ЧеРо-на-Неве», 2004
Алгебра и начала анализа: математика для техникумов/под ред. Г.Н.Яковлева.-М.: Наука, 1987
6
Изучение логарифмов в старшей школе
Понятие логарифма
При решении показательных уравнений удается представить обе части уравнения в виде степеней с одинаковыми основаниями и рациональными показателями. Так, например, при решении уравнения мы заменяем степенью и из равенства степеней с одинаковыми основаниями делаем вывод о равенстве показателей: х = −5/6. Однако, чтобы решить, казалось бы, более простое уравнение 2х = 3, стандартных знаний оказывается недостаточно. Дело в том, что число 3 нельзя представить в виде степени с основанием 2 и рациональным показателем.
Действительно, если бы равенство , где m и n — натуральные числа, было верным, то, возведя его в степень n, мы должны были бы получить верное равенство 2m = 3n. Но последнее равенство неверно, так как левая его часть является четным числом, а правая — нечетным. Значит, не может быть верным и равенство .
С другой стороны, график непрерывной функции y = 2xпересекается с прямой y = 3, и, значит, уравнение 2x = 3 имеет корень. Таким образом, перед нами стоят два вопроса: «Как записать этот корень?» и «Как его вычислить?».
Показатель степени, в которую нужно возвести число a (a > 0, a ≠ 1), чтобы получить число b, называется логарифмом b по основанию a и обозначается logab.
Теперь мы можем записать корень уравнения 2х = 3:
х = loga3
Равенства ax = b и x = logab, в которых число a положительно и не равно единице, число b положительно, а число x может быть любым, выражают одно и то же соотношение между числами a, b и x. Подставив в первое равенство выражение x из второго, получим основное логарифмическое тождество.
После проверки ученикам предлагается ответить на вопрос, какое из заданий показалось им наиболее трудным. Вероятный ответ: 2 (в), так как в нем нужно было приводить дробь к степени числа 5. Затем школьникам предлагается высказать мнение о сравнительной с заданием 2 (в) трудности уравнения 2x = 3. На первый взгляд кажется, что это уравнение проще, однако представить 3 в виде степени числа 2 школьникам не удается.
Дальше изучение нового материала проводится в соответствии с учебником. При этом в зависимости от уровня класса рассматривается или не рассматривается дополнительный материал о невозможности представления 3 в виде 2r , где r=m/n.
После этого диалог с классом можно строить примерно так:
— Как вы думаете, имеет ли уравнение 2x = 3 корень? Ответ обоснуйте. [Если построить график функции у = 2x и провести прямую у = 3, то они пересекутся в одной точке, значит, уравнение имеет один корень.] — Что можно сказать о корне уравнения ax = b, где а > 0 и а ≠ 1? При всех ли значениях b оно имеет корни?
Затем вводится определение логарифма числа b по основанию а и записывается основное логарифмическое тождество . При этом выписывание равенства происходит синхронно с повторным чтением определения теперь уже в обратном, по сравнению с учебником, порядке. Теперь можно записать корень уравнения 2х = 3: х = loga3 и предложить школьникам серию самостоятельных работ.
Логарифмическая функция
Выразим x из равенства y = logax, получим x = ay. Последнее равенство задает функцию x = ay, график которой симметричен графику показательной функции y = ax относительно прямой y = x.
Показательная функция x = ay является монотонной, и, значит, разные значения y соответствуют разным значениям x, но это говорит о том, что y = logax, в свою очередь, является функцией x.
Показательная функция y = ax и логарифмическая функция y = logax являются взаимно обратными. Сравнивая их графики, можно отметить некоторые основные свойства логарифмической функции.
Свойства функции y = logax, a > 0, a ≠ 11:
Функция y = logax определена и непрерывна на множестве положительных чисел.
Область значений функции y = logax — множество действительных чисел.
При 0 < a < 1 функция y = logax является убывающей; при a > 1 функция y = logax является возрастающей.
График функции y = logax проходит через точку (1; 0).
Ось ординат — вертикальная асимптота графика функции y = loga.
Математика: алгебра и начала математического анализа, геометрия. Алгебра и начала математического анализа. Углубленный уровень. 10 класс. Учебник
Учебник входит в учебно-методический комплекс по математике для 10–11 классов, изучающих предмет на углубленном уровне. Теоретический материал в нем разделен на обязательный и дополнительный. Каждая глава завершается домашней контрольной работой, а каждый пункт главы — контрольными вопросами и заданиями. Учебник соответствует Федеральному государственному образовательному стандарту среднего (полного) общего образования, имеет гриф «Рекомендовано» и включен в Федеральный перечень учебников.
Купить
Решение логарифмических уравнений и неравенств на основе свойств логарифмической функции
Освобождаясь от внешнего логарифма, имеющего основание 3, мы ссылаемся на возрастание соответствующей логарифмической функции, то есть на то, что большему значению логарифма соответствует большее значение выражения, стоящего под его знаком. Однако следует иметь в виду, что если функцию y = log3 log0,5(2x + 1) считать логарифмической, то ее аргумент не переменная x, а все выражение log0,5(2x + 1). Если же все-таки рассматривать x как аргумент функции y = log3 log0,5(2x + 1), то эта функция окажется убывающей, так как при увеличении значения x увеличивается значение выражения 2x + 1, уменьшается значение выражения log0,5(2x + 1) и, соответственно, уменьшается значение самой функции.
Свойства логарифмов
Связь двух форм записи соотношения между числами a, b и x (речь о ax = b и x = logab) позволяет получить свойства логарифмов, основываясь на известных свойствах степеней.
Рассмотрим, например, произведение степеней с одинаковым основанием: axay. Пусть a x = b и a y = c. Перейдем к логарифмической форме: x = logab и y = logac, тогда bc = a logab × a logac = a logab +logac. От показательной формы равенства bc = a logab +logac перейдем к логарифмической форме:
loga(bc) = logab + logac
Заметим, что в левой части формулы числа a и b могут быть отрицательными. Тогда формула будет выглядеть так:
loga(bc) = loga|b| + loga|c|
Аналогично можно получить еще два свойства для логарифмов частного и степени.
логарифм произведения loga (bc) = loga |b| + loga |c|
логарифм частного
логарифм степени logabp = p loga|b|
Последнее свойство дает возможность вывести важную формулу, с помощью которой можно выразить логарифм с одним основанием через логарифм с другим основанием.
Пусть logab = x. Перейдем к показательной форме ax = b. Прологарифмируем это равенство по основанию c, т.е. найдем логарифмы с основанием c обеих частей этого равенства: logcax = logcb. Применяя к левой части свойство логарифма степени, получим x logca = logcb или , откуда .
Формула перехода от одного основания логарифма к другому
Полезно запомнить частный случай формулы перехода, когда одно из оснований является степенью другого:
Рассмотренные свойства и формула перехода «работают», конечно, только когда все входящие в них выражения имеют смысл.
Что ещё почитать?
Логарифмы на ЕГЭ
Логарифмы встречаются на ЕГЭ: как во второй части (обычно, это задание 15), так и, реже, в первой части. Задания из аттестации — одно из средств мотивации детей на уроках. Зная, что упражнение на доске аналогично заданию ЕГЭ, ученик будет внимательнее следить за его решением.
Разберем несколько таких заданий.
Из первой части (определение логарифма на ЕГЭ профильного уровня)
Решите уравнение log3(x+1)2 + log3|x+1| = 6 . Если корней несколько, укажите наименьший из них.
Решение. Решаем квадратное относительно log3|x+1| уравнение. Его корни 2 и −3.
log3|x+1| = 2, |x+1| = 9, x = −10 — это наименьший из корней.
Ответ: −10.
Из второй части (логарифмическое неравенство на ЕГЭ профильного уровня)
Решите неравенство .
Решение. ОДЗ: x > 0, x ≠ 1. Перейдем к логарифмам по основанию 10:
;
;
Умножим числитель и знаменатель на 2, чтобы уйти от радикала:
;
Нули числителя: 2/3, 3, с учетом положительности x, нуль заменяется на 1.
Ответ:
Алгебра в таблицах. 7-11 классы. Справочное пособие
Пособие содержит таблицы по всем наиболее важным разделам школьного курса арифметики, алгебры, начал анализа. В таблицах кратко изложена теория по каждой теме, приведены основные формулы, графики и примеры решения типовых задач. В конце книги помещен предметный указатель. Пособие будет полезно учащимся 7-11 классов, абитуриентам, студентам, учителям и родителям.
Купить
Из второй части (логарифмическое уравнение с параметром на ЕГЭ профильного уровня)
Найдите все значения a, для которых при любом положительном значении b уравнение имеет хотя бы одно решение, меньше 1/3.
Решение. Найдем ОДЗ:
Стандартно приводим логарифмы к одному основанию
,
.
Получили квадратное уравнение относительно .
Оно должно иметь корень при
Обозначим, что и рассмотрим квадратичную функцию y = t2 — bt — 2a.
Ветви ее графика направлены вверх, а вершина, поскольку b > 0, расположена в левой координатной полуплоскости. Первая ветвь параболы пересекает ось абсцисс правее t = 0, значит при t = 0 y < 0. Получаем −2a < 0 a > 0.
Ответ: a > 0.
Учебник
«Алгебра и начала математического анализа. Углубленный уровень. 10 класс» схож по структуре с учебником базового уровня, однако предполагает больше часов на изучение сложных задач. Эти и другие издания линейки вы можете апробировать прямо сейчас, воспользовавшись акцией
«5 учебников бесплатно». Методическое пособие представлено в свободном доступе. Приглашаем познакомиться с другими вебинарами экспертов и порекомендовать нам интересующую вас тему для последующих трансляций.
#ADVERTISING_INSERT#
Решение логарифмических функций — объяснения и примеры
В этой статье мы узнаем, как вычислять и решать логарифмические функции с неизвестными переменными.
Логарифмы и экспоненты — две тесно связанные между собой темы в математике. Поэтому полезно взять краткий обзор показателей.
Показатель степени — это форма записи многократного умножения числа на само себя. Показательная функция имеет вид f (x) = b y , где b> 0
Например, , 32 = 2 × 2 × 2 × 2 × 2 = 2 2 .
Экспоненциальная функция 2 2 читается как « два в степени пяти, » или « два в возведении в пятерку » или « два в пятой степени. ”
С другой стороны, логарифмическая функция определяется как функция, обратная возведению в степень. Снова рассмотрим экспоненциальную функцию f (x) = b y , где b> 0
y = журнал b x
Тогда логарифмическая функция имеет вид;
f (x) = log b x = y, где b — основание, y — показатель степени, а x — аргумент.
Функция f (x) = log b x читается как «log base b of x». Логарифмы полезны в математике, потому что они позволяют нам выполнять вычисления с очень большими числами.
Как решать логарифмические функции?
Для решения логарифмических функций важно использовать экспоненциальные функции в данном выражении.Натуральное бревно или ln — это обратное значение e . Это означает, что один может отменить другой, то есть
ln (e x ) = x
e ln x = x
Чтобы решить уравнение с логарифмом (ами), важно знать их свойства.
Свойства логарифмических функций
Свойства логарифмических функций — это просто правила для упрощения логарифмов, когда входные данные имеют форму деления, умножения или показателя степени логарифмических значений.
Некоторые из объектов недвижимости перечислены ниже.
Правило произведения логарифмов гласит, что логарифм произведения двух чисел, имеющих общее основание, равен сумме отдельных логарифмов.
⟹ log a (p q) = log a p + log a q.
Правило частного логарифмов гласит, что логарифм отношения двух чисел с одинаковыми основаниями равен разности каждого логарифма.
⟹ log a (p / q) = log a p — log a q
Правило степени логарифма утверждает, что логарифм числа с рациональной экспонентой равен произведению показателя степени и его логарифма.
⟹ журнал a (p q ) = q журнал a p
⟹ журнал a p = журнал x p ⋅ журнал a x
⟹ log q p = log x p / log x q
⟹ журнал p 1 = 0.
Другие свойства логарифмических функций включают:
Основания экспоненциальной функции и ее эквивалентной логарифмической функции равны.
Логарифмы положительного числа по основанию того же числа равны 1.
журнал a a = 1
Логарифмы от 1 до любого основания равны 0.
log a 1 = 0
Журнал a 0 не определено
Логарифмы отрицательных чисел не определены.
Основание логарифмов никогда не может быть отрицательным или 1.
Логарифмическая функция с основанием 10 называется десятичным логарифмом. Всегда принимайте основание 10 при решении с помощью логарифмических функций без маленького индекса для основания.
Сравнение экспоненциальной функции и логарифмической функции
Каждый раз, когда вы видите логарифмы в уравнении, вы всегда думаете о том, как отменить логарифм, чтобы решить уравнение. Для этого вы используете экспоненциальную функцию . Обе эти функции взаимозаменяемы.
В следующей таблице описан способ записи и перестановки экспоненциальных функций и логарифмических функций . В третьем столбце рассказывается о том, как читать обе логарифмические функции.
Экспоненциальная функция
Логарифмическая функция
Читать как
8 2 = 64
журнал 8 64 = 2
журнал, основание 8 из 64
10 3 = 1000
журнал 1000 = 3
лог по основанию 10 из 1000
10 0 = 1
журнал 1 = 0
лог по основанию 10 из 1
25 2 = 625
журнал 25 625 = 2
бревно, база 25 из 625
12 2 = 144
журнал 12 144 = 2
бревно, основание 12 из 144
Давайте воспользуемся этими свойствами для решения пары задач, связанных с логарифмическими функциями.
Пример 1
Записываем экспоненциальную функцию 7 2 = 49 в ее эквивалентную логарифмическую функцию.
Раствор
Дано 7 2 = 64.
Здесь основание = 7, показатель степени = 2 и аргумент = 49. Следовательно, 7 2 = 64 в логарифмической функции;
⟹ лог 7 49 = 2
Пример 2
Запишите логарифмический эквивалент 5 3 = 125.
Раствор
База = 5;
показатель степени = 3;
и аргумент = 125
5 3 = 125 ⟹ лог 5 125 = 3
Пример 3
Решить относительно x в журнале 3 x = 2
Раствор
журнал 3 x = 2 3 2 = x ⟹ x = 9
Пример 4
Если 2 log x = 4 log 3, найдите значение «x».
Раствор
2 журнала x = 4 журнала 3
Разделите каждую сторону на 2.
журнал x = (4 журнал 3) / 2
журнал x = 2 журнал 3
журнал x = журнал 3 2
журнал x = журнал 9
х = 9
Пример 5
Найдите логарифм 1024 по основанию 2.
Раствор
1024 = 2 10
журнал 2 1024 = 10
Пример 6
Найдите значение x в журнале 2 ( x ) = 4
Раствор
Перепишите логарифмическую функцию log 2 ( x ) = 4 в экспоненциальную форму.
2 4 = x
16 = x
Пример 7
Найдите x в следующей логарифмической функции log 2 (x — 1) = 5.
Решение Записываем логарифм в экспоненциальной форме как;
журнал 2 (x — 1) = 5 ⟹ x — 1 = 2 5
Теперь решите относительно x в алгебраическом уравнении. ⟹ х — 1 = 32 х = 33
Пример 8
Найдите значение x в логарифме x 900 = 2.
Раствор
Запишите логарифм в экспоненциальной форме как;
х 2 = 900
Найдите квадратный корень из обеих частей уравнения, чтобы получить;
x = -30 и 30
Но поскольку основание логарифмов никогда не может быть отрицательным или 1, то правильный ответ — 30.
Пример 9
Решить относительно заданного x, log x = log 2 + log 5
Раствор
Используя правило продукта Log b (m n) = log b m + log b n получаем;
⟹ журнал 2 + журнал 5 = журнал (2 * 5) = журнал (10).
Следовательно, x = 10.
Пример 10
Журнал решения x (4x — 3) = 2
Раствор
Записываем логарифм в экспоненциальной форме, чтобы получить;
x 2 = 4x — 3
Теперь решите квадратное уравнение. x 2 = 4x — 3 x 2 — 4x + 3 = 0 (x -1) (x — 3) = 0
x = 1 или 3
Поскольку основание логарифма никогда не может быть 1, единственное решение — 3.
Практические вопросы
1. Выразите следующие логарифмы в экспоненциальной форме.
а. 1ог 2 6
г. журнал 9 3
г. журнал 4 1
г. журнал 6 6
e. журнал 8 25
ф. журнал 3 (-9)
2. Найдите x в каждом из следующих логарифмов
а. журнал 3 (x + 1) = 2
г. журнал 5 (3x — 8) = 2
г.журнал (x + 2) + журнал (x — 1) = 1
г. журнал x 4 — журнал 3 = журнал (3x 2 )
3. Найдите значение y в каждом из следующих логарифмов.
а. журнал 2 8 = y
г. журнал 5 1 = y
г. журнал 4 1/8 = y
г. журнал y = 100000
4. Решите относительно xif log x (9/25) = 2.
5. Решить журнал 2 3 — журнал 2 24
6. Найдите значение x в следующем логарифме log 5 (125x) = 4
7.Учитывая, что Log 10 2 = 0,30103, Log 10 3 = 0,47712 и Log 10 7 = 0,84510, решите следующие логарифмы:
а. журнал 6
г. журнал 21
г. журнал 14
Предыдущий урок | Главная страница | Следующий урок
Вопросы по логарифму — Вопросы, основанные на логарифме и решениях
В доске CBSE главы логарифма включены в программу 9, 10 и 11 класса.Учащимся 9 класса впервые будут представлены вопросы и ответы по логарифму. Следовательно, тщательная практика решения логарифмических задач и ответов требует времени.
Однако, прежде чем перейти к главе, посвященной логарифму, учащиеся должны быть абсолютно ясны в основных понятиях. Только тогда решение сложных логарифмических вопросов станет значительно проще.
Вопросы, основанные на логарифме
Вот несколько вопросов, связанных с логарифмом, которые могут дать учащимся некоторое представление.
Вопрос 1: Найдите неверное утверждение снизу —
(a) log (1 + 2 + 3) = log 1 + log 2 + log 3
(b) log (2 + 3) = log (2 x 3)
(c) log10 10 = 1
(d) log10 1 = 0
Решение: ответ: вариант (b) log (2 + 3) = log (2 x 3).
Вопрос 2: Каково значение log5512, когда log 2 = 0,3010 и log 3 = 0,4771?
(а) 3,912
(б) 3,876
(в) 2,967
(г) 2,870
Решение: ответ — вариант (б) 3.876.
Вопрос 3: Найдите значение log 9, когда log 27 составляет 1,431.
(а) 0,954
(б) 0,945
(в) 0,958
(г) 0,934
Решение: ответ — вариант (а) 0,954.
Вопрос 4. Каково значение log2 10, когда log10 2 = 0,3010?
(a) 1000/301
(b) 699/301
(c) 0,6990
(d) 0,3010
Решение: ответ — вариант (a) 1000/301.
Вопрос 5: Каково значение log10 80, когда log10 2 = 0.3010?
(a) 3,9030
(b) 1,9030
(c) 1,6020
(d) Ни один из вышеперечисленных вариантов
Решение: Ответ — вариант (b) 1.9030.
Вопрос 6: Сколько цифр в 264, если log 2 = 0,30103?
(a) 21
(b) 20
(c) 18
(d) 19
Решение: ответ — вариант (b) 20.
Вопрос 7: Что из следующего верно, если топор = по?
(a) log a / log b = x / y
(b) log a / b = x / y
(c) log a / log b = y / x
(d) Ничего из вышеперечисленного option
Решение: Ответ: вариант (c) log a / log b = y / x.
Вопрос 8: Каково значение log2 16?
(a) 8
(b) 4
(c) 1/8
(d) 16
Решение: Ответ: (b) 4.
Вопрос 9: Найдите значение y, если logx y = 100 и log2 x = 10.
(a) 21000
(b) 210
(c) 2100
(d) 210000
Решение: ответ — вариант (a) 21000.
Вопрос 10: Найдите значение log10 (0,0001).
(a) — 1/4
(b) 1/4
(c) 4
(d) — 4
Решение: ответ — вариант (d) — 4.
Вопрос 11: Каково значение x, когда log2 [log3 (log2x)] = 1?
(a) 512
(b) 12
(c) 0
(d) 128
Решение: ответ — вариант (a) 512.
Вопрос студентов по логарифмическим вопросам можно пояснить в Веданту. онлайн-классы. У вас также есть возможность скачать материалы в формате PDF с официального сайта. Загрузите приложение сегодня!
Log-Base-10 — Алгебра II
Если вы считаете, что контент, доступный через Веб-сайт (как определено в наших Условиях обслуживания), нарушает
или другие ваши авторские права, сообщите нам, отправив письменное уведомление («Уведомление о нарушении»), содержащее
в
информацию, описанную ниже, назначенному ниже агенту.Если репетиторы университета предпримут действия в ответ на
ан
Уведомление о нарушении, оно предпримет добросовестную попытку связаться со стороной, которая предоставила такой контент
средствами самого последнего адреса электронной почты, если таковой имеется, предоставленного такой стороной Varsity Tutors.
Ваше Уведомление о нарушении прав может быть отправлено стороне, предоставившей доступ к контенту, или третьим лицам, таким как
в виде
ChillingEffects.org.
Обратите внимание, что вы будете нести ответственность за ущерб (включая расходы и гонорары адвокатам), если вы существенно
искажать информацию о том, что продукт или действие нарушает ваши авторские права.Таким образом, если вы не уверены, что контент находится
на Веб-сайте или по ссылке с него нарушает ваши авторские права, вам следует сначала обратиться к юристу.
Чтобы отправить уведомление, выполните следующие действия:
Вы должны включить следующее:
Физическая или электронная подпись правообладателя или лица, уполномоченного действовать от их имени;
Идентификация авторских прав, которые, как утверждается, были нарушены;
Описание характера и точного местонахождения контента, который, по вашему мнению, нарушает ваши авторские права, в \
достаточно подробностей, чтобы позволить репетиторам университетских школ найти и точно идентифицировать этот контент; например нам требуется
а
ссылка на конкретный вопрос (а не только на название вопроса), который содержит содержание и описание
к какой конкретной части вопроса — изображению, ссылке, тексту и т. д. — относится ваша жалоба;
Ваше имя, адрес, номер телефона и адрес электронной почты; а также
Ваше заявление: (а) вы добросовестно считаете, что использование контента, который, по вашему мнению, нарушает
ваши авторские права не разрешены законом, владельцем авторских прав или его агентом; (б) что все
информация, содержащаяся в вашем Уведомлении о нарушении, является точной, и (c) под страхом наказания за лжесвидетельство, что вы
либо владелец авторских прав, либо лицо, уполномоченное действовать от их имени.
Отправьте жалобу нашему уполномоченному агенту по адресу:
Чарльз Кон
Varsity Tutors LLC 101 S. Hanley Rd, Suite 300 St. Louis, MO 63105
Или заполните форму ниже:
Обогащение: подробнее о логарифмах | Функции
\ (\ log_ {3} {a} — \ log {\ text {1,2}} = 0 \)
\ begin {align *}
\ log_ {3} {a} — \ log {\ text {1,2}} & = 0 \\
\ log_ {3} {a} & = \ log {\ text {1,2}} \\
\ text {Перейти к экспоненциальной форме:} & \\
3 ^ {\ log {\ text {1,2}}} & = a \\
\ поэтому a & = \ text {1,09}
\ end {выровнять *}
Альтернативный (более длинный) метод:
\ begin {align *}
\ log_ {3} {a} — \ log {\ text {1,2}} & = 0 \\
\ log_ {3} {a} & = \ log {\ text {1,2}} \\
\ frac {\ log {a}} {\ log {3}} & = \ log {\ text {1,2}} \\
\ log {a} & = \ log {3} \ times \ log {\ text {1,2}} \\
\ log {a} & = \ text {0,037} \ ldots \\
\ поэтому a & = \ text {1,09}
\ end {выровнять *}
\ (\ log_ {2} {(a — 1)} = \ text {1,5} \)
\ begin {align *}
\ log_ {2} {(a — 1)} & = \ text {1,5} \\
\ text {Перейти к экспоненциальной форме:} & \\
2 ^ {\ text {1,5}} & = a — 1 \\
2 ^ {\ text {1,5}} + 1 & = a \\
\ поэтому a & = \ text {3,83}
\ end {выровнять *}
Альтернативный (более длинный) метод:
\ begin {align *}
\ log_ {2} {(a — 1)} & = \ text {1,5} \\
\ frac {\ log {(a — 1)}} {\ log {2}} & = \ text {1,5} \\
\ log {(a — 1)} & = \ log {2} \ times \ text {1,5} \\
\ поэтому a — 1 & = \ text {2,83} \ ldots \\
\ поэтому a & = \ text {3,83}
\ end {выровнять *}
\ (\ log_ {2} {a} — 1 = \ text {1,5} \)
\ begin {align *}
\ log_ {2} {a — 1} & = \ text {1,5} \\
\ log_ {2} {a} & = \ text {2,5} \\
\ text {Перейти к экспоненциальной форме:} & \\
2 ^ {\ text {2,5}} & = а \\
\ поэтому a & = \ text {5,66}
\ end {выровнять *}
Альтернативный (более длинный) метод:
\ begin {align *}
\ log_ {2} {a} — 1 & = \ text {1,5} \\
\ frac {\ log {a}} {\ log {2}} & = \ text {2,5} \\
\ log {a} & = \ log {2} \ times \ text {2,5} \\
\ поэтому a & = \ text {5,66}
\ end {выровнять *}
\ (3 ^ {a} = \ text {2,2} \)
\ begin {align *}
3 ^ {a} & = \ text {2,2} \\
\ поэтому a & = \ log_ {3} {\ text {2,2}} \\
& = \ frac {\ log {\ text {2,2}}} {\ log {3}} \\
\ поэтому a & = \ text {0,72}
\ end {выровнять *}
\ (2 ^ {(a + 1)} = \ text {0,7} \)
\ begin {align *}
2 ^ {(a + 1)} & = \ text {0,7} \\
\ поэтому a + 1 & = \ log_ {2} {\ text {0,7}} \\
\ поэтому a & = \ frac {\ log {\ text {0,7}}} {\ log {2}} — 1 \\
& = — \ text {1,51}
\ end {выровнять *}
\ ((\ text {1,03}) ^ {\ frac {a} {2}} = \ text {2,65} \)
\ begin {align *}
(\ text {1,03}) ^ {\ frac {a} {2}} & = \ text {2,65} \\
\ поэтому \ frac {a} {2} & = \ log _ {\ text {1,03}} {\ text {2,65}} \\
\ поэтому a & = 2 \ times \ frac {\ log {\ text {2,65}}} {\ log {\ text {1,03}}} \\
& = \ text {65,94}
\ end {выровнять *}
\ ((\ text {9}) ^ {(1 — 2a)} = \ text {101} \)
\ begin {align *}
(\ text {9}) ^ {(1 — 2a)} & = \ text {101} \\
\ поэтому 1 — 2a & = \ log _ {\ text {9}} {\ text {101}} \\
\ поэтому 1 — \ frac {\ log {\ text {101}}} {\ log {\ text {9}}} & = 2a \\
— \ text {1,10} \ ldots & = 2a \\
\ поэтому — \ text {0,55} & = a
\ end {выровнять *}
Свойства логарифмов | Колледж алгебры
Результаты обучения
Перепишите логарифмическое выражение, используя правило степени, правило произведения или правило частного. {1} = 5 [/ latex].{{\ mathrm {log}} _ {e} 7} = 7 [/ латекс].
Наконец, у нас есть свойство однозначно .
[латекс] {\ mathrm {log}} _ {b} M = {\ mathrm {log}} _ {b} N \ text {тогда и только тогда, когда} \ text {} M = N [/ latex]
Мы можем использовать однозначное свойство для решения уравнения [латекс] {\ mathrm {log}} _ {3} \ left (3x \ right) = {\ mathrm {log}} _ {3} \ left (2x + 5 \ right) [/ latex] для x . Поскольку основы одинаковы, мы можем применить свойство «один к одному», установив равные аргументы и решив для x :
[латекс] \ begin {array} {l} 3x = 2x + 5 \ hfill & \ text {Установите равные аргументы} \ text {.} \ hfill \\ x = 5 \ hfill & \ text {Вычесть 2} x \ text {.} \ hfill \ end {array} [/ latex]
А как насчет уравнения [латекс] {\ mathrm {log}} _ {3} \ left (3x \ right) + {\ mathrm {log}} _ {3} \ left (2x + 5 \ right) = 2 [/латекс]? Свойство «один к одному» в данном случае нам не помогает. {a + b} [/ латекс].У нас есть аналогичное свойство для логарифмов, которое называется правилом произведения для логарифмов , которое гласит, что логарифм произведения равен сумме логарифмов. Поскольку бревна — это экспоненты, и мы умножаем их как основания, мы можем складывать экспоненты. Мы будем использовать обратное свойство для вывода правила произведения ниже.
Для любого действительного числа x и положительных вещественных чисел M , N и b , где [latex] b \ ne 1 [/ latex], мы покажем
[латекс] {\ mathrm {log}} _ {b} \ left (MN \ right) \ text {=} {\ mathrm {log}} _ {b} \ left (M \ right) + {\ mathrm { log}} _ {b} \ left (N \ right) [/ latex].{m + n} \ right) \ hfill & \ text {Применить правило продукта для показателей степени}. \ hfill \\ \ hfill & = m + n \ hfill & \ text {Применить обратное свойство журналов}. \ hfill \ \ \ hfill & = {\ mathrm {log}} _ {b} \ left (M \ right) + {\ mathrm {log}} _ {b} \ left (N \ right) \ hfill & \ text {Заменить на } m \ text {и} n. \ hfill \ end {array} [/ latex]
Обратите внимание, что повторное применение правила произведения для логарифмов позволяет упростить логарифм произведения любого количества факторов. Например, рассмотрим [латекс] \ mathrm {log} _ {b} (wxyz) [/ latex].Используя правило продукта для логарифмов, мы можем переписать этот логарифм продукта как сумму логарифмов его множителей:
[латекс] \ mathrm {log} _ {b} (wxyz) = \ mathrm {log} _ {b} w + \ mathrm {log} _ {b} x + \ mathrm {log} _ {b} y + \ mathrm { log} _ {b} z [/ латекс]
Общее примечание: правило произведения логарифмов
Правило произведения для логарифмов можно использовать для упрощения логарифма произведения, переписав его как сумму отдельных логарифмов.
[латекс] {\ mathrm {log}} _ {b} \ left (MN \ right) = {\ mathrm {log}} _ {b} \ left (M \ right) + {\ mathrm {log}} _ {b} \ left (N \ right) \ text {for} b> 0 [/ latex]
Пример: использование правила произведения для логарифмов
Разверните [латекс] {\ mathrm {log}} _ {b} \ left (8k \ right) [/ latex].{a-b} [/ латекс]. Правило частного для логарифмов говорит, что логарифм частного равен разности логарифмов. Как и в случае с правилом произведения, мы можем использовать обратное свойство для получения правила частного.
Для любого действительного числа x и положительных вещественных чисел M , N и b , где [latex] b \ ne 1 [/ latex], мы покажем
[латекс] {\ mathrm {log}} _ {b} \ left (\ frac {M} {N} \ right) \ text {=} {\ mathrm {log}} _ {b} \ left (M \ справа) — {\ mathrm {log}} _ {b} \ left (N \ right) [/ latex].{2} + 6x} {3x + 9} \ right) & = \ mathrm {log} \ left (\ frac {2x \ left (x + 3 \ right)} {3 \ left (x + 3 \ right)} \ right) \ hfill & \ text {Разложите числитель и знаменатель на множители}. \ hfill \\ & \ text {} = \ mathrm {log} \ left (\ frac {2x} {3} \ right) \ hfill & \ text {Отменить общие множители}. \ Hfill \ end {array} [/ latex]
Затем мы применяем правило частного, вычитая логарифм знаменателя из логарифма числителя. Затем применяем правило продукта.
[латекс] \ begin {array} {lll} \ mathrm {log} \ left (\ frac {2x} {3} \ right) & = \ mathrm {log} \ left (2x \ right) — \ mathrm {log } \ left (3 \ right) \ hfill \\ \ text {} & = \ mathrm {log} \ left (2 \ right) + \ mathrm {log} \ left (x \ right) — \ mathrm {log} \ слева (3 \ справа) \ hfill \ end {array} [/ latex]
Общее примечание: Правило частного для логарифмов
Правило частного для логарифмов можно использовать для упрощения логарифма или частного, переписав его как разность отдельных логарифмов.
[латекс] {\ mathrm {log}} _ {b} \ left (\ frac {M} {N} \ right) = {\ mathrm {log}} _ {b} M — {\ mathrm {log}} _ {b} N [/ латекс]
Как сделать: учитывая логарифм частного, используйте правило частного логарифмов, чтобы записать эквивалентную разницу логарифмов
Выразите аргумент в наименьших числах, разложив числитель и знаменатель на множители и исключив общие термины.
Напишите эквивалентное выражение, вычтя логарифм знаменателя из логарифма числителя.
Убедитесь, что каждый член полностью раскрыт. Если нет, примените правило произведения для логарифмов, чтобы полностью раскрыть логарифм.
Пример: использование правила частного для логарифмов
Разверните [латекс] {\ mathrm {log}} _ {2} \ left (\ frac {15x \ left (x — 1 \ right)} {\ left (3x + 4 \ right) \ left (2-x \ right)} \ right) [/ латекс].
Показать решение
Сначала отметим, что частное факторизуется в наименьших значениях, поэтому мы применяем правило частного.
[латекс] {\ mathrm {log}} _ {2} \ left (\ frac {15x \ left (x — 1 \ right)} {\ left (3x + 4 \ right) \ left (2-x \ right) )} \ right) = {\ mathrm {log}} _ {2} \ left (15x \ left (x — 1 \ right) \ right) — {\ mathrm {log}} _ {2} \ left (\ left (3x + 4 \ right) \ left (2-x \ right) \ right) [/ латекс]
Обратите внимание, что полученные члены являются логарифмами произведений.Для полного расширения мы применяем правило продукта.
[латекс] \ begin {array} {l} {\ mathrm {log}} _ {2} \ left (15x \ left (x — 1 \ right) \ right) — {\ mathrm {log}} _ {2 } \ left (\ left (3x + 4 \ right) \ left (2-x \ right) \ right) \\\ text {} = \ left [{\ mathrm {log}} _ {2} \ left (15 \ right) + {\ mathrm {log}} _ {2} \ left (x \ right) + {\ mathrm {log}} _ {2} \ left (x — 1 \ right) \ right] — \ left [ {\ mathrm {log}} _ {2} \ left (3x + 4 \ right) + {\ mathrm {log}} _ {2} \ left (2-x \ right) \ right] \ hfill \\ \ text {} = {\ mathrm {log}} _ {2} \ left (15 \ right) + {\ mathrm {log}} _ {2} \ left (x \ right) + {\ mathrm {log}} _ { 2} \ left (x — 1 \ right) — {\ mathrm {log}} _ {2} \ left (3x + 4 \ right) — {\ mathrm {log}} _ {2} \ left (2-x \ right) \ hfill \ end {array} [/ latex]
Анализ решения
В этом и последующих примерах есть исключения. {2} + 21x} {7x \ left (x — 1 \ right) \ left (x — 2 \ right)} \ right) [/ латекс].{2} \ right) \ hfill & = {\ mathrm {log}} _ {b} \ left (x \ cdot x \ right) \ hfill \\ \ hfill & = {\ mathrm {log}} _ {b} x + {\ mathrm {log}} _ {b} x \ hfill \\ \ hfill & = 2 {\ mathrm {log}} _ {b} x \ hfill \ end {array} [/ latex]
Обратите внимание, что мы использовали правило произведения для логарифмов , чтобы найти решение для приведенного выше примера. Таким образом, мы вывели правило мощности для логарифмов , которое гласит, что логарифм степени равен экспоненте, умноженной на логарифм основания. Имейте в виду, что хотя вход логарифма не может быть записан как степень, мы можем изменить его на степень.{2}} \ right) [/ латекс].
У вас была идея улучшить этот контент? Нам очень понравится ваш вклад.
Улучшить эту страницуПодробнее
Основы — примеры проблем с решениями
Логарифм
Логарифм положительного числа x по основанию a (a — положительное число, не равное 1) — это степень y, до которой необходимо возвести основание a, чтобы получить число x.
журнал 10 1000 журнал 10 1000 = 3, потому что 10 3 = 1000 журнал 3 81 журнал 3 81 = 4, потому что 3 4 = 81 log 2 0,5 log 2 0,5 = -1, потому что 2 -1 = 0,5 журнал 17 1 журнал 17 1 = 0, потому что 17 0 = 1 журнал 11 11 журнал 11 11 = 1, потому что 11 1 = 11 log 5 0,2 log 5 0,2 = -1, потому что5 -1 = 0,2 журнал 15 0 журнал 15 0 = журнал 5 (-25) журнал 5 (-25) = n0 log 0,4 0,4 log 0,4 0,4 = 1, потому что 0,4 1 = 0,4 журнал 1 49 журнал 1 49 = 0 не определено
3.Определите x:
журнал 2 x = 3 x = 2 3 = 8 журнал 10 x = -4 x = 10 -4 = 0,0001 журнал 16 x = 0,5 x = 16 0,5 = 4 журнал 20 x = 1 x = 20 1 = 20 журнал 25 x = -0,5 x = 25 -0,5 = 0,2 журнал 0,2487 x = 0 x = 0,2487 0 = 1
4. Определите:
журнал a 25 = 2 a = 5 журнал a 81 = 4 a = 3 журнал a 100000 = 5 a = 10 журнал a 512 = 3 a = 8 журнал a 0,01 = -2 a = 10 журнал a 5 = 0,5 a = 25 журнал a 36 = 2 a = 6 журнал a 64 = 1 a = 64
5.Логарифмируем следующие выражения (с основанием a)
6. Определите x:
7. Пронумеруйте выражение:
Решение:
Причина:
8. Логарифмируем выражение (с основанием a):
Решение:
9. Пронумеруйте выражение:
Решение:
Причина:
10.Перечислите выражение:
Решение:
Причина:
11. Используйте десятичный логарифм, чтобы решить уравнение:
Решение:
12. Используйте десятичный логарифм, чтобы решить уравнение:
Решение:
13. Используйте десятичный логарифм, чтобы решить уравнение:
Решение:
14.За t = 50 часов активность радиоактивного натрия снижается до 1/10 от исходного значения. x \), где \ (x \) представляет количество недель, в течение которых прошли.Икс . \ nonumber \]
Хотя мы создали экспоненциальные модели и использовали их для прогнозов, вы, возможно, заметили, что решение экспоненциальных уравнений еще не упоминалось. Причина проста: ни один из рассмотренных до сих пор алгебраических инструментов не достаточен для решения экспоненциальных уравнений. Рассмотрим уравнение 2 x = 10 выше. Мы знаем, что 2 3 = 8 и 2 4 = 16, поэтому ясно, что x должно быть некоторым значением от 3 до 4, поскольку g ( x ) = 2 x — это увеличивается.Мы могли бы использовать технологию для создания таблицы значений или графика, чтобы лучше оценить решение, но мы хотели бы найти алгебраический способ решения уравнения.
Нам нужна операция, обратная возведению в степень, чтобы найти переменную, если переменная находится в экспоненте. Как мы узнали на уроке алгебры (предварительное условие для этого конечного курса математики), обратная функция для экспоненциальной функции является логарифмической функцией.
Мы также узнали, что экспоненциальная функция имеет обратную функцию, потому что каждое выходное значение (y) соответствует только одному входному значению (x).Этому свойству присвоено имя «один к одному».
Источник: Материал в этом разделе учебника взят из книги Дэвида Липпмана и Мелони Расмуссен, Книжный магазин Open Text, Precalculus: Исследование функций, «Глава 4: Экспоненциальные и логарифмические функции» под лицензией Creative Commons CC BY-SA 3.0 лицензия. Приведенный здесь материал основан на материалах, содержащихся в этом учебнике, но был изменен Робертой Блум в соответствии с этой лицензией.
Логарифм
Логарифм (основание b ), записанный журнал b ( x ), является обратной экспоненциальной функции (основание b ), b x .{\ log_ {b} (x)} = x \ nonumber \]
Поскольку журнал является функцией, его наиболее правильно записать как журнал b ( c ), используя круглые скобки для обозначения оценки функции, как и в случае с f (c) . {- 3} = \ frac {1} {1000} \)
Решение
а.{2} = 9 \)
Установив связь между экспоненциальными и логарифмическими функциями, теперь мы можем решать основные логарифмические и экспоненциальные уравнения путем переписывания.
Пример \ (\ PageIndex {3} \)
Журнал решения 4 ( x ) = 2 для x .
Решение
Переписав это выражение в экспоненту, 4 2 = x , поэтому x = 16
Пример \ (\ PageIndex {4} \)
Решите 2 x = 10 для x .
Решение
Переписав это выражение в виде логарифма, мы получим x = log 2 (10)
Хотя это и определяет решение, вы можете найти его несколько неудовлетворительным, поскольку трудно сравнить это выражение с десятичной оценкой, которую мы сделали ранее. Кроме того, предоставление точного выражения для решения не всегда полезно — часто нам действительно нужно десятичное приближение к решению. К счастью, это задача, с которой калькуляторы и компьютеры неплохо справляются.К несчастью для нас, большинство калькуляторов и компьютеров оценивают только логарифмы двух оснований: 10 и и . К счастью, это не проблема, так как вскоре мы увидим, что можем использовать формулу «изменения основания» для вычисления логарифмов для других оснований.
Обычный и натуральный логарифмы
Общий журнал представляет собой логарифм с основанием 10 и обычно записывается как \ (\ log (x) \), а иногда как \ (\ log_ {10} (x) \). Если база не указана в функции журнала, то используется база b \ (b = 10 \).
натуральный логарифм — это логарифм с основанием \ (e \), обычно записывается как \ (\ ln (x) \).
Обратите внимание, что для любой другой базы b, кроме 10, база должна быть указана в виде \ (\ log_b (x) \).
Пример \ (\ PageIndex {5} \)
Оцените \ (\ log (1000) \), используя определение общего журнала.
Решение
В таблице приведены значения общего журнала
номер
число в виде экспоненты
журнал (номер )
1000
10 3
3
100
10 2
2
10
10 1
1
1
10 0
0
0.1
10 -1
–1
0,01
10 -2
-2
0,001
10 -3
-3
Чтобы оценить log (1000), мы можем сказать
\ [x = \ log (1000) \ nonumber \]
Затем перепишите уравнение в экспоненциальной форме, используя общий логарифм с основанием 10
. 5 \)
\ (\ ln \ sqrt {e} \)
Решение
а.{1/2} \ right) = 1/2 \ nonumber \]
Пример \ (\ PageIndex {8} \)
Оцените следующее с помощью калькулятора или компьютера:
\ (\ лог 500 \)
\ (\ ln 500 \)
Решение
а. Используя кнопку LOG на калькуляторе для вычисления логарифмов по основанию 10, мы вычисляем LOG (500)
Ответ: \ (\ log 500 \ приблизительно 2.69897 \)
г. Используя клавишу LN на калькуляторе для вычисления натуральных логарифмов , , мы вычисляем LN (500)
Ответ: \ (\ ln 500 \ примерно 6.{x} = \ log _ {c} A \).
Теперь используется свойство экспоненты для журналов с левой стороны, \ [x \ log _ {c} b = \ log _ {c} A \ nonumber \]
Разделив, мы получим \ (x = \ frac {\ log _ {c} (A)} {\ log _ {c} (b)} \), который является заменой базовой формулы.
Вычисление логарифмов
С изменением базовой формулы \ (\ log _ {b} (A) = \ frac {\ log _ {c} (A)} {\ log _ {c} (b)} \) для любых оснований \ (b \), \ (c> 0 \), мы наконец можем найти десятичное приближение к нашему вопросу с начала раздела.х = 10 \) для \ (х \).
Решение
Перепишите экспоненциальное уравнение 2 x = 10 в виде логарифмического уравнения
\ [x = \ log _ {2} (10) \ nonumber \]
Используя формулу изменения базы, мы можем переписать логарифм по основанию 2 как логарифм любого другого основания. Поскольку наши калькуляторы могут вычислять натуральный логарифм, мы можем использовать натуральный логарифм, который является логарифмической базой e :
.
Используя наши калькуляторы, чтобы оценить это, \ (\ frac {\ ln (10)} {\ ln (2)} = \ mathrm {LN} (10) / \ mathrm {LN} (2) \ приблизительно 3.3219 \)
Это, наконец, позволяет нам ответить на наш первоначальный вопрос из начала этого раздела: Для популяции из 50 мух, которая удваивается каждую неделю, потребуется примерно 3,32 недели, чтобы вырасти до 500 мух.
Пример \ (\ PageIndex {10} \)
Вычислить \ (\ log_ {5} (100) \), используя изменение базовой формулы.
Решение
Мы можем переписать это выражение, используя любую другую основу.
Метод 1: Мы можем использовать натуральный логарифм с основанием e с заменой основной формулы
Резюмируем взаимосвязь между экспоненциальными и логарифмическими функциями
Логарифмы
Логарифм (основание b ), записанный журнал b ( x ), является обратной экспоненциальной функции (основание b ), b x .{q} \ right) = q \ log _ {b} (A) \ nonumber \)
Свойства журналов: изменение базы: \ (\ log _ {b} (A) = \ frac {\ log _ {c} (A)} {\ log _ {c} (b)} \ text { для любого основания} b, c> 0 \ nonumber \)
Обратное, экспоненциальное и изменение основных свойств, указанных выше, позволит нам решить уравнения, которые возникают в задачах, с которыми мы сталкиваемся в этом учебнике. Сформулируем для полноты картины еще несколько свойств логарифмов
Источник: материалы в этом разделе учебника взяты из книги Дэвида Липпмана и Мелони Расмуссен, Книжный магазин Open Text, Precalculus: An Investigation of Functions, «Глава 4: Экспоненциальные и логарифмические функции» под лицензией Creative Commons CC BY-SA 3 .0 лицензия. Приведенный здесь материал основан на материалах, содержащихся в этом учебнике, но был изменен Робертой Блум в соответствии с этой лицензией.
Профессия — специалист по эконометрике :: Федеральный образовательный портал
Ольга Демидова, доцент кафедры математической экономики и эконометрики НИУ ВШЭ
— Ольга Анатольевна, многие считают, что эконометрика и математическая экономика – это одно и то же. Есть ли между ними различие?
— Термин «эконометрика» был введен в широкий научный обиход норвежским экономистом и статистиком, лауреатом Нобелевской премии Рагнаром Фришем в 1930-е годы. В 1933 году Фриш начал издавать одноименный журнал. До 1950–1960-х годов эконометрикой называли все математические измерения в экономике, а потом произошло разделение на математическую экономику – и эконометрику. Если специалист в области математической экономики стремится выразить утверждения экономической теории в форме математических уравнений, то эконометрист стремится верифицировать (проверить) эти модели с помощью эмпирических данных.
Для специалиста по математической экономике достаточно сказать, что между такими величинами, как выпуск, труд и капитал существует определенная связь, которую можно описать математически и предложить достаточно абстрактное, универсальное ее описание, например, функцию Кобба-Дугласа. Она характеризует положительную зависимость объема производства от затрат труда и капитала. Специалист по эконометрике сначала соберет данные по объему производства на интересующих его предприятиях. После этого он оценит параметры функции, характеризующей зависимость выпуска от различных факторов для конкретных предприятий в определенных условиях.
— Не могли бы вы привести пример использования эконометрики на практике?
— Приведу один из моих любимых примеров. В 1980-е годы на Нью-Йоркской фондовой бирже комиссионные, которые брокеры получают по итогам сделок, регулировал биржевой комитет. Клиент не мог договориться непосредственно с брокером о размере комиссионных за услуги, а был вынужден платить проценты, установленные биржевым комитетом.
Американский аналог нашей Федеральной антимонопольной службы усмотрел в этом признаки монополии и потребовал либерализовать цены. На суде представители биржевого комитета привели уравнение регрессии, оцененное по конкретным данным для сделок, из которого следовало, что имеет место естественная монополия. То есть в результате либерализации комиссионные только вырастут. Тогда антимонопольная служба заявила, что уравнение неправильно характеризует зависимость вознаграждения брокеров и объема проданных акций, и на самом деле естественной монополии нет. Их оппоненты не учли проблемы гетероскедастичности[1] данных. Если учесть гетероскедастичность, то результат приводит к противоположным выводам. Прошло несколько заседаний, на которых специалисты выясняли, чьи оценки правильнее. В результате борцы с монополией, видимо, лучше знавшие эконометрику, выиграли процесс.
— В каких областях чаще всего работают специалисты по эконометрике?
— В самых разных. На мой взгляд, лучше всего о востребованности специалистов по эконометрике на рынке труда говорит тот факт, что из четырех лауреатов премии «Золотая Вышка» в номинации «Успех выпускника» за последние годы двое были выпускниками кафедры математической экономики и эконометрики, а один (первый заместитель председателя Центрального банка России Владислав Конторович) писал магистерскую работу под руководством профессора нашей кафедры Эмиля Ершова.
Многие наши выпускники работают в банковской сфере, где их познания в математике очень востребованы. Так, одна студентка, писавшая под моим руководством магистерскую диссертацию, работала в ВТБ24 и занималась вопросами ипотечного кредитования. Тема ее работы была связана с исследованием, которое она проводила для банка. Нужно было попытаться предсказать поведение людей, берущих ипотечные кредиты: выяснить, кто и с какой вероятностью вернет кредит заранее или выплатит его в срок, или не выплатит вовсе. Банкам не всегда выгодно то, что клиент заранее возвращает кредит. Для них невыгодно получить деньги, на которые они сейчас не рассчитывают. Соответственно банку нужно заранее знать, сколько людей может вернуть кредит раньше срока и на какой объем средств в каждый момент времени он может рассчитывать. В рамках исследования был собран большой объем данных. После их анализа стало ясно, что помимо таких факторов, как возраст и образование, на поведение заемщиков влияет их место жительства. Живущие за Уралом оказались склонны погашать кредиты раньше, чем жители европейской территории.
Пример из совершенно другой области: один из проектов, в котором я сейчас принимаю участие, называется SEARCH. Он посвящен изучению разнообразных вопросов, связанных с взаимодействием стран – членов ЕС и их соседей, в частности – России. Например, как распределяются потоки мигрантов, торговые потоки, происходит ли «диффузия» инноваций и т.д. Я включена в блок, посвященный оценке социального капитала и пытаюсь с помощью эконометрических моделей сравнить отношение жителей двух выделенных групп стран к основным социальным и политическим институтам.
Специалисты по эконометрике могут заниматься достаточно широким спектром вопросов. Наши выпускники работают и в рекламе. Здесь важно оценить, в каких средствах массовой информации реклама наиболее эффективна, какая реклама лучше. Многие работают в аналитических отделах достаточно известных торговых фирм и с помощью эконометрических моделей пытаются оценить, допустим, эффект от проведения рекламной компании или обосновать выбор ассортимента торговых точек. Некоторые выпускники нашей кафедры заняты на госслужбе и сделали неплохую карьеру, некоторые принимают участие в работе экспертных групп, нередко дают в средствах массовой информации комментарии по поводу различных макроэкономических проблем. Немало выпускников кафедры после окончания магистратуры или аспирантуры занимаются преподавательской и научной деятельностью.
— Как вы считаете, что является самой большой сложностью для молодых специалистов по эконометрике в их работе?
— Мне бы хотелось предостеречь своих молодых коллег от одной очень распространенной практики. Часто они, прочитав какую-нибудь статью западного автора, берут использованные им модели и методы и просто переносят их на наши реалии. Это не всегда позволяет получить адекватные результаты. Надо попытаться преодолеть искушение использовать какую-либо модель только потому, что «все так делают». Молодые исследователи, насколько я могу судить по моему опыту участия в конференциях, как отечественных, так и зарубежных, очень любят включать в свои работы модель Арелано-Бонда, модель стохастической границы, метод разностей в разностях и т. д., иногда просто следуя эконометрической моде, благо современные статистические пакеты легко позволяют оценить эти модели. Из полученных результатов зачастую очевидно, что для использованных в работе данных выбранная модель не годится, предварительный анализ данных был проведен достаточно поверхностно, сделанные на основе оцененных моделей выводы весьма сомнительны.
Работающим с российскими данными надо четко понимать, что западные модели и методы к нашим параметрам могут быть неприменимы. Не стоит просто брать западную статью и оценивать приведенные в ней модели по российским данным, хотя иногда это и может дать интересные результаты. Одна моя дипломница, Полина Ковалева (сейчас она учится в аспирантуре университета Сити в Лондоне) пыталась вслед за Джеймсом Хекманом выяснить, применимы ли модели типа Минцера для оценки отдачи от образования. Напомню, что в моделях такого типа отдача от образования считается постоянной, т.е. каждый дополнительный год обучения увеличивает заработную плату на одну и ту же величину. Если это так, то профили (графики зависимости) «зарплата – опыт работы» должны быть параллельны для различных лет обучения, т.е. получаться один из другого простым сдвигом. Для американских данных 1980 года параллельность профилей имела место. Однако для российских данных этот факт не подтвердился. Наличие послевузовского образования сначала приводило к достаточно быстрому росту заработной платы, а затем к достаточно быстрому ее иснижению. Из этого результата можно сделать вывод, что полученные знания достаточно быстро устаревают, и если ты не хочешь допустить падения заработной платы, то должен все время повышать свою квалификацию.
— Часто приходится слышать, что в российских условиях самая трудная задача для аналитика — получить достоверные данные. Так ли это?
— Это не только российская проблема: зарубежные исследователи тоже жалуются на недостаток данных, проведение социологических опросов – достаточно дорогое удовольствие.
Но даже когда данные есть, казалось бы, в открытом доступе, их не всегда легко использовать. При работе в проекте «Анализ системы госзакупок в России» в Институте анализа предприятий и рынков НИУ ВШЭ я вместе с коллегами столкнулась со следующей проблемой. Есть сайт, где публикуется вся информация о государственных контрактах, однако в неудобном для пользователей виде. Если требуется выгрузить информацию о контрактах на группу каких-либо однородных товаров, то система «зависает», а собирать информацию по каждому контракту вручную очень долго.
— Каким, по-вашему, должен быть хороший учебник по эконометрике?
— Большинство учебников по эконометрике строится так: сначала теория, потом практические примеры. Причем для реальных данных, увы, не всегда выполняются предположения, позволяющие получить удобные аналитические формулы, приведенные в учебнике.
Недаром Марно Вербик, автор очень известного и переведенного на русский язык учебника «Путеводитель по современной эконометрике» приводит высказывание своего слушателя: «Эконометрика была бы гораздо проще без данных». Однако есть точка зрения, что учебники по эконометрике должны идти от практики к теории и изобиловать примерами.
Есть очень известный американский учебник «Практика эконометрики» профессора Массачусетского технологического института Эрнста Р. Берндта. Он как раз построен по противоположному принципу: берется практическая задача, например, изучение издержек американских фирм-производителей электроэнергии, диверсификация портфеля ценных бумаг, а дальше рассказывается о способах ее решения с применением эконометрики. Студенты сразу погружаются в практику. При составлении своих учебных пособий я попыталась частично взять на вооружение тот же принцип и по максимуму использовать российские кейсы.
— Каково соотношение теории и практики в вашем лекционном курсе эконометрики?
— Я пытаюсь соблюсти баланс теории и практики. На каждой лекции я сопровождаю теоретический материал практическими примерами. На компьютерных занятиях мы со студентами работаем с реальными данными, конечно, интереснее всего для них российские.
Темой последнего семинара были модели бинарного выбора. По данным мониторинга экономического положения и здоровья населения мы исследовали, какие факторы влияют на удовлетворенность человека жизнью. Оказалось, что влияют и доход, и образование, и пол. Тогда студенты решили выяснить, делает ли законный брак человека счастливее. Проверили, оказалось, что женщин – да, а мужчин – нет. Конечно, студенты не остановились на достигнутом и проверили еще много интересных предположений. Возможно, они сделали первый шаг к будущим научным исследованиям.
— Эконометрика традиционно считается сложным для изучения предметом. Что бы вы посоветовали студентам для успешной сдачи этого курса?
— Как и в математике, в эконометрике нет «королевской дороги». Изучение эконометрики требует вдумчивой, планомерной работы с теоретическим материалом и освоения современных статистических пакетов. Настойчивость и трудолюбие будут вознаграждены не только хорошей оценкой за курс, но и возможностью в будущем проводить полноценные эконометрические исследования, а это очень увлекательное занятие!
Беседовала Екатерина Рылько
[1] То есть в уравнении регрессии дисперсия ошибки отличалась от наблюдения к наблюдению.
Объект эконометрики
Сущность эконометрики
Определение 1
Эконометрика — это наука, которая изучает качественные и количественные экономические взаимосвязи, применяя математические статистические методы и модели.
Современная трактовка объекта эконометрики выработана в соответствии с положениями устава «Эконометрического общества», при этом главными целями стали применение математики и статистики для дальнейшего совершенствования экономической теории.
Эконометрика является наукой, которая позволяет качественному социальному процессу присвоить количественную характеристику и интерпретировать их с экономической позиции.
С теоретической точки зрения, эконометрика изучает статистические свойства испытаний и оценок, тогда как с прикладной позиции эконометрика отвечает за применение эконометрических методов для проведения оценки различных экономических теорий. Эконометрика предоставляет инструментарий для проведения экономических измерений, определяет методологию анализа параметров микро- и макроэкономических моделей.
Помимо этого, эконометрика часто используется для составления прогнозов экономических процессов не только в масштабе экономики и целом, но и на уровне отдельного предприятия, Вместе с тем, эконометрика — это такая же часть экономической теории, как макро- и микроэкономика.
Замечание 1
Объектом изучения эконометрики являются экономико-математические модели (эконометрические модели), в основе построения которых — случайные факторы.
Эконометрика — составной элемент обширного семейства дисциплин, которые посвящены измерениям и использованию статистических инструментов и методов в различных научно-практических областях. Эго семейство, в частности, включает биометрию, технометрику, наукометрию, психометрию, хемометрию, квалиметрию. Особая роль отводится социометрии, которая изучает статистические методы анализа взаимоотношений малых групп и является частью статистического анализов в психологии и социологии.
Цели и задачи эконометрики
Основные задачи эконометрики:
выявить связи отдельных количественных характеристик экономических объектов для построения математических правил прогнозирования;
установить значения каждого числового параметра, входящего в модель;
и привести их в соответствие поведению объекта в реальности;
получить наилучшие опенки параметров экономико-математических моделей, сконструированных в прикладных целях;
проверить теоретико-экономические положения и выводы на фактическом материале;
создать универсальные и специальные методы для выявления в экономике статистических закономерностей.
Замечание 2
Основной целью эконометрики является поиск адекватного инструмента прогнозирования поведения экономических объектов в разнообразных ситуациях, а также решение на базе прогнозирования практических задач в части оптимального управления объектом; выбора стратегии рыночного поведения.
Специфика экономических измерений
Измерение экономических данных характеризуются следующими специфическими особенностями:
Измерению поддаются только данные, определенные операционально.
Экономические измерения при этом подвержены сильному воздействию теоретических мнений относительно данных величин.
Короткие ряды наблюдений и неэкспериментальный характер данных заставляют сомневаться в адекватности полученного результата.
Косвенный характер экономических данных, при этом зачастую первичные изменения не несут экономического характера.
Изменчивый характер единиц измерения.
Острая проблема, связанная с влиянием инструментов измерения на изучаемый объект.
Что такое Эконометрика — классификация и задачи
Рубрика: Экономический глоссарий Опубликовано 07.06.2014 · Комментарии: 0 · На чтение: 2 мин · Просмотры:
Post Views: 484
Эконометрика -это наука об экономических измерениях. Термин происходит от двух слов: «экономика» и «метрика». Греческий корень «метрон» означает правило определения расстояния между двумя точками в пространстве, «метрия» – измерение.
Эконометрика — это наука, базирующаяся на анализе связи между различными экономическими показателями с учётом реальных статистических данных, а также с применением математической статистики и методов теории вероятностей. Она позволяет выявить, уточнить, опровергнуть связи, и гипотезы, отражающие существование данных связей между экономическими показателями, предлагаемые конкретной экономической теорией.
Цель эконометрики заключается в модельном описании количественных взаимосвязей. Данные взаимосвязи обусловливаются общими качественными закономерностями, которые выявляются и оцениваются в экономической теории.
Предметом исследования являются массовые экономические явления и процессы.
Основные задачи эконометрики
1.обнаружение статистических закономерностей в экономике
2.анализ данных закономерностей
3.выявление эмпирических экономических зависимостей
4.построение на их базе эконометрических моделей.
Классификация задач эконометрики
Основные признаки классификации всех задач, рассматриваемых эконометрикой:
1. Классификация задач в зависимости от конечных прикладных целей (прогноз социально-экономических показателей, моделирование возможных вариантов социально-экономического развития системы, выявление факторов, оказывающих наиболее мощное влияние на состояние системы в целом).
2. Классификация задач в зависимости от уровня иерархии (макроуровень, мезоуровень, микроуровень).
3. Классификация задач в зависимости от профиля изучаемой экономической системы (рынок,инвестиции,спрос, потребление, ценообразование и прочее).
Много общих черт существует у эконометрики и статистики – в некоторой степени, эконометрика является часть статистической науки: статистика изучает глобальные явления всех направлений, в том числе и экономических, а эконометрика занимается теми же процессами, но ограничивается исключительно экономическими задачами.
Post Views: 484
План. Что такое эконометрика. Как это работает на первый взгляд. Литература. Как это работает на самом деле. три истории
Probit, logit, heckit модели
Probit, logit, heckit модели 11 13 июля 2017 г. Курс лекций «Макроэконометрика» 1 Оглавление Дискретные зависимые переменные Probit Logit Цензурированные выборки Tobit Модель Хекмана 2 Дискретные зависимые
Подробнее
https://sites.google.com/site/ekonometriya2014
Тема 1. Введение в эконометрию 1.1. История эконометрии 1.2. Основные понятия и определения эконометрии 1.3. Эконометрическое моделирование 1.4. Литература 1.5. Статистические данные 1.6. Статистические
Подробнее
Модель парной регрессии
Модель парной регрессии 30 25 20 15 10 В статистических данных редко встречаются точные линейные соотношения: y x 1 2 Обычно они бывают приближенными: y x 1 2 5 0 2 4 6 8 10 12 14 16 18 20
Подробнее
Эконометрика (базовая) Лекция 1
Эконометрика (базовая) Лекция 1 Рекомендуемая литература 1. Доугерти К. Введение в эконометрику. М.: ИНФРА-М, 2001. 2. Магнус Я.Р. и др. Эконометрика. Начальный курс. М.: Дело, 2001. 3. Кремер Н.Ш., Путко
Подробнее
Правительство Российской Федерации
Правительство Российской Федерации Федеральное государственное автономное образовательное учреждение высшего профессионального образования «Национальный исследовательский университет «Высшая школа экономики»
Подробнее
ЭКОНОМЕТРИКА Программа
МОСКОВСКИЙ ИНСТИТУТ ЭКОНОМИКИ, МЕНЕДЖМЕНТА И ПРАВА Кафедра общематематических и естественнонаучных дисциплин ЭКОНОМЕТРИКА Программа Москва 2003 1 Составитель: Харламов С.А., доктор технических наук Эконометрика:
Подробнее
1 Предисловие. Ф-ПР Рабочая программа
Предисловие Данная дисциплина рассматривает и изучает эконометрические модели и методы анализа и прогнозирования социально-экономических процессов. Методика преподавания данной дисциплины предусматривает:
Подробнее
Эконометрическое моделирование
Эконометрическое моделирование Лабораторная работа 5 Множественная регрессия Оглавление Множественная регрессия… 3 Мультиколлинеарность… 4 Задание 1. Построение модели множественной регрессии… 5
Подробнее
УЧЕБНО-МЕТОДИЧЕСКИЙ КОМПЛЕКС ДИСЦИЛИНЫ
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РЕСПУБЛИКИ КАЗАХСТАН ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ имени ШАКАРИМА ГОРОДА СЕМЕЙ Документ СМК 3 уровня УМКД Программа дисциплины «Эконометрика» для студентов УМКД Редакция
Подробнее
Введение. кономерности до экономических
Эконометрика является одной из важнейших составляющих современного экономического образования. В ведущих мировых университетах в программах подготовки экономистов ей уделяется большое внимание. Применение
Подробнее
Эконометрика и прогнозирование
Эконометрика и прогнозирование Автор-составитель: доцент кафедры экономической информатики и математической экономики экономического факультета БГУ, к.ф.-м.н. Васенкова Е.И. Цель и учебная задача Эконометрика
Подробнее
Аннотация. Цели и задачи дисциплины
Цели и задачи дисциплины Аннотация Целью курса является приобретение опыта построения эконометрических моделей и определение возможностей их использования для описания, анализа и прогнозирования реальных
Подробнее
ПРОГРАММА ВСТУПИТЕЛЬНОГО ИСПЫТАНИЯ
ПРОГРАММА ВСТУПИТЕЛЬНОГО ИСПЫТАНИЯ для поступающих на основную образовательную программу магистратуры «Математические методы в экономике» по направлению подготовки 38.04.01 «ЭКОНОМИКА» по предмету «МАТЕМАТИЧЕСКИЕ
Подробнее
Рабочая программа дисциплины Эконометрика
Федеральное государственное автономное образовательное учреждение высшего образования «Национальный исследовательский университет «Высшая школа экономики» Факультет экономических наук Департамент прикладной
Подробнее
1. ЦЕЛИ И ЗАДАЧИ ИЗУЧЕНИЯ ДИСЦИПЛИНЫ
1. ЦЕЛИ И ЗАДАЧИ ИЗУЧЕНИЯ ДИСЦИПЛИНЫ Изучение дисциплины «Эконометрика» ориентировано на получение обучающимися знаний о сложной взаимосвязи различных факторов, оказывающих существенное воздействие на
Подробнее
Правительство Российской Федерации
Правительство Российской Федерации Государственное образовательное бюджетное учреждение высшего профессионального образования «Государственный университет — Высшая школа экономики» Нижегородский филиал
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Мурманский государственный гуманитарный университет» (ФГБОУ ВПО
Подробнее
2011 Экономика 2(14)
ВЕСТНИК ТОМСКОГО ГОСУДАРСТВЕННОГО УНИВЕРСИТЕТА 211 Экономика 2(14) УДК 331.11.3:3 МОТИВАЦИЯ ТРУДОВОЙ ДЕЯТЕЛЬНОСТИ: ФАКТОРЫ И ИХ ОЦЕНКА РЫНКОМ ТРУДА Статья посвящена факторам, влияющим на уровень заработной
Подробнее
НОУ ИНТУИТ | Лекция | Сущность и история возникновения эконометрики
1.1. Предмет исследований эконометрики
Курс эконометрики занимает важное место в современных программах экономических вузов во всем мире наряду с такими предметами, как микроэкономика, макроэкономика, финансовый анализ. Эконометрические методы используются для прогнозирования в банковском деле, финансах, бизнесе, при государственном регулировании экономики. Что же такое эконометрика? Эконометрика — быстроразвивающаяся отрасль экономической науки, целью которой является количественное описание экономических отношений. Приведем несколько цитат о существе данной науки.
«Эконометрика позволяет проводить количественный анализ реальных экономических явлений, основываясь на современном развитии теории и наблюдениях, связанных с методами получения выводов» (П. Самуэльсон).
«Цель эконометрики — эмпирический анализ экономических законов. Эконометрика дополняет теорию, используя реальные данные для проверки и уточнения постулируемых отношений» (Э. Маленво).
Термин «эконометрия» впервые ввел П. Цьемпа в 1910 г., который пытался применить методы алгебры и геометрии к анализу хозяйственной деятельности. В настоящее время этот термин используется для того раздела эконометрики и теории экономического анализа, который изучает влияние факторов, формирующих результаты работы фирмы (предприятия).
В мировой науке термин «эконометрика» обычно употребляется применительно к науке об измерении и анализе экономических явлений. Эта наука возникла на стыке трех дисциплин: экономической теории, методов математического анализа и математической статистики. Основатель журнала «Эконометрика» Р. Фриш привел следующее определение эконометрики: «Эконометрика — это не то же самое, что экономическая статистика. Она не идентична тому, что мы называем экономической теорией, хотя значительная часть этой теории носит количественный характер. Эконометрика не является синонимом приложений математики к экономике. Как показывает опыт, каждая из трех отправных точек — статистика, экономическая теория и математика — необходимое, но не достаточное условие для понимания количественных соотношений в современной экономической жизни. Это — единство всех трех составляющих. И это единство образует эконометрику».
Однозначного определения эконометрики пока не существует. Есть по крайней мере еще четыре дисциплины, использующие математические методы применительно к экономике:
многомерный статистический анализ данных, тесно связанный с эконометрикой;
финансовая математика, также использующая в своих современных разделах эконометрические методы;
математические модели в экономике — наука, применяющая для подтверждения теоретических концепций эконометрическую технику верификации моделей;
математические методы в экономике (старое название — исследование операций) — наука о постановках и решении оптимизационных задач в экономике, состоящая из таких широко известных разделов, как линейное и нелинейное программирование, сетевое планирование, управление запасами, теория игр. Несколько особняком стоит теория массового обслуживания.
Некоторые исследователи, в том числе Э. Маленво, придавали широкое толкование эконометрике, интерпретируя ее как любое применение математики или статистических методов к изучению экономических явлений. Однако доминирующим стало мнение, что эконометрика применяет статистические подходы к эконометрическим измерениям. Это обстоятельство обусловило содержание настоящего курса лекций.
Эконометрика содержит два больших раздела: моделирование данных, неупорядоченных во времени, и теория временных рядов.
Тест по эконометрике с ответами
Сборник итоговых тестов по теме Эконометрика с ответами
Правильный вариант ответа отмечен знаком +
1. Что является предметом изучения эконометрики?
— Количественная сторона экономических процессов и явлений
+ Массовые экономические процессы и явления
— Система внутренних связей между явлениями национальной экономики
2. Гетероскедастичность – это в эконометрике термин, обозначающий:
+ Неоднородность наблюдений, которая выражается в непостоянной (неодинаковой) дисперсии случайной ошибки эконометрической (регрессионной) модели
— Однородную вариантность значений наблюдений, которая выражена в относительной стабильности, гомогенности дисперсии случайной ошибки эконометрической (регрессионной) модели
— Меру разброса значений случайной величины относительно ее математического ожидания
3. Мультиколлинеарность – это в эконометрике термин, обозначающий:
— Метод, позволяющий оценить параметры модели, опираясь на случайные выборки
— Статистическую зависимость между последовательными элементами одного ряда, которые взяты со сдвигом
+ Наличие линейной зависимости между факторами (объясняющими переменными) регрессионной модели
4. Теорема Гаусса-Маркова в эконометрике опирается на:
+ Метод наименьших квадратов
— Метод наименьших модулей
— Метод инструментальных переменных
5. Эконометрика – это наука, которая изучает:
— Структуру, порядок и отношения, сложившиеся на основе операций подсчета, измерения и описания формы объектов
— Возможности применения методов математики для решения экономических задач
+ Количественные и качественные экономические взаимосвязи, и взаимозависимости, опираясь на методы и модели математики и статистики
6. Коэффициент эластичности (формула в общем виде) в эконометрике имеет вид:
+
—
—
7. Модели временных рядов в эконометрике – это модели:
— Которые используются для того, чтобы определить, как себя будет вести тот или иной фактор в течение определенного промежутка времени
— Которые позволяют максимально точно рассчитать период времени, требующийся для того, чтобы значение фактора изменилось на значимую величину
+ Для построения которых используются данные, характеризующие один объект за несколько последовательных периодов
8. Метод наименьших квадратов в эконометрике – это метод:
— Который используется для расчета наименьших отклонений случайных величин, влияющих на конечный результат
+ Который позволяет решать задачи, опираясь на минимизацию суммы квадратов отклонений некоторых функций от искомых переменных
— Который позволяет оценить значение неизвестного параметра, минимизируя значение функции правдоподобия
9. Линейный коэффициент корреляции в эконометрике выражается формулой:
—
+
—
тест 10. Истинный коэффициент детерминации в эконометрике выражается формулой:
—
—
+
11. Модели в эконометрике – это:
+ Средство прогнозирования значений определенных переменных
— Экономические и статистические зависимости, выраженные математическим языком
— Данные одного типа, сгруппированные определенным образом
— Параметр, состоящий из случайной и неслучайной величин
+ Некоторая переменная регрессионной модели, которая является функцией регрессии с точностью до случайного возмущения
— Переменная, которая получается путем перевода качественных характеристик в количественные, т.е. путем присвоения цифровой метки
14. Какова цель эконометрики?
— Поиск, трактовка (с использованием математического инструментария) и систематизация факторов, которые влияют на поведение экономического объекта
— Выявление качественных и количественных связей между характеристиками экономических объектов с целью построить экономическую модель их развития
+ Разработка инструментов для прогнозирования поведения экономического объекта в различных ситуациях и на их базе решение практических задач по управлению объектом, выбору поведения в сложившихся экономических условиях и т.д.
15. Что представляет собой выборочная дисперсия?
+ Несмещенную оценку генеральной дисперсии
— Смещенную оценку генеральной дисперсии
— Смещенную оценку моды
16. Какие приемы используют для идентификации модели?
— Априорный, контекстный, информационный, аналитический, прогностический, идентификация модели
— Постановочный, контекстный, информационный, аналитический, идентификация модели, параметризация модели
+ Постановочный, априорный, параметризация, информационный, идентификация модели, верификация модели
26. Эндогенные переменные – это переменные:
— Внешние, задаваемые вне социально-экономической модели и не зависящие от ее состояния
+ Внутренние, сформированные в результате функционирования социально-экономической системы
— Которые постоянно изменяются
27. Что представляет собой априорный этап построения эконометрической модели?
+ Предмодельный анализ экономической сущности изучаемого явления, формирование и формализация априорной информации
— Сбор и регистрация информации об участвующих в модели факторах и показателях
— Независимое оценивание значений участвующих в модели факторах и показателях
28. Если увеличить размер выборки, то оценка математического ожидания:
— Станет менее точной
+ Станет более точной
— Не изменится
тест № 29. Ситуация, при которой нулевая гипотеза была опровергнута, хотя и являлась истинной, называется:
+ Ошибка I рода
— Системная ошибка
— Стандартная ошибка
30. Если предположение о природе гетероскедастичности верно, то дисперсия случайного члена для первых наблюдений в упорядоченном ряду будет … для последних.
— Такой же, как
— Выше, чем
+ Ниже, чем
Эконометрика как учебная дисциплина Текст научной статьи по специальности «Экономика и бизнес»
УДК 519.2:005.521:633.1:004.8
01.00.00 Физико-математические науки
ЭКОНОМЕТРИКА КАК УЧЕБНАЯ ДИСЦИПЛИНА
Орлов Александр Иванович
д.э.н., д.т.н., к.ф.-м.н., профессор
РИНЦ SPIN-код: 4342-4994
Московский государственный технический
университет им. Н.Э. Баумана, Россия, 105005,
Москва, 2-я Бауманская ул., 5, prof-orlov@mail.т
Статистические методы широко используются в отечественных технико-экономических исследованиях. Однако для большинства менеджеров, экономистов и инженеров они являются экзотикой. Это объясняется тем, что в вузах современным статистическим методам не учат. Обсудим сложившуюся ситуацию, уделив основное внимание статистическим методам в экономических и технико-экономических исследованиях, т.е. эконометрике. В мировой науке эконометрика занимает достойное место. Имеются научные журналы по эконометрике, нобелевские премии по экономике присуждены ряду эконометриков. Положение в области научных и практических работ и особенно преподавания эконометрики в России является неблагополучным. Зачастую за эконометрику выдают отдельные частные построения, например, относящиеся к регрессионному анализу. Статья посвящена эконометрике как учебной дисциплине. Начинается курс с обсуждения структуры современной эконометрики, соотношения прикладной статистики и эконометрических методов. Рассмотрены выборочные исследования (анализ результатов опросов), элементы эконометрики чисел, методы статистической проверки гипотез однородности. Даны понятия о регрессионном анализе, эконометрических методах классификации, современной теории измерений. Важное место занимает статистика нечисловых данных (включая нечеткие множества и их связь со случайными), статистика интервальных данных. Обсуждается проблема устойчивости статистических процедур по отношению к допустимым отклонениям исходных данных и предпосылок модели. Дано представление об эконометрических методах экспертных исследований и управления качеством, анализе и прогнозе временных рядов, эконометрике прогнозирования и риска
Ключевые слова: СТАТИСТИЧЕСКИЕ МЕТОДЫ, ЭКОНОМЕТРИКА, УПРАВЛЕНИЕ, ЭКОНОМИКА, СТАТИСТИКА НЕЧИСЛОВЫХ И ИНТЕРВАЛЬНЫХ ДАННЫХ, ИНФЛЯЦИЯ
UDC 519:2:005.521:633.1:004.8
Physics and mathematical sciences
ECONOMETRICS AS AN ACADEMIC DISCIPLINE
Orlov Alexander Ivanovich
Dr.Sci.Econ., Dr.Sci.Tech., Cand.Phys-Math.Sci.,
professor
Bauman Moscow State Technical University, Moscow, Russia
Statistical methods are widely used in domestic feasibility studies. However, for most managers, economists and engineers, they are exotic. This is due to the fact that modern statistical methods are not taught in the universities. We discuss the situation, focusing on the statistical methods for economic and feasibility studies, ie, econometrics. In the world of science, econometrics has a rightful place. There are scientific journals in econometrics, Nobel Prizes in Economics are given to series of researches in econometrics. The situation in the field of scientific and practical work and especially the teaching of econometrics in Russia is disadvantaged. Often, individual particular constructions replace econometrics in general, such as those related to regression analysis. The article is devoted to econometrics as an academic discipline. Our course begins with a discussion of the structure of modern econometrics, the connections between applied statistics and econometric methods. We consider sample researches (analysis of surveys results), the elements of econometrics numbers, and methods of testing of statistical hypothesis about homogeneity. We have given the concepts of regression analysis, econometric classification methods, modern measurement theory. The important places are occupied by the statistics of non-numerical data (including fuzzy sets and their links with random sets) and the statistics of interval data. The problem of the stability of statistical procedures with respect to the tolerances of input data and model prerequisites is discussed. The representations of the econometric methods of expert research and quality control, analysis and forecasting of time series, econometrics of forecasting and risks are given
Keywords: STATISTICAL METHODS, ECONOMETRICS, MANAGEMENT, ECONOMICS, STATISTICS OF NON-NUMERIC AND INTERVAL DATA, INFLATION
йо!: 10.21515/1990-4665-128-050
1. Введение
Известно, что современные эконометрические методы — полезные интеллектуальные инструменты инженера, управленца и экономиста [1]. Эконометрика — самостоятельная научная, прикладная и учебная дисциплина. В настоящей статье рассмотрим примерное содержание эконометрики как учебного предмета в соответствии с подходом отечественной научной школы в области эконометрики [2]. Комментарии к разделам курса показывают их место в современной эконометрике и обосновывают необходимость включения соответствующего материала в учебную программу.
2. Вводный раздел: структура современной эконометрики
Структура современной статистики: математическая статистика, прикладная статистика, применения статистических методов в конкретных областях. Определение эконометрики как науки о применении статистических методов для анализа конкретных экономических данных, а эконометрических методов — как статистических методов анализа экономических данных. Разрыв между математической статистикой и Госкомстатом РФ. Всегда ли можно верить данным Госкомстата РФ? Пример с оцениванием вузовской науки по числу научных ставок в вузах. Особенности экономических данных и их учет при применении методов прикладной статистики. Понятие об эконометрических моделях (на примерах моделей управления качеством, анализа экспертных оценок и др.). Понятие о конкретных применениях эконометрики (на примере динамики цен и индекса инфляции).
Содержание этого вводного раздела достаточно полно раскрыто в статье [1]. Приведем содержание только одного из наиболее интересных
для студентов раздела эконометрики, посвященного изучении динамики цен с помощью индексов инфляции.
Проблемы и методы анализа динамики цен. Инфляция как рост цен. Рост цен на отдельные товары и услуги и проблемы построения сводной характеристики. Различные варианты потребительских корзин. Определение и расчет индексов инфляции. Динамика инфляции в России. Теорема умножения (связь между значениями индексов инфляции для трех значений времени) и средний индекс (темп) инфляции как среднее геометрическое. Распространенные ошибки при агрегировании индексов инфляции. Принципиальная разница между малыми и большими значениями индексов инфляции. Связь годового индекса и помесячными и средним за год. Теорема сложения для индекса инфляции (правило объединения индексов инфляции для отдельных товарных групп).
Применения индекса инфляции в различных экономических расчетах. Приведение к сопоставимым ценам. Сравнения средней заработной платы, пенсий, стипендий в различные моменты времени. Реальные результаты индексирования заработной платы и пенсий. Расчет прожиточного минимума, его динамика. Учет индекса инфляции при расчете реального значения процента на вклад в банк, реального процента платы за кредит. Как процент платы за кредит может быть отрицательным? Оценка динамики курса доллара США в России с помощью потребительских паритетов, сравнение с Китаем. Применение индекса инфляции при оценке стоимости основных и оборотных фондов. Опыт прогнозирования индекса инфляции и стоимости потребительской корзины. Применение индекса инфляции при организации производства. Конверсия, индекс инфляции и сохранность технологических цепочек (на примере специальной техники). Динамика макроэкономических показателей России. Использование индекса инфляции при оценивание
экономического положения предприятий, при финансовом анализе результатов их деятельности.
3. Прикладная статистика и эконометрические методы
Области современных статистических методов: статистика чисел (случайных величин), статистика векторов (многомерный статистический анализ), статистика функций (случайных процессов и временных рядов), статистика нечисловых данных. Современная прикладная статистика и эконометрика. Пять точек роста эконометрических методов: непараметрическая статистика, устойчивость статистических процедур, размножение выборок, статистика нечисловых данных, статистика интервальных данных.
Объем знаний, которым могут овладеть студенты в вузе, ограничен. Перед организаторами образования постоянно стоит проблема — что включать в учебную программу, а что не включать. Эта проблема решается проще, если известно будущее место работы студентов, т.е. подготовка идет для нужд конкретного предприятия. Представляется очевидным, что студент должен владеть современными методами своей специальности. Следовательно, постоянно должна вестись методическая работа по внедрению современных идей, концепций, подходов, методов, расчетных алгоритмов в учебный процесс (этот раздел методики преподавания называют онтодидактикой). Однако онтодидактические работы предполагают хорошее знакомство с современным уровнем знаний и практического применения, личную работу преподавателя на переднем крае науки и постоянное участие в прикладных исследованиях. Кроме того, приходится постоянно пересматривать само содержание преподавания, модернизировать методическое обеспечение — учебники, учебные пособия, задачники, методические разработки по отдельным темам, лабораторные работы, тематики курсовых и дипломных работ.
Это нелегко. Поэтому вполне естественно, что наблюдается тенденция к консервации. Она выгодна для преподавателя — однажды разработанный курс и его методическое обеспечение используется (с небольшими вариациями) десятилетиями. Она удобна для студентов — те пользуются учебниками, которые за несколько изданий доведены до возможного совершенства, обеспечены заблаговременно изданными задачниками, лабораторными работами и пр. Такая тенденция к консервации обычно наблюдается у курсов «Статистика» (она же «Общая теория статистики») и «Теория вероятностей и математическая статистика». Как следствие консервации, студенты получают знания на уровне 40-60-х годов ХХ в., т.е. с запозданием на 50-70 лет. Наивно думать, что им будет легко самостоятельно осознать и тем более овладеть тем, что возникло за последние полвека.
При ориентации на современные методы есть свои опасности. Можно неправильно оценить значимость тех или иных научных направлений, пропустить перспективные или, что еще хуже, посвятить много времени тем, чье время быстро пройдет. Однако предшествующие эконометрике курсы «Статистика» и «Теория вероятностей и математическая статистика», как правило, настолько далеки от современности, что за основу выбора можно взять развитие эконометрических идей в 70-90-х годах ХХ в.
И преподавателю, и студенту труднее при ориентации на курсы с современной тематикой, чем на консервативные. Однако труд студента оправдывается при выходе на самостоятельное поприще по окончании вуза. Автор настоящей статьи более 45 лет разрабатывал и применял эконометрические методы в различных отраслях народного хозяйства и областях науки и смеет надеяться, что опыт научно-прикладной деятельности позволил разработать и внедрить на кафедре «Экономика и организация производства» факультета «Инженерный бизнес и
менеджмент» Московского государственного технического университета им. Н.Э. Баумана современный курс эконометрики (см. [2]).
Пользуясь тем, что студенты уже изучили курс «Теория вероятностей и математическая статистика», в разделе 3 даем представление о современной прикладной статистике согласно [3]. Первые три области современных статистических методов: — статистика чисел (случайных величин), статистика векторов (многомерный статистический анализ), статистика функций (случайных процессов и временных рядов) являются достаточно традиционными, хотя в предваряющих эконометрику курсах о них говорится явно недостаточно, а иногда не так и не то. Статистика нечисловых данных как самостоятельная область возникла в 1970-е годы и до сих пор продолжает активно развиваться, поэтому она выделена как одна из точек роста эконометрических методов.
В соответствии со сказанным выше о необходимости показа студентам современного фронта эконометрических исследований предлагается кратко охарактеризовать основные точки роста, т.е. направления, которые в настоящее время активно развиваются, полезны для практики, но недостаточно представлены в стандартных учебниках. Первой из таких точек указаны непараметрические методы. Хотя они имеют длинную историю, начинающуюся с коэффициентов ранговой корреляции Кендалла и Спирмена начала века и статистик Колмогорова, Смирнова, омега-квадрат тридцатых годов, в преподавании они оттеснены на задний план параметрической статистикой. Почему это произошло? Видимо, тем, что параметрическая статистика, изучающая выборки из семейств распределений, описываемых одним-двумя, максимум тремя числовыми параметрами, имеет дело со сравнительно простым с математической точки зрения объектом. Именно из-за его простоты удалось построить достаточно глубокую, но доступную студентам теорию. Вместе с тем хорошо известно, что распределения реальных данных почти
никогда не удается адекватно описать с помощью какого-либо параметрического семейства. В частности, распределения погрешностей измерений, вопреки распространенному заблуждению, почти всегда отличны от нормальных [4]. Таким образом, анализ данных с помощью параметрических методов статистики напоминает поиск ключей под фонарем, где светлее, а не в кустах, где они потеряны.
В настоящее время непараметрическими методами можно решать тот же круг задач, что и параметрическими. При этом вместе неоправданных предположений о принадлежности функций распределения тому или иному параметрическому семейству делаются лишь общие предположения о непрерывности функций распределения. Из общих соображений можно ожидать, что такое расширение области применения может привести к снижению эффективности непараметрических эконометрических методов по сравнению с параметрическими. Однако во многих случаях непараметрические методы оказываются не хуже параметрических, особенно при больших объемах выборок. Иногда, тем не менее, параметрические методы представляются конкурентоспособными. Тогда необходимо изучить устойчивость эконометрических выводов по отношению к допустимым отклонениям исходных данных и предпосылок модели. Общая схема изучения устойчивости эконометрических и экономико-математических методов и моделей дана в [5]. Кроме термина «устойчивость», в данном контексте используются термины «робастность» (от robust — крепкий, грубый (англ.)), чувствительность. Можно выделить два этапа исследования — анализ устойчивости известных процедур, затем поиск новых наиболее устойчивых и вместе с тем достаточно точных. Иногда параметрические и непараметрические методы дают практически одни и те же алгоритмы, особенно при больших объемах выборок. Например, правила доверительного оценивания математического ожидания (при неизвестной дисперсии) в параметрическом случае
нормального распределения и в непараметрическом случае произвольного распределения (правило строится на основе центральной предельной теоремы теории вероятностей и теорем о наследовании сходимости [6]) отличаются только тем, что в первом случае используются процентные точки распределения Стьюдента, а во втором — процентные точки стандартного распределения. Как известно, при росте объема выборки первые стремятся ко вторым. Однако иногда изучение устойчивости приводит к неожиданным выводам. Так, анализ проблемы обнаружения резко выделяющихся наблюдений (выбросов) привел к выводу о крайней неустойчивости классических методов: если зафиксировать процентную точку (т.е. правило принятия решений), то велик интервал изменения уровня значимости, если же, наоборот, исходить из заданного уровня значимости, то весьма велик интервал для границы, задающей правил отбраковки [4]. Следовательно, правила отбраковки не имеют научного обоснования, их следует рассматривать как эвристические.
Общеинженерным принципом является указание не только точечного значения измеряемой величины, но и погрешности этого измерения. В экономике и менеджменте, к сожалению, не всегда указывают величины возможных погрешностей измерения. Требование изучения устойчивости статистических процедур нацелено на внедрение указанного общеинженерного принципа в область экономики, инженерного бизнеса и менеджмента. Одним из подходов является статистика интервальных данных (СИД). В ней прослеживается, как погрешности исходных данных, влияют на погрешности выводов, а для этого и исходные данные, и выводы приходится описывать с помощью интервалов, а не чисел, как в классической статистике. СИД активно развивается с 1980-90-х гг., основные ее идеи доступны студентам, поэтому элементы СИД включены в программу по эконометрике.
Другой подход к изучению устойчивости статистических (эконометрических) выводов предполагает интенсивное использование современной вычислительной техники и основан на «размножении выборок». По выборке можно рассчитать одно число — точечную оценку характеристики или параметра, но этого мало — надо иметь доверительный интервал, т.е. нижнюю и верхнюю границы, между которыми с заданной вероятностью находится истинное значение. Параметрическая теория позволяет это сделать, но ее предпосылки неприемлемы. Поэтому вполне естественным является желание «размножить выборку» — вместо одной получить много похожих, по каждой из них рассчитать оценку, а по совокупности оценок построить распределение оценки, указать доверительный интервал. Метод размножения может быть очень простым: из одной выборки объема п можно получить п выборок объема (п-1), если исключать из исходной выборки последовательно по одному элементу (возвращая ранее исключенные обратно). Есть и много иных методов размножения выборок.
4. Выборочные исследования (анализ результатов опросов)
Польза и необходимость выборочных эконометрических исследований. Анкетное исследование (на примере маркетингового исследования потребителей растворимого кофе). Различные виды формулировок вопросов (открытый, закрытый, полузакрытый вопросы), их достоинства и недостатки. Техника интервью. Экономика опросов. Биномиальная и гипергеометрическая модели выборки, их близость в случае большого объема генеральной совокупности по сравнению с выборкой. Асимптотическое распределение выборочной доли (в случае ответов типа «да»-«нет»). Интервальное оценивание доли и метод проверки статистической гипотезы о равенстве долей (на основе теоремы Муавра-Лапласа и таблиц ВЦИОМ).
Изучение конкретных эконометрических методов естественно начать с методов выборочных опросов, практическая польза которых очевидна (разбираем маркетинговое исследование, выполненное по заказу конкретной фирмы), а математическая сложность невелика. Естественным образом возникает сюжет о проверке однородности (другими словами. обнаружении различий), который продолжается в следующей теме.
5. Элементы эконометрики чисел
Определения нормального и логарифмически нормального распределений и их плотностей. Центральная предельная теорема в аддитивном и мультипликативном случае. Методы оценивание параметров логарифмически нормального распределения. Логарифмически нормальное распределение доходов (заработной платы) и «данные» Госкомстата РФ. Непараметрическое оценивание характеристик распределений и доверительных границ для них. Непараметрические методы оценивания плотности.
Тема начинается с сопоставления нормального и логарифмически нормального распределений. Первое из них иногда допустимо использовать при решении технических задач. В эконометрике его использовать нельзя, поскольку плотность нормального распределения всюду положительна, т.е. вероятность отрицательных значений, а в эконометрике обычно рассматриваются неотрицательны величины. Основная причина популярности нормального распределения в эконометрике — центральная предельная теорема теории вероятностей, в которой речь идет о суммах большого числа независимых случайных величин. Если же вместо сумм имеем дело с произведениями, то вместо нормального распределения получаем логарифмически нормальное, сосредоточенное на положительной полуоси. Им можно приближать распределения различных экономических величин, например, доходов
населения. В Росстате настолько верят в законность такого приближения, что вместо эмпирических величин публикуют лишь расчетные значения.
При рассмотрении распределения доходов выявляется целесообразность рассмотрения различных видов средних -математического ожидания, медианы, моды. Непараметрическую статистику начинаем с непараметрического точечного и доверительного оценивания таких характеристик распределения, как математическое ожидание, медиана, дисперсия, среднее квадратическое отклонение, коэффициент вариации. Термин «непараметрическое оценивание» означает, что предположения о принадлежности распределения выборки к какому-либо параметрическому семейству отсутствуют, но предполагается существование моментов нужного порядка. С практической точки зрения это всегда выполнено, поскольку реальные распределения всегда сосредоточены на каком-то отрезке (другими словами, финитны).
Завершается раздел рассмотрением непараметрических ядерных оценок плотности распределения, использование которых на базе современной вычислительной техники позволит существенно сузить область применения гистограмм — классического способа наглядного представления данных, обладающего неустранимым недостатками -отсутствием обоснования для выбора числа интервалов и потерей информации из-за группирования.
6. Методы статистической проверки гипотез однородности
Проблема проверки однородности двух выборок (независимых и связанных). Различные формулировки гипотезы однородности двух выборок. Критерий Крамера-Уэлча для проверки равенства математических ожиданий (на основе Центральной предельной теоремы и теоремы о наследовании сходимости).
Эмпирическая функция распределения и основанные на ней непараметрические одновыборочные статистические критерии А.Н.Колмогорова, Н.В.Смирнова, омега-квадрат (Крамера-Мизеса-Смирнова). Проверка гипотезы согласия с параметрическим семейством распределений и распространенная ошибка при использовании критериев Колмогорова и омега-квадрат.
Двухвыборочный критерий Вилкоксона (Манна-Уитни) и его асимптотическая нормальность. Достигаемый уровень значимости. Асимптотическое распределение критерия Вилкоксона при справедливости альтернативной гипотезы и его асимптотическая мощность. Какие выводы можно сделать на основе критерия Вилкоксона? Альтернатива сдвига. Двухвыборочные критерии Смирнова и типа омега-квадрат (Лемана-Розенблатта). Задача обнаружения различия в связанных выборках (письмо главного инженера Рошальского химического комбината). Критерий знаков. Проверка равенства 0 математического ожидания. Одновыборочный критерий Вилкоксона. Проверка симметрии функции распределения относительно 0 с помощью критерия типа омега-квадрат.
Эта тема — одна из примыкающих к классической тематике математической статистики. Однако различия видны с самого начала. Для проверки равенства математических ожиданий двух выборок используем критерий Крамера-Уэлча. Любопытно, что ни в одном «классическом» пособии по математической статистики нельзя найти доказательства асимптотической нормальности этого критерия. Для доказательства (которое в курсе опущено) приходится ссылаться на теорему о наследовании сходимости [6]. Необходимо обратить внимание на отличие критерия Крамера-Уэлча от критерия Стьюдента, который предпочитают рассматривать в курсах математической статистики. Критерий Стьюдента опирается на две предпосылки — нормальность распределения обеих
выборок и равенства дисперсий у них. Ни одна из предпосылок обычно не выполняется, особенно для экономических данных.
Проверку согласия с параметрическим семейством с помощью критериев Колмогорова и омега-квадрат любят включать в учебники по «Общей теории статистики», причем обычно делают это с ошибками, о чем подробно написано в статье [7]. Поэтому уклониться от разбора этого вопроса нельзя. Много недоразумений связано и с двухвыборочным критерием Вилкоксона, самым популярным в переводной литературе (разбору неточных утверждений, связанных со свойствами этого критерия, посвящена статья [8]).
Необходимость решения вопроса об однородности в связанных выборках естественно начать с практической задачи, например, с письма главного инженера Рошальского химического комбината, в котором тот просит установить, есть ли различия в показаниях двух вискозиметров, используемых при производстве мастики. От решения этого вопроса зависит, включать ли в соответствующий нормативный документ указание на средство измерения вязкости или в этом нет необходимости.
7. Понятие о регрессионном анализе
Метод наименьших квадратов для линейной прогностической функции. Вид расчетной таблицы. Оценивание параметров. Критерий правильности расчетов. Точечный и интервальный прогноз. Изменение ширины доверительного интервала при увеличении горизонта прогнозирования. Метод наименьших квадратов в случае линейной функции двух переменных. Вид расчетной таблицы. Оценивание параметров. Критерий правильности расчетов. Более общие варианты метода наименьших квадратов. Модель, линейная по параметрам. Преобразования переменных. Оценивание многочлена. Оценка остаточной
дисперсии как показатель качества модели. Оценивание размерности модели. Непараметрическая регрессия.
Регрессионный анализ — одна из наиболее разработанных частей эконометрики. Имеются толстые монографии, посвященные отдельным направлениям регрессионного анализа. На основе регрессионного анализа построена теория планирования эксперимента, дающая большой экономический эффект. Методы восстановления зависимостей на основе наименьших квадратов и наименьших модулей, модели линейной и нелинейной (по параметрам) регрессии, оценивание необходимой степени полинома, различные варианты непараметрической регрессии, дисперсионный анализ, многочисленные модели планирования эксперимента, в том числе экстремального — весь этот перечень тем заслуживает того, чтобы студенты их изучали. Для этого необходимо увеличение продолжительности преподавания эконометрики, переход от одного к системе курсов, как это сделано, например, в Высшей школе экономики — «Эконометрика-1», «Эконометрика-2», «Эконометрика-3» …
Необходимо рассчитывать не только точечные оценки параметров, но и доверительные границы для прогностической функции. Подробно разбираются методы расчета для линейной регрессии с одной независимой переменной. В то же время вероятностной теории уделяется меньше внимания, хотя и дается общее понятие регрессии как условного математического ожидания, описывается ее непараметрическая оценка.
8. Эконометрические методы классификации
Классификация и прогнозирование. Триада: построение классификаций — анализ классификаций — использование классификаций. Лемма Неймана-Пирсона и непараметрический дискриминантный анализ на основе непараметрических оценок плотности в пространствах произвольной природы. Линейный дискриминантный анализ Р.Фишера.
Многообразие параметрических и непараметрические методов классификации (распознавания образов). Группировки и кластер-анализ. Методы оценки качества алгоритмов классификации.
Хотя теория классификации несколько менее популярна среди научно-технических работников, количество посвященных ей работ измеряется десятками тысяч. Активно работавшая в 1980-е годы Комиссия ВСНТО по классификации охватывала около 1000 специалистов. Однако классификация как область эконометрики еще не достигла достаточной внутренней стройности. Слишком много отдельных подходов и методов, не связанных друг с другом. О том же свидетельствует и разнобой в терминологии. Построение классификаций называют также распознаванием образов без учителя, автоматической классификацией, кластерным анализом. Использование классификаций — дискриминантным анализом, диагностикой, распознаванием образов с учителем. Тем не менее представляется целесообразным познакомить студентов с основными идеями в области классификации, с алгоритмами кластер-анализа (прежде всего иерархическими агломеративными алгоритмами «ближнего соседа», средней связи, «дальнего соседа»), параметрическими (линейный дискриминантный анализ Р. Фишера) и непараметрическими (на основе непараметрических оценок плотностей, построенных по обучающим выборкам) алгоритмами использования классификаций. Используется также теория принятия статистических решений (при известной матрице потерь из-за ошибочной классификации). Анализ классификаций (разбиений) рассматривается позже, как одна из задач статистики объектов нечисловой природы. Важное место в теме занимают методы оценки качества алгоритмов классификации, в том числе метод пересчета на модель линейного дискриминантного анализа, позволяющий проверять обоснованность использования линейных прогностических индексов. Тема связана как с курсом «Теория вероятностей и математическая статистика»
(лемма Неймана-Пирсона), так и с курсом «Статистика» (построение группировок).
Другие многомерные эконометрические методы (многомерное шкалирование, целенаправленное проецирование, метод главных компонент, факторный анализ, канонические корреляции, анализ структуры связей и др.) целесообразно рассмотреть при условии увеличения объема преподавания эконометрики.
9. Современная теория измерений
Шкалы наименований, порядка (ранговая), интервалов, отношений, абсолютная. Проблема адекватности эконометрического вывода. Средние величины, результат сравнения которых инвариантен относительно допустимых преобразований шкалы. Применения к расчету рейтингов.
Рассматриваются основы (репрезентативной) теории измерений: определения, примеры, группы допустимых преобразований для основных типов шкал (наименований, порядка, интервалов, отношений, абсолютной). В качестве основного для эконометрики выдвигается требование устойчивости статистических выводов относительно допустимых преобразований шкал. Сравниваются три вида средних (среднее арифметическое, мода, медиана) для зарплаты работников предприятия. Дается определение средних по Коши. Обсуждается «теорема о медиане» — описание средних, результат сравнения которых устойчив в порядковой шкале. Рассматриваются применения «теоремы о медиане» к рейтингам. Вводятся ассоциативные средние по Колмогорову и дается описание средних, результат сравнения которых устойчив в шкалах интервалов и отношений. Рассматриваются иные применения теории измерений к выбору адекватных методов анализа экономических данных.
10. Статистика нечисловых данных
Различные виды нечисловых данных, связи между ними. Люсианы. Нечеткие множества и их связь со случайными. Метрики (показатели различия), эмпирические и теоретические средние, медиана Кемени, асимптотическое поведение решений экстремальных статистических задач, законы больших чисел непараметрические оценки плотности в произвольных пространствах.
В 1970-х годах стала очевидной большая роль в эконометрике экономических и управленческих данных ранее слабо изучавшихся видов -нечисловых данных, или объектов нечисловой природы. В литературе имеется достаточно подробное описание различных пространств нечисловых данных, а также связей между ними [9]. К нечисловым данным относятся, как уже говорилось, результаты измерений по качественным шкалам (в шкалах наименований и порядка), бинарные отношения (ранжировки (упорядочения), разбиения (отношения эквивалентности), толерантности), последовательности из 0 и 1, множества, нечеткие множества и др. Основные связи между перечисленными видами нечисловых данных были установлены еще в 1970-е годы. Позже была развита, например, теория люсианов (конечных последовательностей испытаний Бернулли с, вообще говоря, различными вероятностями успеха, дающая вероятностную основу для анализа последовательностей из 0 и 1.
Рассматриваются основы теории нечеткости. Даются определения нечетких множеств и операций над ними. Разбираются примеры нечетких множеств, в частности, нечеткие ответы экспертов, и свойства операций над нечеткими множествами. Анализируется связь нечетких множеств со случайными, позволяющая свести теорию нечеткости к теории случайных множеств и тем самым к теории вероятностей.
Вводятся метрики (показатели различия) в пространствах произвольной природы — основа методов статистики нечисловых данных. Дан оптимизационный подход к определению эмпирических и теоретических средних в пространствах произвольной природы, проведено сравнение со свойствами среднего арифметического, математического ожидания, теоретической и выборочной медианы. Эмпирическое среднее предлагается рассматривать как агрегирование мнений экспертов. Обсуждается формулировка законов больших чисел в пространствах произвольной природы.
В качестве эконометрических данных рассматриваются бинарные отношения (ранжировки, разбиения, толерантности). Разбирается их связь с матрицами из 0 и 1 и введение расстояния Кемени между бинарными отношениями. Изучается медиана Кемени, ее асимптотика и свойства при малых объемах выборок и различных предположениях о распределении ранжировок. Вводятся изотропные распределения и устанавливается единственность среднего (медианы). Интерпретация законов больших чисел для нечисловых данных может быть дана в терминах теории экспертного опроса. Устанавливается связь метода средних рангов с коэффициентом ранговой корреляции Спирмена и линейная зависимость расстояния Кемени от коэффициента ранговой корреляции Кендалла. Разбирается метод «идеальной точки» с использованием средних рангов на примере сравнения математических моделей испарения жидкости.
Вводятся расстояния, теоретические и эмпирические средние в пространстве подмножеств конечного множества. Построение эмпирического среднего (итогового мнения комиссии экспертов) проводится по правилу большинства. Вводятся различные расстояния между нечеткими множествами и применяются для усреднение нечетких ответов экспертов.
Полученные результаты применяются для изучения асимптотического поведения решений экстремальных статистических задач. Предлагается использовать непараметрические оценки плотности в пространствах произвольной природы, в частности, для дискретных пространств. Обсуждается применение статистики объектов нечисловой природы при построения новой хронологии и значение полученных выводов для современных социально-экономических проблем.
11. Статистика интервальных данных
Погрешности измерения и интервальные данные. Нотна -максимально возможное отклонение, вызванное интервальностью статистических данных. Рациональный объем выборки. Их расчет для ряда задач оценивания, проверки гипотез, регрессионного, кластерного и дискриминантного анализов.
Необходимость учета в эконометрических методах погрешностей измерения, как уже обсуждалось выше, приводит к введению в теорию и практику статистического анализа интервальных данных. Определяются операции над интервальными числами и дается обоснование правил приближенных вычислений. Сравниваются по точности две формулы для выборочной дисперсии. Обсуждается основная модель интервальной статистики. Вводятся основополагающие понятия нотны — максимально возможного отклонения, вызванного интервальностью статистических данных, и асимптотической нотны (при малой абсолютной погрешности). Дается алгоритм расчета асимптотической нотны для квадратичных функций второго порядка. Изучение влияния интервальности дисконт-факторов на величину NPV (чистой приведенной стоимости, net present value) приводит к признанию интервальности самой величину NPV и необходимости использования экспертных оценок при оценке и сравнении инвестиционных проектов.
Разбираются основные результаты статистики интервальных данных, в том числе второе основополагающее понятие — рациональный объем выборки. Проводится расчет асимптотической нотны, рационального объема выборки и доверительных интервалов при оценивании математического ожидания и дисперсии, а также расчет основных показателей статистики интервальных данных для ряда задач оценивания, проверки гипотез, регрессионного, кластерного и дискриминантного анализов.
12. Проблема устойчивости статистических процедур по отношению к допустимым отклонениям исходных данных и предпосылок модели
Робастные методы статистики. Общая схема устойчивости. Метод складного ножа Кенуя. Бутстреп Эфрона и его критика.. Размножение выборок как эффективный способ интенсивного применения вычислительной техники в эконометрике.
Обсуждаются различные робастные методы и модели статистики и эконометрики, в том числе модель Тьюки-Хубера засорения экономических данных резко выделяющимися наблюдениями и модель Ю.Н. Благовещенского отклонений, имеющих быть на всей числовой оси. Согласно [5] дается формулировка общей схемы изучения устойчивости и разбираются примеры ее применения.
Рассматриваются методы размножения выборок (различные варианты бутстрепа): метод складного ножа Кенуя, бутстреп Эфрона [31] (и его критика). Размножение выборок выдвигается как эффективный способ интенсивного применения информационно-коммуникационных технологий в эконометрике. Даны различные варианты применения метода размножения выборок в эконометрических исследованиях.
13. Эконометрические методы экспертных исследований
Примеры и основные этапы применения методов экспертных оценок. Формирование экспертной комиссии. Метод «снежного кома». Различные виды экспертных процедур (с взаимодействием или без, одно- и многотуровые и др.). Метод средних рангов и метод медиан. Согласование кластеризованных ранжировок. Применение коэффициентов ранговой корреляции, теории люсианов, медианы Кемени и иных методов статистики нечисловых данных.
Обосновывается необходимость проведения экспертных исследований, особенно в ситуациях быстрого изменения, когда нет возможности опираться на длинные временные ряды статистических данных. Основными представлениями о теории и практике экспертного оценивания должен владеть каждый инженер, экономист, менеджер. Примерами процедур экспертных оценок являются методы оценки техники и артистичности фигуристов, успешности команд КВН, целесообразности финансирования научно-технических проектов, анализируемых в Республиканском исследовательском научно-консультативном центре экспертизы (РИНКЦЭ) на основе методических документов РИНКЦЭ. Они используются на соревнованиях, при выборе, распределении финансирования, при экологических экспертизах, в частности, согласно Закону РФ «Об экологических экспертизах». Другие методы экспертных исследований: метод Дельфи, мозговой штурм, метод средних рангов, метод медиан, метод сценариев.
Планирование и организация экспертного исследования как один из видов деятельности менеджера. Сравнение ролей лиц, принимающих решения (ЛПР), и специалистов (экспертов) в процедурах экспертиз и принятия решений. Зоны ответственности Рабочей Группы и Экспертной Комиссии. Основные этапы проведения экспертного исследования как основа деятельности менеджера, организующего экспертное исследование.
Экономические вопросы проведения экспертного исследования — часть знаний менеджера.
Цели экспертного исследования можно поставить по-разному: сбор информации для ЛПР и/или подготовка проекта решения для ЛПР и др. Используется ряд методов формирования состава экспертной комиссии: методы списков (реестров),» снежного кома», самооценки, взаимооценки. Важна проблема априорных предпочтений экспертов. Достоинства и недостатки процедур, используемых при отборе экспертов, заслуживают подробного обсуждения, равно как и. различные варианты организации экспертного исследования, различающиеся по числу туров (один, несколько, не фиксировано), порядку вовлечения экспертов (одновременно, последовательно), способу учета мнений (с весами, без весов), организации общения экспертов (без общения, заочное, очное с ограничениями («мозговой штурм») или без ограничений).
Методы анализа экспертных оценок основаны на статистике нечисловых данных, а также на применении непараметрической статистики (коэффициентов ранговой корреляции). Бинарные отношения на конечном множестве часто возникают как способы описания ответы экспертов. Бинарные отношения находятся во взаимно-однозначном соответствии с матрицами из 0 и 1. При анализе мнений экспертов важны такие свойства бинарных отношений, как рефлексивность, симметричность, транзитивность, и соответствующие им подпространства бинарных отношений — подпространства ранжировок (упорядочений), разбиений (отношений эквивалентности), толерантностей. Аксиоматическое введение расстояния Кемени между бинарными отношениями дает возможность применить методы статистики объектов нечисловой природы для анализа ответов экспертов. Применение теории люсианов, вычисление медианы Кемени и использование иных методов статистики нечисловых и интервальных данных — основа работы
специалиста по анализу экспертных данных. Согласование кластеризованных ранжировок рассматриваем на примере сравнения 8 математических моделей испарения жидкости по экспериментальным данным (при создании банка математических моделей с целью оценки последствий аварий при экологическом страховании).
Обобщенный показатель (полезность) объекта экспертизы строится как функция частных показателей. Разработан ряд методов построения обобщенного показателя. В частности, есть два подхода к определению весовых коэффициентов линейной функции полезности. Один из них -линейная свертка с коэффициентами, которые оценивают эксперты. Критику такого подхода даем на основе анализа реальных предложений по процедуре выбора технологии уничтожения химического оружия. Недостатки экспертных методов непосредственного определения коэффициентов весомости имеют причиной то, что эксперту свойственно работать в порядковой шкале, а не в количественных шкалах. Рассматривается экспертно-статистический метод и его реализация с помощью метода наименьших квадратов.
14. Эконометрические методы управления качеством
Статистический приемочный контроль по альтернативному признаку. Планы контроля. Оперативная характеристика. Приемочный и браковочный уровни дефектности. Предел среднего выходного уровня дефектности. Применение Центральной предельной теоремы теории вероятностей. Статистический приемочный контроль по количественному признаку. Применение статистики люсианов. Всегда ли нужен выходной контроль? Контрольные карты Шухарта и кумулятивных сумм.
В договорах купли-продажи, создания научно-технической продукции и иных договорах между предприятиями практически всегда имеется
раздел «Правила приемки и методы контроля». Эти разделы, как и правила сертификации, часто основаны на статистическом приемочном контроле. Под ним понимают выборочный контроль, основанный на эконометрической теории. Его необходимость связана с применением разрушающих методов контроля и с экономической эффективностью, основанной на сокращении затрат на контроль (в машиностроении они составляют в среднем 10% от стоимости продукции).
Планы контроля по альтернативному признаку разнообразны. Наиболее простым является одноступенчатый контроль. Основной инструмент анализа и синтеза планов контроля — это оперативная характеристика, т.е.функция, определяющая вероятность приемки партии в зависимости от входного уровня дефектности. С помощью оперативной характеристики определяются приемочный и браковочный уровни дефектности. соответствующие заданным рискам поставщика и потребителя. Расчеты наиболее просты для плана (п,0).
Если применяется контроль с разбраковкой, то находят средний выходной уровень дефектности и его предел (ПСВУД), т.е. максимально возможное значение. Нетрудно рассчитать ПСВУД для плана (п,0). Выбор плана контроля на основе ПСВУД целесообразен в ситуации, когда потребитель должен быть защищен от проникновения в поставляемую ему партию продукции доли брака, превышающей заданную.
Если поставщик и потребитель по-разному оценивают качества продукции в партии, поступившей от поставщика к потребителю, то возникает арбитражная ситуация. Арбитражная характеристика задает вероятность возникновения арбитражной ситуации. Для уменьшения числа споров применяют принцип распределения приоритетов. Расчет планов контроля поставщика и потребителя на основе принципа распределения приоритетов отличается тем, что приемлемый уровень качества выступает
для поставщика в качестве браковочного, а для потребителя — в качестве приемочного.
При достаточно большом объеме выборки (несколько десятков единиц продукции) расчет приемочного и браковочного уровней дефектности для одноступенчатого плана с помощью теоремы Муавра-Лапласа теории вероятностей. Выбор одноступенчатого плана контроля по заданным приемочным и браковочным уровням дефектности также может быть проведен на основе асимптотических соотношений, вытекающих из теоремы Муавра-Лапласа.
Ограниченность возможности использования экономических показателей при статистическом контроле основана на том, что последствия отказов изделий типа гибели людей нельзя по этическим соображениям описывать в экономических терминах. Поэтому математические модели типа модели Хальда, учитывающие все виды затрат — затраты на контроль, убытки от излишнего забракования и потери от пропуска брака, — остаются теоретическими.
Основной парадокс теории статистического контроля состоит в том, что чем лучше качество и меньше дефектность, тем больший объем контроля требуется. Поэтому естественно поставить вопрос: всегда ли нужен выходной контроль? Сравнение экономической эффективности сплошного контроля и увеличения объема партии; сплошного контроля и замены дефектных единиц продукции в системе гарантийного обслуживания приводит к выводу о целесообразности во многих случаях отказаться от выходного контроля.
Обычно выделяют следующие виды статистических методов управления качеством (обеспечения, повышения качества): статистический анализ точности и стабильности технологических процессов (методами прикладной статистики), статистический приемочный контроль по альтернативному и количественному признаку., статистическое
регулирование технологических процессов (контрольные карты Шухарта и кумулятивных сумм), планирование экспериментов (в том числе экстремальное, с целью добиться максимального выхода полезного продукта), надежность и испытания. При контроле по нескольким альтернативным признакам полезно применение статистики люсианов -одного из разделов статистики объектов нечисловой природы. Используют наглядные диаграммы Парето и диаграммы причин и результатов (известные также как диаграммы Исикавы или «рыбий скелет»).
Проблемы управления качеством рассматриваются не только на уровне предприятия, но и на отраслевом, государственном и межгосударственном уровнях. Можно указать на проблемы сертификации производства (отдельной партии продукции, конкретного технологического процесса, всего производства в целом) согласно международным стандартам серии ИСО 9000. На всех одиннадцати этапах жизненного цикла продукции (по международному стандарту ИСО 900487). необходимо использование эконометрических методов. В настоящее время переходим от систем контроля качества, основанных на допусках (системы Тейлора), к основанным на функциях потерь (системы Тагути).
Организационные вопросы управления качеством делятся на вопросы, решаемые государством (стандартизация, аттестация, сертификация), и вопросы, решаемые общественностью (кружки качества, защита прав потребителей). Развиваются комплексные системы управления качеством продукции, используется серия международных стандартов ИСО серии 9000 и лозунг тотального (всеобщего) управление качеством, система «Шесть сигм». Статистические методы управления качеством могут использоваться также при решении экологических задач мониторинга, контроля, управления, других экологических проблем на предприятиях и в регионах, при аудите (контроле массива документов), мониторинге социально-экономического положения и в других областях.
15. Анализ и прогноз временных рядов
Методы выделения трендов. Спектральный анализ. Оценивание периода. Модели авторегрессии. Системы эконометрических уравнений.
Применяют методы восстановления временных зависимостей на основе наименьших квадратов и наименьших модулей. Среди них важное место занимают модели линейной (по параметрам) регрессии. Большое значение приобретает задача оценивание необходимой степени полинома. Полезны модели авторегрессии, в том числе простейшая эмпирическая модель экспоненциального сглаживания. Оценка длины периода может быть сделана на основе методов статистики объектов нечисловой природы путем минимизации в функциональном пространстве. Выделение циклов во временных рядах имеет давнюю историю.. Рассматриваются системы эконометрических моделей и примеры их практического применения.
16. Эконометрика прогнозирования и риска
Статистические и экспертные прогнозы. Неопределенности и риски, их моделирование в эконометрике. Диверсификация и страхование. Принятие решений в условиях неопределенности. Применение экспертных оценок при оценке и сравнении инвестиционных проектов.
Среди пяти основных функцией менеджмента первая -прогнозирование и планирование. Необходимость для менеджера владеть различными методиками прогнозирования не вызывает сомнения. Из различных видов прогнозов выделим статистические и экспертные, качественные и количественные. К частным видам прогнозирования относятся прогнозы невозможности, самоосуществляющиеся прогнозы. Прогнозирование является основой планирования.
Вопрос о целях предприятия непрост. Неопределенность выражения «максимизация прибыли» без указания интервала времени показывает это.
Полезно прогнозирование экономической (и не только!) ситуации методом сценариев. Выделены этапы процесса планирования работы отрасли и предприятия, практически на всех нужны те или иные прогнозы.. Часто используется иерархия: миссия и ценности -стратегические цели — задачи — конкретные задания, что соответствует этапам планирования, основанного на прогнозировании: разработка стратегии, бизнес планирование и оперативное планирование.
Неопределенности и риски сопровождают менеджера постоянно. Различные виды рисков в работе предприятия перечислить трудно, но необходимо. Разработаны методы декомпозиции риска, в частности, используются деревья причин и результатов (диаграммы типа «рыбий скелет» — см. выше).
Разработаны различные методы описания неопределенностей, прежде всего вероятностно-статистические (наиболее распространенные), основанные на теории нечетких множеств и на статистике интервальных данных. Вероятностно-статистические методы описания риска широко используются, тесно связаны с теорией надежности, с вероятностным анализом безопасности( в атомной энергетике). Выделяют риск события (когда риск состоит в осуществлении нежелательного события) и риск ущерба (количественный). Есть ряд вариантов количественной оценки риска: по среднему ущербу (математическому ожиданию), по медиане ущерба, по квантилю, близкому к 1, по линейной комбинации среднего ущерба и среднего квадратического отклонения, по функции потерь и даже по дисперсии. Плата за риск может быть выявлена при наблюдении за поведением людей, которые обычно стремятся уменьшить риск, например, путем страхования. Плату за риск можно оценить, вычитая среднюю цену акций и цены гарантированных государством облигаций (в США). Один из приемов уменьшения риска — диверсификация деятельности, в том числе диверсификация при управлении пакетом ценных бумаг в условиях риска.
Дается понятие о вероятностных моделях страхования, в том числе экологического.
Имеются различные подходы к принятию решений в условиях неопределенности: подход пессимиста, основанный на максимизации выигрыша в наихудшей ситуации (это — подход теории антагонистических игр), подход оптимиста (максимизация выигрыша в наилучших условиях), подход на основе среднего выигрыша (возможно, дополненный оценкой доверительного интервала), подход, основанный на минимизации упущенной выгоды, и др. При несовпадении рекомендаций, даваемых различными подходами, необходимо применение оценок экспертов. В частности, имеются различные подходы к оценке эффективности и выбору инвестиционных проектов. С чисто финансовой точки зрения сравнение инвестиционных проектов сводится к сравнению потоков платежей. Очевидна необходимость изучения устойчивости (чувствительности) выводов по отношению к отклонениям коэффициентов дисконтирования и величин платежей. Столь же очевидна необходимость использования метода экспертных оценок в случае получения противоречивых рекомендаций после проведения анализа чувствительности, например, когда интервалы для используемых характеристик потоков платежей перекрываются.
17. Заключение
Подведем итоги. В настоящей статье продемонстрирована необходимость обучения будущих менеджеров, экономистов, инженеров эконометрическим методам. Рассмотрено место курса эконометрики в системе высшего технического образования: опираясь на курсы «Теория вероятностей и математическая статистика» и «Статистика», он призван довести знания студентов до уровня современности. Указаны связи курса эконометрики со многими иными учебными предметами — менеджментом,
маркетингом, экологией, стандартизацией, метрологией и управлением качеством, инвестиционной, инновационной, контрольной и контроллинговой деятельностью, оценкой финансового состояния предприятия, прогнозированием и технико-экономическим планированием, экономико-математическим моделированием
производственных систем и др.
Разработано содержание основного курса эконометрики, который реализован в нескольких конкретных вариантах (многочисленные учебники представлены в [2]). Есть перспективы для его развертывания при увеличении количества часов. о чем подробнее сказано выше. Особенно важным представляется развертывание наиболее современных разделов эконометрики — статистики нечисловых и интервальных данных.
Наряду с очевидными преимуществами ориентация курса эконометрики на последние научные достижения имеет свои отрицательные стороны, в частности, слабым является методическое обеспечение.
Литература
1. Орлов А.И. Современные эконометрические методы — интеллектуальные инструменты инженера, управленца и экономиста // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2016. № 116. С. 484 — 514.
2. Орлов А.И. Отечественная научная школа в области эконометрики / А.И. Орлов // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета (Научный журнал КубГАУ) [Электронный ресурс]. — Краснодар: КубГАУ, 2016. — №07(121). С. 235 — 261. — IDA [article ID]: 1211607006. — Режим доступа: http://ej .kubagro.ru/2016/07/pdf/06.pdf
3. Орлов А.И. Прикладная статистика — состояние и перспективы // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2016. № 119. С. 44-74.
4. Орлов А.И. Распределения реальных статистических данных не являются нормальными // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2016. № 117. С. 71-90.
5. Орлов А.И. Новый подход к изучению устойчивости выводов в математических моделях // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2014. № 100. С. 146-176.
6. Орлов А.И. Теоретические инструменты статистических методов // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2014. № 101. С. 253-274.
7. Орлов А.И. Непараметрические критерии согласия Колмогорова, Смирнова, омега-квадрат и ошибки при их применении // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2014. № 97. С. 32-45.
8. Орлов А.И. Двухвыборочный критерий Вилкоксона — анализ двух мифов // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2014. № 104. С. 91 — 111.
9. Орлов А.И. О развитии статистики объектов нечисловой природы // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. 2013. № 93. С. 41-50.
References
1. Orlov A.I. Sovremennye jekonometricheskie metody — intellektual’nye instrumenty inzhenera, upravlenca i jekonomista // Politematicheskij setevoj jelektronnyj nauchnyj zhurnal Kubanskogo gosudarstvennogo agrarnogo universiteta. 2016. № 116. S. 484
Недавно мы изучали методы маркетинга, и основной целью маркетинга является увеличение прибыли компании. Прежде чем тратить большие деньги, менеджер по маркетингу должен быть уверен в том, как будет работать кампания и как на нее отреагирует аудитория.
В таких ситуациях эконометрика используется для определения взаимосвязи между маркетинговыми усилиями и продажами, например:
Какой дополнительный доход можно получить от дополнительных сотен рупий, потраченных на рекламу?
Какой вид рекламы (цифровая, телевизионная, газетная и т. Д.)) оказывает наибольшее влияние на продажи?
Вопросы такого типа можно решить с помощью эконометрических методов.
Введение в эконометрику
Эконометрика — это количественное применение статистических выводов, экономической теории и математических моделей с использованием данных для разработки теорий или проверки существующих гипотез в экономике и для прогнозирования будущих тенденций на основе огромного количества данных, полученных с течением времени.
Его функция заключается в преобразовании реальных данных в статистические исследования, а затем в сравнении результатов с теорией или теориями, которые проверяются на аналогичные закономерности.
Другими словами, анализирует теоретические экономические модели и использует их для разработки экономической политики .
Основная функция эконометрики — для преобразования качественных отчетов в количественные .
Согласно книге Stock and Watson (2007), «Эконометрические методы используются во многих отраслях экономики, включая финансы, экономику труда, макроэкономику, микроэкономику и экономическую политику».
Лоуренс Кляйн, Рагнар Фриш и Саймон Кузнец считаются пионерами эконометрики, а также получили Нобелевскую премию по экономике в 1971 г. за свой вклад. Сегодня он широко используется как учеными, так и практиками, такими как трейдеры и аналитики с Уолл-стрит.
В зависимости от того, заинтересованы ли вы в проверке существующей теории или в использовании существующих данных для разработки новой гипотезы, основанной на этих выводах, эконометрику можно разделить на следующие категории: теоретическая и прикладная эконометрика.
Типы эконометрики 1. Теоретическая эконометрика
Это исследование свойств существующих статистических моделей и процедур для определения неизвестных значений в модели.При этом мы стремимся разработать новые статистические процедуры, которые действительны, несмотря на то, что природа экономических данных может изменяться одновременно.
Теоретическая эконометрика в значительной степени опирается на математику, теоретическую статистику и числовые величины, чтобы доказать, что новые процедуры способны делать правильные выводы .
(Также проверьте: Статистический анализ данных)
Теоретическая эконометрика фокусируется на таких вопросах, как общая линейная модель, модели одновременных уравнений, распределенные задержки и вспомогательные темы.Большинство из этих проблем возникло при работе над эмпирическими исследованиями.
Типы эконометрики
2. Прикладная эконометрика
Это специальное использование эконометрических методов для преобразования качественных экономических отчетов в количественные, в отличие от теоретического подхода. Поскольку прикладные эконометристы приобретают более близкий опыт работы с данными, они часто сталкиваются с проблемами, связанными с атрибутами данных, которые указывают на ошибки в существующем наборе методов оценки, а также предупреждают их теоретиков-эконометристов об аномалиях.
Прикладная эконометрика посвящена темам производства товаров и их производительности, спросу на рабочую силу, теории арбитражного ценообразования, вопросам спроса на жилье .
Например, эконометрист может обнаружить, что дисперсия данных (насколько отдельные значения в серии отличаются от общего среднего) всегда меняется и никогда не фиксируется с течением времени.
Главный инструмент эконометрики
Основным инструментом эконометрики является модель линейной множественной регрессии, которая помогает оценить, как изменение одной из независимых переменных влияет на работу модели, от объясняемой переменной до изменений, происходящих в зависимой переменной.В современной эконометрике многие статистические инструменты оказались в центре внимания, но простая линейная регрессия по-прежнему является наиболее часто используемой отправной точкой для анализа.
Этот шаг необходим, потому что регрессия имеет тенденцию оценивать предельное влияние конкретной объясняющей переменной после учета дисперсии, вызванной влиянием других объясняющих переменных на модель .
Например, модель может попытаться дифференцировать влияние увеличения налогов на 1 процентный пункт на средние потребительские расходы домохозяйства, предполагая, что другие факторы потребления, такие как доход до налогообложения, богатство и процентные ставки, статичны.
Этапы эконометрики
Методология эконометрики довольно проста.
Этапы эконометрики
Предложение теории
Первый шаг — предложить теорию или гипотезу, чтобы начать изучение определенной части данных.Объясняющие переменные в модели указываются заранее, а знак и / или величина взаимосвязи между каждой отдельной независимой переменной и зависимой переменной четко устанавливаются, чтобы не вызывать путаницы.
На этом этапе в игру вступают прикладные эконометристы, которые в значительной степени полагаются на экономическую теорию, чтобы успешно сформулировать гипотезу на основе предоставленных данных.
(Предлагается прочитать: 7 основных разделов дискретной математики)
Например, философия международной экономики заключается в том, что цены через открытые границы идут рука об руку после того, как разрешен паритет покупательной способности.Эмпирическая взаимосвязь между внутренними ценами и иностранными ценами (с поправкой на сценарии номинального обменного курса) всегда должна быть положительной, и они должны всегда стараться поддерживать паритет.
Определение статистической модели
Второй шаг — определить статистическую модель, отражающую суть теории. Экономист пытается предложить уникальную связь между зависимой переменной и независимыми переменными через модель.
Безусловно, самый простой подход — это допустить линейность, то есть любое изменение независимой переменной всегда будет вызывать аналогичное изменение зависимой переменной. Конечно, невозможно учесть каждое небольшое влияние на зависимую переменную, поэтому в статистическую модель добавляется переменная, чтобы свести на нет внешние возмущения.
Роль новой переменной здесь состоит в том, чтобы представить все детерминанты зависимой переменной, которые не могут быть учтены.В основном из-за сложности данных.
Просто чтобы быть последовательным и обеспечить выполнение всех условий для статистической модели, экономисты обычно предполагают, что этот термин «ошибка» в среднем равен нулю и непредсказуем.
Третий шаг — оценить неизвестные переменные модели с использованием имеющихся экономических данных.Обычно для этого используется соответствующая статистическая процедура и пакет эконометрических программ.
Это называется самой простой частью анализа благодаря легкому доступу к обширным экономическим данным и отличным эконометрическим методам и программному обеспечению. Эконометрика по-прежнему основывается на принципах известного стиля вычислений GIGO (мусор на входе, мусор на выходе).
Корректура
Это четвертый шаг, а также самый важный из всех.На этом этапе нужно задать себе правильные вопросы. Например,
Соответствуют ли знаки и взаимосвязь оценочных параметров, связывающих зависимую переменную с независимыми переменными, с предсказаниями экономической теории?
Если расчетные параметры не имеют смысла, как следует отредактировать статистическую модель специалисту по эконометрике, чтобы получить соответствующие результаты?
А более точная оценка гарантирует получение экономически значимой модели?
На этом этапе, в частности, проверяются навыки и опыт эконометриста в данной области.
Проверка гипотезы
Основным инструментом четвертого этапа является проверка гипотез, статистическая процедура, в которой исследователь отмечает истинное значение экономического параметра, и проводится статистический тест, чтобы выяснить, является ли оцениваемый параметр синонимом конкретной гипотезы.
Если это не так, исследователь должен либо отвергнуть гипотезу, либо внести изменения в статистическую модель и начать все сначала.
Если все четыре этапа проходят успешно, результатом является модель, которую можно использовать в качестве инструмента для оценки эмпирической достоверности экономической модели.
Эмпирическая модель также может использоваться для прогнозирования зависимой переменной, потенциально помогая политикам принимать важные решения об изменениях в денежно-кредитной и / или налогово-бюджетной политике, чтобы экономика оставалась на стабильной платформе.
Студенты, изучающие эконометрику, часто увлекаются возможностью линейной множественной регрессии для прогнозирования экономических отношений.
Стоит помнить о трех основах эконометрики;
Первый , качество вывода параметров зависит от текущего рабочего состояния экономической модели.
Вторая , если релевантная объясняющая переменная исключена из модели, наиболее вероятно, что оценки параметров станут ненадежными и неточными.
В-третьих, , у оценок параметров очень малая вероятность совпадения с фактическими значениями параметров, которые генерируются статистическими данными, даже если эконометрист идентифицирует процесс как источник исходных данных.
В конечном итоге оценки используются, потому что они станут точными по мере того, как будет доступно больше данных, а оценки будут соответствовать широте охвата.
Функции эконометрики
Эконометрика выполняет в основном три тесно взаимосвязанные функции.
Первая функция эконометрики — проверка экономических теорий или гипотез, выдвинутых желанными эконометриками.Например, напрямую связано потребление с доходом? Связано ли количество спроса на определенный товар обратно пропорционально его цене?
Вторая функция эконометрики заключается в предоставлении числовых оценок переменных экономических отношений. Это очень важно для принятия решений.
Например, государственному разработчику политики необходимо иметь точную оценку коэффициента взаимосвязи между потреблением и доходом, чтобы понять стимулирующий эффект предлагаемого снижения налога и принять правильное решение.
Третья функция эконометрики — предсказывать экономические события. Это также необходимо для того, чтобы лица, определяющие политику, предприняли экономически обоснованные действия, если уровень безработицы или инфляции, согласно прогнозам, вырастет в будущем.
Заключение
Ни для кого не секрет, что экономика правит миром, и с помощью эконометрики ежедневно подтверждаются новые теории, делаются новые выводы и статистические модели отвергаются или утверждаются.
Эконометрика делит мир на безграничные возможности для формирования новых теорий, которые дополняются данными, предоставляемыми эконометристам.
Политики считают эти данные очень информативными и полагаются на эти выводы при формировании очень важных политик и решений.
Эконометрика — Изучение экономики
Эконометрика интересна тем, что предоставляет инструменты, позволяющие нам извлекать полезную информацию о важных вопросах экономической политики из имеющихся данных.Студенты, которые приобретают знания в области эконометрики, также обнаруживают, что они улучшают свои перспективы трудоустройства.
Guy Judge , старший преподаватель кафедры количественной экономики Портсмутского университета
Изображение Dunechaser на Flickr
Эконометрика — это использование статистических методов для понимания экономических проблем и проверки теорий. Без доказательств экономические теории абстрактны и могут не иметь отношения к реальности (даже если они абсолютно строгие). Эконометрика — это набор инструментов, которые мы можем использовать для сопоставления теории с данными реального мира.
Если после получения первой степени вы заинтересованы в том, чтобы продолжить свою экономическую деятельность (будь то дальнейшее обучение или профессиональный экономист в правительстве или частном секторе), вам может помочь эконометрика. Большинство магистерских курсов включают в себя обязательные продвинутые компоненты эконометрики, и большинство работодателей экономистов ищут людей, которые смогут вычислять числа и, что особенно важно, интерпретировать результаты.
Целью прикладного эконометрического исследования может быть проверка гипотезы — например, определение того, какая часть «гендерного разрыва в оплате труда» может быть объяснена различиями в образовании и опыте.В качестве альтернативы, исследование может оценить ключевой параметр, например эластичность спроса на нефть по цене. Или же для составления прогнозов можно использовать эконометрические методы, подобные тем, которые Банк Англии использует для определения уровня, на котором базовая процентная ставка должна устанавливаться каждый месяц.
Изучение эконометрики увеличивает ваш человеческий капитал двумя способами. Во-первых, он позволяет вам самостоятельно проводить прикладные эконометрические исследования, что может быть очень полезно, если вы также пишете диссертацию. Современное эконометрическое программное обеспечение значительно облегчает процесс формулирования, оценки и проверки модели и предоставляет полезную графическую информацию, а также таблицы результатов.
Во-вторых, он позволяет критически оценивать эмпирические работы других. Это может быть полезно при обсуждении соответствующей академической литературы в любом другом модуле — и возможность прокомментировать, почему тот или иной метод может быть подходящим, а может и не подходящим, часто может быть очень впечатляющим.
Эконометрика — непростой вариант. Изначально многие студенты находят это сухим и скучным. Но те, кто настойчиво с этим справляются, обычно получают вознаграждение за свои усилия. Когда вы понимаете, что делаете, проведение эконометрического исследования и поиск чего-то нового в этом мире приносит удовлетворение и, осмелюсь сказать, весело.
Ссылки
Нам прислали это отличное видео, которое понравится вам всем экономическим категориям
Наш список источников данных в сети
Предыдущая: Экономика развития
Далее: Экономический анализ закона
Введение в эконометрику Глава 1: Введение
Глава 1. Введение
В этой главе мы обсуждаем содержание этой книги, включая основные
идеи мы пытаемся передать и используемые инструменты анализа.Начнем с нашего определения
темы: Эконометрика — это применение статистических методов
и анализы к изучению проблем и вопросов в экономике.
Термин эконометрика был придуман в 1926 году норвежцем Рагнаром А. К. Фришем.
экономист, получивший первую Нобелевскую премию по экономике в 1969 г.
еще один пионер эконометрики Ян Тинберген. Хотя многие экономисты
использовал данные и провел расчеты задолго до 1926 года, Фриш чувствовал, что ему нужно
новое слово для описания того, как он интерпретировал и использовал данные в экономике.Сегодня эконометрика — это широкая область изучения экономики. Поле
постоянно меняется по мере добавления новых инструментов и методов. Однако его центр
содержит стабильный набор фундаментальных идей и принципов. Эта книга
о сути эконометрики. Мы объясним основную логику и метод
эконометрики, сосредоточившись на точном воплощении основных идей.
Мы делим изучение эконометрики в этой книге на следующие два
основные части:
Часть 1.Описание Часть 2. Вывод
В каждой части регрессионный анализ будет основным инструментом. Показывая
регресс
снова и снова в различных контекстах мы подкрепляем идею о том, что это
является
мощный и гибкий метод, определяющий большую часть эконометрики. В то же
время, однако, мы описываем условия, которые должны быть выполнены для его надлежащего
использование и ситуации, в которых регрессионный анализ может привести к катастрофическим
ошибочные выводы при несоблюдении этих условий.
В дополнение к регрессионному анализу мы будем использовать моделирование Монте-Карло.
на протяжении второй части книги, чтобы смоделировать роль случая в
процесс генерации данных. Метод Монте-Карло является неотъемлемой частью нашего
подход к обучению, который подчеркивает конкретное, визуальное понимание.
В разделе 1.2 используется пример исследования спроса на сигареты для
проиллюстрировать цели и методы эконометрического анализа и то, как регрессия
вписывается в это предприятие.Далее мы обсудим концепцию Монте.
Карло
анализ в главе 9, первой главе части 2 книги.
Эконометрика | Encyclopedia.com
Краткая история
Обзор эконометрики
БИБЛИОГРАФИЯ
Кратко определенная, эконометрика — это исследование экономической теории в ее отношении к статистике и математике. Основная предпосылка состоит в том, что экономическая теория поддается математической формулировке, обычно как система отношений, которая может включать случайные величины.Экономические наблюдения обычно рассматриваются как образец, взятый из вселенной, описываемой теорией. Используя эти наблюдения и методы статистического вывода, эконометрист пытается оценить отношения, составляющие теорию. Затем эти оценки могут быть оценены с точки зрения их статистических свойств и их способности предсказывать дальнейшие наблюдения. Качество оценок и природа ошибок прогноза могут, в свою очередь, привести к пересмотру самой теории, с помощью которой были организованы наблюдения и на основе которой были выведены постулируемые числовые характеристики Вселенной.Таким образом, существует взаимная связь между формулировкой теории и эмпирической оценкой и проверкой. Отличительной чертой является явное использование математики и статистических выводов. Нематематические теории и чисто описательная статистика не являются частью эконометрики.
Объединение экономической теории, математики и статистики было больше стремлением эконометриста, чем ежедневным достижением. Многое из того, что принято называть эконометрикой, является математической экономической теорией, которая не опирается на эмпирическую работу; и часть того, что известно как эконометрика, представляет собой статистическую оценку специальных отношений, которые имеют лишь хрупкую основу в экономической теории.Однако это достижение не оправдывает ожиданий, однако его не следует обескураживать. Частью процесса развития науки является то, что теории могут выдвигаться непроверенными и что поиск эмпирических закономерностей может предшествовать систематическому развитию теоретической основы. Однако следствием этого является то, что, хотя слово «эконометрика» явно подразумевает измерение, многие абстрактные математические теории, которые могут или не могут в конечном итоге поддаются эмпирической проверке, часто упоминаются как часть эконометрики.Значение этого слова часто применялось как к математической экономике, так и к статистической экономике; а в просторечии «эконометрист» — это экономист, опытный и интересующийся применением математики, будь то математическая статистика или нет. В этой статье я приму это расширенное определение и рассмотрю как эконометрику в ее узком смысле, так и математическую экономическую теорию.
Использование математики и статистики в экономике возникло не недавно.Во второй половине семнадцатого века сэр Уильям Петти написал свои эссе о «политической арифметике» [ см. Биографию Петти]. Эта молодая работа, замечательная для своего времени, была эконометрической по своей методологической основе даже с современной точки зрения. Несмотря на то, что на нее не ссылался Адам Смит, она оказала заметное влияние на более поздних авторов. В 1711 году итальянский инженер Джованни Чева призвал использовать математический метод в экономической теории. Хотя за прошедшие годы появилось много статистических исследований, революционное влияние математического метода проявилось только во второй половине девятнадцатого века.Леон Вальрас, профессор Лозаннского университета, больше, чем кто-либо другой, признан создателем экономики общего равновесия, которая является базовой структурой современной математической экономики [ см. Биографию Вальраса]. Его работа, оторванная от каких-либо непосредственных статистических приложений, разработала всеобъемлющую систему отношений между экономическими переменными, включая деньги, чтобы объяснить взаимное определение цен и количества товаров и капитальных благ, производимых и обмениваемых.Вальрас рассматривал экономику как функционирующую в соответствии с классической механикой, при этом состояние экономики определяется балансом сил между всеми участниками рынка. Однако его система общего равновесия была по существу статичной, потому что значения экономических переменных сами по себе не определяли их собственные временные скорости изменения. По этой причине термин «равновесие» употребляется неправильно, поскольку, поскольку общая система Вальраса не была явно динамической, ее решение нельзя описать как состояние равновесия.Тем не менее, как это все еще верно в большинстве экономических теорий, были сторонние дискуссии о регулирующих свойствах экономики, и поэтому, в более широком контексте, решение можно рассматривать как результат уравновешивания динамических сил адаптации.
Значительное сочетание математической теории и статистической оценки впервые произошло в работе Генри Ладделла Мура, профессора Колумбийского университета в начале двадцатого века [ см. Биографию Мура, Генри Л.]. Мур проделал настоящую эконометрическую работу над экономическими циклами, определением ставок заработной платы и спросом на определенные товары. Его главной публикацией, кульминацией которой стало около трех десятилетий работы, была книга Synthetic Economics , вышедшая в 1929 году. Невероятно, но эта работа, имеющая такое основополагающее значение для последующего развития значительной области социальных наук, было продано всего 873 экземплярами (Stigler 1962 ).
Эконометрика приобрела свою идентичность как отдельный подход к изучению экономики в течение 1920-х годов.Число людей, посвятивших себя этой детской области, неуклонно росло, и 29 декабря 1930 года они основали международную ассоциацию под названием Эконометрическое общество. Это было достигнуто во многом благодаря энергии и настойчивости Рагнара Фриша из Университета Осло при помощи и поддержке выдающегося американского экономиста Ирвинга Фишера, профессора Йельского университета [ см. Биографию Фишера, Ирвинга] . Назвать это небольшое меньшинство экономистов культом означало бы приписать им слишком узкие и евангельские взгляды; тем не менее, у них было чувство миссии «продвигать исследования, которые направлены на объединение теоретико-количественного и эмпирическо-количественного подходов к экономическим проблемам, и которые пронизаны конструктивным и строгим мышлением, аналогичным тому, которое стало доминировать в мире. естественные науки »(Frisch 1933).
Их идеи и амбиции были хорошо обоснованы. В последующие годы и в ходе многих методологических споров о роли математики в экономике (тема сейчас довольно устарела) их число росло, а их влияние в более широкой экономической профессии неуклонно расширялось. Сегодня все основные экономические факультеты университетов в западном мире, в том числе совсем недавно в странах советского блока, предлагают работу по эконометрике, и многие придают ей значительный упор.Специальные курсы по эконометрике были введены даже на уровне бакалавриата; написаны учебники; молодое поколение экономистов, поступающих в аспирантуру, прибывает с улучшенной подготовкой по математике и статистическим методам, тяготеет к тому, что, по-видимому, становится все больше, к специализации по эконометрике и вскоре превосходит своих учителей в знании эконометрических методов. Членство в Эконометрическом обществе увеличилось со 163 в 1931 году до более 2500 человек в 1966 году.Журнал общества, Econometrica , за эти годы практически удвоился в размерах, и почти все другие научные журналы по экономике регулярно публикуют статьи, математическая и статистическая сложность которых поразила бы основателей движения в 1920-х и 1930-х годах.
Сферы применения эконометрики в экономике неуклонно расширяются. В настоящее время едва ли есть область прикладной экономики, в которую не вошли бы математическая и статистическая теория, включая экономическую историю.С ростом интереса к эконометрике и ее концентрации со стороны экономистов само понятие специализации стало размытым. Благодаря своему успеху в качестве основного интеллектуального движения в экономике, эконометрика теряет свою идентичность и исчезает как особая отрасль дисциплины, становясь теперь почти совпадающей со всей областью экономики. Однако эти замечания нельзя неправильно понимать. В экономике остается много проблем и много исследований, которые не являются ни математическими, ни статистическими, и хотя общий уровень подготовки современного экономиста и его интерес к математике и статистике намного превосходит уровень его предшественников, вполне надлежащая градация этих навыков и интересов неизбежно продолжается. существовать.Более того, повторяю, многое из того, что известно как эконометрика, все еще не соответствует взаимосвязи математико-теоретического и статистического, что является целью, содержащейся в определении этой области.
Поскольку эконометрика больше не является маленьким анклавом в экономической науке, обзор ее предмета должен охватывать большую часть самой экономики.
Общее равновесие
Следуя концепции Вальраса об общем экономическом равновесии, экономисты-математики в последние годы занимались гораздо более тщательным анализом проблемы, чем предлагал Вальрас [ см. Экономическое равновесие].В более ранней работе общее экономическое равновесие описывалось системой равенств, включающей бесконечно большое количество экономических переменных, но число, равное количеству независимых уравнений. Предполагалось, что система одновременных уравнений с тем же числом неизвестных, что и независимые, будет иметь «равновесное» решение. Это свободная математика, и в последнее время теоретики-экономисты были озабочены тем, чтобы заново разработать более раннюю теорию с большей строгостью.Равенство уравнений и неизвестных не является ни необходимым, ни достаточным условием существования или единственности решения. Следовательно, нельзя быть уверенным в том, что ранняя теория адекватна для объяснения общего состояния равновесия, к которому экономика, как предполагается, должна сходиться. Это может быть связано с тем, что теория не накладывает условий, необходимых для обеспечения существования общего состояния равновесия, или потому, что теория может быть неопределенной, поскольку она подразумевает несколько различных решений.Поэтому современный теоретик равновесия попытался определить необходимые и достаточные условия для существования и уникальности общего экономического равновесия.
Концепция равновесия — это состояние, в котором никакие силы внутри модели, действующие во времени, не приводят к дисбалансу системы. Даже если можно продемонстрировать существование такого состояния в рамках какой-либо модели общего равновесия, остается вопрос, является ли оно стабильным или нестабильным, то есть стремятся ли при любом отклонении системы от него силы восстановить прежнее состояние. исходное равновесие или сдвинуть систему дальше.Анализ этих вопросов, которые являются более сложными, чем предложенные здесь, требует явного введения отношений динамической настройки.
Вопросы существования, уникальности и стабильности равновесия в данном контексте — это не вопросы о реальной экономике, а вопросы, касающиеся свойств теоретической модели, утвержденной для описания реальной экономики. В этом смысле их исследование ориентировано на лучшее понимание последствий альтернативных уточнений самой теории, а не на улучшенное эмпирическое понимание того, как работает наша экономика.
Большая часть этой работы, кроме того, была ограничена исследованием модели общего равновесия конкурентоспособной экономики , что действительно является частным случаем. Тем не менее, это случай особого интереса, потому что, согласно идеализированным предположениям, экономисты благосостояния приписали конкурентному равновесию характеристики, которые удовлетворяют критериям, которые считаются интересными для социальной оценки экономической деятельности [ см. Экономика благосостояния], согласно Согласно концепции Парето, состояние экономики (не считающееся уникальным) считается оптимальным, если нет другого технологически выполнимого состояния, в котором какой-либо человек находился бы в положении, которое он предпочитает, в то время как ни один человек не был бы в положении, которое он считает худшим [ см. биографию Парето].Таким образом, условия, при которых общее экономическое равновесие было бы оптимальным в этом смысле, подвергались жесткой проверке. Таким образом, экономика благосостояния Парето тесно связана с современными исследованиями систем общего равновесия, но она недостаточно развита как эмпирическое исследование.
Экономист-позитивист, озабоченный прогнозированием, в принципе также интересовался системами общего равновесия, но с другой точки зрения. Его центральный вопрос: как изменение экономического параметра (коэффициента или, возможно, значения некоторой автономной переменной, которая сама не определяется системой) вызывает изменение равновесного значения одной или нескольких других переменных, которые определяются системой? ? Короче говоря, как равновесное решение зависит от параметров? Это проблема в сравнительной статике , которая противопоставляет два различных равновесия, определяемых разницей в значениях одного или нескольких параметров.
Сравнительная статика — частичное равновесие
Именно в проблеме сравнительной статики — сравнении альтернативных состояний равновесия — мы можем наиболее точно провести различие между экономикой общего равновесия и экономикой частичного равновесия , что является знакомым контрастом в литературе.
Предположим, что в окрестности равновесия общая система одновременных экономических отношений полностью дифференцируется по отношению к изменению определенного параметра, так что все прямые и косвенные эффекты этого изменения учтены.Затем можно надеяться установить направление изменения конкретной экономической переменной по отношению к этому параметру. Например, если повышается определенная налоговая ставка или предпочтения потребителей смещаются в пользу определенного товара, будет ли увеличиваться, уменьшаться или оставаться неизменным количество спроса на какой-либо другой товар? На этот вопрос иногда можно ответить на основе совокупности знаков (плюс, минус, ноль) многих или всех частных производных функций, составляющих систему (при условии, что они являются непрерывно дифференцируемыми).Теоретические соображения или здравый смысл могут позволить априори указать знаки этих частных производных, например, чтобы утверждать, что эластичность спроса отрицательна или перекрестная эластичность спроса положительна. Однако в некоторых случаях теоретику неудобно делать такие утверждения о производной, и, следовательно, некоторые признаки могут быть оставлены неопределенными. Вопрос в том, достаточны ли ограничения, которые теоретик готов наложить априори, для определения того, является ли полная производная интересующей экономической переменной по данному параметру положительной, отрицательной или нулевой.Формальное рассмотрение необходимых и достаточных ограничений, необходимых для решения этого вопроса, однозначно составляет исследование качественной экономики и представляет собой самостоятельную математическую проблему (Samuelson 1947; Lancaster 1965). В некоторых ситуациях может быть важно знать не только знаки различных частных производных, но и их относительные алгебраические величины. Это указывает на необходимость статистической оценки этих производных, что относится к эконометрике в ее самом узком смысле.
Иногда также полезно знать, что некоторые производные достаточно близки к нулю, и если их принять равными нулю, это не повлияет на вывод о знаке исследуемой полной производной. Уловка или искусство решать, когда рассматривать определенные частные производные как ноль, то есть решить, что определенные экономические переменные не входят в какие-либо существенные отношения в определенные отношения, является сущностью анализа частичного равновесия, названного так потому, что он стремится изолировать часть общей системы из других частей, которые мало с ней взаимодействуют.Таким образом, анализ частичного равновесия является частным случаем анализа общего равновесия, в который были введены более смелые априорные ограничения с целью получения более конкретных и значимых результатов в сравнительной статике. Так же, как экономика общего равновесия обычно ассоциируется с именем Вальраса, так и экономика частичного равновесия ассоциируется с работами Альфреда Маршалла [ см. Биографию Маршалла].
В качественной экономике некоторый свет проливает свет на признаки частных производных системы с учетом динамической устойчивости модели.С допущениями о природе отношений динамической регулировки можно найти соответствия между условиями, необходимыми для того, чтобы равновесие было устойчивым, и знаками частных производных. Таким образом, точно так же, как стабильность зависит от предположений о том, входят ли различные переменные в данное отношение, положительно или отрицательно, точно так же, как эти переменные входят в данное отношение, иногда можно вывести из предположения, что равновесие является стабильным. Это знаменитый принцип соответствия, созданный Самуэльсоном.[ См. Статика и динамика в экономике.]
Пространственные модели
В большинстве моделей общего равновесия экономика рассматривается как существующая в одной точке пространства, игнорируя, таким образом, транспортные расходы, региональную специализацию ресурсов и предпочтения местоположения. Некоторые исследования, однако, явно вводят пространственное измерение, в котором происходит общее равновесие. Это обеспечивает основу для изучения межрегионального расположения, специализации и взаимозависимости в обмене.[ См. Пространственная экономика, статья , посвященная подходу общего равновесия ]. Эти модели, из-за их большей сложности, обычно включают более специальные допущения, такие как линейность отношений и отсутствие возможностей для замены среди факторных услуг в производстве. . Однако они также более непосредственно поддались эмпирической работе.
При применении анализа частичного равновесия к задачам пространственной экономики, кроме того, предполагается, что местоположения определенных видов экономической деятельности определяются независимо от решений о местоположении в отношении других видов экономической деятельности, и, следовательно, первое можно рассматривать как фиксированное в анализ последнего.[ Обсуждение этого направления исследования см. В Пространственная экономика, в статье о подходе частичного равновесия.]
Агрегационные и агрегативные модели
Поскольку системы общего равновесия рассматриваются как охватывающие миллионы индивидуальных отношений, они, очевидно, не поддаются количественной оценке. Поэтому большой интерес представляет уменьшение размерности системы, так что существует некоторая возможность эконометрической оценки.Это означает, что отношения общего типа, например отношения, описывающие поведение фирм в данной отрасли или домохозяйства определенного характера, должны быть объединены в единое отношение, описывающее поведение совокупности сопоставимых экономических агентов. Условия, необходимые для того, чтобы такое агрегирование стало возможным, и используемые методы все еще находятся на довольно предварительной стадии изучения. Но литература по этому поводу развивается. [ См. Агрегирование .]
Более старая проблема — это просто объединение в одну переменную множества похожих переменных. Это известная проблема «индексов» * — например, как лучше всего представить цены на большое количество различных товаров с помощью единого индекса цен. Таким образом, проблема с индексными числами имеет свои теоретические аспекты [ см. индексные номера, статью о теоретических аспектах], а также свои статистические аспекты [ см. индексные номера, статей по практическим приложениям, и выборка].Теория оказалась полезной при интерпретации альтернативных статистических формул.
Основные усилия по эмпирическому исследованию систем общего равновесия, которые до некоторой ограниченной степени были агрегированы, относятся к заголовку «Анализ затрат-выпуска». Этот подход, предложенный Василием Леонтьевым в конце 1930-х годов, состоит, по сути, в рассмотрении экономики как системы одновременных линейных отношений и рассмотрении как постоянных относительных величин входов в производственный процесс, которые необходимы для производства продукции процесса. .Эти входы, конечно, могут быть выходами других процессов. Таким образом, с фиксированными коэффициентами, относящимися к входам и выходам интегрированной производственной структуры, можно определить, какой «перечень товаров» может быть произведен, с учетом количества различных «первичных» непроизведенных ресурсов, которые доступны. В качестве альтернативы также могут быть определены количества первичных ресурсов, необходимых для производства данной товарной накладной. Коэффициенты такой системы можно оценить, наблюдая за соотношениями входов и выходов для различных процессов в данный год, или усредняя эти отношения по последовательности лет, или используя инженерные оценки.Это может быть сделано для экономики, разделенной на большое количество различных секторов (сотня или более), или это может быть сделано для частей экономики, таких как мегаполис. Более того, секторирование экономики может быть как по регионам, так и по отраслям, и первое делает метод применимым к изучению межрегиональных или международных торговых отношений. Было проведено большое количество эмпирических исследований по моделям затрат-выпуска, таблицы коэффициентов к настоящему времени разработаны для более чем сорока стран.Количественный анализ работы этих моделей, как легко предположить, потребовал наличия крупномасштабных компьютеров. [ См. Анализ затрат – выпуска.]
Агрегативные модели в экономике могут относиться к типу частичного или общего равновесия. Те из них, которые относятся к типу частичного равновесия, имеют дело с отдельным сектором экономики изолированно, исходя из предположения, что внешние экономические переменные, которые имеют важное влияние на этот сектор, в свою очередь, не зависят от его поведения.Так, например, рыночная модель спроса и предложения на конкретный товар может рассматривать общий доход потребителей и его распределение как определяемые независимо от цены и выпуска конкретного изучаемого товара. Тем не менее, функции рыночного спроса и предложения являются совокупностью функций спроса и предложения многих людей и фирм. Агрегированные модели типа общего равновесия могут объяснить взаимное определение многих основных экономических переменных, которые являются агрегатами огромного числа индивидуальных переменных.Примерами агрегированных переменных являются общая занятость, общий объем импорта, общие инвестиции в товарные запасы и т. Д. Эти модели обычно называются макроэкономическими моделями , , в отличие от микроэкономических моделей , , которые имеют дело в смысле частичного равновесия с отдельным домохозяйством, фирмы, профсоюзы и т. д. Многие макроэкономические модели рассматривают не только так называемые реальных переменных, которые представляют собой физические запасы и потоки товаров и производственных услуг, но также денежные переменные , такие как уровни цен, количество денег, стоимость общего выпуска и процентная ставка.Подобные модели были особенно распространены с 1936 года, поскольку их стимулировала книга Джона Мейнарда Кейнса «Общая теория занятости, процента и денег» Джона Мейнарда Кейнса и созданная на ее основе литература.
Один тип агрегированной макроэкономической модели — это модель, которая выделяет несколько важных секторов экономики или связывает макроэкономические переменные двух или более экономик, взаимосвязанных в торговле. Большая часть теории международной торговли имеет дело с подобными моделями [ см. Международная торговля, статья по математической теории ].Фактически, поскольку это был естественный способ анализа международных экономических проблем, теория международной торговли исторически была одной из самых оживленных областей для развития экономической теории, как математической, так и иной. Более узкие эконометрические исследования в этой области были сосредоточены на оценках эластичности импортного спроса.
Более того, макроэкономические модели пригодились для изучения экономических изменений, и именно с этими моделями была проведена наиболее значительная работа в экономической динамике.Динамические системы в экономике — это такие системы, в которых значения экономических переменных в данный момент времени определяют либо их собственные скорости изменения (непрерывные модели дифференциальных уравнений), либо их значения в последующий момент времени (дискретные модели разностных уравнений). . [ Для общего обсуждения динамических моделей см. Статика и динамика в экономике.] Таким образом, динамические модели включают как переменные, так и меру их изменений во времени. Первые часто встречаются как «запасы», а вторые — как «потоки».«Когда и запасы, и потоки входят в данную модель, возникают сложности с согласованием желаемых количеств каждого из них. Эти проблемы становятся особенно важными, когда вводятся денежные переменные, например, когда мы рассматриваем желание людей как удерживать определенную стоимость денежных активов, так и откладывать (добавлять к активам) по определенной ставке. [ Конкретные проблемы моделей потока запасов обсуждаются в Анализ потока запасов.]
Динамические модели возникают как в теории долгосрочного экономического роста [ см. Экономический рост, статья по математической теории ], где обе макроэкономические использовались полностью дезагрегированные модели общего равновесия, а также в теории деловых колебаний или деловых циклов [ см. Деловые циклы, статья о математических моделях], где макроэкономические модели являются наиболее распространенными.Не все модели, предназначенные для объяснения уровня деловой активности, должны иметь циклический характер. Современный упор делается на макроэкономические модели, циклические или нет, которые объясняют уровень деловой активности и его изменение динамической системой, которая реагирует на внешние переменные. К ним относятся переменные экономической политики (государственный дефицит, политика центрального банка и т. Д.) И другие переменные, которые, хотя и оказывают важное влияние на экономику, имеют свое объяснение за пределами теории, например, рост населения и темпы роста населения. технологические изменения.Таким образом, внешние переменные, известные как экзогенные или автономные переменные, воздействуют на динамическую экономическую систему и порождают колебания во времени, которые не обязательно должны быть периодическими. Эти модели поддаются эмпирическому исследованию, и для их оценки была проделана большая работа [ см. Эконометрические модели, совокупность]. Структура этих моделей была уточнена и доработана в результате эмпирической работы.
Огромное преимущество агрегированных моделей, конечно, состоит в том, что они существенно сокращают огромное количество переменных и уравнений, которые появляются в системах общего равновесия, и тем самым делают возможными оценки.Даже в этом случае эти модели могут быть довольно сложными либо потому, что они все еще содержат большое количество переменных и уравнений, либо из-за нелинейностей в их функциональных формах. Однако современный компьютер позволяет оценивать системы такой степени сложности. Но если кто-то заинтересован в анализе динамического поведения этих систем, трудности часто выходят за рамки наших возможностей в математическом анализе. На помощь снова приходит компьютер. С помощью компьютера можно моделировать сложные системы рассматриваемого типа, управлять ими с помощью экзогенных переменных и шокировать их случайными возмущениями, извлеченными из определенных распределений вероятностей.Таким образом можно исследовать производительность этих систем при различных предположениях относительно поведения экзогенных переменных и для большой выборки случайных величин.
[ Симуляционные исследования такого рода обсуждаются в Simulation, статье об экономических процессах ].
Переменные, которые обычно возникают в макроэкономических моделях, — это совокупные потребительские расходы, инвестиции в товарные запасы и инвестиции в оборудование. Совокупные потребительские расходы или потребление отражают поведение домохозяйств при принятии решения о том, сколько потратить на потребительские товары, которые в некоторых исследованиях могут быть далее разбиты на такие категории, как потребительские товары длительного пользования, товары краткосрочного пользования и услуги.Используя методы регрессии, потребительские расходы устанавливаются в зависимость от других переменных, некоторые из которых имеют экономический характер (доход потребителей, изменение дохода, самый высокий прошлый доход, уровень потребительских цен и скорость их изменения, процентные ставки и условия потребительского кредита). , ликвидные активы и т. д.), некоторые из которых являются демографическими (раса, размер семьи, проживание в городе или деревне и т. д.). Эмпирическое исследование зависимости потребительских расходов от этих переменных проводилось интенсивно в течение последних двадцати лет.[Для обзора этой работы см. Функция потребления.]
Динамика инвестиций в товарно-материальные запасы также была объектом интенсивного изучения, как с точки зрения того, как запасы менялись с течением времени относительно общего уровня деловой активности, так и с точки зрения того, как инвестиции в товарные запасы отреагировали на такие переменные, как процентная ставка, изменения продаж, невыполненные заказы и т. д. [ Эта работа рассмотрена в статье Inventories, , посвященной поведению запасов .] Есть некоторые тонкие вопросы, связанные с формулировкой функции инвестирования в запасы. Иногда запасы накапливаются, когда фирмы предполагают, что они должны это делать, а в других случаях они накапливаются, несмотря на желание фирм сократить их, например, когда продажи быстро падают относительно способности фирм изменять темпы выпуска продукции. Таким образом, теоретическая работа, посвященная оптимальному поведению фирм в вопросах политики запасов, может дать некоторую основу для выбора и интерпретации роли различных переменных в функции инвестирования в запасы.[ См. Запасы, статья по теории управления запасами.]
Зависимость инвестиций в машины и оборудование от таких переменных, как коммерческие продажи, изменения продаж, коммерческая прибыль, ликвидность и т.д., также может быть изучена с помощью эконометрических методов. и различные теории были выдвинуты в поддержку представлений об относительной важности этих различных переменных. Как и в случае с функцией потребления и определением инвестиций в запасы, функция инвестиций в машины и оборудование также была предметом интенсивных эмпирических исследований в течение последних двух десятилетий.[ Эта работа рассматривается в Investment, статье о совокупной инвестиционной функции.]
Принятие решений
Хотя для экономиста методологически правильно постулировать ad hoc взаимосвязи между макроэкономическими переменными (Peston 1959), это будет более отрадным, более объединяющим экономическую теорию, если поведение макропеременных может быть выведено из элементарных предположений относительно поведения микропеременных, совокупностями которых они являются.Это проблема агрегирования, о которой говорилось ранее. Предполагается, что аксиоматическая теория поведения отдельного лица, принимающего экономические решения, особенно индивидуума (или домохозяйства) и фирмы, может служить основой для теорий взаимодействия агрегированных макропеременных. Однако большая часть поведенческой теории фирм и домашних хозяйств проводится в контексте анализа частичного равновесия, поскольку отдельный экономический агент не заботится о том, чтобы учесть очень незначительное влияние, которое его собственные решения оказывают на рынок или на экономику как целое.Таким образом, каждое домохозяйство и каждая конкурирующая (но не монополистическая) фирма считает рыночные цены фиксированными и не зависит от их собственного выбора. Но, связывая вместе такие модели частичного равновесия поведения огромного множества отдельных домохозяйств и фирм, нельзя игнорировать влияние их совместного поведения на те самые рыночные переменные, которые они считают константами. Таким образом, микромодели частичного равновесия должны быть преобразованы в более общие модели, учитывающие эти индивидуально не воспринимаемые, но коллективно важные взаимодействия.
Микроэкономическая теория в значительной степени дедуктивна, она систематически исходит от аксиом, касающихся предпочтения и выбора, к теоремам об экономическом поведении. Для тщательного изучения логических сложностей этой дедуктивной теории часто используется формальная математика. Рыночные решения экономических агентов обычно предполагаются как осмотрительные или рациональные решения, что означает, что они в целом соответствуют определенным основным критериям принятия решений, которые, как считается, имеют широкую интуитивную привлекательность как предписания осмотрительного или рационального выбора.Ситуации, в которых лицо, принимающее решения, может сделать выбор, можно сформулировать по-разному. Бывают «статические» ситуации, когда не предполагается, что решение имеет временный или последовательный характер. Существуют «динамические» ситуации, в которых необходимо принимать последовательность решений, причем определенным образом. Проблема принятия решения также может быть классифицирована в зависимости от того, насколько лицо, принимающее решения, знает о последствиях своих решений. Одна крайность — это случай полной уверенности, когда предполагается, что последствия полностью известны заранее.Другие случаи связаны с риском и возникают, когда предполагается, что лицо, принимающее решения, знает только распределение вероятностей различных результатов, которые могут возникнуть в результате принятого им решения. Наконец, с другой стороны, проблема принятия решения может рассматриваться как включающая почти полную неопределенность, и в этом случае лицо, принимающее решение, знает, каковы возможные результаты, но не имеет априорной информации об их вероятностях. [Для обсуждение различных критериев, предлагаемых для этих различных ситуаций, см. Принятие решений, статью , посвященную экономическим аспектам .] Однако фундаментальным является представление о том, что лицо, принимающее решения, имеет предпочтения и использует их в пределах доступного ему диапазона выбора. Индекс, определяющий его предпочтения, обычно называется полезностью и рассматривается как функция от выбранных им объектов. В частности, когда человек с фиксированным доходом выбирает среди различных «рыночных корзин» товаров, полезность обычно постулируется как функция компонентов рыночной корзины. Аксиоматические системы, необходимые и достаточные для существования такой функции, были объектом интенсивного изучения экономистов-математиков.[ Эта центральная проблема и многие ее тонкие аспекты рассматриваются в Полезности.] Большие усилия, возможно, с небольшой пользой для эмпирической экономики, были направлены на уточнение аксиоматики теории полезности или теории потребительского выбора; К сожалению, было сделано гораздо меньше работы по укреплению предположений теории и увеличению ее эмпирического содержания. Из теории поведения потребителей вытекает концепция функции спроса потребителя на конкретный товар, зависящей, как правило, от всех цен и дохода.
Что касается теории фирмы, то также предполагается осмотрительное, целенаправленное поведение, и в наиболее распространенной формулировке теории предполагается, что фирма желает в какой-то мере максимизировать свои предпочтения среди потоков будущих прибылей. Это должно происходить с учетом цен, которые фирма должна платить за факторные услуги, рыночных возможностей, с которыми она сталкивается при продаже своей продукции, и ее внутренней технологии производства. Из этого анализа вытекает теория производства и предложения.[Для теория производства фирмы см. Производство; для эконометрических исследований производственных отношений и себестоимости продукции, см. Производство и анализ затрат; , а для эконометрических исследований спроса и предложения см. Спрос и предложение, статью «О эконометрических исследованиях».
При выводе теории поведения потребителей и теории фирмы целеустремленное и осмотрительное поведение обычно ассоциировалось с понятием, что лицо, принимающее решения, пытается максимизировать некоторую функцию с учетом рыночных и технологических ограничений.Таким образом, математика ограниченной максимизации служила экономисту самым важным инструментом в его профессии. В попытке разработать модели максимизирующего поведения, которые лучше поддаются количественной формулировке и решению, интерес сосредоточился на задачах, в которых максимизируемая функция является линейной, а ограничения составляют набор линейных неравенств. Методы решения таких задач получили название линейного программирования. С дальнейшим развитием были введены нелинейности и случайные элементы, и этот метод стал применяться также к задачам последовательного принятия решений.Вся эта область теперь известна как математическое программирование [ см. Программирование]. В силу своей практической полезности эти методы позволяют анализировать различные конкретные проблемы планирования и оптимизации, особенно проблемы, связанные с деятельностью фирмы. Стимулируемый доступностью этих методов, а также достижениями теории вероятностей и некоторым военным опытом в области системного анализа, расцвел современный количественный подход к проблемам производства и управления бизнесом.Это известно как наука об управлении или исследование операций [ см. Исследование операций]. Это развитие представляет собой случай расщепления, поскольку наука управления теперь рассматривается отдельно от эконометрики, хотя обе области имеют много общего, и у них есть много профессоров и практиков.
Самыми сложными проблемами в области осмотрительного принятия решений являются те, которые связаны со стратегическими соображениями. По сути, это означает, что последствия решения или действия, предпринятого одним участником, зависят от действий, предпринятых другими; но их действия, в свою очередь, зависят от действий каждого из других участников.Таким образом, структура проблемы заключается не в простом максимизации даже перед лицом риска или неопределенности, а в стратегической игре. [ См. Game Theory, статья о теоретических аспектах.] Основываясь на соображениях разумной стратегии отдельного участника и стимулов для подмножеств участников формировать коалиции, теорию игр можно представить как общую задачу равновесия. и стал тесно связан с современной работой в области экономики общего равновесия.В более частном контексте теория игр оказалась применимой к решению проблем фирм в ситуациях олигополистической и двусторонней монополии. Они характеризуются тем, что каждая фирма, выбирая наилучший образ действий, должна учитывать влияние своих действий на действия других фирм, которые также действуют осмотрительно. В целом, ранний энтузиазм по поводу применения теории игр к этим проблемам промышленного поведения пока подтвержден лишь в ограниченной степени.[Обзор приложений теории игр к деловому поведению см. В Теория игр, в статье о экономических приложениях.]
Процессы распределения
Давно озабоченным в экономике было распределение экономических переменных по размеру. Что определяет распределение семейных доходов или распределение активов или продаж фирм в данной отрасли? В прошлые годы эти проблемы решались описательно путем подгонки частотных распределений к данным по разным странам, разным годам или различным отраслям.Соответствие данным из разных источников можно было бы объявить эмпирическим «законом»; таким образом, закон Парето распределения доходов. В последние годы проблема распределения по размерам была пересмотрена. Эконометристы теперь рассматривают его как формулировку динамического процесса роста или распада со случайными элементами. Задача состоит в том, чтобы оценить параметры процесса и определить, существует ли равновесное распределение размеров единиц и каково это распределение. Таким образом, хорошее соответствие может иметь теоретический механизм, а параметры могут зависеть от других экономических переменных, которые могут изменяться или могут контролироваться.[ В этой связи см. Распределения размеров в экономике и Цепи Маркова.]
Статистические методы
В естественных науках исследователь должен проводить свои собственные измерения. В экономике, однако, сама экономика генерирует данные в огромных количествах. Налогоплательщики, коммерческие фирмы, банки и т. Д. Регистрируют свои операции, и во многих случаях эти записи доступны экономисту. К сожалению, эти данные не всегда именно те, которые нужны экономисту, и их необходимо часто корректировать в научных целях.В последние десятилетия правительство все активнее занимается сбором и обработкой экономических данных. Это оказало огромную помощь в развитии эконометрики. Это касается не только правительств США и стран Западной Европы, но и данные накапливаются в странах с плановой экономикой, где они имеют решающее значение для операций планирования. [ См. Экономические данные.] Отсутствие адекватных данных наиболее остро ощущается при изучении слаборазвитых экономик, хотя через Организацию Объединенных Наций и другие организации собирается все больший объем данных по этим частям мира и сопоставлено.
Основная форма представления экономических данных — это последовательные записи экономических наблюдений за определенный период времени. Таким образом, могут существовать данные о ценах на определенные товары, данные о занятости и т. Д. За многие годы. Следовательно, эконометристы традиционно серьезно занимались анализом временных рядов [ см. Временные ряды] и особенно использованием методов регрессии, где различные наблюдения упорядочены во временной последовательности. Это привело к разработке уравнений динамической регрессии, пытающихся объяснить наблюдение конкретной даты как функцию не только других переменных, но также одного или нескольких прошлых значений одной и той же переменной.Таким образом, отношение динамической регрессии представляет собой разностное уравнение, включающее случайный член. Когда в разностное уравнение вводится много прошлых значений переменной, так что это уравнение очень высокого порядка, становится трудно оценить коэффициенты этих прошлых переменных без потери многих степеней свободы. В результате эконометрист попытался наложить определенную схему взаимосвязи на эти коэффициенты, чтобы все они могли быть оценены как функции относительно небольшого числа параметров.Это метод регрессии с распределенным запаздыванием. [ См. Распределенные запаздывания.]
Только что описанные методы в значительной степени пришли на смену более старым методам декомпозиции временных рядов, в соответствии с которыми временной ряд разбивается на такие компоненты, как тренд, циклы различной длины, сезонный образец изменения , и случайный компонент. Эти методы предполагали взаимодействие повторяющихся воздействий регулярной периодичности и амплитуды. С переходом к разностному уравнению и подходу регрессии были введены экзогенные переменные, и случайные возмущения стали кумулятивными в их эффектах.Таким образом, временные характеристики временного ряда описываются меньше в терминах некоторого внутреннего закона периодичности и больше в терминах последовательности реакций на случайные воздействия и временные вариации других причинных переменных. Таким образом, прогнозирование не является неумолимой экстраполяцией ритмов, а является пересмотренным прогнозом, период за периодом, возрастающей взаимосвязи, зависящей от настоящих и прошлых значений, от экзогенных переменных и случайных элементов. [ См. Прогнозирование и прогнозирование, экономическое.]
Тем не менее, всегда было разумно предположить довольно строгую периодичность для сезонной составляющей из-за повторяющегося характера сезонов, праздников и т. Д. В результате, при изучении временных рядов, где наблюдения проводятся ежедневно, еженедельно или ежемесячно. , принято сначала оценивать и снимать сезонное влияние. [ Методы для этого обсуждаются в Временных рядах, статье о сезонной корректировке .]
Другой вид данных, которые использует экономист, — это перекрестные данные.Например, он может использовать выборку наблюдений, сделанных примерно в одно и то же время, за активами, доходами и расходами разных домохозяйств, фирм или отраслей. [ См. Поперечный анализ.] Наблюдая за различиями в поведении людей в выборке и, опять же, обычно с помощью регрессионного анализа, приписывая эти различия различиям в других переменных, находящихся вне контроля этих людей, эконометрист пытается сделать вывод как изменилось бы поведение аналогичных экономических единиц со временем, если бы изменились значения независимых переменных.Есть много ошибок в этом процессе вывода изменений во времени для данной фирмы или домохозяйства на основе различий между фирмами и домохозяйствами в данный момент времени. Особенно полезными становятся данные, которые являются как поперечными, так и временными рядами по своему характеру, как, например, когда наблюдаются бюджеты выборки домашних хозяйств, каждое за несколько последовательных лет. Для получения полезной информации поперечного сечения или поперечного сечения и сортировки временных рядов обычно требуется разработка выборочного обследования.[ Применение методов обследования в экономике обсуждается в Анализ обследований, статья О приложениях в экономике.]
Очень распространенная проблема в эконометрике возникает, когда разные переменные связаны по-разному. Например, совокупные инвестиции зависят от национального дохода, но национальный доход по-разному зависит от совокупных инвестиций. В анализе спроса и предложения равновесное обмениваемое количество и рыночная цена должны одновременно удовлетворять как функцию спроса, так и функцию предложения.Эта одновременность множественных отношений между одними и теми же переменными представляет особые проблемы при применении методов регрессии. Эти проблемы были тщательно изучены в течение последних двадцати лет, и теперь доступны различные устройства для их решения. Эти методы часто довольно сложны, но с развитием статистической теории и доступности данных и с использованием крупномасштабного компьютера они стали широко использоваться при оценке как частичного равновесия, так и макроэкономических моделей, иногда довольно больших измерение.Хотя здесь упоминается лишь кратко, эта важнейшая проблема статистической методологии, возможно, является самой центральной особенностью эконометрического анализа и является предметом ряда текстов и трактатов. Это также, вероятно, самый большой блок материалов, охватываемых большинством специальных курсов по эконометрике. [ См. Одновременное вычисление уравнений.]
Тем, кто занимается исследованиями на переднем крае любой науки, прогресс всегда кажется чрезвычайно медленным; но обзор достижений эконометристов как в развитии экономической теории, так и в ее количественной оценке и проверке за последние два или три десятилетия дает ощущение большого достижения.Но по мере того, как решаются старые проблемы, изобретаются новые. Таким образом, развитие эконометрики не ослабевает.
Роберт Х. Штроц
Работы, посвященные природе и истории эконометрики: Divisia 1953; Frisch 1933; Tintner 1953; 1954. Основные работ в области: Аллен 1956; Malinvaud 1964; Самуэльсон 1947.
Аллен Р. Г. (1956) 1963 Математическая экономика. 2-е изд. Нью-Йорк: Сент-Мартинс; Лондон: Макмиллан. Divisia, Franéois 1953 La Société d’Économétrie a atteint sa Majorité. Econometrica 21: 1–30.
[Фриш, Рагнар] 1933 г. От редакции. Econometrica 1: 1–4.
Ланкастер, К. Дж. 1965 Теория качественных линейных систем. Econometrica 33: 395–408.
Малинво, Эдмонд (1964) 1966 Статистические методы в эконометрике. Чикаго: Рэнд МакНалли. → Впервые опубликовано на французском языке.
Пестон, М. Х. 1959 Взгляд на проблему агрегирования. Обзор экономических исследований 27, вып. 1: 58–64.
Самуэльсон, Пол А. (1947) 1958 Основы экономического анализа. Гарвардские экономические исследования, Vol. 80. Кембридж, Массачусетс: Harvard Univ. Нажмите. → Издание в мягкой обложке было опубликовано в 1965 году издательством Atheneum.
Стиглер, Джордж Дж. 1962 Генри Л. Мур и статистическая экономика. Econometrica 30: 1–21.
Тинтнер, Герхард 1953 Определение эконометрики. Econometrica 21: 31–40.
Тинтнер, Герхард 1954 г. Преподавание эконометрики. Econometrica 22: 77–100.
Что следует знать об эконометрике
Есть много способов определить эконометрику, самый простой из которых — это статистические методы, используемые экономистами для проверки гипотез с использованием реальных данных. В частности, он количественно анализирует экономические явления в связи с текущими теориями и наблюдениями, чтобы сделать краткие предположения о больших наборах данных.
Вопросы типа «Связана ли стоимость канадского доллара с ценами на нефть?» или «Действительно ли бюджетные стимулы стимулируют экономику?» На это можно ответить, применив эконометрику к наборам данных по канадским долларам, ценам на нефть, бюджетным стимулам и показателям экономического благосостояния.
Университет Монаша определяет эконометрику как «набор количественных методов, которые полезны для принятия экономических решений», в то время как «Экономический словарь» The Economist определяет ее как «создание математических моделей, описывающих математические модели, описывающие экономические отношения (например, требуемое количество товара зависит положительно от дохода и отрицательно от цены), проверяя обоснованность таких гипотез и оценивая параметры, чтобы получить меру силы влияний различных независимых переменных.»
Базовый инструмент эконометрики: модель множественной линейной регрессии
Эконометристы используют множество простых моделей, чтобы наблюдать и находить корреляцию в больших наборах данных, но наиболее важной из них является модель множественной линейной регрессии, которая функционально предсказывает значение двух зависимых переменных как функцию независимой переменной.
Визуально модель множественной линейной регрессии можно рассматривать как прямую линию, проходящую через точки данных, которые представляют парные значения зависимых и независимых переменных.При этом специалисты по эконометрике пытаются найти объективные, эффективные и последовательные оценщики для прогнозирования значений, представленных этой функцией.
Таким образом, прикладная эконометрика использует эти теоретические практики для наблюдения за данными из реального мира и формулирования новых экономических теорий, прогнозирования будущих экономических тенденций и разработки новых эконометрических моделей, которые создают основу для оценки будущих экономических событий, связанных с наблюдаемым набором данных.
Использование эконометрического моделирования для оценки данных
В тандеме с моделью множественной линейной регрессии эконометристы используют различные эконометрические модели для изучения, наблюдения и формирования кратких наблюдений за большими наборами данных.
«Экономический глоссарий» определяет эконометрическую модель как модель, «сформулированную таким образом, чтобы ее параметры можно было оценить, если сделать предположение, что модель верна». По сути, эконометрические модели — это модели наблюдений, которые позволяют быстро оценить будущие экономические тенденции на основе текущих оценок и исследовательского анализа данных.
Эконометристы часто используют эти модели для анализа систем уравнений и неравенств, таких как теория равновесия спроса и предложения, или для прогнозирования изменений рынка на основе экономических факторов, таких как фактическая стоимость внутренних денег или налог с продаж на этот конкретный товар или услугу. .
Однако, поскольку эконометристы обычно не могут использовать контролируемые эксперименты, их естественные эксперименты с наборами данных приводят к множеству проблем с данными наблюдений, включая смещение переменных и плохой причинно-следственный анализ, который приводит к искажению корреляций между зависимыми и независимыми переменными.
эконометрики (определение, примеры) | Что такое эконометрика для финансов?
Что такое эконометрика?
Эконометрика — это понимание взаимосвязей экономических данных путем использования ссылок на статистические модели и получения наблюдения или закономерностей из предоставленных данных для разработки приближенного будущего тренда.Эконометрика просто экономична с добавлением математики и статистики и помогает в прогнозировании и оценке с помощью статистических методов.
Методы эконометрики
Наиболее распространенные методы:
Вы можете свободно использовать это изображение на своем веб-сайте, в шаблонах и т. Д. Пожалуйста, предоставьте нам ссылку с указанием авторства Ссылка на статью с гиперссылкой Например: Источник: Econometrics (wallstreetmojo.com)
Примеры эконометрики для финансов
Ниже приведены примеры эконометрики для финансов
Пример № 1 по эконометрике
Майкл имеет доход 50000 долларов.Структура расходов его дохода составляет 10000 — фиксированная арендная плата и другие домашние расходы составляют 50% его валового дохода, полученного в течение периода.
Множественная линейная регрессия — один из лучших инструментов для развития отношений на основе прошлых тенденций.
Уравнение будет иметь вид = B 0 (точка пересечения) + B 1 + e (член ошибки)
Используя уравнение, можно получить сумму, которую Майкл потратит на основе своего заработанного дохода.
Расходы = B 0 (фиксированная арендная плата) + B 1 (эксп.) + e (Член ошибки)
= 10000 + 50% (50000)
= 35000
Термин ошибки показывает, что может быть небольшое отклонение вверх или вниз от результата, полученного с помощью статистических инструментов.
Пример эконометрики 2
Узнаем заработную плату человека исходя из его опыта работы
Минимальная заработная плата: 10 тысяч долларов
На основе регрессии по заработной плате человека получается, что B 1 = 2000
Таким образом, применяя метод, можно понять, что человек получит минимальную заработную плату в размере 10000 + (2000 * No.лет опыта)
Эти 10K и 2K являются гипотетическими значениями и должны быть проверены с помощью статистических инструментов, таких как t-тест. T-тест — это метод определения того, значительно ли отличаются друг от друга средние значения двух групп. Это метод логической статистики, который упрощает проверку гипотез.Подробнее и F-тест. Если они существенно не отличаются от 0, то предполагаемое значение не имеет значения, и необходимо повторить проверку, чтобы получить другое значение.
Как эконометрика работает в финансах?
Входные данные
Выходные данные
Теории, на которые ссылаются
Параметры, используемые в данных
Выбранные модели
Нарисованная область достоверности
Проведение теста на предположение
Применяемые методы
Используемые графические инструменты
Преимущества эконометрики
Вот преимущества эконометрики.
Используя инструменты или прикладную эконометрику, можно преобразовать данные в конкретную модель с целью принятия решения, которое поддерживает эмпирические данные.
Помогите получить указанный узор или результат из разбросанных данных.
Позволяет нам извлекать релевантную информацию из корзины информации.
Недостатки эконометрики
Эконометрика имеет некоторые недостатки.
Иногда построение отношений с помощью экономических инструментов является ложным i.е. даже не существует никакой связи между двумя переменными, но модель показывает закономерность на основе прошлой информации. Бывший. Корреляция между дождем и выплаченными дивидендами
Это показывает, что всякий раз, когда в квартале выпадает дождь, только компания объявляет дивиденды за этот период. Даже дождь не имеет отношения к выплаченным дивидендам, но, согласно установившейся тенденции, он может давать ложные сигналы, которые могут привести к неправильному решению.
Всегда есть выбор между простотой и точностью.Спецификация модели — очень важная задача в прикладной экономике. Выбор меньшего количества переменных может помочь в упрощении и обеспечить более быстрый результат, но он может быть неточным из-за недостатка информации или из-за высокого «нет». переменной, то модель может быть критической, неэкономичной или гигантской.
Может возникнуть проблема мультиколлинеарности между переменными, используемыми в данных. Очень важно, чтобы выбранная переменная имела низкую корреляцию между двумя независимыми переменными.Модель оставила этот раздел на пользователя модели.
Важные моменты
Инструменты эконометрики очень критичны. Окончательный вывод может варьироваться от пользователя к пользователю.
Результат зависит от типа и спецификации модели. Результаты ориентированы на модели.
Данные экономичны, осуществимы, пора получить результаты, которые следует учитывать при применении модели.
Может применяться как к данным поперечного сечения, так и к данным временного ряда.
Должен быть периметр или тест, необходимый для проведения итоговой эффективности, такой как f-тест в Excel, T-тест, таблица статистики, анализ таблицы ANOVA с использованием пакетов инструментов.
Заключение
Всегда не забывайте проверять, являются ли полученные результаты статистически значимыми для принятия решений.
Они развиваются из рассматриваемой модели или периметра.
Результат должен быть как эмпирически, так и футуристически благоприятным.
Это повторяющееся упражнение, и различные модели также могут быть применены к одной проблеме, чтобы получить лучшее понимание.
Переоснащение или недостаточное соответствие результатов может быть разбавлено улучшенной спецификацией модели.
Рекомендуемые статьи
Это был путеводитель по эконометрике и ее определению. Здесь мы обсуждаем основные методы и примеры эконометрики для финансов, а также их преимущества и недостатки. Подробнее о наших статьях по бухгалтерскому учету вы можете узнать ниже —
Что такое эконометрика? | GoCardless
Термин «эконометрика» впервые был введен польским экономистом Павлом Чомпа в 1910 году. Однако именно Рагнар Фриш и Ян Тинберг определили его современное использование и значение, в результате чего в 1969 году им была присуждена Нобелевская премия по экономике.Вот посмотрите, как сегодня используются методы эконометрики.
Понимание эконометрики для финансов
Эконометрика использует сочетание статистических и математических методов для проверки теорий и прогнозирования будущих экономических тенденций. Благодаря сочетанию статистических выводов, экономической теории и основных математических принципов эконометрика для финансов помогает описывать современные экономические системы.
По сути, он превращает качественные идеи в количественные результаты. Например, эконометрический анализ можно использовать для преобразования теоретической модели в реальный инструмент или результат, который политики могут применить на практике.Для этого эконометристы — это те, кто просеивает огромные груды данных, превращая их в количественные утверждения с помощью моделирования и анализа.
Эконометрика против статистики
Хотя между эконометрикой и статистикой есть некоторое совпадение, эти два термина различаются по значению. Эконометрика действительно использует статистические теории и данные при анализе экономических теорий, но она включает в себя больше, чем просто цифры. При применении статистических методов он смотрит на более широкую картину экономики.
Есть еще много общего в изучении эконометрики и статистики. Для выполнения эконометрического анализа экономист может использовать статистические инструменты, в том числе:
Вероятность
Частотные распределения
Статистический вывод
Корреляционный анализ
8 9004 Методы временных рядов
Какова цель эконометрики?
Эконометрический анализ используется для проверки гипотезы, будь то существующая экономическая теория или совершенно новая идея.Его также можно использовать для прогнозирования будущих финансовых или экономических тенденций с использованием текущих данных. Это делает эконометрику для финансов повседневным инструментом трейдеров с Уолл-стрит и финансовых аналитиков.
Идея эконометрики может быть применена для проверки многих теорий. Например, экономист может захотеть проверить гипотезу о том, что по мере увеличения компанией прибыли ее расходы соответственно увеличиваются. Эконометрика будет использовать данные, лежащие в основе этого предположения, а затем использовать статистические инструменты, такие как регрессионный анализ, для более глубокого изучения взаимосвязи между прибылью и расходами.
Основы эконометрики: теоретические и прикладные
Эконометрика состоит из двух основных компонентов: теоретической и прикладной. Вот еще немного информации о том, как работают эти элементы эконометрики для финансов.
Теоретическая эконометрика
Этот вид эконометрического анализа рассматривает свойства существующих статистических процедур или тестов для оценки любых неизвестных. Теоретики-эконометристы могут разработать новые статистические методологии, учитывающие аномалии в экономических данных.Этот раздел эконометрики опирается в первую очередь на теоретическую статистику, числовые данные и математику с целью доказать, что новые процедуры действительно жизнеспособны.
Прикладная эконометрика
Второй компонент эконометрики использует методы преобразования качественных заявлений в количественные. Когда теоретики-эконометристы разрабатывают новые статистические процедуры, это часто является ответом на работу эконометристов-прикладников, которые обнаружили необъяснимые различия в наборах данных.Затем специалисты по прикладной эконометрике могут использовать эти новые методы для проверки своих гипотез.
Методы эконометрики
Стандартные методы эконометрики включают несколько этапов. Самый первый шаг — выбрать набор данных для анализа. Это может быть что угодно, от уровня инфляции до показателей безработицы или исторических цен на акции финансовых технологий.
Выбрав данные, эконометрист предлагает гипотезу или теорию для их объяснения. Эта модель должна определять различные задействованные переменные, а также величину взаимосвязи между переменными.Экономическая теория играет большую роль на этом начальном этапе эконометрического анализа.
Следующим шагом является определение статистической модели, которая наилучшим образом соответствует проверяемой экономической теории. Обычно предполагается линейная зависимость, что означает, что любое изменение независимых переменных приведет к тому же уровню изменения зависимой переменной для линейной прогрессии.
Затем вы воспользуетесь статистической процедурой для оценки любых неизвестных параметров или коэффициентов модели.Программное обеспечение для эконометрики обычно быстро справляется с этим шагом.
Гипотеза должна быть проанализирована логически, чтобы увидеть, имеет ли она смысл в рамках предполагаемых параметров и экономических теорий.
Наконец, пришло время проверить гипотезу, чтобы убедиться, что оцениваемый параметр верен.
Решение дробей онлайн с примерами и разъяснениями!
Сложение дробей онлайн, вычитание дробей, умножение дробей, деление дробей.
Наш онлайн вычисляет дроби с пошаговым решением. Это очень удобно чтобы понять весь алгоритм. На этой станице вы найдете все ответы для решения дробей.
Как решать обыкновенные дроби? Что такое числитель дроби? Что такое знаменатель дроби?
Что такое правильные дроби? Что такое неправильные дроби? Как сократить дробь? Составные дроби.
Онлайн калькулятор сложение и вычитание дробей с одинаковыми знаменателями.
Умножение простых дробей. Умножение дроби на натуральное число.
Умножение, деление смешанных дробей.
Короче говоря наш онлайн калькулятор дробей умеет все!!!
Введите числа в калькулятор:
Рубли
Рубли с НДС
Калькулятор-календарь
Дроби
Шпаргалка, сложение и вычитание дробей с одинаковыми знаменателями.
В этом примере разберем сложение дробей с одинаковыми знаменателями.
Для примера начертим единичный отрезок и разделим его на девять частей.
Вычислим выражение
Отметим три части на отрезке, это и будет
Затем отметим еще две части на отрезке, это будет
Запишем полное решение
Откуда получился ответ пять девятых?
Мы взяли отрезок и разделили его на девять частей.
Отметили на отрезке три части и получили дробь три девятых.
Затем отметили на отрезке еще две части и получили дробь две девятых.
Прибавляем к трем частям еще две. Получаем ответ пять девятых.
Вычитание дробей с общим знаменателем.
Вычитание дробей происходит очень просто, так же как и сложение.
Рассмотрим выражение дробей:
Как получит правила вычитания? Необходимо знаменатель оставить тот же
а из числителя уменьшаемого, вычесть числитель вычитаемого.
Семь минус четыре равняется три девятых.
При вычитании дробей с одинаковым числителем и знаменателем ответ всегда будет «0» .
Шпаргалка, сложение и вычитание дробей с разными знаменателями.
Запишем выражение:
Как видим в данном выражении разные знаменатели.
Сначала на нужно привести дроби к общему знаменателю.
Для этого нам нужно до множить эти дроби на какие то числа и числитель и знаменатель
так, чтобы в результате мы получили в знаменателе обоих дробей одно и тоже число.
Если дробь одну третью до множить на 2 и числитель и знаменатель, мы получим результат две шестых.
Пример: Дробь две шестых будет равняться дроби одной третьей
Теперь знаменатель у наших дробей одинаковый. Берем дробь одну шестую и прибавляем две шестых.
Складываем числители: 1 + 2 = 3, знаменатель остается тот же.
Пример:
Полученный результат необходимо сократитьРезультат три шестых необходимо разделить на максимальное делимое число, в нашем случае это три.
Запишем решение полностью
Ответ:
Вычитание дробей с разными знаменателями происходит так же как и сложение,
сначала приводим дроби к общему знаменателю методом до множить. Когда знаменатели у нас одинаковые, отнимаем числители а знаменатель остается тот же.
Решить дроби в онлайн калькуляторе
Умножение простых дробей
Решить дроби в онлайн калькуляторе
Умножить натуральное число на простую дробь или простую дробь умножить на натуральное число.
Тут все очень просто, чтобы умножить натуральное число на простую дробь, нужно натуральное число умножить на числитель а знаменатель перенести.
Пример:
Таким же способом происходит умножение дроби на натуральное число.
ДУМАЮ НЕТ СМЫСЛА ДАЛЬШЕ ПРИВОДИТЬ ПРИМЕРЫ РЕШЕНИЯ ДРОБЕЙ, ТАК КАК НАШ ОНЛАЙН КАЛЬКУЛЯТОР В НАЧАЛЕ СТРАНИЦЫ, РЕШАЕТ ЛЮБЫЕ ДРОБИ С ПОДРОБНЫМ РАЗЪЯСНЕНИЕМ В АВТОМАТИЧЕСКОМ РЕЖИМЕ.
Поделитесь пожалуйста в соцсетях!
Учимся решать дроби в онлайн калькуляторе
В этом материале рассмотрим, каким образом применяя онлайн-калькулятор узнать, как решать дроби.
Беседа пойдет о калькуляторе дробей http://reshit.ru/Kalkulyator-drobey-onlayn-s-resheniem
Этот калькулятор дает возможность решить стандартные операции с двумя дробями.Благодаря калькулятору возможно суммировать, отнимать, делить и множить дроби. Результат выходит в форме компактного изображения, на котором ясно указано всё решение. Приведем к рассмотрению стандартные варианты вычисления дробей, применяя этот онлайн-калькулятор попытаемся написать в него 2 дроби разъеденив их соответствующим знаком Берем например 2/3 и 3/7.
Для умножения вставляем между ними *
Для деления ÷
Для суммирования + и — для того чтобы отнять.
Калькулятор покажет нам результат в изображениях.
Как вы заметили, чтобы прибавить дроби нужно всего лишь перемножить знаменатели и числители. Чтобы разделить две дроби, требуется умножить одну дробь, на другую перевернутую. Для прибавления или вычитания требуется всего-лишь привести дроби к одному знаменателю и провести нужные операции с числителями.
И что в результате нужно сделать-это прибавить или отнять числители приведенных к одному знаменателю дробей.
Сложнейшие дроби, с целой частью, неположительные , случаи в которых у вас 3 и больше имеют решение.Нужно разделить этот более лёгкий пример на лёгкие операции с 2 дробями, и вы тоже будете иметь возможность сосчитать их на калькуляторе.
Например, у вас задача из сложения 3-ех дробей.Изначально суммируйте 2, а затем сложите к ней 3, чтобы получить результат.
Если дробь имеет целую часть, достаточно занести ее в дробное выражение, умножьте знаменатель на целую часть и добавьте умноженное к числителю. Отрицательные дробные выражения вычисляются так как и простые.Если вы умеете вычитать, прибавлять, делить, умножать отрицательные, целочисленные выражения, то с дробями те же знаковые законы.
Но даже, если исследовав систему калькулятора, вы не совсем уловили смысл, то можете посмотреть ролик, в котором суть вычисления дробей показана на яблоках.
После изучения теории, закрепите полученные знания практикой.Вычислите несколько выражений самостоятельно, затем сверьтесь с онлайн-калькулятором. Несколько примеров вполне подойдет.
Знать как вычисляются дроби, очень нужно, так как они часто попадаются в заданиях университета, старшей школы, да и в жизни. Они легки и изучаются с 3-5 класса, затем часто используются в дальнейшем.Усвоив суть их решения, вы навсегда запомните и вряд ли разучитесь их решать.
Но если вы и забудете, на помощь всегда придет онлайн-калькулятор дробей и напомнит умения и знания. На этом можно завершить обзор онлайн-дробей. Также кроме этих знаний на сайте, вы можете найти таблицу производных, онлайн-калькулятор вычисляющий квадратные уравнения (http://reshit.ru/reshit-kvadratnoe-uravnenie-onlain) и другие сервисы и материалы.
Онлайн калькулятор дробей с решением
Обыкновенная дробь — это способ представления рациональных чисел. На деле дробные числа используются для работы с частями целого, поэтому находят широкое применение не только в чистой математике или прикладных науках, но и в повседневной жизни.
Что такое дробь
Простая дробь — это рациональное число, в числителе которого стоит натуральное число, а в знаменателе — целое число. Любое рациональное число можно представить в виде дроби: 1/2, 2/3 или 22/7 — все это рациональные числа. Иррациональные объекты, такие как квадратные корни, числа Пи, е или фи нельзя выразить в виде отношения двух чисел, так как эти числа бесконечные и непериодические.
Виды дробей
Дробное число, у которого по модулям числитель меньше знаменателя, называется правильным. К таким математическим объектам относятся правильные дроби 1/3, 5/8 иди 14/27. Если по модулям числитель больше знаменателя, то дробь считается неправильной. Например, 22/7 — неправильная дробь. Неправильные дроби удобны для проведения вычислений, однако сложны для восприятия. Именно поэтому после арифметических операций с дробями правила хорошего тона требуют преобразования неправильных дробей в смешанные.
Смешанная дробь — это представление рационального числа в виде целой и дробной части. То же число 22/7 можно представить в виде 3 + 1/7, что гораздо проще для восприятия. Кроме того, существуют составные и цепные дроби, которые представляют собой «многоэтажные» выражения для записи приблизительных значений иррациональных чисел.
Арифметические операции с дробями
Еще в античные времена людям приходилось работать с частями целого. Торговцы и ремесленники постоянно оперировали дробями в своей повседневной деятельности, и хотя древние дроби отличались от современных, смысл был тот же. Рассмотрим основные правила работы с дробными числами.
Сложение и вычитание дробей
Для начала уясним, что одно и то же число можно представить множеством различных дробей. К примеру, очевидно, что число 0,5 — это 1/2. Если прочитать значение 0,5 вслух, мы получим пять десятых и соответствующую дробь — 5/10. Это же число можно записать и как 2/4, 3/6, 9/18 или 50/100 — список можно продолжать бесконечно. Это важное свойство дробей и его понимание необходимо для успешного сложения и вычитания рациональных чисел.
Сложение и вычитание дробей с одинаковыми знаменателями не требует никаких дополнительных преобразований: для совершения операции достаточно сложить или вычесть числители. Например:
1/5 + 2/5 = 3/5;
12/17 − 4/17 = 8/17.
Если же у дробей знаменатели разные, требуется привести все члены выражения к общему знаменателю. Для этого используется метод поиска наименьшего общего кратного или разложение знаменателей на множители. Например, если вы хотите сложить или вычесть 1/5, 1/12 и 1/15, то все дроби должны иметь одинаковый знаменатель. Каждую из этих дробей мы можем увеличить на произвольное число, и ее значение при этом не изменится. Так, 1/5 — это все равно, что 2/10, 3/15 или 10/50.
НОК (5, 12, 15) = 60, следовательно, требуется умножить каждую дробь таким образом, чтобы в знаменателе получить 60:
1/5 умножим на 12 и получим 12/60;
1/12 умножим на 5, что равно 5/60;
1/15 умножим на 4 и получим 4/60.
Теперь мы легко можем сложить или вычесть эти числа, оперируя только числителями:
12/60 + 5/60 + 4/60 = 21/60;
12/60 − 5/60 − 4/60 = 3/60 = 1/20.
Если в задаче требуется сложить или вычесть смешанные дроби, то их необходимо преобразовать в неправильные, после чего привести слагаемые к общему знаменателю и выполнить необходимые расчеты. Например:
С этим все проще. Для произведения дробных чисел не требуется проводить дополнительные преобразования — достаточно выполнить операции между числителями и между знаменателями. Для произведения правильных и неправильных дробей, а также рациональных чисел с разными знаменателями операция умножения осуществляется по формуле:
a/b × c/d = a × c / b × d.
На практике это выглядит следующим образом:
1/2 × 1/2 = 1/4;
2/3 × 4/5 = 8/15;
5/10 × 3/12 = 15/120.
Деление — это действие, обратное умножению. В случае с дробями это определение приобретает буквальный смысл. Если требуется разделить первую дробь на вторую, то достаточно первую умножить на дробь, обратную второй. Математическим языком правило записывается так:
a/b / c/d = a/b × d/c = a × d / b × c.
Рассмотрим численные примеры:
1/2 / 1/2 = 1/2 × 2/1 = 2/2 = 1;
2/3 / 4/5 = 2/3 × 5/4 = 10/12 = 5/6;
5/10 / 3/12 = 5/10 × 12/3 = 60/30 = 2.
Наша программа представляет собой полноценный калькулятор для решения дробных выражений. Меню калькулятора предлагает выбор одного из четырех арифметических действий (сложение, вычитание, умножение и деление), а поля программы рассчитаны на ввод составных или обыкновенных дробей. Результирующую дробь программа автоматически представит в виде правильной дроби с выделением целой части. Интуитивно понятный интерфейс калькулятора позволит вам решать любые примеры на тему арифметических операций с дробными числами.
Заключение
Во время изучения школьного курса математики нам кажется, что полученные знания нам никогда не пригодятся в жизни. Однако операции с дробями мы производим постоянно на интуитивном уровне, даже когда просим в магазине половинку хлеба или 300 грамм сыра, когда готовим пищу или занимаемся сборкой моделей. Дроби пронизывают человеческую реальность, а наша программа позволит вам научиться быстро оперировать частями целого.
Калькулятор уравнений, интегралов, производных, пределов и пр.
Онлайн-калькулятор позволяет решать математические выражения любой сложности с выводом подробного результата решения по шагам. Также универсальный калькулятор умеет решать уравнения, неравенства, системы уравнений/неравенств и выражения с логарифмами, вычислять пределы функций, определенные/неопределенные интегралы и производные любого порядка (дифференцирование), производить действия с комплексными числами, калькулятор дробей и пр.
Пояснения к калькулятору
Для решения математического выражения необходимо набрать его в поле ввода с помощью предложенной виртуальной клавиатуры и нажать кнопку ↵.
Управлять курсором можно кликами в нужное местоположение в поле ввода или с помощью клавиш со стрелками ← и →.
⌫ — удалить в поле ввода символ слева от курсора.
C — очистить поле ввода.
При использовании скобок ( ) в выражении в целях упрощения может производится автоматическое закрытие, ранее открытых скобок.
Для того чтобы ввести смешанное число или дробь необходимо нажать кнопку ½, ввести сначала значение числителя, затем нажать кнопку со стрелкой вправо → и внести значение знаменателя дроби. Для ввода целой части смешанного числа необходимо установить курсор перед дробью с помощью клавиши ← и ввести число.
Ввод числа в n-ой степени и квадратного корня прозводится кнопками ab и √ соответственно.2}(решить неравенство)
Решение систем уравнений и неравенств
Системы уравнений и неравенств также решаются с помощью онлайн калькулятора. Чтобы задать систему необходимо ввести уравнения/неравенства, разделяя их точкой с запятой с помощью кнопки ;.
Вычисление выражений с логарифмами
В калькуляторе кнопкой loge(x) возможно задать натуральный логарифм, т.е логарифм с основанием «e»: loge(x) — это ln(x). Для того чтобы ввести логарифм с другим основанием нужно преобразовать логарифм по следующей формуле: $$\log_a \left(b\right) = \frac{\log \left(b\right)}{\log \left(a\right)}$$ Например, $$\log_{3} \left(5x-1\right) = \frac{\log \left(5x-1\right)}{\log \left(3\right)}$$
$$\log _2\left(x\right)=2\log _x\left(2\right)-1$$ преобразуем в $$\frac{\log \left(x\right)}{\log \left(2\right)}=2\cdot \frac{\log \left(2\right)}{\log \left(x\right)}-1$$ (найти x в уравнении)
Вычисление пределов функций
Предел функции задается последовательным нажатием групповой кнопки f(x) и функциональной кнопки lim.
Решение интегралов
Онлайн калькулятор предоставляет инструменты для интегрирования функций. Вычисления производятся как с неопределенными, так и с определенными интегралами. Ввод интегралов в поле калькулятора осуществляется вызовом групповой кнопки f(x) и далее: ∫ f(x) — для неопределенного интеграла; ba∫ f(x) — для определенного интеграла.
В определенном интеграле кроме самой функции необходимо задать нижний и верхний пределы.
Вычисление производных
Математический калькулятор может дифференцировать функции (нахождение производной) произвольного порядка в точке «x». Ввод производной в поле калькулятора осуществляется вызовом групповой кнопки f(x) и далее: f'(x) — производная первого порядка; f»(x) — производная второго порядка; f»'(x) — производная третьего порядка. fn(x) — производная любого n-о порядка.
Действия над комплексными числами
Онлайн калькулятор имеет функционал для работы с комплексными числами (операции сложения, вычитания, умножения, деления, возведения в степень и пр.). Комплексное число обзначается символом «i» и вводится с помощью групповой кнопки xyz и кнопки i
.
Калькулятор онлайн для расчетов процентов, дробей, степеней
Калькулятор давно и прочно вошел в нашу жизнь. Мы часто пользуемся им в повседневной жизни подбивая свои расходы за день, неделю, рассчитывая выплату коммунальных за месяц и т.д. С помощью онлайн калькулятора осуществляют простые арифметические расчеты студенты и школьники, продавцы в магазинах, торговцы на рынках, работники коммунальных служб, что позволяет сэкономить время, получить точные расчеты, избежать досадных ошибок.
Функции онлайн-калькулятораФункции онлайн-калькулятора
Клавиша
Символ
Операция
pi
pi
Постоянная pi
е
е
Число Эйлера
%
%
Процент
( )
( )
Открыть/Закрыть скобки
,
,
Запятая
sin
sin (α)
Синус угла
cos
cos (β)
Косинус
tan
tan (y)
Тангенс
sinh
sinh ()
Гиперболический синус
cosh
cosh ()
Гиперболический косинус
tanh
tanh ()
Гиперболический тангенс
sin-1
asin ()
Обратный синус
cos-1
acos ()
Обратный косинус
tan-1
atan ()
Обратный тангенс
sinh-1
asinh ()
Обратный гиперболический синус
cosh-1
acosh ()
Обратный гиперболический косинус
tanh-1
atanh ()
Обратный гиперболический тангенс
x2
^2
Возведение в квадрат
х3
^3
Возведение в куб
xy
^
Возведение в степень
10x
10^()
Возведение в степень по основанию 10
ex
exp ()
Возведение в степень числа Эйлера
vx
sqrt (x)
Квадратный корень
3vx
sqrt3 (x)
Корень 3-ей степени
yvx
sqrt (x,y)
Извлечение корня
log2x
log2 (x)
Двоичный логарифм
log
log (x)
Десятичный логарифм
ln
ln (x)
Натуральный логарифм
logyx
log (x,y)
Логарифм
I / II
Сворачивание/Вызов дополнительных функций
Unit
Конвертер величин
Matrix
Матрицы
Solve
Уравнения и системы уравнений
Построение графиков
Дополнительные функции (вызов клавишей II)
mod
mod
Деление с остатком
!
!
Факториал
i / j
i / j
Мнимая единица
Re
Re ()
Выделение целой действительной части
Im
Im ()
Исключение действительной части
|x|
abs ()
Модуль числа
Arg
arg ()
Аргумент функции
nCr
ncr ()
Биноминальный коэффициент
gcd
gcd ()
НОД
lcm
lcm ()
НОК
sum
sum ()
Суммарное значение всех решений
fac
factorize ()
Разложение на простые множители
diff
diff ()
Дифференцирование
Deg
Градусы
Rad
Радианы
Виды калькуляторов
В зависимости от возможностей и сферы применения калькуляторы бывают простые, бухгалтерские, финансовые, инженерные.
Бухгалтерскими калькуляторами пользуются бухгалтера и кассиры для арифметических расчетов с денежными суммами.
Для финансовых расчетов пользуются финансовыми калькуляторами, у которых к стандартному набору математических функций добавлены операции со сложными процентами и функции, характерные для банковской сферы и финансовых приложений.
Специализированные — это калькуляторы, применяемые для вычислений в конкретной сфере деятельности (строительные, ипотечные, статистические, медицинские).
Печатающие — калькуляторы, которые с помощью печатающего устройства выводят полученные результаты, расчеты, графики и вычисления на бумажную ленту.
Отдельно выделяются:
программируемые калькуляторы, используемые для выполнения сложных вычислений по заранее заложенной программе пользователя;
графические, выполняющие построение и отображение графиков функций.
Простейший калькулятор предназначен выполнять ординарные арифметические расчеты (сложение, вычитание и т.п.), вычислять процент, извлекать квадратный корень, возводить число в степень. Помимо простых расчетов, строителям и архитекторам, инженерно-техническим и научным работникам, математикам и геодезистам, старшеклассникам и студентам технических специальностей очень часто приходится решать важнейшие инженерные задачи, осуществлять сложные математические расчеты.
Представленный на сайте тригонометрический калькулятор выполняет расчет:
синусов;
косинусов;
тангенсов;
котангенсов.
А также обратных тригонометрических функций:
арксинусов;
арккосинусов;
арктангенсов;
арккотангенсов.
Все тригонометрические расчеты с углами выполняются в радианах, градах и градусах.
На нашем сайте вы сможете пользоваться инженерным онлайн калькулятором, предназначенным для инженерных и научных расчетов разного уровня сложности.
Инженерный калькулятор позволяет:
производить сложные расчеты с дробями;
возводить любое число в степень, извлекать корень из числа;
рассчитать онлайн проценты, логарифмы, интегралы любой сложности;
выполнять необходимые математические операции с одной или несколькими матрицами;
находить производную онлайн как от элементарной, так и от сложной функции;
решать алгебраические, линейные, логарифмические, тригонометрические и другие уравнения.
Онлайн калькулятор прост и понятен в обращении, применять его не составит труда тем, кто пользуется настольным инженерным калькулятором, принципы работы функций и программ аналогичны. По своему виду инженерный калькулятор онлайн имитирует настоящий калькулятор, поэтому для ознакомления с ним вам не понадобится много времени.
Калькулятор дробей. Решаем дроби онлайн.
В статье мы рассмотрим, как можно используя современный онлайн калькулятор, научиться решать дроби.
Речь пойдет о калькуляторе дробей — http://reshit.ru/Kalkulyator-drobey-onlayn-s-resheniem.
Данный калькулятор позволяет выполнить базовые операции с двумя дробями.
С помощью калькулятора можно складывать, вычитать, делить и умножать дроби.
Ответ получается в виде удобной картинки, где понятно расписано все решение.
Рассмотрим базовые приемы решения дробей, используя данный онлайн калькулятор.
Попробуем взять и написать в него 2 дроби, разделив их нужным знаком.
Возьмем к примеру 2/3 и 3/7.
Для умножения ставим между ними *
Для деления :
Для сложения +, и — для вычитания.
Калькулятор выдаст нам готовое решение в виде картинок:
Как вы можете видеть, чтобы сложить дроби достаточно просто перемножить числители и знаменатели.
Чтобы поделить одну дробь на другую, нужно умножить первую дробь на перевернутую вторую.
Чтобы сложить или вычесть, нужно просто привести дроби к общему знаменателю и выполнить соответствующие операции с числителями.
Все, что останется по итогу сделать — это соответственно сложить или вычесть числители приведенных к общему знаменателю дробей.
Более сложные дроби, с целой частью, отрицательные, ситуации, когда вы имеете 3 и более вполне разрешимы. Достаточно поделить данную более сложную задачу на простые операции по 2 дроби и вы также сможете решить их в калькуляторе.
Это удобный и достаточно универсальный инструмент.
Если у вас пример из сложения 3-х дробей, сложите сначала первые 2, а потом прибавьте к ней третью, чтобы получить ответ.
Если у вас дроби с целой частью, просто занесите её в дробь, умножив целую часть на знаменатель и прибавив к числителю полученное произведение.
Отрицательные дроби решаются точно также, как и обычные. Если вы умеете складывать, умножать, вычитать и делить отрицательные целые числа, то с дробями действуют все те же самые правила знаков.
Если, изучив работу калькулятора, вы что-то до конца не поняли, то можете посмотреть видео, где на дольках яблока рассказывается суть дробей и показываются основные приемы решения на примерах. После того, как вы усвоите теорию, обязательно закрепите материал на практике.
Прорешайте несколько дробей сначала на листочке, а потом сверьте решение с тем, что выдаст онлайн калькулятор.
По 2-3 примера на каждую операцию будет вполне достаточно.
Уметь решать дроби крайне важно, поскольку они встречаются достаточно часто в задачах в старших классах школы, университете и по жизни.
Дроби не являются сложными сами по себе. Изучают их обычно с 3-5 классе и далее используют постоянно. Научившись решать их один раз и сформировав правильное понимание, вы вряд ли когда-то разучитесь решать дроби.
Даже если такое когда-нибудь случиться, вы всегда можете найти калькулятор дробей и быстро освежить знания и умения.
На этом хочется закончить обзор онлайн калькулятора дробей.
Помимо рассмотренного инструмента на сайте, вы найдете таблицу производных http://reshit.ru/tablica-proizvodnyh, калькулятор для решения квадратных уравнений онлайн и другие полезные материалы.
как возвести число в дробную степень примеры
Как возвести число в дробную степень, если не представлять, как это работает, то можно, наверное, свихнуться! Но друзья мои! Я с вами и сегодня мы разберемся в такой непонятной вещи, как число в дробной дроби!
Видео: Как возвести число в дробную степень примеры
С самого начала выясним, что такое дробь, что я понимаю под этим – мы будем рассматривать дробь вида, например, как неудобная дробь 1/3, мы не будем сейчас обсуждать именно такую дробь и почему она очень неудобная в десятичном виде и десятичных степенях мы поговорим в другой раз! И конечно же будем разбираться вместе с примерами и потом, мы уже… как раз сегодня доделали работу нашего калькулятора. Который мы научили работать с дробями!
Как вообще считать числа в степени дроби!?
Если степень числа равна дроби, то это число можно представить, как корень в степени знаменателя из числа в степени числителя. Мы как-то уже размещали картинку, когда разбирались с разными корнями и степенями: Если не совсем понятно! То давайте приведём пример, который для меня всегда остается эталоном и если я когда забываю, то сразу вспоминаю эту схему: Чему равно число в степени одна третья!? Кубическом корню из этого числа! Единицу мы не видим, потому, что число в степени 1 будет число.
Как возвести число в степень примеры
Для примера мы можем взять число 8 в степени одна третья и это будет равно кубическому корню из 8, что в свою очередь равно 2.
81/3 = 3√8 =2
Какая скукотища – вы должны сказать! И вот мы подошли к самом интересному, из-за чего мы сделали данную страницу!
Возвести число в дробную степень онлайн калькулятор.
Мы уже писали, как возводить в любую степень, и сегодня же решили сделать возведение числа в дробь в нашем калькуляторе!
Как мы видим. Что степень не активна, и она таковой останется до тех пор, пока вы не выберете то число, которое хотите возвести в степень дроби. 1.Не будем далеко ходить, возьмем то же число 8, как мы и делали сверху! Нажимаем кнопку 8. 2.Нажимаем кнопку степени – это кнопка «P» Как видим, кнопка степени стала активна, и справа сверху табло, так же высветлялась буква P 3.После этого набираем нашу дробь… 1/3 и равно = 4.Видим результат возведения числа в степень дроби.
Написать что-нибудь…
как возвести число в дробную степень ,
программа возводящая число в степень ,
возвести число в дробную степень онлайн ,
калькулятор возвести число в дробную степень ,
что значит возвести число в степень ,
возвести число в дробную степень онлайн калькулятор ,
как возвести число в степень в дробях ,
как возвести число в степень примеры ,
число в степени дроби ,
степень числа в виде дроби ,
число со степенью дробь ,
как возвести число в степень в дробях ,
возведение числа в степень дроби ,
число в степени дробь как решать ,
как считать числа в степени дроби ,
калькулятор чисел со степенями и дробями ,
возведение числа в степень десятичной дроби ,
Калькулятор дробей
Калькулятор выполняет базовые и расширенные операции с дробями, выражениями с дробями, объединенными с целыми числами, десятичными знаками и смешанными числами. Он также показывает подробную пошаговую информацию о процедуре расчета дроби. Решайте задачи с двумя, тремя или более дробями и числами в одном выражении.
Правила для выражений с дробями:
Дроби — используйте косую черту «/» между числителем и знаменателем, т.е.е., для пяти сотых введите 5/100 . Если вы используете смешанные числа, не забудьте оставить один пробел между целой и дробной частью. Косая черта разделяет числитель (число над дробной чертой) и знаменатель (число ниже).
Смешанные числа (смешанные дроби или смешанные числа) записываются как ненулевое целое число, разделенное одним пробелом и дробью, то есть 1 2/3 (с тем же знаком). Пример отрицательной смешанной дроби: -5 1/2 . Поскольку косая черта является одновременно знаком для дробной линии и деления, мы рекомендуем использовать двоеточие (:) в качестве оператора деления дробей, т. Е. 1/2: 3 .
Десятичные числа (десятичные числа) вводятся с десятичной запятой . , и они автоматически конвертируются в дроби — то есть 1,45 .
Двоеточие : и косая черта / являются символом деления. Может использоваться для деления смешанных чисел 1 2/3: 4 3/8 или может использоваться для записи сложных дробей i.1/2 • сложение дробей и смешанных чисел: 8/5 + 6 2/7 • деление целого и дробного числа: 5 ÷ 1/2 • комплексные дроби: 5/8: 2 2/3 • десятичное дробное: 0,625 • Дробь в десятичную: 1/4 • Дробь в проценты: 1/8% • сравнение дробей: 1/4 2/3 • умножение дроби на целое число: 6 * 3/4 • квадратный корень дроби: sqrt (1/16) • уменьшение или упрощение дроби (упрощение) — деление числителя и знаменателя дроби на одно и то же ненулевое число — эквивалентная дробь: 4/22 • выражение в скобках: 1 / 3 * (1/2 — 3 3/8) • сложная дробь: 3/4 от 5/7 • кратная дробь: 2/3 от 3/5 • разделите, чтобы найти частное: 3/5 ÷ 2 / 3
Калькулятор следует известным правилам для порядка операций .Наиболее распространенные мнемоники для запоминания этого порядка операций: PEMDAS — круглые скобки, экспоненты, умножение, деление, сложение, вычитание. BEDMAS — Скобки, экспоненты, деление, умножение, сложение, вычитание BODMAS — Скобки, порядок или, деление, умножение, сложение, вычитание. GEMDAS — Группирующие символы — скобки () {}, экспоненты, умножение, деление, сложение, вычитание. Будьте осторожны, всегда выполняйте умножение и деление перед сложением и вычитанием .Некоторые операторы (+ и -) и (* и /) имеют одинаковый приоритет и должны вычисляться слева направо.
Дроби в задачах со словами:
следующие математические задачи »
Калькулятор дробей — Сайт калькулятора
Используйте этот популярный калькулятор дробей, чтобы складывать, вычитать, умножать и делить дроби, включая смешанные числовые дроби. Калькулятор
дает объяснение задействованных рабочих шагов и упрощает результат, используя наибольший общий знаменатель.
Нравится? Пожалуйста, поделитесь
Пожалуйста, помогите мне распространить информацию, поделившись этим с друзьями или на своем веб-сайте / в блоге.Спасибо.
Ссылка на сайт
Заявление об ограничении ответственности: Несмотря на то, что для создания этого калькулятора были приложены все усилия, мы не можем
несет ответственность за любой ущерб или денежные убытки, возникшие в результате или в связи с его использованием.
Этот инструмент предназначен исключительно в качестве услуги для вас, пожалуйста, используйте его на свой страх и риск. Полный отказ от ответственности.
Не используйте расчеты для тех случаев, когда неточные расчеты могут привести к гибели людей, деньгам, имуществу и т. Д.
Как складывать дроби
Проверьте, совпадают ли ваши знаменатели (нижние числа).
Они делают? Отлично. Переходите к шагу 5.
Нет? ОК. Умножьте ваши разные знаменатели вместе…
… И пропорционально скорректируйте обоих ваших номинаторов (верхние числа). Например. если вы удвоили знаменатель, то удвоите его числитель.
Сложите знаменатели и положите полученную сумму над общим знаменателем.
Упростите дробь до наименьшего возможного знаменателя, при этом знаменатель также уменьшится пропорционально.
Если вам нужна помощь с преобразованием десятичных знаков в дроби, см. Наш
статья как преобразовать десятичную дробь в дробь.
Рекламное объявление
Если вы хотите преобразовать десятичное число в дробь, попробуйте калькулятор десятичной дроби.
Когда дело доходит до выполнения математического расчета, важно выполнять операции в правильном порядке. Вот где
Порядок операций Приходит . К счастью, есть несколько мнемоник, которые помогут нам запомнить порядок выполнения
операции. Прочтите нашу статью о PEMDAS.
Калькулятор фракций — Расчет фракций
Fraction Calc — это специальный калькулятор для умножения, деления, сложения и вычитания двух или более дробей и целых чисел.Он может обрабатывать сразу несколько дробей и целых чисел. Затем он отображает пошаговые решения любой операции, которую он обработал. Иногда мало кто назовет это решателем дробей, в то время как другие могут сказать, что это калькулятор смешанных чисел или калькулятор смешанных дробей. Это онлайн-калькулятор с кнопкой дроби. На данный момент он может вычислять до десяти дробей и смешанных чисел. Это полезно для всех учащихся всех уровней обучения. Его можно использовать в качестве справочника для всех учителей математики и даже тех профессионалов, которые часто используют дроби на рабочем месте или дома.
Как использовать?
Этот калькулятор разработан для удобного использования.
Нажмите любую цифру с помощью кнопок с цифрами.
Нажмите любое число из кнопок знаменателя.
Нажмите кнопку добавления (+) .
Нажмите любую цифру на кнопках числителя для второй дроби.
Нажмите любое число на кнопках знаменателя второй дроби.
Нажмите кнопку «равно (=) », чтобы вычислить ответ.Ответ и решение будут отображаться выше.
Сложение трех или более дробей
Повторите шаги выше, кроме последнего шага.
Нажмите кнопку добавления (+) .
Нажмите любую цифру из кнопок числителя для третьей дроби.
Нажмите любое число из кнопок знаменателя для третьей дроби.
Нажмите кнопку «равно (=) », чтобы вычислить ответ, или нажмите кнопку «добавить (+) », чтобы сложить дроби.
Тот же процесс будет использован для четвертой, пятой или любого количества дробей. Просто нажмите кнопку « (=) » для вычисления.
Вычитание двух, трех или более дробей
Следуйте инструкциям по сложению дробей, но вместо нажатия кнопки добавления (+) нажмите кнопку вычитания (-) .
Умножение и деление двух, трех и более дробей
Следуйте инструкциям по сложению дробей, но вместо нажатия кнопки сложения (+) нажмите кнопку умножения (x) для умножения и кнопку деления (÷) для деления.
Сложение, вычитание, умножение и деление смешанных чисел
При работе со смешанными числами важно помнить, что при использовании этого калькулятора никогда не забывайте вводить целые числа. Кнопки с целыми числами в калькуляторе больше, чем кнопки числителя и знаменателя. Вам нужно только сначала нажать кнопку с целым числом, а затем с дробью, после чего вы можете перейти к любой операции, которую хотите.
Операции с дробями, целыми и смешанными числами
Нажмите кнопку целого числа, если дробь состоит из целого числа, или вы можете напрямую нажать кнопку числителя, если целое число вам не нужно.Вы не можете нажать кнопку знаменателя, если вы не нажали кнопку целого числа или знаменателя. Это означает, что вам нужно сначала нажать кнопку целого числа или числителя. После нажатия кнопки числителя вы больше не можете нажимать кнопку с целым числом. Вы можете снова нажать кнопку целого числа, только если вы удалите числитель, нажав кнопку возврата. Не следует сначала нажимать нули. Ноль будет нажата после нажатия ненулевых чисел.
Нажмите кнопку знаменателя для вашего знаменателя.После нажатия вы не сможете снова нажать целую цифру или кнопку с числителем. Вы можете нажать кнопку числителя только в том случае, если вы удалите знаменатель, нажав кнопку возврата.
Выберите любую операцию, которую хотите.
Нажмите кнопку Равно , если вы закончили с дробью. Решение будет отображаться выше.
Нажмите Backspace , если вы хотите удалять по одному номеру за раз.
Нажмите кнопку AC , чтобы очистить уравнение дроби.
На данный момент этот калькулятор ограничен только 10 дробями.
Fraction Calc на мобильных телефонах Android
Выпущен наш Fraction Calc для мобильных телефонов Android. Он может обрабатывать основные и сложные операции дроби и может отображать решение как в методе перекрестного умножения, так и в методе ЖКД (наименьшего общего знаменателя). Вы можете получить его в магазине Google Play.
Как производился расчет?
Иногда возникают сомнения в том, как производится расчет при использовании нескольких операций.В нотации MDAS умножение и деление имеют тот же приоритет, но выше, чем сложение и вычитание. Сложение и вычитание имеют одинаковый приоритет. Сначала обрабатывается более высокий приоритет. Это всегда правило, и его повсеместно соблюдают. Хотя с тем же приоритетом, операция выполняется слева направо.
Калькулятор целых чисел
Fraction Calc также является калькулятором дроби целых чисел, потому что он может обрабатывать множество целых чисел.Работа с целыми числами означает, что вам нужно больше учиться и делать дополнительные шаги, преобразовывая целые числа в формат, подходящий для математических операций. Выполнение математических операций с целыми числами означает, что вам придется проделать дополнительные шаги, чтобы получить правильный ответ. Это означает дополнительную энергию и нагрузку для людей, попавших в ситуацию, когда им приходится решать целые числа и дроби. Вот почему некоторые люди ищут калькулятор дробей и целых чисел, чтобы не только найти простые решения сложных проблем, но и сэкономить время и энергию.Экономия времени и энергии на выполнении определенной задачи означает, что вы получаете дополнительные ресурсы для выполнения еще более важной задачи, которая может оказаться очень полезной.
3 Калькулятор дробей
В большинстве случаев в математической арифметике используются только две дроби. Очень редко в какой-либо операции задействованы 3 фракции. Но если это так, то вам очень повезло, что вы нашли этот инструмент. Вы можете легко использовать этот инструмент в качестве калькулятора трех дробей, потому что он может ее решить.Это основная цель этого инструмента. Некоторые люди никогда не слышали об этом инструменте, поэтому они специально искали калькулятор с 3 дробями. Но теперь, когда его инструмент создан, я думаю, у них больше нет времени для беспокойства.
Калькулятор множественных дробей
Большинство созданных калькуляторов имеют ограниченные возможности до такой степени, что они могут вычислять только две дроби за раз. Но Fraction Calc может даже больше. Он может решить до 10 целых чисел или дробей вместе.Вот почему многие называют это калькулятором дробей. Это очень специализированный калькулятор с целыми числами. С комбинацией целого числа и дроби сложно справиться, но с этим калькулятором дробей вычисления становятся проще. Этот калькулятор может выполнять сложение смешанных чисел, преобразование дробей в целые числа, умножение дробей на целые числа, вычитание смешанных чисел и умножение смешанных дробей.
Преимущества и недостатки использования калькулятора дробей.
Легко использовать.
Это экономит больше времени и энергии.
Нет необходимости в ручном вычислении.
Вычисленный результат точен и точен.
Недостатки:
Это может сделать вас скучным в вычислении дробей.
Вы будете очень зависеть от него в будущем.
Вы можете забыть правила вычислений.
Правила работы с дробями
Сложение и вычитание дробей
Сложение и вычитание дроби происходит по тем же правилам.У них должны быть одинаковые знаменатели для обработки выбранной операции. Вы можете сложить или вычесть две дроби, если у них одинаковый знаменатель, если нет; вы должны создать общий знаменатель, прежде чем добавлять или вычитать их.
Подобные дроби — это дроби с одинаковыми знаменателями. Чтобы сложить дроби с одинаковым знаменателем, добавьте его числитель. Например, 2/5 + 1/5 = 3/5.
Дроби с разными знаменателями не похожи на дроби. Чтобы сложить непохожие дроби, вам нужно сделать так, чтобы у них был общий знаменатель.Самый простой способ сделать это — использовать метод бабочки. Чтобы выполнить метод бабочки, выполните следующие действия.
Умножьте числитель первой дроби на знаменатель второй дроби. Результатом будет числитель первой дроби.
Умножьте знаменатель первой дроби на знаменатель второй дроби. Результатом будет новый знаменатель первой дроби.
Умножьте числитель второй дроби на знаменатель первой дроби.Результатом будет новый числитель второй дроби.
Умножьте знаменатель второй дроби на знаменатель первой дроби. Результатом является новый знаменатель второй дроби.
Например: 2/3 + 3/5.
2 x 5 = 10.
3 х 5 = 15.
3 x 3 = 9.
5 x 3 = 15.
Новая дробь — 10/15 и 9/15. 15/10 + 9/15 = 19/15. Новая дробь — 19/15.
Чтобы вычесть дроби с одинаковым знаменателем, просто вычтите числитель второй дроби из числителя первой дроби. Пример: 4/6 — 3/6 = 1/6.
Для дробей с разным знаменателем установите одинаковый знаменатель с помощью метода бабочки, а затем произведите вычитание после того, как у них будет одинаковый знаменатель.
Умножение и деление дробей
Правило умножения двух дробей простое. Умножьте числитель первой дроби на числитель второй дроби и умножьте знаменатель первой дроби на знаменатель второй дроби.Пример: 2/3 x 1/5 = 2/15.
Чтобы разделить две дроби, вы должны сначала инвертировать вторую дробь, а затем начать умножение двух дробей. Пример: 2/3 разделить на 1/5 = 2/3 x 5/1 = 10/3.
Как заменить неправильную дробь на смешанное число
Когда вы сокращаете неправильную дробь до наименьшего члена, вам нужно изменить ее на смешанное число. Это делается путем деления числителя на знаменатель. Частное будет целым числом. Остаток будет новым числителем, а знаменатель останется без изменений.
Как заменить смешанное число на неправильную дробь
При делении или умножении смешанных чисел вам нужно преобразовать его в неправильную дробь. Это делается путем умножения целого числа на знаменатель и добавления текущего числителя. Результатом будет новый числитель, а знаменатель останется без изменений.
Сравнение дробей
Для дробей с одинаковыми знаменателями дробь с наибольшим числителем является большей дробью, чем дробь с меньшим числителем. Для дробей с одинаковыми числителями дробь с наибольшим знаменателем меньше дроби с меньшим знаменателем.
Упрощающие дроби
Из темы выше мы уже знаем, что есть эквивалентные дроби-дроби, которые имеют одинаковое значение, даже если у них разные числители и знаменатели. Упрощение дроби означает, что используется наименьший числитель и знаменатель, но одно и то же значение. Дробь находится в своей простейшей форме, когда нет общего множителя для числителя и знаменателя.Например, вместо 7/14 мы можем использовать ½, что является самой простой формой.
Наибольший общий множитель
Наибольший общий делитель — это наибольшее число, используемое для деления числителя и знаменателя, чтобы получить простейшую форму дроби. Например, для дроби 12/30 наибольшее число для деления числителя и знаменателя равно 6. Разделив его на 6, вы придете к его простейшей форме — 2/5.
Факты о дробях
Дроби — это части целого.Например, есть один торт на пятерых детей. Итак, торт делится на пять частей. Каждый ребенок получит по одной части торта. Дробь будет 1/5. Каждый ребенок получит 1/5 торта.
Дробь состоит из двух частей. Верхняя половина называется числителем. Нижняя половина называется знаменателем. Числитель — это часть целого, в которой он используется или обрабатывается в настоящее время.
Существует три типа дробей: правильная дробь, неправильная дробь и смешанные числа.
Правильная дробь — это дробь, числитель которой всегда меньше знаменателя.
Неправильная дробь — это дробь, числитель которой больше или равен знаменателю.
Смешанное число представляет собой целые числа плюс дробь.
Эквивалентные дроби — это дроби, которые имеют разные числители и знаменатели, но имеют одинаковое значение, например 1/2, 2/4, 7/14, 8/16, 10/20, 20/40 и 50/100.
Как рассчитывалась фракция?
Когда я был студентом, у меня был этот предмет по математике.Одна из тем была о фракции. Хотя эта тема сложна, меня очень удивило, почему так трудно определить, правильное решение или неправильное. Вы должны просмотреть его несколько раз, чтобы убедиться, что ваше решение правильное. Это случилось не только со мной. Я узнал, что большинство студентов испытали то же самое. Так что с этого момента я мечтаю, что так или иначе помогу им. Я помогу им убедиться, что их решение верное, не проходя много обзоров.Вот почему я создал этот калькулятор. Этот калькулятор был создан в качестве справочника или руководства только для того, чтобы убедиться, что учащийся правильно ответит на свои задачи с дробями. От основателя FractionCalc.com
Калькулятор дробей
— лучший инструмент для сложения дробей
Сложите, вычтите, умножьте или разделите две дроби, указав их ниже. Используйте пробел, чтобы отделить целые числа от дроби.
Результат в виде дроби:
Результат как дробь
Результат в виде десятичной дроби:
Шаги для решения
Результат как дробь
Результат в виде десятичной дроби:
Шаги для решения
Результат как дробь
Результат в виде десятичной дроби:
Шаги для решения
Вы пытаетесь рассчитать дюймовые доли?
Как считать дроби
Калькулятор выше позволяет легко складывать, вычитать, умножать или делить дроби и даже показывает всю работу.
Но как считать дроби без калькулятора? См. Инструкции ниже, чтобы узнать, как их складывать, вычитать, умножать или делить.
Как складывать и вычитать дроби
Сложение и вычитание дробей немного отличается от сложения обычных целых чисел. Есть три простых шага, чтобы складывать или вычитать дроби.
Шаг первый: преобразование в дроби с общим знаменателем
При сложении или вычитании дробей первым делом необходимо преобразовать их в эквивалентные дроби с тем же знаменателем.
Для этого сначала найдите наименьший общий знаменатель знаменателей обеих дробей. Наименьший общий знаменатель — это наименьшее число, на которое можно равномерно разделить оба знаменателя.
Затем найдите кратное для каждого знаменателя, которое при умножении равно общему знаменателю. Найдите кратное, разделив общий знаменатель на каждый знаменатель.
Затем умножьте числитель и знаменатель на кратное, чтобы найти эквивалентные дроби с совпадающими знаменателями.
Например, преобразовываем дроби 13 и 14 в дроби с одинаковым знаменателем.
13 = 1 × 43 × 4 = 412 14 = 1 × 34 × 3 = 312
Шаг второй: сложите или вычтите числители
Как только знаменатели совпадают, сложение и вычитание дробей так же просто, как сложение или вычитание числителей.
Чтобы сложить дроби, сложите числители и положите их над общим знаменателем.
Чтобы вычесть, найдите разницу между числителями и положите разницу над общим знаменателем.
Например, , продолжая предыдущий пример, добавим 412 и 312.
412 + 312 = 4 + 312 = 712
Шаг третий: упростите дробь
Последний шаг к сложению или вычитанию дробей — это упростить полученную дробь. Начните с поиска наибольшего общего делителя числителя и знаменателя.Узнайте больше о поиске наибольшего общего фактора для получения дополнительных сведений.
Затем разделите числитель и знаменатель на наибольший общий множитель, который нужно уменьшить. Или просто используйте наш упрощитель дробей, чтобы упростить и увидеть всю работу, необходимую для этого.
Вы также можете использовать наши калькуляторы сложения или вычитания, чтобы легко складывать и вычитать дроби.
Как умножать дроби
Умножить две дроби немного проще, чем сложить или вычесть, выполнив два простых шага.
Шаг первый: умножение числителей и знаменателей
Первый шаг — перемножить числители и умножить знаменатели. Результатом может быть неправильная дробь, но мы уменьшим ее на следующем шаге.
Например, , умножим 23 × 34.
23 × 34 = (2 × 3) (3 × 4) 23 × 34 = 612
Шаг второй: упростите дробь
Как и сложение и вычитание, последний шаг умножения дробей — это упрощение.Для упрощения найдите наибольший общий множитель числителя и знаменателя, а затем разделите их на общий множитель.
Чтобы упростить 612, найдите наибольший общий множитель.
Наибольший общий делитель 6 и 12 равен 6 .
Затем разделите числитель и знаменатель на наибольший общий множитель.
612 = (6 ÷ 6) (12 ÷ 6) 612 = 12
Как разделить дроби
Есть два шага, чтобы разделить одну дробь на другую.
Шаг первый: умножьте каждый числитель на противоположный знаменатель
Чтобы разделить одну дробь на другую, начните с умножения первого числителя на второй знаменатель. Затем умножьте второй числитель на первый знаменатель.
Например, разделим 23 на 34.
23 ÷ 34 = (2 × 4) (3 × 3) 23 ÷ 34 = 89
Шаг второй: упростите дробь
Как и при умножении дробей, последний шаг их деления — упростить дробь.См. Инструкции, чтобы упростить дробь выше.
Как рассчитать смешанные дроби
Смешанные дроби могут показаться пугающими, но процесс их вычисления почти такой же, как и для обычных дробей с одним дополнительным шагом.
Первое, что нужно сделать при вычислении смешанной дроби, — это удалить целое число и увеличить числитель.
Начните с умножения целого числа на знаменатель.
Затем добавьте результат к числителю в оставшейся дроби.
Продолжайте выполнять описанные выше шаги, чтобы вычислить дроби после переноса результата в числитель.
Например, преобразовываем смешанную дробь 2 25 в целое число.
Умножьте целое число на знаменатель.
2 × 5 = 10
Добавьте результат в числитель.
10 + 2 = 12
Перепишите дробь.
2 25 = 125
Ознакомьтесь с нашим полным набором инструментов для вычисления дробей.
КАЛЬКУЛЯТОР НА 3 ФРАКЦИИ — EXAMN8.COM
РАССЧИТАТЬ, СРАВНИТЬ, УМЕНЬШИТЬ
ПРОЧТИ МЕНЯ
Вычислить : введите 2 или 3 дроби, выберите арифметические операторы с помощью раскрывающихся списков
и нажмите кнопку [=], чтобы получить результат.Эквивалентные десятичные дроби (D) и уменьшенные
Внизу появятся дроби (R).
Сравните : вычтите вторую дробь из первой:
положительный результат означает, что первый больше, и наоборот.
Уменьшить : введите «Дробь» в первое поле и нажмите [=].
1/3 + 5/12 = 9/12
D = 0,75 R = 3/4
1 4/5 ÷ 0,75 = 2 6/15
D = 2,4 R = 2 2/5
1/2 — 2 3/4 + 0,75 = -1 2/4
D = -1,5 R = -1 1/2
3/4 — 2 3/4 x 3/8 = 12/24
D = 0.5 R = 1/2
ОБРАЗОВАТЕЛЬНЫЕ РЕСУРСЫ
КАЛЬКУЛЯТОРЫ
РЕШЕНИЕ УРАВНЕНИЙ
РУКОВОДСТВО И ПРАКТИЧЕСКИЕ ИСПЫТАНИЯ
Сложение, вычитание, деление и умножение дробей
Инструкция по эксплуатации
Введите дроби в калькулятор выше.
Выберите математическую операцию, которую вы хотите выполнить (сложение, вычитание, умножение, деление), используя серое раскрывающееся поле выбора между двумя дробями.
Результаты будут обновляться автоматически при изменении любого значения в калькуляторе.
Флажок под калькулятором позволяет вам выбирать между уменьшением дроби до эквивалента наименьшего общего знаменателя (если установлен) или отказом от уменьшения (если не отмечен).
Как вычислить дроби вручную
Как складывать дроби
Найдите наименьший общий знаменатель, умножив каждый знаменатель на другой.
Умножьте каждый числитель на те же числа, на которые были умножены знаменатели.
Сложите числители.
Уменьшить результат до наиболее упрощенного числа.
Как вычесть дроби
Найдите наименьший общий знаменатель, умножив каждый знаменатель на другой.
Умножьте каждый числитель на те же числа, на которые были умножены знаменатели.
Складываем второй числитель с первого.
Уменьшить результат до наиболее упрощенного числа.
Как умножать дроби
Умножьте числа сверху вместе.
Умножьте числа внизу вместе.
Уменьшить результат до наиболее упрощенного числа.
Как делить дроби
Переверните вторую дробь вверх дном, чтобы получить обратное число.
Умножьте дроби вместе (как в разделе умножения выше).
Уменьшить результат до наиболее упрощенного числа.
Дроби: история, актуальность и популярное использование
— Руководство Автор: Корин Б. Аренас , опубликовано 22 октября 2019 г.
Практически каждый день мы имеем дело с дробями. Подумай об этом. Независимо от того, получаете ли вы четвертинки для разнообразия, покупаете одежду со скидкой 75% или готовите с половиной стакана масла, вы используете дроби.
В этом разделе мы поговорим о происхождении дробей, их важности при передаче информации и золотом сечении.
Что такое дроби?
Дроби
представляют части целого числа или любое количество равных частей. Он функционирует
чтобы описать, как части соотносятся с целым числом.
Для иллюстрации представьте целое число как торт. Если вы разрежете торт на 4 равные части, один кусок будет частью этого торта. В данном случае это 1/4 часть всего торта.
1 представляет один фрагмент или часть целого числа, которое называется числителем .
4 представляет, сколько всего частей в целом числе, которое называется знаменателем .
Краткая история дробей
Слово Происхождение: Термин дробь происходит от латинского
слово fractio что означает «сломанный». В раннем английском языке это означает «сломанный кусок или
фрагмент ». Английское слово« разрушение »также
имеет то же происхождение слова.
Концепция дробей существует уже более 4000 лет.Но у разных цивилизаций есть свой способ стандартизации дробей для универсального использования.
Египтяне
Согласно Математика на протяжении веков : Мягкая история для учителей и других, египтяне были одними из первых, кто придумал форму дроби еще в 1800 году до нашей эры. Их концепция в основном ограничивалась частями, иначе известными как единичные дроби. Дроби единиц используют 1 в качестве числителя.
Египетские математики создали систему с основанием 10.
идея, которая похожа на системы счисления, которые мы используем сегодня.Цифра
иероглифы представляли их числа, что означает символы, соответствующие
определенное значение.
Поскольку числитель всегда равен 1, они должны были указать только знаменатель. Египтяне отметили знаменатель овалом или точкой над значением. Вот несколько примеров из книги Math Through the Ages :
Части были выражены как суммы долей единиц. Однако система не позволяла повторять дроби единиц в этой последовательности, что затрудняло выполнение расчетов.Чтобы решить эту проблему, египтяне создали обширные списки таблиц, в которых указаны двойные значения различных частей.
Вавилоняне
Другая цивилизация, создавшая сложную систему для
По словам преподавателя математики и автора Лиз Памфри, фракции принадлежали вавилонянам.
Вавилоняне организовали фракции в группы по 60 человек (основание 60). Сегодня мы обычно организуем числа в группы по 10. Но для вычислений, таких как углы и минуты для времени, мы также используем основание 60.Система сгруппировала дроби по 10 и использовала два символа, один для единицы, а другой для 10.
Ниже приведены символы, представляющие вавилонскую систему счисления от 1 до 20:
.
Однако у них не было символа нуля (который они позже добавили около 311 года до н.э.) или знака, который функционировал как десятичная точка для обозначения дробей целого числа. Это затрудняло интерпретацию чисел.
Например, цифры ниже читаются как 12 и 15.
По словам Памфри, символы также могут читаться как разные
значения:
x60
шт.
Шестидесятые
Номер
12
15
12
15
720 + 15
12 и 15 как отдельные номера
15/12
12 15/60
720 + 15
Как видите, отсутствие индикатора дроби делает его
трудно отделить целые числа от дробей.Вероятно, они полагались на контекст, чтобы
разобраться в числовых значениях.
Как египетская, так и вавилонская системы были переданы позже людям в Греции, а затем и к средиземноморской цивилизации.
Греки
В Греции практика использования дробных величин в качестве сумм
единицы дроби были довольно распространены до средневековья. Например, Liber
Abbaci итальянского математика Фибоначчи — это
примечательный текст 13 века. В нем широко использовались дроби, описывающие
различные способы преобразования других дробей в суммы единичных дробей.
Чтобы лучше понять, ниже приведена таблица греческого языка.
цифровые символы. Обратите внимание, что они такие же, как буквы в греческом
алфавит:
Значение
Шт.
Десятки
сотен
1
α
ι
ρ
2
β
κ
σ
3
γ
λ
τ
4
δ
µ
υ
5
ε
ν
φ
6
ϝ
ξ
χ
7
ζ
ο
ψ
8
η
π
ω
9
θ
ϙ
ϡ
Греческий
запись дробей требует от читателя понимания контекста для правильного
интерпретация.Чтобы выделить дробь, они ставят диакритический знак .
знак (‘) после знаменателя дроби.
Например, число β (2) становится ½ при записи с
диакритический знак, β ’.
Аналогично, µβ (42) становится 1/42 при записи в µβ ’.
Однако здесь возникает путаница: µβ ’также может означать 40 ½. Вот почему понимание контекста имеет решающее значение при интерпретации греческих дробей.
Римлянам
У римлян дроби выражались только словами, которые
усложняли любые вычисления.
Их система была основана на единице веса, называемой «as».
При таком подходе 1 as было равно 12 uncia (римский
базовая единица измерения, основа современной унции). Таким образом, дроби
имеют знаменатели со значениями, кратными 12.
В таблице ниже указаны римские дроби.
с соответствующими условиями:
Дробь
Римский термин
11/12
deunx для de uncia, забрал 1/12
10/12
декстанов для декстанов, 1/6 отнято
9/12
dodrans for de quadrans, 1/4 отнято
8/12
bes — bi as for duae partes, 2/3
7/12
перегородка для septem unciae
6/12
полуфабрикаты
5/12
quincunx для quinque unciae
4/12
триенс
3/12
квадрант
2/12
секстан
1/12
UNCIA
1/24
semuncia
1/48
сицилийский
1/72
сценарий
1/144
скрипичный лист
1/288
scrupulum
китайский
Китайцы написали Девять
Главы по математическому искусству , датируемые примерно 100 годом до н. Э.С.
Он включает текст о дробях, аналогичный тем, которые мы используем сегодня.
Согласно Math Through the Ages , он содержал большинство обычных правил вычисления с дробями, например, как складывать, делить и умножать дроби, а также сокращать дробь до наименьшего значения.
Однако в их системе не использовались неправильные дроби. Например, вместо неправильной дроби 9/4 они использовали бы ее эквивалентную смешанную дробь 2 1/4.
В отличие от западной математики, китайцы сосредоточились на практических приложениях, а не на теоретических рассуждениях и геометрии.
Индейцы
Индейцы разработали способ записи дробей,
ближе к тому, что мы используем сегодня.
До 1000 г. до н.э. индуистские мантры в ранний ведический период вызывали силы от десяти до ста и даже до триллиона, согласно сайту The Story of Mathematics. Это свидетельство того, что ранняя индийская цивилизация использовала сложные математические операции, включая дроби, квадраты, кубы и корни.
Около 500 г. до н. Э. Они изобрели систему письма, называемую брахми, которая состояла из 9 цифровых символов и нуля. Учитель математики и писатель Лиз Памфри отмечает, что эти числа во многом повлияли на современные числа, которые мы используем сегодня. См. Изображение ниже.
Индийская система записывала дроби, помещая одно значение поверх другого, точно так же, как сегодня числитель пишется над знаменателем. Однако они не поставили между ними черту. Например, дробь 4/5 будет выглядеть так:
Позже эту систему использовали арабы при торговле с индейцами.Именно арабы нарисовали черту, чтобы отличить верхнее число от нижнего числа в дроби. В конечном итоге это привело к тому, что в современную эпоху мы пишем дроби.
Как дроби улучшают способ передачи информации
По словам доктора Петерсона из MathForum.org: «дроби были изобретены, чтобы обеспечить способ работы с величинами меньше единицы».
Если люди использовали только целые числа, единственный способ сослаться на
меньшие количества — использовать меньшие единицы.Это то, что сделали римляне — они
использовали целые числа при измерении футов и использовали дюймы, когда им нужно было
учитывать меньшие единицы.
Например, вместо 1/12 фута они будут обозначать длину как 1 дюйм, а 1/4 фута будет 3 дюйма. Но что, если вы имеете в виду 2 с половиной фута? Как насчет 1 и 3/4 фута?
Если вы выбираете стандартную длину в соответствии с футами, это
сбивает с толку одновременное упоминание футов и дюймов. По сути,
фракции позволяют проводить измерения без необходимости создания
новые юниты.Было бы лучше учесть измерения в
последовательная мода.
США, как правило, больше используют дроби (английское измерение), поскольку они используют чашки, а не весы для измерения при приготовлении пищи и выпечке.
американцев еще не приняли метрическую систему, которая является
десятичная система, в которой используются единицы, относящиеся к десятичному коэффициенту.
Метрическая система обычно использует граммы и литры вместо американских единиц измерения.
за унции, чашки, пинты и так далее.
В таблице ниже показано преобразование объема из английской единицы измерения в ее метрический эквивалент:
Преобразование объемов из США в метрическую систему
Обычное количество в США (на английском языке)
Метрический эквивалент
1 чайная ложка
5 мл
1 столовая ложка
15 мл
2 столовых ложки
1/4 стакана или 2 жидких унции
60 мл
1/3 стакана
80 мл
1/2 стакана или 4 жидких унции
125 мл
2 / 3 стакана
160 мл
3/4 стакана или 6 жидких унций
180 мл
1 стакан или 8 жидких унций или 1/2 пинты
250 мл
1 ½ стакана или 12 жидких унций
375 мл
2 c ИБП или 1 пинта или 16 жидких унций
500 мл
3 чашки или 1 ½ пинты
700 мл
4 чашки или
или
литра 950 мл
4 литра или 1 галлон
3.8 л
1 унция
28 граммов
1/4 фунта (4 унции)
112 граммов
1/2 фунта (8 унций)
225 граммов
3/4 фунта (12 унций)
337 грамм
1 фунт (16 унций)
450 грамм
Кроме того, сохранение измерений в одной единице позволяет нам складывать, вычитать, умножать и легко делить дроби.Это устраняет проблему преобразования, которая невозможна при измерении между двумя разными единицами.
Чтобы упростить вычисление дробей, воспользуйтесь калькулятором в верхней части этой страницы.
В то время как десятичные дроби предоставляют альтернативный способ обозначения
дроби (и более простой способ вычисления дробей с помощью калькулятора), это
необходимо понимать традиционные дроби и то, как их значения влияют на
целое число.
По данным Thoughtco.com,
студенты, которые не осваивают дроби в ранние годы, имеют тенденцию
запутаться и испытать математическое беспокойство.Они также упомянули половину американской восьмерки
грейдеры не могут расположить дроби по значению.
Интуитивное обучение дробям помогает детям развить более широкое понимание теоретических математических концепций, позволяя им использовать их в реальной жизни. Это намного лучше, чем запоминать таблицы с единицами измерения или символами.
Золотое сечение и последовательность Фибоначчи
В математике соотношение — это, по сути, сравнение двух
числа, которые зависят от типа сравниваемых чисел.
Вы можете встретить такой пример: 1: 3 или 1
из 3. Например, бутылка концентрата апельсинового сока состоит из 1 части апельсина.
сок и 3 части воды. Это также можно записать в виде дроби, 1/3.
Коэффициенты относятся к дробям, потому что они сравнивают разные
ценности, которые могут представлять собой целое. В этом примере бутылка целиком
апельсинового сока.
Золотое сечение
— специальное число, представленное греческим символом фи ( φ )
с приблизительным значением 1.618.
Получается путем разделения линии на 2 части, так что длинный отрезок
(а) деленная на короткую часть (б) равна всей длине, разделенной на
длинный раздел.
Чтобы дать вам лучшее представление, вот иллюстрация со стандартным уравнением:
Исторически сложилось так, что соотношение соблюдалось в древних
такие сооружения, как Парфенон и пирамиды Египта. В Великой пирамиде
Гизы отношение основания к высоте примерно 1.5717, что является
близко к золотому сечению. Он также встречается в повторяющихся закономерностях в природе, таких как
как лепестки цветов, ракушки, ветви деревьев и спиральные галактики.
С другой стороны, Фибоначчи
последовательность — еще одна известная математическая формула. Последовательность получена из
сумма двух предшествующих чисел. Многие источники говорят, что Леонардо Фибоначчи
(Леонардо Пизанский) популяризировал его в своей книге Liber Abacci .
Но согласно Live Science,
математик Кейт Девлин, автор книги Finding Fibonacci: The Quest to
«Откройте для себя заново забытого математического гения, который изменил мир, », — говорится в заявлении.
что Леонардо Фибоначчи на самом деле не «открыл» последовательность.
Древние санскритские письма, в которых использовались индо-арабские цифры
системы были первыми, кто обсудил это за столетия до Леонардо Фибоначчи.
Когда математики создают квадраты на основе этой последовательности, они могут нарисовать спираль.
Как золотое сечение связано с последовательностью Фибоначчи?
Исследователи заметили, что когда вы берете любые два последовательных числа Фибоначчи, их отношение очень близко к золотому сечению.Таким образом, φ составляет приблизительно 1,618. Чтобы дать вам представление, см. Таблицу ниже.
A
B
B / A
2
3
1,5
3
5
1,6666668 9067
8
13
1,625
Итог
Понятие дроби разработали разные древние цивилизации.Одними из первых, кто изобрели дробную систему с обширными таблицами, были египтяне. Другие древние общества, такие как вавилоняне, греки, римляне и китайцы, также внесли свой вклад в его улучшение. Но на современные цифры и то, как мы пишем дроби, в основном повлияли индейцы, которые ввели индуистско-арабскую систему счисления.
Использование дробей помогает нам легко передавать информацию об измерениях. Это не позволяет людям использовать разные единицы измерения, что упрощает их расчет.
Наконец, дроби связаны со знаменитым золотым рационом и последовательностью Фибоначчи, которая во многом повлияла на то, как мы проектируем все виды структур.
Об авторе
Корин — страстный исследователь и автор финансовых тем, изучающий экономические тенденции, их влияние на население, а также то, как помочь потребителям принимать более мудрые финансовые решения. Другие ее тематические статьи можно прочитать на Inquirer.net и Manileno.com. Она имеет степень магистра творческого письма в Филиппинском университете, одном из ведущих учебных заведений в мире, и степень бакалавра коммуникационных искусств в колледже Мириам.
Веселые мультфильмы по математике
Калькулятор дробей
— умножение, деление, сложение и вычитание
Эта страница содержит калькулятор дробей . Введите две дроби и выберите, нужно ли сложить, вычесть, умножить или разделить дроби. Мы выполним математику по вашему выбору и позволим инструменту вернуть вам простейшую форму дроби.
Дроби Арифметический калькулятор
Что такое дроби?
Дроби — это два числа, выраженные как часть целого.Они состоят из верхнего числа (числитель) и нижнего числа (знаменатель) и подразумевают деления .
дробь \ form = \ frac {числитель} {знаменатель}
Арифметика дроби
Для четырех основных арифметических функций — сложение , вычитание , деление и умножение — есть основные правила, которым нужно следовать при работе с дробями. Я проведу вас по каждому из них и покажу пример.
Сложение дробей
Чтобы сложить две дроби:
Сначала преобразуйте обе дроби в общее основание, умножив верхнюю и нижнюю части на одно и то же число, чтобы получить основание.(Вы можете найти наименьший общий знаменатель или лениво перемножить все знаменатели вместе).
Сложите два числителя и поместите результат в новый числитель.
Сложите два знаменателя и поместите результат в новый знаменатель.
(Необязательно) Найдите сокращенную или простейшую форму дроби.
Сначала преобразуйте обе дроби в общее база.Затем вам нужно умножить верхнее и нижнее числа на одно и то же число, чтобы получить основание. (Либо найдите наименьший общий знаменатель, либо просто умножьте знаменатели вместе).
Вычтите второй числитель из первого, поместив результат в новый числитель.
Вычтите второй знаменатель из первого, поместив результат в новый знаменатель.
(Необязательно) Найдите сокращенную или простейшую форму дроби.

 На этой странице вы найдёте калькулятор,
который поможет решить любой вопрос, в том числе и y корень x 2. Просто введите задачу в окошко и нажмите
«решить» здесь (например, корень из x 2 y 2).
На этой странице вы найдёте калькулятор,
который поможет решить любой вопрос, в том числе и y корень x 2. Просто введите задачу в окошко и нажмите
«решить» здесь (например, корень из x 2 y 2).
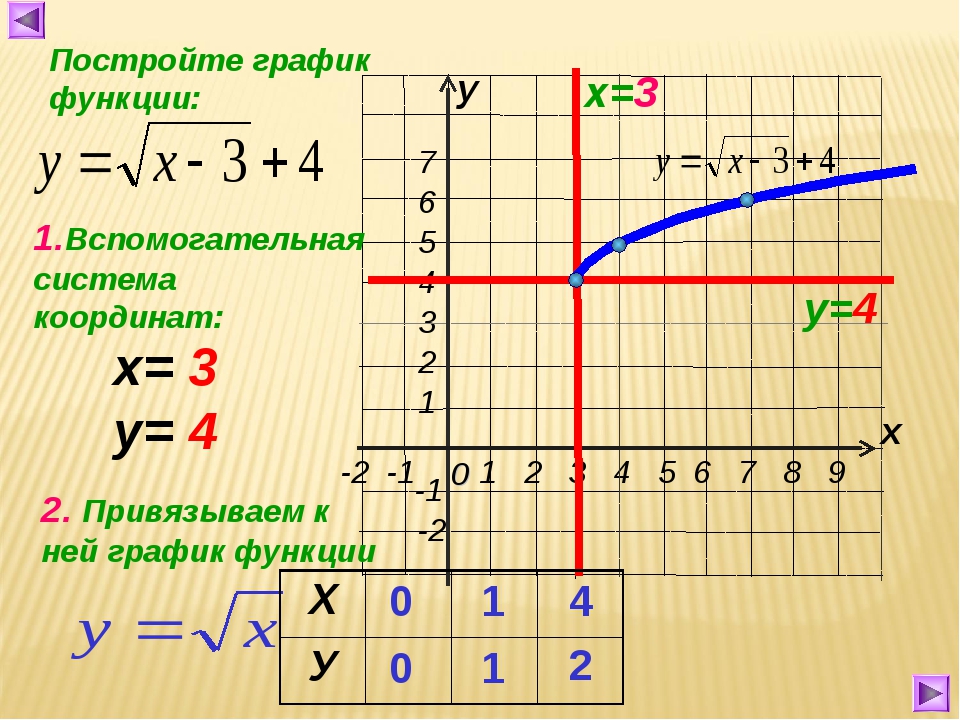
 Для этого нужно углубить знания данной статьей. Будут рассмотрены различные сложнейшие комбинации функций вида y=x+x-2 или y=5·x2+1·x3, y=xx-5 или y=x-15-3. Рассмотрим теорию и решим несколько примеров с подобными заданиями.
Для этого нужно углубить знания данной статьей. Будут рассмотрены различные сложнейшие комбинации функций вида y=x+x-2 или y=5·x2+1·x3, y=xx-5 или y=x-15-3. Рассмотрим теорию и решим несколько примеров с подобными заданиями.
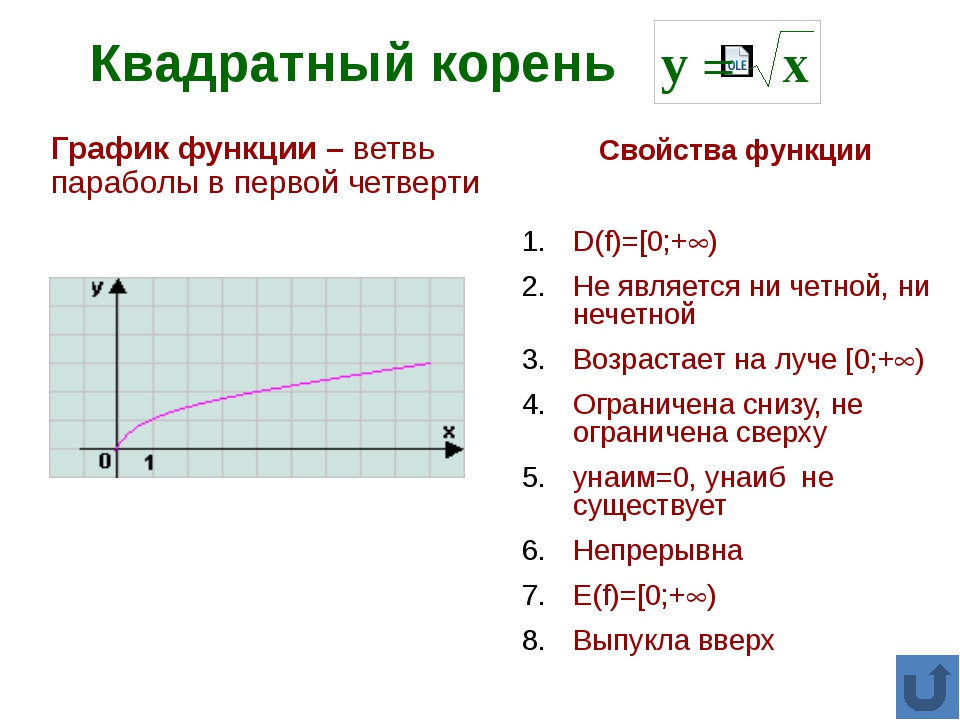
 Значит запись примет вид x2−5·x+6≥0. После решения неравенства получим, что имеются две точки, которые делят область определения на отрезки, которые записываются как (−∞, 2]∪[3, +∞).
Значит запись примет вид x2−5·x+6≥0. После решения неравенства получим, что имеются две точки, которые делят область определения на отрезки, которые записываются как (−∞, 2]∪[3, +∞).

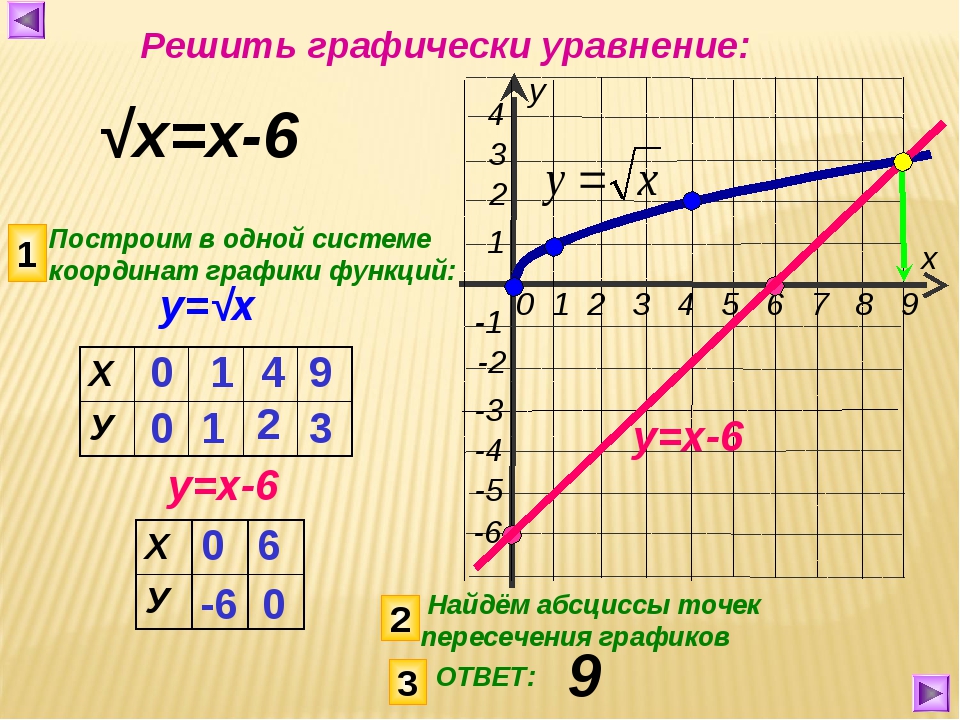

 Известно, что D(f)является множеством всех x из определения функции f2, где область определения f2(x) принадлежит области определения f1.
Известно, что D(f)является множеством всех x из определения функции f2, где область определения f2(x) принадлежит области определения f1.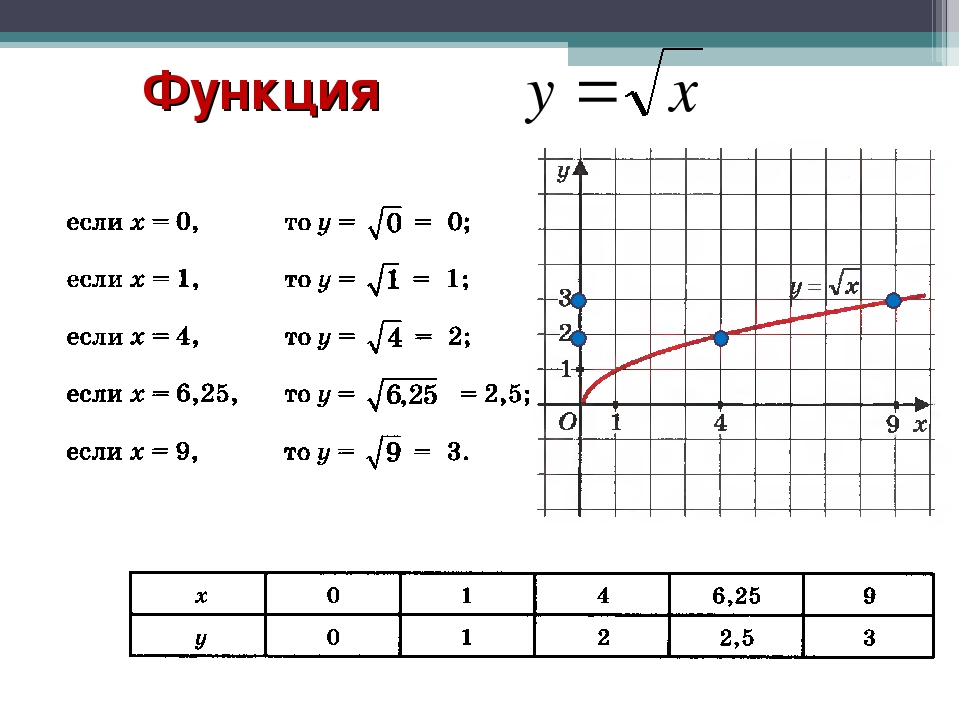


 Отсюда видно, что функция y=logf2(x)f1(x) имеет область определения, которая выглядит так:
Отсюда видно, что функция y=logf2(x)f1(x) имеет область определения, которая выглядит так: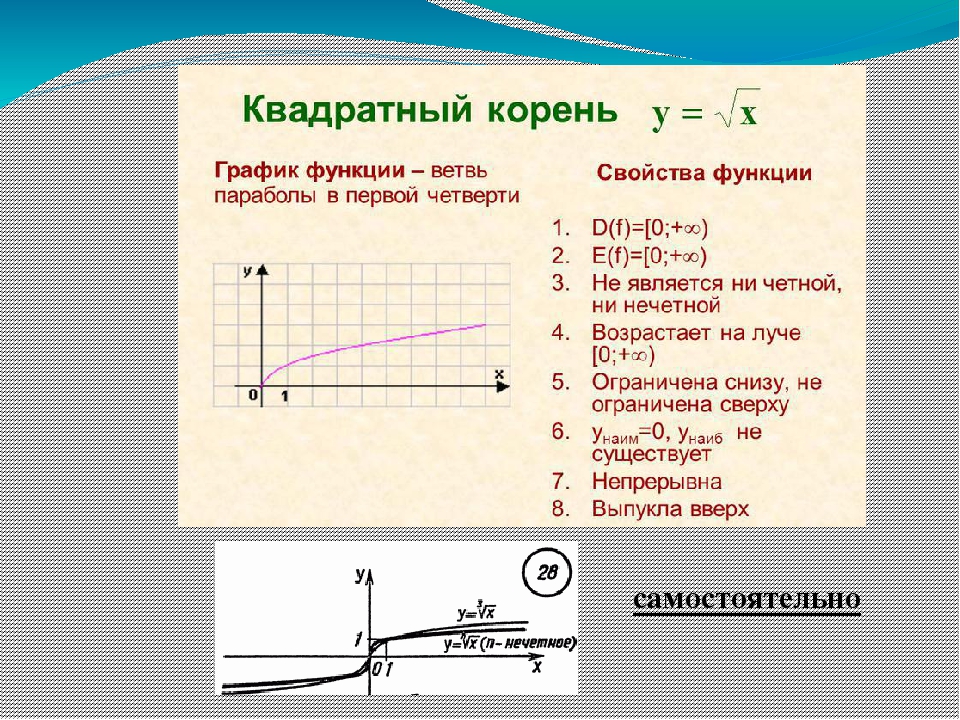 Необходимо приступить к поиску множества x, где выполняется условие x∈D(f1), f1(x)>0, x∈D(f2), f2(x)>0, f2(x)≠1. Тогда получаем систему вида
Необходимо приступить к поиску множества x, где выполняется условие x∈D(f1), f1(x)>0, x∈D(f2), f2(x)>0, f2(x)≠1. Тогда получаем систему вида
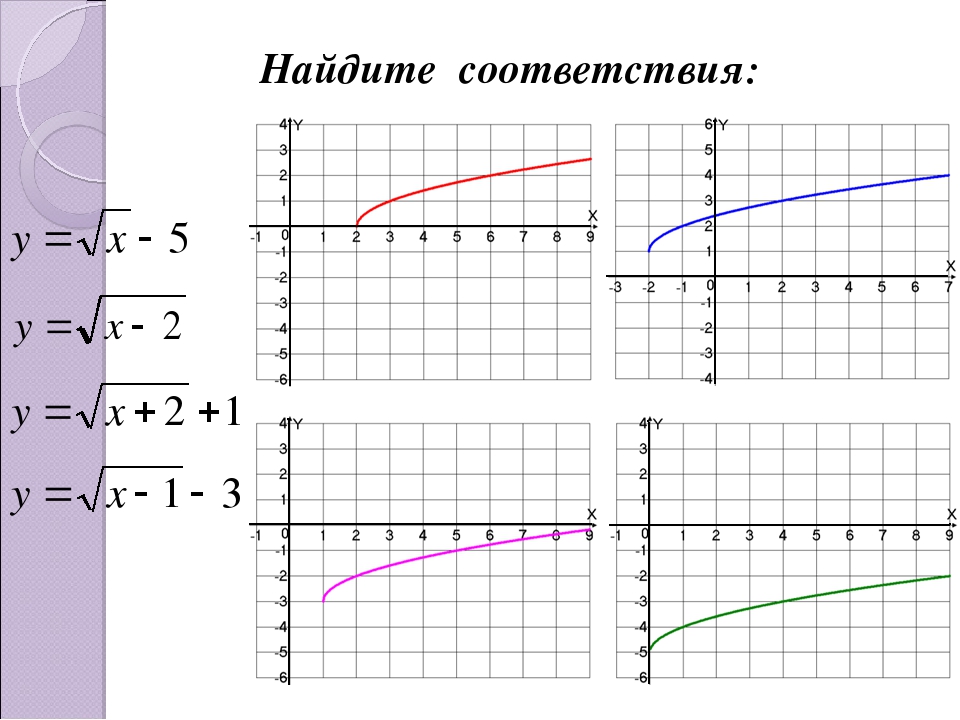 Области определения сложных и дробных функций нередко вызывают сложность. Благодаря выше указанным правилам можно правильно определять ОДЗ и быстро решать задание на области определения.
Области определения сложных и дробных функций нередко вызывают сложность. Благодаря выше указанным правилам можно правильно определять ОДЗ и быстро решать задание на области определения.
 Отсюда видно, что допускаются тождественные преобразования, которые на область определения не влияют. Например, y=x2-4x-2 и y=x+2 являются разными функциями, так как первая определяется на (−∞, 2)∪(2, +∞), а вторая из множества действительных чисел. Из преобразования y=x2-4x-2=x-2x+2x-2=x+2 видно, что функция имеет смысл при x≠2.
Отсюда видно, что допускаются тождественные преобразования, которые на область определения не влияют. Например, y=x2-4x-2 и y=x+2 являются разными функциями, так как первая определяется на (−∞, 2)∪(2, +∞), а вторая из множества действительных чисел. Из преобразования y=x2-4x-2=x-2x+2x-2=x+2 видно, что функция имеет смысл при x≠2. А в конце урока обобщим понятие на уровне теории. Пока же —
краткое определение. Область определения функции y=f(x)
— это множество значений X, для которых существуют значения Y.
А в конце урока обобщим понятие на уровне теории. Пока же —
краткое определение. Область определения функции y=f(x)
— это множество значений X, для которых существуют значения Y. Как найти область
определения функции игрек равен квадратному корню из икса минус пять (подкоренное выражение икс минус пять)
()? Нужно всего лишь
решить неравенство
Как найти область
определения функции игрек равен квадратному корню из икса минус пять (подкоренное выражение икс минус пять)
()? Нужно всего лишь
решить неравенство Это можно записать и так:
областью определения данной функции является вся числовая прямая ]- ∞; + ∞[.
Это можно записать и так:
областью определения данной функции является вся числовая прямая ]- ∞; + ∞[.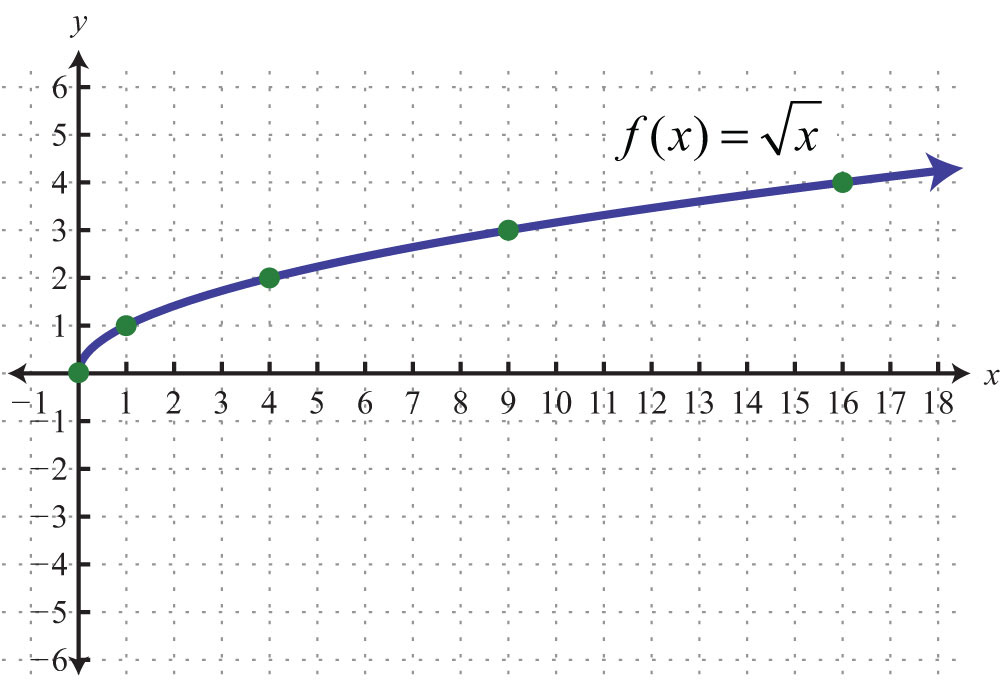 Следовательно, область определения данной функции — [- 1; 1].
Следовательно, область определения данной функции — [- 1; 1].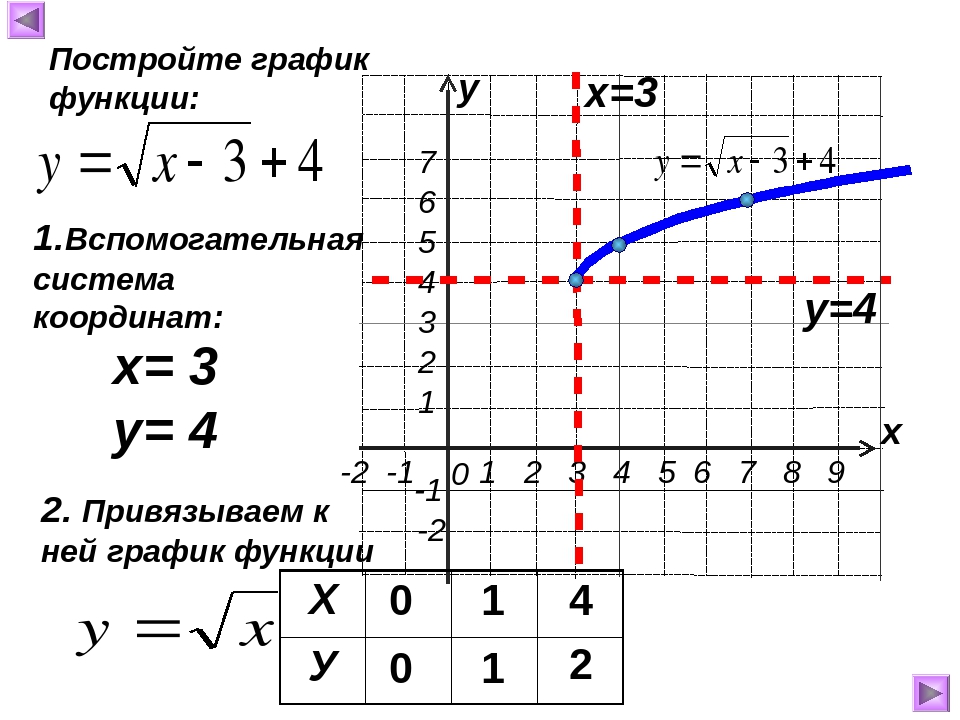

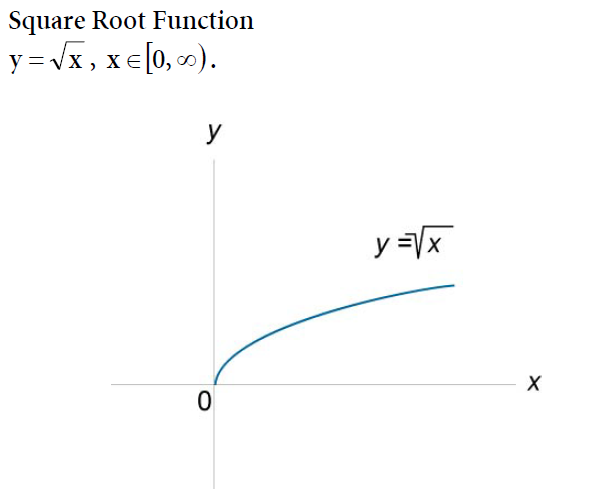

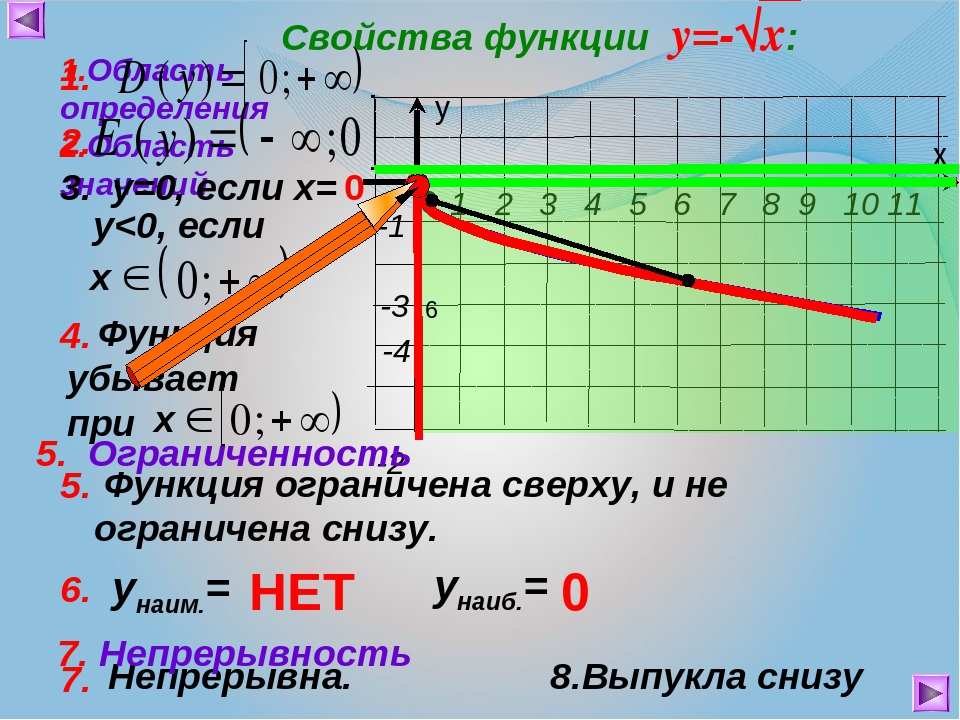 Найти область определения функции
.
Найти область определения функции
. Но функция определена только на действительных
числах. Таким образом, получаем область определения данной функции — вся числовая прямая или, что
то же самое — множество R действительных чисел или,
что то же самое — ]- ∞; + ∞[.
Но функция определена только на действительных
числах. Таким образом, получаем область определения данной функции — вся числовая прямая или, что
то же самое — множество R действительных чисел или,
что то же самое — ]- ∞; + ∞[.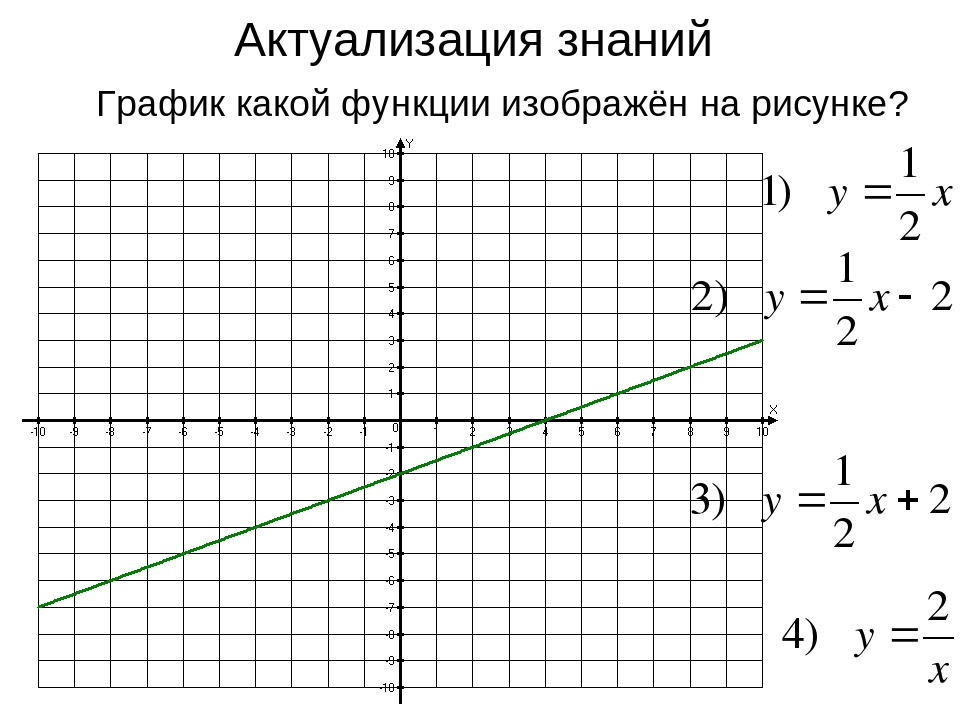 Как следует из решения квадратного уравнения, парабола пересекает ось Ox в точках
1 и 2. Между этими точками линия параболы находится ниже оси Ox, следовательно значения
квадратичной функции между этими точками отрицательное. Таким образом, исходная функция не определена
на отрезке [1; 2].
Как следует из решения квадратного уравнения, парабола пересекает ось Ox в точках
1 и 2. Между этими точками линия параболы находится ниже оси Ox, следовательно значения
квадратичной функции между этими точками отрицательное. Таким образом, исходная функция не определена
на отрезке [1; 2].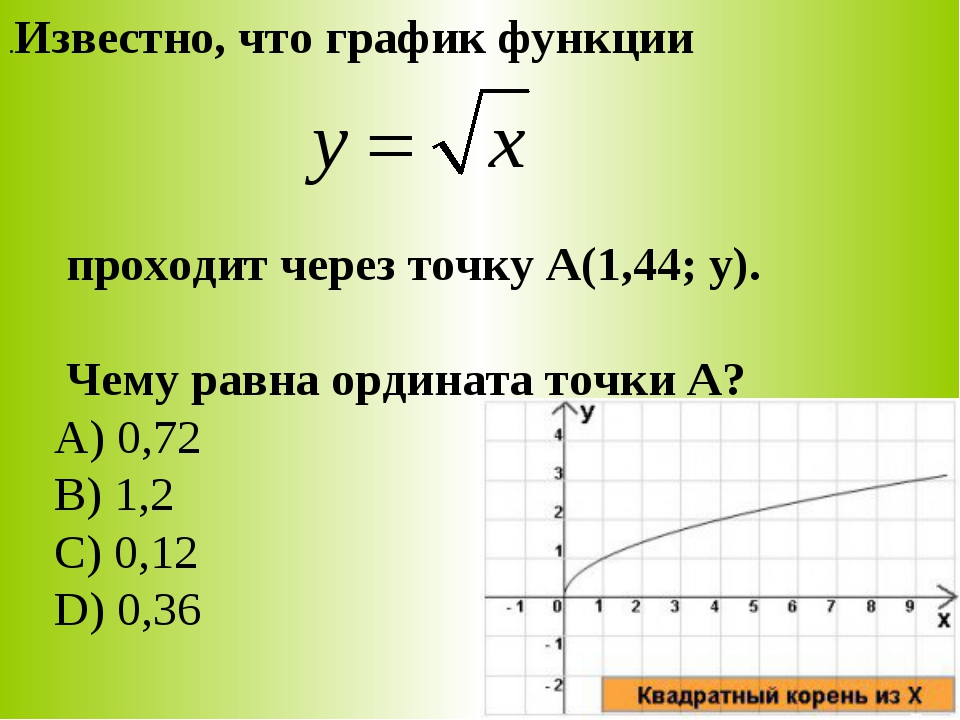 Иначе говоря, множество значений аргумента, на котором
«функция работает».
Иначе говоря, множество значений аргумента, на котором
«функция работает».
 Основание а – заданное число.
Основание а – заданное число.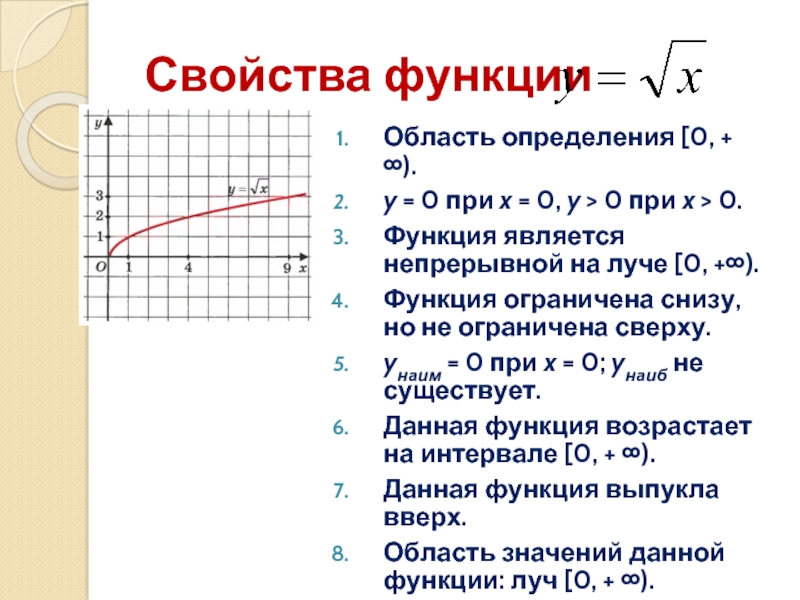


 д.
д.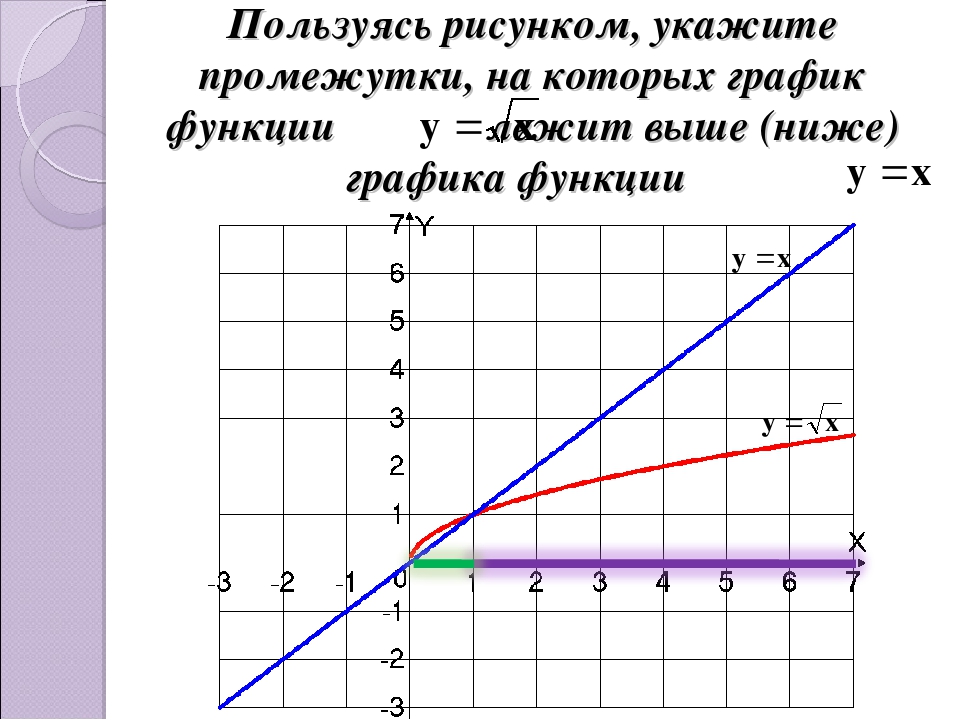
 С.
С. В конце урока мы проверим ваши знания с помощью теста.
В конце урока мы проверим ваши знания с помощью теста.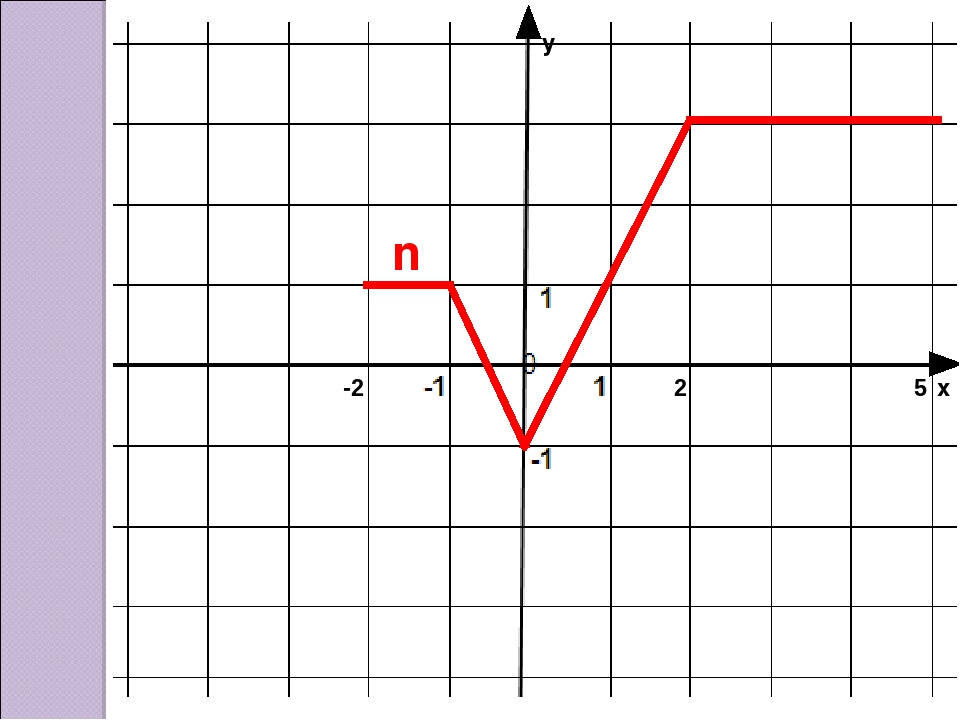
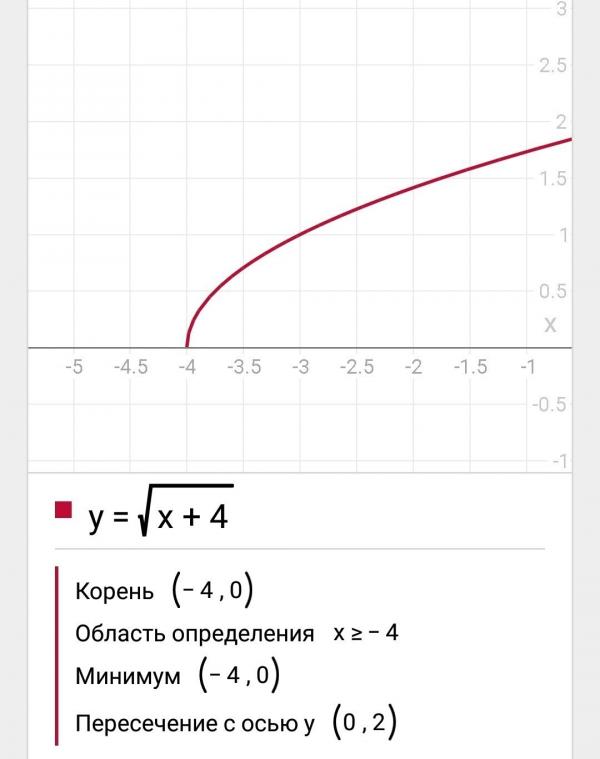
 Если задания будут выполнены верно, то вы получите фамилию математика. (ДЕКАРТ).
Если задания будут выполнены верно, то вы получите фамилию математика. (ДЕКАРТ).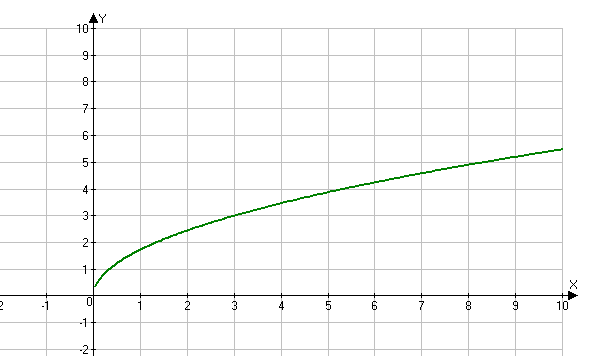 Домашнее задание: §15 прочитать, выучить свойства функции,
Домашнее задание: §15 прочитать, выучить свойства функции,  Укажите его домен и диапазон.
Укажите его домен и диапазон.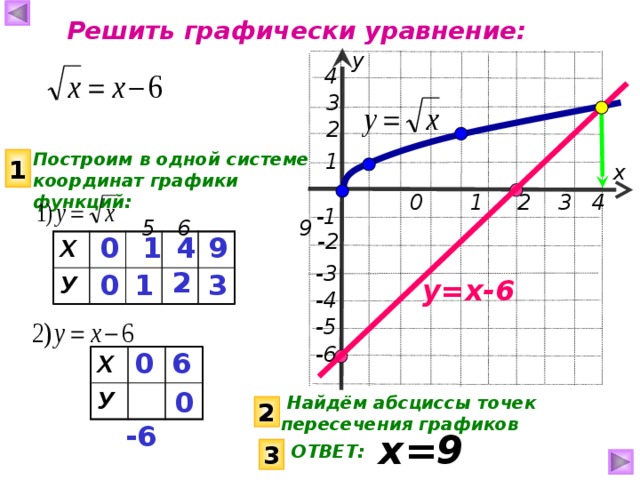 Однако вы должны сделать это с обеими сторонами уравнения, чтобы сохранить баланс.
Однако вы должны сделать это с обеими сторонами уравнения, чтобы сохранить баланс.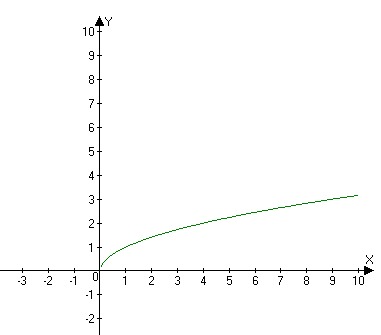
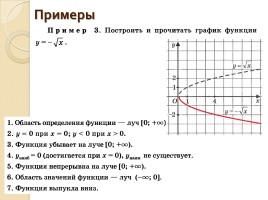 Поступая так, у меня будет плюс или минус. Это ситуация, когда я приму решение, какую из них выбрать в качестве правильной обратной функции. Помните, что обратная функция уникальна, поэтому я не могу позволить получить два ответа.
Поступая так, у меня будет плюс или минус. Это ситуация, когда я приму решение, какую из них выбрать в качестве правильной обратной функции. Помните, что обратная функция уникальна, поэтому я не могу позволить получить два ответа. Укажите его домен и диапазон.
Укажите его домен и диапазон.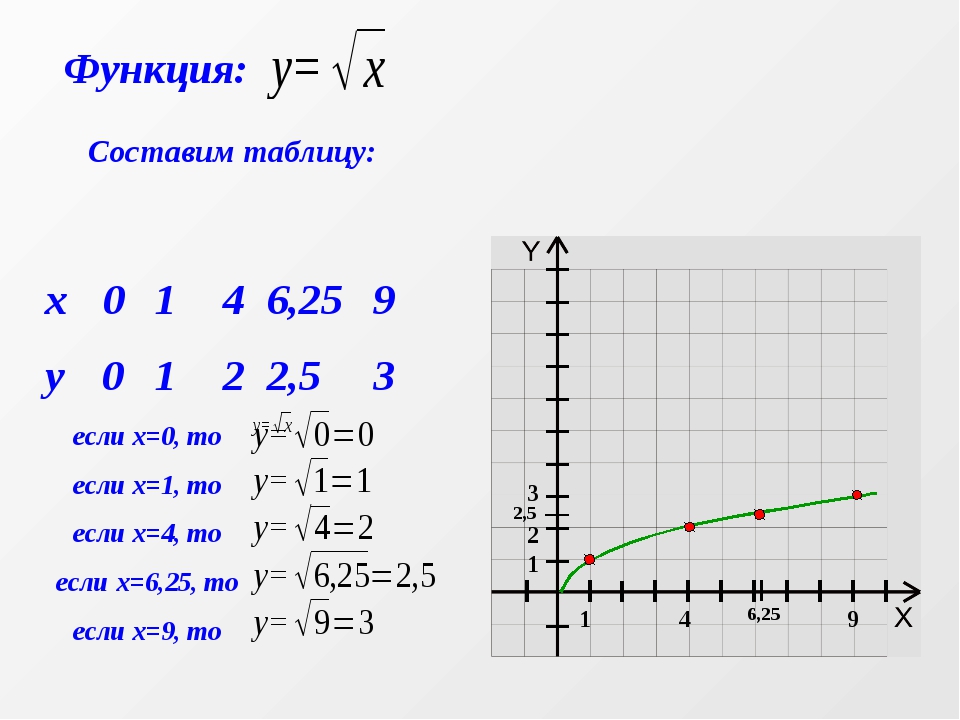 1: Функция квадратного корня
1: Функция квадратного корня Мы поместили эти числа как значения x в таблицу на рис. , рис. 1, (b), а затем вычислили квадратный корень из каждого значения. На рис. 1 (a) каждая точка из таблицы изображена сплошной точкой. Если мы продолжим добавлять точки в таблицу, наносим их на график, график в конечном итоге заполнится и примет форму сплошной кривой, показанной на , рис. 1, (c).2 \), \ (x \ ge 0 \), что изображено на рис. 2 (c). Обратите внимание на точное совпадение с графиком функции квадратного корня в Рисунок 1 (c).
Мы поместили эти числа как значения x в таблицу на рис. , рис. 1, (b), а затем вычислили квадратный корень из каждого значения. На рис. 1 (a) каждая точка из таблицы изображена сплошной точкой. Если мы продолжим добавлять точки в таблицу, наносим их на график, график в конечном итоге заполнится и примет форму сплошной кривой, показанной на , рис. 1, (c).2 \), \ (x \ ge 0 \), что изображено на рис. 2 (c). Обратите внимание на точное совпадение с графиком функции квадратного корня в Рисунок 1 (c).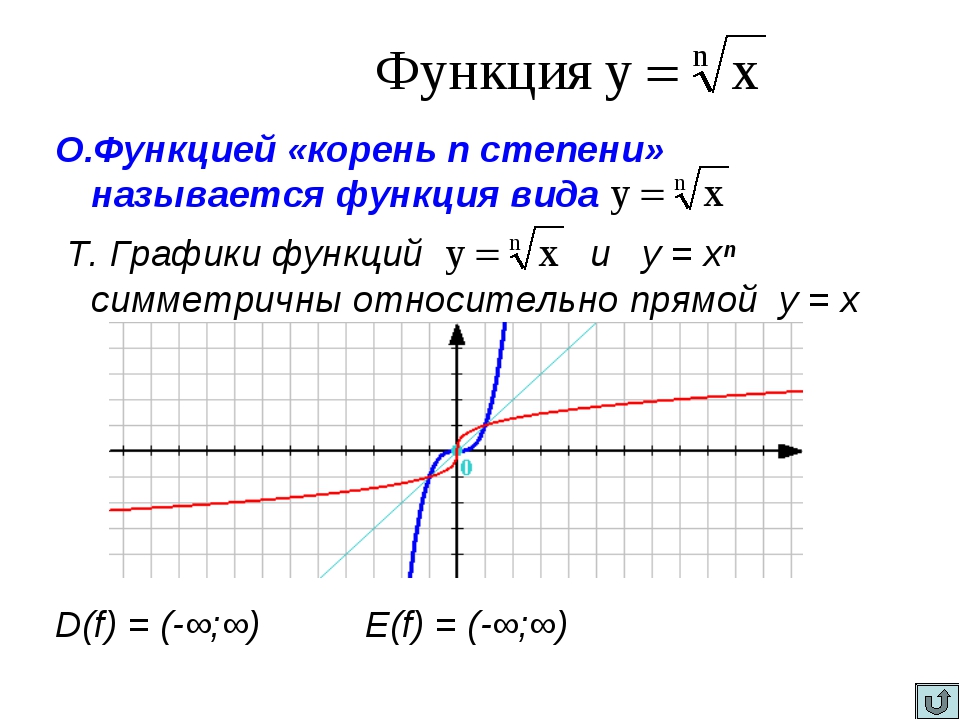 {−1}} = [0, \ infty) \).
{−1}} = [0, \ infty) \).
 Чтобы найти диапазон, мы проецируем каждую точку графика на ось y, как показано на рис. , рис. , , 4, (b).Обратите внимание, что все точки, равные нулю и выше, заштрихованы на оси ординат. Таким образом, диапазон f равен
Чтобы найти диапазон, мы проецируем каждую точку графика на ось y, как показано на рис. , рис. , , 4, (b).Обратите внимание, что все точки, равные нулю и выше, заштрихованы на оси ординат. Таким образом, диапазон f равен Используйте свой график, чтобы определить домен и диапазон f.
Используйте свой график, чтобы определить домен и диапазон f.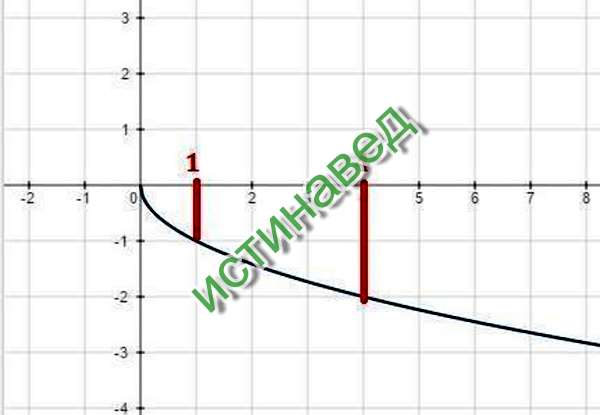 6, (a).Обратите внимание, что все точки справа от — 4 или включая его заштрихованы на оси x . Таким образом, область определения \ (f (x) = \ sqrt {x + 4} + 2 \) равна
6, (a).Обратите внимание, что все точки справа от — 4 или включая его заштрихованы на оси x . Таким образом, область определения \ (f (x) = \ sqrt {x + 4} + 2 \) равна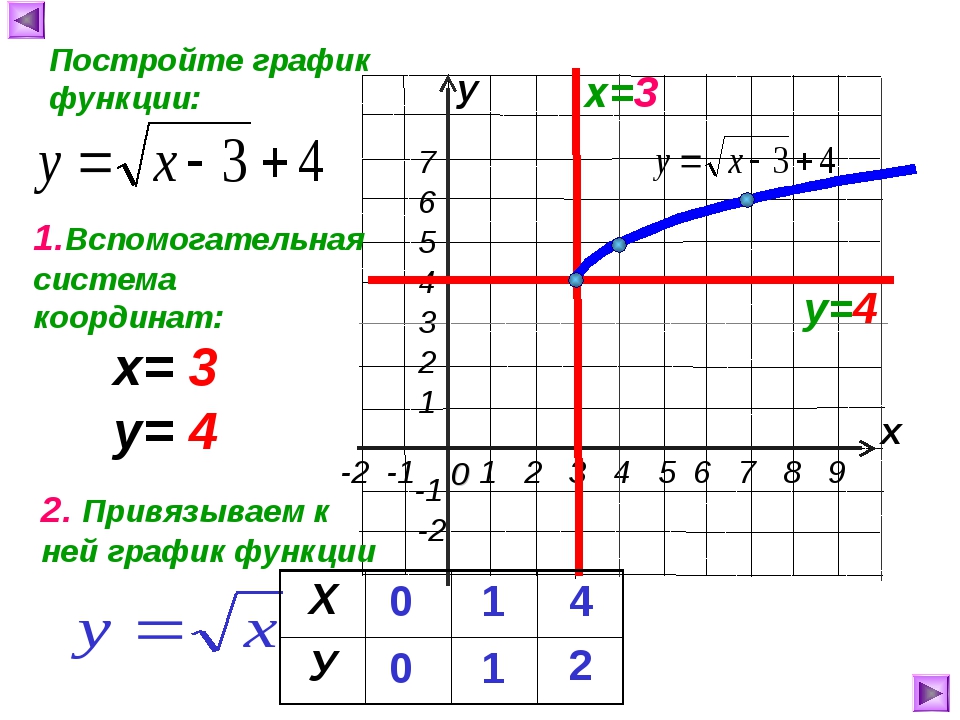
 Используйте полученный график, чтобы определить домен и диапазон f.
Используйте полученный график, чтобы определить домен и диапазон f. 9 (a). Обратите внимание, что все действительные числа, меньшие или равные 4, заштрихованы на оси x . Следовательно, домен f равен
9 (a). Обратите внимание, что все действительные числа, меньшие или равные 4, заштрихованы на оси x . Следовательно, домен f равен 10 (b).
10 (b).
 Обозначьте и масштабируйте каждую ось.
Обозначьте и масштабируйте каждую ось.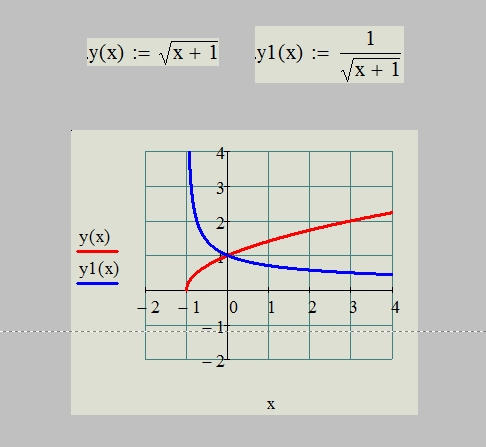


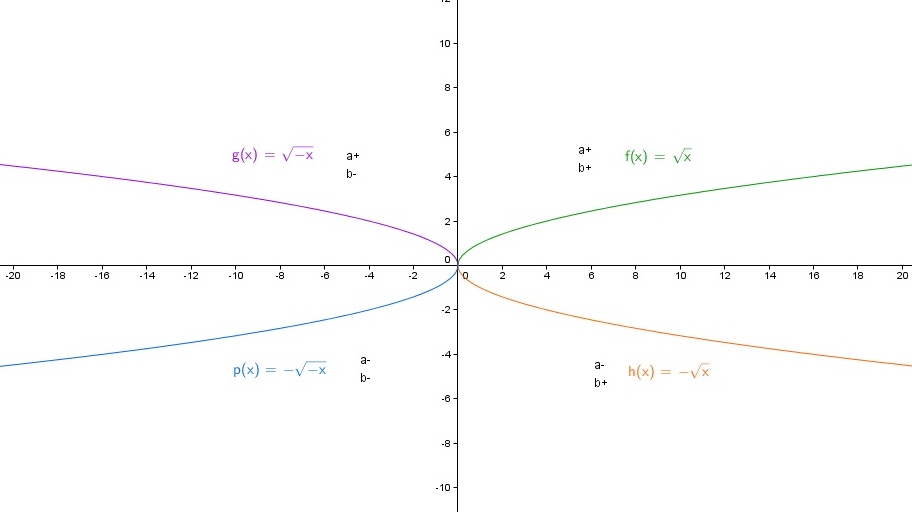
 Используйте обозначение интервала для описания области и диапазона функции.
Используйте обозначение интервала для описания области и диапазона функции.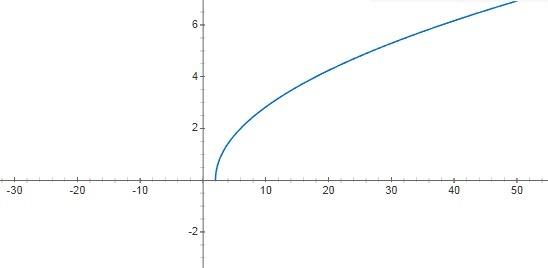 Затем замените x на x — 2, чтобы получить уравнение \ (y = \ sqrt {x − 2} \). Это сдвинет график \ (y = \ sqrt {x} \) вправо на 2 единицы, как показано в (b).
Затем замените x на x — 2, чтобы получить уравнение \ (y = \ sqrt {x − 2} \). Это сдвинет график \ (y = \ sqrt {x} \) вправо на 2 единицы, как показано в (b). Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([1, \ infty) \).
Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([1, \ infty) \).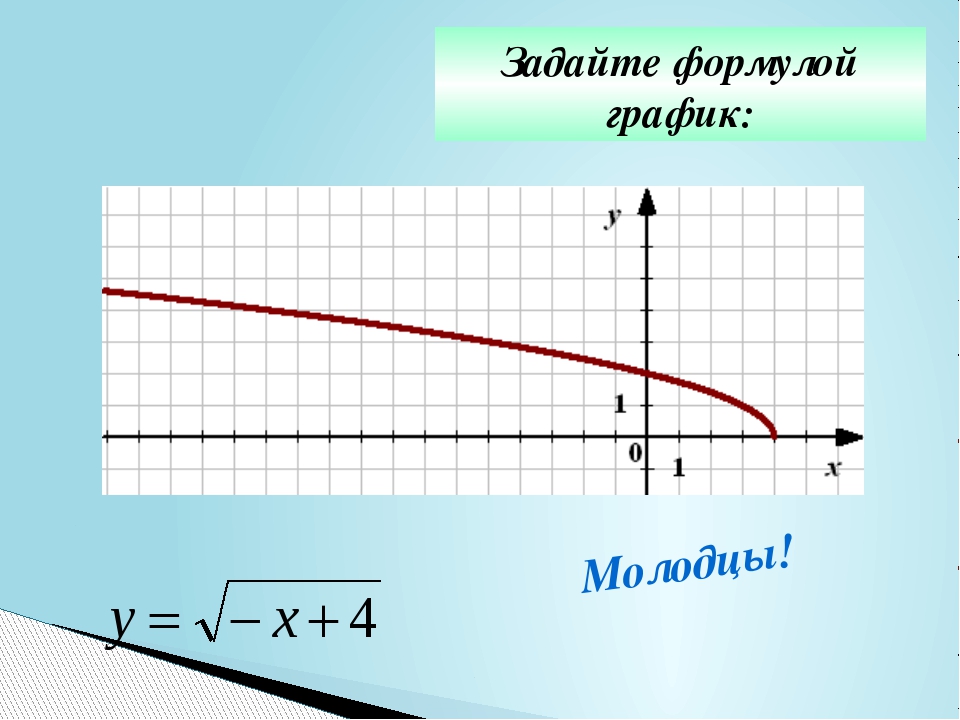 Затем инвертируйте, чтобы получить \ (y = — \ sqrt {x} \). Это отразит график \ (y = \ sqrt {x} \) по оси x, как показано в (b). Наконец, добавьте 3, чтобы получить уравнение \ (y = — \ sqrt {x} +3 \).Это сдвинет график \ (y = — \ sqrt {x} \) на три единицы вверх, как показано в (c).
Затем инвертируйте, чтобы получить \ (y = — \ sqrt {x} \). Это отразит график \ (y = \ sqrt {x} \) по оси x, как показано в (b). Наконец, добавьте 3, чтобы получить уравнение \ (y = — \ sqrt {x} +3 \).Это сдвинет график \ (y = — \ sqrt {x} \) на три единицы вверх, как показано в (c). Обозначьте график соответствующим уравнением.
Обозначьте график соответствующим уравнением.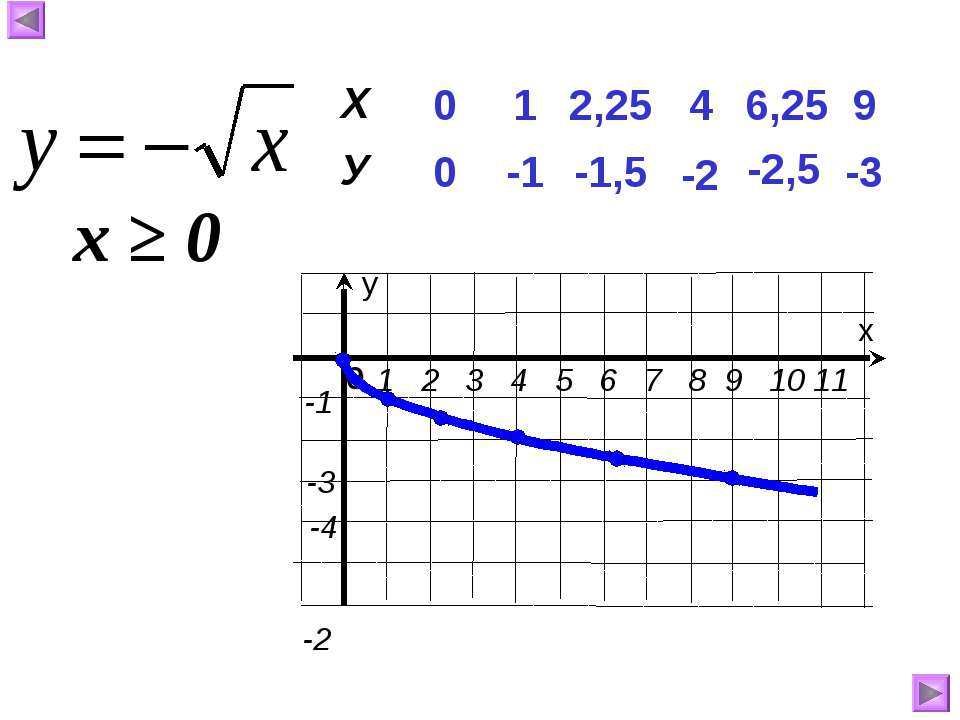 Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([0, \ infty) \).
Спроецируйте все точки на графике на ось Y, чтобы определить диапазон: Range = \ ([0, \ infty) \).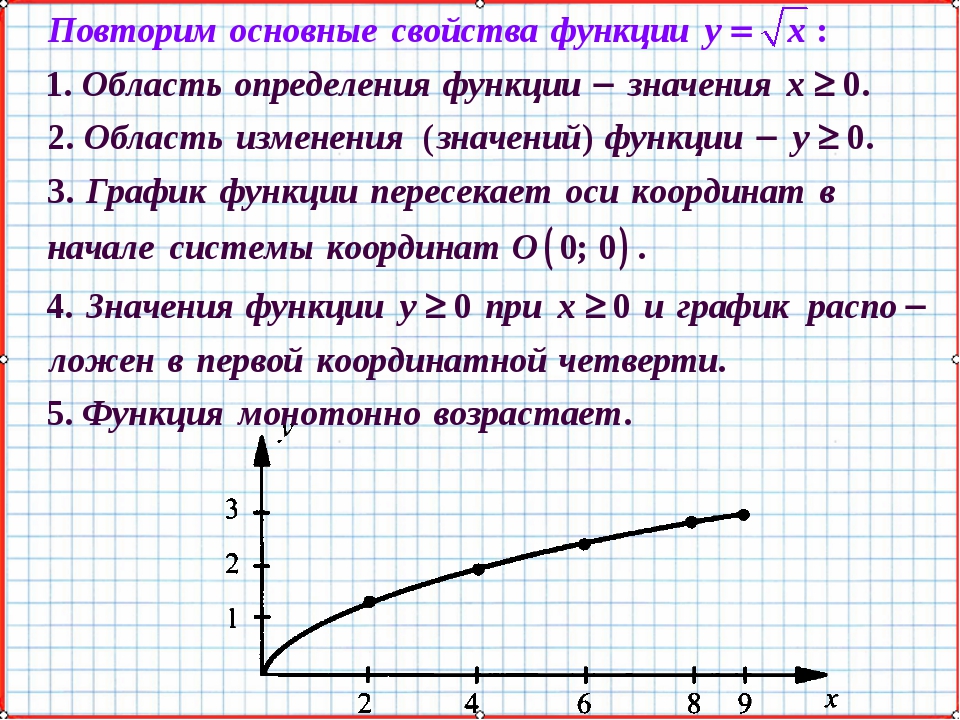
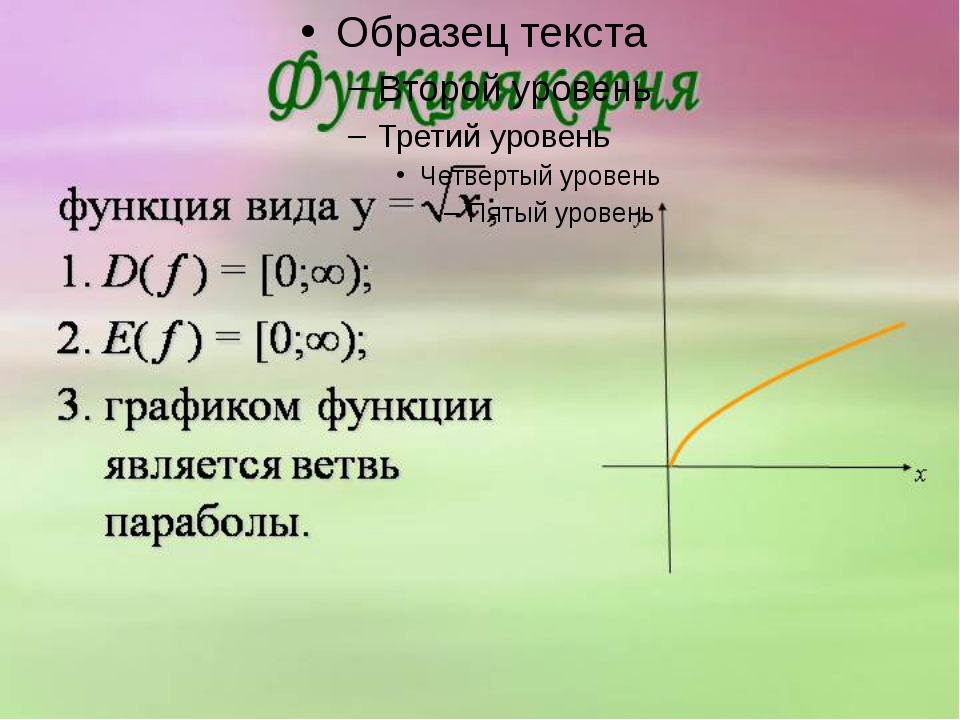 Спроецируйте все точки на графике на ось y, чтобы определить диапазон: Range = \ ([0, \ infty) \).
Спроецируйте все точки на графике на ось y, чтобы определить диапазон: Range = \ ([0, \ infty) \). Скопируйте изображение из окна просмотра на свою домашнюю работу. Обозначьте и масштабируйте каждую ось с помощью xmin, xmax, ymin и ymax. Обозначьте свой график его уравнением.Используйте график, чтобы определить область определения функции и описать область с помощью интервальной записи.
Скопируйте изображение из окна просмотра на свою домашнюю работу. Обозначьте и масштабируйте каждую ось с помощью xmin, xmax, ymin и ymax. Обозначьте свой график его уравнением.Используйте график, чтобы определить область определения функции и описать область с помощью интервальной записи. Следовательно, выражение под корнем в \ (f (x) = \ sqrt {2x + 7} \) должно быть больше или равно нулю.
Следовательно, выражение под корнем в \ (f (x) = \ sqrt {2x + 7} \) должно быть больше или равно нулю.
 Данцигом в 1949 г.
Данцигом в 1949 г. Создадим область переменных
Создадим область переменных Вызовем окно диалога Поиск решения
Вызовем окно диалога Поиск решения А. Исследование
А. Исследование


 Выберите категорию Математические и функцию СУММПРОИЗВ. На экране появится диалоговое окно СУММПРОИЗВ. В строку Массив 1 введем В$3:Е$3, в строку Массив 2 введем В4:Е4 и ОК.
Выберите категорию Математические и функцию СУММПРОИЗВ. На экране появится диалоговое окно СУММПРОИЗВ. В строку Массив 1 введем В$3:Е$3, в строку Массив 2 введем В4:Е4 и ОК. На экране появится окно Поиск решения с введенными условиями.
На экране появится окно Поиск решения с введенными условиями. -384с.
-384с. ru
ru Однако не все предлагаемые ей методы равнозначны при поиске альтернативных оптимальных решений. Кроме того, эффективность поиска зависит от начального приближения целевой функции. Поэтому целью настоящей работы являются выбор наиболее эффективного метода поиска альтернативных оптимальных решений задач линейного программирования с помощью надстройки Excel «поиск решения» и задание наилучших начальных приближений целевой функции.
Однако не все предлагаемые ей методы равнозначны при поиске альтернативных оптимальных решений. Кроме того, эффективность поиска зависит от начального приближения целевой функции. Поэтому целью настоящей работы являются выбор наиболее эффективного метода поиска альтернативных оптимальных решений задач линейного программирования с помощью надстройки Excel «поиск решения» и задание наилучших начальных приближений целевой функции.
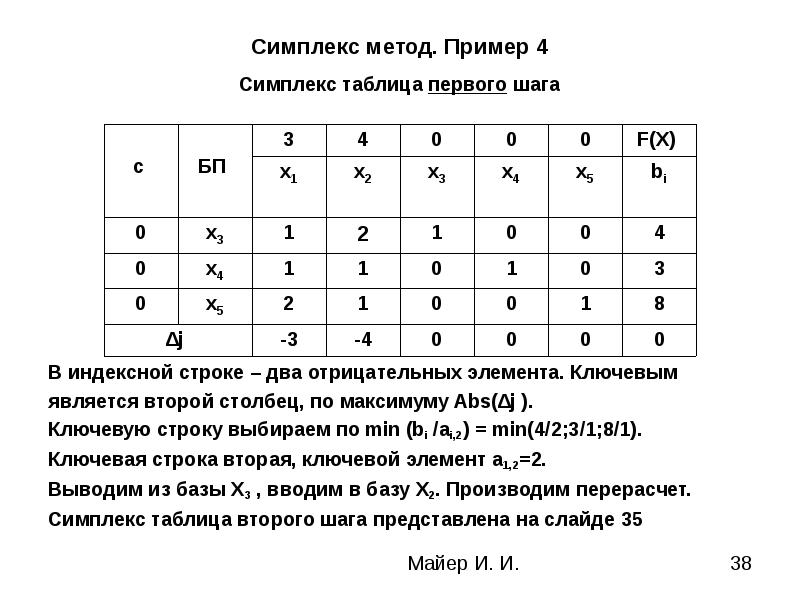
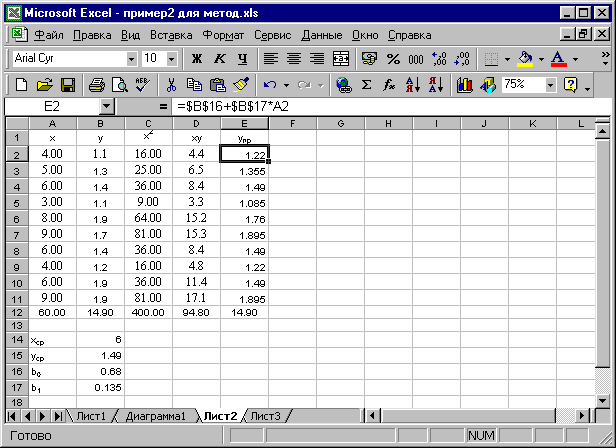 ..» (отчет получают при использовании симплексного метода решения) [8]. Однако, найти эти оптимальные альтернативные решения не так просто, поскольку результат поиска решения зависит от начального приближения и не только. Рассмотрим этот вопрос подробнее. Для этого возьмем несколько конкретных примеров.
..» (отчет получают при использовании симплексного метода решения) [8]. Однако, найти эти оптимальные альтернативные решения не так просто, поскольку результат поиска решения зависит от начального приближения и не только. Рассмотрим этот вопрос подробнее. Для этого возьмем несколько конкретных примеров. Фрагмент листа Excel, заполненный данными из формул (1) и (2)
Фрагмент листа Excel, заполненный данными из формул (1) и (2)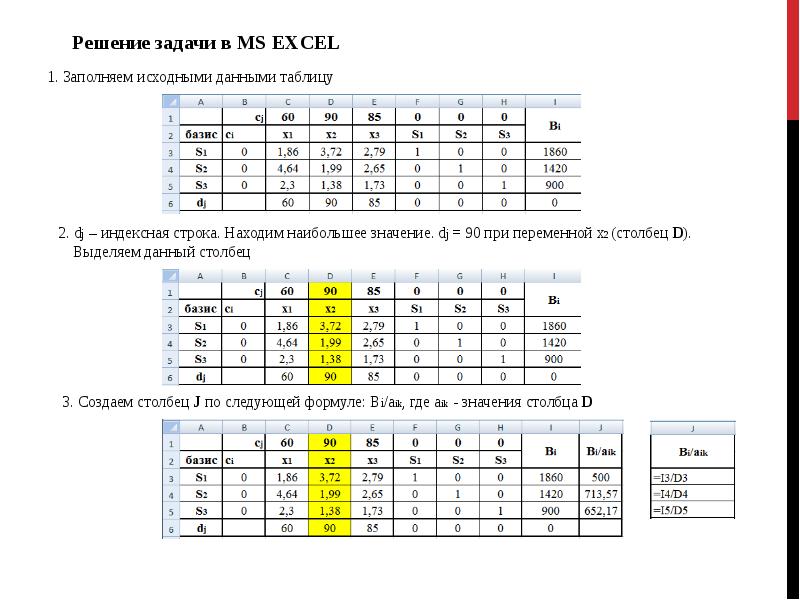


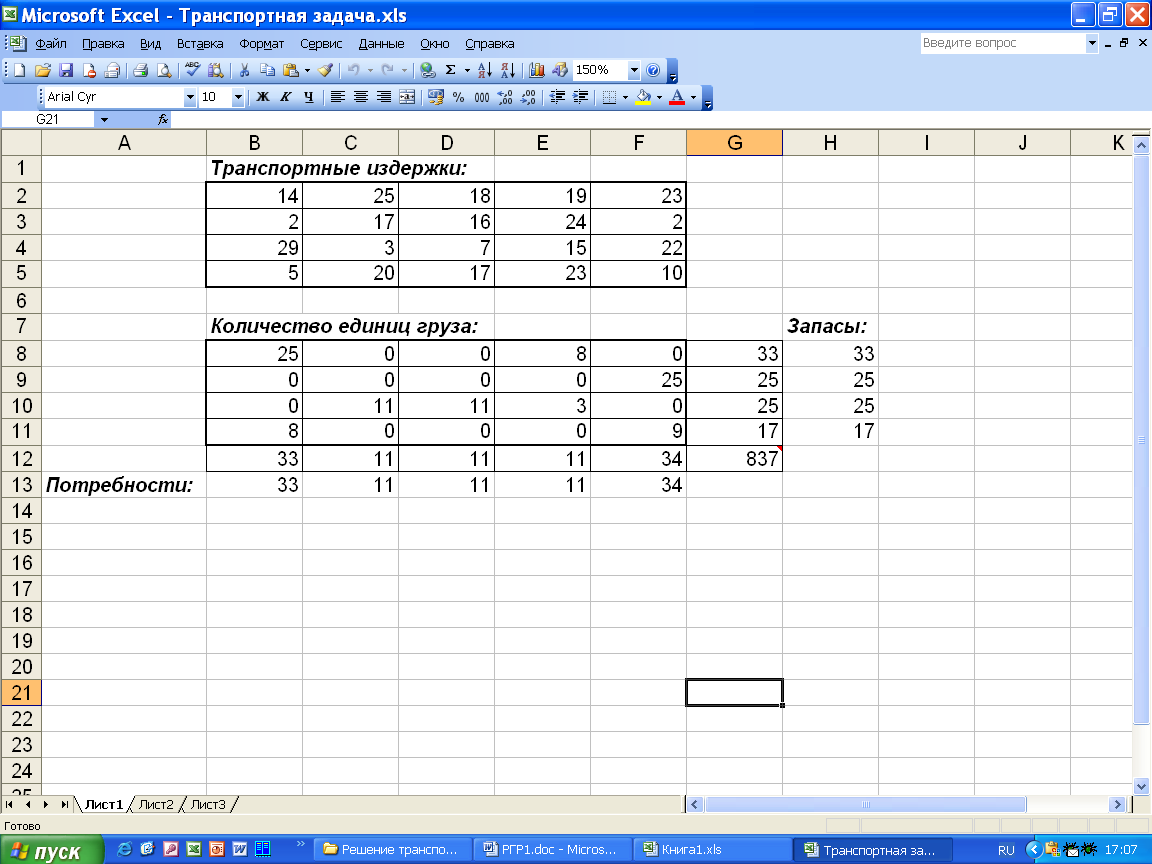 Это указывает на наличие альтернативных оптимальных решений.
Это указывает на наличие альтернативных оптимальных решений.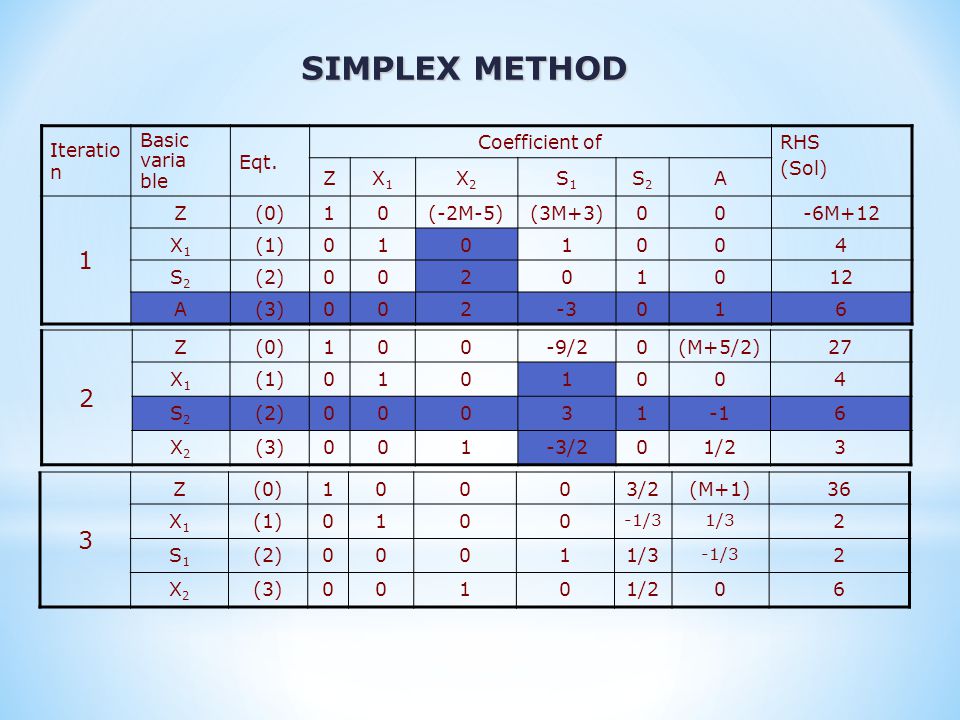 00 Х1= 2.00; Х2=0.00; хз= 2.00
00 Х1= 2.00; Х2=0.00; хз= 2.00 Результаты поместим в таблицу 2.
Результаты поместим в таблицу 2. 00 Х1= 1,27; Х2= 0.00; хз= 2,73
00 Х1= 1,27; Х2= 0.00; хз= 2,73 функции 1 2 3
функции 1 2 3 Результаты поиска поместим в таблицу 3.
Результаты поиска поместим в таблицу 3. 00 Х1= 0.00; х2= 0.00; хз= 3.33
00 Х1= 0.00; х2= 0.00; хз= 3.33 Это позволит сократить затраченное время.
Это позволит сократить затраченное время. А., Елизарова Н.Н. Методы и алгоритмы принятия решений в экономике: учебное пособие. — М.: Финансы и статистика; ИНФРА-М, 2009. -224 с.
А., Елизарова Н.Н. Методы и алгоритмы принятия решений в экономике: учебное пособие. — М.: Финансы и статистика; ИНФРА-М, 2009. -224 с.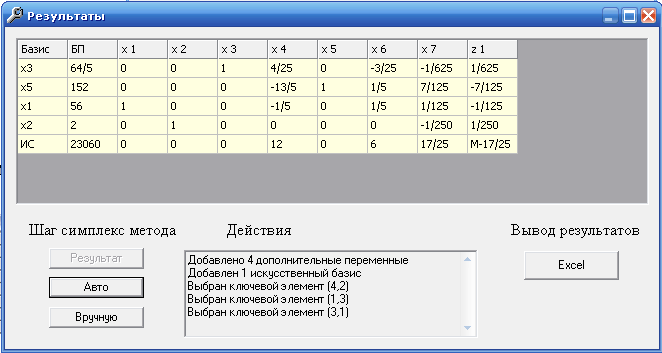 — М.: Эксмо, 2008. 256 с.
— М.: Эксмо, 2008. 256 с. ита! «NAUKOVEDENIE» 2014. №4 http:// http://naukovedenie.ru/PDF/80PVN414.pdf (dostup svobodnyy). Zagl. s екгапа. Yaz. rus.
ита! «NAUKOVEDENIE» 2014. №4 http:// http://naukovedenie.ru/PDF/80PVN414.pdf (dostup svobodnyy). Zagl. s екгапа. Yaz. rus.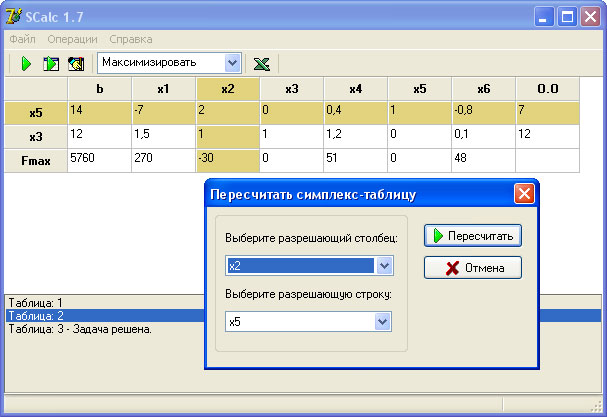 .. и многие другие задачи.
.. и многие другие задачи.  ТЕОРЕТИЧЕСКИЕ ОСНОВЫ СИМПЛЕКСНОГО МЕТОДА РЕШЕНИЯ ЗАДАЧ Л.П.
Методичка, описание решения (скачать 2 документа Word в RAR-архиве — 50кб)
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ СИМПЛЕКСНОГО МЕТОДА РЕШЕНИЯ ЗАДАЧ Л.П.
Методичка, описание решения (скачать 2 документа Word в RAR-архиве — 50кб) Подробнее об этих методах можно прочесть в «Справочнике по высшей математике М.Я. Выгодского»
( см библиотеку)
Подробнее об этих методах можно прочесть в «Справочнике по высшей математике М.Я. Выгодского»
( см библиотеку)
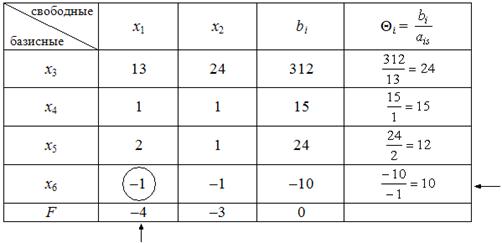 Н. Решение игровых задач с нулевой суммой с помощью Microsoft Excel / Т. Н. Захарова. — Текст : непосредственный // Актуальные задачи педагогики : материалы I Междунар. науч. конф. (г. Чита, декабрь 2011 г.). — Чита : Издательство Молодой ученый, 2011. — С. 176-181. — URL: https://moluch.ru/conf/ped/archive/20/1343/ (дата обращения: 12.06.2021).
Н. Решение игровых задач с нулевой суммой с помощью Microsoft Excel / Т. Н. Захарова. — Текст : непосредственный // Актуальные задачи педагогики : материалы I Междунар. науч. конф. (г. Чита, декабрь 2011 г.). — Чита : Издательство Молодой ученый, 2011. — С. 176-181. — URL: https://moluch.ru/conf/ped/archive/20/1343/ (дата обращения: 12.06.2021).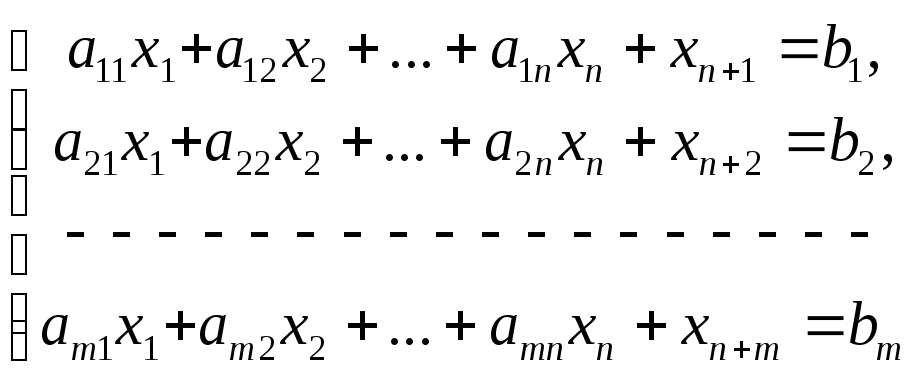

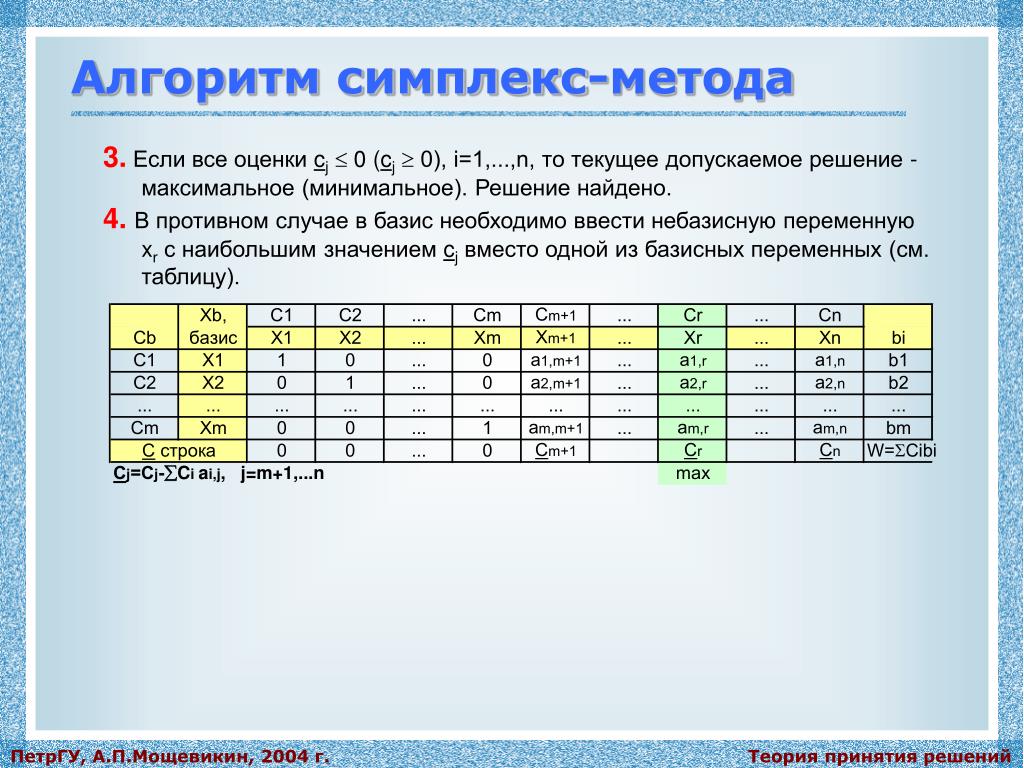
 Параметр shading=opt задает функцию интенсивности заполнителя, его значение равно xyz – по
умолчанию, NONE – без раскраски.
Параметр shading=opt задает функцию интенсивности заполнителя, его значение равно xyz – по
умолчанию, NONE – без раскраски. 2=4.
2=4. 
 п., в которых приходилось уже перерисовывать весь экран, предварительно заготавливая его в памяти, всем нам пришлось обзавестись, по крайней мере, 286 процессором. Но прогресс на этом не остановился. Желание уподобить виртуальный мир в игре реальному миру усилилось, и появился Wolf 3D.
п., в которых приходилось уже перерисовывать весь экран, предварительно заготавливая его в памяти, всем нам пришлось обзавестись, по крайней мере, 286 процессором. Но прогресс на этом не остановился. Желание уподобить виртуальный мир в игре реальному миру усилилось, и появился Wolf 3D. Да и плоские объекты и монстры — кому это интересно. Тут то и взошла звезда Quake. В этой игре был применен революционный подход — z-буфер, позволивший придать объемность всем объектам. Однако вся игра все равно работала в невысоком разрешении и не отличалась высокой реалистичностью.
Да и плоские объекты и монстры — кому это интересно. Тут то и взошла звезда Quake. В этой игре был применен революционный подход — z-буфер, позволивший придать объемность всем объектам. Однако вся игра все равно работала в невысоком разрешении и не отличалась высокой реалистичностью.
 Можно представить, насколько увеличивается объем требуемых вычислений над системой координат, если объект движется.
Можно представить, насколько увеличивается объем требуемых вычислений над системой координат, если объект движется. 
 Итак, появился процессор, обеспечивающий ускорение VGA (Accelerated VGA — AVGA), также известный, как Windows или GUI ускоритель, который стал обязательным элементом в современных компьютерах.
Итак, появился процессор, обеспечивающий ускорение VGA (Accelerated VGA — AVGA), также известный, как Windows или GUI ускоритель, который стал обязательным элементом в современных компьютерах. Первичный стандарт VGA с разрешением 640х480 пикселов был адекватен 14″ мониторам, наиболее распространенных в то время. Сегодня наиболее предпочтительны мониторы с размером диагонали трубки 17″, благодаря возможности выводить изображения с разрешением 1024х768 и более.
Первичный стандарт VGA с разрешением 640х480 пикселов был адекватен 14″ мониторам, наиболее распространенных в то время. Сегодня наиболее предпочтительны мониторы с размером диагонали трубки 17″, благодаря возможности выводить изображения с разрешением 1024х768 и более. Не взирая на то, что в распоряжении разработчиков имеется множество трехмерных API, например — Direct3D, некоторые программисты идут по пути создания собственного 3D игрового интерфейса или двигателя. Собственные игровые двигатели — один из путей для разработчиков добиться невероятной реалистичности изображения, фактически на пределе возможностей графического программирования.
Не взирая на то, что в распоряжении разработчиков имеется множество трехмерных API, например — Direct3D, некоторые программисты идут по пути создания собственного 3D игрового интерфейса или двигателя. Собственные игровые двигатели — один из путей для разработчиков добиться невероятной реалистичности изображения, фактически на пределе возможностей графического программирования.  Эти новые технологические решения, совмещают в себе великолепную поддержку 2D графики, соответствующую сегодняшним требованиям к Windows акселлераторам, аппаратную поддержку функций 3D графики и проигрывают цифровое видео с требуемой частотой смены кадров.
Эти новые технологические решения, совмещают в себе великолепную поддержку 2D графики, соответствующую сегодняшним требованиям к Windows акселлераторам, аппаратную поддержку функций 3D графики и проигрывают цифровое видео с требуемой частотой смены кадров. 
 Каким образом изобразительным средствам PC удалось достигнуть уровня профессиональных студий, занимающихся трехмерной графикой.
Каким образом изобразительным средствам PC удалось достигнуть уровня профессиональных студий, занимающихся трехмерной графикой. Однако текстура (изображение, накладываемое на всю поверхность сразу) дает больше реализма, но требует меньше вычислительных ресурсов, так как позволяет оперировать со всем фасадом как с единой поверхностью. Перед тем, как поверхности попадают на экран, они текстурируются и затеняются. Все текстуры хранятся в памяти, обычно установленной на видеокарте. Кстати, здесь нельзя не заметить, что применение AGP делает возможным хранение текстур в системной памяти, а ее объем гораздо больше.
Однако текстура (изображение, накладываемое на всю поверхность сразу) дает больше реализма, но требует меньше вычислительных ресурсов, так как позволяет оперировать со всем фасадом как с единой поверхностью. Перед тем, как поверхности попадают на экран, они текстурируются и затеняются. Все текстуры хранятся в памяти, обычно установленной на видеокарте. Кстати, здесь нельзя не заметить, что применение AGP делает возможным хранение текстур в системной памяти, а ее объем гораздо больше.
 При движущемся изображении, например, по мере того, как объект удаляется от зрителя, текстурный битмэп должен уменьшаться в размерах вместе с уменьшением размера отображаемого объекта. Для того чтобы выполнить это преобразование, графический процессор преобразует битмэпы текстур вплоть до соответствующего размера для покрытия поверхности объекта, но при этом изображение должно оставаться естественным, т.е. объект не должен деформироваться непредвиденным образом.
При движущемся изображении, например, по мере того, как объект удаляется от зрителя, текстурный битмэп должен уменьшаться в размерах вместе с уменьшением размера отображаемого объекта. Для того чтобы выполнить это преобразование, графический процессор преобразует битмэпы текстур вплоть до соответствующего размера для покрытия поверхности объекта, но при этом изображение должно оставаться естественным, т.е. объект не должен деформироваться непредвиденным образом.  Вот и у нашей дороги появляются «рваные края». И для борьбы с этим недостатком изображения применяется anti-aliasing.
Вот и у нашей дороги появляются «рваные края». И для борьбы с этим недостатком изображения применяется anti-aliasing.  Необходимо иметь информацию и о взаимном расположении объектов. Для решения этой задачи применяется метод, называемый z-буферизация. Это самый надежный метод удаления скрытых поверхностей. В так называемом z-буфере хранятся значения глубины всех пикселей (z-координаты). Когда рассчитывается (рендерится) новый пиксел, его глубина сравнивается со значениями, хранимыми в z-буфере, а конкретнее с глубинами уже срендеренных пикселов с теми же координатами x и y. Если новый пиксел имеет значение глубины больше какого-либо значения в z-буфере, новый пиксел не записывается в буфер для отображения, если меньше — то записывается.
Необходимо иметь информацию и о взаимном расположении объектов. Для решения этой задачи применяется метод, называемый z-буферизация. Это самый надежный метод удаления скрытых поверхностей. В так называемом z-буфере хранятся значения глубины всех пикселей (z-координаты). Когда рассчитывается (рендерится) новый пиксел, его глубина сравнивается со значениями, хранимыми в z-буфере, а конкретнее с глубинами уже срендеренных пикселов с теми же координатами x и y. Если новый пиксел имеет значение глубины больше какого-либо значения в z-буфере, новый пиксел не записывается в буфер для отображения, если меньше — то записывается. Чем выше разрешающая способность, тем выше дискретность z-координат и точнее выполняется рендеринг удаленных объектов. Если при рендеринге разрешающей способности не хватает, то может случиться, что два перекрывающихся объекта получат одну и ту же координату z, в результате аппаратура не будет знать какой объект ближе к наблюдателю, что может вызвать искажение изображения.
Чем выше разрешающая способность, тем выше дискретность z-координат и точнее выполняется рендеринг удаленных объектов. Если при рендеринге разрешающей способности не хватает, то может случиться, что два перекрывающихся объекта получат одну и ту же координату z, в результате аппаратура не будет знать какой объект ближе к наблюдателю, что может вызвать искажение изображения.  С помощью этого же алгоритма далеко отстоящие объекты погружаются в дымку, создавая иллюзию расстояния.
С помощью этого же алгоритма далеко отстоящие объекты погружаются в дымку, создавая иллюзию расстояния. Ключевой — Double Buffering.
Ключевой — Double Buffering.  Таким образом, играющий все время видит отличную картинку.
Таким образом, играющий все время видит отличную картинку.
 Именно по этому для развития 3D-графики особенно перспективно продвижение шины AGP, позволяющее соединить 3D-чип с процессором напрямую и тем самым организовать быстрый обмен данными с оперативной памятью. Это решение, к тому же, должно удешевить трехмерные акселераторы за счет того, что на борту платы останется лишь немного памяти собственно для кадрового буфера.
Именно по этому для развития 3D-графики особенно перспективно продвижение шины AGP, позволяющее соединить 3D-чип с процессором напрямую и тем самым организовать быстрый обмен данными с оперативной памятью. Это решение, к тому же, должно удешевить трехмерные акселераторы за счет того, что на борту платы останется лишь немного памяти собственно для кадрового буфера. Например, средства автоматизированного проектирования уже нуждаются в выводе трехмерных объектов. Теперь создание и проектирование будет возможно и на персональном компьютере благодаря открывающимся возможностям. Трехмерная графика, возможно, сможет также изменить способ взаимодействия человека с компьютером. Использование трехмерных интерфейсов программ должно сделать процесс общения с компьютером еще более простым, чем в настоящее время.
Например, средства автоматизированного проектирования уже нуждаются в выводе трехмерных объектов. Теперь создание и проектирование будет возможно и на персональном компьютере благодаря открывающимся возможностям. Трехмерная графика, возможно, сможет также изменить способ взаимодействия человека с компьютером. Использование трехмерных интерфейсов программ должно сделать процесс общения с компьютером еще более простым, чем в настоящее время.
 На скриншоте ниже вы видите то, как аниматоры смогли спроектировать человеческую руку и анимировать ее на экране.
На скриншоте ниже вы видите то, как аниматоры смогли спроектировать человеческую руку и анимировать ее на экране. Это может быть любой предмет, животное или человек. В общем, все, что нас окружает. Существует несколько видов трехмерного моделирования, каждый из которых имеет свои особенности и принципы, но сейчас не будем вдаваться в эту тему. Если хотите, можете ознакомиться с такими программами, как Blender или 3Ds Max, чтобы узнать, как трехмерные объекты рисуются при помощи программ.
Это может быть любой предмет, животное или человек. В общем, все, что нас окружает. Существует несколько видов трехмерного моделирования, каждый из которых имеет свои особенности и принципы, но сейчас не будем вдаваться в эту тему. Если хотите, можете ознакомиться с такими программами, как Blender или 3Ds Max, чтобы узнать, как трехмерные объекты рисуются при помощи программ. Завершающий процесс работы над проектом. Подразумевает обработку цветов, типов поверхности, освещения и всех других параметров сцены. Для обработки необходим мощный компьютер, способный быстро считывать кадры и выдавать на экран необходимый результат.
Завершающий процесс работы над проектом. Подразумевает обработку цветов, типов поверхности, освещения и всех других параметров сцены. Для обработки необходим мощный компьютер, способный быстро считывать кадры и выдавать на экран необходимый результат. Это и делает 3D-модель похожей на настоящую.
Это и делает 3D-модель похожей на настоящую.
 3),(x,0,2*pi),rgbcolor=hue(0.6))
sage: show(p1+p2+p3, axes=false)
3),(x,0,2*pi),rgbcolor=hue(0.6))
sage: show(p1+p2+p3, axes=false)
 е. график функции \(y=\sin(x)\)
для \(x\) между \(-2\pi\) и \(2\pi\), перевернутый по
отношению к линии в 45 градусов. Следующая команда Sage построит
вышеуказанное:
е. график функции \(y=\sin(x)\)
для \(x\) между \(-2\pi\) и \(2\pi\), перевернутый по
отношению к линии в 45 градусов. Следующая команда Sage построит
вышеуказанное: 2 — 1)
sage: implicit_plot3d(f, (x, -0.5, 0.5), (y, -1, 1), (z, -1, 1))
Graphics3d Object
2 — 1)
sage: implicit_plot3d(f, (x, -0.5, 0.5), (y, -1, 1), (z, -1, 1))
Graphics3d Object  От правильного соблюдения установленного алгоритма зависит качество конечного результата. Специалисты нашей компании проводят комплексную работу по разработке 3D графики в несколько этапов:
От правильного соблюдения установленного алгоритма зависит качество конечного результата. Специалисты нашей компании проводят комплексную работу по разработке 3D графики в несколько этапов: Примечательно, что они доставляют визуальное наслаждение, и при этом приносят реальную прибыль. Встретить трехмерные изображения можно на телевидение, в кино, в играх, на рекламных щитах и т.д. Современная 3D графика, это:
Примечательно, что они доставляют визуальное наслаждение, и при этом приносят реальную прибыль. Встретить трехмерные изображения можно на телевидение, в кино, в играх, на рекламных щитах и т.д. Современная 3D графика, это: А пока, остается лишь заказывать качественный визуал и тем самым повышать узнаваемость бренда!
А пока, остается лишь заказывать качественный визуал и тем самым повышать узнаваемость бренда! Это действие осуществляется в графических редакторах, с использованием установленных источников света
Это действие осуществляется в графических редакторах, с использованием установленных источников света Наиболее востребованными вариантами выступают: полигональное и сплайновое.
Наиболее востребованными вариантами выступают: полигональное и сплайновое. Их линии задаются посредством трехмерного набора контрольных точек, которые и определяют гладкость кривой. Все сплайны подводятся к сплайновому каркасу, на основе которого в дальнейшем создается огибающая трехмерная геометрическая поверхность.
Их линии задаются посредством трехмерного набора контрольных точек, которые и определяют гладкость кривой. Все сплайны подводятся к сплайновому каркасу, на основе которого в дальнейшем создается огибающая трехмерная геометрическая поверхность. Услуги по моделированию решают ряд задач клиентов:
Услуги по моделированию решают ряд задач клиентов: Программа 3Ds Max используется во многих сферах, в частности:
Программа 3Ds Max используется во многих сферах, в частности:
 Но, стоимость способна варьироваться в зависимости от сложности графики и установленных сроков. На конечную цену влияют:
Но, стоимость способна варьироваться в зависимости от сложности графики и установленных сроков. На конечную цену влияют:


 Значение по умолчанию: 50.
Значение по умолчанию: 50.
 add_subplot(111, projection='3d')
ax.plot_surface(x, y, z, cmap='inferno')
ax.legend()
add_subplot(111, projection='3d')
ax.plot_surface(x, y, z, cmap='inferno')
ax.legend()
 3D-анимация дает более точные ощущения пространства и объема. рисование разных углов конкретного объекта в 2D-областях может быть сложным и трудоемким по сравнению с 3D-моделями.
3D-анимация дает более точные ощущения пространства и объема. рисование разных углов конкретного объекта в 2D-областях может быть сложным и трудоемким по сравнению с 3D-моделями.
 Аниматоры создавали виртуальную съемочную площадку, которую можно было крутить, как угодно. Камеры выписывали виражи, как в игровом кино, что придавало динамики. Эта сцена до сих пор выглядит впечатляюще.
Аниматоры создавали виртуальную съемочную площадку, которую можно было крутить, как угодно. Камеры выписывали виражи, как в игровом кино, что придавало динамики. Эта сцена до сих пор выглядит впечатляюще. Во многих проектах массовку создают в 3D. Анимируют одну или несколько моделек и клонируют. Этим приемом пользовались, например, в диснеевском «Горбуне из Нотр-Дама», где многие сцены показывают толпу. Тем же методом сделана массовка в «Мулан».
Во многих проектах массовку создают в 3D. Анимируют одну или несколько моделек и клонируют. Этим приемом пользовались, например, в диснеевском «Горбуне из Нотр-Дама», где многие сцены показывают толпу. Тем же методом сделана массовка в «Мулан». 2D персонажи были нарисованы поверх.
2D персонажи были нарисованы поверх. В мультсериале «Удивительный мир Гамболла» комбинируются всевозможные виды анимации. Есть персонажи, созданные в 2D (Гамболл, Дарвин и др.), в технике фотомонтажа, в технике стоп-моушена. Есть здесь и 3D-персонажи: робот Боберт, воздушный шарик Алан и др. Такое разнообразие технологий позволяет создать уникальный, безумный мир, населенный разношерстными существами.
В мультсериале «Удивительный мир Гамболла» комбинируются всевозможные виды анимации. Есть персонажи, созданные в 2D (Гамболл, Дарвин и др.), в технике фотомонтажа, в технике стоп-моушена. Есть здесь и 3D-персонажи: робот Боберт, воздушный шарик Алан и др. Такое разнообразие технологий позволяет создать уникальный, безумный мир, населенный разношерстными существами. Это трехмерные каркасные модели, анимированные так, будто их толкает невидимая масса воздуха.
Это трехмерные каркасные модели, анимированные так, будто их толкает невидимая масса воздуха. Многие аниме-сериалы грешат халтурными 3D-сценами. Яркий пример — кривая массовка в аниме «Оверлорд». Сравните с 3D-толпой в диснеевских рисованных мультфильмах, о которых говорилось выше.
Многие аниме-сериалы грешат халтурными 3D-сценами. Яркий пример — кривая массовка в аниме «Оверлорд». Сравните с 3D-толпой в диснеевских рисованных мультфильмах, о которых говорилось выше. Здесь на компьютерные модели накладывали изображение, выполненное вручную. В результате получился уникальный визуальный стиль, приближенный к комиксу.
Здесь на компьютерные модели накладывали изображение, выполненное вручную. В результате получился уникальный визуальный стиль, приближенный к комиксу. Во многом это зависит от уровня детализации и того, как деталь ведет себя на движущейся поверхности.
Во многом это зависит от уровня детализации и того, как деталь ведет себя на движущейся поверхности. Origin включает в себя широкий спектр типов трехмерных графиков, в том числе трехмерный разброс, трехмерные полосы и трехмерные поверхности. Создание этих графиков в Origin выполняется быстро и легко: вы можете просто выбрать данные и щелкнуть нужную кнопку графика или команду меню, чтобы создать график. После создания вы можете изменять и манипулировать графиком различными способами, включая вращение, изменение размера, построение пересечения нескольких поверхностей, изменение отображения метки оси и т. Д.Вы можете вращать и изменять размер 3D-графиков графически или вводя точные числа в текстовые поля. Как правило, вы можете изменить внешний вид любого элемента графика, дважды щелкнув по нему, открыв диалоговое окно и изменив настройки. Здесь мы видим три примера трехмерных графиков:
Origin включает в себя широкий спектр типов трехмерных графиков, в том числе трехмерный разброс, трехмерные полосы и трехмерные поверхности. Создание этих графиков в Origin выполняется быстро и легко: вы можете просто выбрать данные и щелкнуть нужную кнопку графика или команду меню, чтобы создать график. После создания вы можете изменять и манипулировать графиком различными способами, включая вращение, изменение размера, построение пересечения нескольких поверхностей, изменение отображения метки оси и т. Д.Вы можете вращать и изменять размер 3D-графиков графически или вводя точные числа в текстовые поля. Как правило, вы можете изменить внешний вид любого элемента графика, дважды щелкнув по нему, открыв диалоговое окно и изменив настройки. Здесь мы видим три примера трехмерных графиков: Ниже приведены минимальные системные требования для Origin 9.0 для построения графиков OpenGL, особенно требования к видеокарте и драйверам:
Ниже приведены минимальные системные требования для Origin 9.0 для построения графиков OpenGL, особенно требования к видеокарте и драйверам: Предыдущие версии выполняли некоторую нормализацию данных X и Y перед построением графика. Таким образом, контурные и трехмерные поверхностные графики данных рабочего листа XYZ, созданные в версии 2016 и выше, могут отличаться от графиков тех же данных, созданных в более ранних версиях. Это изменение будет наиболее заметно, если между значениями X и Y имеются большие различия в диапазоне шкалы. См. FAQ-822 для получения дополнительной информации.
Предыдущие версии выполняли некоторую нормализацию данных X и Y перед построением графика. Таким образом, контурные и трехмерные поверхностные графики данных рабочего листа XYZ, созданные в версии 2016 и выше, могут отличаться от графиков тех же данных, созданных в более ранних версиях. Это изменение будет наиболее заметно, если между значениями X и Y имеются большие различия в диапазоне шкалы. См. FAQ-822 для получения дополнительной информации. m-1/x}=m
m-1/x}=m x = exp
x = exp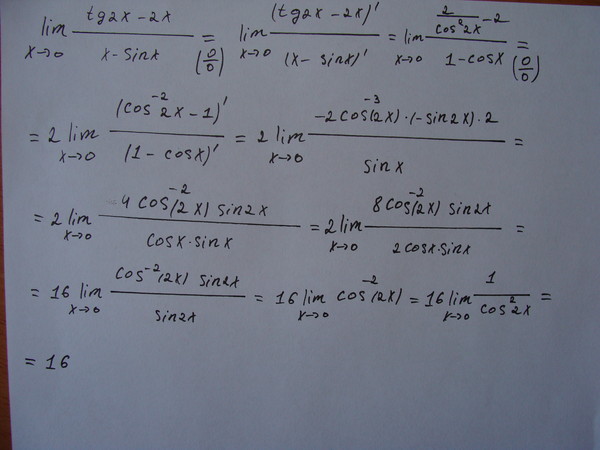
 Это связано с тем, что используемая нами угловая мера является «гладкой и устойчивой», что означает, что, по сути, если у нас есть некоторый угол, мы хотели бы разделить эту угловую меру, чтобы разделить угол таким же образом, как при разрезании кусков пирога: если у меня есть угол с заданной угловой мерой $ \ theta $, то для того, чтобы система измерения работала, я должен иметь возможность получить угол с мерой $ \ frac {\ theta} {n} $, должен быть углом, который геометрически $ n $ -сечение угла на $ n $ конгруэнтных меньших углов, которые в сумме составляют полный угол.
Это связано с тем, что используемая нами угловая мера является «гладкой и устойчивой», что означает, что, по сути, если у нас есть некоторый угол, мы хотели бы разделить эту угловую меру, чтобы разделить угол таким же образом, как при разрезании кусков пирога: если у меня есть угол с заданной угловой мерой $ \ theta $, то для того, чтобы система измерения работала, я должен иметь возможность получить угол с мерой $ \ frac {\ theta} {n} $, должен быть углом, который геометрически $ n $ -сечение угла на $ n $ конгруэнтных меньших углов, которые в сумме составляют полный угол. Д., И в порядке систематически !
Д., И в порядке систематически ! В самом деле, это и есть вся «радианная мера»: это мера углов в терминах длины дуги части, которую они вырезают из единичной окружности (то есть $ r = 1 $). «Градусы» — это просто странная кратная единица фактической длины, равная $ \ frac {2 \ pi} {360} $ (или лучше $ \ frac {\ tau} {360} $) какой-то другой единицы длины. .
В самом деле, это и есть вся «радианная мера»: это мера углов в терминах длины дуги части, которую они вырезают из единичной окружности (то есть $ r = 1 $). «Градусы» — это просто странная кратная единица фактической длины, равная $ \ frac {2 \ pi} {360} $ (или лучше $ \ frac {\ tau} {360} $) какой-то другой единицы длины. .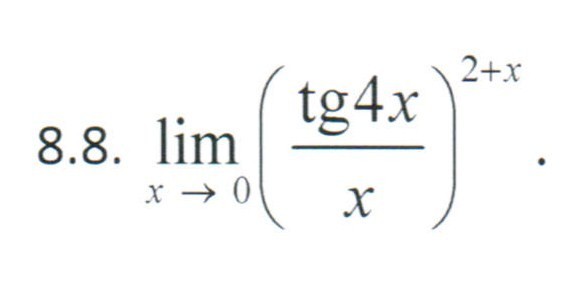 Обратите внимание, что тривиально $ \ arcsin (0) = 0 $ из определения интеграла, поэтому мы получаем
Обратите внимание, что тривиально $ \ arcsin (0) = 0 $ из определения интеграла, поэтому мы получаем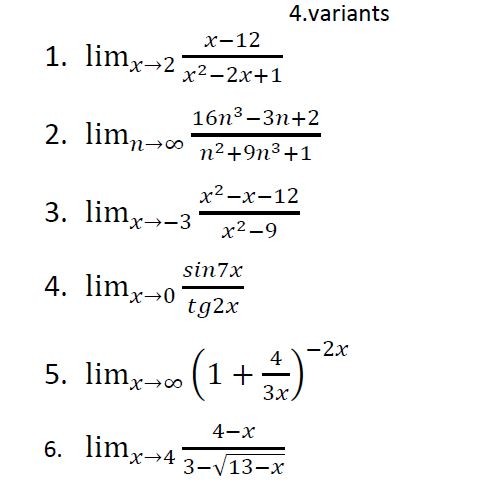 Я говорю о том, что на самом деле это не совсем возможно и показывает слабость учебной программы в том, что она на самом деле не соответствует правильному логическому построению математической конструкции.
Я говорю о том, что на самом деле это не совсем возможно и показывает слабость учебной программы в том, что она на самом деле не соответствует правильному логическому построению математической конструкции.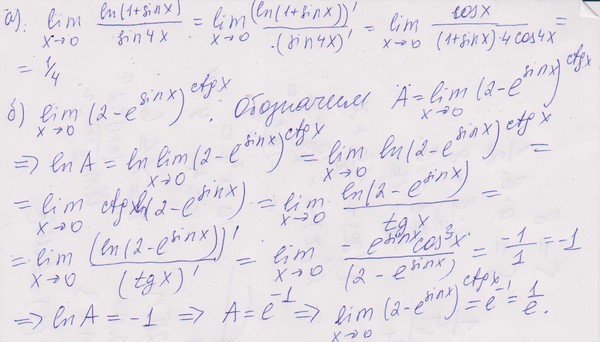 -} \ sin (x) = 0 $$
Я хотел бы иметь возможность проводить доказательство без ссылки на сложные теоремы (теорема о среднем значении, ряды и т. Д.).У меня есть геометрический подход к нахождению предела справа, но мне нужна аналогичная помощь при приближении к нулю слева.
-} \ sin (x) = 0 $$
Я хотел бы иметь возможность проводить доказательство без ссылки на сложные теоремы (теорема о среднем значении, ряды и т. Д.).У меня есть геометрический подход к нахождению предела справа, но мне нужна аналогичная помощь при приближении к нулю слева. $$
Во-вторых, если $ — \ pi / 2 \ le \ theta \ le0 $, то $ 0 \ le- \ theta \ le \ pi / 2 $. Следовательно, мы можем подставить $ — \ theta $ в последнее неравенство, что приведет к:
$$ \ begin {align *}
| \ sin (- \ theta) \, | & \ le | — \ theta \, | \\
| — \ sin (\ theta) \, | & \ le | — \ theta \, | \\
| \ sin (\ theta) \, | & \ le | \, \ theta \, |
\ end {align *} $$
Следовательно, если $ — \ pi / 2 \ le \ theta \ le \ pi / 2 $, то
$$ | \ sin (\ theta) \, | \ le | \, \ theta \, |.$$
Последний шаг связан с тем, что $ | -x | = | x | $ для всех действительных чисел $ x $. Последнее неравенство эквивалентно
$$ — | \, \ theta \, | \ le \ sin \ theta \ le | \, \ theta \, |, $$
и по теореме сжатия, поскольку оба конца стремятся к нулю при $ \ theta \ to0 $, я показал, что
$$ \ lim _ {\ theta-> 0} \ sin \ theta = 0. $$
$$
Во-вторых, если $ — \ pi / 2 \ le \ theta \ le0 $, то $ 0 \ le- \ theta \ le \ pi / 2 $. Следовательно, мы можем подставить $ — \ theta $ в последнее неравенство, что приведет к:
$$ \ begin {align *}
| \ sin (- \ theta) \, | & \ le | — \ theta \, | \\
| — \ sin (\ theta) \, | & \ le | — \ theta \, | \\
| \ sin (\ theta) \, | & \ le | \, \ theta \, |
\ end {align *} $$
Следовательно, если $ — \ pi / 2 \ le \ theta \ le \ pi / 2 $, то
$$ | \ sin (\ theta) \, | \ le | \, \ theta \, |.$$
Последний шаг связан с тем, что $ | -x | = | x | $ для всех действительных чисел $ x $. Последнее неравенство эквивалентно
$$ — | \, \ theta \, | \ le \ sin \ theta \ le | \, \ theta \, |, $$
и по теореме сжатия, поскольку оба конца стремятся к нулю при $ \ theta \ to0 $, я показал, что
$$ \ lim _ {\ theta-> 0} \ sin \ theta = 0. $$

 \]
\]
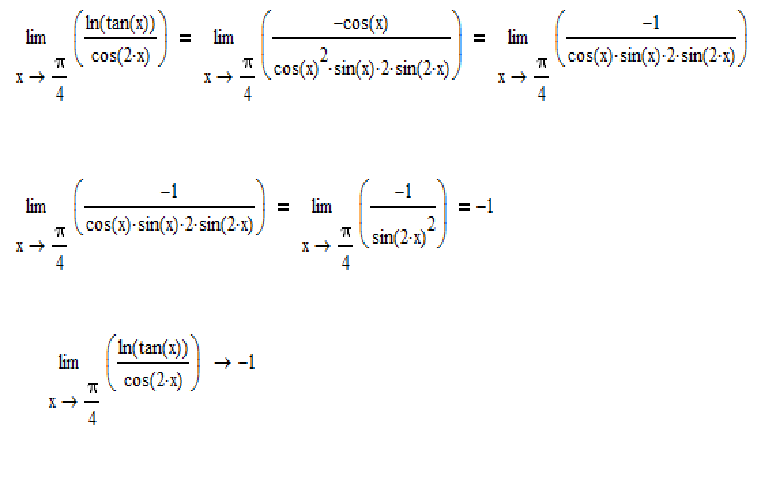 }
}  }
}  ..
..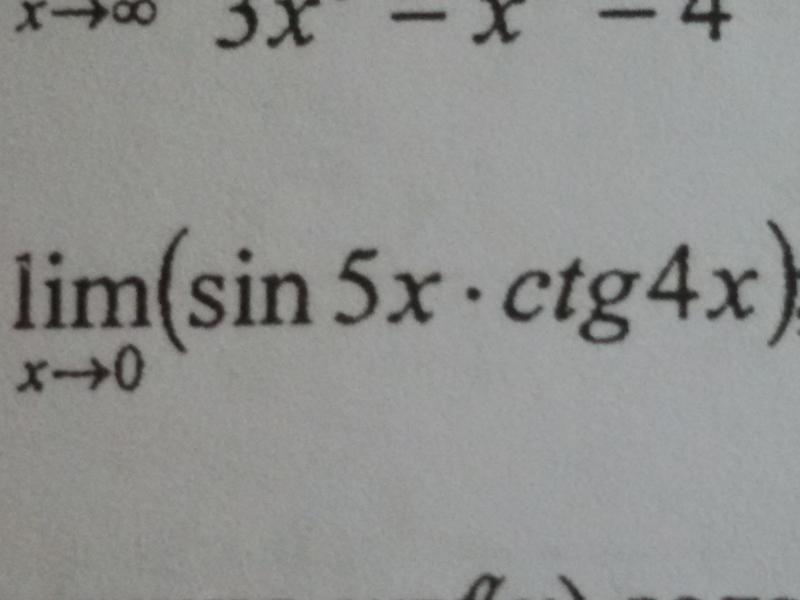 2 Применение углов (Примечания / E01-04 /, WS / KEY)
2 Применение углов (Примечания / E01-04 /, WS / KEY) ..
.. Примеры: Функция f (x) = sin x имеет период 2Pi. Функция f (x) = tan x имеет период Pi. Функция f (x) = sin 2x имеет период Pi.
Примеры: Функция f (x) = sin x имеет период 2Pi. Функция f (x) = tan x имеет период Pi. Функция f (x) = sin 2x имеет период Pi.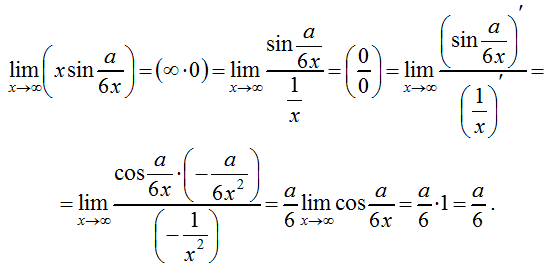 Студенты обычно изучают тригонометрию после завершения предыдущего курса по алгебре и геометрии, но перед тем, как пройти предварительное исчисление и исчисление.
Студенты обычно изучают тригонометрию после завершения предыдущего курса по алгебре и геометрии, но перед тем, как пройти предварительное исчисление и исчисление.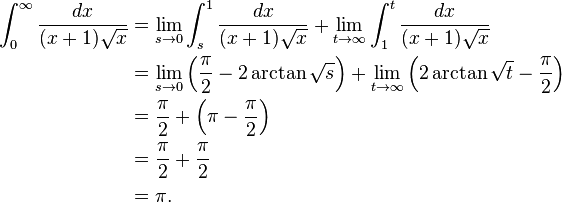 {-1} $ или $ \ arcsin $ («арксинус») и часто записывается asin на различных языках программирования.
{-1} $ или $ \ arcsin $ («арксинус») и часто записывается asin на различных языках программирования.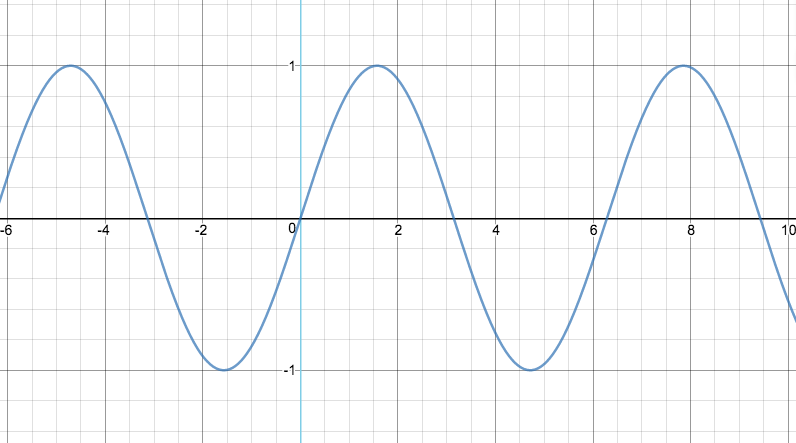 ограничение триггера с использованием тождества двойного угла. пределы тригонометрических функций на бесконечности pdf. предельные примечания к лекциям. пределы триггеров без l hopital.lim 1-cosx / (sinx). два специальных тригонометрические пределы. особые пределы …
ограничение триггера с использованием тождества двойного угла. пределы тригонометрических функций на бесконечности pdf. предельные примечания к лекциям. пределы триггеров без l hopital.lim 1-cosx / (sinx). два специальных тригонометрические пределы. особые пределы … Подробнее об этом см. Функции тригонометрии для больших и отрицательных углов. Идентичности — замена функции другими Тригонометрические идентичности — это просто способы написания одной функции с использованием других.
Подробнее об этом см. Функции тригонометрии для больших и отрицательных углов. Идентичности — замена функции другими Тригонометрические идентичности — это просто способы написания одной функции с использованием других. При интегрировании функции, если в подынтегральном выражении присутствуют тригонометрические функции, мы можем использовать тригонометрические тождества, чтобы упростить функцию и упростить ее интегрирование. Некоторые формулы интегрирования тригонометрических функций приведены ниже: Sin2x = \ [\ frac {1-cos2x} {2} \] cos2x = \ [\ frac {1 + cos2x} {2} \] MATH 1910-Тригонометрические пределы и сжатие Теорема. Нахождение пределов, связанных с тригонометрическими функциями. Двумя важными ограничениями, связанными с тригонометрическими функциями, являются 1. lim x → 0 sinx x 1 2. lim x → 0 1 −cosx x 0 Первый из них мы рассмотрели ранее.Это можно доказать с помощью геометрии. Давайте выведем вторую из первой.
При интегрировании функции, если в подынтегральном выражении присутствуют тригонометрические функции, мы можем использовать тригонометрические тождества, чтобы упростить функцию и упростить ее интегрирование. Некоторые формулы интегрирования тригонометрических функций приведены ниже: Sin2x = \ [\ frac {1-cos2x} {2} \] cos2x = \ [\ frac {1 + cos2x} {2} \] MATH 1910-Тригонометрические пределы и сжатие Теорема. Нахождение пределов, связанных с тригонометрическими функциями. Двумя важными ограничениями, связанными с тригонометрическими функциями, являются 1. lim x → 0 sinx x 1 2. lim x → 0 1 −cosx x 0 Первый из них мы рассмотрели ранее.Это можно доказать с помощью геометрии. Давайте выведем вторую из первой.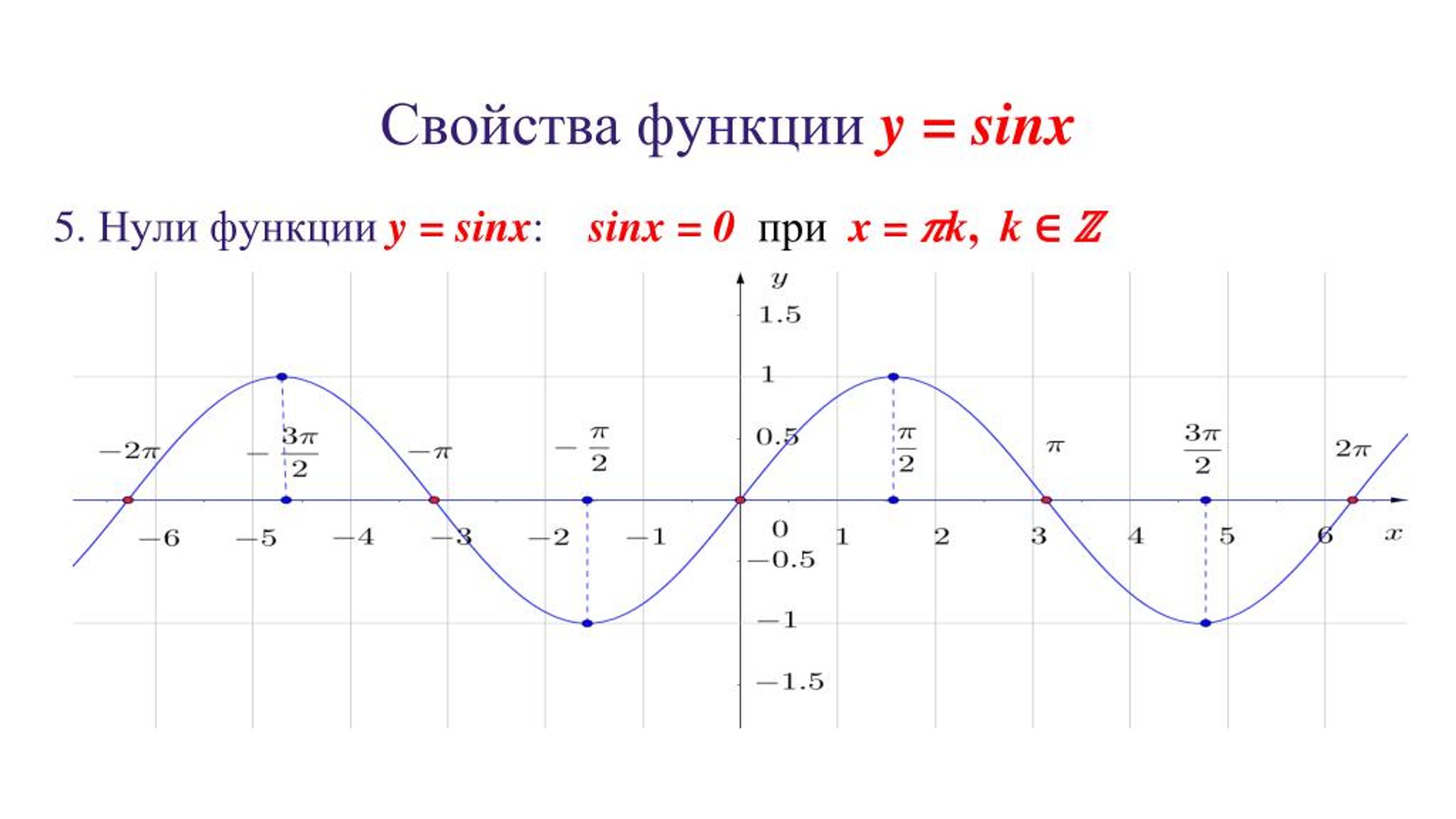
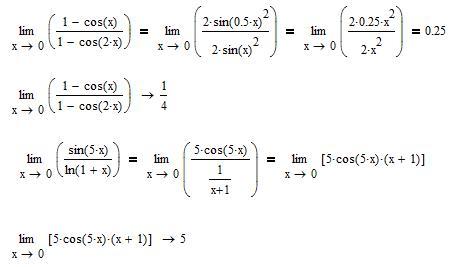 pdf doc; Триггер (часть I) — Толкование триггерных функций и практика с инверсиями. pdf doc; Триггер (часть II) — Больше практики. pdf doc; Дениз и Чад — Иллюстрация эффектов изменения амплитуды и периода. pdf doc Гиперболические тригонометрические функции расширяют понятие параметрических уравнений для единичной окружности (x = cos t (x = \ cos t (x = cos t и y = sin t) y = \ sin t) y = sin t) параметрическим уравнениям для гиперболы, которые дают следующие два фундаментальных гиперболических уравнения:
pdf doc; Триггер (часть I) — Толкование триггерных функций и практика с инверсиями. pdf doc; Триггер (часть II) — Больше практики. pdf doc; Дениз и Чад — Иллюстрация эффектов изменения амплитуды и периода. pdf doc Гиперболические тригонометрические функции расширяют понятие параметрических уравнений для единичной окружности (x = cos t (x = \ cos t (x = cos t и y = sin t) y = \ sin t) y = sin t) параметрическим уравнениям для гиперболы, которые дают следующие два фундаментальных гиперболических уравнения: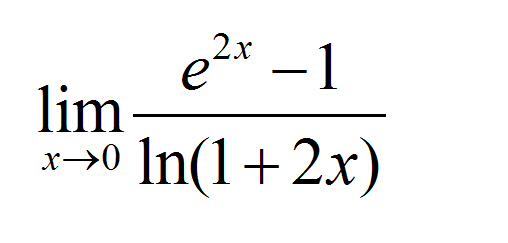
 Решения в формате PDF.Конечная математика и прикладное исчисление (6-е издание), ответы на главу 0 — Раздел 0.1 — Действительные числа — Упражнения — Страница 7 1, включая рабочий шаг по …
Решения в формате PDF.Конечная математика и прикладное исчисление (6-е издание), ответы на главу 0 — Раздел 0.1 — Действительные числа — Упражнения — Страница 7 1, включая рабочий шаг по …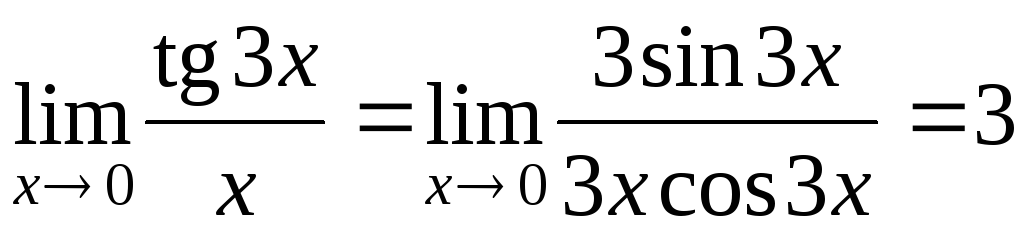 ..
..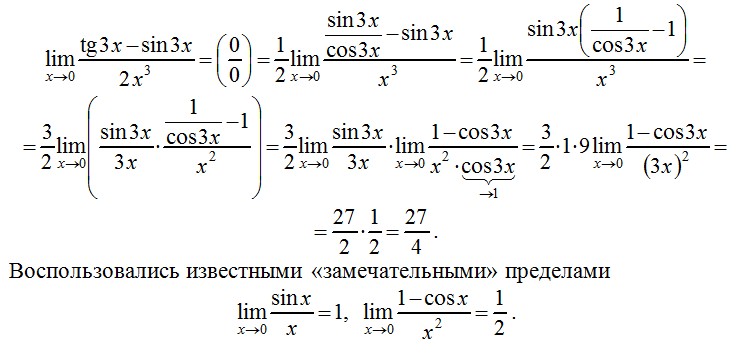

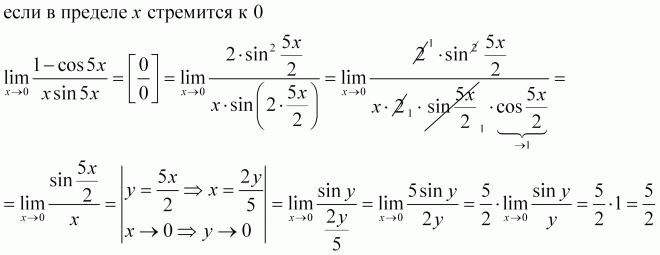
 Используя ряд Тейлора, он показывает, как вычислить линейный интеграл векторного поля по отрезку прямой до второго порядка. Отчасти здесь интересно отметить, насколько легко этот метод обобщается для получения формул более высокого порядка.{- 1}} x $$ с помощью функции расширения ряда Маклорена. Рассмотрим функцию вида \ [f \ left
Используя ряд Тейлора, он показывает, как вычислить линейный интеграл векторного поля по отрезку прямой до второго порядка. Отчасти здесь интересно отметить, насколько легко этот метод обобщается для получения формул более высокого порядка.{- 1}} x $$ с помощью функции расширения ряда Маклорена. Рассмотрим функцию вида \ [f \ left к. |–a – b| = |–(a + b)| = |a + b|). Но уже было доказано, что |a + b| = |a| + |b|, следовательно и |–a – b| = |a| + |b|.
к. |–a – b| = |–(a + b)| = |a + b|). Но уже было доказано, что |a + b| = |a| + |b|, следовательно и |–a – b| = |a| + |b|. 2-1}{4}d$. Равенство в нем достигается, когда $a_1 = \ldots = a_m \lt a_{m+1} = \ldots = a_{2m+1}$.
2-1}{4}d$. Равенство в нем достигается, когда $a_1 = \ldots = a_m \lt a_{m+1} = \ldots = a_{2m+1}$.


 Следовательно, надо поменять его знак на противоположный. Выражением, противоположным 3√5 – 10, является –(3√5 – 10). Раскроем в нем скобки – и получим ответ:
Следовательно, надо поменять его знак на противоположный. Выражением, противоположным 3√5 – 10, является –(3√5 – 10). Раскроем в нем скобки – и получим ответ: Никаких других ограничений на Irul v не существует.
[4]
Никаких других ограничений на Irul v не существует.
[4] [10]
[10] {2}}\Leftrightarrow \\xy>\left| x \right|\cdot \left| y \right|\Leftrightarrow \\xy>\left| xy \right|,\end{array}\)
{2}}\Leftrightarrow \\xy>\left| x \right|\cdot \left| y \right|\Leftrightarrow \\xy>\left| xy \right|,\end{array}\) {2}}\overset{<}{\mathop{\vee }}\,15\cdot 16\text{ }\Rightarrow \text{ }\)
{2}}\overset{<}{\mathop{\vee }}\,15\cdot 16\text{ }\Rightarrow \text{ }\)


 е.
е. 4) являются необходимыми для существования экстремума функции. Но может случиться, что эти условия в некоторых обстоятельствах невыполнимы.
4) являются необходимыми для существования экстремума функции. Но может случиться, что эти условия в некоторых обстоятельствах невыполнимы.
 Поэтому можно приблизительно считать, что между х и у существует линейная зависимость, выражаемая формулой,
Поэтому можно приблизительно считать, что между х и у существует линейная зависимость, выражаемая формулой, В некотором смысле прямая сумма модулей — это «самый общий» модуль, который содержит данные модули как подпространства.
В некотором смысле прямая сумма модулей — это «самый общий» модуль, который содержит данные модули как подпространства.


 Таким образом, прямая сумма становится левым модулем R . Обозначим его через
Таким образом, прямая сумма становится левым модулем R . Обозначим его через


 {\ displaystyle \ sum _ {i \ in I} \ | x (i) \ | _ {X_ {i}} {\ mbox {конечно.}}}
{\ displaystyle \ sum _ {i \ in I} \ | x (i) \ | _ {X_ {i}} {\ mbox {конечно.}}} .., xn), (y1, …, yn)⟩ = ⟨x1, y1⟩ + … + ⟨xn, yn⟩ {\ displaystyle \ langle (x_ {1}, …, x_ {n}), (y_ {1}, …, y_ {n}) \ rangle = \ langle x_ {1}, y_ {1} \ rangle +… + \ langle x_ {n}, y_ {n} \ rangle}
.., xn), (y1, …, yn)⟩ = ⟨x1, y1⟩ + … + ⟨xn, yn⟩ {\ displaystyle \ langle (x_ {1}, …, x_ {n}), (y_ {1}, …, y_ {n}) \ rangle = \ langle x_ {1}, y_ {1} \ rangle +… + \ langle x_ {n}, y_ {n} \ rangle} {2}}. Сравнивая это с примером для банаховых пространств, мы видим, что прямая сумма банахова пространства и прямая сумма гильбертова пространства не обязательно совпадают. Но если имеется только конечное число слагаемых, то прямая сумма банахова пространства изоморфна прямой сумме гильбертова пространства.
{2}}. Сравнивая это с примером для банаховых пространств, мы видим, что прямая сумма банахова пространства и прямая сумма гильбертова пространства не обязательно совпадают. Но если имеется только конечное число слагаемых, то прямая сумма банахова пространства изоморфна прямой сумме гильбертова пространства. Таким образом, P и Q оба являются замыканиями
Таким образом, P и Q оба являются замыканиями Возьмем
Возьмем Тогда и Ltc, и f (L) tc
Тогда и Ltc, и f (L) tc
 Но здесь мы не будем ограничиваться контекстом такой конкретной категории.
Но здесь мы не будем ограничиваться контекстом такой конкретной категории.
 wk_i A_i определяется как направленный копредел этой прямой системы.
wk_i A_i определяется как направленный копредел этой прямой системы.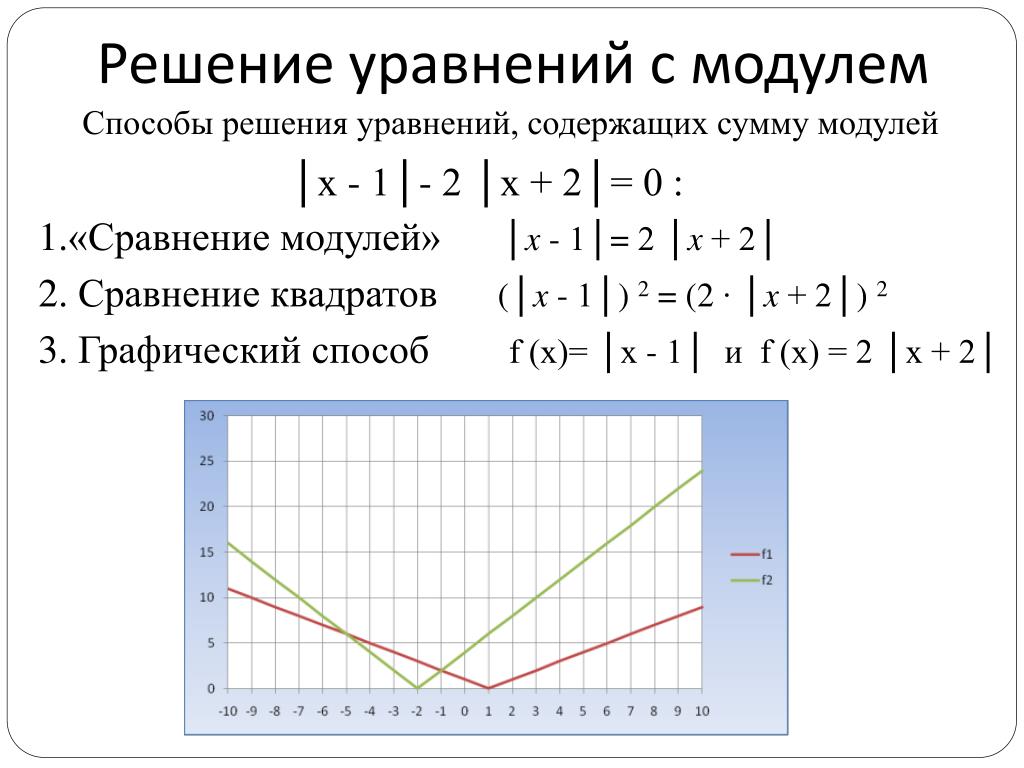
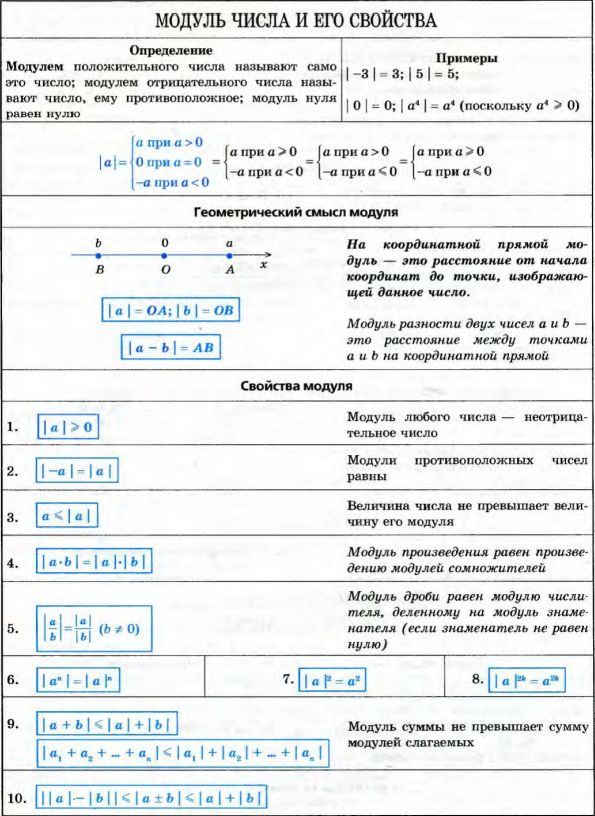 Наконец, предположим, что (или) фактор-отображение ⨁iAi → B \ bigoplus_i A_i \ to B является изическим. Затем мы говорим, что BB — это внутренняя прямая сумма AiA_i.
Наконец, предположим, что (или) фактор-отображение ⨁iAi → B \ bigoplus_i A_i \ to B является изическим. Затем мы говорим, что BB — это внутренняя прямая сумма AiA_i.

 \)
\) com.
com. Получены точные формулы и оценки сумм модулей коэффициентов Уолша.
Получены точные формулы и оценки сумм модулей коэффициентов Уолша. mathnet.ru/mvk240}
mathnet.ru/mvk240} 


 Она характеризует положительную зависимость объема производства от затрат труда и капитала. Специалист по эконометрике сначала соберет данные по объему производства на интересующих его предприятиях. После этого он оценит параметры функции, характеризующей зависимость выпуска от различных факторов для конкретных предприятий в определенных условиях.
Она характеризует положительную зависимость объема производства от затрат труда и капитала. Специалист по эконометрике сначала соберет данные по объему производства на интересующих его предприятиях. После этого он оценит параметры функции, характеризующей зависимость выпуска от различных факторов для конкретных предприятий в определенных условиях.  То есть в результате либерализации комиссионные только вырастут. Тогда антимонопольная служба заявила, что уравнение неправильно характеризует зависимость вознаграждения брокеров и объема проданных акций, и на самом деле естественной монополии нет. Их оппоненты не учли проблемы гетероскедастичности[1] данных. Если учесть гетероскедастичность, то результат приводит к противоположным выводам. Прошло несколько заседаний, на которых специалисты выясняли, чьи оценки правильнее. В результате борцы с монополией, видимо, лучше знавшие эконометрику, выиграли процесс.
То есть в результате либерализации комиссионные только вырастут. Тогда антимонопольная служба заявила, что уравнение неправильно характеризует зависимость вознаграждения брокеров и объема проданных акций, и на самом деле естественной монополии нет. Их оппоненты не учли проблемы гетероскедастичности[1] данных. Если учесть гетероскедастичность, то результат приводит к противоположным выводам. Прошло несколько заседаний, на которых специалисты выясняли, чьи оценки правильнее. В результате борцы с монополией, видимо, лучше знавшие эконометрику, выиграли процесс.
 Живущие за Уралом оказались склонны погашать кредиты раньше, чем жители европейской территории.
Живущие за Уралом оказались склонны погашать кредиты раньше, чем жители европейской территории. Некоторые выпускники нашей кафедры заняты на госслужбе и сделали неплохую карьеру, некоторые принимают участие в работе экспертных групп, нередко дают в средствах массовой информации комментарии по поводу различных макроэкономических проблем. Немало выпускников кафедры после окончания магистратуры или аспирантуры занимаются преподавательской и научной деятельностью.
Некоторые выпускники нашей кафедры заняты на госслужбе и сделали неплохую карьеру, некоторые принимают участие в работе экспертных групп, нередко дают в средствах массовой информации комментарии по поводу различных макроэкономических проблем. Немало выпускников кафедры после окончания магистратуры или аспирантуры занимаются преподавательской и научной деятельностью. д., иногда просто следуя эконометрической моде, благо современные статистические пакеты легко позволяют оценить эти модели. Из полученных результатов зачастую очевидно, что для использованных в работе данных выбранная модель не годится, предварительный анализ данных был проведен достаточно поверхностно, сделанные на основе оцененных моделей выводы весьма сомнительны.
д., иногда просто следуя эконометрической моде, благо современные статистические пакеты легко позволяют оценить эти модели. Из полученных результатов зачастую очевидно, что для использованных в работе данных выбранная модель не годится, предварительный анализ данных был проведен достаточно поверхностно, сделанные на основе оцененных моделей выводы весьма сомнительны. Если это так, то профили (графики зависимости) «зарплата – опыт работы» должны быть параллельны для различных лет обучения, т.е. получаться один из другого простым сдвигом. Для американских данных 1980 года параллельность профилей имела место. Однако для российских данных этот факт не подтвердился. Наличие послевузовского образования сначала приводило к достаточно быстрому росту заработной платы, а затем к достаточно быстрому ее иснижению. Из этого результата можно сделать вывод, что полученные знания достаточно быстро устаревают, и если ты не хочешь допустить падения заработной платы, то должен все время повышать свою квалификацию.
Если это так, то профили (графики зависимости) «зарплата – опыт работы» должны быть параллельны для различных лет обучения, т.е. получаться один из другого простым сдвигом. Для американских данных 1980 года параллельность профилей имела место. Однако для российских данных этот факт не подтвердился. Наличие послевузовского образования сначала приводило к достаточно быстрому росту заработной платы, а затем к достаточно быстрому ее иснижению. Из этого результата можно сделать вывод, что полученные знания достаточно быстро устаревают, и если ты не хочешь допустить падения заработной платы, то должен все время повышать свою квалификацию. При работе в проекте «Анализ системы госзакупок в России» в Институте анализа предприятий и рынков НИУ ВШЭ я вместе с коллегами столкнулась со следующей проблемой. Есть сайт, где публикуется вся информация о государственных контрактах, однако в неудобном для пользователей виде. Если требуется выгрузить информацию о контрактах на группу каких-либо однородных товаров, то система «зависает», а собирать информацию по каждому контракту вручную очень долго.
При работе в проекте «Анализ системы госзакупок в России» в Институте анализа предприятий и рынков НИУ ВШЭ я вместе с коллегами столкнулась со следующей проблемой. Есть сайт, где публикуется вся информация о государственных контрактах, однако в неудобном для пользователей виде. Если требуется выгрузить информацию о контрактах на группу каких-либо однородных товаров, то система «зависает», а собирать информацию по каждому контракту вручную очень долго. Однако есть точка зрения, что учебники по эконометрике должны идти от практики к теории и изобиловать примерами.
Однако есть точка зрения, что учебники по эконометрике должны идти от практики к теории и изобиловать примерами.
